
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this article, we consider a high-dimensional quantile regression model where the sparsity structure may differ between two sub-populations. We develop ℓ1-penalized estimators of both regression coefficients and the threshold parameter. Our penalized estimators not only select covariates but also discriminate between a model with homogenous sparsity and a model with a change point. As a result, it is not necessary to know or pretest whether the change point is present, or where it occurs. Our estimator of the change point achieves an oracle property in the sense that its asymptotic distribution is the same as if the unknown active sets of regression coefficients were known. Importantly, we establish this oracle property without a perfect covariate selection, thereby avoiding the need for the minimum level condition on the signals of active covariates. Dealing with high-dimensional quantile regression with an unknown change point calls for a new proof technique since the quantile loss function is nonsmooth and furthermore the corresponding objective function is nonconvex with respect to the change point. The technique developed in this article is applicable to a general M-estimation framework with a change point, which may be of independent interest. The proposed methods are then illustrated via Monte Carlo experiments and an application to tipping in the dynamics of racial segregation. Supplementary materials for this article are available online.
1. Introduction
In this article, we consider a high-dimensional quantile regression model where the sparsity structure (e.g., identities and effects of contributing regressors) may differ between two sub-populations, thereby allowing for a possible change point in the model. Let be a response variable,
be a scalar random variable that determines a possible change point, and
be a p-dimensional vector of covariates. Here, Q can be a component of X, and p is potentially much larger than the sample size n. Specifically, high-dimensional quantile regression with a change point is modeled as follows:
(1.1)
(1.1) where (βT0, δ0T, τ0) is a vector of unknown parameters and the regression error U satisfies
for some known γ ∈ (0, 1). Unlike mean regression, quantile regression analyzes the effects of active regressors on different parts of the conditional distribution of a response variable. Therefore, it allows the sparsity patterns to differ at different quantiles and also handles heterogeneity due to either heteroscedastic variance or other forms of nonlocation-scale covariate effects. By taking into account a possible change point in the model, we provide a more realistic picture of the sparsity patterns. For instance, when analyzing high-dimensional gene expression data, the identities of contributing genes may depend on the environmental or demographical variables (e.g., exposed temperature, age, or weights).
Our article is closely related to the literature on models with unknown change points (e.g., Tong Citation1990; Chan Citation1993; Hansen Citation1996, Citation2000; Pons Citation2003; Kosorok and Song Citation2007; Seijo and Sen Citation2011a, Citation2011b; Li and Ling Citation2012, among many others). Recent articles on change points under high-dimensional setups include Enikeeva and Harchaoui (Citation2013), Chan, Yau, and Zhang (Citation2014), Frick, Munk, and Sieling (Citation2014), Cho and Fryzlewicz (Citation2015), Chan et al. (Citation2017), Callot et al. (Citation2017), and Lee, Seo, and Shin (Citation2016) among others; however, none of these articles consider a change point in high-dimensional quantile regression. The literature on high-dimensional quantile regression includes Belloni and Chernozhukov (Citation2011), Bradic, Fan, and Wang (Citation2011), Wang, Wu, and Li (Citation2012), Wang (Citation2013), and Fan, Fan, and Barut (Citation2014) among others. All the aforementioned articles on quantile regression are under the homogenous sparsity framework (equivalently, assuming that δ0 = 0 in (Equation1.1(1.1)
(1.1) )). Ciuperca (Citation2013) considered penalized estimation of a quantile regression model with breaks, but the corresponding analysis is restricted to the case when p is small.
In this article, we consider estimating regression coefficients α0 ≡ (βT0, δT0)T as well as the threshold parameter τ0 and selecting the contributing regressors based on ℓ1-penalized estimators. One of the strengths of our proposed procedure is that it does not require to know or pretest whether δ0 = 0 or not, that is, whether the population’s sparsity structure and covariate effects are invariant or not. In other words, we do not need to know whether the threshold τ0 is present in the model.
For a sparse vector , we denote the active set of v as J(v) ≡ {j: vj ≠ 0}. One of the main contributions of this article is that our proposed estimator of τ0 achieves an oracle property in the sense that its asymptotic distribution is the same as if the unknown active sets J(β0) and J(δ0) were known. Importantly, we establish this oracle property without assuming a perfect covariate selection, thereby avoiding the need for the minimum level condition on the signals of active covariates.
The proposed estimation method in this article consists of three main steps: in the first step, we obtain the initial estimators of α0 and τ0, whose rates of convergence may be suboptimal; in the second step, we reestimate τ0 to obtain an improved estimator of τ0 that converges at the rate of OP(n− 1) and achieves the oracle property mentioned above; in the third step, using the second step estimator of τ0, we update the estimator of α0. In particular, we propose two alternative estimators of α0, depending on the purpose of estimation (prediction vs. variable selection).
The most closely related work is Lee, Seo, and Shin (Citation2016). However, there are several important differences: first, Lee, Seo, and Shin (Citation2016) considered a high-dimensional mean regression model with a homoscedastic normal error and with deterministic covariates; second, their method consists of one-step least-square estimation with an ℓ1 penalty; third, they derive nonasymptotic oracle inequalities similar to those in Bickel, Ritov, and Tsybakov (Citation2009) but do not provide any distributional result on the estimator of the change point. Compared to Lee, Seo, and Shin (Citation2016), dealing with high-dimensional quantile regression with an unknown change point calls for a new proof technique since the quantile loss function is different from the least-square objective function and is nonsmooth. In addition, we allow for heteroscedastic and nonnormal regression errors and stochastic covariates. These changes coupled with the fact that the quantile regression objective function is nonconvex with respect to the threshold parameter τ0 raise new challenges. It requires careful derivation and multiple estimation steps to establish the oracle property for the estimator of τ0 and also to obtain desirable properties of the estimator of α0. The technique developed in this article is applicable to a general M-estimation framework with a change point, which may be of independent interest.
