
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Image semantic segmentation methods based on convolutional neural networks rely on supervised learning with labels, and their performance often drops significantly when applied to unlabelled datasets from different sources. The domain adaptation methods can reduce the inconsistency of feature distribution between the unlabelled target domain data used for testing and the labelled source domain data used for training, thus improve the segmentation performance and have more practical applications. However, in the field of remote sensing image processing, if the spatial resolutions of the source domain and the target domain are different and this problem is not to be solved, the performance of the transferred model will be affected. In this paper, we propose a bidirectional semantic segmentation method based on super-resolution and domain adaption (BSSM-SRDA), which is suitable for the transfer learning task of a semantic segmentation model from a low-resolution source domain data to a high-resolution target domain data. BSSM-SRDA mainly consists of three parts: a shared feature extraction network; a super-resolution image translation module, which incorporates a super-resolution approach to reduce spatial resolution differences and visual style differences of the two domains; a domain-adaptive semantic segmentation module, which combines an adversarial domain adaptation approach to reduce differences at the output level. At the same time, we design a new bidirectional self-supervised learning algorithm for BSSM-SRDA that facilitates mutually beneficial learning of the super-resolution image translation module and the domain-adaptive semantic segmentation module. The experiments demonstrate the superiority of the proposed method over other state-of-the-art methods on two remote-sensing image datasets, with mIoU improvements of 2.5% and 3.2%, respectively. Code: https://github.com/mageliang/BSSM-SRDA.git
1. Introduction
Deep neural networks trained with large datasets with pixel-level labels have promoted the development of semantic segmentation, but labelling is a time-consuming and labour-intensive work (Hua et al. Citation2021; Wang and Liang Citation2022). Unsupervised Domain Adaptation (UDA) is an effective way to deal with the problem of inadequate labels (Csurka, Volpi, and Chidlovskii Citation2021). It makes the semantic segmentation model learned from the labelled source domain expand to the unlabelled target domain by reducing the differences between the two domains. However, remote sensing data from different sources often have different spatial resolutions, spectral resolutions and feature distributions, etc. Most of the existing unsupervised domain adaptation methods are proposed for the ordinary optical image, and their application to remote sensing image are less effective. This is due to that remote-sensing images often come from different sources, they are variable in their spatial spectrum resolution and are influenced by different imaging regions, imaging conditions and imaging times. Even images from the same region may appear large differences in spectral features. The generalization of the semantic segmentation model relies on the reduction of these inter-domain differences mentioned above. Therefore, unsupervised domain adaptation methods for remote sensing image should not only reduce the differences in features between domains but also solve the problems such as different spatial resolutions. In contrast, few existing studies on UDA of remote sensing image explicitly consider the problem of different spatial resolutions or use simple interpolation methods. Yan et al. (Citation2020) ignore the resolution problem between domains and propose a triadic adversarial domain adaptation method. Zhang et al. (Citation2020) use a simple interpolation to unify the spatial resolution sizes of the source and the target domains. In the past, interpolation was usually used to increase the resolution of the source domain image and eliminate the image resolution difference in some degree, but these methods are not good in handling detailed information such as texture and edge features, and the reconstructions are biased towards smoothness. The super-resolution methods based on convolutional neural networks greatly improve the quality of the reconstructions (Zhang et al. Citation2021), and the fusion process at different scales can better predict the detailed information of the magnified regions.
For remote sensing image from different sources, the source and target domains often have distinct visual style differences. Unlike normal super-resolution methods that only need to reconstruct the detailed information of the low-resolution source domain image itself, super-resolution methods applied to the field of domain adaptation need to learn the features of the high-resolution target domain image, thus better enable the migration application of the model. Recently, there has been considerable progress in research combining image-to-image translation methods based Generative Adversarial Network (GAN) and deep domain adaptation methods (Tang et al. Citation2021). Zhang et al. (Citation2018) first train a semantic segmentation model using the composite image in the source domain with the style of the target domain obtained by image-to-image translation, then address the feature differences between the real image (target domain) and the composite image (source domain) by an adversarial domain adaptation method. This is the only literature (Wu et al. Citation2022) that we retrieved that combines super-resolution method with the above-mentioned image-to-image translation method. We believe that reducing differences in resolution and style of different domains will help to improve the generalization of the model. Therefore, we propose to incorporate super-resolution method into the generative network of the image-to-image translation model, and then generate high-resolution source domain composite image with target domain style by adversarial learning with a discriminator. However, this one-way solution has some limitations: the segmentation model relies heavily on the quality of the composite image, and the training of the semantic segmentation model is greatly affected once the image translation fails. Fortunately, Self-Supervised Learning (SSL) provides a possible solution.
Recently, a combination of SSL and image-to-image translation methods has proven to be very effective in unsupervised domain adaptation (Cheng et al. Citation2021). SSL uses a segmentation module trained from the source domain data to generate a set of pseudo-labels with high confidence for the unlabelled target domain data, which not only filters out the low confidence labels but also helps the domain discriminator to focus on the target domain data that has not yet been feature aligned with the source domain. Unlike previous approaches that the image-to-image translation module and the semantic segmentation module are trained independently, Li, Yuan, and Vasconcelos (Citation2019) propose a self-supervised learning method for domain-adapted semantic segmentation. To complete the secondary learning of the image-to-image translation module, it uses a pre-trained segmentation module to define the content perceptual loss of the translation module on the segmentation results of the composite image and the source image. However, the two modules are updated independently in this process. If the image-to-image translation module and the semantic segmentation module are integrated into one network, then simultaneous updating of the two modules is more conducive to mutual learning. This means that once the segmentation module is better, it can in turn facilitate the image-to-image translation module to get better learning. Therefore, we integrate the super-resolution image translation module (denote as module-R) and the domain-adapted semantic segmentation module (denote as module-S) into one network and combines SSL to design a new bidirectional learning algorithm for these two modules. By changing unidirectional learning into bidirectional learning, image-to-mage translation and semantic segmentation are synchronously updated and promoted by each other, ultimately achieving the goal of reducing spatial resolution differences and feature differences between domains and improving the performance of model transfer applications.
Unlike previous works (Tang et al. Citation2021; Zhang et al. Citation2018) that the image-to-image translation module and the semantic segmentation module were trained independently, our aim is to make the image translation module (module-R) and the semantic segmentation module (module-S) in BSSM-SRDA reinforce each other, and the proposed bidirectional learning algorithm will be designed in two directions: ‘module-R to module-S’ and ‘module-S to module-R’.
In the forward learning (i.e. ‘module-R to module-S’), several works in the field of supervised semantic segmentation (Tang et al. Citation2021; Wang et al. Citation2020) have shown that the feature of super-resolution streams contains more detailed structural information and enhances the learning of semantic segmentation streams. Therefore, we introduce the Feature Affinity-Loss (FA-Loss) between the module-R and module-S. With the help of FA-Loss, high-resolution features with feature similarity from the super-resolution network further enhance the detailed structural information of deep features in the semantic segmentation network (Wang et al. Citation2020). visualizes the feature maps of the semantic segmentation stream and the super-resolution stream fed into FA-Loss. By comparing (b) and (c) in , it can be seen that (c) from the super-resolution network contains more complete structural information, although these structures do not yet explicitly represent categories, they can help the semantic segmentation module to classify effectively through the semantic information conveyed by the pixel-to-pixel or region-to-region relationships.
