
Abstract
We present a methodology for dealing with recent challenges in testing global hypotheses using multivariate observations. The proposed tests target situations, often arising in emerging applications of neuroimaging, where the sample size n is relatively small compared with the observations’ dimension K. We employ adaptive designs allowing for sequential modifications of the test statistics adapting to accumulated data. The adaptations are optimal in the sense of maximizing the predictive power of the test at each interim analysis while still controlling the Type I error. Optimality is obtained by a general result applicable to typical adaptive design settings. Further, we prove that the potentially high-dimensional design space of the tests can be reduced to a low-dimensional projection space enabling us to perform simpler power analysis studies, including comparisons to alternative tests. We illustrate the substantial improvement in efficiency that the proposed tests can make over standard tests, especially in the case of n smaller or slightly larger than K. The methods are also studied empirically using both simulated data and data from an EEG study, where the use of prior knowledge substantially increases the power of the test. Supplementary materials for this article are available online.
1. INTRODUCTION
In this work, we develop novel methodology for dealing with recent challenges in testing global hypotheses using multivariate observations. The classical approach for studying the problem, Hotelling’s T2-test (Hotelling Citation1931), can efficiently detect effects in every direction of the multivariate space when the sample size n is sufficiently large. However, in settings where n approaches or becomes smaller than the observation dimension K, T2-test becomes respectively inefficient and inapplicable. This cost in efficiency, paid due to the need to search in every direction of the alternative space, seems particularly wasteful (but avoidable), if prior knowledge about the direction of the effect is available. Motivated by the latter settings, often arising in the increasingly important field of neuroimaging, we develop tests which are powerful in studies with n ≫ K, but can also be efficient in situations where n is close to or smaller than K.
The proposed tests employ adaptive designs allowing for sequential modifications of the test statistic based on accumulated data. Such adaptive designs have straightforward but not exclusive application in clinical trials. A large literature on the subject (e.g., Bauer and Köhne Citation1994; Proschan and Hunsberger Citation1995; Lehmacher and Wassmer Citation1999; Müller and Schäfer Citation2001; Brannath, Posch, and Bauer Citation2002; Liu, Proschan, and Pledger Citation2002; Brannath, Gutjahr, and Bauer Citation2012) deals with the derivation of flexible procedures that allow for adaptations of the initial design without inflation of the Type I error rate. Some sequential designs (e.g., Denne and Jennison Citation2000) also permit design adaptations, but the latter need to be preplanned and independent of the interim test statistics. Adaptive designs are employed for many kinds of adaptations including sample size recalculation (Lehmacher and Wassmer Citation1999; Mehta and Pocock Citation2011), treatment or hypothesis selection (Kimani, Stallard, and Hutton Citation2009), and sample allocation to treatments (Zhu and Hu Citation2010). Despite the fact that many authors have stressed the potential for test statistic adaptation (e.g., Bauer and Köhne Citation1994; Bretz et al. Citation2009), there are only a few papers on the subject (Lang, Auterith, and Bauer Citation2000; Kieser, Schneider, and Friede Citation2002). Furthermore, various approaches for adaptive designs in multiple testing are available (see Bretz et al. Citation2009). These methods can efficiently detect few independently significant outcomes. However, it is well known that standard multiple testing methods (e.g., Bonferroni and Simes tests) become conservative and inefficient in settings, such as the typical neuroimaging studies, where strong dependencies and a large number of outcomes are present (D’Agostino and Russell Citation2005).
Similarly to the tests developed by O’Brien (Citation1984), Läuter, Glimm, and Kropf (Citation1998), and Minas et al. (Citation2012), the proposed tests are based on linear combinations of the observation vectors. The crucial element in this approach is the weighting vector reducing the observation vectors to the scalar linear combinations. This defines the direction in which we decide to search for effects, and it can substantially affect both Type I and Type II error rate of the tests. O’Brien proposed deriving the weighting vectors under the assumption of uniform mean structure, while Läuter et al. showed that if the weighting vector is derived from the observation sums of products matrix, the Type I error is controlled and high power is attained under certain factorial structures. On the other hand, the tests in Minas et al. (Citation2012) can attain high power levels independently of the mean and covariance structure but a part of the sample is used in a separate pilot study to learn the weighting vector.
In this work, linear combination test statistics, initially constructed using weighting vectors derived from prior information, are sequentially updated based on observed data at subsequent interim analyses in an adaptive design. Early termination of the study (due to early acceptance or rejection of the null hypothesis at an interim analyses) which is often of interest, especially in clinical trials, is also possible within our approach. Our methods provide a formal framework for optimally using prior information in constructing test statistics as has been suggested, but not implemented, in earlier papers (Pocock, Geller, and Tsiatis Citation1987; Läuter, Glimm, and Kropf Citation1996; Tang, Gnecco, and Geller Citation1989a).
While our tests maintain the two prime targets of adaptive designs, namely flexibility and Type I error control (Brannath et al. Citation2012), we also focus on attaining power optimality. Specifically, we employ the methods proposed by Spiegelhalter, Abrams, and Myles (Citation2002) to derive optimal tests maximizing the predictive power of the test at each interim analysis. The methods of proofs can be useful in deriving optimal adaptive designs in more general settings. As we illustrate in Section 3, the results of Theorem 3.1 could be used to derive optimal designs for regression analysis for example.
