
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We develop scalable methods for fitting penalized regression spline based generalized additive models with of the order of 104 coefficients to up to 108 data. Computational feasibility rests on: (i) a new iteration scheme for estimation of model coefficients and smoothing parameters, avoiding poorly scaling matrix operations; (ii) parallelization of the iteration’s pivoted block Cholesky and basic matrix operations; (iii) the marginal discretization of model covariates to reduce memory footprint, with efficient scalable methods for computing required crossproducts directly from the discrete representation. Marginal discretization enables much finer discretization than joint discretization would permit. We were motivated by the need to model four decades worth of daily particulate data from the U.K. Black Smoke and Sulphur Dioxide Monitoring Network. Although reduced in size recently, over 2000 stations have at some time been part of the network, resulting in some 10 million measurements. Modeling at a daily scale is desirable for accurate trend estimation and mapping, and to provide daily exposure estimates for epidemiological cohort studies. Because of the dataset size, previous work has focused on modeling time or space averaged pollution levels, but this is unsatisfactory from a health perspective, since it is often acute exposure locally and on the time scale of days that is of most importance in driving adverse health outcomes. If computed by conventional means our black smoke model would require a half terabyte of storage just for the model matrix, whereas we are able to compute with it on a desktop workstation. The best previously available reduced memory footprint method would have required three orders of magnitude more computing time than our new method. Supplementary materials for this article are available online.
1. Introduction
This article proposes a method for estimating generalized additive models (a particular class of Gaussian latent process models) for much larger datasets and models than has hitherto been possible. For our application we achieve a three order of magnitude speed up relative to previous big data GAM methods (e.g., Wood, Goude, and Shaw Citation2015). Our new method rests on three innovations: (i) an efficient new fitting iteration, employing a minimal number of matrix operations all of which scale reasonably well, (ii) OpenMP based parallelization of these matrix operations, and (iii) a novel marginal covariate discretization scheme, enabling compact model representation and efficient computation of key matrix crossproducts. These three elements work together, and dropping any one of them leads to an increase in fitting time of an order of magnitude or more.
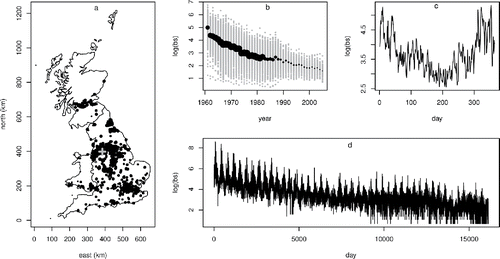
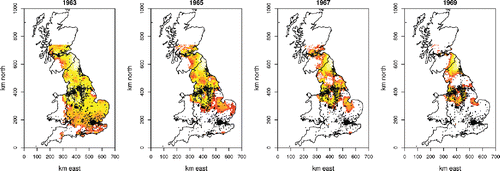
We are motivated by a practical problem in spatial epidemiology: the local estimation of short-term exposure to air pollution, based on monitoring network data. Specifically we focus on the United Kingdom Black Smoke (BS) monitoring network, which collected daily data on (micrograms per cubic meter) of BS particulates (largely from coal and Diesel combustion) from 1961 to 2005. The U.K. BS network fluctuated in size with different stations being added and removed over time, peaking at 1269 stations in 1967 but declining to 73 stations by 2005. (a) shows the network in 1967, indicating the average log BS measurements in that year. The other panels in illustrate the temporal patterns in the data, and in the network size. In total the data comprise 9,451,232 daily measurements from 2862 monitoring sites.
Figure 1. (a) The U.K. Black Smoke Network monitoring network at its largest in 1967. Symbol sizes are proportional to annual average log black smoke. (b) Annual average log black smoke against year. Black dots are averages over space, with dot size proportional to network size. Gray dots are station averages. (c) Daily averages for 1967, across all stations shown in (a). (d) All daily measurements for the longest running site, shown as a gray “+” in (a).
Because of the data volume, previous attempts to model spatiotemporal patterns in the BS data have focused on annual averages (e.g., Shaddick and Zidek Citation2014). This is not entirely satisfactory from an epidemiological perspective, since acute respiratory disease is usually sensitive to exposure to high levels of pollution over short time periods, and such exposure can be completely hidden in an annual average. Retrospective cohort studies, for example, really require estimates of exposure at the daily level, rather than annual averages, if they are to successfully uncover acute effects. This difference between acute and long-term exposure is also reflected in the health guidelines, with EU regulations currently stipulating that annual average exposure should not exceed while daily peak exposure should not exceed
.
Given the data volume, an obvious option is not to model, but simply to estimate daily exposure directly from the raw measurement, but this is a poor option for several reasons. First, the network design is not random but shows a type of preferential sampling (Shaddick and Zidek Citation2014), so that a design based approach to exposure estimation will result in bias, which is only avoidable by taking a model-based approach. Second, the reduced number of stations later in the data make spatial predictions difficult without a model that is able to share information across years. Third, there are strong covariate effects.
We will end up using a model structure
(1)
(1) where
,
and
denote, year, day of year, and day of week;
and
denote location as kilometers north and east;
and
are height (elevation of station) and cube root transformed rainfall (unfortunately only available as monthly average);
and
are daily minimum and maximum temperature, while
and
are daily mean temperature on and two days previously; αk(i) is a fixed effect for the site type k of the
observation (type is one of R (rural), A (industrial), B (residential), C (commercial), D (city/town center), X (mixed), or M (missing));
is a random effect for the
station, while ei is a Gaussian error term following an AR process at each site.
Using reduced rank spline basis expansions for the terms in (Equation1(1)
(1) ) requires around 8000 model coefficients. So estimating the model as a penalized GLM in the manner of Wood (Citation2011) would require half a terabyte of storage just for the model matrix and is clearly infeasible. Our original intention was to use the method of Wood, Goude, and Shaw (Citation2015) (available in R package mgcv) or to follow Shaddick and Zidek (Citation2014) in using the method of Rue, Martino, and Chopin (Citation2009) (via the INLA package), however this proved not to be feasible. Even if the computational load had been acceptable in terms of execution time, our experiments with smaller models and datasets suggested that INLA would require more than the 128Gb of memory that we had available. The Wood, Goude, and Shaw (Citation2015) method would have been possible in terms of memory footprint, but we estimated that fitting would have taken in excess of a month of computing time (12 core Xeon E5-2670 2.3 GHz CPU), even using an enhanced efficiency version of the method employing some of the ideas from the current article for REML smoothing parameter selection. Using just the published method would have required approximately five times as long.
