
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Modern machine learning models often exhibit the benign overfitting phenomenon, which has recently been characterized using the double descent curves. In addition to the classical U-shaped learning curve, the learning risk undergoes another descent as we increase the number of parameters beyond a certain threshold. In this article, we examine the conditions under which benign overfitting occurs in the random feature (RF) models, that is, in a two-layer neural network with fixed first layer weights. Adopting a novel view of random features, we show that benign overfitting emerges because of the noise residing in such features. The noise may already exist in the data and propagates to the features, or it may be added by the user to the features directly. Such noise plays an implicit yet crucial regularization role in the phenomenon. In addition, we derive the explicit tradeoff between the number of parameters and the prediction accuracy, and for the first time demonstrate that overparameterized model can achieve the optimal learning rate in the minimax sense. Finally, our results indicate that the learning risk for overparameterized models has multiple, instead of double descent behavior, which is empirically verified in recent works. Supplementary materials for this article are available online.
1 Introduction
Conventional learning wisdom suggests that one should carefully balance between underfitting and overfitting by controlling the capacity of the function class employed (Friedman, Hastie, and Tibshirani Citation2001). For example, in supervised learning with training data drawn from a probability measure ρ defined on
, we learn a predictor f chosen from some hypothesis space
:
where s represents the number of features in the model. z is some nonlinear function, and
are the parameters associated with z. In this setting, traditional learning theory states that one should control the capacity of
either explicitly (e.g., choosing the right quantity s) or implicitly (e.g., early stopping or regularization) in order to prevent overfitting and achieve small generalization error. However, this classical learning theory has been challenged in recent years. In kernel regression, it has been observed that the lowest prediction error often occurs when λ = 0 (see, e.g., Belkin, Ma, and Mandal Citation2018; Liang and Rakhlin Citation2020). In addition, as demonstrated in Zhang et al. (Citation2016), state-of-the-art deep networks are often trained to the interpolation regime where estimators perfectly fit the training data (i.e., they fit perfectly even when the noises are present in the labels, which indicates overfitting), yet they still generalize well to new examples. This benign overfitting phenomenon is also observed by interpolating kernel machines and deep networks even in the presence of significant label noise. Finally, in a series of insightful papers (Belkin, Ma, and Mandal Citation2018; Belkin et al. Citation2019; Belkin, Hsu, and Xu Citation2019), it is pointed out that the prediction accuracy for interpolating models often exhibits the double descent behavior empirically. In this framework, when the model complexity is small, that is, s < n, we are in the classical learning regime. As s approaches n, the training risk converges to zero while the true risk grows very large. However, as soon as s passes the threshold of n, the true risk starts to decrease again. Empirically, it is also observed that the minimum true risk achieved as
is lower than the minimum risk achieved in the s < n regime.
In this article, we study the benign overfitting behavior under the noisy feature setting, that is, noise that may exist in the covariates x or in the features z(x, w). Classical learning assumes that the training data are iid samples from joint distribution ρ on which the true risk is also evaluated. The prediction function is estimated by applying learning algorithm to the observed x (the covariates) or z(x, w) (the features), where x and z(x, w) are assumed to have no noise. However, in practice, the covariates or the features will often be noisy. The noise may already exist in the data (e.g., due to imperfect measurement equipment), or it may be added by the user (as we will elaborate later). In this contribution, we show that such noise acts as an implicit regularizer and gives rise to the benign overfitting phenomenon. Bartlett et al. (Citation2020) are the first to propose that noisy feature might lead to benign overfitting under the linear regression setting. They have shown that if both the feature noise and eigenvalues of the covariance operator exhibit exponential decay, benign overfitting is observed. In Bunea, Strimas-Mackey, and Wegkamp (Citation2020), the feature noise is taken into account under the linear factor regression setting. They demonstrate that under appropriate conditions of the feature noise, the interpolation yields near-optimal prediction risk, provided that the features and the response are jointly low-dimensional. In contrast, we study the effect of the covariates noises under the more general nonlinear feature map setting. Through adopting a novel random feature model with features sampled via Gaussian process formalism, we are not only able to derive the near-optimal prediction performance of the interpolator with much more relaxed assumptions (as illustrated in Section 3), but also demonstrate that the interpolator can achieve optimal learning rate in the minimax sense.
In our framework, similar to the classical learning, we first transform the covariate x to a feature vector z(x, w) through a nonlinear random map z (parameterized by w), and then apply regression to the feature vector z(x, w). However, a key difference in our work is that we assume each feature vector z(x, w) to be corroded with some noise ξ. In practice, there are multiple scenarios where the feature will have noise ξ. For instance, the noise might already reside in the covariates x, that is, , giving rise to a noisy feature. Alternatively, a noise term ξ could be added deliberately by the user to the feature map z(x, w). For example, in the neural network setting, once we apply the feature map z to the covariates x, a bias term is typically added on top of z(w, x), which can be treated as the noise term. Finally, in factor regression or principal component regression, z(x, w) is either assumed to have noise or it is estimated by some algorithm (such as principal component analysis), which produces noisy features. In order to consider a general framework and to simplify the notation, we will thereafter write the noisy feature as
, where z(x, w) is the true feature while ξ represents the noise attached to z(x, w). Regression is then performed on the noisy feature
. In this setting, we are interested in how the presence of ξ will affect the generalization performance of the interpolating estimator. Specifically, we make the following contributions:
Novel Construction of Random Feature. We first propose a novel representation of the random feature models based on Mercer’s decomposition and Karhunen-Loève expansion (see Section 3.1). This new understanding of the random features reduces the nonlinear learning problem into a linear regression in the random feature space, and allows us to study the eigenspectrum of the sample covariance matrix, which is the key in analyzing the generalization properties of the interpolator. We also provide a detailed tradeoff between computational cost and prediction accuracy of the new random feature in Theorem 1;
Implicit Regularization of Feature Noise. By assuming ξ to follow a normal distribution, Theorem 2 establishes a precise relationship between ξ and the excess learning risk. This characterization explains how ξ can act as an implicit regularization and prevent the explosion of the excess learning risk in the overparameterized setting. We remark that when considering linear regression where ρ has sub-Gaussian distribution, recent works by Bartlett et al. (Citation2020) and Bunea, Strimas-Mackey, and Wegkamp (Citation2020) provide alternatives to our bound in Theorem 2. However, our results apply to a more general nonlinear regression setting with many relaxed assumptions regarding the data generating distribution and the eigenspectrum of the covariance operator (see Section 3 for more details);
Minimax Optimal Estimator. Our finite sample analysis reveals the detailed tradeoff between the number of parameters s and the prediction accuracy represented by the excess learning risk convergence rate. Moreover, under appropriate conditions, we show that the interpolator can achieve the optimal learning rate in the minimax sense;
Multiple Descent Behavior. In Corollary 1, we extend our analysis of the excess learning risk to the case where ξ follows a sub-Gaussian distribution. Our results demonstrate that benign overfitting will occur as long as ξ decays with s at a prescribed rate, while the shape of the distribution is not a key component in driving the benign overfitting phenomenon. In addition, we analyze the behavior of the excess learning risk bound from Corollary 1 and explicitly show that incorporating feature noise into consideration leads to multiple descent of the learning risk. In particular, if the number of parameter s is beyond the
order, the learning risk starts to increase again, complementing the current findings of the double descent phenomenon. Our results are empirically verified in recent works by Adlam and Pennington (Citation2020) and Liang, Rakhlin, and Zhai (Citation2020).
