
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
During the COVID-19 pandemic, many institutions such as universities and workplaces implemented testing regimens with every member of some population tested longitudinally, and those testing positive isolated for some time. Although the primary purpose of such regimens was to suppress disease spread by identifying and isolating infectious individuals, testing results were often also used to obtain prevalence and incidence estimates. Such estimates are helpful in risk assessment and institutional planning and various estimation procedures have been implemented, ranging from simple test-positive rates to complex dynamical modeling. Unfortunately, the popular test-positive rate is a biased estimator of prevalence under many seemingly innocuous longitudinal testing regimens with isolation. We illustrate how such bias arises and identify conditions under which the test-positive rate is unbiased. Further, we identify weaker conditions under which prevalence is identifiable and propose a new estimator of prevalence under longitudinal testing. We evaluate the proposed estimation procedure via simulation study and illustrate its use on a dataset derived by anonymizing testing data from The Ohio State University. Supplementary materials for this article are available online.
1 Introduction
In the wake of the first signs of a global COVID-19 pandemic in early 2020, various tests for detecting SARS-CoV-2 were developed across the world within days of the release of the virus genome (Corman et al. Citation2020; Mina and Andersen Citation2021), with some countries who early on invested in large-scale testing capacity being able to control SARS-CoV-2 transmission (Baker et al. Citation2020). The various testing strategies were also often essential parts of the gradual lifting of lockdowns and the relaxing of mask-wearing rules (Panovska-Griffiths et al. Citation2020; Schultes et al. Citation2021). Accordingly, during different periods of the COVID-19 pandemic, many institutions implemented comprehensive testing regimens in which every member was tested longitudinally. Notable examples include several universities (Schultes et al. Citation2021; Paltiel and Schwartz Citation2021; Chang et al. Citation2021), workplaces (Rosella et al. Citation2022), and sports leagues (Mack et al. Citation2021). The primary purpose of these regimens was to suppress disease spread within the population by identifying and isolating infectious individuals and potentially quarantining their close contacts. Thus, the regimens were designed to attempt to detect as early as possible all infectious individuals during their infectious period, for example by requiring each individual to be tested at least or exactly once during each calendar week, or requiring that an individual go no more than a set small number of days between tests (Chang et al. Citation2021; Frazier et al. Citation2022).
A secondary goal of comprehensive longitudinal testing regimens was to provide frequent estimates of prevalence and incidence within the population. Such estimates may be helpful in risk assessment (e.g., how safe is it to hold gatherings?) and other institutional planning (e.g., isolation and quarantine capacity). Various methods of estimating prevalence have been applied. One particularly simple and popular method is based on the test-positive rate (TPR): the number of positive tests divided by the total number of tests administered. The TPR on a given day has been interpreted as an estimate of prevalence on that day (Kahanec et al. Citation2021). The intuition behind the use of the TPR as an estimator of prevalence arises from sampling arguments: if a sample representative of the population is tested, then the proportion of infectious individuals within that sample (the TPR under perfect test sensitivity and specificity) is an unbiased estimator of the proportion of infectious individuals within the population (the prevalence). Nicholson et al. (Citation2022) provide a framework for debiasing local prevalence estimates from a non-representative surveillance population by incorporating information from broader representative samples. An alternative and more complicated approach is via direct modeling of the process of disease spread, as by Quick et al. (Citation2021), which additionally combines confirmed case reporting with seroprevalence data to handle under-ascertainment and unreliable reporting.
Unfortunately, the test-positive rate described above is a biased estimator of prevalence under large classes of natural longitudinal testing regimens when those testing positive are subsequently isolated. This bias generally arises due to associations between the probability of testing on a given day and the time since the last test. For instance, if individuals not in isolation or quarantine are tested exactly once per calendar week, the individuals eligible to be tested on a given day late in the week (because they have not yet been tested that week) are more likely to be infectious than those ineligible for testing (because they have already been tested that week and are known to have not been infectious at the time), all else equal. Hay et al. (Citation2021) argue that the TPR in a repeatedly tested population falls between incidence and prevalence in the long run, but do not consider bias due to within-week scheduling. Estimation methods that involve modeling the process of disease spread may avoid such biases, but generally involve mechanistic assumptions and may require specific expertise and extensive computational resources to implement.
In this work we give detailed illustrations of how the bias of the TPR as an estimator of prevalence arises and describe a necessary and sufficient condition under which the TPR is unbiased under some simplifying assumptions (Section 3). Further, we identify a set of weaker conditions under which the TPR may be biased but prevalence may be estimated without bias via a Horvitz-Thompson–type estimator (Horvitz and Thompson (Citation1952), Section 4), including under known imperfect test sensitivity and specificity. We evaluate the Horvitz-Thompson (HT) estimator via simulation study (Section 5) and illustrate its application to a dataset derived by anonymizing comprehensive longitudinal testing data of a student population at The Ohio State University (Section 6). We conclude with a discussion of strengths, weaknesses, and potential for future work (Section 7).
2 Disease and Testing Process
We employ two parallel formulations of the joint disease and testing process: one set-theoretic and one time-to-event. The set-theoretic formulation is generally parsimonious when defining and manipulating estimators based on sampling at a specific time with minimal intrusion by time-evolution considerations, while the time-to-event formulation is convenient for describing phenomena arising from time-evolution, for example, associations between probability of infectiousness and probability of testing. The two formulations are mathematically equivalent, and both allow us to consider very general circumstances without positing a specific mechanistic model.
2.1 Set-Theoretic Formulation
Consider a discrete-time compartmental model in which at time t > 0 each of N individuals are in one of three compartments: sets denoted by upright symbols (Well),
(Infectious, the relative size of which we wish to estimate), or
(Removed). Although we use language similar to that of compartmental models for infectious diseases, the considerations here apply to noninfectious conditions as well. Note also differences from common compartmental models for infectious diseases, for example, the SIRS model: individuals in
are not necessarily susceptible (they may be immune for a time following a previous recovery), and individuals in
are not necessarily dead or recovered (they are simply removed from the surveilled population in some way). For individuals indexed by i, let vectors
, and
be the vectors indicating membership in
, and
, respectively, so that, for example,
if individual i is in
and 0 otherwise. The individual subscript i may be dropped where the result is unambiguous, and we will denote sums over all i by a + subscript, for example,
. Other sets will be denoted similarly.
