
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Total Generalized Variation (TGV) regularization in image reconstruction relies on an infimal convolution type combination of generalized first- and second-order derivatives. This helps to avoid the staircasing effect of Total Variation (TV) regularization, while still preserving sharp contrasts in images. The associated regularization effect crucially hinges on two parameters whose proper adjustment represents a challenging task. In this work, a bilevel optimization framework with a suitable statistics-based upper level objective is proposed in order to automatically select these parameters. The framework allows for spatially varying parameters, thus enabling better recovery in high-detail image areas. A rigorous dualization framework is established, and for the numerical solution, a Newton type method for the solution of the lower level problem, i.e. the image reconstruction problem, and a bilevel TGV algorithm are introduced. Denoising tests confirm that automatically selected distributed regularization parameters lead in general to improved reconstructions when compared to results for scalar parameters.
1. Introduction
In this work we analyze and implement a bilevel optimization framework for automatically selecting spatially varying regularization parameters in the following image reconstruction problem:
(1.1)
(1.1)
where the second-order Total Generalized Variation (TGV) regularization is given by
(1.2)
(1.2)
Here, is a bounded, open image domain with Lipschitz boundary,
denotes the space of d × d symmetric matrices,
is a bounded linear (output) operator, and f denotes given data which satisfies
(1.3)
(1.3)
In this context, η models a highly oscillatory (random) component with zero mean and known quadratic deviation (variance) from the mean. Further,
denotes the standard Lebesgue space [Citation1], and
represents the Euclidean vector norm or its associated matrix norm. The space of infinitely differentiable functions with compact support in
and values in
is denoted by
Further, we refer to Section 2 for the definition of the first- and second-order divergences
and
respectively.
Originally, the TGV functional was introduced for scalar parameters only; see [Citation2]. It serves as a higher order extension of the well-known Total Variation (TV) regularizer [Citation3,Citation4], preserves edges (i.e., sharp contrast) [Citation5,Citation6], and promotes piecewise affine reconstructions while avoiding the often adverse staircasing effect (i.e., piecewise constant structures) of TV [Citation7–9]; see for an illustration. These properties of TGV have made it a successful regularizer in variational image restoration for a variety of applications [Citation2, Citation10–16]. Extensions to manifold-valued data, multimodal and dynamic problems [Citation17–22] have been proposed as well. In all of these works, the choice of the scalar parameters
is made “manually” via a direct grid search. Alternatively, selection schemes relying on a known ground truth utrue have been studied; see [Citation23–26]. The latter approach, however, is primarily of interest when investigating the mere capabilities of TGV regularization.
Figure 1. Gaussian denoising: Typical difference between TV (piecewise constant) and TGV reconstructions (piecewise affine).

While there exist automated parameter choice rules for TV regularization, see for instance [Citation27] and the references therein, analogous techniques and results for the TGV parameters are very scarce. One of the very few contributions is [Citation28] where, however, a spatially varying fidelity weight rather then regularization parameter is computed. Compared to the choice of the regularization weight in TV-based models, the infimal convolution type regularization incorporated into the TGV functional significantly complicates the selection; compare the equivalent definition (2.1) below. Further difficulties arise when these parameters are spatially varying as in (1.2). In that case, by appropriately choosing one wishes to smoothen homogeneous areas in the image while preserving fine scale details. The overall target is then to not only select the parameters in order to reduce noise while avoiding oversmoothing, as in the TV case, but also to ensure that the interplay of α0 and α1 will not produce any staircasing.
For this delicate selection task and inspired by [Citation27, Citation29] for TV, in this work we propose a bilevel minimization framework for an automated selection of in the TGV case. Formally, the setting can be characterized as follows:
(1.4)
(1.4)
Note here that the optimization variable enters the lower level minimization problem (1.1) as a parameter, thus giving rise to
We also mention that this optimization format falls into the general framework which is discussed in our review paper [Citation30] where the general opportunities and mathematical as well as algorithmic aspects of bilevel optimization in generating structured non-smooth regularization functionals are discussed in detail.
As our statistical set-up parallels the one in [Citation27, Citation29], here we resort to the upper level objective proposed in that work. It is based on localized residuals with
(1.5)
(1.5)
where
with
Note that
can be interpreted as a local variance keeping in mind that, assuming Gaussian noise of variance
we have that
Consequently, if a reconstructed image u is close to utrue then it is expected that for every
the value of
will be close to
Hence it is natural to consider an upper level objective which aims to approximately keep
within a corridor
with positive bounds
This can be achieved by utilizing the function
with
(1.6)
(1.6)
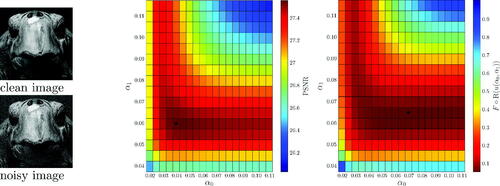
The function is then indeed suitable as an upper level objective. This is demonstrated in , where we show (in the middle and right plots) the objective values for a series of scalar TGV denoising results and for a variety of parameters
for the image depicted on the left. Regarding the choices of
we refer to Section 5. Upon inspection of we find that the functional
is minimized for a pair of scalar parameters
that is close to the one maximizing the peak-signal-to-noise-ratio (PSNR). Note, however, that in order to truly optimize the PSNR, one would need the ground truth image utrue, which is of course typically not available. In contrast to this, we emphasize that
does not involve any ground truth information. Rather, it only relies on statistical properties of the noise.
Figure 2. Suitability of the functional as an upper level objective. Evaluation of
where u solves the TGV denoising problem (1.1) (T = Id), for a variety of scalar parameters
For analytical and numerical reasons, rather than having (1.1) as the lower level problem for the bilevel minimization framework (1.4), one can use alternative formulations, as was done for instance in [Citation27, Citation29] for TV models, where the Fenchel predual problem was used instead, see also [Citation30] for a thorough discussion on the corresponding TGV model. This yields a bilevel problem which is expressed in terms of dual variables and is equivalent to the one stated in terms of the primal variable u. In this way, one has to treat a more amenable variational inequality of the first kind rather than one of second kind in the primal setting in the constraint system of the resulting bilevel optimization problem. Numerically, one may then utilize very efficient and resolution independent, function space based solution algorithms, like (inexact) semismooth Newton methods [Citation31]. The other option that we will consider in this work, is to minimize the upper level objective subject to the primal-dual optimality conditions, for which Newton methods can also be applied for their solution, see for instance [Citation32] for an inexact semismooth Newton solver which operates on the primal-dual optimality conditions for TV regularization. We should also mention that this approach requires to be invertible, with
being the adjoint of T, which is true when T is injective with closed range. We note that this does not exclude the use of our bilevel scheme to inverse problems whose forward operator does not satisfy this condition. A noninvertibility of
can for instance be treated by adding a small regularization term of the form
in combination with a Levenberg-Marquardt algorithmic scheme that sends the parameter κ to zero along the iterations. Alternatively, instead of Newton, one can resort to first-order methods for solving the lower level problem for which invertibility of
is not required. Such approaches are definitely interesting and necessary for many inverse problems however since they would deviate from the main focus of our paper which is the automatic computation of spatially distributed regularization weights, we will keep this invertibility assumption in the following.
2. The structure of the paper
Basic facts on the TGV functional with spatially varying parameters along with functional analytic foundations needed for (pre)dualization are the subjects of Section 2. Section 2.4 is concerned with the derivation of the predual problem of (1.1) and the corresponding primal-dual optimality conditions. Regularized versions of these conditions are the focus of Section 3. Besides respective primal-dual optimality conditions, we study the asymptotic behavior of these problems and their associated solutions under vanishing regularization. Section 4 introduces the bilevel TGV problem for which the primal-dual optimality conditions serve as constraints. The numerical solution of the proposed bilevel problem is the subject of Section 5. It is also argued that every regularized instance of the lower level problem can be solved efficiently by employing an (inexact) semismooth Newton method. The paper ends by a report on extensive numerical tests along with conclusions drawn from these computational results.
Summarizing, this work provides not only a user-friendly and novel hierarchical variational framework for automatic selection of the TGV regularization parameters, but by making these parameters spatially dependent it leads to an overall performance improvement; compare, e.g., the results in Section 5.
