
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Vector autoregressive (VAR) models are popularly adopted for modeling high-dimensional time series, and their piecewise extensions allow for structural changes in the data. In VAR modeling, the number of parameters grow quadratically with the dimensionality which necessitates the sparsity assumption in high dimensions. However, it is debatable whether such an assumption is adequate for handling datasets exhibiting strong serial and cross-sectional correlations. We propose a piecewise stationary time series model that simultaneously allows for strong correlations as well as structural changes, where pervasive serial and cross-sectional correlations are accounted for by a time-varying factor structure, and any remaining idiosyncratic dependence between the variables is handled by a piecewise stationary VAR model. We propose an accompanying two-stage data segmentation methodology which fully addresses the challenges arising from the latency of the component processes. Its consistency in estimating both the total number and the locations of the change points in the latent components, is established under conditions considerably more general than those in the existing literature. We demonstrate the competitive performance of the proposed methodology on simulated datasets and an application to U.S. blue chip stocks data. Supplementary materials for this article are available online.
1 Introduction
Vector autoregressive (VAR) models are popular for modeling cross-sectional and serial correlations in multivariate, possibly high-dimensional time series. With, for example, applications in finance (Barigozzi and Hallin 2017), biology (Shojaie and Michailidis 2010) and genomics (Michailidis and d’Alché Buc 2013). Within such settings, the importance of data segmentation is well-recognized, and several methods exist for detecting change points in VAR models in both fixed (Kirch, Muhsal, and Ombao 2015) and high dimensions (Safikhani and Shojaie 2022; Wang et al. 2019; Bai, Safikhani, and Michailidis 2020; Maeng, Eckley, and Fearnhead 2022).
VAR modeling quickly becomes a high-dimensional problem as the number of parameters grows quadratically with the dimensionality. Accordingly, most existing methods for detecting change points in high-dimensional, piecewise stationary VAR processes assumes sparsity (Basu and Michailidis 2015). However, it is debatable whether highly sparse models are appropriate for some applications. For example, Giannone, Lenza, and Primiceri (2021) note the difficulty of identifying sparse predictive representations for several macroeconomic applications.
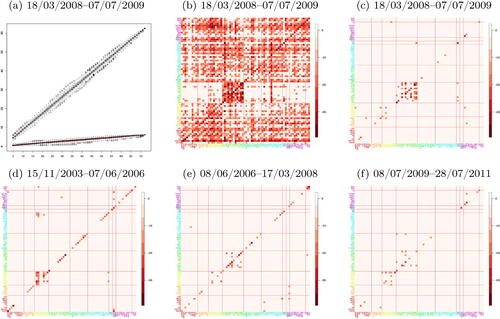
We illustrate the inadequacy of the sparsity assumption on a volatility panel dataset (see Section 5.3 for its description). shows that as the dimensionality increases, the leading eigenvalue of the spectral density matrix at frequency 0 (i.e., the long-run covariance) estimated from the data also increases linearly. This indicates the presence of strong serial and cross-sectional correlations that cannot be accommodated by sparse VAR models. In , we report the logged and truncated p-values obtained from fitting a VAR(5) model to the same dataset (truncation level chosen at by Bonferroni correction with the significance level 0.1) via ridge regression, see Cule, Vineis, and De Iorio (2011). Strong dependence observed from most pairs of the variables further confirms that we cannot infer a sparse pairwise relationship from such data. On the other hand, shows that once we estimate factors driving the strong correlations and adjust for their presence, there is evidence that the remaining dependence in the data can be modeled as being sparse. Together, the plots (d), (e), (c), and (f) display that the relationship between a pair of variables (after factor-adjustment) varies over time, particularly at the level of industrial sectors. Here, the intervals are chosen according to the data segmentation result reported in Section 5.3. This example highlights the importance of (i) accounting for the dominant correlations prior to fitting a model under the sparsity assumption, and (ii) detecting structural changes when analyzing time series datasets covering a long period.
Fig. 1 (a) The two largest eigenvalues of the long-run covariance matrix estimated from the volatility panel analyzed in Section 5.3 (March 18, 2008–July 07, 2009, n = 223) with subsets of cross-sections randomly sampled 100 times for each given dimension (x-axis). (b) and (c): logged and truncated p-values from fitting a VAR(5) model to the same dataset without and with factor-adjustment. (d)–(f): logged and truncated p-values similarly obtained with factor-adjustment from the same variables over different periods. In (b)–(f), for each pair of variables, the minimum p-value over the five lags is reported. Corresponding tickers are given in x- and y-axes and industrial sectors are indicated by the colors and boundaries drawn.
Motivated by the aforementioned characteristics of high-dimensional time series data, factor-adjusted regression modeling has increasingly gained popularity (Fan, Ke, and Wang 2020; Fan, Masini, and Medeiros 2021; Krampe and Margaritella 2021). The factor-adjusted VAR model proposed by Barigozzi, Cho, and Owens (2022) assumes that a handful of common factors capture strong serial and cross-sectional correlations, such that it is reasonable to assume a sparse VAR model on the remaining component to capture idiosyncratic, variable-specific dependence. We extend this framework by proposing a new, piecewise stationary factor-adjusted VAR model and develop FVARseg, an accompanying change point detection methodology. Below we summarize the methodological and theoretical contributions made in this article.
1.1 Generality of the Modeling Framework
We decompose the data into two piecewise stationary latent processes: one is driven by factors and accounts for dominant serial and cross-sectional correlations, and the other models sparse pairwise dependence via a VAR model. We adopt the most general approach to factor modeling and allow both components to undergo changes which, in the case of the latter, are attributed to shifts in the VAR parameters. To the best of our knowledge, such a general model simultaneously permitting the presence of common factors and change points, has not been studied in the literature previously. Accordingly, we are not aware of any method that can comprehensively address the data segmentation problem considered in this article.
