
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Motivated by the problem of selecting representative portfolios for backtesting counterparty credit risks, we propose a matching quantiles estimation (MQE) method for matching a target distribution by that of a linear combination of a set of random variables. An iterative procedure based on the ordinary least-squares estimation (OLS) is proposed to compute MQE. MQE can be easily modified by adding a LASSO penalty term if a sparse representation is desired, or by restricting the matching within certain range of quantiles to match a part of the target distribution. The convergence of the algorithm and the asymptotic properties of the estimation, both with or without LASSO, are established. A measure and an associated statistical test are proposed to assess the goodness-of-match. The finite sample properties are illustrated by simulation. An application in selecting a counterparty representative portfolio with a real dataset is reported. The proposed MQE also finds applications in portfolio tracking, which demonstrates the usefulness of combining MQE with LASSO.
1. INTRODUCTION
Basel III is a global regulatory standard on bank capital adequacy, stress testing and market liquidity risk put forward by the Basel Committee on Banking Supervision in 2010–2011, in response to the deficiencies in risk management revealed by the late-2000s financial crisis. One of the mandated requirements under Basel III is an extension of the backtesting of internal counterparty credit risk (CCR) models. Backtesting tests the performance of CCR measurement, to determine the need for recalibration of the simulation and/or pricing models and readjustment of capital charges. Since the number of the trades between two major banks could easily be in the order of tens of thousands or more, Basel III allows banks to backtest representative portfolios for each counterparty, which consist of subsets of the trades. However, the selected representative portfolios should represent the various characteristics of the total counterparty portfolio including risk exposures, sensitivity to the risk factors, etc. We propose in this article a new method for constructing such a representative portfolio. The basic idea is to match the distribution of total counterparty portfolio by that of a selected portfolio. However, we do not match the two distribution functions directly. Instead we choose the representative portfolio to minimize the mean squared difference between the quantiles of the two distributions across all levels. This leads to the matching quantiles estimation (MQE) for the purpose of matching a target distribution. To the best of our knowledge, MQE has not been used in this particular context, though the idea of matching quantiles has been explored in other contexts; see, for example, Karian and Dudewicz (Citation1999), Small and McLeish (Citation1994), and Dominicy and Veredas (Citation2013). Furthermore, our inference procedure is different from those in the aforementioned papers due to the different nature of our problem.
Formally, the proposed MQE bears some similarities to the ordinary least squares estimation (OLS) for regression models. However, the fundamental difference is that MQE is for matching (unconditional) distribution functions, while OLS is for estimating conditional mean functions. Unlike OLS, MQE seldom admits an explicit expression. We propose an iterative algorithm applying least-squares estimation repeatedly to the recursively sorted data. We show that the algorithm converges as the mean squared difference of the two-sample quantiles decreases monotonically. Some asymptotic properties of MQE are established based on the Bahadur-Kiefer bounds for the empirical quantile processes.
MQE method facilitates some variations naturally. First, it can be performed by matching the quantiles between levels α1 and α2 only, where 0 ⩽ α1 < α2 ⩽ 1. The resulting estimator matches only a part of the target distribution. This could be attractive if we are only interested in mimicking, for example, the behavior at the lower end of the target distribution. Second, MQE can also be performed with a LASSO-penalty, leading to a sparser representation. Though MQE was motivated by the problem of estimating representative portfolios, its potential usefulness is wider. We illustrate how it can be used in a portfolio tracking problem. Since MQE does not require the data being paired together, it can also be used for analyzing asynchronous measurements which arise from various applications including atmospheric sciences (He et al. Citation2012), space physics, and other areas (O’Brien et al. Citation2001).
MQE is an estimation method for matching unconditional distribution functions. It is different from the popular quantile regression which refers to the estimation for conditional quantile functions. See Koenker (Citation2005), and references therein. It also differs from the unconditional quantile regression of Firpo et al. (Citation2009) which deals with the estimation for the impact of explanatory variables on quantiles of the unconditional distribution of an outcome variable. For nonnormal models, sample quantiles have been used for different inference purposes. For example, Kosorok (Citation1999) used quantiles for nonparametric two-sample tests. Gneiting (Citation2011) argued that quantiles should be used as the optimal point forecasts under some circumstances. MQE also differs from the statistical asynchronous regression (SAR) method introduced by O’Brien et al. (Citation2001), although it can provide an alternative way to establish a regression-like relationship based on unpaired data. See Remark 1(v) in Section 2.
The rest of the article is organized as follows. The MQE methodology including an iterative algorithm is presented in Section 2. The convergence of the algorithm is established in Section 3. Section 4 presents some asymptotic properties of MQE. To assess the goodness-of-match, a measure and an associated statistical test are proposed in Section 5. The finite sample properties of MQE are examined in simulation in Section 6. We illustrate in Section 7 how the proposed methodology can be used to select a representative portfolio for CCR backtesting with a real dataset. Section 8 deals with the application of MQE to a different financial problem—tracking portfolios. It also illustrates the usefulness of combining MQE and LASSO together.
2. METHODOLOGY
Let Y be a random variable, and X = (X1, …, Xp)′ be a collection of p random variables. The goal is to find a linear combination
such that its distribution matches the distribution of Y. We propose to search for β such that the following integrated squared difference of the two quantile functions is minimized
where Qξ(α) denotes the αth quantile of random variable ξ, that is,
In fact (Equation2.2
) is a squared Mallows’ metric introduced by Mallows (Citation1972) and Tanaka (Citation1973). It is also known as L2-Wasserstein distance (del Barrio et al. Citation1999). See also Section 8 of Bickel and Freedman (Citation1981) for a mathematical account of the Mallows metrics.
Given the goal is to match the two distributions, one may adopt the approaches of matching the two distribution functions or density functions directly. However, our approach of matching quantiles provides the better fitting at the tails of the distributions, which is important for risk management; see Remark 1(iv) below. Furthermore, it turns out that the method of matching quantiles is easier than that for matching distribution functions or density functions directly.