After reviewing model representation in Section 2, we develop a practical fitting method in Sections 3 and 4, which reduces the fitting time for model (Equation1(1)
(1) ) to under an hour. The novel developments that allow this are covered in Section 4 and appendix A. Sections 5 and 5.1 then discuss the black smoke modeling in more detail.
2. Model Class and Representation
We first review the class of generalized additive models (GAM) introduced by Hastie and Tibshirani (Citation1986, Citation1990) (see also Wahba Citation1990), relating a univariate response, yi to predictors xji (which may be vector). A GAM has the structure
(2)
(2) μi = E(yi), EF denotes an exponential family distribution with known or unknown scale parameter φ, g is a known smooth monotonic link function, A(i, : ) the
row of any parametric model matrix, and
the corresponding parameter vector. The fj are unknown smooth functions to be estimated (and must usually be subjected to sum-to-zero identifiability constraints).
For estimation purposes we adopt the widely used approach of representing the unknown functions using reduced rank smoothing splines. Full smoothing splines arise from solving variational problems. For example, the cubic spline problem seeks f, from some reproducing kernel Hilbert (or appropriate Sobolov) space, to minimize ∑ni = 1{yi − f(xi)}2 + λ∫f′′(x)2dx (λ is a smoothing parameter). The result can be represented in terms of an explicit n-dimensional basis, while the spline penalty becomes a quadratic penalty on the basis coefficients. However, since, at latest, Wahba (Citation1980) and Parker and Rice (Citation1985), it has been recognized that an n-dimensional basis representation is computationally wasteful for negligible statistical gain and use of a k ≪ n dimensional basis is often preferable. Theoretical work by Gu and Kim (Citation2002), Hall and Opsomer (Citation2005), Li and Ruppert (Citation2008), Kauermann, Krivobokova, and Fahrmeir (Citation2009), Claeskens, Krivobokova, and Opsomer (Citation2009) and Wang, Shen, and Ruppert (Citation2011) show that the reduced rank approach is well founded, with k needing to grow only rather slowly with sample size (e.g., k = O(n1/5) for a cubic spline under REML smoothness estimation).
A rich variety of reduced rank model terms are available in addition to cubic splines. Examples are the P-splines of Eilers and Marx (Citation1996); Marx and Eilers (Citation1998); Ruppert, Wand, and Carroll (Citation2003), and adaptive variants (e.g., Wood Citation2011), as well as the isotropic thin plate and other Duchon splines (Duchon Citation1977), for which rank reduction is conveniently performed by the eigen method of Wood (Citation2003). Reduced rank tensor product splines (e.g., Eilers and Marx Citation2003; Wood Citation2006) are important for representing smooth interactions, splines on the sphere (Wahba Citation1981) and Gaussian process smoothers (Kammann and Wand Citation2003; Handcock, Meier, and Nychka Citation1994) are useful in some spatial applications. In all cases if we can write
where Xj is an n × pj model matrix for the smooth, containing its basis functions evaluated at the observed xj values.
is the corresponding coefficient vector. The smoothing penalty for fj can then be written
, where
contains known coefficients. Since the individual fj in (Equation2
(2)
(2) ) are only estimable to within an intercept term, identifiability constraints need to be applied. As discussed in Wood, Scheipl, and Faraway (Citation2013) the sum-to-zero constraints, ∑ifj(xji) = 0 have the advantage of leading to narrow confidence intervals on the constrained fj, and it is easy to reparameterize to incorporate the constraints directly into Xj and
(which, respectively, lose a column, and a row and column in the process).
It is then straightforward to create a single n × p model matrix X = (A, X1, X2, …) with corresponding combined parameter vector . Given some smoothing parameters
a combined smoothing penalty could then be written as
, where Sj is simply a zero padded version of
and Sλ = ∑jλjSj. Hence, we have an overparameterized GLM structure,
. Given smoothing parameters it is estimated via
(3)
(3) This penalized likelihood approach (e.g., Green and Silverman Citation1994) can be viewed as a reasonable approach in its own right. An alternative is to view penalization as the expression of a belief that “smooth is more probable than wiggly” and to express this using the (improper) prior
where S−λ is a Moore-Penrose pseudoinverse (Sλ being rank deficient because the penalties leave some space of functions unpenalized, and in any case do not penalize the fixed effects). In that case
is the MAP estimator of
, and it is clear that we can view the GAM as a Gaussian latent random field model (see Kimeldorf and Wahba Citation1970; Wahba Citation1983; Silverman Citation1985; Fahrmeir and Lang Citation2001; Ruppert, Wand, and Carroll Citation2003, etc.). The smoothing parameters,
, can be estimated by generalized cross-validation or similar (e.g., Craven and Wahba Citation1979), but Reiss and Ogden (Citation2009) showed that a (restricted) marginal likelihood approach (e.g., Wood Citation2011) offers practical reliability advantages, in being less prone to multiple local optima and consequent undersmoothing.
3. The Fitting Iteration
The purpose of this article is to allow the rich existing modeling framework, described in Section 2, to be used with much larger models and datasets than has hitherto been possible, by providing substantially new scalable fitting methods. The new methods are based on the performance iteration (Gu Citation1992) or PQL (Breslow and Clayton Citation1993) approach to model fitting, modified to obtain reasonable scalability. Before introducing the modifications, we motivate the basic approach and provide an alternative justification for its use, suited to penalized regression.