3. The dual form of the weighted TGV functional
3.1. Total generalized variation
We recall here some basic facts about the TGV functional (1.2) with constant parameters and assume throughout that the reader is familiar with the basic concepts of functions of bounded variation (BV); see [Citation33] for a detailed account. For a function
the first- and second-order divergences are, respectively, given by
In [Citation14] it was shown that a function has finite
value if and only if it belongs to
Here
denotes the Banach space of function of bounded variation over
with associated norm
Moreover, the bounded generalized variation norm
is equivalent to
Similarly to TV, TGV is a convex functional which is lower semicontinuous with respect to the strong L1 convergence. In [Citation14, Citation34] it is demonstrated that the TGV functional can be equivalently written as
(2.1)
(2.1)
where
is the Banach space of functions of bounded deformation, with
denoting the distributional symmetrized gradient [Citation35,Citation36]. The asymptotical behavior of the TGV model in image restoration with respect to scalars
was studied in [Citation37]; see also [Citation6]. For instance, when T = Id and either α0 or α1 converges to zero, then the corresponding solutions of (1.1) converge (weakly
in
) to f. When both of the parameters are sent to infinity, then the solutions converge weakly
to the L2-linear regression solution for f. We further note that the set of affine functions constitutes the kernel of the TGV functional.
For specific symmetric functions u, there exist combinations of such that
In general one can show that there exists a constant C > 0 such that if
then the
value does not depend on α0 and, up to an affine correction, it is equivalent to
In that case the reconstructed images still suffer from a kind of (affine) staircasing effect [Citation37].
The fine structure of TGV reconstructions has been studied analytically mainly in dimension one in [Citation5, Citation38–41]. Under some additional regularity assumptions (compare [Citation6]) it can be shown that for TGV denoising the jump set of the solution is essentially contained in the jump set of the data; see [Citation42] for the TV case.
3.2. The space 
Next we introduce several function spaces which will be useful in our subsequent development. For this purpose, let and
Recall that
if there exists
such that
In that case w is unique and we set Based on this first-order divergence, we define the Banach space
endowed with the norm
Similarly one obtains the Banach space
as the space of all functions
whose first- and second-order divergences,
and
respectively, belong to
We note that for a
we have that
if there exists an
such that
with
denoting the L1 function representing the absolutely continuous part of
with respect to the Lebesgue measure. Note that since
is smooth, we have
As before ω is unique and we set
Finally
if there exists a function
such that
This space is equipped with the norm We refer to [Citation12] for a more general definition of these spaces. Note that when q = 2 these spaces are Hilbertian and then the standard notation is
and
see [Citation43]. The Banach spaces
and
are defined as
with the analogous notation
and
for q = 2. Using the definitions above, the following integration by parts formulae hold true:
(2.2)
(2.2)
(2.3)
(2.3)
(2.4)
(2.4)
3.3. Weighted TGV
Throughout the remainder of this work we use the weighted TGV functional (1.2) with and
We denote by
the finite dimensional Euclidean norm. We note that for an
-valued finite Radon measure
we denote by
its total variation measure, where for every Borel
Note also that it can be shown
We will show that for the space
in (1.2) can be substituted by
(and by
for
). This fact will be instrumental when deriving the predual of the TGV minimization problem. For this we need the following result:
Proposition 2.1.
The weighted functional (1.2) admits the equivalent expression
(2.5)
(2.5)
Proof.
The proof is analogous to the one for the scalar TGV functional; see for instance [Citation34, Theorem 3.5] or [Citation12, Proposition 2.8]. Here, we highlight only the significant steps. Indeed, given the idea is to define
Here, denotes the indicator function of a set S. Now, after realizing that
(2.6)
(2.6)
the proof proceeds by showing that the dual problem of (2.6) is equivalent to (2.5) and then applying the Fenchel duality result [Citation44]. We note that in order to achieve zero duality gap between the primal and the dual problem the so-called Attouch-Brezis condition needs to be satisfied see [Citation45], that is one needs to show that the set
is a closed subspace of V. Indeed one can easily see that
Note that for the above equality we crucially used the fact that α1 is bounded away from zero.
The other subtle point is the following density result which is required in order to show that (2.6) is indeed equal to (1.2):
(2.7)
(2.7)
Indeed let ψ belong to the second set in (2.7), and let Choose
such that
(2.8)
(2.8)
Since α0 and α1 are continuous and bounded away from zero there exists smaller than the minimum of
such that
From standard density properties there exists a function such that the following conditions hold for all
(2.9)
(2.9)
which implies
(2.10)
(2.10)
Then, from (2.10) it follows that belongs to the first set in (2.7) and from (2.8) and (2.9) we get that
□
Now we are ready to establish the density result needed for dualization. For the sake of the flow of presentation we defer the proof, which parallels the one of [Citation12, Proposition 3.3], to Appendix A. Below “a.e.” stands for “almost every” with respect to the Lebesgue measure.
Proposition 2.2.
For , the weighted TGV functional (1.2) can be equivalently written as
(2.11)
(2.11)
Remark:
By slightly amending the proof of Proposition 2.2, one can also show that if then the dual variables p can be taken to belong to
rather than
3.4. The predual weighted TGV problem
Now we study the predual problem for the weighted TGV model with continuous weights, i.e., we use the regularization functional (1.2) or equivalently (2.11). For we assume that
is invertible and define
which induces a norm in
equivalent to the standard one; compare [Citation31]. When
is not invertible one can add an extra regularization term of the form
for some small
to the objective in (1.1). Then
will be invertible, see a similar approach in [Citation27, Citation29, Citation31]. We mention that a different set-up, as adopted for instance in [Citation46], assumes
since
continuously embeds to
Then one readily finds that for d > 2,
cannot be invertible, in general. Even though invertibility of
is not necessary when dealing only with the TGV regularization problem (1.1), additional challenges would arise in our overall bilevel optimization context, such as, e.g., a lack of uniqueness of the solution for the lower level problem, i.e., genuine set-valuedness of the regularization-weight-to-reconstruction map cf. the constraint set in (1.4). In the next proposition we prove zero duality gap for (1.1) and its predual. We note however that the invertibility assumption on
is not needed to establish zero duality gap but rather to get an explicit formulation of the predual problem. An adaptation of the following proposition without this invertibility assumption can be done for instance by simply adjusting the corresponding proof of [Citation46, Theorem 5.4] where analogous dualization results for a class of structural TV regularizers were considered.
Proposition 2.3.
Let , then there exists a solution to the primal problem
(2.12)
(2.12)
as well as to its predual problem
(2.13)
(2.13)
and there is no duality gap, i.e., the primal and predual optimal objective values are equal. Moreover, the solutions u and p of these problems satisfy
(2.14)
(2.14)
Proof.
We set
with
and also
and
with
(2.15)
(2.15)
(2.16)
(2.16)
Immediately one gets that
(2.17)
(2.17)
The problem in (2.17) admits a solution. Indeed, first observe that the objective is bounded from below. Then note that since is continuous at
its convex conjugate (see [Citation44] for a general definition) which is equal to
is coercive in
see [Citation47, Theorem 4.4.10]. Hence, any infimizing sequence
is bounded in
and thus there exist an (unrelabeled) subsequence and
such that
and
weakly in L2. We also have that p is a feasible point since the set
is weakly closed. Then p is a minimizer of (2.17) as
is weakly lower semicontinuous in
We now calculate the expression for
As before one verifies by direct computation that
Moreover,
where for the last equality we used Proposition 2.2 and its underlying density result. In order to prove that there is no duality gap, it suffices again to verify the Attouch-Brezis condition and show that the set
is a closed subspace of V. It is immediate to see that
and hence the condition holds true. Thus, we also get existence of a solution for the primal problem (2.12). Finally (2.14) follows from the optimality condition (Euler-Lagrange system) that corresponds to
□
The primal-dual optimality conditions for the problems (2.12) and (2.13) read
(2.18)
(2.18)
(2.19)
(2.19)
and we note once again that (2.14) corresponds to (2.19) with F2 and Λ as in the proof of Proposition 2.12. Instead of making the optimality condition that corresponds to (2.18) explicit, we are interested in the analogous optimality conditions written in the variables u and w of the equivalent primal weighted TGV problem
(2.20)
(2.20)
For this purpose note first that the predual problem (2.13) can be equivalently written as
(2.21)
(2.21)
The next proposition characterizes the solutions (w, u) and (p, q) of the problems (2.20), and (2.21) respectively. Before we state it, we note that in its proof we will make use of the following density results:
(2.22)
(2.22)
where
(2.23)
(2.23)
(2.24)
(2.24)
(2.25)
(2.25)
(2.26)
(2.26)
These results can be proven by using the duality arguments of the proof of Proposition 2.2, which originate from [Citation12], or with the use of mollification techniques; see [Citation48–50].
