
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We introduce and study two new inferential challenges associated with the sequential detection of change in a high-dimensional mean vector. First, we seek a confidence interval for the changepoint, and second, we estimate the set of indices of coordinates in which the mean changes. We propose an online algorithm that produces an interval with guaranteed nominal coverage, and whose length is, with high probability, of the same order as the average detection delay, up to a logarithmic factor. The corresponding support estimate enjoys control of both false negatives and false positives. Simulations confirm the effectiveness of our methodology, and we also illustrate its applicability on the U.S. excess deaths data from 2017 to 2020. The supplementary material, which contains the proofs of our theoretical results, is available online.
1 Introduction
The real-time monitoring of evolving processes has become a characteristic feature of 21st century life. Watches and defibrillators track health data, Covid-19 case numbers are reported on a daily basis and financial decisions are made continuously based on the latest market movements. Given that changes in the dynamics of such processes are frequently of great interest, it is unsurprising that the area of changepoint detection has undergone a renaissance over the last 5–10 years.
One of the features of modern datasets that has driven much of the recent research in changepoint analysis is high dimensionality, where we monitor many processes simultaneously, and seek to borrow strength across the different series to identify changepoints. The nature of series that are tracked in applications, as well as the desire to evade to the greatest extent possible the curse of dimensionality, means that it is commonly assumed that the signal of interest is relatively sparse, in the sense that only a small proportion of the constituent series undergo a change. Furthermore, the large majority of these works have focused on the retrospective (or offline) challenges of detecting and estimating changes after seeing all of the available data (e.g., Chan and Walther Citation2015; Cho and Fryzlewicz Citation2015; Jirak Citation2015; Cho Citation2016; Soh and Chandrasekaran Citation2017; Wang and Samworth Citation2018; Enikeeva and Harchaoui Citation2019; Padilla et al. Citation2021; Kaul et al. Citation2021; Liu, Gao, and Samworth Citation2021; Londschien, Kovács, and Bühlmann Citation2021; Rinaldo et al. Citation2021; Follain, Wang, and Samworth Citation2022). Nevertheless, the related problem where one observes data sequentially and seeks to declare changes as soon as possible after they have occurred, is nowadays receiving increasing attention (e.,g. Kirch and Stoehr Citation2019; Dette and Gösmann Citation2020; Gösmann et al. Citation2020; Chen, Wang, and Samworth Citation2022; Yu et al. Citation2021). Although the focus of our review here has been on recent developments, including finite-sample results in multivariate and high-dimensional settings, we also mention that changepoint analysis has a long history (e.g., Page Citation1954). Entry points to this classical literature include Csörgő and Horváth (Citation1997) and Horváth and Rice (Citation2014). For univariate data, sequential changepoint detection is also studied under the banner of statistical process control (Duncan Citation1952; Tartakovsky, Nikiforov, and Basseville Citation2014). In the field of high-dimensional statistical inference more generally, uncertainty quantification has become a major theme over the last decade, originating with influential work on the debiased Lasso in (generalized) linear models (Javanmard and Montanari Citation2014; van de Geer et al. Citation2014; Zhang and Zhang Citation2014), and subsequently developed in other settings (e.g., Janková and van de Geer Citation2015; Yu, Bradic, and Samworth Citation2021).
The aim of this article is to propose methods to address two new inferential challenges associated with the high-dimensional, sequential detection of a sparse change in mean. The first is to provide a confidence interval for the location of the changepoint, while the second is to estimate the signal set of indices of coordinates that undergo the change. Despite the importance of uncertainty quantification and signal support recovery in changepoint applications, neither of these problems has previously been studied in the multivariate sequential changepoint detection literature, to the best of our knowledge. Of course, one option here would be to apply an offline confidence interval construction (e.g., Kaul et al. Citation2021) after a sequential procedure has declared a change. However, this would be to ignore the essential challenge of the sequential nature of the problem, whereby one wishes to avoid storing all historical data, to enable inference to be carried out in an online manner. By this we mean that the computational complexity for processing each new observation, as well as the storage requirements, should depend only on the number of bits needed to represent the new data point observed.Footnote1 The online requirement turns out to impose severe restrictions on the class of algorithms available to the practitioner, and lies at the heart of the difficulty of the problem.
To give a brief outline of our construction of a confidence interval with guaranteed -level coverage, consider for simplicity the univariate setting, where
form a sequence of independent random variables with
and
. Without loss of generality, we assume that
. Suppose that θ is known to be at least b > 0 and, for
, define residual tail lengths
(1)
(1)
In the case of a tie, we choose the smallest h achieving the maximum. Since can be viewed as the likelihood ratio statistic for testing the null of
against the alternative of
using
, the quantity
is the tail length for which the likelihood ratio statistic is maximized. If N is the stopping time defining a good sequential changepoint detection procedure, then, intuitively,
should be close to the true changepoint location z, and almost pivotal. This motivates the construction of a confidence interval of the form
, where we control the tail probability of the distribution of
to choose
so as to ensure the desired coverage. In the multivariate case, considerable care is required to handle the post-selection nature of the inferential problem, as well as to determine an appropriate left endpoint for the confidence interval. For this latter purpose, we only assume a lower bound on the Euclidean norm of the vector of mean change, and employ a delicate multivariate and multiscale aggregation scheme; see Section 2 for details, as well as Section 3.5 for further discussion.