1.2 Methodological Novelty
The idea of scanning the data for changes over moving windows, has successfully been applied to a variety of data segmentation problems (Preuss, Puchstein, and Dette 2015; Eichinger and Kirch 2018; Chen, Wang, and Wu 2022). We propose FVARseg, a two-stage methodology that combines this idea with statistics carefully designed to have good detection power against different types of changes in the two latent components. In Stage 1 of FVARseg, motivated by that dominant factor-driven correlations appear as leading eigenvalues in the frequency domain, see for example, , we propose a detector statistic that contrasts the local spectral density matrix estimators from neighboring moving windows in operator norm, which is well-suited to detect changes in the factor-driven component.
In Stage 2 for detecting change points in the latent piecewise stationary VAR process, we deliberately avoid estimating the latent process which may incur large errors. Instead, we make use of (i) the Yule-Walker equation that relates autocovariances (ACV) and VAR parameters, and (ii) the availability of local ACV estimators of the latent VAR process after Stage 1. Combining these ingredients, we propose a novel detector statistic that enjoys methodological simplicity as well as statistical efficiency. Further, through sequential evaluation of the detector statistic, the second-stage procedure requires the estimation of local VAR parameters at selected locations only. Consequently it is highly competitive computationally when both the sample size and the dimensionality are large.
1.3 Theoretical Consistency
FVARseg achieves consistency in estimating the total number and locations of the change points in both of the piecewise stationary factor-driven and VAR processes. Our theoretical analysis is conducted in a setting considerably more general than those commonly adopted in the literature, permitting dependence across stationary segments and heavy-tailedness of the data. We also derive the rate of localization for each stage of FVARseg where we make explicit the influence of tail behavior and the size of changes. In particular, under Gaussianity, the estimators from Stage 1 nearly matches the minimax optimal rate derived for the simpler, covariance change point detection problem.
The rest of the article is structured as follows. Section 2 introduces the piecewise stationary factor-adjusted VAR model. Section 3 describes the two stages of FVARseg, the proposed data segmentation methodology, and Section 4 establishes its theoretical consistency. Section 5 demonstrates the performance of FVARseg empirically, and Section 6 concludes the article. R code is available from https://github.com/haeran-cho/fvarseg.
1.4 Notation
Let and
denote an identity matrix and a matrix of zeros whose dimensions depend on the context. For a random variable X and
, denote
. Given
, we denote by
its transposed complex conjugate. We define its element-wise
and
-norms by
,
and
, and its spectral and induced L1,
-norms by
,
and
, respectively. For positive definite
, we denote its minimum eigenvalue by
. For two real numbers,
and
. For two sequences
and
, we write
if, for some constants
, there exists
such that
for all
.
2 Piecewise Stationary Factor-Adjusted VAR Model
2.1 Background
A zero-mean, p-variate process follows a VAR(d) model if it satisfies
(1)
(1) where
, determine how future values of the series depend on their past. The p-variate random vector
has
which are iid for all i and t with
and
. The positive definite matrix
is the covariance matrix of the innovations for the VAR process.
A factor-driven component exhibits strong cross-sectional and/or serial correlations by “loading” finite-dimensional factors linearly. Among many, the generalized dynamic factor model (GDFM, Forni et al. 2000, 2015) provides the most general approach (see Appendix D for further discussions), and defines the p-variate factor-driven component as
(2)
(2)
For fixed q, the q-variate random vector contains the common factors which are shared across the variables and time, and ujt are assumed to be iid for all j and t with
and
. The matrix of square-summable filters
with the lag-operator L and
, serves the role of loadings under (2).
Barigozzi, Cho, and Owens (2022) propose a factor-adjusted VAR model, where the observations are assumed to be decomposed as a sum of the two latent components and
in (1)–(2), with pervasive correlations in the data are accounted for by
and the remaining dependence captured by
. In the next section, we introduce its piecewise stationary extension where both the factor-driven and VAR processes are allowed to undergo structural changes.
2.2 Model
We observe a zero-mean, p-variate piecewise stationary process where
(3)
(3)
Here, , denote the change points in the piecewise stationary factor-driven component
such that at each
, the filter of loadings
undergoes a change. We permit the factor number to vary over time as
, with the factor
associated with
being a sub-vector of
. Similarly,
, denote the change points in the piecewise stationary VAR process
at which the VAR parameters undergo shifts; we permit the VAR innovation covariance matrix to vary as
but our interest lies in detecting changes in VAR parameters, and the VAR order may vary over time as
with
for
. By convention, we denote
and
. In line with the factor modeling literature, we assume that
and
are uncorrelated through having
for any i, j, t and
.
The model (3) does not require that the change points in and
are aligned, or that
. Our goal is to estimate the total number and locations of the change points for both of the piecewise stationary latent processes. Importantly, we allow
(resp.
) to be dependent across k through sharing the innovations
(resp.
). This makes our model considerably more general than those found in the literature on (high-dimensional) data segmentation under VAR models (Wang et al. 2019; Safikhani and Shojaie 2022; Bai, Safikhani, and Michailidis 2022) which assume independence across the segments. Data segmentation under factor models has been considered by Barigozzi, Cho, and Fryzlewicz (2018) and Li, Li, and Fryzlewicz (2023) but they adopt a static approach to factor modeling.
2.3 Assumptions
We introduce assumptions that ensure the (asymptotic) identifiability of the two latent processes in (3) which are framed in terms of spectral properties, as well as controlling the degree of dependence in the data. Denote by the ACV matrix of
at lag
, and its spectral density matrix at frequency
by
with
. Then,
, denote the real, positive eigenvalues of
ordered by decreasing size. We similarly define
and
for
.
Assumption 2.1.
For each , the following holds: There exist a positive integer
, pairs of functions
and
for
and
, and
satisfying
such that for all
,
If for all
as frequently assumed in the literature (Fan, Liao, and Mincheva 2013; Forni et al. 2015), we are in the presence of qk factors which are equally pervasive for the whole cross-sections of
. If
for some j, we permit the presence of ‘weak’ factors. Since our primary interest lies in change point analysis, we later introduce a related but distinct condition on the size of change in
in Assumption 4.2.
Assumption 2.2.
for all
Consider the Wold decomposition
Assumption 2.3.