Figure 1. The visualization of feature maps entered into FA-Loss.

Since the image translation module based on generative adversarial networks belongs to unsupervised learning, the visual content between the generated composite image and the original image in the source domain is often inconsistent, which affects the training of the segmentation module if the loss is calculated directly from the source domain label and the segmentation result of the composite images. Therefore, in the reverse learning (i.e. ‘module-S to module-R’), we first define a new perceptual loss on the pixel-level labelling of the source domain and the segmentation result of the composite image, which bridges the gap between the two modules to constrain the semantic information of the image to be consistent before and after translation. Then, we correct the pixel-level label of the source domain based on the segmentation prediction result of the composite image to obtain the final label of the composite image.
The main contributions of our work include three aspects:
We design a super-resolution image translation module (module-R). There are some works using image translation and super-resolution to reduce domain differences separately, but few works have combined these two approaches. While module-R can perform both super-resolution and style conversion tasks.
We integrate module-R and module-S into one network and propose a bidirectional learning segmentation model BSSM-SRDA. Most of the current related works are one-way training where image translation and/or super-resolution are implemented first, then followed by adversarial domain adaptation. Whereas BSSM-SRDA takes into account the mutually facilitating between module-R and module-S through bidirectional learning.
We design a new bidirectional learning algorithm for BSSM-SRDA by combining self-supervised learning, which enhances the adaptability of the model to the target domain data.
2. Related work
2.1. Domain adaptation methods based on generative adversarial network
For unsupervised semantic segmentation tasks, in order to learn domain invariant features, domain adaptation approaches based on GAN focus on training domain discriminators at the feature level (Hoffman et al. Citation2016; Zhang et al. Citation2020) and the output segmentation result level (Tsai et al. Citation2018). Hoffman et al. (Citation2016) propose to discriminate the features of the source and target domains obtained by the feature extraction network, such that the extracted features of the two domains have similar distribution. Zhang et al. (Citation2020) apply the adversarial loss to the shallow level of the segmentation network that mainly captures the visual information of the images. Tsai et al. (Citation2018) argue that domain adaptation in the feature space is not the best choice for the semantic segmentation task. Makkar, Yang, and Prasad (Citation2022) use adversarial learning at the output level of semantic segmentation network to solve domain adaptation problems in remote sensing. Fan et al. (Citation2022) propose a multi-stage adversarial domain adaptation network in which the output of each layer of the semantic segmentation decoder is fed into the corresponding discriminators separately to extract domain invariant features. They believe that the output segmentation results, although in a low-dimensional space, contain rich structured scene layout information and suggest aligning the feature distribution in the output space. For remote sensing image from different sources, the output of semantic segmentation model has strong spatial and layout similarities, for example, rectangular road areas may cover parts of cars and pedestrians, green plants often grow around buildings. It is meaningful to align feature distribution by setting discriminators at the output space level.
2.2. Domain adaptation methods based on image-to-image translation
Several works (Yoo et al. Citation2019; We et al. Citation2021) have shown that image-to-image translation approaches can reduce the appearance differences between the source and target domain images to some extent, especially the colour differences, thus can improve the domain adaptation performance. Due to the excellent performance of GAN in generating high-quality composite image, many works incorporate GAN for image-to-image translation tasks (Yoo et al. Citation2019; Isola et al. Citation2017). However, these methods require pairs of cross-domain image pairs as training data, which are often difficult to obtain. Recently, GAN-based methods for unpaired image-to-image translation have been proposed, such as CycleGAN (Zhu et al. Citation2017), DiscoGAN (Kim et al. Citation2017) and DualGAN (Yi et al. Citation2017). Although these GAN-based methods present realistic visual results on image translation tasks, the images before and after translation often do not ensure semantic consistency, and the content distortion of the composite images interferes the subsequent semantic segmentation models training significantly. Recently, several approaches in remote sensing have attempted to constraint image translation process through semantic segmentation. BiFDANet (Cai et al. Citation2022) set up an image translation model for the problem of differences in the style of remote sensing images obtained from different satellites or geographical locations, and uses source and target classifiers to constrain the image translation process. ResiDualGAN (Zhao et al. Citation2022) argue that existing image translation methods ignore the scale differences when translating remote sensing data, so a resizer module is used to change the size of the translated image and the stability of the translation process is enhanced through residual linking.
2.3. Domain adaptation methods based on self-supervised learning
Methods incorporating Self-Supervised Learning (SSL) have emerged as an alternative solution to UDA (Xu, Xiao, and López Citation2019) and have achieved state-of-the-art performance on a variety of tasks recently. Such methods generally use pre-trained models to generate pseudo-labels, which are used to update the models (Subhani and Ali Citation2020). Most approaches that follow this strategy are integrated with adversarial learning (Shen et al. Citation2021; Iqbal, Hafiz, and Ali Citation2022), or image-to-image translation (Li, Yuan, and Vasconcelos Citation2019) or both (Gao et al. Citation2022; Yuan et al. Citation2022). For example, Shen et al. (Citation2021) use a trained generator to generate pseudo-labels for the target in order to segment roads from the unlabelled remote sensing images, and classify the target into easy and hard segmentation features based on confidence scores, and then align the hard segmentation features with the easy ones by adversarial learning. Li et al. (Citation2021) propose an objective function with multiple weakly supervised constraints to learn cross-domain remote sensing image semantic segmentation networks. Specifically, it performs weakly supervised transfer invariant constraint by implementing the DualGAN (Yi et al. Citation2017) for image-to-image translation, weakly-supervised pseudo-label constraint by self-supervised learning, and weakly supervised rotation consistency constraint by leveraging the rotation consistency characteristic. BDL (Li, Yuan, and Vasconcelos Citation2019) proposed a self-supervised learning method for domain-adapted semantic segmentation that uses the loss defined on the segmentation results of the composite image and the original image for the translation module to complete the secondary learning, but the three modules are updated independently in this process rather than alternatively updated to promote each other’s learning.
2.4. Domain adaptation method combined with super-resolution
Wu et al. (Citation2022) propose a super-resolution domain adaptation model SRDA for resolution differences in remote sensing images. SRDA uses a super-resolution semantic segmentation network as generator, and sets dual domain discriminators at the image level and output space level. SRDA optimizes the semantic segmentation model by adversarial training to reduce the differences in feature distribution between domains. In particular, SRDA generates high-resolution images by upsampling the feature maps obtained from the feature extraction network. This work illustrates that reducing the resolution difference between the source and target domains can improve the performance of the semantic segmentation model’s migration applications.