Proposition 2.4.
The pair is a solution to (2.21), and
is a solution to (2.20) if and only if the following optimality conditions are satisfied:
(2.27)
(2.27)
(2.28)
(2.28)
(2.29)
(2.29)
(2.30)
(2.30)
Proof.
Define
with
and
with
(2.31)
(2.31)
(2.32)
(2.32)
One checks immediately that corresponds to (2.21) with the dual problem reading
Observe that since
we have
(2.33)
(2.33)
Note that the suprema above are always greater or equal to the corresponding suprema over and
One can easily check that there is no duality gap between these primal and dual problems – the Attouch-Brezis condition is satisfied – and thus since the primal problem is finite so is the dual. Using the fact that α0 is bounded from below, this implies in particular that w, seen as distribution through its action on
has a distributional symmetrized gradient
with bounded Radon norm, and hence it is a Radon measure. It follows that
yielding
see [Citation34], which means that for
we have
Using density of
in
this also implies
and similarly
in (2.33). Using now also the density results (2.22) we have
Here we used the fact that since the distribution Du – w has a finite Radon norm, due to α1 being bounded away from zero, it can be represented by an -valued finite Radon measure and in particular
Furthermore, as in the proof of Proposition 2.3 we have
The fact that there is no duality gap is ensured by Propositions 2.1, 2.2 and 2.3. We now turn our attention to the optimality conditions
(2.34)
(2.34)
(2.35)
(2.35)
It can be checked again that (2.35) gives (2.27) and (2.28). We now expand on (2.34). We have that which is equivalent to
that is
and
with the last two inequalities holding for any
with
for a.e.
and for any
with
for a.e.
Hence we obtain (2.29) and (2.30). □
4. A Series of regularized problems
4.1. Regularization of the primal problem
With the aim of lifting the regularity of u and w to avoid measure-valued derivatives, we next consider the following regularized version of the primal weighted TGV problem (2.20):
(3.1)
(3.1)
for some constants
Existence of solutions for (3.1) follows from standard arguments.
Observe that (3.1) is equivalent to where
with
with
and
Note that the Attouch-Brezis condition is satisfied since
Proposition 3.1.
The pairs and
are solutions to (3.1) and its predual problem, respectively, if and only if the following optimality conditions are satisfied:
(3.2)
(3.2)
(3.3)
(3.3)
(3.4)
(3.4)
(3.5)
(3.5)
where the multiplications are regarded component-wise.
Proof.
The proof follows again easily by calculating the corresponding primal-dual optimality conditions. □
Next we study the relationship between the solutions of (2.20) and (3.1) as the parameters μ, ν tend to zero.
Proposition 3.2.
Let and let
be a sequence of solution pairs of the problem (3.1). Then
and
in
and
respectively, where
is a solution pair for (2.20). The convergence of wn is up to a subsequence.
Proof.
For convenience of notation, define the energies
We have
(3.6)
(3.6)
Thus, the sequences and
are bounded in
and
respectively. In order to see this, note that by setting
i = 0, 1, we get
Hence, is bounded in the sense of second-order TGV. Again using [Citation47, Theorem 4.4.10], we get that
is coercive, since it is the convex conjugate of
which is continuous at
This implies further that this sequence is bounded both on
and
The bound on
in
then follows from (3.6).
From compactness theorems in those spaces (for see for instance [Citation36, Remark 2.4]) we have that there exist
and
such that
in
and weakly in
and
in
along suitable subsequences. Due to the lower semicontinuity of the functional E with respect to these convergences, we have for any pair
(3.7)
(3.7)
Recall now that is a Banach space endowed with the norm
and that
is dense in that space; see [Citation35, Proposition 1.3]. From this, in combination with the fact that
is dense in
we have that for every
there exists a sequence
such that
Hence, since (3.7) holds we have that
(3.8)
(3.8)
Finally, by following similar steps as in the proof of [Citation6, Theorem 3], we can show that for every there exists a sequence
such that
which implies again that
This, together with (3.8) yields
This yields that is a solution pair for (2.20). Finally, from the uniqueness of the solution
for (2.20) we get that the whole initial sequence
converges to
weakly
in
The uniqueness follows from the fact that T is injective and hence the functional
is strictly convex. □
We now proceed to the second level of regularization of the problem (3.1), which, in addition to lifting the regularity of u and w, respectively, also smoothes the non-differentiable constituents. For this purpose, we define the following primal problem, which will also be treated numerically, below:
Here denotes the Huber-regularized version of the Euclidean norm. That is, for a vector
or
and
we use
(3.9)
(3.9)
with
denoting either the Euclidean norm in
or the Frobenius norm in
We mention that this type of Huber regularization of
-type terms in the primal problem corresponds to an L2 regularization of the dual variables in the predual [Citation32, Citation51]. In order to illustrate this consider the following denoising problem
without any H1 regularization:
(3.10)
(3.10)
where
Here and
denote the singular parts with respect to the Lebesgue measure of Du, and
respectively, following the Lebesgue decomposition
and
The corresponding predual problem of (3.10) is given by
(3.11)
(3.11)
The proof is similar to the one of Proposition 2.4 with
and in the dualization process we use the fact that for an S-valued measure μ we have,
see for instance [Citation52].
Returning to the (doubly) regularized primal problem we are primarily interested in its associated first-order optimality conditions.
Proposition 3.3.
We have that the pairs and
are solution to
and its predual problem, respectively, if and only if the following optimality conditions are satisfied:
(3.12)
(3.12)
(3.13)
(3.13)
(3.14)
(3.14)
(3.15)
(3.15)
(3.16)
The proof of Proposition 3.3 follows from calculating the corresponding primal-dual optimality conditions as in Proposition 3.1. Finally, in order to avoid constraint degeneracy and for the sake of differentiability for the bilevel scheme in the next section, we also employ here a smoothed version of
and its derivative, denoted by
defined as follows for
and for
Thus we arrive at the following regularized optimality conditions:
(Opt1)
(Opt1)
(Opt2)
(Opt2)
(Opt3)
(Opt3)
(Opt4)
(Opt4)
Note that these would correspond to the optimality conditions of an analogue problem to
where the Huber function
is substituted by an analogous C2 version
having the property
pointwise, and which do not write down explicitly here. The relevant approximation result now follows, where we have set
for simplicity.
Proposition 3.4.
Let and
satisfy the optimality conditions (3.2)–(3.5) and
–
respectively. Then, as
we have
strongly in
strongly in
as well as
and
weakly
in
and
respectively.
Proof.
By subtracting first two equations of the optimality system of Proposition 3.1 and 3.3, respectively, we get for all
(3.17)
(3.17)
(3.18)
(3.18)
When using and
in the equations above and adding them up we get
(3.19)
(3.19)
where
We now estimate R1 and R2. Consider the partitions of into disjoint sets (up to sets of measure zero)
where
We estimate R1 separately on the disjoint sets
and
Recall that
as well as
for almost every
Starting from
and noticing that
it follows that pointwise on
(with argument x left off for ease of notation) we have
Turning now to the set and recalling
we have
For the set note that
Thus, we can estimate
Similarly, for the set we get
Combining the above estimates we have
and for R2 we similarly get
Hence, from (3.19) and the fact that is equivalent to
we obtain the desired convergences for
and
From this result and using (3.17) and (3.18) we get that for every
and for every
we have
as
This completes the proof. □
Finally, the following approximation result holds true, when all the parameters μ, ν, γ, δ tend to zero.
Proposition 3.5.
