
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Cloud removal is an essential task in remote sensing data analysis. As the image sensors are distant from the earth ground, it is likely that part of the area of interests is covered by cloud. Moreover, the atmosphere in between creates a constant haze layer upon the acquired images. To recover the ground image, we propose to use scattering model for temporal sequence of images of any scene in the framework of low rank and sparse models. We further develop its variant, which is much faster and yet more accurate. To measure the performance of different methods objectively, we develop a semi-realistic simulation method to produce cloud cover so that various methods can be quantitatively analysed, which enables detailed study of many aspects of cloud removal algorithms, including verifying the effectiveness of proposed models in comparison with the state-of-the-arts, including deep learning models, and addressing the long standing problem of the determination of regularization parameters. Theoretic analysis on the range of the sparsity regularization parameter is provided and verified numerically.
1. Introduction
As the imaging sensors are deployed kilometres above the earth ground, cloud usually appears in the acquired images, which complicates data analysis tasks. It is desirable to remove the cloud totally to recover clean ground scene, which gives rise to cloud removal. Due to the versatility of remote sensing imagery, cloud removal methods have to align with the characteristics of the sensors, for example, multiple channels or single band. Meanwhile, the platform is a decisive factor for the design of the algorithm, for example, the computation limitation and power consumption restriction. Furthermore, the analysis tasks after cloud removal have some influence as well. So one has to consider all possible contributing factors in the modelling process.
Our data is single band satellites images of the same scene sampled from different time points which are subjected to light to moderate random cloud coverage at various regions. The aim is to recover images without cloud, i.e. the clear images revealing the ground scene so that subsequent analysis can be performed reliably, for example, object detection and tracking. Therefore the fidelity is the most important factor to be considered, in other words, the recovered must be as close as possible to the truth, not just simply ‘visually fit’ (look plausible from afar). Unfortunately, there is no objective assessment except visual checking, and one of the goals of this paper is to fill this gap.
We focus on non-deep-learning-based methods for cloud removal, although latest deep learning methods were used as contenders in our empirical studies subject to code availability (e.g. Zheng, Liu, and Wang Citation2021; Sarukkai et al. Citation2020). The reason for this is that the fidelity of the recovered images is a concern for deep learning based methods. The workflow of these methods consists of two steps. The first is to identity cloud covered areas and remove them. The second is to apply generative models to fill the removed pixels. Generalised adversial networks (GAN) based models are popular choice for image completion. However, the working mechanism of GAN and its variants heavily rely on the training data on which the distribution is modelled by transforming a specified random distribution, e.g. uniform distribution or multivariate Gaussian distribution. Essentially, GAN is some sort of density estimator. Then the question is, what if the scene that the satellite sampled never appears in the training data? GAN will certainly generate something for the missing areas but will not be able to stretch outside its modelled distribution. Therefore we consider other alternatives, for example, temporal mosaicing (Guo et al. Citation2016, Citation2017). Although enforcing spatial smoothness is the most time-consuming component, the fidelity can be reassured that no ‘alien pixels’ will be inserted into the images like GAN based methods do. Another possibility is matrix completion methods for missing pixel filling, for example Wen et al. (Citation2018), and its later development Zhang et al. (Citation2019). The main model behind these methods is the low-rank robust principal component analysis (Emmanuel et al. Citation2011) coming from a long development of robust PCA (RPCA) (De la Torre and Black Citation2001; Junbin Gao, Guo, and Guo Citation2009) that improves the robustness of the classic linear PCA model by reducing the sensitivity to outliers. The elegance of RPCA comparing to its peers is the simplicity in its formation as well as its theoretical guarantee for the recovery of the low-rank signals and sparse noise. The application of RPCA implies that the observed images are the summation of low rank ground images and sparse cloud cover images (images with cloud only without the ground scene). It makes sense for such arrangement assuming that the ground scene changes little after excluding misalignment and geometric distortion, and clouds cover only small portion of the scene. The low-rank condition on ground component signifies the way of filling missing pixels and hence RPCA has better interpretability than GAN methods.
It seems that the aforementioned two-step workflow can be consolidated to a single one using RPCA. Nonetheless this two-step strategy was still adopted (e.g. in Wen et al. Citation2018; Zhang et al. Citation2019), for no obvious reason, in which RPCA is only used for cloud identification and a low-rank matrix completion follows after those cloud affected areas masked out. Two questions remain though. Firstly, where is the atmosphere modelled in the image data?The atmosphere is reflected as a thin haze layer in the acquired images which may not be negligible. Secondly, is the simple additive model in RPCA really the right description of the physics? Apparently not. The most realistic model so far is the so-called atmosphere scattering model (Narasimhan and Nayar Citation2002) for satellite images. Therefore one should build atmospheric affect into the model for cloud removal and ground scene recover.
2. Models considering atmosphere effects
We first describe RPCA-based methods here in the setting of imagery applications. Let be the
-th sampled image of size
and
;
where
is the vectorization of matrix
to be a column vector, and hence
(
). The RPCA model used in Wen et al. (Citation2018) and Zhang et al. (Citation2019) is the following,
where is the nuclear norm of
, i.e. the summation of all singular values of
, which is the convex envelope for matrix rank,
is the
norm of
,
is the initial recovered ground images,
is the cloud cover images, and both are the same size as
.
is the regularization parameter usually fixed to be
as recommended in Emmanuel et al. (Citation2011). By incorporating group sparsity (defined by super-pixels) into (1) Zhang et al. (Citation2019) claim slightly better performance. After solving (2.1), both methods proceed to matrix completion with the mask derived from
as follows
where is the mask matrix of size
with 0’s for masked out elements and 1’s for others,
is the negated version of
, i.e. flipping 0’s and 1’s, and
is the projection of
on
, i.e. masking out elements indicated by 0’s in
. The
th element in the mask matrix,
if
and
otherwise, where
is the standard deviation of
and
is a pre-set ratio.
is the final recovered ground images, which are supposed to be cloud free.
is the noise. In implementation,
,
and
. Both problems are convex with two blocks of variables. There are many gradient projection based solvers/optimizers for them under the ADMM (Alternating Direction Method of Multipliers) framework (Boyd and Vandenberghe Citation2004). They all work reasonably well for moderate size of images, for example,
and
.