Suppose that the N total individuals in the population participate in a disease surveillance scheme in which each member is tested repeatedly for the condition. We do not posit a particular mechanism for transitions from to
or the reverse (natural recoveries go from
to
), and we assume transitions from
or
to
occur immediately after a positive result is obtained, and only then (no deaths without testing, and self-isolating individuals remain in
or
). At some point after entry into
, an individual may be cleared to reenter
, and this clearance is fully observed. Thus, we have the discrete process:
The compartments
represent the system state at the start of day t.
A subset
Some subset of well individuals
Some subset of infectious individuals
Some subset of removed individuals
Compartments are updated as
Our central point, illustrated in Section 3, is that, depending on the specific subset of the population tested in step (2), the TPR for a day may not be an unbiased estimator of the prevalence of infection in either the entire population (
) or the nonremoved population (
), even with perfect test sensitivity and specificity, under some seemingly innocuous mechanisms for selecting
.
We do not allow for the “exposed” compartment used in many infectious disease models, representing some delay between exposure and either infectiousness or detectability. In the former case, the distinction is not relevant for our approach to prevalence estimation as long as we are only concerned with estimating the prevalence of infectiousness: we may simply redefine as not those who are exposed, but those who are about to become infectious. Delayed detectability is a matter of time-varying sensitivity, discussed in Section 5.3.
2.2 Time-to-Event Formulation
The set-theoretic formulation of may be helpfully re-expressed as a deterministic function of a time-to-event process for infectious exposure and the testing process. Let Cil be the lth time individual i is cleared to enter the monitored population at the next timepoint (in
then
), with the convention that
. While in the monitored population, individuals may be exposed for the mth time at Xim (in
then
) and subsequently exit the infectious compartment via recovery or isolation at Vim (in
then
or
), meanwhile being tested for the kth time at Zik for zero or more values of k. Alternatively, a false positive may send an individual directly from
to
. The indices k and m are cumulative and do not reset after each clearance time. We use the convention that
and
. We write
to mean the time of first infectious exposure in the interval between Cil and subsequent removal from the monitored population, with the convention that
if no such exposure occurs (i.e., due to a false positive test result), and similarly for
. We write
, and
so that, for example,
is the time of the earliest test at or after time t. Coupled with the test result indicator
, the dynamical process is then
(2)
(2)
(3)
(3)
(4)
(4) and
if and only if
for some k.
3 Bias of the Test-Positive Rate
The TPR is biased as an estimator of prevalence under some natural and otherwise attractive longitudinal testing regimens. The magnitude of this bias does not necessarily decrease with increased sample size when the population size increases proportionally. We consider a specific form of bias that arises solely due to the longitudinal structure of the testing regimen coupled with isolation of those who test positive, even under extremely restrictive assumptions including perfect test sensitivity and specificity and independent and identically distributed testing and exposure processes between individuals. We make the following one assumption that will be carried through the remainder of the article, and the following two simplifying assumptions imposed only to illustrate the mechanism of bias of the test-positive rate, and which will be relaxed in later sections when considering our proposed unbiased estimator.
Assumption 1
(No undetected recoveries). Individuals in cannot return to
except by passing through
.
Assumption 1 reflects the original goal of the surveillance scheme: to quickly detect infectious individuals and isolate them from the rest of the population. This goal may be reasonably met (or approximately so) if the test sensitivity is high and the time between tests is sufficiently short relative to the infectious period. The practical consequences of violating this assumption are evaluated in Section 5.3.
Simplifying Assumption 2 (Perfect test sensitivity and specificity).
(5)
(5)
(6)
(6)
Simplifying Assumption 3 (Independent and identically distributed joint processes between individuals). For all ,
(7)
(7)
Again, both Simplifying Assumptions 2 and 3 are applied only for the remainder of this section for illustration and will be relaxed in Section 4.
3.1 Condition for Unbiasedness of the Test-Positive Rate
Under Simplifying Assumptions 2 and 3, the necessary and sufficient condition for unbiasedness of the TPR as an estimator of prevalence in the nonremoved population is that for all nonremoved individuals at any time t, their infectiousness and whether they are tested at that time are independent:
Assumption
4 (Marginal independence of testing and infectiousness (MITI)). For any time t, and for all i, .
Lemma 1.
Under perfect test sensitivity and specificity, and independent and identically distributed joint exposure-testing processes between individuals,
(8)
(8) if and only if, for all i,
(MITI).
Proof.
With perfect tests and independent and identically distributed processes,
(9)
(9)
Finally, we have that if and only if
for all i (MITI). □
We refer to (8) as marginal unbiasedness of the TPR as an estimator for prevalence in the nonremoved population, in contrast to the notion of conditional unbiasedness in which the expectation of the TPR conditional on a realization of is
. The sufficiency of MITI for conditional unbiasedness of the TPR follows from the usual independent sampling arguments, and MITI is necessary for conditional unbiasedness under all realizations of
simultaneously because the latter is sufficient for marginal unbiasedness.
3.2 Examples in Which the Test-Positive Rate Is Biased
Marginal independence of testing and infectiousness (MITI) is straightforward to state and its relationship to the unbiasedness of the TPR is intuitive. Additionally, it is easy to imagine mechanisms by which MITI would be violated: for example, individuals experiencing symptoms of the surveilled illness may volunteer to be tested earlier than they otherwise would be. However, it has apparently gone unrecognized that MITI may be violated solely by the longitudinal nature of a testing regimen with isolation in conjunction with a strictly positive hazard of exposure, without the need for any other confounding or mediating factors. We give four examples of testing schemes: one satisfying MITI, two violating MITI due to longitudinal scheduling and isolation alone, and one violating MITI due to confounding by another factor. For simplicity, we assume in all examples that individuals never return to the surveilled population after being removed.
