
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Clustering in high-dimensions poses many statistical challenges. While traditional distance-based clustering methods are computationally feasible, they lack probabilistic interpretation and rely on heuristics for estimation of the number of clusters. On the other hand, probabilistic model-based clustering techniques often fail to scale and devising algorithms that are able to effectively explore the posterior space is an open problem. Based on recent developments in Bayesian distance-based clustering, we propose a hybrid solution that entails defining a likelihood on pairwise distances between observations. The novelty of the approach consists in including both cohesion and repulsion terms in the likelihood, which allows for cluster identifiability. This implies that clusters are composed of objects which have small dissimilarities among themselves (cohesion) and similar dissimilarities to observations in other clusters (repulsion). We show how this modeling strategy has interesting connection with existing proposals in the literature. The proposed method is computationally efficient and applicable to a wide variety of scenarios. We demonstrate the approach in simulation and an application in digital numismatics. Supplementary Material with code is available online.
1 Introduction
Multidimensional clustering has been a fruitful line of research in statistics for a long time. The surge in the availability of data in recent years poses new challenges to clustering methods and the scalability of the associated computational algorithms, particularly in high dimensions. There are two main classes of clustering methods: those based on probabilistic models (model-based clustering), and constructive approaches based on dissimilarities between observations (distance-based clustering). The first class of methods includes popular tools such as mixture models (Mclachlan and Basford Citation1988; Dasgupta and Raftery Citation1998), product partition models (PPMs) (Hartigan Citation1990; Barry and Hartigan Citation1992), and nonparametric models like the Dirichlet process or more general species sampling models (Pitman Citation1996; Ishwaran and James Citation2003). An overview can be found in the article by Quintana (Citation2006). The second class of methods includes the popular hierarchical clustering, k-means, and its variants like k-medoids.
Distance-based clustering algorithms, although computationally accessible and scalable to high dimensions, are often less interpretable, and do not quantify clustering uncertainty because of the lack of a probabilistic foundation. Out-of-sample prediction is challenging with these algorithms, and inference on the number of clusters relies on heuristics such as the elbow method. Moreover, there are theoretical limitations to the results produced by any distance-based clustering algorithm; in particular, they cannot simultaneously satisfy constraints about scale-invariance and consistency while also exploring all possible partitions (Kleinberg Citation2002). On the other hand the drawbacks of model-based clustering methods are their analytic intractability and computational burden arising when working with high dimensional observations. To add to this, a fundamental difficulty with both types of clustering methods is that there is no consensus on what constitutes a true cluster (Hennig Citation2015), and that the aims of clustering should be application-specific.
The focus of this article is high dimensional clustering, in particular when point-wise evaluation of the likelihood is computationally intractable and posterior inference is infeasible. Our approach builds on recent proposals by Duan and Dunson (Citation2021) and Rigon, Herring, and Dunson (Citation2023) that bridge the gap between model-based and distance-based clustering. The main idea behind this research is to specify a probability model on the distances between observations instead of the observations themselves, reducing a multidimensional problem to a low-dimensional one. An early reference for Bayesian clustering based on distances can be found in Lau and Green (Citation2007).
Let denote a partition of the set
, and let
be a set of observations in
. It is convenient to represent a clustering through cluster allocation indicators
, where
when
. Rigon, Herring, and Dunson (Citation2023) reformulate the clustering problem in terms of decision theory. They show that a large class of distance-based clustering methods based on loss-functions, including k-means and k-medoids, are equivalent to maximum a posteriori estimates in a probabilistic model with appropriately defined likelihood on the distances. Explicitly, they consider product partition models where the likelihood decomposes into cluster-wise cohesions
where
measures the dissimilarity of observation i from cluster
and
is a parameter that controls the posterior dependence on the distances between observations. A major drawback in this approach is that the number of clusters K must be pre-specified, whereas K is an object of inference in many practical scenarios. Inference on K is also problematic in the method proposed by Duan and Dunson (Citation2021). This is due to identifiability issues that arise when working with distances. The starting point of their approach is an overfitted mixture model. By noting that in high dimensions the contribution of the cluster centers to the likelihood is negligible compared to the contribution from pairwise distances within the cluster, they specify a partial likelihood on the pairwise distances between observations
where g is a
density and
is the size of the kth cluster. Although this approach allows for estimation of K, it often relies on the specification of the maximum number of clusters in the sense that the clustering allocation significantly changes with this parameter.
We propose a model for high-dimensional clustering based on pairwise distances that combines cluster-wise cohesions with a repulsive term that imposes a strong identifiability constraint in the likelihood by penalizing clusters that are not well-separated. To this end, we borrow ideas from machine learning such as the cross-cluster penalty in the calculation of a silhouette coefficient, and from the literature on repulsive distributions. The idea of repulsive distributions has been previously studied in the context of mixture models (Petralia, Rao, and Dunson Citation2012; Xu, Müller, and Telesca Citation2016; Quinlan, Quintana, and Page Citation2017) to separate the location and scale parameters of the mixture kernels. We discuss the connection of repulsive distributions to our model in more detail in Section 2.1.
There are other instances of model-based clustering methods which exploit pairwise distances for cluster estimation. One example is the framework of Voronoi tesselations, a partition strategy that has found application in Bayesian statistics and partition models (Denison and Holmes Citation2001; Møller and Skare Citation2001; Corander, Sirén, and Arjas Citation2008). In this approach a set of centers is sampled from a prior and the sample space is partitioned into the associated Voronoi cells. When the centers are chosen from the observations themselves, the implied prior on partitions depends on the pairwise distances between the observations. In the Bayesian random partition model literature, there have been various proposals to include covariate information in cluster allocation probabilities. Most notably, Müller, Quintana, and Rosner (Citation2011) use a similarity function defined on sets of covariates belonging to all experimental units from a given cluster to modify the cohesions of a product partition model. Their similarity function is the marginal density of the covariates from an auxiliary probability model, which can also be interpreted as the marginal density on the distances of the covariates from a latent center in the auxilliary probability space. This approach incorporates information about the distances between covariates into the partition prior. In high-dimensional settings, that is, when the number of covariates is large, the covariate information dominates the clustering and the influence of the response is relatively inconsequential. See for example the work by Barcella, De Iorio, and Baio (Citation2017). Alternatively, Dahl (Citation2008), and Dahl, Day, and Tsai (Citation2017) propose random partition models through different modifications of the Dirichlet process cluster allocation probability: in the first case of the full conditional , and in the second case of the sequential conditional probabilities
.
