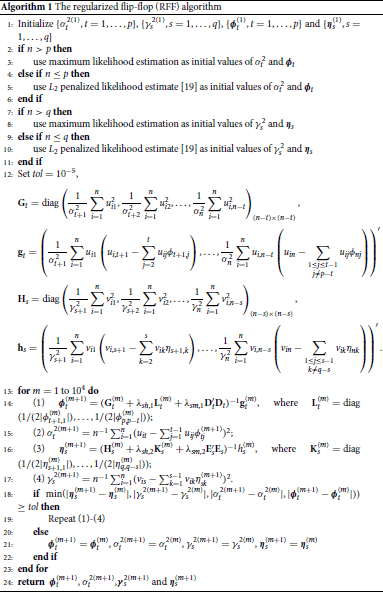?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we study a Kronecker structured model for covariance matrices when data are matrix-valued. Using the modified Cholesky decomposition for Kronecker structured covariance matrix, we propose a regularized covariance estimator by imposing shrinkage and smoothing penalties on the Cholesky factors. A regularized flip-flop (RFF) algorithm is developed to produce a statistically efficient estimator for a large covariance matrix of matrix-valued data. Asymptotic properties are investigated and the performance of the estimator is evaluated by simulations. The results presented are applied to real data example.
1. Introduction
Matrix-valued data are commonly encountered in many practical problems such as environmental science [Citation1], image analysis [Citation2] and electrical engineering [Citation3], to mention a few, when the observations are collected from two different dimensions such as spatial-temporal data with measurements at different locations observed repeatedly over a few times. Kronecker product covariance matrix, which can be represented as a Kronecker product of two covariance matrices, plays an important role when separability of the covariance structure is assumed for the matrix-valued data. The term ‘separability’ comes from the assumption that the temporal correlation is the same for all locations and similarly the spatial correlation is the same for all time points (Kronecker product covariance matrix is also called separable covariance matrix). That is saying, for the spatial-temporal data, the covariance matrix can be represented as a Kronecker product of a covariance matrix which modelling the dependence over the locations and another covariance matrix
which modelling the dependence over the time points.
Using a Kronecker product covariance matrix whenever possible is advantageous since compared with the totally unstructured covariance matrix, it consists of less number of unknown parameters, and at the same time, the separability property for a covariance structure captures the important dependence present in the data. More recently, Bucci et al. [Citation4] proposed a method of forecasting covariance matrices through a parametrization of the matrices. Yang and Kang [Citation5] introduced a way for matrix decomposition for the large banded covariance matrix. Jurek and Katzfuss [Citation6] investigated an algorithm as a hierarchical Vecchia approximation to estimate both covariance matrix and the precision matrix. It should be mentioned, that in some circumstances, it will be reasonable to assume further structures on both and
, which further reduces the number of unknown parameters, see Filipiak and Klein [Citation7], Hao et al. [Citation8], Szczepańska-Álvarez et al. [Citation9] for instance. However, the statistical inference of Kronecker product covariance matrix has faced some challenges, especially regarding the estimating procedure. Among others, this type of structure has a non-identifiability issue which means the estimators will not be unique without imposing a restriction on the parameters. Srivastava et al. [Citation10] imposed a restriction on the matrix
, i.e.
and proved the uniqueness of maximum likelihood estimators (MLEs) of
and
via the flip-flop algorithm.
Nowadays datasets are becoming increasingly large and may be high-dimensional, that is, the number of variables is bigger than the sample size. In a high-dimensional situation, obtaining a stable and efficient estimator for the covariance matrix is difficult, which is one major obstacle in modelling covariance matrices. It has been already pointed out in the 1950s by Stein [Citation11] that the MLE of the covariance matrix, the sample covariance matrix, is not a good estimator when the matrix dimension is relatively or very large with respect to the sample size. The other major obstacle is to preserve positive definiteness of covariance matrices. Many good methods have been developed during the years under the assumption of sparsity of the high-dimensional covariance matrix, for example, the generalized thresholding method [Citation12] and the blocked thresholding method [Citation13]. However, these regularized methods do not guarantee the covariance estimator is positive definite.