Let , and denote by
the solution of (Opt1)–(Opt1) with
. Then
in
, where
solves (2.20).
Proof.
It is easy to show that in
Indeed, we have
According to Proposition 3.2 it holds that The other term tends to zero according to Equationequation (3.19)
(3.19)
(3.19) of Proposition 3.4. There, the estimates for R1, R2 are not affected if we substitute u and
by
and
respectively. In other words, the estimate
holds for some C > 0 and hence
To finish the proof and show that the convergence is weak in
it suffices to establish that
is uniformly bounded in n; see [Citation33, Proposition 3.13]. Observe first that, if
is the C2 regularized Huber function, that corresponds to the δ-smoothing of
then as in the proof of Proposition 3.2 we get
(3.20)
(3.20)
As in (3.9) we also have that and hence we obtain
(3.21)
(3.21)
for some constant K > 0. Then, as in the proof of Proposition 3.2, we get that
is bounded in TGV which, together with the L1 bound, gives the desired bound in TV. □
5. The bilevel optimization scheme
In this section we will adapt the bilevel optimization framework developed in [Citation27, Citation29] in order to automatically select the regularization functions α0 and α1. The main idea is to minimize a suitable upper level objective over both the image u and the regularization parameters α0, α1 subject to u being a solution to a (regularized) TGV-based reconstruction problem with these regularization weights.
It is useful to recall the definitions of the localized residual and the function F as stated in the introduction:
(4.1)
(4.1)
where
with
and
(4.2)
(4.2)
for some appropriately chosen
We thus end up to the following bilevel minimization problem:
(4.3)
(4.3)
Utilizing the regularized primal-dual first-order optimality characterization (Opt1)–(Opt4) of the solution to the lower level problem of (4.3), we arrive at the following mathematical program with equilibrium constraints (MPEC, for short) which is equivalent to (4.3):
Note that in view of the equivalence of (4.3) and (TGV), we will still refer the latter as the bilevel TGV problem. A few words about (
TGV) are in order. Here, αi are forced to be contained in the box constraint sets
(4.4)
(4.4)
with
and
in
for some
i = 0, 1. Note that the H1 regularity on the parameter functions
facilitates the existence and differential sensitivity analysis as established in [Citation27, Citation29] for the TV case. Note, however, that this setting does not guarantee a priori that these functions belong to
the regularity required for applying the dualization results of the previous sections. Nevertheless, under mild data assumptions, one can make use of the following regularity result of the H1–projection onto the sets
and
see [Citation29, Corollary 2.3] for a proof.
Proposition 4.1.
Let with
be a bounded convex set and let
, where
such that
and
in
. Then if
it holds
In particular, if
as well as the initializations for α1 and α0 are constant functions, then along the projected gradient iterations of Algorithm Citation2, the weights are guaranteed to belong to
which (for dimension
) embeds into
We briefly note that in the TV case it can be shown [Citation30, Citation46] that regularity for the regularization parameter α suffices to establish a dualization framework. A corresponding result is not yet known for TGV, even though one expects that it could be shown by similar arguments. Hence, here we will also make use of the H1–projection regularity result as described above.
Regarding the box constraints (4.4) in [Citation25] it was shown that for a PSNR-optimizing upper level objective subject to H1 and Huber regularized TV and TGV denoising problems, under some mild conditions on the data f, the optimal scalar solutions α and
are strictly positive. As depicted in the upper level objective discussed here appears close to optimizing the PSNR, keeping the parameters strictly positive via (4.4) seems, however, necessary for the time being.
We now briefly discuss how to treat the bilevel problem (TGV). Let
denote the solution map for the lower level problem, equivalently of the optimality conditions (Opt1)–(Opt4). Then the problem (
TGV) admits the following reduced version
(4.5)
(4.5)
Similarly to the TV case [Citation27], one can show that the reduced functional is differentiable. We can then apply the KKT framework in Banach spaces [Citation53]:
(4.6)
(4.6)
where
are Banach spaces,
and
are Fréchet differentiable and continuous differentiable functions, respectively, and
is a non-empty, closed convex set. In the bilevel TGV problem (
TGV) we have
and
Here
is defined by the optimality conditions (Opt1)–(Opt4). Finally, for
we have
Note that the framework of (4.6) guarantees the existence of an adjoint variable
with the help of which an optimal solution of (
TGV) can be characterized. This adjoint variable also allows the computation of the derivative of the reduced objective
in an amenable way, see next section.
We will skip here the proofs for the differentiability of the functions g and the reduced objective J as well as the existence proofs for (TGV). These results can be shown similarly to the corresponding assertions for TV; see [Citation27, Theorem. 6.1, Proposition 6.2, Proposition 6.3].
6. Numerical implementation
In this section we will describe a Newton method for the lower level problem, a projected gradient algorithm for the solution of the discretized version of the bilevel problem (TGV), as well as provide corresponding numerical examples in denoising.
6.1. Newton solver for the lower level problem
Before we proceed to devising of a projected gradient algorithm for the solution of the bilevel problem, we discuss first a primal-dual Newton algorithm for the solution of the first-order optimality conditions (Opt1)– (Opt4) re-written here for the sake of readability:
(5.1)
(5.1)
(5.2)
(5.2)
(5.3)
(5.3)
(5.4)
(5.4)
A few words on the discrete involved quantities are in order. Images (d = 2) are considered as elements of where
is a discrete cartesian grid that corresponds to the image pixels. The mesh size, defined as the distance between the grid points, is set to
We define the associated discrete function spaces
so that
with
For the discrete gradient and divergence we have,
and
satisfying the adjoint relation
setting zero values at the ghost points. The discretized symmetrized gradient Ew is defined as
For the discretized versions of the Laplacian, we use the standard five-point stencils with zero Neumann boundary conditions, by setting the function values of ghost grid points to be the same with the function value of the nearest grid point in
Note that these act on the primal variables u and w, which satisfy natural boundary conditions in contrast to the dual variable.
The system of Equationequations (5.1)–(5.4) can be shortly written as where
We compute the derivative of
at a point
as the following block-matrix:
where
(5.5)
(5.5)
(5.6)
(5.6)
Given the Newton iteration for solving the system of Equationequations (5.1)–(5.4), or
for short, reads
which can also be written as
(5.7)
(5.7)
Here it is convenient to introduce the notation
since only the submatrices C and D depend on k. Note that the right-hand side
of the linear system (5.7) can be written as
where
Notation-wise, the components that appear in should be regarded as the diagonals of the corresponding diagonal matrices that we mentioned before, multiplied component-wise. By introducing the notation
the Newton system (5.7) can be written as
(5.8)
(5.8)
The above system can be simplified utilizing the Schur complement: First solve for the primal variables and then recover the dual ones
This yields
The folllowing result then holds.
Lemma 5.1.
If belong to the feasible set, i.e.,
and
component-wise, then the matrix
is positive definite and for the minimum eigenvalues we have
. Furthermore,
is bounded independently of k.
The proof of Lemma 5.1 follows the steps of the analogous proof in [Citation32] and is hence omitted. Summarizing, the Newton method for the solution of the (5.1)–(5.4) is outlined in Algorithm Citation1. Here we have followed [Citation32] and project in every iteration the variables q, p onto the feasible sets such that the result of Lemma 5.1 holds.
Algorithm 1 Newton algorithm for the solution of the regularized TGV primal problem
while some stopping criterion is not satisfied do
Solve the linear system for
Update as follows
Compute as projections of
onto the feasible sets
end while
The projections onto the feasible sets are defined, respectively, as
(5.9)
(5.9)
with the equalities above to be considered component-wise.
6.2. The numerical algorithm for (TGV)
We now describe our strategy for solving the discretized version of the bilevel TGV problem (TGV). We note that in most of the experiments we will keep α0 a scalar – this is justified by the numerical results; see the relevant discussion later on. We will always mention the small modifications on the algorithm when α0 is a scalar. We will also make use here of the discrete Laplacian with zero Neumann boundary conditions
which is used to act on the weight function α1. These are the desired boundary conditions for
as dictated by the regularity result for the H1–projection in [Citation29, Corollary 2.3]. For a function
we define the discrete
norm as
For the discrete H1 norm applied to the weight function α1 we use
while the dual norm is defined as
based on the
Riesz map
For the discrete version of the averaging filter in the definition of the localized residuals (4.1) we use a filter of size
with entries of equal value whose sum is equal to one. With these definitions the discrete version of the bilevel TGV (
TGV), is the following:
Here the box constraint sets are defined as
The discretized versions of (5.1)–(5.4) and the upper level objective are still denoted by and J respectively.