The power performance of a multivariate test, lying in a possibly high-dimensional design space, can be hard to illustrate and interpret. Therefore, power analysis of multivariate tests is typically restricted to a limited part of the design space. We tackle this problem by reexpressing the -dimensional design space as a lower dimensional easily interpretable space that is still sufficient to determine power. The crucial step here is to identify a measure quantifying the angular distance between the selected weighting vector and the optimal weighting vector and proving its sufficiency in computing power. These results provide wide understanding of the behavior of linear combination tests and allow us to extend earlier work on power analysis of single stage (Pocock, Geller, and Tsiatis Citation1987; Follmann Citation1996; Logan and Tamhane Citation2004) and sequential (Tang, Gnecco, and Geller Citation1989b; Tang, Geller, and Pocock Citation1993) linear combination tests, beyond low-dimensional observations or specific mean and covariance structures.
We perform extensive simulation studies to explore and compare the proposed and alternative single stage and sequential procedures throughout the design space. We show that linear combination tests outperform Hotelling’s T2-tests for the latter angular distance being below a certain value which, especially for sample sizes close to K, can be rather high. We further show that, in contrast to linear combination tests, such as O’Brien OLS test, with fixed weighting vectors, the adaptive linear combination tests can attain high power levels even in situations where the weighting vector selected at the planning stage is orthogonal to the true optimal (where, of course, a nonadaptive test would have zero power asymptotically). The advantages of the proposed tests are also illustrated through a real example taken from an EEG depression study (Läuter, Glimm, and Kropf Citation1996).
This article is organized as follows. In Section 2, we formulate the class of linear combination tests while in Section 3 we derive optimal, with respect to power, tests in this class. In Section 4, we present the results allowing us to characterize power based on low-dimensional summaries of the design parameters. In Section 5, we discuss the main results of extensive simulation studies performed using the latter results to explore power and compare the proposed tests with alternative global tests under various conditions, while in Section 6 we apply our procedures to an EEG depression study. Section 7 includes a short summary and discussion of the obtained results. Technical lemmas and proofs are provided in Supplementary Material A, while further illustrations of the simulation studies are provided in Supplementary Material B.
2 FORMULATION OF J-STAGE LINEAR COMBINATION TESTS
In the following, we formulate J-stage linear combination z and t-tests and define their error rate functions. We assume that the K-dimensional observation vectors of subjects i = 1, 2, …, nj, participating in stage j, j = 1, 2, …, J, of the study, are independent and identically distributed Gaussian random variables
(2.1) with mean
and covariance matrix the positive definite
. In medical applications, the mean vector is often interpreted as the treatment effect. We wish to test the global null hypothesis of no treatment effect
against the two-sided alternative
. Note that the methods which follow equally apply to the two-sample test with common covariance matrix, but we continue with the one-sample presentation to simplify notation.
The observation vectors , i = 1, 2, …, nj, of the jth stage are projected on the nonzero weighting vector
and the projection magnitudes form the linear combinations
i = 1, 2, …, nj, j = 1, 2, …, J. The stagewise z and t statistics for testing H0 against H1 using the random sample of linear combinations Lij, i = 1, …, nj, when
is either known or unknown, are respectively
(2.2) Here, σ2j is the variance and
, s2j are the sample mean and sample variance of the linear combination Lj, respectively. Under assumption (2.1), the stagewise z and t statistics, Zj, Tj, j = 1, 2, …, J are respectively normally and noncentrally t distributed,
and
with location parameter
(2.3) and νj = nj − 1. Under H0, the z and t statistics are standard normal and Student’s t random variables, that is, Zj ∼ N(0, 1) and
. The two-sided stagewise p values of the z and t-tests are, respectively,
and
where Φ( · ) and Ψ( · ) are the cumulative distribution functions of the standard normal and Student’s t-distribution with νj degrees of freedom, respectively.
At the jth analysis, j = 1, 2, …, J, performed after the jth stage study, a combination function is used to combine the stagewise p values,
, of stages 1 to j (pj either
or
). Rejection and acceptance critical values α1, j and α0, j (0 ⩽ α1, j ⩽ α < α0, j ⩽ 1, j = 1, 2, …, J) are used to decide whether to stop the study early and either reject or accept H0, respectively. Specifically, the J-stage sequential design has the following form:
(2.4)
Several combination functions are proposed in the literature. Bauer and Köhne (Citation1994) suggested the use of Fisher’s product combination function
(2.5) while Lehmacher and Wassmer (Citation1999) suggested the use of the inverse normal combination function. These two combination functions are the most commonly used in the literature (Bretz et al. Citation2009). The formulation and results which follow use the Fisher’s product function in (2.5), but our results equally apply to other combination functions including the inverse normal.
Herein, we will refer to the J-stage tests with linear combination stagewise z and t-test statistics as the J-stage z and t-tests, respectively. The power function, that is, the probability to reject H0, of the J-stage z or t-test is β = ∑Jj = 1βj where, , the first stage and
(2.6) the jth stage power functions, j = 2, 3, …, J (β, βj either βz,
or βt,
, respectively). The boundaries α1, j, α0, j are suitably chosen to satisfy the Type I error equation
(2.7) where α′1, j = α1, j/p1p2… pj − 1, α′0, j = α0, j/p1p2… pj − 1 the conditional rejection and acceptance boundaries, respectively, of stage j, j = 2, 3, …, J.
3 OPTIMAL J-STAGE z AND t-TESTS
The crucial element for these J-stage linear combination z and t-tests are the stage-wise weighting vectors . In this section we develop a methodology for optimally deriving these weighting vectors. The next lemma is the first step for computing the weighting vectors maximizing the power of the z and t-tests.
Lemma 3.1.
Under (2.1), the power of the J-stage z and t-tests in (2.4) with combination function as in (2.5) is nondecreasing in the absolute value of θj in (2.3), j = 1, 2, …, J.
