
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Whenever we send a message via a channel such as E-mail, Facebook, WhatsApp, WeChat, or LinkedIn, we care about the response rate—the probability that our message will receive a response—and the response time—how long it will take to receive a reply. Recent studies have made considerable efforts to model the sending behaviors of messages in social networks with point processes. However, statistical research on modeling response rates and response times on social networks is still lacking. Compared with sending behaviors, which are often determined by the sender’s characteristics, response rates and response times further depend on the relationship between the sender and the receiver. Here, we develop a survival mixed membership blockmodel (SMMB) that integrates semiparametric cure rate models with a mixed membership stochastic blockmodel to analyze time-to-event data observed for node pairs in a social network, and we are able to prove its model identifiability without the pure node assumption. We develop a Markov chain Monte Carlo algorithm to conduct posterior inference and select the number of social clusters in the network according to the conditional deviance information criterion. The application of the SMMB to the Enron E-mail corpus offers novel insights into the company’s organization and power relations. Supplementary materials for this article are available online.
1 Introduction
With the rapid development of social media and electronic commerce, many social networks now encompass a sequence of time-to-event data for a pair of social actors. In an E-mail network, how long it takes for the receiver of an E-mail to reply to the sender is available; on Twitter and Sina Weibo, the time for a user to repost a message from another user can be recorded; in a company that uses web-based electronic document management systems such as those provided by Dropbox and ParaDM, the time an employee processes a file shared by another employee can be tracked. Compared to the number of events between a pair of actors, time-to-event data can provide alternative perspectives into interpersonal relationships. For instance, an employee may have many more E-mails with a secretary than with the CEO but replies to E-mails from the CEO much faster than to those from the secretary. However, despite the active research on time-to-event data on social networks, statistical research on response times and response rates on a social network is still lacking.
Many previous studies on time-to-event data from a social network focus on the behavior undertaken by a social actor to initiate events, either by sending E-mails or by posting tweets. Such behavior has often been modeled by point processes. Perry and Wolfe (Citation2013) treat the time of sending E-mails between pairs of actors in a network as a multivariate point process. Fox et al. (Citation2016) adopt self-exciting point processes to model the rate of sending E-mails, in which the intensity function comprises a baseline sending rate and triggering functions that characterize the impact of receiving E-mails on sending rates. Matias, Rebafka, and Villers (Citation2018) assume that each actor belongs to one and only one social group, in line with the classical stochastic blockmodel (Wang and Wong Citation1987), and assume a separate conditional inhomogeneous Poisson process for each social group pair. They use the proposed model to analyze the times at which actor A sends E-mails to actor B. Sit, Ying, and Yu (Citation2021) model the times that an actor A sends an E-mail to actor B as recurrent events and develop a pseudo-partial likelihood approach to capture the flexible dependence structures among pairs of actors in the network. Zhang et al. (Citation2022) jointly model the times at which actors initiate two events: posting their own tweets and reposting tweets from others. All of these studies focus on how frequently actor A initiates events (such as by posting tweets) or how frequently actor A interacts with actor B (such as by sending an E-mail to actor B).
Nevertheless, we not only care how frequently friends or colleagues contact us, but we are also always eager to know (a) whether the recipient will reply to our message (response rate) and (b) how long it will take us to receive a reply (response time). Both the response rate and the response time encode important information. For example, even if two actors send E-mails with a similar frequency, the one with a higher response rate will be more influential in their social network. Therefore, instead of studying the sending behaviors, in this article, we will model response rates and response times on a social network.
Noteworthy, the response behavior of actors in a social network can be highly heterogeneous. Recently, Rastelli and Fop (Citation2020) propose the exponential stochastic blockmodel (expSBM) to examine the duration of the interaction between actors. expSBM assumes that the network structure follows the stochastic blockmodel (Wang and Wong Citation1987) and that the interaction lengths follow exponential distributions. To fit into their framework, we may view actors’ E-mail response behaviors as interactions and the time period with no E-mail and with no E-mail reply as a noninteraction period. Because the stochastic blockmodel partitions the network into several communities and lets each actor belong to one and only one community, although expSBM allows individuals’ response speed to vary, it assumes the response speed of a given social actor to be the same no matter whom he or she interacts with. However, even for the same person, his or her response speed can be very different when communicating with different people. For example, the speed of an employee’s responses to the CEO, a secretary, and his or her peers can vary considerably. Moreover, expSBM cannot deal with censoring time and hence E-mails that are never replied to.
To deal with the challenges of nonresponse events, severe heterogeneity, and sparse observations, we integrate the mixed membership stochastic blockmodel (MMSB) (Airoldi et al. Citation2008) with the semiparametric cure rate model (SCRM) (Chen, Ibrahim, and Sinha Citation1999; Ibrahim, Chen, and Sinha Citation2001a, chap. 5) to build a survival mixed membership blockmodel (SMMB). The SMMB allows an actor to play different roles when interacting with different actors, accounts for the impact of covariates, and models nonresponse events. Globally, the SMMB can detect social clusters in a network and characterize between- and within-cluster interaction patterns. Locally, the SMMB is capable of identifying the specific role an actor plays when he or she interacts with another actor. The SMMB simultaneously learns the network structure from the data and uses the learned structure to improve actor pair-specific inference. Consequently, the SMMB pools information across the whole network.