Regarding the choice of the lower and upper bounds for the local variance and
respectively, we follow here the following rules, where
is the variance of the “Gaussian” noise contaminating the data:
(5.10)
(5.10)
The formulae (5.10) are based on the statistics of the extremes; see [Citation29, Section 4.2.1].
We now proceed by describing the algorithm for the numerical solution of (). In essence, we employ a discretized projected gradient method with Armijo line search. We briefly describe how the discrete gradient of the reduced objective functional is computed with the help of the adjoint equation. The corresponding discretized version of the latter
where
is the adjoint variable, reads
(5.11)
(5.11)
where the matrices above were defined in (5.5) and (5.6). The equation can be solved again for
first and then subsequently for
as follows
The derivatives of the reduced objective with respect to α0 and α1, respectively, are
(5.12)
(5.12)
(5.13)
(5.13)
(5.14)
(5.14)
where
solves
for
The corresponding reduced gradients are
(5.15)
(5.15)
We note that in the case of a scalar α0, we set Then,
and
Here
denotes a matrix of size
with all entries equal to one. In summary, the projected gradient algorithm for the solutions of (
) is described in Algorithm Citation2
We lastly note that the projections are computed as described in [Citation29, Algorithm Citation4], that is via the semismooth Newton method developed in [Citation54]. We only mention that the original discretized H1–projection problem
given by
(5.16)
(5.16)
is approximated by the following penalty version:
(5.17)
(5.17)
with some small
For the projection regarding a scalar α0, we simply set
Algorithm 2: Discretized projected gradient method for the bilevel TGV problem ()
Input: f,
λ0, λ1, μ, ν, γ0, γ1, δ,
Initialize:
and set k = 0.
repeat
Use the Algorithm Citation1 to compute the solution of the lower level problem
Solve the adjoint Equationequation (5.11)(5.11)
(5.11) for
Compute the derivative of the reduced objective with respect to α0 and α1 as in (5.13) and (5.14)
Compute the reduced gradients
Compute the trial points
while
do (Armijo line search)
Set and re-compute
end while
Update and
until some stopping condition is satisfied
6.3. Numerical examples in denoising
We now discuss some weighted TGV numerical examples, with regularization weights produced automatically by Algorithm Citation2. We are particularly interested in the degree of improvement over the scalar TGV examples. We are also interested in whether the statistics-based upper level objective enforces an automatic choice of regularization parameters that ultimately leads to a reduction of the staircasing effect. Our TGV results are also compared with the bilevel weighted TV method of [Citation27, Citation29]. In order to have a fair comparison, we use a Huber TV regularization for the corresponding lower lever problem, with the latter substituted by the TV primal-dual optimality conditions,
where α is now the spatially dependent regularization parameter for TV. We use the same values for the Huber parameter γ both in bilevel TV and bilevel TGV. The associated test images are depicted in with resolution
The first one is the well-known “Cameraman” image which essentially consists of a combination of piecewise constant parts and texture. The next two images, “Parrot” and “Turtle” contain large piecewise affine type areas, thus they are more suitable for the TGV prior. The final image “hatchling” is characterized by highly oscillatory patterns of various kinds, depicting sand in various degrees of focus.
Figure 3. Test images, resolution

Parameter values: For the lower level primal-dual TGV problem we used μ = 0, ν = 1,
and a mesh size h = 1. For the H1–projection, we set
and we also weighted the discrete Laplacian Δ with
For the lower and upper bounds of α0 and α1 we set here
and
We also set
and when we spatially varied α0 we also set
We used a normalized
filter for w (i.e., with entries
), with nw = 7. The local variance barriers
and
were set according to (5.10). For our noisy images we have
and thus the corresponding values for
are
For the Armijo line search the parameters were
We solved each lower level problem until the residual of each of the optimality conditions (5.1)–(5.4) had Euclidean norm less than
MATLAB’s backslash was used for the solution of the linear systems.
We note that the initialization of the algorithm needs some attention. As it was done in [Citation29] for the TV case, and
must be large enough in order to produce cartoon-like images, providing the local variance estimator with useful information. However, if α0 is initially too large then there is a danger of falling into the regime, in which the TGV functional and hence the solution map of (at least the non-regularized) lower level problem does not depend on α0. In that case the derivative of the reduced functional with respect to α0 will be close to zero, thus making no or little progress with respect to its optimal choice. Indeed this was confirmed after some numerical experimentation. Note that an analogous phenomenon can occur also in the case where α0 is much smaller than α1. In that case it is the effect of α1 which vanishes. This has been shown theoretically in [Citation37, Proposition 2] for dimension one, but numerical experiments indicate that this phenomenon persists also in higher dimensions. In our examples we used
and
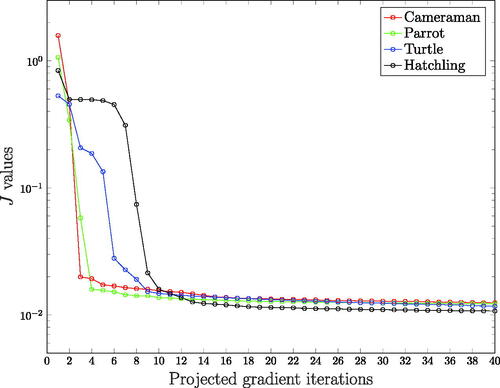
Regarding the termination of the projected gradient algorithm, we used a fixed number of iterations n = 40. Neither the upper level objective nor the argument changed significantly after running the algorithm for more iterations; see for instance . The same holds true for the corresponding PSNR and SSIM values. We also note that a termination criterion as in [Citation29] based on the proximity measures
i = 0, 1, is also possible here.
Figure 4. Upper level objective values vs projected gradient iterations for the problem () (right) of (scalar α0, spatial α1).
We note that due to the line search, the number of times that the lower level problem has to be solved is more than the number of projected gradient iterations. For instance for the four examples the lower level problem had to be solved 58, 57, 57, and 57 times, respectively, with typically 8-12 Newton iterations needed per each lower level problem, This resulted in each bilevel problem (40 projected gradient iterations) requiring approximately 45-50 times the CPU time needed to solve one instance of the lower level problem. We note however that in general after 8-9 projected gradient iterations the PSNR and SSIM values of the reconstruction were essentially reaching their top values, requiring about 6-8 times the CPU time needed for the lower level problem. Further improvement with respect to computational times can be achieved using faster descent methods than the one we used here, like for instance [Citation55,Citation56].
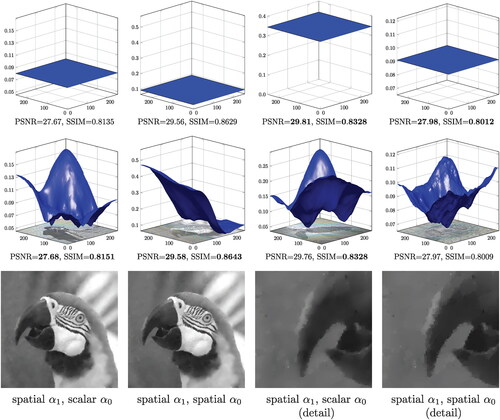
For the first series of examples we keep the parameter α0 scalar, whose value nevertheless is determined by the bilevel algorithms. We depict the examples in . The first row shows the noisy images, while the second contains the bilevel TV results. The third row depicts the best scalar TGV results with respect to SSIM, where we have computed the optimal scalars with a manual grid method. The fourth row shows the results of (
). Detailed sections of all the images of are highlighted in . The weight functions α1 for the bilevel TV and the bilevel TGV algorithms are shown in . In we report all PSNR and SSIM values of the best scalar methods (scalar TV, scalar TGV) with respect to both quality measures, the corresponding values of the bilevel TV and TGV algorithms, as well as the ones the correspond to solving the bilevel TGV with the statistics-based upper level objective (4.2) but using scalar parameters only (third row from the end in ). For the latter case, we used no additional regularization for the weights in the upper level objective. We also report the PSNR and SSIM values of the computed results when both α0, α1 are spatially varying (last row), which we discuss later on in this section. We next comment on the results for each image.