Example 1
(Simple random testing). A surveillance program tests a simple random sample of the nonremoved population at each timepoint. MITI trivially applies and by Lemma 1 the TPR is an unbiased estimator of prevalence in the nonremoved population.
Example 2
(Max-gap testing). A surveillance program requires that no individual spend an interval greater than some maximum length in the nonremoved population without being tested. For example, individuals may go no more than six consecutive days in the nonremoved population without being tested, but may be tested more often.
Max-gap testing does not generally satisfy MITI. Let δ be the maximum consecutive days an individual may spend in the nonremoved population without testing. Then
(10)
(10) and the inequality is strict if
. Note that
, but if all nonremoved individuals have a strictly positive hazard of infectious exposure each day,
. Thus, if further the hazard of exposure does not depend on the time of the last test,
(11)
(11)
Together, (10) and (11) violate MITI.
As a concrete example, consider a scheme in which an individual last testing negative on day t – k, , has probability
of being tested next on day t. On any given day and in the presence of no additional confounding, an individual recently tested (and therefore known to be recently noninfectious) is less likely to be tested than an individual who has been tested longer ago (and who therefore has had more opportunity to become infectious since then). The TPR each day would be skewed toward the prevalence among those tested longer ago and thus biased upward. Other distributions of waiting times could change the magnitude or direction of the bias.
Example 3
(Once-per-period testing). A surveillance program divides the calendar into intervals , and within each interval
each nonremoved individual is tested exactly once. Suppose the intervals are weeks beginning on Monday (
) and ending on Sunday (bk). There may be marginal imbalances, such as overall preference among units to be tested on certain days of the week, and within-unit correlations, such as a preference to be tested on the same day of each week.
Once-per-period testing does not generally satisfy MITI. Suppose and R(t) = 0. Then
(12)
(12) and the inequality is strict if
. Note that
, but if all nonremoved individuals have a strictly positive hazard of infectious exposure each day,
. Thus, if further the hazard of exposure does not depend on the time of the last test,
(13)
(13)
Together, (12) and (13) violate MITI.
As a concrete example, consider the specific case in which the periods are calendar weeks and each day we test a simple random sample of the nonremoved population that has not yet been tested during the week (necessarily a census on the final day). The TPR is an unbiased estimate of the prevalence among the population eligible to be tested on that day. However, in the absence of additional confounding, the prevalence among the eligible population is expected to be higher than among the ineligible population because those in the ineligible population have tested negative more recently. Thus, the TPR would be expected to overestimate the prevalence in the combined population. Other methods of sampling from the eligible population could change the magnitude or direction of bias.
Example 4
(Simple random testing plus contact tracing). A surveillance program tests a simple random sample of the nonremoved population at each timepoint, and all close contacts of those with positive test results from the previous timepoint. It is assumed that those tested via contact tracing are more likely to be infectious than those tested through simple random sampling. Thus, the overall TPR is an overestimate of prevalence, but the TPR from tests from the simple random testing component is an unbiased estimate of prevalence. The discrepancy between the TPRs from the two samples may provide information on transmission of the disease. Note that this example also violates the simplifying assumption of independence between individuals.
3.3 Magnitude of Bias of the Test-Positive Rate
To restrict our attention to bias arising solely due to the longitudinal nature of a testing regimen in conjunction with a strictly positive hazard of exposure, without the need for any other confounding or mediating factors, we consider joint exposure-testing processes satisfying the following conditional independence assumption.
Assumption 5
(Conditional independence of testing and exposure (CITE)). For any time t, and for all individuals i, .
Due to the assumption of no undetected recoveries, encompasses all exposures. CITE will be used in later sections, but for the arguments in this section all that is needed is the following relaxation.
Assumption 6
(Conditional independence of testing and infectiousness (CITI)). For any time t, and for all individuals i, .
CITI is a modification of MITI to apply within strata defined by the most recent test and clearance times, both of which are observed. Thus, in principle the TPR is an unbiased estimate of prevalence within each stratum for which there is a positive probability of testing. Simple random testing trivially satisfies CITI, and the concrete examples of max-gap and once-per-period testing given in the previous section also satisfy CITI. However, CITI may be violated by specific examples of max-gap and once-per-period testing, for instance if symptomatic individuals tend to be tested earlier when eligible. CITI but not CITE may be satisfied if past tests influence future behavior, for example, if the regimen is a simple random testing scheme paired with an exposure process in which individuals tested during business hours behave more riskily that evening.
The expected prevalence at time t may be decomposed as
(14)
(14)
Similarly, under CITI, the expectation of the test-positive rate at time t, marginally over , may be decomposed as
(15)
(15)
Consider the ratio of the expectation of TPR to the expectation of prevalence
(16)
(16) which can be viewed as the ratio of weighted averages of prevalences in strata defined by time of last test. Note that scaling prevelence does not affect B(t) as long as prevalence is scaled uniformly across the strata defined by time of last test.
The bias can be quite large, even for nonpathological hazards and testing schemes. Consider a testing scheme in which every individual is tested on an τ-day rotation, that is, every time an individual is tested, their next test is τ days later (as considered in Chang et al. Citation2021), and the same number of individuals is tested each day. Under such a scheme,
(17)
(17)
Suppose that the infection hazard is such that approximately the same proportion p of nonremoved individuals are infected each day independently of time since last test, that is, . An approximately constant infection probability is reasonable when the hazard is constant and small. Then
(18)
(18)
That is, on average the TPR over-estimates the prevalence by approximately 100%.
4 Identifiability of Prevalence
In the previous section we illustrated how bias of the TPR as an estimator of prevalence can arise from the longitudinal nature of the testing regimen, even under strict assumptions of perfect test sensitivity and specificity, independence and identical distributions of processes between individuals, and conditional independence of testing and exposure (CITE). In this section we relax the first two assumptions and illustrate a Horvitz-Thompson–type (HT) estimator that is unbiased if the testing regimen is correctly specified (in the form of known testing probabilities), and nearly unbiased when the testing regimen is nonparametrically estimated in the sense that bias only arises due to Jensen’s inequality applied to estimated testing probabilities.
