
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this article we develop semiparametric regression techniques for fitting partially linear additive models. The methods are for a general Hilbert-space-valued response. They use a powerful technique of additive regression in profiling out the additive nonparametric components of the models, which necessarily involves additive regression of the nonadditive effects of covariates. We show that the estimators of the parametric components are -consistent and asymptotically Gaussian under weak conditions. We also prove that the estimators of the nonparametric components, which are random elements taking values in a space of Hilbert-space-valued maps, achieve the univariate rate of convergence regardless of the dimension of covariates. We present some numerical evidence for the success of the proposed method and discuss real data applications. Supplementary materials for this article are available online.
1 Introduction
We study useful semiparametric regression techniques that can be used for analyzing a finite or infinite dimensional response variable. The response variable takes values in a general separable Hilbert space. The model consists of a parametric and a nonparametric part. The parametric part is linear in a covariate (predictor) vector, say for
, and the nonparametric part is to model the effect of another covariate vector, say
for
. To avoid the curse of dimensionality in estimating the nonparametric part, it is assumed that the nonparametric effect is additive in Z, that is, it adds the unknown nonparametric effects of the individual covariates Zk. We consider two scenarios for X. One is that both Xj and Zk are real-valued, and the other that Xj take values in the Hilbert space where the response variable takes values while Zk are real-valued. The new techniques are important extensions of the partially linear additive regression for scalar responses coupled with scalar covariates studied by Yu, Mammen, and Park (Citation2011). In this article, we develop powerful techniques of estimating the models and provide sound theory that supports the methodology.
Our framework of Hilbert-space-valued (henceforth, Hilbertian) responses can be specialized to various data types. Its coverage is broad enough to include random variables, random vectors, random functions, random densities, compositional random vectors, infinite sequence random vectors, and compositional random functions, etc. All these types are commonly encountered in today’s data environments. The present work also provides a base toward semiparametric regression for other response spaces, such as Riemannian manifolds and Lie groups, along the way paved by Lin, Müller, and Park (Citation2022). The latter work pioneered a link connecting additive regression for manifold-valued responses to Hilbertian additive regression (Jeon and Park Citation2020) via Riemannian logarithmic map. Despite its importance, semiparametric regression with Hilbertian responses remains unexplored. To the best of our knowledge, this is the first attempt to study a semiparametric regression model for general Hilbertian responses.
We prove that our estimators of the parametric effects of Xj are -consistent in case Xj are real-valued. We also derive the joint asymptotic distribution of the parametric estimators. For Hilbertian Xj, we show that the corresponding parametric estimators are still
-consistent if the Hilbert space where Xj take values is of finite-dimension, while they achieve a slightly slower rate if the Hilbert space is of infinite-dimension. Furthermore, we show that our methodology of estimating the nonparametric effect of the covariate Z is free from the curse of dimensionality, that is, affords a univariate rate of convergence regardless of the dimension of Z. This is in contrast with the partially linear modeling approach that does not have additivity structure in the nonparametric part. The latter suffers from the dimensionality problem. Not only the nonparametric part, our approach also improves the estimation of the parametric part. Indeed, we demonstrate, theoretically and numerically, that using additivity structure in the nonparametric part leads to efficiency gain in the estimation of the parametric part. It turns out that the gain is larger if
are farther from being additive.
The present work is not considered a direct extension of Yu, Mammen, and Park (Citation2011). Dealing with a general Hilbert space, instead of the conventional , as the space of the values of the response variable, needs a number of innovations in developing relevant methodology and theory. In case Xj takes values in
, the theory requires to assess the stochastic magnitude of terms of the form
for some
, which is a known function of
, and for some stochastic (random) map
, which is a random element taking values in the space of Hilbertian maps
for a Hilbert space
and a compact subset S of
. The usual way of analyzing such a
-weighted average is to consider a large set
to which
belongs with a high probability, and then derive the maximal stochastic size of
over
using an entropy bound for the set
. The set
embodies Hilbertian maps
. In case
is finite-dimensional as Euclidean spaces, the entropy of
is finite although the dimension of
may be infinite, particularly when
is a class of nonparametric maps g. In case
is infinite-dimensional, however, the entropy of
is infinite so that it is not feasible to apply the empirical process theory directly to the
-weighted average. To resolve this difficulty we take the Hilbertian norm of the
-weighted average, and convert its maximal stochastic size to that of a
-weighted average where
is a stochastic map from S to
. The conversion with the associated calculation of the sizes of various stochastic terms is one of the challenges we tackle in this article. For Hilbertian Xj taking values in
, however, a similar idea leads to dealing with
, where
is an
-valued function of
and
is a stochastic map from
to
. It turns out that the class embodying the latter stochastic map with a high probability does not necessarily have a finite entropy. Thus, the case of Hilbertian Xj needs a different treatment, which is another difficulty we resolve in this work.
Our proposals are related to Jeon and Park (Citation2020), which developed a smooth backfitting technique for additive regression with Hilbertian responses. The latter, however, is for additive models without parametric component X, and for additive regression of additive effect, that is, for estimating the “assumed” additive effect of Z. It does not cover cases where the additivity model assumption is violated in additive regression. In contrast, our work is for models with linear effect of X in addition to the additive nonparametric effect of the covariate vector Z. Dealing with the additional linear effect necessarily involves additive regression of nonadditive effects. In this respect, our theory for additive regression is more general than the one in Jeon and Park (Citation2020). Moreover, our modeling approach allows for discrete type covariates (ordinal or nominal), which arise in a variety of statistical problems.
In the case of a functional response, say for a domain
, which is a special case of Hilbetian response, one might think of applying a technique for scalar responses, such as the one in Yu, Mammen, and Park (Citation2011), in a pointwise manner to Y(t) for each
and combine the pointwise results
, to construct
. However, this naive approach is problematic since the resulting
is not guaranteed to take values in the space where
comes from. This is particularly the case when
has constraints, for example,
and
, like a random density. Similarly, for a compositional response
with
and
, component-wise regression with Yj for each j does not give simplex-valued
as a whole. Our approach does not have these drawbacks when specialized to functional and compositional data since it applies directly to the observations of functional
and of compositional vector Y, respectively, as data objects.
