
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Motivated by demand prediction for the custodial prison population in England and Wales, this paper describes an approach to the study of service systems using infinite server queues, where the system has non-empty initial state and the elapsed time of individuals initially present is not known. By separating the population into initial content and new arrivals, we can apply several techniques either separately or jointly to those sub-populations, to enable both short-term queue length predictions and longer-term considerations such as managing congestion and analysing the impact of potential interventions. The focus in the paper is the transient behaviour of the queue with a non-homogeneous Poisson arrival process and our analysis considers various possible simplifications, including approximation. We illustrate the approach in that domain using publicly available data in a Bayesian framework to perform model inference.
1. Introduction
This work is motivated by the problem of predicting short and longer-term implications of policy changes on the custodial elements of the prison system in England and Wales. The model described here was developed following consultation with the Ministry of Justice (MoJ) to add to their methods of forecasting the prison population, to help analyse the implications of changing external factors accounting for the prison population such as government guidelines and sentencing policies, and to consider the uncertainty involved in the model and its predictions.
The nature of the prison system is such that arrivals can’t be turned away, hence infinite server queueing models are directly applicable as they support the assumption of no queueing delay for service. While such models have been widely used in modelling service systems, including call centres (Ibrahim et al., Citation2016), hospital staffing (Pender, Citation2016), software reliability (Huang & Huang, Citation2008) and insurance claims (Cheung et al., Citation2019), the assumptions relevant to our scenario lead us to consider some less well-known results from the queueing systems literature and discuss how they can be useful in this setting.
In this domain, matters of capacity management and overcrowding at individual institutions have to be handled by adjustments involving medium term system-wide considerations such as sentencing patterns, parole guidelines and the use of community service arrangements. This intent to support policy makers leads to a focus on the strategic level of decision support (Grieco et al., Citation2021; Hulshof et al., Citation2012), and to some considerations on the development of models expressed in terms that are interpretable by policy makers and can enable “what if?” studies, including quantification of the impact of prospective policy change (Bravo et al., Citation2019; Dong & Perry, Citation2020; Kegel et al., Citation2017; Petris et al., Citation2009; Tuominen et al., Citation2022).
The value of decision support tools that can analyse the impact of interventions linked to policy change has been demonstrated in care pathways in health services (Demir & Southern, Citation2017). While modelling flows through a prison system has not been widely studied, there has been some work using queueing models to study the relationship between policy changes and prison occupancy. For example, Usta and Wein (Citation2015) used a queueing network model of the jail system and a simulation approach to study the optimal mix of pretrial release and forms of sentencing to minimise the amount of recidivism, subject to constraints on the available prison occupancy; and Master et al. (Citation2018) used a queueing system to assess performance of alternative pretrial release policies, and of sentences with a split of custodial and supervised outcomes.
Using public data, we study a single phase of a prisoner’s journey through the prison system, as it is well out of scope to model the full system. Our analysis is both informed by, and limited by, the availability of service system data: the size of the prison population is collected and recorded on a monthly basis, but the time served and the remaining length of stay (service times) of those individuals are not. Indeed for custodial sentence admissions, even within offence types (the 12 main offence groups are listed in ), sentence lengths differ, and there is a difference between a court imposed sentence length and the actual service time, so the model cannot assume remaining service times for those individuals present at a given time, even if their formal sentence lengths are known. This contrasts with, for example, work on bed demand in an intensive care unit that considered existing patients as well as arrivals, but could use knowledge of the length of stay of existing patients (Pagel et al., Citation2017).
Queueing model analyses typically assume the system begins in an empty state (Li et al., Citation2019) and then, assuming a Poisson arrival process, the well-known results of Eick et al. (Citation1993) mean that the queue length exhibits a Poisson distribution with a mean derivable from properties of the service time distribution. The scenario motivating the work in this paper involves the less well-studied situation where there are n > 0 individuals initially present and where the elapsed time at t = 0 of each individual is not known (Goldberg & Whitt, Citation2008; Korhan Aras et al., Citation2017; Weber, Citation2005). In this case, the departure process is no longer Poisson, but the queue dynamics can be analysed as a combination involving those already in service at t = 0 and those who subsequently arrive, and the departure process is the superposition of a binomial and a Poisson process (Weber, Citation2005). This separation into initial content and new input allow these sub-populations to be analysed jointly or separately.
As pointed out by Pagel et al. (Citation2017), in contrast to much research involving applications of queueing systems that rely on steady state distributions, when considering the use of models for informing short term consequences associated with operational decision making, results involving transient distributions of queueing systems become relevant.
As highlighted in a recent review of major healthcare applications of infinite server queuing models (Worthington et al., Citation2020), time-inhomogeneous infinite server models have been used both for predictive modelling (e.g., ward capacity planning (Bekker & de Bruin, Citation2010)) and for investigating the impact of policy changes (e.g., the introduction of specialised treatment centres for specified illnesses (Utley et al., Citation2008)). Our ambition to support the analysis of both short and longer-term policy change means we also consider time-varying arrivals.
Another key choice in formulating a queueing theory model is the assumptions regarding service time. The available data suggest a heavy tailed service time (Ministry of Justice, Citation2020b). Hence, we are led to the model as it is well recognised that there is an effect on the performance of the queue of the tail of the distribution as it becomes less exponential (Goldberg & Whitt, Citation2008).
To employ our model as a prediction tool, we must also consider the uncertainty involved as we are considering behaviour beyond the sample of the original data set used to estimate the model parameters (Gans et al., Citation2003). Incorporating parameter uncertainty as part of model inference is an important step to avoid overconfidence in our results (Aktekin & Soyer, Citation2011). We consider parameter uncertainty involved in the prediction of the system size using estimates from aggregate historical data. Techniques typically rely on summary observable data such as queue lengths, visit counts and response times, but perform inference in different ways (Spinner et al., Citation2015). A common approach is by Jongbloed and Koole (Citation2001) using a Poisson mixture model and a recent survey on forecasting of the arrival process is by Ibrahim et al. (Citation2016). We employ a Bayesian framework to perform model inference and prediction (Aktekin & Soyer, Citation2011; Xie et al., Citation2014). The Bayesian framework allows us to incorporate expert knowledge about the system into prior distributions of model parameters, which is particularly important since we have limited historical data available to us (O’Hagan, Citation1998).
In summary, we study the transient behaviour of the time-varying infinite server queue, fed by a non-homogeneous Poisson arrival process whose occupancy is observed at discrete points in time, but the time in service to that point is not known. The contributions of this paper are: (i) the novel synthesis of results from several authors about transient and stationary behaviour of the
queue; and (ii) application of the approach, using Bayesian inference, to the real-world domain of prison occupancy—a domain that has not been well-studied in the literature.
