
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We introduce a simple diagnostic test for assessing the overall or partial goodness of fit of a linear causal model with errors being independent of the covariates. In particular, we consider situations where hidden confounding is potentially present. We develop a method and discuss its capability to distinguish between covariates that are confounded with the response by latent variables and those that are not. Thus, we provide a test and methodology for partial goodness of fit. The test is based on comparing a novel higher-order least squares principle with ordinary least squares. In spite of its simplicity, the proposed method is extremely general and is also proven to be valid for high-dimensional settings. Supplementary materials for this article are available online.
1 Introduction
Linear models are the most commonly used statistical tools to study the relationship between a response and a set of covariates. The regression coefficient corresponding to a particular covariate is usually interpreted as its net effect on the response variable when all else is held fixed. Such an interpretation is essential in many applications and yet could be rather misleading when the linear model assumptions are in question, in particular, when there are hidden confounders.
In this work, we develop a simple but powerful approach to goodness of fit tests for potentially high-dimensional linear causal models, including also tests for partial goodness of fit of single predictor variables. While hidden confounding is the primary alternative in mind, different nonlinear deviations from the linear model assumption are also in scope. Tests for goodness of fit are essential to statistical modeling (e.g., Lehmann, Romano, and Casella Citation2005) and the concept is also very popular in econometrics where it is referred to as specification tests. For an overview of such methods; see, for example, Godfrey (Citation1991) or Maddala and Lahiri (Citation2009).
Another set of related works is Buja et al. (Citation2019a, Citation2019b), which elaborately discusses deviations from the (linear) model and how distributional robustness, that is, robustenss against shifts in the covariates’ distribution, links to correctly specified models. For this, they introduce the definition of “well-specified” statistical functionals. Distributional robustness, implied by well-specification, is also related to the causal interpretation of a linear model as discussed in Peters, Bühlmann, and Meinshausen (Citation2016).
We consider here the question when and which causal effects can be inferred from the ordinary least squares estimator or a debiased Lasso procedure for the high-dimensional setting, even when there is hidden confounding. We address this by partial goodness of fit testing: if the data speaks against a linear causal model, we are able to specify which components of the least squares estimator should be rejected to be linear causal effects and which not. In the case of a joint Gaussian distribution, one cannot detect anything: this corresponds to a well-known unidentifiability result in causality (Hyvärinen and Oja Citation2000; Peters et al. Citation2014). But, in certain models, we are able to identify some causal relations. Of particular importance are non-Gaussian linear structural equation models, as used in Shimizu et al. (Citation2006) or Wang and Drton (Citation2020) among others. The latter constructs the causal graph from observational data in a stepwise procedure using a test statistic similar to the one we suggest.
Our strategy has a very different focus than other approaches which do not rely on the least squares principle any longer to deal with the issue of hidden confounding. Most prominent, particularly in econometrics, is the framework of instrumental variables regression: assuming valid instruments, one can identify all causal effects, see, for example, Angrist, Imbens, and Rubin (Citation1996) or the books by Bowden and Turkington (Citation1990) and Imbens and Rubin (Citation2015). The popular Durbin-Wu-Hausman test (Hausman Citation1978) for validity of instruments bears a relation to our methodology, namely that we are also looking at the difference of two estimators to test goodness of fit.
Our automated partial goodness of fit methodology is easy to be used as it is based on ordinary (or high-dimensional adaptions of) least squares and its novel higher-order version: we believe that this simplicity is attractive for statistical practice.
1.1 Our Contribution
We propose a novel method with a corresponding test, called higher-order least squares (HOLS). The test statistic is based on the residuals from an ordinary least squares or Lasso fit. In that regard, it is related to Shah and Bühlmann (Citation2018) who use “residual prediction” to test for deviation from the linear model. However, our approach does neither assume Gaussian errors nor does it rely on sample splitting, and our novel test statistic has a convergence rate (with n denoting the sample size).
In addition to presenting a “global” goodness of fit test for the entire model, we also develop a local interpretation that allows detecting which among the covariates are giving evidence for hidden confounding or nonlinear relations. Thus, we strongly increase the amount of extracted information compared to a global goodness-of-fit test. In particular, in the case of localized (partial) confounding in linear structural equation models, we are able to recover the unconfounded regression parameters for a subset of predictors. This is a setting where techniques assuming dense (essentially global) confounding, as in Ćevid, Bühlmann, and Meinshausen (Citation2020) or Guo, Ćevid, and Bühlmann (Citation2022), fail.
The work by Buja et al. (Citation2019a, Citation2019b) especially the second paper, shows how to detect deviations in a linear model using reweighting of the data. Our HOLS technique can be seen as a special way of reweighting. In contrast to their work, we provide a simple test statistic that tests for well-specification without requiring any resampling. Furthermore, we provide guarantees for a local interpretation under suitable modeling assumptions while as their per-covariate view remains rather exploratory.
1.2 Outline
The remainder of this article will be structured as follows. We conclude this section with the necessary notation. In Section 2, we present the main idea of HOLS and the according global null hypothesis. For illustrative purposes, we first discuss univariate regression. Then, we consider multivariate regression and extend our theory to high-dimensional problems incorporating the (debiased) Lasso. In Section 3, we present the local interpretation when the global null does not hold true alongside with theoretical guarantees. Models for which this local interpretation is most suitable are discussed in Section 4. Section 5 contains a real data analysis. We conclude with a summarizing discussion in Section 6.