To overcome these obstacles, the study of high-dimensional covariance estimation has paid a lot of attention to the framework of the modified Cholesky decomposition (MCD). MCD is a completely unconstrained and interpretable reparameterization of a covariance matrix [Citation14,Citation15]. Bickel and Levina [Citation16] showed that banding the Cholesky factor can produce a consistent estimator in the operator norm under weak assumptions on the covariance matrix. Huang et al. [Citation17] showed that shrinkage is very useful in providing a more stable estimate of a covariance matrix, especially when the dimension is high. Dai et al. [Citation18] proposed a new type of Mahalanobis distance based on the regularized estimator of precision matrix.
Imposing only regularization on MCD ignores the dependence among the neighbouring elements of the covariance matrix which is a natural property for longitudinal data. In this paper, we adopt the idea of Tai [Citation19] and employ not only shrinkage but also smoothing penalty. The proposed regularization scheme of Dai et al. [Citation18] was motivated by two observations of the Cholesky factor. Firstly, the Cholesky factor is likely to have many off-diagonal elements that are zero or close to zero. Secondly, continuity is a natural property among neighbouring elements of the Cholesky factor for the covariance matrices of longitudinal data. Taking smoothness into account can help to provide more efficient covariance matrix estimates.
This paper aims to obtain regularized MLEs for and
which are computationally feasible when p, q are large, as well as to develop exploratory tools to investigate further structures of column/row covariance matrices of the matrix-valued data. The novelty of this paper is that the separability assumption is taken into account and the regularization techniques are incorporated when estimating the covariance of matrix-valued data using MCD. A so-called regularized flip-flop algorithm (RFF) will be proposed in a later section.
The rest of the paper is organized as follows. In Section 2, we introduce the modified Cholesky decomposition and the extension when it is applied to the Kronecker product covariance structures as well as review the MLE procedure of this type of covariance structure. In Section 3, we propose regularized estimators of and
based on combining shrinkage and smoothing. The main theoretical results are presented in Section 4. A simulation study is conducted in Section 5 to evaluate the performance of the proposed estimators. In Section 6 the obtained results are illustrated with a real data example. Some discussions are given in Section 7.
Throughout the paper, we use the following notations. For a matrix ,
denotes the transpose,
is the trace,
is the inverse matrix,
is the determinant,
is the diagonalizing operator and
is the vectorizing operator of
, respectively. Moreover,
,
and the matrix
denotes the Kronecker product of
and
. As such,
denotes the Kronecker product of
and
.
denotes the true parameter of the underlying model. Operators
and
are the infinitely large quantity and infinitely small quantity, and
and
denote that relationships hold with probability tending to 1.
2. Modified Cholesky decomposition of a Kronecker product covariance structure
In this section, we will first give a short review of MCD. Then we present the MLE of the Kronecker product covariance structure. The MLE is provided by using an iterative algorithm which is referred to as the ‘flip-flop algorithm’ [Citation20]. At the end of this section, the MCD of the Kronecker product covariance structure is given.
2.1. Modified Cholesky decomposition
Suppose that is a random matrix which consists of n independent p-dimensional random vectors with mean
and the covariance matrix
. Let
follow
. With a covariance matrix
of order p, the modified Cholesky decomposition [Citation14] of
is specified by
(1)
(1) and thus,
, where
is a unique unit lower triangular matrix with ones on the main diagonal and
is a unique diagonal matrix, i.e.
Based on Equation (Equation1
(1)
(1) ) and the property that normality is preserved under linear transformations, we have
(2)
(2) which turns out that Equation (Equation2
(2)
(2) ) can be represented as the following linear model:
(3)
(3) where
and
are the generalized autoregressive parameters and innovation variances, respectively. Observing Equation (Equation2
(2)
(2) ) has been split into p independent simple linear regression models and the MLEs of the unknown parameters in (Equation3
(3)
(3) ) are actually ordinary least squares (OLS) estimators. It can be seen that MCD provides an alternative MLE estimation procedure of
through a sequential regression scheme, which reduces the challenge of estimating a covariance matrix.