One particular application of (Equation1.1(1.1)
(1.1) ) comes from tipping in the racial segregation in social sciences (see, e.g., Card, Mas, and Rothstein Citation2008). The empirical question addressed in Card, Mas, and Rothstein (Citation2008) is whether and the extent to which the neighborhood’s white population decreases substantially when the minority share in the area exceeds a tipping point (or change point). In Section 5, we use the US Census tract dataset constructed by Card, Mas, and Rothstein (Citation2008) and confirm that the tipping exists in the neighborhoods of Chicago.
The remainder of the article is organized as follows. Section 2 provides an informal description of our estimation methodology. In Section 3.1, we derive the consistency of the estimators in terms of the excess risk. Further asymptotic properties of the proposed estimators are given in Sections 3.2 and 3.3. Section 4 gives a summary of our extensive simulation results. Section 5 illustrates the usefulness of our method by applying it to tipping in the racial segregation and Section 6 concludes. In Appendix A, we provide a set of regularity assumptions to derive asymptotic properties of the proposed estimators in Section 3. Online supplements are comprised of six appendices for all the proofs as well as additional theoretical and numerical results that are left out for the brevity of the article.
Notation. Throughout the article, we use |v|q for the ℓq norm for a vector v with q = 0, 1, 2. We use |v|∞ to denote the sup norm. For two sequences of positive real numbers an and bn, we write an ≪ bn and equivalently bn ≫ an if an = o(bn). If there exists a positive finite constant c such that an = c · bn, then we write an∝bn. Let λmin (A) denote the minimum eigenvalue of a matrix A. We use w.p.a.1 to mean “with probability approaching one.” We write θ0 ≡ β0 + δ0. For a 2p dimensional vector α, let αJ and denote its subvectors formed by indices in J(α0) and {1, …, 2p}∖J(α0), respectively. Likewise, let XJ(τ) denote the subvector of X(τ) ≡ (XT, XT1{Q > τ})T whose indices are in J(α0). The true parameter vectors β0, δ0, and θ0 (except τ0) are implicitly indexed by the sample size n, and we allow that the dimensions of J(β0), J(δ0), and J(θ0) can go to infinity as n → ∞. For simplicity, we omit their dependence on n in our notation. We also use the terms “change point” and “threshold” interchangeably throughout the article.
2. Estimators
2.1. Definitions
In this section, we describe our estimation method. We take the check function approach of Koenker and Bassett (Citation1978). Let ρ(t1, t2) ≡ (t1 − t2)(γ − 1{t1 − t2 ⩽ 0}) denote the loss function for quantile regression. Let and
denote the parameter spaces for α0 ≡ (βT0, δT0)T and τ0, respectively. For each
and
, we write XTβ + XTδ1{Q > τ} = X(τ)Tα with the shorthand notation that X(τ) ≡ (XT, XT1{Q > τ})T. We suppose that the vector of true parameters is defined as the minimizer of the expected loss:
(2.1)
(2.1) By construction, τ0 is not unique when δ0 = 0. However, if δ0 = 0, then the model reduces to the linear quantile regression model in which β0 is identifiable under the standard assumptions. In Online Appendix C.1, we provide sufficient conditions under which α0 and τ0 are identified when δ0 ≠ 0.
Suppose we observe independent and identically distributed samples {Yi, Xi, Qi}i ⩽ n. Let Xi(τ) and Xij(τ) denote the ith realization of X(τ) and jth element of Xi(τ), respectively, i = 1, …, n and j = 1, …, 2p, so that Xij(τ) ≡ Xij if j ⩽ p and Xij(τ) ≡ Xi, j − p1{Qi > τ} otherwise. Define
In addition, let Dj(τ) ≡ {n− 1∑ni = 1Xij(τ)2}1/2, j = 1, …, 2p.
We describe the main steps of our ℓ1-penalized estimation method. For some tuning parameter κn, define:
(2.2)
(2.2) where αj is the jth element of α. This step produces an initial estimator
. The tuning parameter κn is required to satisfy
(2.3)
(2.3) Note that we take κn that converges to zero at a rate slower than the standard (log p/n)1/2 rate in the literature. This modified rate of κn is useful in our context to deal with an unknown τ0. A data-dependent method of choosing κn is discussed in Section 2.3.
Remark 1.
Define and
. Note that ∑2pj = 1Dj(τ)|αj| = ∑pj = 1dj|βj| + ∑pj = 1dj(τ)|δj|, so that the weight Dj(τ) adequately balances the regressors; the weight dj regarding |βj| does not depend on τ, while the weight dj(τ) with respect to |δj| does, which takes into account the effect of the threshold τ on the parameter change δ.
Remark 2.
The computational cost in Step 1 is the multiple of grid points to the computational time of estimating the linear quantile model with an ℓ1 penalty, which is solvable in polynomial time (see, e.g., Belloni and Chernozhukov Citation2011; Koenker and Mizera Citation2014 among others). In other words, the computation cost increases linearly in terms of the number of grid points. In practice, one may choose the grid to be .
The main purpose of the first step is to obtain an initial estimator of α0. The achieved convergence rates of this step might be suboptimal due to the uniform control of the score functions over the space of the unknown τ0.
In the second step, we introduce our improved estimator of the change point τ0. It does not use a penalty term, while using the first-step estimator of α0. Define:
(2.4)
(2.4) where
is the first-step estimator of α0 in (Equation2.2
(2.2)
(2.2) ). In Section 3.2, we show that when τ0 is identifiable,
is consistent for τ0 at a rate of n− 1. Furthermore, we obtain the limiting distribution of
, and establish conditions under which its asymptotic distribution is the same as if the true α0 were known, without a perfect model selection on α0, nor assuming the minimum signal condition on the nonzero elements of α0.
In the third step, we update the Lasso estimator of α0 using a different value of the penalization tuning parameter and the second step estimator of τ0. In particular, we recommend two different estimators of α0 : one for the prediction and the other for the variable selection, serving for different purposes of practitioners. For two different tuning parameters ωn and μn whose rates will be specified later by (Equation2.7(2.7)
(2.7) ) and (Equation3.2
(3.2)
(3.2) ), define:
(2.5)
(2.5)
(2.6)
(2.6) where
is the second step estimator of τ0 in (Equation2.4
(2.4)
(2.4) ), and the “signal-adaptive” weight wj in (Equation2.6
(2.6)
(2.6) ), motivated by the local linear approximation of the SCAD penalties (Fan and Li Citation2001; Zou and Li Citation2008), is calculated based on the Step 3a estimator
from (Equation2.5
(2.5)
(2.5) ):
Here, a > 1 is some prescribed constant, and a = 3.7 is often used in the literature. We take this as our choice of a.
