
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose a novel Bayesian methodology for analyzing nonstationary time series that exhibit oscillatory behavior. We approximate the time series using a piecewise oscillatory model with unknown periodicities, where our goal is to estimate the change-points while simultaneously identifying the potentially changing periodicities in the data. Our proposed methodology is based on a trans-dimensional Markov chain Monte Carlo algorithm that simultaneously updates the change-points and the periodicities relevant to any segment between them. We show that the proposed methodology successfully identifies time changing oscillatory behavior in two applications which are relevant to e-Health and sleep research, namely the occurrence of ultradian oscillations in human skin temperature during the time of night rest, and the detection of instances of sleep apnea in plethysmographic respiratory traces. Supplementary materials for this article are available online.
1 Introduction
Identifying the periodicities present in a cyclical phenomenon allows us to gain insight into the sources of variability that drive the phenomenon. For example, respiratory traces obtained from a plethysmograph used on rodents in experimental sleep apnea research exhibit many abrupt changes in their periodic components as the rat naturally changes their breathing pattern in the course of its sleep-wake activities (Han et al. Citation2002; Nakamura, Fukuda, and Kuwaki Citation2003). Similarly, human temperature, as measured by a wearable sensing device over several days at relatively high temporal resolution, may be subject to a different periodic behavior during the night when the individual transitions between ultradian sleep stages (Carskadon and Dement Citation2005; Komarzynski et al. Citation2018). While the theory and methods for analyzing the periodicities of time series data whenever the time series is stationary are relatively well-developed, the task of modelling time series that show regime shifts in periodicity, amplitude, and phase remain challenging because the timing of changes and the relevant periodicities are usually unknown.
There have been many developments for modeling stationary oscillatory time series data. Rife and Boorstyn (Citation1976) and Stoica et al. (Citation1989) addressed the problem of estimating the frequencies, phases, and amplitudes of sinusoidal signals under the assumption of a known number of sinusoids, where inference is based on maximum likelihood frequency estimators. These models, however, require very long time series and a large separation in the frequencies that drive the process, which will not always be the case in practice (Djuric Citation1996; Andrieu and Doucet Citation1999). Quinn (Citation1989), Yau and Bresler (Citation1993), and Zhang and Wong (Citation1993) tackled the problem of model selection on the number of sinusoidal signals by employing the Akaike information criterion (Akaike Citation1974) and the minimum description length principle (Rissanen Citation1978). Djuric (Citation1996) showed that these procedures tend to estimate a wrong number of components when the sample size is small and the signal-to-noise ratio is low.
Bayesian approaches to modeling stationary oscillatory signals were explored for the first time by Bretthorst (Citation1988, Citation1990) with applications to nuclear magnetic resonance spectroscopy. Dou and Hodgson (Citation1995, Citation1996) presented a Bayesian approach that uses a Gibbs sampler to identify multiple frequencies that drive the signal. Their method required the number of frequencies to be fixed in advance, and model selection was achieved by choosing the most probable model based on the estimation of the parameters for all possible models. Bayesian model selection for stationary oscillatory signals based on posterior model probabilities were also investigated by Djuric (Citation1996). Andrieu and Doucet (Citation1999) introduced a more efficient reversible-jump Markov chain Monte Carlo (MCMC) method (Green Citation1995) that jointly tackles model selection and parameter estimation for an unknown number of stationary sinusoidal signals and avoids the computationally expensive numerical optimization of Dou and Hodgson (Citation1995, Citation1996) by sampling the frequencies one-at-time via Metropolis–Hastings (M-H) steps. To the best of our knowledge, currently there is no extension of this methodology to analyze nonstationary oscillatory signals.
A formal statistical modeling framework for a specific class of nonstationary time series data, called locally stationary time series, was developed by Dahlhaus (Citation1997). Extending this framework to a Bayesian setting, Rosen, Stoffer, and Wood (Citation2009) proposed an approach to model the log of the time-varying spectral density using a mixture of smoothing splines. Rosen, Wood, and Stoffer (Citation2012) improved on this by splitting the time series into an unknown but finite number of segments of variable lengths, thereby avoiding the need to preselect partitions, and to estimate the time-varying spectral density using a fixed number of smoothing splines. For a given partition of the time series, the likelihood function is approximated via a product of local Whittle likelihoods (Whittle Citation1957). The methodology was developed using a Bayesian framework and is based on the assumption that, conditional on the position and number of partitions, the time series are piecewise stationary, and the underlying spectral density for each partition is smooth over frequencies. However, exploratory analyses of the time series in both of our case studies revealed spectral densities with very sharp peaks, often at several nearby frequencies, thus invalidating the assumption that the spectral density is smooth over frequencies. In addition, the frequency location of these sharp peaks changed over time.
In this article, we propose a novel Bayesian methodology for modeling oscillatory data that show regime shifts in periodicity, amplitude and phase. In contrast to previous work our approach does not require prespecifying the number of regimes or the order of the model within a regime. We assume that, conditional on the position and number of change-points, the time series can be approximated by a piecewise changing sinusoidal regression model. The timing and number of changes are unknown, along with the number and values of relevant periodicities in each segment. We develop a reversible jump MCMC technique that jointly explores the parameter space of the change-points and sub-models for all segments.
The article is organized as follows. Sections 2 and 3 present the model, the prior specifications, and the general structure of our Bayesian approach. Sections 4 and 5 provide a detailed explanation of our sampling scheme and simulation studies to demonstrate the performance of our approach. In Section 6, we illustrate the use of our methodology in two data-rich scenarios related to sleep, circadian rhythm, and e-Health research, namely the identification of the spectral properties of experimental breathing traces arising in sleep apnea research, and the analysis of human temperature data measured over several days by a wearable sensor. We conclude and discuss our current findings in Section 7.
2 The Model
Consider a time series realization whose periodic behavior may change at k unknown time-points
where k is also unknown. Assume that in each sub-interval
there are mj
relevant frequencies
, for
. Setting
and
, we can write the following sinusoidal model (Andrieu and Doucet Citation1999)
(1)
(1) where
(2)
(2)
,
,
denotes the indicator function, and μj
and αj
may, if needed, account for a linear trend within each segment. For simplicity we assume independent zero-mean Gaussian errors with regime-specific variances
(3)
(3) noting that the methodology can in principle be extended to the non-Gaussian case.
The dimension of the model is given by the number of change-points k and the number of frequency components in each regime denoted by . Furthermore, let
,
, and
. Using EquationEquation (1)
(1)
(1) , the likelihood of
given the data
is
(4)
(4) where
(5)
(5)
is the vector of parameters, nj
the number of observations of the jth segment, and the vector of basis functions
is defined as
3 Bayesian Inference
Given some prefixed maximal numbers of change-points, , and frequencies per regime,
, inference is achieved by assuming that the true model is unknown but comes from a finite class of models where each model
, with k change-points, is parameterized by the vector
Let and
denote, respectively, the sample space for the locations of change-points and the frequencies of the jth segment. The overall parameter space can be written as a finite union of subspaces
Bayesian inference on and
is based on the following factorization of the joint posterior distribution
where we use
as generic notation for probability density or mass function, whichever is appropriate. Sampling from it poses a multiple model selection problem, namely of the number of change-points and number of frequencies in each regime, which can be addressed by constructing a reversible-jump MCMC algorithm Green (Citation1995). The algorithm in its basic structure iterates between the following two moves:
Segment model move: Given a partition of the data at k locations
, inference on the parameters
Change-point model move: This step performs a reversible-jump MCMC algorithm for change-point model search where the number k and locations of change-points
Our prior specifications assume independent Poisson distributions for the number of break-points k and frequencies in each segment mj, conditioned on and
, respectively. Given k, a prior distribution for the positions of the change-points
can be chosen as in Green (Citation1995)
(6)
(6)
Conditional on k and , we choose a uniform prior for the frequencies
Analogous to a Bayesian regression (Bishop Citation2006), a zero-mean isotropic Gaussian prior is assumed for the coefficients of the jth segment,
where
is a prespecified large value, and the prior on the residual variance
of the jth partition is
, where η0 and ν0 are fixed at small values.
