
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Electricity price forecasting plays a crucial role in a liberalised electricity market. Generally speaking, long-term electricity price is widely utilised for investment profitability analysis, grid or transmission expansion planning, while medium-term forecasting is important to markets that involve medium-term contracts. Typical applications of medium-term forecasting are risk management, balance sheet calculation, derivative pricing, and bilateral contracting. Short-term electricity price forecasting is essential for market providers to adjust the schedule of production, i.e., balancing consumers' demands and electricity generation. Results from short-term forecasting are utilised by market players to decide the timing of purchasing or selling to maximise profits. Among existing forecasting approaches, neural networks are regarded as the state of art method due to their capability of modelling high non-linearity and complex patterns inside time series data. However, deep neural networks are not studied comprehensively in this field, which represents a good motivation to fill this research gap. In this article, a deep neural network-based hybrid approach is proposed for short-term electricity price forecasting. To be more specific, categorical boosting (Catboost) algorithm is used for feature selection and a bidirectional long short-term memory neural network (BDLSTM) will serve as the main forecasting engine in the proposed method. To evaluate the effectiveness of the proposed approach, 2018 hourly electricity price data from the Nord Pool market are invoked as a case study. Moreover, the performance of the proposed approach is compared with those of multi-layer perception (MLP) neural network, support vector regression (SVR), ensemble tree, ARIMA as well as two recent deep learning-based models, gated recurrent units (GRU) and LSTM models. A real-world dataset of Nord Pool market is used in this study to validate the proposed approach. Mean percentage error (MAPE), root mean square error (RMSE), and mean absolute error (MAE) are used to measure the model performance. Experiment results show that the proposed model achieves lower forecasting errors than other models considered in this study although the proposed model is more time consuming in terms of training and forecasting.
1. Introduction
The first liberalisation directive of European Union's electricity markets was adopted in 1996. It was also regarded as the “First Energy Package” which was followed by the second directive in 2003. As a result of these two directives, third parties are granted access to transmission and distribution networks, independent regulatory agencies are introduced as well as domestic and industrial consumers being free to choose electricity suppliers. In 2009, the third directive further strengthened the implementation of the internal electricity market liberalizations (Barnes, Citation2017; Berglund, Citation2009). Owing to the aforementioned factors, electricity price forecasting becomes increasingly important to the stakeholders in a liberalised and deregulated market. Accurate price forecasting can be utilized to minimise the cost, mitigate potential risks as well as to fulfil the environment policy goals (Pezzutto et al., Citation2018).
According to forecasting horizons, electricity price forecasting can be divided into three categories based on the time frame of the forecast. Long-term electricity price forecasting ranges from months to years, which is commonly utilised for investment profitability analysis, grid, or transmission expansion planning (Cabero et al., Citation2005; Pandey & Upadhyay, Citation2016; Ventosa et al., Citation2005). Medium-term forecasting is from days to months, which is useful in the areas of risk management, derivative pricing, balance sheet calculation as well as bilateral contracting (Weron, Citation2014). Short-term electricity price forecasting is for minutes to days ahead. According to the short-term forecasting result, a generator can optimise the schedule of production that meets the short-term demand at the least cost combination of generation resources. In addition, short-term forecasting results can be utilised by a firm to develop bidding strategies to gain maximised profit (Girish & Vijayalakshmi, Citation2015).
Although neural networks are considered as the state of art techniques for forecasting tasks, deep neural networks are not studied comprehensively with respect to electricity price forecasting and none of them has been applied for Nord Pool market. This represents a strong motivation to study deep learning neural network and its performance in electricity price forecasting. The other motivation is that in recent years, boosting algorithms became increasingly popular among researchers for feature selection as well as hybrid models are proved to be capable of tackling complex real-life problems, but there are very few hybrid deep neural networks applications found in the existing literature.
The main contribution of this article is to propose a novel hybrid approach for short-term electricity spot price forecasting. The proposed approach consists of two main building blocks; CatBoost and bidirectional long short-term memory (BDLSTM) neural network. Catboost algorithm is applied for feature selection and ranking. Conventional boosting algorithms, such as XGboost (Chen & Carlos, Citation2016) and LightGBM (Ke et al., Citation2017) require categorical input variables to be converted into numeric representations before being processed. Catboost algorithm, however, automatically converts categorical values into numbers using various statistics on combinations of categorical features as well as combinations of both categorical and numerical features, which reduces the explicit pre-processing process. Moreover, the procedure of conventional gradient boosting algorithms is prone to overfitting due to the fact that models are trained using the same data points in each iteration. To reduce overfitting, a random permutation mechanism is introduced in Catboost when dividing a given dataset.
In addition, DBLSTM is used as the main forecasting engine of the proposed approach. It tackles the gradient vanishing problem by introducing various gating mechanisms, therefore, performs better in learning dependencies of a time series than conventional neural networks. Besides, by preserving information from both past and future, BDLSTM has been proved to be superior to LSTM in various application areas (Graves & Schmidhuber, Citation2005; Graves et al., Citation2013). The proposed hybrid approach is novel and has not been found in any state of art literature.
The rest of this article is organised as follow: Section 2 reviews past literature of applying recurrent neural networks (RNNs) and deep neural networks for electricity price forecasting. Overviews of LSTMs and CatBoost algorithms are described in Section 3. In Section 4, the proposed forecasting approach and data used in the experiment are presented in detail. Details of the experiment as well as the analysis of experimental results are presented in Section 5. Finally, limitations and conclusions of this study are summarised in Sections 6 and 7.
2. Literature review
Mirikitani and Nikolaev (Citation2011) proposed an RNN-based approach for one hour ahead electricity spot price forecasting. The major contribution of this study was the utilisation of Expectation Maximisation (EM) algorithm with Kalman filtering and smoothing, which estimate both noise in the data and model uncertainty. Hourly MCP data of Ontario HOEP year 2004 and Spanish power exchange year 2002 were used in the case study. For the Ontario case, 48 days' data from Spring, Summer, and Winter were selected for training while testing set consisted of two weeks' data. The least MAPE of the proposed model was 15.09, 10.21, and 15.71 for Spring, Summer, and Winter, respectively. In terms of the Spanish market dataset, 42 days' data of four seasons prior to the week to be forecasted were used for training. MAPE of the proposed model was 4.87, 10.38, 8.93, and 4.26 for Spring, Summer, Autumn, and Winter, respectively.