All these methods are linked through the use of pairwise dissimilarities, often in the form of distances, to define a partition prior for flexible Bayesian modeling. Here, we use the same strategy to define the likelihood on pairwise distances while using standard partition priors such as the Dirichlet process or the recently proposed microclustering priors (Zanella et al. Citation2016; Betancourt, Zanella, and Steorts Citation2022). In this respect, our model is strongly related to composite likelihood methods which will be discussed in Section 2.1.
The article is structured as follows. In Section 2 we introduce the model and the computational strategy. In Section 3 we apply the proposed methodology to a problem from digital numismatics. We conclude the article in Section 4. In supplementary material we present details of the computational algorithm, extensive simulation studies, and further results from the data application.
2 Model
In this section we describe the pairwise distance-based likelihood, and we present a justification for our modeling approach. The proposed strategy can accommodate different partition priors. In particular, we discuss a microclustering prior (Betancourt, Zanella, and Steorts Citation2022) as it is the most relevant for our application in digital numismatics. We conclude the section with a discussion on the choice of hyperparameters, and of the MCMC algorithm.
2.1 Likelihood Specification
We specify the likelihood on pairwise distances between observations instead of directly on the observations. This strategy falls naturally into the framework of composite likelihood. In its most general form, a composite likelihood is obtained by multiplying together a collection of component functions, each of which is a valid conditional or marginal density (Lindsay Citation1988). The utility of composite likelihoods is in their computational tractability when a full likelihood is difficult to specify or computationally challenging to work with. In this context, the working assumption is the conditional independence of the individual likelihood components. Key examples of composite likelihood approaches include pseudolikelihood methods for approximate inference in spatial processes (Besag Citation1975), posterior inference in population genetics models (Li and Stephens Citation2003; Larribe and Fearnhead Citation2011), pairwise difference likelihood and maximum composite likelihood in the analysis of dependence structure (Lele and Taper Citation2002), and the use of independence log-likelihood for inference on clustered data (Chandler and Bate Citation2007). See Varin, Reid, and Firth (Citation2011) for an overview. Other approaches to overcome likelihood intractability include specifying the likelihood on summary statistics of the data (Beaumont, Zhang, and Balding Citation2002), or comparing simulated data from the model with the observed data (Fearnhead and Prangle Citation2012). Both these ideas underlie approximate Bayesian computation (Marjoram et al. Citation2003).
Combining ideas from composite likelihood methods and distance-based clustering, our strategy is to specify a likelihood on the distances that decomposes into a contribution from within-cluster distances and cross-cluster distances:
(1)
(1) where
is the matrix of all pairwise distances,
, and f and g are probability densities. Note that this formulation does not result in a valid probability model on the data, but rather on a space
that is obtained as follows: let G be the group of isometries of
(with respect to the chosen distance metric), and let
be the diagonal subgroup of
. Then
is the orbit space
(for a reference see Klaus Citation1995). In Section 2.3 we discuss the choice of f and g in (1). The first term in (1) is similar to the cohesions of Duan and Dunson (Citation2021) and Rigon, Herring, and Dunson (Citation2023) and quantifies how similar the observations within each cluster are to each other; we call this the cohesive part of the likelihood.
The second multiplicative term in the likelihood, which we call the repulsive term, is related to the idea of repulsive mixtures. Typical mixture models associate with each cluster a location parameter , and these are assumed to be iid from a fixed prior. Petralia, Rao, and Dunson (Citation2012), and Quinlan, Quintana, and Page (Citation2017) relax the iid assumption and use a repulsive joint prior of the form
(2)
(2) where d is a distance measure and h decays to 0 for small values of its input. They do this to penalize clusters that are too close to each other, inducing parsimony. We generalize this idea by using a repulsive distribution on the observations themselves, that is, by setting g in (1) to a density that decays as its input approaches 0. This form of repulsion is important to our application because it encourages the formation of clusters from points that are not only close to each other but also have similar distances to points in other clusters. Moreover the repulsion allows for inter-cluster distances of different magnitude for different pairs of clusters. Consequently, this strategy allows for estimation of the number of clusters. Using repulsion on the observations instead of the cluster centers is also a viable strategy when the location parameters are not of interest or when posterior inference on the location parameters is computationally difficult, as is usually the case in high-dimensional clustering (Johnstone and Titterington Citation2009). In doing so, we relax the assumption of conditional independence between clusters given their cluster-specific parameters. In supplementary material we further investigate the role of the repulsion term, showing its importance in identifying the number of clusters. This is consistent with the work by Fúquene, Steel, and Rossell (Citation2019) that shows that repulsion leads to faster learning of K in model-based settings.
2.2 Posterior Uncertainty
The distance based likelihood in (1) has sharper peaks and flatter tails than the model-based likelihood from the raw data, as is typical in composite likelihood or pseudo-likelihood frameworks due to the artificial independence assumption. Intuitively, our model assumes independent pieces of information whereas the data generation process may only produce
independent pieces of information. Consequently, well-separated clusters are associated to high posterior probability with corresponding underestimation of uncertainty, while poorly separated clusters will often be split into smaller clusters due to the artificially increased uncertainty. Although the estimation of uncertainty is inaccurate, localization of modes in the posterior is satisfactory (as is typically the case for composite likelihood methods) and the model is able to provide some measure of uncertainty even when direct approaches fail to recover the clustering structure. This is demonstrated in our simulations in supplementary materials. Moreover, our model can be used to guide more direct model-based approaches with better prior information. We believe that the major drawback of our approach is its dependence on a choice of dissimilarity measure, as we remark in the discussion section. Finally we note that a common strategy in composite likelihood models to counteract the underestimation of uncertainty is to artificially flatten the likelihood, raising it to the power
. We cannot employ the same approach as this would flatten both the within-cluster terms and the cross-cluster terms, making them overlap significantly and making the clusters unidentifiable. We have nevertheless tried this approach, and as expected we obtained poor inference results (not shown).
