
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
How does armed conflict influence tropical forest loss? For Colombia, both enhancing and reducing effect estimates have been reported. However, a lack of causal methodology has prevented establishing clear causal links between these two variables. In this work, we propose a class of causal models for spatio-temporal stochastic processes which allows us to formally define and quantify the causal effect of a vector of covariates X on a real-valued response Y. We introduce a procedure for estimating causal effects and a nonparametric hypothesis test for these effects being zero. Our application is based on geospatial information on conflict events and remote-sensing-based data on forest loss between 2000 and 2018 in Colombia. Across the entire country, we estimate the effect to be slightly negative (conflict reduces forest loss) but insignificant (P = 0.578), while at the provincial level, we find both positive effects (e.g., La Guajira, P = 0.047) and negative effects (e.g., Magdalena, P = 0.004). The proposed methods do not make strong distributional assumptions, and allow for arbitrarily many latent confounders, given that these confounders do not vary across time. Our theoretical findings are supported by simulations, and code is available online.
1 Introduction
1.1 Spatio-Temporal Data Analysis
In principle, all data are spatio-temporal data: Any observation of any phenomenon occurs at a particular point in space and time. If information on the spatio-temporal origin of data is available, this information can be exploited for statistical modeling in various ways; this is the study of spatio-temporal statistics (e.g., Cressie and Wikle Citation2015; Wikle, Zammit-Mangion, and Cressie Citation2019). Spatio-temporal statistical models find their application in many environmental and sustainability sciences, and have been used, for example, for the analysis of biological growth patterns (Chaplain, Singh, and McLachlan Citation1999), to model meteorological fields (Bertolacci et al. Citation2019), or to assess the development of land-use change (Liu, Huang, and Zhang Citation2017) and sea level rise (Zammit-Mangion et al. Citation2015). They are used in epidemiology for prevalence mapping of infectious diseases (Giorgi et al. Citation2018), and play a key role in socio-economic research, for example, for the modeling of housing prices (Holly, Pesaran, and Yamagata Citation2010), or for election forecasting (Pavía, Larraz, and Montero Citation2008). In almost all of these domains, the abundance of spatio-temporal data has increased rapidly over the last decades. Several advances aim to improve the accessibility of such datasets, for example, via “data cube” approaches (e.g., Nativi, Mazzetti, and Craglia Citation2017; Mahecha et al. Citation2020).
Most spatio-temporal statistical models are models for the observational distribution, that is, they model processes that are passively observed. By allowing for spatio-temporal trends and dependence structures, such models can be accurate descriptions of complex processes, and have proven to be effective tools for spatio-temporal prediction, inference and forecasting (e.g., Wikle, Zammit-Mangion, and Cressie Citation2019). However, to answer interventional questions such as “How does a certain policy change affect land-use patterns?”, we require a model for the intervention distribution, that is, for data generated under a change in the data generating mechanism—we require a causal model for the data-generating process.
1.2 Causality
Causal models can be used to quantify causal relations between random variables, (e.g., by analyzing the change in expected value of Y when intervening on X). However, existing causal models do not apply well to our setting, since they are either restricted to independent and identically distributed (iid) or time series data, or they rely on various assumptions which cannot be expected to hold in our application (see Appendix A for a review of existing work). In this article, we introduce a novel class of causal models for multivariate spatio-temporal stochastic processes. A spatio-temporal dataset may then be viewed as a single realization from such a model, observed at discrete points in space and time. The full causal structure among all variables of a spatio-temporal process can hardly be fully specified. In practice, however, a full causal specification may also not be necessary: we are often interested in quantifying only certain causal relationships, while being indifferent to other parts of the causal structure. The causal models introduced in this article are well adapted to such settings. They allow us to model a causal influence of a vector of covariates X on a target variable Y while leaving other parts of the causal structure unspecified. In particular, the models accommodate largely unspecified autocorrelation patterns in the response variable, which are a common phenomena in spatio-temporal data.
The introduced framework allows us to formally talk about causality in a spatio-temporal context and can be used to construct well-defined targets of inference. As an example, we define the intervention effect (“causal effect”) of X on Y. We show that this effect can be estimated from observational spatio-temporal data and introduce a corresponding estimator. We prove consistency and verify this finding by a simulation experiment. We furthermore construct a nonparametric hypothesis test for the causal effect being zero. Our methods do not rely on any distributional assumptions on the data-generating process. They furthermore allow for the influence of arbitrarily many latent confounders if these confounders do not vary across time. In principle, our method also allows to analyze problems where temporal and spatial dimensions are interchanged, meaning that confounders may vary in time but remain static across space.
Our work has been motivated by the following application.
1.3 Conflict and Forest Loss in Colombia
Tropical forests are rich in biodiversity (Kreft and Jetz Citation2007), store large amounts of carbon (Avitabile et al. Citation2016), play an important role in climate-regulation, and provide livelihoods to millions of people (Lambin and P. Meyfroidt Citation2011). Yet, tropical forests continue to be under pressure due to agricultural expansion (Angelsen and Kaimowitz Citation1999), mining (Sonter et al. Citation2017), timber harvest (Pearson, Brown, and Casarim Citation2014), or urban expansion (DeFries et al. Citation2010). A problem that is still only partly understood is the interaction between forest loss and armed conflicts (Baumann and Kuemmerle Citation2016), which are frequent events in tropical areas (Pettersson and Wallensteen Citation2015). Armed conflict may have both positive and negative impacts on forest loss. On the one hand, conflict can lead to increasing pressure on forests, as timber may finance warfare activities Harrison (Citation2015). Also, reduced law enforcement in conflict regions may lead to plundering of natural resources leading to increasing forest loss (Butsic et al. Citation2015). On the other hand, the outbreak of armed conflicts can reduce pressure on forest resources, for example, when economic and political insecurity interrupt large-scale mining activities, or when economic sanctions stop international timber trade (Le Billon Citation2000). Investors may furthermore be hesitant to invest in agricultural activities (Collier et al. Citation2000), thereby reducing the pressure on forest areas compared to peace times (Gorsevski et al. Citation2012).
Here, we focus on the specific case of Colombia, where an armed conflict has been present for over 50 years, causing more than 200,000 fatalities, until a peace agreement was reached in 2016. There is evidence that increased forest loss can be, at least regionally, attributed to the armed conflict (Castro-Nunez et al. Citation2017; Landholm, Pradhan, and Kropp Citation2019). At the same time, there are also arguments suggesting that the pressure on forests was partially reduced when armed conflict prevented logging (Dávalos, Sanchez, and Armenteras Citation2016). Most articles report evidence that both positive and negative impacts of conflict on forest loss may happen in parallel, depending on the local conditions (e.g., Sánchez-Cuervo and Aide Citation2013; Castro-Nunez et al. Citation2017). We believe that a purely data-driven approach can be a useful addition to this debate.