Note that it can be straightforwardly shown that the above result hold for both one-sided stagewise tests and for the inverse normal combination function. The proof of the above lemma is surprisingly complex because for some range of values of θj an increase in |θj| decreases the probability to continue to the next stage and therefore the power of the subsequent stages, β(j + 1) = ∑Jl = j + 1βl, decreases. In Supplementary Material A, we prove that even for these range of values of |θj|, the decrease (in absolute value) in β(j + 1) is bounded above by the increase in βj.
The above result, except for being crucial for deriving Theorem 3.1, can also be useful for more general settings of adaptive designs. For example, Lemma 3.1 proves that if investigators wish to apply an adaptive z or t-test and are interested in maximizing the power of these procedures, they only need to sequentially maximize the location parameters of the stagewise test statistics separately. For instance, suppose that one is willing to conduct an adaptive design study to explore the relationship between an observation variable Y with a set of covariates X described by ,
, j = 1, 2, …, J, independent. Then, our results prove that to maximize the power of the J-stage test with stagewise statistics the classical z and t statistics, with respect to the experimental design, it is sufficient to maximize XTjXj, j = 1, 2, …, J, which agrees with the standard practice of deriving optimal designs.
Considering the J-stage linear combination z and t-tests, Lemma 3.1 implies that to maximize the power of these tests with respect to the weighting vectors , it is sufficient to maximize the value of θj, j = 1, 2, …, J. Using this result, we next derive the power-optimal weighting vector.
Theorem 3.1.
Under (2.1), the power of the J-stage z and t-tests in (2.4) with combination function as in (2.5) are maximized with respect to the weighting vectors , j = 1, 2, …, J, if and only if the latter are proportional to
(3.1)
The last result provides the optimal, in terms of power, weighting vector for the J-stage linear combination tests . In Section 3.1, we show that
, which expresses the multivariate treatment effect standardized with respect to the variance matrix
, is central in characterizing the power of these tests. However, this optimal vector
depends on the unknown parameters
and
and therefore is also unknown. In the next section, we develop a methodology for selecting the weighting vectors
in practice. We propose using the information for
and
, available at each interim analysis, to optimally select
, j = 1, 2, …, J, where optimality is expressed here in terms of predictive power. The source of this information is the data collected from the stages completed before each interim analysis, but also prior information extracted from previous studies and expert clinical opinion. Predictive power allows the incorporation of this information into our procedures in a natural and plausible way. Note that, as we also explain in the next section, if Equation (2.7) is satisfied, the Type I error of these tests is controlled.
3.1 The Proposed z * and t * Tests
Prior information, , is used to inform standard conjugate multivariate priors for the observation mean and covariance matrix. We use the Gaussian–inverse-Wishart prior
(3.2) where
represents a prior estimate of the value of
and n0 corresponds to the number of observations on which this prior estimate is based, while ν0 and
respectively represent the degrees of freedom and the (positive definite) scale matrix of the inverse-Wishart prior.
Under this standard Bayesian model (see Gelman et al. Citation2004), the posterior distribution of and
given the information set
, consisting of the prior information
and the data collected up to the jth interim analysis
is
,
. Here,
(3.3) and ν(j) = n0 + n(j) − 1 with n(j) = n1 + n2 + … + nj and
respectively the sample size and sample mean of
. Note that, due to the positive definiteness of the prior estimates
, the posterior estimates
are also positive definite. Positive definiteness of
is required for our procedures to be applicable.
We wish to use this information to select the weighting vectors optimally. Optimality here is expressed in terms of predictive power of the test. Predictive power (Spiegelhalter, Abrams, and Myles Citation2002) in the present context is derived by averaging the power of the J-stage z and t-tests over the distributions of the model parameters for a given information set. The predictive power for the first stage given the prior information set
is
and for the jth stage, j = 2, 3, …, J, given the information set
is
(3.4) The next result presents the weighting vectors that we suggest to use for the stagewise linear combination z and t-tests.
Theorem 3.2.
Under (2.1) and (3.2), the jth stage predictive power, , j = 1, 2, …, J, of the J-stage z-test in (3.4) is maximized with respect to the weighting vector
if and only if
is proportional to
(3.5)
Similarly, as we prove in Supplementary Material A, for n(j − 1) → ∞, the jth stage predictive power, , j = 1, 2, …, J, of the J-stage t-test in (3.4) is maximized with respect to the weighting vector
if and only if
is proportional to
(3.6) where
,
as in (3.3). The proposed J-stage tests, henceforth called (adaptive) z* and t*-tests, proceed as follows: for the jth analysis, j = 1, 2, …, J, (i) obtain
or
using (3.5) or (3.6), (ii) set wj equal to
or
and compute the stage j statistic Zj or Tj as in (2.2), (iii) calculate the stage j p-value,
or
, (iv) use all the observed p-values to perform the combination test in (2.4).
Importantly, the weighting vectors and
, given the prior information and the observed (if any) data
, are fixed before collecting
and hence, under the standard conditions described in the following theorem, the Type I error of z* and t*-test, is preserved.
Theorem 3.3.
Under (Equation2.1(2.1) ) and for α1, j, α0, j, j = 1, 2.…, J satisfying Equation (2.7), the Type I error of the z* and t*-tests is preserved at the nominal α level.
