
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.1 Introduction
By noting the rapid growing trend of “pure prediction algorithms,” Professor Efron compares and bridges the statistics of the 20th Century (estimation and attribution) to that of the current fast growing development of the 21st Century (prediction). The outstanding discussion offers many deep-rooted insights and comments. As did his forward thinking article on Fisher’s influence on modern statistics (Efron Citation1998), which helped shape many recent developments on statistical inference (including our own work on confidence distribution (Singh, Xie, and Strawderman Citation2005; Xie and Singh Citation2013)), this equally inspiring article by Professor Efron will certainly galvanize many contemporary and powerful developments for modern statistics and for the foundations of data science.
In this note, we echo and also provide additional support to two important points made by Professor Efron: (1) prediction is “an easier task than either attribution or estimation”; (2) the IID assumption (e.g. random splitting of training and testing datasets) is crucial in the current developments on predictions, but we also need to do more for the case when the IID assumption is not met. Based on our own research, we provide additional evidence to support these discussions. We discover that prediction has a homeostasis property and works well under the IID setting even if the learning model used is completely wrong. We also highlight the importance of having a good modeling and inference practice: a good learning model with good estimation is important to improve prediction efficiency in the IID case and it becomes essential to maintain validity in the non-IID case. The message remains: we still need to make effort to build a good learning model and estimation algorithm in prediction, even if prediction is an easier task than estimation.
From the outset, we would like to point out that it is not a straw-man argument to consider non-IID testing data. On the contrary, such data are prevalent in data science. In addition to those examples provided by Professor Efron that showed “drift,” we can easily imagine non-IID examples in many typical applications. For instance, a predictive algorithm is trained on a database of patient medical records and we would like to predict potential outcomes of a treatment for a new patient with more severe symptoms than what the average patient shows. The new patient with more severe symptoms is not a typical IID draw from the general patient population. Similarly, in the finance sector, one is often interested in predicting the financial performance of a particular company. If a predictive model is trained on all institutes, then the testing data (of the specific company of interest) are unlikely IID draws from the same general population of the training data. The limitation of the IID assumption, in our opinion, has hampered our efforts to fully take advantage of fast-developing machine learning methodologies (e.g., deep neural network model, tree based methods, etc.) in many real-world applications.
Our discussions in this note are based on a so-called conformal prediction procedure, an attractive new prediction framework that is error (or model) distribution free (see, e.g., Vovk, Gammerman, and Shafer Citation2005; Shafer and Vovk Citation2008). We discover a homeostasis phenomenon that the expected bias caused by using a wrong model can largely be offset by the corresponding negatively shifted predictive errors under the IID setting. Thus, the predictive conclusion is always valid even if the model used to train the data is completely wrong. This robustness result clearly supports the claim that prediction is an easier task than modeling and estimation. However, the use of a wrong training (learning) model has at least two undesirable impacts on prediction: (a) a prediction based on a wrong model typically produces much wider predictive intervals than those based on a correct model; (b) although the IID case enjoys a nice homeostatic cancellation of bias (in fitted model) and shifts (in associated predictive errors) when using a wrong learning model, in the non-IID case this cancellation is often no longer effective, resulting in invalid predictions. The use of a correct learning model can help mitigate and sometimes solve the problem of invalid prediction for non-IID (e.g., drifted or individual-specific) testing data.
Section 2 reviews a conformal predictive procedure and shows that the prediction is valid under the IID setting, even if the learning model is completely wrong. Section 3 is a numerical study using a neural network model to demonstrate the impact of a wrong learning model and estimation on prediction in both the IID and non-IID cases. Section 4 is a concluding remark. A more detailed discussion, including an introduction of predictive curve (to represent predictive intervals of all levels) and an elaborated study of linear models, is in Xie and Zheng (2020).
2 Prediction, Testing Data, and Learning Models
As in Equation (6.4) of Professor Efron’s article, we assume that a training (observed) dataset of size n, say, is available, where
, are IID random samples from an unknown population
. For a given
, we would like to predict what
would be. We first use the typical assumption that
is also an IID draw from
. Later we relax this requirement and only assume that
relates to
the same way as
relates to
, but
follows a marginal distribution that is different from that of
.
For notation convenience, we consider as the
th observation and introduce the index n + 1, with
and
as a potential value of the unobserved
. Unless specified otherwise, the index “n + 1” and index “new” are exchangeable throughout the note.