Therefore, based on the above analysis, we propose a segmentation method integrating the adversarial domain adaptation semantic segmentation method and the image-to-image translation method into one network, it is trained on the source domain data and produces better results with the target domain data. At the same time, we combine self-supervised learning to design a new bidirectional learning algorithm, so that the image translation module and the semantic segmentation module can contribute to each other’s learning.
3. Methodology
Given the labelled low spatial resolution source domain data and the unlabelled high spatial resolution target domain data, our aim is to train a semantic segmentation model that performs close to the model trained on the labelled target domain. To achieve this goal, BSSM-SRDA not only sets up domain discriminator in the module-S to help extract domain invariant features but also designs the module-R to align the visual style and resolution of the source domain data towards the target domain. When the domain differences are reduced, the semantic segmentation model for the target domain is easier to learn. However, the learnable transferable information is very limited if the two modules learn in a one-way process. We designed a bidirectional learning algorithm by SSL for BSSM-SRDA, in which detailed structural features are added to semantic segmentation through forwards learning, and the content consistency is constrained during image translation through reverse learning. The model structure of BSSM-SRDA and the loss functions of the two modules are presented in Subsections 3.1, 3.2 and 3.3, respectively. The loss function of the BSSM-SRDA model with the addition of bidirectional learning and the bidirectional learning algorithm are presented in Subsections 3.4 and 3.5.
3.1. Model structure of BSSM-SRDA
The model structure of BSSM-SRDA is shown in . BSSM-SRDA uses the residual ASPPnet (Wang et al. Citation2019) as a shared feature extraction network. The top half of shows the super-resolution image translation module (module-R), which consists of a high-resolution image generation network and a Pixel-level Domain Discriminator (PDD). The generation network uses PixelShuffle (Shi et al. Citation2016), whose main function is to reconstruct higher resolution images by convolution and channel shuffle. By setting the number of the feature channels, high-resolution images with different scale factors can be reconstructed. Since the spatial resolution difference between the remote sensing image datasets we used in the experiments was 2× and 3×, the super-resolution generation network was designed as two PixelShuffle layers with the scale factor of 2 and a bilinear interpolation layer that restores the feature maps to the size of the target domain image. The network structure of PDD is the same as PatchGAN (Isola et al. Citation2017), which is designed to pay more attention to image details and consists of five convolutional layers with 4 × 4 convolutional kernel size, where the channel number is {64, 128, 256, 512, 1}, respectively. The bottom half of shows the domain-adapted semantic segmentation module (module-S), which consists of semantic segmentation decoders and an Output-space Domain Discriminator (ODD). The decoder consists of three convolutional layers with convolutional kernels of size 3 × 3, 3 × 3 and 9 × 9. The final predicted segmentation result is output by the SoftMax function. The orange arrow between the two modules represents the feature pyramid fusion structure (Lin et al. Citation2017), where the feature maps obtained from module-R are migrated and fused to the corresponding layer of module-S. The network structure of the ODD discriminator consists of five convolutional layers with a convolutional kernel size of 4 × 4, where the channel number is {64, 128, 256, 512, 1}, respectively. Except for the last layer, each convolution layer is followed by a leakyReLU function. BSSM-SRDA combines SSL to implement a bidirectional learning algorithm with FA-Loss, a new perceptual loss and a label correction strategy.
Figure 2. The structure of BSSM-SRDA.
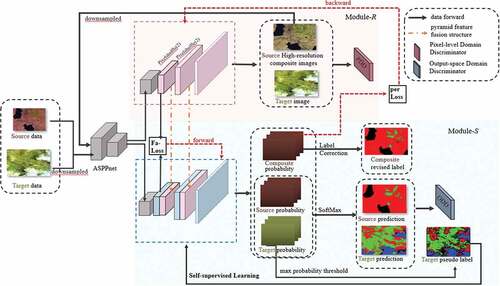
In the training stage, the source domain image and the target domain image downsampled to the size of the source are fed into the BSSM-SRDA. The input to module-R and module-S is the feature map produced by ASPPnet and is one-half the size of the source domain input image. In the module-R, we take the high-resolution target domain data as the reference data. Through generative adversarial training of the generation network and the PDD, high-resolution composite images of the source domain with detailed texture features of the high-resolution target-domain images are obtained, which accomplishes the super-resolution task for the source-domain image while reducing the style difference between domains. In the module-S, the labelled source domain images and the composite images are used for supervised learning, and the unlabelled target domain images are used for self-supervised learning. At the same time, we do label correction on the source domain labels based on the segmentation results of the composite images to obtain the labels of the composite images. The feature distributions of the two domains are further aligned by training against the ODD. The input to the PDD are the source domain composite images and the target domain images, and the input to the ODD are the segmentation prediction results of the two domains. In the test stage, the target domain test set images are input to the well-trained BSSM-SRDA to obtain the predicted segmentation result.
The symbols in the text are defined as follows: We denote module-R, module-S, and ASPPnet as R, S, and E. and
denote the upsampled and downsampled operations. The low-resolution image of the source domain is denoted as
and its label is
.The high-resolution image of the target domain is denoted as
. The high-resolution composite image generated by module-R is denoted as
. According to the above definition, the aim of BSSM-SRDA is to reduce the differences between the source and target domains through a bidirectional facilitated learning of R and S, including spatial resolution difference and feature difference, and ultimately to obtain a semantic segmentation model that is more applicable to the target domain.
3.2. Super-resolution image translation module
PixelShuffle (Shi et al. Citation2016) was used in module-R to generate high-resolution images. PatchGAN (Isola et al. Citation2017), which is more attentive to image details, is applied as the PDD to generate with target domain style by generative adversarial training. The input to module-R are the source domain images and the downsampled target domain images. The mean square error loss
is computed for the target domain with the high-resolution and low-resolution image pairs, and the perceptual loss
(Johnson, Alahi, and Fei Citation2016) is computed for the
and
. The perceptual loss measures the difference in style and semantics between the composite and original images. The loss of module-R and the GAN loss of PDD are shown in EquationEquation (1)
(1)
(1) and (Equation2
(2)
(2) ), respectively.
where denotes the PDD,
denotes the distribution of the data,
denotes the expected value of the distribution function,
denotes the probability that the PDD determines the target domain data
as true, and
denotes the probability that the PDD will determine the composite image
as false. As the number of training iterations increases, PDD grows more discriminative, and the generator of module-R improves the quality of the composite image under adversarial training accordingly. For the generator, it is expected that the probability of the composite image being determined as true is high, which means maximizing the loss function
.
3.3. Domain-adaptive semantic segmentation module
There are no segmentation labels for target domain before self-supervised learning, therefore, the loss of model-S is the cross-entropy loss of the source domain. The loss function is shown in EquationEquation 3
(3)
(3) :
The loss function of ODD is shown in EquationEquation 4(4)
(4) :
where denotes the ODD. We take the segmentation prediction results of the source and target domain images as input to ODD, then ODD determines the domain class (source or target domain) of the input samples, with z = 0 if the samples are from the target domain, and z = 1 if the samples are from the source domain.