Anbazhagan and Kumarappan (Citation2013) applied Elman neural network for day ahead electricity price forecasting. The architecture of the proposed network consisted of an input layer with 16 neurons, one hidden layer with 10 neurons, and an output layer with one neuron. Lagged electricity price was used as the input feature. Day ahead data of Spanish market 2002 and New York 2010 were used in the case study. For the Spanish market, 42 days prior to the week to be forecasted is used for training. MAPE of the proposed model is 4.11, 4.37, 9.09, and 8.66 for winter, spring, summer, and autumn week, respectively. In terms of the result for the New York market, MAPE of the presented model is 5.06, 3.98, 3.30, and 2.93 for Winter, Spring, Summer, and Autumn week, respectively.
Vardhan and Chintham (Citation2015) presented Elman neural network to forecast the day ahead electricity price of a deregulated market. MCP data of the Spanish market were used in the case study. 42 days' data to build the model and 16 lagged prices are selected as the model input. The result showed that MAPE of the proposed method were 5.43 for Winter and 3.00 for Summer week, respectively. It was also reported in the study that the proposed method outperforms ARIMA, Wavelet-ARIMA, fuzzy neural network, Wavelet-ARIMA-RBF in terms of MAPE.
Wang et al. (Citation2017) proposed an extended stacked denoising autoencoder based model (RS-SDA) for short-term electricity prices forecasting. The proposed method was validated using hourly electricity prices data collected from American hubs. Online hourly forecasting and day ahead hourly forecasting were performed. The proposed method was compared with classical ANN, SVM, multivariate adaptive regression splines (MARS), and least absolute shrinkage selection operator (Lasso). Performance metrics used in this study were hit rage (HR), MAPE, and different variations of MAPE. Experiment results showed that the proposed method outperforms the rest baseline models considered in this study. One important conclusion of this study was that the performance of models depredates when fluctuation or spikes are presented in the series to be forecasted.
Ugurlu et al. (Citation2018) presented a Gated Recurrent Unit (GRU) based recurrent neural network for electricity price forecasting. Hourly price data from 1 January 2013 to 21 December 2016 of Turkish day ahead market were employed in this case study. Data from 1 January 2013 to 21 December 2015 were used for training. The trained model was used to forecast the hourly price of the next day by 24 steps ahead forecasting approach. Input features consisted of lagged prices along with exogenous variables such as forecast Demand/Supply (D/S), temperature, realised D/S, and balancing market prices. Two groups of case studies were presented; a group with shallow (one hidden layer) and deep (three hidden layers) architectures. The result showed that deep neural networks outperform shallow networks in most cases.
Lago et al. (Citation2018) proposed a hybrid deep neural networks approach for the day ahead electricity spot price forecasting. Two hybrid deep neural network models were presented in this study, namely LSTM-DNN and GRU-DNN. The motivation of LSTM-DNN was to include both the recurrent layer and regular layer for modelling relations inside the sequential time series data and non-sequential data. A GRU (Cho et al., Citation2014) layer was used in GRU-DNN, which is faster to train than LSTM. EPEX-Belgium market data from 1 January 2010 to 31 November 2016 were employed in the case study. sMAPE of LSTM-DNN and GRU-DNN were 13.06 and 13.04, respectively.
Kuo and Huang (Citation2018) presented a hybrid deep neural network model for electricity price forecasting. The proposed hybrid model consisted of two deep neural network layers: CNN and LSTM. In the first step, CNN was used to extract the features, which were fed to LSTM for forecasting. Model input was historic electricity price of 24 h and the output was the forecasted price of the next hour. PJM Regulation Zone Preliminary Billing Data which is composed of regulation market capacity clearing price of every half hour in 2017 was employed in the study. Ten datasets, three months’ data for each set were used for training, and one month’s data for testing. The average MAE of the proposed hybrid model was 8.85 which was lower than a single LSTM and single CNN.
3. Theoretical background
3.1. Overview of LSTMs
LSTM is a variation of the recurrent neural network (RNN) (Sulehria & Zhang, Citation2007) which was first proposed in Hochreiter and Schmidhuber (Citation1997). To tackle the problem of vanishing gradients of the conventional recurrent neural network, LSTM cells are introduced in its architecture (Bengio et al., Citation1994; Hochreiter, Citation1991). A standard topology of LSTM is shown in (Olah, Citation2015). At each iteration t, the input of LSTM cell is and
denotes its output. The current cell input and output state are denoted by
and
while the cell output state of previous time step is denoted by
Figure 1. LSTM topology.
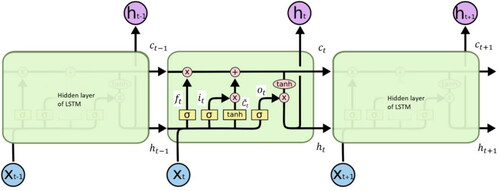
As mentioned earlier, the structure of celled gates enables LSTM to model long-term dependences of sequence data. Gates are served to control cell states of LSTM by allowing information to pass through optionally. There are three types of gates; the input gate, the forget gate, and the output gate denoted by
respectively. Values of the cell input state and gates are calculated by EquationEquations (1)–(4).
(1)
(1)
(2)
(2)
(3)
(3)
(4)
(4)
where
denote the weight matrices between the input of the hidden layer, the input gate, the forget gate, the output gate and the input cell state.
denote the weight matrices between previous cell output state, input gate, forget gate, output gate and input cell state.
denote the corresponding bias vectors.
3.2. Overview of bidirectional LSTM (BDLSTM)
BDLSTM is derived by the idea of bidirectional recurrent neural network (Baldi et al., Citation1999; Schuster & Paliwal, Citation1997). In bidirectional recurrent neural network, each training sequence is presented forwards and backwards to two recurrent networks separately, both of which are connected to the same output layer. This means that complete sequential information of all points before or after the given point in sequence data can be retrieved using bidirectional recurrent neural network (Graves & Schmidhuber, Citation2005). Similarly, in a BDLSTM, sequence data are processed in both directions with forward LSTM and backward LSTM layer and these two hidden layers are connected to the same output layer. A standard topology of BDLSTM is shown in (Yildirim, Citation2018).