The critical step is in (1) where cloud cover is supposed to be separated. Note that the decomposition of the observed data
reflects the basic model assumption. As mentioned earlier, this departures from the reality by ignoring atmosphere effect. So instead of simple additive model we propose to use atmosphere scattering (Narasimhan and Nayar Citation2002),
, in the modelling, and hence optimize the following
where
is the element-wise product of matrix
and
of the same size. In the above formulation, it is assumed that the pixels in observed images are rescaled to
, which is easily done by dividing the maximum digital number of the sensor, but not the maximum of the observed values. Note that (3) is no longer a convex problem as the equality condition is not affine. It is supposed to be much difficult to solve on itself, let alone the boxed conditions clamping the elements in both
and
within
. Nonetheless, there are still some strategies for the optimization. For example, introducing a dummy variable
to untangle the interaction between
and
and proceed with the normal ADMM. However, we observed that this does not converge well enough to be practically useful. Instead, we employ linearization using primal accelerated proximal gradient method (Kei Pong et al. Citation2010) for its ease in handling entangled nuclear norm optimization and stability. The Lagrange of (3) with proximity is
leading to
by ignoring constants, where is the Frobenius norm of
,
is Lagrangian parameters for the equality condition and
is the proximity coefficient. Note that (5) and (6) are the proximal form, and the boxed conditions in (3) are ignored at this stage, which will be handled later by feasibility projection after updating all unknowns. Alternating the minimization w.r.t.
and
is adopted here. Apparently minimizing
with respect to
is difficult due to the term
although no much trouble for
. The gradients are shown below.
where and
are subgradients of
norm and nuclear norm respectively. The stationary point of (7) gives closed form solution
where ,
and
is the sign function of
which takes 1 when
and
when
. It is a straightforward soft thresholding for
norm minimization. The only difference is the regularization is not global but local or adaptive as the regularization parameter
is rescaled by each
as shown in (9). Whereas there is no closed form solution for
because the singular value thresholding (SVT) (Cai, Candès, and Shen Citation2010) only works for the following general form
where is an arbitrary scaler (normally regularization parameter) and
is a matrix the size as
. The solution
to above is
and
is the so-called SVT operator defined as
where and
are from SVD of
, i.e.
and
.
To work around it, we linearize the smooth part in (6)
by the first-order Taylor expansion with a proximal term w.r.t , the
th value of
in the iterative optimization for (6), and optimize
while holding other variables constant as
In above, .
is the Lipschitz constant of
, which is the operator norm of
that maps a matrix of the same size of
to
It is straightforward to see that due to the box conditions of
and
. This leads to
The above linear approximation results is very convenient as the interaction between and
has been removed and therefore (12) has closed form solution using SVT. We apply Nesterov acceleration to speed up the process, which is proven to be convergent for (12) with carefully chosen optimization parameters (Nesterov Citation2003). This iterative procedure for
has to be embedded into the optimization for (6) and hence there are two loops in the entire algorithm. The detailed optimization algorithm for solving (3) is listed in Alg. 1. Note that the boxed conditions are satisfied by clamping in Alg. 1, which is the feasibility projection commonly used in many implementations (Jun Liu and Jieping Citation2009). We call the model in (3) and its realization in Alg. 1 atmosphere cloud removal model and ATM for short.
Algorithm 1 Solving atmosphere scattering model for cloud removal in (3)Require: ,
,
1:
,
,
2:
,
,
3: while
do4: update
using (2.9)5:
,
▷ Feasibility projection for
6:
,
,
7:
,
,
8: while
and
do9:
10:
,
11:
,
12:
,
13: end while14:
,
▷ Feasibility projection for
15:
16:
17: end while
Due to the double iterative procedure for solving in ATM, it is expected to be slow. However, the recovered cloud component, i.e.
is closer to reality than that obtained from RPCA as shown in , where the source images are from GaoFen4 satellite captured at the same scene at seven time points. GF-4 is the first Chinese geosynchronous orbit remote sensing satellite and equipped with one array camera with resolution of 50 m for the panchromatic band and 400 m for the MWIR band. The test panchromatic data were captured on 20 August 2016, and the geographic coordinates are
north latitude and
east longitude (Hainan Province in China). Since the width of a single-field GF-4 satellite image is 10,240 × 10240 pixels, we cropped the west part of the Hainan Province with lots of clouds as the test data.
Figure 1. Cloud detection for GaoFen4 images of the same scene at seven time points. (a) original GF4 images, (b) ATM detected clouds, (c) RPCA detected clouds. Note that all the images are in vector form, including the ones in later sections. Please zoom in to see details in the PDF file of this paper.

It is clear that the ATM detected clouds are much brighter than those detected by RPCA thanks to its detailed atmosphere model, at the cost of much higher computational load as shown in . This motivates us to reduce its computational cost while maintaining model capacity. The key is to disentangle the interaction between and
that breaks the convexity. Let us take a closer look at the core in ATM model in (2.3), i.e.
. We decompose
as
for
and
, where
means element-wise
, i.e.
. We proceed using this decomposition
Under the choice of ,
. The above can be written as
for . We can easily write out an equivalent optimization problem to (3) using (13) with many coupling conditions, which complicate the optimization. However, if we drop some coupling conditions via relaxation and approximation, it will be much easier to solve, and yet the coupled problem is still a special case of the relaxed version. So we optimize the following
Note that in above replace
which is an approximation. We highlight this is a relaxed version of (3) with its own interpretation, that is
acts as a thin haze layer accounting for the atmosphere.
In (14) the values in are controlled by the Frobenius norm. It is well known that the Frobenius norm will not encourage sparsity, but compress the values towards zeros uniformly. Depending on the value of
,
can reach the so-called
-sparsity (Yonina and Kutyniok Citation2012), i.e. sparsity beyond value
. Note that we fix
throughout this paper.
EquationEquations (14)(14)
(14) is significantly easier to solve than EquationEquation (3)
(3)
(3) for being convex with no interaction terms in the low-rank component. Although direct generalization of ADMM to more than two blocks of variables like those in (14) may not converge as discussed in (Chen et al. Citation2014) with hand-crafted counter examples, from many other applications, and vast amount of experiments we carried out, the optimization converged quite quickly. Detailed optimization algorithm is listed in Alg. 2. We call the model in (14) and its optimization algorithm in Alg. 2 alternative ATM, or aATM for short.