To improve the generalization of module-S to the target domain data, we next combine self-supervised training to further train module-S using the unlabelled target domain data. We used a common method known as maximum probability thresholding (Shin et al. Citation2020) to select pixels from the predicted probability of target domain with high confidence as pseudo labels, and the target domain data with pseudo labels are used as training samples in subsequent training procedure to provide cross-entropy loss for the update of module-S. Therefore, the loss function used for training module-S (EquationEquation 3(3)
(3) ) is redefined as follows:
where is the target domain data with pseudo label. As module-S gets better, more pseudo labels with high confidence will be obtained.
3.4. Bidirectional learning of BSSM-SRDA
The deep feature extracted by module-S is abundant in semantic information and less in detail, while the deep feature from module-R has more detailed structural information. The composite images generated by module-R based on GAN inevitably introduces noise, while module-R cannot provide much constraint for its own training process. However, it is possible to determine whether there is content inconsistency between the segmentation result of the composite images and the source domain labels by module-S. Based on the above two points, we design the forward and reverse learning for the two modules of BSSM-SRDA.
3.4.1. Forward learning (module-R to module-S)
The deep feature maps from module-R include more detailed information. To achieve the forward facilitated learning of module-R to module-S, Feature Affinity-Loss (FA-Loss) is involved to enhance the detailed structural information of the semantic segmentation decoder feature maps. The similarity matrix C in EquationEquation 6(6)
(6) is used to describe the similarity relationship between pairs of pixels. As shown in EquationEquation 7
(7)
(7) , the goal of FA-Loss is to learn the distance between the deep feature similarity matrices of module-R and module-S. If the distance value is small, the proportion in
is also small, indicating that the structural information of the features extracted by the two modules is similar. If the distance value is large, the proportion in
is also large, which enables module-S to learn more high-resolution structural features.
In EquationEquation 7(7)
(7) ,
denotes the spatial dimension,
denotes the relationship between the i-th and j-th pixels,
denotes the similarity matrix of the feature map from module-R, and
denotes the similarity matrix of the feature map from module-S. For a feature map F of size
, the similarity relationship between each pair of pixels needs to be calculated. The similarity relationship graph contains
pairs of connections, and each value in the relationship graph is the sum of the similarity relationships of all the channels. After adding
to Equations (3) and (5), the loss functions of module-S during pre-training and self-supervised training are shown in Equations (8) and (9), respectively.
3.4.2. Reverse learning (module-S to module-R)
The aim of module-R is to reduce the resolution differences and the visual style differences between the source and target domains, and to avoid introducing visual inconsistencies. However, the composite images generated based on GAN may be noisy, and the semantic content of the composite images may not match the source domain label. If the cross-entropy loss is calculated by the segmentation results of the composite images and the source domain labels, it may bring interference to the training of module-S. Therefore, we propose a label correction strategy (LCS) to obtain the label of the composite images through the source domain labels and the segmentation prediction results of the composite images. First, we generate pseudo labels
for the composite images by the maximum probability thresholding method. Then, some pixel-level labels in
are replaced with high-confidence pixel-level labels in
. The label of the corrected composite images
is defined as:
where is the predicted probability map of the segmentation model,
and
denote the category indexes in
and
respectively, and δ is the correction rate. As shown in Equation 10, in the predicted probability map of the segmentation result of the composite image, for a pixel which has a pseudo-label, if its probability value of the pseudo-label category is higher than the probability value of the original label category by δ, the label of the pixel is replaced with the pseudo-label category. In summary, the loss function of module -S is shown in Equation (11).
From EquationEquation 1(1)
(1) , it is clear that module-R constrains the semantic consistency of the original and composite images in the source domain by their perceptual loss when training, but we find that the visual content of the composite images still may be changed. Thus, after obtaining a better semantic segmentation module, we propose a new perceptual loss between the segmentation result of the composite image and the pixel-level label of the source domain, which in turn further constrains the learning of module-R. In summary, the loss function of module-R is shown in EquationEquation 13
(13)
(13) .
In the forward learning, FA-Loss is used to enhance the detailed structural information of module-S by module-R. In the reverse learning, the interference introduced by the composite images is eliminated and the training process of module-R is constrained by LCS and the new perceptual loss. This enables BSSM-SRDA to finally accomplish a bidirectional facilitated learning. Similar to the standard generative adversarial network, the ultimate goal of BSSM-SRDA is to optimize EquationEquation 13
(13)
(13) , minimizing
and
, as well as maximizing the probability of the target domain being discriminated as the source domain in the discriminator (both PDD and ODD).
3.5. Bidirectional learning algorithm for BSSM-SRDA
Generally, there are considerable differences in feature distribution and spatial resolution between the source and target domains of remote sensing images. BSSM-SRDA integrates a super-resolution image translation module (module-R) and a domain-adaptive semantic segmentation module (module-S), and it is hard to learn all the transferable information in a unidirectional way. To address this problem, we propose a new bidirectional learning algorithm combining self-supervised learning. Algorithm 1 gives the training procedure of BSSM-SRDA, which mainly consists of pre-training of module-R and BSSM-SRDA, and the iterative training that implements SSL and LCS. N refers to the number of the self-supervised learning iterations.
Table
In the training phase, firstly, pre-trained module-R provides well-translated composite images for the subsequent training of the semantic segmentation module. Then, BSSM-SRDA0 was trained on the basis of the pre-trained module-R, and FA-Loss increases the learning speed of module-S by the already well-trained module-R. Finally, self-supervised learning was implemented in an iterative way. BSSM-SRDA was trained for N iterations with self-supervised loss in the target domain added to and new perceptual loss added to
. And label correction is performed on the source domain composite image after each pseudo-label is generated by self-supervised training in the target domain. In the test phase, the target domain test data is input to the well-trained BSSM-SRDAN to obtain the final segmentation prediction results.
4. Experiments and analysis
4.1. Datasets
To validate the proposed method BSSM-SRDA, we conduct experiments on two groups of datasets.
Vaih-Pots: Vaihingen (Vaih) and Potsdam (Pots) are two remote sensing datasets with six categories: impervious, building, vegetation, tree, car and clutter (Rottensteiner et al. Citation2014), where the vegetation refers to low vegetation. They are provided by ISPRS for multi-class semantic segmentation experiments. Vaihingen dataset, which consists of 33 images with the spatial resolution of 9 cm, is considered as the source domain. Potsdam dataset, which consists of 38 images with the spatial resolution of 5 cm is considered as the target domain. All images in the source domain are used as the training set, 19 images in the target domain are divided as the training set, and the other 19 images are used as the test set. Since the spatial resolution difference between the source and target domain data is about 2 times, Vaihingen is cropped to 180 × 180 and Potsdam is cropped to 360 × 360.
