

ABSTRACT
Conversational memory is subject to a number of biases. For instances, references which were reused during dialogue are remembered better than non-reused references. Two experiments examined whether speakers are aware that they are subject to such biases and whether they use information about reference origin (i.e., information about who said what) to determine which references are remembered better by their partner. Pairs of participants performed a map task followed by a questionnaire that assessed each participant’s content memory as well as each participant’s estimation of his or her partner’s memory. In Experiment 1, the participants were unaware that they would perform a memory test after the map task, whereas the participants were mutually aware of the upcoming memory test in Experiment 2. The results revealed that participants did know that their partner was subject to memory biases and that their estimation of these biases was mainly accurate. The results prevented us from drawing any conclusions about the role of origin memory in this process. These results have important implications for subsequent dialogic partner-adaptation.
Acknowledgments
We thank Cordetta Richmond for her assistance with data collection and Angèle Brunellière for her helpful comments on our manuscript.
Disclosure statement
The authors declare that there is no conflict of interest.
Notes
1. We used a map of a real town in order to make the task as natural as possible for the participants. One caveat of this was that the landmarks and streets shown on the map were not counterbalanced across dyads. Thus, in the subsequent memory test, “old” items (i.e., landmarks and streets featured on the map) were always the same and “new” items were always the same. However, because participants within each dyad chose which landmarks and street names they mentioned, old-mentioned items and old-unmentioned items were different across dyads. Following the same rationale, presentation, acceptance, and reuse for each item were different for each dyad.
2. The labels of the columns included no references to the actual questions (as shown in , the labels used were “Question #1,” “Question #2,” and “Question #3” so that the participants could not guess in advance which questions they would be asked (as mentioned in the task and procedure section, the participants answered question 1 for all items, then answered question 2 for all items which they believed had been mentioned, and finally answered question 3 for all items which they believed had been mentioned). The rationale behind this was that knowing in advance which questions they would be asked might have caused the participants to modify their responses to the current questions. For instance, knowing that they would have to say whether the reference were initially self- or partner-produced (question 3) could have led them to think of information origin more while they responded to questions 1 and 2, thus potentially affecting their responses to these questions.
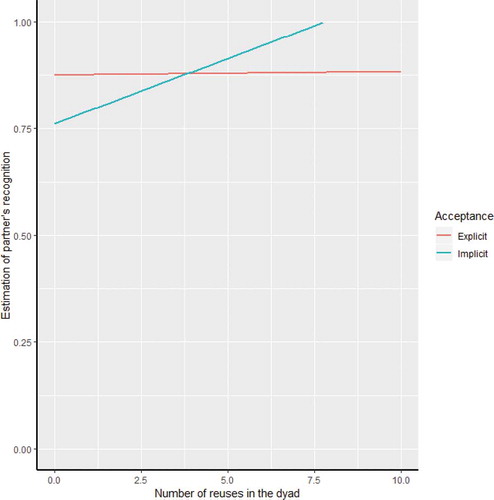
Estimation of partner’s recognition as a function of acceptance and the number of reuses in the dyad
3. As highlighted below, this created a strong unbalance in the experimental design. This was accounted for by correcting the degrees of freedom associated with each IV (Satterthwaite correction).
4. The degrees of freedom are not identical because the number of participants included varied slightly across analyses. Indeed, in some cases, the number of false alarms or misses was 0, making it impossible to calculate d’ for this participant. Such occurrences were removed from the analysis.
5. The degrees of freedom are not identical because the number of participants included varied slightly across analyses. Indeed, in some cases, the number of false alarms or misses was 0, making it impossible to calculate d’ for this participant. Such occurrences were removed from the analysis.
6. The number of participants was not the same in both experiments: We accounted for this in the statistical analyses reported in this section by using the Satterthwaite correction.