Borrowing from the insight of Mercer’s decomposition and Karhunen-Loève expansion, we provide a detailed analysis of the generalization properties of the interpolator. All of our results apply to both the finite sample and the asymptotic case. They are also valid for data of arbitrary dimension. In addition, our results only impose very weak conditions on the kernel structure, that is, as long as its corresponding covariance operator is of trace class (see Assumption A.1). This is fundamentally different from the existing analysis of nonlinear feature map (Mei and Montanari Citation2019; Liao, Couillet, and Mahoney Citation2020), which only work for the Gaussian kernel. More importantly, our results have no specific assumption regarding the data generation distribution, which is a significant improvement on existing works (Mei and Montanari Citation2019; Bartlett et al. Citation2020; Bunea, Strimas-Mackey, and Wegkamp Citation2020), as they often assume the Gaussian or sub-Gaussian data generating distribution.
1.1 Related Work
The benign overfitting phenomenon of the interpolating estimator has drawn much interest in the machine learning community recently. For example Liang and Rakhlin (Citation2020) derive the learning risk of the interpolating estimator in kernel ridgeless regression. They show that with certain properties of the kernel matrix and training data, there is an implicit regularization coming from the curvature of the kernel function. A follow-up work (Liang, Rakhlin, and Zhai Citation2020) further demonstrates that in very high dimension, kernel interpolator exhibits the multiple descent phenomenon. Belkin et al. (Citation2019) experimentally demonstrate the double descent curve in both linear and nonlinear regression cases, and Belkin, Hsu, and Xu (Citation2019) subsequently provide a finite sample analysis of the excess risk for the interpolating estimator in some special settings (where it is assumed that the responses and features are jointly Gaussian). By appealing to random matrix theory, Hastie et al. (Citation2019) obtain the asymptotic behavior of the prediction accuracy in the linear regression setting with correlated features, where sample size n and the covariate dimension d both approach infinity with asymptotic ratio . They also study the asymptotic behavior of the variance term in the random nonlinear feature regression setting. Recently, by letting n, d and s all grow to infinity such that d/n and n/s remain bounded, Mei and Montanari (Citation2019) derive the double descent curve in the random feature regression setting and obtain the asymptotic behavior. Later, Liao, Couillet, and Mahoney (Citation2020) further extend the analysis of Mei and Montanari (Citation2019) by relaxing the Gaussian assumptions on the data distribution while holding all other settings the same. A similar asymptotic behavior of the excess learning risk is obtained and the precise characterization of double descent is demonstrated. Finally, in a work that is most related to ours, Bartlett et al. (Citation2020) study the upper and lower bound on the excess risk by assuming that the covariates belong to an infinite-dimensional Hilbert space and follow a sub-Gaussian distribution. Through investigating the finite sample learning risk behavior, they explicitly list the conditions for the overfitted linear model to have near-optimal prediction accuracy. Intuitively, for infinite dimensional covariates, the covariance operator spectrum has to decay slowly enough so that the sum of the tail of its eigenvalues is large compared to n. While for finite dimensional covariates, exponential decay for both the eigenspectrum of the covariance operator and the noise attached to the covariates is sufficient to guarantee the consistency of the interpolator.
2 Definitions and Notation
2.1 Regularized ERM and Kernel Learning
Let and
be random variables with joint probability distribution
. In this article, we consider the regression problem where covariate
and response variable
. In addition, we will use the squared loss
as the loss function.
In the regularized ERM with the squared loss, the optimal estimating regression function is
Let and
denote the training inputs and outputs. Given the function
which is estimated based on (X, Y), we will consider the notion of excess risk as a measure of its generalization performance (Caponnetto and De Vito Citation2007)
Note that the excess risk is conditional on the training inputs X as emphasized by our notation RX. However, when the context is clear, we will drop the subscript X for brevity.
The following kernel ridge regression (KRR) is an important class of ERM problems
Definition 1.
Given training example from ρ, a kernel function
, and its corresponding reproducing kernel Hilbert space (RKHS)
, the KRR problem is
(1)
(1)
Here, λ is the regularization parameter and represents the RKHS norm. Applying the representer theorem (Steinwart and Christmann Citation2008, Theorem 5.5), the solution to EquationEquation (1)
(1)
(1) can be written as
, where
and
is the Gram matrix.