Figure 2. BDLSTM topology.
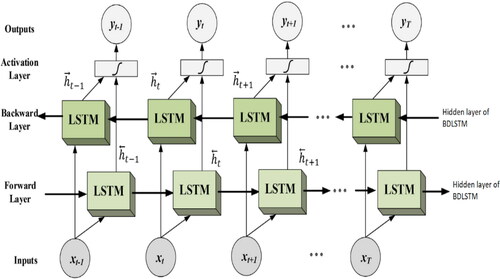
According to EquationEquations (1)–(4), at each iteration t, cell output state and LSTM layer output
are calculated using EquationEquations (5)
(5)
(5) and Equation(6)
(6)
(6) .
(5)
(5)
(6)
(6)
BDLSTMs have been applied in the field of trajectory prediction (Xue et al., Citation2017; Zhao et al., Citation2018), speech recognition (Zeyer et al, Citation2017; Zheng et al., Citation2016), biomedical event analysis (Wang et al., Citation2017), natural language processing (Xu et al., Citation2018), traffic speed prediction (Cui & Wang, Citation2018), etc. It is reported in the literature that BDLSTM outperforms conventional LSTM in some areas such as frame wise phoneme classification (Graves & Schmidhuber, Citation2005) as well as automatic speech recognition and understanding (Graves et al., Citation2013).
3.3. Overview of CatBoost
Boosting is an ensemble algorithm that trains and combines weak learners into a strong learner in a systematic manner (Freund & Schapire, Citation1997). However, pre-processing steps that convert categorical input variables into numeric representations are required by conventional boosting algorithms. For example, one of the most common approaches to pre-process categorical features is one-hot encoding (Micci-Barreca, Citation2001), which replaces the original categorical feature with binary values for each category. This approach consumes large memory and is computationally intensive, especially when dealing with categorical features of high cardinalities. Another approach to deal with categorical inputs, adopted by the LightGBM algorithm, converts categorical features into gradient statistics at each gradient boosting step. However, this approach results in a high computation cost due to the fact that statistics calculation is performed for each categorical feature at each step (Prokhorenkova et al., Citation2018).
A more efficient boosting approach, namely categorical boosting (CatBoost) (Dorogush et al., Citation2018), is proposed to tackle this problem. To be more specific, a modified target-based statistics (TBS) algorithm is used in CatBoost. Assume that dataset where
is a vector consists of both numerical and categorical features, m is the number of features.
is the corresponding label. First, the dataset is randomly permutated. Then, for each sample, the average value of the label is calculated for samples with the same category value prior to the given one in the permutation. Let
denotes the permutation. Then, the permutated observation
is replaced with
and
is calculated by
where
= 1 if
and 0 otherwise.
denotes the prior value and
is the corresponding weight. Prior is the average label value for regression and a priori probability of encountering a positive label for classification. Adding prior serves to reduce the noise from minor categories (Cestnik, Citation1990). On the one hand, the proposed method utilises the whole dataset for training. On the other hand, it avoids the overfitting problem by performing random permutations.
Moreover, to overcome the biased gradients problems in conventional boosting algorithms (Friedman, Citation2002), a new schema of calculating leaf values when selecting tree structure is presented in CatBoost. To be more specific, assume denotes the built model and
denotes the gradient value of the k-th training sample after building i trees. To keep the gradient unbiased, for each sample
a separate model
is trained, which is not updated using a gradient estimate for this sample. The gradient on
is estimated using
Then, the resulting tree is scored according to the estimation. Detailed steps of the algorithm are presented in (Dorogush et al., Citation2018).
Table 1. Gradient estimation by CatBoost.
4. The proposed method and data description
The overall process of the proposed method is shown in .
Figure 3. The overall process of the proposed method.
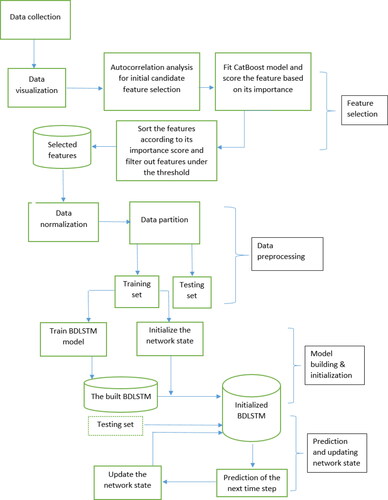
After data collection and visualisation, a two-phase feature selection step is performed. Then, the data are normalised and split in to training and testing set for training and testing the model. Details of the proposed method are discussed in the following subsection. To verify the effectiveness of the proposed method, historical hourly Stockholm electricity price data of Nord Pool market are employed as a case study. Details of the dataset are discussed in the following subsection.
4.1. Data description
Nord Pool (“as of May 19, 2020,” “Nord Pool Website”, Citation2015) runs the leading power market in Europe with both day ahead and intraday markets being offered. There are four series randomly selected from each season used in this study. Details of each series are shown in .
Table 2. Details of each series.
Plots of four series are shown in , respectively. It can be seen from the plot that series 1 and 3 have greater fluctuation compared with the other two series, while series 2 and 4 present stronger seasonality.
Figure 4. Spring electricity price of Stockholm – series 1.
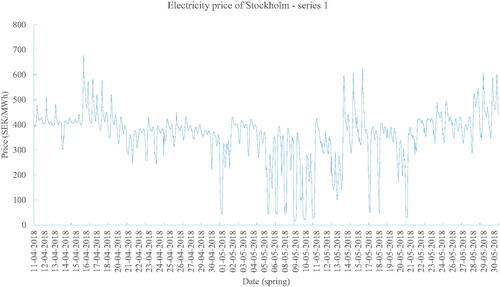
Figure 5. Summer electricity price of Stockholm – series 2.
Figure 6. Autumn electricity price of Stockholm – series 3.
Figure 7. Winter electricity price of Stockholm – series 4.