The structure of this paper is as follows: in Section 2 we describe the motivating application; Section 3 outlines relevant results from the literature for analysing an observed queue; Section 4 presents a Bayesian framework for the estimation of the model parameters using domain data to illustrate the use of the model to both short-term and longer-term predictions, and includes a discussion of the mathematical assumptions of the model. In Section 5 we provide concluding remarks, with comments comparing the presented queueing theoretic approach with time-series based estimation methods. The Appendices contain further information about the prison system (Appendix A), use of the theory (Appendix B), and some examples of how analysis with our model compares with using a time-series based ARIMA model (Appendix C).
2. Motivating application: Prison occupancy
The study in this paper was produced following consultation with the Ministry of Justice (MoJ). We briefly describe the custodial elements of the prison system, that is, those that require accommodation, with more details in Appendix A. Data on the prison population is collected and managed by MoJ and the HM Prison and Probation Service (HMPPS). Statistics are regularly released as well as projections of the prison population (Ministry of Justice, Citation2018).
Attributes of the application domain that guided our modelling choices include: a large system of multiclass arrivals with a high offered load, no abandonments, input parameters that are subject to change and operation over a long time scale. Further, the domain data suggests the use of a non-exponential service time distribution and that a stationarity assumption is reasonable over short time frames, which allowed us to take advantage that several questions of interest have more tractable solutions under the assumptions of a stationary model.
Factors such as the conviction rate (the proportion of those arriving to court that are convicted and sentenced) and the custody rate (the proportion of those sentenced that are given custodial sentences) influence the sentenced population. Hence the size and composition of the prison population is subject to policy and legislation changes, for example, changes in Home Office (government department) resources that can affect charge rates and modifications to the sentencing guidelines (MoJ, 2019). Patterns in the published data illustrate how policy and legislative changes have had subsequent impacts on prison occupancy. Hence, from a policy maker’s perspective, being able to adjust model parameters to allow, for example, for a more serious mix of offence groups coming before the courts reflects the importance of reviewing model parameters over time.
Of course, describing the dynamics of the prison system is beyond the scope of this paper, but from a modelling perspective it requires only some reasonable assumptions to treat the flow of prisoners as an queue (Schwarz et al., Citation2016). displays our model of a simplified prisoner journey with the prison population divided into three main holding phases (displayed percentages are as of June 2019) (MoJ, 2019): (i) on remand (11%), (ii) sentenced prisoners (79%) and (iii) on recall (9%). Prisoners within the licence phase are in the community. A broader view of the prison system and its constraints would include, for example, the number of offenders on probation, staffing resources required for supervision, demands on the courts and parole hearing frequencies (Crowhurst & Harwich, Citation2016; Ministry of Justice, Citation2016, Citation2018).
3. An observed  queue
queue
Motivated by obtaining a prediction of the population given partial information, we describe results applicable to an infinite server system with Poisson arrivals and general service times observed at time under the assumption that we have no information on when the n individuals present at this time each began their service, namely an observed
queue. We define the infinite server queue in Section 3.1 and then present results for the conditional distribution for the observed queue in Section 3.2. As the n individuals initially observed at time τ complete service, this sub-population will go to zero as
Arrivals after time τ will occur according to the Poisson dynamics described in Section 3.1. These results are used in our empirical study in Section 4.
3.1. The queue
The queue is a service system in which individuals arrive according to a non-homogeneous Poisson process with rate function
for
and where the service times are independent and identically distributed (i.i.d.) and independent of the arrival process (Eick et al., Citation1993). Let S be the service time and denote by G its cumulative distribution function (cdf) and g its density. Assume
is bounded and integrable and define the associated random variable Se, the stationary excess of the service time, with cdf
for
(1)
(1)
where
Let Q(t) represent the number of busy servers at time t and let
Theorem 3.1.
(Eick et al., Citation1993, Theorem 1) For an queue that was initially empty at t = – ∞, for each t, Q(t) has a Poisson distribution with mean
(2)
(2)
The departure process is a Poisson process with time dependent rate function , where
(3)
(3)
For each t, Q(t) is independent of the departure process in the interval
The impact of the service time beyond its mean can be seen from where
is the squared coefficient of variation (SCV).
For the approach to the steady state is given by
(4)
(4)
where the steady state has the insensitivity property, as
Similarly, the transient behaviour of a stationary model that has been terminated, that is, for t < 0,
and zero otherwise, is
In an empty system, the approach to steady state is seen from EquationEquation (4)(4)
(4) . For a non-empty system observed at time τ, we note a result by Mandjes and Uraniewski (Citation2011) who analysed the approach to steady state identifying a function that behaves as the difference between the transient and stationary distributions in the limit, and of relevance in the following Section 3.2.
Example 3.2.
We use the Pareto distribution as it exhibits the heavy tailed non-exponential survival times observed in the prison domain, and we draw upon this later. For with shift parameter
and shape parameter
for
The high variability of G is indicated by the fact that the tail decays as a power instead of exponentially. For
otherwise if
then S has infinite mean and
is not a directly integrable function. For
for
the variance is infinite, and for α otherwise the variance is undefined. For
If
then the SCV is
then
3.2. Conditional distribution
Denote by τ the observation time, by the prediction time, and define the vector of the past arrival intensity,
For a stochastic process f(t) cut at an observation time τ, define the past process
if
and
if
and define the future process as
if
and
if
The past process can be thought of as an
process in which arrivals are terminated at time τ, so we are able to draw on results by Goldberg and Whitt (Citation2008) who, motivated by a model of a two-stage item inspection process, studied the distribution of the last departure time from a queue of a terminating arrival process.
For the analysis of the observed queue, we separate the contributions of the sub-populations of those observed at time τ and those arriving later. It is useful to consider the regions describing arrival and service pairs as depicted in , where for each individual arriving to the system, a point is placed at (u, v), with the u-axis recording arrival times and v-axis recording service times. For example, Region Equation(1)(1)
(1) corresponds to individuals arriving and departing by τ, and the region
corresponds to individuals arriving on or before time τ. Denote by N(A) the number of arrival-service pairs in a region A. As per Theorem 3.1, the Poisson arrivals and general service times generate a Poisson process on the plane with the intensity of a point occurring at (u, v) being
As independent splitting of Poisson processes results in Poisson processes, the numbers of points in two disjoint regions are independent Poisson random variables. For example, consider
corresponding to individuals arriving by τ and present at
Then the proportion of individuals present at time τ whose remaining service time from that point is at least δ, is clearly
This geometric depiction is captured in the following result.
Theorem 3.3.
(Goldberg & Whitt, Citation2008, Theorem 2.1) Conditional on there being n individuals in the system at time τ, the remaining service times are i.i.d., each distributed as a random variable with ccdf
(5)
(5) where mean
is given by
(6)
(6)
It directly follows that if for
and
for t < 0, then
and
(7)
(7)
The above result provides an expression for the remaining service time distribution in EquationEquation (5)(5)
(5) , which is required to calculate the conditional distribution in the following result.
Theorem 3.4.
(Weber, Citation2005, Theorem 6) The random variable with
can be expressed as
(8)
(8) where
(9)
(9) where
is given in EquationEquation (5)
(5)
(5) , and
and
are the Poisson and Binomial random variables, respectively.
