
Abstract
Multiple choice questions (MCQs) suffer from cueing, item quality and factual knowledge testing. This study presents a novel multimodal test containing alternative item types in a computer-based assessment (CBA) format, designated as Proxy-CBA. The Proxy-CBA was compared to a standard MCQ-CBA, regarding validity, reliability, standard error of measurement, and cognitive load, using a quasi-experimental crossover design. Biomedical students were randomized into two groups to sit a 65-item formative exam starting with the MCQ-CBA followed by the Proxy-CBA (group 1, n = 38), or the reverse (group 2, n = 35). Subsequently, a questionnaire on perceived cognitive load was taken, answered by 71 participants. Both CBA formats were analyzed according to parameters of the Classical Test Theory and the Rasch model. Compared to the MCQ-CBA, the Proxy-CBA had lower raw scores (p < 0.001, η2 = 0.276), higher reliability estimates (p < 0.001, η2 = 0.498), lower SEM estimates (p < 0.001, η2 = 0.807), and lower theta ability scores (p < 0.001, η2 = 0.288). The questionnaire revealed no significant differences between both CBA tests regarding perceived cognitive load. Compared to the MCQ-CBA, the Proxy-CBA showed increased reliability and a higher degree of validity with similar cognitive load, suggesting its utility as an alternative assessment format.
Introduction
With a transfer from paper-based exams to computer-based assessment (CBA) (Buerger et al. Citation2016), particularly with the swift transfer under COVID-19 conditions (Ahmed et al. Citation2021), it is tempting to copy existing multiple choice question (MCQ) tests into CBA format, due to the ease of machine marking (Mowla et al. Citation2007). MCQ tests are widely applied in medical education programs worldwide to test large groups because of efficiency and accurate marking (Al-Rukban Citation2006). Strengths of MCQ tests are the possibility to assess cognitive knowledge in an objective manner, the broad sampling possibility, and the potential for high validity and reliability (Schuwirth and van der Vleuten Citation2017). However, MCQ tests may not always provide a true reflection of the knowledge level as they tend to be focused on answer recognitions or recall of memorized factual information (Zaidi et al. Citation2018). Students appear to score better with MCQ tests than on tests with alternative formats such as open-ended questions and free-response or short-answer questions (Newble et al. Citation1979; Veloski et al. Citation1999; Shaibah and van der Vleuten Citation2013; Sam et al. Citation2018), most likely due to the cueing effect when test-takers have presented a list of possible answer options (Schuwirth et al. Citation1996; Desjardins et al. Citation2014). MCQ tests are also hampered by the difficulty to make numerous high-quality questions and distractors (Tarrant et al. Citation2009). As a result, MCQ tests often tend to assess factual knowledge with a focus on the ‘knows’ from the Miller pyramid, which represents the lowest cognitive testing level (Epstein Citation2007; van der Vleuten et al Citation2010).
Practice points
Multiple choice question (MCQ) exams suffer from cuing, item quality, and a tendency to test factual knowledge. Alternative test formats are required.
Computer-based assessment (CBA) has gained popularity, particularly during the COVID-19 pandemic. Still, emerging questions related to the implementation of CBA are the issues of validity and reliability of different CBA formats and their cognitive load.
The utility of alternative CBA formats depends on reliability, validity, acceptability, educational impact, and required resources.
A novel multimodal CBA format is presented, designated as Proxy-CBA, showing increased reliability and a higher degree of validity, but similar cognitive load, when compared to an MCQ-CBA testing similar constructs.
It is suggested that the Proxy-CBA can be used as an alternative assessment format.
The theory that assessment drives learning is well recognized and still holds (Schuwirth and van der Vleuten Citation2020). If the aim of testing is less on recognizing correct answers and more on synthesizing correct answers, then other test formats besides MCQs might provide greater validity. For example, very short answer question (VSAQ) items have been demonstrated to have lower levels of measurement error and better discrimination of the test-takers’ ability levels when compared to MCQ items (Sam et al. Citation2018). Currently, CBA offers the technical possibility to present a variety of content-rich item types such as extended matching questions (EMQs) (Case and Swanson Citation2002), key feature questions (KFQs) (Farmer and Page Citation2005) and VSAQ (Sam et al. Citation2018), with the addition of different multimedia types like videos and images (Hols-Elders et al. Citation2008). These can be implemented for the application of knowledge and problem solving and as such a higher cognitive testing level compared to standard MCQs (Schuwirth and van der Vleuten Citation2004).
CBA offers several assessment benefits including (i) efficiency, (ii) immediate scoring combined with instant feedback, (iii) easily obtained feedback to evaluate course designs, and (iv) the inclusion of innovative and authentic assessments due to more technological capacities (Cantillon et al. Citation2004; Nguyen et al. Citation2017). These advantages, together with the extended possibilities for alternative item constructs, offer an additional format of assessment. Still, emerging questions related to the implementation of CBA are the issues of validity and reliability of different CBA formats. Due to the nature of possible test items CBA allows a higher order of cognitive skill testing. However, it is still unclear whether test-takers experience this higher cognitive testing level with different CBA formats. According to the cognitive load theory, the working memory can only process a limited amount of information elements in a given time (Young et al. Citation2014). So, a comparison between different CBA formats concerning experienced cognitive load is required to determine the cognitive skill testing capacity of each CBA format. Care should be taken not to exceed the cognitive load of test-takers (Young et al. Citation2014) by specific CBA formats.
