
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we propose a score test to study a vector autoregressive model and its detection of extreme values. We take a likelihood approach to derive the corresponding maximum likelihood estimators and information matrix. We establish the score statistic for the vector autoregressive model under two perturbation schemes for identifying possible influential cases or outliers. The effectiveness of the proposed diagnostics is examined by a simulation study. To make an application, a data analysis is performed using the model to fit monthly log-returns of International Business Machines Corporation stock and the Standard & Poor's 500 index. Lastly, comparisons between the results by the score test and the local influence method are made. We establish two important findings that the score test is more effective while the local influence analysis can be used to diagnose more influential cases.
1. Introduction
The vector autoregressive (VAR) structure is a multivariate time series model that can be applied in many disciplines such as economics, finance and meteorology. In multivariate time series analysis, the VAR model is in the position of the basic structure so that it is used for constructing more complex frameworks. For example, a vector autoregressive moving average (VARMA) model may be obtained by adding a vector moving average (VMA) component on the basis of the VAR model. The VAR model has been favoured by scholars since it was initiated, who have reported that the VAR model is superior than the structural equation model in the prediction of multi-dimensional time series data. In fact, the main reason for generating a VAR model is also based on this. There are extensive studies on the VAR and related models with applications, see, e.g. [Citation1–10].
Statistical diagnostics for regression and time series models is equally important in data analysis and applications, see, e.g. [Citation11–18]. The local influence analysis and the score (SC) test are two essential techniques used to diagnose influential cases or outliers. Influence diagnostics is widely employed in several regression and time series models. [Citation19–23] investigated the local influence of linear regression models with first-order autoregressive (AR) or other error structures. In a framework of time series data, [Citation24–29] studied diagnostics in conditionally heteroskedastic time series models under normal, elliptical and skew-normal distributions. [Citation30] utilized the local influence method proposed by [Citation12] to detect outliers in ARIMA models and suggested a new perturbation scheme to indicate dependent structure in time series. This perturbation scheme can significantly restrain swamping effect. [Citation14,Citation28] examined estimation and influence diagnostics for an AR model under skew-normal distributions.
The SC test is also a helpful statistical method to detect the impact of small perturbations on the model fitting and inference. It is used in various regression and time series models due to its simple calculation. It was proposed by [Citation31,Citation32] to be an alternative to the likelihood ratio (LR) and Wald tests. Subsequently, [Citation33,Citation34] gave a comprehensive interpretation on the application of the SC test in econometrics, [Citation35] considered a variance shift model for the detection of outliers in the linear mixed model, while [Citation36] used the SC test to analyze for large-dimensional covariance structures.
Regarding VAR models, [Citation5] explored the local influence under the normal distribution, derived curvature and slope of influence diagrams, and accomplished an empirical study with real data. [Citation6] investigated the local influence in a VAR model under the Student-t distribution to obtain its maximum likelihood (ML) estimates, the Hessian matrix and the curvatures in three perturbation schemes, illustrating the proposed diagnostics by examining CVX and S&P 500 stock weekly returns. [Citation37] used a score type test to study change points.
To the best of our knowledge, there are not many studies reported on detecting extreme cases using the SC test in VAR models. Therefore, the objective of the present investigation is to formulate a VAR model using an ML approach and the SC statistic with two perturbation schemes to detect possible extreme cases and conduct diagnostic analysis.
The remainder of this paper proceeds as follows. In Section 2, we present the VAR model and SC test. In Section 3, we derive the SC statistic under mean-shift (MSOM) and case-weight (CWM) models. In Section 4, two simulations are conducted to evaluate the correctness of the proposed SC statistic and validity of outlier detecting process. In Section 5, a VAR model is applied to the monthly log-returns of International Business Machines Corporation stock and the Standard & Poor's 500 index as an example of real-world data analysis. Then, the results are compared with the counterparts obtained in [Citation5] to illustrate the relevance of our work. In Appendix, the proofs of the theorems are presented by using the matrix differential calculus developed in [Citation14,Citation38,Citation39].
2. Vector autoregressive model and SC test
In this section, we present the VAR model and SC test, indicating how the SC test is better than the LR test in our study.
2.1. VAR(p) model
We assume a k-dimensional time series, named, which is generated by a stationary VAR(p) process by means of
(1)
(1) where
is a
vector, for
,
is a
intercept vector,
is a
coefficient matrix, for
, and
is a
independent error vector following the k-variate normal distribution with mean vector 0 and variance matrix
.