TPDS-TPDT: Tibetan Plateau Dataset (TPD), produced by our group, is selected from remote sensing images of the Tibetan Plateau region taken by different sensors in 2020 and 2021. The source domain TPDS has two remote sensing images of 8192 × 5200 with the spatial resolution of 90 m. The target domain TPDT has one remote sensing image of 5004 × 5549 with the spatial resolution of 30 m. We manually labelled this dataset with four categories: vegetation, bare ground, water and clutter, where the vegetation includes trees, low vegetation and grassland. Since the spatial resolution difference between the source and target domains is 3 times, the source domain images are cropped to 5500 images of 86 × 86 and the target domain is cropped to 399 images of 256 × 256. All the cropped images in the source domain are used as the training set, and all the images in the target domain are divided into training set and testing set in the ratio of 2:1. We augment the target domain training set data by image flipping.
4.2. Experiment setup
The experiments are implemented on an NVIDIA GeForce RTX™ 3090 GPU with 24 GB RAM and the deep learning framework is PyTorch. We use the Adam optimizer with a momentum of 0.9. In the training process, all samples are trained 20 times for pre-training module-R, 30 times for pre-training BSSM-SRDA0, and 30 times for iterative training BSSM-SRDAi. The initial learning rate is set to 2 × 10-4. Indicators mIoU and Macro-F1, which are suitable for multi-classification task evaluation, are used in our experiments.
4.3. Experimental results and analysis
4.3.1. Hyperparameters experiments
We choose the hyperparameters mentioned in the method by performing experiments on the Vaih-Pots dataset, including the number of self-supervised learning iterations N, the confidence threshold ɛ for selecting pseudo labels, the number of iterations of LCS, and the correction rate δ.
4.3.1.1. Confidence threshold ɛ and the number of SSL iterations N
When the number of the self-supervised learning iterations N of BSSM-SRDAN takes different values, mIoU results obtained after training BSSM-SRDAN by selecting pseudo-labels under different confidence thresholds ɛ are shown in . When the threshold ɛ is lower than 0.9, some wrong predictions may be selected as pseudo labels and may bring interference to the training of the semantic segmentation module. When the threshold ɛ is 0.95, the number of the pseudo-labels that can be used is decreased, resulting in a decrease in BSSM-SRDAN’s performance. Therefore, in the subsequent experiments, the confidence threshold ɛ is set to 0.9.
Table 1. The influence of hyperparameters ɛ and N from vaih to pots.
As the number of the self-supervised learning iterations N increases, BSSM-SRDAN assigns pseudo labels to more high-confidence pixels in the target domain to increase the number of training samples, which enables BSSM-SRDAN to perform better transfer learning on the target domain data. Once the set of the target domain data with pseudo labels stops increasing, it means that the learning of BSSM-SRDAN has converged. When the confidence threshold ɛ is 0.9, the segmentation results of the method in on the Pots training set and the pseudo labels obtained by the maximum probability thresholding method MPT are shown in the second row of , where the white pixels are the low confidence pixels, and the coloured ones are the pixels with confidence higher than 0.9 and being used as pseudo labels. It can be found that as N increases, the performance of BSSM-SRDA is improving, and the number of the pseudo labels are increasing. When N = 3, mIoU increases only by 0.1% than N = 2. Considering that increasing N leads to higher computational cost, the number of N is set to 2 in the subsequent experiments.
Figure 3. The visualization of the segmentation results and the pseudo-labels for each iteration in SSL.

4.3.1.2. Correction rate δ and the number of LCS
We determine the labels of the composite images through the label correction strategy to avoid inconsistency between the content of the composite images and the original labels in the source domain, and then reduce interference to the learning of the semantic segmentation module. The correction rate δ determines the number of pixels in the original labels of the source domain that need correction. shows mIoU of BSSM-SRDAN with different correction rates δ. It can be found that δ is a less sensitive hyperparameter and is set to 0.3 in the subsequent experiments. When the correction rate δ is 0.3, LCS improved mIoU of BSSM-SRDA1 by 0.9% after the first training iteration, improved mIoU of BSSM-SRDA2 by 0.6% after the second iteration training, but improved mIoU of BSSM-SRDA3 by only 0.1% after the third iteration training. The experiments show that BSSM-SRDA learning has converged after 2 or 3 iterations and the performance will not improve with more iterations. This conclusion coincides with the experimental conclusion of the number of SSL iterations N. Therefore, the number of the iterations for LCS in subsequent experiments is the same as N, which is set to 2.
Table 2. The influence of hyperparameters δ and the number of LCS from Vaih to Pots.
4.3.2. Ablation experiments
To validate the effectiveness of BSSM-SRDA, we conducted ablation experiments on the Vaih-Pots dataset in two parts: forward learning and reverse learning.
4.3.2.1. Forward learning of BSSM-SRDA
In the forward learning, since the super-resolution module contains more complete structural information than the features extracted by the semantic segmentation decoder, FA-Loss is introduced to enhance the learning effect of the module-S using the well-trained module-R. We take the experiment result of BSSM-SRDA0 as an example to illustrate the effectiveness of FA-Loss in . Moreover, to compare with the reverse learning experiment results in the next part, the experiment result for BSSM-SRDA1 with only forward learning is also shown in . After adding the FA-Loss, mIoU of BSSM-SRDA0 is increased by 1.6% and mIoU of BSSM-SRDA1 is increased by 1.1%, demonstrating that module-R can promote module-S.
Table 3. Quantifying the effectiveness of FA-Loss from vaih to pots.
4.3.2.2. Reverse learning of BSSM-SRDA
In the reverse learning, module-R improves visual content consistency by two proposed approaches: the new perceptual loss and the label correction strategy. Since LCS and are added from the training phase of BSSM-SRDA1, we take the experiment result of the BSSM-SRDA1 as an example to indicate the effectiveness of LCS and
. shows the results of the ablation experiments on the first iteration of BSSM-SRDA1 (N = 1) for reverse learning. Where
denotes the common perceptual loss in the field of image-to-image translation, which is computed from the composite images and the original images;
denotes the new perceptual loss used in BSSM-SRDA, which is computed from the segmentation prediction results of the composite images and the source domain labels. The experimental results in the first and second rows of demonstrate the effectiveness of
. mIoU of BSSM-SRDA1 is improved by 1.3% after adding
. The experimental results for the label correction of the composite image on the basis of
are shown in the third row, where the mIoU of BSSM-SRDA1 is improved by 0.8% after adding LCS. BSSM-SRDA1 achieves the best result when both
and LCS were used (mIoU of 47.0%), an increase of 2.2% over the mIoU when only
was used, indicating that the combination of
and LCS can further alleviate the impact of visual inconsistencies caused by image-to-image translation.
Table 4. Quantifying the effectiveness of and LCS from Vaih to Pots.
Table 5. Characteristics of BSSM-SRDA and the compared methods.
Table 6. The quantitative evaluation results of different methods from Vaih to Pots.