It is readily shown that maximization of (Equation3(3)
(3) ) by Fisher scoring is equivalent to the following penalized iteratively reweighted least squares (PIRLS) scheme. Initialize
and
where δi is a small constant (often zero) chosen to ensure
exists. Then iterate the following to convergence
| 1. | Form “pseudodata” | ||||
| 2. | By penalized least squares, estimate | ||||
Now let us eliminate the false assumption of normality of z, replacing it with central limit theorem justification. Consider the QR decomposition , where
has orthogonal columns and
is upper triangular (this decomposition is purely a theoretical device, nowhere in the new methods below do we actually need to compute a QR decomposition). Define
, r = ‖z‖2w − ‖f‖2. In that case
,
, and we have the alternative working model
(6)
(6) where the multivariate central limit theorem justifies e ∼ N(0, Iφ) as an n/p → ∞ approximation. The twice negative log restricted marginal likelihood for this model is
For a given φ,
and
differ only by an additive constant, and therefore result in identical inference about
and
. Inference about φ would of course differ, since r carries information about φ, but if we plug the Pearson estimate (Equation5
(5)
(5) ) into
then we obtain identical inference to that obtained by simply using
for φ and
. This justifies use of (Equation4
(4)
(4) ) for
estimation.
Note that once the coefficients and smoothing parameters are estimated, further inference can be based on the large sample Bayesian result,
(7)
(7) which turns out to provide well calibrated frequentist inference (Wahba Citation1983; Silverman Citation1985; Nychka Citation1988; Marra and Wood Citation2012; Wood Citation2013).
4. A Practical Fitting Method
Implementation of the fitting iteration of Section 3 is limited by several practical considerations.
| 1. | For the target datasets and models, it is impractical to explicitly form X whole. | ||||
| 2. | The log determinant terms in | ||||
| 3. | For maximal efficiency it is not sensible to optimize | ||||
| 4. | The update step for | ||||
Wood, Goude, and Shaw (Citation2015) addressed 1 by iteratively updating the QR factorization of X, and then applying the method of Wood (Citation2011) to (Equation6(6)
(6) ). This approach ignored 3, requires pivoted QR decomposition and addressed 2 by stabilizing reparameterizations involving p × p symmetric eigen decomposition: the QR and eigen decompositions do not scale well. For example the state of the art block pivoted QR decomposition of Quintana-Ortí, Sun, and Bischof (Citation1998), only has around half the floating point operations as matrix-matrix computations. In consequence the Wood, Goude, and Shaw (Citation2015) was computationally impractical for the black smoke model. See appendix C for a discussion of the issues around multicore computing.
Our proposal here addresses 3 by taking a single Newton step to update at each cycle of the iteration (rather than fully optimizing
at each cycle). We propose to avoid the stabilizing reparameterization step by avoiding evaluation of the log determinants altogether (hence, addressing 2). This is based on the observation that the Newton step,
, only involves the derivative of
, and the derivatives of the log determinants are less numerically problematic. Evaluation of
is usually required to ensure that the Newton step results in an improvement of
. We cannot skip such a check, but we can substitute the alternative check that
, that is, that
is nonincreasing in the direction of
at the end of the Newton step (see, e.g., Wood, Citation2015, sec. 5.1.1).
Adopting this approach we find that the derivatives of can be obtained using simple matrix operations and a pivoted Cholesky decomposition of
, which can be accumulated blockwise, thereby dealing with 1. Lucas (Citation2004) provides a block oriented pivoted Cholesky decomposition readily parallelized using openMP (OpenMP Architecture Review Board, Citation2008), which deals with point 4. The resulting method has the further advantage that, with some further work, it turns out to be possible to produce further substantial efficiency savings by discretization of the model covariates (see Section 4.5).
4.1. The Modified Fitting Iteration
Based on the above considerations, the proposed fitting iteration is as follows. Its convergence properties are discussed in Appendix B.
Perform the term by term reparameterization described in Section 4.3.
Initialize
,
Repeat...
| 1. | Accumulate | ||||
| 2. | Test for convergence, terminate if achieved. | ||||
| 3. | Except at iteration one, if | ||||
| 4. |
| ||||
| 5. |
| ||||
| 6. | Given | ||||
| 7. | If | ||||
| 8. |
| ||||
Note that Step 1 does not require the explicit formation of the whole matrix X. Step 3 reduces the step taken if the Newton step was too long, in that it increased the penalized deviance at the
value at which it was computed. Step 5 reduces the
step if it was so long that the REML score was increasing at the end of the step. When log φ is unknown it can be included as an extra element of
.
Step 6 consists of estimating the implied by the proposed
and the current W and z. Further more the marginal likelihood of the working penalized linear model is uses as a smoothing parameter estimation criterion, and the gradient vector of this criterion along with the first Newton step for optimizing it are also computed. The next sections detail how Step 6 is accomplished.
4.2. The REML Update
Now consider the calculation of the Newton step, , to improve (Equation4
(4)
(4) ). We have that
is the solution of
. The actual computation proceeds by taking a Cholesky decomposition
using a parallel version of Lucas (Citation2004). This is usually done with pivoting, in which case the rank of R is then estimated and unidentifiable parameters set to zero and dropped from subsequent computations. We then compute
(by backward and forwards substitution). In what follows “pivoting” and “unpivoting” refer to the application of the Cholesky pivoting order and its reversal.
The Newton step is , where
will have been perturbed if necessary to ensure definiteness (see Nocedal and Wright Citation2006). Recalling that
, we have
(8)
(8) and, defining δjk = 1 if k = j and 0 otherwise,
Implicit differentiation implies that
This latter computation is most efficient if
is first unpivoted,
is formed and this is then repivoted: the block structure of Sj (see next section) can then be be exploited. The next two sections cover computation of the derivatives of the log determinants.
4.3. Computing The Derivatives Of log |Sλ|+
Sλ has block diagonal structure that can be exploited. For example, denoting zero blocks by ‘.’,
That is there are some blocks with single smoothing parameters, and others with a more complicated additive structure. There are usually also some zero blocks on the diagonal. The block structure means that the generalized determinant and its derivatives w.r.t. ρk = log λk can be computed blockwise. Note in particular that, for the above example,
For any ρk relating to a single parameter block we have
and zero second derivatives. For multi-λ blocks there will generally be first and second derivatives to compute. There are no second derivatives “between-blocks.” To facilitate computations some prefit reparameterization is undertaken, according to the type of block.
| 1. | Single parameter diagonal blocks. These can be reparameterized so that all nonzero elements are one, and the rank precomputed. | ||||
| 2. | Single parameter dense blocks. These can be reparameterized to look like the previous type, by similarity transform, again computing rank. | ||||
| 3. | Multi-λ blocks are transformed so that ∑jλjSj has full rank in the new parameterization. Again a similarity transform is used. Typically the Sj are of smaller dimension in the reparameterization and consequently an extra zero block is introduced on the diagonal of Sj. | ||||
The generalized determinant of type 3 blocks becomes an ordinary determinant of ∑jλjSj after reparameterization. Hence, its derivatives follow from the standard result
4.4. Computing The Derivatives of
The following computations build on the Cholesky decomposition of the previous sections
| 1. | Form P = R− 1, and unpivot the rows of P. Then form | ||||
| 2. | Form the matrices containing the nonzero rows of | ||||
| 3. | Compute the required derivatives using
| ||||
Note that , the Bayesian covariance matrix.