2.2. Maximum likelihood estimation
Let be a random matrix which is normally distributed and we can write
(4)
(4) where
is an
unstructured mean,
is an
unstructured covariance between rows of
at any given column and
is an
unstructured covariance between columns of
at any given row. Both
and
are unknown, positive definite matrices. Without loss of generality, we consider the case
. Equivalently, the vectorized version of model (Equation4
(4)
(4) ) can be written as
(5)
(5) How to estimate the covariance structure
in Equation (Equation5
(5)
(5) ) has been discussed intensively in the statistical literature, especially in the MLE framework, see, e.g. Galecki [Citation21], Lu and Zimmerman [Citation20], Manceur and Dutilleul [Citation22], Naik and Rao [Citation23], Roy and Khattree [Citation24]. The log-likelihood function of (Equation5
(5)
(5) ) is
(6)
(6) where
. It has been noticed that there is no explicit expression for the MLE of both
and
, and the reason is that there are no analytical solutions to the system of two matrix equations below:
(7)
(7) where
and
is
,
. An iterative algorithm, the flip-flop algorithm, is therefore required and it proceeds by iteratively updating
and
, and iterations continue until some convergence criterion is fulfilled, e.g. the Euclidean distance between successive Kronecker product estimates is smaller than some given threshold. Regarding conditions on the sample size n for the existence of the MLE of a Kronecker product covariance matrix, see Table 1 of Dutilleul [Citation25] for a summary. Nevertheless, for positive definiteness of the estimators
and
, the sample size n must be greater than p and greater than q, giving
, which was suggested by Srivastava et al. [Citation10].
It is worth mentioning that there is an unidentifiable issue in since
for any constant c, see, e.g. Galecki [Citation21], Naik and Rao [Citation23]. Thus, for the purpose of identifiability, we shall assume the first element of
as
. Denote
as
under the restriction
.
2.3. MCD of a Kronecker product covariance structure
The estimating equations in (Equation7(7)
(7) ) will look different depending on the structures of
and
. Szczepańska-Álvarez et al. [Citation9] studied four Kronecker product covariance structures by imposing different restrictions on the pair of matrices
,
. The authors have obtained likelihood estimation equations for these covariance structures which give the possibility to utilize flip-flop type algorithms with clear stopping rules.
In this subsection, we consider MCD of the covariance matrix . The following theorem provides us with an important result concerning the parameter space of
when the MCD is performed.
Theorem 2.1
Let , the unique MCD for
such that
has the following pattern:
where
and
are two different unique unit lower triangular matrices,
,
,
,
. The matrices
and
are two different diagonal matrices.
Proof.
Since is a unique unit lower triangular matrix, it can be reformulated as
, where
and
are also triangular matrices. Then we have
Observing that under the identifiable restriction
, it follows that
, which implies that
. On the other hand, if
, based on the fact
, where
is also a unit triangular matrix [Citation26], hence we have
in
, i.e.
.
The results in Theorem 2.1 reveal that the MCD of Kronecker product covariance structure also has a Kronecker product pattern and it is a one-to-one transformation of the original parameter space. Moreover, the identifiable restriction only affects the diagonal matrix
and does not affect the matrices
and
, which is important when we introduce the penalty terms in the next section.
3. Regularized estimation of Kronecker product covariance structure
Using Theorem 2.1 and the property that matrix-variate normality is preserved under linear transformations, model (Equation4(4)
(4) ) gives
. With the facts
,
,
and
, the log-likelihood function given in (Equation6
(6)
(6) ), can be expressed as
(8)
(8) We will now discuss how to estimate
when both
and
have patterned structures (certain parsimonies) such as first-order autoregressive (AR(1)) and compound symmetry (CS). Parsimony in a covariance matrix leads to parsimony in the Cholesky factor, which corresponds to many zeros or small elemetns in the regression coefficients. For example, for an AR(1) covariance matrix, there could be considerable amount of zeros in the subdiagonals of the
matrices. In particular, the first subdiagonal of
has the same entry in all places, and the rest of the subdiagonals are either zero or contain minor values that are close to zero. For a CS covariance matrix, the elements of each row of the Cholesky factor matrix are the same, and one can expect that there are many small value elements in the last few rows of the lower triangular part of
. One can observe that, with a specific pattern for
and
, the corresponding Cholesky factor matrix components in Theorem 2.1,
matrices where m = 1, 2, are potentially sparse or nearly sparse.
In order to take into account both sparsity and smoothness, we apply the penalty which shrinks the estimates of
's and
's toward zero, and at the same time introduce the smoothing penalties in the framework of penalized likelihood. The shrinkage penalties are given as follows:
(9)
(9) where
and
are the shrinkage tuning parameters. The smoothing penalties have the forms
(10)
(10) where
and
are the smoothing tuning parameters, and
are the second order differences of
and
, respectively. Combining the penalties given in (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ), the penalized likelihood function can be presented as:
(11)
(11) where
is given in (Equation8
(8)
(8) ).