The network structure inferred from time-to-event data can be very different from the structure learned from a binary network W that records the connectivity between actors. In this article, we use “communities” to refer to the grouping of actors according to their connectivity encoded by W and “roles” to refer to the grouping of actors according to their response times and response rates. If W follows an MMSB, then actors belonging to the same community have a high probability of communicating with each other—sending E-mails in the case of the Enron E-mail corpus. In comparison, actors sharing the same role have similar distributions of response times and response rates in the SMMB. Therefore, communities and roles reveal different aspects of a social network with time-to-event data. For example, different communities can correspond to the various departments of a company, whereas roles reflect employees’ levels of seniority. Employees in the same department tend to have more E-mail contacts, and thus are grouped together by W, but have very different E-mail response speeds and rates because of their different levels of seniority.
As pointed out by Zhang, Levina, and Zhu (Citation2020), it is nontrivial to establish identifiability for social network models that allow actors to belong to multiple social clusters such as the MMSB (Airoldi et al. Citation2008). Recently, Mao, Sarkar, and Chakrabarti (Citation2021) prove that the requirement of the existence of at least one pure node, defined as a social actor who acts as a member of only one social cluster irrespective of whom he or she communicates with, for each social cluster is not only sufficient (Kaufmanna, Bonaldb, and Lelargec Citation2018; Zhang, Levina, and Zhu Citation2020) but also necessary for the MMSB for binary networks to be identifiable. Fortunately, compared with binary data, time-to-event data encode more information, and hence we are able to prove that the SMMB is identifiable up to label switching without the pure node assumption.
We conduct statistical inference under the Bayesian framework and develop a Markov chain Monte Carlo (MCMC) algorithm. The application of the SMMB to the Enron E-mail corpus reveals network structure that better represent leadership patterns than those obtained from the state-of-the-art methods.
2 Model Formulation
Suppose that a social network consists of N actors and has sequences of time-to-event data, instead of binary outcomes Wijs, recorded for actor pairs. For a pair of actors (i, j), when actor i sends a sequence of E-mails to actor j, the response (failure) time and the censoring time for the gth E-mail by actor j are denoted as Tijg and Cijg, respectively. The associated p-dimensional covariates are denoted as , where
corresponds to the intercept term. If actor i sends nij E-mails to actor j, then we observe a sequence of survival times
and censoring indicators
satisfying
and
, and the corresponding covariates
. Here,
denotes the set of actors and
represents the set of actor pairs with at least one failure or censoring observation.
Following the MMSB, assume that there exist K roles with Dirichlet parameters . Here,
represents the abundance of the kth role in the network. Each pair of roles has a unique SCRM.
For the SCRM, we adopt the formulation (Chen, Ibrahim, and Sinha Citation1999; Ibrahim, Chen, and Sinha Citation2001a, chap. 5), which enjoys a population level proportional hazards structure. Here,
is a proper survival function for the baseline, and its hazard function
is piecewise constant:
if
, with
being a partition of the time axis and
for
. Meanwhile,
is the cure proportion. The survival time of this model can be viewed as the earliest event time of
iid competing risks with survival probability
and
following a Poisson distribution
, so θ can be interpreted as the average number of competing risks (Chen, Ibrahim, and Sinha Citation1999). Similarly, we may suppose that there exist
latent intentions to reply to an E-mail and view θ as the average number of latent response intentions. Furthermore, we can model covariate effects
via
, which corresponds to a log-log link for τ:
. Consequently, the hazard function of the SCRM is
, where
denotes the probability density function for
. In the SMMB, we let both the baseline hazards and covariate effects to be role-pair-specific.
When role k replies to the E-mails sent by role l, the piecewise constant baseline hazard function in interval is
. We collect
and denote the role-pair-specific covariate effects as
. Notably, the time-to-event data from role l to role
do not necessarily have the same distribution as those from role k to role l. In other words,
is not required. Instead, the interactions are allowed to be asymmetric.
When actor j replies to an E-mail sent by actor i, actor i and actor j pick up their latent social role Qij and Rij according to their latent role proportions and
, respectively. Given the latent roles
and
, a sequence of failure times
are iid generated according to a SCRM with the piecewise constant baseline hazards
and the coefficients
.
We denote and
. The proposed SMMB can then be described by the following data generation mechanism:
(1)
(1) where
, are iid given
; Qij (Rij) for
are independent conditional on
(
); conditional on Qij, Rij and given the parameters
and covariates
, failure time Tijg and censoring time Cijg are independent, and for
, the corresponding observed survival times and censoring indicators
s are independent. It is also interesting to note the link between the SMMB and the MMSB. When yij is a binary random variable and there is exactly one observation yij on each edge with no censoring
, the SMMB reduces to the MMSB.
Following the inference for the SCRM model (Chen, Ibrahim, and Sinha Citation1999), we can augment a latent variable Uijg for each E-mail by each pair of actors to facilitate the computation. If actor i plays role and actor j plays role
when actor j replies to actor i’s E-mails, then Uijg follows
. Consequently, in the SMMB,
are the parameters of interest;
,
and
are the observed data; and
,
,
and
are latent variables. Let
if
and zero otherwise. Then, the complete data likelihood function becomes:
(2)
(2) where
, and
.
