
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The understanding and acquisition of a language in a real-world environment is an important task for future robotics services. Natural language processing and cognitive robotics have both been focusing on the problem for decades using machine learning. However, many problems remain unsolved despite significant progress in machine learning (such as deep learning and probabilistic generative models) during the past decade. The remaining problems have not been systematically surveyed and organized, as most of them are highly interdisciplinary challenges for language and robotics. This study conducts a survey on the frontier of the intersection of the research fields of language and robotics, ranging from logic probabilistic programming to designing a competition to evaluate language understanding systems. We focus on cognitive developmental robots that can learn a language from interaction with their environment and unsupervised learning methods that enable robots to learn a language without hand-crafted training data.
GRAPHICAL ABSTRACT
1. Introduction
Language acquisition and understanding are still linked to a wide range of challenges in robotics, despite significant progress and achievements in artificial intelligence (AI) through recent advances in machine learning during this decade. These advances have especially been in deep learning, fields related to language (such as machine translation), speech recognition, image recognition, image captioning, distributed semantic representation learning, and parsing. Although several studies demonstrated that an agent without pre-existing linguistic knowledge can learn to understand linguistic commands solely with deep learning and a labeled dataset, problems still abound. The actual linguistic phenomena that future service robots interacting with human users naturally in their daily lives will have to deal with are complex, diverse, dynamic, and highly uncertain. The goal of this study is to expose the scientific and engineering challenges clearly at the intersection of robotics and natural language processing (NLP) that must be solved to develop future service robots.
There are many reasons why language is still challenging in AI and robotics, as we describe later in this paper. Further exploration of this field should be conducted based on a clear understanding of the difficulties of the challenges. We would argue that the ad-hoc implementation of language skills in robots and an at-random exploration of the language system cannot lead to an appropriate understanding of the language used by humans, or to the creation of robots that can deal with language in the same way as humans. This is because language itself is dynamic, systemic, cognitive, and a social phenomenon.
The goal of this survey paper is to clarify the frontier, i.e. the challenges, in language and robotics by surveying achievements of the related research communities and linguistic phenomena that have been mostly ignored in robotics to date. Accordingly, we first conduct a background review of this research field and share our ideas on language and robotics, including thoughts on the importance of this research field. This is not only for building future intelligent robots, but also for understanding human intelligence and language phenomena. The definition of language may depend on the relevant academic field. In this paper, we use the term language to represent a natural language that we humans use in our daily lives, e.g. English or Japanese. Although it is sometimes argued that other animals have language-like systems, e.g. the syntactic structure of the songs of certain birds, this study focuses on human language. A language is a type of social sign system, such as gestures or traffic signs. Nonlinguistic social signs can be used as signs for social communication; e.g. nonverbal communication has been studied in social robotics for decades [Citation1–5]. However, we have excluded such signs from the scope of this survey and focused on natural language, which has syntax, semantics, and lexicons.
The remainder of this paper is organized as follows. Section 2 introduces the background of the research field of language and robotics, and points to seven distinct topics in the field. These seven topics are described in Sections 3–9, respectively, i.e. logic probabilistic programming and learning distributed semantics, unsupervised syntactic parsing with grounding phrases and predicates, category and concept formation, metaphorical expressions, affordance and action learning, pragmatics and social language, and resources and criteria for evaluation, i.e. dataset, simulator, and competition. Finally, Section 10 concludes this paper with a discussion and future perspectives.
2. Background
This section introduces the background for the research field of language and robotics and highlights seven distinct challenges in the field.
2.1. Language in robotics
Robots interacting with human users using speech signals try to behave correctly based on speech commands from the users in a real-world environment, which is full of uncertainty. To deal with the problems related to language understanding in a real-world environment, robot audition and vision have been studied to improve the robustness of automatic speech recognition and scene understanding for decades [Citation6–13]. However, challenges still abound in this field. Several studies have attempted to enable robots to understand the meaning of sentences. However, many applications still use manual rules, which only enable robots to understand a very small proportion of language. They also often have difficulty in dealing with uncertainty in language, e.g. treating speech recognition errors and the ambiguity of expressions.