2.1 Conformal Prediction Inference With Quantified Confidence Levels
The conformal prediction method has attracted increasing attention in learning communities in recent years (see, e.g., Vovk, Gammerman, and Shafer Citation2005; Shafer and Vovk Citation2008; Lei et al. Citation2018; Barber et al. Citation2019a, 2019b). The idea is straightforward. To make a prediction of the unknown given
, we examine a potential value
, and see how “conformal” the pair
is among the observed n pairs of IID data points
. The higher the “conformality,” the more likely
takes the potential value
. Frequently, a learning model, say
for
, is used to assist prediction. However, the learning model is not essential. As we will see later, even if
is totally wrong or does not exist, a conformal prediction can still provide us a valid prediction, as long as the IID assumption holds.
To be specific, this note employs a conformal prediction procedure known as the Jackknife-plus method (see, e.g., Barber et al. 2019b). Consider a combined collection of both the training and testing data but with the unknown replaced by a potential value
:
. We define conformal residuals
where
is the prediction of yi
based on the leave-two-out dataset
. If a working model
is used, for instance, the model is first fit based on the leave-two-out dataset
and the point prediction is set to be
, where
is the fitted (trained) model using
.
For each given (a potential value of
), we define
(1)
(1) which relates to the degree of “conformity” of the residual values
among the conformal residuals
. (Here,
are in fact the leave-one-out residuals of using the training dataset
.) If
, then
is around the middle of the training data residuals
and thus “most conformal.” When
or
is at the extreme ends of the training data residuals
and thus “least conformal.” This intuition leads us to define a conformal predictive interval of
as
(2)
(2)
where
is the αth quantile of
. The interval (2) is a variant version of the Jackknife-plus predictive interval proposed by Barber et al. (2019b) in which
is replaced by
instead. The following proposition states that, under the IID assumption,
defined in (2) is a predictive set for
with guaranteed level-
.
Proposition 1.
If , for
, then
.
A proof of the proposition can be found in Xie and Zheng (2020), which holds for a finite n. Barber et al. (2019b) pointed out empirically intervals like have a typical coverage rate of
. In the rest of the note, we treat
as an approximate level-
predictive interval.
Note that the function defined in (1) is in essence a predictive distribution function of
(see, e.g., Shen, Liu, and Xie Citation2018; Vovk et al. Citation2019). The corresponding predictive curve of
is
Clearly, . A plot of predictive curve function
provides a full picture of conformal predictive intervals of all levels. Analogous to that of confidence distribution and Birnbaum’s confidence curve, predictive function
has a confidence interpretation as the p-value function of the one-sided test
versus
, and the predictive curve
has the same implementation for the corresponding two sided test (see. e.g., Xie and Zheng 2020, sec. 2.2). A formal definition of conformal predictive function is in Vovk et al. (Citation2019).
A striking result is that Proposition 1 holds, even if the learning model used to obtain the prediction is completely wrong, as long as the IID assumption holds. This robust property against model misspecification is highly touted in the machine learning community. It gives support to the sentiment of using “black box” algorithms where the role of model fitting is reduced to an afterthought, although we will also provide arguments to counter this sentiment.
2.2 IID Versus Non-IID: Efficiency and Validity Under a Wrong Model
Although the validity of prediction is robust against wrong learning models in the IID case, there is no free lunch. The predictive intervals obtained under a wrong model are typically wider. For instance, suppose that the true model is , but a wrong model
is used. Since
, we have
. So, when
is independent of x,
and the equality holds only when
. Thus, the error term e under a wrong model has a larger variance than the error term
under the true model. The larger the variance
is (i.e., the more discrepant
and
are), the larger the variance of the error term e is. A larger error translates to less accurate estimation and prediction. See also Proposition 2 of Xie and Zheng (2020) for a formal statement regarding the predictive interval lengths in linear models.
We have an explanation why a conformal predictive algorithm can still provide valid prediction even under a totally wrong learning model in the IID case. Specifically, when we use a wrong model , the corresponding point predictor will be biased by the magnitude of
, but at the same time the error term e absorbs the bias and produces residuals with a shift by the magnitude of
. In the conformal predictive interval (2), the quantiles of residuals are added back to the point prediction to form the interval bounds. If the IID assumption holds, the bias is offset by the shift. See also Xie and Zheng (2020) in which an explicit mathematical expression of this cancellation in linear models is derived. Along with greater residual variance, the offsetting ensures the validity of the conformal prediction in the IID case. We call this tendency of self-balance to maintain validity a homeostasis phenomenon.