Let be a
matrix and its transpose
follow the matrix-variate normal distribution, that is,
(2)
(2) where
is the null matrix,
is the
identity matrix, ⊗ denotes the Kronecker product, and the probability density function of
is given by
(3)
(3) For simplicity, we use the matrix form of the VAR (p) model stated as
(4)
(4) where
is a
matrix,
is a
matrix,
is a
matrix, rewritten as
, and the distribution of
is shown in (Equation2
(2)
(2) ).
Let denote the vector of parameters, where
is a
vector composed by the first column to the last column of
, and
is a
vector, which is superimposed from the parts below of the principal diagonal. For the convenience of subsequent derivation, the log-likelihood function
of the model formulated in (Equation4
(4)
(4) ) is respectively expressed in three forms as
(5)
(5)
(6)
(6)
(7)
(7) where the expression given in (Equation5
(5)
(5) ) is the cumulative formula, the representation stated in (Equation6
(6)
(6) ) is the matrix trace, and the formula established in (Equation7
(7)
(7) ) involves the Kronecker product. Subsequently, the operator vec should be changed into the operator
when calculating the partial derivative of the log-likelihood function with respect to
so that the conversion formula between them is given.
Lemma 2.1
Magnus and Neudecker (2019)
There is a duplication matrix
such that
, where the columns of
are linearly independent. For an
matrix
, we get
Using Lemma 2.1 and the formula stated in (Equation6(6)
(6) ), the corresponding ML estimator of
can be obtained. The consequent result is presented below, and the derivation may be used as in [Citation5]. The first derivatives of
with respect to
and
can be expressed as
The ML estimators of
and
are stated as
(8)
(8)
(9)
(9) where
(10)
(10)
2.2. SC statistic
The SC test is one of the most crucial methods in statistical diagnostics and is used to detect outliers that deviate significantly from the established model. The SC test statistic is a special form of generalized LR test statistic, which is mainly applied to compound hypothesis testing problems with redundant parameters. The SC test statistic only needs to calculate the ML estimator under the null hypothesis, while the LR statistic also needs to calculate the ML estimate under the alternative hypothesis. Therefore, calculating SC statistic is more convenient. In this study, the diagnostic method aims to detect outliers in the MSOM and CWM models. Basic principles of the SC test are introduced briefly as follows.
Let represent the log-likelihood function of the perturbation model, where
, with
being the parameter of interest with dimension
, and
being called redundant parameter with dimension
. The ML estimator of
is denoted by
.
Consider the hypothesis testing problem stated as
(11)
(11) When
is true, the ML estimator of
is
), and
. Then, the LR statistic of the hypothesis testing problem stated in (Equation11
(11)
(11) ) can be simplified as
(12)
(12) where the asymptotic distribution of
is
as
, with n being the sample size, and
indicating convergence in distribution. Thus the corresponding rejection region is
.
If satisfies all regularization conditions of Wilks' theorem, the LR statistic
can be transformed into a SC statistic by using the score function
and the Fisher information matrix
along the line of [Citation33], and the LR and SC tests are asymptotically equivalent:
(13)
(13) where
(14)
(14)
is the top-left subset of
corresponding to
,
is calculated with
being the second derivative of the log-likelihood function, and they are established to be
(15)
(15) From the above results, we must calculate the SC statistic and obtain its critical value at a given significance level. If the value of the statistic is greater than the critical value, the null hypothesis should be rejected. However, since we need to perform multiple hypothesis tests on the same dataset, this may lead to an increase in small probability events to occur more than expected and an increase in the probability of incorrectly rejecting the null hypothesis. Then, using the original critical value may not be accurate. The Bonferroni correction method helps us to address this shortcoming with the following idea. For a time series of n cases, when testing the null hypothesis for each of these cases, we use
instead of a given significance level α. If the value of the SC statistic of a case is greater than the critical value at that significance level, we reject the null hypothesis and the corresponding case is justified to be an outlier.
3. SC test of VAR(p) model
In this section, we test a VAR model under the normal distribution introduced in Section 2.1 by using the SC statistic proposed in Section 2.2. We first introduce two perturbation models: MSOM and CWM, and then present the information matrix results for the SC test under the mentioned models.
3.1. Mean-shift perturbation model
The MSOM model is given by
(16)
(16) where γ represents the shift of mean, also known as the shift parameter. If
has a significant deviation from zero, we can assume that the mean value at case i is different from the other cases and then it is an outlier. This method was first proposed by [Citation40].