4 POWER CHARACTERIZATION (POC)
To study the performance of a test, we primarily need to explore the relationship between its power function and the design parameters. The latter might be, among others, the critical values, the sample size(s), and the model parameters. The critical values and the sample size(s) are scalar and therefore it is straightforward to visualize power even across all their possible values (e.g., using simulations). Their relation to power can then be easily described and understood. In univariate settings, this is also the case for the model parameters. However, in the multivariate setting, model parameters can be high-dimensional and therefore it is not practically feasible to visualize power over the whole design space. Power analysis is then typically restricted to a limited range of different structures of the model parameters. This might be sufficient for power analysis in specific settings, but it has obvious limitations in considering the general behavior of a testing procedure.
In the following, we encounter this problem in the context of linear combination tests and we provide a solution. We first consider the case of J-stage linear combination z and t-tests with fixed weighting vectors which, apart from providing a method for performing simple and efficient power analysis of tests such as the OLS test in O’Brien (Citation1984, see Logan and Tamhane Citation2004; Pocock, Geller, and Tsiatis Citation1987; Tang, Geller, and Pocock Citation1993 for earlier work), also provides the intuition for the results considering the z* and t* tests. Note that in Section 4, the critical values and sample sizes (including the “prior” sample sizes) are assumed to be fixed and described by the design vector .
To provide greater insight to the subsequent results, it is also worth noting the joint distribution of the stagewise linear combination z statistics, Zj, j = 1, 2, …, J, here for J = 2,
where
the cdf of the first stage data,
, and
the location parameter as in (2.3). The latter parameter is independent of
, that is
, for the linear combination tests with fixed weighting vector, while for the adaptive z* and t* tests,
depends on
through the weighting vectors in (3.5) or (3.6), respectively. The next section focuses on characterizing further the effect of the weighting vector, through the parameters
, on the power function. Note that the power function can be easily derived from the joint distribution of the stagewise statistics by replacing zj with suitable rejection or acceptance boundaries. In Supplementary Material A, we show that the above expression can be easily generalized to any J > 1 and that by replacing Φ( · ) with the cdf of the Student’s t-distribution Ψ( · ), we can easily derive the joint distribution of Tj, j = 1, 2, …, J.
4.1 PoC for the J-Stage z and t-Tests With Fixed Weighting Vectors
To compute the power of the J-stage z and t-tests with fixed weighting vectors , it is sufficient to know the design vector
, as well as the stagewise location parameters θj in (2.3) which in this case are also fixed, that is, θj = θ. The latter can be reexpressed as
(4.1) where
denotes the angle, in measured radians at the origin, between the vectors
and
. Here,
,
are the standardized selected and optimal weighting vectors. In particular, the latter expresses the standardized multivariate treatment effect, generalizing the univariate (K = 1) standardized treatment effect μ/σ. Considering the weighting vector selection problem, the first equation in (4.1) implies that a weighting vector that increases the mean and/or decreases the variance of the linear combination gives higher power. The ambiguity in the latter expression becomes clearer by the standardization in the second equation which implies that the weighting vector selection can be expressed as a process of learning the standardized optimal weighting vector
.
The last equation in (4.1) establishes two scalar measures which are sufficient to determine power. The first is the magnitude of ,
, which is the Mahalanobis distance between the distributions of the observation
under the null and the alternative hypotheses. The Mahalanobis distance is a generalization of the univariate signal-to-noise ratio and can be interpreted as a measure of deviation from the null hypothesis. In medical settings, it is a well-known global measure of the strength of the treatment effect. The second,
, is a measure of angular distance between the selected and the optimal weighting vector. It is a measure, in other words, of the distance of our weighting vector selection to the optimal choice. Under this representation, it becomes clear that, for fixed weighting vectors, the location parameter θ is equal to a measure (
) of the strength of the treatment effect scaled down by a measure
of the distance between the parameters and their prior estimates. The last results are formally stated in the next theorem.
Theorem 4.1.
The design vector , the Mahalanobis distance
and the angle
between the vectors
and
are sufficient to determine the power function β of the J-stage linear combination z and t-tests with fixed weighting vectors
.
4.2 PoC for the z *-Test
The sequential adaptation of the weighting vector increases the complexity within the relation between the power function and the design parameters. However, following similar methodology as above, analogous results can be derived. For this we use two steps, the first of which involves standardizing the procedure, similarly to (4.1), and the second establishing a rotation invariance property of the power function. The next lemma is a direct consequence of the standardization step summarizing ,
, and
to the vectors
and
.
Lemma 4.1.
The design vector , the standardized optimal weighting vector
and the standardized first-stage weighting vector
in (3.5) are sufficient to determine the power function
.
In the above result, we make use of the fact that the location parameter, , of the z*-test can be written as
(4.2) which implies that the adaptive selection of the weighting vectors can be reexpressed as a procedure of adaptive estimation of the vector
. Under this standardization, we can proceed to the rotation-invariance step which results in the next lemma.
Lemma 4.2.
The power, , of the z*-test is invariant to rotations of the weighting vector
around the optimal weighting vector
.
The idea behind Lemma 4.2 is that if is rotated around
, that is,
is replaced by
, where
is a rotation matrix with rotation axis
, the rejection region of the test is changed. However, the new rejection region is simply a rotation of the initial rejection region. That is, for each point say
in the initial rejection region, we can find a unique point, say
, in the rotated rejection region such that
. Because the symmetrical Gaussian distribution of the observations
remains unchanged under the rotation, the likelihood of the rejection region, that is, the power of the z*-test, remains the same. The next theorem is direct consequence of Lemmas 4.1 and 4.2.
Theorem 4.2.
The design vector , the Mahalanobis distance
and the angle
between the vectors
and
are sufficient to determine the power function
.