In our analysis, we use a dataset containing the following variables.
binary conflict indicator for location s at year t.
Data are annually aggregated, covering the years from 2000 to 2018, and spatially explicit at a -resolution. We provide a detailed description of the data processing in Section 4.
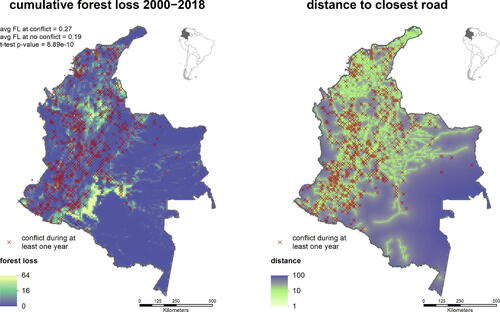
A summary of the dataset can be seen in . Visually, there is a strong positive dependence between the occurrence of a conflict and the loss of forest canopy. This observation is supported by simple summary statistics: the average forest loss across measurements classified as conflict events significantly exceeds that from non-conflict events by almost 50% (, left), conforming previous findings (e.g., Landholm, Pradhan, and Kropp Citation2019). When seeking a causal explanation for the observed data, however, we regard such an analysis as flawed in two ways. First, both conflicts and forest loss predominantly occur in areas with high accessibility (, right), indicating that the potential causal effect of X on Y is confounded by W. In fact, we expect the existence of several other confounders (e.g., population density, market infrastructure, etc.), many of which may be unobserved. Failing to account for confounding variables leads to biased estimates of the causal effect. Second, strong spatial dependencies in X and Y reduce the effective sample size, and a standard t-test thus exaggerates the significance of the observed difference in sample averages. To test hypotheses about X and Y, we need statistical tests which are adapted to the spatio-temporal nature of data.
Fig. 1 Temporally aggregated summary of the dataset described in Section 1.3. Conflicts are predictive of exceedances in forest loss (left), but this dependence is partly induced by a common dependence on accessibility, which we measure by the mean distance to a road (right). Failing to account for this variable and other confounders biases our estimate of the causal influence of conflict on forest loss.
1.4 Contributions and Structure of the Article
Apart from the case study, this article contains three main theoretical contributions: the definition of a causal model for spatio-temporal data, a method for estimating causal effects (both Section 2), and a hypothesis test for the overall existence of such effects (Section 3). Section 4 applies our methodology to the above example. All data used for our analysis are publicly available. A description of how it can be obtained, along with an implementation of our method and reproducing scripts for all our figures and results, can be found at github.com/runesen/spatio_temporal_causality. All proofs are contained in Appendix H.
2 Quantifying Causal Effects for Spatio-Temporal Data
A spatio-temporal dataset may be viewed as a single realization of a spatio-temporal stochastic process, observed at discrete points in space-time. In this section, we provide a formal framework to quantify causal relations among the components of a multivariate spatio-temporal process, and show how to estimate causal effects from observational data.
2.1 Causal Models for Spatio-Temporal Processes
Throughout this section, let be some background probability space. A p-dimensional spatio-temporal process Z is a random variable taking values in the sample space
of all
-measurable functions, where
denotes the Borel σ-algebra. We equip
with the σ-algebra
, defined as the smallest σ-algebra such that for all
, the mapping
is
-measurable. The induced probability measure
on the measurable space
, for every
defined by
, is said to be the distribution of
Z
. Throughout this article, we use the notation
to denote the random vector obtained from marginalizing Z at location s and time point t. We use
for the time series
for the spatial process
, and
for the spatio-temporal process corresponding to the coordinates in
. We call a spatio-temporal process weakly stationary if the marginal distribution of
is the same for all
, and time-invariant if
.
Multivariate spatio-temporal processes are used for the joint modeling of different phenomena, each of which corresponds to a coordinate process. Let us consider a decomposition of these coordinate processes into disjoint ‘bundles’. We are interested in specifying causal relations among these bundles while leaving the causal structure among variables within each bundle unspecified. Similarly to a graphical model (Lauritzen Citation1996), our approach relies on a factorization of the joint distribution of Z into a number of components, each of which models the conditional distribution for one bundle given several others. This approach induces a graphical relation among the different bundles. We will equip these relations with a causal interpretation by additionally specifying the distribution of Z under certain interventions on the data-generating process.
Definition 1
(Causal graphical models for spatio-temporal processes). A causal graphical model for a p-dimensional spatio-temporal process Z is a triplet consisting of
a family
a directed acyclic graph
a family
Since is acyclic, we can without loss of generality assume that
are indexed such that
in
whenever i > j. The above components induce a unique joint distribution
over Z. For every
, it is defined by
(1)
(1)
We call the observational distribution. For each
, the conditional distribution of
given
as induced by
equals
. We define an intervention on
as replacing
by another model
. This operation results in a new graphical model
for Z which induces, via Equation(1)
(1)
(1) , a new distribution
, the interventional distribution.
Assume that we perform an intervention on . By definition, the resulting interventional distribution differs from the observational distribution only in the way in which
depends on
, while all other conditional distributions
, remain the same. This property is analogous to the modularity property of structural causal models (Haavelmo Citation1944; Pearl Citation2009; Peters, Janzing, and Schölkopf Citation2017) and justifies a causal interpretation of the conditionals in
. We refer to the graph
as the causal structure of Z, and sometimes write
to emphasize this structure.
2.2 Latent Spatial Confounder Model
Motivated by the example introduced in Section 1.3, we are particularly interested in scenarios where a target variable Y is causally influenced by a vector of covariates X, and where (X, Y) are additionally affected by some latent variables H. In general, inferring causal effects under arbitrary influences of latent confounders is impossible, and we therefore need to impose additional restrictions on the variables in H. We here make the fundamental assumption that they do not vary across time (alternatively, one can assume that the hidden variables are invariant over space, see Appendix B.3).
Definition 2
(Latent spatial confounder model). Consider a spatio-temporal process over a real-valued response Y, a vector of covariates
and a vector of latent variables
. We call a causal graphical model over
with causal structure
a latent spatial confounder model (LSCM) if both of the following conditions hold true for the observational distribution.
The latent process H is weakly stationary and time-invariant.
There exists a measurable function
We require that for all has finite expectation.