The procedure for the inference tasks discussed above, which we call ocd_CI (short for online changepoint detection Confidence Intervals), can be run in conjunction with any base sequential changepoint detection procedure. However, we recommend using the ocd algorithm introduced by Chen, Wang, and Samworth (Citation2022), or its variant ocd’, which provides guarantees on both the average and worst-case detection delays, subject to a guarantee on the patience, or average false alarm rate under the null hypothesis of no change. Crucially, these are both online algorithms. The corresponding inferential procedures inherit this same online property, thereby making them applicable even in very high-dimensional settings and where changes may be rare, so we may need to see many new data points before declaring a change.
In Section 3 we study the theoretical performance of the ocd_CI procedure. In particular, we prove in Theorem 1 that, whenever the base sequential detection procedure satisfies a patience and detection delay condition, the confidence interval has at least nominal coverage for a suitable choice of input parameters. Theorem 2 provides a corresponding guarantee on the length of the interval. In Section 3.3, we show that by using ocd’ as the base procedure, the aforementioned patience and detection delay condition is indeed satisfied. As a result, the output confidence interval has guaranteed nominal coverage and the length of the interval is of the same order as the average detection delay for the base ocd’ procedure, up to a poly-logarithmic factor. This is remarkable in view of the intrinsic challenge that the better such a changepoint detection procedure performs, the fewer post-change observations are available for inferential tasks.
A very useful byproduct of our ocd_CI methodology is that we obtain a natural estimate of the set of signal coordinates (i.e., those that undergo change). In Theorem 3, we prove that, with high probability, it is able both to recover the effective support of the signal (see Section 3.1 for a formal definition), and to avoid noise coordinates. We then broaden the scope of applicability of our methodology in Section 3.4 by relaxing our distributional assumptions to deal with sub-Gaussian or sub-exponential data. Finally, in Section 3.5, we introduce a modification of our algorithm that permits an arbitrarily loose lower bound on the Euclidean norm of the vector of mean change to be employed, with only a logarithmic increase in the confidence interval length guarantee and the computational cost.
An attraction of our theoretical results is that we are able to handle arbitrary spatial (cross-sectional) dependence between the different coordinates of our data stream. On the other hand, two limitations of our analysis for practical use are that real data may exhibit both heavier than sub-exponential tails and temporal dependence. While a full theoretical analysis of the ocd_CI algorithm in these contexts appears to be challenging, we have made some practical suggestions regarding these issues in Sections 3.4 and 4.4, respectively.
Section 4 is devoted to a study of the numerical performance of our methodological proposals. Our simulations confirm that the ocd_CI methodology (with the ocd base procedure) attains the desired coverage level across a wide range of parameter settings, that the average confidence interval length is of comparable order to the average detection delay and that our support recovery guarantees are validated empirically. We further demonstrate the way in which naive application of offline methods may lead to poor performance in this problem. Moreover, in Section 4.4, we apply our methods to excess death data from the Covid-19 pandemic in the United States. Proofs, auxiliary results, extensions to sub-Gaussian and sub-exponential settings and additional simulation results are provided in the supplementary material.
We conclude this introduction with some notation used throughout the article. We write for the set of all nonnegative integers. For
, we write
. Given
, we denote
and
. For a set S, we use
and
to denote its indicator function and cardinality, respectively. For a real-valued function f on a totally ordered set S, we write
and
for the smallest and largest maximizers of f in S, and define
and
analogously. For a vector
, we define
and
. In addition, for
, we define
. For a matrix
and
, we write
and
. We use
and
to denote the distribution function, survivor function and density function of the standard normal distribution, respectively. For two real-valued random variables U and V, we write
or
if
for all
. We adopt conventions that an empty sum is 0 and that
.
2 Confidence Interval Construction and Support Estimation Methodology
In the multivariate sequential changepoint detection problem, we observe p-variate observations in turn, and seek to report a stopping time N by which we believe a change has occurred. Here and throughout, a stopping time is understood to be with respect to the natural filtration, so that the event
belongs to the σ-algebra generated by
. The focus of this work is on changes in the mean of the underlying process, and we denote the time of the changepoint by z. Moreover, since our primary interest is in high-dimensional settings, we will also seek to exploit sparsity in the vector of mean change. Given
, then, our primary goal is to construct a confidence interval
with the property that
with probability at least
.
For and
, let
denote the jth coordinate of Xi. The ocd_CI algorithm relies on a lower bound
for the
-norm of the vector of mean change, sets of signed scales
and
defined in terms of β and a base sequential changepoint detection procedure CP. As CP processes each new data vector, we update the matrix of residual tail lengths
with
, as well as corresponding tail partial sum vectors
, where
.
After the base procedure CP declares a change at a stopping time N, we identify an “anchor” coordinate and a signed anchor scale
, where
The intuition is that the anchor coordinate and signed anchor scale are chosen so that the final observations provide the best evidence among all of the residual tail lengths against the null hypothesis of no change. Meanwhile,
aggregates the last
observations in each coordinate, providing a measure of the strength of this evidence against the null.
The main idea of our confidence interval construction is to seek to identify coordinates with large post-change signal. To this end, observe when is not too much larger than N – z, the quantity
should be centered close to
for
, with variance close to 1. Indeed, if
, N and
were fixed, and if
, then the former quantity would have unit variance around this centering value. The random nature of these quantities, however, introduces a post-selection inference aspect to the problem. Nevertheless, by choosing an appropriate threshold value
, we can ensure that with high probability, when
is a noise coordinate, we have
, and when
is a coordinate with sufficiently large signal, there exists a signed scale
, having the same sign as θj, for which
. In fact, such a signed scale, if it exists, can always be chosen to be from
. As a convenient byproduct, the set of indices j for which the latter inequality holds, which we denote as
, forms a natural estimate of the set of coordinates in which the mean change is large.