Algorithm 2 Solving (2.14)
Require: ,
,
,
,
,
,
,
,
while do
,
▷ Feasibility projection for
,
▷ Feasibility projection for
,
▷ Feasibility projection for
but not necessary
end while
For the regularization parameters, we provide theoretic analysis on the range of the main regularization parameter in Appendix A. The results align with the empirical study outcomes presented in the next section. Furthermore, we will present an empirical equation based on numerical method to determine the best value for
as a guidance for practical use. shows the flow chart of our method. It is indeed very straightforward. The input stack of images is first normalized by dividing the maximum digital number of the instrument. Then determine regularization parameter
by the procedure provided in 3.4. Finally run Algorithm in 2 to obtain the clean images and cloud cover. We need to point out that all our models can be used directly to recover ground images unlike the main contenders (Wen et al. Citation2018; Zhang et al. Citation2019) where a matrix completion (MC) step has to follow although it is debatable whether MC is necessary. However, without some sort of ground truth, it would be a myth and the arguments would be meaningless. To address this long standing issue, we design a semi-realistic simulation of cloud covered images so that all methods can be analysed quantitatively.
Figure 2. Flowchart of the proposed method. Note that .

3. Quantification of performance
3.1. Simulation and performance indicator
Cloud removal experiments are normally conducted on real images from satellites and the evaluation of the effectiveness of the recovery is based on visual checking and cloud cover by IoU (Intersection over Union) originated from computer vision (Liggins et al. Citation1997) which is basically Jaccard index (Jaccard Citation1912). The ground truth of cloud cover is obtained by time-consuming manual labelling of cloud clusters. Due to the complexity of the nature of cloud, it is extremely difficult to delineate the boundary of cloud clusters accurately, especially for thin clouds, and hence there exists large amount of errors when segmenting clouds manually. An ideal solution is to build cloud model to capture the shape and formation of all sorts of cloud, thick or thin. Unfortunately it is quite involved in physics and mathematics and it is a multi-facet problem (Dobashi et al. Citation1999, Citation2017; Yuan et al. Citation2014; Yumeihui Xing et al. Citation2017). Even if the cloud cover is known, the other side of the problem, way more important than cloud, is the ground truth of the ground scene. The ultimate goal of cloud removal is to recover ground scene accurately. Whereas current practice largely relies on subjective evaluation, i.e. ‘eye-balling’, which is apparently very vulnerable to bias. Therefore, an objective and robust evaluation is highly desirable. The work in Zheng, Liu, and Wang (Citation2021) used an overly simplified method to train the Unet for cloud separation by simulating random strips of white rectangles or from brightest to darkest colour gradient boxes on top of clear ground images. This is a bit primitive. Not only are they far from real clouds, but most importantly the regular shape reduces the complexity of the problem. Inspired by the success of applying Perlin noise (Perlin Citation1985, Citation2002) in the simulation of virtual landscapes, we adopt Perlin noise to generate synthetic cloud. We take a cloud free image, say from the Inria aerial image labelling dataset (Maggiori et al. Citation0000), convert it to greyscale as true ground image (pixels rescaled to
), and generate multiple 2D Perlin noise the same size as the image, as
,
. Then the observed image
is
where pixels in are rescaled within
. Optionally one can apply any transformation
to
before combining to clouds, e.g. geometric distortion to study some aspects of the methods; or generate a base
and apply dynamics to
for cloud time series mimicking clouds movement. We leave these for future work. By varying the parameters in Perlin noise generator, we can control the density of the generated clouds, from sparse to heavy cover. We also apply some image correction, e.g. Gamma correction and histogram equalization, totally optional, to enhance the similarity to real clouds and haze.
As the ground truth is readily accessible, we can apply any suitable quantitative evaluation to the cloud removal methods for detailed study. Given the main focus is the fidelity of the recovered image, we use the following to quantify the goodness of recovery
Where is the recovered image from any method. The quantity
defined in (15) is the normalized distance metric, which is not meant to be the best. Other sophisticated measures could be applied certainly. However, (15) is sufficient by virtual of equivalency of norms (Åžuhubi Citation2010, Ch6.6), although in modelling process, different norms affect model behaviours vastly.
3.2. Performance evaluation on simulations on single image
Thanks to the above semi-realistic simulation, we can now investigate another important aspect, that is the regularization parameters used in the models. Using the goodness of recovery , we can determine the best values from large-scale randomized trials. Meanwhile we can also verify the necessity of the MC step.
Let us first visually check the outcomes of different methods on one set of simulated images. The true image is from Inria dataset named tyrol-w1 from Lienz in Austrian Tyrol resized to (
). It is a mixture of urbane and nature scene with some high intensity areas such as roads and roof tops shown in . We simulate seven thin cloud covers. One simulated image and the cloud layer are also shown in .
Figure 3. Simulated image. Left to right: true clear image, one of the simulated image, its cloud cover.

The cloud looks very nature. Note that the cloud cover image appears to be sparse as large dark areas exist as shown in the histograms in top panel where the right one is showing details in the range of . However, they are not exactly zero and correspond to thin haze. If one thresholds them to zero, the cloud cover then becomes very artificial visually. The bottom panels in show thresholded results, by 0.1 and 0.2 respectively from left to right. The visible boundaries of clouds are unpleasant and against the intuition due to the lack of the critical smoothness commonly present in natural images with cloud. This also shows the tremendous difficulty to manually separate clouds in real images.
Figure 4. Details of a simulated cloud cover.
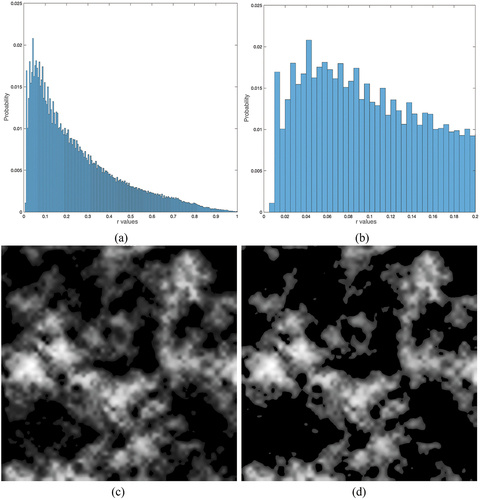
shows the recovered images by different methods obtained with the setting of the regularization parameters as and
in aATM. Simple visual checking tells us that aATM and RPCA are better than ATM as ATM results (with and without MC) contain fair amount of cloud pixels. This may be straightforward. However, it is not clear which one is the best. It appears that aATM is slightly better for less ‘washed away’ areas. It is also impossible to identify the effect of MC. These indicate the limit of visual examination. Nonetheless, the
values of these methods are 0.1758,0.3195, 0.1754 in the order of aATM, ATM, RPCA with MC, and 0.1678, 0.3373, 0.1681 without MC. Now it is clear that aATM without MC is the best and MC does not do anything useful to enhance the results.