After marginalizing over the latent variables, the observed data likelihood is as follows:
(3)
(3)
For reference, we have summarized all the notations in Table S1.
3 Model Identifiability
There is emerging research on the identifiability of the MMSB (Mao, Sarkar, and Chakrabarti Citation2017; Zhang, Levina, and Zhu Citation2020; Mao, Sarkar, and Chakrabarti Citation2021). As mixture models, both the regular stochastic blockmodel (Wang and Wong Citation1987) and the MMSB are only identifiable up to the label switching of communities. Theorem 1 shows that the SMMB is also identifiable up to the label switching of roles given easily met regularity conditions.
Theorem 1. In a network denotes a set of actors and
represents the set of actor pairs with at least one observation. Suppose that we observe nij time-to-event data for each actor pair (i, j). Let
denote the number of roles and V be an open set that consist of all possible covariate values. Given that
(C1) There exist three actors
such that
(C2) There exists a covariate set
at knot ;then the SMMB is identifiable (up to label switching) in the sense that if two sets of parameters
and
give rise to the same likelihood function as (3) for any yijg and
, then
and
, where ρ is a permutation of
.
Condition 1 requires the existence of an actor who has time-to-event data with at least two actors, which is easily met for real social networks. Condition 2 requires each covariate to take at least two values so that the survival functions of different role pairs are distinct at all of the knots; this is similar to the non-singular block matrix assumption that ensures the identifiability of the MMSB for binary networks (Mao, Sarkar, and Chakrabarti Citation2021). For the identifiability of the MMSB, Mao, Sarkar, and Chakrabarti (Citation2021) require the existence of pure nodes who each play one and only one role. Fortunately, because a sequence of survival outcomes yijg rather than a single binary or continuous weight is observed for each pair of actors, much more information is available for the SMMB to distinguish between different role pairs. Consequently, the assumption of the existence of pure nodes is released in our theorem.
In the proof, we need to show that if two sets of parameters and
give rise to the same observed data likelihood function, then
must be a permutation of Θ with
and
. It is difficult to show the existence of such a permutation
directly. Instead, by first viewing the model as a mixture of cure rate models with K2 components, we are able to find a permutation
of all K2 role pairs such that these two sets of parameters satisfy
and
. Then, we show that the permutation
can be decomposed with the single permutation
so that
. Finally, these two sets of parameters can be equal up to the label switching
, that is,
and
The proof of Theorem 1 is outlined in the Appendix and provided in details in Supplementary Sections S2–S4.
4 Statistical Inference
We conduct the statistical inference under the Bayesian framework. We first reparameterize as
and
. For the MMSB, Airoldi et al. (Citation2008) let
vary between 0.05 and 0.25, so here following the same philosophy, we impose a
prior on α and a non-informative
prior on
independently. We follow the common practice in choosing independent Gaussian priors for
with
for
and independent Gamma priors for the baseline hazard
. By default,
is set as (1, 5, 50), and b1 and
s rely on their empirical estimators. In particular, we first use the Kaplan-Meier estimator (Kaplan and Meier Citation1958) to estimate an overall survival function for all of the observations. As a result, an empirical estimation
is
, where
represents the Kaplan-Meier estimator of the survival probability at time t. Given
and
, we then sample latent variables
from
and set
as the estimated baseline hazard (Robbins Citation1955):
Let us now discuss the asymptotic behavior of the posterior distribution of the SMMB. Without loss of generality, let for all actor pairs
. Let us denote
as the number of active edges. When two actor pairs share an actor, for example,
and
, their survival outcomes are dependent. Inspired by the Bayesian consistency results for non-iid data (Ghosal and Van Der Vaart Citation2007; Ghosal and Van der Vaart Citation2017), we provide sufficient conditions under which the posterior of the SMMB concentrates on the true parameters as E goes to infinity.
Theorem 2. Assume that the conditions in Theorem 1 hold so that the SMMB is identifiable and that Xijg are generated iid from a bounded distribution such that
. Let
denote the joint distribution of E observations
given
that admits the density
where
follows the SMMB. Let
indicate the joint distribution under the true parameters
and
represent the prior distribution of
. If for
, there exists an ε-neighborhood
such that
and it satisfies
(C1) For some constant b > 0 and B > 0, there exist test functions for testing
versus
such that
(C2) There exists some positive such that for any
then as E goes to infinity, the posterior distribution
The proof of Theorem 2 is provided in Supplementary Section S5.
We develop an MCMC algorithm to draw samples from the posterior distribution. Here, we use superscript to denote the corresponding posterior samples of parameters or latent variables at the tth iteration of the MCMC algorithm. At the tth iteration:
1. To update the latent variable
2. To update the roles
3. To update
4. To update
and a rate parameter equal to
5. To update
6. To update
7. To update
To accelerate the convergence of the MCMC algorithm, inspired by the shift-mode Metropolis step proposed by Liu (Citation1994), we incorporate another Metropolis step into the above algorithm to allow the global swapping of two randomly selected role pairs. Because this step involves extra sampling and computation, we insert it into the above algorithm every few iterations, such as every 10 iterations. We call the new step a global swapping Metropolis step. Specifically, a pair of role pairs (l1, k1) and are randomly selected and their role-pair-specific parameters
and
are swapped to obtain the proposed values
. We correspondingly swap the role labels Qij’s and Rij’s as
. To propose
, we incorporate an MH step to draw a sequence of
and
from their full conditional distributions given
. To reach convergence, we run the MH step for 50 iterations and take the samples at the 50th iteration as the proposed values
and
. If the swapping is rejected, we keep all of the parameters and latent variables unchanged; otherwise, we swap the role pair and update the parameters and latent variables with the proposed values. The detailed derivations of the full conditional distributions and the acceptance ratios are listed in Supplementary Section S6.