A few past works on semiparametric regression for real-valued responses include the estimation of partially linear models without additivity structure in the nonparametric part (Bhattacharya and Zhao Citation1997; Liang Citation2006), and of partially linear additive models (Opsomer and Ruppert Citation1999; Liang et al. Citation2008; Yu, Mammen, and Park Citation2011; Lee, Han, and Park Citation2018). Among the latter four studying partially linear additive models, Opsomer and Ruppert (Citation1999) and Liang et al. (Citation2008) employed the ordinary backfitting technique (Buja, Hastie, and Tibshirani Citation1989) to estimate the additive nonparametric part, while Yu, Mammen, and Park (Citation2011) and Lee, Han, and Park (Citation2018) used the smooth backfitting technique (Mammen, Linton, and Nielsen Citation1999). The smooth backfitting method has been proved to be successful in various structured nonparametric models under weak conditions (Yu, Park, and Mammen Citation2008; Linton, Sperlich, and van Keilegom Citation2008; Lee, Mammen, and Park Citation2010, Citation2012; Zhang, Park, and Wang Citation2013; Bissantz et al. Citation2016; Han and Park Citation2018; Han, Müller, and Park Citation2020). On the contrary, the ordinary backfitting is known to work under stronger conditions on covariates (Opsomer and Ruppert Citation1997).
2 Additive Regression
Our approach to the semiparametric regression requires the estimation of “best” approximations of for W being a general Hilbertian random element, or a real-valued random variable in the respective spaces of “additive” maps. This section is devoted to characterizing the best approximations and their estimation. We assume that Z is supported on
.
2.1 Projection on Additive Function Space
We consider a general separable Hilbert space, denoted by . Euclidean spaces, L2 spaces, Bayes-Hilbert spaces and simplices are special cases of
. Here and below, we denote
-valued maps, random elements taking values in
and their values in
, by bold-faced symbols. Note that we also use bold-faced symbols to denote random vectors and their realizations. Let
be the zero vector in
the inner product of
and
the associated norm. We denote by
and
the operations of vector addition and of scalar multiplication in
, respectively. Let
denote the subtraction operation defined by
.
We let denote the space of additive maps
such that
and
for some
. For a random element W taking values in
with
, let
denote the projection of the mean regression map
onto
. That is,
(2.1)
(2.1) where f is the joint density of Z. For the definition of the conditional expectation for Hilbertian W, we refer to Bosq (Citation2000). The minimizer
with
satisfies
(2.2)
(2.2)
for each
and for all zj with
. Here and below,
for a d-vector z is
, and fj and fjk are the densities of Zj and (Zj, Zk), respectively. The integrals in (2.2) are special cases of the so called “Bochner integral” (Jeon and Park Citation2020), the latter being for Banach-space-valued maps. From (2.2), we see that the additive map
is characterized as the solution of the following system of Hilbertian integral equations:
(2.3)
(2.3)
We note that (2.3) does not define a component tuple , but only the sum of its entries,
. Obviously, if
satisfies (2.3), then
also satisfies (2.3) for any constant
. We also note that
is different from the regression map
unless
belongs to
. Thus, the problem of estimating
, which we present in Section 2.2, is different from that of estimating
under the assumption
, the latter having been studied by Jeon and Park (Citation2020).
2.2 Estimation of Additive Projection
We now discuss the estimation of . The basic idea is to replace the marginal regression maps
and the densities fj and fjk in (2.3) by the corresponding kernel estimators and then to solve the resulting system of equations. We note that our method requires the estimation of
for real-valued Xj and of
for Hilbertian
, as well. Below, we describe the method for W taking values in a general Hilbert space, since specialization to the case of random variables is immediate from the general treatment.
Suppose that we have n observations, , with
. We estimate the marginal regression map
for
by
(2.4)
(2.4) where
is a kernel estimator of fj. We also estimate fjk by
. Here and throughout the article,
is a normalized kernel function defined by
where h > 0 is the bandwidth,
and
is the baseline kernel function. This type of normalized kernels have been used in the literature (Yu, Park, and Mammen Citation2008; Lee, Mammen, and Park Citation2010, Citation2012; Jeon and Park Citation2020). It has the property that
for all
, which gives
and
for all
. Plugging these estimators into (2.3) gives the following estimated system of Hilbertian integral equations:
(2.5)
(2.5)
In the supplement S.7, we will show that the system of Equationequations (2.5)(2.5)
(2.5) has a unique solution, which we denote by
. Just like that the system of equations at (2.3) determines only
, the EquationEquation (2.5)
(2.5)
(2.5) by itself defines only
, not individual components
. The solution
does not have a closed form, but can be computed by iteration starting with an initial tuple
. We may simply take
, for example. In the rth (
) cycle of the iteration, we update
by
(2.6)
(2.6)
In the supplement S.7, we will show that converges to
as
, see Proposition S.1. In the iteration, we can evaluate the Bochner integrals in (2.6) by the conventional Lebesgue integrals, provided that
are linear in
, that is,
for some real-valued functions
. This is because the marginal
are also linear in
so that all the subsequent updates
for
are linear in
. For a linear form
with real-valued weight functions
, it holds that
where the integral on the left side is in Bochner sense while the one on the right hand side is a Lebesgue integral.
The regression map is not assumed to be additive and thus estimating the additive map
is considered additive regression of nonadditive effect, which is different from additive regression of additive effect, developed by Mammen, Linton, and Nielsen (Citation1999) and Jeon and Park (Citation2020). The very core of the matter in the present case regarding additive regression is that, when we write
with
as an error term,
. Instead, by the definition of
, we have
for all
. This implies that, for all
and for all
with
,
. This gives
(2.7)
(2.7)
We show that the latter is enough for the theory of , see the supplement S.7 for details.
3 Hilbertian PLAM with Scalar Covariates
We introduce a partially linear additive model for a -valued response Y and covariate vectors
and
taking values in
and
, respectively, and present a way of estimating the model. We allow the entries of X to be discrete (nominal or ordinal) while assuming that all entries of Z are of continuous type supported on
. We assume that
for all
.