The above theorem states that the dependence of the power function on the model parameters and their prior estimates is described by simply a scalar measure of the strength of the treatment effect and a scalar measure of distance between the parameters and their prior estimates. It provides a sufficient description of power which is based on easily interpretable summaries and is considerably lower dimensional (importantly not depending on K, see Table 1). This allows us to perform power analysis of the adaptive J-stage z*-test in a simple way potentially covering the whole design space.
4.3 PoC for the t * Test
The need to estimate the unknown increases substantially the dimension and the complexity of the design space. The sequential estimation of
, in addition to
, to obtain the weighting vectors
, implies that the power analysis needs to account for both estimation procedures. For this, we write the weighting vector
, j = 1, 2, …, J in (3.6) as
(4.3) and
the jth standardized weighting vector of the z*-test in (4.2). Here the
-deviation matrix
is a measure of deviation of the estimate
in (3.3) from the parameter
. The weighting vector
is then written as a product of the inverse of the matrix
, that accounts for the estimation of
, and the vector
which accounts for the estimation of
, the latter taking
as known. We next follow the same steps as in Section 4.2 for deriving the PoC of the t*-test. The standardization step results in the next lemma summarizing
and
and their prior estimates
and
to the vectors
,
and the matrix
that have clear interpretation.
Lemma 4.3.
The design vector , the matrix
in (4.3) and the vectors
and
are sufficient to determine the power function
.
Here, we use that the location parameter and the
-deviation matrix
can be written as
(4.4) and that
can be written as the weighted average in (4.2). Here,
is the covariance matrix of the sample
, i = 1, 2, …, nl, l = 1, 2, …, j, where, importantly,
.
In a similar fashion to the previous section, we next establish the invariance of the power function under certain rotations of the prior estimates. For this, we define to be the matrix with columns the orthonormal eigenvectors of
and
the diagonal matrix with diagonal
the vector of the corresponding eigenvalues (λ11 ⩾ λ21 ⩾ … ⩾ λ1K > 0). We can then write
,
, and
where
(4.5) The rotation invariance property of the t*-test is described in the next lemma.
Lemma 4.4.
The power function is invariant to simultaneous rotations of the vector
and the eigenvectors of the matrix
around the optimal weighting vector
.
The proof of Lemma (4.4) is similar to the proof of Lemma (4.2), albeit rather more complex. The next theorem is direct consequence of Lemmas 4.3 and 4.4.
Theorem 4.3.
The design vector , the vector of eigenvalues
of the matrix
in (4.3), and the vectors
and
in (4.5) are sufficient to determine the power function
.
As we can see in , the last result reduces the dimension of the design space of the t*-test substantially, allowing us to explore power across the design space. While the design space, due to the covariance matrix estimation, still depends on K, it is reduced from order K2 to order K.
Table 1. Model and prior parameters of the z* and t*-tests, respectively, and their dimension
Furthermore, this reduction provides an understanding of how the selection of the weighting vector affects power. This becomes clearer if we consider that in (4.4) can be written as
where
Here, and
are the sample mean and sample covariance matrix of the transformed observation vectors
with
, l = 1, 2, …, j, the matrix with columns
, i = 1, 2, …, nj. The last expressions show that the distance of the prior estimates
,
to the model parameters
,
can be expressed by the distances of the vectors
and
to
, the latter directly reflected to power through
(see the next section for more information).
In the special case of the first stage -deviation matrix being proportional to the identity matrix, that is,
(λ11 = λ12 = … = λ1K), as the next result shows, the design space can be reduced further.
Theorem 4.4.
For , the design vector
, the constant c, the Mahalanobis distance
, and the angle
are sufficient to determine the power function
.
The last theorem proves that, for , we can use the fact that the prior
-deviation matrix
does not change the directions of
’s, to show that the relation of
to the model parameters and their prior estimates can be described simply by the scalars
and
. In the next section, we use this result and the results of Theorems 4.2 and 4.3 to perform power analysis studies.
5 EMPIRICAL STUDIES
To explore properties of the adaptive z* and t*-tests as well as alternative global tests and to perform comparisons, we present empirical studies making use of the results in Theorems 4.2, 4.3, and 4.4.
In addition to z* and t*-tests, we consider linear combination z and t-tests with fixed weighting vectors, a class that includes the OLS z and t-test in O’Brien (Citation1984). We also consider the likelihood-ratio χ2 and Hotelling’s T2-test with statistics and
that follow the noncentral χ2 and F distribution with K and (K, n − K) degrees of freedom, respectively, and noncentrality parameter
. We consider both single stage and sequential J-stage designs for all these tests. Finally, the two-step, single-stage linear combination z+ and t+ tests proposed in Minas et al. (Citation2012) are also considered. Note that the latter tests can be derived as special cases of the z* and t*-tests for J = 2, (α1, 1, α0, 1) = (0, 1) and
.
A range of experiments are performed under different values of the design parameters. The power function of J-stage (J > 1) tests is not analytically tractable and therefore power is approximated by the rate of rejections in a large number of simulated replications, here R = 10, 000, of a single experiment. Furthermore, to study the reduction in sample size due to early stopping of the study, we also empirically compute the rate of sample size reduction (),
where nT = n1 + n2 + … + nJ the total sample size, N the sample size used for a single replication of the study and E(N) its expected value. Note that single-stage tests have
, in contrast to sequential tests that allow for early stopping and thus have nonzero
.