4.2. The proposed method
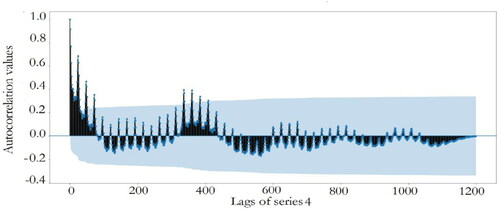
After data collection and visualisation, autocorrelation tests of four series data are performed and the corresponding results are plotted in . The blue areas represent the approximate 95% confidence intervals of autocorrelations. Dots that appear outside the blue area are statistically significant, which indicate potential autocorrelations at a 95% confidence interval.
Figure 8. Autocorrelation plot of series 1.
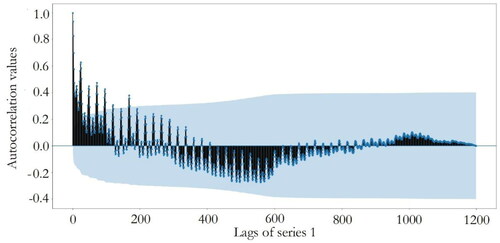
Figure 9. Autocorrelation plot of series 2.
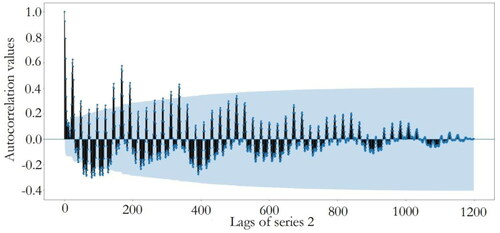
Figure 10. Autocorrelation plot of series 3.
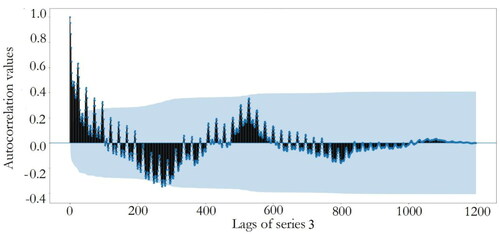
Figure 11. Autocorrelation plot of series 4.
Initial input features are selected from the lags of original series according to Autocorrelation Function (ACF) plots. Apart from numeric features, there are three categorical variables derived from the dataset which are the hour of the day, weekend (the current day is weekend or no), and the day name.
show that there exists significant correlation near the 200th lag for series 1 and significant autocorrelation values are observed after the 300th lag in series 2 and 3. For series 4, there is significant correlation near the 400th lag. Therefore, the first 200, 400, 400, and 450 lags of electricity price along with the three categorical features are chosen as the initial candidate features for series one to four, respectively.
To eliminate features that present less useful information for forecasting, the initial candidate features are fed to CatBoost algorithm first. After model fitting, the importance of each feature is calculated by EquationEquation (8)(8)
(8) .
(8)
(8)
where
denote the number of samples at a leaf node, while
denote the formula value of the leaf. After the importance score is calculated for each feature, it is sorted from highest to lowest, a threshold score of 0.05 is adopted and features with a lower importance score are filtered out. As a result, there are 123, 136, 156, and 143 features selected for series 1–4, respectively. A full list of selected features and the corresponding importance rankings for each series are presented in Appendix 2.
After feature selection, top rows with NA values are removed. As a result, Series 1 consists of data points from 19 April 2018, 10:00 am to 30 May 2018, 0:00 am. Series 2 consists of data points from 20 July 2018, 2:00 am to 22 August 2018, 8:00 am. Series 3 consists of data points from 27 September 2018, 6:00 am to 30 October 2018, 11:00 am and Series 4 consists of data points from 23 January 2018, 0:00 am to 24 February 2018, 4:00 am, respectively.
Then, data normalisation is performed for by EquationEquation (9)(9)
(9) .
(9)
(9)
where
denotes the mean value of the series data and σ denotes the corresponding standard deviation.
The resultant preprocessed data are split, so that 80% of the normalised dataset is used for training and 20% for testing. The experiment is repeated 15 times for each model and initial weights of BDLSTM, GRU, LSTM, and MLP are randomly initialised for each run.
The state of BDLSTM is initialised by predicting on the training data first. After that, to perform the forecasting of n time steps ahead of data points in the testing set, one-time step forecasting approach is used. To be more specific, prediction of the first testing sample is made by the initialised BDLSTM model. Next, the prediction value is utilised to update the network state, after that, the test sample of the next time step is predicted using the updated model. The process is iterated for the remaining time steps to be predicted.
5. Results and discussions
The forecasting results of the proposed BDLSTM together with the other baseline models (SVR, MLP, ARIMA, ensemble tree, GRU, and LSTM) for each series are presented in .
Figure 12. A plot of the actual price and the predictions by non-deep learning models for series 1.
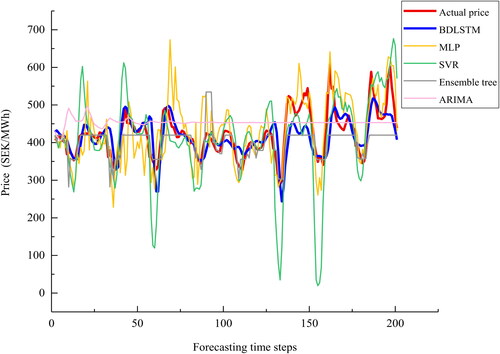
Figure 13. A plot of the actual price and the predictions by deep learning models for series 1.
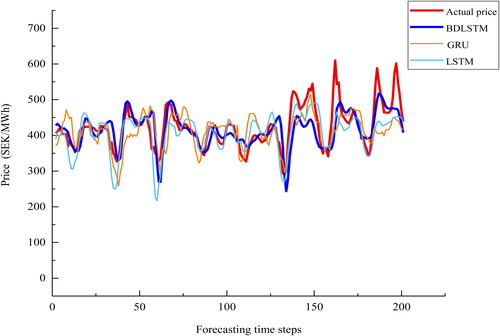
Figure 14. A plot of the actual price and the predictions by non-deep learning models for series 2.
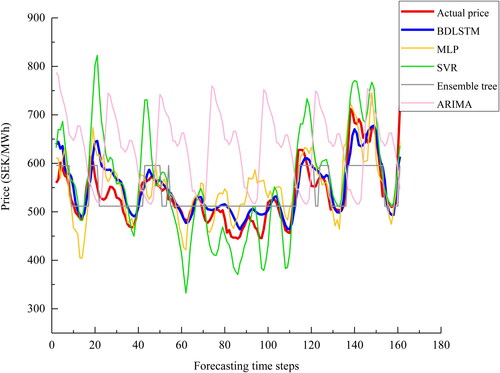
Figure 15. A plot of the actual price and the predictions by deep learning models for series 2.