3.1 The Model
The Hilbertian partially linear additive model (HPLAM) is given by
(3.1)
(3.1)
where are unknown constants in
,
are unknown component maps with
satisfying the constraints
(3.2)
(3.2) and
is a Hilbertian error term such that
and
. Below, we give a proposition that establishes the identifiability of
and
in the model (3.1). Let
denote the distribution of a random vector or element U. We make the following weak assumption.
(A0) The has a density with respect to the product measure
, which is bounded away from zero on the support of
. The marginal distribution
has a density f with respect to the Lebesgue measure such that
for all
, and the support of
is not contained in a hyperplane in
.
Proposition 3.1.
Let for
be Hilbertian constants and
for
be Hilbertian maps with
and
. Assume the condition (A0). Then,
(3.3)
(3.3) implies
and
a.s. for all
and
.
A proof of Proposition 3.1 is given in the supplement S.1. With (3.2), we have , so that by plugging the expression into (3.1) we may rewrite the model (3.1) as
where
and
.
3.2 Estimation of Parametric Components
Here, we discuss the estimation of using the profiling technique (Severini and Wong Citation1992) in conjunction with the estimation of additive projections presented in Section 2.2. Let
and put
. Note that
does not involve
. Then, under the model specification (3.1),
(3.4)
(3.4) where
. Here and below,
for
and
. Considering
for each
, which solves the system of Equationequations (2.3)
(2.3)
(2.3) with
and noting that
, we get
According to the arguments leading to Corollary S.1 in the supplement S.7, is linear in W in the sense that
and
for all Hilbertian variables
and Hilbertian constant c. Also, it holds that
for all Hilbertian constants
and random variables Wj. Thus,
. Furthermore, we also get
and likewise
. This gives
(3.5)
(3.5)
We estimate by minimizing an empirical version of the objective functional at (3.5). Define
where
for
and
, respectively, are the solutions of (2.5) for
and
. Put
. Then,
. We propose to estimate
by
(3.6)
(3.6)
We present an explicit form of defined at (3.6). The Gâteaux derivative of the objective functional in (3.6) at
to an arbitrary direction
equals
Equating the above derivative with zero for all gives
From this we get that, whenever the p × p matrix is invertible,
(3.7)
(3.7) where
for
and
, and
for a p × p real matrix
and
. With
defined at (3.7) we estimate
in the model (3.1) by
where
and
. In Section 7.1, we will show that
is invertible with probability tending to one and that
is
-consistent and
converges to a mean zero Gaussian random element taking values in
.
3.3 Estimation of Nonparametric Components
We estimate in the model (3.1) by
, which solves the system of equations at (2.5) with
. From the linearity of
in
(Corollary S.1 in the supplement S.7), it holds that
, where
. To estimate the individual component maps
satisfying the constraints
, we put the following constraints on
:
(3.8)
(3.8) where the integrals are in Bochner sense. Then, the constraints (3.8) identify the individual
uniquely such that
.
To see how the constraints identify a unique set of , let
be an arbitrary tuple such that
. Choose
. Obviously, each
satisfies (3.8). It also holds
(3.9)
(3.9) which gives
. To see (3.9), we note that, since
, the tuple
satisfies
for all k. Integrating both sides over
then gives
The first equality in the above equations follows from , and the second from
in view of (2.4).
3.4 Hilbertian PLM
We discuss briefly the estimation of the Hilbertian partially linear model (HPLM): , where m is allowed to be nonadditive, that is, m may not belong to
. It deserves being discussed in this article since there has been no study on this model for Hilbertian responses, to the best of our knowledge, and it helps to understand our numerical results to be presented in Section 5.
Let be a multivariate kernel estimator of
defined by
(3.10)
(3.10)
Likewise, let be a multivariate kernel estimator of
, which is obtained by changing
in (3.10) to
and the vector operations for
to those for
. Let
, which should be differentiated from
. Put
. Also, let
and
. Define
Applying the idea of profiling, explored in Section 3.2 for the HPLAM, now to the HPLM, we may estimate by
(3.11)
(3.11) and
by
, where
is the jth entry of
. We note that
takes the same form as
at (3.7) with
and
taking the roles of
and
, respectively.
Let . Note that
if all
are additive maps, that is, belong to
. According to the theory in Section 7.1, under the HPLAM model (3.1), the asymptotic variances of
are equal to or larger than those of the respective
, see the EquationEquation (7.2)
(7.2)
(7.2) . The gains by
against
get larger as the diagonal entries of
grow farther away from the respective diagonal entries of
.
4 Hilbertian PLAM with Hilbertian Covariates
In this section we consider the case where the covariates in the parametric part are also Hilbertian. We continue to use the notation for Hilbertian
. Assume that
for all
.
4.1 The Model
Here, we assume that the Hilbert spaces for are the same as
. In Section 4.3, we discuss the case where the spaces for
are different from each other or from
. We study the following Hilbertian partially linear additive model
(4.1)
(4.1) where
is an unknown constant in
but βj for
are now unknown constants in
. The component maps
and the error term
are as in the model (3.1) with the constraints (3.2). As in Section 3.1, we find
and thus may rewrite the model (4.1) as
(4.2)
(4.2)
where
and
.
Under a weak assumption, the constraints (3.2) also entail the identifiability of the model (4.1). To state a proposition for the identifiability, we introduce new symbols for matrices and vectors of Hilbertian elements. Let for
and
denote the p × p matrix whose (j, k) element equals
. Also, let
and
for
and
denote
and
vectors, respectively, whose jth entries are
and
. In this notation,
denotes the p × p matrix whose (j, k)th element equals
. We make the following assumption.
(B0) The joint distribution has a density with respect to the product measure
, which is bounded away from zero on the support of
. The marginal distribution
has a density f with respect to the Lebesgue measure such that
for all
, and the matrix
is positive-definite.
Proposition 4.1.
Let and
for
be constants and
for
satisfy
and
. Assume the condition (B0). Then,
(4.3)
(4.3) implies
and
a.s. for all
and
.
A proof of Proposition 4.1 can be found in the supplement S.2.