Factors that play a role in the utility of an assessment method are validity, reliability, acceptability, education impact, and costs (van der Vleuten Citation1996; van der Vleuten and Schuwirth Citation2005). Despite the potential benefits of a CBA, large-scale exams with different item formats than just MCQ items have not been widely applied due to limitations in machine marking (Ullah et al. Citation2018). However, with the emerging enrolment of CBA (Blundell Citation2021), there is a need for obtaining evidence of validity, reliability, and cognitive load experience of different CBA test formats. In this study, two different exams in CBA formats were designed: a CBA with only standard MCQ items (MCQ-CBA) and a multimodal CBA with MCQs, KFQs, EMQs, multiple response questions (MRQs), and (very) short answer questions (VSAQs), here designated as Proxy-CBA. The word Proxy-CBA is chosen to indicate the possible substitution of the standard MCQ-CBA. The purpose of this study was to compare these two different test formats and to assess the utility of the Proxy-CBA as an assessment method. In addition, the experienced cognitive load and educational impact of both CBA formats were measured and compared using a post-test survey.
In assessment, the overarching question is whether a given test can accurately measure the ability and performance of the test-taker. Test theories are therefore required to better explain the relationship between actual test scores and estimated performance in the domain. In psychometrics three test theory frameworks exist: Classical Test Theory (CTT), Generalizability Theory (G-Theory), and Item Response Theory (IRT) (Brennan Citation2010; De Champlain Citation2010). CTT is a widely applied and relatively simple model to test performances that uses total test scores to calculate the candidate’s ability (Traub Citation2005). CTT is applicable for tests where groups of candidates are comparable in ability. In addition, CTT assumes that measurement errors are identical for all scores. While with CTT all sources or errors in measurement are confounded in one error term, G-Theory disentangles these errors in multiple error terms (Brennan Citation2010). However, in practice, groups of test-takers are not homogenously in ability level and scores located in the tails of the score distribution are not estimated as accurately as the ones in the middle of the distribution, which skews reliability and precision (De Champlain Citation2010). In contrast to CTT and G-Theory, IRT takes into account the difficulty of each test item to estimate the candidate’s ability (Downing Citation2003). This is also applicable in this study since the designed MCQ-CBA and the Proxy-CBA measured similar constructs (cell signaling knowledge), in near-identical breadth and depth, by similar stimuli but with a different response format. IRT entails a family of nonlinear models to estimate the probability of a correct response on a test item as a function of the item’s characteristics (e.g. difficulty, discrimination) and the test-taker’s ability. All these models aim to explain observed item performance as a function of underlying ability, also known as a latent trait, denoted as Θ (theta). A widely used IRT approach is the Rasch model (De Champlain Citation2010).
The following research questions were postulated for this study: (1) how do the MCQ-CBA and the Proxy-CBA formats relate to each other concerning reliability and validity and (2) how do test-takers experience the cognitive testing possibilities with both CBA formats? Related to these research questions two null hypotheses have been formulated. For research question 1 the null hypothesis is: there is no difference between a Proxy-CBA and an MCQ-CBA regarding reliability and validity. For research question 2 the null hypothesis is: test-takers do experience a higher cognitive load with a Proxy-CBA compared to an MCQ-CBA. This study was conducted as a design-based experimental study with a crossover design and quantitative analysis according to parameters of CTT and the Rasch model.
Materials and methods
Setting and participants
This study was conducted at the Maastricht University, The Netherlands in March 2021. The MCQ-CBA and the Proxy-CBA were provided as intermediate exams of the course Cell Signaling in the second year of the Biomedical Sciences curriculum at Maastricht University. On average about 100 students enroll each year in this course. At the start of the course, all students enrolled were informed about the intermediate exams and the connected study via the course opening lecture. Students were invited to participate via the Canvas learning management system. Details about the study and the informed consent were posted on Canvas.
Ethical approval
Ethical approval for this study was obtained from the Ethics Review Committee, Faculty of Health Medicine and Life Sciences (FHML), Maastricht University. The approval number is FHML-REC/2019/059.
Ethical approval was granted to invite all students participating in the Cell Signaling course. The study participants were asked to sign an informed consent before they entered the study. The only inclusion criterion was enrolment in the Cell Signaling course of 2021. There were no other inclusion or exclusion criteria. It was made clear that participation, no participation, or dropping out would not lead to any positive or negative consequences for any of the teaching and learning activities nor for any test results in the course Cell Signaling. So, in this study, no stakes were at play.
Power analysis
A power calculation was performed by a repeated-measures ANOVA using G*Power software (Faul et al. Citation2007). The analysis revealed that with an effect size f = 0.15 and a correction among repeated measures of 0.7 an estimated group size of 56 participants would be sufficient to detect the effect size with a power estimate of 0.8123.
