
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Benford’s law defines a probability distribution for patterns of significant digits in real numbers. When the law is expected to hold for genuine observations, deviation from it can be taken as evidence of possible data manipulation. We derive results on a transform of the significand function that provide motivation for new tests of conformance to Benford’s law exploiting its sum-invariance characterization. We also study the connection between sum invariance of the first digit and the corresponding marginal probability distribution. We approximate the exact distribution of the new test statistics through a computationally efficient Monte Carlo algorithm. We investigate the power of our tests under different alternatives and we point out relevant situations in which they are clearly preferable to the available procedures. Finally, we show the application potential of our approach in the context of fraud detection in international trade.
1 Introduction
Benford’s law is a well-known probability distribution for significant digits (Berger and Hill Citation2015; Miller Citation2015). It relies on the intriguing fact that in many natural and human phenomena the significant digits are not uniformly scattered, as one could naively expect, but follow a logarithmic-type distribution: see Raimi (Citation1976), Hill (Citation1995a), and Berger and Hill (Citation2011, Citation2020) for historical reviews from a mathematical perspective. A major statistical result is the limit theorem presented by Hill (Citation1995b), which motivates the adoption of Benford’s law as the digit-generating model in many real-world situations. If Benford’s law is expected to hold for genuine observations, then deviations from the law can be taken as evidence of possible data manipulation. This idea has opened the door to a rapidly increasing literature on the statistical detection of frauds through Benford’s law, whose applications span over diverse fields such as accounting and finance (Tam Cho and Gaines Citation2007; Nigrini Citation2012; Kossovsky Citation2015), electoral processes (Mebane Citation2010, Citation2011; Pericchi and Torres Citation2011; Fernandez-Gracia and Lacasa Citation2018), and international trade (Barabesi et al. Citation2018; Cerioli et al. Citation2019; Lacasa Citation2019).
Checking conformance to Benford’s law requires the availability of appropriate test statistics. The most popular choice is to perform goodness-of-fit tests, often of Pearson’s type or variants thereof, that compare the observed digit counts to those expected under the law. For instance, if X is a random variable and solely the leading digit of X, say , is analyzed, Benford’s law states that the probability of the event
, with
, is
(1)
(1)
Goodness-of-fit tests stem on the characterization of Benford’s law provided by its joint-digit probability function, for which (1) is usually called the first-digit marginal.
In this work, we develop new tests that exploit an alternative characterization of Benford’s law based on the sum-invariance property. This characterization is perhaps even farther from intuition than (1) and was first guessed by Nigrini (Citation1992), who noted that for datasets following the law the sum of the values with the same first significant digit d1 are approximately equal for all . He also argued that the sum-invariance property provides a characterization of Benford’s law, so that the sum of the values with the same first-k significant digits, say
, should be approximately equal for all
and
, with
, and for all
. The conjecture was formally proven by Allaart (Citation1997) in terms of the significands (to be defined in Section 2) of the values with the same first significant digit(s). On the basis of such a property, Nigrini (Citation2012, chap. 5) suggested a graphical comparison of the (normalized) empirical sums of the observed values sharing the same first-two significant digits. Large spikes in the resulting plot informally indicate deviation from the law, but the magnitude of these spikes, and their evidence against the hypothesis, cannot be assessed outside the framework of a formal statistical testing procedure. Indeed, in an exploratory approach the origin of each spike can be explained only by inspecting the original data.
The contribution of this article is 2-fold. First, we derive some theoretical results on a transform of the significand function that are related to the sum-invariance characterization of Benford’s law. When just the leading digit is considered, neither sum invariance nor the one-dimensional marginal probability (1) necessarily imply Benford’s law. We thus derive some conditions that relate the sum-invariance property to the validity of (1). Then, we use these results to provide motivation and statistical tools for new tests of conformance to Benford’s law based on the sum-invariance characterization. We approximate the exact distribution of each test through a simple but computationally efficient Monte Carlo algorithm and we investigate the power of our tests under different alternatives. We show situations where the sum-invariance approach is not only preferable to the classical test of (1), but also outperforms a Kolmogorov–Smirnov test built upon the properties of the significand function. A further bonus of our work is the possibility of combining different tests when no information on the digit-generating process is available.
We show the application potential of our approach in the context of fraud detection in international trade, where the main available anti-fraud tools are derived from the theory of outlier identification in robust regression (see, e.g., Riani, Atkinson, and Perrotta Citation2014; Perrotta et al. Citation2020). We then compare the assumptions about the data-generating model behind our approach with those that underlie fraud detection through robust statistical methods, and we point out relevant situations where the new tests are clearly to be recommended. The sum-invariance tests are also preferable when manipulation occurs in one or more digits in unspecified positions, as it might be the case with probability-savvy fraudsters who ensure compliance of the first digit of their numbers to Benford’s law. Being almost as easy to calculate as the standard goodness-of-fit statistics, our tests thus provide a powerful addition to the battery of tools available for statistical anti-fraud analysis.
2 Two Characterizations of Benford’s Law
We start by introducing the alternative characterizations of Benford’s law that are useful for the present work. We refer to Berger and Hill (Citation2015, chaps. 4 and 5) for a comprehensive and authoritative account of these and other mathematical characterizations of the law.
The fractional part of x is , where
is the “floor function” (Graham, Knuth, and Patashnik Citation1994). For each nonnull
, the significand function
is defined as
For convenience, we take . The first significant digit of x, say
, can be expressed as a function of S(x) since
Similarly, for , the kth significant digit of x, say
, is
Let and
, where
and
for
. The following equivalence holds for
(see Barabesi et al. Citation2018, p. 357)
where
. We have suppressed the dependence of cd on k for notational simplicity.
Let X be an absolutely continuous random variable defined on the probability space . Furthermore, let
be the distribution function of the significand S(X). According to Berger and Hill (Citation2015, p. 30), X is defined to be Benford if
(2)
(2) where
is the indicator function of the set E. Condition (2) is equivalent to assume that
or that
, where U is a Uniform random variable on
, that is, to assume that
is uniformly distributed modulo one (Diaconis Citation1977; Berger and Hill Citation2015, p. 43). Thus, for each k, the joint probability function of the random vector D(X) is
(3)
(3)
When X is Benford expression (3) becomes(4)
(4) which reduces to (1) when k = 1. Berger and Hill (Citation2015, p. 44) prove the key probabilistic result that (2) holds if and only if the probability distribution (4) holds for all
. Therefore, expression (1) on the first digit alone does not imply (2).
In turn, (2) implies (and is implied by) the sum-invariance property. This property states that, for each d and for each ,
(5)
(5) where
(Allaart Citation1997; Berger and Hill Citation2015, §5.3). Therefore, the expected value (5) does not depend on d if (and only if) X is Benford. In the first-digit setting, (5) simplifies to
(6)
(6)
In this case also, condition (6) alone does not imply (2).
3 Some Results on the Significand Transform
The key ingredient for developing tests of the sum-invariance property (5) is the transform(7)
(7) with
. We write
for the distribution function of
and we adopt the notation
when k = 1.
Our first result gives the general expression for . We prove in the Appendix that
(8)
(8)
By recalling (2), if X is Benford then expression (8) specializes to(9)
(9) which, when k = 1, in turn reduces to
(10)
(10)
The mean and the variance of are crucial for the development of statistical testing procedures. From the results given in the Appendix (see (A.1)), we obtain
and
In the case of Benford’s law we then recover the sum invariance property (5). We also obtain the variance of Zd as(11)
(11)
Furthermore, since for
, it holds that
, and under Benford’s law the covariances have the constant value
(12)
(12)
The moments given above provide the basis for the testing procedures proposed in Section 5. In the following example, we illustrate the relevance of the previous results in a family of significand distributions that includes Benford’s law as a special case. The family will also be used to assess the power of the proposed tests in one scenario of Section 6.2, since it contains significand distributions which are continuously indexed by a parameter which can be taken as a measure of departure from the law.