4.2 Estimation of the Model
Put . From (4.2), it holds that
where
. Noting that
with
, and using that
is linear in W for any Hilbertian W, we get
Let and
. We estimate
by
(4.4)
(4.4)
Put and let
denote the p × p matrix whose (j, k)th element is given by
. Also, let
denote the p-vector whose jth element is given by
. By taking the Gâteaux derivative of the objective functional in (4.4), we find that
(4.5)
(4.5) provided that
is invertible. In Section 7.2, we show that
is invertible with probability tending to one. With
defined at (4.5) we estimate
in the model (4.1) by
, where
and
.
We also estimate by the solution
of the system of Equationequations (2.5)
(2.5)
(2.5) with
By arguing as in Section 3.3, we may show that is uniquely decomposed into
with the constraints at (3.8).
4.3 Discussion
One may wonder if the linear part of the model (4.1) covers the standard function-on-function linear regression model when and Y are functional variables of infinite-dimension. In fact, such a functional linear model reduces to the model (3.1), not to the one at (4.1). To see this, consider the case with p = 1 for simplicity, that is, in the linear part of the model, there is only one covariate, say X, taking values in
with
. Let the response variable
take values in
for some
. The standard function-on-function linear regression model (Ramsay and Silverman Citation2005; Yao, Müller, and Wang Citation2005; Benatia, Carrasco, and Florens Citation2017) with the covariate
is given by
such that
(4.6)
(4.6) where
and
are considered as parameters. Let
and
be known bases of
and
, respectively. An approach in, for example, Ramsay and Silverman (Citation2005) is to take, as the space for
, a tensor product of finite-dimensional subspaces of
and
. In this approach θ is represented as
(4.7)
(4.7)
for some
. In our discussion, we allow
while we assume L1 is finite and fixed. For the functional covariate
, put
Then, plugging the representation at (4.7) into the model (4.6) we get
(4.8)
(4.8)
Letting ξj and take the respective roles of Xj and
in the model (3.1), the model (4.8) reduces to a special case of the linear part of the model (3.1) in Section 3.1. The above observation manifests that our model at (3.1) accommodates even infinite-dimensional θ in the standard function-on-function linear regression model (4.6), and the theory developed in Section 7.1 applies directly to this case.
One may think of an alternative basis generating θ, based on the functional principal components of and
. In this way, θ is represented as at (4.7) but now with
and ψk being the eigenfunctions of the respective covariance operators of
and
. The main difference from the previous approach is that
and ψk are unknown. Thus, incorporating the unknown basis into the model at (4.6), ξj at (4.8) are not observed but need to be estimated. Put
where
are the eigenfunctions of the sample covariance operator based on
. Then, the estimation of the model (3.1), which incorporates (4.8) into the linear part, boils down to an errors-in-variables problem with “small” errors in observing the true covariate values
. Certainly, the “measurement errors,”
, affect the estimation of
and
in the model (3.1). However, it is different from a typical errors-in-variables problem since the measurement errors are vanishing as
. Elaborating more on this, we let
now diverge as
. If
and the eigenvalues λj corresponding to
satisfy the standard separation condition that
for some constants C > 0 and
as in, for example, Hall and Horowitz (Citation2007), then Lemma 2.3 in Horváth and Kokoszka (Citation2012) assures that
. The latter implies that
for each i. If we further assume that
for some constant
, then we may show that
. Following the arguments as in, for example, Jeon and Van Bever (Citation2022), we expect that this would add an extra error of size
to the errors of
and
presented in Section 7.1.
The model (4.1), as it stands, assumes that the spaces for are the same as
, the space for Y. However, the limitation is not essential. Basically, there is an isometric isomorphism that maps the space for
, say
, to
, provided that
. Let it be called
. Then, one may let Y depend on
, via
, so that one may postulate
(4.9)
(4.9)
The methodology of estimating the above model (4.9) and the associated theory follow directly from those for the model (4.1) by letting in the model (4.9) take the roles of
in the model (4.1).
One may be also interested in the case where the covariates in the nonparametric part, now denoted by for
, are also Hilbertian. Here, we briefly discuss a method designed for finite-dimensional
. Dealing with infinite-dimensional
in our framework is infeasible since then one needs to estimate nonparametric functions defined on infinite-dimensional domains. Let
take values in a compact subset
of a qk-dimensional Hilbert space
. Then, one may consider a version of the model (3.1) or of the model (4.1) with
now being defined as a map from
to
. For a general Hilbertian W, one may also obtain the following version of the system of equations at (2.5):
(4.10)
(4.10)
Here, μk is the pushforward measure induced by the qk-dimensional Lebesgue measure given by
for
, and
is an isometric isomorphism. Also,
and
are kernel-based estimators of
, the density fj of
and fjk of
, respectively. We refer to Jeon, Park, and Van Keilegom (Citation2021) for concrete forms of these estimators. Then, one is able to estimate the model with Hilbertian
in the same way as we estimate the models (3.1) and (4.1), solving the system of Equationequations (4.10)
(4.10)
(4.10) for various choices of W.
5 Simulation Studies
5.1 Bandwidth Selection
The construction of or
for
and
in computing
, requires choosing a set of bandwidths
. There is another set of bandwidths we need to select to construct
, solving (2.5) with
. In our theoretical development in Section 7, we allow these bandwidth sets to be different from each other. In our numerical study, however, we simply took
from the already calculated
,
and
based on a set of bandwidths
. To choose the single bandwidth set, we used the CBS (Coordinate-wise Bandwidth Selection) algorithm introduced in Jeon and Park (Citation2020), instead of a full-dimensional grid search. The algorithm is reproduced in the supplement S.3. However, for the approach of HPLM without additive modeling introduced in Section 3.4, we used the bandwidths obtained from a full-dimensional grid search. The CBS algorithm is based on a cross-validation criterion. In our simulation study discussed below within Section 5, we used a 10-fold cross-validation, while in the real data applications presented in Section 6, we employed a 5-fold cross-validation. For numerical integration in the implementation of the iterative algorithm at (2.6), we used a trapezoidal rule with 101 equally spaced grid points.