The process can be written as
where
has arrival rate
and
has arrival rate
As constructed above,
will be the number of points in regions
of .
has Poisson distribution with mean given in Theorem 3.1 and the result for
is given by EquationEquation (9)
(9)
(9) . The distribution of
is binomial with n trials and parameter
given in EquationEquation (5)
(5)
(5) .
Depending on the size of δ relative to τ, either existing or new arrivals can dominate the prediction. The calculations can reveal the contribution of each component to future demand requirements. For some quantities of interest the two sub-processes from the expression in EquationEquation (8)
(8)
(8) can be studied separately. The results extend easily to multiple classes, i,
as each class is treated independently.
Proposition 3.5.
The conditional distribution is(10)
(10) with mean
, and variance
The departure process of the observed queue at time
will be the superposition of a Poisson process with intensity
and a binomial process with parameters n and
(Weber, Citation2005). A consequence of which is that the Poisson-in-Poisson-out feature of the unobserved
system does not hold.
Under a high load, the binomial process will be the superposition of several point processes and will be approximately Poisson: for large n,
(11)
(11)
Thus considering the system began with an initial population drawn from a Poisson distribution with mean n and we employ this approximation in Section 4.
3.2.1. Last departure time
The behaviour of the decay of the initial population can be described by results of Goldberg and Whitt (Citation2008). Suppose n individuals are observed at time τ and consider the time of the last departure. Define
where each
is distributed according to EquationEquation (5)
(5)
(5) , then
Now consider the case where the arrival process is terminated at time γ, but where an observation is not made. Following Goldberg and Whitt (Citation2008), let D be the last departure time and define
the remaining time after γ until the last departure. To determine the distribution of T, let
be a random variable with a Poisson distribution having mean
then
For any random variable Y with continuous cdf, let its quantile function be such that the number
Write
as
when
as
Theorem 3.6.
(Goldberg & Whitt, Citation2008, Theorem 2.2) For any x > 0,(12)
(12)
Then as and for
(13)
(13)
The moments of which can be calculated by
Example 3.7.
For ), and with
for
(14)
(14)
with
(15)
(15)
In for fixed we illustrate varying values
The effect of increasing the SCV is seen in the quantiles of the last departure time T. These results can be employed in the application domain to study the decreasing content of a prison population with no new arrivals.
4. Empirical study and simulations
The statistical inference of infinite server queues has been studied given various types of incomplete data: (i) queue length data (Goldenshluger & Koops, Citation2019; Picklands, Citation1997); (ii) unmatched arrival and service times (Blanghaps et al., Citation2013); (iii) busy period data (Hall & Park, Citation2004); and (iv) arrival and departure counts (Li et al., Citation2019).
In this section, we present a method to generate predictions that consider the parameter uncertainty using Bayesian inference, considering queue length data from March 2015 to March 2019 on the Adult/Male sentenced population (MoJ, Citation2020b, Table 1.2b: Sentenced to immediate custody). We refer to the MoJ documentation for details on counting processes, but we interpret this as the sentenced population and only consider data from 2015 due to changes in the reporting processes.
We aim to provide a demonstration of the estimation approach for the model parameters using simulated monthly counts generated from published quarterly data, as the data is not sufficient to perform Bayesian inference about the system and model parameters. To generate monthly counts we: (i) divide the quarterly counts to obtain a monthly mean count; (ii) fit a smoothing spline to produce monthly predictions; (iii) add noise equal to the residual standard error from a linear model fit.
4.1. Bayesian analysis of the sentenced population
To specify the model, we adopt a linear arrival rate of the form and assume that the service time distribution for each offence group is Pareto, and can be adequately estimated from historical data (over a much longer time interval than the prediction lead time). Using public data (MoJ, 2020a, July 2018: June 2019) for the mean sentence length for each offence group, we specify that the service time is 50% of the sentence length for this demonstration.
For a large system, define the mean function using EquationEquation (11)
(11)
(11) , and Pareto
distribution as in Example 3.2, we have
(16)
(16)
(17)
(17)
(18)
(18)
We specify prior distributions for arrival rate function and service distribution time parameters where arrival data is used to specify informative priors for arrival rate function. We define a Bayesian model for the monthly numbers of arrivals with non-informative priors. Denote by
the number of individuals that arrive in
) and is Poisson distributed with mean
We extract the posterior samples of β0 and β1. Since both posterior densities are bell-shaped, we define normal priors for β0 and β1 centred on the mean of posterior samples and standard deviation equal to the scaled posterior sample standard deviation for the model. We use a scaled posterior sample standard deviation in order to fully explore the parameter space during Markov chain Monte Carlo (MCMC). We specify a uniform prior for
where the lower bound avoids infinite variance and the upper bound ensures good convergence and mixing of the Markov chains. In practice, we observe that increasing the upper bound of α leads to non-identifiability. We use RStan to perform full Bayesian statistical inference by adopting the Hamiltonian Monte Carlo (HMC) and no-U-turn samplers (NUTS) (Carpenter et al., Citation2017).
We demonstrate long-term (k-step ahead prediction) and short-term (one-step ahead prediction) forecasts. The long-term forecasts are useful in informing long-term planning decisions in relation to the prison system capacity, whereas short-term forecasts could provide the insight needed for the day-to-day prison system operation. To generate predictions about the system behaviour, we perform the following steps:
Sample
For each
Compute sample mean
Compute sample standard deviation,
4.2. Predictions and simulation results
Example 4.1.
We demonstrate the Bayesian model specification to predict the number of prisoners in the Theft offence group where months. From the arrival count data, we obtain the posterior sample for β0 with mean 1376.5 and standard deviation 9.7. Similarly, the mean and standard deviation of posterior sample for β1 are -11.5 and 0.3 respectively. We then specify the priors:
and
with
We set two Markov chains with 10,000 iterations for each chain (including warmup).
In , we produce the density plots of marginal posterior distributions for model parameters. We observe that the posterior sample density of β0 is bell shaped and centered around 677.4 and the standard deviation of posterior samples is 17.76. Similarly, the values of β1 is centred around −3.77 with posterior standard deviation 0.54. We observe that under our model specification the number of arrivals in Theft Offence group gradually decreases over time. The distributions of posterior samples for θ and α are less informative, since we included the mean of service time in our prior specification.
In we illustrate long and short term predictions from August 2019 to March 2020. We note that the short-term projections are more computationally expensive as in order to obtain a new observation, we update the posterior distribution by re-running a Stan programme. The left panel plot in shows the long-term forecast (for 8 months). The number of offenders in Theft offence category is expected to decrease over time. Our predictions slightly underestimate the true values, however the true values lie within two standard deviation prediction interval. We observe that uncertainty about our projections increases with time. The right panel plot in shows the short-term forecasts. The predictions are closer to the true values together with the slightly lower uncertainty about our predictions. To access the performance of the proposed model, we use the Root Mean Square Error (RMSE): where a lower value indicates a better model performance. The RMSE for long-term predictions is 53.08, whereas for short-term predictions is 20.9.
