
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Neural demyelination and brain damage accumulated in white matter appear as hyperintense areas on T2-weighted MRI scans in the form of lesions. Modeling binary images at the population level, where each voxel represents the existence of a lesion, plays an important role in understanding aging and inflammatory diseases. We propose a scalable hierarchical Bayesian spatial model, called BLESS, capable of handling binary responses by placing continuous spike-and-slab mixture priors on spatially varying parameters and enforcing spatial dependency on the parameter dictating the amount of sparsity within the probability of inclusion. The use of mean-field variational inference with dynamic posterior exploration, which is an annealing-like strategy that improves optimization, allows our method to scale to large sample sizes. Our method also accounts for underestimation of posterior variance due to variational inference by providing an approximate posterior sampling approach based on Bayesian bootstrap ideas and spike-and-slab priors with random shrinkage targets. Besides accurate uncertainty quantification, this approach is capable of producing novel cluster size based imaging statistics, such as credible intervals of cluster size, and measures of reliability of cluster occurrence. Lastly, we validate our results via simulation studies and an application to the UK Biobank, a large-scale lesion mapping study with a sample size of 40,000 subjects. Supplementary materials for this article are available online.
1 Introduction
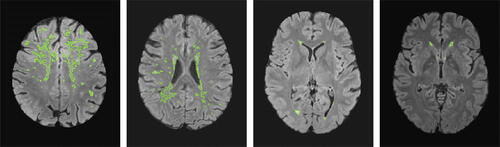
Magnetic resonance imaging (MRI) is a noninvasive imaging technique to study human brain structure and function. Accumulated damages to the white matter, known as lesions, appear as localized hypo-/hyperintensities in MRI scans (Wardlaw et al. Citation2013). The total burden of these lesions is often associated with cognitive disorders, aging, and cerebral small vessel disease (Wardlaw et al. Citation2013; Wardlaw, Valdés Hernández, and Muñoz-Maniega Citation2015). Lesion prevalence is higher for older adults (Griffanti et al. Citation2018) and for individuals with cerebrovascular risk factors, such as hypertension, alcohol consumption or smoking history (Rostrup et al. Citation2012). White matter lesions are also an overall indicator of poor brain health and have been found to triple the risk of stroke and double the risk of dementia and death and are associated with cognitive impairment, functional decline, sensory changes or motor abnormalities (Debette and Markus Citation2010). Not all white matter lesions however are attributed to aging or an increased cerebrovascular risk burden. For example, white matter hyperintensities can also occur due to multiple sclerosis, Alzheimer’s disease or as a result of a stroke (Debette and Markus Citation2010; Prins and Scheltens Citation2015). While white matter lesions due to vascular origin are a result of chronically reduced blood flow and incomplete infarction leading to altered cerebral autoregulation, the nonvascular demyelination as seen in multiple sclerosis is caused by an autoimmune response against myelin proteins (Sharma and Sekhon Citation2021). Regardless of etiology, an important clinical feature is the spatial location of lesions; while noting that lesions exhibit a high level of variability, together with the size and number of lesions, for both between and within subjects, as seen in the binary lesion masks in . Elderly patients tend to present scattered lesions which later form to confluent lesions whereas white matter lesions of nonvascular origin have a particularly heterogeneous presentation where the disease course can result in rapid progression or alternation between relapses and remissions (Sharma and Sekhon Citation2021). Identifying spatial locations in the brain where lesion incidence is associated with different covariates (e.g., age, hypertension, cardiovascular disease) is known as lesion mapping and is an essential tool to locate the brain regions that are particularly vulnerable to damage from various risk factors and inform development of interventions to reduce incidence or severity of disease (Veldsman et al. Citation2020).
Fig. 1 Contours of binary lesion masks from four healthy subjects from the UK Biobank with varying lesion numbers and sizes, where green outlines indicate lesions which show the heterogeneity of lesion incidence at various 2D axial slices from the 3D lesion mask, see Section 4.2 of the supplementary materials for further detail.
1.1 Mass-Univariate Methods and Other Spatial Models
The standard practice for lesion mapping is mass-univariate (Rostrup et al. Citation2012). In this approach a logistic regression model is fitted at each voxel or spatial location independently, any form of spatial dependence among neighboring locations is ignored. Moreover, most methods fail to address the problem of complete separation which often occurs in logistic regression models when the output variable separates a subject-specific predictor variable or a combination of input features perfectly and hence leads to infinite and biased maximum-likelihood estimates (Firth Citation1993). This problem can be addressed with a logistic regression approach known as Firth Regression, which using a penalized likelihood approach and produces mean-bias reduced parameter estimates (Firth Citation1993; Kosmidis, Kenne Pagui, and Sartori Citation2020).
Bayesian spatial models on the other hand are capable of accounting for the spatial dependence structure among neighboring voxels in a single joint model. For example, Ge et al. (Citation2014) have developed a Bayesian spatial generalized linear mixed model (BSGLMM) with a probit link function where the probability of lesion presence is modeled via a linear combination of fixed and random effects and subject-specific covariates. BSGLMM places a spatial smoothing prior directly on the parameters, specifically a conditional autoregressive model prior (Besag Citation1974), which may induce bias due to oversmoothing of regression coefficients. Moreover, BSGLMM relies on sequential Markov chain Monte Carlo (MCMC) methods for posterior computation which do not scale well to the large sample sizes found in the UK Biobank.
The last decade of brain imaging has brought immense insight into our understanding of the human brain. However, these findings suffer from small and unrepresentative samples. In addition, environmental and genetic factors that may explain individual differences are ignored which in turn undermines brain related findings. These limitations are being addressed in large-scale epidemiological studies, such as the UK Biobank or the ABCD study, by collecting data on thousands (instead of tens) of subjects. While the main advantage of these data sources lies in their larger sample sizes, they are also beneficial due to their inclusion of multiple high-dimensional imaging modalities as well as recording numerous environmental factors, neurocognitive scores, and other clinical data. The existing methods for brain mapping, specifically lesions, are either simplistic, ignoring complex spatial dependency, or are not scalable to large-scale studies.
In order to address the limitations of previous methods, we propose a multivariate Bayesian model for lesion mapping in large-scale epidemiological studies that (a) uses variable selection and shrinkage priors, (b) takes into account the spatial dependency through a parameter that controls the level of sparsity rather than directly smoothing regression coefficients, and (c) relies on an approximate posterior sampling method based on Bayesian bootstrap techniques rather than MCMC, for parameter estimation and inference. Hence, this allows us to fit the model to thousands of subjects and appropriately account for the spatial dependency in lesion mapping studies containing over 50,000 voxel locations. We also want to acknowledge that other model choices in the literature may better capture the association between lesions and covariates (Li et al. Citation2021; Zeng, Li, and Vannucci Citation2022; Whiteman Citation2022); however, we favor a model that enables us to scale parameter estimation and inference to large-scale epidemiological studies, see Section 13 of the supplementary material for a detailed literature review.
1.2 Bayesian Variable Selection
In this and the following section we will cover a short overview on the literature of Bayesian variable selection and approximate posterior sampling and refer readers to an in depth discussion in Section 14 of the supplementary materials. We use Bayesian variable selection to improve brain lesion mapping by shrinking small coefficients toward zero, thus, helping with prediction, interpretation and reduction of spurious associations in high-dimensional settings. A commonly applied technique for Bayesian variable selection is spike-and-slab regression which aims to identify a selection of predictors within a regression model. The original spike-and-slab mixture prior places a mixture of a point mass at zero and a diffuse distribution on the coefficients (Mitchell and Beauchamp Citation1988). George and McCulloch (Citation1993, Citation1997) have increased the computational feasibility of spike-and-slab regressions by introducing a continuous mixture of Gaussians formulation where the spike distribution is defined by a normal distribution with a small variance rather than a point mass prior. The binary latent variable, sampled from a Bernoulli distribution with inclusion probability, determines which mixture component a variable belongs to and enables variable selection. Overall, the options of continuous shrinkage priors in the literature are large, see Piironen and Vehtari (Citation2017) for a comparison of different methods.