Random Fourier Features
Typically, kernel learning suffers from huge computation costs. Random Fourier features approximation (Rahimi and Recht Citation2007) is proposed to alleviate this problem. Specifically, if kernel K is translation invariant , based on Bochner’s Theorem Bochner (Citation1932), it can be written as
where
are certain probability distributions. As a result, if we sample
and
, we can approximate the kernel as
We now let be the L2 norm if A is a vector, or the operator norm if A is an operator. Since
is a random feature vector approximating the kernel k, we use these features to perform standard (linear) ridge regression on these features.
Definition 2.
Given and corresponding feature matrix
, the random feature regression is
(2)
(2)
Informally, we can see that instead of using functions in , random Fourier feature approximation employs functions in the RKHS spanned by the feature matrix
to perform learning. As discussed before, we will mainly focus on the interpolator that perfectly fits the training data in this article. However, because there are infinitely many estimators as such, we will be working with the one that has the minimum norm defined as following
Definition 3.
Given feature vectors and response variables , we define the minimum norm least squares (MNLS) estimator as
By the projection theorem, the closed-form solution of the MNLS estimator is
(3)
(3) where
denotes the pseudoinverse for matrix A.
Remark 1.
We remark that in analyzing the generalization properties of the random Fourier feature interpolator , a key issue is that the random variables
are embedded in the nonlinear feature map
. This nonlinear feature embedding makes the analysis of the eigenspectrum of
significantly hard. In light of this, we propose a novel way to construct random features in Section 3.1 to overcome this issue.
2.2 Bias-Variance Decomposition
The analysis of the excess learning risk often starts with the bias-variance decomposition. Hence, we present the bias-variance decomposition and introduce some relevant notations here to ease our following discussion. The following lemma gives the bias-variance decomposition. Its proof in Appendix B.1, supplementary materials is a simple nonlinear extension of the one in Hastie et al. (Citation2019). Note that instead of working with , we will use a different feature matrix in the rest of the article. As a result, we state the following bias-variance decomposition with an arbitrary feature matrix Z.
Lemma 1.
Let be the MNLS estimator as defined in EquationEquation (3)
(3)
(3) with feature matrix Z. Let
be the prediction from the MNLS estimator at a test point x. Define
as the RKHS spanned by the feature matrix Z and
as the best estimator such that
. Since
, we let
for some
. Define the bias and the variance as
where . In addition, we define the misspecification as
Then the following decomposition of the excess risk of holds
We can see that the excess learning risk is comprised of the bias , the variance
and the misspecification error
. While we do not have a thorough understanding on how
evolves with the number of parameters s, we can reasonably assume that
decreases as we increase s. In addition, even in the classical regime where s < n, we observe that
. As a result, in the interpolation regime where
, it is safe to assume that
. In other words, the evolution of the excess learning risk is dominated by
and
. Therefore, in the interpolating regime, our following analysis will mainly focus on
and
under the assumption that
. In other words, we have
.
3 Main Results
3.1 Warm Up: Random Feature Approximation
Traditionally, random Fourier features approximation is a simple way to construct a finite-dimensional approximation of an infinite-dimensional kernel introduced by (Rahimi and Recht Citation2007). However, in this article, we propose a new way of constructing random feature approximation based on Mercer’s decomposition and Karhunen-Loève expansion. This novel construction can separate the random feature from the nonlinear feature map and hence reduce the nonlinear feature regression to a linear one. To the best of our knowledge, this novel perspective on random feature approximation is new to the literature.
Suppose that we consider kernel regression learning with a continuous kernel . By Mercer’s Theorem (Steinwart and Christmann Citation2008), we have
(4)
(4) where
is the eigensystem corresponding to Mercer’s decomposition.
is an at most countable orthonormal set of
and
is a sequence of nonincreasing strictly positive eigenvalues. Based on Mercer’s decomposition, we have Karhunen-Loève expansion theorem (Kanagawa et al. Citation2018, Theorem 4.3) (also see (Steinwart Citation2019, Lemmas 3.3 and 3.7)) for Gaussian Process with kernel K.
Lemma 2
(Karhunen-Loève Expansion (Kanagawa et al. Citation2018, Theorem 4.3)). Let be a continuous kernel, ν be a finite Borel measure with support on
and
be that defined in EquationEquation (4)
(4)
(4) . For a Gaussian process
, define
Then the following are true
1. We have
2. For all and for all finite
we have
3. If , we have
where the convergence is uniform in
.
Based on Karhunen-Loève expansion and denote wi’s as iid , we can see that a Gaussian process
has the expansion as
Since kernel K can be infinite-dimensional, that is, , to ease the discussion, we will define a low-rank kernel k that approximates K by only using the top p < P eigenvalues and eigenvectors of Mercer’s decomposition in our analysis, that is,
where we denote
and
.
Now for GP , we can express it using Karhunen-Loève expansion
where
is a p-dimensional Gaussian random vector with each entry being a standard normal random variable. From now on, we will use kernel k, and whenever we need to refer to K, we will treat K as the limit of k when
.
If we sample iid
, and let
,
are iid sample paths
, such that
and
In other words, we use as the random feature and approximate the kernel as
In addition, we let
where
It is easy to verify that and
. In addition, the MNLS estimator under the new random feature model is similar to EquationEquation (3)
(3)
(3) and has the following form
Covariance Operator
Based on the new random feature, we define the following various forms of covariance operator
Let Σ be the population covariance operator of kernel k with eigenvalue matrix D
Let
Let
The eigenvalue matrix is denoted to be .
3.1.1 Generalization Property
Recently, there has been a large research interest in understanding the efficiency of the random Fourier feature introduced in Section 2.1 (see, e.g., Bach Citation2017; Avron et al. Citation2017; Rudi and Rosasco Citation2017; Li et al. Citation2019). In particular, a detailed tradeoff between computational cost and prediction accuracy is thoroughly investigated in the regression setting, that is, Definition 2. These results show that
random Fourier features can guarantee the minimax optimal
learning rate, which reduces the computational cost and memory from
and
to
and
. Hence, one might be interested in whether the new constructed random feature can achieve a similar computational savings. Theorem 1 provides a definitive answer.
Theorem 1.