1.3 Notation
We present some notation that is used throughout this work. Vectors and matrices are written in boldface, while scalars have the usual lettering. This holds for both random and fixed quantities. We use upper case letters to denote a random variable, for example, X or Y. We use lower case letters to denote iid copies of a random variable, for example, x. If , then
. With a slight abuse of notation, x can either denote the copies or realizations thereof. We write
to denote the jth column of matrix x and
to denote all but the jth column. We write
to state that equality holds under H0. With ←, we emphasize that an equality between random variables is induced by a causal mechanism. We use
to denote elementwise multiplication of two vectors, for example,
. Similarly, potencies of vectors are also to be understood in an elementwise fashion, for example,
.
is the n-dimensional identity matrix.
denotes the orthogonal projection onto
and
denotes the orthogonal projection onto its complement. For some random vector X, we have the moment matrix
. Note that this equals the covariance matrix for centered X. We denote statistical independence by
. We write e to denote a vector for which every entry is 1 and
to denote the unit vector in the direction of the jth coordinate axis.
2 Higher-Order Least Squares (HOLS)
We develop here the main idea of HOLS estimation.
2.1 Univariate Regression as a Motivating Case
It is instructive to begin with the case of simple linear regression where we have a pair of random variables X and Y. We consider the causal linear model
(1)
(1)
We formulate a null hypothesis that the model in (1) is correct and we denote such a hypothesis by H0. This model is of interest as β describes the effect of a unit change if we were to intervene on covariate X without intervening on the independent . Such model, or its multivariate extension, is often assumed in causal discovery, see, for example, Shimizu et al. (Citation2006) or Hoyer et al. (Citation2008). Therefore, we aim to provide a test for its well-specification.
Estimation of the regression parameter is typically done by the least squares principlewhere we use the superscript OLS to denote ordinary least squares. Alternatively, we can pre-multiply the linear model (1) with X: the parameter minimizing the expected squared error loss is then
More generally, , if
. Using the definition from Buja et al. (Citation2019b), this means that the OLS parameter is well-specified. The estimation principle is called higher-order least squares, or HOLS for short, as it involves higher-order moments of X. One could also multiply the linear model with a factor other than X, which may have implications on the power to detect deviations from (1). We shall focus here on the specific choice to fix ideas.
The motivation to look at HOLS is when H0 is violated, in terms of a hidden confounding variable: let H be a hidden confounder leading to a model
where
, H, and
are all independent and α and ρ define additional model parameters. In particular, we can compute under such a confounding model that
(2)
(2)
For simplicity, we assumed here . In practice, one can get rid of this assumption by including an intercept in the model. If either α or ρ equals to 0, we see that the difference in (2) is 0. This is not surprising as there is no confounding effect when either X or Y is unaffected. However, this is not the only possibility how the difference can be 0. Namely,
Especially, if neither nor H have excess kurtosis, the difference is 0 for any ρ. This can be intuitively explained as it corresponds to Gaussian data (up to the moments we consider). For Gaussian
and H, one can always write
which cannot be distinguished from the null model (1). Or in other words
, that is, the OLS parameter is well-specified although it is not the parameter β that we would like to recover. For other data-generating distributions, one should be able to distinguish H0 from certain deviations when hidden confounding is present. We discuss the implications of this in the general multivariate setting in Section 3.2. Similar behavior occurs for a violation of H0 in terms of a nonlinear model
which then (typically) leads to
.
One can construct a test based on the sample estimates of and
. We consider the centered data
where we use the upper bar to denote sample means. We can derive
We now obtain from regression through the origin of
versus
with an error term of
and
from regression through the origin of
versus
with an error term of
. More precisely, we define
Under H0, one can see that given x is some known linear combination of
. Assuming further Gaussianity of
, it is conditionally Gaussian. We find
(3)
(3)
We can calculate this variance except for . Further, we can consistently estimate
, for example, with the standard formula
Thus, we receive asymptotically valid z-tests for the null-hypothesis H0 that the model (1) holds. We treat the extension to non-Gaussian in Section 2.2 (for the multivariate case directly). As discussed above, in the presence of confounding, we can have that
. In such situations, a test assuming (3) will have asymptotic power equal to 1 for correctly rejecting H0 under some conditions. These asymptotic results are discussed in Sections 3.1 and 3.2.
2.2 Multivariate Regression
We typically want to examine the goodness of fit of a linear model with p > 1 covariates. We consider p to be fixed in this section and discuss the case where p is allowed to diverge with n in Section 2.3.
We consider the causal model(4)
(4) with
and
. Note that
can always be enforced by including an intercept in the set of predictors. We assume the according moment matrix
to be invertible. Then, the principal submatrices
are also invertible. We formulate a global null hypothesis that the model in (4) is correct and we denote it by H0. To make use of the test described for the univariate case, we consider every component
separately and work with partial regression, see, for example, Belsley, Kuh, and Welsch (Citation2005). For the population version, we define
(5)
(5)
Under H0, it holds that .
For , we find
The first equality is a well-known application of the Frish-Waugh theorem, see, for example, Greene (Citation2003). We define the according HOLS parameter by partial regression for every component j separately, namely
We define a local, that is, per-covariate null hypothesis . The difference
can detect certain local alternatives from the null hypothesis H0. Here, local refers to the covariate Xj whose effect on Y is potentially confounded or involves a nonlinearity. Under model (4),
holds true for every j. We discuss in Sections 3 and 4 some concrete examples, where it is insightful to consider tests for individual
.