The IID assumption is a crucial condition to ensure the validity of a prediction under a wrong model. If the IID assumption does not hold for the testing data, the prediction based on a wrong learning model (or a correct model but a wrong parameter estimation) is often invalid with large errors, as we see in our case studies. We think this IID assumption also explains why deep neural network and other machine learning methods work so well in academic research settings (where random split of data into training and testing sets is a common practice) but fail to produce “killer applications” to make predictions for a given patient or company whose are often not close to the center of the training data. The good news is that, if we use a correct model for training and can get good model estimates, it is still possible to get a valid prediction for a specific
. Modeling and estimation remain relevant and often crucial for prediction in both IID and non-IID cases.
3 Case Study: Prediction Under Neural Network Models
We use a neural network model and a simulation study to provide an empirical support for our discussion. In the current neural network development, model fitting algorithms do not pay much attention to correctly estimate the model parameters. We find that the estimation of model parameters also plays an important role in prediction, in addition to a correct model specification.
Example 1.
Suppose our training data , are IID samples from the model
(3)
(3) where
and
and
are independent. Here,
, the
-element of Σx
is
, for
and n = 300. Model (3) is in fact a neural network model (with a diagram presented in ) and we can re-express
as
(4)
(4)
Fig. 1 Diagrams of four neural network models: (a) true ; (b) partial
; and (c, d) over-parameterized
and
of (20 nodes in each layer) × L layers, with L = 20 and 100, respectively.
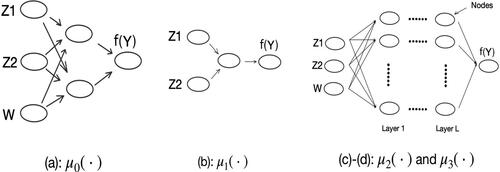
Here, is the ReLU activate function, and
and
are the model parameters. Corresponding to (3), the true model parameter values are
and
. In our analysis, we assume that we know the model form (4) but do not know the values of model parameters A1 and A2.
For the testing data, we consider two scenarios: (i) [IID case] and, given
follows (3); (ii) [Non-IID case] the marginal distribution
and, given
follows (3). Here,
are iid random variables from the t-distribution with degrees of freedom 3 and non-centrality parameter 1.
In addition to (a) the true model , four wrong learning models are considered:
where
, and
. In our analysis, the neural network models
-
are fit using the neuralnet package (cran.r-project.org/web/packages/neuralnet/).
The Neuralnet package is an off-the-shelf machine learning algorithm. Its emphasis is on learning and not on model parameter estimation. Even under the true model , the estimates of model parameters from Neuralnet are not very accurate (see ). In the table, “Opt-MSE” refers to a code that we wrote by directly minimizing
, which can be implemented when the neural network is small. The calculation in the table is based on 20 repeated runs, each with a training dataset of size n = 300 from model (3).
Table 1 Mean square error of each parameter in μ0 (training data n = 300; repetition = 10).
Reported in are the coverage rate and average interval length of predictive intervals computed under 10 = 5 × 2 settings with five different learning models , and in two scenarios. The analysis is repeated for 10 times with 10 simulated training datasets from model (3). We use 10 repetitions and not a greater number, because it takes a long time to fit a neural network model. However, for each of the 10 training datasets, 20 pairs of
are used. So, for the reported values, each is computed using 10 × 20 = 200 pairs of
. For the true neural network model
, Opt-MSE is also used to fit the model. As we can see in , under the IID scenario, all predictive intervals are valid with a correct coverage. The best one with the shortest interval length is the one that uses the correct model and Opt-MSE estimation method. In the non-IID case, only the shallow neural network models provide valid predictions, and among them, Opt-MSE can give us confidence intervals with half the width. Indeed, when a wrong learning model is used, the IID assumption is essential for the prediction validity and the use of a wrong model often results in wider intervals. Furthermore, the estimation of model parameters seems to also have a big impact on prediction.
Table 2 Performance of 95% predictive intervals under five different learning models and in two scenarios: coverage rates (before brackets) and average interval lengths (inside brackets) (training data size = 300; testing data size = 20; repetition = 10).