2.3 Choice of Distance Densities
The likelihood in (1) results in a monotonically decreasing density on the within-cluster distances if the cohesive term is chosen as the exponential of a loss function, as suggested by Rigon, Herring, and Dunson (Citation2023). This choice might be too restrictive in application, as more flexible distributions are required to accommodate the complexity in the data. As a consequence of such a restrictive choice, more dispersed clusters may be broken up into smaller clusters. Rigon, Herring, and Dunson (Citation2023) alleviate this problem by fixing the number of clusters. We instead propose a more flexible choice of f and g motivated by the following commonly encountered scenario.
Assume that the original data have a multivariate Normal distribution such that each cluster is defined by a Normal kernel
Hence, the within-cluster differences are distributed as and the corresponding squared Euclidean distances have a
distribution. On the other hand, inter-cluster squared distances are distributed as a three-parameter noncentral
:
where
is the noncentrality parameter and corresponds to the squared distance between the cluster centers
and
,
is a scale parameter related to the within-cluster variances of the two clusters, l is the dimension of the original data, and
is a
density. This setup would cover many real world applications, but posterior inference on the parameters of a noncentral
is unnecessarily complicated. Moreover the noncentral
is defined on the squared Euclidean distance, which will lead to a noncentral
distribution on the distances. Indeed when we know that the data generation process coincides with a Normal mixture, we should use the correct distribution but this is not often the case. As such when the data generating process is unknown we work with Gamma distributions on the distances mainly for computational convenience. We propose setting f to be a
as in Duan and Dunson (Citation2021):
where x is a pairwise distance and
is a fixed shape parameter that controls the cluster dispersion. When
, f is a monotonically decreasing density. We set g in (1) to be a
density, where
is a fixed shape parameter that controls the shape of the decay of g toward the origin. We note that the constraint
ensures that g is a repulsive density by forcing
. An appropriate choice of
and
is application-specific, and we discuss possible alternatives in Section 2.4.
In our experiments we find that using a Gamma distribution directly on the distances does not have an appreciable effect on posterior inference, suggesting that the methodology is robust. This strategy is also followed by Duan and Dunson (Citation2021) but for different reasons.
2.4 Prior Specification
Here we discuss the choice of priors for the cluster-specific parameters and the partition.
2.4.1 Prior Cluster-Specific Parameters
For computational convenience, we choose conjugate Gamma priors and
. To set
, and
, we follow a procedure in the spirit of empirical Bayes methods, as straightforward application of empirical Bayes is hindered by an often flat marginal likelihood of the parameters in question. We summarize our method in Algorithm 1.
Algorithm 1
Choosing , and
Compute a heuristic initial value for K, say
, via the elbow method, fitting k-means clustering for a range of values of K and with the within-cluster-sum-of-squares (WSS) score as the objective function.
Use k-means clustering with
Split the pairwise distances into two groups A and B that correspond to the within-cluster and inter-cluster distances in this initial configuration.
Fit a Gamma distribution to the values in A using maximum likelihood estimation and set
Set
Repeat Steps 4 and 5 to obtain values for
The range for K in step 1 of the algorithm can be chosen to be quite broad, for example from one to . When only pairwise distances or dissimilarities are available and not the raw data, k-medoids and the within-cluster-sum-of-dissimilarities can be used instead.
The proposed method depends on the choice of K obtained by the elbow method. In supplementary material we show that posterior inference is robust to the choice of K obtained, as long as this choice lies within a sensible range. We also propose an alternative method to fit the prior that results in a mixture prior on possible values for K.
2.4.2 Prior on Partitions
The model can accommodate any prior on partitions of the observations, which is equivalent to specifying a prior on the partitions of . Let
denote a partition of [n] where the
are pairwise disjoint and
. A common choice is to use a product partition model (PPM) as the prior for
; see for example the paper by Hartigan (Citation1990) or Barry and Hartigan (Citation1992). In a PPM there is a nonnegative function
, usually referred to as a cohesion function, which is used to define the prior
where M is a normalizing constant. This prior includes as special cases the Dirichlet Process (Quintana and Iglesias Citation2003) as well as Gibbs-type priors. Alternatively one can consider the implied prior on partitions derived from a species sampling model (Pitman Citation1996); in this case it can be shown that
where
is the number of elements in
and p is a symmetric function of its arguments called the exchangeable partition probability function (EPPF).
In our application, we opt for a prior that has the microclustering property (Miller et al. Citation2015; Zanella et al. Citation2016; Betancourt, Zanella, and Steorts Citation2022); that is, cluster sizes grow sublinearly in the number of observations n. This property is appropriate for die analysis in numismatics where each die is represented by a very limited number of samples. We use a class of random partition models described in Betancourt, Zanella, and Steorts (Citation2022) called Exchangeable Sequence of Clusters (ESC). In this model a generative process gives rise to a prior on partitions, which we describe briefly. A random distribution is drawn from the set
of distributions on the positive integers;
is distributed according to some
. The cluster sizes
are sampled from
, conditional upon the following event
We require that for all
in the support of
to ensure that
for all
. A random partition with cluster sizes
is drawn by allocating cluster labels from a uniform permutation of
The resulting partition model is denoted . Here we give details on the clustering structure implied by the microclustering prior in (3) and (4), as well as on the prior predictive distribution of the cluster label for a new observation in (5). Betancourt, Zanella, and Steorts (Citation2022) derive the conditional and marginal EPPF for the class of microclustering priors as well as the conditional allocation probabilities. Let
be the cluster allocation labels for
. Then for any
Betancourt, Zanella, and Steorts (Citation2022) show that:
(3)
(3)
(4)
(4)
(5)
(5) where
is the set of cluster labels excluding
,
is the numerosity of
, and
is the number of clusters in the induced partition of
. Betancourt, Zanella, and Steorts (Citation2022) suggest setting
to a negative binomial truncated to the positive integers and show that the resulting model, which they call the ESC-NB model, exhibits the microclustering property. We use a variant of the ESC-NB model by setting
to a shifted negative binomial as it aids the choice of hyperparameters. We set
where
and
. To set the hyperparameters
, and v, one can use the conditional distribution on the number of clusters K and a prior guess on the number of clusters. In general posterior inference is not sensitive to the choice of the hyperparameters in the prior for r and p. Nevertheless, the marginal and conditional distributions of K can be analytically calculated or approximated as in the following proposition. The proposition can be used for setting the hyperparameters in the priors for r and p, especially when relevant prior information on K is available.