For each , there exists a largest scale
for which
. We denote the signed version of this quantity, where the sign is chosen to agree with that of
, by
; this can be regarded as a shrunken estimate of θj, so plays the role of the lower bound b from the univariate problem discussed in the introduction. Finally, then, our confidence interval is constructed as the intersection over indices
of the confidence interval from the univariate problem in coordinate j, with signed scale
.
As a device to facilitate our theory, the ocd_CI algorithm allows the practitioner the possibility of observing a further observations after the time of changepoint declaration, before constructing the confidence interval. The additional observations are used to determine the anchor coordinate
and scale
, as well as the estimated support
and the estimated scale
for each
. Thus, the extra sampling is used to guard against an unusually early changepoint declaration that leaves very few post-change observations for inference. Nevertheless, we will see in Theorem 1 that the output confidence interval has guaranteed nominal coverage even with
, so that additional observations are only used to control the length of the interval. In fact, even for this latter aspect, the numerical evidence presented in Section 4 indicates that
provides confidence intervals of reasonable length in practice. Similarly, Theorem 3 ensures that with high probability, our support estimate
contains no noise coordinates (i.e., has false positive control) even with
, so that the extra sampling is only used to provide false negative control.
Pseudo-code for this ocd_CI confidence interval construction is given in Algorithm 1, where we suppress the n dependence on quantities that are updated at each time step. The computational complexity per new observation, as well as the storage requirements, of this algorithm is equal to the sum of the corresponding quantities for the CP base procedure and regardless of the observation history. Thus, the ocd_CI method inherits the property of being an online algorithm, as discussed in the introduction, from any online CP base procedure.
A natural choice for the base online changepoint detection procedure CP is the ocd algorithm, or its variant ocd’, introduced by Chen, Wang, and Samworth (Citation2022). Both are online algorithms, with computational complexity per new observation and storage requirements of . The ocd’ base procedure is considered for the theoretical analysis in Section 3 due to its known patience and detection delay guarantees, while we prefer ocd for numerical studies and practical use. For the reader’s convenience, the ocd and ocd’ algorithms are provided as Algorithms S1 and S2, respectively in Section S3 of the supplementary materials.
Algorithm 1
: Pseudo-code for the confidence interval construction algorithm ocd_CI
Input: observed sequentially,
, an online changepoint detection procedure
and
Set: ,
, n = 0,
and
for all
repeat
observe new data vector Xn and update CP with Xn
for
do
if
then
and
until CP declares a change; Observe
new data vectors
Set for
Compute for
for
do
Output: Confidence interval
3 Theoretical Analysis
Throughout this section, we will assume that the sequential observations are independent, and that for some unknown covariance matrix
whose diagonal entries are all equal to 1, there exist
and
for which
and
. We let
, and write
for probabilities computed under this model, though in places we omit the subscripts for brevity. Define the effective sparsity of θ, denoted
, to be the smallest
such that the corresponding effective support
has cardinality at least
. Thus, the sum of squares of coordinates in the effective support of θ has the same order of magnitude as
, up to logarithmic factors. Moreover, if at most s components of θ are nonzero, then
, and the equality is attained when, for example, all nonzero coordinates have the same magnitude.
For r > 0 and an online changepoint detection procedure CP characterized by an extended stopping time N, we define
(2)
(2)
3.1 Coverage Probability and Length of the Confidence Interval
The following theorem shows that the confidence interval constructed in the ocd_CI algorithm has the desired coverage level whenever the base online changepoint detection procedure satisfies a patience and detection delay condition.
Theorem 1.
Let and fix
. Suppose that
. Let CP be an online changepoint procedure characterized by an extended stopping time N satisfying
(3)
(3) for some
. Then, with inputs
and
, the output confidence interval
from Algorithm 1 satisfies
As mentioned in Section 2, our coverage guarantee in Theorem 1 holds even with , that is, with no additional sampling. Condition (3) places a joint assumption on the base changepoint procedure CP and the parameter r, the latter of which appears in the inputs d1 and d2 of Algorithm 1. The first term on the left-hand side of (3) is the false alarm rate of the stopping time N associated with CP. The second term can be interpreted as an upper bound on the probability of the detection delay of N being larger than r, and in addition we also need r to be at least of order
up to logarithmic factors for the third term to be sufficiently small. See Section 3.3 for further discussion, where in particular we provide a choice of r for which (3) holds with the ocd’ base procedure.
We now provide a guarantee on the length of the ocd_CI confidence interval.
Theorem 2.
Fix . Assume that θ has an effective sparsity of
and that
. let CP be an online changepoint detection procedure characterized by an extended stopping time N that satisfies (3) for some
. Then there exists a universal constant C > 0 such that, with inputs
, the length L of the output confidence interval
satisfies
As mentioned following Theorem 1, we can take r to be the maximum of an appropriate quantile of the detection delay distribution of CP and a quantity that is of order up to logarithmic factors. The main conclusion of Theorem 2 is that, with high probability, the length of the confidence interval is then of this same order r. Whenever the quantile of the detection delay distribution achieves the maximum above—which is the case, up to logarithmic factors, for the ocd’ base procedure (see Proposition 5)—we can conclude that with high probability, the length of the ocd_CI confidence interval is of the same order as this detection delay quantile (which is the best one could hope for). Note that the choices of inputs in Theorem 2 are identical to those in Theorem 1, except that we now ask for order r additional observations after the changepoint declaration.