Suppose the availability of random samples {Y1, …, Yn} and {X1, …, Xn} drawn respectively from the distributions of Y and X. Let Y(1) ⩽ ⋅⋅⋅ ⩽ Y(n) be the order statistics of Y1, …, Yn. Then Y(j) is the j/nth sample quantile. To find the sample counterpart of the minimizer of (Equation2.2), we define the estimator
where (β′X)(1) ⩽ ⋅⋅⋅ ⩽ (β′X)(n) are the order statistics of β′X1, …, β′Xn. We call
the matching quantiles estimator (MQE), as it tries to match the quantiles at all possible levels between 0 and 1. Unfortunately
does not admit an explicit solution. We define below an iterative algorithm to evaluate its values. We will show that the algorithm converges. To this end, we introduce some notation first. Suppose that β(k) is the kth iterated value, let {X(k)(j)} be a permutation of {Xj} such that
Step 1. Set an initial value β(0).
Step 2. For k ⩾ 1, let
, where
In the above algorithm, we may take the ordinary least squares estimator (OLS) as an initial estimator β(0), where
and
,
is an n × p matrix with X′j as its jth row. However we stress that OLS
is an estimator for the minimizer of the mean squared error
which is different from the minimizer of (Equation2.2
) in general. Hence, OLS
and MQE
are two estimators for two different parameters, although the MQE is obtained by applying least squares estimation repeatedly to the recursively sorted data; see Step 2 above.
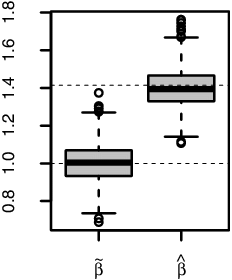
To gain some intuitive appreciation of MQE and the difference from OLS, we report below some simulation results with two toy models.
Example 1.
Consider a simple scenario
where X and Z are independent and N(0, 1), and Z is unobservable. Now p = 1, the minimizer of (Equation2.7
) is β(1) = 1. Note that
. Thus, (Equation2.2
) admits a minimizer β(2) = 1.414. We generate 1000 samples from (Equation2.8
) with each sample of size n = 100. For each sample, we calculate MQE
using the iterative algorithm above with OLS
as the initial value. presents the boxplots of the 1000 estimates. It is clear that both OLS
and MQE
provide accurate estimates for β(1) and β(2), respectively. In fact, the mean squared estimation errors over the 1000 replications is, respectively, 0.0107 for
and 0.0109 for
. The algorithm for computing
only took two iterations to reach the convergence in all the 1000 replications.
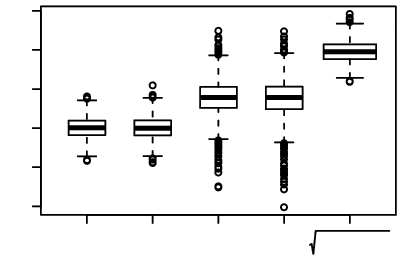
Example 2.
Now we repeat the exercise in Example 1 above for the modelwhere X1, X2, and Z are independent and N(0, 1), and Z is unobservable. The boxplots of the estimates are displayed in . Now p = 2, the minimizer of (Equation2.7
) is (β(1)1, β2(1)) = (1, 1). Since
, there are infinite numbers of minimizers of (Equation2.2
). In fact any (β1, β2) satisfying the condition
is a minimizer of (Equation2.2
), as then
One such minimizer is (β(2)1, β2(2)) = (1.414, 1.414). It is clear from that over the 1000 replications, OLS
are centered at the minimizer (β(1)1, β2(1)) of (Equation2.7
). While MQE
are centered around one minimizer (β(2)1, β2(2)) of (Equation2.2
), their variations over 1000 replications are significantly larger. On the other hand, the values of
are centered around its unique true value 2 with the variation comparable to those of the OLS
and
. In fact, the mean squared estimation errors of
, and
are, respectively, 0.0191, 0.0196, and 0.0198. The mean squared differences between
and β(2)1, and between
and β(2)2 are 0.0608 and 0.0661, respectively. All these clearly indicate that in the 1000 replications, MQE may estimate different minimizers of (Equation2.2
). However, the end-product, that is, the estimation for the distribution of Y is very accurate, measured by the mean squared error 0.0198 for estimating {β21 + β22}1/2. The iterative algorithm for calculating the MQE always converges quickly in the 1000 replications. The average number of iterations is 5.15 with the standard deviation 4.85. Like in Example 1, we used the OLS as the initial values for calculating the MQE. We repeated the exercise with the two initial values generated randomly from U[ − 2, 2]. The boxplots for
and
, not presented here to save space, are now centered at 0 with about [ − 1.5, 1.5] as their inter-half ranges. But remarkably the boxplot for
remains about the same. The mean and the standard deviation for the number of iterations required in calculating the MQE are 7.83 and 9.12.
We conclude this section with some remarks.
Remark 1.
When there exist more than one minimizer of (Equation2.2
If we are interested only in matching a part of distribution of Y, say, that between the α1th quantile and the α2th quantile, 0 ⩽ α1 < α2 ⩽ 1, we may replace (Equation2.5
To obtain a sparse MQE, we change Rk(β) in Step 2 of the iteration to
Since our goal is to match the distribution of Y by that of β′X, a natural approach is to estimate β which minimizes, for example,
MQE does not require that Yj and Xj are paired together. It can be used to recover the nearly perfect linear relationship Y ≈ β′X based on unpaired observations {Yj} and {Xj}, as then
When Yj and Xj are paired together, as in many applications, the pairing is ignored in the MQE estimation (Equation2.3
3. CONVERGENCE OF THE ALGORITHMS
We will show in this section that the iterative algorithm proposed in Section 2 above for computing MQE converges—a property reminiscent of the convergence of the EM algorithm (Wu Citation1983). We introduce a lemma first.
Lemma 1.
Let a1, …, an and b1, …, bn be any two sequences of real numbers. Thenwhere {a(i)} and {b(i)} are, respectively, the order statistics of {ai} and {bi}.
Proof.
We proceed by the mathematical induction. When n = 2, we only need to show that
which is equivalent to
This is true.
Assuming the lemma is true for all n = k, we show below that it is also true for n = k + 1. Without loss of generality, we may assume that ak + 1 = a(1) and bℓ = b(1). If ℓ = k + 1, (Equation3.1) holds for k + 1 now. When ℓ ≠ k + 1, it follows the proof above for the case of n = 2,
Consequently,
The last inequality follows from the induction assumption for n = k. This completes the proof.
Theorem 1.
For Rk( · ) defined in (Equation2.5) or (Equation2.11
), and
, it holds that Rk(β(k)) → c as k → ∞, where c ⩾ 0 is a constant.
Proof.
