
Abstract
Multivariate discrete response data can be found in diverse fields, including econometrics, finance, biometrics, and psychometrics. Our contribution, through this study, is to introduce a new class of models for multivariate discrete data based on pair copula constructions (PCCs) that has two major advantages. First, by deriving the conditions under which any multivariate discrete distribution can be decomposed as a PCC, we show that discrete PCCs attain highly flexible dependence structures. Second, the computational burden of evaluating the likelihood for an m-dimensional discrete PCC only grows quadratically with m. This compares favorably to existing models for which computing the likelihood either requires the evaluation of 2 m terms or slow numerical integration methods. We demonstrate the high quality of inference function for margins and maximum likelihood estimates, both under a simulated setting and for an application to a longitudinal discrete dataset on headache severity. This article has online supplementary material.
SUPPLEMENTARY MATERIALS
The supplementary materials include an algorithm for generating from a discrete D-vine and additional materials on the application to headache severity data including an out of sample validation.
Anastasios Panagiotelis acknowledges the support of the Alexander von Humboldt Foundation, Claudia Czado is partially supported by the German Research Foundation grant (CZ86_1_3), and Harry Joe is supported by an NSERC (Natural Sciences and Engineering Research Council of Canada) Discovery grant. The numerical computations were performed on a Linux cluster supported by a DFG (Deutsche Forschungsgemeinschaft: German Research Foundation) grant INST 95/919-1 FUGG. The authors also acknowledge the Associate Editor and an anonymous referee for helpful comments.
Notes
Although the MTCJ copula should be attributed to Mardia, Takahashi, Cook, and Johnson (see Joe, Li, and Nikoloulopoulos Citation2010 for a detailed discussion), the bivariate version is more commonly referred to as the Clayton copula. We use the name MTCJ/Clayton throughout the article as a compromise.
We thank a referee for pointing this out to us.
NOTE: The leftmost column describes the realization of Y; for example, “01010” denotes Y 1 = 0, Y 2 = 1, Y 3 = 0, Y 4 = 1, and Y 5 = 0. Here, “low Pr(Yj = 0)” refers to the case where Pr(Yj = 0) = 0.3 for all j, “high Pr(Yj = 0)” refers to the case where Pr(Yj = 0) = 0.7 for all j, “low dependence” refers to the case where Kendall's τ = 0.3, 0.2, 0.1, 0.05 for pair copulas corresponding to the first, second, third, and fourth tree, respectively, and “high dependence” refers to the case where Kendall's τ = 0.7, 0.4, 0.3, 0.2 for pair copulas corresponding to the first, second, third, and fourth tree, respectively. In the rightmost column, the joint probabilities for independent margins are given for comparison.
NOTE: Results are averaged over 100 replications of data, each having sample size 300. Coverage refers to the proportion of simulations where a 95% bootstrapped confidence interval contains the true parameter value.
NOTE: The pair copulas on the first two trees are Gaussian with Kendall's τ = 0.3, while all other pair copulas are the independence copula. The sample size is 1000, and similar results were obtained for 30 replications of data generated from this model.
NOTE: Parentheses are for estimated Kendall's τ of the copula and the corresponding lower/upper confidence intervals (CIs). Here, “M” denotes morning, “A” afternoon, “E” evening, and “N” night, so 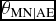 , for example, describes the dependence between headache severity in the morning and night, conditional on headache severity in the afternoon and evening.
, for example, describes the dependence between headache severity in the morning and night, conditional on headache severity in the afternoon and evening.
NOTE: The covariates that correspond to each of the coefficients (β's) are described in the online supplement. The figures in bold have 95% bootstrapped confidence intervals that do not contain 0.