The spike-and-slab regression is also able to incorporate spatial information, replacing the exchangeable Bernoulli prior on the inclusion indicator variables, with a structured spatial prior using a vector of inclusion probabilities. Previous examples of introducing structure within a spike-and-slab regression include the placement of a logistic regression product prior (Stingo et al. Citation2010) on the latents in order to group biological information for a genetics application, an Ising prior which incorporates structural information for a high-dimensional genomics application (Li and Zhang Citation2010) or a structured spike-and-slab prior with a spatial Gaussian process prior (Andersen, Winther, and Hansen Citation2014).
1.3 Approximate Posterior Inference and Sampling
The gold standard of parameter estimation and inference for spike-and-slab regression with a continuous mixture of Gaussians prior is Gibbs sampling (George and McCulloch Citation1993). However, in high-dimensional regression settings as well as large sample size scenarios other more scalable approximate methods are required due to the intense computational burden.
Expectation propagation (EP) (Minka Citation2001) or variational inference (Jordan et al. Citation1999) algorithms redefine the problem of approximating densities through optimization (Blei, Kucukelbir, and McAuliffe Citation2017). Both of these methods have been extensively studied for spike-and-slab regression problems (Carbonetto and Stephens Citation2012; Hernández-Lobato, Hernández-Lobato, and Dupont Citation2013). The EP algorithm however, poses several challenges as it is computationally intensive for even moderate sample sizes, there is no guarantee of convergence, and its poor performance for multimodal posteriors due to the problematic need to incorporate all modes in its approximation (Bishop Citation2006). Poor variational approximations can arise due to slow convergence, a simplistic choice of variational families, or due to underestimation of the posterior variance as the KL-divergence tends to under-penalize thin tails (Yao et al. Citation2018).
In neuroimaging applications, however, we require accurate uncertainty estimates and hence we use approximate posterior sampling which captures the marginal posterior density more accurately than variational densities while remaining to be highly scalable due to embarrassingly parallel implementations (Fong, Lyddon, and Holmes Citation2019). The cornerstone of these methods lies in the Bayesian bootstrap (Rubin Citation1981) and the Weighted Likelihood Bootstrap (WLB) (Newton and Raftery Citation1994). The WLB randomly re-weights the likelihood with Dirichlet weights for the observations and maximizes this likelihood with respect to the parameter of interest. Using WLB, Lyddon, Walker, and Holmes (Citation2018) and Fong, Lyddon, and Holmes (Citation2019) developed Bayesian nonparametric learning (BNL) routines which use parametric models to achieve posterior sampling through the optimization of randomized objective functions.
Our focus lies on the recently introduced method by Nie and Ročková (Citation2022) which combines Bayesian bootstrap methods with a new class of jittered spike-and-slab LASSO priors and obtains samples via optimization of many independently perturbed datasets by re-weighting the likelihood and by jittering the prior with a random mean shift. This procedure is equivalent to adding pseudo-samples from a prior sampling distribution as in the case of BNL (Fong, Lyddon, and Holmes Citation2019). We argue that for high-dimensional datasets with large samples, where memory allocation is already a computational concern, the approach by Nie and Ročková (Citation2022) is favorable as it merely requires storing a set of mean shift parameters compared to an arbitrarily large number of pseudo-samples (Fong, Lyddon, and Holmes Citation2019).
The remainder of this article is organized as follows. In Section 2, we formulate a Bayesian spatial spike-and-slab regression model with approximate posterior sampling via a Bayesian bootstrap procedure. We then assess the quality of our method, called BLESS, via simulation studies in Section 3 and give the results from the UK Biobank application in Section 4. We conclude the article with a discussion in Section 5 and provide further details on the variational distributions as well as more simulation study results in the supplementary material. Additionally, we make all code publicly available on Github.Footnote1
2 Methods
Our model for Bayesian Lesion Estimation with a Structured Spike-and-Slab (BLESS) prior is formulated as a Bayesian spatial hierarchical generalized linear model. While we specifically focus on neuroimaging applications within this article, the model can be applied to any form of spatial binary data on a lattice and can equally be extended to various neuroimaging modalities other than lesion masks.
Throughout this article we use boldface to indicate a vector or matrix. We model the binary data for every subject
at voxel location
, with a Bernoulli random variable with lesion probability
. Due to computational reasons, we choose to model the binary data via a probit link function which defines the relationship between the conditional expectation
and the linear combination of input features
containing P subject-specific covariates, spatially varying parameters
and a spatially varying intercept
. While the data comprise an image for each subject, we store the data as unraveled M-vectors
for each subject or N-vectors
for each voxel.
The Bayesian spatial generalized linear model for subject i at location sj is specified as
(1)
(1)
(2)
(2) where the equations reflect the random and systematic component, respectively and the link function is given by the cumulative Gaussian density
.
Furthermore, we reparameterize the Bayesian probit regression model defined in (1) and (2) exactly via the data augmentation approach by Albert and Chib (Citation1993) by introducing latent normal variables in (3) and (4) into the model in order to ease the computational complexity. This approach assumes that the probit regression has an underlying normal regression structure on latent continuous data. These independent continuous latent variables for every subject
and voxel
are drawn from the following normal distribution
(3)
(3) where the conditional probability of
is given by
(4)
(4)
2.1 Prior Specifications
We build a Bayesian hierarchical regression model by placing a continuous version of a spike-and-slab prior on the spatially-varying P-coefficient vector . The continuous mixture of Gaussians with two different variances, consisting of the spike and the slab distribution, is given by
(5)
(5) where
is a latent binary indicator variable for covariate
and locations
, ν0 is the spike variance and ν1 is the slab variance which determine the amount of regularization. Variable selection is implemented via the latents
, and specifically it localizes the spatial effect of each variable. Due to the continuous spike-and-slab specification, the variance within the spike distribution is always
which ensures the continuity of the spike distribution and therefore the derivation of closed form solutions of the variational parameter updates. The slab variance on the other hand is a set to a fixed value to include the range of all possible values of the spatially-varying coefficients. The combination of a small spike variance and a large slab variance with latent indicator variables for every covariate and location introduces a selective spatial shrinkage property that shrinks smaller coefficients close to zero and leaves the large parameters unaffected.
In order to account for the spatial dependence across the brain, we place an independent logistic regression prior with non-exchangeable inclusion probabilities on the latent binary indicator variables sampled from a Bernoulli distribution, similar to Stingo et al. (Citation2010). The prior is non-exchangeable because we incorporate structural information via the sparsity parameter
which ensures that certain voxel locations are more likely to be included in the model than others. In the context of brain imaging data this means that voxels that are nearby each other probably have a similar inclusion probability. Specifically, we model the latents
via
(6)
(6) where
is a sigmoid function.
The hierarchical spatial regression model is completed by placing a spatial prior on the sparsity parameter : a length PM column vector. We choose a multivariate conditional autoregressive (MCAR) prior as a spatial prior due to computational reasons (Gelfand and Vounatsou Citation2003). Alternative priors could be considered in lieu of this type of a simple smoothing prior; however, this would significantly increase the computational complexity of the model at hand.
The full conditional distribution for is given by the following multivariate normal distribution and uses the notation defined by Mardia (Citation1988):
(7)
(7) where
is a symmetric positive definite smoothing matrix. The sum
defines the sum over the neighborhood voxels at location sj,
defines the set of neighbors at location sj and
is the cardinality of the neighborhood set. For our MRI scans we consider only neighbors sharing a face, so therefore most of the interior of the brain has
neighbors whereas locations near the brain mask have
.