The Dirichlet parameters , the role-pair-specific piecewise constant hazards
’s, the covariate coefficients
’s, and the user-specific role proportions
’s are estimated by their posterior means, and the latent role pairs
of each pair
are estimated by their posterior modes.
Denoting as the total number of observed survival times, the time complexity of each step of the MCMC algorithm is shown in . In general, the number of covariates p is fixed, and the number of knots M is not very large. Therefore, the scalability of the proposed MCMC algorithm is determined by the number of roles K and the total number of observed survival times L. The total time complexity, which is the summation of all of the terms in , is linear in L and quadratic in K.
Table 1 Time complexity of MCMC steps.
We determine the number of roles K present in the network according to the conditional deviance information criterion (DIC) (Celeux et al. Citation2006; Lu and Song Citation2012) and select K as the one that attains the minimum (see Supplementary Section S7 for details).
5 Simulation
5.1 A Simulation Dataset Mimicking the Enron E-mail Corpus
To evaluate the performance of the SMMB, we first generate a simulation dataset that mimics the Enron E-mail corpus. We generate a binary network with N = 150 actors using a stochastic block model (Wang and Wong Citation1987). Specifically, we assume the existence of four communities, which contain 25, 30, 40, and 55 actors, respectively (Figure S1). For each active edge, we generate the number of E-mails nij from a shifted negative binomial distribution. We assume that when replying to E-mails, actors can play K = 3 roles, incorporate two covariates, one binary and the other continuous, and divide the time axis by M = 5 knots. Consequently, the true underlying response times Tijg’s are generated sequentially according to the SMMB. Finally, we generate the censoring time (see Supplementary Section S8 and Table S2 for more details).
We run 50,000 MCMC iterations with the first 25,000 as burnins. The estimated potential scale reduction (EPSR) criterion (Gelman et al. Citation2013) shows that the Markov chain has reached convergence after 25,000 iterations (Supplementary Section S9 and Table S7). To identify the number of roles, we vary the number of roles K from 1 to 5, and the conditional DIC correctly selects the number of roles as the true value K = 3. The estimated is consistent with the true
. Figure S2 shows that the posterior means of piecewise constant hazards
and intercept terms
recover the true values of the baseline survival function of each role pair well (see also Tables S4–S6 and Figures S3–S4). The credible intervals of all the covariate coefficients
s
cover the true values (Table S2).
The contingency table of the estimated versus the true role pairs shows that the roles of the actors in each pair are inferred accurately (Table S3). Extensive sensitivity analyses (Supplementary Section S10) show that SMMB is robust to the choice of hyperparameters (Table S8) and the selection of knots (Table S9).
We perform posterior predictive check and use the L measure (Ibrahim, Chen, and Sinha Citation2001b) to compare the SMMB with (a) fitting a single SCRM (overall SCRM) to all the data and (b) fitting a separate SCRM to each actor pair (pairwise SCRM) (Supplementary Section S11). The SMMB achieves the smallest L measure and hence outperforms the two benchmark methods in goodness of fit (Table S10).
5.2 Simulation Datasets with Different Heterogeneity and Sparsity Levels
We further test the performance of the SMMB using datasets generated with different heterogeneity levels, different numbers of active edges and different numbers of observed survival times per active edge. In order to vary the sparsity of the network, here we generate the binary networks W with N = 150 using the Erdős-Rényi model (Erdős and Rényi Citation1960) with the connectivity probability pc, which denotes the probability that a directed edge is drawn between two arbitrary actors. We generate the baseline probabilities, the censoring times Cijg, and the underlying response times Tijg similarly as in Section 5.1. Details are presented in Supplementary Section S12.
First, we fix the number of roles at K = 3 and vary the connectivity probability pc over to investigate how the network sparsity affects the recovery performance. Next, we fix the number of roles at K = 3 and the connectivity probability
but vary the average number of observations on each edge. In particular, we sample the number of E-mails nij from
and vary μ over
. Finally, we are also interested in the impact of pattern heterogeneity on parameter estimation. Thus, we fix the connectivity probability
and generate the number of E-mails per active edge from
while varying the number of roles K from 2 to 5. We generate 100 replicated datasets for each setting. In total, there are 1,200 simulation datasets.
For each simulation dataset, we run 50,000 MCMC iterations with the first 25,000 as burnins. Almost all of the parameters enjoy small biases, standard deviation (SD), and root mean square errors (RMSE), and their coverage probabilities (CP) of the 95% credible interval are high ( and Supplement Tables S12–S47).