For convenience of derivation, three forms of the log-likelihood function of the MSOM model are given by
(17)
(17)
(18)
(18)
(19)
(19) where ‘(i)’ in the variable indicates that case i is missing in that variable. In the model,
,
and
.
Next, we derive the following theorem by using Lemma 2.1 and (Equation14(14)
(14) ), (Equation18
(18)
(18) ) and (Equation19
(19)
(19) ).
Theorem 3.1
For the MSOM model under the normal distribution, the information matrix is
and the corresponding SC statistic is
where
Now, we verify the correctness of the derivation in the following three aspects:
It is well known that two mixed partial derivatives are equal as long as the mixed second-order partial derivatives are continuous. Therefore, to verify the proof to be correct, the two mixed partial derivatives are found separately, and the derivation procedure is proved to be correct.
Considering dimensionality, the information matrix has equal row dimensions for the second-order partial derivatives in each row, so does each column. This dimension matrix of the information matrix is given by
The corresponding information matrix is based on a multidimensional time series model. Thus the information matrix of the one-dimensional time series model is a special case of it. The information matrix of the one-dimensional time series model is stated as
3.2. Case-weight perturbation model
The CWM model can be indicated as
(20)
(20) where ω represents the weight of variance of case i. If ω is significantly different from one, consider that the variance of case i is different from the other cases, and therefore, case i is an outlier. This model was also first proposed by [Citation40]. For the convenience of derivation, three forms of the log-likelihood function of the CWM model are given as
(21)
(21)
(22)
(22)
(23)
(23) In the model,
,
, and
.
Next, we derive a theorem by using Lemma 2.1 and (Equation14(14)
(14) ), (Equation22
(22)
(22) ) and (Equation23
(23)
(23) ).
Theorem 3.2
For the CWM model under the normal distribution, the information matrix is
and the corresponding SC statistic is
where
Next, we verify the correctness of the derivation in the following three aspects:
The corresponding mixed partial derivatives in the information matrix are equal and then the results also prove that the derivation process is correct.
Considering dimensionality, the dimension matrix of the information matrix is given by
The information matrix of the one-dimensional time series model is as follows:
4. Monte Carlo simulation
In this section, to confirm the validity of the SC test, two Monte Carlo simulations are performed. First, a three-dimensional variable and a model lag one order are assumed. Then, a two-dimensional variable and a model lag of three order are considered. The two simulations differ only in the model parameters, and the steps are the same, while the simulation procedure is given below.
4.1. The simulation process
The simulation process is as follows:
Step 1. Construct a VAR model with the errors following a multivariate normal distribution.
Step 2. Generate 1000 cases using the model set in Step 1.
Step 3. Perturb the 200th, 400th, 600th and 800th cases with values from 1 to 5 in steps of 0.5 and hence there are 9 perturbation sizes in total.
Step 4. Detect outliers employing the MSOM and CWM structures, let the frequency of correct identification be the accuracy of the model, and record computational performance of the model at the same time.
Step 5. Repeat Step 2 to Step 4 1000 times to obtain the average accuracy of the two perturbation models.
4.2. VAR(1) model in three dimensions
The model parameters in Step 1 are set to generate stationary data by constructing a VAR model with lag 1 and a three-dimensional variable, on the stationarity conditions as described by e.g. [Citation10], stated by:
where
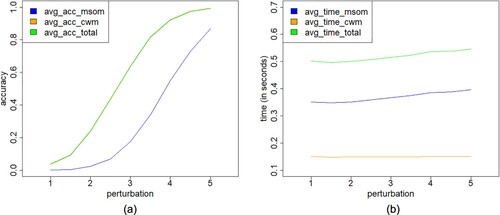
is a three-dimensional vector and follows a three-variate normal distribution. We obtain the average accuracy and computational performance of the two perturbation models for detecting outliers by using the same procedure as with the VAR(1) model. From Figure (a), the average accuracy curve of the CWM structure does not seem to be on the graph, but this is due to the fact that such a curve overlaps with the total accuracy curve as the cases detected by the MSOM are all detected by The CWM. From Figure (b), the average time curve of MSOM is nearly three times as much as the CWM curve. Thus the CWM structure performs better than the MSOM in computational efficiency.
Figure 1. Plots of simulation results for the (a) average accuracy versus perturbation in the VAR(1) model with three dimensions and (b) computational performance versus perturbation of MSOM and CWM structures, for the indicated case.