Example 4.2.
Adopting a similar approach as in Example 4.1, we consider the number of offenders for two further offence groups: Sexual offences and Public order offences. The predictions for Public order offences are illustrated in . For Sexual offences the RMSE for long-term forecast is 7.16, whereas for short-term forecast is 5.10. For Public order offences: the RMSE for long-term forecast is 2.97, whereas for short-term forecast is 1.89.
In the next example we reuse the posterior samples of model parameters derived in Examples 4.1 and 4.2 to demonstrate how the model can provide insight into policy modifications.
Example 4.3.
A change point can be studied, representing switching from one kind of service to another at time τ (that does not involve an observation), the model is an (Korhan Aras et al., Citation2017) (using the superscript o for old and ν for new). The distribution of
is Poisson with mean
In we simulate the effect of increasing and decreasing the mean service time on the offence group population for theft offences, sexual offences and public order offences, respectively, and where the solid lines are the predictors and the dashed lines represent two standard deviation prediction intervals. We remark that to produce these results we reuse samples from the posterior distributions of and α. The new values of θ are given by
4.3. Discussion
In the previous section we illustrated how to use the Bayesian model for short and longer-term predictions, and to provide insight into the implications of possible policy modifications. In Appendix B, drawing on other theoretical results, we briefly describe how modification of sentencing and custody rates can be seen as a form of intervention to enable congestion event recovery. Empirical demonstration of the value of such analysis is beyond the scope of the paper, as this would require data not available to us.
With regard to the predictions in Section 4.2, we note that time-series forecasting methods such as ARIMA models (Shumway et al., Citation2000) can predict the future prison population by describing the autocorrelation in the data. A direct comparison, using the data from Section 4.1, is presented in Appendix C, and in Section 5 we provide some comments on the different approaches to forecasting.
We now briefly discuss the impact of the assumptions of the mathematical model described in Section 3. It is assumed that the time served by individuals at the observation point t = 0 is unknown, but if the elapsed service times of the observed population
are recorded, it can be more effective to use this information to make predictions, while carrying a greater cost (Duffield & Whitt, Citation1997). In contrast to EquationEquation (5)
(5)
(5) , the conditional remaining service time ccdf for elapsed service time x is
As the conditional remaining service times are no longer identically distributed, the complication of the distribution increases and the resulting process is a Markov process (Korhan Aras et al., Citation2017), although the estimates for the mean number remaining at time t and variance have simple forms:
Further, as noted by Whitt (Citation1999), the importance of conditioning upon the time served at an observation point increases as the service-time distribution differs more from an exponential distribution. If G is highly variable, then the elapsed holding time can greatly help in future prediction and a long elapsed holding time tends to imply a very long remaining holding time. Let denote the Pareto service time distribution G as defined in Example 3.2 and let
the associated ccdf for elapsed service time x. By the result for
above, Duffield and Whitt (Citation1997, Theorem 8) showed that
which implied
Hence
that is, the mean remaining service time
is approximately proportional to the elapsed service time t.
5. Concluding remarks
This work was motivated by the problem of predicting the population of housed inmates within the prison system in England and Wales, where the size of the prison population is recorded on a regular basis, with attention both to short-term predictions to enable local resource planning, and longer-term projections that can provide insight to policy makers regarding the impact of potential policy variations.
We studied the transient behaviour of the time-varying infinite server queue, fed by a non-homogeneous Poisson arrival process whose occupancy is observed at discrete points in time, but the time in service to that point is not known. Drawing on this analysis, and using publicly available data, we built a model that could be used as a decision support tool for custodial elements of the prison system. We illustrated the use of such a model for population prediction and for analysing the implications of changing external factors influencing the prison population such as government guidelines and sentencing policies. The proposed model produces predictions together with uncertainty bands and aligns with the current guidelines on informed decision making in the UK government (Treasury, Citation2015).
It is beyond our scope to compare the queueing theory approach to generating predictions with multiple forecasting methods, but we note recent work arguing that for time-series methods Liu et al. (Citation2021) to support general scenario analysis requires extracting components known as “features” from the time-series data, that in turn can be used to generate alternative scenarios (Kegel et al., Citation2017; Tuominen et al., Citation2022). In the queueing theory approach, model parameters have a direct interpretation for the application domain, which straightforwardly enables the study of a variety of public policy initiatives by setting different input values to the model. We demonstrated this in Example 4.3 for changes in the distribution of sentence lengths. As a further example, changes under consideration to the sentencing and release of serious and dangerous sexual and violent offenders (MoJ, 2019), could be studied by changes in the arrival rate (e.g., the custody rate, conviction rate), studies we were unable to undertake, as they require data not available to us. In contrast, time-series methods are not so amenable to what-if style scenario analysis as they offer the possibility of forecasting future observations, but with limited interpretability of the fitted model (Petris et al., Citation2009).
The contributions of this paper are: (i) the novel synthesis of results from several authors about transient and stationary behaviour of the queue to enable construction of a model suited to short and longer-term predictions, and to supporting considerations of parameter uncertainty; and (ii) illustration of the approach to potential policy changes in the real-world domain of prison occupancy.
Reflecting the data available for model building, we focused on the situation where the system has non-empty initial state and where the elapsed time of each individual in the system is not known. The dynamics of the queue is a combination of those already in service at some time and those who subsequently arrive, and separation into initial content and new input allowed these sub-populations to be analysed jointly and separately. We drew on results for the transient and stationary distributions of these queueing systems from several authors to enable an analytic approach. Then, using a Bayesian approach with public historical data that allows the inclusion of expert knowledge, we considered parameter uncertainty involved in the prediction of future arrivals and presented a model that maintains interpretability for the domain application. Incorporating other sources of uncertainty into our process Whitt (Citation2002), including model and process uncertainty, and quantifying the contribution from each within our application is a topic of future research.
Further, we note that restoration of the departure process as approximately Poisson also allows the approach to be extended to a network of processes, referred to as a model, in which queue length distribution models have time-dependent product form and would be appropriate for models of many service systems (Massey & Whitt, Citation1993), including further development of a model specific to the prison domain.
The approach is potentially applicable to other service systems, but the queueing model properties of interest will vary according to the application context, and the choice of what approach to take will also depend on the available data. Data driven development of a system model is an increasingly popular approach as discussed in Mandelbaum et al. (Citation2019). However, the infrastructure to collect and manage data at multiple phases and timescales is not yet comprehensive, so parameter inference remains a challenging problem because of limited data availability about successive system states, and for model building methods that can take advantage of available but incomplete data are essential. We acknowledge that some of our articulated modelling assumptions may not apply in domains where fine-grained staffing implications are of interest, for example, hospitals and call centres.
The availability of future information (via predictive algorithms, machine learning, or local observation) and the resultant novel queueing analysis, has policy design implications, described as “a broader shift from being reactive to proactive” as future information becomes part of the policy maker’s toolkit (Spencer et al., Citation2014; Walton & Xu, Citation2021).