Example: Generalized Benford’s law. A random variable X is distributed according to the generalized Benford’s law with parameter α iffor
. This law has been introduced to represent digit distributions generated by a power-law (Pietronero et al. Citation2001). It includes Benford’s law as the special case α = 0 by continuity. Noteworthy, it also describes the leading-digit distribution of the sequences of prime numbers and nontrivial Riemann zeta zeroes (Luque and Lacasa Citation2009). Under the generalized Benford’s law, by means of (3), it holds
Therefore, for expression (8) becomes
while it reduces to (9) for α = 0. In the first-digit case, under the generalized Benford’s law
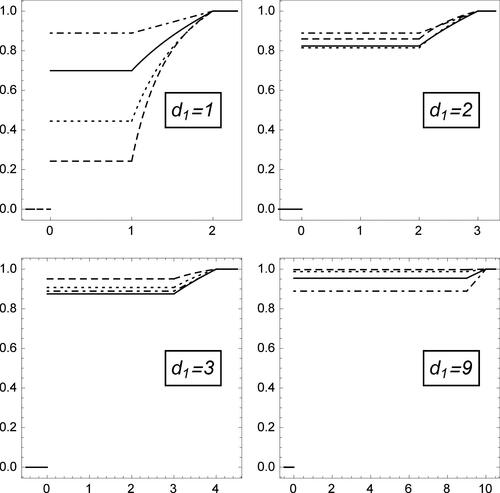
Therefore, the first-digit marginal of (8) becomesfurther specializing to (10) for α = 0. shows the shape of
for selected values of α and d1, when X follows the generalized Benford’s law. In each panel the (solid) line drawn for α = 0 yields the corresponding first-digit distribution function under Benford’s law, while that for α = 1 (dot-dashed line) corresponds to the Uniform distribution. The generalized Benford’s law does not display symmetry with respect to α, that is, negative parameter values yield structurally different patterns in
than their positive counterparts: see, for example, the lines corresponding to
and α = 1. However, note that X is distributed according to the generalized Benford’s law with parameter α if and only if
is distributed according to the generalized Benford’s law with parameter
. We refer to Barabesi and Pratelli (Citation2020) for further results on products of generalized Benford random variables. We prove in the Appendix that under the generalized Benford’s law
(13)
(13)
which reduces to
for k = 1. Again, the case α = 0 yields the sum-invariance property (5).
Fig. 1 Plot of for different values of
and for
(dashed line),
(dotted line), α = 0 (solid line), and α = 1 (dot-dashed line), when X follows the generalized Benford’s law.
4 First-Digit Benford’s Law
We recall that, when the random variable X is Benford, characterization (2) is equivalent to both (3) and (5), while it implies (1) and (6). Instead, the first-digit properties (1) and (6) may still hold even if X is not Benford and condition (2) is not true. In such a case, we are interested in studying whether (1) is equivalent to (6), or (1) implies (6), or (1) is implied by (6). For simplicity, and with a slight abuse of notation, in what follows we take d = d1 in such a way that .
If X is an absolutely continuous random variable and S(X) admits a probability density function with respect to the Lebesgue measure on
, condition (1) is equivalent to
(14)
(14) for all
, while condition (6) is equivalent to
(15)
(15)
for all
. Expressions (14) and (15) provide a system of functional equations in
, with the constraint that
be a proper density function. It seems prohibitive to address the relationship between (1) and (6) in such a general setting, although inequalities involving πd and ηd may be easily obtained. Indeed, by integrating
by parts, it can be proved that
since
. By also recalling that
, the following two inequalities are then obtained:
(16)
(16)
and(17)
(17)
To obtain workable results, it is convenient to consider for the following family of simple functions
(18)
(18) where the coefficients ad and bd are real numbers that satisfy the set of constraints
and
. These constraints ensure that
is a bona fide probability density function. In such a case, we obtain
(19)
(19)
and(20)
(20)
The constants and
must be chosen in such a way that they jointly satisfy the set of constraints on the coefficients
and
. It follows from expressions (19) and (20) that
(21)
(21) and
(22)
(22)
If the set is fixed, from the nonnegativity of ad and bd, we thus obtain
(23)
(23)
while if the set is fixed, it must hold
(24)
(24) with
. It is worth noting that the previous bounds are close to the universal bounds obtained in (16) and (17). Therefore, the considered family of simple functions covers a wide range of models, also encompassing extreme situations.
We can see from (23) that the interval of values (if it exists) for which ηd is a fixed constant for , say
, is given by
Therefore, if (1) holds, it can be easily shown that(25)
(25)
The interval given in (25) contains the value , as it must be under Benford’s law.
We can retrieve the simple function for which expressions (1) and (6) jointly hold, without necessarily assuming (2), by substituting the values
and
in EquationEquations (21)
(21)
(21) and Equation(22)
(22)
(22) . The resulting function is displayed in . In addition, on the basis of (25), we can obtain simple functions
such that (1) holds while
, but with
. These functions provide examples of cases where the first-digit marginal distribution (1) holds, albeit the corresponding sum-invariance property (6) does not. One similar instance is described in Section 6.1.
Fig. 2 The simple function for which expressions (1) and (6) jointly hold.
Conversely, if for
, we see from (24) that it must be
(26)
(26) with the constraint
. Therefore, examples of simple functions
for which expression (6) is true, but expression (1) is not, can be easily achieved. We again refer to Section 6.1 for a similar instance. On the basis of the well-known inequalities on the Neper number, it is also worth noting that for the Benford’s first-digit probability (1) it holds
in agreement with (17). Hence, the constraints provided by (26) are rather severe, as it can be numerically assessed. At least for the considered class of simple functions, when (6) holds the probabilities
are likely to resemble rather closely to
, especially for
.
5 A Battery of Sum-Invariance Test Statistics for the First Digit
5.1 Null Hypotheses and Significand-Based Test Statistics
Following the argument of Section 4, in the present section we detail the simple, but practically important, first-digit case. We again take d = d1 in such a way that .
Given a random sample of n independent copies of X, the inferential target consists in assessing whether X is Benford. According to (2), this hypothesis is stated as
or as
, where U is a Uniform random variable on
. However, a test of the strong Benford null H0 might be considered too restrictive in practical applications owing to measurement limitations, since the realizations of X are often recorded up to few significant digits. We provide a more precise qualification of this common-sense statement in Section 6.1. As a consequence of the perceived limitations of H0, the null hypothesis on the first digit
is often preferred by fraud examiners in practice.
does not imply H0, but the converse is true. Rejection of
thus leads to rejection of H0.
Similarly, in its simplest first-digit form, a sum-invariance test aims at assessing the one-dimensional null hypothesis(27)
(27) where
. According to property (6), the sub-hypotheses
must hold for all
when X is Benford. As for
, rejection of
leads to rejection of H0. The connection between
and
originates from the relationship between the corresponding first-digit properties (6) and (1), investigated in Section 4. Furthermore, in Section 6, we show evidence that examination of the first-digit properties of X may, perhaps surprisingly, lead to more powerful conclusions about departure from Benford’s law than considering a test statistic specifically constructed for the assessment of H0.
Several tests exist for . In what follows we define a battery of test statistics constructed for
. To this aim, we consider the standardized sample mean
where
and the denominator is obtained from (11) with k = 1 and
. The developments in Section 4 show that the exact distribution function of the new test statistics under
will be tractable only in special cases. Their distribution is instead readily estimable under the more stringent Benford null H0. Therefore, our suggestion in view of anti-fraud applications is to evaluate the significance of these statistics under H0, even if they are defined under the more general
, and to interpret them as proper tests of conformance to Benford’s law. We do the same with the available tests of
. The consequences of this choice are assessed in Section 6.1, where we compare the behavior of the tests under the different hypotheses, and in Section 6.2 in terms of power under several alternatives when H0 is the relevant null.