We turn to sample estimates of the parameters. The residuals are estimated by
With ordinary least squares, we receive from regression of
versus
, where the error term is
. Accordingly, we calculate
from regression of
versus
with an error term
. Thus, we define
This is analogous to the univariate case, where we have instead of
instead of
and
instead of
, and
can be thought of as orthogonal projection onto e’s complement, which completes the analogy. Again, we see that given x,
is some known linear combination of
, thus, it is conditionally Gaussian for Gaussian
. The same holds for
.
Naturally, Gaussian is an overly strong assumption. Therefore, we consider additional assumptions such that the central limit theorem can be invoked.
(A1) The moment matrix
has positive smallest eigenvalue.
(A2)
Further, let(6)
(6)
Note that .
Theorem 1.
Assume that the data follows the model (4) and that (A1)–(A2) hold. Let p be fixed and . Then,
Note that
Following Theorem 1, we can test the null hypothesis H0 with a consistent estimate for . Such an estimate can be obtained, for example, using the standard formula
We define for later reference(7)
(7)
To test , we can compare
to the quantiles of the univariate normal distribution with the according variance. The joint distribution leads to a global test that controls the Type I error. Namely, one can look at the maximum test statistic
, where
can be easily simulated. Further, one receives multiplicity corrected individual p-values for
by comparing each
to the distribution of
. This is in analogy to the multiplicity correction suggested by Bühlmann (Citation2013). Naturally, other multiplicity correction techniques such as Bonferroni-Holm are valid as well.
Algorithm 1 summarizes how to find both raw and multiplicity corrected p-values for each component j corresponding to the jth covariate, pj and Pj, respectively. Then, one would reject the global null hypothesis H0 that the model (4) holds if , and such a decision procedure provides control of the Type I error at level α. Note that this means that we have strong control of the FWER for testing all
.
Algorithm 1
HOLS check
1: for j = 1 to p do
2:
3: Regress versus
via least squares, denote the residual by
4: Regress y versus via least squares, denote the residual by
5: and
6:
7: Create nsim i.i.d copies of , say,
to
8: for j = 1 to p do
9:
10:
Corollary 1.
Assume the conditions of Theorem 1. Consider the decision rule to reject H0 iff , where Pj is as in Step 10 of Algorithm 1. Then, the Type I error is asymptotically controlled at α. Furthermore, the FWER is asymptotically controlled at level α for testing all local hypotheses
with the decision rule to reject
iff
.
We provide simulation results supporting this theory in Section A of the supplemental materials.
2.3 High-Dimensional Data
We now turn to high-dimensional situations. We assume the global null hypothesis (4) but allow for p to diverge with and even exceed n such that ordinary least squares regression is not applicable. Instead, we apply the debiased Lasso introduced in Zhang and Zhang (Citation2014) and further discussed in van de Geer et al. (Citation2014). We denote the estimator again by since it converges under certain conditions to the population parameter
.
From the debiased Lasso, we receive , where
is obtained by regressing
versus
using the Lasso, and
with
coming from the Lasso fit of y versus x. Since
, one might want to use
for HOLS. However, this leads in general to an uncontrollable approximation error since
. As a remedy, we suggest a second level of orthogonalization based on
and
as defined in (6). Naturally, we have
iff
and always
. To approximate
we use the Lasso for the regression
versus
leading to
. We define
as
Finally, we are interested in the difference between and
. Under suitable assumptions for the sparsity, the moment matrix, and the tail behavior of X and
, we can derive the limiting Gaussian distribution of this difference allowing for asymptotically valid tests. W apply Algorithm 2 where we make use of the (asymptotic) normality of the nonvanishing term in this difference. For non-Gaussian
, a multiplicity correction method that does not rely on exact Gaussianity of this remainder might be preferred since the CLT does not apply for dimensions growing too fast.
Algorithm 2
HOLS check for p > n
1: Regress y versus x via Lasso with a penalty parameter λ, denote the estimated regression coefficients by
2: for j = 1 to p do
3: Regress versus
via Lasso with a penalty parameter λj, denote the residual by
4: Regress versus
via Lasso with a penalty parameter
, denote the residual by
5:
6: and
7: (or any other reasonable variance estimator)
8: Create nsim i.i.d copies of , say,
to
9: for j = 1 to p do
10:
11:
We provide here the main result to justify Algorithm 2 invoking additional assumptions on the dimensionality and sparsity of the problem. We use the definitions and
to denote the different levels of sparsity.
(C1) The design matrix x has iid sub-Gaussian rows. The moment matrix
(C2)
(C3)
(C4)
(C5)
(C6)
Theorem 2.
Assume that the data follows the model (4) with sub-Gaussian and that (C1)–(C6) hold (
). Let
come from Lasso regression with
from nodewise Lasso regression using
, and
from nodewise Lasso regression of
versus
using
. Let
be any consistent estimator for σ. Then,
We defer the technical details to Section C of the supplemental materials. Simulation results concerning high-dimensional data can be found in Section A of the supplemental materials.
3 The Confounded Case and Local Null Hypotheses
In this section and the following, we mainly exploit confounding in linear models as the alternative hypothesis since these are the models where our tests for the local null hypotheses are most informative. For a discussion of which interpretations might carry over to more general data generating distributions, we refer to Section 4.3.
Note that everything that is discussed in Sections 3 and 4 implicitly applies to high-dimensional data as well under suitable assumptions. We refrain from going into detail for the sake of brevity. Thus, Theorems 3–6 which contain our main asymptotic results for the local intepretation are designed explicitly for the fixed p case.