The maximizer of (Equation11(11)
(11) ) does not have a closed-form expression. Hence, we extend the flip-flop algorithm [Citation20,Citation27] to incorporate the
penalties in (Equation9
(9)
(9) ) and smoothing penalties in (Equation10
(10)
(10) ). We estimate the matrices
based on the following steps.
Step 1: With fixed and
, update
,
with
Step 2: With fixed
and
, update
,
, with
where
is the tth row of the mode 1 unfolding of
and
is the sth column of the mode 2 unfolding of
. The pseudo-code of the algorithm, the regularized flip-flop (RFF) algorithm, is described in Algorithm 1 in Appendix 3.
4. Main results: theoretical convergence
This section shows the asymptotic properties of the proposed estimator. We start with some assumptions that are needed for the theoretical analysis of the penalized likelihood function.
Let and
be the number of nonzero elements in the lower-triangular part of
and
, respectively. Suppose that
| (C1) | There exists a constant d such that: | ||||
| (C2) |
| ||||
| (C3) |
| ||||
Under the above assumptions, we can establish the following theorem.
Theorem 4.1
Suppose that Assumptions (C1) to (C3) hold. Let the shrinkage tuning parameters satisfy and
. Let the smoothing tuning parameters satisfy
where
,
,
, and
. Then, we have
The proof of this theorem is relegated to Appendix 2. Theorem 4.1 shows convergence rates for the decomposed components of the covariance matrices and
. This result suggests a small scope for choosing the candidate values for
. On the other hand, adding smoothing terms together with shrinkage will avoid unnecessary disturbances that may be caused by very few but irregular roughness values in the covariance matrices. This problem is not obvious in the estimation of the covariance matrix. But it can lead to some difficulties when inverting covariance matrix is needed. Jiang [Citation28] considered the MCD of the covariance matrix
, without the Kronecker product of
and
. It gives the following convergence rates,
Theorem 4.1 implies that, when taking the Kronecker structure into account, the convergence rates are faster than the rates obtained by [Citation28].
5. Simulations
In this section, we conduct a simulation study in order to assess the finite-sample performance of the proposed estimation presented in Section 3.
We generate as defined in (Equation4
(4)
(4) ), from a matrix-normal distribution with
with the covariance matrices
and
. We assume that
has an AR(1) structure with a correlation coefficient
and
has a CS structure with a correlation coefficient of 0.5. Additionally, we allow both covariance matrices to have different variances along the main diagonals, i.e.
has a heterogeneous AR(1) and
has a heterogeneous CS structure, respectively. They are denoted ARH(1) and CSH. The correlation matrix of ARH(1) is AR(1) and correspondingly the correlation matrix of CSH is CS.
The combinations of dimensions (n, p, q) are chosen to be ,
,
, and
. The first combination corresponds to the scenario where
, and the second combination corresponds to the scenario where
. The third and fourth scenarios correspond to
. The fourth scenario also allows us to test the performance of the estimator in an extreme case with n = q<<p. For each combination, the number of replications is 1000. The estimators considered include the
penalized estimator with smoothing. As a comparison, we also include the unpenalized MLE, the
penalized estimator without smoothing, and only smoothing penalties. To select the tuning parameters, the candidate values of the tuning parameters
are chosen from the interval of
with an increment of 10 each time. A five-fold cross-validation is utilized in order to find out the optimal values of
and
.
Let be the estimated covariance matrix of
. In order to compare different estimators we use the following entropy and quadratic loss of two matrices to assess the estimator error:
For each estimated correlation matrix, we compute the risk function which is the mean of the entropy loss across 1000 replications. The simulation results are presented in Tables . The cases which have the smallest risk are in bold face.
Table 1. Risk functions based on the entropy and quadratic loss for the corresponding estimated covariance matrices with
.
Table 2. Risk functions based on the entropy and quadratic loss for the corresponding estimated covariance matrices with
.
Table 3. Risk functions based on the entropy and quadratic loss for the corresponding estimated covariance matrices with
.
Based on the estimated risks as shown in the tables above, it is evident that shrinkage combined with smoothing along the subdiagonals outperforms the unpenalized MLE, using only shrinkage, and only smoothing, for every combination of under both loss functions. The case where
is a classical set of dimensions and the differences between MLE and other penalized methods are relatively small since MLE works satisfactorily when n is large. It is interesting to see that combining the shrinkage
penalty and the smoothing outperforms when p is much larger than n and q and the improvement is substantial especially. This setting is introduced with the consideration that both the ratio
and
could be troublesome from the estimation point of view.