Fig. 1 Boxplot of coverage probabilities among 100 synthetic replicated datasets (a) when K = 3, and the connectivity probabilities pc varies over
; (b) when K = 3,
,
and μ varies over
; (c) when
and K varies over
.
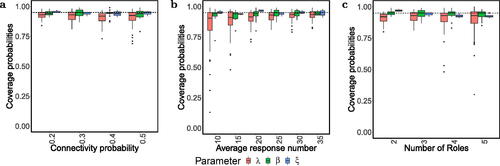
Moreover, these simulation studies allow us to verify the theoretical calculation of time complexity of our MCMC algorithm. confirms that the time complexity of the algorithm is linear in the total number of observed survival times L and quadratic in the number of roles K.
Fig. 2 Running time of 100,000 iterations of the MCMC algorithm on one core of an Intel Xeon Gold 6226R Processor. The number of observations per edge . (a) We fix the connectivity probability
and μ = 25 while varying the number of roles K from 2 to 5. (b) We fix K = 3 and μ = 25 but vary pc from 0.2 to 0.5. (c) We fix K = 3 and
but vary μ from 10 to 35.
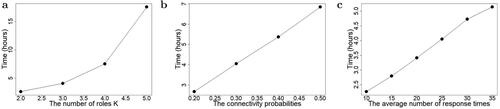
Fig. 3 Patterns learned from the Enron E-mail corpus. (a), (b) The scatterplots of the employee-specific probability of belonging to the first role and the log-scale E-mail numbers (a) when the SMMB is applied to time-to-event data, and (b) when the MMSB is applied to relational data. Each node represents an employee, with the color indicating his or her position. The size of each node represents the number of E-mails related to the employee. (c) The estimated baseline survival curve
of role l replying E-mails to role k when
.
![Fig. 3 Patterns learned from the Enron E-mail corpus. (a), (b) The scatterplots of the employee-specific probability πi1 of belonging to the first role and the log-scale E-mail numbers (a) when the SMMB is applied to time-to-event data, and (b) when the MMSB is applied to relational data. Each node represents an employee, with the color indicating his or her position. The size of each node represents the number of E-mails related to the employee. (c) The estimated baseline survival curve exp {− exp (β̂1lk)[1−S0(t|λ̂lk)]} of role l replying E-mails to role k when x=(1,0,0,…,0)T.](/cms/asset/e928559e-0077-4008-bbea-e3c51d810561/uasa_a_2213466_f0003_c.jpg)
We also examine the performance of the conditional DIC in determining the number of roles in the network. For the 100 sets of simulated data with K = 3 roles, and
, we run the MCMC algorithm with the number of roles K varying from 2 to 4 for each dataset. It turns out that the conditional DIC correctly identifies the optimal K as three for all of the replicates. Moreover, the conditional DIC also performs well in selecting the optimal number of knots and outperforms the Bayesian information criterion (BIC) (Airoldi et al. Citation2008) and the Watanabe-Akaike information criterion (WAIC) (Watanabe and Opper Citation2010) (Supplementary Section S13 and Figures S5–S6).
6 The Enron E-mail Corpus
The Enron E-mail corpus (Klimt and Yang Citation2004) is the largest publicly available E-mail dataset to date and was released by the Federal Energy Regulatory Commission during its investigation of Enron’s bankruptcy. The dataset contains E-mails generated by 158 Enron employees between November 13, 1998 and June 21, 2002. Because “It’s always about the people. Enron is no different,” (Diesner, Frantz, and Carley Citation2005) the Enron E-mail corpus provides a unique opportunity to study the communication patterns, company organization, and power spread inside a company. The corpus contains the user information and timestamp of each E-mail. Following the enrondata GitHub repository, we focus on the E-mail folders of 148 Enron users whose positions in the company are known.
We apply the SMMB to the preprocessed dataset (see Supplementary Section S14 for preprocessing details and Table S48). The dataset contains the response times for 25,629 E-mails, 1886 of which are observed and 23,743 are censored. The Kaplan-Meier estimate of the survival probability after three weeks is 92.36%; thus, a cure rate model is necessary to fit the survival function of the response time. We set the number of knots as five and let hours such that each interval
contains the same number of failure times.
6.1 Analysis Without Confidential Information
We first consider the following four covariates: whether the E-mail was sent over the weekend, whether the E-mail was forwarded, the number of recipients of the E-mail, and the number of words in the E-mail. We log-transform the latter two covariates to reduce the impact of skewness. If a series of E-mails had the same subject, we denote the first E-mail as the original E-mail and record the fourth covariate as the number of words in the contents of the original E-mail. The hyperparameters for
are set as (1, 50, 5). We vary the number of roles K from one to five and run 100,000 MCMC iterations with the first 50,000 iterations as burnins for each value of K. The EPSR values shows that the Markov chain has reached convergence after 50,000 iterations (Supplementary Section S9 and Table S7).
The conditional DIC attains its minimum at K = 2 (Figure S7a), and the SMMB fits the data well (Supplementary Table S11). For K = 2, when we vary the number of knots, the conditional DIC also selects the optimal number of knots as five, thus, M = 5 is a reasonable choice for the data analysis (Figure S7b). In , we plot the probability of belonging to the first role as opposed to the second role. Warmer colors (red and deep orange) represent higher positions (CEO and president). The warmer colored points are concentrated on the left-hand side, thus, preferring to belong to the second role, especially the four CEOs shown as red (). Thus, we regard the second role as the senior group and the first role as the junior group.