3.2 Support Recovery
Recall the definition of from the beginning of this section, and denote
, where
, defined in Algorithm 1, is the smallest positive scale in
, We will suppress the dependence on θ of both these quantities in this section. Theorem 3 provides a support recovery guarantee for
, defined in Algorithm 1. Since neither
nor the anchor coordinate
defined in the algorithm depend on d2, we omit its specification; the choices of other tuning parameters mimic those in Theorems 1 and 2.
Theorem 3.
Let and fix
. Suppose that
. Let CP be an online changepoint detection procedure characterized by an extended stopping time N that satisfies (3) for some
.
Then, with inputs
, we have
Now assume that θ has an effective sparsity of
Note that . Thus, part (a) of the theorem reveals that with high probability, our support estimate
does not contain any noise coordinates. Part (b) offers a complementary guarantee on the inclusion of all “big” signal coordinates, provided we augment our support estimate with the anchor coordinate
. See also the further discussion of this result following Proposition 4 and in Section 3.3.
We now turn our attention to the optimality of our support recovery algorithm, by establishing a complementary minimax lower bound on the performance of any support estimator. In fact, we can already establish this optimality by restricting the cross-sectional covariance matrix to be the identity matrix. Thus, given and
, we write
for a probability measure under which
are independent with
. For r > 0 and
, write
Define to be the set of stopping times with respect to the natural filtration
, and set
Write for the power set of
, equipped with the symmetric difference metric
. For any stopping time N, denote
where we recall that ψ is said to be
-measurable if for any
and
, we have that
is
-measurable.
Proposition 4.
For r > 0 and , we have
This proposition considers any support estimation algorithm obtained from a stopping time in , and we note that such a competing procedure is even allowed to store all data up to this stopping time, in contrast to our online algorithm. This result can be interpreted as an optimality guarantee for the support recovery property of the ocd_CI algorithm presented in Theorem 3(b), provided that the base procedure N belongs to the class
, and that N and r satisfy (3). See Section 3.3 for further discussion.
3.3 Using ocd’ as the Base Procedure
In this section, we provide a value of r that suffices for condition (3) to hold when we take our base procedure to be ocd’. For the convenience of the reader, this algorithm is presented as Algorithm S2 in Section S3 of the supplementary materials, where we also provide interpretation to the input parameters and
.
Proposition 5.
Fix and
. Assume that θ has an effective sparsity of
, that
and that
. Then with inputs
and
in the
procedure, there exists a universal constant
such that for all
(4)
(4) the output N satisfies (3).
By combining Proposition 5 with Theorems 1–3, respectively, we immediately arrive at the following corollary.
Corollary 6.
Fix . Assume that θ has an effective sparsity of
, that
and that
. Let
and
be the inputs of the
procedure. Then the following statements hold:
With extra inputs
There exists a universal constant C > 0 such that, with extra inputs
Corollary 6 reveals that, when ocd’ is used as the base procedure, the ocd_CI methodology provides guaranteed confidence interval coverage. Moreover, up to poly-logarithmic factors, with an additional post-change observations, the ocd_CI interval length is of the same order as the average detection delay. In terms of signal recovery, Corollary 6(b) shows that with high probability, ocd_CI with inputs as given in that result selects all signal coordinates whose magnitude exceeds
, up to logarithmic factors. Focusing on the case
and where
is bounded away from zero for simplicity of discussion (though see also Section 3.5 for discussion of the effect of the choice of β), Proposition S3 in the supplementary materials also reveals that the ocd’ base procedure belongs to
with r of order
, up to logarithmic factors, and
. On the other hand, Proposition 4 shows that any such support estimation algorithm makes on average a nonvanishing fraction of errors in distinguishing between noise coordinates and signals that are below the level
, again up to logarithmic factors. In other words, with high probability, the ocd_CI algorithm with base procedure ocd’ selects all signals that are strong enough (up to logarithmic factors) to be reliably detected, while at the same time including no noise coordinates (see Corollary 6(a)).
3.4 Relaxing the Gaussianity Assumption
It is natural to ask to what extent the theory of Sections 3.1–3.3 can be generalized beyond the Gaussian setting. The purpose of this section, then, is to describe how our earlier results can be modified to handle both sub-Gaussian and sub-exponential data. Recall that we say a random variable Z with is sub-Gaussian with variance parameter
if
for all
, and is sub-exponential with variance parameter
and rate parameter A > 0 if
for all
.
We first consider the sub-Gaussian setting where are independent, each having sub-Gaussian components with variance parameter 1. Note that this data generating mechanism no longer requires all pre-change observations to be identically distributed, and likewise the post-change observations need not all have the same distribution. We assume that the base changepoint procedure, characterized by an extended stopping time N, satisfies a slightly strengthened version of (3), namely that
(5)
(5) for some
. Under (5), Theorems 1–3 hold with the same choices of input parameters. Moreover, the ocd’ base procedure satisfies the conclusion of Proposition 5, that is, there exists a universal constant
such that (5) holds for
in (4), provided that we use the modified input
.