4 Sampling Scheme for Nonstationary Periodic Processes
Here we provide the sampling scheme associated with the nonstationary periodic processes that we wish to model. An outline of the overall procedure is as follows. Start with an initial configuration of number of change-points k, along with their locations ; this yields a partition of the data
. Initialize the number of frequencies in each regime
and their values
, along with the coefficients
and residual variances
At each iteration of the algorithm a segment model and a change-point model move are estimated. A random choice with probabilities (7) based on the current number of parameters will determine whether to attempt a birth, death or a within-model move. In particular, let z denote the current number of parameters, that is, change-points k in the change-point model or frequencies mj in the jth segment model; then, the dimension may increase by one (birth step) with probability bz, decrease by one (death step) with probability dz or remain unchanged (within step) with probability
, where
(7)
(7) for some constant
, and
is the prior probability of the model including z. Reversibility of the Markov chain is guaranteed for move types that involve a change in dimensionality as
Here we chose c = 0.4 but other values are legitimate as long as c is not larger than 0.5, to assure that the sum of the probabilities does not exceed 1 for some values of z. Naturally,
and
. The pseudocode of the overall algorithm that describes an iteration of the sampler is given in Algorithm 1. We next describe in more detail the specific procedures needed to update the moves.
Algorithm 1:
1. For each segment , perform a segment model move (Section 4.1)
Draw
if birth-step
else if death-step
else within-step
2. Perform a change-point model move (Section 4.2):
Draw
if birth-step
else if death-step
else within-step
4.1 Updating a Segment Model
Given the number of change-points k and their locations , a segment model move is performed independently and in parallel on each of the k + 1 partitions. Hence, throughout this subsection the subscript relating to the jth segment may be dropped and a segment of interest is denoted by
, which contains n observations. Assume that the current number of frequencies is set at m; then, an independent random choice is made between attempting a birth, death or within-model step, with probabilities given in (7). An outline of these moves is as follows (further details are provided in the Appendix).
4.1.1 Within-Model Move
Conditioned on the number of frequencies m, we sample the vector of frequencies following Andrieu and Doucet (Citation1999), that is, by sampling the frequencies one-at-time using a mixture of M-H steps, with target distribution
(8)
(8)
In particular, the proposal distribution is a combination of a normal random walk centered around the current frequency and a sample from values of the discrete Fourier transform of y. The corresponding vector of linear parameters is then updated in a M-H step, from the target posterior conditional distribution
(9)
(9) where the proposed values are drawn from normal approximations to their posterior conditional distribution. Finally, the residual variance σ2 is then updated in a Gibbs step from
(10)
(10)
4.1.2 Between-Model Moves
For this type of move, the number of frequencies is either proposed to increase by one (birth) or decrease by one (death). If a birth move is proposed, we have that , where current and proposed values are denoted by the superscripts c and p, respectively. The proposed vector of frequencies is constructed by proposing an additional frequency to include in the current vector. Conditional on the frequencies, the corresponding vector of linear coefficients and the residual variance are sampled as in the within-model move. If a death move is proposed, we have that
. Hence, one of the current frequencies is randomly chosen to be removed. The proposed corresponding vector of linear coefficients is drawn, along with the residual variance. For both moves, the updates are jointly accepted or rejected in a M-H step.
4.2 Updating the Change-Point Model
This part of the algorithm identifies the number and locations of change-points. Suppose the number of change-points is currently set to some value k, then according to the probabilities given in (7) a random decision is made between adding, removing, or moving a change-point. The rules for updating these types of moves are described below and more details are given in the Appendix.
4.2.1 Within-Model Move
An existing change-point is proposed to be relocated with probability , obtaining say
. The update for the selected change-point is proposed from a mixture of a normal random walk centered on the current change-point
and a sample from a uniform distribution on the interval
. Here, we introduced ψs as a fixed minimum time between change-points avoiding change-points being too close to each other. Rosen, Wood, and Stoffer (Citation2012) used a similar scheme, but on a discrete-scale. The number of frequencies and their values are kept fixed, and, conditional on the relocation, the linear coefficients for the segments affected by the relocation are sampled. These updates are jointly accepted or rejected in a M-H step and the residual variances are updated in a Gibbs step.
4.2.2 Between-Model Moves
For this type of move, the number of change-points may either increase (birth) or decrease (death) by one. If a birth move is proposed, we have that . The new proposed change-point is drawn uniformly on
, the support of
given the constraints imposed by ψs, that is,
. The latter involves splitting an existing segment. The number of frequencies and their values in the proposed segments are selected from the current states. Two residual variances for the new proposed segments are then constructed from the current single residual variance. Finally, two new vectors of linear parameters are sampled. If a death move is proposed, we have that
. Hence, a candidate change-point to be removed is selected from the vector of existing change-points, with probability
. The latter involves merging two existing partitions. The number of frequencies and their values in the proposed segments are selected from the current states. A single residual variance is constructed from the current variances relative to the segments affected by the relocation. Finally, a new vector of linear coefficient is drawn. For both type of moves, these updates are jointly accepted or rejected.
5 Simulation Studies
We carry out simulation studies to explore the performance of our method, which will be referred to as Automatic Nonstationary Oscillatory Modeling (AutoNOM). In Section 5.1, we illustrate the performance of our methodology when the simulated data are generated from the proposed model. Section 5.2 deals with scenarios when the model is misspecified relative to the generating process. Our results are compared with two state-of-the-art existing methods.
5.1 Illustrative Example
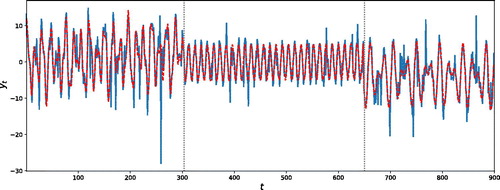
In this simulation example, we generate a time series consisting of n = 900 data points from model (1) with k = 2 change-points located at positions , and fixed number of frequencies per regime
. (Further details of the parameterization are available in supplementary materials, Section 1.1.) (top panel) shows a realization from this model. The prior means
and λs, say, on the number of frequencies and change-points, respectively, were set to 2, to reflect a fair degree of prior information on their numbers. We discuss in Section 1.2 of the supplementary materials that AutoNOM was relatively insensitive to these prior specifications, for this example. The maximum number of change-points
was set to 15, and the maximum number of frequencies per regime
was set to 10. Furthermore, we fixed
and
= 0.25 (Appendix A.1.2) for the uniform distribution for sampling the frequencies. The full estimation algorithm was ran for 20,000 updates, 5000 of which are discarded as burn-in period. The estimation took 390 sec with a (serial) program written in Julia 0.62 on a Intel® Core™ i7-4790S Processor 16 GB RAM. The results, summarized in clearly show that a model with two change-points has the highest estimated posterior probability (left panel) and that AutoNOM correctly identifies the right number of significant frequencies in each regime (right panel).
Fig. 1 Illustrative example. (Top) Simulated time series. (Middle) Estimated posterior distribution for the location of the change-points, conditioned on k = 2. The dotted vertical lines represent true location of change-points. (Bottom) Estimated posterior distribution of the frequencies for each different segment, conditioned on k = 2, , and
. The dotted vertical lines represent true values of the frequencies.