We show that the LASSO estimation with Rk defined in (Equation2.11) converges. When λ = 0, (Equation2.11
) reduces to (Equation2.5
).
We only need to show that This is true because
In the above expression, the first inequality follows from the definition of β(k + 1) and the second inequality is guaranteed by Lemma 1. < tex − math/ >
Remark 2.
Theorem 1 shows that the iterations in Step 2 of the algorithm in Section 2 above converge. But it does not guarantee that they will converge to the global minimum. In practice, one may start with multiple initial values selected, for example, randomly, and take the minimum among the converged values from the different initial values. If necessary, one may also treat the algorithm as a function of the initial value and apply, for example, simulated annealing to search for the global minimizer.
In practice, we may search for β′X to match a part of distribution of Y only, that is, we use Rk( · ; α1, α2) defined in (Equation2.10
Lemma 1 above can be deduced from Lemmas 8.1 and 8.2 of Bickel and Freedman (Citation1981) in an implicit manner, while the proof presented here is simpler and more direct.
4. ASYMPTOTIC PROPERTIES OF THE ESTIMATION
We present the asymptotic properties for a more general setting in which MQE is combined with LASSO, and the estimation is defined to match a part of the distribution between the α1th quantile and the α2th quantile, where 0 ⩽ α1 < α2 ⩽ 1 are fixed. Obviously matching the whole distribution is a special case with α1 = 0 and α2 = 1. Furthermore when λ = 0 in (Equation4.1) and (Equation4.3
), it reduces to the MQE without LASSO.
For λ ⩾ 0, letIntuitively β0 could be regarded as the true value to be estimated. However, it is likely that β0 so defined is not unique. Such a scenario may occur when, for example, two components of X are identically distributed. Furthermore it is conceivable that those different β0 may lead to different distributions
which provide an equally good approximation to
in the sense that S(β0) takes the same value for those different β0.
Similar to (Equation2.3), the MQE for matching a part of the distribution is defined as
where
ni = [nαi], (β′X)(1) ⩽ ⋅⋅⋅ ⩽ (β′X)(n) are the order statistics of β′X1, …, β′Xn, Qn, Y( · ) is the quantile function corresponding to the empirical distribution of {Yj}, that is,
In the above expression, Fn, Y(y) = n− 1∑1 ⩽ j ⩽ nI(Yj ⩽ y).
and
are defined in the same manner.
Similar to its theoretical counterpart β0 in (Equation4.1), the estimator
defined in (Equation4.2
) may not be unique either, see Example 2 and Remark 1(i) above. Hence, we show below that
converges to S(β0). This implies that the distribution of
provides an optimal approximation to the distribution of Y in the sense that the mean square residuals
converge to the minimum of S(β), although
may not converge to a fixed distribution. Furthermore, we also show that
is consistent in the sense that
converges to 0, where ‖ · ‖ denotes the Euclidean norm for vectors, and
is the set consisting of all the minimizers of S( · ) defined in (Equation4.1
), that is,
We introduce some regularity conditions first. We denote by, respectively, Fξ( · ) and fξ( · ) the distribution function and the probability density function of a random variable ξ.
Condition B.
Let {Yj} be a random sample from the distribution of Y and {Xj} be a random sample from the distribution of X. Both fY( · ) and fX( · ) exist.
(The Kiefer condition.) It holds for any fixed β that
X has bounded support.
Remark 3.
Condition B (ii) is the Kiefer condition. It ensures the uniform Bahadur–Kiefer bounds for empirical quantile processes for iid samples. More precisely, (Equation4.5
The assumption of independent samples in Condition B(i) is imposed for simplicity of the technical proofs. In fact, Theorem 2 still holds for some weakly dependent processes, as the Bahadur-Kiefer bounds (Equation4.7
The requirement for X having a bounded support is for technical convenience. When α1 = 0 and α2 = 1, it is implied by Condition B(ii), as (Equation4.5
Theorem 2.
Let Condition B hold and λ in (Equation4.1) and (Equation4.3
) be a nonnegative constant. Then as n → ∞,
in probability, and
in probability.
We present the proof of Theorem 2 in Appendix I.
5. GOODNESS OF MATCH
The goal of MQE is to match the distribution of Y by that of a selected linear combination β′X. We introduce below a measure for the goodness of match, and also a statistical test for the hypothesis
5.1 A Measure for the Matching Goodness
Let F( · ) be the distribution function of Y. Let g( · ) be the probability density function of the random variable F(β′X). When Y and β′X have the same distribution, F(β′X) is a random variable uniformly distributed on the interval [0, 1], and g(x) ≡ 1 for x ∈ [0, 1]. We define a measure for the goodness of match as follows:
It is easy to see that ρ ∈ [0, 1], and ρ = 1 if and only if the matching is perfect in the sense that
. When the difference between g( · ) and 1 (i.e., the density function of U[0, 1]) increases, ρ decreases. Hence the larger the difference between the distributions of Y and β′X, the smaller the value of ρ. For example, ρ = 0.5 if Y ∼ U[0, 1] and β′X ∼ U[0, 0.5], and ρ = 1/m if Y ∼ U[0, 1] and β′X ∼ U[0, 1/m] for any m ⩾ 1.
With the given observations {(Yi, Xi)}, let
A natural estimator for ρ defined in (Equation5.2
) is
In the above expression, k ⩾ 1 is an integer, [x] denotes the integer part of x. It also holds that
. Furthermore,
if and only if n/k is an integer and each of the n/k intervals
(j = 1, …, n/k) contains exactly k points from U1, …, Un. This also indicates that we should choose k large enough such that there are enough sample points on each of those [n/k] intervals and, hence, the relative frequency on each interval is a reasonable estimate for its corresponding probability.
Remark 4.
Formula (Equation5.2) only applies when the distribution of F(β′X) is continuous. If this is not the case, the random variable F(β′X) has nonzero probability masses at 0 or/and 1, and (Equation5.2
) should be written in a more general form ρ = 1 − 0.5∫10|dG − dx|, where G( · ) denotes the probability measure of F(β′X). It is clear now that ρ = 0 if and only if the supports of
and
do not overlap. Note that the estimator
defined in (Equation5.3
) still applies.
