
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Suppose we observe a random vector X from some distribution in a known family with unknown parameters. We ask the following question: when is it possible to split X into two pieces f(X) and g(X) such that neither part is sufficient to reconstruct X by itself, but both together can recover X fully, and their joint distribution is tractable? One common solution to this problem when multiple samples of X are observed is data splitting, but Rasines and Young offers an alternative approach that uses additive Gaussian noise—this enables post-selection inference in finite samples for Gaussian distributed data and asymptotically when errors are non-Gaussian. In this article, we offer a more general methodology for achieving such a split in finite samples by borrowing ideas from Bayesian inference to yield a (frequentist) solution that can be viewed as a continuous analog of data splitting. We call our method data fission, as an alternative to data splitting, data carving and p-value masking. We exemplify the method on several prototypical applications, such as post-selection inference for trend filtering and other regression problems, and effect size estimation after interactive multiple testing. Supplementary materials for this article are available online.
1 Introduction
One of the most common practices in applied statistics is data splitting. Given a dataset containing n independent samples, suppose an analyst wishes to divide the data into two smaller independent datasets in order to complete an analysis. The typical method for accomplishing this would be to choose m such that
and then form two new datasets:
and
. However, there are alternative approaches for accomplishing this goal that may be preferable. As a simplified example, consider the setting where we only observe a single data point
, and we would like to “split” X into two parts such that each part contains some information about X, X can be reconstructed from both parts taken together, but neither part is sufficient by itself to reconstruct X, and yet the joint distribution of these two parts is known. The constraints mentioned in the previous sentence avoid trivial solutions like outputting f(X) = X and g(X) = 0, or
and
, and so on.
Luckily, this example has a simple solution with external randomization. Generate an independent , and set
and
. One can then reconstruct X by addition (and Z by subtraction, but we care less about Z, which has no utility of its own). Just knowing one out of f(X) or g(X) does not allow one to reconstruct X, but both parts have nontrivial information about X because their mutual information with X is nonzero. We also know that f(X) and g(X) are actually independent, and their marginal distributions are also Gaussian, so their joint distribution is tractable and known.
More generally, we seek to construct a family of pairs of functions , for some totally ordered set
(typically a subset of the real line), such that we can smoothly tradeoff the amount of information that each part contains about X. When τ approaches
, f(X) will approach independence from X, while g(X) will essentially equal X, but when τ approaches
, the opposite will happen. To see how to do this, simply choose Z as before, and define
and
and let
. We call this procedure “data fission” because we divide X into two parts, each of which provides an independent yet complementary view of the original data.
Data fission is similar in spirit to data splitting. However, data fission manages to achieve the same effect from just a single sample X and not an n-dimensional vector. Nevertheless, the connection to data splitting is more than a mere analogy, and the exactly relationship between τ and m can be quantified such that data fission is viewable as a continuous analog of data splitting in the Gaussian case; we do this in the next section.
Now, can the above ideas be generalized to other distributions? In other words, can we employ external randomization to “split” a single data point into two nontrivial parts when the distribution P is not Gaussian? This is the topic of study for the rest of this article. We provide a positive answer when P is conjugate (in the standard Bayesian sense) to some other distribution Q, where the latter will be used (along with X) to determine the external randomization. In most cases, f(X) and g(X) will not simply be the sum/difference of X with some Z; such a form was achieved only in the Gaussian case. Similarly, f(X) and g(X) will typically not be independent. Nevertheless, they will satisfy the conditions set out in the first paragraph of the paper and can be treated for inferential purposes as single sample variants of data splitting, justifying the title of the article.
1.1 An Application: Data Fission for Post-Selection Inference
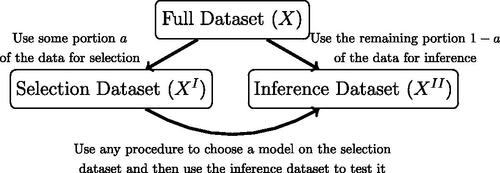
We primarily focus on demonstrating the applicability of these ideas in the context of (potentially high-dimensional) model selection and post-selection inference. With data splitting, the analyst picks some fraction of the data to use for model selection and the remaining
fraction to use for inference as illustrated in . Data fission is similar in spirit to this idea but instead uses randomization so that part of the information contained in every data point is used for both selection and inference. The procedure broadly works in three stages.
Fig. 1 Illustration of typical data splitting procedures for post-selection inference. Splitting the data has the advantage of allowing the user to choose any selection strategy for model selection, but at the cost of decreased power during the inference stage.
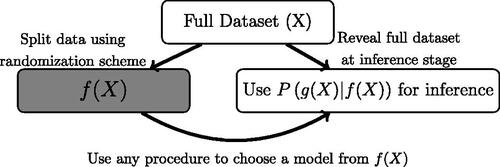
Split X into f(X) and g(X) such that
is tractable to compute. The parameter τ controls the proportion of the information to be used for model selection.
Use f(X) to select a model and/or or hypotheses to test using any procedure available.
Use
See for a graphical representation of the above steps. This approach can be viewed as a generalization of the methodologies discussed in Tian and Taylor (Citation2018) and Rasines and Young (Citation2022). In the above framework, these approaches amount to letting and g(X) = X with
for some fixed constant
. In the case where
with known
, the authors show that
has a tractable finite sample distribution. In cases where X is non-Gaussian, however,
is only described asymptotically. In the next section, we will explore alternative ways to construct g(X) that result in tractable finite sample distributions for non-Gaussian data.
Fig. 2 Illustration of the proposed data fission procedure. Similar to data splitting, it allows for any selection procedure for choosing the model. However, it achieves this through randomization rather than a direct splitting of the data.