5.1 Simulation Data Examples
We next summarize the main results of a comprehensive study of the power behavior of the above tests in relation to the design parameters (more illustrations are included in Supplementary Material B). First, larger values of and/or nT result in higher power values for all tests considered, except the z and t-tests with fixed weighting vectors
orthogonal to
for which β = α. Considering the prior sample size, the results indicate that for n0 ∈ (0.5n1, 0.75n1) the prior estimates become influential, but they do not dominate the accumulated data when selecting the weighting vector while larger values of n0 enforces z* and t* to have more similar behavior to z and t-tests with fixed weighting vector. Furthermore, simulation examples confirm that larger values of the acceptance critical values α0, j increase the power of multistage tests especially for larger potential power gain in subsequent stages, at the expense of less chance of early acceptance. Simulation examples also confirm that larger power is gained if larger rejection critical values α1, j are allocated to stages with larger potential power gain, while the value of
increases for larger α1, j in early stages.
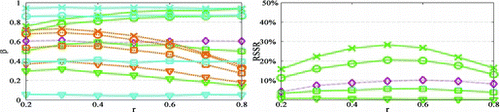
We also consider power behavior related to allocation of sample size to stages (). For the sequential z and χ2-test, the results show that higher power is achieved if sample allocation is analogous to α-rate allocation. The z* and t*-tests generally attain higher efficiency for close to balanced allocations. For close to (far from) the optimal
, slightly higher power is attained for assigning more sample to early (late) stages. Small to moderate allocation ratios r are more appropriate for the z+ test since no α rate is spent in the first stage. Further, as in the χ2-test, the z* achieves higher
for r = 0.5.
Before we proceed to comparisons, it is worth considering the impact of being unknown and thus estimated on the performance of the t*-test. First, in the case of
(
), which as we show in Theorem 4.4 is somewhat easier case to consider, the
estimation variability is substantially reduced and thus we generally expect
to be closer to
. On the other hand, if
(
), the direction of
is more influential on
with the consequence being double-edged (see Figure ). That is, compared to the situation of
, the distance of
’s to optimal can be larger (left panel) but also smaller (right panel) depending on how close the direction of
is to the optimal direction
.
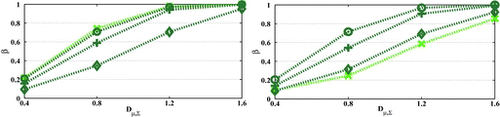
Finally, it is useful to note that throughout our simulations of t*-test, the is shown to be a robust summary, albeit not sufficient (see Supplementary Material B, Figure 7, Section 2.1), of the distance between the model parameters and their prior estimates. For this reason, but also to reduce complexity, in the comparisons to follow, we focus on the case of
(particularly, as we explain later on, in cases resembling the right panel of Figure 2), for various values of the summary
.
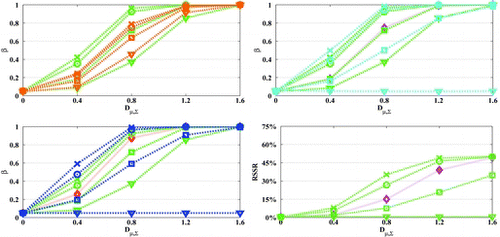
In terms of comparisons, first note that, for fixed design parameters, single-stage tests attain higher power levels than multi-stage tests, nevertheless at the expense of not allowing for early stopping and thus not allowing for sample size reduction (). Furthermore, it might be useful to emphasize that for fixed design parameters, the power of the linear combination test with weighting vector (either fixed or initial) set equal to the optimal weighting vector
attains the maximum power and provides an upper bound to all the other presented procedures, including Hotelling’s T2-test as proved in Minas et al. (Citation2012) (Corollary 1). Compared to the z-tests with fixed weighting vectors
, as we can see in , the adaptive z* lose some power for
(
) close to optimal but gains substantial amounts of power for
far from optimal, importantly avoiding the problem of z-tests having zero power for
orthogonal to optimal. This result emphasizes that, even though the power of the proposed tests remains sensitive to the prior information used to select the weighting vector, they are less sensitive to the initial selection of the weighting vector than the z and t-tests, where the weighting vector is fixed. The adaptive z*-test also has substantially higher power to z+ for small angles to the optimal and slightly lower power for large angles. Finally, the power of the single-stage and sequential χ2-tests is approximately equal to the power of the z*-test for
having respectively 60° and 45° angle with
. Note that, as the results in confirm, all the considered tests control the Type I error at the nominal level α = 0.05.
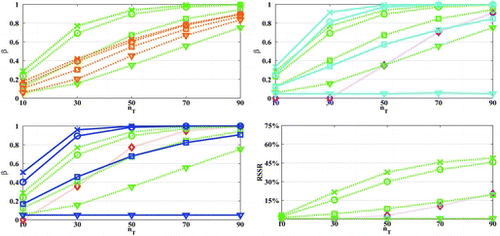
In the case of unknown, we consider comparisons for the case of
which, using the results of Theorem 4.4, they can be performed in a similar way to the case of known
. For the simulations in , the case of
can be thought of as representative of
fairly distant to
(right panel of ), since we take
resulting in
(≅0.26, angle 75°, for K = 15). As we would expect, the power of all tests is lower than their counterparts for
known (same design parameters), but the patterns of power difference across tests remain the same except from Hotelling’s T2 which in contrast to χ2-test is highly dependent on the sample size.
As Figure 4 illustrates, for nT ⩽ K or nT slightly larger than K (here, nT = 10 − 30 for K = 15), T2 is respectively inapplicable or very inefficient with power levels lower than the power of t* even for angles close to orthogonal. As sample size becomes considerably bigger than K (nT > 50), the power of T2-test increases sharply to yield power levels analogous to the χ2-test. For instance, for the design parameters in , the single stage and sequential T2-tests, likewise to the χ2-test, have power close to the power of the t* for angle 60° and 45°, respectively, for large sample sizes.