5.2 Hotelling-Type Test
Let and let μ be the vector of order 9 given by
. Under H0,
and
where, according to (11) and (12),
is a
matrix such that
and
if
. Hence, a Hotelling-type statistic is defined as
In principle, the distribution function of the test statistic Q under Benford’s law, say FQ, could be computed exactly, but this task is prohibitive in practice. A Monte Carlo approximation of this distribution is instead readily available by bearing in mind that is a Benford random variable and that
. Specifically, B Monte Carlo replicates of
, say
, are generated as
where
and
are independent Uniform random variables on
, for
. Therefore, B Monte Carlo replicates of Q, say
, are
yielding the Monte Carlo approximation of FQ
Correspondingly, for a realization q of Q, the p-value is approximated by
. Finally, on the basis of Corollary 1.7 by Serfling (Citation1980, p. 26),
as
, where
denotes the chi-square random variable with ν degrees of freedom.
5.3 Sup-Norm Test
A sup-norm test statistic for assessing in (27) is
(28)
(28)
This test rejects for large realizations of M. Furthermore, if FM denotes the distribution function of M under H0 and
is its
th quantile, simultaneous acceptance intervals at significance level γ for the marginal test statistics
are, for
,
(29)
(29)
These simultaneous acceptance intervals can supplement exploratory procedures, such as those presented by Nigrini (Citation2012, chap. 5), with inferential statements about the digits involved in rejection of .
As shown in Section 5.2, Monte Carlo replicates of M can be generated as , for
, where
From these replicates we obtain the Monte Carlo approximation of FM, say , while
is the approximated p-value for a realization m of M. Moreover,
is the quantile estimate to be substituted for
in (29).
5.4 Min p-Value Test
Combination of p-values provides an alternative procedure for assessing the null hypothesis and simultaneously the sub-hypotheses
(see, e.g., Rubin-Delanchy, Heard, and Lawson Citation2019, for a recent discussion in the field of anomaly detection in computer networks). If
is the distribution function of
under H0, let
be the p-value for a realization td of
. Moreover, let
be a suitable combining function, usually chosen as a function of the minimum. The min-p-value test statistic is
If the test rejects for large values of G, its p-value is
, where
is a realization of G and FG is the distribution function of G under H0.
Now, , for
, provide B Monte Carlo replicates of G, where
The Monte Carlo approximation of FG is thenwhile
is the Monte Carlo estimate of
, with
The same are now considered for computing
, to keep the dependence structure of
.
5.5 A Combined Test
Since is not equivalent to
, our final proposal is to consider a combined test statistic tailored to the null hypothesis
. The aim of this strategy is to develop a robust procedure with good power under different alternatives, such as those which are likely to be detected by focusing on
and
separately. For simplicity, we only detail the case where Q is combined with the first-digit Pearson’s statistic, that is,
(30)
(30)
with . The choice of a suitable combining function
yields the test statistic
where, for a realization x of
is the p-value and
is the distribution function of
under H0. If the test rejects for large values of L, the p-value is
, where
is a realization of L and FL is the distribution function of L under H0.
As before, the Monte Carlo approximation of the distribution function of under H0 is
where the replicates
of
are generated as
with
for
. The p-value is approximated by
. Correspondingly, the B Monte Carlo replicates of L are
, for
, where
and
are computed by means of the same
. The Monte Carlo approximation of FL is
while the Monte Carlo estimate of
is
, where
.
5.6 Extension to the First-k Significant Digits
Generalization to the case k > 1 is straightforward, even if more cumbersome notation is required. We report the details as supplementary materials.
6 Simulation Study
As in Section 5, we consider sum-invariance test statistics based on the first-digit. We take the minimum as the combining function in the computation of L. For this test statistic, we write , and
when (30) is combined with Q, M, and G, respectively. In our simulation study, we address two major issues: the behavior of the tests when
and
hold, but H0 does not, and their power under several alternative distributions, some of which are directly related to the anti-fraud context of our application domain. In the latter instance we take H0 to be the relevant null, since the exact distribution function of the test statistics under
is not available in general, as emphasized in Section 4.
In anti-fraud operations related to international trade, like the one reported by European Commission (Citation2014) and like those mentioned in Section 7, it is advisable to limit the number of false rejections, because substantial investigations are often demanding and time consuming. We thus display the results obtained when is the nominal test size. A selection of results for
is instead given as supplementary materials. Unless otherwise stated, we take
as the number of Monte Carlo replicates for estimating distribution functions. Rejection rates are computed on 100,000 independent simulation runs.
6.1 Test Behavior Under the First-Digit Benford’s Law
The Monte Carlo approximation to the distribution function of our test statistics assumes that the data are generated from a Benford random variable, implying that the samples are drawn from the strong Benford null hypothesis H0. The resulting tests are thus exact under Benford’s law and their empirical size under the law will differ from the nominal one solely because of simulation error.
Since H0 is more restrictive than and
, it is of interest to see the behavior of the tests when X satisfies one (or both) of these more general hypotheses but not H0. We rely upon the results obtained in Section 4 to provide examples of this behavior. We elaborate the models belonging to class (18) in a variety of situations that span both worst-case scenarios and alternatives very close to H0. Specifically, we consider the data generating models that follow:
EquationEquations (21)
(21)
the lower endpoint of interval (23) with
three instances where
a “small” chi-square distance from Benford’s law within intervals (26), for
an “intermediate” chi-square distance from Benford’s law within intervals (26), for
the largest chi-square distance from Benford’s law within intervals (26), for
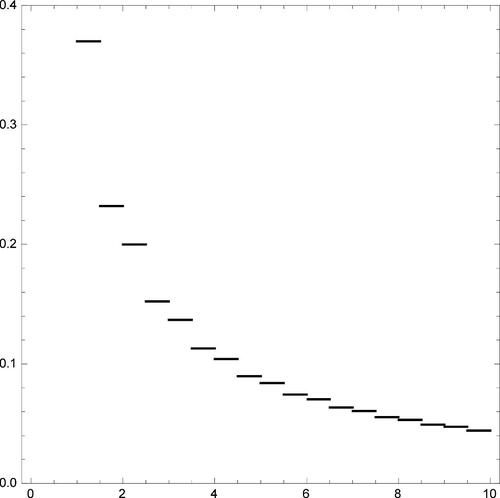
The distribution functions associated to the five selected models are displayed in , where they are also compared to the Benford’s distribution function (2). Case (a) is extremely close to H0, as can be assessed both visually and numerically (the sup-norm distance from (2) is 0.008). Cases (b) and (c3) correspond instead to the most extreme deviations from H0 in the considered class, the sup-norm distance of the distribution functions from (2) being 0.124 and 0.162, respectively. Alternatives (c1) and (c2) are milder and yield sup-norm distances from (2) of 0.026 and 0.058, respectively.
Fig. 3 Plot of under different data-generating models. From left to right: Benford’s law, (a) and (b) (first row); (c1), (c2), and (c3) (second row). See text for explanation.
gives the Monte Carlo estimate of the rejection probability for each test in the five instances described above and under the strong Benford null hypothesis H0. The results refer to the case n = 100, while those for different sample sizes are reported as supplementary materials. In our comparison, we also include a Kolmogorov–Smirnov test statistic which is built upon characterization (2) of the significand function under Benford’s law. This statistic is defined as(31)
(31) where
is the empirical distribution function of S(X) based on the available random sample
. Strictly speaking, KS is constructed to provide a test of the strong Benford null H0, not just of
and
. It can thus be considered a sensible competitor to our tests when their focus is on checking the fit to Benford’s law, as it happens in the simulation study of Section 6.2 and in anti-fraud applications.