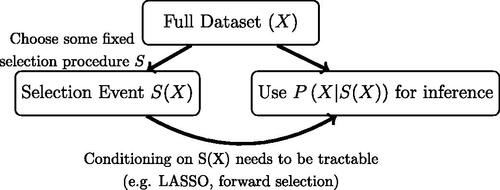
In some ways, these methodologies can be seen as a compromise between data splitting and the approach of data carving as introduced in Fithian, Sun, and Taylor (Citation2014). Data carving, as illustrated in , improves on data splitting in cases where the conditional distribution of the data given a selection event is known by including the leftover portion of Fisher information that was not used to inform the model choice in the inference procedure. A key limitation of this approach, however, is that it confines the analyst to model selection techniques with tractable post-selective distributions, such as the LASSO as described by Lee et al. (Citation2016) or more general sequential regression procedures such as those discussed in Tibshirani et al. (Citation2016). In many settings, ad-hoc exploratory data analyses such as the plotting of data or removal of outliers are ubiquitous and make data carving intractable.
Fig. 3 Illustration of data carving procedure as discussed in Fithian, Sun, and Taylor (Citation2014). Data carving has the advantage of using all unused information for inference, but requires the selection procedure to be fixed at the onset of investigation. Moreover, computing the conditional distribution needs to be tractable, either in closed form (e.g., LASSO as described in Lee et al. Citation2016) or through numerical simulation. Thus, data carving and fission have complementary benefits and tradeoffs.
Although data fission conditions on f(X) rather than the selection event itself, it retains some similarities to data carving insofar as it uses a portion of every data point to inform both selection and inference. This has advantages relative to data splitting in at least two distinct ways. First, certain settings that involve sparse or rarely occurring features may result in a handful of data points having a disproportionate amount of influence—data fission allows for the analyst to “hedge their bets” by including these points in both the selection and inference steps. Second, in settings where the selected model is defined relative to a set of fixed covariates, the theoretical justification for data splitting becomes less clear conceptually. (In a fixed-X setup, how can a model that has been selected based on its ability to estimate the conditional distribution also be understood to model the distribution that conditions on the other half of the split dataset
?) For example, consider a time series dataset, where splitting a sample may require the analyst to have a selection and inference dataset that span entirely different time periods, or graph data where there is only one observation available for each location on a graph. On the other hand, similar to data splitting, data fission affords the analyst complete flexibility in how they choose their model based on the information revealed in the selection stage. In particular, the procedure can accommodate a model selection process that relies on qualitative or heuristic methods such as visual examination of residual plots or the consultation of domain experts to determine plausibility of the discovered relationships.
Although we anticipate that these ideas may have other downstream applications beyond selective inference such as data privacy (including differential privacy), creation of fake (synthetic) datasets, and comparing machine learning algorithms, these require new techniques that are out of the scope of the current work.
1.2 Related Work on Data Splitting and Carving
Our work is influenced by the existing literature on procedures for selective inference after model selection. Although data splitting is perhaps the oldest and most commonly used method for ensuring valid coverage guarantees after model selection, rigorous examination of data splitting has only recently emerged in the literature. Rinaldo, Wasserman, and G’Sell (Citation2019) is one such example where the authors examine data splitting in an assumption-lean context.
Previously, the idea of adding and subtracting Gaussian noise has been employed for various goals in the literature. Tian and Taylor (Citation2018) use this method for selective inference by introducing a noise variable that is independent of the original data, and involve it at various stages of the selection procedure (e.g., introducing perturbations to the gradient when using LASSO to select features). An alternative route for selective inference in Gaussian regression that is explored in Xing, Zhao, and Liu (Citation2021) is to leave the response data unperturbed but create randomized versions of the covariates (termed “Gaussian mirrors”) by adding and subtracting Gaussian noise. This allows the authors to create test statistics with symmetric distributions under the null, enabling FDR control for the LASSO in high-dimensional settings. In contrast to both of these approaches, we focus on creating a perturbed version of the response that allows the analyst to conduct hypothesis selection in an arbitrary and heuristic fashion, as opposed to relying on a specific selection procedure such as the LASSO.
Randomization was also used in Li and Fithian (Citation2021) to recast the knockoff procedure of Barber and Candès (Citation2015) as a selective inference procedure for the linear Gaussian model that adds noise to the OLS estimates () to create a “whitened” version of
to use for hypothesis selection. The work of Sarkar and Tang (Citation2021) explores similar ways of using knockoffs to split
into independent pieces for hypothesis selection but uses a deterministic splitting procedure. Although conceptually quite similar to our approach, these methods focus on splitting the coefficient estimates for a fixed model into two independent pieces and then adaptively choosing the hypotheses to test during the inference stage. As such, it is most naturally applied in low dimensional settings where model selection is less necessary. Similar randomization schemes for Gaussian distributed data are also explored in Ignatiadis et al. (Citation2021) but are used for empirical Bayes procedures and not selective inference.
Outline of the article
The general methodology for data fission is introduced in Section 2. We illustrate how the procedure is used in the context of Gaussian data but then generalize this for the broader class of distributions where the data has a known conjugate prior. Examples are given across a variety of distributions commonly used for regression and data analysis such as Gaussian, Poisson, and Binomial. The remainder of the article explores the use of data fission for four different applications: selective CIs after interactive multiple testing in Section 3, fixed-design linear regression in Section 4, fixed-design generalized linear models in Section 5, and trend filtering in Section 6. Proofs for all theoretical results are omitted from the main body but included in Appendix B.
A key limitation within all of these applications—shared by much of classical statistics and conditional inference—is that theoretical guarantees can only be given under correct specification of the distribution of errors due to the need to ensure that the post-selective distribution is known and tractable. However, these guarantees are still assumption-lean in the sense of assuming an unknown form for the conditional mean μ. Situations where the variance is unknown and is estimated before data fission in the Gaussian case are discussed in low dimensional settings, but we leave theoretical guarantees in higher dimensions as an open avenue for future investigation. We provide some concluding remarks in Section 7.
2 Techniques to Accomplish Data Fission
With statistical inference in mind, we explore decompositions of X to f(X) and g(X) such that both parts contain information about a parameter θ of interest, and there exists some function h such that , and with either of the following two properties:
(P1).f(X) and g(X) are independent with known distributions (up to the unknown θ); or
(P2).f(X) has a known marginal distribution and g(X) has a known conditional distribution given f(X) (up to knowledge of θ).
The former property implies the latter, but the latter is generally more tractable. We explore alternative formulations that require weaker assumptions in Section 5.