Proposition 1
.
The conditional distribution on the number of clusters K in the ESC model with a shifted negative binomial is given by
(6)
(6) where
is the Beta function. The marginal distribution of K is approximated by
(7)
(7)
where
is the confluent hypergeometric function of the second kind. If
, the marginal distribution of K is exactly given by
(8)
(8)
where
and
.
Proof.
See supplementary material. □
In our simulation studies and real data analyses, we opt for an empirical Bayes approach (see Algorithm 2) to set the hyperparameters for r and p, which is consistent with our method for setting the hyperparameters for and
.
Algorithm 2
Choosing values for , and v.
Fix the cluster labels at the initial clustering configuration obtained in Step 2 of Algorithm 1.
Sample r and p from their conditional posteriors in the model using a
Use MLE to fit a
We conclude this section by noting that the model lends itself to any choice of partition prior. Particular choices could favor a different clustering structure and should be tailored to the application in question. For instance, Pitman-Yor (Pitman and Yor Citation1997) or Gibbs-type priors (Gnedin and Pitman Citation2006) could be used as drop-in replacements for the microclustering prior and cover a wide range of partition priors such as mixture with random number of components (Miller and Harrison Citation2018; Argiento and De Iorio Citation2022). When prior information on the partition is available a more direct approach could be employed; see for example Paganin et al. (Citation2021). We also note that as the number of observations n grows larger than the number of clusters K (i.e., when not all clusters are singletons), posterior inference quickly becomes less sensitive to the choice of partition prior as the likelihood will dominate the posterior.
2.5 Posterior Inference
Posterior inference is performed through an MCMC scheme. Cluster allocations can be updated either through a Gibbs update of individual cluster labels, or through a split-merge algorithm as proposed by Jain and Neal (Citation2004). The split-merge algorithm is more efficient for large n as it leads to better mixing of the chain. In our applications we combine a Gibbs step and a split-merge step in each iteration as suggested by Jain and Neal (Citation2004). In supplementary material we show that the time complexity of the cluster reallocation step is . We note that the pre-computation of the
pairwise distances is typically not a bottleneck, as the distances are computed only once. Posterior inference for r and p are performed through a Metropolis step and a Gibbs update, respectively. We do not sample the
and
as we marginalize over them. If required, they can be sampled by conditioning on the cluster allocation and sampling from a Gamma-Gamma conjugate model. See supplementary material for derivations of the posterior conditionals and the full details of the Gibbs and split-merge algorithms.
We note that the MCMC scheme can be modified as necessary to accommodate different choice of partition priors, as efficient algorithms are available for most Bayesian nonparametric processes.
3 Application to Digital Numismatics
3.1 Description of the Data
Die studies determine the number of dies used to mint a discreet issue of coinage. With almost no exceptions, dies were destroyed after they wore out, which is why die studies rely on an analysis of the coins struck by them. From a statistical viewpoint the first task to be accomplished is clustering the coins with the goal of identifying if they were cast from the same die.
Die studies are an indispensable tool for pre-modern historical chronology and economic and political history. They are used for putting coins (and by extension rulers and events) into chronological order, to identify mints, and for estimating the output of a mint over time. While digital technology has made large amounts of coinage accessible, numismatic research still requires meticulous and time-consuming manual work. Conducting a die study is time consuming because each coin has to be compared visually to every other coin at least once to determine whether their obverse (front face) and their reverse (back face) were struck from the same dies. For example, a study of 800 coin obverses would require more than 300,000 visual comparisons and could take an expert numismatist approximately 450 hours from scratch. This makes it practically impossible to conduct large scale die studies of coinages like that of the Roman Empire, which would be historically more valuable than the small-scale die studies done today. The practical difficulties of manual die-studies calls for computer-assisted die studies.
We consider here silver coins from one of several issues minted between late 64 C.E and mid 66 C.E., immediately after the great fire of Rome. Pressed for funds, Nero reduced the weight of gold and silver coins by c. 12%, so that he could produce more coinage out of the available bullion stock. Determining the number of dies used to strike this coinage will make it possible to come up with reasonable estimates of how many gold and silver coins Nero minted during this period, and help to determine how much bullion he may have saved in the immediate aftermath of the great fire. This type of numismatic work would require time-consuming effort by highly trained experts if performed manually. Here we demonstrate the potential in digital numismatics of our strategy by clustering a dataset of 81 coins, which requires a few hours for pre-processing of the images and a few minutes to fit our model. The distance computation is straightforward to parallelize, further speeding up computation. The data consists of 81 high-resolution images of obverses taken from a forthcoming die study on Nero’s coinage. To test the performance of our model, die analysis is first performed by visual inspection by a numismatic expert to provide the ground truth. This analysis identifies 10 distinct die groups. The images were standardized to 380 380 pixels to compute the pairwise distances.
3.2 Computing Pairwise Distances
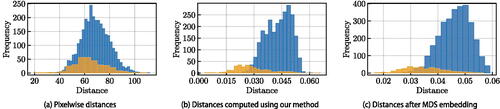
Fitting the model in (1) requires the definition of a distance between images that has the potential to differentiate between images of coins minted from different dies and to capture the similarity of images of coins minted from the same die. The pixelwise Euclidean distance between the digital images cannot be used to obtain such information about the semantic dissimilarity of images. Due to the high dimensionality of the ambient image space the dataset of images is sparse, with little separation between the largest and smallest pairwise Euclidean distances in the dataset (Beyer et al. Citation1999). illustrates this for our dataset. In contrast, numismatists rely on domain knowledge and often years of experience to identify few key feature points in images of coins to aid comparisons. This essentially coincides with disregarding irrelevant features and performing dimension reduction. When defining the distance between images, our goal is to automate expert knowledge acquisition and focus on extraction of key features. This is a common strategy in many tasks in computer vision (Szeliski Citation2010) and, more generally, in statistical shape analysis (Dryden and Mardia Citation2016; Gao et al. Citation2019a). Taylor (Citation2020) uses landmarking to define a distance between images of ancient coins with the ultimate goal of die-analysis using simple hierarchical clustering. They do not provide an estimate of the number of dies represented in the sample or an overall subdivision of coins into die groups.