Table 1 Monte Carlo estimate of the rejection probability of each test under different data generating models, when n = 100.
The first two lines of confirm that the joint set of constraints implied by the validity of both and
(model (a)) makes the distribution of each test statistic virtually indistinguishable from that obtained under the strong Benford null H0. In this case even the omnibus KS test is not able to detect the departure from H0 with customary sample sizes and much larger values of n are required. For instance, the power of KS under model (a), computed for simplicity over 1000 replications, raises to 0.052 if
.
When moving to the scenario where only is true (models (c1)–(c3)), we first note that class (18) provides a rather extreme choice with respect to H0, since it gives rise to absolutely continuous distribution functions for S(X) which are not differentiable at 18 points. We also recall that the universal bounds for πd under
, given in (16), are fairly close to those obtained from (26). The considered class is thus convenient to assess the behavior of our sum-invariance tests in a relatively unfavorable framework. By imposing more realistic models (e.g., by considering continuously differentiable distribution functions for S(X)), the proposed tests should arguably improve their empirical performance under
when significance is instead evaluated under the more stringent H0.
In spite of the “pessimistic” nature of the selected class, the empirical size of our tests is close to the nominal value under both models (c1) and (c2). In the supplementary materials, it can be seen that the same conclusion is also true when and when n = 500. Therefore, the distribution functions of our test statistics under H0 are good approximations to those under
for customary sample sizes even when the two hypotheses are relatively far apart. On the other hand, assuming H0 when model (c2) holds can have more severe consequences on the Kolmogorov–Smirnov test, especially when n is of the order of a few hundreds (see the supplementary materials). This result reinforces the idea that a test specifically tailored to H0, such as KS, may be too stringent under moderate violations of Benford’s law which are very unlikely to correspond to frauds, since
is still satisfied.
The least favorable choice for our tests under is data generating model (c3), where the true density
is the farthest admissible one from Benford’s law within class (18). Even in this problematic instance the empirical size of M and G is close to the nominal target. Both Q and
instead exhibit some liberality, thus showing moderate discrepancy between the actual test distribution and the approximation provided by the Monte Carlo procedure described in Section 5. Although the performance of our approach is not ideal in this scenario, we note that similar and even worse degrees of liberality may hold for the asymptotic version of the chi-square test (see, e.g., Cerioli et al. Citation2019, ), which is often the selected choice in practice. Furthermore, a correction procedure similar to that proposed in Cerioli et al. (Citation2019), and applied in Section 7.2, can be adopted if strict control of the nominal size under
is deemed necessary. This procedure, which can be easily extended should class (18) be replaced by a wider family of density functions, computes the Monte Carlo estimates of the null quantiles under model (c3) and compares the observed test statistics to such quantiles. The sum-invariance tests thus become exact under the least favorable specification of
. They also become slightly conservative under the other models that satisfy
and that are closer to H0. To provide a quantification of the corresponding conservativeness, in the supplementary materials we repeat the information given in when the null distribution function of each test statistic is estimated by Monte Carlo simulation from model (c3).
The situation is considerably different when only holds. The distribution of
is virtually unchanged by this relaxation of the data-generating process, even if model (b) is the most extreme choice in the selected class. The effect on both KS and Q is instead paramount. It is perhaps surprising to see that the rejection rate of the first-digit statistic Q is much higher than that of the significand-based statistic KS, which is specifically constructed to provide a test of the strong Benford null H0. However, we argue that this is a positive feature of Q in view of anti-fraud applications, since it is much easier in practice to fabricate first digits that conform to (1) than to replicate the sum-invariance property (6). One reason for the large power of Q under model (b) is that the generalized variance of
is much smaller than under Benford’s law. The deviance matrix
under model (b), say
, is reported in the supplementary materials and we obtain
The information provided by the random vector and by its full covariance matrix can thus outperform a complete test of fit of model (2) if just the first-digit distribution conforms to Benford’s law. Further examples of the advantages of Q in possibly fraudulent situations where
holds, but H0 does not, are reported in the sections below.
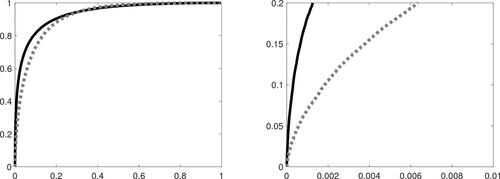
We conclude our analysis of model (b) by noting the remarkable difference in power between the Hotelling-type and the other two sum-invariance tests. The reason is the peculiar distribution of M and G, which turns out to be more concentrated than under Benford’s law. compares the estimated quantiles of M under the two models, in the case n = 100. The shorter right tail of the distribution of M under model (b) yields a reduced variability of the test statistic, whose standard error drops from 0.55 under H0 to 0.49 under model (b). A corresponding decrease is observed for the 99th quantile. Such a peculiar behavior can be explained by looking at , which reports the estimates of and
, for
, under both models. When H0 holds all the first-digit statistics have roughly the same mean and the same variance, thus ensuring good properties to the sup-norm metric in (28). On the contrary, we observe a noticeable shift in the parameters of
under model (b). The resulting heteroscedasticy is not taken into account by M, as it instead happens with Q.
Fig. 4 Quantile plot comparing the empirical distribution of M when X is a Benford random variable (horizontal axis) with the same distribution when X is generated according to model (b) (vertical axis), in the case n = 100. Both distributions are estimated from 100,000 Monte Carlo replicates.
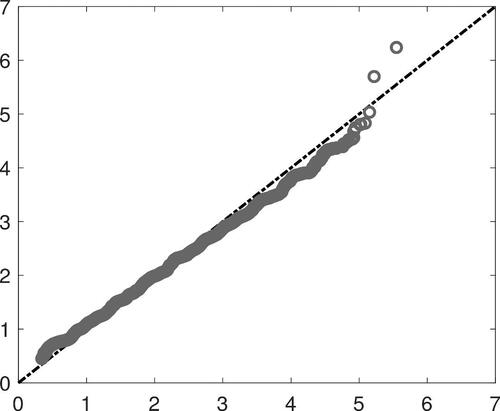
Table 2 Monte Carlo estimates of and
, for
, under H0 (Benford’s law) and model (b), based on 100,000 Monte Carlo replicates.
6.2 Power Comparison
We now investigate the ability of our tests, as well as that of and KS, to detect departures from Benford’s law in a number of practically relevant alternative models, some of which can be directly related to the anti-fraud context of our application domain. The null distribution function of each test statistic is estimated using the Monte Carlo procedure described in Section 5. Therefore, all the tests under comparison are exact under H0 and their empirical performance under the strong Benford null is shown in the first line of .
In our first power scenario we assume that X is a Lognormal random variable, so that the observed data come from one of the most frequently adopted distributional models in many fields, including the analysis of the economic aggregates that arise in international trade (Barabesi et al. Citation2016a, Citation2016b). It is well known (Berger and Hill Citation2015, p. 55) that a Lognormal random variable becomes practically indistinguishable from a Benford random variable when the shape parameter is large. Therefore, this popular data-generating mechanism provides an alternative to Benford’s law whose separation from the null model can be continuously indexed by its shape parameter. We take the scale parameter equal to 1, but similar results have been observed for different choices. In our simulations, the shape parameter ranges between 0.5 and 0.8, since outside this interval all the tests share similar performances. shows the power of our tests, together with that of the Pearson’s chi-square statistic (30) and of the Kolmogorov–Smirnov statistic (31), when n = 100. The results for different sample sizes are reported as supplementary materials. All our tests have sensible properties, with power converging to 1 as the shape parameter of the Lognormal distribution decreases and as the sample size grows (see the supplementary materials). There is a considerable advantage of Q over M and G, due to the information provided by the deviance matrix .