Study design
This study was a design-based experiment with a crossover design. Both CBA formats were provided as intermediate formative tests. For both CBA tests TestVision software (Teelen, Wilp, The Netherlands) was used which has already been implemented as assessment software at the Maastricht University since 2019. Access to TestVision for participants was secured as well as technical support during test taking. Due to COVID-19 restrictions and due to privacy concerns, both tests were taken online without proctoring. The MCQ-CBA was conducted with 65 MCQ items in plain text formats, while the Proxy-CBA was conducted with 65 items, consisting of 47 VSAQs, from which 5 with more than 1 answer option, 8 MCQs, 5 MRQs, 4 KFQs, and 1 EMQ. Examples of VSAQs, MRQs, and KFQs are provided in Supplementary File 1. In contrast to the MCQ-CBA, the Proxy-CBA contained items with images and one item with a video. All items from both CBA formats were newly developed and had the same content blueprint. Items had similar stimuli and the only difference is that the Proxy-CBA had most items with a different response format. Items in both CBA formats were presented in randomized order to the test-takers. A key validation was performed. In both tests, two items had a higher discrimination in the distractor rather than the answer key. However, no items were dropped as the contents deemed to be correct.
The participants were randomly assigned to two groups. Group 1 started with the MCQ-CBA, and group 2 started with the Proxy-CBA. Exam time was 1.5 h for both groups. After a break of 20 min group 1 took the Proxy-CBA while group 2 took the MCQ-CBA for another 1.5 h. Directly after the two tests, an online questionnaire was offered to the participants to measure experienced cognitive load and experienced cognitive testing level. Participants took both tests and the questionnaire with their own devices. Since the CBA could not be proctored, in both tests the questions were randomized, backtracking was disabled and a time restriction of 90 min per test was set to prevent checking of learning resources and communication among students via social media.
Marking
Scoring of both tests was done automatically via TestVision and checked manually afterward. According to Cecilio-Fernandes et al. (Citation2017), a number-right scoring was applied for marking the MCQ’s. In the Proxy-CBA all nonexact matches and match failures were reviewed by two markers for the decision on acceptance or rejection of the provided response. The test system allows marking judgments to all identical answers to ensure consistency. TestVision also allows adding alternative correct answers to the preapproved answers to ease automatic marking for future use of the item. Individual student and item performance data were exported from TestVision for further statistical analysis.
Questionnaire
To answer the second research question, an adapted Assessment Preference Inventory (API) was used. The original API is a 67-item Likert-type questionnaire designed to measure seven dimensions of assessment (Birenbaum Citation1994). This API has been used in an adapted format to measure both high and low cognitive processes in a new learning environment compared to a traditional learning environment (van de Watering et al. Citation2008). A similar situation is present in this study where the experienced cognitive testing level from traditional MCQ testing is compared with the multimodal Proxy format. As such, the adapted API format (van de Watering et al. Citation2008) was used here to measure cognitive load experiences with both CBA formats (Supplementary File 2).
Statistical analysis
Raw test scores were retrieved from TestVision. Statistical analysis on item difficulty and total group reliability coefficients (McDonald’s ω and Cronbach’s α) in both tests were analyzed according to CTT measures using JASP software (JASP Team (2021), JASP (Version 0.16.1), URL: https://jasp-stats.org/). Individual Rasch reliability estimates were calculated according to Lahner et al. (Citation2020).
Further statistical analysis was performed by the Rasch model (De Champlain Citation2010) to compare the two different CBA test formats, concerning the standard error of measurement, and the candidate’s ability (theta scores). Analysis was performed with Xcalibre 4.2.2.0 IRT Item Parameter Estimation Software (version 2014) (Assessment Systems Corporation, Stillwater, MN, USA). Differences in raw test scores, reliability estimates, standard error of measurements, and theta scores within and between groups were analyzed using a mixed-design analysis of variance (ANOVA) with effect sizes expressed as eta-squared (η2) by using Jamovi software (The Jamovi Project (2021) jamovi (Version 1.6), retrieved from https://www.jamovi.org).
The effect of question type on the difficulty of the Proxy-CBA, as well as on infit and outfit measures was determined by three separate linear regressions with item type as an independent variable and difficulty (b-parameter), infit and outfit measures as dependent variables by using JASP software.
Results from the adapted API questionnaire were initially analyzed by exploratory factor analysis. Subsequently, confirmatory crossvalidation of the proposed constructs was performed using a multi-dimensional IRT analysis (Samejima Citation1997; Osteen Citation2010) by using Mplus software, version 8.4 (Muthén and Muthén Citation2017).
Reliability coefficients for the questionnaire’s subscales were estimated by JASP software. Differences between the three identified constructs in the IRT-mediated exploratory factor analysis (Experienced types of questions, Experienced level of complexity, Contribution to increasing knowledge level) were further analyzed by a mixed-design ANOVA using Jamovi software.
Results from mixed ANOVA analyses are presented in box plots and were generated using the R package ggplot2 (Wickham Citation2016).
Results
Study participation
Of the 110 students enrolled in the Cell Signaling course in 2021, 74 students (67%) completed both exams and 71 (61%) completed the post-test questionnaire.