Remark 3.
For in (Equation2.5
(2.5)
(2.5) ), we set ωn to converge to zero at a rate of (log (p∨n)/n)1/2:
(2.7)
(2.7) which is a more standard rate compared to κn in (Equation2.3
(2.3)
(2.3) ). Therefore, the estimator
converges in probability to α0 faster than
. In addition, μn in (Equation2.6
(2.6)
(2.6) ) is chosen to be slightly larger than ωn for the purpose of the variable selection. A data-dependent method of choosing ωn as well as μn is discussed in Section 2.3. In Sections 3.2 and 3.3, we establish conditions under which
achieves the (minimax) optimal rate of convergence in probability for α0 regardless of the identifiability of τ0.
Remark 4.
Step 2 can be repeated using the updated estimator of α0 in Step 3. Analogously, Step 3 can be iterated after that. This would give asymptotically equivalent estimators but might improve the finite-sample performance especially when p is very large. Repeating Step 2 might be useful especially when in the first step. In this case, there is no unique
in Step 2. So, we skip the second step by setting
and move to the third step directly. If a preferred estimator of δ0 in the third step (either
or
), depending on the estimation purpose, is different from zero, we could go back to Step 2 and reestimate τ0. If the third step estimator of δ0 is also zero, then we conclude that there is no change point and disregard the first-step estimator
since τ0 is not identifiable in this case.
2.2. Comparison of Estimators in Step 3
Step 3 defines two estimators for α0. In this subsection, we briefly explain their major differences and purposes. Step 3b is particularly useful when the variable selection consistency is the main objective, yet it often requires the minimum signal condition ( is well separated from zero). In contrast, Step 3a does not require the minimum signal condition, and is recommended for predictionCitationpurposes. More specifically:
| 1. | If the minimum signal condition (Equation3.3 | ||||
| 2. | In the presence of the minimum signal condition, not only does Step 3b achieve the variable selection consistency, it also has a better rate of convergence than Step 3a (Theorem 6). The faster rate of convergence is built on the variable selection consistency, and is still a consequence of the signal-adaptive weights. Intuitively, nonzero elements of α0 are easier to identify and estimate when the signal is strong. | ||||
| 3. | In the absence of the minimum signal condition, neither method can achieve variable selection consistency. However, it is not a requirement for the prediction purpose. In this case, we recommend the estimator of Step 3a, because it achieves a fast (minimax) rate of convergence (Theorem 5), which is useful for predictions. | ||||
2.3. Tuning Parameter Selection
In this subsection, we provide details on how to choose tuning parameters in applications. Recall that our procedure involves three tuning parameters in the penalization: (1) κn in Step 1 ought to dominate the score function uniformly over the range of τ, and hence should be slightly larger than the others; (2) ωn is used in Step 3a for the prediction, and (3) μn in Step 3b for the variable selection should be larger than ωn. Note that the tuning parameters in both Steps 3a and 3b are similar to those of the existing literature since the change point has been estimated.
We build on the data-dependent selection method by Belloni and Chernozhukov (Citation2011). Define
(2.8)
(2.8) where Ui is simulated from the iid uniform distribution on the interval [0, 1]; γ is the quantile of interest (e.g., γ = 0.5 for median regression). Note that Λ(τ) is a stochastic process indexed by τ. Let
be the (1 − ε*)-quantile of
, where ε* is a small positive constant that will be selected by a user. Then, we select the tuning parameter in Step 1 by
Similarly, let
be the (1 − ε*)-quantile of
, where
is chosen in Step 2. We select ωn and μn in Step 3 by
and μn = c2 · ωn. It is also necessary to choose
in applications. In our Monte Carlo experiments in online Appendix F, we take
to be the interval from the 15th percentile to the 85th percentile of the empirical distribution of the threshold variable Qi. For example, Hansen (Citation1996) employed the same range in his application to U.S. GNP dynamics. In practice, it is important to have a sufficient number of observations lying outside
.
Based on the suggestions by Belloni and Chernozhukov (Citation2011) and some preliminary simulations, we choose to set c1 = 1.1, c2 = log log n, and ε* = 0.1. In addition, recall that we set a = 3.7 when calculating the SCAD weights wj in Step 3b following the convention in the literature (e.g., Fan and Li Citation2001; Loh and Wainwright Citation2013). In Step 1, we first solve the lasso problem for α given each grid point of . Then, we choose
and the corresponding
that minimize the objective function. Step 2 can be solved simply by the grid search. Step 3 is a standard lasso quantile regression estimation given
, whose numerical implementation is well established. We use the rq() function of the R “quantreg” package with the method = ”lasso” in each implementation of the standard lasso quantile regression estimation (Koenker Citation2016).
3. Asymptotic Properties
Throughout the article, we let s ≡ |J(α0)|0, namely, the cardinality of J(α0). We allow that s → ∞ as n → ∞ and will give precise regularity conditions regarding its growth rates. In Appendix A, we list a set of assumptions that are needed to derive these properties.
3.1. Risk Consistency
Given the loss function ρ(t1, t2) ≡ (t1 − t2)(γ − 1{t1 − t2 ⩽ 0}) for the quantile regression model, define the excess risk to be
(3.1)
(3.1) By the definition of (α0, τ0) in (Equation2.1
(2.1)
(2.1) ), we have that R(α, τ) ⩾ 0 for any
and
. What we mean by the “risk consistency” here is that the excess risk converges in probability to zero for the proposed estimators.
The following theorem is concerned about the convergence of with the first-step estimator.
Theorem 1 (Risk Consistency).