We begin by relaxing Simplifying Assumption 2 (perfect test sensitivity and specificity) and Simplifying Assumption 3 (iid individuals) to the following assumptions, respectively.
Assumption 7
(Simple random sensitivity and specificity). Positive test results are indicated by with
Bernoulli random variables with success probabilities
(test sensitivity) and
(test specificity), respectively, and independent of all other variables.
Assumption 8
(Identically distributed individuals). For all i, j,
Assumption 9
(Independence of testing from others’ states (ITOS)).
ITOS allows a priori dependence in testing schemes (e.g., preferring to test or avoiding testing members of the same household on the same day), but not dependence induced by whether or not others are in . For example, ITOS would not be expected to hold if the testing program included contact tracing because an individual being removed to
after recently testing positive would increase the likelihood of their close contacts being tested versus what it would have been had they tested negative and remained in
.
Rather than estimating the prevalence directly, we will estimate
and use the known values of N and
to transform our estimate into one of prevalence. We provide an estimator that is unbiased for
conditional on a priori unobserved
via a modification of the argument of Horvitz and Thompson (Citation1952), weighting transformed test results by
. We will estimate
separately within strata defined by the observed
and combine the estimates into one estimate for the overall population. The following assumption of positivity conditional on last clearance and current membership in the Well compartment (but not on intervening test times) guarantees finite weights:
Assumption 10
(Positivity). For any t and c < t, .
Because the positivity assumption does not condition on past test times, it is compatible with scenarios in which , for example, if
and testing on one day precludes testing on the next. It is also compatible with testing individuals on the same day each week as in the example of Section 3.3 as long as at the time of last clearance each individual has a positive probability of being assigned to each day of the week. In the latter case, if the day of testing completely determines the day of clearance, test days may need to be reassigned after each clearance, though simulations indicate that estimation is not catastrophically biased absent reassignment (Section 5.3).
Theorem 1 provides an unbiased estimator of given known inverse testing probability weights, and the subsequent Theorem 2 provides an expression for the testing probabilities computable under a known testing regimen or estimable from testing data.
Theorem 1
(Unbiased estimator of prevalence). Assume simple random sensitivity η and specificity ν (Assumption 7), independence of testing from others’ states (ITOS, Assumption 9), and positivity (Assumption 10). Let . Then,
(19)
(19)
Full proof of Theorem 1 is given in the appendix. As a brief sketch, simple random sensitivity and specificity allows to be replaced by
, ITOS allows for each i the condition
to be replaced by
, and positivity ensures that
for all i.
Theorem 2
(Identifiability of testing probabilities). Assume no undetected recoveries (Assumption 1), conditional independence of testing and exposure (CITE, Assumption 5), simple random sensitivity and specificity (Assumption 7), and identically distributed individuals (Assumption 8). Let if z > t and 0 otherwise, and
be a
matrix with
(20)
(20) where the + 2 in each dimension allows the first row and first column to represent time 0, the last column to represent time after t, and the last row to keep the matrix square. Then
(21)
(21)
with
identifiable by plugging in observed proportions to its definition.
Full proof of Theorem 2 is given in the appendix. Key points are that no undetected recoveries and CITE imply that under the real data generating mechanism is equal to that under one in which the infection hazard is zero, and identically distributed individuals allow all individuals to share the same
, which is a stochastic upper-triangular matrix interpretable as describing the transition probabilities among Zk as k increases under zero hazard and perfect specificity.
Note that under the assumptions of Theorem 2 all elements of admit unbiased estimators whenever at least one individual satisfies the corresponding condition, for example,
(22)
(22)
If a condition is not met by any individual, estimators may be replaced by . If
is known (e.g., controlled entirely by a central scheduler), prevalence may be estimated without bias, or with arbitrarily small bias via Monte Carlo estimation of (22) after forward simulation of the testing process with zero exposure hazard. If testing probabilities are not known, they may be nonparametrically estimated from testing data via (22).
Bias in the prevalence estimate with unknown weights arises solely from Jensen’s inequality applied to the inversion of testing probabilities for weighting. The bias therefore approaches zero asymptotically (population size going to infinity while tested proportion is held constant) due to the law of large numbers. In practice, the bias due to noise in estimating testing probabilities appears largest when there exist nonempty strata in which the expected number of tested individuals is low, especially when there is a moderate-to-large probability of no individuals within a stratum being tested. When no individuals are tested within a stratum, the within-stratum estimator takes the same value as if all stratum members had tested positive, yielding a high prevalence estimate that cannot be completely counterweighted by instances in which some tests are performed. Because very small strata are most likely when incidence is low (as fewer individuals are detected and therefore cleared at the same time) and this issue has the largest effect in the same cases (because the estimator behaves as if all individuals were infectious), we propose in such situations instead estimating by the total number of nonremoved individuals with
, that is, assuming all nonremoved individuals in the stratum are well. It is likely possible to evaluate the reasonableness of such a strategy in practice because prevalence estimates will be available from other strata and timepoints.
Following the argument of Horvitz and Thompson (Citation1952), we have under known testing probabilities and independent testing between individuals the variance expression
(23)
(23) from which an unbiased estimator of the variance (still under known testing probabilities) may be obtained by summing over the tested individuals instead of all individuals. Horvitz and Thompson (Citation1952) also provides an extension to scenarios in which tests are dependent between individuals. When estimating testing probabilities, we recommend using bias-corrected and accelerated bootstrap intervals, as illustrated in Section 5.