Suppose we perform ridge random feature regression with regularization parameter λ and the new feature by replacing with Z in EquationEquation (2)
(2)
(2) . Let the random feature regression estimator to be
and recall our original kernel is K with its RKHS
. Denote
and
. In addition, for kernel K with Gram-matrix K, we denote
. For any
and some parameter λ and η depend only on n, if
we have
(5)
(5)
Theorem 1 shows that using the new random feature can indeed provide us computational gain without sacrificing the prediction accuracy in ridge regression. To see this, we first note that for kernel ridge regression, the computational cost and the memory is and
, respectively, and the minimax optimal learning rate is
(Caponnetto and De Vito Citation2007). On the other hand, regression with our constructed random feature requires
in time and O(ns) in memory. Hence, to what extend can random feature regression provide computational gain depends on the choice of s. Theorem 1 states that the excess risk learning rate of
can be achieved if we let
and
. Under this setting, we can see that
and
2
. In other words, we obtain the same learning rate as kernel ridge regression while the computational cost and the memory is reduced to
and
. In addition, Theorem 1 provides a detailed tradeoff between computational cost and prediction accuracy. For example, if we are willing to decrease the prediction accuracy to
by letting
and
, we can see that the random feature regression only requires
in time and
in memory.
Remark 2.
Theorem 1 mainly considers the worst-case scenario where the regression estimator achieves the minimax optimal learning rate . However, we remark that a similar tradeoff in the fast learning rate case can be easily obtained via using the local Rademacher complexity technique (Bartlett, Bousquet, and Mendelson Citation2005). Moreover, the computational requirement can be further reduced to even a constant number of features. Nevertheless, we skip the results since our major focus is to understand the benign overfitting phenomenon. Interested readers can refer to Rudi and Rosasco (Citation2017) and Li et al. (Citation2021) for the refined analysis in the fast learning rate setting.
3.2 Benign Overfitting with Noisy Random Features
In this section, we discuss how the behavior of the excess learning risk of the MNLS estimator is affected by the noise in the features. We demonstrate how the new evolution of the excess learning risk leads to benign overfitting and, in particular, to the double descent phenomenon. In the following discussion, we let without loss of generality. In addition, since we are mainly interested in the overparameterized regime, we let
.
As discussed, we consider the noisy feature setting: . We denote the s-dimensional noisy feature as
, where
with
iid
. In addition, recall that we define the feature matrix as
. In the noisy setting, we write the noisy feature matrix as
, where
with each ξij iid
. We let
to be the RKHS spanned by the noisy feature matrix
. Finally, similar to EquationEquation (3)
(3)
(3) , we write the MNLS estimator for
as
.
We first list our assumptions (which we will use throughout the article)
The RKHS Condition: Assume
Label Noise Condition:
Feature Noise Condition:
Assumption A.1 is a weak condition to ensure K is trace class, that is, , and admits Mercer’s decomposition. A.1 further ensures that the low rank kernel k has Mercer’s decomposition. A.2 is a standard regression assumption. A.3 describes the shape and size of the feature noise ξ. Note that we need the variance to be
to ensure that the variance of the feature vector does not explode because
.
In the noisy setting, the excess learning risk admits the bias-variance decomposition similar to Lemma 1. We will denote the bias and the variance term as
and
, respectively. We are now ready to present our analysis of the excess learning risk in the noisy feature regime.
Theorem 2.
Under Assumptions A.1–A3 and suppose we are in the overparameterized regime where , denote
. Recall that W is a p × s matrix with each
iid
. Let
and
be some universal constants. Denote
and
. If we assume that there exists
defined as
(6)
(6)
for any , with probability at least
, we have
(7)
(7)
(8)
(8)
Theorem 2 explains precisely how ξ affects the excess learning risk. In fact, the upper bound of the bias and the variance term indicate that the MNLS estimator asymptotically achieves the optimal prediction accuracy, that is, the excess risk
can decay to zero.
Before we analyze the asymptotic behavior of the excess risk, we would like to first discuss our key assumption: EquationEquation (6)(6)
(6) . There are two scenarios here: α = 0 and
. We start with the first one. In this case,
is a constant. EquationEquation (6)
(6)
(6) states that there is a
such that we have
. This is equivalent to
Now, if , we have for each
. As a result,
. If
, there is some universal constant a, such that
. To conclude, if we have both
and
. On the other hand, both
and
, implying both the population and empirical eigenvalues decay. We therefore assume that
for some constant ω1 and
. Based on different values of γ, there are three different cases
γ is a constant:
The analysis in the second scenario where is similar to the first one. The key is that there exists
such that
. The difference here is that
decays with s at rate
. However, if we control the decay rate α such that
, we can guarantee the existence of
. In summary, as long as
, we can find a
such that EquationEquation (6)
(6)
(6) holds.
We are now ready to analyze the asymptotic behavior of the excess risk. We start with where we can see that the variance
is governed by
. Thus, if we let
, we have
. For the bias
, σ0 and
decay to zero as long as
. In addition, it is easy to see that
. Consequently, if we have
.
Therefore, risk convergence requires the following two conditions
We can see that if we let for some
since
. In other words, even in the heavily overparameterized model, the excess learning risk of the MNLS estimator
converges, since both
and
converge to zero. However, our theorem indicates that once s is beyond the order of n2, the variance starts to increase again. This result is aligned with the recent study by Adlam and Pennington (Citation2020), where the excess risk is found to increase if s is close to the order of n2.
Optimality
Theorem 2 not only establishes the consistency of the MNLS estimator under the noisy feature setting but also provides the tradeoff between the number of parameters s and the prediction accuracy (as represented by the excess learning risk convergence rate).
We first notice that the excess learning risk converges at rate (note that we use O(p) to represent the order of λW and omit the
term because we often have
). By letting
and
, we can see that even in this heavily overparameterized regime, as long as p/s remains constant, the excess learning risk
converges at the
, which is the minimax optimal learning rate achieved for kernel ridge regression and regularized random feature regression (Caponnetto and De Vito Citation2007; Rudi and Rosasco Citation2017). In addition, if the effective dimension of the kernel is small in the sense that
, and if we let
and α = 2, we can achieve an even faster learning rate at
. Note that the fast learning rate is also achieved in the heavily overparameterized settings because
. We have summarized our findings in .