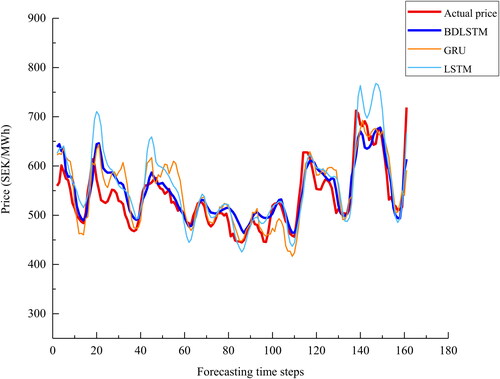
Figure 16. A plot of the actual price and the predictions by non-deep learning models for series 3.
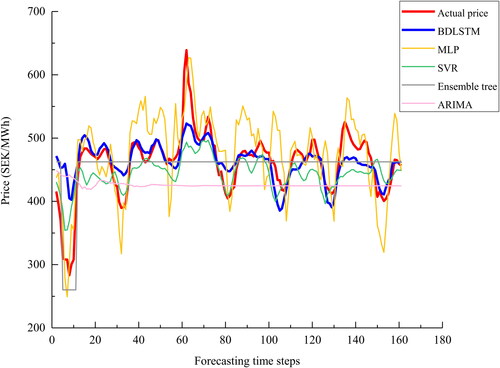
Figure 17. A plot of the actual price and the predictions by deep learning models for series 3.
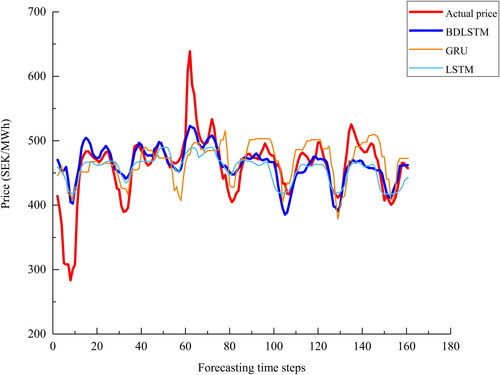
Figure 18. A plot of the actual price and the predictions by non-deep learning models for series 4.
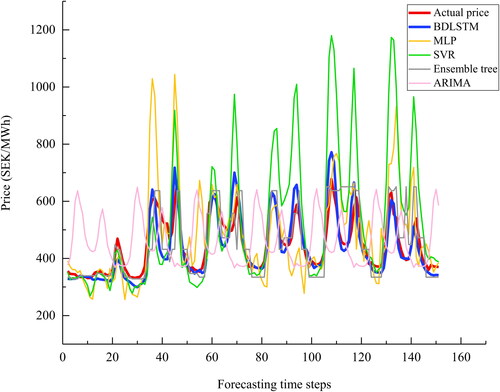
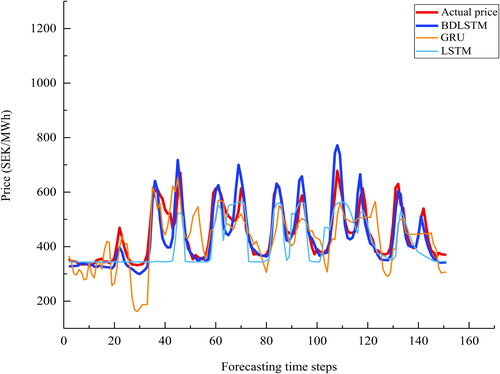
Figure 19. A plot of the actual price and the predictions by deep learning models for series 4.
Series 1: and show that the proposed BDLSTM model captures the overall trend of the original price. Especially from the beginning time step until approximately 130th time step, forecasting values of the proposed model fit the actual electricity price closely. From approximately the 130th time step afterwards, where spikes and valleys are present, the proposed model tends to underestimate the actual values, although the trend is still fully captured by the model. There are two major reasons that contribute to this phenomenon. The first is due to the presence of spikes in the entire series. Spikes are generally caused by certain short-term events or gaming behaviours, which are not the long-term trends of market factors. These events are usually subjective and difficult to forecast (Zhao et al., Citation2007). Amjady and Keynia (Citation2011) reported that model price spikes, in general, cannot be modelled by conventional electricity price forecast approaches effectively due to the highly erratic behaviours and dependency on complex factors (L. Wang et al., Citation2017). There are particular studies focussing on the forecasting of electricity price spikes (Amjady & Keynia, Citation2011; Fragkioudaki et al., Citation2015; Manner et al., Citation2016; Sandhu et al., Citation2016; Voronin & Partanen, Citation2013). However, forecasting of electricity price spikes is not within the scope of this study and is considered as future work. Another factor is that the one-step ahead forecasting suffers from the problem of error accumulation, as predicted values are served as inputs to predict the next time step (Chevillon, Citation2007; Ching-Kang, Citation2003). Overall, the figure shows that the proposed BDLSTM model outperforms the rest.
The plot of MLP shows that trends of certain time steps, e.g., time steps between 38 and 51, are not captured correctly by the model. The curve of actual prices displays a small peak between time steps 38 and 51. However, the curve predicted by MLP shows a small valley. SVR model tends to overestimate peak values and underestimate valleys more than the proposed model, e.g., at around time steps 135 and 152, predicted values of SVR deviate far from actual prices. Ensemble tree outperforms MLP and SVR models. However, predicted values of ensemble tree model are over smoothed, this being more pronounced for series two and three than for series one and four. Therefore, ensemble tree fails to capture the detailed dynamics presented in the series. ARIMA model overestimates for almost all forecasting time steps and predicts constant price after time step 60 approximately. In addition, predictions of GRU model deviate to actual prices at the start and the end of forecasting time steps, while LSTM shows an overall better performance than that of GRU, thought it underestimates the valleys more than BDLSTM.