5.2 A Goodness-of-Match Test
There exist several goodness-of-fit tests for the hypothesis H0 defined in (Equation5.1); see, for example, Section 2.1 of Serfling (Citation1980). We propose a test statistic Tn below, which is closely associated with the goodness-of-match measure
in (Equation5.3
) and is reminiscent of the Cramér-von Mises goodness-of-fit statistic. Under the hypothesis H0, U1, …, Un behave like a sample from U[0, 1] for large n. Hence based on the relative counts {Cj} defined in (Equation5.3
), we may define the following goodness-of-match test statistic for testing hypothesis H0.
By Proposition 1, the distribution of Tn under H0 is distribution-free. The critical values listed below was evaluated from a simulation with 50,000 replications, n = 1000, and both {ξi} and {ηi} drawn independently from U[0, 1].
The changes in the critical values led by different sample sizes n, as long as n ⩾ 300, are smaller than 0.05 when k/n ⩾ 0.05, and are smaller than 0.1 when k/n = 0.025.
Proposition 1.
Let {ξ1, …, ξn} and {η1, …, ηn} be two independent random samples from two distributions F and G, and F be a continuous distribution. Let and Ui = Fn(ηi). Let Cj be defined as in (Equation5.3
) and Tn as in (Equation5.4
). Then, the distribution Tn is independent of F and G provided F( · ) ≡ G( · ).
This proposition follows immediately from the fact that almost surely, and {F(ξi)} and {F(ηi)} are two independent samples from U[0, 1] when F( · ) ≡ G( · ).
6. SIMULATION
To illustrate the finite-sample properties, we conduct simulations under the setting
to check the performance of MQE for β = (β1, …, βp)′, where Xj = (Xj1, …, Xjp)′ represent p observed variables, and Zj represents collectively the unobserved factors. We let Xj be defined by a factor model
where A is a p × 3 constant factor loading matrix, the components of Uj are three independently linear AR(1) processes defined with positive or negative centered log-N(0, 1) innovations, the components of
are all independent and t-distributed with 4 degrees of freedom. Hence, the components of Xj are correlated with each other with skewed and heavy tailed distributions. We let Zj in (Equation6.1
) be independent N(0, σ2). For each sample, the coefficients βj are drawn independently from U[ − 0.5, 0.5], the elements of the factor loading matrix A are drawn independently from U[ − 1, 1], and the three autoregressive coefficients in the three AR(1) factor processes are drawn independently from U[ − 0.95, 0.95]. For this example, no linear combinations of Xj can provide a perfect match for the distribution of Yj.
Table 1 The means and standard deviations (STD) of the number of iterations required for computing MQE in a simulation with 1000 replications
Table 2 The means and standard deviations (in parentheses) of estimated goodness-of-match measure defined in (Equation5.3) in a simulation with 1000 replications, calculated for both the sample used for estimating β and the post-sample
For comparison purposes, we also compute OLS defined in (Equation2.6
). For computing MQE
, we use
as the initial value, and let
and
when
where Rk( · ) is defined in (Equation2.5
). The reason to use square-root of Rk instead of Rk in the above is that Rk itself can be very small. We set the sample size n = 300 or 800, the dimension p = 50, 100, or 200, the ratio
For the simplicity, we call r the noise-to-signal ratio, which represents the ratio of the unobserved signal to the observed signal. For each setting, we draw 1000 samples and calculate both
and
for each sample.
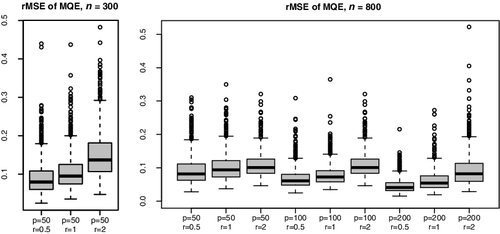
displays the boxplots of the rMSE() defined in (Equation6.2
). It indicates that the approximation with n = 800 is more accurate than that with n = 300. When the noise-to-signal ratio r increases from 0.5, 1, to 2, the values and also the variation of
increase. shows that rMSE(
) is right-skewed, indicating that the algorithm may be stuck at a local minimum. This problem can be significantly alleviated by using multiple initial values generated randomly, which was confirmed in an experiment not reported here.
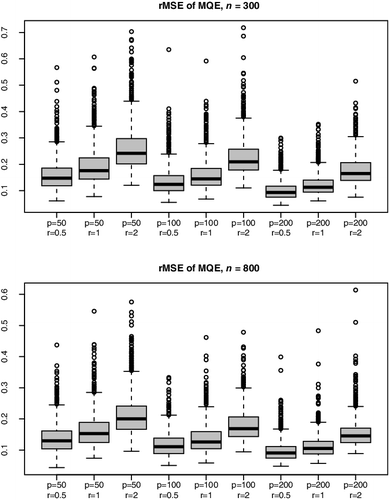
list the means and standard deviations of the number of iterations required in calculating MQE , controlled by (Equation6.3
), over the 1000 replications. Over all tested settings, the algorithm converges fast. The number of iterations tends to decrease when the dimension p increases. This may be because there are more “true values” of β when p is larger, or simply when p becomes really large.
With each drawn sample, we also generate a post-sample of size 300 denoted by {(yj, xj), i = 1, …, 300}. We measure the matching power for the distribution Y by rMME for MQE, and by rMME
for OLS, where the root mean matching error rMME is defined as
where y(1) ⩽ ⋅⋅⋅ ⩽ y(300) are the order statistics of {yj}, and (β′x)(1) ⩽ ⋅⋅⋅ ⩽ (β′x)(300) are the order statistics of {β′xj}. presents the scatterplots of
against
with sample size n = 800. The dashed diagonal lines mark the positions y = x. Since most the dots are below the diagonals, the matching error for the distribution Y based on MQE
is smaller than the corresponding matching error based on OLS
in most cases. When the noise-to-signal ratio r is as small as 0.5, the difference between the two methods is relatively small, as then the minimizers of (Equation2.2
) do not differ that much from the minimizer of (Equation2.7
). However when the ratio increases to 1 and 2, the matching based on the MQE is overwhelmingly better. This confirms that MQE should be used when the goal is to match the distribution of Y.
