Abstract
Land-cover characterization of large heterogeneous landscapes is challenging because of the confusion caused by high intra-class variability and heterogeneous landscape artefacts. Neighbourhood context can be used to supplement spectral information, and a novel way of incorporating spatial dependence in a heterogeneous region is tested here using an ensemble learning technique called random forests and a measure of local spatial dependence called the Getis statistic. The overall Kappa accuracy of the random forest classifier that used a combination of spectral and local spatial (Getis) variables at three different neighbourhood sizes (3 × 3, 7 × 7, and 11 × 11) ranged from 0.85 to 0.92. This accuracy was higher than that of a non-spatial random forest classifier having an overall Kappa accuracy of 0.78, which was run using the spectral variables only. This study demonstrated that the use of the Getis statistic with different neighbourhood sizes leads to substantial increase in per class classification accuracy of heterogeneous land-cover categories.
1. Introduction
Methods of land-cover characterization using medium spatial resolution data (15–30 m) are well established and near operational (Franklin and Wulder Citation2002). Unfortunately, at fine spatial scales, the size of the pixel is still often larger than the land-cover element causing class mixing within pixels (Blaschke et al. Citation2004), and over large areas map products lack spatial precision owing to heterogeneous landscape artefacts such as topographic displacement, moisture gradients, and antecedent disturbances (i.e. natural and anthropogenic) (Rogan and Miller Citation2006). Random forest classifiers provide a new way to produce thematic maps that are potentially robust to variations in class reflectance caused by gradients or disturbances in regional scale mapping and high intra-class variability influenced by landscape heterogeneity, which is evident in the class labelling errors in the calibration data used in land-cover characterization (see Ham et al. Citation2005, Gislason et al. Citation2006, Lippitt et al. Citation2008, Rogan et al. Citation2008).
Random forest classifiers are ensemble algorithms developed in the field of machine learning and use bootstrap samples with replacement to grow a large set of classification trees (Breiman Citation2001). In a land-cover classification context, pixels are assigned to categories that receive the maximum number of votes from the collection of multiple trees. Random forests do not overfit the data distributions because the large number of trees grown reduces generalization error (Breiman Citation2001, Pal Citation2005) and has been shown to increase land-cover classification accuracy (Ham et al. Citation2005, Pal Citation2005, Gislason et al. Citation2006), because the classification error of one permutation can be overcome by the ensemble of permutations (Kotsiantis and Pintelas Citation2004). Furthermore, random forests provide measures of variable importance (e.g. mean decrease in Gini coefficient) that can be used to understand the contribution of specific variables in a classification (Gislason et al. Citation2006).
Random forests represent the state of the art in land-cover classification but, as with most classification methods, do not include spatial dependence among neighbouring pixels even though spatial dependence or context can be used to increase land-cover classification accuracies (Stuckens et al. Citation2000). The incorporation of spatial dependence into random forests classification has the potential to increase the precision of class designation by minimizing intra-class variation (Wulder and Boots Citation1998). Thus, the incorporation of spatial dependence in random forests has the potential to complement its inability to utilize spatial relationships among neighbouring pixels. The incorporation of spatial dependence or context has been approached in the literature using (i) texture-based transformed spectral bands as variables in land-cover classification in order to capture the local variability of the digital numbers within a neighbourhood using geostatistics (Atkinson and Lewis Citation2000) and spatial autocorrelation statistics (Myint et al. Citation2007) and (ii) majority smoothing filter applied to the classified image (Mather Citation2004). In this context, this study presents a novel contextual texture-based classification method to assess the capability of a random forest algorithm to classify land cover by integrating spectral and Getis variables in a heterogeneous landscape using Landsat-7 Enhanced Thematic Mapper-plus (ETM+) imagery.
An improved approach to incorporate spatial dependence in land-cover classification is through the Getis statistic, Gi*. This statistic behaves similarly to a moving filter in a remote sensing context by considering pixel values within a local neighbourhood of the focus pixel (which helps to remove labelling errors caused by noisy data or complex spectral measurement space) while simultaneously accommodating the values in the entire image reflecting global landscape heterogeneity characteristics (Wulder and Boots Citation1998, Richards and Jia Citation2006).