From the last two rows in , it can be seen that with only forward learning, BSSM-SRDA1 showed a 1.1% improvement in mIoU compared with only self-supervised training (i.e. from 43.7% to 44.8% before and after adding forward learning). From the last row of , it can be found that there is a 3.3% improvement in mIoU after adding bidirectional learning (i.e. from 43.7% to 47.0% before and after adding bidirectional learning). This indicates that the bidirectional learning algorithm of BSSM-SRDA improves the performance of the semantic segmentation model significantly.
4.3.3. Comparison experiment
We use the residual ASPPnet as the feature extraction network for the baseline model, and then we apply the up-sampling layer along with the softmax output to match the size of the input image. We selected five comparable state-of-the-art methods in the area of adversarial domain adaptation semantic segmentation for comparison: AdapSegNet (Tsai et al. Citation2018), FCAN (Zhang et al. Citation2018), BDL (Li, Yuan, and Vasconcelos Citation2019), SRDA (Wu et al. Citation2022) and ScaleDA (Deng et al. Citation2021). The characteristics of these methods can be seen in . In terms of image-to-image translation, FCAN and BDL train the image translation module and the domain-adaptive semantic segmentation module independently, while SRDA and BSSM-SRDA fuse the two into a single network, specifically BSSM-SRDA maintains visual consistency of image translation through a new perceptual loss. In terms of self-supervised learning, BDL generates pseudo-labels for unlabelled target domain images. While BSSM-SRDA generates pseudo-labels not only for the target domain images but also for the source domain composite images to perform label correction in the iterative training process. In terms of reducing spatial resolution differences, SRDA uses simple bilinear interpolation to enlarge the source domain image to the size of the target domain image. ScaleDA proposes a scale discriminator to reduce the objects’ scale difference caused by different spatial resolution. BSSM-SRDA combines super-resolution into the image-to-image translation module and reconstructs the source image to the size of the target domain image.
4.3.3.1. Vaih-Pots
The results on the Vaih-Pots dataset are shown in . It can be seen that BSSM-SRDA achieves the best performance (mIoU of 48.5% and Macro-F1 of 64.1%). Compared to the Baseline model, the mIoU of AdapSegNet is increased by 6%, the Macro-F1 of AdapSegNet is increased by 7.8%, which illustrates the effectiveness of the adversarial domain adaptation method. FCAN with an image-to-image translation module (mIoU of 42.0%) gained a 6.9% improvement in mIoU over AdapSegNet (mIoU of 35.1%). BDL (mIoU of 44.9%), which combines self-supervised learning to alternately train the image-to-image translation module and the semantic segmentation module, gained a 2.9% improvement over FCAN. Compared to the current best performing SRDA (mIoU of 46.0%), BSSM-SRDA improves mIoU of 2.5% with the help of super-resolution and bidirectional learning. Without image translation, ScaleDA (mIoU of 43.4%) improved mIoU by 8.3% over AdapSegNet by means of a proposed scale discriminator and scale attention for the spatial resolution difference problem between domains, indicating that it is essential to solve spatial resolution differences in the field of remote sensing image domain adaptation. BSSM-SRDA has the best results on four categories (impervious, building, vegetation and car), and the next best results on the other two categories (tree and clutter). The segmentation results of categories impervious and building, which have more structured features, improved by 3.3% and 2.2% on mIoU, respectively, than that of the SOTA method (SRDA). The mIoU of class Clutter of all the methods are lower, since this class is complex in content and structure.
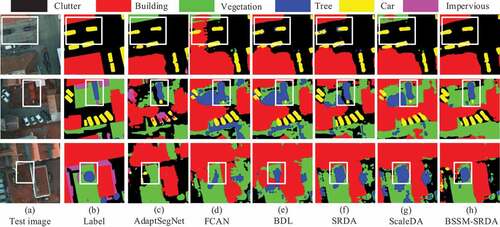
shows the segmentation results for BSSM-SRDA and the other five compared methods. The first column is the original images in the Pots test dataset, the second column are the corresponding labels, and the rest of the columns are the segmentation results of the comparison methods. It can be observed that the segmentation results of BSSM-SRDA outperform AdaptSegnet, FCAN, BDL, SRDA and ScaleDA in terms of structure and details.
Figure 4. Some segmentation results of different methods on potsdam testing set.
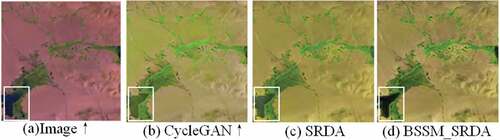
The composite images of the source domain which have the target domain style and generated by different image-to-image translation methods are presented in , (b) shows the result of CycleGAN image translation model which used by BDL and FCAN, (c) shows the result of the image translation model of SRDA, and (d) shows the result of the super-resolution image translation module of BSSM-SRDA. Since both SRDA and BSSM-SRDA have processed the image resolution difference, upsampling operations were performed on (a) and (b) for comparability. It can be found that BSSM-SRDA showed the best reconstructed ability and retained more detailed information. From the region inside the white rectangular box in , it can be found that CycleGAN and SRDA tend to generate tree-like artefacts in the vegetation to deceive the discriminator, which may cause interference in the learning of subsequent semantic segmentation tasks. BSSM-SRDA benefits from the proposed super-resolution approach and the new perceptual loss makes the generated high-resolution composite images more consistent with the visual content of the original image.
Figure 5. The composite images generated by different GAN methods on Vaih training set.

4.3.3.2. Tpds-tpdt
The results on the TPDS-TPDT dataset are shown in . It can be seen that BSSM-SRDA achieves the best results in all the categories and the comprehensive indicators (mIoU of 61.5% and Macro-F1 of 73.1%). Compared to the current best performing SRDA (mIoU of 58.3% and Macro-F1 of 69.2%), BSSM-SRDA improves mIoU by 3.2% and Macro-F1 by 3.9%. BSSM-SRDA achieves the best results on each category. In particular, compared to the SOTA method (SRDA), the mIoU results of BSSM-SRDA improve significantly for the categories with smaller area (water, vegetation and clutter) by 2.6%, 3.4% and 4.0%, respectively. The results of the comparison experiments in show that the methods reducing the difference in image resolution (i.e. SRDA, ScaleDA and BSSM-SRDA) perform better than most of the other methods (i.e. Baseline, AdapSegNet and FCAN). For the methods that include both image-to-image translation and self-supervised learning, BSSM-SRDA performs better than BDL.
Table 7. The quantitative evaluation results of different methods from TPDS to TPDT.
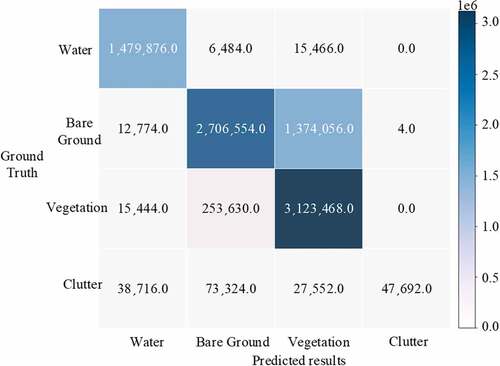
shows some segmentation results for BSSM-SRDA and the other five compared methods. It can be seen that visually, the segmentation results of BSSM-SRDA are the closest to the ground truth. shows the confusion matrix obtained by BSSM-SRDA on the target domain testing set, where the rows represent the labels of each category and the columns represent the predicted category. A large number of pixels in the vegetation and bare ground categories were mis-segmented from each other since the two categories were mixed together in the target domain dataset TPDT and hard to be distinguished.