Acknowledgements
We would like to thank our colleagues from the Ministry of Justice for helpful discussions in the development of this work, and the journal reviewers for constructive comments that helped to improve the presentation. The work was conducted as part of the Managing Uncertainty in Government Modelling project supported by The Alan Turing Institute. This work was supported by the Additional Funding Programme for Mathematical Sciences, delivered by EPSRC (EP/V521917/1) and the Heilbronn Institute for Mathematical Research.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Aktekin, T., & Soyer, R. (2011). Call center arrival modeling: A Bayesian state space approach. Naval Research Logistics (NRL), 58(1), 28–42. https://doi.org/10.1002/nav.20436
- Bekker, R., & de Bruin, A. (2010). Time-dependent analysis for refused admissions in clinical wards. Annals of Operations Research, 178(1), 45–65. https://doi.org/10.1007/s10479-009-0570-z
- Blanghaps, N., Nov, Y., & Weiss, G. (2013). Sojourn time estimation in an M/G/∞ queue with partial information. Journal of Applied Probability, 50(4), 1044–1056.
- Bravo, F., Rudin, C., Rudin, C., Shaposhnik, Y., & Yuan, Y. (2019). Simple Rules for Predicting Congestion Risk in Queueing Systems: Application to ICUs. https://doi.org/10.2139/ssrn.3384148
- Carpenter, B., Gelman, A., Hoffman, M., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32. https://doi.org/10.18637/jss.v076.i01
- Cheung, E., Rabehasaina, L., Woo, J., & Xu, R. (2019). Asymptotic correlation structure of discounted Incurred But Not Reported claims under fractional Poisson arrival process. European Journal of Operational Research, 276(2), 582–601. https://doi.org/10.1016/j.ejor.2019.01.033
- Crowhurst, E., Harwich, E. (2016). Unlocking Prison Performance. https://reform.uk/sites/default/files/2018-10/Unlocking\%20prison\%20performance\%20web.pdf.
- Demir, E., & Southern, D. (2017). Enabling better management of patients: Discrete event simulation combined with the star approach. Journal of the Operational Research Society, 68(5), 577–590. https://doi.org/10.1057/s41274-016-0029-y
- Dong, J., & Perry, O. (2020). Queueing Models for Patient-Flow Dynamics in Inpatient Wards. Operations Research, 68(1), 250–275. https://doi.org/10.1287/opre.2019.1845
- Duffield, N., & Whitt, W. (1997). Control and recovery from rare congestion events in a large multi-server system. Queueing Systems, 26(1/2), 69–104. https://doi.org/10.1023/A:1019168821588
- Eick, S., Massey, W., & Whitt, W. (1993). The physics of the Mt/G/∞ queue. Operations Research, 41(4), 731–742.
- Gans, N., Koole, G., & Mandelbaum, A. (2003). Telephone Call Centers: Tutorial, Review, and Research Prospects. Manufacturing & Service Operations Management, 5(2), 79–141. https://doi.org/10.1287/msom.5.2.79.16071
- Goldberg, D., & Whitt, W. (2008). The last departure time from an Mt/G/∞ queue with a terminating arrival process. Queueing Systems, 58(2), 77–104.
- Goldenshluger, A., & Koops, D. (2019). Nonparametric Estimation of Service Time Characteristics in Infinite-Server Queues with Nonstationary Poisson Input. Stochastic Systems, 9(3), 183–207. https://doi.org/10.1287/stsy.2018.0026
- Grieco, L., Utley, M., & Crowe, S. (2021). Operational research applied to decisions in home health care: A systematic literature review. Journal of the Operational Research Society, 72(9), 1960–1991. https://doi.org/10.1080/01605682.2020.1750311
- Hall, P., & Park, J. (2004). Nonparametric Inference about Service Time Distribution from Indirect Measurements. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 66(4), 861–875. https://doi.org/10.1111/j.1467-9868.2004.B5725.x
- Huang, C. Y., & Huang, W. C. (2008). Software reliability analysis and measurement using finite and infinite server queueing models. IEEE Transactions on Reliability, 57(1), 192–203.
- Hulshof, P. J., Kortbeek, N., Boucherie, R. J., Hans, E. W., & Bakker, P. J. (2012). Taxonomic classification of planning decisions in health care: A structured review of the state of the art in or/ms. Health Systems, 1(2), 129–175. https://doi.org/10.1057/hs.2012.18
- Ibrahim, R., Ye, H., L’Ecuyer, P., & Shen, H. (2016). Modeling and forecasting call center arrivals: A literature survey and a case study. International Journal of Forecasting, 32(3), 865–874. https://doi.org/10.1016/j.ijforecast.2015.11.012
- Jongbloed, G., & Koole, G. (2001). Managing uncertainty in call centres using poisson mixtures. Applied Stochastic Models in Business and Industry, 17(4), 307–318. https://doi.org/10.1002/asmb.444
- Kegel, L., Hahmann, M., & Lehner, W. (2017). Generating what-if scenarios for time series data [Paper presentation].Proceedings of the 29th International Conference on Scientific and Statistical Database Management, SSDBM ’17, In, New York, NY, USA. Association for Computing Machinery. https://doi.org/10.1145/3085504.3085507
- Korhan Aras, A., Liu, Y., & Whitt, W. (2017). Heavy-traffic limit for the initial content process. Stochastic Systems, 7(1), 95–142. https://doi.org/10.1287/15-SSY175
- Li, D., Hu, Q., Wang, L., & Yu, D. (2019). Statistical inference for Mt/G/∞ queueing systems under incomplete observations. European Journal of Operational Research, 279(3), 882–901.
- Liu, Z., Zhu, Z., Gao, J., & Xu, C. (2021). Forecast methods for time series data: A survey. IEEE Access. 9, 91896–91912. https://doi.org/10.1109/ACCESS.2021.3091162
- Mandelbaum, A., Momčilović, P., Trichakis, N., Kadish, S., Leib, R., & Bunnell, C. (2019). Data-Driven Appointment-Scheduling Under Uncertainty: The Case of an Infusion Unit in a Cancer Center. Management Science, 1909, 1–28.
- Mandjes, M., & Uraniewski, P. (2011). M/G/∞ transience, and its applications to overload detection. Performance Evaluation, 68(6), 507–527.
- Massey, W., & Whitt, W. (1993). Networks of infinite-server queues with nonstationary Poisson input. Queueing Systems, 13(1-3), 183–250. https://doi.org/10.1007/BF01158933
- Master, N., Reiman, M., Wang, C., & Wein, L. (2018). A Continuous-Class Queueing Model With Proportional Hazards-Based Routing. SSRN Electronic Journal, 1–44. https://doi.org/10.2139/ssrn.3390476
- Ministry of Justice (2016). Story of the Prison Population: 1993 – 2016 England and Wales.
- Ministry of Justice (2018). Guide to Offender Management Statistics England and Wales Ministry of Justice Guidance Documentation, pages 1–45.
- Ministry of Justice (2019). Prison population projections 2019 to 2024. England and Wales.