We then describe the joint distribution over the sparsity parameters, up to a proportionality constant, by using Brooks’s lemma (Brook Citation1964) which is given by
(8)
(8) where the sum
describes the sum over neighborhood voxels, and
indicates that sj and
are neighbors. This joint prior distribution is improper and not identifiable according to Besag (Citation1986). However, the posterior of
is proper, if there is information in the data with respect to the sparsity parameters. Lastly, we finish specifying the Bayesian hierarchical regression model by placing an uninformative, conjugate Wishart prior over the precision matrix
to fully specify the model with
(9)
(9)
where the degrees of freedom are given by
and the scale matrix is defined by the identity matrix I (Ge et al. Citation2014).
2.2 Posterior Approximation
The first element of our scalable approximate posterior sampling approach is a variational approximation to the posterior using optimization instead of MCMC sampling. Every sample within the approach in Section 2.4 is acquired by optimizing the posterior via variational inference. We opt for variational inference due to the non-conjugacy in the hierarchical model induced by specifying a logistic function around the sparsity parameters in the inclusion probabilities of the spike-and-slab priors. Local variational approximations solve this problem by finding a bound on an individual set of variables via a first-order Taylor approximation (Jaakkola and Jordan Citation2000). For general variational inference, we then require the full joint distribution of the Bayesian spatial regression model, consisting of the likelihood
and the joint prior
, which is given by
(10)
(10)
We write the entire set of model parameters as where the conditional distribution of each model parameter
is obtained as
. We acquire an approximation to the exact posterior by first specifying a family of densities
over each model parameter ψj and second identifying the parameters of the candidate distribution
that minimizes the Kullback-Leibler (KL) divergence, given by
(11)
(11)
We aim to minimize the difference between the exact posterior and the variational distribution
to find the best approximate distribution
. However, rather than computing the KL-divergence which contains the log-marginal of the data, a quantity that is often not computable, we optimize the evidence lower bound (ELBO) (Blei, Kucukelbir, and McAuliffe Citation2017)
(12)
(12)
The derivation of the variational distributions and the ELBO can be found in supplementary material in Sections 2.2 and 2.3, respectively. The variational density is derived by taking the exponentiated expected log of the complete conditional given all the other parameters and the data which is defined by
where the expectation is over the fixed variational density of other variables
, given by
. By determining the variational distributions q, we successively update each parameter
, while holding the others fixed, via mean-field coordinate ascent variational inference (Bishop Citation2006). Further details on initialization and convergence of variational inference can be found in the supplements.
2.3 Dynamic Posterior Exploration
Dynamic posterior exploration (DPE) (Ročková and George Citation2014), is an annealing-like strategy, which fixes the slab variance to a large, fixed value. The procedure works by starting in a smooth posterior landscape and aims to discover a sparse, multimodal posterior by gradually decreasing the value of the spike parameter until it approximates the spike-and-slab point mass prior. When the starting spike variance is large, we should be able to easily identify a small set of local optima by maximizing the ELBO. Thereafter, the technique uses the result as a warm start for the next optimization with a reduced spike variance which leads to a more peaked posterior until the last value within a range of spike variances is evaluated and a stable solution to the optimization problem is found.
The process of dynamic posterior exploration can be split into three parts. First, we perform parameter estimation via variational inference over a sequence of K increasing spike variances . After the initial evaluation of the backwards DPE procedure with
, every subsequent optimization is run with a successively smaller ν0 and initialized with the previously estimated variational parameters as a “warm start” solution. Second, the output of every optimization run within the sequence of spike parameter values V is thresholded via the posterior inclusion probabilities. The thresholding rule for BLESS is based on the following inclusion probabilities
(13)
(13) which is equivalent to the local version of the median probability model defined by Barbieri et al. (Citation2021). Furthermore, the determination of active versus inactive voxels based on the inclusion probability
is equivalent to thresholding the parameter estimates
themselves where the threshold is given by the intersection of the weighted mixture of the spike-and-slab priors (George and McCulloch Citation1993; Ročková and George Citation2014). For BLESS, we choose the former thresholding rule based on the posterior inclusion probabilities considering that thresholding the parameters
would require the calculation of a different set of intersection points for every coefficient due to the non-exchangeable nature of the spatial prior within the inclusion probability. Third, the estimated posterior with the smallest spike variance ν0 within the range of parameters V is used. We do not assert that this ν0 is optimal per se, but that our annealing-like strategy obviates the need for a precise determination of ν0 as the estimates for the larger effects tend to stabilize at a particular solution of variational posterior parameters.
This behavior can be validated by two types of plots. Regularization plots enable the examination of the estimated coefficients over a sequence of spike variances. For each ν0, the color of the parameter values indicates whether or not a variable is included in (red) or excluded from (blue) the model based on the thresholded posterior probability of inclusion. (a) illustrates how the negligible coefficients are drawn to zero as the values of ν0 decrease, while the larger parameters of the active voxels stabilize and are unaffected by regularization. Hence, for the plot in (a) this occurs at a log-spike variance where a local optimum has been identified and any further decrease in spike variance only leads to further shrinkage of the negligible coefficients.
Fig. 2 (a) Regularization plot (active voxel: red, inactive voxel: blue) and (b) plot of marginal posterior of under
over a sequence of equidistant
within log-space for the simulation study described in Section 3 for sample size
1000 and base rate intensity λ = 3. Both plots indicate that parameter estimates have stabilized past spike variances of
within the DPE procedure. The regularization plot also shows how negligible (blue) coefficients are progressively shrunk toward 0 while the larger (red) coefficients remain almost unregularized.
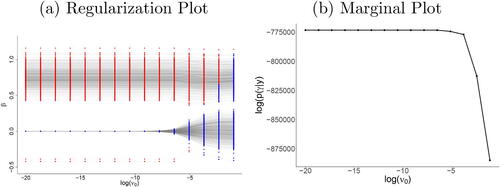
A complementary plot, especially useful when overplotting makes the regularization plot difficult to interpret, is the log-marginal posterior plot for the latents. The maximum value of this quantity yields the posterior closest to approximating the point mass prior which is the goal of backwards DPE. Since our model contains intractable integrals, we use a variational approximation to the marginal posterior of
under the prior of
. We use Jensen’s inequality to bound the marginal probability integrating out the parameters
and the latent variables Z via their respective variational approximation. The other model parameters
and
are regarded as nuisance parameters. Specifically, the log-marginal posterior under
and its approximation
(14)
(14)
(15)
(15)
(16)
(16) where
, can be used to determine whether or not the parameters identified as active have stabilized by checking a single quantity rather than the solution path of all parameters of the model. (b) illustrates the marginal
, showing a plateau for any log-spike variance
indicating a good approximation of the point mass prior. The marginal plot can be used in an equivalent manner to the regularization plot as a sanity check for visualizing the stabilization of large effects and continued shrinkage for the negligible coefficients at the end of the annealing-like process.
2.4 Uncertainty Quantification via Bayesian Bootstrap – BLESS
We use Bayesian bootstrapping techniques (Nie and Ročková Citation2022) to obtain approximate posterior samples. The approach for Bayesian Bootstrap – BLESS (BB-BLESS) is 3-fold and is described by Algorithm 1: First, weights are sampled for every observation
and bootstrap sample
from a Dirichlet distribution, which has been scaled by the sample size N, in order to re-weight the likelihood following the weighted likelihood bootstrap by Newton and Raftery (Citation1994). Every weight
hereby perturbs the contribution of each observation to the likelihood. Second, a prior mean shift
is sampled for every covariate
and voxel
from the spike distribution. For initialization, the variational parameters estimated when performing DPE for BLESS-VI (BLESS estimated via variational inference alone) at the target spike variance value ν0 are used as initial values to BB-BLESS. This prior mean shift
is then
Algorithm 1:
BB-BLESS
Result: Sample of parameter estimates from approximate posterior distribution.