Figure 6. Some segmentation results of different methods on TPDT testing set.
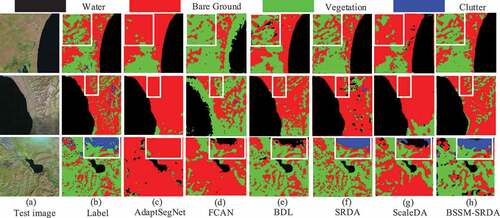
Figure 7. The confusion matrix of BSSM-SRDA on TPDT testing set.
The TPDS and TPDT datasets have more distinct visual style differences and feature differences than the Vaih and Pots datasets, for example, the source domain TPDS has a large number of small lakes and fewer vegetation classes, while the target domain TPDT has almost no small lakes and more vegetation classes. The composite images generated by the different image-to-image translation models are presented in . From the region inside the white rectangular box in , it can be found that the features of small lake are generated as the features of green vegetation in CycleGAN and SRDA, while BSSM-SRDA achieves the best performance in terms of content consistency. At the same time, because BSSM-SRDA combines a super-resolution approach, which generates images with higher resolution and more detailed information.
Figure 8. The composite images generated by different GAN methods on TPDS training set.
4.3.3.3. Comparison of training time and testing time
The training time and the testing time of all the compared methods on the two datasets with the same experimental settings are given in . Combining , we can find that the training time is higher for all the integrated methods (FCAN, BDL, SRDA and BSSM-SRDA). BDL and BSSM-SRDA, which need to be trained in stages, take more training time. SRDA and BSSM-SRDA, which combine super-resolution and semantic segmentation into one network, take more testing time. Compared with other methods, BSSM-SRDA takes longer training time, but more training cost brings the best model performance. Meanwhile, the testing of BSSM-SRDA is relatively efficient.
Table 8. The training and testing times of different methods.
5. Conclusion
We propose a bidirectional semantic segmentation method BSSM-SRDA for remote sensing images based on domain adaptation and super-resolution to address the problems of spatial resolution differences and feature differences faced in the field of remote sensing image domain adaptation. We propose a super-resolution image translation module by combining a GAN-based super-resolution method with an image-to-image translation method. At the same time, we design a new bidirectional learning algorithm by self-supervised learning for BSSM-SRDA. The algorithm enhances the semantic segmentation module’s training by making full use of the detailed structural information provided by the super-resolution image translation module, and constrains the image translation process through the segmentation results reversely, so that the two modules learn mutually and promote each other. Through generative adversarial learning and iterated mutual learning between the super-resolution image translation module and the domain adaptation semantic segmentation module, the segmentation performance of BSSM-SRDA in the unlabelled target domain is improved significantly. We conduct experiments on two groups of datasets, Vaih-Pots and TPDS-TPDT, with different spatial resolutions. In the practical application of remote sensing, spatial resolution differences and feature differences often exist for different source’s data. But few studies have addressed these issues simultaneously, BSSM-SRDA proposes a feasible and effective method for this challenge, and achieves the best results compared to the five state-of-the-art methods. We will extend BSSM-SRDA to more practical applications in the future, such as application scenarios with different categories or different spectral resolutions between the two domains.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Cai, Y., Y. Yang, Q. Zheng, Z. Shen, Y. Shang, J. Yin, and Z. Shi. 2022. “BiFdanet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images.” Remote Sensing 14 (1): 190. doi:10.3390/rs14010190.
- Cheng, Y., F. Wei, J. Bao, D. Chen, F. Wen, and W. Zhang. “Dual Path Learning for Domain Adaptation of Semantic Segmentation.” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, 9062–9071. doi: 10.1109/ICCV48922.2021.00895.
- Csurka, G., R. Volpi, and B. Chidlovskii. 2021. “Unsupervised Domain Adaptation for Semantic Image Segmentation: A Comprehensive Survey.” (arXiv:2112.03241, 2021).
- Deng, X., Y. Zhu, Y. Tian, and S. Newsam. 2021. “Scale Aware Adaptation for Land-Cover Classification in Remote Sensing Imagery.” 2021 IEEE/CVF Winter Conference on Applications of Computer Vision: 2160–2169. doi: 10.1109/WACV48630.2021.00221.
- Fan, X., P. Cao, P. Shi, X. Chen, X. Zhou, and Q. Gong. 2022. “An Underwater Dam Crack Image Segmentation Method Based on Multi-Level Adversarial Transfer Learning.” Neurocomputing 505: 19–29. doi:10.1016/j.neucom.2022.07.036.
- Gao, H., Y. Zhao, P. Guo, Z. Sun, X. Chen, and Y. Tang. 2022. “Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images.” Remote Sensing 14 (7): 1527. doi:10.3390/rs14071527.
- Hoffman, J., D. Wang, F. Yu, and T. Darrell. 2016. “Fcns in the Wild: Pixel-Level Adversarial and Constraint-Based Adaptation .” (arXiv:1612.02649, 2016).
- Hua, Y., D. Marcos, L. Mou, X. Zhu, and D. Tuia. 2021. “Semantic Segmentation of Remote Sensing Images with Sparse Annotations.” IEEE Geoscience and Remote Sensing Letters 19: 1–5. doi:10.1109/LGRS.2021.3051053.
- Iqbal, J., R. Hafiz, and M. Ali. 2022. “FogAdapt: Self-Supervised Domain Adaptation for Semantic Segmentation of Foggy Images.” Neurocomputing 501 (2022): 844–856. doi:10.1016/j.neucom.2022.05.086.
- Isola, P., J. Y. Zhu, T. Zhou, and A. A. Efros. “Image-To-Image Translation with Conditional Adversarial Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, 5967–5976. doi: 10.1109/CVPR.2017.632.
- Johnson, J., A. Alahi, and L. Fei. “Perceptual Losses for Real-Time Style Transfer and Super-Resolution.” 2016 European conference on computer vision (ECCV), 2016: 694–711. doi: 10.1007/978-3-319-46475-6_43.
- Kim, T., M. Cha, H. Kim, J. K. Lee, and J. Kim. “Learning to Discover Cross-Domain Relations with Generative Adversarial Networks.” 2017 International Conference on Machine Learning-Volume (ICML), 2017, 1857–1865. doi: 10.5555/3305381.3305573.
- Lei, S., Z. Shi, X. Wu, B. Pan, X. Xu, and H. Hao. “Simultaneous Super-Resolution and Segmentation for Remote Sensing Images.” 2019 IEEE International Geoscience and Remote Sensing Symposium, 2019, 3121–3124. doi: 10.1109/IGARSS.2019.8900402.