Series 2: this series contains certain seasonality, but with fewer spikes and valleys than series 1. The proposed model fits the data very well for series 2 as depicted in and with slightly underestimated prediction between time steps 20 and 40 as well as time steps 80 and 100. MLP and SVR overestimate high values as well as underestimate low values. ARIMA predicts a similar seasonality as that is presented in the actual series, though predicted values are overestimated for almost all forecasting time steps. In terms of the forecasting results of deep learning models, LSTM tends to overestimate the peaks, while GRU predictions deviate more from time steps 50 to 60 and the valley at time step 110 is underestimated more by GRU comparing to the other two deep learning models. Due to the presence of spikes and less significant valleys in Series 2 comparing to Series 1, the proposed model tends to overestimate these peak values rather than underestimating valleys.
Series 3: as depicted in and , the overall trend is well captured by BDLSTM, however, the same problem of prediction of valleys and spikes remains at approximate time step 9 and 61. MLP underestimates valleys and overestimates peaks of almost the entire series while predictions by ensemble tree remain the same after the 20th time step. The ARIMA suffers from the similar over smoothed problem as ensemble tree does. In addition, GRU model shows a relatively big deviation to the actual price at approximately time step 58, while LSTM underestimates the peak between time step 60 and 70. Overall, the predicted values of the proposed model follow the actual prices more closely than predicted values of the rest models.
Series 4: from and , the predicted values of BDLSTM follow the actual prices closely, obvious deviation from the actual prices is not observed for almost all time steps. Besides, the over smoothed problem of ensemble tree and ARIMA is less obvious. It is also observed that forecasted values of ARIMA model display certain seasonality present in the actual electricity prices. However, other dynamics such as trend, peaks, and valleys are not captured properly by ARIMA. This is due to the factor that when complex nonlinearity dynamics are presented in a time series, the performance of ARIMA suffers (Deb et al., Citation2017). Concerning SVR, the major problem is that it overestimates the peak values of the actual prices most among all models considered. In terms of the performance of deep learning models, except BDLSTM, the other two models suffer to predict the first forecasting time steps. To be more specific, GRU model shows noisy predictions at the first 20 forecasting time steps. On the contrary, LSTM prediction values are over smoothed before the 40 time step. The plots of Series 4 show relatively regular seasonality patterns than the other three series. Therefore, forecasting errors of the proposed model are more evenly distributed instead of showing relatively obvious overestimated or underestimated predictions in certain time steps especially where peaks and valleys are presented as shown in the other three series.
In general, BDLSTM outperforms the other models for all series, SVR and MLP tend to overestimate peaks and underestimate valleys. While predicted values of ensemble tree and ARIMA are over smoothed. Error measures adopted in this study are MAPE, RMSE, and MAE. Apart from the error measurement, training and forecasting time of each model are also measured. Average results are reported in and the best run results with least errors of each model are presented in . Besides, the detailed results of all 15 runs can be found in Appendix 1.
Table 3. Average results of the models for each series.
Table 4. The best run of each model for each series.
Results show that the proposed model outperforms the other models considered in the experiment for all series for the chosen error measures. The lowest MAPE is achieved by the proposed model with values of 7.015%, 4.441%, 5.265%, and 7.137% for series 1–4, respectively. However, the average time for training the BDLSTM model is higher than for training the other models except ARIMA. Furthermore, the trained BDLSTM is less time efficient in forecasting comparing with the other models. Ensemble tree is the most time efficient model in terms of forecasting efficiency but has lower accuracy. To further compare predictive accuracy, a Diebold–Mariano test (Diebold & Mariano, Citation2012) is performed. The null hypothesis is that the proposed BDLSTM is as accurate as the other model it is compared with. While the alternative hypothesis is that the model to be compared with is less accurate than BDLSTM. p values of Diebold–Mariano test are reported in .
Table 5. DM test p values of models to be compared with the proposed BDLSTM for each series.
Diebold–Mariano test results show that BDLSTM is more accurate than the other models considered in this study for almost all tested series with a significance level of 0.05, apart from Series 3 forecasting result of SVR and Series 1 forecasting result of LSTM. Although the overall errors of BDLSTM reported in and are lower, there is not enough evidence to prove BDLSTM is more accurate than SVR for Series 3 or LSTM for Series 1 with a significance level of 0.05 in this case.
6. Limitations and notes for future researchers
According to the latest review of short-term electricity prices forecasting (Zhang & Fleyeh, Citation2019), there is a lack of recognised benchmarking procedure and a standard dataset for benchmarking of different models, which make the direct comparison of different results difficult. To be more specific, researchers use different error measures, dataset, length of training/testing time steps, start/end date used, and so forth. To make the future benchmarking procedure easier, the instructions of accessing the dataset used in this study are provided, the dataset can be accessed by the link of Nord Pool (“Nord Pool Historical Market Data”) website in “.xls” format, the filtering criteria used for historical hourly electricity spot prices data retrieve is “Elspot Prices” in the “Filter by category” filter and “Hourly” in the “Filter by resolution” filter. The motivation of the instructions is for the ease of other researchers to access the dataset used in this study and encourage future researchers to use the published dataset for benchmarking or upload their own datasets and provide the instructions of how to access them if possible. In addition, it is advised to use the same error measures, length of training/testing, and other factors involved in the benchmarking procedure.
7. Conclusion and future work
In this article, a novel hybrid model is proposed for short-term electricity price forecasting. It combines a Catboost algorithm for feature selection and BDLSTM neural network model for forecasting. The major advantages of the proposed method are that categorical features are handled more efficiently. Besides, BDLSTM is superior to other methods for modelling complex dependencies inside the series data. The experiment results show that the proposed approach outperforms the other models in terms of MAPE, RMSE, and MAE for series with large fluctuations of electricity prices as well as series with smaller fluctuation but with seasonality present. A limitation of the proposed model is that it consumes more time in terms of both training and forecasting comparing with other models.