Figure 5. Recovered images. Top row: simulated images with cloud cover; 2nd-3rd row (in green box): aATM results with/without MC; 4th-5th row (in blue box): ATM results with/without MC; 6th-7th row (in yellow box): RPCA results with/without MC.

shows the cloud covers detected by these methods. The clouds separated by ATM are in better contrast, i.e. very bright and very dark although it appears very conservative, that is visually sparser than others. In contrast, aATM and RPCA seem to have more cloud pixels identified. Again, it is impossible to tell the difference between aATM cloud and RPCA cloud by visual examination. Note that for aATM the cloud is the summation of and
.
Figure 6. Cloud covers estimated by various methods. From top: known cloud covers, aATM results, ATM results, RPCA results.
One major benefit of simulation is to validate the sensitivity of the regularization parameter, mainly in the models. We ran large-scale simulation with
and 15, using the same true image. We tested 51 values of
equally spaced in log scale with the recommend value,
, in the middle, i.e. from 9.7656e-05 to 0.0098, and for each value of
, we ran 50 randomized trials. The results are collected in , where each data point is the mean and
standard deviation of the
values across all trials for a given
value.
Figure 7. Randomised trials .
in log scale.
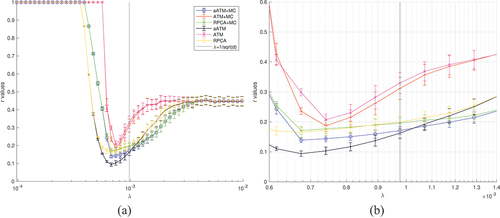
Figure 8. Randomised trials ().
in log scale.
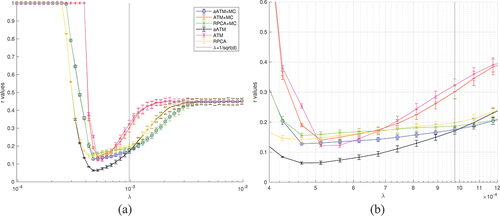
Many things can be read out from the plots. The first is that ATM is not as good as competitors for small , e.g.
, regardless of the choice of the
values. However, it begins to gain advantage when
is larger. This will be investigated later. The second is that
has roughly three zones: 1) failure zone, where the sparsity is too weak and all methods fail with no recovered images; 2) clamping zone, where the sparsity is overwhelming such that sparse component is wiped out and all methods lose the capacity to identify cloud; 3) Goldilock zone, where the algorithms work reasonably well (
for
), including their bests. Of course, these zones have different boundaries for different methods, and their
values inside these zones have different shapes. For example, RPCA seems to have rather flat
values in its Goldilock zone meaning that its performance varies just a little bit if
is from that zone. There exists a value for
which is better than the default recommended value. This holds true for all methods, interestingly with different margin of being true. For example, for RPCA, the margin is smaller, that is the optimal value of
brings 17.23% reduction of
value on average in
case, while that is 42.11% for aATM. Similar observation for
. When all methods take the default value of
, aATM without MC works the best on average, which is 22.84% better than RPCA in expectation sense. The overall best performance of aATM against that of RPCA is 43.06% reduction in
value, down from 0.1625 to 0.0941, which is very significant. This is verified by a one-side t-test with null hypothesis of no
values reduction performed on the trials with the optimal and default
values where significance level
. The resulting p-value for null hypothesis is extremely low
strongly supporting the alternative hypothesis that the reduction is quite significant. A very interesting observation is that ATM without MC comes to the second when
in terms of the overall best performance, better than RPCA. reveals the details of the
values of both methods in the trials when holding
value constant,
e
, the optimal value for both methods. The
values of each method vary during the trials due to the randomness of the simulation. RPCA has higher values of
almost constantly with greater variation than ATM. There is no doubt that ATM outperforms RPCA when
is optimal. The third is that MC does not bring much improvement even acts adversely when
is in the Goldilock zone. This claim is strongly supported by statistical evidence. shows the one-side t-tests results performed on the trials of various methods with optimal
values for both
and
cases. The null hypothesis is that MC brings
value reduction on average, i.e. the mean of
is no greater than 0.
and
are the
values of a method with and without MC respectively. The significance level
is set as low as
. The p-values are extremely low suggesting that the null hypothesis should be rejected almost surely. The only exception is ATM when
, which favours the MC to further improve its performance. So clearly the recommendation is to omit MC step in cloud removal in these methods, which is extra computation with little benefit. However, we need to point out here though that there are regularization parameters as well in MC, for which we took the default/recommended values. See previous sections for detail.
Figure 9. values of ATM and RPCA in randomised trials (
) with their best
values (
e
for both). X-axis is the repeat indices from 1 to 50. The coloured horizontal lines are the means of corresponding
values.
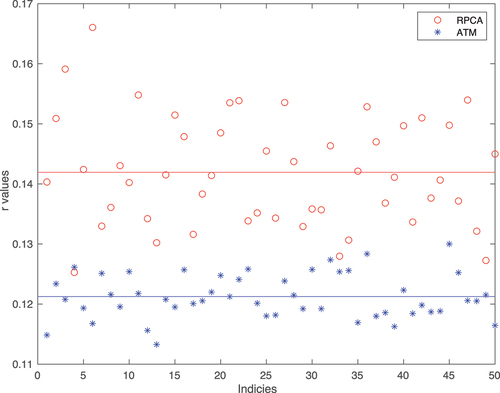
Table 1. Null hypothesis is
. Significance level
in t-tests.
To see the comparison more clearly, we present the mean and standard deviation values of the results in some range (in the Goldilock zone) in for clarity. The column in the middle of the tables with double column indicates the values when
is equal to the default value. The column-wise best (minimum among all methods) is highlighted by italic font and overall best is highlighted by bold font. They show clearly that aATM is the best in terms of both expected
value and stability reflected by smaller standard deviations.