We look at the causal model(8)
(8) where
and
are independent and centered random variables, and
and
are fixed model parameters. Thus, there exists some hidden confounder H. For the inner product matrices, it holds that
Furthermore, we have(9)
(9)
We will generally refer to , where βj is according to model (8), as confounding bias on
. Further, when writing directly confounded, we mean covariate indices j for which
.
Note that we can always decompose Y both globally and locally as follows(10)
(10)
(11)
(11) using the definitions from (5). We now want to see how
relates to
in certain models. Especially, we are interested in whether there is some potential local interpretation in the sense of distinguishing between “confounded” and “unconfounded” variables. From (9), we see that this is linked to the structure of the covariance matrices as well as
and
. We define the sets
(12)
(12)
Using the Woodbury matrix identity, we find a sufficient condition(13)
(13)
Thus, if the intersection between covariates that have linear predictive power for Xj and covariates that are directly confounded is empty, it must hold that . Therefore, we can indeed say that for these variables we estimate the true causal effect using ordinary least squares.
To correctly detect V, we would like . As
involves higher-order moments, knowledge of the covariance structure is not sufficient to check this. From (11), we see that
is necessary and sufficient to ensure
. In Section 3.2, we discuss the two cases where detection fails, that is,
and
. We present models for which we can characterize a set of variables which are in
in Section 4.
3.1 Sample Estimates
For a confounded model, the hope is that the global test , where Pj is the adjusted p-value according to Step 10 in Algorithm 1, leads to a rejection of H0, that is, the modeling assumption (4). One could further examine the local structure and, based on the corrected p-values Pj, distinguish the predictors for which we have evidence that
. We consider in the following this local interpretation, showing that we asymptotically control the Type-I error and receive power approaching 1. Implicitly, we assume that U is a useful proxy for V.
For all asymptotic results in this section, we assume p to be fixed and as in Theorem 1.
Theorem 3.
Assume that the data follows the model (10) and that (A1)–(A2) hold. Assume further . Then,
where
is according to (7).
Thus, for some fixed alternative , the absolute z-statistics increases as
.
In order to get some local interpretation, the behavior for variables is of importance. If
, Theorem 3 is not sufficient to understand the asymptotic behavior. We refine the results using additional assumptions.
(A3)
(B1)
(B2)
(B3)
Note that we use different letters for the assumptions to distinguish between those that are essentially some (mild) moment conditions and those that truly make nodes unconfounded. Obviously, (B2) is not necessary for , but we will focus on these variables as these are the ones that are truly unconfounded in the sense that the projected single variable model (11) has an independent error term, while as for other variables it can be rather considered an unwanted artifact of our method. Furthermore, the derived asymptotic variance results only hold true when assuming (B2) and (B3) as well. Assumption (A3) implies a further moment condition. Especially, when considering nonlinearities, there exist cases for which (A3) is not implied by (A2). We discuss Assumptions (B1)–(B3) for certain models in Section 4. Condition (B1) seems to be a bit artificial but is invoked in the proofs. We argue in Section 4 that it is naturally linked to the models in scope.
Theorem 4.
Assume that the data follows the model (10) and that (A1)–(A3) hold. Let j be some covariate with for which (B1)–(B3) hold. Then,
Thus, for these predictors we receive asymptotically valid tests.
Multiplicity correction
In order not to falsely reject the local null hypothesis for any covariate with
(with probability at least
), we need to invoke some multiplicity correction. Analogously to Section 2.2, one can see that
, which enables the multiplicity correction as in Algorithm 1.
Theorem 5.
Assume that the data follows the model (10) and that (A1)–(A3) hold. Let be the set of variables j for which
and (B1)–(B3) hold. Then,
Corollary 2.
Assume the conditions of Theorem 5. Consider the decision rule to reject iff
, where Pj is as in Step 10 of Algorithm 1. Then, the familywise error rate amongst the set
is asymptotically controlled at α.
3.2 Inferring V from U
Recall the definitions in (12). U is the set that we try to infer with our HOLS check. Naturally, one would rather be interested in the set V, which consists of the variables for which we can consistently estimate the true linear causal effect according to (8) through linear regression. We discuss here when using U as proxy for V might fail and especially analyze how variables could belong to the difference between the sets. For this, recall our formulation of the model when the global null hypothesis does not hold true in (10) and (11). Note that is equivalent to
.
For any variable , certain modeling assumptions, that we discuss in the sequel, cannot be fulfilled but they are not necessary for
. Especially, the last equality always holds if both
and H jointly have Gaussian kurtosis. If they are even jointly Gaussian, then it is clear that
such that the model
has independent Gaussian error. Thus, when using only observational data, it behaves exactly like a model under the global null hypothesis and, naturally, we cannot infer the confounding effect. Apart from Gaussian kurtosis,
would be mainly due to special constellations implying cancelation of terms that one does not expect to encounter in normal circumstances.
For , Zj and
must not be independent. As
, the single-covariate model (11) is not a linear causal model with independent error term as given in (1). Therefore, from a causal inference perspective, one can argue that rejecting the local null hypothesis
is the right thing to do in this case. Furthermore, having variables
is usually related to certain model assumptions except for very specific data setups that lead to cancelation of terms. Under these assumptions,
is then usually implied. An example where
, but (potentially)
is data for which
using the definitions from model (8).
Recovery of U
Based on our asymptotic results when the global null does not hold true, we would like to construct a method that perfectly detects the unconfounded variables as . Define
(14)
(14)
The question is how and when can we ensure that
Suppose that we conduct our local z-tests at level αn, which varies with the sample size such that as
. It will be more convenient to interpret this as a threshold on the (scaled) absolute z-statistics, say, τn that grows with n, where the z-statistics is defined as
We refrain from calling it zj to avoid confusion. We use an additional assumption which is a relaxed version of (B3).