2. Methodology
2.1 Random forests
A random forest classifier (i.e. random forests) consists of a group of tree-based classifiers {h ( x , Θ k ), k= 1,…} where x is the input vector and Θ k are the independent identically distributed random vectors (Breiman Citation2001). Random forests use bootstrap samples with replacement to grow a large collection of classification trees, which assign each pixel to a class based on the maximum number of votes that a class receives from the collection of trees. Each tree is grown from a randomly and independently selected subspace (certain proportion of pixels) of the measurement space (training pixels) that is used to train the random forest classifier and the remaining samples called out of bag cases are used to assess the accuracy of the classification. Variable importance is calculated as the sum of the decrease in Gini for each variable calculated from the group of tree-based classifiers. This algorithm is easy to implement because the user has to adjust for only two parameters: (i) number of trees to grow and (ii) number of randomly selected split variables at each node. The strong law of large numbers ensures that the solution always converges with no over fitting.
2.2 Getis statistic
The Getis statistic is a local indicator of spatial dependence (Getis and Ord Citation1992, Ord and Getis Citation1995), which describes local variability in spatial dependence (Wulder and Boots Citation1998). The application of the Getis statistic results in the creation of a new image representing the spatial structure of a given spectral image (Wulder and Boots Citation1998). The Getis statistic, , can be used to identify clusters of high values called hot spots or clusters of low values called cold spots. It is computed as
2.3 Data and methods
Satellite sensor images of Cape Cod, Massachusetts, captured by Landsat-7 ETM+ on 7 September 2001 (path/row 11/31) were used in this analysis. True-colour 1:5000 orthorectified aerial photographs from April 2001 (http://www.mass.gov/mgis/) were used to identify land-cover categories in the area and serve as a source for calibration and validation datasets. The eight land-cover classes considered in this study were cranberry bogs, pasture or row crops, forest, grassland, urban, water, wetland, and sand quarry. The ground reference dataset of land-cover categories was split randomly into a 75% subset of calibration samples and 25% subset of validation samples. presents the different land-cover categories examined in this analysis and the number of calibration and validation pixels assigned to each category.
Table 1. Number of calibration and validation pixels for different land-cover classes
A random forest classification model, hereafter called non-spatial random forest classifier, was run on the six spectral bands using the random forest package in the R statistical software (R Development Core Team Citation2008). This model was calibrated by varying two input parameters: (i) the number of trees from 100 to 1000 in increments of 100 and (ii) the number of randomly selected split variables from 1 to 6 (where 6 refers to the number of bands) in increments of 1 in order to select a single model built by the combination of these input parameters having the highest accuracy. Post-classification smoothing majority filters of 3 × 3, 7 × 7, and 11 × 11 pixel sizes using a mode decision rule were applied to this non-spatial random forest classified image.
In contrast, another classification model, hereafter called random forest Getis classifier, utilized the random forest classification algorithm run on the six Getis variables computed on each spectral band in addition to the six spectral bands. Three different random forest Getis classifiers were tested for Getis statistic neighbourhood sizes of 3 × 3, 7 × 7, and 11 × 11 pixels with the same input parameters as those used for the non-spatial random forest classifier, in order to provide consistent results for comparison with the non-spatial random forest classifier. These three neighbourhood sizes were considered to investigate the influence of different spatial scales on the classification accuracy. Comparison of the accuracy of the different variants of the random forest model was performed using the Kappa statistic that takes into account the actual agreement specified by the major diagonal of the confusion matrix and chance agreement indicated by the row and column totals of the confusion matrix (Congalton Citation1991). Furthermore, accuracies of individual classes were assessed with per class Kappa measures (Stehman Citation1997).
3. Results
The non-spatial random forest classifier parameterized with 600 trees and 3 randomly selected split variables at each node had the highest overall validation accuracy (overall Kappa = 0.78 with Z= 29.15; average per class Kappa = 0.72 with standard deviation = 0.24) amongst the non-spatial random forest classifiers parameterized by varying the number of trees and number of split variables (). shows the classified map produced by the non-spatial random forest classifier. shows the confusion matrix of the non-spatial random forest classifier. The post-classification smoothing majority filters applied to the non-spatial random forest classified image showed a decreasing trend in accuracy with increasing neighbourhood size (), reflecting the trade-off between retaining the signal versus the unwarranted noisy pixels. A majority filter neighbourhood size of 3 × 3 pixels produced the highest accuracy (overall Kappa = 0.89 with Z= 43.81; average per class Kappa = 0.82 with standard deviation = 0.30), whereas 11 × 11 pixels had the lowest accuracy (overall Kappa = 0.72 with Z= 24.79; average per class Kappa = 0.61 with standard deviation = 0.32).