Table 2 The estimated role probabilities by the SMMB from time-to-event data and by the MMSB from binary data of the four CEOs, respectively.
The estimated baseline survival function of each role pair reveals communication patterns between employees (). Let us recall that the role pair (l, k) denotes role k replying to the E-mails from role l. Comparing the survival function of the role pair (1, 2) with that of the other three role pairs, the longest response time was that of a senior employee replying to an E-mail from a junior employee. Meanwhile, the response times between junior employees, which correspond to the role pair (1, 1), were the shortest among all of the role pairs. This may be because junior employees often need to communicate via E-mails about routine daily work. As expected, when a senior employee communicated with a junior employee, which corresponds to the role pairs (1, 2) and (2, 1), junior employees replied to the E-mails from senior employees much faster than the reverse situation. Therefore, the level of seniority affected the speed of E-mail response.
An employee can play different roles when communicating with different colleagues. For example, John Zufferli (User 148) held the position of vice president. When he replied to the E-mails from John Lavorato (User 62), a CEO, the estimated role pair . Meanwhile, when John Lavorato replied to the E-mails from John Zufferli, the estimated role pair became
. Thus, John Zufferli occupied a junior position in the communications with the CEO. However, when John Zufferli communicated with Chris Dorland (User 28), a manager, the estimated role pair
and
became (2, 1) and (1, 2), respectively. In other words, compared with Chris Dorland, John Zufferli held a higher position. Thus, although the positions of senders and receivers are not incorporated as covariates, the SMMB is able to reveal the seniority of employees within a company according to E-mail response times.
With regard to the weekend effect (), among all role pairs, only the 95% credible interval [–5.4631, –0.7872] for the coefficient do not cover zero. The negativity of
indicates that at weekends, junior employees replied to the E-mails sent by other junior employees more slowly, which is unsurprising, as most junior employees are likely to rest over the weekend. The coefficients for the forwarded E-mails are negative across all of the role pairs, indicating that the response times for forwarded E-mails were often longer (). Moreover, the coefficients for the number of recipients are also negative across role pairs. Thus, an E-mail with more recipients was likely to receive longer response times or was never replied, which is consistent with our experience that people are less likely to respond to circulating E-mails. The effects of E-mail length are only negative for the role pair (1, 1). In other words, for E-mail communications between junior employees, longer E-mails were usually replied to more slowly. The most likely reason for this is that junior employees use E-mails to discuss routine daily work, and a longer E-mail indicates that the task may be more complicated and require more time to handle. Consequently, the SMMB is able to uncover heterogeneous effects across different role pairs.
Table 3 The posterior mean, posterior standard deviation (SD), and 95% credible interval (CI) of coefficient ’s for the SMMB learned from the Enron E-mail corpus without considering confidential information.
For comparison, we apply the MMSB (Airoldi et al. Citation2008) to the binary social network W by running the C# program provided by Burnap et al. (Citation2015). The estimated employee-specific community proportions fail to reflect the leadership among users (). For example, the four CEOs had very distinct community proportions (); therefore, compared with the relational data, the time-to-event data contain much more information about the leadership and power spread of a company. The true position information of these employees shows that the estimated employee-specific role proportions learned from the response times are much more indicative of the leadership among the employees than those estimated from E-mail counts ().
We also apply the expSBM (Rastelli and Fop Citation2020) by regarding E-mail responses as the interactions in the setting of expSBM. expSBM identifies K = 6 clusters (Table S52). However, the distribution of employees in different groups is very uneven: 127 of 148 employees are clustered into group 2 whereas group 3 contains only one person, the CEO John Lavorato. Moreover, the patterns learned by expSBM fail to characterize the response rates (Tables S53–S54 and Supplementary Section S16).
6.2 Analysis with Confidential Information
Although we usually have no access to E-mail contents or the genders of senders and receivers because of privacy and potential legal issues, we have the unique opportunity to identify each employee and retrieve the E-mail contents for the Enron E-mail corpus. Therefore, we first conduct a sentiment analysis for the E-mail contents. The Loughran and McDonald lexicon (Loughran and McDonald Citation2011) categorizes words into classes of constraining, litigious, negative, positive, superfluous, and uncertainty (Table S49). For each E-mail, we count the number of words belonging to each category, log-transform them, and add them as six extra covariates to the model. To incorporate gender into the model, we take the male-male actor pair—both the sender and the recipient being male—as the baseline—and create three dummy variables: male–female, female–male, and female–female.
We then refit the SMMB model with 13 covariates. We run 500,000 iterations of the MCMC algorithm, regard the first 250,000 iterations as burnins, and set the variance of the normal prior distribution of as 1. The role proportions (Figure S8) and the baseline survival functions of all role pairs (Figure S9) have similar patterns before and after we incorporate sentiment and gender covariates.