(A4)
Theorem 6.
Assume that the data follows the model (10) and that (A1)–(A3) hold. Assume that (B1) and (A4) hold . Let τn be the threshold on the absolute z-statistics to reject the according null hypothesis with
and
. Then,
In other words, we can choose τn to grow at any rate slower than .
4 Specific Models
In this section, we discuss two types of models where the local interpretation applies. In these settings, there are variables for which and Assumptions (B1)–(B3) hold even though the overall data follows the model (8). We note here first that the model of jointly Gaussian
, for which the method is suited, is a special case of the model in Section 4.2.
4.1 Block Independence of
Assume that the errors can be grouped into two or more independent and disjoint blocks. Denote the block that includes j by
. Then, it is clear that
if
. If
, that is, the confounder has no effect onto
, (13) holds for all covariates in
. Then, no variable in
contributes to the best linear predictor for
. Due to the block independence, this yields
and
, that is, (B2) is fulfilled. This also ensures
. We consider the remaining assumptions: Naturally, the regression
versus
only involves
and (B3) holds as well. For (B1), separately consider the case
and
. In the first case,
. In the second case,
.
Theorem 7.
Assume the data follows the model (8) with errors that can be grouped into independent blocks. Then,
In some cases, block independence may be a restrictive assumption. Testing this assumption is not an easy problem, and will remain out of the scope of this article. However, the HOLS check still provides an indirect check of such an assumption since HOLS would likely reject the local null-hypotheses for all covariates, at least for large datasets, if there is no block that is unaffected by the confounding.
4.2 Linear Structural Equation Model
From the previous sections, we know that locally unconfounded structures, in the sense that , are strongly related to zeroes in the precision matrix. Thus, the question arises for what type of models having zeroes in the precision matrix is a usual thing. Besides block independence, which we have discussed in Section 4.1, this will mainly be the case if the data follows a linear structural equation model (SEM). Thus, we will focus on these linear SEMs for the interpretation of local, that is, by parameter, null hypotheses.
To start, assume that there are no hidden variables. So, let X be given by the following linear SEM(15)
(15) where the
are independent and centered random variables. We use the notation
and
for j’s parents, children and ancestors. Further, assume that there exists a directed acyclic graph (DAG) representing this structure. For this type of model, we know that a variable’s Markov boundary consists of its parents, its children, and its children’s other parents. For every other variable k outside of j’s Markov boundary, we have
. Thus, these 0 partial correlations are very usual. In the following, we will analyze how our local tests are especially applicable to this structure.
In the context of linear SEMs, hidden linear confounders can be thought of as unmeasured variables. Therefore, we split X which contains all possible predictors into two parts. Let be the measured variables and
the hidden confounder variables. Let
with the according subsets
and
. Then, we can write
for some suitable
, where
for
if
and
. Note that
is always invertible since it can be written as a triangular matrix with ones on the diagonal if permuted properly. Under model (8), Y can be thought of as a sink node in (15). To avoid confusion, we call the parameter if all predictors were observed
. This leads to the definitions
(16)
(16)
When only the given subset is observed we are interested in the parameter as before. We have
iff
.
Theorem 8.
Assume that the data follows the model (15) and (16). Let and
be the observed and hidden variables. Denote by
the closest ancestors of k that are in M. Consider some
.
In other words, the causal parameter can only change for variables that have at least one direct descendant in the hidden set which is a parent of Y itself. By direct descendant, we mean that there is a path from j to k that does not pass any other observed variable. We analyze for which variables we can reconstruct this causal parameter using ordinary least squares regression.
Theorem 9.
Assume that the data follows the model (15) and (16). Let and
be the observed and hidden variables. Then,
Thus, for those variables, we can (a) correctly retrieve the causal parameter using ordinary least squares regression and (b) detect that this is the true parameter by comparing it to .
Simulation example
We assess the performance of our HOLS method in a linear SEM using a simple example. In , we show the DAG that represents the setup.
Fig. 1 DAG of the linear SEM. X3 is assumed to be hidden which is depicted by the dashed circle. We use the following specifications: and
.
and
.
![Fig. 1 DAG of the linear SEM. X3 is assumed to be hidden which is depicted by the dashed circle. We use the following specifications: Ψ1=DΨ3=DΨ5∼t7/7/5, Ψ2=DΨ6=DΨ7∼N(0,1/2), Ψ4∼Unif[−3/2,3/2] and E∼N(0,1). θ2,1=θ7,6=1/2, θ4,2=θ4,3=θ6,4=θ6,5=0.5 and β3*=5/2.](/cms/asset/1a05c11b-e5e0-4b98-b542-2a33c780d274/uasa_a_2157728_f0001_b.jpg)
For simplicity, the parameters are set such that X1 to X7 all have unit variance. X3 is the only parent of Y and we apply the HOLS method using all but X3 as predictors, that is, X3 is treated as hidden variable. Following Theorem 9, we know that for variables X1 and X5 to X7 the causal effect on Y is consistently estimated with OLS, while we chose the detailed setup such that there is a detectable confounding bias on and
. Thus, ideally, our local tests reject the null hypothesis for those two covariates but not for the rest.