- Ministry of Justice (2020a). (Accessed August 3, Criminal Justice System statistics quarterly: June 2019. https://www.gov.uk/government/statistics/criminal-justice-system-statistics-quarterly-june-2019.
- Ministry of Justice (2020b). (Accessed August 3Offender management statistics quarterly. https://www.gov.uk/government/collections/offender-management-statistics-quarterly.
- O’Hagan, A. (1998). Eliciting expert beliefs in substantial practical applications. Journal of the Royal Statistical Society Series D: The Statistician, 47(1), 21–35.
- Pagel, C., Banks, V., Pope, C., Whitmore, P., Brown, K., Goldman, A., & Utley, M. (2017). Development, implementation and evaluation of a tool for forecasting short term demand for beds in an intensive care unit. Operations Research for Health Care, 15, 19–31. https://doi.org/10.1016/j.orhc.2017.08.003
- Pender, J. (2016). Risk measures and their application to staffing nonstationary service systems. European Journal of Operational Research, 254(1), 113–126. https://doi.org/10.1016/j.ejor.2016.03.012
- Petris, G., Petrone, S., & Campagnoli, P. (2009). Model specification. In Dynamic Linear Models with R., pages 85–142 Springer.
- Picklands, J. (1997). Estimation for an M/G/∞ queue with incomplete information. Biometrika, 84(2), 295–308.
- Schwarz, J., Selinka, G., & Stolletz, R. (2016). Performance analysis of time-dependent queueing systems: Survey and classification. Omega, 63, 170–189. https://doi.org/10.1016/j.omega.2015.10.013
- Shumway, R. H., Stoffer, D. S., & Stoffer, D. S. (2000). Time series analysis and its applications., volume 3 Springer.
- Spencer, J., Sudan, M., & Xu, K. (2014). Queueing with future information. ACM SIGMETRICS Performance Evaluation Review, 41(3), 40–42. https://doi.org/10.1145/2567529.2567542
- Spinner, S., Casale, G., Brosig, F., & Kounev, S. (2015). Evaluating approaches to resource demand estimation. Performance Evaluation, 92, 51–71. https://doi.org/10.1016/j.peva.2015.07.005
- Treasury, H. (2015). The aqua book: Guidance on producing quality analysis for government. https://www.gov.uk/government/publications/the-aqua-book-guidance-on-producing-quality-analysis-for-government.
- Tuominen, J., Lomio, F., Oksala, N., Palomäki, A., Peltonen, J., Huttunen, H., & Roine, A. (2022). Forecasting daily emergency department arrivals using high-dimensional multivariate data: A feature selection approach. BMC Medical Informatics and Decision Making, 22(1), 1–12. https://doi.org/10.1186/s12911-022-01878-7
- Usta, M., & Wein, L. (2015). Assessing risk-based policies for pretrial release and split sentencing in Los Angeles County Jails. Plos One, 10(12), e0144967–16. https://doi.org/10.1371/journal.pone.0144967
- Utley, M., Jit, M., & Gallivan, S. (2008). Restructuring routine elective services to reduce overall capacity requirements within a local health economy. Health Care Management Science, 11(3), 240–247. https://doi.org/10.1007/s10729-007-9052-5
- Walton, N., & Xu, K. (2021). Learning and information in stochastic networks and queues. Tutorials in Operations Research: Emerging Optimization Methods and Modeling Techniques with Applications, pages 161–198.
- Weber, T. (2005). Conditional dynamics of non-markovian, infinite-server queues. Thesis, Massachusetts Institute of Technology
- Whitt, W. (1999). Predicting queueing delays. Management Science, 45(6), 870–888. https://doi.org/10.1287/mnsc.45.6.870
- Whitt, W. (2002). Stochastic models for the design and management of customer contact centers: Some research directions. Technical report. Columbia University.
- Worthington, D., Utley, M., & Suen, D. (2020). Infinite-server queueing models of demand in healthcare: A review of applications and ideas for further work. Journal of the Operational Research Society, 71(8), 1145–1160. https://doi.org/10.1080/01605682.2019.1609878
- Xie, W., Nelson, B., & Barton, R. (2014). A Bayesian framework for quantifying uncertainty in stochastic simulation. Operations Research, 62(6), 1439–1452. https://doi.org/10.1287/opre.2014.1316
Appendix A:
Prison occupancy
Phases of the prison system
Following an arrest by the police and being charged with a crime, individuals are classified within 12 offence main groups (), which naturally form different service classes. The police decide if a person can be released on bail, but may have to follow certain rules until a hearing at a court, or if they are held on remand in prison until a hearing at a court. If an individual is found guilty by a court, a custodial sentence can be imposed. A sentence can be suspended, or served in the community and the vast majority of sentenced offenders do not spend their whole sentence in custody. The sentenced population is made up of Determinate sentenced and Indeterminate sentenced. Each sentence is marked as one of two types: a standard determinate sentence (SDS) or an extended determinate sentence (EDS). Most offenders are given an SDS, which means that half way through their sentence they are released from prison and serve the remaining time in the community. An EDS means an offender serves 2/3 of their sentence in prison before being considered for release. Sentenced offenders who have been released from prison before the end of their sentence can be recalled to custody for breach of release conditions.
displays a simplified version of prisoner journeys through the custodial system, with the total prison population divided into three main holding phases (displayed percentages are as at June 2019) (MoJ, 2019): (i) on remand (11%), (ii) sentenced prisoners (79%) and (iii) on recall (9%). Prisoners within the licence phase are in the community.
Arrivals to the Remand phase, are recorded in two streams, Untried prisoners and Sentenced prisoners. Individuals remain in remand for some time according to a length of stay distribution Upon completion of the Remand phase, the model assumes all Sentenced prisoners proceed to the Sentenced population and a proportion of the Untried prisoners, with the remaining released. An arrival stream from the courts
brings individuals directly into the Sentenced population. All departures from the Sentenced population are released into the community, and are all under Licence, for some time, during which they can be Recalled into custody. If an individual is recalled, they re-enter the custodial system and this figure assumes a prisoner can only be recalled once. In practice, this is not the case, although the data available does not provide information on repeatedly recalled prisoners.
Data
Individual prison establishments record details of individuals on a prison IT system and this data is collected as a central database managed by MoJ and the HM Prison and Probation Service (HMPPS) to produce the various analyses of prison population. Statistics are regularly released as well as projections of the prison population (Ministry of Justice, Citation2016, Citation2018).
Between 1993 and 2012 the prison population in England and Wales increased by 41,800 prisoners to over 86,000, studies of this growth can point to patterns in the data that align with earlier identifiable policy changes. Such examples illustrate how modelling approaches enabling an understanding of the impact of possible policy changes can be valuable in this domain.
Since 1993 the courts sentenced more offenders each year. Almost all of the increase (98%) took place within two segments of the population - those sentenced to immediate custody (85% of the increase) and those recalled to prison for breaking the conditions of their release (13% of the increase). Three offence groups, violence against the person, drug offences and sexual offences have had a particular impact on the prison population: the number of these offenders increased and the mean length of stay increased.