Item difficulty and time used for each CBA format
Paired t-test analyses showed that the items from the Proxy-CBA were more difficult compared to the MCQ-CBA, using both CTT percentage of correct answers (t(64) = −3.20, p = 0.002, Cohen’s d = 0.397) and Rasch difficulty-based b parameters (t(63) = −7.61, p < 0.001, Cohen’s d = −0.951 (Supplementary File 3). The Proxy-CBA had higher discrimination compared to the MCQ-CBA based on comparison of item-rest correlations (t(64) = −2.67, p = 0.010, Cohens’s d = 0.331).
A Fisher exact test showed that there were no differences between the groups regarding reaching the time limit of 90 min (F = 0.497, p = 0.248). However, the time taken for the two CBA formats differs significantly with more time taken for the Proxy-CBA compared to the MCQ-CBA (F(1,70) =41.2, p < 0.001, η2= 0.074). However, the effect size was much larger considering the order in which the tests were presented (F(1,70) = 176.5, p < 0.001, η2= 0.318). Group 2, starting with the Proxy-CBA required less time for the MCQ-CBA compared to group 1, which first took the MCQ-CBA ().
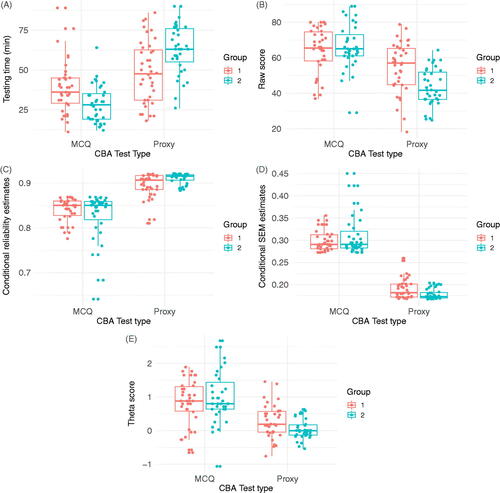
Figure 1. Mixed-design ANOVA analyses of differences between group 1 and 2 with respect to test time (A), raw test scores (B), conditional reliability estimates (C), conditional SEM estimates (D), and theta scores (E).
A reliability coefficient for the total group of test-takers
A CTT analysis was performed to measure reliability coefficients for the total group of test-takers in either MCQ-CBA or Proxy-CBA. Results are presented in . CTT reliability coefficients (McDonald’s ω and Cronbach’s α) were comparable between both CBA formats ().
Table 1. Total test reliability analysis according to CTT measures.
Raw test scores analysis per group
Raw scores specified per group of test-takers for each CBA test are shown in . Raw scores for MCQ-CBA and Proxy-CBA in group 1 were 61.15 ± 16.10% and 53.08 ± 16.29%, respectively. In group 2, raw scores for MCQ-CBA and Proxy-CBA were 66.31 ± 12.52% and 42.85 ± 10.46%, respectively. A significant difference in raw scores between test types was observed with a medium effect size (F(1,70) = 273.5, p < 0.001, η2= 0.276) with higher raw scores for MCQ-CBA (). Although a significant interaction effect was observed between type of CBA and group (F(1,70) = 46.7, p < 0.001), the size effect was small (η2= 0.047) and the between-group effect was not significant (F(1,70) =2.50, p = 0.118, η2= 0.021).
Table 2. Mean ± SD raw scores, Cronbach’s α for MCQ-CBA and proxy-CBA in groups 1 and 2.
Reliability and discrimination
shows reliability per group (Cronbach’s α) for the MCQ-CBA and the Proxy CBA. The MCQ-CBA tests had Cronbach’s α values of 0.88 and 0.80 for groups 1 and 2, respectively. For the Proxy-CBA these values were 0.91 and 0.78 for groups 1 and 2, respectively. An advantage of the Rasch model is to produce conditional reliability estimates for each individual using the full information of the data matrices. As such, individual reliability estimates were calculated and showed a significant difference between MCQ-CBA and Proxy-CBA (F(1,70) = 236.2, p < 0.001, η2 = 0.498) with higher scores for the Proxy-CBA ().
The Rasch model was further used to estimate standard error of measurement (SEM) values and latent ability estimates, known as theta scores. The Proxy-CBA had significantly lower SEM estimates with a large effect size compared to the MCQ-CBA (F(1,70) = 1083.5, p < 0.01, η2= 0.807) (). An interaction effect between type of CBA and group was observed (F(1,70) = 11.4, p = 0.001), but the effect size was negligible (η2 = 0.008) and no significant difference between group effect was observed (F(1,70) = 0.0298, p = 0.863, η2 = 0.000).
The theta ability scores were significantly different between MCQ-CBA and Proxy-CBA (F(1,70) = 141,86, p < 0.01, η2 = 0.288) with lower scores for Proxy-CBA compared to MCQ-CBA (). An interaction effect between type of CBA and group was observed (F(1,70) = 9.32, p = 0.019), but similar as with the SEM estimates, the effect size was small (η2 = 0.019) and no significant between group effect was observed (F(1,70) = 0.0731, p = 0.788, η2 = 0.001).
A correlation analysis between raw scores and theta ability scores showed for both test types a significant positive correlation, MCQ-CBA (Pearson’s r = 0.975, p < 0.001), Proxy-CBA (Pearson’s r = 0.885, p < 0.001) (Supplementary File 4).