Set: ; ν1: large, fixed value; α: concentration parameter; ϵ: convergence criterion; B: number of bootstrapsfor b = 1, …, B do
1) Sample weights .
2) Sample mean shifts for all
from
.
3) Calculate by acquiring variational posterior mean via approximating pseudo-posterior via variational inference.
used to center the prior for on
instead of 0 (Nie and Ročková Citation2022). This combination of Bayesian bootstrap methods and the jittering of the spike-and-slab prior allows for approximate posterior sampling by repeatedly optimizing the updated ELBO with respect to its variational parameters to approximate a posterior density. The variational posteriors for all other nuisance parameters are also refitted for every bootstrap sample. Third, we acquire a sample
by optimizing the ELBO with respect to the spatially-varying coefficient
. The following is a variational approximation to the pseudo-posterior, defined by a re-weighted likelihood and perturbed prior:
(17)
(17)
where the Dirichlet weights are
and the jitter is drawn via the spike distribution
. Each bootstrap sample
is acquired by taking the marginal variational posterior mean of the pseudo-posterior defined in (17) where the nuisance parameters are approximately marginalized out. Note that we prefer the variational posterior mean opposed to the maximum-a-posteriori (MAP) estimate for each bootstrap draw due to the computational tractability of the former. Using the MAP estimate would result in having to use numerical optimization at each iteration as some updates do not have a closed-form solution. We also acknowledge that while we do not provide theoretical guarantees within this article, we do validate our work with numerical simulations. The full derivations of this method can be found in Section 3 of the supplementary material.
3 Simulation Study
In this section, we first explain the process of simulating lesion data where the ground truth is known. We perform various simulation studies to assess the performance of BLESS, estimated via variational inference (BLESS-VI), approximate posterior sampling (BB-BLESS) and traditional Gibbs sampling (BLESS-Gibbs), by assessing their marginal posterior distributions and quantities. In addition, we compare parameter estimates and predictive performance of our method to the mass-univariate approach, Firth regression (Firth Citation1993), and the Bayesian spatial model, BSGLMM (Ge et al. Citation2014). For comparison, the latter is adopted to fit a Bayesian hierarchical modeling framework, similar to BLESS, where we add a spatially-varying intercept to match the setup of BLESS. For Firth regression, which fits an independent probit regression model with a mean bias reduction for every voxel location, we use the R package brglm2 (Kosmidis Citation2021).
The main aim of many neuroimaging studies lies in the provision of accurate inference results. We therefore tailor the assessment of simulation studies on the evaluation of inference results rather than on coverage probabilities. We compare inference results by assessing true positive (TP), false positive (FP), true negative (TN), and false negative (FN) discoveries in the following measures: (a) sensitivity/true positive rate (TPR = ), (b) true discovery rate (TDR =
), (c) specificity/1 – false positive rate (FPR =
), and (d) false discovery rate (FDR =
). Lastly, we provide extensive simulation studies on the performance of BLESS-VI compared to a frequentist, mass-univariate approach as well as a Bayesian spatial model with a simulation study addressing varying sample sizes N, base rate intensities λ, and sizes of effect within an image. Base rate intensities hereby provide an indicator for the magnitude of various regression coefficient effect sizes where a smaller λ value yields smaller regression coefficients.
For simulating the data, we adopt a data generating process that is different from our model in order to guarantee a fair comparison between the method we propose, BLESS, to the other methods, BSGLMM and Firth regression. We therefore use a data generating mechanism which simulates homogeneous regions of lesions proposed by Ge et al. (Citation2014), with intensities that vary over subjects, which provides us with a tool to provide a fair comparison among the three methods evaluated. For our study, we consider P = 2 effects in addition to an intercept, we label sex and group (e.g., patient and control). We simulate 2-D binary lesion masks of size 50 × 50, M = 2500, with homogeneous effects in each 25 × 25 quadrant. The effect of sex leads to 4 times more lesions on the right side of an image for female subjects compared to the baseline. The second effect of group membership introduces an effect of 4 times more lesions within the lower left quadrant of an image for subjects within group 2. A Poisson random variable with base rate λ determines the number of lesions. Further details and plots of the simulated data can be found in the supplementary materials in Section 5 alongside further sensitivity analyses, such as extending the neighborhood definition of the MCAR prior, in Section 10, supplementary materials. We also use a simulation framework developed by Kindalova, Kosmidis, and Nichols (Citation2021) to generate realistic looking lesion masks utilizing summary statistics from Firth regression based on UK Biobank data as truth. The results are similar and can be found in the supplements in Section 12.
3.1 BB-BLESS Simulation Study
In this simulation study on a low base rate and sample size scenario (N = 500, λ = 1) as well as a high base rate and sample size scenario ( 1000, λ = 3), we want to assess the performance of BLESS-VI, BB-BLESS, and BLESS-Gibbs on two scenarios with small and large regression coefficients based on their base rate intensity λ = 1 and λ = 3. The posterior quantities of BLESS-VI are acquired by running a separate backwards dynamic posterior exploration procedure for every dataset with an equispaced spike sequence of
of length 15 and a slab variance of
. The method is initialized with the coefficients of Firth regression where we use the parameter estimates and respective inference results from the final run in the backwards DPE procedure (
). We estimate BB-BLESS by drawing B = 1000 bootstrap replicates and Dirichlet weights with a concentration parameter α = 1. We run the Gibbs sampler for 15,000 iterations and discard 5000 iterations as burn-in. The performance of BB-BLESS and BLESS-Gibbs is then greatly improved by utilizing the output of the backwards DPE procedure as parameter initialization for the respective parameter estimation techniques.
First, we examine the marginal posterior densities of a random active and inactive voxel. As expected, the posterior variance from BLESS estimated via variational inference is underestimated as the posterior distribution is very peaked around the posterior mean (). On the other hand, the posterior estimated via BB-BLESS aligns well with the distribution acquired via the gold standard method of Gibbs sampling. This is further illustrated by comparing the marginal posterior densities of all voxels within an effect image via KL-divergence and Wasserstein distance in . Both methods show the higher quality of posterior approximation via BB-BLESS compared to BLESS-VI when calculating the discrepancy of the distributions acquired via approximate methods and Gibbs sampling.
Fig. 3 Comparison of marginal posterior distributions for an (a) active and (b) inactive voxel between BB-BLESS, BLESS-Gibbs, and BLESS-VI where the posterior mean is indicated via a vertical line. Overall evaluation of marginal posterior distributions for all voxels between Gibbs and BB-BLESS and BLESS-VI via (c) KL-divergence and (d) Wasserstein distance. Comparison of posterior quantities, such as posterior mean (e)–(f) and standard deviation (g)–(h), of the parameter estimates for all voxels for N = 1000 and λ = 3 (lighter values indicate higher density of values). Parameters acquired via BLESS-VI exhibit similar point estimates to BB-BLESS and Gibbs but their posterior distributions are too peaked and variances are underestimated.