Figure 1: Coin data: Histogram of within-cluster distances (orange) and inter-cluster distances (blue). The clusters correspond to the true clusters obtained by a die study conducted by an expert numismatist.
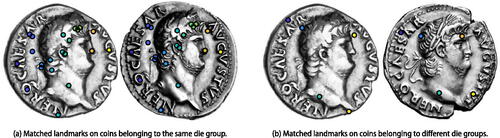
To identify comparable key features across pairs of coin images, we find sets of matched landmark pairs between images by exploiting the Scale-Invariant Feature Transform (SIFT) (Lowe Citation2004) and a low-distortion correspondence filtering procedure (Lipman et al. Citation2014). We use the landmark ranking algorithm of Gao, Kovalsky, and Daubechies (Citation2019b) and Gao et al. (Citation2019a), which we extend for ranking pairs of landmarks. We define a dissimilarity score between images using these ranked landmark pairs. shows an example of matched landmark sets for images from the same die group and from different die groups. Details of the pipeline are provided in the supplementary material. These dissimilarity scores are used as input for our algorithm. The pairwise dissimilarities are shown in , and in supplementary material we compare the prior predictive distribution on dissimilarities as implied by our data-driven prior specification process to the kernel density estimate of the dissimilarities.
Figure 2: Matched sets of landmarks are used to construct a dissimilarity measure between images of coins. The number of landmarks is one of the components of this dissimilarity measure. Original unprocessed images are courtesy of the American Numismatic Society (n.d.) (left image in (a) and (b)), the Classical Numismatic Group (n.d.) (right image in (a)), and Gerhard Hirsch Nachfolger (Citation2013) (right image in (b)).
3.3 Results
We run our model on the coin data for 50,000 iterations, discarding the first 10,000 iterations as burnin. We compare our model to the Mixture of Finite Mixtures (MFM) model proposed by Miller and Harrison (Citation2018) and a Dirichlet Process Mixture (DPM), both as implemented in the Julia package BayesianMixtures.jl (Miller Citation2020), using Normal mixture kernels with diagonal covariance matrix and conjugate priors. For the purposes of the comparison, we embed the coins as points in Euclidean space by applying Multi-Dimensional Scaling (Kruskal Citation1964) (as implemented by the MultivariateStats.jl package in Julia) to the dissimilarity scores between the coins. We run the MFM and DPM samplers on the MDS output, which is 80-dimensional.
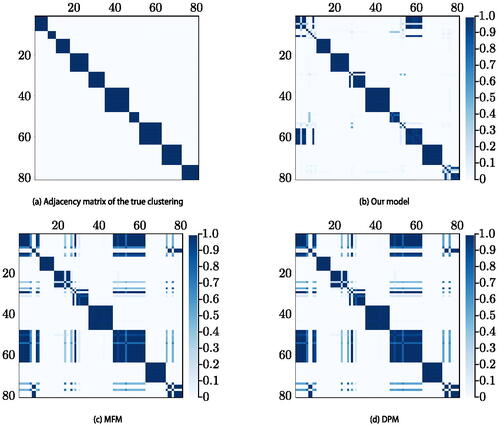
To evaluate algorithm performance, we compute the co-clustering matrix whose entries are given by
. Each
can be estimated from the MCMC output and its estimate is not affected by the label-switching phenomenon (Stephens Citation2000; Fritsch and Ickstadt Citation2009). In we compare the true adjacency matrix to the co-clustering matrices obtained by our model, MFM, and DPM. In we show the marginal prior predictive distribution on the number of clusters K implied by our choice of prior hyperparameters, as well as the posterior distribution on K for each method. In Supplementary Material we show the posterior co-clustering matrix for our model without repulsion, the posterior distributions of r and p, and we provide convergence diagnostics for the sampler.
Figure 3: Coins data: Posterior distribution of the number of clusters K.
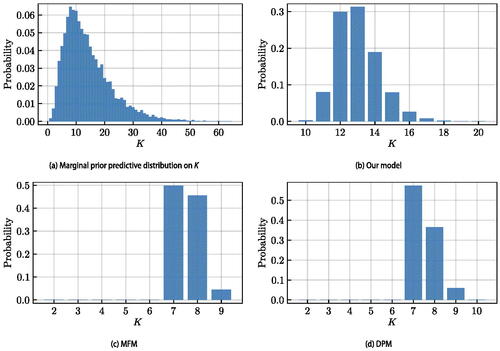
Figure 4: Coins data: Posterior co-clustering matrices.
For each method a clustering point-estimate is obtained via the SALSO algorithm (Dahl, Johnson, and Müller Citation2022). This algorithm takes as its input the posterior samples of cluster allocations and searches for a point estimate that minimizes the posterior expectation of the Variation of Information distance (Meilǎ Citation2007; Wade and Ghahramani Citation2018). Point estimates are also obtained via k-means (on the MDS output) and k-medoids (on the dissimilarities), as implemented in the Clustering.jl package in Julia, using the value of K obtained by the elbow method as in Section 2.4.1. shows the Binder loss, Normalized Variation of Information (NVI) distance, Adjusted Rand Index (ARI), and Normalized Mutual Information (NMI) of these point estimates with respect to the true clustering. In supplementary material we show the adjacency matrices for the various point estimates.
Table 1: Coins data: Comparison of point estimates with the true clustering.
The findings from this application suggest that clustering with our model on the distances alone can produce sensible results in terms of the original data, providing a viable strategy for high-dimensional settings. We further demonstrate the effectiveness of our model through simulation studies in supplementary material. These studies (a) show the effect of dimensionality and cluster separation on posterior inference, (b) demonstrate the robustness of our method to choice of prior hyperparameters, and (c) demonstrate the importance of the repulsion term in our likelihood. We remind the reader that our model underestimates uncertainty as discussed in Section 2.2.