Table 2. Mean values of various methods from all trials for some
values.
Table 3. Standard deviations of values of various methods from all trials for some
values.
3.3. Computation costs comparison on simulations using single fixed image
We report the time for computation. shows the time consumed by various methods, with and without MC. Similar to previous plots, the data points in the plot are the means and standard deviation of the times (in seconds) across all trials for a given
value. Apparently they vary across simulations.
Figure 10. Time consumed in randomised trials ().
in log scale.
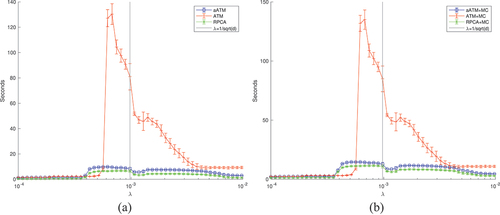
It is quite obviously that MC is extra work. Given no extra benefit, the computation for MC should be saved. ATM is pretty difficult to solve indeed, reflected by the skyrocketed computational time compared with others. There are double optimization loops inside its solver. Interestingly, when is correct, ATM takes the most of time to compute on average. When
is growing from the failure zone to the Goldilock zone, a huge jump of needed computation can be observed, which is statistically significant. As ATM’s performance turns very sharply along
values, its computation cost varies accordingly, peaking at where ATM works the best and jumping down quickly. This is a very interesting observation that may lead to a way of selection of its regularization parameter as well as a hypothesis of required computational cost vs
value. Along with the well known regularization path in sparse models (Hastie et al. Citation2004; Friedman, Hastie, and Tibshirani Citation2010; Tibshirani and Taylor Citation2011), this may be a useful route leading to optimal regularization selection in future. This was never possible previously without simulation. In general, aATM is more expensive to compute than RPCA because of the extra block of variables
, doubling the cost almost for all
values. However, the base is quite small. when
is in the Goldilock zone, aATM is doubling RPCA from about 6 seconds to 10 seconds. Therefore it is not dramatic.
Again, we present the mean and standard deviation values of the results in some range (in the Goldilock zone) in for clarity. The column in the middle of the tables with double column indicates the values when
equal to the default value. The column-wise best (minimum time among all methods) is highlighted by italic font and overall best is highlighted by bold font. They show clearly that RPCA is the fastest and aATM is about 50% more expensive to run at this range of
values. Considering its superiority in recovery performance, this cost is absolutely worthwhile.
Table 4. Means of time consumed by various methods from all trials for some values.
Table 5. Standard deviations of time consumed by various methods from all trials for some values.
Both aATM and RPCA exhibit the same pattern observed from ATM but less pronounced. When goes form failure zone to Goldilock zone, there is time cost leap and stabilizes for a while and then some up and downs. Again, the zone changing pattern of time cost is a good indicator of entering the Goldilock zone from failure zone. It is possible to exploit it for finding a better
value than the default one, although it is tricker than ATM where the pattern is very clear.
3.4. Determining the best  value
value
What is the best value for the regularization parameter ? This is an inevitable and yet critical question in practice. It is almost impossible to address it without many assumptions and lengthy theoretic analysis. Please refer to Appendix A for Goldilock zone bounds to see the complexity. However, thanks to simulation, we can fit the data to derive some equation for the best
value. Different from drilling into the computational cost pattern suggested by previous section, we look at the best
values of different methods by stretching
from 2 to 250. The ‘best’ is defined as the
value corresponding to the minimum average
value across trials, which we denote as
. shows the ratio of
of all methods to the suggested default value
, i.e.
. As
becomes larger,
decreases exponentially. We turn this into almost linear by applying
twice to
, as shown in right panel. From this data, we fit a linear model and derive the following
estimator
Figure 11. v.S
.
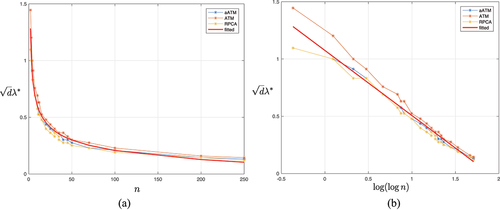
The red curves in are the values of at different scales of
.
Remark 3.1. is estimated for all methods. However, it is possible to derive the estimator for individual method. ATM may be disadvantaged as the fit is not as good as others.
should be lower bounded by the minimum value of
in Lemma A.1 so
prevents from being too small. Finally this
is empirical and approximate with no model assumption. More sophisticated regression methods are possible.
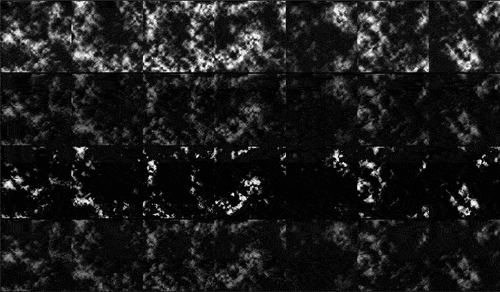
3.5. Performance evaluation on simulations on multiple images
Now we are ready for more comprehensive tests. One last question is how these evaluations hold across different (image sequence length) and different scenes? To this end, we picked three other images from Inria data set, chicago1, kitsap1 and vienna1, and ran the same randomized trials with
, each with 50 repeats. The ground truth images are displayed in . In this experiment, we bring in the state-of-the-art deep learning methods (Sarukkai et al. Citation2020) (called STGAN+Resnet and STGAN+Unet) and (Zheng, Liu, and Wang Citation2021) (called UNET and UNET+GAN) for a thorough comparison. STGAN provides two variants using Resnet and Unet backbone networks. UNET separates cloud and ground only and UNET+GAN uses GAN to fill thick cloud covered areas. The training of these deep learning models strictly followed the procedures in their code base repository, and were optimized for best performance as per instructions. For our models and RPCA,
was automatically determined by (16) for different
.
Figure 12. Four base images for randomised trials. (a) tyrol-w1,(b) chicago1,(c) kitsap1 and (d) vienna1.