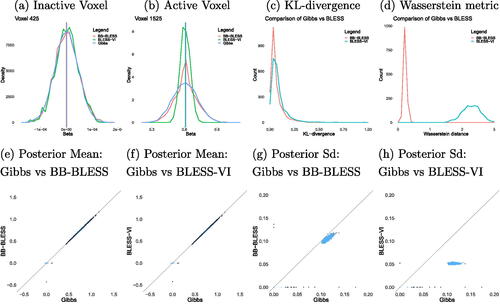
illustrates that both BB-BLESS and BLESS-VI are able to better capture the posterior mean of all voxel locations within an image when compared to BLESS estimated via Gibbs sampling. However, BLESS-VI severely underestimates the posterior standard deviation for both active and inactive voxels. Lastly, we compare the inference results of our method BLESS-VI, where we use the marginal posterior probability of inclusion as a proxy for inference, to the approximate posterior sampling technique BB-BLESS and the gold standard of BLESS-Gibbs, for which we determine activation via test statistics , for two simulation study setups. BLESS estimated via Gibbs sampling yields high sensitivity and a very low false positive rate for both settings in . More importantly, the inference results for BB-BLESS and BLESS-VI are very similar, that is the false positive rate for both BB-BLESS and BLESS-VI lies at 2.57% for a sample size of N = 500 and base rate intensity of λ = 1. Hence, we showcase empirically that, when it comes to inference, thresholding posterior inclusion probabilities in BLESS-VI yields similar results to the approximate posterior sampling approach BB-BLESS which determines effect detection via test statistics. Hence, if a researcher is uninterested in the additional features of BB-BLESS, such as acquiring uncertainty estimates of coefficients or more complex imaging statistics, then the application of BLESS-VI alone can be considered for parameter estimation and inference, as we get empirically similar voxelwise inference results in our simulation studies at a lower overall computational cost for BLESS-VI compared to BB-BLESS.
Table 1 Evaluation of parameter estimates and inference results for BLESS (Gibbs, BB, VI), BSGLMM and Firth for two simulation study scenarios (N = 500, λ = 1 and N = 1000, λ = 3) for the effect of sex.
3.2 BLESS-VI Simulation Study
We extend our simulation study to evaluate the performance of BLESS-VI for a broader set of scenarios with varying sample sizes 1000
5000
, base rate intensities
and sizes of spatial effect, where 25% (group effect) or 50% (sex effect) of the image are active, compared to BSGLMM and Firth regression. The true and estimated parameter estimates are available in the supplementary materials alongside more results from simulation studies with different spatial priors and varying magnitudes of the slab variance. We will focus on the effect map for the covariate sex and generate 100 datasets for each sample size and base rate scenario to provide robustness by averaging over the results of each dataset. The setup for BLESS-VI is otherwise identical to above.
The quality of parameter estimates and prediction for BLESS-VI, BSGLMM and Firth regression are evaluated via bias, variance and mean squared error (MSE) in . BLESS-VI exhibits comparatively low bias for the evaluation of the parameter estimates for the sex effect and moreover outperforms the mass-univariate approach when comparing the quality of the coefficients via MSE. For example, the MSE of the parameter estimates for a small sample size N = 500 and low base rate intensity λ = 1 is approximately 5 times larger for Firth regression with a value of 0.0563 compared to our method BLESS with a value of 0.0106. This showcases how BLESS adequately regularizes negligible coefficients to zero while the larger effects are unaffected by shrinkage. The quality of the predictive performance is determined by comparing the true empirical lesion rates to the estimated lesion probabilities. BLESS-VI yields slightly better predictive results with respect to MSE, by exhibiting less biased estimates, compared to Firth regression for all scenarios except for the instance with low sample size and base rate intensity (N = 500, λ = 1) where Firth regression exhibits a slightly lower MSE. This result motivates the usage of BLESS for studies with larger sample sizes where BLESS outperforms the mass-univariate approach.
Table 2 Evaluation of parameter estimates from the methods, BLESS-VI, BSGLMM and Firth Regression via bias, variance and MSE of the spatially-varying coefficients , and the predictive performance
. Improved bias and MSE for prediction for BLESS compared to Firth regression due to selective shrinkage property of BLESS.
Our simulation study enforces 50% of the voxels as active on the right side of an image for the covariate sex. Hence, by knowing the true location of the effect, we can evaluate the quality of the inference results of BLESS compared to BSGLMM and Firth regression. Effect detection for BLESS is determined by utilizing the latent variables , marking voxels sj significant if
. For BSGLMM and Firth regression we acquire test statistics
and threshold them at a significance level of 5%. We perform a multiple testing adjustment via a Benjamini-Hochberg procedure (Benjamini and Hochberg Citation1995).
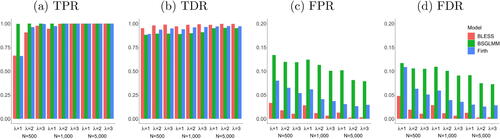
All methods have comparable results with respect to their performance in parameter estimation and prediction. However, the evaluation of the inference results in showcases that the Bayesian spatial model BSGLMM has a particularly high number of false positives and hence a very low level of specificity compared to the other methods. BLESS’s key advantage is therefore shown by comparable levels of sensitivity and high values of specificity for all configurations of sample size and base rate intensity.
Fig. 4 Evaluation of inference results from the methods, BLESS, BSGLMM and Firth Regression (FDR correction at 5%) via True Positive Rate (TPR), True Discovery Rate (TDR), False Positive Rate (FPR) and False Discovery Rate (FDR) for parameter estimate . BLESS outperforms Firth regression and BSGLMM with consistently high TPRs and low FPRs for various sample sizes and base rate intensities.
4 UK Biobank Application
4.1 Data Description and Model Estimation
Our motivating dataset is from the UK Biobank, a large-scale biomedical database containing imaging data from predominately healthy individuals. With a target of 100,000 subjects, there is currently imaging data available for 40,000 participants (Miller et al. Citation2016). We refer the reader to Miller et al. (Citation2016) for a detailed description of the scanning and processing protocols. Our goal is to map the influence of risk factors on the incidence of matter hyperintensities to understand their potential clinical significance and how they may contribute to neurological and cognitive deficits. Our dataset consists of 38,331 subjects for which white matter hyperintensity binary lesion masks have been generated via the automatic lesion segmentation algorithm BIANCA (Griffanti et al. Citation2016). The binary lesion maps in subject space are then registered to a common 2mm MNI template across subjects. Each 3D binary image with voxel size
mm3 and dimensions
contains a total of 902,629 voxel locations. Our region of interest lies in the white matter tracts of the brain and hence the total number of voxels is restricted to
54,728 by masking the 3D-lesion masks. We are interested in modeling the influence of age on lesion incidence while accounting for the confounding variables sex, head size scaling factor and the interaction of age and sex. In order to ensure interpretability across studies we have chosen confounds based on research by Alfaro-Almagro et al. (Citation2021) where a head size scaling factor is commonly included to normalize brain tissue volumes for head size compared to the MNI template. The mean age of the participants in our study is 63.6 years (
years) and 53.04% of individuals are female (20,332 women).
For model estimation, we first perform backwards dynamic posterior exploration over to help with the optimization of the variational parameters; otherwise, we fit the model identically to the simulation study as described in the previous section. The regularization and marginal plot for this application to the UK Biobank can be found in the supplementary material in Section 4.3. We further estimate BB-BLESS by acquiring B = 1500 bootstrap replicates in which we re-weight the likelihood by drawing Dirichlet weights for every subject with a concentration parameter α = 1 and perturb the prior mean of the structured spike-and-slab prior by drawing a “jitter” from
. We initialize the parameters via the results from the DPE procedure and validate the behavior of the annealing-like strategy by examining the regularization and marginal plot. This approximate posterior sampling method remains highly scalable as each optimization can be performed in parallel.
4.2 Results
compares the raw age effect size images of our method BLESS, estimated via (a) approximate posterior sampling and (b) variational inference, to (c) the mass-univariate approach Firth regression. It should be noted that we omit the comparison to the other baseline method BSGLMM as the computation of the Bayesian spatial model becomes infeasible due to the large sample size of this study. We highlight how BLESS sufficiently regularizes the negligible age coefficients to zero while leaving the larger effects unaffected. This is a direct consequence of the structured spike-and-slab prior placed on the spatially-varying coefficients. Furthermore, the spatial MCAR prior allows the sparsity dictating parameters within the spike-and-slab prior to borrow strength from their respective neighboring voxels. We further illustrate this behavior by plotting the coefficients of the feature age of the entire 3D effect map of the brain in the scatterplots in . The comparison between BLESS-VI and BB-BLESS coefficients again showcases the alignment of posterior mean estimates between the two parameter estimation procedures. The other scatterplots on the other hand capture the induced shrinkage of small effects to zero via BB-BLESS and BLESS-VI while the Firth regression parameter estimates vary for the negligible effects and exhibit nonzero values.