Let Assumption A.1 hold. Suppose that the tuning parameter κn satisfies (Equation2.3(2.3)
(2.3) ). Then,
Note that Theorem 1 holds regardless of the identifiability of τ0 (i.e., whether δ0 = 0 or not). In addition, the rate OP(κns) is achieved regardless of whether κns converges, and we have the risk consistency if κns → 0 as n → ∞. The restriction on s is slightly stronger than that of the standard result in the literature for the M-estimation (see, e.g., van de Geer Citation2008 and chap. 6.6 of Bühlmann and van de Geer Citation2011) since the objective function ρ(Y, X(τ)Tα) is nonconvex in τ, due to the unknown change point.
Remark 5.
The extra logarithmic factor (log p)(log n) in the definition of κn (see (Equation2.3(2.3)
(2.3) )) is due to the existence of the unknown and possibly nonidentifiable threshold parameter τ0. In fact, an inspection of the proof of Theorem 1 reveals that it suffices to assume that κn satisfies κn ≫ log 2(p/s)[log (np)/n]1/2. The term log 2(p/s) and the additional (log n)1/2 term inside the brackets are needed to establish the stochastic equicontinuity of the empirical process
uniformly over
.
In Appendix C.2, we show that an improved rate of convergence, OP(ωns), is possible for the excess risk by taking the second and third steps of estimation.
3.2. Asymptotic Properties: Case I. δ0 ≠ 0
We first establish the consistency of for τ0.
Theorem 2 (Consistency of ).
Let Assumptions A.1, A.2, A.5, and A.6 hold. Furthermore, assume that κns = o(1). Then, .
The following theorem presents the rates of convergence for the first-step estimators of α0 and τ0. Recall that κn is the first-step penalization tuning parameter that satisfies (Equation2.3(2.3)
(2.3) ).
Theorem 3 (Rates of Convergence When δ0 ≠ 0).
Suppose that κns2log p = o(1). Then under Assumptions A.1–A.6, we have
In Theorem 1, we have that The improved rate of convergence for
in Theorem 3 is due to additional assumptions (in particular, compatibility conditions in Assumption A.3 among others). It is worth noting that
converges to τ0 faster than the standard parametric rate of n− 1/2, as long as s2(log p)6(log n)4 = o(n). The main reason for such super-consistency is that the objective function behaves locally linearly around τ0 with a kink at τ0, unlike in the regular estimation problem where the objective function behaves locally quadratically around the true parameter value. Moreover, the achieved convergence rate for
is nearly minimax optimal, with an additional factor (log p)(log n) compared to the rate of regular Lasso estimation (e.g., Bickel, Ritov, and Tsybakov Citation2009; Raskutti, Wainwright, and Yu Citation2011). This factor arises due to the unknown change point τ0. We will improve the rates of convergence for both τ0 and α0 further by taking the second and third steps of estimation.
Recall that the second-step estimator of τ0 is defined as
where
is the first-step estimator of α0 in (Equation2.2
(2.2)
(2.2) ). Consider an oracle case for which α in Rn(α, τ) is fixed at α0. Let R*n(τ) = Rn(α0, τ) and
We now give one of the main results of this article.
Theorem 4 (Oracle Estimation of τ0).
Let Assumptions A.1–A.6 hold. Furthermore, suppose that κns2log p = o(1). Then, we have that
Furthermore,
converges in distribution to the smallest minimizer of a compound Poisson process, which is given by
where N1 and N2 are Poisson processes with the same jump rate fQ(τ0), and {ρ1i} and {ρ2i} are two sequences of independent and identically distributed random variables. The distributions of ρ1i and ρ2i, respectively, are identical to the conditional distributions of
and
given Qi = τ0, where
and Ui ≡ Yi − XTiβ0 − XTiδ01{Qi > τ0} for each i = 1, …, n. Here, N1, N2, {ρ1i}, and {ρ2i} are mutually independent.
The first conclusion of Theorem 4 establishes that the second-step estimator of τ0 is an oracle estimator in the sense that it is asymptotically equivalent to the infeasible, oracle estimator . As emphasized in the introduction, the oracle property is obtained without relying on the perfect model selection in the first step nor on the existence of the minimum signal condition on active covariates. The second conclusion of Theorem 4 follows from combining well-known weak convergence results in the literature (see, e.g., Pons Citation2003; Kosorok and Song Citation2007; Lee and Seo Citation2008) with the argmax continuous mapping theorem by Seijo and Sen (Citation2011b).
Remark 6.
Li and Ling (Citation2012) proposed a numerical approach for constructing a confidence interval by simulating a compound Poisson process in the context of least-square estimation. We adopt their approach to simulate the compound Poisson process for quantile regression. See Online Appendix B for a detailed description of how to construct a confidence interval for τ0.
We now consider the Step 3a estimator of α0 defined in (Equation2.5(2.5)
(2.5) ). Recall that ωn is the Step 3a penalization tuning parameter that satisfies (Equation2.7
(2.7)
(2.7) ).
Theorem 5 (Improved Rates of Convergence When δ0 ≠ 0).
Suppose that κns2log p = o(1). Then under Assumptions A.1–A.6,
Theorem 5 shows that the estimator defined in Step 3a achieves the optimal rate of convergence in terms of prediction and estimation. In other words, when ωn is proportional to {log (p∨n)/n}1/2 in Equation (Equation2.7
(2.7)
(2.7) ) and p is larger than n, it obtains the minimax rates as in, for example, Raskutti, Wainwright, and Yu (Citation2011).
As we mentioned in Section 2, the Step 3b estimator of α0 has the purpose of the variable selection. The nonzero components of are expected to identify contributing regressors. Partition
such that
and
. Note that
consists of the estimators of β0J and δ0J, whereas
consists of the estimators of all the zero components of β0 and δ0. Let α(j)0J denote the jth element of α0J.
We now establish conditions under which the estimator defined in Step 3b has the change-point-oracle properties, meaning that it achieves the variable selection consistency and has the limiting distributions as though the identities of the important regressors and the location of the change point were known.
Theorem 6 (Variable Selection When δ0 ≠ 0).