Generalizing these ideas further, now consider the model where are independent, each having sub-exponential components with variance parameter 1 and rate parameter A > 0. In this setting, provided the base procedure satisfies (5) for some
and
, Theorems 1–3 hold when we redefine
and
. Furthermore, with the modified input
, the ocd’ base procedure satisfies the conclusion of Proposition 5 for
where
is a universal constant.
The claims made in the previous two paragraphs are justified in Section S4 of the supplementary materials. These results confirm the flexible scope of the ocd_CI methodology beyond the original Gaussian setting, at least as far as sub-exponential tails are concerned. Where data may exhibit heavier tails than this, clipping (truncation) and quantile transformations may represent viable ways to proceed, though further research is needed to confirm the theoretical validity of such approaches.
3.5 Confidence Interval Construction with Unknown Signal Size
In some settings, an experienced practitioner may have a reasonable idea of the magnitude ϑ of the -norm of the vector of mean change that would be of interest to them, and this would facilitate a choice of a lower bound β for ϑ in Algorithm 1. However, it is also worth considering the effect of this choice, and the extent to which its impact can be mitigated.
We first remark that the coverage probability guarantee for the ocd_CI interval in Corollary 6 remains valid for any (arbitrarily loose) lower bound β on ϑ. The only issue is in terms of power: if β is chosen to be too small, then both the average detection delay and the high-probability bound on the length of the confidence interval may be inflated. In the remainder of this section, then, we describe a simple modification to Algorithm 1 that permits a loose lower bound β to be employed that retains coverage validity with only a logarithmic effect on the high-probability bound on the length of the confidence interval. The only other price we pay is that the computational cost increases as β decreases, as we describe below.
Our change to Algorithm 1 is as follows: we replace the definition of by setting
set
and define
in both the ocd’ base procedure and in Algorithm 1. The rest of algorithm remains as previously stated. Thus, if we choose a conservative (very small) β, then the effect of the modification is to increase the number of scales on which we search for a change, so that the largest element of
is of order 1. In order to state our theoretical results for this modified algorithm, first define
, which satisfies
. Under the same assumptions as in Proposition 5, and modifying the inputs to
and
, it can be shown using very similar arguments to those in the proof of Proposition 5 that there exists a universal constant
such that with
the output N satisfies
With this in place, we can derive Corollary 7, which is the analog of Corollary 6 for our modified algorithm.
Corollary 7.
Fix . Assume that θ has an effective sparsity of
, that
and that
. Let
and
be the inputs of the modified
procedure. Let
and
. Then the following statements hold:
With extra inputs
There exists a universal constant C > 0 such that, with extra inputs
The main difference between Corollaries 7 and 6 concerns the high-probability guarantees on the length of the confidence interval. Ignoring logarithmic factors, with high probability the length of the confidence interval in the modified algorithm is at most of order , whereas for the original algorithm it was of order
. Thus, the modified algorithm has the significant advantage of enabling a conservative choice of β with only a logarithmic effect on the length guarantee relative to an oracle procedure with knowledge of
. The computational complexity per new observation and the storage requirements of this modified algorithm are
, so the order of magnitude is increased relative to the original algorithm only in an asymptotic regime where β is small by comparison with
for every K > 0. Moreover, the modified algorithm still does not require storage of historical data and the computational time per new observation after observing n observations does not increase with n. Nevertheless, since the computational complexity now depends on β, the modified algorithm does not strictly satisfy our definition of an online algorithm given in introduction.
4 Numerical Studies
In this section, we study the empirical performance of the ocd_CI algorithm. Throughout this section, by default, the ocd_CI algorithm is used in conjunction with the recommended base online changepoint detection procedure .
4.1 Tuning Parameters
Chen, Wang, and Samworth (Citation2022) found that the theoretical choices of thresholds and
for the ocd procedure were a little conservative, and therefore recommended determining these thresholds via Monte Carlo simulation; we replicate the method for choosing these thresholds described in their Section 4.1. Likewise, as in Chen, Wang, and Samworth (Citation2022), we take
in our simulations.
For d1 and d2, as suggested by our theory, we take , and take d1 to be of the form
. Here, we tune the parameter c > 0 through Monte Carlo simulation, as we now describe. We considered the parameter settings
and z = 500. Then, with θ generated as
, where U is uniformly distributed on the union of all s-sparse unit spheres in
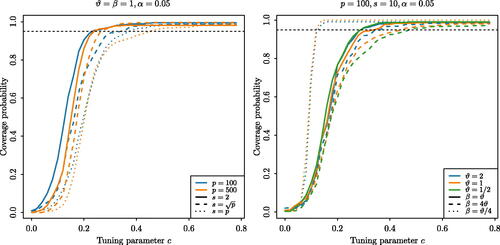
(independent of our data), we studied the coverage probabilities, estimated over 2000 repetitions as c varies, of the ocd_CI confidence interval for data generated according to the Gaussian model defined at the beginning of Section 3. displays a subset of the results (the omitted curves were qualitatively similar). On this basis, we recommend c = 0.5 as a safe choice across a wide range of data generating mechanisms, and we used this value of c throughout our confidence interval simulations.
Fig. 1 Coverage probabilities of the ocd_CI confidence interval as the parameter c, involved in the choice of tuning parameter d1, varies.
The previous two paragraphs, in combination with Algorithms 1 and S1, provide the practical implementation of the ocd_CI algorithm that we use in our numerical studies and that we recommend for practitioners. The only quantity that remains for the practitioner to input (other than the data) is β, which represents a lower bound on the Euclidean norm of the vector of mean change. Fortunately, this description makes β easily interpretable by practitioners. In cases where an informed default choice is not available, practitioners can make a conservative (very small) choice and use an increased grid of scales to with only a small inflation in the confidence interval length guarantee and computational cost; see Section 3.5.