Throughout this section, we assume that come from an LSCM. The above definition says that for every s, t,
depends on
only via
, and that this dependence remains the same for all points in space-time. Together with the weak stationarity of H and
, this assumption ensures that the average causal effect of
on
(which we introduce below) remains the same for all s, t. Our model class imposes no restrictions on the marginal distribution of X. The spatial dependence structure of the error process
must have the same marginal distributions everywhere, but is otherwise unspecified (in particular,
is not required to be stationary). The temporal independence assumption on
is necessary for our construction of resampling tests, see Section 3. We now formally define our inferential target.
Definition 3
(Average causal effect). The average causal effect of X on Y is defined as the function , for every
given by
(3)
(3)
Here, the causal effect is an average effect in that it takes the expectation over both the noise variable (as opposed to making counterfactual statements (Rubin Citation1974)) and the hidden variables. Alternatively, one may define the inferential target in terms of the single realization of H which manifested itself in the data, see Appendix C.Footnote
1
The following proposition justifies as a quantification of the causal influence of X on Y.
Proposition 1
(Causal interpretation). Let and
be fixed, and consider any intervention on X such that
holds almost surely in the induced interventional distribution
. We then have that
That is,
is the expected value of
under any intervention that enforces
.
In many applications, we do not have explicit knowledge of, or data from, the interventional distributions . If we have access to the causal graph, however, we can sometimes compute intervention effects from the observational distribution. In the iid setting, depending on which variables are observed, this can be done by covariate adjustment or G-computation (Pearl Citation2009; Rubin Citation1974; Shpitser, VanderWeele, and Robins Citation2010), for example. The following proposition shows a similar result in the case of an LSCM. It follows directly from Fubini’s theorem.
Proposition 2
(Covariate adjustment). Let denote the regression function
(by definition of an LSCM, this function is the same for all s, t). For all
, it holds that
(4)
(4)
Proposition 2 shows that is identified from the full observational distribution over
(given that the LSCM structure is known). Since H is unobserved, the main challenge is to estimate Equation(4)
(4)
(4) merely based on data from
, see Section 2.3. (We discuss in Appendix B.1 how to furthermore include observable time-varying covariates.)
2.3 Estimation of the Average Causal Effect
2.3.1 Definition and Consistency
In practice, we only observe the process at a finite number of points in space and time. We assume that at every temporal instance, we observe the process at the same spatial locations
(these locations need not lie on a regular grid). To simplify notation, we furthermore assume that the observed time points are
, that is, we have access to a dataset
. The proposed method is based on the following key idea: for every
, we observe several time instances
, all with the same conditionals
. Since H is time-invariant, we can, for every s, estimate
for the (unobserved) realization hs
of
using the data
. The expectation in Equation(4)
(4)
(4) is then approximated by averaging estimates obtained from different spatial locations. This idea is visualized in . More formally, our method requires as input a model class for the regressions
, alongside with a suitable estimator
, and returns
(5)
(5) an estimator of the average causal effect (3) within the given model class. In Section 3, we furthermore provide a statistical test for the overall existence of a causal effect. Our approach may be seen as summarizing the output of a spatially varying regression model (e.g., Gelfand et al. Citation2003) that is allowed to change arbitrarily from one location to the other (within the model class dictated by
). By permitting such flexibility, our method does not rely on observing data from a continuous or spatially connected domain, and accommodates complex influences of the latent variables. An implementation can be found in our code package, see Section 1.4.
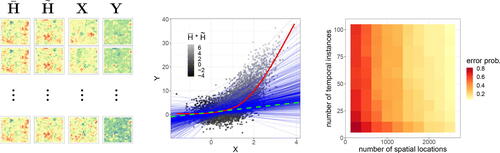
Fig. 2 Conceptual idea for estimating the average causal effect (green line) defined in Equation(3)(3)
(3) . In both the left and right panel, we do not display time and space. The middle figure shows the data at different locations, that is, every small plot corresponds to a single time series. The dashed curve illustrates the latent spatial confounder
(for visual purposes, we here consider one-dimensional space). Due to
, regressing
on
(red line in left plot) leads to a biased estimator. Our estimator (blue line in right plot) removes this bias. The procedure is shown in the middle figure: for all s, we observe several instances
, with the same conditionals
and the same (unobserved) value of
. For each realization hs
of
, we can thus estimate the regression
only using the data
(blue lines in middle figure). A final estimate of the average causal effect (blue line in right plot) is obtained by approximating the expectation in Equation(5)
(5)
(5) by a sample average over all spatial locations, see Section 2.3.
![Fig. 2 Conceptual idea for estimating the average causal effect (green line) defined in Equation(3)(3) fAVE(X→Y)(x):=E[f(x,H01,ε01)].(3) . In both the left and right panel, we do not display time and space. The middle figure shows the data at different locations, that is, every small plot corresponds to a single time series. The dashed curve illustrates the latent spatial confounder Hst (for visual purposes, we here consider one-dimensional space). Due to Hst, regressing Yst on Xst (red line in left plot) leads to a biased estimator. Our estimator (blue line in right plot) removes this bias. The procedure is shown in the middle figure: for all s, we observe several instances (Xst,Yst), t=1,…,m, with the same conditionals Yst | (Xst,Hst) and the same (unobserved) value of Hst. For each realization hs of Hs1, we can thus estimate the regression fY|(X,H)(·,hs) only using the data (Xsm,Ysm) (blue lines in middle figure). A final estimate of the average causal effect (blue line in right plot) is obtained by approximating the expectation in Equation(5)(5) f̂AVE(X→Y)nm(Xnm,Ynm)(x):=1n∑i=1nf̂Y|Xm(Xsim,Ysim)(x),(5) by a sample average over all spatial locations, see Section 2.3.](/cms/asset/09e5c42e-1731-407a-83e9-022afebbeb60/uasa_a_2013241_f0002_c.jpg)
To prove consistency of our estimator, we let the number of observable points in space-time increase. Let therefore be a sequence of spatial coordinates, and consider the array of data
, where for every
. We want to prove that the corresponding sequence of estimators Equation(5)
(5)
(5) consistently estimates Equation(3)
(3)
(3) . To obtain such a result, we need two central assumptions.
Assumption 1
(LLN for the latent process). For all measurable functions with
it holds that
in probability as
.
Assumption 1 ensures that, for an increasing number of spatial locations at which data are observed, the spatial average in Equation(5)(5)
(5) approximates the expectation in Equation(3)
(3)
(3) . The assumption is satisfied, for example, for a stationary Gaussian process
that is sampled regularly across an increasing spatial domain, see Proposition 1 in Appendix D. As the number of observed time points tends to infinity, we furthermore require the estimators
to converge to the integrand in Equation(3)
(3)
(3) , at least in some area
.