Suppose that κns2log p = o(1), s4log s = o(n), and
(3.2)
(3.2) Then under Assumptions A.1–A.6, we have: (i)
(ii)
and (iii)
We see that (Equation3.2(3.2)
(3.2) ) provides a condition on the strength of the signal via
, and the tuning parameter in Step 3b should satisfy ωn ≪ μn and s2log s/n ≪ μ2n. Hence, the variable selection consistency demands a larger tuning parameter than in Step 3a.
To conduct statistical inference, we now discuss the asymptotic distribution of . Define
. Note that the asymptotic distribution for
corresponds to an oracle case that we know τ0 as well as the true active set J(α0) a priori. The limiting distribution of
is the same as that of
. Hence, we call this result the change-point-oracle property of the Step 3b estimator and the following theorem establishes this property.
Theorem 7 (Change-Point-Oracle Properties).
Suppose that all the conditions imposed in Theorem 6 are satisfied. Furthermore, assume that exists for all t in a neighborhood of τ0 and all its elements are continuous and bounded, and that s3(log s)(log n) = o(n). Then, we have that
Since the sparsity index (s) grows at a rate slower than the sample size (n), it is straightforward to establish the asymptotic normality of a linear transformation of that is,
where
with |L|2 = 1, by combing the existing results on quantile regression with parameters of increasing dimension (see, e.g., He and Shao Citation2000) with Theorem 7.
Remark 7.
Without the condition on the strength of minimal signals, it may not be possible to achieve the variable selection consistency or establish change-point-oracle properties. However, the following theorem shows that the SCAD-weighted penalized estimation can still achieve a satisfactory rate of convergence in estimation of α0 without the condition that . Yet, the rates of convergence are slower than those of Theorem 6.
Theorem 8 (Satisfactory Rates Without Minimum Signal Condition).
Assume that Assumptions A.1–A.6 hold. Suppose that κns2log p = o(1) and ωn ≪ μn. Then, without the lower bound requirement on , we have that
In addition,
3.3. Asymptotic Properties: Case II. δ0 = 0
In this section, we show that our estimators have desirable results even if there is no change point in the true model. The case of δ0 = 0 corresponds to the high-dimensional linear quantile regression model. Since XTβ0 + XTδ01{Q > τ0} = XTβ0, τ0 is nonidentifiable, and there is no structural change on the coefficient. But a new analysis different from that of the standard high-dimensional model is still required because in practice we do not know whether δ0 = 0 or not. Thus, the proposed estimation method still estimates τ0 to account for possible structural changes. The following results show that in this case, the first-step estimator of α0 will asymptotically behave as if δ0 = 0 were a priori known.
Theorem 9 (Rates of Convergence When δ0 = 0).
Suppose that κns = o(1). Then under Assumptions A.1–A.4, we have that
The results obtained in Theorem 9 combined with those obtained in Theorem 3 imply that the first-step estimator performs equally well in terms of rates of convergence for both the ℓ1 loss for and the excess risk regardless of the existence of the threshold effect. It is straightforward to obtain an improved rate result for the Step 3a estimator, equivalent to Theorem 5 under Assumptions A.1–A.4. We omit the details for brevity.
We now give a result that is similar to Theorem 6 and Theorem 8.
Theorem 10 (Variable Selection When δ0 = 0).
Suppose that κns = o(1), s4log s = o(n), , and Assumptions A.1–A.4 hold. We have:
| (i) | If the minimum signal condition holds:
| ||||
| (ii) | Withoutthe minimum signal condition (Equation3.3 | ||||
Theorem 10 demonstrates that when there is in fact no change point, our estimator for δ0 is exactly zero with a high probability. Therefore, the estimator can also be used as a diagnostic tool to check whether there exists any change point. Results similar to Theorems 7 can be established straightforwardly as well; however, their details are omitted for brevity.
4. Summary of Monte Carlo Experiments
We have carried out extensive Monte Carlo experiments to examine the finite sample performance of our proposed estimators. To save space, we provide a summary of simulation results and show full results in online Appendix F.
| 1. | The proposed estimator (Step 3b) selected different nonzero coefficients at different quantile levels. The mean regression estimator in Lee, Seo, and Shin (Citation2016) cannot detect these heterogenous models. | ||||
| 2. | The coverage probabilities of the confidence interval for τ0 were good and the root mean squared error of | ||||
| 3. | The median regression estimator showed better performances than the mean regression estimator for heteroscedastic designs and for the fat-tail error distributions. | ||||
| 4. | The performanceof our proposed estimators was satisfactory when δ0 = 0. | ||||
| 5. | When the model contains low minimal signals in δ, the Step 3b estimator performed worse than the step 3a estimator. | ||||
| 6. | The main qualitative results were not sensitive to different simulation designs on τ0 and Qi as well as to some variation on tuning parameter values. | ||||
Overall, the simulation results confirm the asymptotic theory developed in the previous sections and show the advantage of quantile regression models over the existing mean regression models with a change point.
5. Estimating a Change Point in Racial Segregation
As an empirical illustration, we investigate the existence of tipping in the dynamics of racial segregation using the dataset constructed by Card, Mas, and Rothstein (Citation2008). They showed that the neighborhood’s white population decreases substantially when the minority share in the area exceeds a tipping point (or threshold point), using U.S. Census tract-level data. Lee, Seo, and Shin (Citation2011) developed a test for the existence of threshold effects and applied their test to this dataset. Different from these existing studies, we consider a high-dimensional setup by allowing both possibly highly nonlinear effects of the main covariate (minority share in the neighborhood) and possibly higher-order interactions between additional covariates.
We build on the specifications used by Card, Mas, and Rothstein (Citation2008) and Lee, Seo, and Shin (Citation2011) to choose the following median regression with a constant shift due to the tipping effect:
(5.1)
(5.1) where for census tract i, the dependent variable Yi is the 10 year change in the neighborhood’s white population, Qi is the base-year minority share in the neighborhood, and Xi is a vector of six tract-level control variables and their various interactions depending on the model specification. Both Yi and Qi are in percentage terms. The basic six variables in Xi include the unemployment rate, the log of mean family income, the fractions of single-unit, vacant, and renter-occupied housing units, and the fraction of workers who use public transport to travel to work. The function g( · ) is approximated by the cubic b-splines with 15 knots over equi-quantile locations, so the degrees of freedom are 19 including an intercept term. In our empirical illustration, we use the census-tract-level sample of Chicago whose base year is 1980.