There exist constants and
such that for all
,
Assumption 2.2(i)–(ii) are standard conditions in the literature (Lütkepohl 2005; Basu and Michailidis 2015). Under condition (iii) and Assumption 2.3, we have time-varying serial dependence in (across all segments) decay at an algebraic rate. Assumption 2.2(iii) allows for mild cross-correlations in
while ensuring that
is uniformly bounded:
Proposition 2.1.
Under Assumption 2.2, uniformly over all , there exists some
depending only on
, Ξ and Ϛ such that
.
Remark 2.1.
Proposition 2.1, together with Assumption 2.2(iv), establishes the boundedness of the eigenvalues of , which is commonly assumed in the high-dimensional VAR literature for the consistency of Lasso estimators. Assumption 2.2(iv) holds if there exists some constant
satisfying
(Basu and Michailidis 2015). When d = 1, we have
such that if
, Assumption 2.2(iii) is readily satisfied with
.
From Assumption 2.1 and Proposition 2.1, the latent components in (3) are asymptotically identifiable as , thanks to the gap between
diverging with p and
which is uniformly bounded, which agrees with the phenomenon observed in .
3 Methodology
3.1 Stage 1: Factor-Driven Component Segmentation
3.1.1 Change Point Detection
The spectral density matrix of is given by
for
, that is it varies over time in a piecewise constant manner with change points at
. By Weyl’s inequality, Assumption 2.1 and Proposition 2.1 jointly indicate a gap in the eigenvalues of (time-varying) spectral density matrix of
, that is, those attributed to the factor-driven component diverges with p while the remaining ones are bounded for all p. This suggests an approach that looks for changes in
from the behavior of
in the frequency domain which we further justify below.
Example 3.1.
Suppose that contains a single change point at
at which a new factor is introduced, that is
and
with
, which leads to
. Then, from the uncorrelatedness between
and
and Proposition 2.1, the time-varying spectral density of
, satisfies
. That is, the change in the spectral density of
is detectable as a change in time-varying spectral density matrix of
in operator norm, with the size of change diverging with p as
does so under Assumption 2.1.
Thus, we detect changes in by scanning for any large change in the spectral density matrix of
measured in operator norm, and propose the following moving window-based approach. Given a bandwidth G, we estimate the local spectral density matrix of
by
(4)
(4) where
denotes the Bartlett kernel,
the kernel bandwidth with
, and
(5)
(5)
Then the following statistic
(6)
(6) serves as a good proxy of the difference in local spectral density matrices of
over
and
. To make it more precise, let
denote a weighted average
with weights
corresponding to the proportion of
, belonging to
(see F.1). Then,
, as a function of v, linearly increases and then decreases around the change points with a peak of size
formed at
for all
, provided that the bandwidth G is not too large (in the sense of Assumption 4.2(ii)). The detector statistic
is designed to approximate
when
is not directly observed, and thus is well-suited to detect and locate the change points therein. Unlike other methods for detecting changes in the factor structure (e.g., Li, Li, and Fryzlewicz 2023), we do not require the number of factors, either for each segment or for the whole dataset, as an input for the construction of
.
Once is evaluated at the Fourier frequencies
, we adapt the maximum-check of Eichinger and Kirch (2018) for simultaneous detection of the multiple change points. Taking the pointwise maximum over the frequencies at each given location v, we check if
exceeds some threshold
where
denotes the frequency at which
is maximized, that is
. If so, it provides evidence that a change point
is located near the time point v, but some care is needed to avoid detecting duplicate estimators, since the detector statistic is expected to take a large value over an interval containing
. Therefore, denoting by
the set containing all time points at which
, we regard
as a change point estimator if it is a local maximizer of
within an interval of radius ηG centered at
with some
, that is
. Once
is added to the set of final estimators, say
, in order to avoid the risk of duplicate estimators, we remove the interval of radius G centered at
from
, and repeat the same procedure with the maximizer of
at time points v remaining in
until the set
is empty. Algorithm 1 in Appendix C outlines the steps of Stage 1 of FVARseg.
3.1.2 Post-Segmentation Factor Adjustment
Following the detection of change points in , we are able to estimate the segment-specific quantities related to
. In view of the second-stage of FVARseg detecting change points in
, we describe how to estimate
with which we can estimate the ACV of
.
For each , we first estimate the spectral density of
over the segment
by
as in (4) using the sample ACV computed from the segment (we use the same kernel bandwidth m for simplicity). Then noting that the spectral density matrix of
is of rank qk under (3), we estimate it from the eigendecomposition of
by retaining only the qk largest eigenvalues, say
, and the associated eigenvectors
, and then estimate the ACV of
by inverse Fourier transform, that is
(7)
(7)
The estimators in (7) require the factor number qk as an input. We refer to Hallin and Liška (2007) for an information criterion (IC)-based estimator of qk that make use of the postulated eigengap in the spectral density matrix of .
3.2 Stage 2: Piecewise VAR Process Segmentation
Applying the existing VAR segmentation methods in our setting requires estimating the np elements of the latent piecewise stationary VAR process , which introduces additional errors and possibly results in the loss of statistical efficiency. In addition, as discussed in Appendix A.2, the existing methods tend to be computationally demanding, for example by evaluating the Lasso estimators
times in a dynamic programming algorithm, or solving a large fused Lasso objective function of dimension
. Instead, since we can estimate the local ACV of
from the post-segmentation factor-adjustment in Stage 1, our proposed methodology for segmenting the latent VAR component avoids estimating
directly. Also, as described below, the proposed method evaluates the local VAR parameters at carefully selected locations only, and thus is computationally efficient.
Specifically, our approach makes use of the Yule-Walker equation (Lütkepohl 2005). Let contain all VAR parameters in the kth segment. Then, it is related to the ACV matrices
as
, where
(8)
(8) with
being invertible due to Assumption 2.2(iv). We propose to use this estimating equation in combination with the local ACV estimators of
obtained as described below.