Assumption 2
(Consistent estimators of the conditional expectations). There exists such that for all
and
, it holds that
, in probability as
.
A slightly stronger, but maybe more intuitive formulation is to require the above consistency to hold conditionally on H, that is, assuming that for all and almost all h,
as
, in probability under
. It follows from the dominated convergence theorem that this assumption implies Assumption 2. Under Assumptions 1 and 2, we obtain the following consistency result.
Theorem 1
(Consistent estimator of the average causal effect). Let come from an LSCM as defined in Definition 2. Let
be a sequence of spatial coordinates such that the marginalized process
satisfies Assumption 1, and assume that for all
. Let furthermore
be an estimator satisfying Assumption 2. We then have the following consistency result. For all
and
, there exists
such that for all
we can find
such that for all
we have that
(6)
(6)
Apart from the LSCM structure, the above result does not rely on any particular distributional properties of the data. Assumptions 1 and 2 do not impose strong restrictions on the data-generating process and hold true for several model classes, including linear and nonlinear models. In Appendix D, we provide sufficient conditions under which these assumptions are true.
2.3.2 An Example LSCM
To illustrate the consistency result in Theorem 1, we now consider a simple example with one covariate (d = 1) and two hidden variables ().
Example 1
(Latent Gaussian process and a linear average causal effect). Let ,
, be independent versions of a univariate stationary spatial Gaussian process with mean 0 and covariance function
. For notational simplicity, let
and
denote the respective first and second coordinate process of H. We define a marginal distribution over H and conditional distributions
and
by specifying that for all
,
Interventions on X, Y, or H are defined as in Definition 1. In this LSCM, the average causal effect is the linear function
, with
and
. We define a spatial sampling scheme
for every
and
by
. Given a sample
from
, we construct an estimator of
by
(7)
(7) where
is the OLS estimator for the linear regression at spatial location si
, that is of
on
(we assume that the regression includes an intercept term). It follows by Propositions 1 and 2 (see in particular Example 4 and Remark 6 in Appendix E) that Assumptions 1 and 2 are satisfied.Footnote
2
Hence, (7) is a consistent estimator of
.
illustrates our procedure using a numerical experiment based on Example 1.Footnote
3
The example shows that we can estimate causal effects even under complex influences of the latent process H. To construct the estimator , we have used that the influence of
on Y is linear in X. However, we do not assume knowledge of the particular functional dependence of Y on H; we obtain consistency under any influence of the form
, see Proposition 2.
Fig. 3 Results for applying our methodology to Example 1. The left panel shows a sample dataset of observed at the spatial grid
and at several time instances. The middle panel illustrates our method applied to the same dataset. The average causal effect, our inferential target, is indicated by a green line. Due to confounding by
, a standard nonlinear regression (red curve) severely overestimates the causal influence of
on
. By regressing
on
in each location separately (thin blue lines), and aggregating the results into a final estimate (thick blue line), all spatial confounding is removed. In the right panel, we investigate the consistency result from Theorem 1 empirically. For increasing n and m, we generate several datasets
, compute estimates
of the causal coefficients β, and use these to compute empirical error probabilities
. In the above plot, we have chosen
. As n and m increase, the error probability tends toward zero.
2.3.3 Extensions
Our methodology can be extended in several directions. In Appendix B, we provide details on how to model the influence of observed (time- and space-varying) confounders and temporally lagged causal effects of X on Y. We furthermore argue that our method also applies in situations where the roles of time and space are interchanged, that is, when the hidden confounders are time-varying, but remain static across space. The extension which includes observed confounders is furthermore explored empirically in Appendix F.1.
3 Testing for the Existence of Causal Effects
The previous section has been concerned with the quantification and estimation of the causal effect of X on Y. In this section, we introduce hypothesis tests for this effect being zero. We consider the null hypothesiswhich formalizes the assumption of “no causal effect of X on Y” within the LSCM framework. We construct a hypothesis test for H
0 using data resampling. Our approach acknowledges the existence of spatial dependence in the data without modeling it explicitly. It thus does not rely on distributional assumptions apart from the LSCM structure.
For the construction of a resampling test, we closely follow the setup presented in Pfister et al. (Citation2018). We require a data permutation scheme which, under the null hypothesis, leaves the distribution of the data unaffected. In particular, it must preserve the dependence between X and Y that is induced by H. The idea is to permute observations of Y corresponding to the same (unobserved) values of H. Since H is assumed to be constant within every spatial location, this is achieved by permuting Y along the time axis. Let be the observed data. For every
and every permutation σ of the elements in
, let
denote the permuted array with entries
. We then have the following exchangeability property.
Proposition 3
(Exchangeability). For any permutation σ of the elements in , we have that, under H
0,
is equal in distribution to
.
Proposition 3 is the cornerstone for the construction of a valid resampling test. Under the null hypothesis, we can compute pseudo-replications of the observed sample using the permutation scheme described above. Given any test statistic
, we obtain a p-value for H
0 by comparing the value of
calculated on the original dataset with the empirical null distribution of
obtained from the resampled datasets. The choice of
determines the power of the test. More formally, let
and let
be all permutations of the elements in
. By Proposition 3, each σi
yields a new dataset with the same distribution as
. Let
and let
be independent, uniform draws from
. For every
, we define
and construct for every
a test
of H
0 defined by
.Footnote
4
The following level guarantee for
follows directly from (Pfister et al. Citation2018, prop. B.4).
Corollary 1
(Level guarantee of resampling test). Assume that for all , it holds that, under H
0,
. Then, for every
, the test
has correct level α.
Corollary 1 ensures valid test level for a large class of test statistics. The particular choice of test statistic should depend on the alternative hypothesis that we seek to have power against. Within the LSCM model class, it makes sense to quantify deviations from the null hypothesis using functionals of the average causal effect, that is, for some suitable function ψ. As a test statistic, we then use the plug-in estimator
An implementation of the above testing procedure is contained in our code package, see Section 1.4. A power-analysis can be found in Appendix F.3.
4 Conflict and Forest Loss in Colombia
We return to the problem of conflict (X) and forest loss (Y). As discussed in Section 1.3, there may exist several confounders of the (potential) causal effect of X on Y. We believe that many of these vary at a relatively low temporal frequency (e.g., population density, market infrastructure), justifying the application of the methods developed above.