Table 1 The tradeoff between the learning rate and the number of parameters.
Comparison to Existing Finite Sample Bounds
Benign overfitting has attracted much research interest recently. Currently, there are two main lines of research addressing the finite sample bounds for the MNLS estimator. The first line (Bartlett et al. Citation2020; Bunea, Strimas-Mackey, and Wegkamp Citation2020) assumes the linear regression setting, while the second line (Liang and Rakhlin Citation2020; Liang, Rakhlin, and Zhai Citation2020) pursues the consistency of nonregularized kernel regression estimators, assuming high data dimension: .
In the linear regression setting, the work of Bartlett et al. (Citation2020) relates most closely to our results. Under the assumption that and
follow a sub-Gaussian distribution, Bartlett et al. (Citation2020) provide the first finite sample bounds on the consistency of the MNLS estimator. Specifically, in the finite dimensional case, if a small amount of noise is added into the covariates
where both the noise and the eigenspectrum of Σ decay exponentially with n, benign overfitting is observed. A noisy feature linear regression is also considered in Bunea, Strimas-Mackey, and Wegkamp (Citation2020) under the factor regression models. By assuming that the covariates have a low dimension representation, Bunea, Strimas-Mackey, and Wegkamp (Citation2020) obtain an improved convergence rate than that in Bartlett et al. (Citation2020). They also demonstrate that their finite sample bound can apply to a more general setting. The consistency proof relies on the sub-Gaussian property of
. Moreover, Liang and Rakhlin (Citation2020) and Liang, Rakhlin, and Zhai (Citation2020) consider the regression with no regularization in the kernel regression setting and provide a finite sample analysis of the kernel ridgeless estimator. They are able to demonstrate the consistency of the kernel ridgeless estimator as long as the dimension d of the data is sufficiently high, that is,
for
.
In contrast, our work relaxes the sub-Gaussian assumption on the data generating distribution, as the results impose no specific assumption on . The requirement of the exponential decay of the noise and eigenspectrum is also released. Our results demonstrate that as long as the decay rate of the noise α is smaller than that of the eigenspectrum γ, we would be able to observe benign overfitting. Hence, our results apply to much more general scenarios where the eigenspectrum is allowed to decay polynomially. Most importantly, our results not only prove the consistency of the MNLS estimator, but also provide a detailed tradeoff between the number of parameters s and the prediction accuracy in Theorem 2. As discussed before, the MNLS estimator can obtain the minimax optimal learning rate in certain cases, which is the first result that demonstrates minimax optimality for overparameterized models. Finally, we remark that our results are valid for data with arbitrary dimension and therefore, can be applied to both low and high dimensional settings.
3.3 Motivation
Before providing a sketch proof of Theorem 2, we first state a motivational result that leads to the consideration of noisy feature . The result arises from analyzing the excess risk of the MNLS estimator in the noiseless version, that is,
in EquationEquation (3)
(3)
(3) . Proposition 1 establishes nearly matching upper and lower bounds for the excess risk of
. The proof is listed in Section A.2 of the supplementary materials.
Proposition 1.
Consider the regression problem EquationEquation (2)(2)
(2) with feature matrix Z and suppose we are in the overparameterized regime where
. Let
be some universal constants and assume
. Let
and denote
Then with probability greater than , we have
(9)
(9)
We can also lower bound the risk with probability greater than
(10)
(10)
Inspecting EquationEquation (9)(9)
(9) , we can see that the bias term
decays as long as
(since
). Therefore, if the variance term decays,
decreases to zero. Therefore, Proposition 1 states that following conditions are needed to obtain the optimal prediction accuracy
The covariance operator is of trace-class.
The sum of the tail eigenvalues of
The first condition is a standard requirement for a typical learning problem, and the second condition states that we need s to be of order . While these two conditions seem reasonable individually, the second condition appears to be at odds with the first one. Namely, according to the classical concentration inequality,
as
. We thus have
which is finite and does not grow with n. However, traditional concentration theory requires that the observed samples
are iid from the marginal distribution
.
is simply an empirical estimate of
. However, if the feature z(x, w) is corroded with noise ξ, the noise will distort the behavior of
. Below we provide a qualitative discussion to provide an intuition on how benign overfitting arises.
Recall the definitions of Σ, and
in Section 3.1. In the noiseless setting,
. As
, implying
. In the noisy setting, supposing the feature matrix is corroded with some iid noise:
, the covariance matrix now is
Denote as the eigenvalues of
. As
, we approximately have
. Since
decays, there will be a
such that
. However,
is on the same scale of
for all
, in the sense that
Since has at most n eigenvalues, summing up the tails gives
This condition indicates that the sum of the tail eigenvalues of the covariance matrix is of the order of n, leading to the decay of
. This analysis further motivates us to quantify how exactly the noise ξ affects the behavior of the excess learning risk in Theorem 2.
Proof
(Sketch of Proof for Theorem 2). The proof starts with the Bias-Variance decomposition. We employ the noisy feature version of Lemma 1, where the excess learning risk is decomposed to the bias term and the variance term
. While the treatment of
is relatively standard, the technical part is how to analyze
. The key is to express
as a sum of the outer product of random vectors with each entry being iid standard Gaussian random variables. After that, we apply concentration inequalities to the outer products, which gives us the desired results. For detailed derivation, please refer to Section A.3 of the supplementary materials. □
3.4 Benign Overfitting with sub-Gaussian Noisy Features
Theorem 2 demonstrates that if ξ is Gaussian with decaying variance, benign overfitting can be observed. However, Gaussian noise is sometimes a strong assumption. A close investigation of Theorem 2 indicates that the key driving force of benign overfitting is that decays with s, rather than the shape of ξ. Hence, we conjecture that benign overfitting will occur even if we have non-Gaussian distributions. It transpires that a simple extension of Theorem 2 would allow us to generalize our results to sub-Gaussian noise. Thus, we modify Assumption A.4 to
A.Feature Noise Condition: ξ is a sub-Gaussian in the sense that
, where
and u is zero mean, unit variance and
-sub-Gaussian, that is,
.