For numerical results, we let the sample size grow from 102 to 106. For each sample size, we do 200 simulation runs. On the left-hand side of , we show the average absolute z-statistics per predictor for the different sample sizes. For X2 and X4 we see the expected -growth. For the other variables, the empirical averages are close to the theoretical mean, which equals
, with a minimum of 0.70 and a maximum of 0.88. Further, we see that the confounding bias on the OLS parameter for X4, which is a child of the hidden variable, is easier to detect than the bias onto the parameter for X2, which is a child’s other parent. The multiplicity corrected p-value for X4 is rejected at level
in 91.5% of the cases for
, while as the null hypothesis for X2 is only rejected with a empirical probability of 3%. For X2, it takes
samples to reject the local null hypothesis in 89% of the simulation runs.
Fig. 2 Simulation in a linear SEM corresponding to . The results are based on 200 simulation runs. On the left: Average absolute z-statistics per covariate for different sample sizes. The dotted lines grow as and are fit to match perfectly at
. On the right: Empirical probability of perfectly recovering U (see, EquationEquation (12)
(12)
(12) ) for different sample sizes.
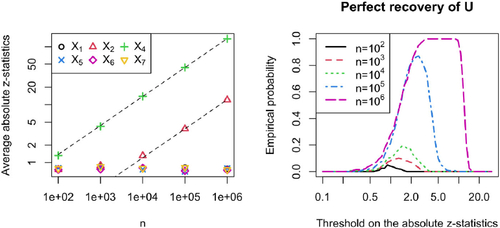
Following Section 3.2, we should be able to perfectly recover the set U (see, EquationEquation (12)(12)
(12) ) as
if we let the threshold on the absolute z-statistics grow at the right rate. Therefore, we plot on the right-hand side of the empirical probability of perfectly recovering U over a range of possible thresholds for the different sample sizes. For
, we could achieve an empirical probability of 1. For
the optimum probability is 87%, while as for
it is only 19%.
Naturally, perfectly recovering U is a very ambitious goal for smaller sample sizes, and one might want to consider different objectives. In , we plot two different performance metrics. On the left-hand side, we plot the empirical probability of not falsely including any variable in against the average intersection size
. The curve is parameterized implicitly by the threshold on the absolute z-statistics in order to reject the local null hypothesis for some variable. Thus, the graphic considers the question of how many variables in U can be recovered while keeping the probability of not falsely including any low. For a sample size of 105, we have an average intersection size of 3.97 allowing for a 10% probability of false inclusions. For 104, it is still 0.995. Thus, we can find (almost) one of the four variables in U on average. As we see in , the bias on
is much easier to detect than the bias on
. Thus, keeping the probability of including X2 in
low is still an ambitious task. Therefore, we analyze on the right-hand side of how many variables in U we can find while removing a certain amount of confounding signal. We define the remaining fraction as
that is, how much of the difference
persists in terms of
norm.
Fig. 3 Simulation in a linear SEM corresponding to . The results are based on 200 simulation runs. On the left: Probability of not falsely including a variable in versus average intersection size
(see, EquationEquation (14)
(14)
(14) ). On the right: average remaining fraction of confounding signal versus average intersection size
. It holds that
. Both curves use the threshold on the absolute z-statistics as implicit curve parameter. Note that the legend applies to either plot.
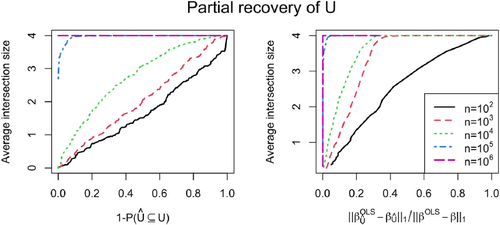
In this SEM, caries 2/3 of the confounding signal,
only 1/3. Accepting 1/3 of remaining confounding signal, we receive an average intersection size of 3.885 for a sample size of 103. For 104, the average is 4. Thus, if we allow for false inclusion of X2 we can almost perfectly retrieve all of U for sample size 103 already.
What if X includes descendants of Y? So far, we have only considered the case where X causally affects Y, but potentially, some of Y’s parents are missing leading to a confounding effect. However, another possibility for to not denote a causal effect is that there are descendants of Y amongst the predictors. The two different situations are depicted in . The case with descendants in the set of predictors fits our theory from before if interpreted properly. If the model (4) for Y holds true using only the parents as predictors, Y can be naturally included in the assumed linear SEM for X in (15). Then, one can also think of
as an unobserved confounder. The Markov boundary of
with respect to the observed predictors is the same as the Markov boundary of Y. Of course, it holds
, that is,
. Using Theorem 9, we find
Fig. 4 Left: SEM with a hidden confounder. Right: SEM with a descendant of Y.
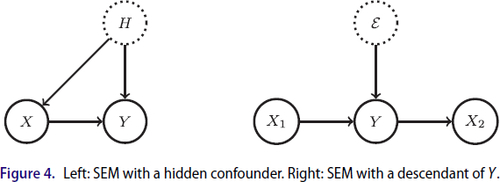
Thus, for all variables outside Y’s Markov boundary, one can correctly detect that they have no causal effect onto Y ceteris paribus. The coefficients for the variables in the boundary, which includes all parents, are up to term cancelations all subject to confounding bias. This can be detected under some conditions, as discussed in Section 3.2.