6 APPLICATION TO AN EEG STUDY
We consider applications to an electroencephalogram (EEG) study, the results of which are provided in Läuter, Glimm, and Kropf (Citation1996). As Läuter et al. described, the data are collected from nT = 19 depressive patients at the beginning and at the end of a six week therapy. For demonstration, K = 9 variables are used which represent the changes of the absolute theta power in channels ,
of EEG during the therapy of each patient. In Table 2, we present the means, standard deviations, and correlation matrix of the data. Note that although an increase is indicated in all channels, none of them (min kpk = 0.04) fall below the Bonferroni corrected threshold α/K≅0.0056 at the α = 5% significance level. Hotelling’s T2-test also fails to reject H0 (
). On the contrary, the SS and PC t-tests proposed by Läuter et al. reject H0 at the 5% significance level (pSS = 0.0489,
).
We perform power analysis by setting the design parameters as in the above study, that is, nT = 19, K = 9, ,
, α = 0.05. For these design parameters, the power of Hotelling’s T2 is
(
). This is larger than the power of the SS and PC tests which are respectively
,
(the contrasting results of the tests performed using these data are because of the different shape of the t and F distributions). The latter power values are very close to the power of the OLS t-test in O’Brien (Citation1984),
, which uses the uniform weighting vector
. This gives angle
. Taking into account that the single-stage t-test for a weighting vector equal to the optimal has power βt≅1, we can easily see that there is considerable scope for improvement.
Since the study was performed, there has been considerable research into EEG studies on depressive patients. There is now literature (see, e.g., Davidson et al. Citation2002) indicating that left-frontal hypoactivation and right-frontal hyperactivation are present in such subjects. This would indicate that a nonuniform prior over these frontal regions should be used. Using prior information based on such evidence, the adaptive t*-test can attain high power levels. For example, the prior estimates given in Table 2 are in agreement with the evidence in the literature and further, the prior correlation structure is set to be roughly coherent to the distances between the channels, that is, larger distances have smaller correlations, with larger correlations set at the highly active frontal regions (in accordance with the literature).
Table 2. Means, standard deviations, correlations, and their prior estimates for the EEG depression study presented in Läuter, Glimm, and Kropf (Citation1996)
This prior estimate gives which is much smaller than the angle under the uniform weighting vector. For a two-stage design (J = 2), with balanced sample allocation, n1 = 10, n2 = 9, and α allocation α1, 1 = 0.01, a2 = 0.0087, no early acceptance allowed, α0, 1 = 1, prior sample size n0 = 7 = 0.7n1, ν0 = 6 (see previous section) and the remaining design parameters as the original study, the t*-test has power
with
(E(N)≅15). Substantial power improvement is also obtained over the t+ which, for n0 = 6, n1 = 13, n2 = 6 (r = 0.3) and the remaining design parameters as above, has power
.
7 DISCUSSION
The methods developed in this work demonstrate that linear combination tests provide a substantial alternative to the classical Hotelling’s T2 global test, especially in the setting, commonly encountered in recent important applications of clinical neuroscience, of the available sample size n being small compared to the observation dimension K. It is also shown that adaptive linear combination tests provide power robustness across the set of alternative hypotheses since they can correct initial selections of the weighting vector which are far from the optimal selection. The adaptive J-stage z* and t*-tests achieve high power levels for large n, independently of the initial selection of weighting vector, but most importantly they can achieve high-power performance even if n is limited.
The proposed tests achieve optimality in the sense of maximizing the predictive power of the test at each interim analysis. Predictive power has been used for sample size calculation (O’Hagan and Stevens Citation2001), treatment selection (Kimani, Stallard, and Hutton Citation2009) and to select the component-wise significance levels in multiple testing (Westfall, Krishen, and Young Citation1998). It is a useful tool for incorporating prior information into the design of a study, particularly as such studies can often be viewed as a decision-making process. The application in Section 6 provides an example of a setting in which prior information is available and can substantially improve the performance of existing tests.
Optimality is attained in our methods without undermining the two main targets of adaptive designs: flexibility and test specificity. This allows for future developments of the proposed test to consider further optimal design adaptations. The use of other adaptive designs techniques, such as sample size reassessment, within our methodology can improve further the performance of the proposed tests.
The power characterization in Section 4 provides a tool for understanding and alleviating to some extent the complexities of multivariate tests especially those based on response dimension reductions. The possibly high-dimensional model parameters and their prior estimates are reduced to low-dimensional summaries which are still sufficient to compute power. Importantly, these summaries have interpretations directly related to the strength of the treatment effect and the effect of the dimension reduction on power. They provide a method for performing simple power analysis, but also understanding the behavior of linear combination tests.
The methods used to derive the power characterization are also interesting in their own right. They can be generally described by two steps: standardization and rotation invariance. The first standardization step is a prevalent technique for reexpressing statistical models in the standard deviation unit and eliminating correlations. Here, it allows us to reexpress the weighting vector selection, which involves estimating the unknown model parameters, as a procedure of learning a single vector, that is, the optimal weighting vector. The second step of establishing a rotation invariance property for the power function allows us to identify the measure quantifying the angular distance between the selected and the optimal weighting vector, reducing further the design space. The question whether these results can be derived under more relaxed modeling assumptions is an area of ongoing research.
SUPPLEMENTARY MATERIALS
Additional supplementary material is provided in the following documents:
Supplement A: Technical results Technical details, lemmas, and proofs.
Supplement B: Extended simulation examples Examples from the extensive simulation studies performed to study the power of the considered tests.
Supplementary Materials
Download Zip (3 MB)REFERENCES
- Bauer, P., Köhne, K. (1994), Evaluation of Experiments With Adaptive Interim Analyses, Biometrics, 50, 1029–1041.