4.1 Data Description and Preprocessing
Our analysis is based on two main datasets: (i) a remote sensing-based forest loss dataset for the period 2000–2018, which identifies annual forest loss at a spatial resolution of using Landsat satellites (Hansen et al. Citation2013). Here, forest loss is defined as complete canopy removal. (ii) Spatially explicit information on conflict events from 2000 to 2018, based on the Georeferenced Event Dataset (GED) from the Uppsala Conflict Data Program (UCDP) (Croicu and Sundberg Citation2015). In this dataset, a conflict event is defined as “an incident where armed force was used by an organized actor against another organized actor, or against civilians, resulting in at least one direct death at a specific location and a specifc date”. Such events were identified through global newswire reporting, global monitoring of local news, and other secondary sources such as reports by non-governmental organizations (for information on the data collection as well as control for quality and consistency of the data, please refer to Croicu and Sundberg Citation2015). We homogenized these datasets through aggregation to a spatial resolution of
by averaging the annual forest loss within each grid, and by counting all conflict events occurring in the same year and within the same grid. As a proxy for accessibility, we additionally calculated, for each spatial grid, the average Euclidean distance to the closest road segment, using spatial data from https://diva-gis.org containing all primary and secondary roads in Colombia. We regard this variable as relatively constant throughout the considered time-span.
4.2 Quantifying the Causal Influence of Conflict on Forest Loss
We assume that come from an LSCM as defined in Definition 2. Since
is binary, we can characterize the causal influence of X on Y by
, that is, the difference in expected forest loss
under the respective interventions enforcing conflict (
) and peace (
). Positive values of T correspond to an augmenting effect of conflict on forest loss and negative values correspond to a reducing effect. Our goal is to estimate T, and to test the hypothesis
(no causal effect of X on Y). To construct an estimator of the average causal effect of the form Equation(5)
(5)
(5) , we require estimators of the conditional expectations
. Since
is binary, we use simple sample averages of the response variable. To make the resulting estimator of
well-defined, we omit all locations which do not contain at least one observation from each of the regimes
and
. More precisely, let
be the observed dataset. We then use the estimator
(8)
(8)
, where
. To test H
0, we use the resampling test from Section 3 with
. In Appendix F.4, we argue that, under additional assumptions on the underlying LSCM, the above estimator is approximately unbiased. Note, however, that even if the above estimator is biased, this does not affect the level guarantee of our testing procedure—we obtain a valid test level for any test statistic
satisfying the assumptions of Corollary 1.
4.3 Alternative Assumptions on the Causal Structure
To emphasize the relevance of the assumed causal structure, we compare our method with two alternative approaches based on different assumptions about the ground truth: Model 1 assumes no confounders of and Model 2 assumes that the only confounder is the observed process W (mean distance to a road). In reality, we expect the existence of several confounders in addition to W, for example, population density or market infrastructure. Even though none of the models may be a precise description of the data-generating mechanism, we therefore regard both Models 1 and 2 as less realistic than the LSCM. In both models we can, similarly to Definition 3, define the average causal effect of X on Y. Under Model 1,
coincides with the conditional expectation of
given
, which can be estimated simply using sample averages (as is done in left). Under Model 2,
can, analogously to Proposition 2, be computed by adjusting for the confounder W. For each
, we obtain an estimate
by calculating sample averages of Y across different subsets
(we here construct these by considering 100 equidistant quantiles of W), and subsequently averaging over the resulting values. In both models, we furthermore test the hypothesis of no causal effect of X on Y using approaches similar to the ones presented in Section 3. Under the LSCM assumption, we have constructed a permutation scheme that permutes the values of Y along the time axis, to preserve the dependence between Y and H, see Proposition 3. Similarly, we construct a permutation scheme for Model 2 by permuting observations of Y corresponding to similar values of the confounder W (i.e., values within the same quantile range). Under the null hypothesis corresponding to Model 1, X and Y are (unconditionally) independent, and we therefore permute the values of Y completely at random. Strictly speaking, the permutation schemes for Models 1 and 2 require additional exchangeability assumptions on Y in order to yield valid tests. In Appendix G, we repeat the analysis for Model 1 using a spatial block-permutation to account for the spatial dependence in Y, and obtain similar results.
4.4 Results
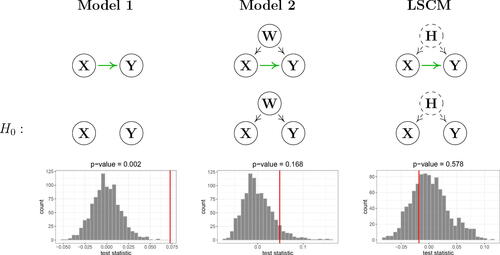
The results of applying our method and the two alternative approaches to the entire study region are depicted in . Under Model 1, there is an enhancing, highly significant causal effect of conflict on forest loss (, P = 0.002). When adjusting for accessibility (quantified by W, Model 2), the size of the estimated causal effect shrinks, and becomes insignificant (
, P = 0.168). (Note that we have considered other confounders, too, yet obtained similar results. For example, when adjusting for population density, which we consider as moderately temporally varying, we obtain
and P = 0.214.) When applying the methodology proposed in this article, that is, adjusting for all time-invariant confounders, the estimated effect swaps sign (
), but is insignificant. We also tested for spatial spill-over effects by modeling causal effects that are spatially lagged by up to one or two pixels, respectively. In both cases, the effect was negative and insignificant (results not shown here). One reason for the above non-finding could be the time delay between the proposed cause (conflict) and effect (forest loss). To account for this potential issue, we also test for a causal effect of X on Y that is temporally lagged by one year, that is, we use an estimator similar to Equation(8)
(8)
(8) , where we compare the average forest loss succeeding conflict events with the average forest loss succeeding non-conflict events. Again, the estimated influence of X on Y is negative and insignificant (
, P = 0.354). Additionally, we perform alternative versions of the last two tests to account for potential autocorrelation in the response variable, by adopting a temporal block-permutation scheme. In both cases, the test is insignificant, see Appendix G.
Fig. 4 Testing for a causal influence of conflict (X) on forest loss (Y) using our method (right) and two alternative approaches (left and middle) which are based on different and arguably less realistic assumptions on the causal structure. The process W corresponds to the mean distance to a road, and H represents unobserved time-invariant confounders. Each of the above models gives rise to a different expression for the test statistic (indicated by red vertical bars), see Sections 4.2 and 4.3. The gray histograms illustrate the empirical null distributions of
under the respective null hypotheses obtained from 999 resampled datasets. The results show that our conclusions about the causal influence of conflict on forest loss strongly depend on the assumed causal structure: under Model 1, there is a positive, highly significant effect (
). When adjusting for the confounder W, the effect size decreases and becomes insignificant (
). When applying our proposed methodology, the estimated effect is negative (
).