There are four suggestions for future studies. Firstly, optimisation techniques such as particle swarm optimisation (PSO), genetic algorithm (GA), differential evolutionary (DE) can be explored to optimise the model structure and parameters such as number of hidden layers, number of neurons as well as the weights of each connection. Secondly, to reduce the accumulated error introduced by the one-step-ahead forecasting approach, other approaches such as training separate models for each time horizon separately using only past observations, multi-step ahead approach can be examined. Besides, electricity price spikes shall be handled more carefully by a separate approach to further improve the forecasting accuracy. Moreover, to enhance time efficiency, graphic processing unit (GPU) and parallel computing techniques can be considered. Finally, instructions of accessing the dataset used in this study are provided, which can be served as a benchmarking dataset for future researchers, suggestions of making future benchmarking procedure smoother are advised as well.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Amjady, N., & Keynia, F. (2011). A new prediction strategy for price spike forecasting of day-ahead electricity markets. Applied Soft Computing Journal, 11(6), 4246–4256. https://doi.org/https://doi.org/10.1016/j.asoc.2011.03.024
- Anbazhagan, S., & Kumarappan, N. (2013). Day-ahead deregulated electricity market price forecasting using recurrent neural network. Systems Journal, IEEE, 7(4), 866–872. https://doi.org/https://doi.org/10.1109/JSYST.2012.2225733
- Baldi, P., Brunak, S., Frasconi, P., Soda, G., & Pollastri, G. (1999). Exploiting the past and the future in protein secondary structure prediction. Bioinformatics, 15(11), 937–946. https://doi.org/https://doi.org/10.1093/bioinformatics/15.11.937
- Barnes, P. M. (2017). The politics of nuclear energy in the European Union: Framing the discourse. Barbara Budrich Publishers.
- Bengio, Y., Simard, P., & Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157–166. https://doi.org/https://doi.org/10.1109/72.279181
- Berglund, S. (2009). Putting politics into perspective: A study of the implementation of EU public utilities directives. Eburon Uitgeverij B.V., 2009 – European Union countries.
- Cabero, J., Baillo, A., Cerisola, S., Ventosa, M., Garcia-Alcalde, A., Peran, F., & Relano, G. (2005). A medium-term integrated risk management model for a hydrothermal generation company. IEEE Transactions on Power Systems, 20(3), 1379–1388. https://doi.org/https://doi.org/10.1109/TPWRS.2005.851934
- Cestnik, B. (1990). Estimating probabilities: A crucial task in machine learning. In ECAI’90: Proceedings of the 9th European Conference on Artificial Intelligence January (pp. 147–149).
- Chen, T., Carlos, G. (2016). XGBoost: A Scalable Tree Boosting System. In Publication:KDD ’16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining August (pp. 785–794). https://doi.org/https://doi.org/10.1145/2939672.2939785
- Chevillon, G. (2007). Direct multi-step estimation and forecasting. Journal of Economic Surveys, 21(4), 746–785. https://doi.org/https://doi.org/10.1111/j.1467-6419.2007.00518.x
- Ching-Kang, I. (2003). Multistep prediction in autoregressive processes. Econometric Theory, 19(02), 254–279. https://doi.org/https://doi.org/10.1017/S0266466603192031
- Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. http://arxiv.org/abs/1406.1078
- Cui, Z., & Wang, Y. (2018). Deep stacked bidirectional and unidirectional LSTM recurrent neural network for network-wide traffic speed prediction. In 23rd ACM SIGKDD conference on knowledge discovery and data mining (KDD) (pp. 22–25). New York, NY, United States: Association for Computing Machinery.
- Deb, C., Zhang, F., Yang, J., Eang, S., & Wei, K. (2017). A review on time series forecasting techniques for building energy consumption. Renewable and Sustainable Energy Reviews, 74(February), 902–924. https://doi.org/https://doi.org/10.1016/j.rser.2017.02.085
- Diebold, F. X., & Mariano, R. S. (2012). Comparing predictive accuracy. Journal of Business & Economic Statistics, 13(3), 253–263. https://doi.org/https://doi.org/10.1080/07350015.1995.10524599
- Dorogush, A. V., Ershov, V., & Gulin, A. (2018). CatBoost: Gradient boosting with categorical features support, arXiv:1810.11363.
- Fragkioudaki, A., Marinakis, A., & Cherkaoui, R. (2015). Forecasting price spikes in European day-ahead electricity markets using decision trees. International Conference on the European Energy Market, EEM, 2015-August. https://doi.org/https://doi.org/10.1109/EEM.2015.7216672
- Freund, Y., & Schapire, R. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119–139. https://doi.org/https://doi.org/10.1006/jcss.1997.1504
- Friedman, J. H. (2002). Stochastic gradient boosting. Computational Statistics & Data Analysis, 38(4), 367–378. https://doi.org/https://doi.org/10.1016/S0167-9473(01)00065-2
- Girish, G. P., & Vijayalakshmi, S. (2015). Role of energy exchanges for power trading in India. International Journal of Energy Economics and Policy, 5(3), 673–676.
- Graves, A., & Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks: The Official Journal of the International Neural Network Society, 18(5-6), 602–610. https://doi.org/https://doi.org/10.1016/j.neunet.2005.06.042
- Graves, A., Jaitly, N., & Mohamed, A. (2013). Hybrid speech recognition with Deep Bidirectional LSTM. In 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (pp. 273–278). https://doi.org/https://doi.org/10.1109/ASRU.2013.6707742
- Hochreiter, S. (1991). Untersuchungen zu dynamischen neuronalen netzen. Diploma, Technische Universitat Munchen.
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780. https://doi.org/https://doi.org/10.1162/neco.1997.9.8.1735
- Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., & Liu, T. (2017). LightGBM: A highly efficient gradient boosting decision tree. In NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems (pp. 3149–3157). Curran Associates Inc.