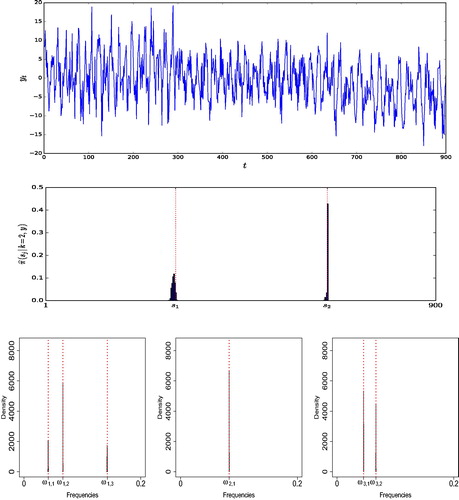
Table 1 Illustrative example.
(middle panel) shows the estimated posterior distribution for the location of the change-points, conditioned on three segments. The posterior means of the change-point locations are and
. (bottom panel) shows that the estimated posterior distributions are an excellent match to the true frequencies. In addition, we provide details about acceptance rates in supplementary materials, Section 2.
5.1.1 Detecting Spectral Peaks
We simulate a time series from the same simulation model as above with the only difference that the residual variances were set equal to one for all segments and thus are smaller than above. The performance of AutoNOM is compared with two existing methods, namely the Bayesian adaptive spectral estimation for nonstationary time series proposed by Rosen, Wood, and Stoffer (Citation2012), referred to as AdaptSPEC, and the frequentist piecewise vector autoregressive method of Davis, Lee, and Rodriguez-Yam (Citation2006), referred to as AutoPARM. Specifically, we explore the performances of these methodologies in identifying the number and location of change-points, and the number and location of frequency peaks in each estimated segment. AdaptSPEC requires the user to specify in advance the number of basis function J used for smoothing the periodogram in the segments. We run AdaptSPEC for two different specifications, namely J = 7 and J = 15 basis functions. The model is fitted with a total of 15,000 iterations, 5,000 of which are discarded as burn-in, by using the R package provided by the authors. Posterior samples of peak frequencies are obtained by considering the modes of the spectrum per MCMC iteration. AutoPARM is performed with default tuning parameters. We note that Davis, Lee, and Rodriguez-Yam (Citation2006) do not discuss computation of confidence intervals for frequencies.
The modal number of change-points for AdaptSPEC is 2 for both J = 7 and J = 15, with posterior probability of 76% and 88%, respectively; the modal number of change-points for AutoNOM is 2 and AutoPARM identifies 2 change-points as well. Conditioned on the modal number of change-points, displays the estimated location of changes (left panel) and frequency peaks (right panel) for the different compared methods, where we report the standard deviation for the estimate obtained from the empirical distribution of the posterior samples. Similarly, we show in the estimated location of the frequency peaks and their 95% credible intervals, for each of the three identified segments; dotted vertical lines represents the true location of the frequency peaks. Results for AutoNOM are conditioned on the modal number of frequencies per regime.
Fig. 2 Illustrative example with unitary residual variances. Estimated frequency peaks for AutoNOM (AN), AdaptSPEC (AS, ), and AutoPARM (AP); 95% credible intervals (horizontal lines) are also reported for Bayesian methods. Dotted vertical lines are true locations of the frequency peaks.
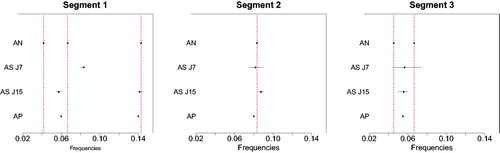
Table 2 Illustrative example with unitary residual variances.
It becomes clear that the detection of periodicities by AdaptSPEC is affected by the specification of the number of spline basis functions used for the smoothing, where increasing the number of basis function yields a better performance for AdaptSPEC. The example also shows that smoothing by splines may lead to peaks in the periodogram to be over-smoothed and neighboring close peaks to be merged. AutoPARM seems to also suffer from the latter problem.
When we increased the residual variance to the high levels set originally, AdaptSPEC failed to detect any change-points for both J = 7 and J = 15, with posterior probability of 69% and 93%, respectively, while AutoPARM found 7 change-points and thus severely overestimates their number. Our conclusion from this comparison is that although AdaptSPEC and AutoPARM may be well suited for time series processes with smooth time-varying spectra with few or no peaks, both methods are severely challenged in detecting changes in spectra that exhibit pronounced peakedness, possibly at nearby frequencies, as can be expected to occur in reality for the type of time series that we wish to analyze.
5.2 Misspecified Model
We investigate the performance of our proposed method for identifying spectral peaks when the model is misspecified relative to the generating process. In particular, we explored simulation studies under three different settings. In the first two scenarios we generated data from two types of autoregressive (AR) processes, namely a piecewise AR process and a slowly varying AR process. We compare the performance of our procedure with AutoPARM and AdaptSPEC. In the third setting, we assumed that the innovations are t-distributed, and therefore violate the Gaussianity assumption of in EquationEquation (3)
(3)
(3) . For all models, our estimation algorithm was run for 20,000 iterations, 5000 of which were used as burn in, and the hyperparameters were chosen as
and
.
5.2.1 Piecewise Autoregressive Process
As pointed out by a referee, although modeling a time series as a linear combination of a finite number of sinusoids plus noise is common in the signal processing literature, such line-spectrum based models are rare in the statistics literature. In fact, it is commonly assumed that the power spectrum is continuous across frequencies. We investigate the performance of the proposed procedure when analyzing data generated from a piecewise AR process whose local spectral density functions show sharp peaks. Specifically, a realization is simulated from(11)
(11) where
and
for i = 2, 3. (top panel) shows a realization from model (11). After applying our methodology AutoNOM, the posterior probability of two change-points is 97.93% and the posterior means of the change-point locations are
and
. The estimated location of the frequency peaks for our proposed procedure in comparison to AdaptSPEC and AutoPARM and the true values are shown in (bottom panels). It is evident that the proposed and existing methodologies successfully identify the true location of the frequency peaks in each segment, with AdaptSPEC showing less precision.
Fig. 3 Piecewise AR process. (Top) A realization from model (11). Vertical dotted lines are the estimated locations of the change-points. (Bottom) Estimated frequency peaks for AutoNOM (AN), AdaptSPEC (AS J = 10), and AutoPARM (AP); 95% credible intervals (horizontal lines) are also reported for Bayesian methods. Dotted vertical lines are true locations of the frequency peaks.
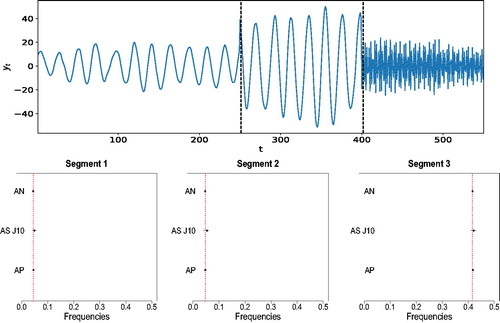
5.2.2 Slowly Varying Autoregressive Process
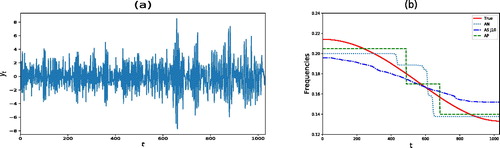
In this section, we analyze an AR process whose continuous spectral density is changing slowly over time. We note though that this scenario is a large departure from the assumptions of our model. In particular, we consider the same slowly varying AR(2) process investigated by Ombao et al. (Citation2001) and Davis, Lee, and Rodriguez-Yam (Citation2006), namely(12)
(12) where
and
. Notice that the parameter at is changing gradually over time whereas the coefficient associated with the second lag remains constant. A realization from model (12) is shown in and the corresponding time varying frequency peak is displayed in as a solid line. also shows the estimated time varying frequency peak for AutoNOM, AdaptSPEC, and AutoPARM. For AutoNOM and AdaptSpec, the time changing frequency peak has been averaged across the MCMC samples, giving a smoother estimate (especially for AdaptSPEC) than the one obtained by AutoPARM. For each method, we compute the residual sum of squares
between the true time changing frequency peak ωt and its estimate
. The RSS in this example was 0.111, 0.174, and 0.085 for AutoNOM, AdaptSPEC, and AutoPARM, respectively. It is clear that even in this scenario where the data generating model was very different from the underlying assumptions of our model, our approach seems to outperform AdaptSPEC and remains competitive with AutoPARM in estimating the time varying frequency peak.