5.2 Data Generating Models
We conducted simulation studies for the model (3.1) with a density response taking values in the Bayes-Hilbert space
defined in the supplement S.4. We considered several cases with p = 2 and d = 2 or 3. For the covariates Zj in the nonparametric part, we took
, where
is the cumulative distribution function of N(0, 1) and
is a multivariate normal random vectors with
and
for all
. This allows for dependence among Zj when
. For X1 in the parametric part, we took
with
Here, is
independent of Z and
We note that is nonadditive while
is additive such that
(5.1)
(5.1)
(5.2)
(5.2) for all
with
for some gj. For X2, we set
, where
is
independent of Z and
, and η2 is given by
so that it is nonadditive with
(5.3)
(5.3)
We note that, if α = 0, then . Because of (5.2),
is perpendicular to
when ρ = 0, in which case Z1 and Z2 are independent with densities
, in the sense that
for all
. This implies that
when ρ = 0, and thus
gets farther away from
as α increases, so that α controls the degree of departure of
from
. We also note that (5.1) and (5.3) give
(5.4)
(5.4)
We considered four models to generate . The first model is given by
For in Model 1 and others below, we took
where
is a linear interpolation of
for
and
are iid
, independent of
and
. Put
. Then,
where
is the norm for the space
defined through (S.6) in the supplementary materials. Since
are iid N(0, 1), we get
. The coefficients
, which themselves are densities on
, are chosen as follows:
where
and Cj are chosen so that
. Because of (5.4), it holds that
The components m1 and m2 are also normalized. Specifically,
where c1 and c2 are chosen so that
for j = 1, 2.
As discussed briefly in Section 3.4 and demonstrated by our theory in Section 7.1, our estimator gets more stable than
at (3.11), which ignores the additivity structure in the nonparametric part of the model, if
grows farther away from the zero vector. Put
(5.5)
(5.5)
In Model 1 where ρ = 0, we may find exact formulas for and
. Indeed, when ρ = 0, we get
from (5.2) and
, where
is the projection of η2 onto
. Since
and
are independent,
and
are also independent conditional on Z. From these, we may find that the ith diagonal entries
and
of
and
, respectively, are:
(5.6)
(5.6)
From the formula (5.6) and according to Theorem 7.1 with the discussion that follows, we get that, under Model 1, the asymptotic gains by against
are
(5.7)
(5.7)
Through the simulation with various values of α under Model 1, we may see how these theoretical gains by take effect empirically.
For the second model we specialized to
, that is, took α = 1, and also fix
in the generation of
. Other than that, it is the same as Model 1. The third and fourth models have the same parametric part as the second one. The third model has a nonadditive map in the nonparametric part, while the fourth has a three dimensional additive map. Specifically,
Here, the density-valued maps m3 and are given by
where c3 and
are chosen so that
. We considered Model 3 to see the sensitivity of our approach to the violation of additivity in the nonparametric part, and Model 4 to learn the effect of increased dimension of Z, in comparison with Model 2.
5.3 Simulation Results
We generated N = 500 pseudo samples of sizes n = 200 and 400 according to the four models specified in Section 5.2. We computed Monte Carlo approximations of
(5.8)
(5.8) and those for
. For the estimators of the nonparametric parts, we approximated
(5.9)
(5.9)
and those for the PLM, based on the 500 pseudo samples. The target
in this computation was the centered version of
or
, that is, for Models 1 and 2, for example,
(5.10)
(5.10)
The centering introduces the coefficient , which for Models 1 and 2 is given by
.
reports the values of the measures for Model 1. For Model 1, the theoretical gain by against
does not depend on α as shown by (5.6) and (5.7). This is confirmed by the MSE values in the column of β2 in the table. For
against
, however, we get from (5.1) and (5.7) that
. The MSE values in the column of β1 are roughly in accordance with this formula. For example, in case α = 1 and n = 200, the theoretical value equals
while the corresponding empirical value is
. The results in the table also demonstrate that our approach leads to more accurate estimation for the nonparametric part as well.
Table 1 Mean squared error (MSE), squared bias (SB), and variance of , as defined at (5.8), and mean integrated squared error (MISE), integrated squared bias (ISB), and integrated variance (IV), as defined at (5.9), under Model 1, multiplied by 103.
Comparing the values for different sample sizes, we see that the results in obey the theoretical rates of convergence. The rate for the parametric part is for both PLAM and PLM, while those for the nonparametric part equal
for our method and
for the PLM, provided that the corresponding optimal bandwidth sizes are used. We find that, in estimating m0 and βj, the ratios of the MSE values for n = 400 against n = 200 roughly coincide with the theoretical value
. In estimating the nonparametric part
, the ratios of the MISE values are nearly identical to the theoretical values
and
, respectively, for our estimator and for the PLM. For instance, in case α = 0, the empirical ratio
for our estimator is roughly the same as 0.574, while
for the PLM approximates well the theoretical value 0.630.
reports the values of the measures at (5.8) and (5.9) for Models 2–4. Recall that, in these models, X1 is the same as the one under Model 1 when α = 1, but are correlated to each other via the correlation
among Uj. From the table, we first learn that our proposal continues to dominate the PLM when the covariates in the nonparametric part are correlated, when their effects are nonadditive, or when their number increases. The comparison between the values for Model 2 and those for Model 1 with α = 1 may reveal the effect of correlation among covariates. We observe that the presence of the correlation increased the values of MSE and MISE slightly for our estimators. For the PLM, in estimating βj, the asymptotic theory at (7.1) in Section 7.1 tells that introducing correlation between Zj does not affect the asymptotic MSE properties of
because
and
are independent of Z in our simulation setting. This is confirmed empirically by comparing the values, corresponding to the PLM, in the columns of βj for Model 2 in , with those for Model 1 (α = 1) in .
Table 2 Values of measures of performance for and
(
) under Models 2, 3, and 4 where Zj are correlated, multiplied by 103.