In the first set of models, we consider possible interactions among the six tract-level control variables up to six-way interactions. Specifically, the vector X in the six-way interactions will be composed of the following 63 regressors,
where X(j) is the jth element among those tract-level control variables. Note that the lower order interaction vector (e.g., two-way or three-way) is nested by the higher order interaction vector (e.g., three-way or four-way). The total number of regressors varies from 26 (19 from b-splines, 6 from Xi and 1{Qi > τ}) when there is no interaction to 83 when there are full six-way interactions. In the next set of models, we add the square of each tract-level control variable and generate similar interactions up to six. In this case the total number of regressors varies from 32 to 2529. For example, the number of regressors in the largest model consists of
(interactions up to six-way out of
. This number is much larger than the sample size (n = 1813).
summarizes the estimation results at the 0.25, 0.5, and 0.75 quantiles, respectively. We report the total number of regressors in each model and the number of selected regressors in Step 3b. The change point τ is estimated by the grid search over 591 equi-spaced points in [1, 60]. The lower bound value 1% corresponds to the 1.6 sample percentile of Qi and the upper bound value 60%, which is about the upper sample quartile of Qi, is the same as one used by Card, Mas, and Rothstein (Citation2008). In this empirical example, we report the estimates of τ0 and the confidence intervals updated after Step 3b (i.e., τ is reestimated using the estimates of α0 in Step 3b). If this estimate is different from the previous one in Step 2, then we repeat Step 3b and Step 2 until it converges.
Table 1. Estimation results from quantile regression.
The estimation results suggest several interesting points. First, at each quantile, the proposed method selects sparse representations in all model specifications even when the number of regressors is relatively large. Furthermore, the number of selected regressors does not grow rapidly when we increase the number of possible covariates. It seems that the set of selected covariates overlaps across different dictionaries at each quantile. See Appendix G for details on selected regressors. Second, the estimation results are different across different quantiles, indicating that there may exist heterogeneity in this application. The confidence intervals for τ0 at the 0.25 quantile are quite tight in all cases and they provide convincing evidence of the tipping effect. If we look at the case of six-way interactions with 12 control variables, the estimated tipping point is 5.65% and the estimated jump size is − 5.50%. However, this strong tipping effect becomes weaker at the 0.50 and 0.75 quantiles as shown either by wider confidence intervals or by the zero jump size, that is, .
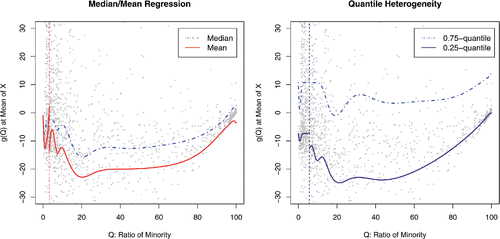
shows the fitted values over Qi at the sample mean of the six basic covariates. They are from the model of six-way interactions with 12 control variables and the vertical line indicates the location of a tipping point. The left panel of compares the results between the mean and median regression results and the right panel shows the interquartile range of the conditional distribution of Yi as a function of Qi given other regressors. It can be seen that the mean regression estimates are much more volatile around the tipping point than the median regression estimates, although the estimated tipping point is the same. Looking at the right panel of , we can see that the 25 percentile of the conditional distribution drops at the tipping point of 5.65% but no such change at the 75% quantile. This shows that the quantile regression estimates can provide insights into distributional threshold effects in racial segregation.
Figure 1. Estimation results: 12 control variables and six-way interaction.
6. Conclusions
In this article, we have developed ℓ1-penalized estimators of a high-dimensional quantile regression model with an unknown change point due to a covariate threshold. We have shown among other things that our estimator of the change point achieves an oracle property without relying on a perfect covariate selection, thereby avoiding the need for the minimum level condition on the signals of active covariates. We have illustrated the usefulness of our estimation methods via Monte Carlo experiments and an application to tipping in the racial segregation.
One of the important remaining questions is how to extend our approach to a high-dimensional quantile regression model with multiple change points. A computationally attractive approach is to use the binary segmentation algorithm (see, e.g., Fryzlewicz Citation2014; Cho and Fryzlewicz Citation2015 among others). In a recent working article, Leonardi and Bühlmann (Citation2016) considered a high-dimensional mean regression model with multiple change points whose number may grow as the sample size increases. They have proposed a binary segmentation algorithm to choose the number and locations of change points. It is an important future research topic to develop a computationally efficient algorithm to detect multiple changes for high-dimensional quantile regression models.
Supplementary Materials
Online supplements are comprised of 6 appendices. In Appendix B, we provide the al- gorithm of constructing the confidence interval for τ0. In Appendix C, we provide sufficient conditions for the identification and show that an improved rate of convergence is possible for the excess risk by taking the second and third steps of estimation. To prove the theoretical results in the main text, we consider a general M-estimation framework that includes quantile regression as a special case. We provide high-level regularity conditions on the loss function in Appendix D. Under these conditions, we derive asymptotic properties and then we verify all the high level assumptions for the quantile regression model in Appendix E. Hence, our general results are of independent interest and can be applicable to other models, for example logistic regression models. In Section F, we present the results of extensive Monte Carlo experiments, and Appendix G gives additional results for the empirical example.
Supplementary Materials
Download PDF (557.2 KB)Acknowledgment
The authors thank Bernd Fitzenberger, an editor, an associate editor, and three anonymous referees for helpful comments.
Additional information
Funding
Related Research Data
References
- Belloni, A., and Chernozhukov, V. (2011), “ℓ1-Penalized Quantile Regression in High Dimensional Sparse Models,” Annals of Statistics, 39, 82–130.