Our results below confirm that benign overfitting can be observed in the sub-Gaussian noise setting.
Corollary 1.
Under A.1–A, suppose
. Let
be some universal constants. Recall that
. If we assume that there exists
defined as
(11)
(11)
for any , with probability at least
, we have
(12)
(12)
(13)
(13)
The behavior of the excess learning risk in the sub-Gaussian case is almost identical to the Gaussian case up to some constant. As discussed in the Gaussian case, the noise term leads to the asymptotical decay of the learning risk. The results verify our conjecture that as long as the noise ξ decays with s, we will observe benign overfitting. Corollary 1 further confirms that the noise ξ in the covariate or the feature vector can serve as an implicit regularizer to prevent overfitting.
3.5 The Double Descent Phenomenon
The classical U-shape learning curve (Friedman, Hastie, and Tibshirani Citation2001, Figure 2.11) has been greatly challenged recently (Belkin, Ma, and Mandal Citation2018; Belkin et al. Citation2019; Belkin, Hsu, and Xu Citation2019), because empirically it is often observed that the relationship between the prediction accuracy and the complexity of the learning machine exhibits the double descent phenomenon. For instance, in Figure 4 in (Belkin et al. Citation2019) in Section C, the double descent curve states that when we increase the capacity of the hypothesis space , the excess learning risk first decreases, but then starts to increase as we keep increasing the model complexity. The excess learning risk increases to the maximum (or potentially diverges to infinity) at some interpolation threshold. After that, as we keep increasing the complexity of
, the excess learning risk decreases either to a global minimum or vanishes to zero. Overall, the behavior of the excess learning risk regarding the model complexity forms a double descent curve.
The double descent phenomenon has attracted much research interest recently, although a conclusive explanation has not been proposed. In this section, we try to explicate how double descent occurs as a result of noisy features through analyzing the risk behavior in Corollary 1.
Before delivering our results, we first state our notation and assumptions. Recall Lemma 1 where we have decomposed the excess learning risk into the misspecification error (or
in the noisy feature setting), the bias
(or
) and the variance
(or
). Corollary 1 and the double descent are connected through analyzing these errors in the noisy feature setting. We now demonstrate the finite sample behavior of the excess learning risk from Corollary 1.
Corollary 2.
Under Assumptions A.1–A, the behavior of the excess learning risk
can be described as following
If s = n,
If
If
Corollary 2 describes the precise behavior of the excess learning risk in the overparameterized regime . Before we give a detailed discussion on that, we first qualitatively discuss the behavior of the excess learning risk in the underparameterized regime, that is, the first U-shape in Figure 4, supplementary materials. When s < n, Corollary 1 indicates that
by Lemma 9. However, Corollary 1 assumes that we are in the realizable case (
). When s is small, this is unlikely to happen. As a result, we have the misspecification error
. In other words, in the finite sample case where s < n, the excess learning risk is governed by the misspecification error and the variance. Intuitively, we can see that
decreases as we increase s, and typically, when s is small,
dominates the excess learning risk. As we increase s,
decreases and
increases up to some point, where
starts to dominate the excess learning risk. Therefore, we will observe that the excess learning risk initially decreases with s and after some point, it starts to increase with s, which forms the classical U-shape curve.
When we approach the interpolation threshold where s = n, Corollary 2 shows that the bias term starts to dominate the excess learning risk by the term
, because
at this point. In particular, if we use kernel K where
, the bias
diverges to infinity.
Furthermore, if we keep increasing s so that it passes the interpolation threshold, the excess learning risk is now dominated by and
, since the misspecification error becomes negligible. As discussed earlier, if
converges to zero, and
, both terms vanish to zero asymptotically, driving the learning risk to its global minimum. In particular, if
with
, the overfitted model with
can still have excess learning risk to converge. In addition, if we keep increase s such that it is beyond the order of n2, we can see that the variance starts to increase again. Overall, Corollary 2 gives us the precise description of the double descent curve up to the point where s is within the n2 order. Our theoretical results are empirically verified by recent findings from Adlam and Pennington (Citation2020). Figure 5 in Section C of the supplementary materials gives a sample path of how our upper bound evolves with the number of features s. We can see that it closely resembles the double descent curve in Figure 4 from (Belkin et al. Citation2019).
4 Numerical Experiments
In this section, we report numerical experiments to corroborate theoretical results established in the previous sections. Throughout this section, we consider and an orthonormal basis of
consisting of the following functions
We thus write the Mercer decomposition of the kernel with eigenfunctions of g and h in the following format (Bach Citation2017; Rudi and Rosasco Citation2017; Li et al. Citation2019)
(14)
(14)
where λi’s are the eigenvalues3
. Furthermore, we can show that if for some
, the kernel admits a closed-form expression (Bach Citation2017; Wahba Citation1990)
where
denotes the 2qth order Bernoulli polynomials (Wahba Citation1990) and
denotes the fractional part of x – y.
For a spline kernel with eigenvalues
, EquationEquation (14)
(14)
(14) gives its Mercer’s decomposition. To approximate the kernel
, we first construct the truncated kernel
by choosing the first p eigenvalues and eigenfunctions
Let and
, we form the random features as
Figure 6 in Section C of the supplementary materials provides the approximation accuracy of the constructed random features against the number of features s with various values of p and q.