5 Simulation Study
5.1 General Setup
We performed a simulation study to evaluate the properties of three estimators under four scenarios satisfying the assumptions required by our Horvitz-Thompson-type (HT) estimators, and six scenarios violating assumptions. Unless otherwise noted, general parameters of the scenarios were as follows. A population of 1000 individuals with identically distributed processes was simulated for 21 days. Individuals were grouped into 250 exchangeable clusters of 4 exchangeable individuals per cluster. The hazard of initial exposure from outside the cluster while in the nonremoved population was , where τ is the time since day 0 or last clearance time. The hazard of initial exposure from within the cluster while in the nonremoved population was 1/5 times the number of infectious individuals within the cluster, independently from exposure from outside the cluster. The hazard of subsequent exposures was halved. Each simulation began with 2% prevalence and peaked near 5% prevalence. Test sensitivity and specificity were set to 83.2% and 99.2%, respectively, corresponding to estimates from the meta-analysis of saliva-based pCR tests for SARS-CoV-2 by Butler-Laporte et al. (Citation2021). At 5% prevalence, these values yield 84.6% positive predictive value and 99.1% negative predictive value. Individuals spent 5 days in the Removed compartment before returning to the Well compartment.
On each day within each simulation, we evaluate the test-positive rate and HT estimator with estimated testing probabilities (HT-E) as estimates of prevalence. We produce confidence intervals at the 95% confidence level via the exact method (Clopper and Pearson Citation1934) with no finite population correction (for conservativeness) for the TPR and the bias-corrected and accelerated bootstrap approach (BCa, Efron (Citation1987)) for the HT-E estimator, with 399 bootstrap iterations and acceleration factor estimated via jackknife with blocks of size 10. When testing probabilities of individuals never exposed do not depend on exposure dynamics (e.g., as they do in the presence of contact tracing), we also give the Horvitz-Thompson estimator with known testing probabilities (HT-K), with Wald confidence intervals produced on according to the variance formula (23) and transformed to the prevalence scale. We simulated 1000 datasets for the TPR and HT-E estimators, and 10,000 for the HT-K estimator to account for its larger variance.
Estimates from the HT estimators are not automatically restricted to , and are sometimes below zero in the simulations above. In practice, we recommend restricting estimates to
post hoc, as the restricted estimates are never farther than the unrestricted estimates from the truth, and are sometimes closer. In the simulations described above, the post hoc restriction caused the HT-K estimator to be biased upward but reduced the RMSE by approximately 20%, and did not substantially affect the HT-E estimator.
5.2 Scenarios Satisfying Assumptions
The scenarios satisfying the assumptions of the HT estimators are based on the first three example testing regimens in Section 3.2.
Simple random testing regimen: nonremoved individuals are tested independently each day with probability 1/6.
Max-gap regimen: the time of first test is uniformly distributed among the first 10 days, and for subsequent times t at which the most recent test or clearance time is z, nonremoved individuals are tested with probability
Once-per-period regimen: each nonremoved individual is tested at a uniformly distributed time within each 7-day calendar interval, or within the remainder of a 7-day interval in which they return to the nonremoved population.
Min-max regimen: operates similarly to the max-gap regimen but tests are not allowed within 5 days of the most recent test.
displays the results of the assumption-satisfying scenarios. For the simple random testing scenario, all three estimators were approximately unbiased, and confidence interval coverage was near the nominal level, with the Clopper-Pearson intervals for the TPR being slightly conservative, as expected. The RMSEs of the TPR and HT-E estimators are identical, and that of the HT-K substantially higher. The substantially lower RMSE of the HT-estimated compared to HT-known estimator is likely due to a favorable bias-variance tradeoff from weight smoothing, an estimation-based relative of trimming large survey weights (Haziza and Beaumont Citation2017). For all other assumption-satisfying scenarios, the HT estimators were unbiased and their confidence interval coverage was near the nominal level. However, the TPR was biased upwards (except on the first day of each week in the once-per-period scenario), yielding higher RMSE and anticonservative confidence interval coverage except where the bias was small. Coverage of TPR intervals is expected to decrease with increased sample size as the bias would remain unchanged. In once-per-period scenario, the bias increased steadily within each period before returning to zero at the start of the next period. In the max-gap and min-max scenarios, the first 10 days look similar to the once-per-period scenario because the first test of each individual was uniformly distributed over that period, then the bias of the test-positive rate stabilizes at roughly +30% to +50% as the testing hazard becomes quadratic.
Fig. 1 Simulations satisfying assumptions. Target for mean row is the mean of true prevalences across datasets. The RMSEs of the test-positive rate and HT-known estimator are identical under simple random testing. The variance of the HT-known estimator is higher than that of the HT-estimated due to occasionally very large weights.
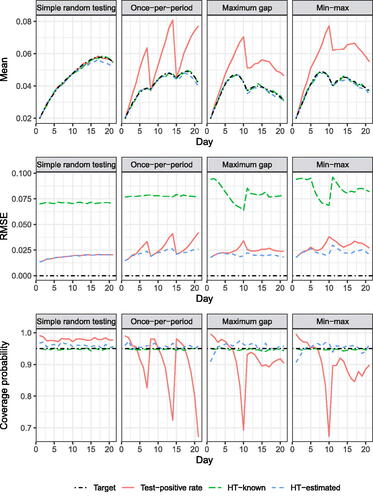
Fig. 2 Daily test counts, including multiple tests per week by the same student. Vertical grid lines correspond to Mondays.
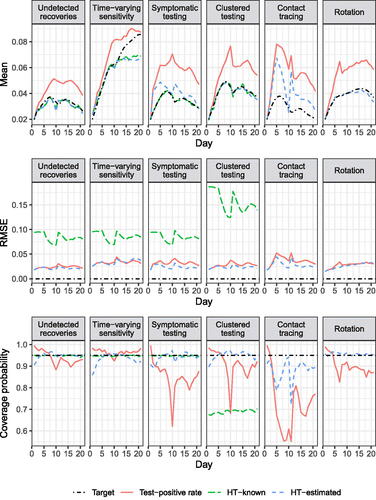
Fig. 3 Daily test counts, including multiple tests per week by the same student. Vertical grid lines correspond to Mondays.