2.1 Achieving (P2) Using “Conjugate Prior Reversal”
Suppose X follows a distribution that is a conjugate prior distribution of the parameter in some likelihood. We then construct a new random variable Z following that likelihood (with the parameter being X). Letting f(X) = Z and g(X) = X, the conditional distribution of will have the same form as X (with a different parameter depending on the value of f(X)). For example, suppose
, which is conjugate prior to the Poisson distribution. Thus, we draw
where each element is iid
and
is a tuning parameter. Let
and g(X) = X. Then, the conditional distribution of
is
On the other hand,
. Larger B results in a more informative f(X). More examples of such decompositions, which we term “conjugate prior reversal”, are in Appendix A. One drawback of this approach, however, is that it will often result in a distribution that is no longer straightforwardly related to the original parameter of interest and so extra care needs to be taken when performing inference—we explore this implication in greater detail in Section 5.
For exponential family distributions, we can construct f(X) and g(X) as follows.
Theorem 1.
Suppose that for some , the density of X is given by
(1)
(1)
Suppose also that we can find and θ3 such that
(2)
(2)
is a well-defined distribution. First, draw
, and let
and
. Then,
satisfy the data fission property (P2). Specifically, note that f(X) has a known marginal distribution
, while g(X) has a known conditional distribution given f(X), which is
.
Recall that all proofs are in Appendix B.
Remark 1
(Trading off information in f and g). As an extension to the above result, we can draw B samples independently from (2) denoted as Zi for , in which case
has marginal distribution
and
has conditional distribution
Larger B indicates more information in f(X), and thus less left over in g(X).
2.2 Example Decompositions
Below, we draw attention to techniques used in Sections 3, 4, 5, and 6.
Gaussian. Suppose
Bernoulli (P2). Suppose
Poisson. Suppose
A larger (but still incomplete) list of decomposition strategies for specific distributions is available in Appendix A. We encourage the reader to consult this list in order to get a full appreciation for the applicability of this approach to disparate problems in statistics.
2.3 Relationship Between Data Splitting and Data Fission
We explore the conditions under which data fission yields estimators that are comparable to data splitting. Suppose we are given n iid observations , where
. The data splitting approach chooses S as a random subset of
of size a where
is a tuning parameter. Letting
denote the Fisher information for the complete sample and
denote the Fisher information for a single observation, we then have
For data fission, note the following identity for smooth parametric models: . Taking expectations, and denoting
as the Fisher information for the selection and inference datasets yields
For a fixed parameter a in data splitting, one can choose τ such that to find a comparable information split for data fission. This selected τ will only guarantee that the inference datasets created by data splitting and data fission approach contain the same information in expectation. For any particular realization of the fission step,
may be different than
. In situations where g(X) and f(X) are independent, this equality can be modified to hold exactly since
.
Remark 2
(Trading information between f and g, part II). In the list of decompositions and in Remark 1 we noted that we could trade off “information” between f(X) and g(X) by varying certain hyperparameters. We can now clarify what this means. For a hyperparameter , we say that larger p corresponds to more informative f(X) and less informative
to mean that
We now elaborate on the informal assertion in Section 1 that data fission for Gaussian data can be viewed as a continuous analog of data splitting with two examples.
Example 1
(Gaussian Datasets). Let be iid
.
and so
is the amount of information used for selection under a data splitting rule. If the data is fissioned using the rule in Section 2.2, then
. To compare the approaches, we note that the relation
results in the same split of information.
Example 2
(Poisson Datasets). Let be iid
. We have that
and so
is the amount of information used for selection under a data splitting rule. If the data is fissioned using the rule described in Section 2.2, then
. The relation that equates the amount of information between data splitting and fission is then a = p.
The above examples are simplified because each data point is identically distributed so that each data point contains equivalent amounts of information about the unknown parameter θ. This symmetry allowed us to find a relation between a and τ that did not depend on the unknown parameters of interest. When the information value of data points varies, the two methods are not as directly comparable
Information splitting with non-identically distributed data
Consider a setting where data is independent but not identically distributed so each data point has different amounts of information. For instance, consider . Or consider the linear model where
for
. In this case,
, which places greater value on points with higher leverage. More generically, assume that
with
denoting the Fisher information for observation Yi about a parameter θ. Consider m different ways of allocating the information for a fixed a which chooses an points for the first dataset and the remaining
points for the second. Denote these hypothetical splits as
, where
refers to the indices that have been allocated to the first dataset. Let S denote the random variable that randomly selects Sj with probability pj. For any j, we let
denote the information allocated to the first dataset and
denote the information allocated to the second dataset.
In what follows, we let and let
denote all possible ways of choosing an data points for the first dataset. We will also make the simplifying assumption that each
so that all possible splits have the same probability of being selected. Following Examples 1 and 2, suppose we try to create a comparable split of the information using data fission by choosing a fixed a and then picking τ such that
. In this framework, this will also equate
because
Proposition 1 of Rasines and Young (Citation2022), which we restate here with some adjustments to account for our setting, demonstrates that there is a sense in which the information split using fission is more efficient even though we have chosen τ such that it has the same expected information content as our data splitting procedure.
Fact 1 (Proposition 1 of Rasines and Young (Citation2022)). Let be deterministic data splitting rules and S be the random variable which returns a particular split Sj with some probability pj such that
. Suppose that data fission is conducted such that
. Assume that all information matrices
, and
are invertible and have dimension p × p. Let
be a real-valued, convex, and strictly increasing function function defined on the set of p × p positive definite matrices. Then
. Furthermore, when g(Y) is independent of f(Y),
.
Intuitively, data fission is more efficient because it splits the information in a determinsitic way, but data splitting introduces randomization into the splitting process which decreases efficiency. Since the width of confidence intervals for MLE parameters is a function of the inverse Fisher information, an immediate consequence of this is that MLE parameters constructed from data fission will have, on average, tighter confidence intervals compared with a data splitting rule with the same expected information split. Note that in the case where the same amount of information is available at each data point (i.e., for all i, j), the above inequality becomes an equality and
. Therefore, in Examples 1 and 2, there is no apparent advantage to data splitting compared to data fission. When the information at each point varies, however, data fission can offer substantial benefits, which we explore in greater detail in Section 4.