The proportion of offenders whose sentences were 4 years or more, grew to 54% of the sentenced prison population in 2012, compared to 45% in 1993. The mean sentence length over all offences in 2018 was 17.3 months. For more serious offences, the mean prison sentence was 58.3 months, more than 24 months longer than in 2006. More than two and a half times as many people were sentenced to 10 years or more in 2018 than in 2006.
From 1999 to 2011, the mean time served increased from 8.1 to 9.5 months for those released from determinate sentences. This was likely due to an increase in the mean custodial determinate sentence length handed down by the courts, and a decline in the parole release rate which meant that offenders had served longer by the time they were released. The second largest increase was within the recall population, caused by changes to the law making it easier to recall prisoners, and changes introduced in the Criminal Justice Act 2003 which lengthened the licence period for most offenders.
Appendix B:
Steady state recovery from congestion
To illustrate the applicability of further theory to support policy analysis, we present Duffield and Whitt (Citation1997)’s analysis of what is termed congestion events, that is, where an unusually high number of individuals has been observed, and allowing one to investigate the effects of possible interventions (such as change of arrival rate, or pausing arrivals) on recovery from congestion. These results rely on an assumption that the system is in steady state, i.e., which could be motivated by a slowly changing arrival rate, or for scenario analysis. These results follow directly from the results for the model described in Section 3.2 and can be employed to characterise the effect of possible interventions that could be introduced to change the rate of recovery.
For all
and
and the conditional mean is
(B1)
(B1)
As Goldberg and Whitt (Citation2008) noted, since and
can be computed, it can be directly determined when the steady state approximation is reasonable.
Duffield and Whitt (Citation1997) proposed the steady state rare event, as an approximation for what is seen at a random (steady state) time and also as an approximation for the associated hitting time event. The likelihood of a high congestion event, that is, having a large number N of individuals present, with
at
Define a recovery level k, then a system has recovered from a rare congestion event at time 0 when first reaches k with
To define the recovery time for the mean, let
(B2)
(B2)
The following result describes how the system recovers from congestion and the way it depends on cdf G.
Theorem B.1.
(Duffield & Whitt, Citation1997, Theorem 2) If there is no t such that , then
is continuous and strictly increasing. Then the recovery time for the mean,
in EquationEquation (B2)
(B2)
(B2) is the unique root of the recovery equation,
(B3)
(B3)
More generally,
This result is obtained by rearranging EquationEquation (B1)(B1)
(B1) . It can be seen that the impact of G on
depends on whether recovery level k is close to n or close to v. When the recovery level k is close to v, the cdf matters greatly. If the recovery level k, is closer to n than v, then the recovery time v depends more on the initial portion of the cdf
than upon its tail. Consistent with this observation, the impact of a long-tail cdf on v differs little from the impact of a short-tail cdf with the same mean if k is suitably close to n, but it differs dramatically if k is suitably close to v. However, “suitably close” depends on the decay rate of the ccdf
If the system does experience a congestion event, the recovery can be aided by reducing the arrival rate, or by pausing arrivals until the congestion has cleared. If the arrival rate is reduced to a new constant rate, is equivalent to reducing the mean, as produces a new recovery equation of the form in EquationEquation (B3)
(B3)
(B3) . For
clearly
is increasing in
so that the recovery time for the mean is reduced by decreasing
If the arrivals are terminated until recovery is achieved,
in the recovery equation. Then further recovery can be achieved by turning the arrivals on and replacing
with
and
for
in the recovery equation, such that
Example B.2.
For ), the recovery equation in EquationEquation (B3)
(B3)
(B3) we have
In , for fixed
and recovery level
the black lines illustrate the recovery time for varying levels of congestion for different scenarios
where the x-axis shows the congestion level relative to the steady state mean
To aid the recovery for the three scenarios (black lines), we reduce the arrival rate by 20 percent, that is,
and illustrate the effect on the corresponding dashed lines (blue lines).
Appendix C:
Comparison to time series analysis
We apply traditional time-series methods, ARIMA models (Shumway et al., Citation2000) to produce prison population predictions for the offence groups considered in Section 4.2. The order and the values of parameters are obtained using R package forecast (Hyndman and Khandakar, 2008). The forecasts of the number of prisoners in the Theft offence group are produced by ARIMA(2,1,0) with drift given by:
Similar to the analysis performed in Section 4.2, one-step ahead predictions are produced by iteratively adding one data point at a time and refitting the model and we note that the order of the model was updating with the changes in the training data set. The RMSE for long-term predictions is 30.21, whereas for short-term predictions is 10.16. The results are presented in , and we observe that the length of the prediction intervals is lower compared to the predictions produced in . This is due to the fact that the parameters of ARIMA model are set to the fixed quantities, whereas we assign probability distributions for the parameters in our proposed model. Similar results are presented for the Sexual offences and Public order offences groups in . For example we present the -step ahead forecasts for the Sexual offences group which are produced by ARIMA(2, 2, 2):
where the RMSE for long-term predictions is 4.71, whereas for short-term predictions is 4.42, where the above comment holds observing lower prediction intervals. The
-step ahead forecasts for the Public order offence group was produced by ARIMA(2,0,2):
where the RMSE for long-term predictions is 5.44, whereas for short-term predictions is 2.16.
Figure 1. Phases of the prison system.
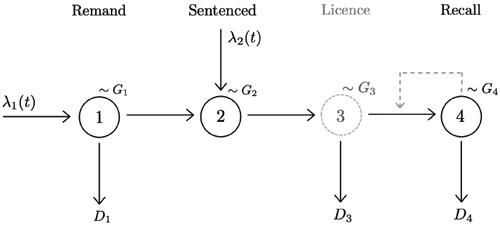
Figure 2. Regions describing arrival and service pairs (u, v).
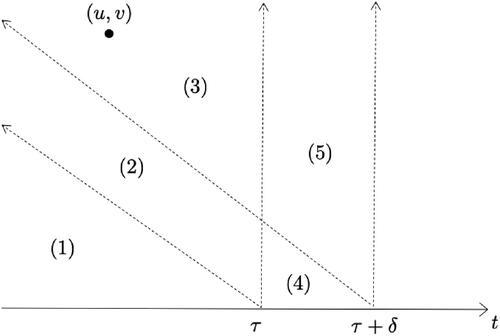
Figure 3. Left to right: density plots of marginal posterior distributions for parameters β0, β1, α and θ.