Fig. 5 Comparison of results between (a) BB-BLESS, (b) BLESS-VI, and (c) Firth Regression for a single axial slice (z = 45, third dimension of 3D image). (1) Spatially-varying age coefficient maps. (2) Thresholded age significance maps where the threshold for BLESS-VI is determined via the probability of inclusion/exclusion and the threshold for BB-BLESS and Firth regression via the test statistic
(significant voxels: red, not signficant voxels: blue, FDR-correction applied at 5%). (3) The scatterplots compare the age coefficients for all voxel locations within the 3D image (lighter values indicate higher density of values). The parameter maps estimated via BLESS in (1a) and (1b) exhibit a larger spatial area with values close to 0 compared to Firth in (1c). The scatterplots in (3) show that BLESS regularizes small effects almost completely to 0 compared to Firth.
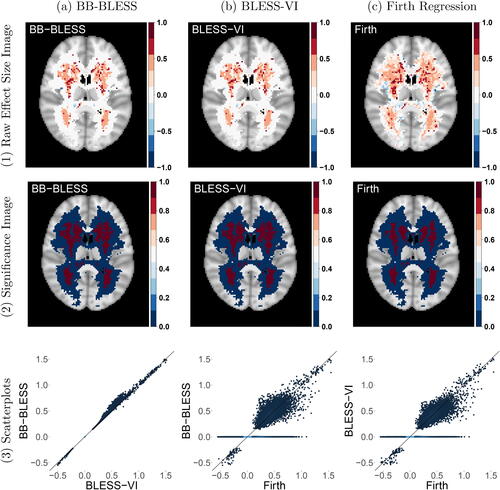
For inference, we threshold the test statistics of BB-BLESS at a significance level of 5%. In contrast, for BLESS-VI we threshold the posterior probability of inclusion at 0.5 in order to acquire its respective binary significance map. Hence, we exploit variable selection as a means to conduct inference. On the other hand, the mass-univariate approach Firth regression ignores any form of spatial dependence and hence requires the application of a multiple testing correction where we adjust the p-values with a FDR correction (Benjamini and Hochberg Citation1995) at a significance level of 5%. The results in indicate a slightly larger extent of spatial activation for BB-BLESS and BLESS-VI compared to Firth regression for a sample size of N = 2000. For the covariate age, in the regression model estimated via Firth regression 10,171 voxels are deemed active based on uncorrected p-values. On the other hand, only 6278 voxels pass the FDR adjusted threshold whereas in BB-BLESS 8385 effect locations are detected by using the full posterior to derive test statistics and similarly in BLESS-VI 8257 effects are detected via simply thresholding the posterior inclusion probabilities.
4.3 Cluster Size Imaging Statistics
Cluster-extent based thresholding is the most commonly used inference technique for statistical maps in neuroimaging studies. By proposing BB-BLESS and hence by sampling from an approximate posterior, we are able to provide novel cluster size based imaging statistics, such as cluster size credible intervals, in addition to reliable uncertainty quantification of the spatially-varying coefficients.
We have shown that the raw age effect size image of the posterior mean for BB-BLESS in obtained as an average over the bootstrap replicates is almost identical to BLESS-VI. From our simulation studies, we expect the point estimates from both approximate methods to be identical. Moreover, BB-BLESS is able to capture the uncertainty of coefficients more reliably than BLESS-VI. This is important not only for providing uncertainty quantification at a population level but also for evaluating the predictive performance via posterior predictive checks and ensuring model robustness via calibration plots (see Section 4.4 of the supplementary material). With the latter we show that our model is well calibrated in predictive uncertainty and hence the model performance for BLESS does not change to a large extent when using new out-of-sample data. The approximate posterior samples can also be used to calculate cluster size based imaging statistics which require test statistics in their estimation. The statistical map in the top middle part of , acquired by the standardization of the raw effects
with the posterior standard deviation
, shows that voxelwise inference based on thresholding the posterior probabilities of inclusion from BLESS-VI at 0.5 is similar to thresholding test statistics at a significance level of
.
Fig. 6 (1) Cluster Size Inference: Top left: Raw age effect size image. Top middle: Test statistic map for age effect. Top right: Cluster size distribution for the largest cluster detected by a cluster defining threshold of 2.3 (The solid line indicates the observed cluster size from BLESS-VI and the dashed lines signify the 95% credible interval of cluster size.). (2) Cluster Size Mapping: Lower left, middle, right: Prevalence, posterior mean and posterior standard deviation map of cluster size, where the latter two statistics are determined for instances where the prevalence map exceeds a probability of 50%. The prevalence map here indicates that both clusters have reliably large effects with values close to 1.
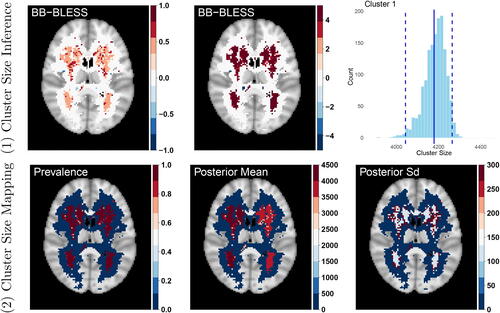
We now highlight two novel cluster size approaches, based on cluster size inference and cluster size mapping, that can be calculated via BB-BLESS. In the first approach we acquire credible intervals of cluster size by utilizing the more accurate posterior standard deviation estimates of BB-BLESS to standardize the bootstrap samples. The resampled statistical maps are then thresholded by a cluster-defining threshold of 2.3 (equivalent to thresholding p-values at a significance level of 0.01) which generates cluster size maps for every bootstrap replicate. We then build a distribution of cluster size by identifying the intersection of each bootstrap cluster with the observed one and recording its respective cluster size. A distribution over cluster sizes for any cluster within the brain allows us to calculate an array of statistical quantities, such as credible intervals of cluster size. In the top right part of , we display the cluster size distribution for the largest cluster identified across the brain alongside its 95% credible interval which ranges between a cluster size of 4063 and 4265 voxels and contains the observed cluster size value of 4179 voxels.
In a second cluster size mapping approach, we compute the voxelwise posterior probability of the standardized effect exceeding 2.3. This allows us to create a map of not just large effect but reliably large effect voxels. Comparing the cluster map with the occurrence map provides a measure for the reliability of cluster occurrence at a particular location within the brain. Due to the large spatial extent of the effect of age across the brain and viewing the central axial slice of the 3D maps, almost all voxel locations have a cluster prevalence close to 1. For these locations we then report posterior mean and standard deviation of reliable cluster size at locations where the prevalence of a cluster exceeds 50%.
To summarize, highlights how BLESS is able to reduce the identification of spurious associations for high-dimensional problems by shrinking the model’s negligible coefficients to zero and leaving larger effects unaffected. In the UK Biobank, where we study how age is associated with occurrence of lesions, age has a very large effect on lesion incidence. However, many studies require methods to identify much subtler risk factors for lesion incidence and BLESS is able to identify these smaller effects alike with a higher level of specificity and sensitivity compared to the mass-univariate approach. Our methods aid a more accurate spatial localization of effects where we show that the effect of age on lesion incidence predominantly covers periventricular and deep white matter regions. Hence, our model provides us with a tool to identify the brain regions impacted by lesion occurrence within a large population and to determine the impact on cognitive, sensory, or autonomic loss potentially induced by a higher lesion burden due to increased age. In in the supplementary materials we also highlight the change of lesion incidence across the brain in 1000 out-of-sample subjects under 50 years and over 75 years old. While the lesion location is still focused around the ventricles, the predicted lesion incidence increases greatly with age which validates previous research findings (Kindalova, Kosmidis, and Nichols Citation2021).