Fig. 4 Slowly varying AR(2) process. (a) A realization from model (12). (b) True time varying frequency peak (solid line) and estimated time varying frequency peak for AutoNOM (AN), AdaptSPEC (AS J = 10), and AutoPARM (AP).
5.2.3 Non-Gaussian Time Series
We investigate the performance of our approach in the scenario when the innovations are t-distributed. We simulate a time series from the same simulation model presented in Section 5.1, where errors were generated from a t-distribution with 2, 3, and 2 degrees of freedom for the sequence of three segments, respectively. The degrees of freedom were chosen low such that the corresponding distributions show heavy tails. A realization of this time series is shown in . Our proposed methodology correctly identifies the 2 change-points, as the estimated posterior probability is 0.99. The posterior means of the change-point locations are
and
, showing an excellent match to the true values
. Furthermore, the posterior mode of the number of frequencies in each segment is
, which is a correct estimate of
. We also display in the estimated signal (using EquationEquation (1)
(1)
(1) , supplementary materials) as a dotted line. We can conclude that, although our model assumes Gaussianity, AutoNOM seems to perform well even in the case where the oscillatory underlying process is t-distributed with heavy tails.
Fig. 5 Illustrative example with t-distributed residual variances. Simulated time series (solid line) and estimated signal (dotted line). The dotted vertical lines represent the estimated location of the change-points.
6 Case Studies
The development of our methodology was motivated by the following two case studies where dense physiological signals were observed which exhibit unknown periodicities whose role may change over time in a more or less abrupt manner and where their detection is of relevance to the health and well-being of the subject.
6.1 Analysis of Human Skin Temperature
The development of information and communication technologies, in particular widespread internet access and availability of mobile phones and tablets, allows considering new developments in the health care system. To address the issue of personalized medical treatment according to the circadian timing system of the patient, referred to as chronotherapy (Levi and Schibler Citation2007), a novel and validated noninvasive mobile e-Health platform pioneered by the French project PiCADo (Komarzynski et al. Citation2018) is used to record and teletransmit skin surface temperature as well as physical activity data (Huang et al. Citation2018) from an upper chest e-sensor. shows an example of 4 days of 5-min temperature recording for a healthy individual. The circadian rhythms in core and skin surface temperature are usually 8–12 hr out of phase, with respective maxima occurring near 16:00 at day time, and near 2:00 at night (Krauchi and Wirz-Justice Citation1994). The early night drop in core body temperature, which is critical for triggering the onset of sleep (Van Someren Citation2006), results from the vasodilatation of the skin vessels and associated rise in skin surface temperature (Kräuchi Citation2002). Under the assumption of stationarity, Komarzynski et al. (Citation2018) analyzed the skin temperature time series identifying both strong 12 hr (circahemidian) and 24 hr (circadian) rhythms.
Fig. 6 Analysis of skin temperature of a healthy subject. Panel (a) are the time series of skin temperature and corresponding physical activity. Panel (b) is the estimated signal (solid line) along with its 95% credible interval; vertical lines are the estimated locations of the change-points. Panel (c) is the estimated posterior density histogram of the locations of the changes, conditioned on change-points. Rectangles on the time axis of each plot correspond to periods from 20.00 to 8.00. The variation in skin temperature finds analogies with the rest-activity pattern that alternates between day activity and night rest.
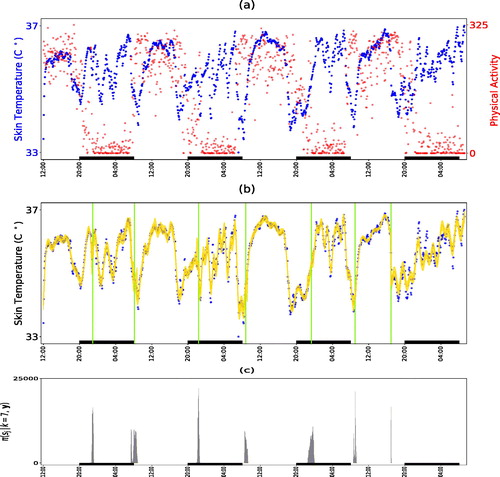
Here, we applied our methodology to the skin-temperature time series shown in for 300,000 iterations, discarding the first 100,000 updates as burn-in. The maximum number of change-points was set to 10, whereas the maximum number of frequencies per regime
was set to 5. The estimated number of change-points had a mode at 7, with
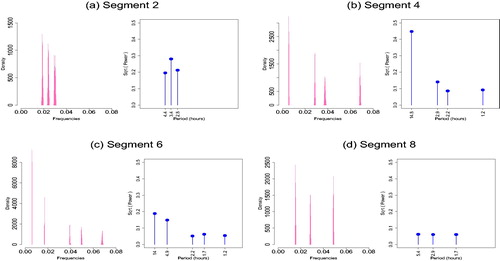
and their estimated posterior distributions are shown in . Inspecting them alongside the physical activity data we can see that the change points mainly correspond to the start and endpoints of the prolonged rest periods at nights showing that skin temperature alternates between day activity and night rest including sleep. shows the estimated posterior distribution of the frequencies for the sleep segments (2, 4, 6, 8) along with the square root of the estimated power of the corresponding frequencies, where the power of each is frequency
is summarized by the sum of squares of the corresponding linear coefficients, that is,
(Shumway and Stoffer Citation2005). shows the piecewise fitted signal, along with a 95% credible interval obtained from the 2.5 and 97.5 empirical percentiles of the posterior sample using EquationEquation (1)
(1)
(1) , supplementary materials. Cycles of approximately 3 hr appear in segments 2, 4, and 6; cycles that range approximately 1–1.5 hr appear in segments 2, 4, 8 and cycles of around 2 hr appear in segments 4 and 6 while some longer periods identified in segments 4, 6, 8 indicate the presence of a trend.
Fig. 7 Spectral properties for segments corresponding to night rest. Estimated posterior distribution of the frequencies along with square root of the estimated power of the corresponding frequencies. The results are conditional on the modal number of frequencies per segment.
Stages of sleep are characterized by ultradian oscillations between rapid eye movements (REM) and non-REM. The biological functionality that regulates the alternations between these two types of sleep is not yet much understood (Altevogt and Colten Citation2006). However, several physiological changes that occur over night differ between REM and non-REM phases, such as heart rate, brain activity, muscle tone and body temperature (Berlad et al. Citation1993; Pace-Schott and Hobson Citation2002). The body cycles between REM and non-REM sleep stages with an average length that ranges approximately between 70 and 120 min, and there are usually four to six of these sleep cycles each night (Carskadon and Dement Citation2005; Shneerson Citation2009). Our analysis was able to use skin temperature data alone to detect periods of sleep throughout the day and identify oscillatory behavior during the night, whose frequencies are compatible with ultradian oscillations between REM and different non-REM sleep stages.
A comparison with the current state-of-the-art methods, AutoPARM and AdaptSPEC, is provided in the supplementary materials, Section 4.1. Circadian and ultradian rhythmicity are expected because body temperature is known to be a circadian biomarker (Krauchi and Wirz-Justice Citation1994), but these existing methods fail. Furthermore, we notice that in the framework of analyzing circadian biomarker data, such as body temperature, a change in acrophase may be of interest to the clinician as this may be indicative of a disruption of the bodyclock. The methodology can indeed be used to investigate phase which can be computed from the sinusoidal function that characterizes the jth segment (see supplementary materials, Section 3).