3 Application: Selective CIs After Interactive Multiple Testing
Suppose we observe for n data points with known
alongside generic covariates
. First, the analyst wishes to choose a subset of hypotheses
to reject from the set
while controlling the false discovery rate (FDR), which is defined as the expected value of the
. After selecting these hypotheses, the analyst then may wish to construct either:
multiple confidence intervals (CIs) with
a single CI with
One method for rejecting hypotheses and constructing CIs that achieve coverage for the individual μi would be using the BH procedure (Benjamini and Hochberg Citation1995) to form the rejection set and then construct CIs as described by Benjamini and Yekutieli (Citation2005). In this problem, these would be calculated as where
. However, we know of no methodology for aggregating the individual CIs to form a single CI that will cover
.
An alternative approach for selective inference is to compute a p-value for testing each yi, and then mask the p-value as proposed by the AdaPT (Lei and Fithian Citation2018) and STAR (Lei, Ramdas, and Fithian Citation2020) procedures. These interactive methods allow the data analyst to iteratively build a rejection set in a data adaptive way. A drawback of these approaches, however, is that they only are designed to work with a p-value. In contrast to the BH procedure, there is no available method to cover either the individual signals μi or . Data fission offers one possible path forward:
Draw
Use
After selecting hypotheses, we can form CIs to cover each
To illustrate this procedure, we repeat the experiments in Section 4.3 of Lei, Ramdas, and Fithian (Citation2020) but with fissioned data. Specifically, we let the data be arranged on a grid with non-nulls arranged in a circle in the center with for each non-null and
for each null. We then form a rejection set using the BH, AdaPT, and STAR procedures and compute confidence intervals for
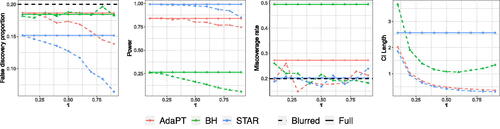
. Results are available in . Fissioning the data allows the analyst to form CIs after forming a rejection set by varying τ, while post-selective CIs for non-fissioned data do not have proper coverage. For a more detailed discussion of the simulation and for additional demonstrations on Poisson data, consult Appendix E.
Fig. 4 Numerical results averaged over 250 trials for a grid of hypotheses with target FDR level chosen at 0.2 and τ varying over (0, 1). Solid lines denote metrics for the rejection sets formed using the full dataset and dotted lines denote metrics calculated using the rejection sets formed through data fission. All methods control FDR at the desired level, but “double dipping” to form CIs after forming a rejection set data results in invalid coverage. Fissioned CIs have the correct coverage. The fissiones CI lengths decrease as τ increases because more of the dataset gets reserved for inference.
4 Application: Selective CIs in Fixed-Design Linear Regression
We now turn to applying data fission to fixed-design Gaussian linear regression. We expand on the discussion in Rasines and Young (Citation2022), and later build on several results in this section in our treatment of trend filtering in Section 6. We assume that yi is the dependent variable and is a nonrandom vector of p features for
samples. We denote
as the model design matrix and
with:
where
is a fixed unknown quantity and
is a random quantity with a known covariance matrix Σ (such as
for known σ; we discuss unknown σ later).
During the fission phase, we introduce the independent quantities f(Y) and g(Y) created by adding Gaussian noise as described in Section 2.2, letting
, and
. We use f(Y) to select a model
that, in turn, defines a model design matrix XM which is a submatrix of X. After selecting M, we then use g(Y) for inference by fitting a linear regression on g(Y) against the selected covariates XM.
Let (as a function of the chosen model M) be defined in the usual way as
(3)
(3)
Note that we make no assumptions that is guaranteed to be a linear combination of the chosen covariates. Our target parameter is therefore the best linear approximator of the regression function using the selected model
(4)
(4)
We are then able to form CIs that guarantee coverage of
as follows.
Theorem 2.
For from (3) and
from (4), we have
Furthermore, we can form a CI for the kth element of
as
An assumption of this procedure is that the variance is known in order to do the initial split between f(Y) and g(Y) during the fission phase. In the case of unknown variance, one can use an estimator to create the split, but this forces the analyst to then condition on both f(Y) and
, which may not have a tractable distribution in high dimensional settings. In the case where p is fixed and
, we explore an extension of this methodology to account for unknown variance in Section B. Extending this approach to finite samples and high-dimensional regimes remains an open question for future lines of research.
A key advantage that data fission has over data splitting is that it allows the analyst to smoothly trade off information between selection and inference datasets by tuning τ, while data splitting forces the analyst to allocate points discretely to either the selection or inference datasets. When the sample size is large and the distribution of covariates is well behaved, data splitting may be able to tradeoff information relatively smoothly by changing the proportion of data points in each sample. However, data fission will outperform data splitting in settings with small sample size with a handful of points with high leverage. Data splitting has a disadvantage in this setting because the analyst is forced to choose to allocate each of these leverage points to either the selection or inference dataset. In contrast, data fission enables the analyst to “hedge their bets” so that a piece of the information contained in each leverage point is allocated to both the selection and inference datasets. offers an illustration of this tendency on an example dataset and an extended discussion on this topic can be found in Appendix C.
Fig. 5 Comparison of data splitting (left) and data fission (middle, right) for dataset with one highly influential point. Splitting the data and fitting a regression results in substantially different fitted models because the fitted values are heavily influenced by a single data point. In contrast, data fission keeps the same X location for every data point, but randomly perturbs the response Y with random noise to create new variables f(Y) and g(Y): notice the slight difference in the two figures. This enables the analyst to keep a “piece” of every data point in both f(Y) and g(Y), ensuring that leverage points have an impact in both copies of the dataset.

We now demonstrate the advantages that data fission has over data splitting through an empirical study. We conduct inference on some vector Y given a set of covariates X and a known covariance matrix as follows:
Decompose yi into
Fit
Fit
Construct CIs for the coefficients trained in step 3, each at level α, using Theorem 2.