4.3. VAR(3) model in two dimensions
The model parameters in Step 1 are set to generate stationary data by constructing a VAR model with lag 1 and a two-dimensional variable, on the stationarity conditions as described by e.g. [Citation10], stated by
where
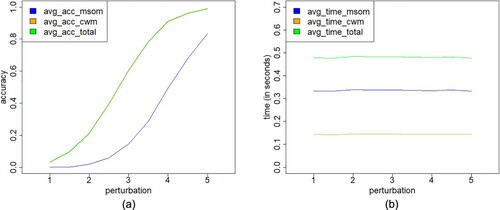
is a two-dimensional vector that follows the bivariate normal distribution. The average accuracy and computational performance of two perturbation models are shown in Figure . From Figure (a), once again, the average accuracy curve of the CWM structure does not seem to be on the graph, but it overlaps with the total accuracy curve. Figures and (a) clearly indicate that the average effect of outlier detecting increases when the size of the perturbation vector increases for both the VAR(1) and VAR(3) models. Also, the average effect of VAR(1) model is higher than that of the VAR(3) model under the same perturbation. Interestingly, the CWM structure seems to be more effective than the MSOM structure. Furthermore, although the computation time of both models is negligible, from Figure (b) and Figure (b), the CWM performs better than the MSOM, which indicates that diagnostic results of CWM may be more effective than in the MSOM. According to the simulation results, the SC test is not only valid but also significant, with its calculation being convenient and fast. However, our study suggests that these two models should be applied in combination in practical applications, because they consider the statistical diagnosis problem from different perturbation perspectives.
Figure 2. Plots of simulation results for the (a) average accuracy versus perturbation in the VAR(3) model with two dimensions and (b) computational performance versus perturbation of MSOM and CWM structures, for the indicated case.
5. Empirical study
In this section, we conduct an empirical study based on our results presented in Section 3 and compare it with local influence analysis. We choose the monthly log-returns of International Business Machines Corporation stock and the Standard & Poor's 500 index.
5.1. The data
We use International Business Machines Corporation stock (IBM) and the Standard & Poor's 500 Index (S&P500) from May 1938 to December 2008 as two-dimensional vectors to construct a VAR model and to conduct our SC test. The selection of IBM and S&P500 is mainly based on the following practical and theoretical considerations:
IBM is the world's largest information technology and business solutions company, and S&P500 is widely regarded as an ideal target of stock index futures contracts because of its wide sampling area, strong representativeness, high accuracy and good continuity. In addition, IBM had a weighting of more than 6 percent in S&P500 during May 1938 and December 2008, so they may influence each other.
There is an obvious relationship between the Student-t and normal distributions. As the degree of freedom increases, the Student-t distribution tends to be close to the normal distribution. Therefore, when the degree of freedom is large, the local influence analysis method of the Student-t distribution can be used to compare with SC test under the normal distribution.
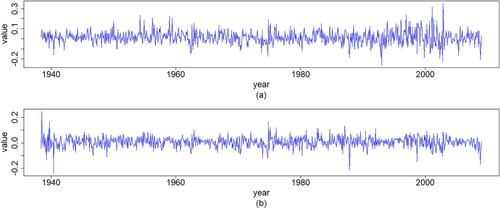
Therefore, based on the interaction between IBM and S&P500, it would be of great practical significance to construct a VAR model between them with the SC test. In addition, based on the relationship between the Student-t and normal distributions, it would be of great theoretical significance to compare the SC test under the normal distribution with local influence analysis under the Student-t distribution. For illustration purposes, we simply consider a bivariate normal distribution. Figure shows the IBM and S&P500's monthly log returns from May 1938 to December 2008 (a total of 848 cases).
Figure 3. Plots of time series for (a) IBM and (b) S&P500 monthly log-returns data.
5.2. Fitting a vector autoregressive model
First, we select the order of the VAR model to be one based on Table which is the result of the VARselect function of the MTS package implemented in the R software.
Table 1. Result of VARselect corresponding to the values of the Akaike (AIC) and Hannan–Quinn information (HQIC) criteria, score (SC), and final prediction error (FPE) for the IBM and S&P500 monthly log returns.