Table 2. Accuracy measures of classifiers with and without spatial dependence
Table 3. Confusion matrix of non-spatial random forest classifier using validation samples
Figure 1. Land-cover maps produced by (a) non-spatial random forest classifier (top left), (b) random forest Getis classifier using 11 × 11 pixels moving window (top right) and (c) difference map of non-spatial random forest and random forest Getis (11 × 11 pixels) land-cover maps (bottom left).
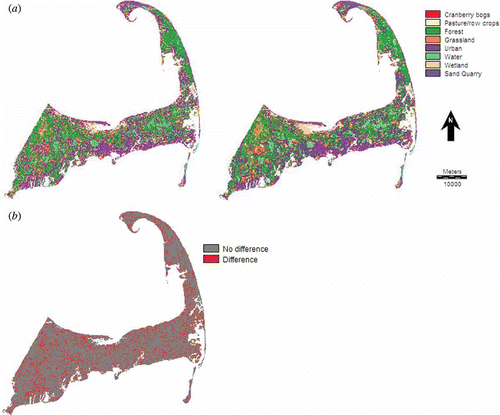
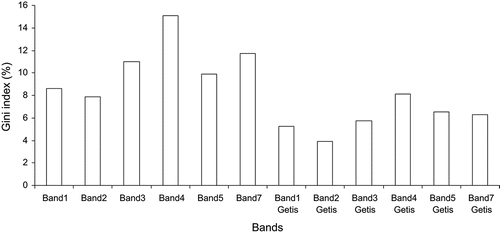
The random forest Getis classifier that integrates the spectral and Getis variables led to a significant increase in land-cover map accuracy (). In general, there was an increase in overall Kappa value with increasing neighbourhood sizes from 3 × 3 to 11 × 11 pixels for the random forest Getis classifiers. The largest neighbourhood size of 11 × 11 pixels resulted in highest overall accuracy (overall Kappa of 0.92 with Z= 53.87; average per class Kappa = 0.93 with standard deviation = 0.06) for the random forest Getis classifier that was significantly different at 0.05 level (Z= 4.51) than that created by the non-spatial random forest classifier and was also higher than that produced by the post-classification majority filters of sizes ranging from 3 × 3 pixels to 11 × 11 pixels applied on the non-spatial random forest classified image. The Getis variables were selected by the random forest classifier because the Getis variables were able to explain a substantial amount of variance indicated by the Gini index variable importance measure (). The predicted categories of the random forest Getis classifier having a window or neighbourhood size of 11 × 11 pixels are shown in . The difference map showing areas of difference and no difference between the land-cover maps produced by the non-spatial random forest classifier and random forest Getis classifier is also revealed in . shows the confusion matrix along with the class-specific accuracy measures for the random forest Getis classifier.
Table 4. Confusion matrix of random forest Getis classifier with 11 × 11 pixels moving window using validation samples
Figure 2. Variable importance contributions of different bands in terms of percent mean reduction in Gini index of the random forest Getis classifier with 11 × 11 pixels moving window.
shows the increase in per class Kappa value of each land-cover category for the random forest Getis classifier over the non-spatial classifier. The highest increase in per class Kappa values was found for heterogeneous map categories, such as pasture or row crops (increase in per class Kappa = 373.23%) and cranberry bogs (increase in per class Kappa = 34.45%). The pasture or row crops category was initially confused with grassland and urban categories and the canberry bog category was confused with the pasture or row crops and grassland categories when the non-spatial classifier was applied, because the pasture or row crops and cranberry bog categories were characterized by low inter-class separability and high intra-class variability. However, the use of the random forest Getis classifier provided additional dimensions in the feature space that increased inter-class separability and reduced intra-class variability. In contrast, small increases in Kappa values were observed for homogeneous classes, such as water (increase in per class Kappa = 0%) and forest (increase in per class Kappa = 4.99%), because the homogeneous categories were highly separable using the spectral variables only and additional Getis variables did not contribute to increasing inter-class separability.
Table 5. Per class Kappa values of non-spatial and random forest Getis classifiers
4. Conclusion
Spatial dependence can describe the local spatial structure and variability of land-cover categories and can increase land-cover classification accuracies in heterogeneous landscapes that are difficult to classify because of high intra-class variability and low inter-class separability. The increase in accuracy of the random forest Getis classifier over the non-spatial random forest classifier can be attributed to the large increase in average per class Kappa of heterogeneous map categories in comparison to homogeneous classes. The variation in Kappa accuracy of the random forest Getis classifier for different neighbourhood sizes is related to the differences in the size of pixel neighbourhood and the shape and size of the land-cover patches or objects represented by the pixel neighbourhood. It is hypothesized that the Getis statistic used to describe contextual or spatial information has distinct advantages over conventional contextual texture-based classification approaches because, unlike standard contextual methods that consider only values at a given neighbourhood of each pixel, the Getis statistic is a ratio of values of the neighbourhood for each pixel versus values of the entire image.