Simulation setup
We choose and generate n = 16 data points with p = 20 covariates. For the first 15 data points, we have an associated vector of covariates
generated from independent Gaussians. The last data point, which we denote
, is generated in such a way as to ensure it is likely to be more influential than the remaining observations due to having much larger leverage. We define
where Xk denotes the the kth column vector of the model design matrix X formed from the first 15 data points and γ is a parameter that we will vary within these simulations that reflects the degree to which the last data point has higher leverage than the first set of data points. We then construct
. The parameter β is nonzero for 4 features:
where
encodes the signal strength. We use 500 repetitions and summarize performance as follows. For the selection stage, we compute the power (defined as
) and precision (defined as
) of selecting features with a nonzero parameter. For inference, we use the false coverage rate (defined as
) where
is the CI for
. We also track the average CI length within the selected model.
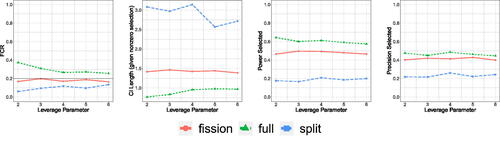
As an illustration, shows an instance of the selected features and corresponding CIs for an example trial run. As a point of comparison, we compare the CIs constructed using data fission with those constructed using data splitting (when 50% of the dataset is used for selection and the remaining for inference). We also compare these results to the (invalid) procedure where the original dependent variable is used twice to both select features and construct intervals The third methodology will not have coverage guarantees but it is still a useful point of comparison for evaluating the performance of the other two (valid) methodologies. shows results averaged over 500 trials. Data splitting and data fission both control the FCR, but data fission dominates data splitting across every other metric—including significantly tighter CIs and higher power and precision. In simulation studies with larger sample sizes and less skewed covariates, data fission and data splitting have comparable performance—see Appendix E for details.
Fig. 6 An instance of the selected feature (blue crosses) and the constructed CIs using fissioned data (left), full data twice (middle), and split data (right) with and target FCR set at 0.2. The selected features are marked by blue crosses, which include all of the nonzero coefficients (corresponding to almost 100% power for selection) and also a few zero coefficients (corresponding to around 70% precision for selection). CIs which do not cover the parameters correctly are marked red.

Fig. 7 FCR, average length of the CIs, and power/precision for the selected features, when varying the leverage parameter γ in . The results are averaged over 500 trials. Both data splitting and data fission still control FCR, but data fission now has higher power and precision, as well as tighter CIs than data splitting.
5 Application to Selective CIs in Fixed-Design Generalized Linear Models and Other Quasi-MLE Problems
For regression problems involving non-Gaussian distributed data, the same generic principle can be used as in Section 4. If the underlying distribution of Y is known up to a set of unknown parameters and aligns with one of the distributions described in Appendix A, we can fission the data and then use f(Y) for selection, while reserving to conduct inference. Even in cases where we are certain that the distribution of Y has been properly specified and the fission procedure is valid, it is important to construct CIs that are robust to model misspecification for two reasons. First, because it is unlikely in practical settings that we are going to be able to select a set of covariates that corresponds to the “actual” conditional mean of the data. Second, the post-selective distribution
may be ill-behaved and difficult to work with even if Y is easy to model. For example, if
, the post-selective distribution
constructed from Section 4 is
. Maximizing this likelihood function will be challenging since the likelihood is non-convex, so it may be practical to model the likelihood as a probit or logistic model as a working assumption.
This approach of using maximum likelihood estimation to train a model but to construct guarantees in an assumption-lean setting is termed quasi-maximum likelihood estimation (QMLE). Most work in this setting, such as Buja et al. (Citation2019), and Rinaldo, Wasserman, and G’Sell (Citation2019), are designed around a background assumption where both the covariates and response are treated as iid random variables. Such theory is inapplicable to data fission since the covariates are observed during the model selection stage and therefore inference on g(Y) is only valid if both X and f(Y) are conditioned on. Fahrmeir (Citation1990), however, works in the setting of non-identically distributed but independent data with fixed covariates and therefore can be applied to this setting. We first recap the relevant theory and then apply it to data fission when used for forming post-selective CIs in GLMs.
5.1 Problem Setup and a Recap of QMLE Methods
Suppose we observe n independent random observations alongside fixed covariates
and that we fission each data point such that the below assumption holds.
Assumption 1.
Data fission is conducted such that
for all
.
This is a different condition compared to the rules described in Section 1. Any fissioning rule which satisfies (P1) would also satisfy this (weaker) condition. The majority of decompositions in Appendix A following also satisfy Assumption 1 but this is not necessarily the case—for instance, the third rule for fissioning Gaussian distributed data would result in a post-selective distribution that is tractable but with correlated entries. However, if a fissioning process exists that creates independent entries in
, the procedures outlined in this section will apply.
During model selection, a model is chosen from f(Y) which result in an annealed set of covariates
and model design matrix XM. We then find an estimate for β using a working model of the density for
as
, which defines the quasi-likelihood function
. Denote the score function
as well as the quantities
, and
. If
is positive definite, the target parameter
is the root of
which is also the parameter which minimizes the KL distance between the true distribution (denoted as
) and the working model because
We define as the quasi-likelihood maximizer. Under mild regularity conditions,
behaves asymptotically like
. Plug-in estimates
and
will yield asymptotically conservative estimates for the covariance matrix, allowing the user to form confidence intervals. For a detailed technical account, see Appendix B.
5.2 Simulation Results
We verify the efficacy of this procedure through an empirical simulation. The advantages of data fission are again most apparent in settings with relatively few data points and a handful of leverage points just as we saw in the Gaussian case in Section 4.
Simulation setup
Let yi be the dependent variable with where
is a vector of p features. We generate n = 16 data points with p = 20 covariates, where the parameter β is nonzero for 4 features:
and
encodes the signal strength. For the first 15 observations,
, where the first two follow
and the rest follow independent standard Gaussians. The last data point, which we again denote
where Xk denotes the the kth column vector of the model design matrix X formed from the first 15 data points and γ is the leverage parameter. Our proposed procedure is
Decompose each yi as
Fit
Fit
Construct CIs for the coefficients trained in the third step, each at level α and with the standard errors estimated as in Theorem 4 in the Appendix. For the experiments shown below, we also apply a finite sample correction as described in Pustejovsky and Tipton (Citation2018).