We find the estimates and
according to (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ) under the VAR(1) model given by
(24)
(24) where
In addition, we get the standardized residuals of the VAR(1) model, which are shown in Figure . In general, multivariate normality is based on the judgment of the marginal distributions, that is, if all marginal distributions of a multivariate distribution are normal, then the vector is considered to be multivariate normal distributed. In this case, there are very few non-normal multivariate sets. Therefore, the Kolmogorov–Smirnov test can be used to assess the normality of the residuals of each variable. Table reports the test results indicating the residuals follow a multivariate normal distribution because the p-value is greater than the critical point often employed for detecting significance, that is,
.
Figure 4. Plots of time series for standardized residuals of the VAR(1) model with (a) IBM and (b) S&P500 monthly log-returns data.
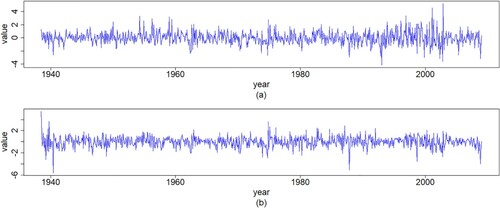
Table 2. Kolmogorov–Smirnov test for the standardized residuals of the VAR(1) model with IBM and S&P500 data.
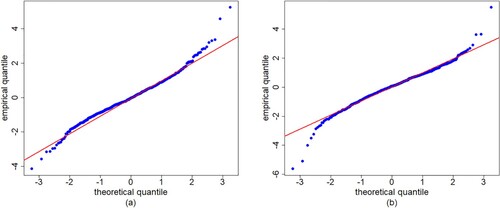
To compare the fit of the normal distribution with the empirical probability density function and the Student-t distribution curves, we standardize the data for these distributions to have the same mean and the same variance. Figure gives the empirical non-parametric estimate of the probability density function of the standardized residuals, considering the normal distribution and Student-t distribution with 10 degrees of freedom. From Figure , we can first see that the normal distribution and Student-t distribution are almost the same. From the quantile–quantile (QQ) plot shown in Figure , the fitting curve deviates from the diagonal and it is obvious that one point deviates from all the points, but most cases tend to fall on the line y = x, so the residual is approximately normal distribution. Then, the two distributions seems to provide an appropriate fit. We select the normal distribution.
Figure 5. Plots of probability density functions of the standardized residuals with (a) IBM and (b) S&P500 monthly log-returns data, for the indicated method/model.
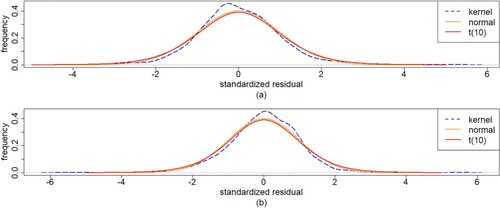
Figure 6. QQ plots of the residuals for the VAR(1) model with (a) IBM and (b) S&P500 monthly log-returns data.
5.3. SC test of the IBM and S&P500 data
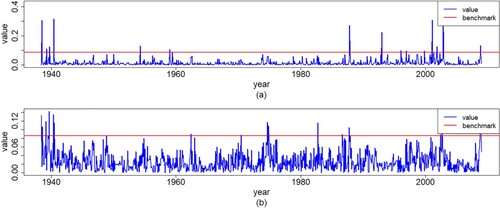
According to the VAR(1) model defined in Section 5.2, we can calculate the SC statistic of the MSOM and CWM structures. Then, we can get cases exceed the benchmark whose value is from the results given in (Equation14
(14)
(14) ). The cases are considered as strong influence cases (or outliers) at the 5% significance level. Thus we calculate the SC statistics of all case points in the two perturbation models and plot them in Figure . The horizontal line in the figures represents the benchmark, which is a reference for detecting whether the case is abnormal. When the SC statistic exceeds the horizontal line, the case result has a significant impact, such as presented in Table by the MSOM or CWM model. The symbol ‘
’ indicates that the outlier is identified by the corresponding perturbation model. We can see that the outliers identified by the CWM include the outliers identified by the MSOM. As mentioned in Section 4, the CWM is better than the MSOM.
Figure 7. Plots of values for the SC statistic and benchmark of the (a) MSOM and (b) CWM models with both IBM and S&P500 monthly log-returns data.
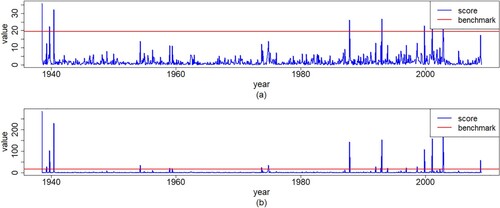
Table 3. Summary of SC test diagnostics with IBM and S&P500 data.