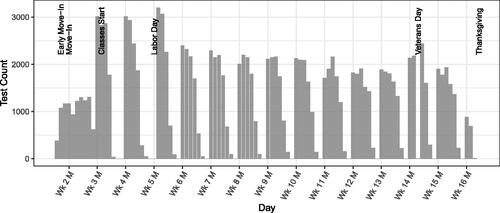
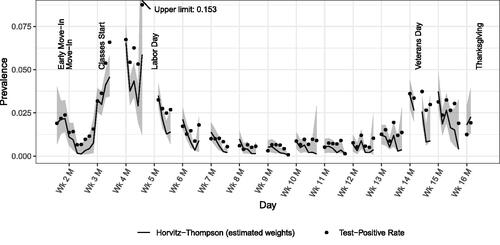
Fig. 4 Daily prevalence estimates, adjusted for test sensitivity and reporting delays. Shaded ribbon is BCa 95% confidence band. No estimates for days with < 100 tests taken. Vertical grid lines correspond to Mondays.
5.3 Scenarios Violating Assumptions
The assumption-violating scenarios (except for the rotation scenario) are based on the min-max testing regimen above because the regimen showcases both temporary ineligibility for testing and unequal testing probabilities by time of last test among those eligible.
Undetected recoveries scenario: allows an infectious individual that had not been removed within 6 days of exposure to return to the Well compartment, and exposures of those infectious at baseline were uniformly distributed among the previous 6 days.
Time-varying sensitivity scenario: (violating simple random sensitivity), a test of an infectious individual exposed at time x and tested at time
Symptomatic testing scenario: (violating CITE), whenever an individual is exposed, they have a 1/4 probability of being symptomatic on their first day infectious, in which case they are tested immediately, regardless of normal eligibility rules.
Contact tracing scenario: (violating ITOS), when an individual tests positive all other nonremoved individuals in their cluster are tested the next day regardless of normal eligibility rules.
Clustered testing scenario: (violating independence assumption for HT-K CIs), individuals are grouped into clusters of four, and the testing schedule is set with clusters instead of individuals as units, with individuals tested whenever the cluster is scheduled for testing and the individual is in the nonremoved population.
Rotation scenario: (violating positivity), before the first day, each individual is assigned a day of the seven-day week on which they will be tested every week while not removed. Test days are not reassigned after clearances, violating positivity.
Figure 7 displays the results of the assumption-violating scenarios. In all scenarios, the TPR was biased upward and had RMSE comparable to or higher than the HT-E estimator. In the undetected recoveries and time-varying sensitivity scenarios, the confidence interval coverage was usually near the nominal level (though lower than in the simple random testing scenario), and in other scenarios coverage was dramatically anticonservative. The HT-E estimator was unbiased for the clustered testing scenario, and very slightly negatively biased in the undetected recoveries scenario. In the time-varying sensitivity and rotation scenarios, the HT-E estimator was negatively biased near the end of the 21-day period, and in the asymptomatic testing and contact tracing scenarios it was substantially biased upward. However, confidence interval coverage was near or above 90% except in the contact tracing scenario, where it was much lower. The HT-K estimator had similar bias to the HT-E estimator for the undetected recoveries and time-varying sensitivity scenarios, and also no bias for the clustered testing scenario, but unlike the HT-E estimator, was unbiased for the asymptomatic testing scenario (because all symptomatic individuals were infectious). In all four of the above scenarios, the HT-K estimator had the highest RMSE but near-nominal confidence interval coverage in all but the clustered testing scenario, in which coverage was near 70%. The HT-K estimator is not available for the contact tracing scenario because the testing probabilities depend on the infectiousness of other cluster members, and for the rotation scenario due to the failure of positivity.
6 Real Data Analysis
We analyze de-identified longitudinal testing data from 11,692 undergraduate students living on-campus at The Ohio State University during the fall 2020 semester. Eligible students were required to undergo a saliva-based PCR test once per calendar workweek (Monday–Friday). Students chose test dates subject to the once-per-week constraint. Students could voluntarily test more than once per week and would also be tested if identified via contact tracing as potentially exposed. There was little-to-no testing on Saturdays, Sundays, or holidays. After taking a test, results were available within 1–2 days. Students with positive test results were isolated for 10 days beginning the day after results were available and were exempt from further testing for 90 days following the date of their positive test. Within the eligible population close contacts of students who received positive test results were tested and quarantined for 14 days beginning the day after results were available. Students were sent home at the start of Thanksgiving break and the remaining class sessions were held remotely. Figure 7 displays the daily test counts during the semester.
We make the following simplifying assumptions to analyze the data. First, we assume that all test results are returned on the second day following the test, and count those who eventually receive a positive result from a test to be part of the infectious (rather than removed) compartment through the date the result was received. Second, when students return from isolation they are assumed to be noninfectious during the remainder of the 90 days of exemption from weekly testing. Third, we attempted to exclude voluntary tests and tests due to contact tracing (which we expect to be nonrepresentative) by retaining only the first test for each student during each calendar week. Finally, although the topic of sensitivity and specificity of COVID-19 tests is complex, we assume 83.2% test sensitivity as reported in the meta-analysis by Butler-Laporte et al. (Citation2021) and perfect specificity, as the vast majority of students during this semester were infection-naïve. Results from changes in both assumptions are also described. Test sensitivity is assumed to be constant as a function of time since exposure. We do not provide prevalence estimates on days for which there were less than 100 tests. Saturdays, Sundays, and holidays comprised all but one such day. The remaining excluded day was the Friday following the first day of class, for which the reason for the low test count is unknown to us.
To anonymize the data, we construct a matrix with days as columns and students as rows. Entries are the results of tests taken on that day, or missing if no test was taken. No student identifiers are present, and the order of the rows is randomized. Iterating through the days, students in the nonremoved population are stratified by last test date and last clearance date, and the vectors of subsequent test times and results were permuted within strata (retaining order within vectors). Shuffling mitigates risk of student identification via their longitudinal testing sequences but does not change any of the estimators considered.