The trace computations in step 3 are very efficient, given the block structure of the Sk, if we employ the following tricks. In general . Now let A have nonzero rows only between k1 and k2, while B has nonzero rows only between j1 and j2.
Of course normally the initial zero rows would not actually be stored in which case we have
4.5. The Model Matrix: Efficient Storage and Computation
We are interested in computing with models in which it is impractical to store the whole model matrix, and in which computing the required matrix cross product may be prohibitively expensive. For this reason we discretize the model covariates so that the columns of the model matrix corresponding to a single smooth term can be stored in compact form. Specifically, suppose that the covariate for the jth term is discretized into m discrete values, then the model matrix columns for that term can be written as
where
has only m rows and k is an index vector. Storing
and k uses much less memory than storing Xj directly. This idea is introduced in Lang et al. (Citation2014) to obtain efficient storage and computation for large datasets. However, in that article they employ smooths of one covariate and only require terms of the form
, but not
. For smoothing parameter estimation we require these “off diagonal” product terms as well. In addition we require tensor product smooths of multiple covariates. Discretizing multiple covariates onto multidimensional grids requires either substantial storage or substantial approximation error, and in the tensor product context it makes sense to instead discretize each component marginal model matrix separately, constructing the full tensor product model matrix “on the fly.”
Appendix A develops the identities and algorithms required to compute with X and its products when the submatrices of X corresponding to individual terms are stored compactly, and when tensor product terms are computed “on-the-fly” from compactly stored marginal model matrices. With the correct structuring each matrix inner product is a factor of p faster than it would be under direct computation, where p is the number of columns in the largest marginal model matrix involved in the product and for nontensor product smooths their only model matrix is their single model matrix. The crucial advance over Lang et al. (Citation2014) is the ability to deal with tensor product smooths efficiently, and to compute the off diagonal crossproducts efficiently (between single smooths, tensor product smooths or a mixture of the two). Our method has the major advantage over alternative discretization approaches (e.g., Helwig and Ma Citation2016) of discretizing covariates independently (marginally), rather than discretizing jointly so that the unique combinations of discretized covariates are stored (or the basis functions evaluated at those unique combinations). The joint approach typically requires more storage, and/or coarser discretization than our fully marginal approach.
An obvious question is how fine a discretization is necessary? Suppose we discretize n observations of covariate x onto a regular grid of m values (just covering the x range). In the large m limit an upper bound on the resulting approximation error is 0.5m− 1max |g′(x)| where g is the true function we are trying to recover. The sampling error on the estimate of g is at best O(n− 1/2), implying that m = O(n1/2) is more than adequate. For any finite sample analysis the approximation error bound can be evaluated to check the adequacy of m. Note however, that for the black smoke network data, many covariates are already discrete: for example, there are only a finite number of site locations, site labels and elevations, temperature is only recorded to within 0.1°C, etc.
5. Black Smoke Model Development
Followingthe industrial revolution, problems associated with air pollution worsened in many countries. During the first half of the 20th century major pollution episodes occurred in London, notably in 1952 an episode of fog, in which levels of black smoke exceeded 4500 μg m− 3, was associated with 4000 excess deaths (Ministry of Health Citation1954). Other early episodes, which were caused by a combination of industrial pollution sources and adverse weather conditions, and resulted in large numbers of deaths among the surrounding populations, include those in the Meuse valley (Firket Citation1936) and the United States (Ciocco and Thompson Citation1961). Attempts to measure levels of air pollution in a regular and systematic way arose as a result of these episodes. In 1961 the world's first coordinated national air pollution monitoring network was established in the United Kingdom, to monitor black smoke and sulphur dioxide at around 1000 sites (Clifton Citation1964). Since then all European countries have established monitoring networks, some of them run at the national level, others by local authorities or municipalities, with the initial focus on black smoke (soot) and sulfur dioxide, initially largely from coal burning but shifting more recently to other pollutants. Monitoring has increased in the wake of national and international legislation and the issuing of air quality guidelines, but most monitoring networks share features of the U.K. BS network that challenge the interpretation of the data for epidemiological and policy purposes: (i) monitoring is expensive and so monitoring networks are typically sparse and change over time, (ii) concentrations may vary greatly over small distances, especially in urban areas and (iii) networks designed to monitor compliance with standards, may not give a good representation of levels over an area. Modeling offers the possibility to alleviate these problems, at least partially, and our approach to the U.K. black smoke data should be applicable to other monitoring networks.
In addition to the Black smoke data (Loader Citation2002), we obtained daily temperature and monthly rainfall data for the United Kingdom (Perry and Hollis Citation2005b, Citation2005a) to use as covariates, alongside site elevation (of Terrain-50 Citation2015). Given the volume of data, our initial exploratory model development concentrated first on modeling space without time, and then time without space. In this way we were able to develop candidate temporal decompositions (in terms of year, day of year, and day of week), and candidate models for covariates and space, which were then combined while allowing space and time effects to interact.
Our basic approach was first to decompose the black smoke signal into components dependent on different temporal scales: year (y) for the long term changes, day of year (doy) for the annual cycle and day of week (dow) for the working week related cycle. These are represented by f1 − f3 in model (Equation1(1)
(1) ). These effects were all allowed to interact: for example, the weekly pattern could change with time of year, and over longer timescales. These interactions are f4 − f6 in model (Equation1
(1)
(1) ). We then allowed the effects of year, time of year and day of the week to vary spatially (terms f8 − f10), as well as allowing a “main effect” of space, f7. Elevation and rainfall effects f11 and f14 were also included alongside effects for site type and a site specific random effect. Residual analysis for a model including only these effects suggested strong temperature dependence, with an interaction of daily minimum and maximum temperatures (f12). Including this latter term still left a correlation with mean temperatures at lags of one and two days, resulting in f13.