5.4. Modified data analysis
Next, we present a new VAR model given in (Equation25(25)
(25) ) after deleting the outliers identified in Section 5.3. The lag order of the new model is still one by using the AIC and BIC. The standardized residuals obtained after remodelling are shown in Figure . Then, the new VAR model is given by
(25)
(25) where
Comparing Figures and , we find that the standardized residuals of the VAR(1) model have almost no extreme values and are more stable. From Table , we see that the residuals of the VAR(1) model still pass the multivariate normal distribution test, which is a very positive signal. In Figure , the kernel density curves of the residuals and the normal density almost overlap, and the effect is better than that in Figure . The QQ plot of the IBM and S&P500 data shown in Figure is also better than that in Figure , and the points are more clearly distributed on the y = x line.
Figure 8. Plots of standardized residuals for the new VAR(1) model with (a) IBM and (b) S&P500 monthly log-returns data.
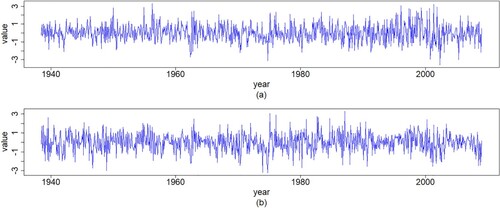
Figure 9. Plots of probability density functions of the standardized residuals with (a) IBM and (b) S&P500 monthly log-returns data, for the indicated method/model.
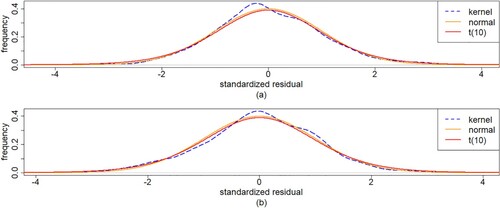
Figure 10. QQ plots of the residuals for the new VAR(1) model with (a) IBM and (b) S&P500 monthly log-returns data.
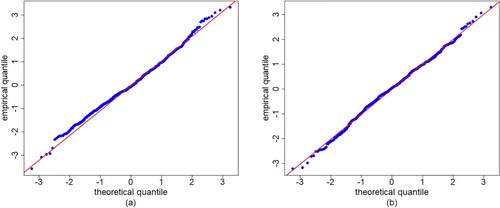
Table 4. Kolmogorov–Smirnov test for the standardized residuals of the new VAR(1) model with IBM and S&P500 data.
5.5. Comparison between SC test and local influence analyses
Next, we compare the result of Table with those presented in [Citation5,Citation6] (see Table ) to analyse the effect of two methods.
Table 5. Summary of the curvature-based diagnostics with log returns data for case-weights and data perturbations.
When the degrees of freedom of the Student-t distribution becomes large enough, this distribution is equivalent to the normal one. Therefore, the result of local influence analysis is obtained under the Student-t distribution such as in [Citation6] or the normal distribution as in [Citation5]. For this reason, the method of [Citation5] can also be used to diagnose the data in Section 5. Employing the bivariate VAR(1) model built in Section 5.2, we calculate the corresponding diagnostic vector and find as the empirical benchmark being the best through many experiments.
The horizontal line represents the empirical benchmark that determines whether a case is significantly influential in Figure . The case is significantly influential when its diagnostic value is beyond the horizontal lines such as reported in Table . It tallies the cases that are identified as influential for both IBM and S&P500 data, and again the symbol '' indicates that the outlier is identified through the perturbation of case-weights and data. Note that the cases indicated in Tables and actually correspond to certain material historical events. All these cases are concentrated in and after the 2008 financial crisis.
Figure 11. Plots of values for diagnostic vectors of (a) case-weights and (b) data perturbations with both IBM and S&P500 monthly log-returns data.
Interestingly, 71% of the SC test findings is exactly the same as those identified by the local influence analysis. It strongly illustrates that both methods are powerful to identify extreme cases including influential cases or outliers. The SC test and the local influence methods do detect different cases. The SC test identifies six outliers that the local influence method does not, while the local influence method detects five influential cases that the SC test does not. The local influence method can detect continuous-time extreme values, while the SC test is more accurate for the other cases. The benchmark of the SC test is dependent on the significance level, which may have statistical implications, while the local influence analysis can detect influential cases, which are not necessarily outliers. To conclude, the SC test method is indeed effective as used in [Citation35].