Figure 5. First row: noisy images. Second row: bilevel TV. Third row: Best scalar TGV (SSIM). Fourth row: bilevel TGV.

Figure 6. Details of the reconstructions shown in .

Figure 7. First row: the computed regularization functions α for bilevel TV. Second row: the computed regularization functions α1 for bilevel TGV.
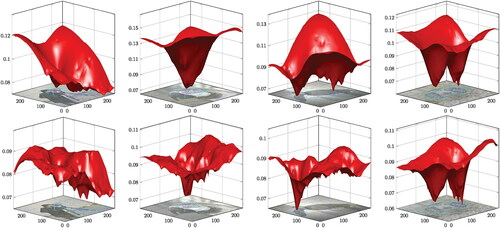
Table 1. PSNR and SSIM comparisons for the images of .
Cameraman: Here both the best PSNR and SSIM are obtained by the bilevel TV algorithm. This is probably not surprising due to the piecewise constant nature of this image. However, the bilevel TGV algorithm improve upon its scalar version with respect to both measures.
Parrot: Here the best results with respect to both PSNR and SSIM are achieved by the bilevel TGV algorithm, (). There is significant improvement over all TV methods, which is due to the parameters being chosen in a way such that the staircasing effect diminishes. Furthermore, we observe improvement over the scalar TGV result especially around the parrot’s eye, where the weights α1 drop significantly; see the second column of .
Turtle: We get analogous results here as well, with the bilevel TGV () producing the best results both with respect to PSNR and SSIM. There is a significant reduction of the staircasing effect, while the weight α1 drops in the detailed areas of the image (head and flipper of the turtle).
Hatchling: In this image, the best PSNR and best SSIM are achieved by the scalar TGV when its parameters are manually optimized with respect to each measure (using the ground truth). However, the (ground truth-free) bilevel TGV achieves a better SSIM and PSNR value compared to these two results, respectively, achieving a better balance with respect to these measures. Similarly the scalar TV results are generally better than the ones of bilevel TV. We attribute this to the fact that the natural oscillatory features of the image are interpreted as noise by the upper level objective. Nevertheless, all the bilevel methods are able to locate and preserve better the eyes area, i.e., sand in focus, with the weight α1 dropping there significantly.
We remark that in all four examples, the ground truth-free bilevel TGV with at least one spatially varying parameter always produces better results with respect to both PSNR and SSIM, than the corresponding ground truth-free bilevel TGV with both parameters being scalar, compare the third last with the second last row of .
Finally, we would like to experiment with the case were also the weight α0 varies spatially. We note that by spatially varying both TGV parameters, the reduced problem becomes highly non-convex with many combinations of these parameters leading to similar values for the upper level objective. In order to deal with this, we solve a slightly different problem by performing one step of alternating optimization. Here we optimize only with respect to a spatially varying α0 having fixed the spatial weight α1 as it has been computed by the previous experiments, see the last row of . According to our numerical experiments, this strategy produces satisfactory results. As initialization for α0, we set it constant, equal to 5.
In we depict the computed spatially varying parameters α0 as well as the corresponding PSNR and SSIM values. Observe that the shape of α0 is different to the one of α1, compare the last row of to the second row of . This implies that a non-constant ratio of is preferred throughout the image domain. Secondly, by spatially varying α0 we only get a slight improvement with respect to PSNR and SSIM in the first two images, compare the second last and the last row of . However, it is interesting to observe the spatial adaptation of α0 with respect to piecewise constant versus piecewise smooth areas. The values of α0 are high in large piecewise constant areas, like the background of cameraman, the left area of the parrot image, as well as the top-right and the bottom-left corner of the turtle image. This is not so surprising as large values of α0 imply a large ratio
and a promotion of TV like behavior in those areas. We can observe this in more detail at the parrot image, see last row of . On the contrary, the values of α0 are kept small in piecewise smooth areas like the right part of the parrot image and the sun rays around the turtle’s body. This results in low ratio
and thus to a more TGV like behavior, reducing the staircasing effect. This is another indication of the fact that by minimizing the statistics-based upper level objective one is able not only to better preserve detailed areas but also to finely adjust the TGV parameters such that the staircasing is reduced.
Figure 8. Experiments with optimizing over a spatially varying α0. Top row: the automatically computed scalar parameters α0, that correspond to the images of the last row of . Middle row: the automatically computed spatially varying parameters α0, where α1 has been kept fixed (last row of ). The weight α0 is adapted to piecewise constant parts having there large values and hence promoting TV like behavior, see for instance the parrot image at the last row. On the contrary α0 has low values in piecewise smooth parts promoting a TGV like behavior reducing the staircasing.
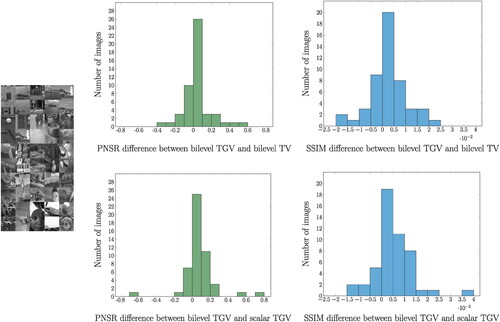
Lastly, we would like to see the degree of improvement of bilevel TGV with spatial parameters over the other ground truth-free approaches, i.e. using the statistics-based upper level objective, over a larger set of images. We thus used the 24 images of the Kodak dataset http://r0k.us/graphics/kodak/, and selected two middle square parts from each photograph, resized to 256 × 256 pixels, see left part of . We added two more photographs (see bottom-right part in the depicted collection) to reach 50 photographs in total. In each photograph, we run the bilevel TV and bilevel TGV experiments after adding the same type of Gaussian noise (with only α1 being spatially varying), as well as the bilevel TGV with both parameters to be scalar and we compared the corresponding PSNR differences,
as well as the corresponding SSIM ones, for every one of the 50 images. The PSNR improvement for the bilevel TGV over bilevel TV (both spatial parameters) was 0.05 ± 0.14 (mean ± standard deviation) while the improvement with respect to SSIM was more moderate, 0.003 ± 0.008. In (top) we also show the corresponding histograms of this difference. The fact that for some images the bilevel TV algorithm produces images of higher PSNR and/or SSIM, as it was the case for the cameraman, is perhaps not so surprising as the same has been observed in similar tests in [Citation26] in the case of scalar parameters only and for a bilevel scheme that maximizes the PSNR of the reconstructed image, using a ground truth-based upper level objective. We stress that for large ratio
TGV is equivalent to TV only up an affine correction [Citation37] and for images that have a piecewise constant structure, setting α0 in TGV to be large enough might not be enough to achieve the same reconstruction as TV. On the other hand the improvement of bilevel TGV with spatially varying α1 versus its scalar analogue was
for the PSNR and 0.005 ± 0.008 for the SSIM, see bottom histograms of . We note that the last two methods require a similar computational effort since the additional H1–projection for the spatially varying weight is typically quite fast and does not significantly contribute to the overall computational time.
Figure 9. Histograms of the PSNR and SSIM differences between the bilevel spatial TGV and bilevel spatial TV (top) and between the bilevel spatial TGV and bilevel scalar TGV (bottom), for reconstructions of noisy versions of the 50 images on the left. In all bilevel algorithms the ground truth-free statistics-based upper level objective was used.
7. Conclusion
In this work we have adapted the bilevel optimization framework of [Citation27, Citation29] for automatically computing spatially dependent regularization parameters for the TGV regularizer. We established a rigorous dualization framework for the lower level TGV minimization problem that formed the basis for its algorithmic treatment via a Newton method. We showed that the bilevel optimization framework with the statistics/localized residual based upper level objective is able to automatically produce spatially varying parameters that not only adapt to the level of detail in the image but also reduce the staircasing effect.