visaulises all values in one place, where the height of the bars are the means and error bars on top show the standard deviation calculated from multiple trials. The results of the same methods are grouped together with different coloured bars showing the results for different
. The overall impression is that deep learning methods are not as good although they have quite stable performance across different
values. They may have some advantages when
is small, say
. STGAN is better than RPCA in kitsap1 although no match for aATM and ATM when
. Deep learning methods have large performance variations across different scenes, while others are rather consistent. All sparse models have better
values when
grows larger. This suggests that a strategy to boost performance is to increase the sampling frequency moderately. It makes perfect sense as more images provide more information for the missing pixels covered by cloud, and it is more likely that some areas covered in one image are not covered in another. The rank minimization in aATM/ATM/RPCA is designed to fully utilize this. The unnecessity of MC is once again verified in this test. The add-on value of MC is only observable for ATM when
is small, i.e.
.
Figure 13. Randomised trials for various base images (in the order shown in ) and sequence length . The legend shows
.
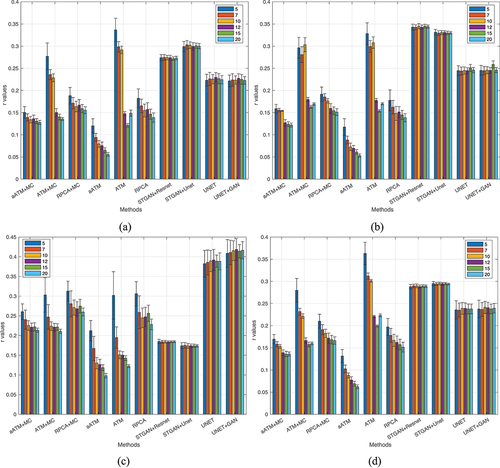
The above observations provide us a clear clue to the questions raised at the beginning of this paper and justify our motivation. Deep learning methods in general have lower fidelity (higher values). This uncertainty poses many questions for subsequent applications. They may have good performance on some specific scenes, for example, pure nature scene like kitsap1. However, it is not clear how GAN’s distribution transformation works. The large performance variation reveals their problems in dealing with different situations. While our models do not have these issues and are interpretable in terms of their working mechanism.
4. Conclusions
In this paper, we introduced atmosphere scattering model into cloud removal modelling process and proposed two ATM models as superior alternatives to RPCA-based model. Furthermore, we proposed a method to simulate controllable cloud cover scenes. This semi-realistic simulation enables detailed study of various cloud removal methods and provides valuable insights to several aspects of the algorithms as large-scale randomized trial and quantitative analysis become available. Examining the methods by using this powerful experimental tool, we saw clearly that the proposed aATM outperforms not only RPCA model, the state-of-the-art in this category of non-deep-learning-based cloud removal methods, but also latest deep learning models constructed on large scale backbone networks, by quite a large margin. There were many interesting findings in this process, for example the zoning of the regularization parameter , computational cost pattern across zones, automated regularization parameter determination and so on. These may be out of the question without the assistance of the simulation. We envisage a robust development of the cloud removal algorithms under this framework in near future. For this purpose, we released the Matlab code at https://github.com/yguo-wsu/clouldremoval.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Åžuhubi, E. S. 2010. Functional Analysis. OCLC: 961064002. Netherlands, Dordrecht: Springer.
- Bai, Z. D., and Y. Q. Yin. 1993. “Limit of the Smallest Eigenvalue of a Large Dimensional Sample Covariance Matrix.” Annals of Probability 21 (3, July). doi:10.1214/aop/1176989118.
- Boyd, S., and L. Vandenberghe. 2004. Convex Optimization. tex.owner: guo020 tex.timestamp: 2014.07.24. Cambridge University Press.
- Cai, J.F., E. J. Candès, and Z. Shen. 2010. “A Singular Value Thresholding Algorithm for Matrix Completion.” SIAM Journal on Optimization 20 (4, January): 1956–1982. doi:10.1137/080738970.
- Chen, C., H. Bingsheng, Y. Yinyu, and X. Yuan. 2014. “The Direct Extension of ADMM for Multi-Block Convex Minimization Problems is Not Necessarily Convergent.” In Mathematical Programming, 1–23. tex.publisher: Springer.
- De la Torre, F. and M. J. Black. Robust Principal Component Analysis for Computer Vision. In Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, volume 1, pages 362–369, Vancouver, BC, Canada, 2001. IEEE Comput. Soc.
- Dobashi, Y., K. Iwasaki, Y. Yue, and T. Nishita. 2017. “Visual Simulation of Clouds.” Visual Informatics 1 (1, March): 1–8. doi:10.1016/j.visinf.2017.01.001.
- Dobashi, Y., T. Nishita, H. Yamashita, and T. Okita. 1999. “Using Metaballs to Modeling and Animate Clouds from Satellite Images.” The Visual Computer 15 (9, December): 471–482. doi:10.1007/s003710050193.
- Emmanuel, J. C., L. Xiaodong, Y. Ma, and J. Wright. Robust principal component analysis? Journal of the ACM, 58(3):1–11:1–11, June 2011. tex.numpages: 37 tex.publisher: ACM.
- Friedman, J. H., T. Hastie, and R. Tibshirani. 2010 February. “Regularization Paths for Generalized Linear Models via Coordinate Descent.” Journal of Statistical Software 33 (1):1–22. doi:10.18637/jss.v033.i01.
- Guo, Y., L. Feng, P. Caccetta, and D. Devereux. 2017. “Multiple Temporal Mosaicing for Landsat Satellite Images.” Journal of Applied Remote Sensing 11 (1, March): 015021. doi:10.1117/1.JRS.11.015021.
- Guo, Y., L. Feng, P. Caccetta, D. Devereux, and M. Berman. Cloud Filtering for Landsat TM Satellite Images Using Multiple Temporal Mosaicing. In 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), pages 7240–7243, Beijing, China, July 2016. IEEE.
- Hastie, T., S. Rosset, R. Tibshirani, and J. Zhu. 2004. “The Entire Regularization Path for the Support Vector Machine.” Journal of Machine Learning Research 5: 1391–1415.
- Jaccard, P. 1912. “THE DISTRIBUTION OF THE FLORA IN THE ALPINE ZONE.1.” The New Phytologist 11 (2, February): 37–50. doi:10.1111/j.1469-8137.1912.tb05611.x.
- Junbin Gao, P. W. K., Y. Guo, and Y. Guo. 2009. “Robust Multivariate L1 Principal Component Analysis and Dimensionality Reduction.” Neurocomputing 72 (4–6): 1242–1249. doi:10.1016/j.neucom.2008.01.027.