Since step 2 may not select the correct model, the CIs in step 4 cover .
Results are shown in . Model performance metrics are the same as those used in Section 4 with replacing
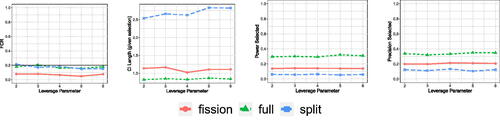
. The CIs for the non-fission approaches (data splitting and full data twice) are also constructed using sandwich estimators of the variance corresponding to Theorem 4 in the Appendix. Every method controls the FCR empirically, but the CI lengths for data fission are significantly tighter than for data splitting. Data fission is also more powerful at the selection stage than data splitting. Results for higher n settings as well as when this general framework is applied to logistic regression are contained in Appendix E. Across all of these cases, using the full dataset twice no longer results in FCR control, as expected.
Fig. 8 FCR, length of the CIs, FSR, power for the sign of parameters, and power and precision for the selected features, when varying the leverage parameter α in for Poisson data over 500 trials. CIs constructed using data fission are tighter than data splitting, and power during the selection stage is higher.
6 Application to Post-Selection Inference for Trend Filtering and Other Nonparametric Regression Problems
Consider a nonparametric setup with yi and covariates xi following , where f0 is the underlying function to be estimated and ϵi is random noise. We denote
and
. For now, assume that
for some known Σ. We can apply the methodologies of Sections 2.2 and 4 to this problem as follows:
Decompose Y into
Use f(X) to choose a basis
Use
Pointwise CI
We first note that the fitted line
(5)
(5)
corresponds to
which is just the projection of g(Y) onto the basis chosen during the model selection stage. Meanwhile, we define the projected regression function as
(6)
(6)
We are then interested in using the fitted estimates to construct intervals that guarantee coverage for the underlying function
projected onto the chosen basis which we denote as
and refer to as the projected mean.
Corollary 1.
Recall the definitions of from (5) and (6). When ϵ has known variance Σ,
and a
CI for
is
Uniformly valid CIs
We can also construct uniformly valid CIs to cover the projected mean, controlling the simultaneous Type I error rate defined as
Here, we further assume homoscedastic errors so
. Construct
, where the width
, where
is a multiplier. By eq. (5.5) in Koenker (Citation2011),
is the solution to the equation
where
is the length of the curve connected by
.
Fact 2. (Koenker Citation2011) The above constructed CIs will cover the projected mean uniformly: where
denotes the projected mean.
6.1 Application to Trend Filtering
We explore how this approach to nonparametric inference performs empirically through the lens of trend filtering as proposed by Kim et al. (Citation2009) and Steidl, Didas, and Neumann (Citation2006). Here, we consider the problem of estimating the underlying smooth trend of a time series with
. We have the same equation as in the standard nonparametric setup, but with
for all i and thus have that
. Our goal is to estimate the underlying trend
. The approach of (first order) trend filtering is to fit a piecewise linear approximation to this data with adaptively chosen breakpoints or knots by solving:
Although we focus on first order trend filtering, our methodology straightforwardly generalizes to higher order trend filtering. For a detailed overview of trend filtering, including generalization to higher order polynomials, see Appendix D.
An issue issue with trend filtering is that uncertainty quantification is not generally tractable since the knots are chosen adaptively. In some settings, data carving approaches may offer a viable path forward. When the (fused or generalized) lasso is used to select the choice of knots, methods such as Chen, Jewell, and Witten (Citation2022), Duy and Takeuchi (Citation2021), and Hyun, G’Sell, and Tibshirani (Citation2018) can be used to construct tests and CIs with valid post-selective distributions. The drawback of these approaches is that they offer the analyst no flexibility during the selection stage. If the analyst wishes to change the degree of the fitted polynomial or decrease the number of chosen knots after seeing preliminary results, inferential guarantees are no longer available. Although such actions are common in applied data analysis, data carving approaches do not easily handle ad-hoc changes to the prespecified selection methodology. Data fission offers the analyst flexibility to change the amount of regularization (alter the number of knots) or change the degree of the trend filtered estimate after a preliminary view of the selected model performance.
Similar to Section 4, an assumption of known variance is required when using data fission in order to ensure the selection and inference datasets are independent. Approaches that estimate variance empirically are explored in Appendix E but we leave theoretical guarantees for future work. The proposed procedure is:
Decompose Y into
Train a kth order trendfilter using f(Y) and select the tuning parameter λ by selecting the set of knots
Construct a kth degree falling factorial basis, as described in Tibshirani (Citation2014), with knots at
Get pointwise CIs for each data point
Simulation setup
We verify the efficacy of this approach through an experiment. We simulate data as for
, where
, and
is generated by
. With probability
, we let
(no slope change in the trend). With probability p, we choose
from a uniform distribution on
. We choose the initial slope
and set
.
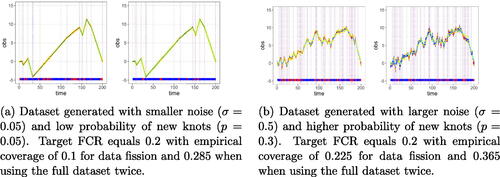
We use the above procedure to select knots and conduct inference. An example of how this methodology performs when compared to the (invalid) approach of using the full dataset twice is shown in for pointwise CIs. As there is not an obvious way to apply data splitting to trend filtering, this view is excluded. Although using the full dataset twice is invalid, it performs worse for datasets that are more volatile, either in terms of the underlying structural trend (i.e., more knots and/or larger slopes) or in terms of the underlying noise level. For a similar demonstration with uniform CIs see Appendix E.