Only shrinkage with the penalty works better than only smoothing along the subdiagonals because there are many zero entries in the
matrix and shrinkage is preferable. For the Kronecker structured covariance with AR(1) and CS, smoothing contributes less to the proposed combined method compared to shrinkage. Smoothing the subdiagonals performs somehow better than MLE due to the subdigonals of
are also smooth and it takes the smoothness of
into account which the shrinkage method entirely ignores.
In general, combining smoothing and shrinkage gives satisfactory results for all settings of dimensions while using shrinkage alone works considerably well in several cases. The reduction in bias has become clear when we combine smoothing and shrinkage or only shrinkage on both and
. But the difference between these two methods is minor especially when the n = p = q. In this case, the shrinkage method is recommended due to the simplicity of implementation and computational efficiency. On the other hand, combining smoothing and shrinkage offers a handy tool when dealing with some extreme situations when n = q<<p.
6. A real data example
In this section, we apply the RFF algorithm with MCD to fit the correlation matrix between channels of Electroencephalography (EEG) data which has been analysed in [Citation29]. The data set is collected from a large study to examine EEG correlates of genetic predisposition to alcoholism. EEG voltages are recorded at 256 Hz for 1 second following the presentation of Figure . There are two groups of subjects: alcoholic and control. Each subject is exposed to either a single stimulus (S1) or two stimuli (S1 and S2) which are pictures of objects. The data contains 26 parietal and occipital channel data with 5 trials (replications) from 10 alcoholic and 10 control subjects.
Figure 1. Presentation of recording on EEG voltages.
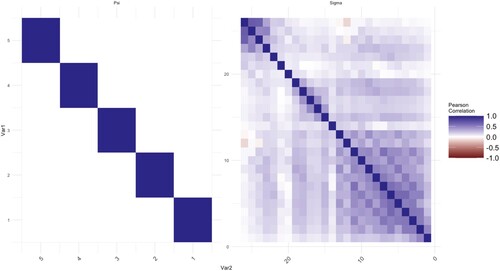
We calculate the means of voltage series. The proposed method is applied to analyse correlations of the mean voltages among channels. Thus, there are two datasets of size p = 26, q = 5, and , respectively. In this application, we use a five-fold cross-validated log-likelihood criterion to choose optimal values of tuning parameters. The estimated covariance matrix and correlation matrix are plotted in Figures where the elements in the matrix are represented by the darkness of two colours. The bluer the colour is, the closer the value of the elements to 1. On the other hand, the redder the colour is, the closer the value of the elements to −1.
Figure 2. Estimated correlation matrices for the alcoholic group using MLE.
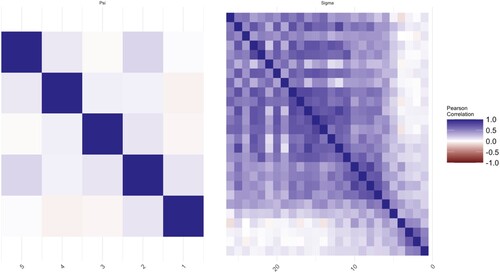
Each figure consists of two parts, the left-hand side is the plot of the elements in the matrix of . The right-hand side is the plot of
. The MLEs of the covariance matrices are given in Figures and as a benchmark. In Figure , there are some non-zero elements exist after a few empty elements in the off-diagonal areas, for example, the further upper-right area and lower-left area of
. This is the sparsity issue for longitudinal data. Intuitively, a further period implies a weaker connection between two-time points. For some practical needing, one would like to get rid of the effect of noises with long-term memory in the repeated measurements to reduce the bias of estimations. The same results can be observed from the MLEs of
as well. The noises in
at control groups are more obvious as we move from the diagonal to the upper-right and lower-left corners. The MCD-based estimations are given in Figures and . The noises for both
and
are shrunk and smoothed out on the further corners from the diagonal respectively. On the other hand, the information which is close to the diagonal is kept as shown in those figures.
Figure 3. Estimated correlation matrices for the control group using MLE.