- Jun Liu, S. J., and Y. Jieping SLEP: Sparse Learning with Efficient Projection. Technical report, Arizona State University, 2009.
- Kei Pong, T., P. Tseng, J. Shuiwang, and Y. Jieping. 2010 . “Trace Norm Regularization: Reformulations, Algorithms, and Multi-Task Learning.” SIAM Journal on Optimization 20 (6):3465–3489. doi:10.1137/090763184.
- Liggins, M. E., C. Y. Chong, I. Kadar, M. G. Alford, V. Vannicola, and S. Thomopoulos. 1997. “Distributed Fusion Architectures and Algorithms for Target Tracking.” Proceedings IEEE 85 (1): 95–107. doi:10.1109/JPROC.1997.554211.
- Maggiori, E., Y. Tarabalka, G. Charpiat, and P. Alliez. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In IEEE international geoscience and remote sensing symposium (IGARSS), 2017. tex.organization: IEEE.
- Narasimhan, S. G., and S. K. Nayar. 2002. “Vision and the Atmosphere.” International Journal of Computer Vision 48 (3, July): 233–254. doi:10.1023/A:1016328200723.
- Nesterov, Y. 2003. “Introductory Lectures on Convex Optimization: A Basic Course.“ Applied Optimization, edited by Pardalos Panos M., and W. Hearn Donald, Vol. 87. Kluwer Academic Publishers.
- Perlin, K. 1985. “An Image Synthesizer.” ACM SIGGRAPH Computer Graphics 19 (3, July): 287–296. doi:10.1145/325165.325247.
- Perlin, K. 2002. “Improving Noise.” ACM Transactions on Graphics 21 (3, July): 681–682. doi:10.1145/566654.566636.
- Sarukkai, V., A. Jain, B. Uzkent, and S. Ermon. Cloud Removal from Satellite Images Using Spatiotemporal Generator Networks. In Proceedings of the IEEE/CVF winter conference on applications of computer vision (WACV), Snowmass, CO, USA, March 2020.
- Tao, T., and V. Van. 2010. “Random Matrices: The Distribution of the Smallest Singular Values.” Geometric and Functional Analysis 20 (1, June): 260–297. doi:10.1007/s00039-010-0057-8.
- Tibshirani, R., and J. Taylor. 2011 . “The Solution Path of the Generalized Lasso.” Annals of Statistics 39 (3):1335–1371. tex.owner: guo020 tex.timestamp: 2014.07.24. doi:10.1214/11-AOS878.
- Vershynin, R. 2012. “Introduction to the Non-Asymptotic Analysis of Random Matrices.” In Compressed Sensing, edited by Y. C. Eldar and G. Kutyniok, 210–268. Cambridge: Cambridge University Press.
- Wen, F., Y. Zhang, Z. Gao, and X. Ling. 2018. “Two-Pass Robust Component Analysis for Cloud Removal in Satellite Image Sequence.” IEEE Geoscience and Remote Sensing Letters 15 (7, July): 1090–1094. doi:10.1109/LGRS.2018.2829028.
- Xing, Y., J. Duan, Y. Zhu, and H. Wang. 2017. “Three-Dimensional Particle Cloud Simulation Based on Illumination Model.” In LIDAR Imaging Detection and Target Recognition 2017, edited by Y. Lv, J. Su, W. Gong, J. Yang, W. Bao, W. Chen, Z. Shi, J. Fei, S. Han, and W. Jin, 74. Changchun, China: SPIE.
- Yonina, C. E., and G. Kutyniok editors. 2012. Compressed Sensing Theory and Applications. United Kingdom: Cambridge University Press
- Yuan, C., X. Liang, S. Hao, Q. Yue, and Q. Zhao. 2014. “Modelling Cumulus Cloud Shape from a Single Image: Modelling Cumulus Cloud Shape from a Single Image.” Computer Graphics Forum 33 (6, September): 288–297. doi:10.1111/cgf.12350.
- Zhang, Y., F. Wen, Z. Gao, and X. Ling. 2019. “A Coarse-To-Fine Framework for Cloud Removal in Remote Sensing Image Sequence.” IEEE Transactions on Geoscience and Remote Sensing 57 (8, August): 5963–5974. doi:10.1109/TGRS.2019.2903594.
- Zheng, J., X.Y. Liu, and X. Wang. 2021. “Single Image Cloud Removal Using U-Net and Generative Adversarial Networks.” IEEE Transactions on Geoscience and Remote Sensing 59 (8, August): 6371–6385. doi:10.1109/TGRS.2020.3027819.
Appendix
A Analysis of regularisation parameter
In this section, we focus on the theoretic analysis on the regularisation parameter in the models, in particular its valid range. We first have the following minimum
value lemma.
Lemma A.1.
For any given data in assuming
, the minimum and maximum value for
in ATM, aATM and RPCA model is
and
respectively. The extremum is in the sense of bound for the models to generate non-trivial solutions.
Proof.
The optimality condition of both RPCA and ATM models requires
leading to
where superscribed star stands for the optimal value,
is the skinny SVD of
(i.e.
,
, and
, identity matrix of size
) and
is any matrix satisfying
It is easy to see that , where
is the complementary components in ambient space that is orthogonal to matrix
, and
is a diagonal matrix with all element
to satisfy
. With the re-wrting Eq. (A.1), we are seeking
where as .
’s are orthogonal to each other and unitary in terms of Frobenius norm. EquationEquation (A.2)
(A.2)
(A.2) shows that the subgradient of
at
is clamped by
regardless
, meaning the elements in the left hand side of (A.2) have to be in the range of
, a boxed condition. The largest norm within the
box is at one of its corners. Without loss of generality, we can choose the first orthant corner. According to Pethagorean, adding an orthogonal component to a vector will only increase the norm. Hence to allow as large as possible for
, one can seek the vector with smallest norm, which reflected to the situation in (A.2) is to let
and set
. It is equivalent to choose
and
to be vectors of all
and all
respectively and let
. In this case,
where
is matrix of all one’s with compatible dimensions. This is the smallest norm the subgradient of
can fit in the
box. Therefore, the infimum in (A.2), i.e. what is required in this lemma is
.