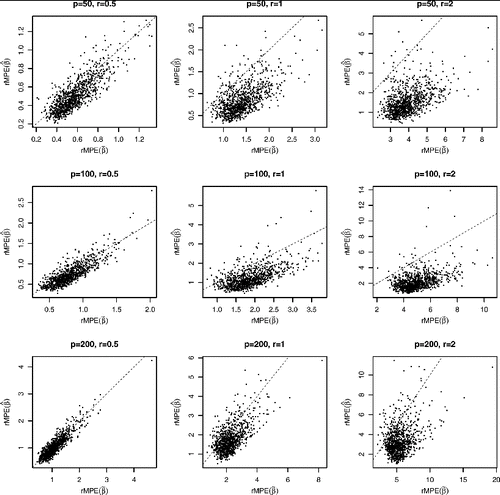
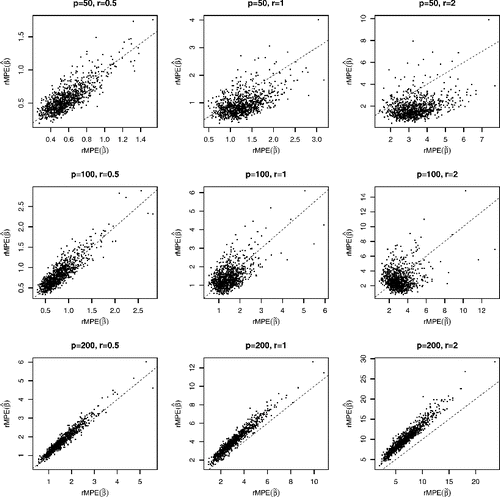
Table 3 The means and standard deviations (in parentheses) of the sample correlation coefficients between Y and , and between Y and in a simulation with 1000 replications, calculated for both the sample used for estimating β and the post-sample
The same plots with sample size n = 300 are presented in . When the dimension p is small such as p = 50 or 100, MQE still provides a better matching performance overall, although the matching errors are greater than those when n = 800. When dimension p = 200 and sample size n = 300, we step into overfitting territory. While the in-sample fitting is fine (see the top panel in and the bottom-left part of below), the post-sample matching power of both OLS and MQE is poor and MQE performs even worse than the “wrong” method OLS.
To assess the goodness-of-match, we also calculate the measure defined in (Equation5.3
) with k = 20. The mean and standard deviation of
over 1000 replications are reported for in . We line up side by side the results calculated using both the sample used for estimating β and the post-sample. Except the overfitting cases (i.e., n = 300 and p = 200), the values of
with MQE are greater (or much greater when r = 2 or 1) than those with OLS, noting the small standard deviations across all the settings. With MQE,
for the in-sample matching, and
for the post-sample matching (except when n = 300 and p = 200). With OLS, the minimum value of
is 0.71 for the in-sample matching, and is 0.72 for the post-sample matching.
One side-effect of MQE is the disregard of the pairing of (Yj, Xj); see (Equation2.3
). Hence we expect that the sample correlation between Y and
will be smaller than that between Y and
. lists the means and standard deviations of the sample correlation coefficients between Y and
, and of those between Y and
in our simulation. Over all different settings, the mean sample correlation coefficient for both in-samples and post-samples between Y and
is always greater than that between Y and
. However the difference is small. In fact if we take the difference of the two means, denoted as D, as the estimator for the “true” difference and treat the two means independently of each other, the (absolute) value of D is always smaller than its standard error over all the settings.
Finally we investigate the performance of MQE in matching only a part of distribution. To this end, we repeat the above exercise but using Rk(β) = Rk(β, 0, 0.3) defined in (Equation2.10) instead, that is, the MQE is sought to match the lower 30% of the distribution of Y. presents the boxplots of
. Comparing it with , there are no entries for n = 300 and p = 100 or 200, for which the algorithm did not converge after 500 iterations. See Remark 2(ii). For the cases presented in ,
are smaller than the corresponding entries in . This is because the matching now is easier, as the MQE is sought such that the lower 30% of
matches the counterpart of
. But there are no any constraints on the upper 70% of
. list the means and standard deviations of the number of iterations required in calculating MQE over the 1000 replications. Comparing it with , the algorithm converges faster for matching a part of
than for matching the whole
.
7. A REAL-DATA EXAMPLE
In the context of selecting a representative portfolio for backtesting counterparty credit risks, Y is the total portfolio of a counterparty, and X = (X1, …, Xp) are the p mark-to-market values of the trades. The goal is to find a linear combination β′X which provides an adequate approximation for the total portfolio Y. Since Basel III requires that a representative portfolio matches various characteristics of the total portfolio, we use the proposed methodology to select β′X to match the whole distribution of Y. We illustrate below how this can be done using the records for a real portfolio.
The data contains 1000 recorded total portfolios at one month tenor (i.e., one month stopping period) and the corresponding mark-to-market values of 146 trades (i.e., p = 146). Those 146 trades were selected from over 2000 trades across different tenors (i.e., from 3 days to 25 years) by the stepwise regression method of An et al. (Citation2008). The data has been rescaled. As some trades are heavily skewed to the left while the total portfolio data are very symmetric for this particular dataset, we truncate those trades at , where
and
denote, respectively, the sample mean and the sample standard deviation of the trade concerned. The absence of the heavy left tail in the total portfolio data is because there exist highly correlated trades in opposite directions (i.e., sales in contrast to buys) which were eliminated at the initial stage by the method of An et al. (Citation2008). We estimate both OLS
and MQE
using the first 700 (i.e., n = 700) of the 1000 available observations. The algorithm for computing MQE took 7 iterations to converge. We compare Y with
and
using the last 300 observations. The in-sample and post-sample correlations between Y and
are 0.566 and 0.248. The in-sample and post-sample correlations between Y and
are 0.558 and 0.230. Once again the loss of correlation with MQE is minor.
Table 4 The means and standard deviations (STD) of the number of iterations required for computing MQE for matching the lower 30% of the distribution of Y
Setting k/n = 0.05 in (Equation5.3), the in-sample and post-sample goodness of fit measures
are 0.905 and 0.855 with MQE, and are 0.741 and 0.785 with OLS. This indicates that MQE provides a much better matching than OLS. The goodness-of-match test presented in Section 5.2 reinforces this assertion. The test statistic Tn defined in (Equation5.4
), when applied to the 300 post-sample points, is equal to 5.023 for the MQE matching, and is 7.448 for the OLS matching. Comparing to the critical values listed in Section 5.2, we reject the OLS matching at the 0.5% significance level, but we cannot reject the MQE matching even at the 10% level. Note that we do not apply the test to the in-sample data as the same data points were used in estimating β (though the conclusions would be the same).