6.2 Characterizing Instances of Sleep Apnea in Rodents
Sleep apnea is the temporary ( 2 breaths) interruption of breathing during sleep. Moderate or severe (
15 events per hour) sleep apnea, occurs in about 50% of men and 25% of women over the age of 40 (Heinzer et al. Citation2015), with 91% of people with sleep apnea being undiagnosed (Tan et al. Citation2016). Sleep apnea is linked to many diseases. Patients with sleep apnea are at increased risk of: cardiovascular events (Lanfranchi et al. Citation1999), cancer (Nieto et al. Citation2012), liver disease (Sundaram et al. Citation2016), diabetes (Harsch et al. Citation2004), metabolic syndrome (Parish, Adam, and Facchiano Citation2007), cognitive decline (Osorio et al. Citation2016), and increased risk of dementia in the elderly (Lal, Strange, and Bachman Citation2012). The motivation of this research is to provide a statistical methodology that can be applied to analyze large breathing datasets resulting from in vivo plethysmograph studies in rats to characterize the occurrence of sleep apnea under different experimental conditions. If this could be attained, a concrete aid to the understanding of the pathological implications of this status could be provided to clinicians and experimental biologists.
An unrestrained whole-body plethysmograph is used to produce a breathing trace from freely behaving rats for periods of up to 3 hr. Plethysmographs were made using an 2 L air-tight box connected to a pressure transducer, with an air pump and outlet valve producing a flow rate of 2 L/min. Airflow pressure signals were amplified using Neurolog system (Digitimer) connected to a 1401 interface and acquired on a computer using Spike2 software (CED).
Apneas are subclassified as post-sigh apneas, if the preceding breath was at least 25% above the average amplitude of prior breaths, or spontaneous apneas, if there was no manifestation of a previous sigh (Davis and O’Donnell Citation2013). Airflow traces from the plethysmograph are shown in (left panels) and consist of three time series, which will be referred to as (a), (b), and (c). They correspond to different actions for this rat: (a) an alternation of sniffing and normal breathing; (b) spontaneous apnea followed by normal breathing; (c) normal breathing followed by a sigh, and a post-sigh apnea. We note that these actions were classified by eye by an experienced experimental researcher. Each time series contains 20,000 observations where the signal was sampled at 2000 Hz so that we have 2000 observations per second.
Fig. 8 Plots of the respiratory traces of a rat (left panels) and corresponding estimated posterior power (right panels). Panel (a) is characterized by an alternation of sniffing and normal breathing. Panel (b) is a plot of the trace of a spontaneous apnea, followed by normal breathing. Panel (c) shows normal breathing followed by a sigh, and a post-sigh apnea. Dotted vertical lines correspond to the estimated locations of the change-points.
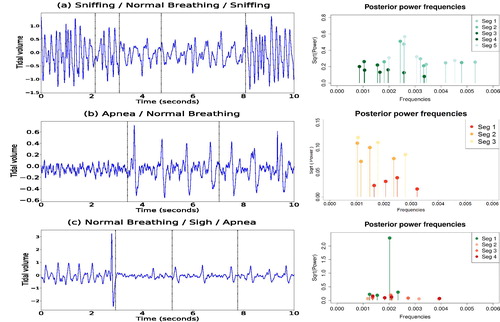
Our procedure allows us to set an upper bound, , (Appendix A.1.2) for the uniform interval where the new frequencies are sampled. As the periodogram ordinates for these data were approximately zero for all frequencies larger than 0.01, we decided accordingly to set
. The locations of the changes (vertical lines) are displayed in (left panels). The posterior power of the frequencies, for each time series, is shown in (right panels). These results are conditional on the modal number of change-points and the modal number of frequencies per segment. For each dataset, we summarize in the spectral properties of each partition by displaying the periodicities corresponding to the first two largest values of the estimated power. When the rat is sniffing, (a), the air flow trace oscillates with a dominant period of approximately 0.2 sec, namely 5 cycles per second. Normal breathing, (a) and (b), is characterized by lower frequencies and lower magnitude than sniffing, by oscillating with a dominant period of around 0.5 sec, namely around 2 cycles every second. Apneas, (b) and (c), appear to be characterized by higher frequencies than normal breathing but with a lower power, with dominant periods of around 0.25 and 0.35 sec. Notice that in the first partition of (c), the highest value of the power corresponds to the frequency responsible for a sigh before apnea. Moreover, our methodology identifies different frequencies that explain the variation between the third and fourth partition of (c), leading to the hypothesis that there might be a time changing spectrum during the occurrence of an apnea instance. A comparison of our results with the results from AutoPARM and AdaptSPEC is provided in the supplementary materials, Section 4.2.
Table 3 Spectral properties of respiratory traces of a rat.
7 Summary and Discussion
We developed a novel Bayesian methodology for analyzing nonstationary time series that exhibit oscillatory behavior. Our approach is based on the assumption that, conditional on the position and number of change-points, the time series can be approximated by a piecewise changing sinusoidal regression model. The timing and number of changes are unknown, along with the number and values of relevant periodicities in each regime. Bayesian inference is performed via a reversible jump MCMC algorithm that can simultaneously estimate both the number and location of change-points, as well as the number, frequency and magnitude of sinusoids within each segment. Our methodology can be seen as a novel and relevant extension of the work in Andrieu and Doucet (Citation1999) to the nonstationary setting.
We illustrated the utility of our methodology in two case studies. First, we analyzed human skin temperature time series data obtained from a wearable device, which exhibited unknown periodicities that changed over time in an abrupt manner. Our proposed methodology identified interesting oscillations whose frequencies are consistent with ultradian oscillations between REM and non-REM sleep stages. Second, we characterized the occurrence of sleep apnea in large breathing datasets resulting from in vivo plethysmograph studies on rodents. Our spectral investigation was able to distinguish very sharp peaks, corresponding to different nearby frequencies, that are responsible for the different actions of the rodent.
Although we have not discussed this in detail here, several diagnostics for monitoring convergence were carried out in both simulation and case studies. In particular, we verified that the target posterior distribution reached a stable regime by analyzing the trace plot of the log-likelihood across MCMC iterations (Marin and Robert Citation2007). We are aware that assessing convergence only based on this simple tool may sometimes be misleading since stable values of the log-likelihood could simply mean that the Markov chain is stuck in some local mode of the posterior distribution. Additionally, conditioned on the modal number of change-points and modal number of frequencies per regime, we have also monitored (within-model) convergence by analyzing the traces and running averages plots for all parameters across MCMC iterations, with satisfactory results. Comparable results were also obtained when running several chains starting at over-dispersed initial values. We notice that the diagnostic tool used by Bruce et al. (Citation2018) and Li and Krafty (Citation2019) to assess convergence for reversible jump MCMC samplers appears relevant. In the context of adaptive spectral analysis of nonstationary time series, they point out that although the number of partitions change across models, a power spectrum is defined at each time point. The power spectrum is modeled with a fixed number of splines, yielding a vector of summary measures of parameters that maintain the same interpretation across models in their samplers. However, our proposed sampler has a further layer of variable dimensionality, as not only the number and locations of the change-points may change from one iteration to the next, but also the number of frequencies in each segment are not fixed throughout the simulation.
We conclude this article by noticing that, although a Gaussian distribution is assumed, it is conceivable that our model can be extended to allow for other error distributions in EquationEquation (1)(1)
(1) . For example, a generalized linear model (McCullagh and Nelder Citation1989) may be used to model periodic count data by assuming that the observed data follows a Poisson distribution, that is,
. The logarithmic link function of the expected value μt of the response variable yt may be expressed as
, where the definitions of the variables are the same as for EquationEquation (1)
(1)
(1) . Bayesian inference can, in principle, be achieved in a similar way as described in the article, namely by iterating between segment and change-point model moves, where the formulation of the acceptance probabilities and some proposal distributions need to be modified accordingly. We believe that such an extension would find use in several ranges of applications, for example, in studying population cycles in ecology and epidemiology, where the abundance of species are measured as count variables (White and Bennetts Citation1996; Bhaskaran et al. Citation2013; Bramness et al. Citation2015).