- Bickel, P., Ritov, Y., and Tsybakov, A. (2009), “Simultaneous Analysis of Lasso and Dantzig Selector,” Annals of Statistics, 37, 1705–1732.
- Bradic, J., Fan, J., and Wang, W. (2011), “Penalized Composite Quasi-Likelihood for Ultrahigh Dimensional Variable Selection,” Journal of the Royal Statistical Society, Series B, 73, 325–349.
- Bühlmann, P., and van de Geer, S. (2011), Statistics for High-Dimensional Data, Methods, Theory and Applications, New York: Springer.
- Callot, L., Caner, M., Kock, A. B., and Riquelme, J. A. (2017), “Sharp Threshold Detection Based on Sup-norm Error Rates in High-dimensional Models,” Journal of Business & Economic Statistics, 35, 250–264.
- Card, D., Mas, A., and Rothstein, J. (2008), “Tipping and the Dynamics of Segregation,” Quarterly Journal of Economics, 123, 177–218.
- Chan, K.-S. (1993), “Consistency and Limiting Distribution of the Least Squares Estimator of a Threshold Autoregressive Model,” Annals of Statistics, 21, 520–533.
- Chan, N. H., Ing, C.-K., Li, Y., and Yau, C. Y. (2017), “Threshold Estimation via Group Orthogonal Greedy Algorithm,” Journal of Business & Economic Statistics, 35, 334–345.
- Chan, N. H., Yau, C. Y., and Zhang, R.-M. (2014), “Group LASSO for Structural Break Time Series,” Journal of the American Statistical Association, 109, 590–599.
- Cho, H., and Fryzlewicz, P. (2015), “Multiple-Change-Point Detection for High Dimensional Time Series via Sparsified Binary Segmentation,” Journal of the Royal Statistical Society, Series B, 77, 475–507.
- Ciuperca, G. (2013), “Quantile Regression in High-Dimension with Breaking,” Journal of Statistical Theory and Applications, 12, 288–305.
- Enikeeva, F., and Harchaoui, Z. (2013), “High-Dimensional Change-Point Detection with Sparse Alternatives,” arXiv preprint, http://arxiv.org/abs/1312.1900.
- Fan, J., Fan, Y., and Barut, E. (2014), “Adaptive Robust Variable Selection,” Annals of Statistics, 42, 324–351.
- Fan, J., and Li, R. (2001), “Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties,” Journal of the American Statistical Association, 96, 1348–1360.
- Frick, K., Munk, A., and Sieling, H. (2014), “Multiscale Change Point Inference,” Journal of the Royal Statistical Society, Series B, 76, 495–580.
- Fryzlewicz, P. (2014), “Wild Binary Segmentation for Multiple Change-Point Detection,” Annals of Statistics, 42, 2243–2281.
- Hansen, B. E. (1996), “Inference When a Nuisance Parameter Is Not Identified Under the Null Hypothesis,” Econometrica, 64, 413–430.
- ——— (2000), “Sample Splitting and Threshold Estimation,” Econometrica, 68, 575–603.
- He, X., and Shao, Q.-M. (2000), “On Parameters of Increasing Dimensions,” Journal of Multivariate Analysis, 73, 120–135.
- Koenker, R. (2016), quantreg: Quantile Regression, R Package Version 5.29, CRAN, available at https://cran.r-project.org/web/packages/quantreg/index.html.
- Koenker, R., and Bassett, G. (1978), “Regression Quantiles,” Econometrica, 46, 33–50.
- Koenker, R., and Mizera, I. (2014), “Convex Optimization in R,” Journal of Statistical Software, 60, 1–23.
- Kosorok, M. R., and Song, R. (2007), “Inference under Right Censoring for Transformation Models with a Change-Point based on a Covariate Threshold,” Annals of Statistics, 35, 957–989.
- Lee, S., and Seo, M. H. (2008), “Semiparametric Estimation of a Binary Response Model with a Change-Point due to a Covariate Threshold,” Journal of Econometrics, 144, 492–499.
- Lee, S., Seo, M. H., and Shin, Y. (2011), “Testing for Threshold Effects in Regression Models,” Journal of the American Statistical Association, 106, 220–231.
- ——— (2016), “The Lasso for High Dimensional Regression with a Possible Change Point,” Journal of the Royal Statistical Society, Series B, 78, 193–210.
- Leonardi, F., and Bühlmann, P. (2016), “Computationally Efficient Change Point Detection for High-Dimensional Regression,” arXiv preprint arXiv:1601.03704, http://arxiv.org/abs/1601.03704.
- Li, D., and Ling, S. (2012), “On the Least Squares Estimation of Multiple-Regime Threshold Autoregressive Models,” Journal of Econometrics, 167, 240–253.
- Loh, P.-L., and Wainwright, M. J. (2013), “Regularized M-Estimators with Nonconvexity: Statistical and Algorithmic Theory for Local Optima,” in Advances in Neural Information Processing Systems 26, eds. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, Curran Associates, Inc., pp. 476–484.
- Lovász, L., and Vempala, S. (2007), “The Geometry of Logconcave Functions and Sampling Algorithms,” Random Structures & Algorithms, 30, 307–358.
- Pons, O. (2003), “Estimation in a Cox Regression Model with a Change-Point According to a Threshold in a Covariate,” Annals of Statistics, 31, 442–463.
- Raskutti, G., Wainwright, M., and Yu, B. (2011), “Minimax Rates of Estimation for High-Dimensional Linear Regression Over ℓq-Balls,” IEEE Transactions on Information Theory, 57, 6976–6994.
- Seijo, E., and Sen, B. (2011a), “Change-Point in Stochastic Design Regression and the Bootstrap,” Annals of Statistics, 39, 1580–1607.
- ——— (2011b), “A Continuous Mapping Theorem for the Smallest Argmax Functional,” Electronic Journal of Statistics, 5, 421–439.
- Tong, H. (1990), Non-Linear Time Series: A Dynamical System Approach, Oxford: Oxford University Press.
- van de Geer, S. A. (2008), “High-Dimensional Generalized Linear Models and the Lasso,” Annals of Statistics, 36, 614–645.