Main effects of time were represented using cubic regression splines for y and cyclic cubic regression splines for doy and dow. Tensor product smooths (e.g., Wood Citation2006) were used for the interactions. In cases in which smooth main effects and interactions were present, then the interaction smooths were constructed to exclude the main effects, by the simple expedient of applying sum-to-zero constraints to the marginal bases of the tensor product smooth, prior to construction of the tensor product basis. Space time interaction terms follow Augustin et al. (Citation2009), that is tensor product smoothers with isotropic smoothers used for the spatial marginal smooth and cubic splines for the temporal margin.
Due to the marked reduction in the size of the network in its last decade, and the uneven spatial coverage, some care is required in the specification of the two-dimensional spatial smoothers of n and e, to avoid extrapolation artifacts in later years. We chose to use Duchon splines (see Duchon Citation1977; Miller and Wood Citation2014), using first derivative penalties with Duchon’s s parameter therefore set to 1/2. The use of first derivative penalties means that such smoothers are smoothing toward the constant function, which is a reasonable modeling assumption for black smoke data in sparsely observed regions. Duchon splines are the general class of splines introduced in Duchon (Citation1977) of which the popular thin plate spline is a special case: see Miller and Wood (Citation2014) for an accessible introduction. For comparison we also tried Gaussian process smoothers with a Matérn covariance function following Kammann and Wand (Citation2003) and Handcock, Meier, and Nychka (Citation1994), as well as thin plate splines, but in both cases basic model checking revealed artifacts in model predictions toward the end of the data. The online supplementary material includes an animation of predicted log black smoke, clearly illustrating such artifacts for the thin plate spline based model (the equivalent animation for the Duchon spline based model is also included).
Given our interest in using the model for prediction away from the stations, we aimed to keep the station specific random effects structure of the model as simple as possible, however it proved impossible to achieve an adequate fit without any random effects at all, and the model therefore includes a single random intercept term per station, reflecting the individual idiosyncrasies of station locations not captured by the available covariates.
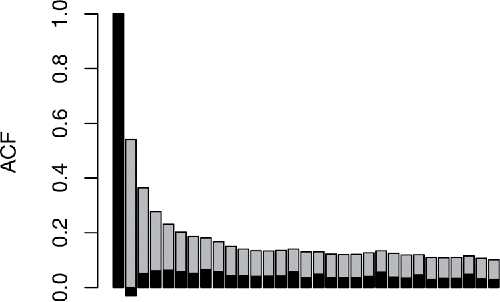
Modeladequacy was checked using standard residual plots, as well as autocorrelation function plots and semivariogram plots to check for unmodeled spatial and temporal correlation. and show such plots for model Equation1(1)
(1) , showing that the model does a reasonable job of capturing spatial and temporal correlation, in the data. Further plots are shown in the online supplementary material. To illustrate the importance of the weather variables and site-specific random effects, models were fitted without these leading to AIC increases of 1.6 × 106 and 2.4 × 106 for models without weather variables and the random effect, respectively (the corresponding r2 reductions were approximately 2% and 1%).
Figure 2. Semivariograms for the 40th (top row) and 200th (bottom row) days of years 1966, 76, 86, and 96, checking for residual spatial autocorrelation. Each plot shows the empirical semivariogram for the log black smoke measurements as black dots, with the corresponding reference bands under zero autocorrelation as black lines. The white dots and dotted lines show the equivalent for the residuals of model (Equation1(1)
(1) ). The reduction of the network in later years leads to wide reference bands, but in all plots the model appears to offer a reasonable representation of the spatial pattern.
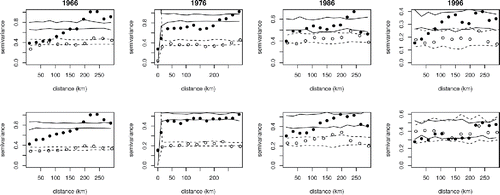
Figure 3. Aggregate ACF for model (Equation1(1)
(1) ) residuals assuming independent residuals in gray, with the equivalent for the standardized residuals assuming AR1 residuals, overlaid in black. While not perfect, the AR1 model greatly reduces the unmodeled temporal autocorrelation.
A concern with these data is that they show evidence of a type of preferential sampling (Shaddick and Zidek Citation2014): as the network was reduced over time, monitors in areas of low concentrations were more likely to be dropped than those in high pollution areas (note that this is different in nature to preferential sampling considered by Diggle, Menezes, and Su (Citation2010), for example). If we had a perfect model without penalties (smoothing priors) then this preferential sampling might reduce efficiency but would not introduce bias. However, when using penalties there is a danger that the reduction of the network so reduces the coverage over some space-time regions that the model predictions for these regions are dominated by the influence of the penalty. If the network reduction is subject to preferential sampling, then it is possible that these space-time regions are systematically those in which pollution is actually lowest, and that the reliance on the penalty/prior then introduces systematic positive bias.
To investigate the potential for such effects, we fitted a reduced model (Equation1(1)
(1) ) to the data from the year with the most complete spatial coverage, 1967, dropping all terms involving long-term effects of time. We also dropped the temperature and rainfall effects, to force the spatial effects to do as much of the explanatory work as possible. Using the actual network design (i.e., with stations added and dropped over time), we then simulated from a model in which the 1967 fitted model spatiotemporal pollution fields were repeated each year, but with a long-term decay matching the full dataset. Station-specific random effects were added with standard deviations as estimated from our fit of (Equation1
(1)
(1) ) to the full dataset. Further details are given in the online supplementary material. So our simulated data comes from a “truth” that maintains a degree of spatiotemporal complexity driven by the most “spatially complete” year throughout the simulated dataset, and in which the sampling is given by the real network evolution and, therefore, preferentially drops stations from low pollution regions of the simulation. We then fitted the complete model (Equation1
(1)
(1) ) to the simulated data, and examined its ability to reconstruct the simulated “true” pollution field at each of the locations of stations present in 1967, throughout the whole modeling period (i.e., without any drop out). If our model is sensitive to the preferential sampling evident in the network evolution, then we should be able to detect a positive bias in the full model predictions, which would be likely to grow over time. In fact we can only detect a very small constant bias of about 0.006 on the log scale (corresponding to a 0.6% bias on the original scale). There is no evidence for a trend in the bias: the online supplementary material includes a plot illustrating this and a fuller discussion.