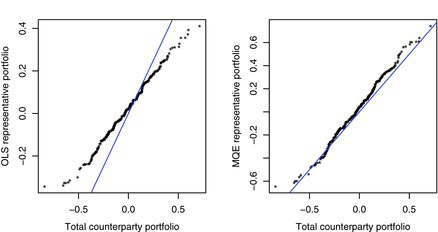
To further showcase the improvement of MQE matching over OLS, plots the sample quantiles of the representative portfolios and
against the sample quantiles of the total counterparty portfolio Y, based on the 300 post-sample points. It shows clearly that the distribution of the representative portfolio based on MQE
provides much more accurate approximation for the distribution of the total counterparty portfolio than that based on the OLS
. For the latter, the discrepancy is alarmingly large at the two tails of the distribution, where matter most for risk management.
8. PORTFOLIO TRACKING
Portfolio tracking refers to a portfolio assembled with securities which mirrors a benchmark index, such as S&P500 or FTSE100 (Jansen and van Dijk Citation2002, and Dose and Cincotti Citation2005). Tracking portfolios can be used as the strategies for investment, hedging and risk management for investment, or as macroeconomic forecasting (Lamont Citation2001).
Let Y be the return of an index to be tracked, X1, …, Xp be the returns of the p securities to be used for tracking Y. One way to choose a tracking portfolio is to select weights {wi} to minimizesubject to
where c ⩾ 1 is a constant. See, for example, Section 3.2 of Fan et al. (Citation2012). In the above expression, wi is the proportion of the capital invested on the ith security Xi, and wi < 0 indicates a short sale on Xi. It follows from (Equation8.2
) that
Hence, the constant c controls the exposure to short sales. When c = 1, short sales are not permitted.
Instead of using the constrained OLS as in above, one alternative in selecting the tracking portfolio is to match the whole (or a part) of distribution of Y. This leads to a constrained MQE, subject to the constraints in (Equation8.2). Given a set of historical returns {(Yj, Xj1, …, Xjp), j = 1, …, n}, we use the iterative algorithm in Section 2 to calculate MQE
subject to the constraint
and
is the unconstrained MQE for β, and δ ∈ (0, 1) is a constant which controls, indirectly, the total exposure to short-sales. This is the standard MQE-LASSO; see (Equation2.12
) in Remark 1(iii) in Section 2. For δ ⩾ 1,
. We transform the constrained MQE
to the estimates for the proportion weights as follows:
Then
fulfill the constraints in (Equation8.2
) with any c satisfying the following condition:
Such a c is always greater than 1 as
see (Equation8.4
). Note that the LARS-LASSO algorithm gives the whole solution path for all positive values of δ. Hence for a given value c in (Equation8.2
), we can always find the largest possible value δ from the solution path for which (Equation8.5
) holds.
Table 5 The mean, maximum and minimum daily log returns (in percentages) of FTSE100 and the estimated track portfolios in 2007. The estimation was based on the data in 2004–2006. Also included in the table are the number of stocks present in each portfolio, the standard deviations (STD) and the negative mean (NM) of the daily returns, and the percentages (of the capital) for short sales
Remark 5.
One would be tempted to absorb the constraint condition ∑jwj = 1 in the estimation directly by letting, for example,
Then, one could estimate w1, …, wp − 1 directly by regressing Y′ on X′1, …, Xp − 1′. However, this puts the pth security Xp on a nonequal footing as the other p − 1 securities, which may lead to an adverse effect.
We illustrate our proposal by tracking FTSE100 using 30 actively traded stocks included in FTSE100. The company names and the symbols of those 30 stocks are listed in Appendix II.
We use the log returns (in percentages) calculated using the adjusted daily close prices in 2004–2006 (n = 758) to estimate the tracking portfolios by MQE with or without the LASSO, and compare their performance with the returns of FTSE100 in 2007 (in total 253 trading days). We also include in the comparison the portfolios estimated by OLS. The market is overall bullish in the period 2004–2007. The data were downloaded from Yahoo!Finance.
list some summary statistics of the daily log-returns in 2007 of FTSE100 and the various tracking portfolios. Both the OLS and the MQE track well the FTSE100 index with almost identical daily mean 0.014%. In addition to the standard deviations (STD), we also include in the table the negative mean (NM) as a risk measure, which is defined as the mean value of all the negative returns. According to both STD and NM, both the OLS and the MQE are slightly less risky than FTSE100 in 2007.
We also form the portfolios based on OLS-LASSO and MQE-LASSO with the truncated parameter δ = 0.7 and 0.5; see (Equation8.4). Now all the four portfolios yield noticeably greater average daily returns than that of FTSE100 with noticeably greater risks. Furthermore, the performances of OLS and MQE part from each other with MQE producing substantially larger returns with larger risks. For example, the MQE-LASSO portfolio with δ = 0.5 yields average daily return of 0.119% and NM −1.336% while the OLS-LASSO yields average daily return of 0.045% and NM −1.119%. The number of stocks selected in portfolio is 10 by MQE, and 14 by OLS.
We continue the experiment by using the MQE matching the lower half, the middle half and the upper half of the distribution only; see Remark 1(ii). With δ = 0.7, the portfolios resulted from matching either the lower or the upper half of the distribution incur excessive short sales of, respectively, 38.4% and 885% of the initial capital, and are therefore too risky. By using δ = 0.5, short sales are reduced to 1.4% and 22% respectively. Especially matching the lower half distribution with δ = 0.5 leads to a portfolio with average daily return 0.223%, the STD 2.33%, the NA −1.56% and short sales 1.4%.
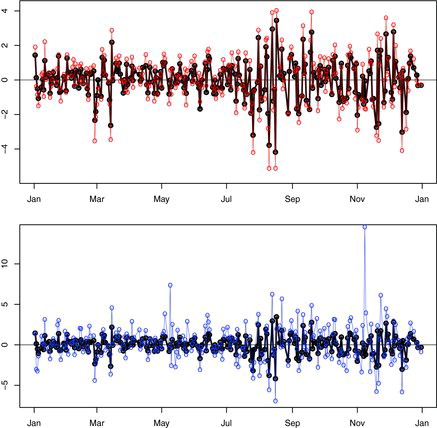
plots the daily returns of FTSE100 together with the two portfolios estimated by the MQE-LASSO with δ = 0.7, and δ = 0.5, (α0, α1) = (0, 0.5), respectively. Both the portfolios track well the index with increased volatility. Especially the portfolio plotted in blue is obtained by matching the lower half distribution only. Comparing with FTSE100, the increase of the STD is 1.23% while the increase of the NM is merely 0.654%. The increase of the return for this portfolio is resulted from mimicking the loss of FTSE100 and “freeing” the top half distribution.