4.2 Coverage Probability and Interval Length
In , we present the detection delay of the ocd procedure, as well as the coverage probabilities and average confidence interval lengths of the ocd_CI procedure, all estimated over 2000 repetitions, with the same set of parameter choices and data generating mechanism as in Section 4.1. From this table, we see that the coverage probabilities are at least at the nominal level (up to Monte Carlo error) across all settings considered. Underspecification of β means that the grid of scales that can be chosen for indices in is shifted downwards, and therefore increases the probability that
will underestimate θj for
. In turn, this leads to a slight conservativeness for the coverage probability (and corresponding increased average confidence interval length). On the other hand, overspecification of β yields a shorter interval on average, though these were nevertheless able to retain the nominal coverage in all cases considered.
Table 1 Estimated coverage and average length of the ocd_CI confidence interval and average detection delay over 2000 repetitions, with standard errors in brackets.
Another interesting feature of is to compare the average confidence interval lengths with the corresponding average detection delays. Corollary 6(b), as well as (Chen, Wang, and Samworth Citation2022, Theorem 4), indicates that both of these quantities are of order , up to polylogarithmic factors in p and γ, but of course whenever the confidence interval includes the changepoint, its length must be at least as long as the detection delay. Nevertheless, in most settings, it is only 2–3 times longer on average, and in all cases considered was less than seven times longer on average. Moreover, we can also observe that the confidence interval length increases with s and decreases with β, as anticipated by our theory.
For comparison, we also present the corresponding coverage probabilities and average lengths of confidence intervals obtained using an offline procedure as described in the introduction. More precisely, after the ocd algorithm has declared a change, we treat the data up to the stopping time as an offline dataset, and apply the inspect algorithm (Wang and Samworth Citation2018), followed by the one-step refinement of Kaul et al. (Citation2021), to construct an estimate, , of the changepoint location. As recommended by Kaul et al. (Citation2021), we obtain an estimator
of ϑ using the
-norm of the soft-thresholded difference in empirical mean vectors before and after
, with the soft-thresholding parameter chosen via the Bayesian Information Criterion. The final confidence interval is then of the form
, where
is the
quantile of the distribution of the (almost surely unique) maximizer of a two-sided Brownian motion with a triangular drift as given by (Kaul et al. Citation2021, Theorem 3.1). In particular, we have
. The last two columns of reveal that both the coverage probabilities and confidence interval lengths from this procedure are disappointing and not competitive with those of the ocd_CI algorithm. There are two main reasons for this: first, the nature of the online problem means that the changepoint is often located near the right-hand end of the dataset up to the stopping time; on the other hand, the theoretical guarantees of Kaul et al. (Citation2021) are obtained under an asymptotic setting where the fraction of data either side of the change is bounded away from zero. Thus, the estimated changepoint from the one-step refinement is often quite poor. Moreover, the estimated magnitude of change,
, is often a significant underestimate of ϑ due to the soft-thresholding operation, and this can lead to substantially inflated confidence interval lengths. We emphasize that the Kaul et al. (Citation2021) procedure was not designed for use in this online setting, but we nevertheless present these results to illustrate the fact that the naive application of offline methods in sequential problems may fail badly.
While covers the most basic setting for our methodology, our theory in Section 3 applies equally well to data with spatial dependence across different coordinates. To assess whether this theory carries over to empirical performance, Table S1 in the supplementary materials presents corresponding coverage probabilities and lengths for the ocd_CI procedure with the cross-sectional covariance matrix taken to be Toeplitz with parameter
; in other words,
. The results are again encouraging: the coverage remains perfectly satisfactory in all settings considered, and moreover, the lengths of the confidence intervals are very similar to those in .
4.3 Support Recovery
We now turn our attention to the empirical support recovery properties of the quantity (in combination with the anchor coordinate
) computed in the ocd_CI algorithm. In , we present the probabilities, estimated over 500 repetitions, that
and that
for p = 100,
, and for three different signal shapes: in the uniform, inverse square root and harmonic cases, we took
and
, respectively. As inputs to the algorithm, we set
, and, motivated by Corollary 6, took an additional
post-declaration observations in constructing the support estimates. The results reported in provide empirical confirmation of the support recovery properties claimed in Corollary 6.
Table 2 Estimated support recovery probabilities (with standard errors in brackets).
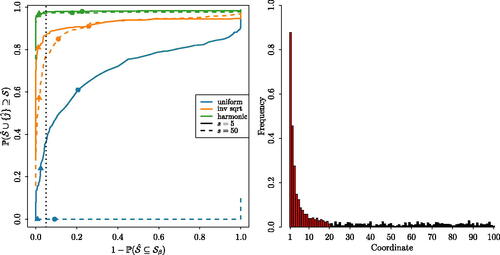
Finally in this section, we consider the extent to which the additional observations are necessary in practice to provide satisfactory support recovery. In the left panel of , we plot Receiver Operating Characteristic (ROC) curves to study the estimated support recovery probabilities with
as a function of the input parameter d1, which can be thought of as controlling the tradeoff between
and
. The fact that the triangles in this plot are all to the left of the dotted vertical line confirms the theoretical guarantee provided in Corollary 6(a), which holds with
, and even with
; the less conservative choice
, which roughly corresponds to an average of one noise coordinate included in
, allows us to capture a larger proportion of the signal. From this panel, we also see that additional sampling is needed to ensure that, with high probability, we recover all of the true signals. This is unsurprising: for instance, with a uniform signal shape and s = 50, it is very unlikely that all 50 signal coordinates will have accumulated such similar levels of evidence to appear in
by the time of declaration. The right panel confirms that, with an inverse square root signal shape, the probability that we capture each signal increases with the signal magnitude, and that even small signals tend to be selected with higher probability than noise coordinates.