5.1. Results and Predictions
The model (Equation1(1)
(1) ) has a conditional r2 of 0.79 (i.e., treating the AR process as induced by a random field), and a marginal r2 of 0.7 (i.e., ignoring the auto-regressive structure of the residuals). The online supplementary material includes an animation showing the evolution of the predicted spatial pollution field over time. Careful examination shows some artifacts in the fields, usually in coastal regions away from observation stations, but otherwise the results appear reasonable, predicting high pollution levels in the industrial centers especially in the first decade or so, generally showing cleaner air in wetter regions, and tending to show an annual cycle reflecting higher fossil fuel use in the winter.
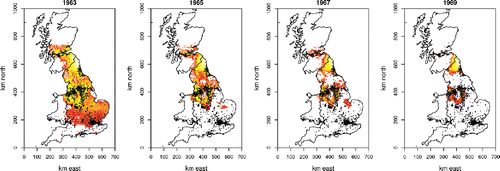
In thissection we illustrate the model results with two sets of plots examining how the chance of exceeding current daily recommended limits (213 ) has changed over time. shows the log of the number of days for which levels are predicted to exceed the daily limit, for a town center location, for several years in the 1960s. These figures are obtained by simply counting up predicted exceedance days by 5 km2.
Figure 4. Image plots of log predicted number of days exceeding the EU daily exposure threshold for town center locations for several years in the 1960s. By 1975 there were essentially no exceedance days predicted.
An alternative is to compute the average posterior probability of the mean exceeding the recommended level using the predicted level and its standard deviation, based on (Equation7(7)
(7) ). shows such a plot. Broadly both figures show the same pattern, with the situation improving rapidly in London in the wake of the U.K. Clean Air Acts, but taking much longer to improve in the cold northern industrial conurbations.
Figure 5. Image plots of log average probability of exceeding the EU daily exposure threshold for town center locations for several years in the 1960s. Red is -6 corresponding to less than one exceedance day expected per year, while the top of the scale is 0.
6. Discussion
Our development of scalable additive model fitting methods rests on three innovations: (i) the development of a fitting method which required only basic easily parallelized matrix computations and a pivoted Cholesky decompostion; (ii) the use of a scalable parallel block pivoted Cholesky algorithm; and (iii) an efficient approach to model matrix storage and computations with the model matrix, using discretized covariates. The approach allows much larger additive/latent Gaussian process models of much larger datasets than has hitherto been feasible, and is general enough for routine use (see R package mgcv). For the black smoke modeling, fitting is three orders of magnitude faster than we could have achieved otherwise.
The three method innovations are interlinked so that cleanly attributing elements of the speed up to each separately is not really possible. However, model fitting time increases from around 55 min to over 7.5 hr if we use a single core, instead of 12 (CPU turbo modes disabled to aid comparability). Using the new method, profiling reveals that the time spent on the matrix crossproduct is approximately equal to the time spent on the other method steps, for the black smoke model. From the operations counts in Appendix A the crossproduct is around a factor of 102 less floating point intensive using the new discrete methods relative to direct crossproduct formation, while the subleading order cost of basis function evaluation is up to 104 times less costly. Similarly the leading order costs of each smoothing parameter update can be compared. The Wood, Goude, and Shaw (Citation2015) method requires approximately 40 times the floating point operations per smoothing parameter update, due to O(p3) costs per smoothing parameter, coupled with a symmetric eigen decompositon and several QR steps. Hence, all three components of the new method are required to achieve the observed efficiency gains.
For discretization we chose to generalize the approach of Lang et al. (Citation2014), rather than attempt to use the grid-based approach of Currie, Durban, and Eilers (Citation2006). This is largely as a result of the very irregular nature of our “grids”: for example, the approach here avoids having to compute anything that will then be given zero weight as a result of data being missing at a grid node. However, our smoothing parameter selection method should be directly applicable to models fit using the Currie, Durban, and Eilers (Citation2006) approach (unlike, e.g., the approach of Wood (Citation2011)).
The Black smoke model presented here is the first successful attempt to model these data on a daily basis over several decades, and offers a basis for estimating daily exposures for use in retrospective cohort studies, for example. While a major advance, we do not believe that this model is definitive. For example, the only meteorological variables available to us on a daily basis were temperature, and the fact that we are forced to use monthly rainfall data offers an obvious area for improvement. The model as it stands shows some artifacts in coastal areas that we are working to improve. Another obvious deficiency is the lack of any pollution source data. One might expect substantial improvements if fine scale data on coal and diesel use were available as predictors.
The method is implemented in the bam function of R package mgcv from version 1.8-9, and is invoked via bam arguments discrete and nthreads. The black smoke data are available from the first author’s web page (http://www.maths.bris.ac.uk/∼sw15190/).
Supplementary Materials
Download Zip (12 MB)Supplementary Materials
The supplementary material contains further information on the data, model checking and preferential sampling. In addition, gigam2-AppBC.pdf contains appendices B and C of the paper, on covergence properties and parallel computing issues. Finally files tps.mp4 and duchon.mp4 contain movies showing the fitted model predictions for the whole UK.
Acknowledgments
We are grateful to the editor and anonymous referees for comments which substantially improved the article, to Electricité de France for funding background investigation of parallel computing methods, and to Yannig Goude for discussion of GAM scalable computing issues.
Funding
This work was funded by EPSRC grant EP/K005251/1 and a University of Bath studentship to ZL.
Related Research Data
References
- Augustin, N. H., Musio, M., von Wilpert, K., Kublin, E. Wood, S. N., and Schumacher, M. (2009), “Modeling Spatiotemporal Forest Health Monitoring Data,” Journal of the American Statistical Association, 104, 899–911.
- Breslow, N. E., and Clayton, D. G. (1993), “Approximate Inference in Generalized Linear Mixed Models,” Journal of the American Statistical Association, 88, 9–25.
- Ciocco, A., and Thompson, D. (1961), “A Follow-Up of Donora Ten Years After: Methodology and Findings,” American journal of Public Health Nations Health, 51, 155–164.
- Claeskens, G., Krivobokova, T. and Opsomer, J. D. (2009), “Asymptotic Properties of Penalized Spline Estimators,” Biometrika, 96, 529–544.