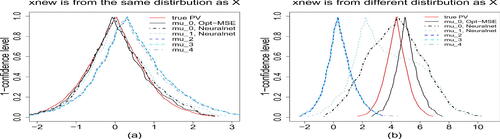
To get a full picture of the predictive intervals at all levels, we plot in the predictive curves of . The plots are based on the first training dataset and making prediction for (a) the IID case with the realization
, and (b) the non-IID case with the realization
. The realized value of
is 0 and 4.338 in (a) and (b), respectively. From , we see that the use of a wrong model
–
results in wider predictive curve (and predictive intervals at all levels
) in both IID and non-IID cases. Although the shallow neural network models
and
can provide good coverage rates, the predictive curves in the non-IID case are much wider than other approaches. This peculiar phenomenon occurs even when we assume to know the true model structure
, indicating the importance of estimating model parameters accurately. Furthermore, in the non-IID case, there are large shifts when we use deep neural network models
and
, leading to invalid predictions. The best prediction result is from the one obtained by using the correct learning model
with the more accurate parameter estimation method Opt-MSE. The message is the same as what we have learned from , which also exactly mirrors what is found in the case study of linear models in Xie and Zheng (2020).
Fig. 2 Plots of predictive curves for (a) and (b)
. In each plot, the red solid curve is the target (oracle) predictive curve
, obtained assuming that the distribution of
is completely known. The two predictive curves obtained using
are in black (solid line for Opt-MSE; dashed line for Neuralnet). The other predictive curves (all in a dashed or broken line and in various colors) are obtained using the other four wrong working models.
4 Conclusion
Professor Efron pointed out that “the 21st Century has seen the rise of a new breed of what can be called ‘pure prediction algorithms’.” We are fully in agreement with Professor Efron’s discussion that the prediction algorithms “can be stunningly successful,” and that “the emperor has nice clothes but they’re not suitable for every occasion.” Along the same line and under the setting of conformal prediction, we have demonstrated and explained how and why a prediction method can be successful under the IID assumption, even if the learning model is completely wrong. More importantly, we have also demonstrated that it is still meaningful, and often crucial, to build our prediction algorithms based on a good practice of modeling, estimation and inference. We fully anticipate and believe that “the most powerful ideas of Twentieth Century statistics”—modeling, estimation, and inference, will play a pivotal role in building the mathematical foundation of modern data science and in fully realizing its potential for real-world applications.
Funding
The research is supported in part by research grants from NSF.
References
- Barber, R. F., Candes, E. J., Ramdas, A., and Tibshirani, R. J. (2019a), “The Limits of Distribution-Free Conditional Predictive Inference,” arXiv no. 1903.04684.
- ——— (2019b), “Predictive Inference With the Jackknife+,” arXiv no. 1905.02928.
- Efron, B. (1998), “R. A. Fisher in the 21st Century (Invited paper Presented at the 1996 R. A. Fisher Lecture),” Statistical Science, 13, 95–122. DOI: 10.1214/ss/1028905930.
- Lei, J., G’Sell, M., Rinaldo, A., Tibshirani, R. J., and Wasserman, L. (2018), “Distribution-Free Predictive Inference for Regression,” Journal of the American Statistical Association, 113, 1094–1111. DOI: 10.1080/01621459.2017.1307116.
- Shafer, G., and Vovk, V. (2008), “A Tutorial on Conformal Prediction,” Journal of Machine Learning Research, 9, 371–421.
- Shen, J., Liu, R., and Xie, M. (2018), “Prediction With Confidence—A General Framework for Predictive Inference,” Journal of Statistical Planning and Inference, 195, 126–140. DOI: 10.1016/j.jspi.2017.09.012.
- Singh, K., Xie, M., and Strawderman, W. E. (2005), “Combining Information From Independent Sources Through Confidence Distributions,” The Annals of Statistics, 33, 159–183. DOI: 10.1214/009053604000001084.
- Vovk, V., Gammerman, A., and Shafer, G. (2005), Algorithmic Learning in a Random World, New York: Springer.
- Vovk, V., Shen, J., Manokhin, V., and Xie, M. (2019), “Nonparametric Predictive Distributions by Conformal Prediction,” Machine Learning, 108, 445–474. DOI: 10.1007/s10994-018-5755-8.
- Xie, M., and Singh, K. (2013), “Confidence Distribution, the Frequentist Distribution Estimator of a Parameter” (with discussion), International Statistical Review, 81, 3–39. DOI: 10.1111/insr.12000.
- Xie, M., and Zheng, Z. (2020), “Homeostasis Phenomenon in Predictive Inference When Using a Wrong Learning Model: A Tale of Random Split of Data Into Training and Test Sets,” arXiv no. 2003.08989.