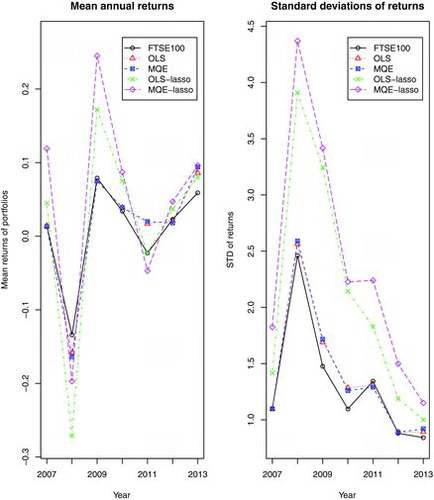
Now we apply the above approach with a rolling window to the data in 2007–2013. More precisely, for each calendar year within the period, we use the data in its previous three years for estimation to form the different portfolios. We then calculate the means and standard deviations for the daily returns in that year based on each of the portfolios. (The data for 2013 were only up to 10 September when this exercise was conducted.) The results for the portfolios based on OLS, MQE with and without LASSO are plotted in . We set δ = 0.5 in all the LASSO estimations. shows that the MQE-LASSO portfolio generated greater average returns in the 5 out of 7 years than the other four portfolios. But it also led to greater losses than FTSE100 index in both 2008 and 2011. Judging by the standard deviations it is the most risky strategy among the five portfolios reported in . Note that both the OLS and MQE portfolios incur small increases in standard deviation while the gains in average returns in 2011 and 2013 are noticeable. This shows that it is possible to match the overall performance of the index by trading on much fewer stocks.
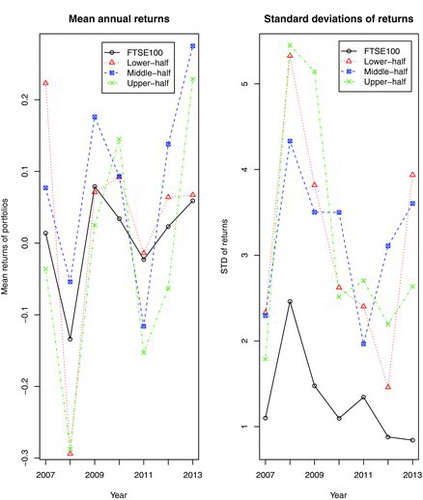
compares the three portfolios based on the MQE-LASSO matching, respectively, the lower half, the middle half and the upper half of the distributions for the returns of FTSE100 index. The first panel in the figure suggests that matching the upper-half distributions leads to very volatile average returns which are worse than the returns of FTSE100 index overall. In contrast, matching the lower half or the middle half of the distributions provide better return than the index in the 6 out of 7 years during the period. The risks of those portfolios, measured by the standard deviations, are higher that those of the index; see the second panel in the figure.
Overall the MQE-LASSO portfolios tend to overshoot at both the peaks and the troughs. Therefore they tend to outperform FTSE100 index when the market is bullish, and they may also do worse than the index when the market is bearish (such as 2008 and 2011).
Additional information
Notes on contributors
Nikolaos Sgouropoulos
Nikolaos Sgouropoulos is Quantitative Analyst, QA Exposure Analytics, Barclays, London, UK (E-mail: [email protected]).
Qiwei Yao
Qiwei Yao is Professor, Department of Statistics, The London School of Economics and Political Science, Houghton Street, London, WC2A 2AE, UK; Guanghua School of Management, Peking University, China (E-mail: [email protected]).
Claudia Yastremiz
Claudia Yastremiz is Senior Technical Specialist, Market and Counterparty Credit Risk Team, Prudential Regulation Authority, Bank of England, London, UK (E-mail: [email protected]).
REFERENCES
- An, H.-Z., Huang, D., Yao, Q., and Zhang, C.-H. (2008), “Stepwise Searching for Feature Variables in High-dimensional Linear Regression,” unpublished manuscript, available at http://stats.lse.ac.uk/q.yao/qyao.links/paper/ahyz08.pdf.
- Bickel, P.J., and Freedman, D.A. (1981), “Some Asymptotic Theory for the Bootstrap,” The Annals of Statistics, 9, 1196–1217.
- del Barrio, E., Cuesta-Albertos, J.A., Matrán, C., and Rodríguez-Rodríguez, J.M. (1999), “Tests of Goodness of Fit Based on the-Wasserstein Distance L2,” The Annals of Statistics, 27, 1230–1239.
- Dominicy, Y., and Veredas, D. (2013), “The Method of Simulated Quantiles,” Journal of Econometrics, 172, 208–221.
- Dose, C., and Cincotti, S. (2005), “Clustering of Financial Time Series with Application to Index and Enhanced Index Tracking Portfolio,” Physica A, 355, 145–151.
- Efron, B., Johnstone, I., Hastie, T., and Tibshirani, R. (2004), “Least Angle Regression” (with discussions), The Annals of Statistics, 32, 409–499.
- Fan, J., Zhang, J., and Yu, K. (2012), “Vast Portfolio Selection with Gross-exposure Constraints,” Journal of the American Statistical Association, 107, 592–606.
- Firpo, S., Fortin, N., and Lemieux, T. (2009), “Unconditional Quantile Regressions,” Econometrica, 77, 953–973.
- Gneiting, T. (2011), “Quantiles as Optimal Point Forecasts,” International Journal of Forecasting, 27, 197–207.
- He, X., Yang, Y., and Zhang, J. (2012), “Bivariate Downscaling with Asynchronous Measurements,” Journal of Agricultural, Biological, and Environmental Statistics, 17, 476–489.
- Jansen, R. and van Dijk, R. (2002), “Optimal Benchmark Tracking with Small Portfolios,” The Journal of Portfolio Management, 28, 33–39.
- Karian, Z., and Dudewicz, E. (1999), “Fitting the Generalized Lambda Distribution to Data: A Method Based on Percentiles,” Communications in Statistics: Simulation and Computation, 28, 793–819.
- Kiefer, J. (1970), “Deviations Between the Sample Quantile Process and the Sample DF,” in Nonparametric Techniques in Statistical Inference ed. M. L. Puri, pp. 299–319, London: Cambridge University Press.