Learning Risk of Random Feature
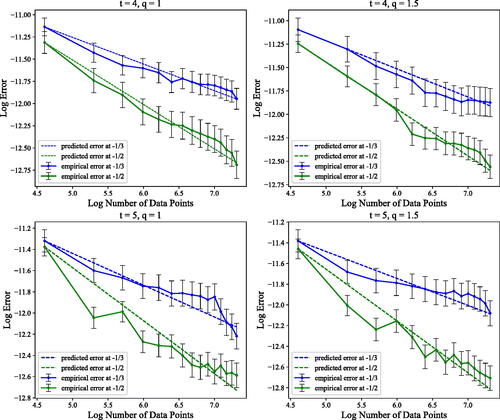
In this experiment, we perform empirical study of the risk behavior in Theorem 1. Specifically, we first let for some
and
to be a Gaussian distribution with mean
and variance
. We then sample the features for kernel
according to Mercer’s decomposition (EquationEquation (14)
(14)
(14) ). Finally we perform ridge regression with regularization parameter λ and compute the excess learning risk for different values of t. According to Theorem 1, if the truncation level p and λ are proportional to
, we should expect the risk to converge at
rate, or at
if the truncation level p and λ are proportional to
. demonstrates that the empirical learning risk behavior follows this pattern for different choices of t and q.
Fig. 1 The plot of the theoretical and empirical excess risk convergence rate for various choice of the target function (represented by t) and different kernels (represented by q).
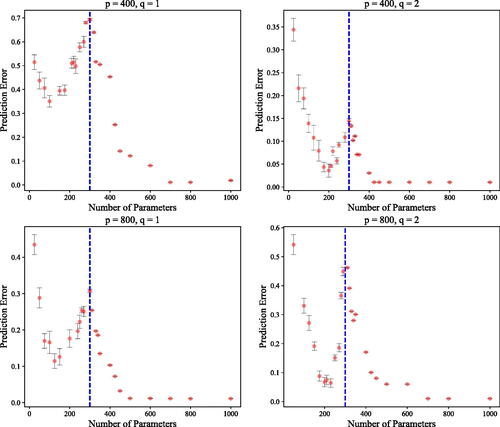
Double Descent
The final two sets of experiments aim to numerically corroborate our theoretical analysis on benign overfitting, that is, Theorem 2, Corollaries 1 and 2. To this end, we again let the target function be for
. We let the number of samples to be n = 300 with input distribution being uniform between 0 and 1 and label noise level of
. For each choice of t, we construct the noisy feature matrix
by appending noise into the original feature matrix Z. We then compute the prediction error of the MNLS estimator using
. The simulation experiment is conducted with 30 replications to compute the standard error. Finally, we plot the empirical test error against the number of features s. and show that the empirical error displays the double descent phenomenon.
Fig. 2 The plot of the theoretical and empirical test error of MNLS estimator where target function has t = 4. Black dotted line represents the theoretical prediction and the vertical blue line is the interpolation threshold.
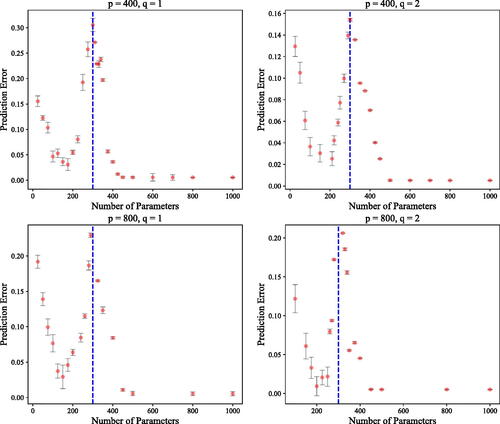
Fig. 3 The plot of the theoretical and empirical test error of MNLS estimator where target function has t = 4. Black dotted line represents the theoretical prediction and the vertical blue line is the interpolation threshold.
5 Discussion
The benign overfitting phenomenon has attracted great research interest since it was first observed by Zhang et al. (Citation2016), Belkin, Ma, and Mandal (Citation2018), and Belkin et al. (Citation2019). Our article continues the lines of work of Belkin, Hsu, and Xu (Citation2019), Bartlett et al. (Citation2020), and Hastie et al. (Citation2019), and focuses on developing a theoretical understanding of this phenomenon. Through analyzing the learning risk of the MNLS estimator, we first provide a nearly matching upper and lower bound for the excess learning risk and point out one possible cause of benign overfitting: the noise ξ in the covariates or in the feature vectors. Moreover, we discover that ξ plays an important implicit regularization role during learning. By incorporating ξ into our analysis, we explicitly derive how the learning risk is affected by ξ. We also provide a detailed tradeoff between the number of parameters and the learning rate, which further demonstrates the optimality in the minimax sense for the MNLS estimator. Our results may shed light on the theoretical understandings of modern deep learning, which open doors for future studies on the design of deep learning architectures. Furthermore, our results only rely on very weak assumptions of the kernel and require almost no assumption about the data generating distribution.
We believe that several extensions are worth exploring. First, although our results shed light on the two-layer neural network with fixed first layer weights, we would like to understand what would happen if we could optimize the first layer weights, that is, optimizing W in our model. Second, in the existing literature, there are many tools in analyzing neural network optimization with connection to its generalization error. Examples include the transport map formulation (Suzuki Citation2020), the mean-field analysis (Mei, Montanari, and Nguyen Citation2018; Sirignano and Spiliopoulos Citation2020), and the neural tangent kernel (Du et al. Citation2019; Jacot, Gabriel, and Hongler Citation2018). How to use these tools in investigating the effect of the noise ξ during neural network training would be an interesting direction. Another direction is to analyze the noise ξ in models with different loss functions.
Supplemental Material
Download PDF (477.4 KB)Acknowledgments
The authors would like to thank Xufan Ma, Jean-Francois Ton, Zhongyi Hu and Chao Zhang for proofreading and fruitful discussions.
Supplementary Materials
The supplementary material contains the proof of Theorem 1 and 2 as well as Proposition 1. In additional, more experiments from Section 4 is included.
Additional information
Funding
References
- Adlam, B., and Pennington, J. (2020), “The Neural Tangent Kernel in High Dimensions: Triple Descent and a Multi-Scale Theory of Generalization,” in International Conference on Machine Learning, pp. 74–84. PMLR.