Fig. 9 Two instances of the observed points (in yellow) and the pointwise CIs (in blue if correctly cover the trend, in red if not; the time points with false coverage are also amplified in the bar at the bottom) using two types of methods: full data twice (left), and data fission (right). The underlying projected mean is marked in cyan, which mostly overlaps with the true underlying trend. The true knots are marked by vertical lines. Using data fission results in correct empirical coverage (the 0.225 above was for just one run, the average is below 0.2). In contrast, the FCR is not controlled when using the full dataset twice; it worsens as the underlying noise and trend become more volatile.
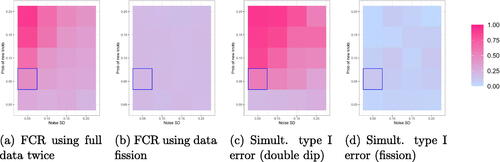
We repeat over 500 trials and report the results in . Reusing the full dataset performs most comparably to data fission when the noise is small and the probability of new knots is low. For noisier data and more volatile trends, reusing the data results in anticonservative CIs. See Appendix E for more detailed empirical results.
Fig. 10 FCR for the pointwise CIs and simultaneous Type I error for uniform CIs when varying the probability of having knots p in and the noise SD in
(the blue circled cell represents the setting for the first shown instance in ). The CIs generated using full data twice do not have valid FCR or simultaneous Type I error control, especially when p is large (more knots) and the noise standard deviation is small, but data fission is always valid.
6.2 Application to Spectroscopy
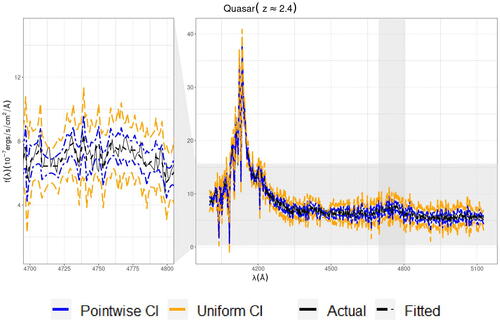
In Politsch et al. (Citation2020), the authors introduce trend filtering as a tool for astronomical data analysis with spectral classification as a motivating example. In spectroscopy, we observe a spectrum consisting of wavelengths (λ) and corresponding measurements of the coadded flux (). Trend filtering can then used to create a “spectral template”—a smoothed line of best fit for the observations. This template is combined with emission-line parameter estimates to classify the astronomical object. The authors demonstrate that trend filtering performs well empirically compared to the existing state-of-the-art for creating spectral templates which revolve around low-dimensional principal component analysis. We use this analysis as a way of demonstrating how CIs constructed using data fission appear for real data.
The dataset used for this analysis is the twelfth data release of the Baryon Oscillation Spectroscopic Survey (Alam et al. Citation2015). We estimate a spectral template using trend filtering, along with pointwise and uniform confidence bands (using the methods from Section 6) designed to cover the conditional mean of the observed spectra of the same three object discussed in Politsch et al. (Citation2020). In this setting, the flux measurement variances are known a priori and account for the statistical uncertainty introduced by photon noise, CCD read noise, and sky-subtraction error. The results are shown in for the quasarFootnote3 and in Appendix F for the remaining objects. Since the confidence bands displayed are covering the conditional mean and not the observed data, there is no objective “ground truth” to compare the outputs of the model to in order to assess goodness of fit. Therefore, the results need to be judged holistically.
Fig. 11 Fitted values as well as uniform and pointwise CIs for a quasar object fit using linear trend filtering. The right view shows the trend filter over the entire spectrum, but the left view “zooms in” on a smaller subset of the data to aid in visual identification.
7 Conclusion
We have proposed a method for selective inference through external randomization that allows flexibility to choose models in an arbitrary and data dependent way, like in data splitting, but also provides a more efficient split of available information in some settings. We demonstrate the efficacy of these methods in four applications: effect size estimation after interactive multiple testing, Gaussian linear regression, generalized linear models, and trend filtering. In the case of linear regression and GLMs, we note tighter CIs and higher power compared to data splitting in settings with leverage points and small sample size. For trend filtering, data fission enables uncertainty quantification while offering flexibility in choosing the number of knots and degree of the polynomial based on heuristic criteria.
Numerous avenues for follow-up work exist. Although we note promising empirical results that suggest this procedure can be generalized to situations where the variance is unknown and the assumed distribution on the error term is misspecified, additional work needs to be done to establish rigorous guarantees, especially in high dimensional settings. Independently, it is possible to repeat the data fission procedure multiple times in parallel, but aggregating results seems nontrivial. Last, we anticipate applications to contemporary problems such as the creation of fake datasets and enabling differential privacy.
Supplemental Material
Download Text (236 B)Supplemental Material
Download PDF (4 MB)Supplemental Material
Download Zip (195.9 KB)Supplemental Material
Download MS Word (47.8 KB)Supplementary Materials
Appendix A contains a list of additional decomposition rules for several commonly encountered distributions. Appendix B contains proofs of all deferred theoretical results as well as a more extensive discussion of asymptotics for QMLE methods. Appendix C contains an extended comparison between data splitting and data fission in the context of linear regression. Appendix D contains background information on trend filtering. Appendix E contains additional simulation results. Appendix F contains additional details on the spectroscopy example.
Disclosure Statement
The authors report there are no competing interests to declare.
Notes
1 In our experiments, we ue cv.glmnet in R package glmnet and choosing the tuning parameter λ by the 1 standard deviation rule, which can be found in the value of lambda.1se)
2 Although we restrict ourselves to a fixed selection rule for simulation purposes, data fission allows for the use of any arbitrary method of choosing the set of knots. For a discussion of alternative methods for choosing the tuning parameter λ, see Appendix E.
3 DR12, Plate = 7130, MJD =5659, Fiber = 58. Located at (RA,Dec, z) .
References
- Alam, S., Albareti, F. D., Prieto, C. A., Anders, F., Anderson, S. F., Anderton, T., Andrews, B. H., Armengaud, E., Aubourg, E., Bailey, S., and et al. (2015), “The Eleventh and Twelfth Data Releases of the Sloan Digital Sky Survey: Final Data from SDSS-III,” The Astrophysical Journal Supplement Series, 219. DOI: 10.1088/0067-0049/219/1/12.