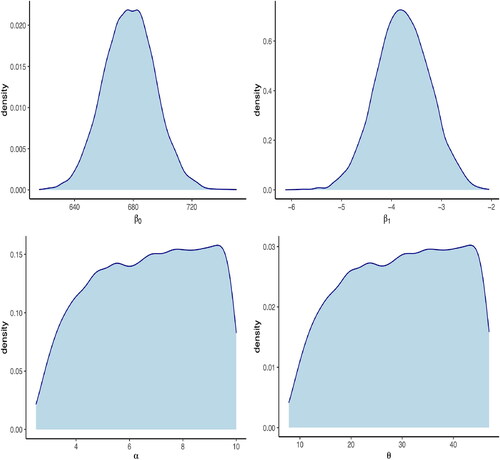
Figure 4. Prediction of the number of prisoners in the Theft offences group from August 2019 to March 2020. Left panel: long-term projections (red line) together with two standard deviation prediction interval (grey shaded region). Right panel: short-term projections (red line) together with two standard deviation prediction interval (grey shaded region). The observed values are in black.
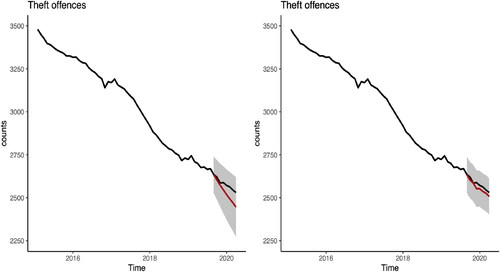
Figure 5. Prediction of the number of prisoners in the Sexual offences (top row) and Public order offences (bottom row) groups from August 2019 to March 2020. Left panel: long-term projections (red line) together with two standard deviation prediction interval (grey shaded region). Right panel: short-term projections (red line) together with two standard deviation prediction interval (grey shaded region). The observed values are in black.
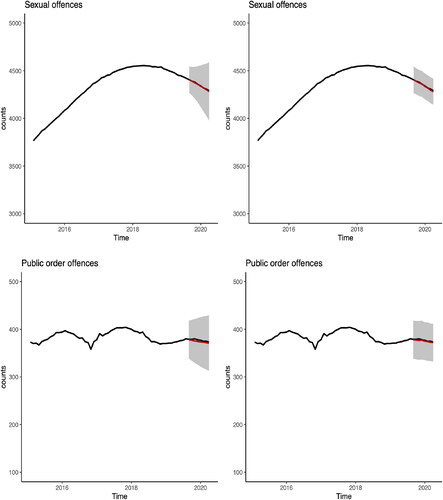
Figure 6. Example 4.3. Sentencing policy modification for Theft offences group where The red line is associated with unchanged parameters, the blue line is associated with
and the green line with
Solid line is the predictor. Dashed lines represent two standard deviation prediction intervals.
![Figure 6. Example 4.3. Sentencing policy modification for Theft offences group where E[So]=5.22. The red line is associated with unchanged parameters, the blue line is associated with E[Sν]=8 and the green line with E[Sν]=3. Solid line is the predictor. Dashed lines represent two standard deviation prediction intervals.](/cms/asset/4a6b6faa-0946-43fc-ac64-4c9eb8551bc5/tjor_a_2189002_f0006_c.jpg)
Figure 7. Example 4.3. Sentencing policy modification for Sexual offences group where The red line is associated with unchanged parameters, the blue line is associated with
and the green line with
Solid line is the predictor. Dashed lines represent two standard deviation prediction intervals.
![Figure 7. Example 4.3. Sentencing policy modification for Sexual offences group where E[So]=29.71. The red line is associated with unchanged parameters, the blue line is associated with E[Sν]=48 and the green line with E[Sν]=24. Solid line is the predictor. Dashed lines represent two standard deviation prediction intervals.](/cms/asset/863a7c50-fbe3-40ba-a007-fa7cc58ecbb7/tjor_a_2189002_f0007_c.jpg)
Figure 8. Example 4.3. Sentencing policy modification for Public order offences group where The red line is associated with unchanged parameters, the blue line is associated with
and the green line with
Solid line is the predictor. Dashed lines represent two standard deviation prediction intervals.
![Figure 8. Example 4.3. Sentencing policy modification for Public order offences group where E[So]=3.79. The red line is associated with unchanged parameters, the blue line is associated with E[Sν]=12 and the green line with E[Sν]=1. Solid line is the predictor. Dashed lines represent two standard deviation prediction intervals.](/cms/asset/93b2d3ef-894f-4273-8480-418030db3a96/tjor_a_2189002_f0008_c.jpg)
Figure 9. Example 3.7. For fixed varying
![Figure 9. Example 3.7. For fixed E[S]=3, varying (λ,cs2).](/cms/asset/625367b3-295e-4630-9149-ccb5a5d95678/tjor_a_2189002_f0009_c.jpg)
Figure C11. ARIMA model prediction of the number of prisoners in the Theft offences group from August 2019 to March 2020. Left panel: long-term projections (red line) together with two standard deviation prediction interval (grey shaded region). Right panel: short-term projections (red line) together with two standard deviation prediction interval (grey shaded region). The observed values are in black.
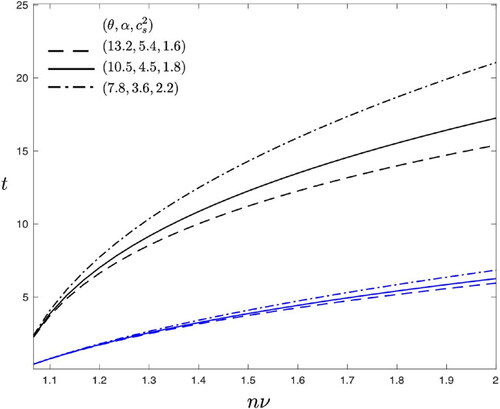
Figure C10. Example B.2. Congestion level relative to the mean vs. recovery time
For fixed
and varying
(black lines). An intervention of
is illustrated by the corresponding blue lines.
![Figure C10. Example B.2. Congestion level relative to the mean nν vs. recovery time t. For fixed E[S]=3, ν=30 and varying (θ,α,cs2) (black lines). An intervention of λ2=0.8λ1 is illustrated by the corresponding blue lines.](/cms/asset/f40d024f-739c-4e69-9757-d94ae6761548/tjor_a_2189002_f0011_c.jpg)
Figure C12. ARIMA model prediction of the number of prisoners in the Sexual offences (top row) and Public order offences (bottom row) groups from August 2019 to March 2020. Left panel: long-term projections (red line) together with two standard deviation prediction interval (grey shaded region). Right panel: short-term projections (red line) together with two standard deviation prediction interval (grey shaded region). The observed values are in black.
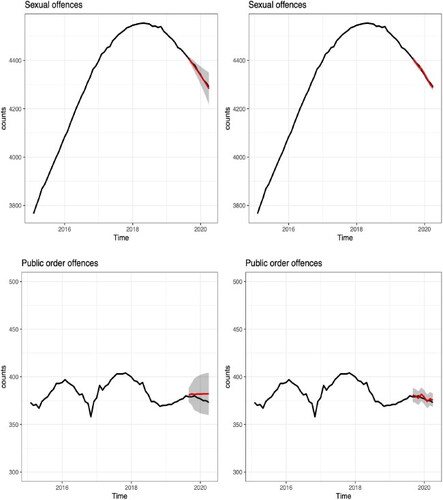
Table 1. Offence groups.