- Avron, H., Kapralov, M., Musco, C., Musco, C., Velingker, A., and Zandieh, A. (2017), “Random Fourier Features for Kernel Ridge Regression: Approximation Bounds and Statistical Guarantees,” in International Conference on Machine Learning, pp. 253–262.
- Bach, F. (2017), “On the Equivalence between Kernel Quadrature Rules and Random Feature Expansions,” Journal of Machine Learning Research, 18, 1–38.
- Bartlett, P. L., Bousquet, O., Mendelson, S. (2005), “Local Rademacher Complexities,” The Annals of Statistics, 33, 1497–1537. DOI: 10.1214/009053605000000282.
- Bartlett, P. L., Long, P. M., Lugosi, G., and Tsigler, A. (2020), “Benign Overfitting in Linear Regression,” in Proceedings of the National Academy of Sciences. DOI: 10.1073/pnas.1907378117.
- Belkin, M., Hsu, D., Ma, S., and Mandal, S. (2019), “Reconciling Modern Machine-Learning Practice and the Classical Bias–Variance Trade-off,” Proceedings of the National Academy of Sciences, 116, 15849–15854.
- Belkin, M., Hsu, D., and Xu, J. (2019), “Two Models of Double Descent for Weak Features,” arXiv preprint arXiv:1903.07571.
- Belkin, M., Ma, S., and Mandal, S. (2018), “To Understand Deep Learning We Need to Understand Kernel Learning,” in International Conference on Machine Learning, pp. 541–549.
- Bochner, S. (1932), “Vorlesungen über Fouriersche Integrale,” in Akademische Verlagsgesellschaft.
- Bunea, F., Strimas-Mackey, S., and Wegkamp, M. (2020), “Interpolation under Latent Factor Regression Models,” arXiv preprint arXiv: 2002.02525.
- Caponnetto, A., and De Vito, E. (2007), “Optimal Rates for the Regularized Least-Squares Algorithm,” Foundations of Computational Mathematics, 7, 331–368. DOI: 10.1007/s10208-006-0196-8.
- Du, S., Lee, J., Li, H., Wang, L., and Zhai, X. (2019), “Gradient Descent Finds Global Minima of Deep Neural Networks,” in International Conference on Machine Learning, pp. 1675–1685. PMLR.
- Friedman, J., Hastie, T., and Tibshirani, R. (2001), The Elements of Statistical Learning, Springer Series in Statistics (Vol. 1). Berlin: Springer.
- Hastie, T., Montanari, A., Rosset, S., and Tibshirani, R. J. (2019), “Surprises in High-Dimensional Ridgeless Least Squares Interpolation,” arXiv preprint arXiv:1903.08560.
- Jacot, A., Gabriel, F., and Hongler, C. (2018), “Neural Tangent Kernel: Convergence and Generalization in Neural Networks,” in Advances in Neural Information Processing Systems, pp. 8571–8580.
- Kanagawa, M., Hennig, P., Sejdinovic, D., and Sriperumbudur, B. K. (2018), “Gaussian Processes and Kernel Methods: A Review on Connections and Equivalences,” arXiv preprint arXiv:1807.02582.
- Li, Z., Ton, J.-F., Oglic, D., and Sejdinovic, D. (2019), “Towards a Unified Analysis of Random Fourier Features,” in International Conference on Machine Learning, pp. 3905–3914.
- Li, Z., Ton, J.-F., Oglic, D., and Sejdinovic, D. (2021), “Towards a Unified Analysis of Random Fourier Features,” Journal of Machine Learning Research, 22, 1–51.
- Liang, T., and Rakhlin, A. (2020), “Just Interpolate: Kernel “Ridgeless” Regression can Generalize,” Annals of Statistics, 48, 1329–1347.
- Liang, T., Rakhlin, A., and Zhai, X. (2020), “On the Multiple Descent of Minimum-Norm Interpolants and Restricted Lower Isometry of Kernels,” in Conference on Learning Theory, pp. 2683–2711. PMLR.
- Liao, Z., Couillet, R., and Mahoney, M. W. (2020), “A Random Matrix Analysis of Random Fourier Features: Beyond the Gaussian Kernel, a Precise Phase Transition, and the Corresponding Double Descent,” arXiv preprint arXiv:2006.05013.
- Mei, S., and Montanari, A. (2019), “The Generalization Error of Random Features Regression: Precise Asymptotics and Double Descent Curve,” arXiv preprint arXiv:1908.05355.
- Mei, S., Montanari, A., and Nguyen, P.-M. (2018), “A Mean Field View of the Landscape of Two-Layer Neural Networks,” Proceedings of the National Academy of Sciences, 115, E7665–E7671.
- Rahimi, A., and Recht, B. (2007), “Random Features for Large-Scale Kernel Machines,” in Advances in Neural Information Processing Systems, pp. 1177–1184.
- Rudi, A., and Rosasco, L. (2017), “Generalization Properties of Learning with Random Features,” in Advances in Neural Information Processing Systems, pp. 3218–3228.
- Sirignano, J., and Spiliopoulos, K. (2020), “Mean Field Analysis of Neural Networks: A Central Limit Theorem,” Stochastic Processes and their Applications, 130, 1820–1852. DOI: 10.1016/j.spa.2019.06.003.
- Steinwart, I. (2019), “Convergence Types and Rates in Generic Karhunen-loève Expansions with Applications to Sample Path Properties,” Potential Analysis, 51, 361–395. DOI: 10.1007/s11118-018-9715-5.
- Steinwart, I., and Christmann, A. (2008), Support Vector Machines, New York: Springer.
- Suzuki, T. (2020), “Generalization Bound of Globally Optimal Non-convex Neural Network Training: Transportation Map Estimation by Infinite Dimensional Langevin Dynamics,” arXiv preprint arXiv:2007.05824.
- Wahba, G. (1990), Spline Models for Observational Data (Vol. 59), Philadelphia, PA: SIAM.
- Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. (2016), “Understanding Deep Learning Requires Rethinking Generalization,” arXiv preprint arXiv:1611.03530.