- Lin, T. Y., P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. “Feature Pyramid Networks for Object Detection.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 936–944. doi: 10.1109/CVPR.2017.106.
- Li, Y., T. Shi, Y. Zhang, W. Chen, Z. Wang, and H. Li. 2021. “Learning Deep Semantic Segmentation Network Under Multiple Weakly-Supervised Constraints for Cross-Domain Remote Sensing Image Semantic Segmentation.” Isprs Journal of Photogrammetry and Remote Sensing 175: 20–33. doi:10.1016/j.isprsjprs.2021.02.009.
- Li, Y., L. Yuan, and N. Vasconcelos. “Bidirectional Learning for Domain Adaptation of Semantic Segmentation.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, 6929–6938. doi: 10.1109/ICCV48922.2021.00895.
- Makkar, N., L. Yang, and S. Prasad. 2022. “Adversarial Learning Based Discriminative Domain Adaptation for Geospatial Image Analysis.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 15: 150–162. doi:10.1109/JSTARS.2021.3132259.
- Rottensteiner, F., G. Sohn, M. Gerke, and J. D. Wegner. 2014. “Data From: ISPRS WG III/4. ISPRS 2D Semantic Labeling Contest” (dataset). http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html.
- Shen, W., Q. Wang, H. Jiang, S. Li, and J. Yin. “Unsupervised Domain Adaptation for Semantic Segmentation via Self-Supervision.” 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 2021: 2747–2750. doi: 10.1109/IGARSS47720.2021.9553451.
- Shi, W., J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang. “Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 1874–1883. doi: 10.1109/CVPR.2016.207.
- Shin, I., S. Woo, F. Pan, and I. S. Kweon. 2020. ““Two-Phase Pseudo Label Densification for Self-Training Based Domain Adaptation.” 2020 European Conference on Computer Vision.” (ECCV) 532–548. doi:10.1007/978-3-030-58601-0_32.
- Subhani, M. N., and M. Ali. “Learning from Scale-Invariant Examples for Domain Adaptation in Semantic Segmentation.” 2020 European conference on computer vision (ECCV), 2020: 290–306. doi: 10.1007/978-3-030-58542-6_18.
- Tang, H., H. Liu, D. Xu, P. H. Torr, and S. N. Sebe. 2021. “Attentiongan: Unpaired Image-To-Image Translation Using Attention-Guided Generative Adversarial Networks.” IEEE Transactions on Neural Networks and Learning Systems. doi: 10.1109/TNNLS.2021.3105725.
- Tsai, Y. H., W. C. Hung, S. Schulter, K. Sohn, M. H. Yang, and M. Chandraker. “Learning to Adapt Structured Output Space for Semantic Segmentation.” 2018 IEEE conference on computer vision and pattern recognition (CVPR)2018, 7472–7481. doi: 10.1109/CVPR.2018.00780.
- Wang, X., and Z. Liang. 2022. “Hybrid Network Model Based on 3D Convolutional Neural Network and Scalable Graph Convolutional Network for Hyperspectral Image Classification.” IET Image Processing 17 (1): 1–18. doi:10.1049/ipr2.12632.
- Wang, L., D. Li, Y. Zhu, L. Tian, and Y. Shan. “Dual Super-Resolution Learning for Semantic Segmentation.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, 3773–3782. doi: 10.1109/CVPR42600.2020.00383.
- Wang, L., Y. Wang, Z. Liang, Z. Lin, J. Yang, W. An, and Y. Guo. “Learning Parallax Attention for Stereo Image Super-Resolution.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 12242–12251. doi: 10.1109/CVPR.2019.01253.
- We, Y., S. Gu, Y. Li, R. Timofte, L. Jin, and H. Song. “Unsupervised Real-World Image Super Resolution via Domain-Distance Aware Training.” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, 13380–13389. doi: 10.1109/CVPR46437.2021.01318.
- Wu, J., Z. Tang, C. Xu, E. Liu, L. Gao, and W. Yan. 2022. “Super-Resolution Domain Adaptation Networks for Semantic Segmentation via Pixel and Output Level Aligning.” Frontiers in Earth Science 10 (2022): 974325. doi:10.3389/feart.2022.974325.
- Xu, J., L. Xiao, and A. M. López. 2019. “Self-Supervised Domain Adaptation for Computer Vision Tasks.” IEEE Access, no. 2019: 156694–156706. doi:10.1109/ACCESS.2019.2949697.
- Yan, L., B. Fan, H. Liu, C. Huo, S. Xiang, and C. Pan. 2020. “Triplet Adversarial Domain Adaptation for Pixel-Level Classification of Vhr Remote Sensing Images.” IEEE Transactions on Geoscience and Remote Sensing 58 (5): 3558–3573. doi:10.1109/TGRS.2019.2958123.
- Yi, Z., H. Zhang, P. Tan, and M. Gong. “DualGan: Unsupervised Dual Learning for Image-To-Image Translation.” 2017 IEEE International Conference on Computer Vision (ICCV), 2017, 2868–2876. doi: 10.1109/ICCV.2017.310.
- Yoo, J., S. C. Uh, B. Kang, and J. W. Ha. “Photorealistic Style Transfer via Wavelet Transforms.” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, 9035–9044. doi: 10.1109/ICCV.2019.00913.
- Yuan, B., D. Zhao, S. Shao, Z. Yuan, and C. Wang. 2022. “Birds of a Feather Flock Together: Category-Divergence Guidance for Domain Adaptive Segmentation.” IEEE Transactions on Image Processing 31: 2878–2892. doi:10.1109/TIP.2022.3162471.
- Zhang, Z., K. Doi, A. Iwasaki, and G. Xu. 2020. “Unsupervised Domain Adaptation of High-Resolution Aerial Images via Correlation Alignment and Self Training.” IEEE Geoscience and Remote Sensing Letters 18 (4): 746–750. doi:10.1109/LGRS.2020.2982783.
- Zhang, L., Z. Lang, W. Wei, and Y. Zhang. 2021. “Embarrassingly Simple Binarization for Deep Single Imagery Super-Resolution Networks.” IEEE Transactions on Image Processing 99 (2021): 1. doi:10.1109/TIP.2021.3066906.
- Zhang, Y., Z. Qiu, T. Yao, D. Liu, and T. Mei. 2018. “Fully Convolutional Adaptation Networks for Semantic Segmentation.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 6810–6818. doi: 10.1109/CVPR.2018.00712.
- Zhao, Y., P. Gao, H. Guo, and Z. Sun. 2022. “ResiDualgan: Resize-Residual DualGan for Cross-Domain Remote Sensing Images Semantic Segmentation.” IEEE Geoscience and Remote Sensing Letters 1. (arXiv:2201.11523). doi:10.1109/LGRS.2022.3233644.
- Zhu, J. Y., T. Park, P. Isola, and A. A. Efros. “Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks.” 2017 IEEE International Conference on Computer Vision (ICCV), 2017, 2242–2251. doi: 10.1109/ICCV.2017.244.