For a given bandwidth G and the interval , we estimate the ACV of
for
, by
. Here,
is defined in (5) and
is a weighted average of
, the estimators of ACV of
in (7), with the weights given by the proportion of
covered by the kth segment (see F.16 for the precise definition). Replacing
with
, we obtain
estimating a weighted average of
, and similarly
. Then, we propose to scan
with some inspection parameter
and a matrix norm
. We motivate this statistic by considering
, its population counterpart. With appropriately chosen G (see Assumption 4.4(ii)),
if v is far from all the change points in
, that is
, while it is tent-shaped near the change points with a local maximum at
, provided that
(9)
(9)
For the inspection parameter, we adopt an -regularized Yule-Walker estimator which, at some
, solves the following constrained
-minimization problem
(10)
(10) with a tuning parameter
. Assuming stationarity, a similar approach has been proposed for the estimation of high-dimensional VAR in Han, Lu, and Liu (2015), and extended to the case where the VAR process of interest is latent in Barigozzi, Cho, and Owens (2022). The
-constraint in (10) naturally leads to the choice
, resulting in the following detector statistic:
For good detection power, the condition in (9) suggests using an estimator of or
in place of
for detecting
. Therefore, we propose to evaluate
for
, with
updated sequentially at locations strategically selected as below.
First we estimate by
in (10) with
and scan the data using
. When
exceeds some threshold, say
, at
for the first time, it signifies that a change has occurred in the neighborhood. Reducing the search for a change point to
, we identify a change point estimator as the local maximizer
. Then updating
with
obtained at
for some
(i.e., only using an interval of length G located strictly to the right of
for its computation), we continue screening
, until it next exceeds
. These steps of screening
and updating
are repeated iteratively until the end of the data sequence is reached. Algorithm 2 in Appendix C outlines the steps of the Stage 2 methodology.
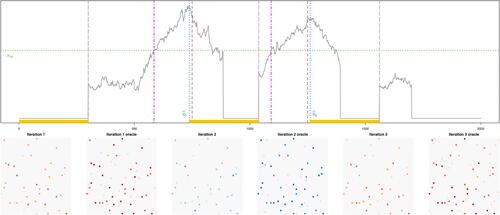
illustrates that although is latent, at each iteration,
does as well as its oracle counterpart (obtained as in (10) with the sample ACV of
replacing
). Computationally, this strategy benefits from that the costly solution to the
-minimization problem in (10) is required (at most)
times with an appropriately chosen threshold
(see Theorem 4.3). We further demonstrate numerically the competitiveness of Stage 2 as a standalone method for VAR time series segmentation in Section 5.2, and provide an in-depth comparative study with the existing methods in Appendix A.2.
Fig. 2 Illustration of Stage 2 applied to a realization from (M1) of Section 5.2 with G = 300 and d = 1. Top: The solid curve represents , computed at the three iterations of Steps 1–3 of Algorithm 2. At each iteration, we use
estimated from each of the sections the data highlighted in the x-axis (left to right); the corresponding estimators are plotted in the bottom panel and for comparison, we also plot the estimators obtained in the oracle setting where
is observable (all plots have the identical z-axis range). The locations of
and
in Algorithm 2, and
are denoted by the vertical long-dashed, dot-dashed, dotted and dashed lines, respectively. The horizontal line represents
chosen as described in Section 5.1.
4 Theoretical Properties
4.1 Consistency of Stage 1 of FVARseg
We carry out our theoretical investigation under two different regimes with respect to the tail behavior of and
; in particular, the weaker condition in Assumption 4.1(i) permits heavy-tailed innovations, while the existing literature on (piecewise stationary) VAR modeling in high dimensions, commonly adopts the Gaussianity as in (ii).
Assumption 4.1.
We assume either of the following conditions.
There exists
In establishing the consistency of Stage 1, we opt to measure the size of changes in using
, the difference in spectral density matrices of
from neighboring segments. As
is Hermitian, we can always find the jth largest (in modulus), real-valued eigenvalue of
which we denote by
, with
. Recall that
for some
, denotes the bandwidth used in local spectral density estimation, see (4).
Assumption 4.2.
For each
The bandwidth G = Gn satisfies
Theorem 4.1.
Suppose that Assumptions 2.1–2.3, 4.1, and 4.2 hold. Let satisfy
for some constant M > 0. Then, there exists a set
with
as
, such that the following holds for
returned by Stage 1 of FVARseg, on
for large enough n and p:
There exists a constant
Remark 4.1.
In Theorem 4.1(b),
Empirically, replacing
Next, we establish the consistency of in (7) estimating the segment-specific ACV of
under the following assumption on the strength of factors.
Assumption 4.3.
Assumption 2.1 holds with for all
and
.
Theorem 4.2.
Suppose that Assumption 4.3 holds in addition to the assumptions made in Theorem 4.1, and define . Also let
Then on defined in Theorem 4.1, for some finite integer
, we have
It is possible to work under the weaker Assumption 2.1 and trace the effect of weak factors or bound estimation errors measured in different norms. Corollary E.16 of Barigozzi, Cho, and Owens (2022) derives such results in the stationary setting, where an additional multiplicative factor of appears in the OP-bound in Theorem (4.2). We work under the stronger Assumption 4.3 as it simplifies the presentation of Theorem 4.2 which plays an important role in the investigation into Stage 2 of FVARseg. Also, for the factor number estimator of Hallin and Liška (2007) which achieves consistency under the general dynamic factor model we adopt in (3), it is required that
for all
. Forni et al. (2004) argue that this assumption is a natural one requiring the influence of the common shocks to be, in some sense, “stationary along the cross-sections,” and also it is compatible with the cross-sectional ordering being completely arbitrary.
4.2 Consistency of Stage 2 of FVARseg
Suppose that the tuning parameter for the -regularized Yule-Walker estimation problem in (10), is set with some constant M > 0 and
and
defined in Theorem 4.2, as
(13)
(13)
This choice reflects the error in estimating the local ACV of
over all v and
.
The following assumption imposes conditions on the size of the changes in VAR parameters and the minimum spacing between the change points.
Assumption 4.4.
For each
The bandwidth G fulfils (12), that is
Remark 4.2.