Effect of item types in the Proxy-CBA
Linear regression analyses revealed that item types explained a small parcel of the variance concerning the b-parameter (R2 = 0.039), with no significant result for each of the item types. The use of fit indices from the Rasch model has been described on AMEE Guide No. 72. For the infit and outfit measures the item types explained a larger part of the variance (infit R2 = 0.435; outfit R2 = 0.405) with VSAQs having the highest impact on reducing infit (t= −6.59, p < 0.001) and outfit (t= −6.25, p < 0.001), followed by MCQs (infit: t= −5.28, p < 0.001; outfit: t= − 5.08, p < 0.001) and KFQs (infit t= −3.6, p < 0.001); outfit t= − 3.6, p < 0.001). For EMQs and MRQs the results were not significant.
However, when a comparison was made between the MCQs and other item types of the Proxy-CBA it appeared that MRQs outranged the intercept estimate, both for infit (intercept 0.92, MRQ 0.46, p < 0.01) and outfit (intercept 0.92, MRQ 0.59, p < 0.01). All other item types had estimates within the range of optimal infit and outfit values.
Questionnaire evaluation
The experienced cognitive load and testing were measured by a questionnaire with a Likert scale. IRT-mediated Exploratory factor analysis revealed four constructs, one common set of questions for both groups regarding general questions about the examination and three other constructs which were defined as ‘Experienced types of questions (Exp. types)’, ‘Experienced level of complexity (Exp. compl)’, and ‘Contribution to increasing knowledge level (Contr. KL)’ divided between the MCQ-CBA and proxy-CBA. Reliability estimates for these constructs were estimated by JASP software and are shown in .
Table 3. Reliability analysis of identified constructs in the questionnaire.
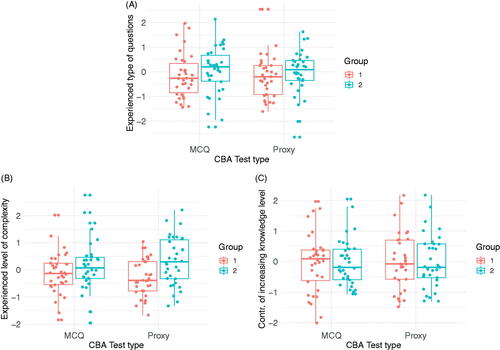
Differences between the groups of test-takers with respect to experienced cognitive load and testing level were further analyzed by a mixed-design ANOVA. No differences were observed for Experienced types of questions (F(1,65) = 0.613, p = 0.437, η2 = 0.009) (), Experienced level of complexity (F(1,65) = 0.310, p = 0.579, η2 = 0.001) ), and Contribution to increasing knowledge level (F(1,64) = 0.1092, p = 0.742, η2 = 0.000) ( and Supplementary File 5).
Figure 2. Mixed-design ANOVA analyses of differences in questionnaire results between group 1 and 2 with respect to Experienced type of questions (A), Experienced level of complexity (B), and Contribution of increasing knowledge level (C).
Discussion
In this study, two research questions were addressed. The first question addressed the comparison between a Proxy-CBA and an MCQ-CBA concerning validity and reliability. The second question was on the experienced cognitive testing capacities of both tests. The null hypothesis for the first research question was that there is no difference between the two CBA formats regarding validity and reliability. However, from the results, it can be concluded that the Proxy-CBA has the advantage over the MCQ-CBA in terms of validity and reliability. As a result, the first null hypothesis can be rejected. The second null hypothesis was on the higher cognitive load of the Proxy-CBA. Despite the higher cognitive testing capacity, the Proxy-CBA was not different from the MCQ-CBA concerning experienced cognitive load. As such, the second null hypothesis can also be rejected.
Compared to the Proxy-CBA raw scores, the higher raw scores in the MCQ-CBA are in line with the literature and can be explained by the cueing effect (Schuwirth et al. Citation1996; Desjardins et al. Citation2014). Concerning cueing, it appeared that test-takers benefited from first making the MCQ-CBA which resulted in higher Proxy-CBA scores. Probably, provided information in the MCQ-CBA helped group 1 to give correct answers in the Proxy-CBA. In contrast, this effect was not observed in group 2 who first made the Proxy-CBA but had no significant higher scores for the MCQ-CBA. This suggests that the Proxy-CBA has a higher validity in testing the ability for correct answering without cueing or guessing as often observed with MCQs (Couch et al. Citation2018).
A Rasch theta score is associated with the probability of correctly answering the item (De Champlain Citation2010). Compared to the MCQ-CBA, the lower theta scores in Proxy-CBA point to more difficult items with increased discriminative capacities, which contributes to the validity of the test (Embretson Citation2007). Considering the linear regression results the item types explained only a small percentage of the variance without meaningful results concerning the b-parameter in the Proxy-CBA. So, the item type per se had hardly any effect on the difficulty level of the test. The item types had a larger impact on reducing infit and outfit measures with VSAQs having the best performance in reducing misfit. This finding suggests that VSAQs contributed to a better validity in terms of internal structure, a result aligned with existing literature (Sam et al. Citation2018, Citation2016). However, when comparing the MCQs of the Proxy-CBA with the other item types it appeared that the MRQs outranged the infit and outfit models and should be considered as a potential threat to the validity of the test scores. We speculate that test-takers may have been inherently afraid to fill in more than one answer option.