The above analysis provides an estimate for the average causal effect, see EquationEquation (3)(3)
(3) , which, in particular, averages over space. Given that Colombia is a country with high ambiental and socio-economic heterogeneity, we furthermore conduct an analysis at the department level (see ). In fact, there is considerable spatial variation in the estimated causal effects, with significant positive as well as negative effects ( middle). This variation may be seen as evidence for an interaction effect between conflict and the assumed hidden confounders. In most departments, the estimated causal effect is negative (although mostly insignificant), meaning that conflict tends to decrease forest loss. The strongest positive and significant causal influence is identified in the La Guajira department (
, P = 0.047). Although this region is commonly associated with semi-arid to very dry conditions, most conflicts occured in the South-Western areas, at the beginning of Caribbean tropical forests (see ). In fact, these zones have also been also identified by Negret et al. (Citation2019) as having been strongly affected by deforestation pressure in the wake of conflict. Interestingly, the neighboring Magdalena department shows the opposite effect (
, P = 0.004). The positive effect in the department of Huila (
, P = 0.023) is again in line with the findings by Negret et al. (Citation2019) (based on a visual inspection of their attribution maps). Out of the 8 departments that are mostly controlled by FARC ( right), 6 have a negative test statistic, meaning that conflict reduces forest loss. This can be explained in part by the internal governance of this group, where forest cover was a strategic advantage for both their own protection as well as for cocaine production. Overall, of course, the peace-induced acceleration of forest loss has to be discussed with caution, and should not be interpreted reversely as if conflict per se is a measure of environmental protection (Clerici et al. Citation2020).
Fig. 5 Regional analysis of conflict and forest loss in Colombia. The left panel shows the total forest loss and the total number of conflict events 2000–2018 at department level. The most severe incidences of forest loss occur in the northern Andean forests and on the northern borders of the Amazon region. In the middle panel, we report for each department estimates and test results for
, using the methodology described in Sections 2 and 3. We used a test level of
, and report significances without multiple-testing adjustment. In most departments, the estimated causal effect is negative (blue, conflict reduces forest loss), although mainly insignificant. We identify four departments with statistically significant results, hereof two with a positive causal effect (La Guarija and Huila) and two with a negative causal effect (Magdalena and Sucre). In total, there are 8 departments that are mostly controlled by FARC (above 75% FARC presence, right panel). Out of these, 6 departments have a negative test statistic (conflict reduces forest loss).
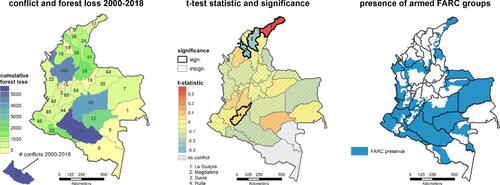
4.5 Interpretation in Light of the Colombian Peace Process
In late 2012, negotiations that later would be known as the “Colombian peace process” started between the then president of Colombia and the strongest group of rebels, the FARC, lasting until 2016. Peace was declared by both parties upon a revised agreement in October 2016, and became effective in 2017.Footnote
5
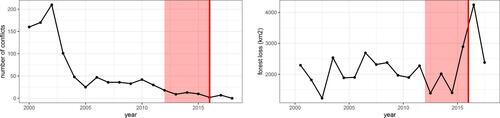
The negotiations marked a steadily decreasing number of conflicts (, left). Since this decrease is the result of governmental intervention, rather than a natural resolution of local tensions, the peace process provides an opportunity to verify the intervention effects estimated in Section 4.4. As can be seen in (right), Colombia experienced a steep increase in the total forest loss in the final phase of the peace negotiations. Although there may be several other factors which have contributed to this development, we observe that these results align with our previous finding of an overall negative causal effect of conflict on forest loss ().
Fig. 6 Number of conflicts (left) and forest loss (right) in the years 2000–2018 in Colombia. In the right panel, the height of the curve at indicates the forest loss between years x and x + 1. Shaded areas mark the Colombian peace process (2012–2016).
5 Conclusions and Future Work
In this article, we have investigated the relationship between conflict and forest loss in Colombia based on yearly measurements from 2000 to 2018. Our methodology allows for a causal rather than a purely predictive analysis. We find that conflicts are predictive of exceedances in forest loss, but we find no significant evidence of a causal relation when analyzing this problem on country level: once all (time-invariant) confounders are adjusted for, there is a negative but insignificant correlation between conflict and forest loss. Our analysis on department level suggests that this nonfinding could be due to locally varying effects of opposite directionality, which would approximately cancel out in our final estimate. In most departments, we find negative (mostly insignificant) effects, although we also identify a few departments where conflict seems to have increased forest loss. It would be interesting to furthermore explore these differences in causal dependence, for example, by adjusting for socio-political factors. The overall negative influence of conflict on forest loss estimated by our method is in line with the observation that during the final phase of the peace process, which stopped many of the existing conflicts, the total forest loss in Colombia has increased. However, these results should be interpreted with caution. Overall, we find that, once all time-invariant confounders are adjusted for, conflicts have only weak explanatory power for predicting forest loss, and the potential causal effect is therefore likely to be small, compared to other drivers of forest loss. Furthermore, our results rely on the assumption that all latent confounders are time-invariant, which, in practice, can only be expected to hold approximately. In Appendix F.1, we explore how our estimator is affected by temporal variation in the latent confounders.
To analyze the relation between conflict and forest loss, we have introduced a novel causal framework for spatio-temporal data. From a methodological perspective, this article contains three main contributions: the definition of a class of causal models for multivariate spatio-temporal stochastic processes, a procedure for estimating causal effects within this model class, and a nonparametric hypothesis test for the overall existence of such effects. Our method allows for the influence of arbitrarily many latent confounders, as long as these confounders do not vary across time (or space). We prove asymptotic consistency of our estimator, and verify this finding empirically using simulated data. Our results hold under weak assumptions on the data generating process, and do not rely on any particular distributional properties of the data. We prove sufficient conditions under which these rather general assumptions hold true. The proposed testing procedure is based on data resampling and provably obtains valid level in finite samples.
Supplemental Material
Download Zip (5 MB)Acknowledgments
This work contributes to the Global Land Programme, and was supported by Carlsberg Foundation (JP) and a research grant (18968) from VILLUM FONDEN (RC, JP). MDM thanks ESA for funding the Earth System Data Lab. We are grateful to Steffen Lauritzen, Niels Richard Hansen and Niklas Pfister for valuable comments on the methodology, and to Lina Estupinan-Suarez and Alejandro Salazar for helpful discussions on the case study. We thank two anonymous referees and the associate editor for many helpful comments.