4 Discussion
It is the curse of dimensionality, a malediction that has plagued the scientist from the earliest days.
—Richard Bellman, 1961
When clustering in large dimensions, the main statistical challenges include (i) accommodating for the sparsity of points in large dimensions, (ii) capturing the complexity of the data generating process in high-dimensions, including the interdependence of features which might be cluster-specific, (iii) estimating model parameters, (iv) developing methods which are robust to different underlying generative processes and cluster characteristics, (v) devising computational algorithms that are scalable to large datasets, (vi) producing interpretable results, (vii) assessing the validity of the cluster allocation, and (viii) determining the degree to which different features contribute to clustering.
We propose a hybrid clustering method for high-dimensional problems which is essentially model-based clustering on pairwise distances between the original observations. This method is also applicable in settings where the likelihood is not computationally tractable. The strategy allows us to overcome many of the aforementioned challenges, bypassing the specification of a model on the original data. The main contribution of our work is to combine cohesive and repulsive components in the likelihood, and we provide theoretical justifications for our model choices. Our method is robust to different generative processes, and computationally more efficient than model-based approaches for high dimensions because it reduces the multi-dimensional likelihood on each data point to a unidimensional likelihood on each distance. Our method also leads to interpretable results as clusters are defined in terms of the original observations. The model can be easily extended to categorical variables by considering (for example) the Hamming distance or cross entropy and specifying appropriate distributions f and g in (1). The main drawbacks of our methodology is that the role of each feature is embedded in the distances and model performance is dependent on the definition of the distances. We do not advise the use of a distance-based approach when the dimension is small because in that case standard model-based approaches work well, and using distances as a summary of the data causes loss of information.
From our application in digital numismatics, it is clear that the definition of the distances plays a crucial role and a future direction of this work is to develop landmark estimation methods better able to capture the distinguishing features of images.
Finally, there is an interesting connection between the likelihood in (1) and the likelihood for a stochastic blockmodel in the p1 family (Snijders and Nowicki Citation1997; Nowicki and Snijders Citation2001; Schmidt and Morup Citation2013) where every block of nodes can be thought of as a cluster of similar objects. This connection is a topic of further research.
Supplementary Materials
Additional results:
Proof of Theorem 1, detailed description of the MCMC algorithm, computational complexity of the MCMC algorithm, details of the method to compute distances between coin images, additional plots and results from the numismatic example, alternative method to choose prior hyperparameters, and simulation studies are available online in a supplementary PDF document.
Code:
Julia code to perform posterior inference is available on Github at https://github.com/abhinavnatarajan/RedClust.jl, and also as a package in the default Julia package registry (“General”). The code used to run the numismatic and simulated examples and generate the corresponding figures is available at https://github.com/abhinavnatarajan/RedClust.jl/tree/examples.
Supplemental Material
Download Zip (4.5 MB)Disclosure Statement
We report that there are no competing interests to declare.
Additional information
Funding
Related Research Data
References
- American Numismatic Society (n.d.). “Silver Denarius of Nero, Rome, AD 64 - AD 65 (BMC 74, RIC I Second Edition Nero 53),” ANS ID: 1944.100.39423, available at http://numismatics.org/collection/1944.100.39423.
- Argiento, R., and De Iorio, M. (2022), “Is infinity that far? A Bayesian Nonparametric Perspective of Finite Mixture Models,” Annals of Statistics, 50, 2641–2663. DOI: 10.1214/22-AOS2201.
- Barcella, W., De Iorio, M., and Baio, G. (2017), “A Comparative Review of Variable Selection Techniques for Covariate Dependent Dirichlet Process Mixture Models,” Canadian Journal of Statistics, 45, 254–273. DOI: 10.1002/cjs.11323.
- Barry, D., and Hartigan, J. A. (1992), “Product Partition Models for Change Point Problems,” The Annals of Statistics, 20, 260–279. DOI: 10.1214/aos/1176348521.
- Beaumont, M. A., Zhang, W., Balding, D. J. (2002), “Approximate Bayesian Computation in Population Genetics,” Genetics, 162, 2025–2035. DOI: 10.1093/genetics/162.4.2025.
- Besag, J. (1975), “Statistical Analysis of Non-Lattice Data,” Journal of the Royal Statistical Society, Series D, 24, 179–195. DOI: 10.2307/2987782.
- Betancourt, B., Zanella, G., and Steorts, R. C. (2022), “Random Partition Models for Microclustering Tasks,” Journal of the American Statistical Association, 117, 1215–1227. DOI: 10.1080/01621459.2020.1841647.
- Beyer, K., Goldstein, J., Ramakrishnan, R., and Shaft, U. (1999), “When Is “Nearest Neighbor” Meaningful?” in Database Theory—ICDT’99, eds. C. Beeri, and P. Buneman, pp. 217–235. Berlin Heidelberg: Springer. DOI: 10.1007/3-540-49257-7˙15.
- Chandler, R. E., and Bate, S. (2007), “Inference for Clustered Data Using the Independence Loglikelihood,” Biometrika, 94, 167–183. DOI: 10.1093/biomet/asm015.
- Classical Numismatic Group (n.d.). “Triton XX, Lot: 673,” RIC I 53; WCN 57; RSC 119; BMCRE 74-6; BN 220-1, available at https://www.cngcoins.com/Coin.aspx?CoinID=324866.
- Corander, J., Sirén, J., and Arjas, E. (2008), “Bayesian Spatial Modeling of Genetic Population Structure,” Computational Statistics, 23, 111–129. DOI: 10.1007/s00180-007-0072-x.
- Dahl, D. B. (2008), “Distance-Based Probability Distribution for Set Partitions with Applications to Bayesian Nonparametrics,” in “2008 JSM Proceedings: Papers Presented at the Joint Statistical Meetings, Denver, Colorado, August 3-7, 2008, and other ASA-sponsored Conferences; Communicating Statistics: Speaking Out and Reaching Out,” Alexandria, VA: American Statistical Association.
- Dahl, D. B., Day, R., and Tsai, J. W. (2017), “Random Partition Distribution Indexed by Pairwise Information,” Journal of the American Statistical Association, 112, 721–732. DOI: 10.1080/01621459.2016.1165103.