Future continuation of this work includes adaptation of the bilevel TGV framework for advanced inverse problems tasks, i.e., Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET) reconstruction as well as in multimodal medical imaging problems where structural TV based regularizers (edge aligning) have been suggested. That will also require devising a bilevel scheme where the invertibility assumption on T is dropped, since the linear operators involved in these inverse problems do not satisfy this assumption. Adaptation of the framework for different noise distributions e.g. Poisson, Salt & Pepper as well as combination of those [Citation57,Citation58], should also be investigated. Finally, a fine structural analysis of the weighted TGV regularized solutions in the spirit of [Citation59,Citation60] would be also of interest.
Additional information
Funding
References
- Adams, R. A., Fournier, J. (2003). Sobolev Spaces. 2nd ed. Cambridge, MA: Academic Press,
- Ambrosio, L., Fusco, N., Pallara, D. (2000). Functions of Bounded Variation and Free Discontinuity Problems. USA: Oxford University Press.
- Attouch, H., Brezis, H. (1986). Duality for the Sum of Convex Functions in General Banach Spaces. Vol. 34, North-Holland Mathematical Library, pp. 125–133.
- Barzilai, J., Borwein, J. M. (1988). Two-point step size gradient methods. IMA J Numer Anal. 8(1):141–148. DOI: 10.1093/imanum/8.1.141.
- Benning, M., Brune, C., Burger, M., Müller, J. (2013). Higher-order TV methods: Enhancement via Bregman iteration. J Sci Comput. 54(2-3):269–310. DOI: 10.1007/s10915-012-9650-3.
- Bergounioux, M., Papoutsellis, E., Stute, S., Tauber, C. (2018). Infimal convolution spatiotemporal PET reconstruction using total variation based priors, HAL preprint https://hal.archives-ouvertes.fr/hal-01694064.
- Borwein, J. M., Vanderwerff, J. D. (2010). Convex Functions. Cambridge: Cambridge University Press.
- Bredies, K., Dong, Y., Hintermüller, M. (2013). Spatially dependent regularization parameter selection in total generalized variation models for image restoration. Inter. J. Comput. Math. 90(1):109–123. DOI: 10.1080/00207160.2012.700400.
- Bredies, K., Holler, M. (2012). Artifact-free JPEG decompression with total generalized variation. VISAP 2012: Proceedings of the International Conference on Computer Vision and Applications,
- Bredies, K., Holler, M. (2013). A TGV regularized wavelet based zooming model. Scale Space and Variational Methods in Computer Vision. Springer, DOI: 10.1007/978-3-642-38267-3_13., pp. 149–160.
- Bredies, K., Holler, M. (2014). Regularization of linear inverse problems with total generalized variation. J. Inverse Ill-Posed Prob. 22(6):871–913. DOI: 10.1515/jip-2013-0068.
- Bredies, K., Holler, M. (2015). A TGV-based framework for variational image decompression, zooming, and reconstruction. Part I: Analytics. SIAM J. Imaging Sci. 8(4):2814–2850. DOI: 10.1137/15M1023865.
- Bredies, K., Holler, M. (2015). A TGV-based framework for variational image decompression, zooming, and reconstruction. Part II: Numerics. SIAM J. Imaging Sci. 8(4):2851–2886. DOI: 10.1137/15M1023877.
- Bredies, K., Holler, M., Storath, M., Weinmann, A. (2018). Total generalized variation for manifold-valued data. SIAM J. Imaging Sci. 11(3):1785–1848. DOI: 10.1137/17M1147597.
- Bredies, K., Kunisch, K., Pock, T. (2010). Total generalized variation. SIAM J. Imaging Sci. 3(3):492–526. DOI: 10.1137/090769521.
- Bredies, K., Kunisch, K., Valkonen, T. (2013). Properties of L1-TGV 2: The one-dimensional case. J. Math. Anal. Appl. 398(1):438–454. DOI: 10.1016/j.jmaa.2012.08.053.
- Bredies, K., Valkonen, T. (2011). Inverse problems with second-order total generalized variation constraints. Proceedings of SampTA 2011 - 9th International Conference on Sampling Theory and Applications, Singapore,
- Burger, M., Papafitsoros, K., Papoutsellis, E., Schönlieb, C. B. (2016). Infimal convolution regularisation functionals of BV and [Formula: see text] Spaces: Part I: The Finite [Formula: see text] Case. J. Math. Imaging Vis. 55(3):343–369. DOI: 10.1007/s10851-015-0624-6.
- Calatroni, L., Chung, C., Los Reyes, J. D., Schönlieb, C. B., Valkonen, T. (2017). Bilevel approaches for learning of variational imaging models. RADON Book Series on Computational and Applied Mathematics. Vol. 18, Berlin, Boston: De Gruyter, https://www.degruyter.com/view/product/458544.
- Calatroni, L., De Los Reyes, J. C., Schönlieb, C. B. (2017). Infimal convolution of data discrepancies for mixed noise removal. SIAM J. Imaging Sci. 10(3):1196–1233. DOI: 10.1137/16M1101684.
- Calatroni, L., Papafitsoros, K. (2019). Analysis and automatic parameter selection of a variational model for mixed gaussian and salt-and-pepper noise removal. Inverse Prob. 35(11):114001. DOI: 10.1088/1361-6420/ab291a.
- Caselles, V., Chambolle, A., Novaga, M. (2007). The discontinuity set of solutions of the TV denoising problem and some extensions. Multiscale Model. Simul. 6(3):879–894. DOI: 10.1137/070683003.
- Chambolle, A., Duval, V., Peyré, G., Poon, C. (2017). Geometric properties of solutions to the total variation denoising problem. Inverse Prob. 33(1):015002. http://stacks.iop.org/0266-5611/33/i=1/a=015002. DOI: 10.1088/0266-5611/33/1/015002.
- Chambolle, A., Lions, P. L. (1997). Image recovery via total variation minimization and related problems. Numerische Mathematik. 76(2):167–188. DOI: 10.1007/s002110050258.
- Van Chung, C., De los Reyes, J. C., Schönlieb, C. B. (2017). Learning optimal spatially-dependent regularization parameters in total variation image denoising. Inverse Prob. 33(7):074005. DOI: 10.1088/1361-6420/33/7/074005.
- De Los Reyes, J. C., Schönlieb, C. B., Valkonen, T. (2016). The structure of optimal parameters for image restoration problems. J. Math. Anal. Appl. 434(1):464–500. DOI: 10.1016/j.jmaa.2015.09.023.
- De Los Reyes, J. C., Schönlieb, C. B., Valkonen, T. (2017). Bilevel parameter learning for higher-order Total Variation regularisation models. J. Math. Imaging Vis. 57(1):1–25. DOI: 10.1007/s10851-016-0662-8.
- Demengel, F., Temam, R. (1984). Convex functions of a measure and applications. Indiana Univ. Math. J. 33(5):673–709. DOI: 10.1512/iumj.1984.33.33036.
- Ekeland, I., Temam, R. (1999). Convex analysis and variational problems. Classics Appl. Mathem. Soci. Indust. Appl. Math.
- Girault, V., Raviart, P. A. (1986). Finite Element Method for Navier-Stokes Equation. Berlin, Germany: Springer.
- Hintermüller, M., Holler, M., Papafitsoros, K. (2018). A function space framework for structural total variation regularization with applications in inverse problems. Inverse Prob. 34(6):064002. http://stacks.iop.org/0266-5611/34/i=6/a=064002. DOI: 10.1088/1361-6420/aab586.
- Hintermüller, M., Kunisch, K. (2006). Path-following methods for a class of constrained minimization problems in function space. SIAM J. Optim. 17(1):159–187. DOI: 10.1137/040611598.
- Hintermüller, M., Papafitsoros, K. (2019). Generating structured nonsmooth priors and associated primal-dual methods. Processing, Analyzing and Learning of Images, Shapes, and Forms: Part 2. In: Ron K. and Xue-Cheng T., eds. Handbook of Numerical Analysis, Vol. 20, DOI: 10.1016/bs.hna.2019.08.001., pp. 437–502.
- Hintermüller, M., Papafitsoros, K., Rautenberg, C. N. (2017). Analytical aspects of spatially adapted total variation regularisation. J. Math. Anal. Appl. 454(2):891–935. DOI: 10.1016/j.jmaa.2017.05.025.