Supplementary Materials
Supplementary materials are available and include further details about simulation studies, acceptance rates, phase investigation, and performances of existing methods in the case studies. Code that implements the methodology and the data used in the case studies are available as online supplemental material and can be also found at https://github.com/Beniamino92/AutoNOM.
Supplemental Material
Download Zip (567.8 KB)Acknowledgments
We wish to thank the referees, the associate editor, Dr. Paul Jenkins, Zeda Li, and Jack Jewson for their insightful and valuable comments. The work presented in this article was developed as part of the first author’s PhD thesis at the University of Warwick.
Additional information
Funding
Related Research Data
References
- Akaike, H. (1974), “A New Look at the Statistical Model Identification,” IEEE Transactions on Automatic Control, 19, 716–723. DOI: 10.1109/TAC.1974.1100705.
- Altevogt, B. M., and Colten, H. R. (2006), Sleep Disorders and Sleep Deprivation: An Unmet Public Health Problem, Washington, DC: National Academies Press.
- Andrieu, C., and Doucet, A. (1999), “Joint Bayesian Model Selection and Estimation of Noisy Sinusoids via Reversible Jump MCMC,” IEEE Transactions on Signal Processing, 47, 2667–2676. DOI: 10.1109/78.790649.
- Berlad, I., Shlitner, A., Ben-Haim, S., and Lavie, P. (1993), “Power Spectrum Analysis and Heart Rate Variability in Stage 4 and REM Sleep: Evidence for State-Specific Changes in Autonomic Dominance,” Journal of Sleep Research, 2, 88–90. DOI: 10.1111/j.1365-2869.1993.tb00067.x.
- Bhaskaran, K., Gasparrini, A., Hajat, S., Smeeth, L., and Armstrong, B. (2013), “Time Series Regression Studies in Environmental Epidemiology,” International Journal of Epidemiology, 42, 1187–1195. DOI: 10.1093/ije/dyt092.
- Bishop, C. M. (2006), Pattern Recognition and Machine Learning, Information Science and Statistics, New York: Springer-Verlag.
- Bramness, J. G., Walby, F. A., Morken, G., and Røislien, J. (2015), “Analyzing Seasonal Variations in Suicide With Fourier Poisson Time-Series Regression: A Registry-Based Study From Norway, 1969–2007,” American Journal of Epidemiology, 182, 244–254. DOI: 10.1093/aje/kwv064.
- Bretthorst, G. L. (1988), Bayesian Spectrum Analysis and Parameter Estimation (Vol. 48), New York: Springer-Verlag.
- Bretthorst, G. L. (1990), “Bayesian Analysis. I. Parameter Estimation Using Quadrature NMR Models,” Journal of Magnetic Resonance, 88, 533–551. DOI: 10.1016/0022-2364(90)90287-J.
- Bruce, S. A., Hall, M. H., Buysse, D. J., and Krafty, R. T. (2018), “Conditional Adaptive Bayesian Spectral Analysis of Nonstationary Biomedical Time Series,” Biometrics, 74, 260–269. DOI: 10.1111/biom.12719.
- Carskadon, M. A., and Dement, W. C. (2005), “Normal Human Sleep: An Overview,” Principles and Practice of Sleep Medicine, 4, 13–23.
- Dahlhaus, R. (1997), “Fitting Time Series Models to Nonstationary Processes,” The Annals of Statistics, 25, 1–37. DOI: 10.1214/aos/1034276620.
- Davis, E. M., and O’Donnell, C. P. (2013), “Rodent Models of Sleep Apnea,” Respiratory Physiology & Neurobiology, 188, 355–361. DOI: 10.1016/j.resp.2013.05.022.
- Davis, R. A., Lee, T. C. M., and Rodriguez-Yam, G. A. (2006), “Structural Break Estimation for Nonstationary Time Series Models,” Journal of the American Statistical Association, 101, 223–239. DOI: 10.1198/016214505000000745.
- Djuric, P. M. (1996), “A Model Selection Rule for Sinusoids in White Gaussian Noise,” IEEE Transactions on Signal Processing, 44, 1744–1751. DOI: 10.1109/78.510621.
- Dou, L., and Hodgson, R. (1995), “Bayesian Inference and Gibbs Sampling in Spectral Analysis and Parameter Estimation. I,” Inverse Problems, 11, 1069. DOI: 10.1088/0266-5611/11/5/011.
- Dou, L., and Hodgson, R. (1996), “Bayesian Inference and Gibbs Sampling in Spectral Analysis and Parameter Estimation: II,” Inverse Problems, 12, 121. DOI: 10.1088/0266-5611/12/2/002.
- Gilks, W. R., Richardson, S., and Spiegelhalter, D. (1995), Markov Chain Monte Carlo in Practice, Boca Raton, FL: CRC Press.
- Green, P. J. (1995), “Reversible Jump Markov Chain Monte Carlo Computation and Bayesian Model Determination,” Biometrika, 82, 711–732. DOI: 10.1093/biomet/82.4.711.
- Han, F., Subramanian, S., Price, E. R., Nadeau, J., and Strohl, K. P. (2002), “Periodic Breathing in the Mouse,” Journal of Applied Physiology, 92, 1133–1140. DOI: 10.1152/japplphysiol.00785.2001.
- Harsch, I. A., Schahin, S. P., Brückner, K., Radespiel-Tröger, M., Fuchs, F. S., Hahn, E. G., Konturek, P. C., Lohmann, T., and Ficker, J. H. (2004), “The Effect of Continuous Positive Airway Pressure Treatment on Insulin Sensitivity in Patients With Obstructive Sleep Apnoea Syndrome and Type 2 Diabetes,” Respiration, 71, 252–259. DOI: 10.1159/000077423.
- Heinzer, R., Vat, S., Marques-Vidal, P., Marti-Soler, H., Andries, D., Tobback, N., Mooser, V., Preisig, M., Malhotra, A., Waeber, G., and Vollenweider, P. (2015), “Prevalence of Sleep-Disordered Breathing in the General Population: The Hypnolaus Study,” The Lancet Respiratory Medicine, 3, 310–318. DOI: 10.1016/S2213-2600(15)00043-0.
- Huang, Q., Cohen, D., Komarzynski, S., Li, X.-M., Innominato, P., Lévi, F., and Finkenstädt, B. (2018), “Hidden Markov Models for Monitoring Circadian Rhythmicity in Telemetric Activity Data,” Journal of the Royal Society Interface, 15, 20170885. DOI: 10.1098/rsif.2017.0885.
- Komarzynski, S., Huang, Q., Innominato, P. F., Maurice, M., Arbaud, A., Beau, J., Bouchahda, M., Ulusakarya, A., Beaumatin, N., Breda, G., and Finkenstädt, B. (2018), “Relevance of a Mobile Internet Platform for Capturing Inter- and Intrasubject Variabilities in Circadian Coordination During Daily Routine: Pilot Study,” Journal of Medical Internet Research, 20, e204. DOI: 10.2196/jmir.9779.
- Kräuchi, K. (2002), “How Is the Circadian Rhythm of Core Body Temperature Regulated?,” Clinical Autonomic Research, 12, 147–149.
- Krauchi, K., and Wirz-Justice, A. (1994), “Circadian Rhythm of Heat Production, Heart Rate, and Skin and Core Temperature Under Unmasking Conditions in Men,” American Journal of Physiology—Regulatory, Integrative and Comparative Physiology, 267, R819–R829. DOI: 10.1152/ajpregu.1994.267.3.R819.