Similarly the maximum is
The only difference is that one has to consider all possibilities, i.e. the maximum of the norm. Therefore, (A.3) is equivalent to
where and
likewise.
Remark A.2. From above, we can see that, when , the only allowed solution is to nullify the elements in
, in which case,
and
. This is what we have seen in , where when
is very small,
value is 1 as
. aATM has the same result although it has another regularisation because the infimum of
happens only when
, otherwise it would further reduce the value of
.
This matches the purpose of regularisation. When is too small, the penalty to sparsity is next to null. Hence the sparse component is free. The sensible choice is of course to set the low rank component zeros, such that the objective is quite small, although this is a trivial solution. Similar logic for maximum value of
.
Note that the extrema values of deduced in Lemma A.1 is for general cases, in other words, no specific conditions. The minimum value of
is very close to the recommended value of
in RPCA, while the maximum is rather loose, due to the generality. Actually we can have the following tighter upper bound of
.
Lemma A.3.
For a given assuming
, the maximum value for
in ATM, aATM with
and RPCA model, written as
, is
where
and
is from the skinny SVD of
and
is the matrix infinity norm, i.e. the maximum absolution value of all its elements.
Proof.
The proof is similar to that of Lemma A.1 except now we consider only one data set , i.e.
as the sparse component is totally zero.
and all its elements are surely less than or equal to
. Therefore when
, the condition in (A.4) holds. This is equivalent to setting
as in (A.3).
The upper bound of in Lemma A.3 is much better than that in Lemma A.1, especially when
and
. However it is possible to further quantify
without actual SVD. We give asymptotic results here of the upper bound of
and hence
. To proceed, we need the following proposition to bound
.
Proposition A.4.
For any matrix of size
(
)and its skinny SVD as
, the following holds
where is the
th largest singular value of
and then
is the smallest singular value of
.
Proof.
Following the same way of thinking from previous lemmas, we see that can only bound the Frobenius norm of the matrix spanned by the same bases up to
. In other words, for any matrix of size
, if
, then
. Also
. Therefore, if
for all
, then
. Combining this observation with the fact that
, we obtain the claim in this proposition, as we have
since
.
Now we treat the observed image matrix as a random matrix whose elements are i.i.d from uniform distribution from
and hence we do not assume any further structure. We are then concerned with the smallest singular value
of a non-central random matrix, i.e. the mean is non-zero. There is limited results on smallest singular values. The closest one is (Tao and Van Citation2010), which deals with centralised random matrix. Fortunately, we only need a lower bound on
. We use the following theorem from (Bai and Yin Citation1993), which also appeared in (Vershynin Citation2012.
Theorem A.5
(Bai-Yin’s law). Let be a
random matrix whose entries are independent copies of a random variable with zero mean, unit variance, and finite fourth moment. Suppose that the dimensions
and
grow to infinity while the aspect ratio
converges to a constant in
. Then
almost surely.
Note in Bai-Yin’s law there is no assumption on the distribution but centrality. We then write where
’s elements are i.i.d from uniform distribution from
. We use the Courant-Fischer minimax characterisation of singular values to obtain the bound
where is any subspace of
. This leads to
as is just
. We have the following lemma tailored to non-central uniform distribution.
Lemma A.6.
Let be a
random matrix whose entries are independent copies of a random variable from uniform distribution with mean
, unit variance. Suppose that the dimensions
and
grow to infinity while the aspect ratio
converges to a constant in
. Then
almost surely.
Proof.
Let be a all 1 matrix with compatible dimensions, then
where
satisfy conditions in A.5. We have
Note we use
to highlight that these minimisations are separated and hence the above holds.
in the third terms gives
where ,
is the
th element in
and
is the vector with all 1 with length
. As
’s are from centralised population, under asymptotic condition,
almost surely and hence the third term vanishes. The first two terms are the square of the smallest singular values of corresponding matrices, i.e.
and
. Since
for
, we have the required inequality by using Theorem A.5.
Combining Lemma A and Proposition A.4, we have the following corollary.
Corollary A.7.
Assume the elements in data matrix of size
is uniformly distributed in
and its size grows asymptoticly as in Lemma A. Given the conditions in Lemma A.3, the maximum value for
is almost surely
Proof.
It is simply the rescaling result of Lemma A by recognizing the standard uniform distribution has variance and also
.
Remark A.8. Although in Corollary A.7 is asymptotic result, as the images are quite large, say
in our experiments, i.e.
, the bound of
is quite good. In practice,
is relatively small, typically at the order of 10,
. Therefore we can further simplify (A.5) to
That is what we see from that when is too large, precisely larger than 0.0032 as shown in the figure, the sparse component is erased, i.e.
. In this case, our theory predicted
, very close to our observation. When
,
and hence the observed images with clouds. The variations we see from the figures are due to the simulated clouds.
B
Deep learning models training details
We describe how the deep learning models were trained. Basically, we strictly followed the training instructions from the original papers [32] and [24].
B.1 U-Net+GAN
We used the training data from the original paper. We use the cloudless aerial imagery data set from the National Institute for Research in Computer Science and Automation in France (INRIA) as the ground images dataset, and use the greyscale infrared image data set from National Oceanic and Atmospheric Administration (NOAA) as cloud images dataset, respectively. A cloud covered satellite image was obtained by combining clear (cloud free) ground images with cloud only image by atmospheric scattering models as follows:
Clear ground images were taken from the INRIA aerial image data set (INRIA), which contains 180 training images. Each image has 5000
Following the instructions from [32], we collected cloud images from the NOAA, totally 150 cloud images from 2018 to form a training set. These images are multispectral (RGB + infrared) images with a resolution of 1920
Cloud and clear images were randomly combined by using atmospheric scattering model to form cloud covered image data with total of 64,980 images for model training.
Finally, model structure and hyperparameters including optimization parameters were set as required in [32].
B.2 STGAN
We used the training data from the original paper [24]. The dataset in the original paper was constructed using publicly available real Sentinel-2 images. When training STGAN, a total of 3130 sets (256 256) of image pairs were constructed, and each set of datasets was obtained by pairing one cloudless ground image with three cloud covered images of the same area at different times. The training, verification and test datasets were split according to the ratio of 8:1:1, and there were 2504, 313 and 313 training, verification and test image groups respectively.
Once again, model structure and hyperparameters including optimization parameters were set as required in [24].