- Kuo, P.-H., & Huang, C.-J. (2018). An electricity price forecasting model by hybrid structured deep neural networks. Sustainability, 10(4), 1280. https://doi.org/https://doi.org/10.3390/su10041280
- Lago, J., De Ridder, F., & De Schutter, B. (2018). Forecasting spot electricity prices: Deep learning approaches and empirical comparison of traditional algorithms. Applied Energy, 221(February), 386–405. https://doi.org/https://doi.org/10.1016/j.apenergy.2018.02.069
- Manner, H., Türk, D., & Eichler, M. (2016). Modeling and forecasting multivariate electricity price spikes. Energy Economics, 60, 255–265. https://doi.org/https://doi.org/10.1016/j.eneco.2016.10.006
- Micci-Barreca, D. (2001). A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems. ACM SIGKDD Explorations Newsletter, 3(1), 27–32. https://doi.org/https://doi.org/10.1145/507533.507538
- Mirikitani, D., & Nikolaev, N. (2011). Nonlinear maximum likelihood estimation of electricity spot prices using recurrent neural networks. Neural Computing and Applications, 20(1), 79–89. https://doi.org/https://doi.org/10.1007/s00521-010-0344-1
- Nord Pool Historical Market Data. (n.d.). Nord Pool. Retrieved November 5, 2020, from https://www.nordpoolgroup.com/historical-market-data/
- Nord Pool Website. (2015). Nord Pool. Retrieved November 5, 2020, from https://www.nordpoolgroup.com/
- Olah, C. (2015). Understanding LSTM networks. Retrieved November 5, 2020, from http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- Pandey, N., & Upadhyay, K. G. (2016). Different price forecasting techniques and their application in deregulated electricity market: A comprehensive study. 2016 International Conference on Emerging Trends in Electrical Electronics & Sustainable Energy Systems (ICETEESES) (pp. 1–4). https://doi.org/https://doi.org/10.1109/ICETEESES.2016.7581342
- Pezzutto, S., Grilli, G., Zambotti, S., & Dunjic, S. (2018). Forecasting electricity market price for end users in EU28 until 2020—Main factors of influence. Energies, 11(6), 1418–1460. https://doi.org/https://doi.org/10.3390/en11061460
- Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: Unbiased boosting with categorical features. In NIPS'18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, December 2018 (pp. 6639–6649). ACM.
- Sandhu, H. S., Fang, L., & Guan, L. (2016). Forecasting day-ahead price spikes for the Ontario electricity market. Electric Power Systems Research, 141, 450–459. https://doi.org/https://doi.org/10.1016/j.epsr.2016.08.005
- Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45(11), 2673–2681. https://doi.org/https://doi.org/10.1109/78.650093
- Sulehria, H. K., & Zhang, Y. (2007). Hopfield neural networks: A survey. In AIKED’07 Proceedings of the 6th Conference on 6th WSEAS Int. Conf. on Artificial Intelligence, Knowledge Engineering and Data Bases (Vol. 6, pp. 125–130).
- Ugurlu, U., Oksuz, I., & Tas, O. (2018). Electricity price forecasting using recurrent neural networks. Energies, 11(5), 1255. https://doi.org/https://doi.org/10.3390/en11051255
- Vardhan, N. H., & Chintham, V. (2015). Electricity price forecasting of deregulated market using Elman neural network. In 2015 Annual IEEE India Conference (INDICON) (pp. 1–5). https://doi.org/https://doi.org/10.1109/INDICON.2015.7443460
- Ventosa, M., Baı́llo, Á., Ramos, A., & Rivier, M. (2005). Electricity market modeling trends. Energy Policy, 33(7), 897–913. https://doi.org/https://doi.org/10.1016/j.enpol.2003.10.013
- Voronin, S., & Partanen, J. (2013). Price forecasting in the day-ahead energy market by an iterative method with separate normal price and price spike frameworks. Energies, 6(11), 5897–5920. https://doi.org/https://doi.org/10.3390/en6115897
- Wang, L., Member, S., Zhang, Z., & Chen, J. (2017). Short-term electricity price forecasting with stacked denoising autoencoders. IEEE Transactions on Power Systems, 32(4), 2673–2681. https://doi.org/https://doi.org/10.1109/TPWRS.2016.2628873
- Wang, Y., Wang, J., Lin, H., Zhang, S., & Li, L. (2017). Biomedical event trigger detection based on bidirectional LSTM and CRF. In 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (pp. 445–450). https://doi.org/https://doi.org/10.1109/BIBM.2017.8217689
- Weron, R. (2014). Electricity price forecasting: A review of the state-of-the-art with a look into the future. International Journal of Forecasting, 30(4), 1030–1081. https://doi.org/https://doi.org/10.1016/j.ijforecast.2014.08.008
- Xu, C., Xie, L., & Xiao, X. (2018). A bidirectional LSTM approach with word embeddings for sentence boundary detection. Journal of Signal Processing Systems, 90(7), 1063–1075. https://doi.org/https://doi.org/10.1007/s11265-017-1289-8
- Xue, H. Q., Huynh, D., & Reynolds, M. (2017). Bi-prediction: Pedestrian trajectory prediction based on bidirectional LSTM classification. In 2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA) (pp. 1–8). https://doi.org/https://doi.org/10.1109/DICTA.2017.8227412
- Yildirim, Ö. (2018). A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification. Computers in Biology and Medicine, 96(March), 189–202. https://doi.org/https://doi.org/10.1016/j.compbiomed.2018.03.016
- Zeyer, A., Doetsch, P., Voigtlaender, P., & Schlüter, R. (2017). A comprehensive study of deep bidirectional LSTM RNNS for acoustic modeling in speech recognition. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2462–2466). https://doi.org/https://doi.org/10.1109/ICASSP.2017.7952599
- Zhang, F., & Fleyeh, H. (2019). A review of single artificial neural network models for electricity spot price forecasting. In 2019 16th International Conference on the European Energy Market (EEM) (pp. 1–6). https://doi.org/https://doi.org/10.1109/EEM.2019.8916423
- Zhao, J. H., Dong, Z. Y., Li, X., & Wong, K. P. (2007). A framework for electricity price spike analysis with advanced data mining methods. IEEE Transactions on Power Systems, 22(1), 376–385. https://doi.org/https://doi.org/10.1109/TPWRS.2006.889139
- Zhao, Y., Yang, R., Chevalier, G., Shah, R. C., & Romijnders, R. (2018). Optik applying deep bidirectional LSTM and mixture density network for basketball trajectory prediction. Optik – International Journal for Light and Electron Optics, 158, 266–272. https://doi.org/https://doi.org/10.1016/j.ijleo.2017.12.038
- Zheng, D., Chen, Z., Wu, Y., & Yu, K. (2016). Directed automatic speech transcription error correction using bidirectional LSTM. In 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP) (pp. 1–5). https://doi.org/https://doi.org/10.1109/ISCSLP.2016.7918446
Appendix 1.
Results of each run
Appendix 2.
A full list of features selected and ranked by Catboost for each series