- Lal, C., Strange, C., and Bachman, D. (2012), “Neurocognitive Impairment in Obstructive Sleep Apnea,” Chest, 141, 1601–1610. DOI: 10.1378/chest.11-2214.
- Lanfranchi, P. A., Braghiroli, A., Bosimini, E., Mazzuero, G., Colombo, R., Donner, C. F., and Giannuzzi, P. (1999), “Prognostic Value of Nocturnal Cheyne-Stokes Respiration in Chronic Heart Failure,” Circulation, 99, 1435–1440. DOI: 10.1161/01.CIR.99.11.1435.
- Levi, F., and Schibler, U. (2007), “Circadian Rhythms: Mechanisms and Therapeutic Implications,” Annual Review of Pharmacology and Toxicology, 47, 593–628. DOI: 10.1146/annurev.pharmtox.47.120505.105208.
- Li, Z., and Krafty, R. T. (2019), “Adaptive Bayesian Time–Frequency Analysis of Multivariate Time Series,” Journal of the American Statistical Association, 114, 453–465. DOI: 10.1080/01621459.2017.1415908.
- Marin, J.-M., and Robert, C. (2007), Bayesian Core: A Practical Approach to Computational Bayesian Statistics, Berlin: Springer Science & Business Media.
- McCullagh, P., and Nelder, J. (1989), Generalized Linear Models, Monographs on Statistics and Applied Probability Series (2nd ed.), London: Chapman & Hall.
- Nakamura, A., Fukuda, Y., and Kuwaki, T. (2003), “Sleep Apnea and Effect of Chemostimulation on Breathing Instability in Mice,” Journal of Applied Physiology, 94, 525–532. DOI: 10.1152/japplphysiol.00226.2002.
- Nieto, F. J., Peppard, P. E., Young, T., Finn, L., Hla, K. M., and Farré, R. (2012), “Sleep-Disordered Breathing and Cancer Mortality: Results From the Wisconsin Sleep Cohort Study,” American Journal of Respiratory and Critical Care Medicine, 186, 190–194. DOI: 10.1164/rccm.201201-0130OC.
- Ombao, H. C., Raz, J. A., von Sachs, R., and Malow, B. A. (2001), “Automatic Statistical Analysis of Bivariate Nonstationary Time Series,” Journal of the American Statistical Association, 96, 543–560. DOI: 10.1198/016214501753168244.
- Osorio, R. S., Ducca, E. L., Wohlleber, M. E., Tanzi, E. B., Gumb, T., Twumasi, A., Tweardy, S., Lewis, C., Fischer, E., Koushyk, V., and Cuartero-Toledo, M. (2016), “Orexin-A Is Associated With Increases in Cerebrospinal Fluid Phosphorylated-Tau in Cognitively Normal Elderly Subjects,” Sleep, 39, 1253–1260. DOI: 10.5665/sleep.5846.
- Pace-Schott, E. F., and Hobson, J. A. (2002), “The Neurobiology of Sleep: Genetics, Cellular Physiology and Subcortical Networks,” Nature Reviews Neuroscience, 3, 591. DOI: 10.1038/nrn895.
- Parish, J. M., Adam, T., and Facchiano, L. (2007), “Relationship of Metabolic Syndrome and Obstructive Sleep Apnea,” Journal of Clinical Sleep Medicine, 3, 467.
- Priestley, M. B. (1981), Spectral Analysis and Time Series, London: Academic Press.
- Quinn, B. G. (1989), “Estimating the Number of Terms in a Sinusoidal Regression,” Journal of Time Series Analysis, 10, 71–75. DOI: 10.1111/j.1467-9892.1989.tb00016.x.
- Rife, D. C., and Boorstyn, R. R. (1976), “Multiple Tone Parameter Estimation From Discrete-Time Observations,” Bell System Technical Journal, 55, 1389–1410. DOI: 10.1002/j.1538-7305.1976.tb02941.x.
- Rissanen, J. (1978), “Modeling by Shortest Data Description,” Automatica, 14, 465–471. DOI: 10.1016/0005-1098(78)90005-5.
- Rosen, O., Stoffer, D. S., and Wood, S. (2009), “Local Spectral Analysis via a Bayesian Mixture of Smoothing Splines,” Journal of the American Statistical Association, 104, 249–262. DOI: 10.1198/jasa.2009.0118.
- Rosen, O., Wood, S., and Stoffer, D. S. (2012), “AdaptSPEC: Adaptive Spectral Estimation for Nonstationary Time Series,” Journal of the American Statistical Association, 107, 1575–1589. DOI: 10.1080/01621459.2012.716340.
- Shneerson, J. M. (2009), Sleep Medicine: A Guide to Sleep and Its Disorders, Hoboken, NJ: Wiley.
- Shumway, R. H., and Stoffer, D. S. (2005), Time Series Analysis and Its Applications, Springer Texts in Statistics, New York: Springer-Verlag.
- Stoica, P., Moses, R. L., Friedlander, B., and Soderstrom, T. (1989), “Maximum Likelihood Estimation of the Parameters of Multiple Sinusoids From Noisy Measurements,” IEEE Transactions on Acoustics, Speech, and Signal Processing, 37, 378–392. DOI: 10.1109/29.21705.
- Sundaram, S. S., Halbower, A., Pan, Z., Robbins, K., Capocelli, K. E., Klawitter, J., Shearn, C. T., and Sokol, R. J. (2016), “Nocturnal Hypoxia-Induced Oxidative Stress Promotes Progression of Pediatric Non-alcoholic Fatty Liver Disease,” Journal of Hepatology, 65, 560–569. DOI: 10.1016/j.jhep.2016.04.010.
- Tan, A., Cheung, Y. Y., Yin, J., Lim, W.-Y., Tan, L. W., and Lee, C.-H. (2016), “Prevalence of Sleep-Disordered Breathing in a Multiethnic Asian Population in Singapore: A Community-Based Study,” Respirology, 21, 943–950. DOI: 10.1111/resp.12747.
- Van Someren, E. J. (2006), “Mechanisms and Functions of Coupling Between Sleep and Temperature Rhythms,” Progress in Brain Research, 153, 309–324.
- White, G. C., and Bennetts, R. E. (1996), “Analysis of Frequency Count Data Using the Negative Binomial Distribution,” Ecology, 77, 2549–2557. DOI: 10.2307/2265753.
- Whittle, P. (1957), “Curve and Periodogram Smoothing,” Journal of the Royal Statistical Society, Series B, 19, 38–63. DOI: 10.1111/j.2517-6161.1957.tb00242.x.
- Yau, S.-F., and Bresler, Y. (1993), “Maximum Likelihood Parameter Estimation of Superimposed Signals by Dynamic Programming,” IEEE Transactions on Signal Processing, 41, 804–820. DOI: 10.1109/78.193219.
- Zhang, Q., and Wong, K. M. (1993), “Information Theoretic Criteria for the Determination of the Number of Signals in Spatially Correlated Noise,” IEEE Transactions on Signal Processing, 41, 1652–1663. DOI: 10.1109/78.212737.
Appendix A:
Details of the Sampling Scheme
A.1 Updating the Segment Model
A.1.1 Within-Model Move
Sampling : To obtain samples from the conditional posterior distribution
(see EquationEquation (8)
(8)
(8) ), we draw the frequencies one-at-time using a mixture of M-H steps. To explore the parameter space efficiently, we design a mixture distribution
, so that
(A.1)
(A.1) where q1 is defined in Equation (A.2), q2 is the density of a univariate normal
is a positive real number such that
, and c and p refer to current and proposed values, respectively. According to Equation (A.1) we carry out with probability
a M-H step with proposal distribution
,
(A.2)
(A.2)
where
and Ih is the value of the squared modulus of the discrete Fourier transform of the observations y evaluated at frequency h/n
In this way frequencies are proposed from regions in parameter space with high posterior density, yielding a Markov chain which converges quickly to its invariant distribution. The proposal distribution is independent of the current state
. The acceptance probability for this move is
where
. On the other hand, with probability
, we perform a random walk M-H step with proposal distribution
, whose density is a univariate normal distribution with mean
and variance
, that is,
. This perturbation around the current value
allows a local exploration of the conditional posterior distribution. The acceptance probability for this move is
Setting to a relative low value integrates a fairly high acceptance rate with a quick exploration of the parameter space. For our experiments, we set
and
.