Figure 7 displays daily test-positive rates and HT-E prevalence estimates, both adjusted for imperfect test sensitivity, delay of test results, and assumed noninfectiousness during the time exempt from testing following the end of isolation. The HT-E BCa confidence bounds were produced using 999 bootstrap iterations and 79 blocks of 148 individuals for the jackknife-estimated acceleration factor. Up to the start of classes, both estimators largely agree, though the TPR is slightly higher, especially late in Week 2, consistent with the results of the simulation study under once-per-period testing. The drop in both estimates immediately following move-in suggests a baseline prevalence of roughly 2% among students moving in that was reduced via testing, isolation, and quarantine.
Following the start of classes, the HT-E estimate generally decreases during each week, consistent with a relatively large number of individuals being infected during weekends then detected and removed by testing. The HT-E estimates but not the TPRs reflect the observation by Hay et al. (Citation2021) that “isolating positive individuals reduces prevalence in the tested population.” Within each week the TPRs increase relative to the HT-E estimates, though they do not increase over the course of every week in absolute terms.
Varying test sensitivity between 77.4% and 91.4%, reflecting the 95% confidence intervals reported by Butler-Laporte et al. (Citation2021), yielded similar patterns and conclusions but scaled estimates within 100%–127% and 76%–100%, respectively. To evaluate the effect of imperfect specificity, we assumed a value of 99.2%, also following Butler-Laporte et al. (Citation2021), with sensitivity ranging from 83.2% to 50%. Although the results were similar on the semester scale, estimates that were below approximately 1% in Figure 7 dropped to zero (TPR) or between 0% and 0.2% (HT-E). We do not consider even this high estimate of imperfect specificity to be realistic: a third of crude test-positive rates are less than 1%, implying that almost all of the positive test results those days were false positives.
7 Discussion
We have identified and characterized an under-recognized bias in prevalence estimates based on test-positive rates of repeated screening tests when those testing positive are subsequently isolated, and have presented unbiased and approximately unbiased estimators of prevalence in such situations. The bias in question arises under natural repeated testing regimens such as once-per-week testing, and is present even when tests have perfect sensitivity and specificity, and without confounding factors such as contact tracing or symptomatic testing. This bias arises due to confounding between the probability of an individual being tested on a given day and the probability that they are infectious, caused in part by the constraints of the testing schedule. Our estimator achieves unbiasedness by weighting test results by the inverse probability of testing under a hypothetical scenario with zero hazard of infection, which may be estimated directly from the data.
We have illustrated the bias of test-positive rates and unbiasedness (or approximate unbiasedness) of our estimators via simulation studies under complications of imperfect test sensitivity and specificity. We have also proposed BCa bootstrap confidence intervals which are straightforward to implement and appear well-calibrated in the correctly-specified simulation study but do not account for real data complications such as clustering of test schedules. Further development of confidence interval constructions would be important.
Analysis of once-per-week testing data from the fall 2020 semester at The Ohio State University illustrated the feasibility of handling complications such as noncompliance to the testing regimen and via crude adjustments contact tracing, reporting delays, and temporary exemption from testing post-isolation. Although on multi-week timescales the prevalence curves given by the test-positive rates and our estimator broadly agreed, the TPR tended to be higher and we identified systematic within-week discrepancies illustrating the bias of the TPR and suggesting a different weekly timing of incidence (higher on weekends rather than uniformly throughout the week) that could have implications for the efficacy of on-campus safety measures (e.g., social transmission vs. in-classroom transmission).
Our estimator relied on assumptions in three classes. First, verifiable conditions on the testing process design that simplify considerations but can be influenced by the surveillant, and violations of which could be handled by book-keeping modifications (such as differentiating between scheduled tests and those induced by contact tracing or symptoms). Second, no-confounding assumptions that preclude alterations of risk-relevant behavior in response to scheduled tests, or of testing schedules in response to perceived risks, are essential to our theoretical results. However, violations of these do not necessarily cause our estimators to perform worse than the TPR. For example, if individuals believing they may have been exposed tended to schedule tests earlier than they otherwise would have, we would expect to see bias patterns similar to those of the symptomatic testing or contact tracing simulation scenarios, even though it may be more difficult to account for via book-keeping. Finally, it may be possible to relax simplifying assumptions on the technical details of disease and testing processes such as known time-invariant test sensitivity (Chang et al. Citation2021) and a long infectious period relative to gaps between tests, though any relaxation would likely introduce significantly more complexity and is reserved for future work.
Our strategy has been to provide an estimation approach to achieving unbiasedness while remaining as close as possible mechanically to the test-positive rate analysis. We focus exclusively on prevalence estimation without modeling transmission or incorporating external data sources to emphasize correction of the repeated testing bias. Combining such approaches with ours could greatly improve the accuracy of estimates, potentially at the expense of ease of implementation or robustness. A promising alternative approach to constructing estimators under similar assumptions is via a hazard-based framework in the style of time-to-event analyses (KhudaBukhsh et al. Citation2020). Under such an approach, some of the independence assumptions may be reinterpretable as independent censoring.
Supplementary Materials
Data and code:
The supplementary materials include R scripts and shuffled data for reproducing the simulation and analysis results.
Appendix:
The appendix contains proofs of results described in the main text.
UASA_A_2238943_supplemental.zip
Download Zip (350.5 KB)Acknowledgments
The authors thank Eben Kenah, Mikkel Quam, and Rebecca Andridge for their advice regarding epidemiological considerations, details of the testing regimen of The Ohio State University, and survey estimation methods, respectively.
Disclosure Statement
No potential conflict of interest was reported by the authors.
References
- Baker, M. G., Wilson, N., and Anglemyer, A. (2020), “Successful Elimination of COVID-19 Transmission in New Zealand,” New England Journal of Medicine, 383, e56. DOI: 10.1056/NEJMc2025203.
- Butler-Laporte, G., Lawandi, A., Schiller, I., Yao, M., Dendukuri, N., McDonald, E. G., and Lee, T. C. (2021), “Comparison of Saliva and Nasopharyngeal swab Nucleic Acid Amplification Testing for Detection of SARS-CoV-2: A Systematic Review and Meta-analysis,” JAMA Internal Medicine, 181, 353–360. DOI: 10.1001/jamainternmed.2020.8876.