Fig. 2 Support recovery properties of ocd_CI. In the left panel, we plot ROC curves for three different signal shapes and for sparsity levels . The triangles and circles correspond to points on the curves with
(with
), and
, respectively. The dotted vertical line corresponds to
. In the right panel, we plot the proportion of 500 repetitions for which each coordinate belongs to
with
; here, the s = 20 signals have an inverse square root shape, and are plotted in red; noise coordinates are plotted in black. Other parameters for both panels: p = 100,
.
4.4 US Covid-19 Data Example
In this section, we apply ocd_CI to a dataset of weekly deaths in the United States between January 2017 and June 2020 (available at: https://www.cdc.gov/nchs/nvss/vsrr/covid19/excess_deaths.htm). The data up to 29 June 2019 are treated as our training data. An obvious discrepancy between underlying dynamics of these weekly deaths and the conditions assumed in our theory in Section 3 is temporal dependence, particularly induced by seasonal and weather effects. Although we can never hope to remove this dependence entirely, we seek to mitigate its impact by pre-processing the data as follows: for each of the 50 states, as well as Washington, D.C. (p = 51), we first estimate the “seasonal death curve,” that is, the mean death numbers for each day of the year, for each state. The seasonal death curve is estimated by first splitting the weekly death numbers evenly across the seven relevant days, and then estimating the average number of deaths on each day of the year from these derived daily death numbers using a Gaussian kernel with a bandwidth of 20 days. As the death numbers follow an approximate Poisson distribution, we apply a square-root transformation to stabilize the variance; more precisely, the transformed weekly excess deaths are computed as the difference of the square roots of the weekly deaths and the predicted weekly deaths from the seasonal death curve. Finally, we standardize the transformed weekly excess deaths using the mean and standard deviation of the transformed data over the training period. The standardized, transformed data are plotted in for 12 states. When applying ocd_CI to these data, we take and
, with
, β = 50 and γ = 1000. On the monitoring data (from 30 June 2019), the ocd_CI algorithm declares a change on the week ending 28 March 2020, and provides a confidence interval from the week ending 21 March 2020 to the week ending 28 March 2020. This coincides with the beginning of the first wave of Covid-19 deaths in the United States. The algorithm also identifies New York, New Jersey, Connecticut, Michigan, and Louisiana as the estimated support of the change. Interestingly, if we run the ocd_CI procedure from the beginning of the training data period (while still standardizing as before, due to the lack of available data prior to 2017), it identifies a subtler change on the week ending January 6, 2018, with a confidence interval of [December 17, 2017, January 6, 2018]. This corresponds to a bad influenza season at the end of 2017 (see, https://www.cdc.gov/flu/about/season/flu-season-2017-2018.htm). Despite the natural interpretation of these findings, we recognize that the model in Section 3 under which we proved our theoretical results cannot capture the full complexity of the temporal dependence in this dataset even after our pre-processing transformations. A complete theoretical analysis of the performance of ocd_CI in time-dependent settings is challenging and beyond the scope of the current work; in practical applications, we advise careful modeling of this dependence to facilitate the construction of appropriate residuals for which the main effects of this dependence have been removed.
Fig. 3 Standardized, transformed weekly excess death data from 12 states (including Washington, D.C.). The monitoring period starts from 30 June 2019 (dashed line). The data from the states in the support estimate are shown in red. The confidence interval [March 8, 2020, March 28, 2020] is shown in the light blue shaded region.
![Fig. 3 Standardized, transformed weekly excess death data from 12 states (including Washington, D.C.). The monitoring period starts from 30 June 2019 (dashed line). The data from the states in the support estimate are shown in red. The confidence interval [March 8, 2020, March 28, 2020] is shown in the light blue shaded region.](/cms/asset/440a0a08-a6b1-4430-af4b-ffc3e26311a4/uasa_a_2199962_f0003_c.jpg)
Supplemental Material
Download Zip (530.4 KB)Acknowledgments
We are grateful to the Editor, the Associate Editor and two anonymous referees for their constructive feedback, which helped to improve the article.
Supplementary Materials
This contains the proofs of our main theoretical results and auxiliary results, as well as pseudocode for the ocd and ocd’ base procedures, extensions of our results to sub-Gaussian and sub-exponential settings and additional simulation results.
H2020 European Research Council;
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
Notes
1 Here, we ignore the errors in rounding real numbers to machine precision; thus, we do not distinguish between continuous random variables and quantized versions where the data have been rounded to machine precision.
Related Research Data
References
- Chan, H. P., and Walther, G. (2015), “Optimal Detection of Multi-Sample Aligned Sparse Signals,” Annals of Statistics, 43, 1865–1895.
- Chen, Y., Wang, T., and Samworth, R. J. (2022), “High-Dimensional, Multiscale Online Changepoint Detection,” Journal of the Royal Statistical Society, Series B, 84, 234–266. DOI: 10.1111/rssb.12447.