For the four covariates analyzed in Section 6.1, the direction and significance of their effects stay the same in the new analysis except that the 95% credible interval of the weekend effect for the role pair (1, 2), , no longer covers zero (Table S50). The positivity of
indicates that at weekends junior employees replied to the E-mails sent by the senior employees even faster. All of the sentiment covariates’ credible intervals cover zero, so they have limited effects on response behavior. Meanwhile, the effects of gender are heterogeneous across different role pairs. As
and
are positive, when two junior employees communicated with each other, they tended to respond faster to E-mails sent by colleagues of the other gender than to those sent by colleagues of the same gender. Moreover, when the sender played a junior role and the receiver played a senior role, male senders were responded faster than female senders as
is significantly greater than 0 but
and
are significantly smaller than 0. In contrast, when senior employees communicated with each other, female senders were responded faster than male senders. Therefore, the analysis with the sentiment and gender covariates again confirms that by allowing different role pairs to have different survival distributions the SMMB model provides novel insights into the company organization.
6.3 Analysis Considering Sending Behavior
To explore whether recent E-mails speed up responses and increase response rates, we introduce a new covariate indicating whether actor i had received an E-mail from actor j within the previous week into the SMMB model in Section 6.1. Table S51 shows that the effects of recent communications are significant and positive for all of the role pairs. However, the patterns of role proportions and baseline survival functions become quite different from those in Section 6.1 (Figures S10–S11). The difference is because the covariate of recent communications encodes information of the frequency of communications, which implies the connectivity of the company but not the leadership relationship. Therefore, to reveal the leadership patterns within the company, we recommend the SMMB model in Section 6.1. Nevertheless, if one is interested in building a prediction model for response times and response rates, we suggest adding covariates related to sending behavior to the SMMB (see Supplementary Section S15 for details).
7 Discussion
In this article, we propose the SMMB to analyze time-to-event data between actor pairs in a social network. In the SMMB, we assume that actor pairs belonging to the same role pairs share the same SCRM, whereas actor pairs belonging to different role pairs have distinct cure rate models. Thus, while keeping the heterogeneity in the response patterns between different role pairs, the SMMB enables us to borrow information across actor pairs for a given role pair. We prove the model identifiability and posterior consistency of the SMMB. We develop an efficient MCMC algorithm for statistical inference.
In our analysis of the Enron E-mail corpus, we did not consider any time-dependent covariates, as they are difficult to construct given the data we have. Nevertheless, for any external time-dependent covariates, we can directly add them into the SMMB (Kalbfleisch and Prentice Citation2011). In contrast, internal time-dependent covariates may influence the rate of failures, so additional modeling will be needed, which we will investigate in the future.
Thus, far, for a pair of actors, conditional on their roles , we assume that the sequence of response times is generated independently. When multiple E-mails are about the same topic, there might be dependence between these E-mails. To model dependence, we can further add multiplicative random effects into hazard functions as classic frailty models (Duchateau and Janssen Citation2008) do (see Supplementary Section S17 for details). As we only have 25,629 E-mails for the Enron E-mail corpus, of which 1886 are observed and the rest are censored, we do not fit these frailty models. Nevertheless, these models might be of interest to large social media and electronic document management systems companies.
With the rapid development of social media and electronic commerce, many social networks now encompass time-to-event data. Although we focus on an E-mail network, many other social networks have similar time-to-event data. For example, the times taken for users to repost messages from other users are available for Twitter. Moreover, in Web-based electronic document management systems such as the services provided by Dropbox and ParaDM, the time that a team member spends on an assigned task can be recorded, and how soon a user responds to the action of another user is also of great interest in this context. We envision that the proposed SMMB can help to analyze these networks and provide insights into information flow, company organization, and working efficiency.
Supplemental Material
Download Zip (1.5 MB)Acknowledgments
We sincerely thank the Editor, Associate Editor, and three reviewers for their helpful comments that have greatly improved the quality of the article.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
References
- Airoldi, E. M., Blei, D. M., Fienberg, S. E., and Xing, E. P. (2008), “Mixed Membership Stochastic Blockmodels,” Journal of Machine Learning Research, 9, 1981–2014.
- Burnap, A., Cruz, E., Rong, X., and Segal, B. (2015), “An Implementation of Mixed Membership Stochastic Blockmodel,” available at https://github.com/aburnap/Mixed-Membership-Stochastic-Blockmodel.
- Celeux, G., Forbes, F., Robert, C. P., and Titterington, D. M. (2006), “Deviance Information Criteria for Missing Data Models,” Bayesian Analysis, 1, 651–673. DOI: 10.1214/06-BA122.
- Chen, M.-H., Ibrahim, J. G., and Sinha, D. (1999), “A New Bayesian Model for Survival Data with a Surviving Fraction,” Journal of the American Statistical Association, 94, 909–919. DOI: 10.1080/01621459.1999.10474196.
- Diesner, J., Frantz, T. L., and Carley, K. M. (2005), “Communication Networks from the Enron Email Corpus: It’s Always about the People. Enron is no Different,” Computational & Mathematical Organization Theory, 11, 201–228. DOI: 10.1007/s10588-005-5377-0.
- Duchateau, L., and Janssen, P. (2008), The Frailty Model, New York: Springer.
- Erdős, P., and Rényi, A. (1960), “On the Evolution of Random Graphs,” Mathematical Institute of the Hungarian Academy of Sciences, 5, 17–60.