We choose to measure the size of change using . From Assumption 2.2(iv), we have
iff
. In the related literature, the
-norm
scaled by the global sparsity (given by the union of the supports of all
), is used to measure the size of change where this global sparsity may be much greater than that of
when
is large, see Appendix A.2. In some instances, we have
, for example, when d = 1 and
such that Assumption 4.4(i) becomes
. More generally, bounding
implicitly assumes (approximate) sparsity on the second-order structure of
. When d = 1, we have
such that the boundedness of
and
follows when
and
are block diagonal with fixed block size (Wang and Tsay 2022). For general
, we have
bounded if
are strictly diagonally dominant (see Definition 6.1.9 of Horn and Johnson (1985) and Han, Lu, and Liu (2015)), which is met for example, when
are diagonal with their diagonal entries fulfilling
(where
); this trivially holds when d = 1.
Theorem 4.3.
Suppose that Assumption 4.4 holds in addition to the assumptions made in Theorem 4.2. With chosen as in (13), we set
to satisfy
Then, there exists a set with
as
, such that the following holds for
returned by Stage 2 of FVARseg, on
for large enough n:
There exists a constant
Due to the sequential nature of FVARseg, the success of Stage 2 is conditional on that of Stage 1 which occurs on an asymptotic one-set, see Theorem 4.1. Theorem 4.3(a) establishes that Stage 2 of FVARseg consistently detects all change points within the distance of
where ϵ0 can be made arbitrarily small as
under Assumption 4.4(i). Theorem 4.3(b) shows that a further refined localization rate can be derived for
when it is sufficiently distanced away from the change points in the factor-driven component. If, say,
lies close to
, a change point in
, the error from estimating the local ACV of
due to the bias in
, prevents applying the arguments involved in the refinement to such
. The refined rate
is always tighter than G under Gaussianity.
It is of independent interest to consider the cases where is stationary (i.e.,
) or where we directly observe the piecewise stationary VAR process (i.e.,
). Consistency of the Stage 2 of FVARseg readily extends to such settings and the improved localization rates in Theorem 4.3(b) apply to all the estimators. Also, further improvement is attained in the heavy-tailed situations (Assumption 4.1(i)) if
is directly observable. For the full statement of the results, we refer to Corollary A.1 in Appendix A where we also provide a detailed comparison between Stage 2 of FVARseg and existing VAR segmentation methods (that do not take into the possible presence of factors), both theoretically and numerically.
5 Empirical Results
5.1 Numerical Considerations
5.1.1 Multiscale Extension
The bandwidth G is required to be large enough to provide a good local estimators of spectral density of (Stage 1) and VAR parameters (Stage 2). However, if G is too large, we may have windows that contain two or more changes when scanning the data for change points, which violates Assumptions 4.2(ii) and 4.4(ii). Cho and Kirch (2022) note the lack of adaptivity of a single-bandwidth moving window procedure in the presence of multiscale change points (a mixture of large changes over short intervals and smaller changes over long intervals), and advocates the use of multiple bandwidths. Accordingly we also propose to apply FVARseg with a range of bandwidths and prune down the outputs using a “bottom-up” method (Messer et al. 2014; Meier, Kirch, and Cho 2021). Let
denote the output from Stage 1 or 2 with a bandwidth G. Given a set of bandwidths
, we accept all estimators from the finest G1 to the set of final estimators
and sequentially for
, accept
iff
. In simulation studies, we use
for Stage 1, and
generated as an equispaced sequence between
and
of length 4 for Stage 2. The choice of
is motivated by the simulation results of Barigozzi, Cho, and Owens (2022) under the stationarity, where the
-regularized estimator in (10) was observed to perform well when the sample size exceeds 2p.
5.1.2 Speeding Up Stage 1
The computational bottleneck of FVARseg is the computation of in Stage 1, which involves singular value decomposition (SVD) of a p × p-matrix at multiple frequencies and over time. We propose to evaluate
on a grid
with
. This may incur additional bias of at most
in change point location estimation which is asymptotically negligible in view of Theorem 4.1, but reduce the computational load by the factor of bn.
5.1.3 Selection of Thresholds
The theoretically permitted ranges of and
(see Theorems 4.1 and 4.3) depend on constants which are not accessible or difficult to estimate in practice. This is an issue commonly encountered by data segmentation methods which involve localized testing, and often a reasonable solution is found by large-scale simulations, an approach we also take. We use simulations to derive a simple rule for selecting the threshold as a function of n, p, and G. For this, we (i) propose a scaling for each of the two detector statistics adopted in Stages 1 and 2 which reduces its dependence on the data generating process, and (ii) fit a linear model for an appropriate percentile of the scaled detector statistics obtained from simulated datasets. Specifically, we simulate B = 100 time series following (3) with
using the models considered in Section 5.2, and record the maximum of the scaled detector statistics
and
over v on each realization. Here, the scaling terms are obtained from the first G observations only, as
Generating the data with varying and repeating the above procedure with multiple choices of G, we fit a linear model to the
th percentile of
with
and
as regressors (
), and use the fitted model to derive a threshold for given n and G that is then applied to the similarly scaled
. Analogously, we regress the
th percentile of
onto
and
(
), and find a threshold applied to the scaled
given n, p, and G from the fitted model. The choice of the regressors is motivated by the definitions of ψn and
which appear in Theorems 4.1 and 4.3. The high values of
indicate the excellent fit of the linear models and consequently, that the threshold selection rule is insensitive to the data generating processes. When Stage 2 is used as a standalone method for segmenting observed VAR processes, a smaller threshold is recommended which is in line with Corollary A.1, and we find that
works well with the proposed scaling.
5.1.4 Other Tuning Parameters
While data-adaptive methods exist for selecting the kernel window size m in (4) (Politis 2003), we find that setting it simply at for given G, works well for the purpose of data segmentation. The results are not highly sensitive to the choice of η in Stage 1 and use
throughout. In Stage 2, we find that not trimming off the data when estimating the VAR parameters by setting η = 0, does not hurt the numerical performance. In factor-adjustment, we select the segment-specific factor number qk using the IC-based approach of Hallin and Liška (2007). Krampe and Margaritella (2021) propose to jointly select the (static) factor number and the VAR order using an IC but generally, the validity of IC is not well-understood for VAR order selection in high dimensions. In our simulations, following the practice in the literature on VAR segmentation, we regard d as known but also investigate the sensitivity of FVARseg when d is misspecified. In analyzing the panel of daily volatilities (Section 5.3), we use d = 5 which has the interpretation of the number of trading days per week. Finally, we select
in (10) via cross validation as in Barigozzi, Cho, and Owens (2022).