Table 3 Estimated power when X is a Lognormal random variable with scale parameter 1, for different values of the shape parameter and n = 100.
Since no parameter is estimated under Benford’s law, taking into account the full covariance matrix of does not lead to overfitting and can thus be recommended.
Our Hotelling-type test also shows a considerable advantage over the KS test of H0 provided by (31), and a slight but systematic improvement over the chi-square test derived under . The advantage of Q over KS is further documented in , which contrasts the empirical distribution of the p-values computed from each test statistic under the Lognormal model with shape parameter 0.6 (horizontal axis) to the Uniform distribution of the same p-values under H0 (vertical axis). It is clearly seen that the distribution of Q under this alternative is considerably farther from the null than that of KS, and especially so in the right tail, where a much larger proportion of very small p-values is observed.
Fig. 5 Left-hand panel: Quantile plot comparing the empirical distribution of the p-values computed from Q (solid line) and from KS (dashed line) when X is a Lognormal random variable with shape parameter 0.6 (horizontal axis) with the Uniform distribution (vertical axis), in the case n = 100. Right-hand panel: Zoom of the quantile plot in a rectangular area close to the origin.
Our second power scenario assumes that X comes from another popular distributional model in economic and engineering applications. Specifically, we take X to be distributed according to a Weibull distribution whose shape parameter ranges between 1.2 and 2.2. Also in this case departure from Benford’s law can be indexed by the shape parameter, since a Weibull random variable is reasonably close to be Benford when the shape parameter is not too large (Miller Citation2015, §3.5.3). Explicit error estimates for convergence of Weibull distributions to Benford’s law can be found in Dümbgen and Leuenberger (Citation2008, Citation2015), while Engel and Leuenberger (Citation2003), Miller and Nigrini (Citation2008), and Berger and Twelves (Citation2018) addressed the special case of the Exponential distribution. We take the scale parameter equal to 1, but similar results have been observed for different choices. gives the findings when n = 100, while those for different sample sizes are reported as supplementary materials. Our results confirm those obtained under the Lognormal alternative, with Q considerably more powerful than M, G and also KS, except when X comes very close to be Benford. We thus see that first-digit test statistics still outperform the ideally more stringent test based on (31) for a large part of the parameter space where comparison among tests is useful. These results also suggest that for the Weibull distribution there might be more effective discrepancy measures than the Kolmogorov–Smirnov metric considered by Miller (Citation2015, p. 101), at least in this part of the parameter space.
Table 4 Estimated power when X is a Weibull random variable with scale parameter 1, for different values of the shape parameter and n = 100.
In our third power scenario, we model the digit distribution directly and we take X to be distributed according to the generalized Benford’s law with . For instance, under this model the first-digit masses span from
to
when
, while we recover the uniform first-digit distribution
when α = 1. reports power for selected values of
when n = 100, while we again refer to the supplementary materials for further sample sizes. The generalized Benford distribution appears to be the least favorable case for first-digit test statistics because KS is the most powerful choice for all values of α. Furthermore, there is no systematic winner between Q and
, since the former dominates when
and the latter is to be preferred for
. However, the performance of the simple combiner
is consistently close to the best solution provided by either Q or
. We thus conclude that combination of these two test statistics provides a robust strategy when the direction of the departure from Benford’s law is unknown. A further strategy, suggested by the results in , will be to combine Q and KS, to borrow strength from the best performer under the specific alternative. We will pursue this path in future research.
Table 5 Estimated power under the generalized Benford’s law with parameter , for n = 100.
Our last power scenario refers to a potentially relevant instance of fraud. Therefore, it is directly related to the application domain considered in Section 7. In this scenario we mimic the behavior of a probability-savvy fraudster who ensures compliance of the first few digits of X to Benford’s law, but is not able to ensure that X is truly Benford, due to administrative or accounting constraints. For instance, Nigrini (Citation2012, p. 255) reports the possibly suspect case of the list of payments made shortly before bankruptcy by a major company. This list shows almost perfect compliance with the two-digit extension of (1), thus calling for the use of more complex analytical tools than digit-conformance tests. Similar cautionary claims about the validity of (1) in the presence of data manipulation abound in the digital forensic literature (see, e.g., Kossovsky Citation2015, p. 82), while some studies seem to indicate that people need not be terribly bad at inventing numbers (Nigrini Citation2012, chap. 13), even without the help of random simulation. An example of this subtle, but potentially very dangerous, contamination framework is given in , where follows (1) while the other digits of X are generated according to the generalized Benford’s law with parameter α. We display the results for n = 200 and n = 500, but similar patterns are observed with smaller sample sizes. As expected, the first-digit Pearson’s statistic (30) is not able to detect the departure from Benford’s law. Therefore, as a benchmark we now compute the two-digit version of (30),
in the notation of the supplementary materials, which is sometimes advocated as the primary choice in applications with moderate sample sizes (see, e.g., Nigrini Citation2012, p. 78). It is clearly seen that Q often outperforms
to a large extent, even if use of the latter implicitly assumes the additional (but usually unknown) information that contamination occurs in one of the first-two digits and not in the subsequent ones. The power values (not shown in the table) of M and G are instead inferior in this example, as they are under model (b) in . We thus argue that also in this framework information on the covariance structure of
is essential to detect departure from Benford’s law when some of the digits marginally do follow the law. Surprisingly, the performance of KS is extremely poor in this setting, in spite of the fact that all the digits after the first one follow a generalized Benford’s model, against which test (31) was seen to have the largest power.
Table 6 Estimated power when follows (1) while the other digits of X follow the generalized Benford’s law with parameter α.
Finally, we show that our sum-invariance statistics are not affected by contamination in the last significant digits, like rounding errors or other numerical inaccuracies, although all the recoded digits of X are involved in their computation through the standardized sample means . In particular, we report the results obtained when each Benford random variable in the sample, simulated according to (2), is multiplied by
. The order of magnitude K is randomly sampled from an empirical data base of customs declarations with the constraint that
and
. The first three digits are then retained, while the others are set equal to zero. , drawn for the different values of
, shows that the power under this contamination scheme is virtually indistinguishable from the test size, meaning that the number of rejections induced by the truncated digits is negligible. This is another important property of test statistics for their use in anti-fraud applications, since rounding and inaccuracies in data typically have very different implications than data fabrication (see, e.g., Diaconis and Freedman Citation1979).
Table 7 Estimated power of sum-invariance statistics under truncation to 0 of the last digits of a Benford random variable (see the text for details), with n = 200.
7 Application to the Detection of Customs Frauds
7.1 Analysis of Trade Data
To show the potential of our sum-invariance tests for the purpose of fraud detection, we describe their application to the transaction data reported in the customs declarations of two traders for which one instance of fraudulent underreporting of the declared value, a so-called undervaluation, was found. These data were collected in the context of a specific operation on import undervaluation in a member state of the European Union. Such anti-fraud operations typically rely on sophisticated risk profiling systems that aim at predicting possible frauds on the basis of the combination of various types of alerts. These systems often give large weight to the signals provided by outlier detection tools that are applied to monthly-aggregated data (see Perrotta et al. Citation2020, and the references therein), thus not being directly comparable to the present proposal. Furthermore, an important issue in the identification of customs frauds by means of outlier diagnostics is that substantive controls are costly and time consuming, so that only a very limited number of individual transactions are usually checked for each suspected trader. It is then essential that statistical tests provide a hint to the cases where more controls are needed. Our sum-invariance approach is a natural candidate to fulfill this need, since it is particularly effective for the purpose of hunting serial fraudsters (see Section 7.2).