- Fox, E. W., Short, M. B., Schoenberg, F. P., Coronges, K. D., and Bertozzi, A. L. (2016), “Modeling E-mail Networks and Inferring Leadership using Self-Exciting Point Processes,” Journal of the American Statistical Association, 111, 564–584. DOI: 10.1080/01621459.2015.1135802.
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2013), Bayesian Data Analysis, Boca Raton,FL: CRC Press.
- Ghosal, S., and Van Der Vaart, A. (2007), “Convergence Rates of Posterior Distributions for Noniid Observations,” The Annals of Statistics, 35, 192–223. DOI: 10.1214/009053606000001172.
- Ghosal, S., and Van der Vaart, A. (2017), Fundamentals of Nonparametric Bayesian Inference (Vol. 44), Cambridge: Cambridge University Press.
- Ibrahim, J. G., Chen, M.-H., and Sinha, D. (2001a), Bayesian Survival Analysis (Vol. 2), New York: Springer.
- Ibrahim, J. G., Chen, M.-H., and Sinha, D. (2001b), “Criterion-based Methods for Bayesian Model Assessment,” Statistica Sinica, 11, 419–443.
- Kalbfleisch, J. D., and Prentice, R. L. (2011), The Statistical Analysis of Failure Time Data, Hoboken: Wiley.
- Kaplan, E. L., and Meier, P. (1958), “Nonparametric Estimation from Incomplete Observations,” Journal of the American Statistical Association, 53, 457–481. DOI: 10.1080/01621459.1958.10501452.
- Kaufmanna, E., Bonaldb, T., and Lelargec, M. (2018), “A Spectral Algorithm with Additive Clustering for the Recovery of Overlapping Communities in Networks,” Theoretical Computer Science, 742, 3–26. DOI: 10.1016/j.tcs.2017.12.028.
- Klimt, B., and Yang, Y. (2004), “The Enron Corpus: A New Dataset for Email Classification Research,” in Machine Learning: ECML 2004, eds. J. F. Boulicaut, F. Esposito, F. Giannotti, and D. Pedreschi, pp. 217–226, Berlin: Springer.
- Liu, J. S. (1994), “The Collapsed Gibbs Sampler in Bayesian Computations with Applications to a Gene Regulation Problem,” Journal of the American Statistical Association, 89, 958–966. DOI: 10.1080/01621459.1994.10476829.
- Loughran, T., and McDonald, B. (2011), “When is a Liability not a Liability? Textual Analysis, Dictionaries, and 10-ks,” The Journal of Finance, 66, 35–65. DOI: 10.1111/j.1540-6261.2010.01625.x.
- Lu, Z., and Song, X. (2012), “Finite Mixture Varying Coefficient Models for Analyzing Longitudinal Heterogenous Data,” Statistics in Medicine, 31, 544–560. DOI: 10.1002/sim.4420.
- Mao, X., Sarkar, P., and Chakrabarti, D. (2017), “On Mixed Memberships and Symmetric Nonnegative Matrix Factorizations,” in International Conference on Machine Learning, pp. 2324–2333.
- Mao, X., Sarkar, P., and Chakrabarti, D. (2021), “Estimating Mixed Memberships with Sharp Eigenvector Deviations,” Journal of the American Statistical Association, 116, 1928–1940. DOI: 10.1080/01621459.2020.1751645.
- Matias, C., Rebafka, T., and Villers, F. (2018), “A Semiparametric Extension of the Stochastic Block Model for Longitudinal Networks,” Biometrika, 105, 665–680. DOI: 10.1093/biomet/asy016.
- Perry, P. O., and Wolfe, P. J. (2013), “Point Process Modelling for Directed Interaction Networks,” Journal of the Royal Statistical Society, Series B, 75, 821–849. DOI: 10.1111/rssb.12013.
- Rastelli, R., and Fop, M. (2020), “A Stochastic Block Model for Interaction Lengths,” Advances in Data Analysis and Classification, 14, 485–512. DOI: 10.1007/s11634-020-00403-w.
- Robbins, H. (1955), An Empirical Bayes Approach to Statistics. Office of Scientific Research, US Air Force.
- Sit, T., Ying, Z., and Yu, Y. (2021), “Event History Analysis of Dynamic Networks,” Biometrika, 108, 223–230. DOI: 10.1093/biomet/asaa045.
- Wang, Y. J., and Wong, G. Y. (1987), “Stochastic Blockmodels for Directed Graphs,” Journal of the American Statistical Association, 82, 8–19. DOI: 10.1080/01621459.1987.10478385.
- Watanabe, S., and Opper, M. (2010), “Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory,” Journal of Machine Learning Research, 11, 3571–3594.
- Zhang, J., Cai, B., Zhu, X., Wang, H., Xu, G., and Guan, Y. (2022), “Learning Human Activity Patterns Using Clustered Point Processes with Active and Inactive States,” Journal of Business & Economic Statistics, 41, 388–398. DOI: 10.1080/07350015.2021.2025065.
- Zhang, Y., Levina, E., and Zhu, J. (2020), “Detecting Overlapping Communities in Networks Using Spectral Methods,” SIAM Journal on Mathematics of Data Science, 2, 265–283. DOI: 10.1137/19M1272238.