5.2 Simulation Studies
In the simulations, we consider the cases when the factor-driven component is present () and when it is not (
). For the former, we consider two models for generating
with q = 2. In the first model, referred to as (C1),
admits a static factor model representation while in the second model (C2), it does not; empirically, the task of factor structure estimation is observed to be more challenging under (C2) (Forni et al. 2017; Barigozzi, Cho, and Owens 2022). We generate
as piecewise stationary Gaussian VAR(d) processes with
and a parameter β that controls the size of the change (with smaller β indicating the smaller change). We refer to Appendix B.1 for the full descriptions of simulation models and for an overview of the 24 data generating processes which also contains information about the sets of change points
and
; under each setting, we generate 100 realizations. Below we provide a summary of the findings from the simulation studies, and –B.2 reporting the results can be found in Appendix B.2.
Table 1 Data generating processes for simulation studies.
To the best of our knowledge, there does not exist a methodology that comprehensively addresses the change point problem under the model (3). Therefore under (M1)–(M2), we compare the Stage 1 of FVARseg with a method proposed in Barigozzi, Cho, and Fryzlewicz (2018), referred to as BCF hereafter, on their performance at detecting changes in . While BCF has a step for detecting change points in the remainder component, it does so nonparametically unlike the Stage 2 of FVARseg, which may lead to unfair comparison. Hence, we separately consider (M3) with
where we compare the Stage 2 method with VARDetect (Safikhani, Bai, and Michailidis 2022), a block-wise variant of Safikhani and Shojaie (2022).
5.2.1 Results under (M1)–(M2)
Overall, FVARseg achieves good accuracy in estimating the total number and locations of the change points for both and
across different data generating processes. Under (M1) adopting the static factor model for generating
, FVARseg shows similar performance as BCF in detecting
when the dimension is small (p = 50), but the latter tends to over-estimate the number of change points as p increases. Also, FVARseg outperforms the binary segmentation-based BCF in change point localization. BCF requires as an input the upper bound on the number of global factors, say
, that includes the ones attributed to the change points, and its performance is sensitive to its choice. In (M1), we have
(which is supplied to BCF) while in (M2),
does not admit a static factor representation and accordingly such
does not exist (we set
for BCF). Accordingly, BCF tends to under-estimate the number of change points under (M2). Generally, the task of detecting change points in
is aggravated by the presence of change points in
due to the sequential nature of FVARseg, and the Stage 2 performs better when
both in terms of detection and localization accuracy, which agrees with the observations made in Corollary A.1(a).
Between (M1) and (M2), the latter poses a more challenging setting for the Stage 2 methodology. This may be attributed to (i) the difficulty posed by the data generating scenario (C2), which is observed to make the estimation tasks related to the latent VAR process more difficult (Barigozzi, Cho, and Owens 2022), and (ii) that where the estimation bias from Stage 1 has a worse effect on the performance of Stage 2 compared to when
and
do not overlap, see the discussion below Theorem 4.3.
5.2.2 Results under (M3)
Table B.2 shows that the Stage 2 of FVARseg outperforms VARDetect in all criteria considered, particularly as p increases. VARDetect struggles to detect any change point when the change is weak (recall that is used when d = 1 which makes the size of change at
small) or when d = 2. FVARseg is faster than VARDetect in most situations except for when
, sometimes more than 10 times for example when d = 2 and there is no change point in the data. Additionally, Stage 2 of FVARseg is less sensitive to the over-specification of the VAR order (d = 2 is used when in fact d = 1). When it is under-specified, there is slight loss of detection power as expected. Generally, an increase in VAR order brings in an increase in the number of VAR parameters which impacts the empirical performance. Compared to the results obtained under (M1)–(M2), the localization performance of the Stage 2 method improves in the absence of the factor-driven component, even though the size of changes under (M3) tends to be smaller. This confirms the theoretical findings reported in Corollary A.1 (b) in Appendix A. Although not reported here, when the full FVARseg methodology is applied to the data generated under (M3), the Stage 1 method does not detect any spurious change point estimators as desired.
5.3 Application: U.S. Blue Chip Data
We consider daily stock prices from p = 72 U.S. blue chip companies across industry sectors between January 3, 2000 and February 16, 2022 (n = 5568 days), retrieved from the Wharton Research Data Services; the list of companies and their corresponding sectors can be found in Appendix E. Following Diebold and Y ilmaz (2014), we measure the volatility using where
(resp.
) denotes the maximum (resp. minimum) log-price of stock i on day t, and set
.
We apply FVARseg to detect change points in the panel of volatility measures . With
denoting the number of trading days per year, we apply Stage 1 with bandwidths chosen as an equispaced sequence between
and
of length 4, implicitly setting the minimum distance between two neighboring change points to be three months. Based on the empirical sample size requirement for VAR parameter estimation (see Section 5.1), we apply Stage 2 with bandwidths chosen as an equispaced sequence between
and
of length 4. The VAR order is set at d = 5 which corresponds to the number of trading days in each week, and the rest of the tuning parameters are selected as in Section 5.1. reports the segmentation results.
Table 2 Sets of change point estimators returned by FVARseg.
Stage 1 detects four change points around the Great Financial Crisis between 2007 and 2009, and the last two estimators from Stage 1 correspond to the onset (2020-02-20) and the end (2020-04-07) of the stock market crash brought in by the instability due to the COVID-19 pandemic. Given the clustering of change points between 2007 and 2009, an alternative approach is to adopt a locally stationary factor model as in Barigozzi et al. (2021). However, such a model does not allow for the number of factors to vary over time, whereas we observe the contrary to be the case when applying the IC-based method of Hallin and Liška (2007) to each segment defined by , see . This supports that it is more appropriate to model the changes in the factor-driven component of this dataset as abrupt changes rather than as smooth transitions.
Table 3 Estimated number of factors from
.