- Koenker, R. (2005), Quantile Regression, Cambridge: Cambridge University Press.
- Kosorok, M.R. (1999), “Two-Sample Quantile Tests Under General Conditions,” Biometrika, 86, 909–921.
- Kulik, R. (2007), “Bahadur-Kiefer Tample Quantiles of Weakly Dependent Linear Processes,” Bernoulli, 13, 1071–1090.
- Lamont, O.A. (2001), “Economic Tracking Portfolios,” Journal of Econometrics, 105, 161–184.
- Mallows, C.L. (1972), “A Note on Asymptotic Joint Normality,” The Annals of Mathematical Statistics, 43, 508–515.
- Massart, P. (1990), “The Tight Constant in the Dvoretzky-Kiefer-Wolfowitz Inequality,” The Annals of Probability, 18, 1269–1283.
- O’Brien, T.P., Sornette, D., and McPherro, R.L. (2001), “Statistical Asynchronous Regression Determining: The Relationship Between Two Quantities that are not Measured Simultaneously,” Journal of Geophysical Research, 106, 13247–13259.
- Serfling, R.J. (1980), Approximation Theorems of Mathematical Statistics, New York: Wiley.
- Small, C., and McLeish, D. (1994), Hilbert Space Methods in Probability and Statistical Inference, New York: Wiley.
- Tanaka, H. (1973), “An Inequality for a Functional of Probability Distribution and its Application to Kac’s One-Dimensional Model of a Maxwellian Gas,” Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete, 27, 47–52.
- Wu, C. F.J. (1983), “On the Convergence Properties of the EM Algorithm,” The Annals of Statistics, 11, 95–103.
APPENDIX I: PROOF OF THEOREM 2
We split the proof of Theorem 2 into several lemmas.
Lemma A.1.
Under Conditions B(i) and (ii), nτ{Sn(β) − S(β)} → 0 in probability for any fixed β and τ < 1/2.
Proof.
Put W = β′X. By (Equation4.7) and (Equation4.8
),
where Rn = OP(n− 1/4(log n)1/2(log log n)1/4) = oP(1). By the Dvoretzky-Kiefer-Wolfowitz inequality (Massart Citation1990), it holds for any constant C > 0 and any integer n ⩾ 1 that
Let
for some τ1 ∈ (τ/2, 1/4), and
Then by (EquationA.2
),
, and on the set An,
which is guaranteed by Condition B(ii) and the fact that
Note that
as |Y|I{GY(α1) < Y ⩽ GY(α2)} is bounded under Condition B(ii). See also condition B(iii) and Remark 3(iii).
Under Condition B(ii), |QY(α) − QY(j/n)| = fY(j/n)− 1/n{1 + o(1)} for any |α − j/n| ⩽ 1/n. Hence
Combining this with (EquationA.3
), we obtain the required result.
Lemma A.2.
Let a1 ⩽ ⋅⋅⋅ ⩽ an be n real numbers. Let bi = ai + δi for i = 1, …, n, and δi are real numbers. Thenwhere b(1) ⩽ ⋅⋅⋅ ⩽ b(n) is a permutation of {b1, …, bn}.
Proof.
We use the mathematical induction to prove the lemma. Let ε = max j|δj|. It is easy to see that (EquationA.4) is true for n = 2. Let it be also true for n = k. We now prove it for n = k + 1.
Let ci = bi for i = 1, …, k. Then by the induction assumption,If bk + 1 = ak + 1 + δk + 1 ⩾ c(k), the required result holds. However, if for some 1 ⩽ i < k,
then
Note that |bk + 1 − ai + 1| ⩽ ε since
The second expression above is implied by (EquationA.5
).
On the other hand, for j = i + 2, …, k + 1, we need to show that |c(j − 1) − aj| ⩽ ε. This is true, as c(j − 1) ⩽ aj − 1 + ε ⩽ aj + ε, and furthermore
Hence |b(j) − aj| ⩽ ε for all 1 ⩽ j ⩽ k + 1. This completes the proof.
Lemma A.3.
Let Condition B hold. Let be any compact subset of Rp. It holds that
converges to 0 in probability.
Proof.
We denote by ||β|| the Euclidean norm of vector β, and |β| = ∑j|βj|. Note that S(β) is a continuous function in β. For any ε > 0, there exist , where m is finite, such that for any
, there exists 1 ⩽ i ⩽ m for which
where M > 0 is a constant such that ||x|| < M for any fX(x) > 0; see Condition B(iii). Thus
Now it follows from Lemma A.2 that
in probability. This limit can be verified in the similar manner as in the proof of Lemma A.1. Consequently, there exists a set A with P(A) ⩾ 1 − ε such that on the set A it holds that
where C > 0 is a constant. Now on the set A,
See (EquationA.6
). Hence it holds on the set A that
Now the required convergence follows from Lemma A.1.
Proof of Theorem 2.
Under Condition B(ii), YI{QY(α1) ⩽ Y ⩽ QY(α2)} is bounded. As X is also bounded, the MQE defined in (Equation4.2
) is also bounded. Let
be a compact set which contains
with probability 1.
By (Equation4.1) and (Equation4.2
),
Now it follows from Lemma A.3 that both Sn(β0) − S(β0) and
converge to 0 in probability. Hence,
also converges to 0 in probability.
For the second assertion, we need to prove that for any constant ϵ > 0. We now write
to indicate explicitly that the estimator is defined with the sample of size n. We proceed by contradiction. Suppose there exists an ϵ > 0 for which
Hence, there exists an integer subsequence nk such that limkP(Ak) = δ > 0, where Ak is defined as
Let
. Then
is a compact set which is ϵ-distance away from
. By the definition of
in (Equation4.4
),
where δ > 0 is a constant. By Lemma A.3, P(Bk) → 1 for
Now it holds on the set Ak∩Bk that
This contradicts to the fact that
converges to S(β0) in probability, which was established earlier. This completes the proof.
ACKNOWLEDGMENTS
We thank Professor Wolfgang Polonik for his helpful comments, in particular for drawing our attention to references Kiefer (Citation1970) and Kulik (Citation2007). We also thank the Editor and three reviewers for their critical and helpful comments and suggestions.
APPENDIX II: THE NAMES OF SYMBOLS OF THE 30 STOCKS USED IN TRACKING FTSE100