6. Concluding remarks
In this paper, we have studied statistical diagnostics based on the score test with a vector autoregressive model under normal distributions. We have derived the information matrix under the mean-shift perturbation and case-weight perturbation models, and obtained their corresponding score statistics. Then, building the three-dimensional and two-dimensional vector autoregressive models, we have examined the effectiveness of the mean-shift and the case-weight perturbations. In addition, we have made an empirical analysis for the logarithm of the weekly returns of IBM and S&P500 from May 1938 to December 2008. After deleting those outliers identified, our updated model is better than the original model. We have also compared our results with those by the local influence analysis. Finally, we have concluded that the score test method is effective.
Acknowledgements
We would like to thank the Editors and Reviewers very much for their insightful and constructive comments which led to an improved presentation of the manuscript. The research of Y. Liu was supported by the National Social Science Fund of China [grant No. 19BTJ036]. The research of V. Leiva was partially funded by the National Agency for Research and Development (ANID) [project grant number FONDECYT 1200525] of the Chilean government under the Ministry of Science, Technology, Knowledge, and Innovation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Dai X, Jin L, Tian M. Bayesian local influence for spatial autoregressive models with heteroscedasticity. Stat Pap. 2019;60(5):1423–1446.
- Kargoll B, Dorndorf A, Omidalizarandi M, et al. Adjustment models for multivariate geodetic time series with vector-autoregressive errors. J Appl Geodesy. 2021;15(3):243–267.
- Leiva V, Saulo H, Souza R, et al. A new BISARMA time series model for forecasting mortality using weather and particulate matter data. J Forecast. 2021;40(2):346–364.
- Liu T, Liu S, Shi L. Time series analysis using SAS enterprise guide. Singapore: Springer; 2020.
- Liu Y, Ji G, Liu S. Influence diagnostics in a vector autoregressive model. J Stat Comput Simul. 2015;85(13):2632–2655.
- Liu Y, Sang R, Liu S. Diagnostic analysis for a vector autoregressive model under student-t distributions. Stat Neerl. 2017;71(2):86–114.
- Lütkepohl H. New introduction to multiple time series analysis. Berlin, Germany: Springer; 2005.
- Meintanis SG, Ngatchou-Wandji J, Allison J. Testing for serial independence in vector autoregressive models. Stat Pap. 2018;59(4):1379–1410.
- Nduka UC, Ugah TE, Izunobi CH. Robust estimation using multivariate t innovations for vector autoregressive models via ECM algorithm. J Appl Stat. 2021;48(4):693–711.
- Tsay RS. Multivariate time series analysis: with R and financial applications. New York: Wiley; 2014.
- Atkinson AC, Riani M, Cerioli A. Exploring multivariate data with the forward search. Berlin, Germany: Springer; 2004.
- Cook RD. Assessment of local influence (with discussion). J R Stat Soc B. 1986;48:133–169.
- Li WK. Diagnostic checks in time series. Boca Raton, FL: Chapman & Hall/CRC; 2004.
- Liu S, Leiva V, Zhuang D, et al. Matrix differential calculus with applications in the multivariate linear model and its diagnostics. J Multivar Anal. 2022;188:104849.
- Liu S, Welsh AH. Regression diagnostics. In Lovric M editor. International Encyclopedia of Statistical Science. New York: Springer; 2011. p. 1206–1208.
- Pan JX, Fang KT. Growth curve models and statistical diagnostics. New York: Springer; 2002.
- von Rosen D. Influential observations in multivariate linear models. Scand J Stat. 1995;22: 207–222.
- von Rosen D. Bilinear regression analysis. Cham, Switzerland: Springer; 2018.
- Hao CC, von Rosen D, von Rosen T. Local influence analysis in AB-BA crossover designs. Scand J Stat. 2014;41(4):1153–1166.
- Kim SK, Huggins R. Diagnostics for autocorrelated regression models. Aust N Z J Stat. 1998;40(1):65–71.
- Paula GA. Influence diagnostics for linear models with first-order autoregressive elliptical errors. Stat Probab Lett. 2009;79(3):339–346.
- Shi L, Ojeda M. Local influence in multilevel regression for growth curve. J Multivar Anal. 2004;91(2):282–304.
- Tsai CL, Wu X. Assessing local influence in linear regression models with first-order autoregressive or heteroscedastic error structure. Stat Probab Lett. 1992;14(3):247–252.