The estimators from Stage 2 are spread across the period in consideration. illustrate how the linkages between different companies vary over the four segments identified between 2003 and 2011 particularly at the level of industrial sectors, although this information is not used by FVARseg.
To further validate the segmentation obtained by FVARseg, we perform a forecasting exercise. Two approaches, referred to as (F1) and (F2), are adopted to build forecasting models where the difference lies in how a sub-sample of , is chosen to forecast
. Simply put, (F1) uses the observations belonging to the same segment as
only, for constructing the forecast of
(resp.
) according to the segmentation defined by
(resp.
), while (F2) ignores the presence of the most recent change point estimator. We expect (F1) to give more accurate predictions if the data undergoes structural changes at the detected change points. On the other hand, if some of the change point estimators are spurious, (F2) is expected to produce better forecasts since it makes use of more observations. We select
, the set of time points at which to perform forecasting, such that each
does not belong to the first two segments (i.e.,
), and there are at least n0 of observations to build a forecast model separately for
and
, respectively. Denoting by
the index of
nearest to and strictly left of v and similarly defining
, this means that
and
for all
. We have
. For such
, we obtain
for some
, where
denotes an estimator of the best linear predictor of
given
, and
is defined analogously. The difference between the two approaches we take lies in the selection of
.
(F1)We set and
.
(F2)We set and
.
Barigozzi, Cho, and Owens (2022) propose two methods for estimating the best linear predictors of and
under a stationary factor-adjusted VAR model, one based on a more restrictive assumption on the factor structure (“restricted”) than the other (“unrestricted”); we refer to the paper for their detailed descriptions. Both estimators are combined with the two approaches (F1) and (F2). reports the summary of the forecasting errors measured as
and
, obtained from combining different best linear predictors with (F1)–(F2). According to all evaluation criteria, (F1) produces forecasts that are more accurate than (F2) regardless of the forecasting methods, which supports the validity of the change point estimators returned by FVARseg.
Table 4 Mean and standard errors of and
for
where
.
6 Conclusions
We consider the problem of high-dimensional time series segmentation under a piecewise stationary, factor-adjusted VAR model which, adopting the most general approach to time series factor modeling, permits pervasive cross-sectional and serial correlations in the data as well as accommodating structural changes. The FVARseg proceeds in two stages, detecting change points in the factor-driven component and the idiosyncratic VAR process separately, and fully addresses the challenges arising from the presence of latent factors. Theoretical consistency of FVARseg is established under general conditions permitting heavy tails and dependence across the stationary segments, and we derive the estimation rates that make explicit the influence of the tail behavior and the size of changes. It is competitive both theoretically and computationally in comparison with the existing methods that are proposed for special instances of the proposed factor-adjusted VAR model.
Supplementary Materials
In the supplement, Section F contains preliminary lemmas and all proofs for theoretical results stated in the paper. Section B presents further information on simulation studies and Section A includes further discussions on Stage 2 of FVARseg.
UASA_A_2240054_Supplemental.zip
Download Zip (4 MB)Disclosure Statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Bai, P., Safikhani, A., and Michailidis, G. (2020), “Multiple Change Points Detection in Low Rank and Sparse High Dimensional Vector Autoregressive Models,” IEEE Transactions on Signal Processing, 68, 3074–3089. DOI: 10.1109/TSP.2020.2993145.
- Bai, P., Safikhani, A., and Michailidis, G. (2022), “Multiple Change Point Detection in Reduced Rank High Dimensional Vector Autoregressive Models,” Journal of the American Statistical Association (to appear). DOI: 10.1080/01621459.2022.2079514.
- Barigozzi, M., Cho, H., and Fryzlewicz, P. (2018), “Simultaneous Multiple Change-Point and Factor Analysis for High-Dimensional Time Series,” Journal of Econometrics, 206, 187–225. DOI: 10.1016/j.jeconom.2018.05.003.
- Barigozzi, M., Cho, H., and Owens, D. (2022), “FNETS: Factor-Adjusted Network Estimation and Forecasting for High-Dimensional Time Series,” arXiv preprint arXiv:2201.06110. DOI: 10.1080/07350015.2023.2257270.
- Barigozzi, M., and Hallin, M. (2017), “A Network Analysis of the Volatility of High Dimensional Financial Series,” Journal of the Royal Statistical Society, Series C, 66, 581–605. DOI: 10.1111/rssc.12177.
- Barigozzi, M., Hallin, M., Soccorsi, S., and von Sachs, R. (2021), “Time-Varying General Dynamic Factor Models and the Measurement of Financial Connectedness,” Journal of Econometrics, 222, 324–343. DOI: 10.1016/j.jeconom.2020.07.004.
- Basu, S., and Michailidis, G. (2015), “Regularized Estimation in Sparse High-Dimensional Time Series Models,” The Annals of Statistics, 43, 1535–1567. DOI: 10.1214/15-AOS1315.
- Chen, L., Wang, W., and Wu, W. B. (2022), “Inference of Breakpoints in High-Dimensional Time Series,” Journal of the American Statistical Association, 117, 1951–1963, DOI: 10.1080/01621459.2021.1893178.
- Cho, H., and Kirch, C. (2022), “Two-Stage Data Segmentation Prmitting Multiscale Change Points, Heavy Tails and Dependence,” Annals of the Institute of Statistical Mathematics, 74, 653–684. DOI: 10.1007/s10463-021-00811-5.
- Cule, E., Vineis, P., and De Iorio, M. (2011), “Significance Testing in Ridge Regression for Genetic Data,” BMC Bioinformatics, 12, 1–15. DOI: 10.1186/1471-2105-12-372.
- Diebold, F. X., and Yilmaz, K. (2014), “On the Network Topology of Variance Decompositions: Measuring the Connectedness of Financial Firms,” Journal of Econometrics, 182, 119–134. DOI: 10.1016/j.jeconom.2014.04.012.
- Duan, J., Bai, J., and Han, X. (2022), “Quasi-Maximum Likelihood Estimation of Break Point in High-Dimensional Factor Models,” Journal of Econometrics (to appear). DOI: 10.1016/j.jeconom.2021.12.011.