Now, we note that Models 3 and 4 differ from Model 2 only in the nonparametric part. In the computation of the values for Model 3, the target was actually the centered version as at (5.10) for
. The MSE values in the columns of βj for Model 3, in comparison with those for Model 2, demonstrate empirically the insensitivity of both
and
to non-additivity in the nonparametric part, as asserted by Theorem 7.1 and the discussion that follows. Indeed, our theory tells that
and
determine the asymptotic distributions of
and
, respectively, and these have nothing to do with the structure of the nonparametric part. As for the estimation of the nonparametric part, the MISE values of both our estimator and the PLM for Model 3 are smaller than the corresponding ones for Model 2. This is due to the fact that
is easier to estimate than
. Comparing the values for Models 2 and 4, we see that the increased dimension of Z does not affect the precision of the estimators of βj. It increases the MISE values of the nonparametric part, moderately for our estimator but substantially for the PLM. This illustrates the dimensionality problem with the PLM approach. Finally, we find that, as the results in , those in as well are in accordance with the corresponding theoretical rates of convergence.
and also report the average computing time, given a set of bandwidths chosen by a cross-validation criterion. The results indicate that the calculation of the Hilbertian PLAM estimators takes two or three times more than the computation of the Hilbertian PLM estimators, except in the case of Model 4 where the covariate dimension in the nonparametric part is higher than the other models. The comparison of computing time demonstrates how much extra computational time one needs to perform the smooth backfitting iteration, which the Hilbertian PLAM requires while the Hilbertian PLM does not.
6 Application to U.S. Presidential Election Data
We present a real data application for the model (4.1). Another real data application for the model (3.1) can be found in the supplement S.6. It is believed that the underlying political orientation and population characteristics of a region affect an election result for the region. To validate this belief in the United States, we analyzed the 2020 U.S. presidential election data. We put the observed proportions of votes earned by Democratic Party (), Repulican Party (
) and the rest (
) for the ith state into a vector
, and took the compositional vectors as the observations of the response Y. We considered such three categories since the first two parties received the major spotlight in the election. We note that Y satisfies the two constraints
and
, and thus, it takes values in
, which is a two-dimensional Hilbert space as detailed in the supplement S.5. As a covariate, we considered a compositional vector
that comprises the proportions of votes earned by the same parties in the 2016 U.S. presidential election. We added three other covariates in the model building, which are the proportion of people who have a bachelor or a higher degree (Z1), per capita income (Z2) and median age (Z3). The observations on these socio-demographic variables Zj were obtained from https://www.census.gov/acs/www/data/data-tables-and-tools/data-profiles/2019/. The observed value
of the Hilbertian covariate
is considered to represent the political orientation of the ith state, and the values of the socio-demographic covariates, Zij for
, measure the state’s education, wealth and age levels, respectively.
We applied the Hilbertian partially linear additive regression approach based on the model (4.1) with the covariates and Z3. In doing so, we applied trapezoidal rules based on two different grids to approximate the integrals in the iterative algorithm at (2.6): one with 101 equally spaced points (Dense) and the other with 21 (Sparse). We also used two different bandwidth selectors: one was the CBS bandwidth introduced in Section 5.1, and the other an optimally chosen bandwidth for density estimation (KDE) according to the R function “h.amise” in R package “kedd (version 1.0.3).” Based on these options we implemented the three combinations: Dense-CBS, Sparse-CBS, and Dense-KDE. As a competing approach, we also chose the Hilbertian additive regression approach of Jeon and Park (Citation2020), which uses only the scalar covariates
, with the Dense-CBS scheme. We compared the prediction performance of these approaches via the leave-one-out average squared prediction error (ASPE) defined by
where n = 51 and
is the predicted value of
obtained without the ith observation. The above definition of ASPE is based on the geometry of
given in the supplement S.5. The values of the ASPE for our approach with the Dense-CBS, Sparse-CBS, and Dense-KDE schemes were respectively 0.063, 0.063, and 0.070, while the application of Jeon and Park (Citation2020) gave 0.198. Thus, our partially linear additive modeling approach incorporating the compositional covariate improved the prediction performance greatly. It turned out that the size of grid in numerical integration does not have significant effects on the prediction performance. However, it turned out that the CBS scheme taking into account the values of Y outperforms the scheme based on KDE.
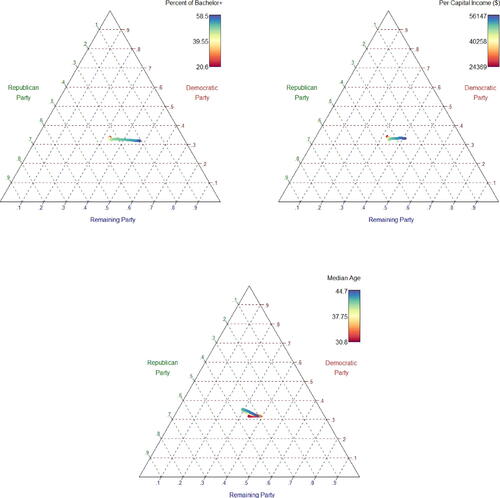
To see the effects of the covariates, we estimated the model (4.1) using the whole dataset with the Dense-CBS scheme. We obtained that . The result with such a large positive value demonstrates that the party supporting tendency in the 2020 U.S. election is tied strongly with that in the 2016 election. Thus, the empirical result provides a strong evidence that the underlying political orientation is an important determinant for the presidential election. The estimated component maps are depicted in , which visualize the effects of the socio-demographic variables on the election results. A clear lesson from the estimated maps is that the approval rate for the Democratic candidate remains unchanged as education level or income level increases, while it decreases for the Republican candidate and increases for the group of other candidates. The effects of age do not seem to have a monotone pattern.
Fig. 1 The estimated component maps for the population characteristics based on the proposed method applied to the U.S. election data.
7 Theoretical Development
7.1 Asymptotic Theory: Scalar Covariates
Here, we discuss the case where and
take values in
and
, respectively. We assume that
for
are iid copies of
such that
. Recall that
, for each
, is the solution of (2.3) with
,
and
. We let
denote the bandwidth set we use in the construction of
and
for
and
. Recall
, which solves (2.5) with
. We let
denote the bandwidth set we use in the construction of
with
and
at hand.
7.1.1 Technical Assumptions and Invertibility of 
We collect the technical assumptions we use for our theoretical development.