4.3 Beyond Linearity
We have mainly focused on linear models, that is, the data is either generated by model (4) or model (8). Naturally, this assumption might be questionable in practice. Therefore, we provide some intuition about how HOLS might be applied in a more general setup. As we only detect misspecification of the OLS coefficient without identifying the type of misspecification, one should not try to over-interpret the effect of the regressors in (see, Section 3.2). However, the linear effect of the variables in
can always be interpreted to be well-specified, meaning that
or at least “sufficiently” well-specified such that no misspecification is detected in the data. Generally, we can write
Thus, well-specification of implies
, that is, after linearly adjusting for
, Xj does not have any predictive power for
. If it does not have any predictive power after linear adjustment, it would be a natural conclusion that it does not have predictive power after optimally adjusting for
implying that
can be written as function of
only. This would then imply
Except for Gaussian data, such a linear relationship must be either causal or due to very pathological data setups. Excluding such unusual cancelations, the conclusion is that for there must be a true linear causal effect from Xj to Y keeping the other predictors fixed, which can be consistently estimated using OLS. Of course, if there are no locally linear structures, it might well be that
such that the local tests are not more informative than the global test. However, there is also nothing to be lost by exploiting this local view.
Note that the asymptotic results presented in Sections 3.1 and 3.2 hold for nonlinear data as well since they only assume model (10)–(11), which is the most general formulation.
5 Real Data Example
We analyze the flow cytometry dataset presented by Sachs et al. (Citation2005). It contains cytometry measurements of 11 phosphorylated proteins and phospholipids. There is a “ground truth” on how these quantities affect each other, the so-called consensus network (Sachs et al. Citation2005). Data is available from various experimental conditions, some of which are interventional environments. The dataset has been further analyzed in various projects, see, for example, Mooij and Heskes (Citation2013), Meinshausen et al. (Citation2016), and Taeb et al. (Citation2021). Following these works, we consider data from eight different environments, seven of which are interventional. The sample size per environment ranges from 707 to 913.
In our analysis, we focus on the consensus network from Sachs et al. (Citation2005). For each node, we go through all environments, fit a linear model using all its claimed parents as predictors, and assess the goodness of fit of the model using our HOLS check. In the consensus network, there is one bidirected edge between the variables PIP2 and PIP3. We include it as a parent for either direction. For each suggested edge, we also collect the p-values from the linear model fit in all environments, keeping only those where the edge passes the local HOLS check at level without multiplicity correction. We omit the multiplicity correction here to lower the tendency to falsely claim causal detection. In , we report the minimum p-value from OLS, over the environments where the HOLS check is passed, sorted by increasing p-values. Additionally, we show the number of environments in which the check is passed and out of these the number where the edge is significant at level
in the respective linear model fit (with Bonferroni correction over all 8 environments and 17 edges, that is, we require a p-value of at most
). Note that there is one p-value 0 reported corresponding to a t-value of 174, which exceeds the precision that can be obtained with the standard R-function lm.
Table 1 The working model is taken from the consensus network.
We see that the edge RAF → MEK is the most significant. Further, every edge of the consensus network passes the HOLS check in at least one environment. Frequently, we see that edges pass the HOLS check in certain environments without being significant in the linear model. Considering our discussion around linear SEMs, this could easily happen if the alleged predictor node is not actually in the Markov boundary of the response. In fact, there are seven edges that pass the HOLS check in every environment which are not significant based on the linear model fits. This is in agreement with Taeb et al. (Citation2021), where none of them is reported.
As we cannot guarantee that the data follows a linear SEM as in EquationEquation (15)(15)
(15) , we shall not interpret the edges that do not pass the HOLS check to be subject to hidden confounding. However, the fact that we still find a decent number of suggested edges that pass the HOLS check, at least in some environments, leads to evidence that the assumption of some local unconfounded linear structures is not unrealistic, see also the discussion in Section 4.3.
We can also analyze our results in the light of invariant causal prediction, see, for example, Peters, Bühlmann, and Meinshausen (Citation2016), where one typically assumes that interventions do not change the underlying graph except for edges that point toward the node that is intervened on. This assumption is highly questionable in practice, and our findings, which vary a lot over different environments, indicate that the assumption is likely not fulfilled in the given setup.
6 Discussion
We have introduced the so-called HOLS check to assess the goodness of fit of linear causal models. It is based on the dependence between residuals and predictors in misspecified models, leading to nonvanishing higher moments. Besides checking whether the overall model might hold true, the method allows to detect a set of variable for which linear regression consistently estimates a true (unconfounded) causal effect for certain model classes.
We extend the HOLS method to high-dimensional datasets based on the idea of the debiased Lasso (Zhang and Zhang Citation2014; van de Geer et al. Citation2014). This extension comes very naturally as our HOLS check involves nodewise regression just as the debiased Lasso.
Of particular interest are linear structural equation models, for which our method allows for very precise characterizations regarding which least squares parameters are causal effects. The result requires some non-Gaussianity. We complement our theory with a simulation study as well as a real data example.
A drawback of our method is that it does not distinguish whether a model is misspecified due to confounding or due to nonlinearities in the model. Therefore, an interesting follow-up direction would be to extend our methodology and theory from linear to nonlinear SEM using more flexible regression methods. This could allow to detect local causal structures in nonlinear settings as well.
Supplemental Material
Download PDF (124.6 KB)Supplemental Material
Download PDF (1.2 MB)Supplementary Materials
Simulation results as well as proofs and extended theory can be found in the supplemental material.
Data Availability Statement
Code scripts to reproduce the results presented in this article are available here https://github.com/cschultheiss/HOLS.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
Related Research Data
References
- Angrist, J. D., Imbens, G. W., and Rubin, D. B. (1996), “Identification of Causal Effects using Instrumental Variables,” Journal of the American Statistical Association, 91, 444–455. DOI: 10.1080/01621459.1996.10476902.
- Belsley, D. A., Kuh, E., and Welsch, R. E. (2005), Regression Diagnostics: Identifying Influential Data and Sources of Collinearity, Hoboken, NJ: Wiley.