Supplementary Material
The supplementary material is structured as follows. Appendix A contains a review of existing causal methodology, Appendix B explores several extensions of our methods, and Appendix C proposes an alternative definition of the average causal effect, our inferential target. In Appendix D, we provide sufficient conditions for Assumptions A1 and A2, and Appendix E provides two examples of data generating processes which satisfy these assumptions. Appendix F contains several simulation experiments which investigate the numerical performance of our methods, Appendix G shows results of the case study where we use adapted versions of our testing procedure, and Appendix H contains all proofs.
Additional information
Funding
Notes
1 We are grateful to Steffen Lauritzen for emphasizing this viewpoint.
2 Strictly speaking, Example 4 and Remark 6 in Appendix E show that (L1)–(L3) are satisfied for bounded basis functions. We are confident that the same holds true in the current example.
3 In this example, a standard regression approach overestimates the causal effect. Similarly, one can construct examples where the causal effect would be underestimated.
4 Two-sided tests can be obtained using , for example.
5 The agreement was signed only by the FARC, while other guerilla groups remain active.
Related Research Data
References
- Angelsen, A. , and Kaimowitz, D. (1999), “Rethinking the Causes of Deforestation: Lessons From Economic Models,” The World Bank Research Observer 14, 73–98. DOI: https://doi.org/10.1093/wbro/14.1.73.
- Avitabile, V. , Herold, M. , Heuvelink, G. B. M. , Lewis, S. L. , Phillips, O. L. , Asner, G. P. , John Armston, P. S. , Ashton, L. B. , Bayol, N. , Berry, N. J. , Boeckx, P. , de Jong, B. H. J. , DeVries, B. , Girardin, C. A. J. , Kearsley, E. , Lindsell, J. A. , Lopez-Gonzalez, G. , Lucas, R. , Malhi, Y. , Morel, A. , Mitchard, E. T. A. , Nagy, L. , Qie, L. , Quinones, M. J. , Ryan, C. M. , Ferry, S. J. W. , Sunderland, T. , Laurin, G. V. , Gatti, R. C. , Valentini, R. , Verbeeck, H. , Wijaya, A. , and Willcock, S. (2016), “An Integrated Pan-Tropical Biomass Map Using Multiple Reference Datasets,” Global Change Biology , 22, 1406–1420. DOI: https://doi.org/10.1111/gcb.13139.
- Baumann, M. , and Kuemmerle, T. (2016), “The Impacts of Warfare and Armed Conflict on Land Systems,” Journal of Land Use Science , 11, 672–688. DOI: https://doi.org/10.1080/1747423X.2016.1241317.
- Bertolacci, M. , Cripps, E. , Rosen, O. , Lau, J. W. , Cripps, S. (2019), “Climate Inference on Daily Rainfall Across the Australian Continent, 1876–2015,” The Annals of Applied Statistics , 13, 683–712. DOI: https://doi.org/10.1214/18-AOAS1218.
- Butsic, V. , Baumann, M. , Shortland, A. , Walker, S. , and Kuemmerle, T. (2015), “Conservation and Conflict in the Democratic Republic of Congo: The Impacts of Warfare, Mining, and Protected Areas on Deforestation,” Biological Conservation , 191, 266–273. DOI: https://doi.org/10.1016/j.biocon.2015.06.037.
- Castro-Nunez, A. , Mertz, O. , Buritica, A. , Sosa, C. C. , and Lee, S. T. (2017), “Land Related Grievances Shape Tropical Forest-Cover in Areas Affected by Armed-Conflict,” Applied Geography , 85, 39–50. DOI: https://doi.org/10.1016/j.apgeog.2017.05.007.
- Chaplain, M. A. J. G. , Singh, D. , and McLachlan, J. C. (1999), On Growth and Form: Spatio-Temporal Pattern Formation in Biology . Hoboken, NJ: Wiley.
- Clerici, N. , Armenteras, D. , Kareiva, P. , Botero, R. , Ramírez-Delgado, J. P. , Forero-Medina, G. , Ochoa, J. , Pedraza, C. , Schneider, L. , Lora, C. , Gómez, C. , Linares, M. , Hirashiki, C. , Biggs, D. (2020), “Deforestation in Colombian Protected Areas Increased During Post-Conflict Periods,” Scientific Reports , 10, 1–10. DOI: https://doi.org/10.1038/s41598-020-61861-y.
- Collier, P. (2000), “Economic Causes of Civil Conflict and Their Implications for Policy.” Technical Report 76632 . Washington, DC: The World Bank.
- Cressie, N. , and Wikle, C. K. (2015), Statistics for Spatio-Temporal Data . Hoboken, NJ: Wiley.
- Croicu, M. , and Sundberg, R. (2015), “UCDP Georeferenced Event Dataset Codebook Version 4.0.” Journal of Peace Research , 50, 523–532.
- Dávalos, L. M. , Sanchez, K. M. , and Armenteras, D. (2016), “Deforestation and Coca Cultivation Rooted in Twentieth-Century Development Projects,” BioScience , 66, 974–982. DOI: https://doi.org/10.1093/biosci/biw118.
- DeFries, R. S. , Rudel, T. , Uriarte, M. , and Hansen, M. (2010), “Deforestation Driven by Urban Population Growth and Agricultural Trade in the Twenty-First Century,” Nature Geoscience , 3, 178–181. DOI: https://doi.org/10.1038/ngeo756.
- Gelfand, A. E. , Kim, H.-J. , Sirmans, C. F. , and Banerjee, S. (2003), “Spatial Modeling With Spatially Varying Coefficient Processes,” Journal of the American Statistical Association , 98, 387–396. DOI: https://doi.org/10.1198/016214503000170.
- Giorgi, E. , Diggle, P. J. , Snow, R. W. , and Noor, A. M. (2018), “Geostatistical Methods for Disease Mapping and Visualisation Using Data From Spatio-Temporally Referenced Prevalence Surveys,” International Statistical Review , 86, 571–597. DOI: https://doi.org/10.1111/insr.12268.
- Gorsevski, V. , Kasischke, E. , Dempewolf, J. , Loboda, T. , and Grossmann, F. (2012), “Analysis of the Impacts of Armed Conflict on the Eastern Afromontane Forest Region on the South Sudan—Uganda Border Using Multitemporal Landsat Imagery,” Remote Sensing of Environment , 118, 10–20. DOI: https://doi.org/10.1016/j.rse.2011.10.023.
- Haavelmo, T. (1944), “The Probability Approach in Econometrics,” Econometrica , 12, S1–S115. DOI: https://doi.org/10.2307/1906935.