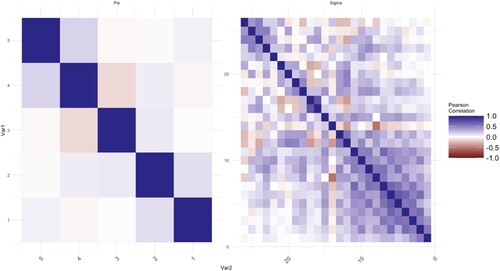
Figure 4. Estimated correlation matrices for the alcoholic group using the proposed method.
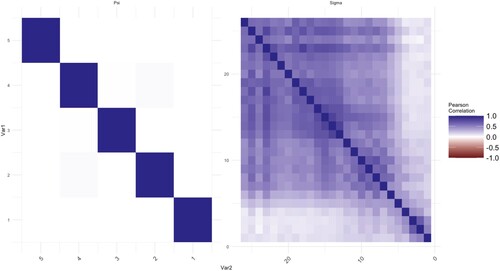
Figure 5. Estimated correlation matrices for the control group using the proposed method.
7. Conclusion
We propose a novel method to estimate Kronecker structured covariance matrix for matrix-valued data. The considered matrix is decomposed by MCD and each component from the decomposition is considered separately. Shrinkage and smoothing techniques are employed to take the typical features of the Cholesky factors into account and reduce the bias caused by the sparsity from large longitudinal data. The performance of RFF is illustrated by both simulations and empirical studies, which shows that the combination is useful. The theoretical results give the estimators' convergence rates and the upper bounds to the Kronecker product of components via MCD are derived.
The proposed approach is developed using MCD method which requires a pre-knowledge on the variable ordering. Natural ordering is typical for longitudinal data. When the situation arises that the variables do not have a natural ordering among themselves, this problem is of great interest and will be studied separately.
In this article we only study the Kronecker estimate for matrix-valued data. One possible extension is to consider the Kronecker covariance structure on array data, i.e. the Kronecker products of three or more components matrices, in this case model (Equation5(5)
(5) ) becomes the array-normal distribution [Citation30,Citation31]. It is worthwhile to develop regularized methods further under this framework.
Acknowledgments
The authors thank the editor, the associate editor and two anonymous reviewers for their insightful comments which have resulted in significant improvement of this manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Srivastava MS, von Rosen T, von Rosen D. Estimation and testing in general multivariate linear models with Kronecker product covariance structure. Sankhyā: Indian J Stat Ser A. 2009;71(2):137–163.
- Dryden IL, Kume A, Le H, et al. A multi-dimensional scaling approach to shape analysis. Biometrika. 2008;95:779–798. doi: 10.1093/biomet/asn050
- Werner K, Jansson M, Stoica P. On estimation of covariance matrices with Kronecker product structure. IEEE Trans Signal Process. 2008;56:478–491. doi: 10.1109/TSP.2007.907834
- Bucci A, Ippoliti L, Valentini P. Comparing unconstrained parametrization methods for return covariance matrix prediction. Stat Comput. 2022;32:90. doi: 10.1007/s11222-022-10157-4
- Yang W, Kang X. An improved banded estimation for large covariance matrix. Commun Stat – Theory Methods. 2023;52:141–155. doi: 10.1080/03610926.2021.1910839
- Jurek M, Katzfuss M. Hierarchical sparse Cholesky decomposition with applications to high-dimensional spatio-temporal filtering. Stat Comput. 2022;32:15. doi: 10.1007/s11222-021-10077-9
- Filipiak K, Klein D. Approximation with a Kronecker product structure with one component as compound symmetry or autoregression. Linear Algebra Appl. 2018;559:11–33. doi: 10.1016/j.laa.2018.08.031
- Hao C, Liang Y, Mathew T. Testing variance parameters in models with a Kronecker product covariance structure. Stat Probab Lett. 2016;118:182–189. doi: 10.1016/j.spl.2016.06.027
- Szczepańska-Álvarez A, Hao C, Liang Y, et al. Estimation equations for multivariate linear models with Kronecker structured covariance matrices. Commun Stat – Theory Methods. 2017;46:7902–7915. doi: 10.1080/03610926.2016.1165852
- Srivastava MS, von Rosen T, Von Rosen D. Models with a Kronecker product covariance structure: estimation and testing. Math Methods Stat. 2008;17:357–370. doi: 10.3103/S1066530708040066
- Stein C. Some problems in multivariate analysis. Stanford University, Department of Statistics; 1956. (Part I, Technical Report 6).