- Chang, J. T., Crawford, F. W., and Kaplan, E. H. (2021), “Repeat SARS-CoV-2 Testing Models for Residential College Populations,” Health Care Management Science, 24, 305–318. DOI: 10.1007/s10729-020-09526-0.
- Clopper, C. J., and Pearson, E. S. (1934), “The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial,” Biometrika, 26, 404–413. DOI: 10.1093/biomet/26.4.404.
- Corman, V. M., Landt, O., Kaiser, M., Molenkamp, R., Meijer, A., Chu, D. K., Bleicker, T., Brünink, S., Schneider, J., Schmidt, M. L., Mulders, D. G., Haagmans, B. L., van der Veer, B., van den Brink, S., Wijsman, L., Goderski, G., Romette, J.-L., Ellis, J., Zambon, M., Peiris, M., Goossens, H., Reusken, C., Koopmans, M. P., and Drosten, C. (2020), “Detection of 2019 Novel Coronavirus (2019-nCoV) by Real-Time RT-PCR,” Eurosurveillance, 25, 2000045. DOI: 10.2807/1560-7917.ES.2020.25.3.2000045.
- Efron, B. (1987), “Better Bootstrap Confidence Intervals,” Journal of the American Statistical Association, 82, 171–185. DOI: 10.1080/01621459.1987.10478410.
- Frazier, P. I., Cashore, J. M., Duan, N., Henderson, S. G., Janmohamed, A., Liu, B., Shmoys, D. B., Wan, J., and Zhang, Y. (2022), “Modeling for COVID-19 College Reopening Decisions: Cornell, a Case Study,” Proceedings of the National Academy of Sciences, 119, e2112532119. DOI: 10.1073/pnas.2112532119.
- Hay, J. A., Hellewell, J., and Qiu, X. (2021), “When Intuition Falters: Repeated Testing Accuracy during an Epidemic,” European Journal of Epidemiology, 36, 749–752. DOI: 10.1007/s10654-021-00786-w.
- Haziza, D., and Beaumont, J.-F. (2017), “Construction of Weights in Surveys: A Review,” Statistical Science, 32, 206–226. DOI: 10.1214/16-STS608.
- Horvitz, D. G., and Thompson, D. J. (1952), “A Generalization of Sampling Without Replacement from a Finite Universe,” Journal of the American Statistical Association, 47, 663–685. DOI: 10.1080/01621459.1952.10483446.
- Kahanec, M., Lafférs, L., and Schmidpeter, B. (2021), “The Impact of Repeated Mass Antigen Testing for COVID-19 on the Prevalence of the Disease,” Journal of Population Economics, 34, 1105–1140. DOI: 10.1007/s00148-021-00856-z.
- KhudaBukhsh, W. R., Choi, B., Kenah, E., and Rempała, G. A. (2020), “Survival Dynamical Systems: Individual-Level Survival Analysis from Population-Level Epidemic Models,” Interface Focus, 10, 20190048. DOI: 10.1098/rsfs.2019.0048.
- Mack, C. D., DiFiori, J., Tai, C. G., Shiue, K. Y., Grad, Y. H., Anderson, D. J., Ho, D. D., Sims, L., LeMay, C., Mancell, J., et al. (2021), “SARS-CoV-2 Transmission Risk among National Basketball Association Players, Staff, and Vendors Exposed to Individuals with Positive Test Results after COVID-19 Recovery during the 2020 Regular and Postseasonm,” JAMA Internal Medicine, 181, 960–966. DOI: 10.1001/jamainternmed.2021.2114.
- Mina, M. J., and Andersen, K. G. (2021), “COVID-19 Testing: One Size Does Not Fit All,” Science, 371, 126–127. DOI: 10.1126/science.abe9187.
- Nicholson, G., Lehmann, B., Padellini, T., Pouwels, K. B., Jersakova, R., Lomax, J., King, R. E., Mallon, A.-M., Diggle, P. J., Richardson, S., Blangiardo, M., and Holmes, C. (2022), “Improving Local Prevalence Estimates of SARS-CoV-2 Infections Using a Causal Debiasing Framework,” Nature Microbiology, 7, 97–107. DOI: 10.1038/s41564-021-01029-0.
- Paltiel, A. D., and Schwartz, J. L. (2021), “Assessing COVID-19 Prevention Strategies to Permit the Safe Opening of Residential Colleges in Fall 2021,” Annals of Internal Medicine, 174, 1563–1571. DOI: 10.7326/M21-2965.
- Panovska-Griffiths, J., Kerr, C. C., Stuart, R. M., Mistry, D., Klein, D. J., Viner, R. M., and Bonell, C. (2020), “Determining the Optimal Strategy for Reopening Schools, the Impact of Test and Trace Interventions, and the Risk of Occurrence of a Second COVID-19 Epidemic Wave in the UK: A Modelling Study,” The Lancet Child & Adolescent Health, 4, 817–827. DOI: 10.1016/S2352-4642(20)30250-9.
- Quick, C., Dey, R., and Lin, X. (2021), “Regression Models for Understanding COVID-19 Epidemic Dynamics with Incomplete Data,” Journal of the American Statistical Association, 116, 1561–1577. DOI: 10.1080/01621459.2021.2001339.
- Rosella, L. C., Agrawal, A., Gans, J., Goldfarb, A., Sennik, S., and Stein, J. (2022), “Large-Scale Implementation of Rapid Antigen Testing System for COVID-19 in Workplaces,” Science Advances, 8, eabm3608. DOI: 10.1126/sciadv.abm3608.
- Schultes, O., Clarke, V., Paltiel, A. D., Cartter, M., Sosa, L., and Crawford, F. W. (2021), “COVID-19 Testing and Case Rates and Social Contact among Residential College Students in Connecticut during the 2020–2021 Academic Year,” JAMA Network Open, 4, e2140602. DOI: 10.1001/jamanetworkopen.2021.40602.