(A1) The joint density f is bounded away from zero and infinity on its support
(A2) The real-valued additive functions
(A3) The Hilbertian error variable
(A4) The p × p matrix
(A5) There exist constants
(A6) The baseline kernel K is symmetric and positive on
(A7) The bandwidths hk satisfy
(A8) The bandwidths bk satisfy that
The conditions (A1) and (A2) for are typically assumed in the smooth backfitting literature, see Jeon and Park (Citation2020). The moment conditions at (A3) ensure
for finite-dimensional
and
for infinite-dimensional
, so that the bandwidth ranges in (A7) make sense. The range for infinite-dimensional
does not cover the optimal size for univariate nonparametric smoothing, which is
, but we note that the bandwidths hk are for estimating the parametric part of the model, not for the nonparametric part. For the latter, we use bk for which we assume (A8). The condition (A4) ensures that the matrix
is invertible with probability tending to one, which we detail below. The exponential moment condition (A5) is assumed to use empirical process theory (e.g., van de Geer Citation2000) in developing technical discussion for
. The condition (A6) is stronger than the typical one in kernel smoothing that K itself is Lipschitz continuous. The latter condition is required to make our estimator
smoother, so that it belongs to an
-valued function class with a proper entropy.
We now state a proposition that demonstrates the invertibility of .
Proposition 7.1.
Assume (A1), (A2) for and (A4)–(A7). Then,
so that
is invertible with probability tending to one.
7.1.2 Estimation of Parametric Components
We present the limit distribution of defined at (3.7). For this we need to introduce several terminologies. First, we let
be equipped with an inner product
defined by
for
and
in
. Let
be the associated norm such that
. For
, define
, an outer product in
, by
For a general -valued random element V, a linear operator
such that
is called the covariance operator of V. For a random vector U taking values in
,
so that
, defined by
, is the covariance operator of
. Let
denote a Gaussian random element taking values in
with mean
and covariance operator S, that is, the real-valued random variable
for any
is normally distributed with mean 0 and variance
. Let
, which is the covariance operator of
. Note that, in case
is independent of
, then
reduces to
.
Theorem 7.1.
Under the assumptions (A1)–(A7), it holds that
The following corollary for is an immediate consequence of Theorem 7.1. Recall that
.
Corollary 7.1.
Under the assumptions (A1)–(A7), it holds that .
7.1.3 Comparison with HPLM
We make a theoretical comparison of and
, the latter of which is defined at (3.11). Let
. Then, along the lines of the proof of Theorem 7.1 in the supplement S.11, we may prove that, under suitable conditions,
(7.1)
(7.1)
A special case of (7.1) for and d = 1 has been derived by Liang (Citation2006). The result (7.1) for
is valid under the PLM and thus remains true under the PLAM as well. In case
is independent of
reduces to
. The following definition is an extension of the classical notion of “asymptotic efficiency” for real-valued parameters to that for Hilbertian parameters.
Definition 7.1.
Let and
be estimators of a parameter
in a separable Hilbert space
such that
for a sequence sn and covariance operators
for j = 1, 2. We say that
is asymptotically more efficient than
if
is a nonnegative definite operator, that is,
for all
.
We note that is nonnegative definite and it is zero only if
. A direct computation shows that
(7.2)
(7.2) which implies that
is asymptotically more efficient than
in the sense of Definition 7.1. Let dj denote the jth diagonal entry of
. Then, under the PLAM (3.1), it holds that
with
, which is the gain by
against
under (3.1).
7.1.4 Estimation of Nonparametric Components
As we discussed in Section 3.3, is uniquely decomposed into
with the constraints at (3.8). We study the error rates for
and
. The asymptotic results presented here do not follow immediately from the results in Jeon and Park (Citation2020) since
. Furthermore, as seen in the assumption (A8), our work allows for a flexible range for the bandwidths bk, instead of assuming
as in Jeon and Park (Citation2020). Put
for
and
. Also, let
.
Theorem 7.2.
Assume (A1)–(A8). Then, it holds that, for each ,
Consequently,
In the case where for all
, the rates in Theorem 7.2 reduce to the usual ones for univariate smoothing. Indeed, for each
,
We also derive the asymptotic distributions of and
, which we defer to the supplement S.15.
7.2 Asymptotic Theory: Hilbertian Covariates
Here, we discuss the case where the covariates in the linear part of the model, which we denoted by for
, take values in
. Define now
. Recall that
is the p × p matrix whose (j, k) element equals
. We first introduce some technical assumptions for Hilbertian
. We note that the assumptions (A1), (A6) and (A8) in Section 7.1 still apply in the present case, which we call (B1), (B6), and (B8), respectively, here. The corresponding versions of the others are given below.
(B2) The
(B3) The Hilbertian error variable
(B4) The p × p matrix
(B5) There exist constants
(B7) The bandwidths hk satisfy
The conditions (B3) and (B7) are the same as (A3) and (A7), respectively, for finite-dimensional . In fact, for infinite-dimensional
, we are able to derive a slower rate for
and
, see below the second parts of Theorem 7.3 and Corollary 7.2. For such rate of convergence, we find that (B3) and (B7) are sufficient. The following proposition is an analogue of Proposition 7.1 for Hilbertian
.
Proposition 7.2.
Assume (B1), (B2) for and (B4)–(B7). Then,
so that
is invertible with probability tending to one.
We now derive the asymptotic properties of . Note that
is the p × p matrix whose (j, k) element is given by
. Define
Let denote the multivariate normal distribution with mean
and covariance matrix Σp.
Theorem 7.3.
Assume (B1)–(B7). If is finite-dimensional, then it holds that
If is infinite-dimensional, then
.
The following corollary for is an immediate consequence of Theorem 7.3. Recall that
.
Corollary 7.2.
Assume (B1)–(B7). If is finite-dimensional, then
. If
is infinite-dimensional, then
.
Next, we present the asymptotic properties of and
satisfying the constraints at (3.8). As in Section 7.1, we let
denote the set of bandwidths for defining (2.5) with
. Recall
and
. Put
if
is finite-dimensional, and
if
is infinite-dimensional.
Theorem 7.4.
Assume (B1)–(B8). Then, Theorem 7.2 remains to hold with δk being replaced by .
We also derive the asymptotic distributions of and
in the case of Hilbertian
, which we defer to the supplement S.18.
Supplementary Materials
The supplementary material contains the description of the CBS algorithm, the geometries of Bayes-Hilbert spaces and simplices, and an additional real data application. It also includes two additional theorems for the asymptotic distributions of the estimators of the nonparametric components of the partially linear additive models, and all technical proofs.