A limitation of MCQs is the one best answer per item, which hampers item development with multiple defensible answers (Elstein Citation1993). Particularly in the medical field, this plays a role (Veloski et al. Citation1999), but also in the biomedical field, e.g., with cell signaling, where several pathways are involved in similar biological processes. The Proxy-CBA format offers the option to students to provide alternative answers that may be as good or are second-option alternatives. In this respect the Proxy-CBA allows students to demonstrate the scope of their knowledge, which additionally contributes to assessment validity.
A crucial issue in assessment is the reliability of a test (Downing Citation2004). While the Cronbach’s α values were lower in group 2 for both tests, the conditional reliability estimates were significantly higher and SEM estimates were significantly lower with a large effect size for the Proxy-CBA compared to the MCQ-CBA. This points to higher reliability in testing with the Proxy-CBA in comparison with the MCQ-CBA. A result that is in line with a previous experimental study showing higher reliability in testing with VSAQs compared to MCQs (Sam et al. Citation2018).
It was expected that the Proxy-CBA would impose a higher cognitive appeal compared to the MCQ-CBA. However, the questionnaire results show that the experienced level of complexity was not different between the two test formats. Maybe the formative nature of both tests was responsible for this effect. It has previously been shown that the cognitive load did not differ between two groups of students taking two different formative test formats, presumably because the two groups learned with similar subject materials and tasks (Chu et al. Citation2019). A similar situation was present in this study where all students learned the same course contents.
The acceptability of an alternative assessment format depends, next to the reliability, validity, and cognitive load, of required resources (van der Vleuten Citation1996; van der Vleuten and Schuwirth Citation2005). CBA has already been accepted as an assessment format (Escudier et al. Citation2011; Karay et al. Citation2012), but too much workload for making and marking a CBA test will hamper its introduction. In this study time to make the items did not differ between a previous paper-based MCQ exam and the MCQ-CBA and between the MCQ-CBA and the Proxy-CBA. Regarding marking of the test scores, TestVision allowed initial machine marking for all questions. However, with the Proxy-CBA manual checking was required, which took about 1 h for 74 students, which can be considered a potential limitation. However, TestVision allows marking alternative answers as correct for future use, reducing marking time when items are used again. In addition, developments in the automated marking of non-MCQs in terms of computational linguistics and machine learning are in progress (Das et al. Citation2021). So, shortly, it is expected that manual marking is still required, but it is anticipated that the speed and reliability of automated marking will continue to improve.
Limitations of this study include the small sample size, the single-center set-up, and the stability of the CBA infrastructure. The small sample size precludes the use of IRT models that estimate parameters for discrimination and pseudo guessing, which may have augmented the disadvantage of MCQs in the Rasch model-based analyses of reliability, measurement error, and validity based on internal structure as given by the infit and outfit values. The use of the Rasch model with samples smaller than 50 might lead to paradoxal results in comparison to larger samples, which limits the generalizability of the findings (Chen et al. Citation2014). Still, despite the difference in the methods, the results obtained in this study are aligned with results from Sam et al. (Citation2018), in terms of demonstrating lower performance of MCQs.
The two groups in this study were randomly assigned, without differences in gender distribution. Still, the student population in the BBS bachelor is international and as a consequence, cultural backgrounds cannot be excluded as differential characteristics in item functioning. The single-center set-up limits the external validity of this study (Slack and Draugalis Citation2001). However, the internal validity of this study was secured by the experimental crossover design and the analysis approach (Slack and Draugalis Citation2001). Results of this study may therefore apply to other test developers. Future multicenter studies should be conducted to investigate the utility of the Proxy-CBA with larger student numbers. An interesting question might be to test the utility of the Proxy-CBA with students with different levels of expertise.
An intrinsic limitation of CBA is the stability of hard- and software applied (Hols-Elders et al. Citation2008). Hardware infrastructure should function without any downtime during the test, while the software must run smoothly in combination with the hardware. The assessment software used in this study exists already for more than 20 years.
In conclusion, results from this study showed the increased validity and reliability properties of the Proxy-CBA compared to the MCQ-CBA, without a higher cognitive load. As such, this study provides evidence that the Proxy-CBA may be used as a multimodal assessment instrument with the potential to improve existing assessment programs.
Author contributions
Johan Renes designed and performed the study and wrote the manuscript. Cees P.M. van der Vleuten supervised the study and advised on the manuscript contents. Carlos F. Collares supervised the study, performed the statistical analyses and advised on interpretation of the data and writing the manuscript.
Glossary
Computer-based assessment: Assessment using a computer to present items and to collect to collect response data.
Infit and outfit: Statistical Rash terms to indicate how accurately or predictably the data fit the model.
Infit: Inlier-sensitive or information-weighted fit. This is more sensitive to the pattern of responses to items targeted on the person, and vice-versa.
Outfit: Means outlier-sensitive fit. This is more sensitive to responses to items with difficulty far from a person, and vice-versa.