References
- Atkinson , P.M. and Lewis , P. 2000 . Geostatistical classification for remote sensing: an introduction . Computers and Geosciences , 26 : 361 – 371 .
- Blaschke , T. , Burnett , C. and Pekkarinen , A. 2004 . “ Image segmentation methods for object-based analysis and classification ” . In Remote Sensing Image Analysis: Including the Spatial Domain , Edited by: de Jong , S.M. and van der Meer , F.D. 211 – 236 . Dordrecht : Kluwer Academic Publishers .
- Breiman , L. 2001 . Random forests . Machine Learning , 45 : 5 – 32 .
- Congalton , R.G. 1991 . A review of assessing the accuracy of classifications of remotely sensed data . Remote Sensing of Environment , 37 : 35 – 46 .
- Franklin , S.E. and Wulder , M.A. 2002 . Remote sensing methods in medium spatial resolution satellite data land cover classification of large areas . Progress in Physical Geography , 26 : 173 – 205 .
- Getis , A. and Ord , J.K. 1992 . The analysis of spatial association by use of distance statistics . Geographical Analysis , 24 : 189 – 206 .
- Gislason , P.O. , Benediktsson , J.A. and Sveinsson , J.R. 2006 . Random forests for land cover classification . Pattern Recognition Letters , 27 : 294 – 300 .
- Ham , J. , Chen , Y. , Crawford , M.M. and Ghosh , J. 2005 . Investigation of the random forest framework for classification of hyperspectral data . IEEE Transactions on Geoscience and Remote Sensing , 43 : 492 – 501 .
- Kotsiantis , S.B. and Pintelas , P.E. 2004 . Combining bagging and boosting . International Journal of Computational Intelligence , 1 : 324 – 333 .
- Lippitt , C.D. , Rogan , J. , Li , Z. , Eastman , J.R. and Jones , T.G. 2008 . Mapping selective logging in mixed deciduous forest: a comparison of machine learning algorithms . Photogrammetric Engineering and Remote Sensing , 74 : 1201 – 1211 .
- Mather , P.M. 2004 . Computer Processing of Remotely-Sensed Images: An Introduction , Chichester, , UK : John Wiley & Sons Ltd .
- Myint , S.W. , Wentz , E.A. and Purkis , S.J. 2007 . Employing spatial metrics in urban land-use/land-cover mapping: comparing the Getis and Geary indices . Photogrammetric Engineering and Remote Sensing , 73 : 1403 – 1415 .
- Ord , J.K. and Getis , A. 1995 . Local spatial autocorrelation statistics: distributional issues and an application . Geographical Analysis , 27 : 286 – 306 .
- Pal , M. 2005 . Random forest classifier for remote sensing classification . International Journal of Remote Sensing , 26 : 217 – 222 .
- R Development Core Team . 2008 . R: A Language and Environment for Statistical Computing , Vienna, , Austria : R Foundation for Statistical Computing .
- Richards , J.A. and JIA , X. 2006 . Remote Sensing Digitial Image Analysis: An Introduction , Berlin, , Germany : Springer-Verlag .
- Rogan , J. , Franklin , J. , Stow , D. , Miller , J. , Woodcock , C. and Roberts , D. 2008 . Mapping land-cover modifications over large areas: a comparison of machine learning algorithms . Remote Sensing of Environment , 112 : 2272 – 2283 .
- Rogan , J. and Miller , J. 2006 . “ Integrating GIS and remotely sensed data for mapping forest disturbance and change ” . In Understanding Forest Disturbance and Spatial Pattern: Remote Sensing and GIS Approaches , Edited by: Wulder , M. and Franklin , S.E. 133 – 170 . Boca Raton, FL : Taylor & Francis .
- Stehman , S.V. 1997 . Selecting and interpreting measures of thematic classification accuracy . Remote Sensing of Environment , 62 : 77 – 89 .
- Stuckens , J. , Coppin , P.R. and Bauer , M.E. 2000 . Integrating contextual information with per-pixel classification for improved land cover classification . Remote Sensing of Environment , 71 : 282 – 296 .
- Wulder , M. and Boots , B. 1998 . Local spatial autocorrelation characteristics of remotely sensed imagery assessed with the Getis statistic . International Journal of Remote Sensing , 19 : 2223 – 2231 .