- Clifton, M. (1964), “Air Pollution,” Journal of the Royal Society of Medicine, 57, 615–618.
- Craven, P., and Wahba, G. (1979), “Smoothing Noisy Data With Spline Functions,” Numerische Mathematik, 31, 377–403.
- Currie, I. D., Durban, M. and Eilers, P. H. (2006), “Generalized Linear Array Models With Applications to Multidimensional Smoothing,” Journal of the Royal Statistical Society, Series B, 68, 259–280.
- Diggle, P. J., Menezes, R., and Su, T.-l. (2010), “Geostatistical Inference Under Preferential Sampling,” Journal of the Royal Statistical Society, Series C, 59, 191–232.
- Duchon, J. (1977), “Splines Minimizing Rotation-Invariant Semi-Norms in Solobev Spaces,” in Construction Theory of Functions of Several Variables, eds. W. Schemp and K. Zeller, Berlin: Springer, pp. 85–100.
- Eilers, P. H., and Marx, B. D. (2003), “Multivariate Calibration With Temperature Interaction Using Two-Dimensional Penalized Signal Regression,” Chemometrics and Intelligent Laboratory Systems, 66(2), 159–174.
- Eilers, P. H. C., and Marx, B. D. (1996), “Flexible Smoothing With B-Splines and Penalties,” Statistical Science, 11(2), 89–121.
- Fahrmeir, L., and Lang, S. (2001), “Bayesian Inference for Generalized Additive Mixed Models Based on Markov Random Field Priors,” Applied Statistics, 50, 201–220.
- Firket, J. (1936), “Fog Along the Meuse Valley,” Transactions of the Faraday Society, 32, 1191–1194.
- Green, P. J., and Silverman, B. W. (1994), Nonparametric Regression and Generalized Linear Models, London: Chapman & Hall.
- Gu, C. (1992), “Cross-Validating Non-Gaussian Data,” Journal of Computational and Graphical Statistics, 1, 169–179.
- Gu, C., and Kim, Y. J. (2002), “Penalized Likelihood Regression: General Approximation and Efficient Approximation,” Canadian Journal of Statistics, 34(4), 619–628.
- Hall, P., and Opsomer, J. D. (2005), “Theory For Penalised Spline Regression,” Biometrika, 92(1), 105–118.
- Handcock, M. S., Meier, K., and Nychka, D. (1994), “Comment,” Journal of the American Statistical Association, 89(426), 401–403.
- Hastie, T., and Tibshirani, R. (1986), “Generalized Additive Models” ( with discussion), Statistical Science, 1, 297–318.
- Hastie, T., and Tibshirani, R. (1990), Generalized Additive Models, London: Chapman & Hall.
- Helwig, N. E., and Ma, P. (2016), “Smoothing Spline Anova for Super-Large Samples: Scalable Computation Via Rounding Parameters,” arXiv preprint arXiv:1602.05208.
- Kammann, E. E., and Wand, M. P. (2003), “Geoadditive Models,” Applied Statistics, 52(1), 1–18.
- Kauermann, G., Krivobokova, T., and Fahrmeir, L. (2009), “Some Asymptotic Results on Generalized Penalized Spline Smoothing,” Journal of the Royal Statistical Society, Series B, 71, 487–503.
- Kimeldorf, G. S., and Wahba, G. (1970), “A Correspondence Between Bayesian Estimation on Stochastic Processes and Smoothing by Splines,” The Annals of Mathematical Statistics, 41, 495–502.
- Lang, S., Umlauf, N., Wechselberger, P., Harttgen, K., and Kneib, T. (2014), “Multilevel Structured Additive Regression,” Statistics and Computing, 24, 223–238.
- Li, Y., and Ruppert, D. (2008), “On the Asymptotics of Penalized Splines,” Biometrika, 95, 415–436.
- Loader, A. (2002), Instruction manual: UK Smoke and Sulphur Dioxide Network, Culham Science Centre: Netcen, AEA Technology.
- Lucas, C. (2004), “Lapack-Style Codes for Level 2 and 3 Pivoted Cholesky Factorizations,” LAPACK Working.
- Marra, G., and Wood, S. N. (2012), “Coverage Properties of Confidence Intervals for Generalized Additive Model Components,” Scandinavian Journal of Statistics, 39, 53–74.
- Marx, B. D., and Eilers, P. H. (1998), “Direct Generalized Additive Modeling With Penalized Likelihood,” Computational Statistics and Data Analysis, 28, 193–209.
- McCullagh, P., and Nelder, J. A. (1989), Generalized Linear Models ( 2nd ed.), London: Chapman & Hall.
- Miller, D. L., and Wood, S. N. (2014), “Finite Area Smoothing With Generalized Distance Splines,” Environmental and Ecological Statistics, 1–17.
- Ministry of Health, (1954), Mortality and Morbidity During the London Fog of December 1952, London: HMSO.
- Nocedal, J., and Wright, S. (2006), Numerical Optimization ( 2nd ed.), New York: Springer verlag.
- Nychka, D. (1988), “Bayesian Confidence Intervals for Smoothing Splines,” Journal of the American Statistical Association, 83, 1134–1143.
- of Terrain-50, C. (2015), OS Terrain 50: User Guide and Technical Specification, Adanac Drive, Southampton, SO16 0AS: Ordnance Survey.
- OpenMP Architecture Review Board (2008, May). OpenMP application program interface version 3.0.
- Parker, R., and Rice, J. (1985), Discussion of “Some Aspects of the Spline Smoothing Approach to Non-Parametric Regression Curve Fitting,” by Silverman, Journal of the Royal Statistical Society, Series B, 47, 40–42.
- Perry, M., and Hollis, D. (2005a), “The Development of a New Set of Long-Term Climate Averages for the UK,” International Journal of Climatology, 25, 1023–1039.
- Perry, M., and Hollis, D. (2005b), “The Generation of Monthly Gridded Datasets for a Range of Climatic Variables Over the UK,” International Journal of Climatology, 25, 1041–1054.
- Quintana-Ortí, G., Sun, X., and Bischof, C. H. (1998), “A BLAS-3 Version of the QR Factorization With Column Pivoting,” SIAM Journal on Scientific Computing, 19, 1486–1494.