Moreover, we are also able to provide uncertainty estimates of parameter maps which help in the assessment of spatial associations at a population level, attaching risk assessments for identified biomarkers for diseases, and enabling the acquisition of cluster size based imaging statistics. The UK Biobank application for analyzing the effect of age on lesion occurrence only identifies two big clusters, which validates our expectation based around the magnitude of the effect for age. More importantly, BB-BLESS has the unique advantage to provide us with prevalence statements of cluster size quantities. A spatial map that can aid decisions for follow-up studies, when resources are scarce and a researcher needs to know the reliability of large effect voxels and cluster occurrence across the brain.
5 Discussion
We have proposed a novel Bayesian spatial generalized linear model with a structured spike-and-slab prior for the analysis of binary lesion data. Our main contribution to the neuroimaging community is the development of a scalable version of a Bayesian spatial model that is able to diminish spurious associations by shrinking negligible coefficients to zero, to increase model interpretation via Bayesian variable selection and to provide a model that is also easily extendable to other neuroimaging modalities, such as functional MRI with a continuous response variable.
The computational tractability of our method is also facilitated by using a data augmentation approach for the probit model and an analytical approximation to estimate the parameters in the logistic function in the Bernoulli prior on the latents within the spike-and-slab distribution (Albert and Chib Citation1993; Jaakkola and Jordan Citation2000). For future work, switching the probit link to a logit link enables the interpretation of the spatially-varying coefficients via log-odds ratios. Moreover, advances in Bayesian inference for efficient posterior estimation of logistic regressions using Pólya-Gamma latent variables circumvent the approximation by Jaakkola and Jordan (Citation2000) and therefore have potential for gains in accuracy and computational efficiency (Polson, Scott, and Windle Citation2013; Durante and Rigon Citation2019).
Lastly, we would like to address that we limit our application of BLESS to a clinical application aiming at identifying the association between age and lesion incidence in a large scale population health study, the UK Biobank. However, it is a well established finding in the analysis of white matter hyperintensities that age is one of the strongest predictors of lesion incidence (Wardlaw et al. Citation2013). Therefore, the study of more subtle risk factors for disease and the application of our cluster size based imaging statistics poses an interesting future research direction, as for example the further exploration of the cognitive impact of cerebrovascular risk-related white matter lesions (Veldsman et al. Citation2020).
Supplementary Materials
The supplementary materials contain derivations of the variational inference algorithm for BLESS-VI and the approximate posterior sampling technique for BB-BLESS, further simulation studies, additional real data analyses and posterior predictive checks, sensitivity analyses and more comprehensive literature reviews. The code for this work is available at https://github.com/annamenacher/BLESS in addition to the JASA ACC form describing the contents of our code.
Supplemental Material
Download PDF (5.6 MB)Supplemental Material
Download PDF (122 KB)Acknowledgments
We thank Sahra Ghalebikesabi, Lorenzo Pacchiardi and Edwin Fong for valuable feedback.
Disclosure Statement
The authors do not have any conflicts of interest to declare with respect to this work.
Additional information
Funding
Notes
References
- Albert, J. H., and Chib, S. (1993), “Bayesian Analysis of Binary and Polychotomous Response Data,” Journal of the American Statistical Association, 88, 669–679. DOI: 10.1080/01621459.1993.10476321.
- Alfaro-Almagro, F., McCarthy, P., Afyouni, S., Andersson, J. L., Bastiani, M., Miller, K. L., Nichols, T. E., and Smith, S. M. (2021), “Confound Modelling in UK Biobank Brain Imaging,” NeuroImage, 224, 117002. DOI: 10.1016/j.neuroimage.2020.117002.
- Andersen, M. R., Winther, O., and Hansen, L. K. (2014), “Bayesian Inference for Structured Spike and Slab Priors,” Advances in Neural Information Processing Systems, 2, 1745–1753.
- Barbieri, M. M., Berger, J. O., George, E. I., and Ročková, V. (2021), “The Median Probability Model and Correlated Variables,” Bayesian Analysis, 16, 1085–1112. DOI: 10.1214/20-BA1249.
- Benjamini, Y., and Hochberg, Y. (1995), “Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing,” Journal of the Royal Statistical Society, Series B, 57, 289–300. DOI: 10.1111/j.2517-6161.1995.tb02031.x.
- Besag, J. (1974), “Spatial Interaction and the Statistical Analysis of Lattice Systems,” Journal of the Royal Statistical Society, Series B, 36, 192–225. DOI: 10.1111/j.2517-6161.1974.tb00999.x.
- Besag, J. (1986), “On the Statistical Analysis of Dirty Pictures,” Journal of the Royal Statistical Society, Series B, 48, 259–302.
- Bishop, C. M. (2006), Pattern Recognition and Machine Learning, New York: Springer.
- Blei, D. M., Kucukelbir, A., and McAuliffe, J. D. (2017), “Variational Inference: A Review for Statisticians,” Journal of the American Statistical Association, 112, 859–877. DOI: 10.1080/01621459.2017.1285773.
- Brook, D. (1964), “On the Distinction between the Conditional Probability and the Joint Probability Approaches in the Specification of Nearest-Neighbour Systems,” Biometrika, 51, 481–483. DOI: 10.1093/biomet/51.3-4.481.
- Carbonetto, P., and Stephens, M. (2012), “Scalable Variational Inference for Bayesian Variable Selection in Regression, and its Accuracy in Genetic Association Studies,” Bayesian Analysis, 7, 73–108. DOI: 10.1214/12-BA703.
- Debette, S., and Markus, H. S. (2010), “The Clinical Importance of White Matter Hyperintensities on Brain Magnetic Resonance Imaging: Systematic Review and Meta-Analysis,” BMJ, 341, c3666. DOI: 10.1136/bmj.c3666.
- Durante, D., and Rigon, T. (2019), “Conditionally Conjugate Mean-Field Variational Bayes for Logistic Models,” Statistical Science, 34, 472–485. DOI: 10.1214/19-STS712.
- Firth, D. (1993), “Bias Reduction of Maximum Likelihood Estimates,” Biometrika, 80, 27–38. DOI: 10.1093/biomet/80.1.27.
- Fong, E., Lyddon, S., and Holmes, C. (2019), “Scalable Nonparametric Sampling from Multimodal Posteriors with the Posterior Bootstrap,” Proceedings of Machine Learning Research, 97, 1952–1962.
- Ge, T., Müller-Lenke, N., Bendfeldt, K., Nichols, T. E., and Johnson, T. D. (2014), “Analysis of Multiple Sclerosis Lesions via Spatially Varying Coefficients,” The Annals of Applied Statistics, 8, 1095–1118. DOI: 10.1214/14-aoas718.
- Gelfand, A. E., and Vounatsou, P. (2003), “Proper Multivariate Conditional Autoregressive Models for Spatial Data Analysis,” Biostatistics, 4, 11–15. DOI: 10.1093/biostatistics/4.1.11.
- George, E. I., and McCulloch, R. E. (1993), “Variable Selection via Gibbs Sampling,” Journal of the American Statistical Association, 88, 881–889. DOI: 10.1080/01621459.1993.10476353.
- George, E. I., and McCulloch, R. E. (1997), “Approaches for Bayesian Variable Selection,” Statistica Sinica, 7, 339–373.
- Griffanti, L., Zamboni, G., Khan, A., Li, L., Bonifacio, G., Sundaresan, V., Schulz, U. G., Kuker, W., Battaglini, M., Rothwell, P. M., and Jenkinson, M. (2016), “BIANCA (Brain Intensity AbNormality Classification Algorithm): A New Tool for Automated Segmentation of White Matter Hyperintensities,” NeuroImage, 141, 191–205. DOI: 10.1016/j.neuroimage.2016.07.018.