- Dahl, D. B., Johnson, D. J., and Müller, P. (2022), “Search Algorithms and Loss Functions for Bayesian Clustering,” Journal of Computational and Graphical Statistics, 31, 1189–1201. DOI: 10.1080/10618600.2022.2069779.
- Dasgupta, A., and Raftery, A. E. (1998), “Detecting Features in Spatial Point Processes with Clutter via Model-Based Clustering,” Journal of the American Statistical Association, 93, 294–302. DOI: 10.2307/2669625.
- Denison, D. G. T., and Holmes, C. C. (2001), “Bayesian Partitioning for Estimating Disease Risk,” Biometrics, 57, 143–149. DOI: 10.1111/j.0006-341X.2001.00143.x.
- Dryden, I. L., and Mardia, K. V. (2016), Statistical Shape Analysis, with Applications in R, New York, NY: Wiley. DOI: 10.1002/9781119072492.
- Duan, L. L., and Dunson, D. B. (2021), “Bayesian Distance Clustering,” Journal of Machine Learning Research, 22, 1–27. http://jmlr.org/papers/v22/20-688.html.
- Fearnhead, P., and Prangle, D. (2012), “Constructing Summary Statistics for Approximate Bayesian Computation: Semi-Automatic Approximate Bayesian Computation,” Journal of the Royal Statistical Society, Series B, 74, 419–474. DOI: 10.1111/j.1467-9868.2011.01010.x.
- Fúquene, J., Steel, M., and Rossell, D. (2019), “On Choosing Mixture Components via Non-Local Priors,” Journal of the Royal Statistical Society, Series B, 81, 809–837. DOI: 10.1111/rssb.12333.
- Fritsch, A., and Ickstadt, K. (2009), “Improved Criteria for Clustering based on the Posterior Similarity Matrix,” Bayesian Analysis, 4, 367–391. DOI: 10.1214/09-BA414.
- Gao, T., Kovalsky, S. Z., Boyer, D. M., and Daubechies, I. (2019a), “Gaussian Process Landmarking for Three-Dimensional Geometric Morphometrics,” SIAM Journal on Mathematics of Data Science, 1, 237–267. DOI: 10.1137/18M1203481.
- Gao, T., Kovalsky, S. Z., and Daubechies, I. (2019b). “Gaussian Process Landmarking on Manifolds,” SIAM Journal on Mathematics of Data Science, 1, 208–236. DOI: 10.1137/18M1184035.
- Gerhard Hirsch Nachfolger (2013). “Auktion 293, Lot 2656,” image available at https://www.numisbids.com/n.php?p=lot&sid=514&lot=2656.
- Gnedin, A. V., and Pitman, J. (2006), “Exchangeable Gibbs Partitions and Stirling Triangles,” Journal of Mathematical Sciences, 138, 5674–5685. DOI: 10.1007/s10958-006-0335-z.
- Hartigan, J. (1990), “Partition Models,” Communications in Statistics - Theory and Methods, 19, 2745–2756. DOI: 10.1080/03610929008830345.
- Hennig, C. (2015), “What are the True Clusters?” Pattern Recognition Letters, 64, 53–62. DOI: 10.1016/j.patrec.2015.04.009.
- Ishwaran, H., and James, L. F. (2003), “Generalized Weighted Chinese Restaurant Processes for Species Sampling Mixture Models,” Statistica Sinica, 13, 1211–1235. https://www.jstor.org/stable/24307169.
- Jain, S., and Neal, R. M. (2004), “A Split-Merge Markov chain Monte Carlo Procedure for the Dirichlet Process Mixture Model,” Journal of Computational and Graphical Statistics, 13, 158–182. DOI: 10.1198/1061860043001.
- Johnstone, I. M., and Titterington, D. M. (2009), “Statistical Challenges of Hhigh-Dimensional Data,” Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 367, 4237–4253. DOI: 10.1098/rsta.2009.0159.
- Klaus, J. (1995), Topology (2nd ed.), New York: Springer-Verlag.
- Kleinberg, J. (2002), “An Impossibility Theorem for Clustering,” in “Proceedings of the 15th International Conference on Neural Information Processing Systems,” NIPS’02, pp. 463–470, Cambridge, MA: MIT Press. DOI: 10.5555/2968618.2968676.
- Kruskal, J. B. (1964), “Multidimensional Scaling by Optimizing Goodness of Fit to a Nonmetric Hypothesis,” Psychometrika, 29, 1–27. DOI: 10.1007/BF02289565.
- Larribe, F., and Fearnhead, P. (2011), “On Composite Likelihoods in Statistical Genetics,” Statistica Sinica, 21, 43–69. https://www.jstor.org/stable/24309262.
- Lau, J. W., and Green, P. J. (2007), “Bayesian Model-Based Clustering Procedures,” Journal of Computational and Graphical Statistics, 16, 526–558. DOI: 10.1198/106186007X238855.
- Lele, S., and Taper, M. L. (2002), “A Composite Likelihood Approach to (co)variance Components Estimation,” Journal of Statistical Planning and Inference, 103, 117–135. DOI: 10.1016/S0378-3758(01)00215-4.
- Li, N., and Stephens, M. (2003), “Modeling Linkage Disequilibrium and Identifying Recombination Hotspots Using Single-Nucleotide Polymorphism Data,” Genetics, 165, 2213–2233. DOI: 10.1093/genetics/165.4.2213.
- Lindsay, B. G. (1988), “Composite Likelihood Methods,” in “Statistical Inference from Stochastic Processes (Ithaca, NY, 1987),” volume 80 of Contemporary Mathematics, pp. 221–239. Providence, RI: American Mathematical Society. DOI: 10.1090/conm/080/999014.
- Lipman, Y., Yagev, S., Poranne, R., Jacobs, D. W., and Basri, R. (2014), “Feature Matching with Bounded Distortion,” ACM Transactions on Graphics, 33, 1–14. DOI: 10.1145/2602142.
- Lowe, D. (2004). “Distinctive Image Features from Scale-Invariant Keypoints,” International Journal of Computer Vision, 60, 91–110. DOI: 10.1023/B:VISI.0000029664.99615.94.