Sampling : Given values of
and
, the vector of linear parameters
can be sampled via a M-H step from the target posterior conditional distribution
(see EquationEquation (9)
(9)
(9) ). The proposed vector of coefficients
can be drawn from normal approximations to their posterior conditional distribution (e.g., Gilks, Richardson, and Spiegelhalter Citation1995; Rosen, Wood, and Stoffer Citation2012),
(A.3)
(A.3) where
and
The proposal for is independent of the current values
, and the acceptance probability for this move is
where
and
denote the normal proposal densities
and
, respectively.
A.1.2 Between-Model Moves
The number of frequencies on a segment is proposed to either increase or decrease by one. Let and assume the Markov chain is currently at
. We propose a move to
by drawing from a proposal density
and accepting this update with probability
(A.4)
(A.4)
The proposed state is drawn by first drawing
, followed by
,
and
. In fact, we can rewrite the proposal density as
Birth move: If a birth move is proposed, we have that . The proposed frequency vector
is constructed as
namely by keeping the current vector of frequencies and proposing an additional frequency
. Alternatively to Andrieu and Doucet (Citation1999), we choose to sample
uniformly on the interval
, where
. The value of
can be chosen to reflect prior information about the significant frequencies that drive the variation in the data, for example, by choosing
in the low frequencies range (
). Additionally, for computational and/or modelling reasons, we would like not to sample frequencies that are too close to each other. Hence, we choose to draw a candidate value
uniformly from the union of intervals of the form
, for
and denoting
and
. Here,
is a fixed minimum distance between frequencies, which is chosen larger than
; in fact, when the separation of two frequencies is less than the Nyquist step (Priestley Citation1981), that is,
, the two frequencies are indistinguishable (Dou and Hodgson Citation1995). Moreover, we sort the proposed vector of frequencies
to ensure identifiability and perform practical estimation, as suggested in Andrieu and Doucet (Citation1999). For proposed
and given
, the proposed vector of linear coefficients
is sampled following the same procedure of Section A.1.1, namely we draw
from a normal approximation to their posterior conditional distribution
. Finally, the residual variance
is sampled directly from its posterior conditional distribution
(see EquationEquation (10)
(10)
(10) ). The proposed state
is accepted or reject in a M-H step with probability
where the likelihood function is given in EquationEquation (5)
(5)
(5) ,
is the density of the Poisson distribution truncated at
and
are defined in EquationEquation (7)
(7)
(7) ,
is the density of the uniform proposal for sampling the additional frequency,
and
are the multivariate normal proposal densities
and
, respectively;
and
are the Inverse-Gamma proposal densities defined in EquationEquation (10)
(10)
(10) .
Death move: If a death move is proposed, then . A vector of frequencies
is constructed by randomly selecting with probability
one of the current frequencies as the candidate frequency for removal. Given
and
, a vector of linear coefficients
is sampled from a normal approximation to its posterior conditional distribution. Finally, conditioned on
and
, the residual variance
is drawn from its posterior Inverse-Gamma distribution. It is straightforward to see that the acceptance probability for the death step has the same form as the birth step, with the proper change of labelling of the variables, and the ratio terms inverted.
A.2 Updating the Change-Point Model
A.2.1 Within-Model Move
Let be the current vector of change-points locations,
be the current vector of number of frequencies,
be the current vector of frequencies. Let
and
be the current vectors of linear coefficients and residual variances, respectively.
Let us also define Following Green (Citation1995), a change-point,
say, is randomly selected with probability
from the existing set of change-points. To explore the parameter space in an efficient way and similar to above we construct a mixture distribution
, as
(A.5)
(A.5) where q1 is the density of a Uniform
, q2 is the density of a univariate normal
and δs is a positive real number such that
. We propose with probability δs a candidate value
from the above uniform distribution where ψ is a fixed minimum time between change-points avoiding change-points being too close to each other. On the other hand, with probability
arises as a normal random walk proposal centered at the current change-point
. The proposed vector of change-points locations is denoted by
and hence the proposed value
induces a new proposed data partition on
corresponding to
and
. We denote the vectors of observations belonging to these two proposed segments as
and
, which include
and
observations, respectively. Given
, the proposed number of frequencies
are set equal to the current ones
, so that
. Similarly, the proposed pair of frequency vectors
is chosen equal to the current pair
in the corresponding segments, that is,
. The proposed vectors
are sampled from normal approximations to their posterior conditional distributions
and
and are accepted in a M-H step with probability
where the likelihood is specified in EquationEquation (4)
(4)
(4) and
and
are multivariate Gaussian as in Equation (A.3). Note that the likelihood ratio and the prior ratio differ from one only for the two segments affected by the move of the change-points. Finally, the residual variances
,
are drawn from their posterior conditional distributions
in a Gibbs step.
A.2.2 Between-Model Moves
Let and assume the Markov chain is at
. We propose a move to
by first drawing
, followed by sampling the change-point locations
. The latter involves either merging two segments (death) or splitting a segment (birth). The number of frequencies and their values in the proposed segments are selected from the current state. We draw
and jointly update the entire state
. Hence, we propose a move to
by drawing from a proposal density of the form
Birth move: If a birth move is proposed, we have that . We draw a new change-point uniformly on
, the support of
given the constraints imposed by ψs, that is,
Hence, the new proposed location
is sampled from a
, where the proposal density is given by
(A.6)
(A.6)
As the proposed location will lie within an existing interval
with probability one, we can define the proposed change-points location vector as
The number of frequencies corresponding to the two newly proposed segments
and
are set equal to the current number of frequencies on the whole segment
. Therefore, we can construct the proposed vector of the number of frequencies
and the proposed vector of frequencies
as
The proposed vector of residual variances is
where the residual variances
for the split partition are constructed following Green (Citation1995), namely as a perturbation of the current variance
. Specifically, we draw
and let
be deterministic transformations of
, that is
(A.7)
(A.7)
Finally, the proposed vector of linear coefficients is
where the vectors
are drawn from normal approximations of their posterior conditional distribution, as in Section A.1.1. The proposed move to the state
is accepted with probability
where the likelihood function is provided in EquationEquation (4)
(4)
(4) ,
is the uniform density defined in Equation (A.6);
,
are the multivariate normal proposal densities, and the Jacobian
is
The numerator of the proposal ratio is better understood by looking at the details of the death step, which are given below.
Death move: If a death step is proposed, then . A candidate change-point
to be removed is sampled uniformly from the vector of existing change-points; that is, we propose to remove
with probability
. Then, the proposed vector of change-points locations
is defined as
The number and the vector of relevant frequencies
of the newly merged segment
are selected by drawing an index at random from
, obtaining say
, and setting the proposed parameters equal to the current ones relative to the selected index. That is, we set
and
. Hence, the proposed vectors of number of frequencies
and their values
are constructed as follows
The residual variance of the newly merged segment is obtained by inverting the transformation of Equation (A.7). Specifically, we construct
and set the proposed vector of residual variances
as
The proposed vector of linear coefficients is
where the vector of coefficients
is drawn from normal approximation to its posterior conditional distribution. The acceptance probability for the death step has the same form of the birth step, with the proper change of labelling of the variables, and the ratio terms inverted.