- Griffanti, L., Jenkinson, M., Suri, S., Zsoldos, E., Mahmood, A., Filippini, N., Sexton, C. E., Topiwala, A., Allan, C., Kivimäki, M., Singh-Manoux, A., Ebmeier, K. P., Mackay, C. E., and Zamboni, G. (2018), “Classification and Characterization of Periventricular and Deep White Matter Hyperintensities on MRI: A Study in Older Adults,” NeuroImage, 170, 174–181. DOI: 10.1016/j.neuroimage.2017.03.024.
- Hernández-Lobato, D., Hernández-Lobato, J. M., and Dupont, P. (2013), “Generalized Spike-and-Slab Priors for Bayesian Group Feature Selection Using Expectation Propagation,” Proceedings of Machine Learning Research, 14, 1891–1945.
- Jaakkola, T. S., and Jordan, M. I. (2000), “Bayesian Parameter Estimation via Variational Methods,” Statistics and Computing, 10, 25–37.
- Jordan, M. I., Ghahramani, Z., Jaakkola, T. S., and Saul, L. K. (1999), “An Introduction to Variational Methods for Graphical Models,” Machine Learning, 37, 183–233. DOI: 10.1023/A:1007665907178.
- Kindalova, P., Kosmidis, I., and Nichols, T. E. (2021), “Voxel-Wise and Spatial Modelling of Binary Lesion Masks: Comparison of Methods with a Realistic Simulation Framework,” NeuroImage, 236, 118090. DOI: 10.1016/j.neuroimage.2021.118090.
- Kosmidis, I., Kenne Pagui, E., and Sartori, N. (2020), “Mean and Median Bias Reduction in Generalized Linear Models,” Statistics and Computing, 30, 43–59. DOI: 10.1007/s11222-019-09860-6.
- Kosmidis, I. (2021), brglm2: Bias Reduction in Generalized Linear Models. R package version 0.8.0. Available at https://CRAN.R-project.org/package=brglm2.
- Li, F., and Zhang, N. R. (2010), “Bayesian Variable Selection in Structured High-Dimensional Covariate Spaces with Applications in Genomics,” Journal of the American Statistical Association, 105, 1202–1214. DOI: 10.1198/jasa.2010.tm08177.
- Li, X., Wang, L., Wang, H. J., and for the Alzheimer’s Disease Neuroimaging Initiative. (2021), “Sparse Learning and Structure Identification for Ultrahigh-Dimensional Image-on-Scalar Regression,” Journal of the American Statistical Association, 116, 1994–2008. DOI: 10.1080/01621459.2020.1753523.
- Lyddon, S., Walker, S., and Holmes, C. (2018), “Nonparametric Learning from Bayesian Models with Randomized Objective Functions,” in NeurIPS 2018, pp. 2075–2085.
- Mardia, K. V. (1988), “Multi-Dimensional Multivariate Gaussian Markov Random Fields with Application to Image Processing,” Journal of Multivariate Analysis, 24, 265–284. DOI: 10.1016/0047-259X(88)90040-1.
- Miller, K., Alfaro-Almagro, F., Bangerter, N., and Thomas, D. L. (2016), “Multimodal Population Brain Imaging in the UK Biobank Prospective Epidemiological Study,” Nature Neuroscience, 19, 1523–1536. DOI: 10.1038/nn.4393.
- Minka, T. E. (2001), “Expectation Propagation for Approximate Bayesian Inference,” DOI: 10.5555/2074022.2074067.
- Mitchell, T. J., and Beauchamp, J. J. (1988), “Bayesian Variable Selection in Linear Regression,” Journal of the American Statistical Association, 83, 1023–1032. DOI: 10.1080/01621459.1988.10478694.
- Newton, M. A., and Raftery, A. E. (1994), “Approximate Bayesian Inference with the Weighted Likelihood Bootstrap,” Journal of the Royal Statistical Society, Series B, 56, 3–26. DOI: 10.1111/j.2517-6161.1994.tb01956.x.
- Nie, L., and Ročková, V. (2022), “Bayesian Bootstrap Spike-and-Slab LASSO,” Journal of the American Statistical Association, 118, 2013–2028. DOI: 10.1080/01621459.2022.2025815.
- Piironen, J., and Vehtari, A. (2017), “Sparsity Information and Regularization in the Horseshoe and Other Shrinkage Priors,” Electronic Journal of Statistics, 11, 5018–5051. DOI: 10.1214/17-EJS1337SI.
- Polson, N. G., Scott, J. G., and Windle, J. (2013), “Bayesian Inference for Logistic Models Using Pólya–Gamma Latent Variables,” Journal of the American Statistical Association, 108, 1339–1349. DOI: 10.1080/01621459.2013.829001.
- Prins, N. D., and Scheltens, P. (2015), “White Matter Hyperintensities, Cognitive Impairment and Dementia: An Update,” Nature Reviews Neurology, 11, 157–165. DOI: 10.1038/nrneurol.2015.10.
- Ročková, V., and George, E. I. (2014), “EMVS: The EM Approach to Bayesian Variable Selection,” Journal of the American Statistical Association, 109, 828–846. DOI: 10.1080/01621459.2013.869223.
- Rostrup, E., Gouw, A., Vrenken, H., van Straaten, E., Ropele, S., Pantoni, L., Inzitari, D., Barkhof, F., and Waldemar, G. (2012), “The Spatial Distribution of Age-Related White Matter Changes as a Function of Vascular Risk Factors–Results from the LADIS Study,” NeuroImage, 60, 1597–1607. DOI: 10.1016/j.neuroimage.2012.01.106.
- Rubin, D. B. (1981), “The Bayesian Bootstrap,” The Annals of Statistics, 9, 130–134. DOI: 10.1214/aos/1176345338.
- Sharma, R., and Sekhon, S. (2021), White Matter Lesions, Treasure Island, FL: StatPearls Publishing.
- Stingo, F. C., Chen, Y. A., Vannucci, M., Barrier, M., and Mirkes, P. E. (2010), “A Bayesian Graphical Modeling Approach to MicroRNA Regulatory Network Inference,” The Annals of Applied Statistics, 4, 2024–2048. DOI: 10.1214/10-AOAS360.
- Veldsman, M., Kindalova, P., Husain, M., Kosmidis, I., and Nichols, T. E. (2020), “Spatial Distribution and Cognitive Impact of Cerebrovascular Risk-Related White Matter Hyperintensities,” NeuroImage: Clinical, 28, 102405. DOI: 10.1016/j.nicl.2020.102405.
- Wardlaw, J., Smith, E., Biessels, G., and Cordonnier, C. (2013), “Neuroimaging Standards for Research into Small Vessel Disease and Its Contribution to Ageing and Neurodegeneration,” The Lancet Neurology, 12, 822–838. DOI: 10.1016/S1474-4422(13)70124-8.
- Wardlaw, J., Valdés Hernández, M., and Muñoz-Maniega, S. (2015), “What Are White Matter Hyperintensities Made Of? Relevance to Vascular Cognitive Impairment,” Journal of the American Heart Association, 4, e001140. DOI: 10.1161/JAHA.114.001140.
- Whiteman, A. (2022), “Bayesian Analysis of Neuroimage Data Using Gaussian Process Priors,” available at https://deepblue.lib.umich.edu/handle/2027.42/174640.
- Yao, Y., Vehtari, A., Simpson, D., and Gelman, A. (2018), “Yes, But Did It Work?: Evaluating Variational Inference,” Proceedings of Machine Learning Research, 80, 5581–5590.
- Zeng, Z., Li, M., and Vannucci, M. (2022), “Bayesian Image-on-Scalar Regression with a Spatial Global-Local Spike-and-Slab Prior,” Bayesian Analysis, 1, 1–26. DOI: 10.1214/22-BA1352.