Supplemental Material
Download Zip (893.7 KB)Supplemental Material
Download PDF (1.2 MB)Supplemental Material
Download MS Word (41.4 KB)Acknowledgments
The authors thank an Associate Editor and two referees for giving thoughtful and constructive comments on the earlier versions of the article.
Additional information
Funding
Related Research Data
References
- Benatia, D., Carrasco, M., and Florens, J.-P. (2017), “Functional Linear Regression with Functional Response,” Journal of Econometrics, 201, 269–291. DOI: 10.1016/j.jeconom.2017.08.008.
- Bhattacharya, P. K., and Zhao, P.-L. (1997), “Semiparametric Inference in a Partial Linear Model,” The Annals of Statistics, 25, 244–262. DOI: 10.1214/aos/1034276628.
- Bissantz, N., Dette, H., Hildebrandt, T., and Bissantz, K. (2016), “Smooth Backfitting in Additive Inverse Regression,” Annals of the Institute of Statistical Mathematics, 68, 827–853. DOI: 10.1007/s10463-015-0517-x.
- Bosq, D. (2000), Linear Processes in Function Spaces, New York: Springer.
- Buja, A., Hastie, T., and Tibshirani, R. (1989), “Linear Smoothers and Additive Models,” (with discussion), The Annals of Statistics, 17, 453–555. DOI: 10.1214/aos/1176347115.
- Hall, P., and Horowitz, J. L. (2007), “Methodology and Convergence Rates for Functional Linear Regression,” The Annals of Statistics, 35, 70–91. DOI: 10.1214/009053606000000957.
- Han, K., and Park, B. U. (2018), “Smooth Backfitting for Errors-in-Variables Additive Models,” The Annals of Statistics, 46, 2216–2250. DOI: 10.1214/17-AOS1617.
- Han, K., Müller, H.-G., and Park, B. U. (2020), “Additive Functional Regression for Densities as Responses,” Journal of the American Statistical Association, 115, 997–1010. DOI: 10.1080/01621459.2019.1604365.
- Horváth, L., and Kokoszka, P. (2012), Inference for Functional Data with Applications, New York: Springer.
- Jeon, J. M., and Park, B. U. (2020), “Additive Regression with Hilbertian Responses,” The Annals of Statistics, 48, 2671–2697. DOI: 10.1214/19-AOS1902.
- Jeon, J. M., Park, B. U., and Van Keilegom, I. (2021), “Additive Regression with Non-Euclidean Responses and Predictors,” The Annals of Statistics, 49, 2611–2641. DOI: 10.1214/21-AOS2048.
- Jeon, J. M., and Van Bever, G. (2022), “Additive Regression with General Imperfect Variables,” arXiv:2212.05745.
- Lee, E. R., Han, K., and Park, B. U. (2018), “Estimation of Errors-in-Variables Partially Linear Additive Models,” Statistica Sinica, 28, 2353–2373.
- Lee, Y. K., Mammen, E., and Park, B. U. (2010), “Backfitting and Smooth Backfitting for Additive Quantile Models,” The Annals of Statistics, 38, 2857–2883. DOI: 10.1214/10-AOS808.
- Lee, Y. K., Mammen, E., and Park, B. U. (2012), “Flexible Generalized Varying Coefficient Regression Models,” The Annals of Statistics, 40, 1906–1933.
- Liang, H. (2006), “Estimation in Partially Linear Models and Numerical Comparisons,” Computational Statistics & Data Analysis, 50, 675–687. DOI: 10.1016/j.csda.2004.10.007.
- Liang, H., Thurston, S. W., Ruppert, D., Apanasovich, T., and Hauser, R. (2008), “Additive Partially Linear Models with Measurement Errors,” Biometrika, 95, 667–678. DOI: 10.1093/biomet/asn024.
- Lin, Z., Müller, H.-G., and Park, B. U. (2022), “Additive Models for Symmetric Positive-Definite Matrices and Lie Groups,” Biometrika (to appear). DOI: 10.1093/biomet/asac055.
- Linton, O., Sperlich, S., and van Keilegom, I. (2008), “Estimation of a Semiparametric Transformation Model,” The Annals of Statistics, 36, 686–718. DOI: 10.1214/009053607000000848.
- Mammen, E., Linton, O., and Nielsen, J. P. (1999), “The Existence and Asymptotic Properties of a Backfitting Projection Algorithm under Weak Conditions,” The Annals of Statistics, 27, 1443–1490. DOI: 10.1214/aos/1017939138.
- Opsomer, J. D., and Ruppert, D. (1997), “Fitting a Bivariate Additive Model by Local Polynomial Regression,” The Annals of Statistics, 25, 186–211. DOI: 10.1214/aos/1034276626.
- Opsomer, J. D., and Ruppert, D. (1999), “A Root-n Consistent Backfitting Estimator for Semiparametric Additive Modeling,” Journal of Computational and Graphical Statistics, 8, 715–732.
- Ramsay, J. O., and Silverman, B. W. (2005), Functional Data Analysis, New York: Springer.
- Severini, T., and Wong, W. (1992), “Profile Likelihood and Conditionally Parametric Models,” The Annals of Statistics, 20, 1768–1802. DOI: 10.1214/aos/1176348889.
- van de Geer, S. (2000), Empirical Processes in M-Estimation, Cambridge: Cambridge University Press.
- Yao, F., Müller, H.-G., and Wang, J.-L. (2005), “Functional Linear Regression Analysis for Longitudinal Data,” The Annals of Statistics, 33, 2873–2903. DOI: 10.1214/009053605000000660.
- Yu, K., Mammen, E., and Park, B. U. (2011), “Semi-Parametric Regression: Efficiency Gains from Modeling the Nonparametric Part,” Bernoulli, 17, 736–748. DOI: 10.3150/10-BEJ296.
- Yu, K., Park, B. U., and Mammen, E. (2008), “Smooth Backfitting in Generalized Additive Models,” The Annals of Statistics, 36, 228–260. DOI: 10.1214/009053607000000596.
- Zhang, X., Park, B. U., and Wang, J.-L. (2013), “Time-Varying Additive Models for Longitudinal Data,” Journal of the American Statistical Association, 108, 983–998. DOI: 10.1080/01621459.2013.778776.