- Barber, R. F., and Candès, E. J. (2015), “Controlling the False Discovery Rate via Knockoffs,” Annals of Statistics, 43, 2055–2085.
- Benjamini, Y., and Hochberg, Y. (1995), “Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing,” Journal of the Royal Statistical Society, Series B, 57, 289–300. DOI: 10.1111/j.2517-6161.1995.tb02031.x.
- Benjamini, Y., and Yekutieli, D. (2005), “False Discovery Rate–Adjusted Multiple Confidence Intervals for Selected Parameters,” Journal of the American Statistical Association, 100, 71–81. DOI: 10.1198/016214504000001907.
- Buja, A., Brown, L., Kuchibhotla, A. K., Berk, R., George, E., and Zhao, L. (2019), “Models as Approximations II: A Model-Free Theory of Parametric Regression,” Statistical Science, 34, 545–565. DOI: 10.1214/18-STS694.
- Chen, Y., Jewell, S., and Witten, D. (2022), “More Powerful Selective Inference for the Graph Fused Lasso,” The Journal of Computational and Graphical Statistics, 32, 577–587. DOI: 10.1080/10618600.2022.2097246.
- Duy, V. N. L., and Takeuchi, I. (2021), “Parametric Programming Approach for More Powerful and General Lasso Selective Inference,” in Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, Volume 130 of Proceedings of Machine Learning Research, eds. A. Banerjee and K. Fukumizu, pp. 901–909. PMLR.
- Fahrmeir, L. (1990), “Maximum Likelihood Estimation in Misspecified Generalized Linear Models,” Statistics, 21, 487–502.
- Fithian, W., Sun, D., and Taylor, J. (2014), “Optimal Inference after Model Selection,” arXiv:1410.2597.
- Hyun, S., G’Sell, M., and Tibshirani, R. J. (2018), “Exact Post-Selection Inference for the Generalized Lasso Path,” Electronic Journal of Statistics, 12, 1053–1097. DOI: 10.1214/17-EJS1363.
- Ignatiadis, N., Saha, S., Sun, D. L., and Muralidharan, O. (2021), “Empirical Bayes Mean Estimation with Nonparametric Errors via Order Statistic Regression on Replicated Data,” Journal of the American Statistical Association, 118, 987–999. DOI: 10.1080/01621459.2021.1967164.
- Kim, S.-J., Koh, K., Boyd, S., and Gorinevsky, D. (2009), l1 trend Filtering,” SIAM Review, 51, 339–360.
- Koenker, R. (2011), “Additive Models for Quantile Regression: Model Selection and Confidence Bandaids,” Brazilian Journal of Probability and Statistics, 25, 239–262. DOI: 10.1214/10-BJPS131.
- Lee, J. D., Sun, D. L., Sun, Y., and Taylor, J. E. (2016), “Exact Post-Selection Inference, with Application to the Lasso,” The Annals of Statistics, 44, 907–927. DOI: 10.1214/15-AOS1371.
- Lei, L., and Fithian, W. (2018), “AdaPT: An Interactive Procedure for Multiple Testing with Side Information,” Journal of the Royal Statistical Society, Series B, 80, 649–679. DOI: 10.1111/rssb.12274.
- Lei, L., Ramdas, A., and Fithian, W. (2020), “A General Interactive Framework for False Discovery Rate Control Under Structural Constraints,” Biometrika, 108, 253–267. DOI: 10.1093/biomet/asaa064.
- Li, X., and Fithian, W. (2021), “Whiteout: When Do Fixed-X Knockoffs Fail?” arXiv:2107.06388.
- Politsch, C. A., Cisewski-Kehe, J., Croft, R. A. C., and Wasserman, L. (2020), “Trend Filtering – II. Denoising Astronomical Signals with Varying Degrees of Smoothness,” Monthly Notices of the Royal Astronomical Society, 492, 4019–4032. DOI: 10.1093/mnras/staa110.
- Pustejovsky, J. E., and Tipton, E. (2018), “Small-Sample Methods for Cluster-Robust Variance Estimation and Hypothesis Testing in Fixed Effects Models,” Journal of Business & Economic Statistics, 36, 672–683. DOI: 10.1080/07350015.2016.1247004.
- Rasines, D. G., and Young, G. A. (2022), “Splitting Strategies for Post-Selection Inference,” Biometrika, 110, 597–614. DOI: 10.1093/biomet/asac070.
- Rinaldo, A., Wasserman, L., and G’Sell, M. (2019), “Bootstrapping and Sample Splitting for High-Dimensional, Assumption-Lean Inference,” The Annals of Statistics, 47, 3438–3469. DOI: 10.1214/18-AOS1784.
- Sarkar, S. K., and Tang, C. Y. (2021), “Adjusting the Benjamini–Hochberg Method for Controlling the False Discovery Rate in Knockoff-Assisted Variable Selection,” Biometrika, 109, 1149–1155. DOI: 10.1093/biomet/asab066.
- Steidl, G., Didas, S., and Neumann, J. (2006), “Splines in Higher Order TV Regularization,” Journal of Computational and Graphical Statistics, 70, 241–255. DOI: 10.1007/s11263-006-8066-7.
- Tian, X., and Taylor, J. (2018), “Selective Inference with a Randomized Response,” The Annals of Statistics, 46, 679–710. DOI: 10.1214/17-AOS1564.
- Tibshirani, R. J. (2014), “Adaptive Piecewise Polynomial Estimation via Trend Filtering,” The Annals of Statistics, 42, 285–323. DOI: 10.1214/13-AOS1189.
- Tibshirani, R. J., Taylor, J., Lockhart, R., and Tibshirani, R. (2016), “Exact Post-selection Inference for Sequential Regression Procedures,” Journal of the American Statistical Association, 111, 600–620. DOI: 10.1080/01621459.2015.1108848.
- Xing, X., Zhao, Z., and Liu, J. S. (2021), “Controlling False Discovery Rate Using Gaussian Mirrors,” Journal of the American Statistical Association, 118, 222–241. DOI: 10.1080/01621459.2021.1923510.