For the first trader that we analyze n = 171, but only 6 transactions were actually checked. The p-value of the Pearson’s statistic (30) is 0.023, suggesting only mild evidence of data manipulation in the whole set of transactions. On the contrary, for the sum-invariance tests we obtain q = 25.326, m = 3.402, and g = 0.999, yielding p-values and
, respectively. Combination of
and Q retains the high power of the sum-invariance test, since
. Therefore, our approach suggests that more transactions of this trader should be checked in the search for frauds.
For the second trader we observe n = 292 transactions, of which only 3 were checked. The results that we obtain resemble those for the savvy contamination scheme described in Section 6.2, since the p-value of (30) is 0.611, whereas , and
. Therefore, Q points to the conclusion that more transactions could have been manipulated, even if their first-digit distribution conforms to Benford’s law. Combination of
and Q again provides a powerful, yet robust, strategy, yielding a p-value of 0.006. In this example the information mainly comes from the inclusion in the test statistic of the null covariance structure of the standardized averages
involving all the recorded digits. Further inspection of the trader indeed shows strong discrepancy between the estimated conditional probabilities of subsequent digits given the first one and the corresponding values expected under Benford’s law (see Hill Citation1995b, p. 355). For instance, for
, reports the estimates of
computed for this trader, together with the null conditional probabilities obtained from (4). The chi-square statistic for this table (based on a subset of 91 transactions) is 23.12 and suggests strong disagreement between estimated and null conditional digit probabilities. Neither (30) nor its multi-digit extensions would be able to detect this subtle departure from Benford’s law, whose anti-fraud implications are worth to be investigated.
Table 8 Estimates of the conditional probabilities for
(first row), and their values under Benford’s law (second row).
7.2 Comparison With Outlier Detection
Following Bolton and Hand (Citation2002), most unsupervised fraud detection methods look for anomalies in the data. Therefore, all of these techniques assume (either explicitly or implicitly) that the available data have been generated by a k-variate random vector, say Y, whose distribution function FY is an (unknown) element within the following family of distribution functions (see, e.g., Cerioli, Farcomeni, and Riani Citation2019, and the references therein)
(32)
(32)
In this model, F0 is the distribution function of the “good” part of the data, that is, F0 represents the postulated null model, F1 is the contaminant distribution, which is usually left unspecified except at most for the assumption of some regularity conditions, and λ is the contamination rate. Consistent estimation of the parameters in F0, which is crucial for correct identification of the outliers, requires the adoption of robust high-breakdown techniques and often assumes Y to be normally distributed in the absence of contamination. See, for example, Cerioli (Citation2010), Riani, Atkinson, and Perrotta (Citation2014), Riani, Corbellini, and Atkinson (Citation2018), and Rousseeuw et al. (Citation2019) for a description of relevant methods in the anti-fraud domain.
Cast in the framework of international trade, where k = 1 and the value of an individual import transaction originates from the product of the traded amount with the unit price, a simple form of the postulated null model in (32) is(33)
(33) where y denotes the transaction value and v is the traded amount, both on a logarithmic scale, β0 and β1 are unknown parameters, and
is the distribution function of a standard Normal random variable. Therefore, if a random sample of N transaction values is available together with the associated traded amounts, yielding vectors
and
, it is assumed that in the absence of fraud each transaction follows the simple regression model
(34)
(34)
for
, where
are independent Normal errors with mean 0 and variance b2. In this setting, λ defines the probability of contamination, and thus of potential fraud, for each transaction drawn from population (32). Therefore, for transaction i we have that
and outlier detection aims at checking whether
, for
.
Our conformance tests to Benford’s law instead rely on a different specification of contamination model (32) for international trade data. Although k = 1 as in (33), in our framework Y is the significand of the transaction value and(35)
(35) as in (2). It is apparent that no parameter has to be estimated under model (35). Even more importantly, our operational generating model for outlier-free significands is trader-specific. Given a set of L traders, the model for trader l is written as
(36)
(36)
where
and
is the significand of the ith transaction value for trader l, nl is the total number of transactions for this trader and Ui is a Uniform random variable on
. Cerioli et al. (Citation2019) investigated the trade conditions under which (36) may yield a reasonable approximation for the first-digit distribution of the customs values of the selected trader. They also suggested a correction to the distribution of Pearson’s statistic (30) when these conditions are not met. Since λ now defines the probability of contamination among the transactions of trader l, that is,
, rejection of the hypothesis
labels trader l as a potential fraudster. This information is not available under model (33).
Comparison of models (34) and (36) shows that outlier detection and conformance to Benford’s law look at different types of anomalies. They also entail different computational efforts, since the former requires that a complex algorithm for robust parameter estimation be applied to a potentially very large number N of market transactions, while the latter only needs L repeated calls to a goodness-of-fit algorithm which is generally fast (even allowing for Monte Carlo estimation of the test distribution).
It may be expected that outlier detection could help to identify large individual frauds in specific markets, while Benford analysis could be beneficial for the labeling of serial fraudsters. To provide empirical evidence of this intuition, in what follows we make the simplifying assumption that only one product originates all the transactions under investigation, so that (34) may become a suitable data generating model for outlier-free data, on a logarithmic scale. Among the five robust regression methods applied to trade data by Riani, Atkinson, and Perrotta (Citation2014), we first adopt least trimmed squares (LTS) to estimate the parameters in (34) and to identify the outliers. We perform our analysis with the implementation of LTS which is available in the MATLAB FSDA toolbox described by Perrotta et al. (Citation2020, p. 9) and accessible from http://rosa.unipr.it/fsda.html. This algorithm appears to be reasonably fast with just one predictor, allowing us to handle a realistic number of traders and market transactions. We select the default initialization option, involving examination of 3000 random subsamples, and a breakdown value of 0.25. The latter is often deemed to be a sensible compromise between robustness and efficiency when the expected number of outliers in not too large (Hubert, Rousseeuw, and Van Aelst Citation2008, p. 95). Outlier labeling comes from the analysis of robust regression residuals, which can be compared to their asymptotic Normal distribution when the number of transactions is large. We set 0.01 as the nominal test size for outlier detection, to ensure comparison with the simulation results in Section 6.2. Correspondingly, we apply the correction method of Cerioli et al. (Citation2019) to the distribution of our sum-invariance tests, as well as to the distribution of and KS, since (35) is not an adequate model under a trade scenario involving just one product. The nominal size of such tests is again 0.01.
We simulate transaction values for L = 1000 “idealized” traders of the selected product, whose specific description is omitted for confidentiality reasons. This product is chosen, after appropriate anonymization that makes it impossible to infer the features of individual operators, from a national database of one calendar-year customs declarations (see Cerioli et al. Citation2019, for further details on the data). Our simulation scheme is able to mimic the main features observed in the original market of the product. Therefore, in the selection process we have carefully avoided the products involving multiple populations, a pattern that often affects customs trade data (Cerioli and Perrotta Citation2014; Cerasa, Torti, and Perrotta Citation2016) but that violates the assumption of model (34) for genuine transactions. We assume that each idealized operator trades a constant number of nl = 100 transactions, thus replicating the case n = 100 described in Section 6.2. The total number of transactions for outlier detection in (34) is then , with the assumption that at least
of them follow the null model. For simplicity, in our trader-specific version of contamination model (32) we also assume that each fraudster has the same propensity to fraud, so that λl is constant among the cheating traders. It is worth noting that the absence of parameters to be estimated under (35) allows us to extend model (32) to include the extreme case
, defining a “complete” fraudster.
We generate noncontaminated transactions by picking unit price and traded quantity of the selected product at random from the same national database of customs declarations. Specifically, we adopt a product-constrained version of the simulation algorithm of Cerioli et al. (Citation2019, SI Appendix, §2) and we randomly assign each transaction to a trader. The first column of reports the empirical size of the Benford tests Q, X2, and KS (for these tests size corresponds to the instance where for
) and also the empirical size of outlier detection through LTS, over 100 replications of the market simulation exercise. It is seen that all the Benford methods provide good control of the proportion of false fraud signals when indeed no contamination is present in the data, while LTS turns out to be somewhat conservative with this kind of data structures. They also confirm that the correction method of Cerioli et al. (Citation2019) works equally well for Q and KS, as it was for
.
Table 9 Estimated size and power over 100 replications of the market simulation exercise for different proportions τ of fraudsters (the corresponding propensity to fraud of each fraudster l, λl, is also shown).
We then contaminate 4000 transactions in the market through the digit contamination scheme which is detailed in the supplementary materials. The artificially introduced frauds are uniformly split within a proportion τ of fraudulent traders, with . This framework allows us to compare our Benford analysis with outlier detection under different cheating scenarios. For instance, if
we only have 40 fraudsters among the 1000 traders and all the 100 transactions of each fraudster are then contaminated, yielding
if trader l is a fraudster and
otherwise. On the opposite end, if
as many as 400 traders are cheating, but all of them in 10 transactions only (hence,
if trader l is a fraudster). gives the corresponding power results, again averaged over 100 replications of the market simulation exercise. As expected, the detection power of LTS does not depend on τ (and hence neither on λl), since testing is performed on the N available transactions independently of the trader. Outlier detection is advantageous when the propensity to fraud is low, so that information about the behavior of each trader is less relevant. However, it is clearly outperformed by both Q and KS in the case of serial cheating, with a large gap already for
, at least for this specific product and choice of robust method.
To investigate the stability of our results under the same market conditions, we perform a further comparison with the Forward Search (FS) for regression, which is another major robust tool for parameter estimation in (34) and for outlier detection in the domain of international trade (Perrotta et al. Citation2020). FS is also the recommended method in Riani, Atkinson, and Perrotta (Citation2014). It is not advisable to run the full FS algorithm in the present context, where N is very large and the contamination rate is not extreme. We thus adopt the “batch” version of FS for regression developed by Torti, Corbellini, and Atkinson (Citation2021), who suggested to reduce the number of updating steps in the algorithm for the analysis of big datasets. In our implementation each FS step corresponds to the inclusion of 100 additional observations in the fitting subset. For simplicity we now restrict to a single fraud scenario, again with 4000 contaminated transactions and 100 market replicates as in , since we have seen that outlier detection does not depend on the propensity to fraud. To save computing time we also take advantage of the knowledge of the contamination rate and we start the usual monitoring process implied by FS from a subset of cardinality (the robust fitting algorithm is instead unaltered). Using now a larger proportion of uncontaminated data, we may expect to reach higher efficiency in parameter estimation, and larger power in the subsequent outlier identification phase, than through LTS. The estimated power of FS is in fact 0.498, about ten decimal points higher than the average value obtained for LTS. However, this gain comes at the cost of moderate liberality, the empirical size in 100 uncontaminated markets being 0.043. Even more important for the present comparison is the fact that the gain in power of outlier detection through FS is still limited when contrasted to the effectiveness of our sum-invariance test (and also of KS) in the case of serial cheating.
As a final cautionary note, we recall that our comparison relies on the major simplifying assumption that all the available transactions be generated by trades involving a single product. Much more complex data structures, often displaying multiple linear populations, instead arise when this assumption is relaxed. Model (34) then becomes inadequate to represent genuine trade values and the performance of robust regression techniques, such as FS, LTS and their competitors, is greatly affected. A more accurate comparison would entail the use of formal outlier detection procedures for such complex structures, which are not yet available. One possible solution in this direction could be to build inferential statements for the robust clustering techniques adopted by Cerioli and Perrotta (Citation2014) and by Cerioli, Farcomeni, and Riani (Citation2019), which might be broadly regarded as cluster-wise extensions of LTS and FS, respectively. The development of suitable diagnostics and formal outlier labeling rules for clustered trade-data structures will be the subject of future research.
Supplemental Material
Download PDF (208.3 KB)Acknowledgments
The authors are grateful to three anonymous reviewers, an associate editor, and Editor Prof. Marina Vannucci for many helpful comments on two previous drafts which led to considerable improvements. They also thank Dr. Francesca Torti for assistance with the Forward Search analysis of Section 7.2 and for enabling the application of the methods to large collections of datasets through the development of a dedicated SAS package, to be deployed in a web application.
Supplementary Materials
Supplementary materials include:
the extension to the first-k significant digits of the results on the significand transform and of the sum-invariance test statistics;
additional simulation results that complement those given in the article;
the details of the contamination scheme adopted in Section 7.2.
Additional information
Funding
References
- Allaart, P. C. (1997), “An Invariant-Sum Characterization of Benford’s Law,” Journal of Applied Probability, 34, 288–291. DOI: 10.2307/3215195.
- Barabesi, L., Cerasa, A., Cerioli, A., and Perrotta, D. (2016a), “A New Family of Tempered Distributions,” Electronic Journal of Statistics, 10, 3871–3893. DOI: 10.1214/16-EJS1214.
- Barabesi, L., Cerasa, A., Cerioli, A., and Perrotta, D. (2018), “Goodness-of-Fit Testing for the Newcomb-Benford Law With Application to the Detection of Customs Fraud,” Journal of Business and Economic Statistics, 36, 346–358.
- Barabesi, L., Cerasa, A., Perrotta, D., and Cerioli, A. (2016b), “Modeling International Trade Data With the Tweedie Distribution for Anti-Fraud and Policy Support,” European Journal of Operational Research, 248, 1031–1043. DOI: 10.1016/j.ejor.2015.08.042.
- Barabesi, L., and Pratelli, L. (2020), “On the Generalized Benford Law,” Statistics and Probability Letters, 160, Article 108702. DOI: 10.1016/j.spl.2020.108702.
- Berger, A., and Hill, T. P. (2011), “Benford’s Law Strikes Back: No Simple Explanation in Sight for Mathematical Gem,” Mathematical Intelligencer, 33, 85–91. DOI: 10.1007/s00283-010-9182-3.
- Berger, A., and Hill, T. P. (2015), An Introduction to Benford’s Law, Princeton, NJ: Princeton University Press.
- Berger, A., and Hill, T. P. (2020), “The Mathematics of Benford’s Law: A Primer,” Statistical Methods and Applications, DOI: 10.1007/s10260-020-00532-8.
- Berger, A., and Twelves, I. (2018), “On the Significands of Uniform Random Variables,” Journal of Applied Probability, 55, 353–367. DOI: 10.1017/jpr.2018.23.
- Bolton, R. J., and Hand, D. J. (2002), “Statistical Fraud Detection: A Review,” Statistical Science, 17, 235–255. DOI: 10.1214/ss/1042727940.
- Cerasa, A., Torti, F., and Perrotta, D. (2016), “Heteroscedasticity, Multiple Populations and Outliers in Trade Data,” in Topics on Methodological and Applied Statistical Inference, eds. T. Di Battista, E. Moreno, and W. Racugno, Cham: Springer, pp. 43–50.
- Cerioli, A. (2010), “Multivariate Outlier Detection With High-Breakdown Estimators,” Journal of the American Statistical Association, 105, 147–156. DOI: 10.1198/jasa.2009.tm09147.
- Cerioli, A., Barabesi, L., Cerasa, A., Menegatti, M., and Perrotta, D. (2019), “Newcomb-Benford Law and the Detection of Frauds in International Trade,” Proceedings of the National Academy of Sciences of the United States of America, 116, 106–115. DOI: 10.1073/pnas.1806617115.
- Cerioli, A., Farcomeni, A., and Riani, M. (2019), “Wild Adaptive Trimming for Robust Estimation and Cluster Analysis,” Scandinavian Journal of Statistics, 46, 235–256. DOI: 10.1111/sjos.12349.
- Cerioli, A., and Perrotta, D. (2014), “Robust Clustering Around Regression Lines With High Density Regions,” Advances in Data Analysis and Classification, 8, 5–26. DOI: 10.1007/s11634-013-0151-5.
- Diaconis, P. (1977), “The Distribution of Leading Digits and Uniform Distribution mod 1,” The Annals of Probability, 5, 72–81. DOI: 10.1214/aop/1176995891.
- Diaconis, P., and Freedman, D. (1979), “On Rounding Percentages,” Journal of the American Statistical Association, 74, 359–364.
- Dümbgen, L., and Leuenberger, C. (2008), “Explicit Bounds for the Approximation Error in Benford’s Law,” Electronic Communications in Probability, 13, 99–112.
- Dümbgen, L., and Leuenberger, C. (2015), “Explicit Error Bounds via Total Variation,” in Benford’s Law: Theory and Applications, ed. S. J. Miller, Princeton, NJ: Princeton University Press, pp. 119–134.
- Engel, H. A., and Leuenberger, C. (2003), “Benford’s Law for Exponential Random Variables,” Statistics and Probability Letters, 63, 361–365. DOI: 10.1016/S0167-7152(03)00101-9.
- European Commission (2014), “Operation SNAKE: EU and Chinese Customs Join Forces to Target Undervaluation of Goods at Customs,” Press Release IP-14-1001, available at https://ec.europa.eu/commission/presscorner/detail/en/IP/_14/_1001.
- Fernandez-Gracia, J., and Lacasa, L. (2018), “Bipartisanship Breakdown, Functional Networks, and Forensic Analysis in Spanish 2015 and 2016 National Elections,” Complexity, 2018, Article ID 9684749, DOI: 10.1155/2018/9684749.
- Graham, R. L., Knuth, D. E., and Patashnik, O. (1994), Concrete Mathematics: A Foundation for Computer Science (2nd ed.), Reading, MA: Addison-Wesley.
- Hill, T. P. (1995a), “The Significant-Digit Phenomenon,” The American Mathematical Monthly, 102, 322–327. DOI: 10.2307/2974952.
- Hill, T. P. (1995b), “A Statistical Derivation of the Significant-Digit Law,” Statistical Science, 10, 354–363.
- Hubert, M., Rousseeuw, P. J., and Van Aelst, S. (2008), “High-Breakdown Robust Multivariate Methods,” Statistical Science, 23, 92–119. DOI: 10.1214/088342307000000087.
- Kossovsky, A. E. (2015), Benford’s Law: Theory, The General Law of Relative Quantities, and Forensic Fraud Detection Applications, Singapore: World Scientific.
- Lacasa, L. (2019), “Newcomb-Benford Law Helps Customs Officers to Detect Fraud in International Trade,” Proceedings of the National Academy of Sciences of the United States of America, 116, 11–13. DOI: 10.1073/pnas.1819470116.
- Luque, B., and Lacasa, L. (2009), “The First-Digit Frequencies of Prime Numbers and Riemann Zeta Zeros,” Proceedings of the Royal Society A, 465, 2197–2216. DOI: 10.1098/rspa.2009.0126.
- Mebane, W. R., Jr. (2010), “Fraud in the 2009 Presidential Election in Iran?,” Chance, 23, 6–15. DOI: 10.1080/09332480.2010.10739785.
- Mebane, W. R., Jr. (2011), “Comment on ‘Benford’s Law and the Detection of Election Fraud’,” Political Analysis, 19, 269–272.
- Miller, S. J., ed. (2015), Benford’s Law: Theory and Applications, Princeton, NJ: Princeton University Press.
- Miller, S. J., and Nigrini, M. (2008), “Order Statistics and Benford’s Law,” International Journal of Mathematics and Mathematical Sciences, 2008, Article ID 382948, DOI: 10.1155/2008/382948.
- Nigrini, M. J. (1992), “The Detection of Income Tax Evasion Through an Analysis of Digital Distributions,” Ph.D. thesis, Department of Accounting, University of Cincinnati.
- Nigrini, M. J. (2012), Benford’s Law, Hoboken, NJ: Wiley.
- Pericchi, L., and Torres, D. (2011), “Quick Anomaly Detection by the Newcomb-Benford Law, With Applications to Electoral Processes Data From the USA, Puerto Rico and Venezuela,” Statistical Science, 26, 502–516. DOI: 10.1214/09-STS296.
- Perrotta, D., Cerasa, A., Torti, F., and Riani, M. (2020), “The Robust Estimation of Monthly Prices of Goods Traded by the European Union,” Technical Report JRC120407, EUR 30188 EN, Publications Office of the European Union, Luxembourg. DOI: 10.2760/635844.
- Pietronero, L., Tosatti, E., Tosatti, V., and Vespignani, A. (2001), “Explaining the Uneven Distribution of Numbers in Nature: The Laws of Benford and Zipf,” Physica A, 293, 297–304. DOI: 10.1016/S0378-4371(00)00633-6.
- Raimi, R. A. (1976), “The First Digit Problem,” The American Mathematical Monthly, 83, 521–538. DOI: 10.1080/00029890.1976.11994162.
- Riani, M., Atkinson, A. C., and Perrotta, D. (2014), “A Parametric Framework for the Comparison of Methods of Very Robust Regression,” Statistical Science, 29, 128–143. DOI: 10.1214/13-STS437.
- Riani, M., Corbellini, A., and Atkinson, A. C. (2018), “The Use of Prior Information in Very Robust Regression for Fraud Detection,” International Statistical Review, 86, 205–218. DOI: 10.1111/insr.12247.
- Rousseeuw, P., Perrotta, D., Riani, M., and Hubert, M. (2019), “Robust Monitoring of Time Series With Application to Fraud Detection,” Econometrics and Statistics, 9, 108–121. DOI: 10.1016/j.ecosta.2018.05.001.
- Rubin-Delanchy, P., Heard, N. A., and Lawson, D. J. (2019), “Meta-Analysis of Mid-p-Values: Some New Results Based on the Convex Order,” Journal of the American Statistical Association, 114, 1105–1112. DOI: 10.1080/01621459.2018.1469994.
- Serfling, R. J. (1980), Approximation Theorems of Mathematical Statistics, Hoboken, NJ: Wiley.
- Tam Cho, W. K., and Gaines, B. J. (2007), “Breaking the (Benford) Law,” The American Statistician, 61, 218–223. DOI: 10.1198/000313007X223496.
- Torti, F., Corbellini, A., and Atkinson, A. C. (2021), “fsdaSAS: a Package for Robust Regression for Very Large Datasets including the Batch Forward Search” (submitted).
Appendix:
Technical Results
Proof o
f result (8). We adopt the same notation as in Section 3. From definition (7), it holds that with probability
if
. Otherwise,
with probability
. The distribution of
is thus a mixture of an absolutely-continuous law and the Dirac law with mass at zero. In addition, by using expression (3), we have
while
We then obtain that the distribution function of is
Proof o
f result (13).
From expression (7) and for , it follows that
(A.1)
In the case of the generalized Benford’s law, the random variable S(X) is absolutely continuous. Thus, the probability density function of S(X) with respect to the Lebesgue measure on is
for
. In the case of Benford’s law, that is, when α = 0, it follows
On the other hand, for , it holds