- Rothman AJ, Levina E, Zhu J. Generalized thresholding of large covariance matrices. J Am Stat Assoc. 2009;104:177–186. doi: 10.1198/jasa.2009.0101
- Cai TT, Yuan M. Adaptive covariance matrix estimation through block thresholding. Ann Statist. 2012;40:2014–2042.
- Pourahmadi M. Joint mean-covariance models with applications to longitudinal data: unconstrained parameterisation. Biometrika. 1999;86:677–690. doi: 10.1093/biomet/86.3.677
- Pourahmadi M. Maximum likelihood estimation of generalised linear models for multivariate normal covariance matrix. Biometrika. 2000;87:425–435. doi: 10.1093/biomet/87.2.425
- Bickel PJ, Levina E. Covariance regularization by thresholding. Ann Statist. 2008;36:2577–2604.
- Huang JZ, Liu N, Pourahmadi M, et al. Covariance matrix selection and estimation via penalised normal likelihood. Biometrika. 2006;93:85–98. doi: 10.1093/biomet/93.1.85
- Dai D, Pan J, Liang Y. Regularized estimation of the Mahalanobis distance based on modified Cholesky decomposition. Commun Stat Case Stud Data Anal Appl. 2022;8(4):1–15.
- Tai W. Regularized estimation of covariance matrices for longitudinal data through smoothing and shrinkage [PhD thesis]. Columbia University; 2009.
- Lu N, Zimmerman DL. The likelihood ratio test for a separable covariance matrix. Stat Probab Lett. 2005;73:449–457. doi: 10.1016/j.spl.2005.04.020
- Galecki AT. General class of covariance structures for two or more repeated factors in longitudinal data analysis. Commun Stat – Theory Methods. 1994;23:3105–3119. doi: 10.1080/03610929408831436
- Manceur AM, Dutilleul P. Maximum likelihood estimation for the tensor normal distribution: algorithm, minimum sample size, and empirical bias and dispersion. J Comput Appl Math. 2013;239:37–49. doi: 10.1016/j.cam.2012.09.017
- Naik DN, Rao SS. Analysis of multivariate repeated measures data with a Kronecker product structured covariance matrix. J Appl Stat. 2001;28:91–105. doi: 10.1080/02664760120011626
- Roy A, Khattree R. On implementation of a test for Kronecker product covariance structure for multivariate repeated measures data. Stat Methodol. 2005;2:297–306. doi: 10.1016/j.stamet.2005.07.003
- Dutilleul P. A note on necessary and sufficient conditions of existence and uniqueness for the maximum likelihood estimator of a Kronecker-product variance–covariance matrix. J Korean Stat Soc. 2021;50:607–614. doi: 10.1007/s42952-020-00066-5
- Harville DA. Matrix algebra from a statistician's perspective; New York, NY: Springer; 1998.
- Dutilleul P. The MLE algorithm for the matrix normal distribution. J Stat Comput Simul. 1999;64:105–123. doi: 10.1080/00949659908811970
- Jiang X. Joint estimation of covariance matrix via Cholesky decomposition [PhD thesis]. National University of Singapore; 2012.
- Sykacek P, Roberts SJ. Adaptive classification by variational Kalman filtering. Adv Neural Inf Process Syst. 2002;15:753–760.
- Hoff PD. Separable covariance arrays via the tucker product, with applications to multivariate relational data. Bayesian Anal. 2011;6:179–196.
- Leng C, Pan G. Covariance estimation via sparse Kronecker structures. Bernoulli. 2018;24:3833–3863. doi: 10.3150/17-BEJ980
- Lam C, Fan J. Sparsistency and rates of convergence in large covariance matrix estimation. Ann Stat. 2009;37:4254. doi: 10.1214/09-AOS720
Appendices
Appendix 1.
Some lemmas
Lemma A.1
Suppose that the eigenvalues of ,
,
and
are bounded by
and d, and that
. Consider
and
, such that Assumption (C2) holds. Then, for any
, there exists
and
such that
for all
.
Proof of Lemma A.1.
Since the eigenvalues of and
are bounded,
is also bounded. Then,
By Assumption (C2),
. Hence, by Lemma 3 in [Citation32], we have
which establishes the first claim in this lemma.
Note that
Hence, by Lemma 3 in [Citation32], we have
Consequently,
which establishes the second claim in this lemma.