- Hansen, M. C. , Potapov, P. V. , Moore, R. , Hancher, M. , Turubanova, S. A. , Tyukavina, A. , Thau, D. , Stehman, S. V. , Goetz, S. J. , Loveland, T. R. , Kommareddy, A. , Egorov, A. V. , Chini, L. P. , Justice, C.O. , Townshend, J. R. G. (2013), “High-Resolution Global Maps of 21st-Century Forest Cover Change,” Science , 342, 850–853. DOI: https://doi.org/10.1126/science.1244693.
- Harrison, A. (2015), “Blood Timber: How Europe Helped Fund War in the Central African Republic: A Report.” Available at: https://apo.org.au/node/55984.
- Holly, S. , Pesaran, M. H. , and Yamagata, T. (2010), “A Spatio-Temporal Model of House Prices in the USA,” Journal of Econometrics , 158, 160–173. DOI: https://doi.org/10.1016/j.jeconom.2010.03.040.
- Kreft, H. , and Jetz, W. (2007), “Global Patterns and Determinants of Vascular Plant Diversity,” Proceedings of the National Academy of Sciences , 104, 5925–5930. DOI: https://doi.org/10.1073/pnas.0608361104.
- Lambin, E. F. , and Meyfroidt, P. (2011), “Global Land Use Change, Economic Globalization, and the Looming Land Scarcity,” Proceedings of the National Academy of Sciences , 108, 3465–3472. DOI: https://doi.org/10.1073/pnas.1100480108.
- Landholm, D. M. , Pradhan, P. , and Kropp, J. P. (2019), “Diverging Forest Land Use Dynamics Induced by Armed Conflict Across the Tropics,” Global Environmental Change , 56, 86–94. DOI: https://doi.org/10.1016/j.gloenvcha.2019.03.006.
- Lauritzen, S. L. (1996), Graphical Models , Vol. 17. Clarendon Press.
- Le Billon, P. (2000), “The Political Ecology of Transition in Cambodia 1989–1999: War, Peace and Forest Exploitation,” Development and Change , 31, 785–805.
- Liu, B. , Huang, B. , and Zhang, W. (2017), Spatio-Temporal Analysis and Optimization of Land Use/Cover Change: Shenzhen as a Case Study , Boca Raton, FL: CRC Press.
- Mahecha, M. D. , Gans, F. , Brandt, G. , Christiansen, R. , Cornell, S. E. , Fomferra, N. , Kraemer, G. , Peters, J. , Bodesheim, P. , Camps-Valls, G. , Donges, J. F. , Dorigo, W. , Estupinan-Suarez, L. M. , Gutierrez-Velez11, V. H. , Gutwin, M. , Jung, M. , Londoǹo, M. C. , Miralles, D. G. , Papastefanou, P. , and Reichstein, M. (2020), “Earth System Data Cubes Unravel Global Multivariate Dynamics,” Earth System Dynamics Discussions , 11, 201–234. DOI: https://doi.org/10.5194/esd-11-201-2020.
- Nativi, S. , Mazzetti, P. , and Craglia, M. (2017), “A View-Based Model of Data-Cube to Support Big Earth Data Systems Interoperability,” Big Earth Data , 1, 75–99. DOI: https://doi.org/10.1080/20964471.2017.1404232.
- Negret, P. J. , Sonter, L. , Watson, J. E. M. , Possingham, H. P. , Jones, K. R. , Suarez, C. , Ochoa-Quintero, J. M. , and Maron, M. (2019), “Emerging Evidence That Armed Conflict and Coca Cultivation Influence Deforestation Patterns,” Biological Conservation , 239, 108176. DOI: https://doi.org/10.1016/j.biocon.2019.07.021.
- Pavía, J. M. , Larraz, B. , and Montero, J. M. (2008), “Election Forecasts Using Spatiotemporal Models,” Journal of the American Statistical Association , 103, 1050–1059. DOI: https://doi.org/10.1198/016214507000001427.
- Pearl, J. (2009), Causality: Models, Reasoning and Inference , 2nd ed., Vol. 29, New York: Springer.
- Pearson, T. R. H. , Brown, S. , and Casarim, F. M. (2014), “Carbon Emissions From Tropical Forest Degradation Caused by Logging,” Environmental Research Letters , 9, 034017. DOI: https://doi.org/10.1088/1748-9326/9/3/034017.
- Peters, J. , Janzing, D. , and Schölkopf, B. (2017), Elements of Causal Inference: Foundations and Learning Algorithms . Cambridge, MA: MIT Press.
- Pettersson, T. , and Wallensteen, P. (2015), “Armed Conflicts, 1946–2014,” Journal of Peace Research , 52, 536–550. DOI: https://doi.org/10.1177/0022343315595927.
- Pfister, N. , Bühlmann, P. , Schölkopf, B. , and Peters, J. (2018), “Kernel-Based Tests for Joint Independence,” Journal of the Royal Statistical Society, Series B, 80, 5–31. DOI: https://doi.org/10.1111/rssb.12235.
- Rubin, D. B. (1974), “Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies,” Journal of Educational Psychology , 66, 688. DOI: https://doi.org/10.1037/h0037350.
- Sánchez-Cuervo, A. M. , and Aide, T. M. (2013), “Consequences of the Armed Conflict, Forced Human Displacement, and Land Abandonment on Forest Cover Change in Colombia: A Multi-Scaled Analysis,” Ecosystems , 16, 1052–1070. DOI: https://doi.org/10.1007/s10021-013-9667-y.
- Shpitser, I. , VanderWeele, T. , and Robins, J. M. (2010), “On the Validity of Covariate Adjustment for Estimating Causal Effects,” in Proceedings of the 26th Conference on Uncertainty in Artificial Intelligence, UAI 2010 , pp. 527–536.
- Sonter, L. J. , Herrera, D. , Barrett, D. J. , Galford, G. L. , Moran, C. J. , and Soares-Filho, B. S. (2017), “Mining Drives Extensive Deforestation in the Brazilian Amazon,” Nature Communications , 8, 1–7. DOI: https://doi.org/10.1038/s41467-017-00557-w.
- Wikle, C. K. , Zammit-Mangion, A. , and Cressie, N. (2019), Spatio-Temporal Statistics With R . Boca Raton, FL: CRC Press.
- Zammit-Mangion, A. , Rougier, J. , Schön, N. , Lindgren, F. , and Bamber, J. (2015), “Multivariate Spatio-Temporal Modelling for Assessing Antarctica’s Present-Day Contribution to Sea-Level Rise,” Environmetrics , 26, 159–177. DOI: https://doi.org/10.1002/env.2323.