- Wang, L. (2013), “The L1 Penalized LAD Estimator for High Dimensional Linear Regression,” Journal of Multivariate Analysis, 120, 135–151.
- Wang, L., Wu, Y., and Li, R. (2012), “Quantile Regression for Analyzing Heterogeneity in Ultra-High Dimension,” Journal of the American Statistical Association, 107, 214–222.
- Zhao, P., and Yu, B. (2006), “On Model Selection Consistency of Lasso,” Journal of Machine Learning Research, 7, 2541–2563.
- Zou, H., and Li, R. (2008), “One-Step Sparse Estimations in Non Concave Penalized Likelihood Models,” Annals of Statistics, 36, 1509–1533.
Appendix A: Assumptions for Asymptotic Properties
In this section, we list a set of assumptions that will be useful to derive asymptotic properties of the proposed estimators. The first two assumptions are standard.
Assumption A.1 (Setting).
| (i) | The data {(Yi, Xi, Qi)}ni = 1 are independent and identically distributed. Furthermore, for all j and every integer m ⩾ 1, there is a constant K1 < ∞ such that | ||||
| (ii) |
| ||||
| (iii) |
| ||||
| (iv) | There exist universal constants | ||||
| (v) |
| ||||
A simple sufficient condition for condition (v) is that the eigenvalues of are bounded uniformly in τ, where
denotes the subvector of X corresponding to the nonzero components of δ0.
Assumption A.2 (Underlying Distribution).
| (i) | The conditional distribution Y|X, Q has a continuously differentiable density function fY|X, Q(y|x, q) with respect to y, whose derivative is denoted by | ||||
| (ii) | There are constants C1, C2 > 0 such that for all (y, x, q) in the support of (Y, X, Q),
| ||||
| (iii) | When δ0 ≠ 0, Γ(τ, α0) is positive definite uniformly in a neighborhood of τ0, where
| ||||
A.1. Compatibility Conditions
We now make an assumption that is an extension of the well-known compatibility condition (see Bühlmann and van de Geer Citation2011, chap. 6). In particular, the following condition is a uniform-in-τ version of the compatibility condition. Recall that for a 2p dimensional vector α, we use αJ and to denote its subvectors formed by indices in J(α0) and {1, …, 2p}∖J(α0), respectively.
Assumption A.3 (Compatibility Condition).
| (i) | When δ0 ≠ 0, there is a neighborhood | ||||
| (ii) | When δ0 = 0, there is a constant φ > 0 such that for all | ||||
Assumption A.3 requires that the compatibility condition holds uniformly in τ over a neighborhood of τ0 when δ0 ≠ 0 and over the entire parameter space when δ0 = 0. Note that this assumption is imposed on the population covariance matrix
; thus, a simple sufficient condition of Assumption A.3 is that the smallest eigenvalue of
is bounded away from zero uniformly in τ. Even if p > n, the population covariance can still be strictly positive definite while the sample covariance is not.
A.2. Restricted Nonlinearity Conditions
In this subsection, we make an assumption called a restricted nonlinear condition to deal with the quantile loss function. We extend condition D.4 in Belloni and Chernozhukov (Citation2011) to accommodate the possible existence of the unknown threshold in our model (specifically, a uniform-in-τ version of the restricted nonlinear condition as in the compatibility condition).
We define the “prediction balls” with radius r and corresponding centers as follows:
(A.3)
(A.3) where
and
are parameter spaces for β0 and θ0, respectively. To deal with the case that δ0 = 0, we also define
(A.4)
(A.4)
Assumption A.4 (Restricted Nonlinearity).
The following holds for the constants C1 and C2 defined in Assumption A.2 (ii).
| (i) | When δ0 ≠ 0, there exists a constant r*QR > 0 such that
| ||||
| (ii) | When δ0 = 0, there exists a constant r*QR > 0 such that
| ||||
Remark A.1.
As pointed out by Belloni and Chernozhukov (Citation2011), if XTc follows a logconcave distribution conditional on Q for any nonzero c (e.g., if the distribution of X is multivariate normal), then Theorem 5.22 of Lovász and Vempala (Citation2007) and the Hölder inequality imply that for all ,
which provides a sufficient condition for Assumption A.4. On the other hand, this assumption can hold more generally since Equations (EquationA.5
(A.5)
(A.5) )–(EquationA.8
(A.8)
(A.8) ) in Assumption A.4 need to hold only locally around true parameters α0.
A.3. Additional Assumptions When δ0 ≠ 0
Assumption A.5 (Additional Conditions on the Distribution of (X, Q)).
Assume δ0 ≠ 0. In addition, there exists a neighborhood of τ0 that satisfies the following.
| (i) | Q has a density function fQ( · ) that is continuous and bounded away from zero on | ||||
| (ii) | Let | ||||
| (iii) | There exists M3 > 0 such that | ||||
When τ0 is identified, we require δ0 to be considerably different from zero. This requirement is given in condition (iii). Note that this condition is concerned with , which is an important quantity to develop asymptotic results when δ0 ≠ 0. Note that condition (iii) is a local condition with respect to τ in the sense that it has to hold only locally in a neighborhood of τ0.
Assumption A.6 (Moment Bounds).
| (i) | There exist finite positive constants | ||||
| (ii) | There exist finite positive constants M, r and the neighborhood | ||||
Remark A.2.
Condition (i) requires that Q have nonnegligible support on both sides of τ0. This condition can be viewed as a rank condition for identification of α0. In the standard threshold model with a fixed dimension, our condition is trivially satisfied by the rank condition such that both and
are positive definite (see, e.g., Chan Citation1993 or Hansen Citation2000). If the rank condition fails, the regression coefficient may not be identified and thus affecting the identification of the change point. In the high-dimensional setup, it is undesirable to impose the same rank condition due to the high-dimensionality. Instead, we replace it with condition (i). Condition (ii) requires the boundedness and certain smoothness of the conditional expectation functions
,
, and
, and prohibits degeneracy in one regime. The last two inequalities in condition (ii) are satisfied if
for all
and for all β satisfying
for some small c > 0.