- Liu S. On diagnostics in conditionally heteroskedastic time series models under elliptical distributions. J Appl Probab. 2004;41A:393–405.
- Liu S, Heyde CC. On estimation in conditional heteroskedastic time series models under non-normal distributions. Stat Pap. 2008;4(3):455–469.
- Liu S, Neudecker H. On pseudo maximum likelihood estimation for multivariate time series models with conditional heteroskedasticity. Math Comput Simul. 2009;79(8):2556–2565.
- Liu Y, Mao C, Leiva V, et al. Asymmetric autoregressive models: statistical aspects and a financial application under COVID-19 pandemic. J Appl Stat. 2022;49(5):1323–1347.
- Liu Y, Mao G, Leiva V, et al. Diagnostic analytics for an autoregressive model under the skew-normal distribution. Mathematics. 2020;8(5):693.
- Liu Y, Wang J, Yao Z, et al. Diagnostic analytics for a GARCH model under skew-normal distributions. Commun Stat Simul Comput. 2022;1:1–25. doi:10.1080/03610918.2022.2157015
- Lu J, Shi L, Chen F. Outlier detection in time series models using local influence method. Commun Stat: Theory Methods. 2012;41(12):2202–2220.
- Rao CR. Linear statistical inference and its applications. New York: Wiley; 1973.
- Rao CR. Score test: Historical review and recent developments. In Balakrishnan N, Nagaraja HN, Kannan N, editors, Advances in Ranking and Selection, Multiple Comparisons, and Reliability. Boston: Birkhäuser; 2005. p. 3–20.
- Engle RF. Wald, likelihood ratio, and Lagrange multiplier tests in econometrics. In: Intriligator MD and Griliches Z, editors. Handbook of Econometrics. Vol. II, Amsterdam: Elsevier; 1984. p. 775–826.
- Godfrey LG. Misspecification tests in econometrics. Cambridge: Cambridge University Press; 1988.
- Gumedze F, Welham S, Gogel B. A variance shift model for detection of outliers in the linear mixed model. Comput Stat Data Anal. 2010;54(9):2128–2144.
- Jiang D. Tests for large-dimensional covariance structure based on Rao's score test. J Multi Anal. 2016;152:28–39.
- Kirch C, Muhsal B, Ombao H. Detection of changes in multivariate time series with application to EEG data. J Am Stat Assoc. 2015;110(511):1197–1216.
- Kollo T, von Rosen D. Advanced multivariate statistics with matrices. New York: Springer; 2005.
- Magnus JR, Neudecker H. Matrix differential calculus with applications in statistics and econometrics. Chichester: Wiley; 2019.
- Ferguson TS. On the rejection of outliers. In: Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability. Vol. 1, 1961. p. 253–287.
Appendix
Based on the matrix differential calculus developed and used in, e.g. [Citation14,Citation38,Citation39], we establish the results.
A.1. Proof of Theorem 3.1
Proof.
For Equation (Equation19(19)
(19) ), we obtain
so
and with regard to
, we obtain that
Therefore, we acquire that
By
, in the same way, we attain that
Then
By
, we get that
So
Taking equation (Equation19
(19)
(19) ) into consideration, we obtain
From
, we deduce that
So we gain that
By considering
, in the same way, we attain that
Thereby we arrive that
Another form of
should be applied due to deriving
. By Equation (Equation18
(18)
(18) ), we know that
Through
, we obtain that
Then, we get that
According to Equation (Equation18
(18)
(18) ), we have that
We gain that, by
,
Thus we have
By
, we have that
Therefore, we acquire that
We have that, through
,
Hence, we derive that
In summary, the information matrix of mean-shift model is proposed as
A.2. Proof of Theorem 3.2
Proof.
For Equation (Equation23(23)
(23) ), we obtain
Hence,
and with regard to
, we obtain that
Therefore, we acquire that
By
, in the same way, we attain that
Thus
Taking Equation (Equation22
(22)
(22) ) into consideration, we get
From
we deduce that
Then, we gain that
By considering
, in the same way, we attain that
Thereby, we arrive that
Another form of
should be applied due to deriving
. By Equation (Equation22
(22)
(22) ) we know that
Through
, we obtain that
Thus we get that
According to Equation (Equation22
(22)
(22) ), we have that
We gain that by
So we have
By
we have that
Therefore, we acquire that
We have that, through
,
Thus we derive that
In summary, the information matrix of case-weight model is proposed as follows: