
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Fredholm integral equations of the first kind are the prototypical example of ill-posed linear inverse problems. They model, among other things, reconstruction of distorted noisy observations and indirect density estimation and also appear in instrumental variable regression. However, their numerical solution remains a challenging problem. Many techniques currently available require a preliminary discretization of the domain of the solution and make strong assumptions about its regularity. For example, the popular expectation maximization smoothing (EMS) scheme requires the assumption of piecewise constant solutions which is inappropriate for most applications. We propose here a novel particle method that circumvents these two issues. This algorithm can be thought of as a Monte Carlo approximation of the EMS scheme which not only performs an adaptive stochastic discretization of the domain but also results in smooth approximate solutions. We analyze the theoretical properties of the EMS iteration and of the corresponding particle algorithm. Compared to standard EMS, we show experimentally that our novel particle method provides state-of-the-art performance for realistic systems, including motion deblurring and reconstruction of cross-section images of the brain from positron emission tomography.
1 Introduction
We consider Fredholm equations of the first kind of the form(1)
(1) with f(x) and h(y) probability densities on
and
, respectively, and
the density of a Markov kernel from
to
. Given g and (some characterization of) h, we aim to estimate f. Our particular interest is the setting in which we have access to a collection of samples from h, rather than the function itself.
This class of equations has numerous applications in statistics and applied mathematics. For example, h might correspond to a mixture model for which we wish to estimate its mixing distribution, f, from samples from h. This problem is known as density deconvolution or indirect density estimation (Delaigle, Citation2008; Ma, Citation2011; Pensky et al., Citation2017; Yang et al., Citation2020). In epidemiology, (1) links the incidence curve of a disease to the observed number of cases (Goldstein et al., Citation2009; Gostic et al., Citation2020; Marschner, Citation2020). In instrumental variable regression and causal inference, Fredholm equations can be used to estimate a nonlinear regression function or identify causal effects in the presence of confounders (Hall et al., Citation2005; Miao et al., Citation2018). Since the seminal work of Vardi et al. (Citation1985); Vardi and Lee (Citation1993), Fredholm equations have also been widely used in positron emission tomography. In this and similar contexts, f corresponds to an image which needs to be inferred from noisy measurements (Aster et al., Citation2018; Clason et al., Citation2019; Snyder et al., Citation1992; Zhang et al., Citation2019).
In most interesting cases, Fredholm integral equations of the first kind are ill-posed and it is necessary to introduce a regularizer to obtain a unique solution. Solving the regularized problem remains computationally very challenging. For certain subclasses of this problem, such as density deconvolution (Delaigle, Citation2008) good methods exist and can achieve optimal convergence rates as the number of observations increases (Carroll and Hall, Citation1988). However, generally applicable approaches which do not assume a particular form of g typically require discretization of the domain, , which restricts their applications to low-dimensional scenarios, and often assume a piecewise-constant solution (Burger et al., Citation2019; Koenker and Mizera, Citation2014; Ma, Citation2011; Tanana et al., Citation2016; Yang et al., Citation2020). This is the case for the popular Expectation Maximization Smoothing (EMS) scheme (Silverman et al., Citation1990), a smoothed version of the infinite dimensional expectation maximization algorithm of Kondor (Citation1983).
In this paper, our contributions are three-fold. First, we provide novel theoretical results for the EMS scheme on continuous spaces, establishing that it admits a fixed point under weak assumptions. Second, we propose a novel particle version of EMS which does not suffer from the limitations of the original scheme. This Monte Carlo algorithm provides an adaptive stochastic discretization of the domain and outputs a sample approximation of f through which a smooth approximation can be obtained via a natural kernel density estimation procedure. Although this algorithm is related to sequential Monte Carlo (SMC) methods which have been widely used to perform inference for complex Bayesian models (Chopin and Papaspiliopoulos, Citation2020; Del Moral, Citation2013; Douc et al., Citation2014; Doucet and Johansen, Citation2011; Liu and Chen, Citation1998; Liu, Citation2001), standard SMC convergence results do not apply to this scheme so we also provide an original theoretical analysis of the algorithm. Third, we demonstrate this algorithm on both illustrative examples and realistic image processing applications.
The rest of this paper is organized as follows. In Section 2, we review Fredholm integral equations of the first kind and the EMS algorithm, and establish existence of a fixed point for the continuous version. In Section 3, we introduce a particle approximation of the EMS recursion and provide convergence results for this scheme. We demonstrate the application of the algorithm in Section 4 and then briefly conclude.
2 Fredholm equations and EMS
2.1 Fredholm integral equations of the first kind
We recall that we consider equations of the form (1). We concern ourselves in particular with the case in which
(A0)
and
are compact subsets of Euclidean spaces, g can be evaluated pointwise and a sample, Y, from h is available.
In most applications the space is closed and bounded and (A0) is satisfied. For instance, in image processing both
and
are typically of the form
for
, f and h are continuous densities on
and
, respectively. In applications the analytic form of h is often unknown, and the available data arise from discretization of h over
, as in, e.g., Vardi and Lee (Citation1993), or from sampling, as in, e.g. Ma (Citation2011). In the image processing context, the available data are usually either the values of h over the discretization of
induced by the pixels of the image (e.g. an image with 10 × 10 pixels induces a discretization on
in which the intervals
and
are each divided into 10 bins) or samples from h. We focus here on the sampling case.
Considering (1) in the context of probability densities is not too restrictive. A wider class of integral equations can be recast in this framework by appropriate normalizations and translations, provided that f and h are bounded below (Chae et al., Citation2018, Section 6).
As the set of probability densities on is not finite, if the kernel g is not degenerate then the resulting integral equation is in general ill-posed (Kress, Citation2014, Theorem 15.4). Fredholm’s alternative (see, e.g., (Kress, Citation2014, Corollary 4.18)) gives a criterion to assess the existence of solutions of (1); however, the lack of continuous dependence on h causes the solutions to be unstable and regularization techniques are needed (Kress, Citation2014; Groetsch, Citation2007). Common methods are Tikhonov regularization (Tikhonov, Citation1963) and iterative methods (Landweber, Citation1951; Kondor, Citation1983). See Yuan and Zhang (Citation2019) for a recent review.
2.2 Expectation Maximization and Related Algorithms
2.2.1 Expectation Maximization
From a statistical point of view, (1) describes an indirect density estimation problem: the mixing density f has to be recovered from the mixture h. This can in principle be achieved by maximizing an incomplete data likelihood for f through the Expectation Maximization (EM) algorithm (Dempster et al., Citation1977). Nevertheless, the maximum likelihood estimator is not consistent, as the parameter to be estimated (i.e. f) is infinite dimensional (Laird, Citation1978); a problem aggravated by the ill-posedness of (1) (Silverman et al., Citation1990).
We briefly review a number of iterative schemes based on the EM algorithm which aim to find approximate solutions of (1) through regularization. The starting point is the iterative method of Kondor (Citation1983), an infinite dimensional EM algorithm,(2)
(2) which minimizes the Kullback–Leibler divergence,
(3)
(3)
with respect to f over the set of probability densities on
(Mülthei et al., Citation1989). Minimizing (3) is equivalent to maximizing
a continuous version of the incomplete data log-likelihood for the function f (Mülthei et al., Citation1989). This scheme has several good properties, iterating (2) monotonically decreases (3) (Mülthei et al., Citation1987, Theorem 7) and if the iterative formula converges, then the limit is a minimizer of (3) (Mülthei et al., Citation1987, Theorem 8) — but the minimizer need not be unique. Convergence of the EM iteration (2) to a fixed point has been proved under the existence of a sequence
with
, such that
converges to the infimum of (3) and additional integrability conditions (Chae et al., Citation2018).
In general, implementing the recursive formula (2) analytically is not possible and discretization schemes are needed. Under the assumption of piecewise constant densities f, h and g, with the discretization grid fixed in advance, the EM recursion (2) reduces to the EM algorithm for Poisson data (Vardi and Lee, Citation1993), known as the Richardson–Lucy (RL) algorithm in the image processing field (Richardson, Citation1972; Lucy, Citation1974), where the intensities of pixels are modeled as Poisson counts,(4)
(4) here fb
for
and hd
for
are the constant values over the deterministic discretization of the space for f and h respectively.
The Iterative Bayes (IB) algorithm of Ma (Citation2011) considers the case in which only samples from h are available. These samples are used to build a kernel density estimator (KDE) for h, which is then plugged into the discretized EM iteration (4).
As discussed earlier, despite being popular and easy to implement, the EM algorithm (4) has a number of drawbacks: after a certain number of iterations the EM approximations deteriorate resulting in unstable estimates that lack smoothness and give spiky estimates of f (Silverman et al., Citation1990; Nychka, Citation1990); in fact minimizing (3) does not deal with the ill-posedness of the problem and regularization is needed (Byrne and Eggermont, Citation2015).
A natural way to introduce regularization is via maximum penalized likelihood estimation (MPLE; see, e.g. Green (Citation1990)), maximizing, for some penalty term, P:
In most cases, an updating formula like (4) cannot be obtained straightforwardly for MPLE because the derivative of P(f) usually involves several derivatives of f. A possible solution is to update the estimate of f from iteration fn
to evaluating the penalty term at fn
, rather than at the new value
. This is known as the one-step late (OSL) algorithm (Green, Citation1990). The resulting update formula is usually easier to compute but there is no guarantee that each iteration will increase the penalized log-likelihood. However, if convergence occurs, the OSL algorithm converges more quickly than the corresponding EM for the penalized likelihood.
2.2.2 Expectation Maximization Smoothing
An easy-to-implement regularized version of the EM recursion (4) is the EMS algorithm of Silverman et al. (Citation1990), an EM-like algorithm in which a smoothing matrix is applied to the EM estimates at each iteration
(5)
(5)
The EMS algorithm has long been attractive from a practical point of view as the addition of the smoothing step to the EM recursion (4) gives good empirical results, with convergence occurring empirically in a relatively small number of iterations (e.g. Silverman et al. (Citation1990); Li et al. (Citation2017); Becker et al. (Citation1991)).
Under mild conditions on the smoothing matrix the discretized EMS recursion (5) has a fixed point (Latham and Anderssen, Citation1992). In addition, with a particular choice of smoothing matrix, the fixed point of (5) minimizes a penalized likelihood with a particular roughness penalty (Nychka, Citation1990). With this choice of penalty, the OSL and the EMS recursion have the same fixed point (Green, Citation1990). Fan et al. (Citation2011) establish convergence of (5) to local-EM, an EM algorithm for maximum local-likelihood estimation, when the smoothing kernel is a symmetric positive convolution kernel with positive bandwidth and bounded support. If the space on which the EMS mapping is defined is bounded, the discrete EMS mapping is globally convergent for sufficiently large bandwidth.
The focus of this work is a continuous version of the EMS recursion, in which we do not discretize the space and use smoothing convolutions in place of smoothing matrices, i.e.
(6)
(6)
2.3 Properties of the Continuous EMS Recursion
Contrary to the discrete EMS map (5), relatively little is known about the continuous EMS mapping. We prove, under the following assumptions, that it also admits a fixed point in the space of probability distributions:
(A1)The density of the kernel is continuous and bounded away from 0 and
:
(A2)The smoothing kernel is specified via a continuous bounded density, T, over , such that
as:
Assumption (A1) is common in the literature on Fredholm integral equations as continuity of g rules out degenerate integral equations which require special treatment (Kress, Citation2014, Chapter 5). The boundedness condition on g ensures the existence of a minimizer of (3) (Mülthei, Citation1992, Theorem 1). Assumption (A2) on T is mild and is satisfied by most commonly used kernels for density estimation (Silverman, Citation1986) and implies that is a density over
for any fixed v. We can draw samples from
, e.g. by rejection sampling whenever T is proportional to a density from which sampling is feasible.
The EMS map describes one iteration of this algorithm, for a probability density f,
It is the composition of linear smoothing by the kernel K defined in (A2) and the non-linear map corresponding to the EM iteration, ,
(7)
(7) and we introduce the normalizing constant
to highlight the connection with the particle methods introduced in Section 3 (here and elsewhere we adopt the convention that for any suitable integrable function,
, and probability or density, f,
). That is,
corresponds to a simple reweighting of a probability, with the weight being given by
.
The existence of the fixed point of is established in the supplementary material using results from non-linear functional analysis. This result is obtained taking h to be any probability distribution over
, and shows that a fixed point exists both in the case in which h admits a density and that in which h is the empirical distribution of a sample Y — the latter is common in applications, and is the setting we are concerned with.
Proposition 1.
Under (A0), (A1)and (A2), the EMS map, , has a fixed point in the space of probability distributions over
.
3 Particle implementation of the EMS Recursion
In order to make use of the continuous EMS recursion in practice, it is necessary to approximate the integrals which it contains. To do so, we develop a particle method specialized to our context via a stochastic interpretation of the recursion.
3.1 Particle methods
Particle methods also known as Sequential Monte Carlo (SMC) methods are a class of Monte Carlo methods that sequentially approximate a sequence of target probability densities defined on the product spaces
of increasing dimension, whose evolution is described by Markov transition kernels Mn
and positive potential functions Gn
(Del Moral, Citation2013)
(8)
(8)
These sequences naturally arise in state space models (e.g. Liu and Chen (Citation1998); Doucet and Johansen (Citation2011); Li et al. (Citation2016)) and many inferential problems can be described by (8) (see, e.g., Liu (Citation2001); Chopin and Papaspiliopoulos (Citation2020), and references therein).
The approximations of ηn
for are obtained through a population of Monte Carlo samples, called particles. The population consists of a set of N weighted particles
which evolve in time according to the dynamic in (8). Given the equally weighted population at time n – 1,
, new particle locations
are sampled from
to obtain the equally weighted population at time n,
. Then, the fitness of the new particles is measured through
, which gives the weights
. The new particles are then replicated or discarded using a resampling mechanism, giving the equally weighted population at time n,
. Several resampling mechanisms have been considered in the literature ((Douc et al., Citation2014, page 336), Gerber et al. (Citation2019)) the simplest of which consists of sampling the number of copies of each particle from a multinomial distribution with weights
(Gordon et al., Citation1993).
At each n, the empirical distribution of the particle population provides an approximation of the marginal distribution of Zn
under via
Throughout, in the interests of brevity, we will abuse notation slightly and treat
as a density, allowing
to denote a probability concentrated at x0. These approximations possess various convergence properties (e.g. Del Moral (Citation2013)), in particular
error estimates and a strong law of large numbers for the expectations
of sufficiently regular test functions
(Crisan and Doucet, Citation2002; Míguez et al., Citation2013).
3.2 A stochastic interpretation of EMS
The EMS recursion (6) can be modeled as a sequence of densities satisfying (8) by considering an extended state space. Denote by the joint density at
defined by
so that
. This density satisfies a recursion similar to that in (6)
(9)
(9)
With a slight abuse of notation, we denote by ηn
the joint density of obtained by iterative application of (9) with the integrals removed.
Proposition 2.
The sequence of densities defined over the product spaces
by (8) with
,
(10)
(10) and
(11)
(11)
satisfies, marginally, recursion (9). In particular, the marginal distribution over xn
of
,
(12)
(12)
satisfies recursion (6) with the identification
.
Proof.
Starting from (8) with and
as in (10)-(11)
(13)
(13) where
, and integrating out
We can then compute the marginal over
which, with the given identifications, satisfies the EMS recursion (6). □
To facilitate the theoretical analysis we separate the contribution of the mutation kernels (10) and of the potential functions (11), in particular, we denote the weighted distribution obtained from ηn
by .
3.3 A particle method for EMS
Having shown that the EMS recursion describes a sequence of densities satisfying (8), it is possible to use SMC techniques to approximate this recursion. This involves replacing the true density at each step with a sample approximation obtained at the previous iteration, giving rise to Algorithm 1, which describes the case in which only a fixed number of samples from h are available and in line 1-2 we draw from their empirical distribution; when sampling freely from h is feasible one could instead draw these samples from it.
The resulting SMC scheme is not a standard particle approximation of (8), because of the definition of the potential (11). Indeed, cannot be computed exactly, because
is not known. The SMC scheme provides an approximation for
at time n. Let us denote by
the particle approximation of the marginal
in (12)
We can approximateusing the particle approximation of the denominator
,
(14)
(14)
to obtain the approximate potentials
(15)
(15)
Algorithm 1: Particle Method for Fredholm Equations of the First Kind
At time n = 1
1 Sample uniformly from Y for
and set
At time n > 1
2 Sample and
uniformly from Y for
3 Compute the approximated potentials in (15) and obtain the normalized weights
4 (Re)Sample to get
for
5 Estimate as in (17)
The use of within the importance weighting step corresponds to an additional approximation which is not found in standard SMC algorithms. In particular, (15) are biased estimators of the true potentials (11). As a consequence, it is not possible to use arguments based on extensions of the state space (as in particle filters using unbiased estimates of the potentials (Liu and Chen, Citation1998; Del Moral et al., Citation2006; Fearnhead et al., Citation2008)) to provide theoretical guarantees for this SMC scheme. If
itself were available then it would be preferable to make use of it; in practice this will never be the case but the idealized algorithm which employs such a strategy is of use for theoretical analysis.
At time n + 1, we estimate by computing a kernel density estimate (KDE) of the weighted particle approximation
and then applying the EMS smoothing kernel K. This approach may seem counter-intuitive but the KDE kernel and the EMS kernel are fulfilling different roles. The KDE gives a good smooth approximation of the density associated with the EMS recursion at a point in that recursion which we expect to be under-smoothed and is driven by the usual considerations of KDE when obtaining a smooth density approximation from an empirical distribution; going on to apply the EMS smoothing kernel is simply part of the EMS regularization procedure. One could instead apply kernel density estimation after step 2 of the subsequent iteration of the algorithm but this would simply introduce additional Monte Carlo variance, with the described approach corresponding to a Rao-Blackwellisation of that slightly simpler strategy. Using the kernel of Fredholm equations of the second kind to extract smooth approximations of their solution from Monte Carlo samples has also been found empirically to perform well (Doucet et al., Citation2010). Depending on the intended use of the approximation, the KDE step can be omitted entirely; the empirical distribution provides a good (in the sense of Proposition 4) approximation to that given by the EMS recursion but one which does not admit a density.
We consider standard -dimensional kernels for KDE,
, where
is the smoothing bandwidth and S is a continuous bounded symmetric density (Silverman, Citation1986). To account for the dependence between samples, when computing the bandwidth,
, instead of N we use the effective sample size (Kong et al., Citation1994)
(16)
(16)
The resulting estimator,(17)
(17) satisfies the standard KDE convergence results in
and in
(see Section 3.4.2).
As the EMS recursion (6) aims at finding a fixed point, after a certain number of iterations the approximation of f provided by the SMC scheme stabilizes. We could therefore average over approximations obtained at different iterations to get more stable reconstructions. When the storage cost is prohibitive, a thinned set of iterations could be used.
In principle, one could reduce the variance of associated estimators by using a different proposal distribution within Algorithm 1 just as in standard particle methods (see, e.g., (Doucet and Johansen, Citation2011, Section 25.4.1)) but this proved unnecessary in all of the examples which we explored as we obtained good performances with this simple generic scheme (the effective sample size was above 70% in all the examples considered). Another strategy to reduce the variance of the estimators would be to implement the quasi-Monte Carlo version of SMC (Gerber and Chopin, Citation2015) which is particularly efficient in the relatively low-dimensional settings typically found in the context of Fredholm equations.
3.3.1 Algorithmic Setting
Algorithm 1 requires specification of a number of parameters. The initial density, f1, must be specified but we did not find performance to be sensitive to this choice (see Section E.1 in the supplementary material). We advocate choosing f1 to be a diffuse distribution with support intended to include that of f because the resampling step allows SMC to more quickly forget overly diffuse initializations than overly concentrated ones. For problems with bounded domains, choosing f1 to be uniform over is a sensible default choice.
We propose to stop the iteration in Algorithm 1 when the difference between successive approximations, measured through the norm of the reconstruction of h obtained by convolution of
with g,
, is smaller than the variability due to the Monte Carlo approximation of (6)
(18)
(18) where ζ is some function of the estimator
and we consider its variance over the last m iterations. The term on the left-hand side is an indicator of whether the EMS recursion (6) has reached a fixed point, while the variance takes into account the error introduced by approximating (6) through Monte Carlo. For given N there is a point at which further increasing n does not improve the estimate because Monte Carlo variability dominates. We employ this stopping rule in the PET example in Section 4.2.
The amount of regularization introduced by the smoothing step is controlled by the smoothing kernel K. In principle, any density T can be used to specify K as in (A2); we opted for isotropic Gaussian kernels since in this case the integral in (17) can be computed analytically with an appropriate choice of S. In this case, the amount of smoothing is controlled by the variance . If the expected smoothness of the fixed point of the EMS recursion (6) is known, ε should be chosen so that (17) matches this knowledge. If no information is known on the expected smoothness, the level of smoothing introduced could be picked by cross validation, comparing, e.g., the reconstruction accuracy or smoothness. In addition, one could allow extra flexibility by letting K change at each iteration: e.g., allowing larger moves in early iterations can be beneficial in standard SMC settings to improve stability and ergodicity; alternatively one could choose the smoothing parameter adaptively using information on the smoothness of the current estimate.
We end this section by identifying a further degree of freedom which can be exploited to improve performance: a variance reduction can be achieved by averaging over several when computing the approximated potentials
. At time n, draw M samples
without replacement for each particle
and compute the approximated potentials by averaging over the M replicates
This incurs an O(MN) computational cost and can be justified by further extending the state space to . Unfortunately, the results on the optimal choice of M obtained for pseudo-marginal methods (e.g. Pitt et al. (Citation2012)) cannot be applied here, as the estimates of
given by (15) are not unbiased. In the examples shown in Section 4 we resample without replacement M samples from Y where M is the smallest between N and the size of Y, but smaller values of M could be considered (see Section E.1 in the supplement).
3.3.2 Comparison with EMS
The discretized EMS (5) and Algorithm 1 both approximate the EMS recursion (6). There are two main aspects under which the SMC implementation of EMS is an improvement with respect to the one obtained by brute-force discretization: the information on h which is needed to run the algorithm and the scaling with the dimensionality of the domain of f.
The discretized EMS (5) requires the value of h on each of the D bins of the space discretization of , when we only have a sample Y from h, as it is the case in most applications (Delaigle, Citation2008; Miao et al., Citation2018; Goldstein et al., Citation2009; Gostic et al., Citation2020; Marschner, Citation2020; Hall et al., Citation2005), h should then be approximated through a histogram or a kernel density estimator as in the Iterative Bayes algorithm (Ma, Citation2011). On the contrary, Algorithm 1 does not require this additional approximation and naturally deals with samples from h. In Section 4.1 we show on a one dimensional example that the brute-force discretization (5) struggles at recovering the shape of a bimodal distribution while the SMC implementation achieves much better performances in terms of accuracy. In addition, increasing the number of bins for EMS has a milder effect on the accuracy than increasing the number of particles in the SMC implementation.
Similar considerations apply when are higher dimensional (i.e.
). The number of bins B in the EMS recursion (5) necessary to achieve reasonable accuracy increases exponentially with
, resulting in higher runtime which quickly exceed those needed to run Algorithm 1. On the contrary the convergence rate for SMC remains
, and although the associated constants may grow with
, its performance is shown empirically to scale better with dimension than EMS in the supplementary material.
3.4 Convergence properties
As the potentials (11) cannot be computed exactly but need to be estimated, the convergence results for standard SMC (e.g., Del Moral (Citation2013)) do not hold. We present here a strong law of large numbers (SLLN) and error estimates for our particle approximation of the EMS and also provide theoretical guarantees for the estimator (17).
3.4.1 Strong law of large numbers
For simplicity, we only consider multinomial resampling (Gordon et al., Citation1993). Lower variance resampling schemes can be employed but considerably complicate the theoretical analysis ((Douc et al., Citation2014, page 336), Gerber et al. (Citation2019)). Compared to the SLLN proof for standard SMC methods, we need to analyze here the contribution of the additional approximation introduced by using instead of
and then combine the results with existing arguments for standard SMC; see, e.g., Míguez et al. (Citation2013).
The SSLN is stated in Corollary 1. This result follows from the inequality in Proposition 3, the proof of which is given in the supplementary material and follows the inductive argument of Crisan and Doucet (Citation2002); Míguez et al. (Citation2013). Both results are proved for bounded measurable test functions
, a set we denote
.
As a consequence of (A1), the potentials and
are bounded and bounded away from 0 (see Lemma 1 in the supplement), a strong mixing condition that is common in the SMC literature and is satisfied in most of the applications which we have considered.
Proposition 3
(-inequality). Under (A0), (A1)and (A2), for every
and every
there exist finite constants
such that
(19)
(19)
(20)
(20) for every bounded measurable function
, where the expectations are taken with respect to the law of all random variables generated within the SMC algorithm.
The SLLN follows from the -inequality using a standard Borel-Cantelli argument (see, e.g. (Boustati et al., Citation2020, Appendix D) for a reference in the context of SMC):
Corollary 1 (Strong law of large numbers). Under (A0), (A1)and (A2), for all and for every
, we have almost surely as
:
A standard approach detailed in the supplementary material yields convergence of the sequence itself, showing that the particle approximations of the distributions converge to the sequence in (13), whose marginal over x satisfies the EMS recursion (6).
Proposition 4.
Under (A0), (A1)and (A2), for all converges weakly to
with probability 1.
3.4.2 Convergence of kernel density estimator
Under standard assumptions on the bandwidth we can show that the estimator
converges in
to
and its mean integrated square error (MISE) goes to 0 as N goes to infinity as shown in the supplementary material:
Proposition 5.
Under (A0), (A1)and (A2), if as
converges almost surely to
in
for every
:
(21)
(21)
and the MISE satisfies(22)
(22)
4 Examples
This section shows the results obtained using the SMC implementation of the recursive formula (6) on some common examples. Two additional examples are investigated in the supplementary material. We consider a simple density estimation problem and a realistic example of image restoration in positron emission tomography (Webb, Citation2017). In the first example, the analytic form of h is known and is used to implement the discretized EM and EMS. IB and SMC are implemented using a fixed sample Y drawn from h. For image restoration problems we consider the observed distorted image as the empirical distribution of a sample Y from h and resample from it at each iteration of line 2 in Algorithm 1.
The initial distribution f1 is uniform over and the number of iterations is either fixed to n = 100 (we observed that convergence occurs in a smaller number of steps for all algorithms; see Section E.1 in the supplement) or determined using the stopping criterion (18). For the smoothing kernel K, we use isotropic Gaussian kernels with marginal variance
. The bandwidth
is the plug-in optimal bandwidth for Gaussian distributions where the effective sample size (16) is used instead of the sample size N (Silverman, Citation1986, page 45).
The deterministic discretization of EM and EMS ((4) and (5) respectively) is obtained by considering B equally spaced bins for and D for
. The number of bins, and the number of particles, N, for SMC vary between examples. In the first example, the choice of D, B and N is motivated by a comparison of error and runtime. For the image restoration problems, D, B are the number of pixels in each image, while the number of particles N is chosen to achieve a good trade-off between reconstruction accuracy and runtime.
For the SMC implementation, we use the adaptive multinomial resampling scheme described by (Liu, Citation2001, page 35). At each iteration the effective sample size (16) is evaluated and multinomial resampling is performed if . This choice is motivated by the fact that up to adaptivity (which we anticipate could be addressed by the approach of Del Moral et al. (Citation2012)) this is the setting considered in the theoretical analysis of Section 3.4 and we observed only modest improvements when using lower variance resampling schemes (e.g. residual resampling, see Liu (Citation2001)) instead of multinomial resampling. The accuracy of the reconstructions is measured through the integrated square error
(23)
(23)
Although the density estimation example of Section 4.1 does not satisfy conditions (A0) or (A1) under which our theoretical guarantees hold; we nonetheless observe good results in terms of reconstruction accuracy and smoothness, demonstrating that assumption (A1) is not necessary and could be relaxed (see also Section G in the supplementary material). The other examples do satisfy all of our theoretical assumptions.
4.1 Indirect density estimation
The first example is the Gaussian mixture model used in Ma (Citation2011) to compare the Iterative Bayes (IB) algorithm with EM. Take (although note that
and restricting out attention to
would not significantly alter the results) and
The initial distribution f1 is Uniform on and the bins for the discretized EMS are B equally spaced intervals in
, noting that discretization schemes essentially require known compact support and this interval contains almost all of the probability mass. We run Algorithm 1 assuming that we have a sample Y of size 103 from h from which we re-sample
times without replacement at each iteration of line 2. We analyze the influence of the number of bins B and of the number of particles N on the integrated square error and on the runtime for the deterministic discretization of EMS (5) and for the SMC implementation of EMS (). We compare the two implementations of EMS with a class of estimators for deconvolution problems, deconvolution kernel density estimators with cross validated bandwidth (DKDE-cv; Stefanski and Carroll (Citation1990)) and plug-in bandwidth (DKDE-pi; Delaigle and Gijbels (Citation2004))Footnote1. These estimators take as input a sample from h of size N and output a kernel density estimator for f.
Fig. 1 Average and runtime for 1,000 repetitions of discretized EMS, SMC and DKDE. The number of bins and of particles/samples N ranges between 102 and 104.
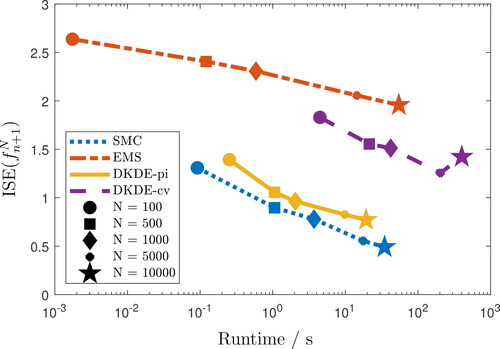
The discretized EMS has the lowest runtime for fixed N, however is the highest and finer discretizations for EMS do not significantly improve accuracy. The runtime of DKDE are closer to those of the SMC implementation, however, the SMC implementation gives better results in terms of
for any particle size and, indeed, for given computational cost. We set
, for both EMS and SMC, somewhat arbitrarily, based on the support of the target in this example; where that is not possible cross validation could be used — and might be expected to provide better reconstructions — at the expense of some additional computational cost. We did not find solutions overly sensitive to the precise value of ε (see Appendix E.1 in the supplementary material). A significant portion of the runtime of DKDE-cv is needed to obtain the bandwidth through cross validation and in this sense the comparison may not be quite fair, but the use of the much cheaper plug-in estimates of bandwidth within DKDE-pi also led to poorer estimates at given cost than those provided by the SMC-EMS algorithm.
Secondly, we compare the reconstructions provided by the proposed SMC scheme with those given by deterministic discretization of the EM iteration (4) with exact h and when only samples are available (IB) and deterministic discretization of the EMS iteration (5).
Having observed a small decrease in for large B, we fix the number of bins
. For the SMC scheme, we compare N = 500, N = 1, 000 and N = 5, 000. We discard N = 10, 000, as it shows little improvement in
with respect to N = 5, 000, and N = 100, because of the higher
. We draw a sample Y from h of size 103 and we use this sample to get a kernel density estimator for the IB algorithm, compute the DKDE and (re)sample points at line 2 of Algorithm 1.
We set and compare the smoothing matrix obtained by discretization of the Gaussian kernel (EMS (
)) with the three-point smoothing proposed in (Silverman et al., Citation1990, Section 3.2.2), where the value
is obtained by a weighted average over the values
of the two nearest neighbors (the third point is
), with weights proportional to the distance
The reconstruction process is repeated 1,000 times and the reconstructions are compared by computing their means and variances, the integrated squared error (23) and the Kullback–Leibler divergence between h and the reconstruction of h obtained by convolution of with g,
, (). To characterize the roughness of
, we evaluate both
and f at the 100 bin centers xc
and for each bin center we approximate (with 1,000 replicates) the mean squared error (MSE)
(24)
(24)
Table 1 Estimates of mean, variance, ISE, 95th-percentile of MSE, KL-divergence and runtime for 1,000 repetitions of EM, EMS, IB, SMC and DKDE for the Gaussian mixture example. The mean of f is 0.43333, the variance is 0.010196. Bold indicates best values.
shows the 95th percentile w.r.t. the 100 bin centers xc .
The discretized EM (4) gives the best results in terms of Kullback–Leibler divergence (restricting to the interval and computing by numerical integration). This is not surprising, as IB is an approximation of EM when the analytic form of h is not known, and the EMS algorithms (both those with the deterministic discretization (5) and those with the stochastic one given by the SMC scheme) do not seek to minimize the
divergence, but to provide a more regular solution. The solutions recovered by EM and IB have considerably higher
than that given by the other algorithms and are considerably worse than the other algorithms at recovering the smoothness of the solution.
SMC is generally better at recovering the global shape of the solution (ISE is at least two times smaller than EM and EMS (K) and about half than EMS (3-point) and IB) and the smoothness of the solution (the 95th-percentile for is at least two times smaller). For the discretized EMS (5) and the SMC implementation the estimates of the variance are higher than those of EM, this is a consequence of the addition of the smoothing step and can be controlled by selecting smaller values of ε. DKDEs behave similarly to SMC, however their reconstruction accuracy and smoothness are slightly worse than those of SMC (even when both algorithms use the same sample size N = 1, 000). In particular, DKDE-cv has runtime of the same order of that of SMC but achieves considerably worse results. IB, SMC and DKDE give similar values for the KL divergence. The slight increase observed for the SMC scheme with N = 5, 000 is apparently due to the sensitivity of this divergence to tail behaviors; taking a bandwidth independent of N eliminated this effect (results not shown).
4.2 Positron emission tomography
Positron Emission Tomography (PET) is a medical diagnosis technique used to analyze internal biological processes from radial projections to detect medical conditions such as schizophrenia, cancer, Alzheimer’s disease and coronary artery disease (Phelps, Citation2000).
The data distribution of the radial projections is defined on
for R > 0 and is linked to the cross-section image of the organ of interest f(x, y) defined on the 2D square
for r > 0 through the kernel g describing the geometry of the PET scanner. The Markov kernel
gives the probability that the projection onto
corresponds to point (x, y) (Vardi et al., Citation1985) and is modeled as a zero-mean Gaussian distribution with small variance (we use
) to mimic the alignment between projections and recovered emissions (see the supplementary material). As g is defined on
where
and
, assumption (A1) is satisfied.
The data used in this work are obtained from the reference image in the final panel of , a simplified imitation of the brain’s metabolic activity (e.g. Vardi and Lee (Citation1993)). The collected data are the values of h at 128 evenly spaced projections over and 185 values of ξ in
to which Poisson noise is added. shows the reconstructions obtained with the SMC scheme with smoothing parameter
and number of particles is N = 20, 000. Convergence to a fixed point occurs in less than 100 iterations, in fact the criterion (18) with
and m = 15 stops the iteration at n = 15. The
between the original image and the reconstructions stabilizes around 0.08. Additional results and model details are given in the supplementary material.
Fig. 2 Reconstruction of the Shepp–Logan phantom with N = 20, 000 particles and . The stopping criterion (18) is satisfied at iteration 15.
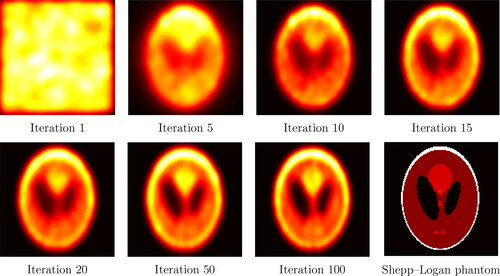
The results above show that the SMC implementation of the EMS recursion achieves convergence in a small number of steps ( 12 minutes on a standard laptop) and that, contrary to EM (Silverman et al., Citation1990, Section 4.2), these reconstructions are smooth and do not deteriorate with the number of iterations. In addition, contrary to standard reconstruction methods, e.g. filtered back-projection, ordered-subset EM, Tikhonov regularization (see, e.g., Tong et al. (Citation2010)) the SMC implementation does not require that a discretization grid is fixed in advance.
5 Conclusion
We have proposed a novel particle algorithm to solve a wide class of Fredholm equations of the first kind. This algorithm has been obtained by identifying a close connection between the continuous EMS recursion and the dynamics (8). It performs a stochastic discretization of the EMS recursion and can be naturally implemented when only samples from the distorted signal h are available. Additionally, it does not require the assumption of piecewise constant solutions common to deterministic discretization schemes.
Having established that the continuous EMS recursion admits a fixed point, we have studied the asymptotic properties of the proposed particle scheme, showing that the empirical measures obtained by this scheme converge almost surely in the weak topology to those given by the EMS recursion as the number of particles N goes to infinity. This result is a consequence of the convergence of expectations and the strong law of large numbers which we extended to the particle scheme under study. We have also provided theoretical guarantees on the proposed estimator for the solution f of the Fredholm integral equation. This algorithm outperforms the state of the art in this area in several examples.
supplementary_smcems
Download PDF (1,015.8 KB)Supplementary Material
The supplementary material contains the analysis of the EMS map, proofs of all results and additional examples. MATLAB code to reproduce all examples is available online at https://github.com/FrancescaCrucinio/smcems.
Additional information
Funding
Notes
1 MATLAB code is available on the authors’ web page: https://researchers.ms.unimelb.edu.au/∼aurored/links.html\#Code
References
- Aster, R. C., Borchers, B. and Thurber, C. H. (2018), Parameter Estimation and Inverse Problems, Elsevier.
- Becker, N. G., Watson, L. F. and Carlin, J. B. (1991), ‘A method of non-parametric back-projection and its application to AIDS data’, Stat Med 10, 1527–1542. DOI: 10.1002/sim.4780101005.
- Boustati, A., Akyildiz, O. D., Damoulas, T. and Johansen, A. M. (2020), Generalised Bayesian Filtering via Sequential Monte Carlo, in H. Larochelle et al., eds, ‘Advances in Neural Information Processing Systems’, Vol. 33, Curran Associates, Inc., pp. 418–429.
- Burger, M., Resmerita, E. and Benning, M. (2019), ‘An entropic Landweber method for linear ill-posed problems’, Inverse Probl 36(1), 015009. DOI: 10.1088/1361-6420/ab5c49.
- Byrne, C. and Eggermont, P. P. (2015), EM algorithms, in ‘Handbook of Mathematical Methods in Imaging’, Springer, pp. 305–388.
- Carroll, R. J. and Hall, P. (1988), ‘Optimal rates of convergence for deconvolving a density’, J Am Stat Assoc 83(404), 1184–1186. DOI: 10.1080/01621459.1988.10478718.
- Chae, M., Martin, R. and Walker, S. G. (2018), ‘On an algorithm for solving Fredholm integrals of the first kind’, Stat Comput 29, 645–654. DOI: 10.1007/s11222-018-9829-z.
- Chopin, N. and Papaspiliopoulos, O. (2020), An Introduction to Sequential Monte Carlo, Springer.
- Clason, C., Kaltenbacher, B. and Resmerita, E. (2019), Regularization of ill-posed problems with non-negative solutions, in ‘Splitting Algorithms, Modern Operator Theory, and Applications’, Springer, pp. 113–135.
- Crisan, D. and Doucet, A. (2002), ‘A survey of convergence results on particle filtering methods for practitioners’, IEEE T Signal Proces 50(3), 736–746. DOI: 10.1109/78.984773.
- Del Moral, P. (2013), Mean Field Simulation for Monte Carlo Integration, Chapman and Hall/CRC.
- Del Moral, P., Doucet, A. and Jasra, A. (2006), Sequential Monte Carlo for Bayesian computation, in J. Bernardo, M. Bayarri, J. Berger, A. Dawid, D. Heckerman, A. Smith and M. West, eds, ‘Bayesian Statistics 8’, Oxford: Oxford University Press.
- Del Moral, P., Doucet, A. and Jasra, A. (2012), ‘On adaptive resampling procedures for sequential Monte Carlo methods’, Bernoulli 18(1), 252–278.
- Delaigle, A. (2008), ‘An alternative view of the deconvolution problem’, Stat Sinica pp. 1025–1045.
- Delaigle, A. and Gijbels, I. (2004), ‘Practical bandwidth selection in deconvolution kernel density estimation’, Comput Stat Data An 45(2), 249–267. DOI: 10.1016/S0167-9473(02)00329-8.
- Dempster, A. P., Laird, N. M. and Rubin, D. B. (1977), ‘Maximum likelihood from incomplete data via the EM algorithm’, J R Stat Soc B 39, 2–38.
- Douc, R., Moulines, E. and Stoffer, D. (2014), Nonlinear Time Series: Theory, Methods and Applications with R examples, CRC press.
- Doucet, A. and Johansen, A. M. (2011), A tutorial on particle filtering and smoothing: Fifteen years later, in D. Crisan and B. Rozovsky, eds, ‘The Oxford Handbook of Nonlinear Filtering’, Oxford University Press, pp. 656–704.
- Doucet, A., Johansen, A. M. and Tadić, V. B. (2010), ‘On solving integral equations using Markov chain Monte Carlo methods’, Appl Math Comput 216(10), 2869–2880. DOI: 10.1016/j.amc.2010.03.138.
- Fan, C. P. S., Stafford, J. and Brown, P. E. (2011), ‘Local-EM and the EMS Algorithm’, J Comput Graph Stat 20(3), 750–766. DOI: 10.1198/jcgs.2011.10106.
- Fearnhead, P., Papaspiliopoulos, O. and Roberts, G. O. (2008), ‘Particle filters for partially observed diffusions’, J R Stat Soc B 70(4), 755–777. DOI: 10.1111/j.1467-9868.2008.00661.x.
- Gerber, M. and Chopin, N. (2015), ‘Sequential quasi-Monte Carlo’, J R Stat Soc B 3(77), 509–579. DOI: 10.1111/rssb.12104.
- Gerber, M., Chopin, N. and Whiteley, N. (2019), ‘Negative association, ordering and convergence of resampling methods’, Ann Stat 47(4), 2236–2260.
- Goldstein, E., Dushoff, J., Ma, J., Plotkin, J. B., Earn, D. J. and Lipsitch, M. (2009), ‘Reconstructing influenza incidence by deconvolution of daily mortality time series’, P Natl Acad Sci 106(51), 21825–21829. DOI: 10.1073/pnas.0902958106.
- Gordon, N. J., Salmond, D. J. and Smith, A. F. (1993), ‘Novel approach to nonlinear/non-Gaussian Bayesian state estimation’, IEE Proc F-Radar and Sig Proc 140, 107–113. DOI: 10.1049/ip-f-2.1993.0015.
- Gostic, K. M., McGough, L., Baskerville, E. B., Abbott, S., Joshi, K., Tedijanto, C., Kahn, R., Niehus, R., Hay, J. A., De Salazar, P. M. et al. (2020), ‘Practical considerations for measuring the effective reproductive number, Rt’, PLoS Computational Biology 16(12).
- Green, P. J. (1990), ‘On use of the EM for penalized likelihood estimation’, J R Stat Soc B 52(3), 443–452.
- Groetsch, C. W. (2007), ‘Integral equations of the first kind, inverse problems and regularization: a crash course’, J Phys Conf Ser 73(1), 012001. DOI: 10.1088/1742-6596/73/1/012001.
- Hall, P., Horowitz, J. L. et al. (2005), ‘Nonparametric methods for inference in the presence of instrumental variables’, Ann Stat 33(6), 2904–2929.
- Koenker, R. and Mizera, I. (2014), ‘Convex optimization, shape constraints, compound decisions, and empirical Bayes rules’, J Am Stat Assoc 109(506), 674–685. DOI: 10.1080/01621459.2013.869224.
- Kondor, A. (1983), ‘Method of convergent weights–An iterative procedure for solving Fredholm’s integral equations of the first kind’, Nucl Instrum Methods Phys Res 216(1-2), 177–181. DOI: 10.1016/0167-5087(83)90348-4.
- Kong, A., Liu, J. S. and Wong, W. H. (1994), ‘Sequential imputations and Bayesian missing data problems’, J Am Stat Assoc 89(425), 278–288. DOI: 10.1080/01621459.1994.10476469.
- Kress, R. (2014), Linear Integral Equations, Vol. 82, Springer.
- Laird, N. (1978), ‘Nonparametric maximum likelihood estimation of a mixing distribution’, J Am Stat Assoc 73(364), 805–811. DOI: 10.1080/01621459.1978.10480103.
- Landweber, L. (1951), ‘An iteration formula for Fredholm integral equations of the first kind’, Am J Math 73(3), 615–624. DOI: 10.2307/2372313.
- Latham, G. A. and Anderssen, R. S. (1992), ‘A hyperplane approach to the EMS algorithm’, Appl Math Lett 5(5), 71–74. DOI: 10.1016/0893-9659(92)90068-K.
- Li, B., Tambe, A., Aviran, S. and Pachter, L. (2017), ‘PROBer provides a general toolkit for analyzing sequencing-based toeprinting assays’, Cell Systems 4(5), 568–574. DOI: 10.1016/j.cels.2017.04.007.
- Li, W., Chen, R. and Tan, Z. (2016), ‘Efficient sequential Monte Carlo with multiple proposals and control variates’, J Am Stat Assoc 111(513), 298–313. DOI: 10.1080/01621459.2015.1006364.
- Liu, J. S. (2001), Monte Carlo Strategies in Scientific Computing, Springer, New York.
- Liu, J. S. and Chen, R. (1998), ‘Sequential Monte Carlo methods for dynamic systems’, J Am Stat Assoc 93(443), 1032–1044. DOI: 10.1080/01621459.1998.10473765.
- Lucy, L. B. (1974), ‘An iterative technique for the rectification of observed distributions’, Astron J 79, 745–754. DOI: 10.1086/111605.
- Ma, J. (2011), ‘Indirect density estimation using the iterative Bayes algorithm’, Comput Stat Data An 55(3), 1180–1195. DOI: 10.1016/j.csda.2010.09.018.
- Marschner, I. C. (2020), ‘Back-projection of COVID-19 diagnosis counts to assess infection incidence and control measures: analysis of Australian data’, Epidemiol Infect 148, e97.
- Miao, W., Geng, Z. and Tchetgen Tchetgen, E. J. (2018), ‘Identifying causal effects with proxy variables of an unmeasured confounder’, Biometrika 105(4), 987–993. DOI: 10.1093/biomet/asy038.
- Míguez, J., Crisan, D. and Djurić, P. M. (2013), ‘On the convergence of two sequential Monte Carlo methods for maximum a posteriori sequence estimation and stochastic global optimization’, Stat Comput 23(1), 91–107. DOI: 10.1007/s11222-011-9294-4.
- Mülthei, H. (1992), ‘Iterative continuous maximum-likelihood reconstruction method’, Math Method Appl Sci 15(4), 275–286. DOI: 10.1002/mma.1670150405.
- Mülthei, H., Schorr, B. and Törnig, W. (1987), ‘On an iterative method for a class of integral equations of the first kind’, Math Method Appl Sci 9(1), 137–168. DOI: 10.1002/mma.1670090112.
- Mülthei, H., Schorr, B. and Törnig, W. (1989), ‘On properties of the iterative maximum likelihood reconstruction method’, Math Method Appl Sci 11(3), 331–342. DOI: 10.1002/mma.1670110303.
- Nychka, D. (1990), ‘Some properties of adding a smoothing step to the EM algorithm’, Stat Probabil Lett 9(2), 187–193. DOI: 10.1016/0167-7152(92)90015-W.
- Pensky, M. et al. (2017), ‘Minimax theory of estimation of linear functionals of the deconvolution density with or without sparsity’, Ann Stat 45(4), 1516–1541.
- Phelps, M. E. (2000), ‘Positron emission tomography provides molecular imaging of biological processes’, P Natl Acad Sci 97(16), 9226–9233. DOI: 10.1073/pnas.97.16.9226.
- Pitt, M. K., dos Santos Silva, R., Giordani, P. and Kohn, R. (2012), ‘On some properties of Markov chain Monte Carlo simulation methods based on the particle filter’, J Econometrics 171(2), 134–151. DOI: 10.1016/j.jeconom.2012.06.004.
- Richardson, W. H. (1972), ‘Bayesian-based iterative method of image restoration’, J Opt Soc Am 62(1), 55–59. DOI: 10.1364/JOSA.62.000055.
- Silverman, B. W. (1986), Density Estimation for Statistics and Data Analysis, Chapman & Hall.
- Silverman, B. W., Jones, M. C., Wilson, J. D. and Nychka, D. W. (1990), ‘A smoothed EM approach to indirect estimation problems, with particular, reference to stereology and emission tomography’, J R Stat Soc B 52(2), 271–324. DOI: 10.1111/j.2517-6161.1990.tb01788.x.
- Snyder, D. L., Schulz, T. J. and O’Sullivan, J. A. (1992), ‘Deblurring subject to nonnegativity constraints’, IEEE T Signal Proces 40(5), 1143–1150. DOI: 10.1109/78.134477.
- Stefanski, L. A. and Carroll, R. J. (1990), ‘Deconvolving kernel density estimators’, Statistics 21(2), 169–184. DOI: 10.1080/02331889008802238.
- Tanana, V. P., Vishnyakov, E. Y. and Sidikova, A. I. (2016), ‘An approximate solution of a Fredholm integral equation of the first kind by the residual method’, Numer Anal Appl 9(1), 74–81. DOI: 10.1134/S1995423916010080.
- Tikhonov, A. N. (1963), ‘Solution of incorrectly formulated problems and the regularization method’, Soviet Mathematics Doklady 4, 1035–1038.
- Tong, S., Alessio, A. M. and Kinahan, P. E. (2010), ‘Image reconstruction for PET/CT scanners: past achievements and future challenges’, Imaging Med 2(5), 529. DOI: 10.2217/iim.10.49.
- Vardi, Y. and Lee, D. (1993), ‘From image deblurring to optimal investments: Maximum likelihood solutions for positive linear inverse problems’, J R Stat Soc B 55(3), 569–612. DOI: 10.1111/j.2517-6161.1993.tb01925.x.
- Vardi, Y., Shepp, L. and Kaufman, L. (1985), ‘A statistical model for positron emission tomography’, J Am Stat Assoc 80(389), 8–20. DOI: 10.1080/01621459.1985.10477119.
- Webb, A. G. (2017), Introduction to Biomedical Imaging, John Wiley & Sons.
- Yang, R., Apley, D. W., Staum, J. and Ruppert, D. (2020), ‘Density deconvolution with additive measurement errors using quadratic programming’, J Comput Graph Stat 29(3), 580–591. DOI: 10.1080/10618600.2019.1704294.
- Yuan, D. and Zhang, X. (2019), ‘An overview of numerical methods for the first kind Fredholm integral equation’, Springer Nature Applied Sciences 1(10), 1178.
- Zhang, C., Arridge, S. and Jin, B. (2019), ‘Expectation propagation for Poisson data’, Inverse Probl 35(8), 085006. DOI: 10.1088/1361-6420/ab15a3.