- Brannath, W., Gutjahr, G., Bauer, P. (2012), Probabilistic Foundation of Confirmatory Adaptive Designs, Journal of the American Statistical Association, 107, 824–832.
- Brannath, W., Posch, M., Bauer, P. (2002), Recursive Combination Tests, Journal of the American Statistical Association, 97, 236–244.
- Bretz, F., Koenig, F., Brannath, W., Glimm, E., Posch, M. (2009), Adaptive Designs for Confirmatory Clinical Trials, Statistics in Medicine, 28, 1181–1217.
- D’Agostino, R. B., and Russell, H. K. (2005), Multiple Endpoints, Multivariate Global Tests, New York: Wiley.
- Davidson, R.J., Pizzagalli, D., Nitschke, J.B., Putnam, K. (2002), Depression: Perspectives From Affective Neuroscience, Annual Review of Psychology, 53, 545–574.
- Denne, J.S., Jennison, C. (2000), A Group Sequential T-test With Updating of Sample Size, Biometrika, 87, 125–134.
- Follmann, D. (1996), A Simple Multivariate Test for One-Sided Alternatives, Journal of the American Statistical Association, 91, 854–861.
- Gelman, A., Carlin, J. B., Stern, H. S., and Rubin, D. B. (2004), Bayesian Data Analysis, Boca Raton, FL: Chapman & Hall.
- Hotelling, H. (1931), The Generalization of Student’s Ratio, The Annals of Mathematical Statistics, 2, 360–378.
- Kieser, M., Schneider, B., Friede, T. (2002), A Bootstrap Procedure for Adaptive Selection of the Test Statistic in Flexible Two-Stage Designs, Biometrical Journal, 44, 641–652.
- Kimani, P.K., Stallard, N., Hutton, J.L. (2009), Dose Selection in Seamless Phase II/III Clinical Trials Based on Efficacy and Safety, Statistics in Medicine, 28, 917–936.
- Lang, T., Auterith, A., Bauer, P. (2000), Trendtests With Adaptive Scoring, Biometrical Journal, 42, 1007–1020.
- Läuter, J., Glimm, E., Kropf, S. (1996), New Multivariate Tests for Data With an Inherent Structure, Biometrical Journal, 38, 1–23.
- Läuter, J., Glimm, E., Kropf, S. (1998), “Multivariate Tests Based on Left-Spherically Distributed Linear Scores, The Annals of Statistics, 26, 1972–1988.
- Lehmacher, W., Wassmer, G. (1999), Adaptive Sample Size Calculations in Group Sequential Trials, Biometrics, 55, 1286–1290.
- Liu, Q., Proschan, M.A., Pledger, G.W. (2002), A Unified Theory of Two-Stage Adaptive Designs, Journal of the American Statistical Association, 97, 1034–1041.
- Logan, B.R., Tamhane, A.C. (2004), On O’Brien’s OLS and GLS Tests for Multiple Endpoints, Lecture Notes-Monograph Series, 47, 76–88.
- Mehta, C.R., Pocock, S.J. (2011), Adaptive Increase in Sample Size When Interim Results are Promising: A Practical Guide With Examples, Statistics in Medicine, 30, 3267–3284.
- Minas, G., Rigat, F., Nichols, T.E., Aston, J.A. D., Stallard, N. (2012), A Hybrid Procedure for Detecting Global Treatment Effects in Multivariate Clinical Trials: Theory and Applications to fMRI Studies, Statistics in Medicine, 31, 253–268.
- Müller, H.-H., Schäfer, H. (2001), Adaptive Group Sequential Designs for Clinical Trials: Combining the Advantages of Adaptive and of Classical Group Sequential Approaches, Biometrics, 57, 886–891.
- O’Brien, P.C. (1984), Procedures for Comparing Samples With Multiple Endpoints, Biometrics, 40, 1079–1087.
- O’Hagan, A., Stevens, J. W. (2001), Bayesian Assessment of Sample Size for Clinical Trials of Cost-Effectiveness, Medical Decision Making, 21, 219–230.
- Pocock, S.J., Geller, N.L., Tsiatis, A.A. (1987), The Analysis of Multiple End-Points in Clinical-Trials, Biometrics, 43, 487–498.
- Proschan, M.A., Hunsberger, S.A. (1995), Designed Extension of Studies Based on Conditional Power, Biometrics, 51, 1315–1324.
- Spiegelhalter, D., Abrams, K. R., and Myles, J. (2002), Bayesian Approaches to Clinical Trials and Health-Care Evaluation, Chichester: Wiley.
- Tang, D.-I., Geller, N.L., Pocock, S.J. (1993), On the Design and Analysis of Randomized Clinical Trials With Multiple Endpoints, Biometrics, 49, 23–30.
- Tang, D.-I., Gnecco, C., Geller, N.L. (1989a), An Approximate Likelihood Ratio Test for a Normal Mean Vector With Nonnegative Components With Application to Clinical Trials, Biometrika, 76, 577–583.
- Tang, D.-I., Gnecco, C., Geller, N.L. (1989b), Design of Group Sequential Clinical Trials With Multiple Endpoints, Journal of the American Statistical Association, 84, 776–779.
- Westfall, P.H., Krishen, A., Young, S.S. (1998), Using Prior Information to Allocate Significance Levels for Multiple Endpoints, Statistics in Medicine, 17, 2107–2119.
- Zhu, H.J., Hu, F.F. (2010), Sequential Monitoring of Response-Adaptive Randomized Clinical Trials, The Annals of Statistics, 38, 2218–2241.