Supplemental Material
Download Zip (1.2 MB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Johan Renes
Johan Renes, PhD, was appointed as Assistant Professor at the Department of Human Biology, Maastricht University, The Netherlands, in 2001. Since 2018 he works as lecturer at this university, focussed on education. In 2021 Dr. Renes graduated Cum Laude for the Master of Health Profession Education at Maastricht University.
Cees P.M. van der Vleuten
Cees van der Vleuten, PhD, works at the Maastricht University, The Netherlands since 1982. In1996 he was appointed Professor of Education and chair of the Department of Educational Development and Research. Since 2005 he has been the Scientific Director of the School of Health Professions Education (until 2020).
Carlos F. Collares
Carlos Collares, MD, PhD, works as Assistant Professor at the Department of Educational Development and Research, Maastricht University, The Netherlands, coordinating the International Progress Testing Programme since 2012. Since 2015 he is an Assessment Specialist for the European Board of Medical Assessors with a focus on quality assurance and psychometrics.
References
- Ahmed FRA, Ahmed TE, Saeed RA, Alhumyani H, Abdel-Khalek S, Abu-Zinadah H. 2021. Analysis and challenges of robust E-exams performance under COVID-19. Res Phys. 23:103987.
- Al-Rukban MO. 2006. Guidelines for the construction of multiple choice questions tests. J Fam Comm Med. 13:125–133.
- Birenbaum M. 1994. Toward adaptive assessment-the student’s angle. Stud Educ Eval. 20(2):239–255.
- Blundell CN. 2021. Teacher use of digital technologies for school-based assessment: a scoping review. Ass Edu Princ Pol Pract. 28(3):279–300.
- Brennan RL. 2010. Generalizability theory and classical test theory. Appl Measur Educ. 24(1):1–21.
- Buerger S, Kroehne U, Goldhammer F. 2016. The transition to computer-based testing in large-scale assessments: Investigating (partial) measurement invariance between modes. Psychol Test Assess Model. 58(4):597.
- Cantillon P, Irish B, Sales D. 2004. Using computers for assessment in medicine. Br Med J. 329(7466):606–609.
- Case SM, Swanson DB. 2002. Constructing written test questions for the basic and clinical sciences. 3rd ed. Philadelphia (PA): National Board of Examiners.
- Cecilio-Fernandes D, Medema H, Collares CF, Schuwirth L, Cohen-Schotanus J, Tio RA. 2017. Comparison of formula and number-right scoring in undergraduate medical training: a Rasch model analysis. BMC Med Educ. 17(1):1–9.
- Chen W-H, Lenderking W, Jin Y, Wyrwich KW, Gelhorn H, Revicki DA. 2014. Is Rasch model analysis applicable in small sample size pilot studies for assessing item characteristics? An example using PROMIS pain behavior item bank data. Qual Life Res. 23(2):485–493.
- Chu HC, Chen JM, Hwang GJ, Chen TW. 2019. Effects of formative assessment in an augmented reality approach to conducting ubiquitous learning activities for architecture courses. Univ Access Inf Soc. 18(2):221–230.
- Couch BA, Hubbard JK, Brassil CE. 2018. Multiple–true–false questions reveal the limits of the multiple–choice format for detecting students with incomplete understandings. BioSciences. 68(6):455–463.
- Das B, Majumder M, Phadikar S, Sekh AA. 2021. Automatic question generation and answer assessment: a survey. Res Pract Technol Enhanc Learning. 16:1–15.
- De Champlain AF. 2010. A primer on classical test theory and item response theory for assessments in medical education. Med Educ. 44(1):109–117.
- Desjardins I, Touchie C, Pugh D, Wood TJ, Humphrey‐Murto S. 2014. The impact of cueing on written examinations of clinical decision making: a case study. Med Educ. 48(3):255–261.
- Downing SM. 2003. Item response theory: applications of modern test theory in medical education. Med Educ. 37(8):739–745.
- Downing SM. 2004. Reliability: on the reproducibility of assessment data. Med Educ. 38(9):1006–1012.
- Escudier M, Newton T, Cox M, Reynolds P, Odell E. 2011. University students’ attainment and perceptions of computer delivered assessment; a comparison between computer‐based and traditional tests in a ‘high‐stakes’ examination. J Comp Assist Learning. 27(5):440–447.
- Elstein AS. 1993. Beyond multiple-choice questions and essays: the need for a new way to assess clinical competence. Acad Med. 68(4):244–249.
- Embretson SE. 2007. Construct validity: a universal validity system or just another test evaluation procedure? Educ Res. 36(8):449–455.
- Epstein RM. 2007. Assessment in medical education. N Engl J Med. 356(4):387–396.
- Farmer EA, Page G. 2005. A practical guide to assessing clinical decision‐making skills using the key features approach. Med Educ. 39(12):1188–1194.
- Faul F, Erdfelder E, Lang AG, Buchner A. 2007. G* Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav Res Methods. 39(2):175–191.
- Hols-Elders W, Bloemendaal P, Bos N, Quaak M, Sijstermans R, De Jong P. 2008. Twelve tips for computer-based assessment in medical education. Med Teach. 30(7):673–678.
- Karay Y, Schauber SK, Stosch C, Schuettpelz-Brauns K. 2012. Can computer-based assessment enhance the acceptance of formative multiple choice exams? A utility analysis. Med Teach. 34(4):292–296.