- Hintermüller, M., Papafitsoros, K., Rautenberg, C. N. (2020). Variable step mollifiers and applications. Integr. Equ. Oper. Theory. 92(6). DOI: 10.1007/s00020-020-02608-2.
- Hintermüller, M., Rautenberg, C. N. (2015). On the density of classes of closed convex sets with pointwise constraints in Sobolev spaces. J. Math. Anal. Appl. 426(1):585–593. DOI: 10.1016/j.jmaa.2015.01.060.
- Hintermüller, M., Rautenberg, C. N. (2017). Optimal selection of the regularization function in a weighted total variation model. Part I: Modelling and theory. J. Math. Imaging Vis. 59(3):498–514. DOI: 10.1007/s10851-017-0744-2.
- Hintermüller, M., Rautenberg, C. N., Rösel, S. (2017). Density of convex intersections and applications. Proc. Royal Soci. London A Math. Phys. Engng Sci. 473(2205) DOI: 10.1098/rspa.2016.0919.
- Hintermüller, M., Rautenberg, C. N., Wu, T., Langer, A. (2017). Optimal selection of the regularization function in a weighted total variation model. Part II: Algorithm, its analysis and numerical tests. J. Math. Imaging Vis. 59(3):515–533. DOI: 10.1007/s10851-017-0736-2.
- Hintermüller, M., Stadler, G. (2006). An infeasible primal-dual algorithm for total bounded variation–based inf-convolution-type image restoration. SIAM J. Sci. Comput. 28(1):1–23. DOI: 10.1137/040613263.
- Holler, M., Kunisch, K. (2014). On infimal convolution of TV-type functionals and applications to video and image reconstruction. SIAM J. Imaging Sci. 7(4):2258–2300. DOI: 10.1137/130948793.
- Huber, R., Haberfehlner, G., Holler, M., Kothleitner, G., Bredies, K. (2019). Total generalized variation regularization for multi-modal electron tomography. Nanoscale. 11(12):5617–5632. DOI: 10.1039/c8nr09058k.
- Jalalzai, K. Discontinuities of the minimizers of the weighted or anisotropic total variation for image reconstruction, arXiv preprint 1402.0026 (2014), http://arxiv.org/abs/1402.0026.
- Jalalzai, K. (2016). Some remarks on the staircasing phenomenon in total variation-based image denoising. J. Math. Imaging Vis. 54(2):256–268. DOI: http://dx.doi.org/10.1007/s10851-015-0600-1.
- Knoll, F., Bredies, K., Pock, T., Stollberger, R. (2011). Second order total generalized variation (TGV) for MRI. Magn. Reson. Med. 65(2):480–491. DOI: 10.1002/mrm.22595.
- Knoll, F., Holler, M., Koesters, T., Otazo, R., Bredies, K., Sodickson, D. K. (2017). Joint MR-PET reconstruction using a multi-channel image regularizer. IEEE Trans. Med. Imaging. 36(1):1–16. DOI: 10.1109/TMI.2016.2564989.
- Kunisch, K., Hintermüller, M. (2004). Total bounded variation regularization as a bilaterally constrained optimization problem. SIAM J. Appl. Math. 64(4):1311–1333. DOI: 10.1137/S0036139903422784.
- Nesterov, Y. E. (1983). A method for solving the convex programming problem with convergence rate O(1/k2). Soviet Math. Dokl. 27:367–372.
- Papafitsoros, K. (2014). Novel higher order regularisation methods for image reconstruction. Ph.D. thesis. University of Cambridge. https://www.repository.cam.ac.uk/handle/1810/246692.
- Papafitsoros, K., Bredies, K. (2015). Department of Applied Mathematics and Theoretical Physics, University of Cambridge, Wilberforce Road, CB3 0WA, Cambridge A study of the one dimensional total generalised variation regularisation problem. Inverse Prob. Imaging. 9(2):511–550. DOI: 10.3934/ipi.2015.9.511.
- Papafitsoros, K., Valkonen, T. (2015). Asymptotic behaviour of total generalised variation. Scale Space and Variational Methods in Computer Vision: 5th International Conference, SSVM 2015, Proceedings. In: Jean-François A., Mila N., and Nicolas P., eds. Springer International Publishing, pp. 702–714. DOI: 10.1007/978-3-319-18461-6_56.
- Pöschl, C., Scherzer, O. (2015). Exact solutions of one-dimensional total generalized variation. Comm. Math. Sci. 13(1):171–202. DOI: 10.4310/CMS.2015.v13.n1.a9.
- Ring, W. (2000). Structural properties of solutions to total variation regularization problems. Esaim: M2an. 34(4):799–810. DOI: 10.1051/m2an:2000104.
- Rudin, L. I., Osher, S., Fatemi, E. (1992). Nonlinear total variation based noise removal algorithms. Physica D: Nonlinear Phenomena. 60(1-4):259–268. DOI: 10.1016/0167-2789(92)90242-F.
- Schloegl, M., Holler, M., Schwarzl, A., Bredies, K., Stollberger, R. (2017). Infimal convolution of total generalized variation functionals for dynamic MRI. Magn Reson Med. 78(1):142–155. DOI: 10.1002/mrm.26352.
- Temam, R. (1985). Mathematical Problems in Plasticity. Vol. 15, Gauthier-Villars Paris.
- Temam, R., Strang, G. (1980). Functions of bounded deformation. Arch. Rational Mech. Anal. 75(1):7–21. DOI: 10.1007/BF00284617.
- Valkonen, T. (2017). The jump set under geometric regularisation. Part 2: Higher-order approaches. J. Math. Anal. Appl. 453(2):1044–1085. DOI: 10.1016/j.jmaa.2017.04.037.
- Valkonen, T., Bredies, K., Knoll, F. (2013). Total generalized variation in diffusion tensor imaging. SIAM J. Imaging Sci. 6(1):487–525. DOI: 10.1137/120867172.
- Zowe, J., Kurcyusz, S. (1979). Regularity and stability for the mathematical programming problem in Banach spaces. Appl Math Optim. 5(1):49–62. DOI: 10.1007/BF01442543.
Appendix A
We provide here the proof of Proposition 2.2:
Proof of Proposition 2.2
. The proof follows [Citation12, Proposition 3.3]. Denote by the following convex sets
(A.1)
(A.1)
(A.2)
(A.2)
It suffices to show that
(A.3)
(A.3)
We first show that is closed in
Let
and assume that there exists
where every pn satisfies the convex constraints and
in
By boundedness of
we have that there exist
and a subsequence of
such that
in
and
respectively. Using that, we have for every
(A.4)
(A.4)
thus
Similarly we derive that
and hence
Finally note that the set
is a norm-closed and convex subset of
and hence weakly closed. Since
belongs to that set, converging weakly to
we get that the latter also belongs there. Thus,
is closed in
and since
we get
It remains to show the other direction, i.e., Toward that, note first that the functional
can also be written as
Using the convexity of one gets
Secondly, note that due to the lower bounds on for
we have that
if and only if
Indeed this holds from the equivalence of the (scalar)
with
and from the estimate
for every
This means that if for
it holds
(A.5)
(A.5)
then in fact the inequality (A.5) will hold for every
and thus
which implies
Thus in order to finish the proof it suffices to show (A.5) for every
In view of Proposition 2.1 it suffices to show
(A.6)
(A.6)
for all
The first step toward that is to show that for every
and for every
with
and
for a.e.
it holds
(A.7)
(A.7)
Indeed, note first that from (2.3), we get for every
(A.8)
(A.8)
Recall now that every can be strictly approximated by a sequence
that is
in
and
see [Citation12, Proposition 2.10]. Furthermore, using that, along with Reshetnyak’s continuity theorem [Citation33, Theorem 2.39] we also get that
Using the above and the fact that by taking limits in (A.8) we obtain (A.7). Finally in order to obtain (A.5) let again
with
and
for a.e.
and let
Then by using (2.4) and (A.7), we have for every
Similarly as before given and
there exists a sequence
such that
in
and
This follows from a modification of the proof of [Citation12, Proposition 2.10] where one takes advantage of the L2 integrability of u. Using again the Reshetnyak’s continuity theorem and taking limits we get that for every
By taking the minimum over we obtain (A.5). □