Lemma A.2
For the lower triangular matrices and
in MCD,
Proof
Proof of Lemma A.2
Note that the diagonal entries of and
are all 1's. Then, for
, the
th block of
is simply
. When
, the
th block matrix is
. Its diagonal entries are all
, yielding
. Hence,
which establishes the lemma.
Appendix 2.
Proof of Theorem 4.1
In this section, we will prove Theorem 4.1. Our proof by and large follows the steps in [Citation28], but takes the MCD structure into account.
Under Assumption (C1), Lemma 2 of Jiang [Citation28] implies that
for i = 1, 2, where
denotes the singular value of
. Set
,
, i = 1, 2. Since the eigenvalues of
are bounded, we also have
Let
be the log-likelihood, and
be
times the difference between the penalized likelihood function of the estimated covariance matrix and the true covariance matrix, where
,
,
, and
. Consider
,
,
, and
. We will show that, for every
,
,
, and
at the boundaries of respective
,
,
, and
, the probability
tends to 1 for sufficiently large
and
.
Define ,
, and
. Let
be the sample covariance matrix of size
. Then,
times the difference between the unpenalized likelihood function of the estimated covariance matrix and the true covariance matrix can be expressed as
where we have used Taylor expansion with the integral form of the remainder in the second equality.
We can partition as
where
We consider these terms separately.
A2.1. The term 
Using triangular inequality, we have where
by Assumption (C3). Since
is bounded from above and below, for a sufficiently large n,
is dominated by
for any
. That is saying,
(A1)
(A1) Therefore, we have
where the last inequality holds because of (EquationA1
(A1)
(A1) ). It is straightforward to see that
(A2)
(A2) where
is the ith diagonal element of
,
is the jth diagonal element of
, and the subscript ‘0’ indicates the true value of the element. Hence
.
A2.2. The term
For ,
By Lemma A.1, for a sufficiently large n, there exists a
such that
where the second inequality holds since
A2.3. The term
can be partitioned into
, where
We will consider
,
, and
separately. For
,
Hence, by Lemma A.1, for a sufficiently large n, there exists a
such that with probability greater than
we have
Let
be the set of indices such that
is nonzero. Then, with a probability of greater than
,
For
,
where the inequality holds from the result that the maximum value of
with a symmetric matrix
and a unit vector
is
. Hence,
where the equality holds since the proof of Lemma 3 in [Citation32] shows that
. For
,
where the inequality holds from the result that the minimum value of
with a symmetric matrix
and a unit vector
is
. Hence,
is dominated by
, such that
for a sufficiently large n.
A2.3.1. The shrinkage penalty term
The shrinkage penalty term is , where
and
. It is easy to see that
. For
,
. Likewise,
.
A2.3.2. The smoothing penalty term
Let be the difference between two neighbouring elements on the off-diagonal of
. Likewise, let
,
and
. Then,
(A3)
(A3) where the last inequality holds since
Note,
Likewise,
. By Cauchy-Schwarz inequality,
Then we obtain
. Similarly, we achieve the same conclusion that
A2.4. Combine all terms
Note that
is the sum of squared eigenvalues of
. Then,
. As a result, for a sufficiently large n,
By Assumption (C3), we have
for a sufficiently large n. Then, we can let
, and consequently,
Likewise, we can let
and
Again, using triangular inequality
(A4)
(A4) Then, by Lemma A.2, (EquationA4
(A4)
(A4) ), and the rates of
and
, we obtain
which is positive for sufficiently large n by Assumption (C2). Following the same way, we have
If
, then
for a sufficiently large n. Hence, we can choose a sufficiently small
such that
Likewise, we can choose a sufficiently small
such that
At last, we only need to show
It suffices to show the part inside the square brackets as follows,
Expanding
yields
By Lagrange multiplier, the minimum of
subject to the boundaries
, and
is attained when
Evaluated at such stationary points,
They are dominated by
since
by Assumption (C3). Hence,
which will be larger than
for sufficiently large
and
such that
is sufficiently large.
Above all, with probability larger than ,
which completes the proof.
Appendix 3.
The regularized flip-flop (RFF) algorithm
Denote and
be the
and
matrix representations of the difference operator
,
such that
and
, respectively. We summarize in Algorithm 1 for the regularized estimation of the Kronecker structured covariance matrix by combining shrinkage and smoothing subdiagonals of
and
matrices.