- Bowden, R. J., and Turkington, D. A. (1990), Instrumental Variables, Cambridge: Cambridge University Press.
- Bühlmann, P. (2013), “Statistical Significance in High-Dimensional Linear Models,” Bernoulli, 19, 1212–1242. DOI: 10.3150/12-BEJSP11.
- Buja, A., Brown, L., Berk, R., George, E., Pitkin, E., Traskin, M., Zhang, K., and Zhao, L. (2019a), “Models as Approximations I: Consequences Illustrated with Linear Regression,” Statistical Science, 34, 523–544. DOI: 10.1214/18-STS693.
- Buja, A., Brown, L., Kuchibhotla, A. K., Berk, R., George, E., and Zhao, L. (2019b), “Models as Approximations II: A Model-Free Theory of Parametric Regression,” Statistical Science, 34, 545–565. DOI: 10.1214/18-STS694.
- Ćevid, D., Bühlmann, P., and Meinshausen, N. (2020), “Spectral Deconfounding via Perturbed Sparse Linear Models,” Journal of Machine Learning Research, 21, 9442–9482.
- Godfrey, L. G. (1991), Misspecification Tests in Econometrics: The Lagrange Multiplier Principle and Other Approaches, Cambridge: Cambridge University Press.
- Greene, W. H. (2003), Econometric Analysis, Noida: Pearson Education India.
- Guo, Z., Ćevid, D., and Bühlmann, P. (2022), “Doubly Debiased Lasso: High-Dimensional Inference Under Hidden Confounding,” Annals of Statistics, 50, 1320–1347. DOI: 10.1214/21-aos2152.
- Hausman, J. A. (1978), “Specification Tests in Econometrics,” Econometrica: Journal of the Econometric Society, 46, 1251–1271. DOI: 10.2307/1913827.
- Hoyer, P. O., Hyvärinen, A., Scheines, R., Spirtes, P., Ramsey, J., Lacerda, G., and Shimizu, S. (2008), “Causal Discovery of Linear Acyclic Models with Arbitrary Distributions,” in Proceedings of the Twenty-Fourth Conference on Uncertainty in Artificial Intelligence, pp. 282–289.
- Hyvärinen, A., and Oja, E. (2000), “Independent Component Analysis: Algorithms and Applications,” Neural Networks, 13, 411–430. DOI: 10.1016/s0893-6080(00)00026-5.
- Imbens, G. W., and Rubin, D. B. (2015), Causal Inference in Statistics, Social, and Biomedical Sciences, New York: Cambridge University Press.
- Lehmann, E. L., Romano, J. P., and Casella, G. (2005), Testing Statistical Hypotheses (Vol. 3), Cham: Springer.
- Maddala, G., and Lahiri, K. (2009), Introduction to Econometrics (4th ed), Chichester: Wiley.
- Meinshausen, N., Hauser, A., Mooij, J. M., Peters, J., Versteeg, P., and Bühlmann, P. (2016), “Methods for Causal Inference from Gene Perturbation Experiments and Validation,” Proceedings of the National Academy of Sciences, 113, 7361–7368. DOI: 10.1073/pnas.1510493113.
- Mooij, J. M., and Heskes, T. (2013), “Cyclic Causal Discovery from Continuous Equilibrium Data,” in Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence, pp. 431–439.
- Peters, J., Bühlmann, P., and Meinshausen, N. (2016), “Causal Inference by using Invariant Prediction: Identification and Confidence Intervals,” Journal of the Royal Statistical Society, Series B, 78, 947–1012. DOI: 10.1111/rssb.12167.
- Peters, J., Mooij, J. M., Janzing, D., and Schölkopf, B. (2014), “Causal Discovery with Continuous Additive Noise Models,” Journal of Machine Learning Research, 15, 2009–2053.
- Sachs, K., Perez, O., Pe’er, D., Lauffenburger, D. A., and Nolan, G. P. (2005), “Causal Protein-Signaling Networks Derived from Multiparameter Single-Cell Data,” Science, 308, 523–529. DOI: 10.1126/science.1105809.
- Shah, R. D., and Bühlmann, P. (2018), “Goodness-of-Fit Tests for High Dimensional Linear Models,” Journal of the Royal Statistical Society, Series B, 80, 113–135. DOI: 10.1111/rssb.12234.
- Shimizu, S., Hoyer, P. O., Hyvärinen, A., Kerminen, A., and Jordan, M. (2006), “A Linear Non-Gaussian Acyclic Model for Causal Discovery,” Journal of Machine Learning Research, 7, 2003–2030.
- Taeb, A., Gamella, J. L., Heinze-Deml, C., and Bühlmann, P. (2021), “Perturbations and Causality in Gaussian Latent Variable Models,” arXiv preprint arXiv:2101.06950.
- van de Geer, S., Bühlmann, P., Ritov, Y., and Dezeure, R. (2014), “On Asymptotically Optimal Confidence Regions and Tests for High-Dimensional Models,” The Annals of Statistics, 42, 1166–1202. DOI: 10.1214/14-AOS1221.
- Wang, Y. S., and Drton, M. (2020), “High-Dimensional Causal Discovery under Non-Gaussianity,” Biometrika, 107, 41–59. DOI: 10.1093/biomet/asz055.
- Zhang, C.-H., and Zhang, S. S. (2014), “Confidence Intervals for Low Dimensional Parameters in High Dimensional Linear Models,” Journal of the Royal Statistical Society, Series B, 76, 217–242. DOI: 10.1111/rssb.12026.