- Eichinger, B., and Kirch, C. (2018), “A MOSUM Procedure for the Estimation of Multiple Random Change Points,” Bernoulli, 24, 526–564. DOI: 10.3150/16-BEJ887.
- Fan, J., Ke, Y., and Wang, K. (2020), “Factor-Adjusted Regularized Model Selection,” Journal of Econometrics, 216, 71–85. DOI: 10.1016/j.jeconom.2020.01.006.
- Fan, J., Liao, Y., and Mincheva, M. (2013), “Large Covariance Estimation by Thresholding Principal Orthogonal Complements,” Journal of the Royal Statistical Society, Series B, 75, 603–680. DOI: 10.1111/rssb.12016.
- Fan, J., Masini, R., and Medeiros, M. C. (2021), “Bridging Factor and Sparse Models,” arXiv preprint arXiv:2102.11341.
- Forni, M., Hallin, M., Lippi, M., and Reichlin, L. (2000), “The Generalized Dynamic Factor Model: Identification and Estimation,” The Review of Economics and Statistics, 82, 540–554. DOI: 10.1162/003465300559037.
- Forni, M., Hallin, M., Lippi, M., and Reichlin, L. (2004), “The Generalized Dynamic Factor Model Consistency and Rates,” Journal of Econometrics, 119, 231–255.
- Forni, M., Hallin, M., Lippi, M., and Zaffaroni, P. (2015), “Dynamic Factor Models with Infinite-Dimensional Factor Spaces: One-Sided Representations,” Journal of Econometrics, 185, 359–371. DOI: 10.1016/j.jeconom.2013.10.017.
- Forni, M., Hallin, M., Lippi, M., and Zaffaroni, P. (2017), “Dynamic Factor Models with Infinite-Dimensional Factor Space: Asymptotic Analysis,” Journal of Econometrics, 199, 74–92.
- Giannone, D., Lenza, M., and Primiceri, G. E. (2021), “Economic Predictions with Big Data: The Illusion of Sparsity,” ECB Working Paper 2542, European Central Bank.
- Hallin, M., and Liška, R. (2007), “Determining the Number of Factors in the General Dynamic Factor Model,” Journal of the American Statistical Association, 102, 603–617. DOI: 10.1198/016214506000001275.
- Han, F., Lu, H., and Liu, H. (2015), “A Direct Estimation of High Dimensional Stationary Vector Autoregressions,” Journal of Machine Learning Research, 16, 3115–3150.
- Horn, R. A., and Johnson, C. R. (1985), Matrix Analysis, Cambridge: Cambridge University Press.
- Kirch, C., Muhsal, B., and Ombao, H. (2015), “Detection of Changes in Multivariate Time Series with Application to EEG Data,” Journal of the American Statistical Association, 110, 1197–1216. DOI: 10.1080/01621459.2014.957545.
- Krampe, J., and Margaritella, L. (2021), “Dynamic Factor Models with Sparse VAR Idiosyncratic Components,” arXiv preprint arXiv:2112.07149.
- Li, Y.-N., Li, D., and Fryzlewicz, P. (2023), “Detection of Multiple Structural Breaks in Large Covariance Matrices,” Journal of Business and Economic Statistics, 41, 846–861, DOI: 10.1080/07350015.2022.2076686.
- Lütkepohl, H. (2005), New Introduction to Multiple Time Series Analysis, Berlin: Springer.
- Maeng, H., Eckley, I., and Fearnhead, P. (2022), “Collective Anomaly Detection in High-Dimensional VAR Models, Statistica Sinica (to appear).
- Meier, A., Kirch, C., and Cho, H. (2021), “mosum: A Package for Moving Sums in Change-Point Analysis,” Journal of Statistical Software, 97, 1–42. DOI: 10.18637/jss.v097.i08.
- Messer, M., Kirchner, M., Schiemann, J., Roeper, J., Neininger, R., and Schneider, G. (2014), “A Multiple Filter Test for the Detection of Rate Changes in Renewal Processes with Varying Variance,” Annals of Applied Statistics, 8, 2027–2067.
- Michailidis, G., and d’Alché Buc, F. (2013), “Autoregressive Models for Gene Regulatory Network Inference: Sparsity, Stability and Causality Issues, Mathematical Biosciences, 246, 326–334. DOI: 10.1016/j.mbs.2013.10.003.
- Politis, D. N. (2003), “Adaptive Bandwidth Choice,” Journal of Nonparametric Statistics, 15, 517–533. DOI: 10.1080/10485250310001604659.
- Preuss, P., Puchstein, R., and Dette, H. (2015), “Detection of Multiple Structural Breaks in Multivariate Time Series,” Journal of the American Statistical Association, 110, 654–668. DOI: 10.1080/01621459.2014.920613.
- Safikhani, A., Bai, Y., and Michailidis, G. (2022), “Fast and Scalable Algorithm for Detection of Structural Breaks in Big VAR Models,” Journal of Computational and Graphical Statistics, 31, 176–189. DOI: 10.1080/10618600.2021.1950005.
- Safikhani, A., and Shojaie, A. (2022), “Joint Structural Break Detection and Parameter Estimation in High-Dimensional Nonstationary VAR Models,” Journal of the American Statistical Association, 117, 251–264. DOI: 10.1080/01621459.2020.1770097.
- Shojaie, A., and Michailidis, G. (2010), “Discovering Graphical Granger Causality Using the Truncating Lasso Penalty,” Bioinformatics, 26, i517–i523. DOI: 10.1093/bioinformatics/btq377.
- Wang, D., and Tsay, R. S. (2022), “Rate-Optimal Robust Estimation of High-Dimensional Vector Autoregressive Models,” arXiv preprint arXiv:2107.11002.
- Wang, D., Yu, Y., and Rinaldo, A. (2021), “Optimal Covariance Change Point Localization in High Dimensions,” Bernoulli, 27, 554–575. DOI: 10.3150/20-BEJ1249.
- Wang, D., Yu, Y., Rinaldo, A., and Willett, R. (2019), “Localizing Changes in High-Dimensional Vector Autoregressive Processes,” arXiv preprint arXiv:1909.06359.