- Marjoram, P., Molitor, J., Plagnol, V., and Tavaré, S. (2003), “Markov Chain Monte Carlo Without Likelihoods,” Proceedings of the National Academy of Sciences, 100, 15324–15328. DOI: 10.1073/pnas.0306899100.
- Mclachlan, G., and Basford, K. (1988), “Mixture Models: Inference and Applications to Clustering,” Journal of the Royal Statistical Society, Series C, 38, 384–384. DOI: 10.2307/2348072.
- Meilǎ, M. (2007), “Comparing Clusterings—An Information based Distance,” Journal of Multivariate Analysis, 98, 873–895. DOI: 10.1016/j.jmva.2006.11.013.
- Miller, J. (2020), “BayesianMixtures.” Version 0.1.1, available at https://github.com/jwmi/BayesianMixtures.jl.
- Miller, J., Betancourt, B., Zaidi, A., Wallach, H., and Steorts, R. C. (2015), “Microclustering: When the Cluster Sizes Grow Sublinearly with the Size of the Data Set,” online preprint. DOI: 10.48550/arXiv.1512.00792.
- Miller, J. W., and Harrison, M. T. (2018), “Mixture Models With a Prior on the Number of Components,” Journal of the American Statistical Association, 113, 340–356. DOI: 10.1080/01621459.2016.1255636.
- Møller, J., and Skare, Ø. (2001), “Coloured Voronoi Tessellations for Bayesian Image Analysis and Reservoir Modelling,” Statistical Modelling, 1, 213–232. DOI: 10.1177/1471082X0100100304.
- Müller, P., Quintana, F., and Rosner, G. L. (2011), “A Product Partition Model With Regression on Covariates,” Journal of Computational and Graphical Statistics, 20, 260–278. DOI: 10.1198/jcgs.2011.09066.
- Nowicki, K., and Snijders, T. A. B. (2001), “Estimation and Prediction for Stochastic Blockstructures,” Journal of the American Statistical Association, 96, 1077–1087. DOI: 10.1198/016214501753208735.
- Paganin, S., Herring, A. H., Olshan, A. F., and Dunson, D. B. (2021), “Centered Partition Processes: Informative Priors for Clustering (with Discussion),” Bayesian Analysis, 16, 301–670. DOI: 10.1214/20-BA1197.
- Petralia, F., Rao, V., and Dunson, D. (2012), “Repulsive Mixtures,” in “Advances in Neural Information Processing Systems” (Vol. 25), eds. F. Pereira, C. J. C. Burges, L. Bottou, K. Q. Weinberger. Curran Associates, Inc. Available at https://proceedings.neurips.cc/paper/2012/file/8d6dc35e506fc23349dd10ee68dabb64-Paper.pdf.
- Pitman, J. (1996). “Some Developments of the Blackwell-MacQueen URN Scheme,” Lecture Notes-Monograph Series, 30, 245–267. DOI: 10.1214/lnms/1215453576.
- Pitman, J., and Yor, M. (1997), “The Two-Parameter Poisson-Dirichlet Distribution Derived from a Stable Subordinator,” The Annals of Probability, 25, 855–900. http://www.jstor.org/stable/2959614. DOI: 10.1214/aop/1024404422.
- Quinlan, J. J., Quintana, F. A., and Page, G. L. (2017), “Parsimonious Hierarchical Modeling Using Repulsive Distributions,” DOI: 10.48550/arXiv.1701.04457.
- Quintana, F. A. (2006), “A Predictive View of Bayesian Clustering,” Journal of Statistical Planning and Inference, 136, 2407–2429. DOI: 10.1016/j.jspi.2004.09.015.
- Quintana, F. A., and Iglesias, P. L. (2003), “Bayesian Clustering and Product Partition Models,” Journal of the Royal Statistical Society, Series B, 65, 557–574. DOI: 10.1111/1467-9868.00402.
- Rigon, T., Herring, A. H., and Dunson, D. B. (2023), “A Generalized Bayes Framework for Probabilistic Clustering,” Biometrika. DOI: 10.1093/biomet/asad004.
- Schmidt, M. N., and Morup, M. (2013), “Nonparametric Bayesian Modeling of Complex Networks: An Introduction,” IEEE Signal Processing Magazine, 30, 110–128. DOI: 10.1109/MSP.2012.2235191.
- Snijders, T. A. B., and Nowicki, K. (1997), “Estimation and Prediction for Stochastic Blockmodels for Graphs with Latent Block Structure,” Journal of the Classification, 14, 75–100. DOI: 10.1198/016214501753208735.
- Stephens, M. (2000), “Dealing with Label Switching in Mixture Models,” Journal of the Royal Statistical Society, Series B, 62, 795–809. DOI: 10.1111/1467-9868.00265.
- Szeliski, R. (2010), Computer Vision: Algorithms and Applications, London: Springer. DOI: 10.1007/978-3-030-34372-9.
- Taylor, Z. M. (2020), “The Computer-Aided Die Study (CADS): A Tool for Conducting Numismatic Die Studies with Computer Vision and Hierarchical Clustering,” Bachelor’s thesis, Trinity Uni. Available at https://digitalcommons.trinity.edu/compsci_honors/54/.
- Varin, C., Reid, N., and Firth, D. (2011), “An Overview of Composite Likelihood Methods,” Statistica Sinica, 21, 5–42. https://www.jstor.org/stable/24309261.
- Wade, S., and Ghahramani, Z. (2018), “Bayesian Cluster Analysis: Point Estimation and Credible Balls”, (with Discussion), Bayesian Analysis, 13, 559–626. DOI: 10.1214/17-BA1073.
- Xu, Y., Müller, P., and Telesca, D. (2016), “Bayesian Inference for Latent Biologic Structure with Determinantal Point Processes (DPP),” Biometrics, 72, 955–964. DOI: 10.1111/biom.12482.
- Zanella, G., Betancourt, B., Wallach, H., Miller, J., Zaidi, A., and Steorts, R. C. (2016), “Flexible Models for Microclustering with Application to Entity Resolution,” in “Proceedings of the 30th International Conference on Neural Information Processing Systems,” NIPS’16, pp. 1425–1433. Red Hook, NY: Curran Associates Inc.