- Reiss, P. T., and Ogden, T. R. (2009), “Smoothing Parameter Selection for a Class of Semiparametric Linear Models,” Journal of the Royal Statistical Society, Series B, 71, 505–523.
- Rue, H., S. Martino, and Chopin, N., (2009), “Approximate Bayesian Inference for Latent Gaussian Models by Using Integrated Nested Laplace Approximations,” Journal of the Royal Statistical Society, Series B, 71(2), 319–392.
- Ruppert, D., Wand, M. P., and Carroll, R. J. (2003), Semiparametric Regression, Cambridge, MA: Cambridge University Press.
- Shaddick, G., and Zidek, J. V. (2014), “A Case Study in Preferential Sampling: Long Term Monitoring of Air Pollution in the UK,” Spatial Statistics, 9, 51–65.
- Silverman, B. W. (1985), “Some Aspects of the Spline Smoothing Approach to Non-Parametric Regression Curve Fitting,” Journal of the Royal Statistical Society Series B, 47, 1–53.
- Wahba, G. (1980), “Spline Bases, Regularization, and Generalized Cross Validation for Solving Approximation Problems With Large Quantities of Noisy Data,” in Approximation Theory III, eds. E. Cheney, London: Academic Press.
- Wahba, G. (1981), “Spline Interpolation and Smoothing on the Sphere,” SIAM Journal on Scientific and Statistical Computing, 2, 5–16.
- Wahba, G. (1983), “Bayesian Confidence Intervals for the Cross Validated Smoothing Spline,” Journal of the Royal Statistical Society, Series B, 45, 133–150.
- Wahba, G. (1990), Spline Models for Observational Data, Philadelphia, PA: SIAM.
- Wang, X., J., Shen, and Ruppert,, D., (2011), “On the Asymptotics of Penalized Spline Smoothing,” Electronic Journal of Statistics, 5, 1–17.
- Wood, S. N. (2003), “Thin Plate Regression Splines,” Journal of the Royal Statistical Society, Series B, 65, 95–114.
- Wood, S. N. (2006), “Low-Rank Scale-Invariant Tensor Product Smooths for Generalized Additive Mixed Models,” Biometrics, 62, 1025–1036.
- Wood, S. N. (2011), “Fast Stable Restricted Maximum Likelihood and Marginal Likelihood Estimation of Semiparametric Generalized Linear Models,” Journal of the Royal Statistical Society, Series B, 73(1), 3–36.
- Wood, S. N. (2013), “On p-Values for Smooth Components of an Extended Generalized Additive Model,” Biometrika, 100, 221–228.
- Wood, S. N. (2015), Core Statistics, Cambridge, MA: Cambridge University Press.
- Wood, S. N., Goude, Y., and Shaw, S. (2015), “Generalized Additive Models for Large Data Sets,” Journal of the Royal Statistical Society, Series C, 64, 139–155.
- Wood, S. N., Scheipl, F., and Faraway, J. J. (2013), “Straightforward Intermediate Rank Tensor Product Smoothing in Mixed Models,” Statistics and Computing, 23, 341–360.
A. Methods for Discretized Covariates
This section describes the algorithms required to compute efficiently with marginally gridded covariates in detail. The idea is that we have a model matrix X = (X0: X1: ⋅⋅⋅). Each Xj represents either a single smooth, or a tensor product smooth (e.g. Wood Citation2006). In the case of a single smooth
(9)
(9) where
is an mj × pj matrix evaluating the smooth at the corresponding gridded values. For a tensor product
where Mjk are marginal model matrices and Qj is a constraint matrix, usually imposing a sum to zero constraint over a representative subset of the data. ⊙ denotes the Kronecker product (⊗) applied row-wise (i.e., one row at a time). In this case the marginal model matrices are stored in compact form:
The following algorithms are most efficient if tensor product terms are always arranged so that the marginal model matrix with the most columns is last, but this can be achieved by automatic rearrangement.
Note that in principle covariates could be discretized jointly onto a multidimensional grid, so that we store the unique combinations of covariates, rather than storing the unique covariate values independently. With the joint scheme the cross product is easy to compute. If
and
contain the unique model matrix rows and corresponding unique weights, respectively, while
is the diagonal matrix containing the number of occurrences of each now of
in X then
. The problem is that the number of unique combinations of covariates, and hence number of rows of
can be very large, unless very coarse discretisation is used. Hence the requirement for the methods of this appendix.
A variant of the scheme is required when the model contains terms of the form , where
If z is n × m, then
is n × nm, and the index vectors must be of length nm, which is also the number of rows in
(the model matrix for
). The regular case corresponds to
. Note that an L term can be treated as an extra single column tensor product marginal. A1, A2, A5 and A6, below, simply require
to be applied as the final step, while A3 and A4 require the extra work detailed.
The matrix products required in fitting require the following basic algorithms.
| A1 | Extraction of a single column of a single term Xj uses (Equation9 | ||||||||||||||||||||||
| A2 | Extraction of a single column of a tensor product term Xj. Let pk denote the number of columns of Mjk, and qk = ∏dj − 1i = k + 1pi, with | ||||||||||||||||||||||
| A3 | Single term | ||||||||||||||||||||||
| A4 | Tensor product term
| ||||||||||||||||||||||
| A5 |
| ||||||||||||||||||||||
| A6 |
| ||||||||||||||||||||||
The formation of then uses these basic algorithms as follows. First, if the final marginal of k has more columns than the final marginal of j then form
and transpose (a single smooth is its own marginal, of course). This maximizes efficiency, since the factor saved relative to direct formation is the dimension of the largest final marginal. The algorithm is then as follows.
| 1. | For i = 0, …, pk − 1…
| ||||||||||||||||||||||
| 2. | If the Xk is a tensor product then we may need to update
| ||||||||||||||||||||||
Q is usually implemented as a single Householder matrix, so that multiplication by Q is an efficient rank one update. Step one is easily parallelized using openMP (OpenMP Architecture Review Board Citation2008). Finally note that it is easy to substitute W with a banded matrix, such as the tri-diagonal precision matrix implied by an AR1 residual error model.
Prediction from the fitted model can use A5 and A6, but the computation of prediction variances also requires that we compute where V is a covariance matrix. This computation can also be built from A5 and A6 using the fact that