- Cho, H. (2016), “Change-Point Detection in Panel Data via Double CUSUM Statistic,” Electronic Journal of Statistics, 10, 2000–2038. DOI: 10.1214/16-EJS1155.
- Cho, H., and Fryzlewicz, P. (2015), “Multiple-Change-Point Detection for High Dimensional Time Series via Sparsified Binary Segmentation,” Journal of the Royal Statistical Society, Series B, 77, 475–507. DOI: 10.1111/rssb.12079.
- Csörgő, M., and Horváth, L. (1997), Limit Theorems in Change-Point Analysis, New York: Wiley.
- Dette, H., and Gösmann, J. (2020), “A Likelihood Ratio Approach to Sequential Change Point Detection for a General Class of Parameters,” Journal of the American Statistical Association, 115, 1361–1377. DOI: 10.1080/01621459.2019.1630562.
- Duncan, A. J. (1952), Quality Control and Industrial Statistics, Chicago: Richard D. Irwin Professional Publishing Inc.
- Enikeeva, F., and Harchaoui, Z. (2019), “High-Dimensional Change-Point Detection Under Sparse Alternatives,” Annals of Statistics, 47, 2051–2079.
- Follain, B., Wang, T., and Samworth, R. J. (2022), “High-Dimensional Changepoint Estimation With Heterogeneous Missingness,” Journal of the Royal Statistical Society, Series B, 84, 1023–1055. DOI: 10.1111/rssb.12540.
- Gösmann, J., Stoehr, C., Heiny, J., and Dette, H. (2020), “Sequential Change Point Detection in High Dimensional Time Series,” arXiv preprint, arxiv:2006.00636.
- Horváth, L., and Rice, G. (2014), “Extensions of Some Classical Methods in Change Point Analysis,” TEST, 23, 219–255. DOI: 10.1007/s11749-014-0368-4.
- Janková, J., and van de Geer, S. (2015), “Confidence Intervals for High-dimensional Inverse Covariance Estimation,” Electronic Journal of Statistics, 9, 1205–1229. DOI: 10.1214/15-EJS1031.
- Javanmard, A., and Montanari, A. (2014), “Confidence Intervals and Hypothesis Testing for High-Dimensional Regression,” Journal of Machine Learning Research, 15, 2869–2909.
- Jirak, M. (2015), “Uniform Change Point Tests in High Dimension,” Annals of Statistics, 43, 2451–2483.
- Kaul, A., Fotopoulos, S. B., Jandhyala, V. K., and Safikhani, A. (2021), “Inference on the Change Point Under a High Dimensional Sparse Mean Shift,” Electronic Journal of Statistics, 15, 71–134. DOI: 10.1214/20-EJS1791.
- Kirch, C., and Stoehr, C. (2019), “Sequential Change Point Tests Based on U-statistics,” arXiv preprint, arxiv:1912.08580.
- Liu, H., Gao, C., and Samworth, R. J. (2021), “Minimax Rates in Sparse, High-dimensional Changepoint Detection,” Annals of Statistics, 49, 1081–1112.
- Londschien, M., Kovács, S., and Bühlmann, P. (2021), “Change-Point Detection for Graphical Models in the Presence of Missing Values,” Journal of Computational and Graphical Statistics, 30, 1–12. DOI: 10.1080/10618600.2020.1853549.
- Padilla, O. H. M., Yu, Y., Wang, D., and Rinaldo, A. (2021), “Optimal Nonparametric Multivariate Change Point Detection and Localization,” IEEE Transactions on Information Theory, 68, 1922–1944. DOI: 10.1109/TIT.2021.3130330.
- Page, E. S. (1954), “Continuous Inspection Schemes,” Biometrika, 41, 100–115.
- Rinaldo, A., Wang, D., Wen, Q., Willett, R., and Yu, Y. (2021), “Localizing Changes in High-dimensional Regression Models,” Proceedings of Machine Learning Research, pp. 2089–2097.
- Soh, Y. S., and Chandrasekaran, V. (2017), “High-Dimensional Change-Point Estimation: Combining Filtering With Convex Optimization,” Applied and Computational Harmonic Analysis, 43, 122–147. DOI: 10.1016/j.acha.2015.11.003.
- Tartakovsky, A., Nikiforov, I., and Basseville, M. (2014), Sequential Analysis: Hypothesis Testing and Changepoint Detection, London: Chapman and Hall.
- van de Geer, S., Bühlmann, P., Ritov, Y., and Dezeure, R. (2014), “On Asymptotically Optimal Confidence Regions and Tests for High-Dimensional Models,” Annals of Statistics, 42, 1166–1202.
- Wang, T., and Samworth, R. J. (2018), “High Dimensional Change Point Estimation via Sparse Projection,” Journal of the Royal Statistical Society, Series B, 80, 57–83. DOI: 10.1111/rssb.12243.
- Yu, Y., Bradic, J., and Samworth, R. J. (2021), “Confidence Intervals for High-Dimensional Cox Models,” Statistica Sinica, 31, 243–267. DOI: 10.5705/ss.202018.0247.
- Yu, Y., Padilla, O. H. M., Wang, D., and Rinaldo, A. (2021), “Optimal Network Online Change Point Localisation,” arXiv preprint, arxiv:2021.05477.
- Zhang, C.-H., and Zhang, S. S. (2014), “Confidence Intervals for Low Dimensional Parameters in High Dimensional Linear Models,” Journal of the Royal Statistical Society, Series B, 76, 217–242. DOI: 10.1111/rssb.12026.