- Lahner FM, Schauber S, Lörwald AC, Kropf R, Guttormsen S, Fischer MR, Huwendiek S. 2020. Measurement precision at the cut score in medical multiple choice exams: theory matters. Perspect Med Educ. 9(4):220–228.
- Mowla MJ, Zaman MS, Chowdhury MM, Abdal SN. 2007. Electronic MCQ answering system for classroom e-learning and examination. In: 2007 10th International Conference on Computer and Information Technology; Dec 27–29; Dhaka, Bangladesh, IEEE. p. 1–5.
- Muthén B, Muthén L. 2017. Mplus. In Handbook of item response theory. London, UK: Chapman and Hall/CRC; p. 507-518.
- Newble DI, Baxter A, Elmslie RG. 1979. A comparison of multiple‐choice tests and free‐response tests in examinations of clinical competence.Med Educ. 13(4):263–268.
- Nguyen Q, Rienties B, Toetenel L, Ferguson R, Whitelock D. 2017. Examining the designs of computer-based assessment and its impact on student engagement, satisfaction, and pass rates. Comp Hum Behav. 76:703–714.
- Osteen P. 2010. An introduction to using multidimensional item response theory to assess latent factor structures. J Soc Work Res. 1(2):66–82.
- Sam AH, Field SM, Collares CF, van der Vleuten CPM, Wass VJ, Melville C, Harris J, Meeran K. 2018. Very‐short‐answer questions: reliability, discrimination and acceptability. Med Educ. 52(4):447–455.
- Sam AH, Hameed S, Harris J, Meeran K. 2016. Validity of very short answer versus single best answer questions for undergraduate assessment. BMC Med Educ. 16(1):1–4.
- Samejima F. 1997. Graded response model. In: van der Linden WJ, Hambleton RK, editors. Handbook of modern item response theory. New York (NY): Springer Science & Business Media; p. 85–100.
- Schuwirth LW, van der Vleuten CP. 2020. A history of assessment in medical education. Adv Health Sci Educ Theory Pract. 25(5):1045–1056.
- Schuwith LW, van der Vleuten CP. 2017. Written assessments. In: Dent JA, Harden RM. editors. A practical guide for medical teachers. 5th ed. Amsterdam: Elsevier Health Sciences; p. 260–266.
- Schuwirth LWT, van der Vleuten CPM. 2004. Different written assessment methods: what can be said about their strengths and weaknesses? Med Educ. 38(9):974–979.
- Schuwirth LWT, van der Vleuten CPM, Donkers HHLM. 1996. A closer look at cueing effects in multiple‐choice questions. Med Educ. 30(1):44–49.
- Shaibah HS, van der Vleuten CP. 2013. The validity of multiple choice practical examinations as an alternative to traditional free response examination formats in gross anatomy. Anat Sci Educ. 6(3):149–156.
- Slack MK, Draugalis JR. Jr. 2001. Establishing the internal and external validity of experimental studies. Am J Health Syst Pharm. 58(22):2173–2181.
- Tarrant M, Ware J, Mohammed AM. 2009. An assessment of functioning and non-functioning distractors in multiple-choice questions: a descriptive analysis. BMC Med Educ. 9(1):40.
- Traub RE. 2005. Classical test theory in historical perspective. Educ Meas: Iss Pract. 16(4):8–14.
- Ullah Z, Lajis A, Jamjoom M, Altalhi A, Al‐Ghamdi A, Saleem F. 2018. The effect of automatic assessment on novice programming: strengths and limitations of existing systems. Comput Appl Eng Educ. 26(6):2328–2341.
- Van Der Vleuten CP. 1996. The assessment of professional competence: developments, research and practical implications. Adv Health Sci Educ Theory Pract. 1(1):41–67.
- Van Der Vleuten CP, Schuwirth LW. 2005. Assessing professional competence: from methods to programmes. Med Educ. 39(3):309–317.
- Van der Vleuten CPM, Schuwirth LTW, Scheele F, Driessen EW, Hodges B. 2010. The assessment of professional competence: building blocks for theory development. Best Pract Res Clin Obstet Gynaecol. 24(6):703–719.
- Van de Watering G, Gijbels D, Dochy F, Van der Rijt J. 2008. Students’ assessment preferences, perceptions of assessment and their relationships to study results. High Educ. 56(6):645–658.
- Veloski JJ, Rabinowitz HK, Robeson MR, Young PR. 1999. Patients don’t present with five choices: an alternative to multiple-choice tests in assessing physicians’ competence. Acad Med. 74(5):539–546.
- Wickham H. 2016. ggplot2: elegant graphics for data analysis. New York (NY): Springer.
- Young JQ, Van Merrienboer J, Durning S, Ten Cate O. 2014. Cognitive load theory: implications for medical education: AMEE Guide No. 86. Med Teach. 36(5):371–384.
- Zaidi NLB, Grob KL, Monrad SM, Kurtz JB, Tai A, Ahmed AZ, Gruppen LD, Santen SA. 2018. Pushing critical thinking skills with multiple-choice questions: does bloom’s taxonomy work? Acad Med. 93(6):856–859.