The number of studies on language learning by robots has been increasing recently. One representative approach is based on deep learning. Several studies successfully enabled artificial agents to understand simple sentences using neural networks by composing linguistics, visuals, and other information based on supervised learning or reinforcement learning (RL) [Citation14–16]. Another representative approach has been taken in the field of symbol emergence in robotics [Citation17,Citation18]. Many types of unsupervised learning systems that can discover words, categories, and motions from sensor–motor information based on hierarchical Bayesian models have been developed. We must specifically highlight achievements in object category and concept formation by robots with cognitive scientists and linguists, as many parts of category formation discussed in cognitive science, typically nominal category formation, have already been modeled and reproduced in robotics (see Section 5). Of course, there are many types of categories and concepts. However, that which has been learned is still a very limited set of linguistic phenomena. For example, current robots cannot learn logic and reasoning, use metaphorical expressions, or infer a variety of concepts from abstract and functional words using a bottom-up approach.
To create robots that can communicate naturally with people in a real-world environment, e.g. offices and houses, we need to develop methods that enable them to process uttered sentences robustly in a real-world environment, despite inevitable uncertainties. We need to recognize that language is not a material object or a set of objective signals, but rather a dynamic symbol system in which the meaning of signs depends on the context and is understood subjectively. Further, language needs to be understood from a social viewpoint. Considering mutual (or shared) belief systems is indispensable to develop a theory of language understanding in communication [Citation19].
Symbol grounding is a long-standing problem in AI and robotics [Citation20], even though several researchers pointed out that the definition of the problem itself is somewhat misleading [Citation17,Citation18,Citation21,Citation22]. In all cases, it is important for a robot to ground symbols in their sensor–motor information, i.e. the perceptual world.Many studies related to the symbol grounding problem attempted to ground ‘words'. However, the meaning of a sentence is not the sum of the meanings of its words. Robots must ground the meaning of phrases and sentences. For this purpose, unsupervised learning of syntactic parsing with grounding phrases and predicates is also important. The meanings of words and phrases are not only determined by what they represent, but also by their relationship with other words. This is called distributional semantics. Therefore, learning distributional semantics is also crucial.
As we addressed in this section, creating a robot capable of ultimately communicating naturally with humans in a real-world environment is a great scientific challenge. To make progress in this field, we need to define appropriate tasks, and have an appropriate dataset. Considering the reality of the communication and collaboration to which the language contributes, these cannot be described as one-shot input–output information processing steps; instead, they involve continuous interaction. Therefore, a static dataset prepared by recording a series of interactions is insufficient for the study. However, using actual robots is not cost-efficient. Therefore, having a suitable simulator is important to accelerate such studies. This point is also addressed in the following section.
2.2. Robotics for language
The language that we, human beings, use is far more complex and structured than the sign systems that other animals use. The linguistic capability enables us to collaborate with other agents, i.e. leads to multi-agent coordination, and to form social norms and structures. Such magnificent capabilities gave humans the highest position among the species on earth. This language capability can be regarded as the fruit of our evolution and adaptation to the real-world environment. We can argue that language is meaningful in terms of adaptation and competition in a real-world environment. Furthermore, we can argue that the main functions of language are to enable people to communicate with each other and to represent objects, actions, events, emotions, intentions, and phenomena in the real-world, including the physical and social environment, to survive and prosper.
Therefore, it is crucially important to explore how language can help agents to adapt to the environment and collaborate with others to grasp its central function. However, researchers in the field of classical linguistics have not been able to address these problems, as stereotypical linguists have been focusing on written sentences alone. In studies of linguistics and NLP, real-world sensor–motor information has rarely been involved. However, currently, we can use robots with sensor–motor systems to experience multimodal information and perform real-world tasks. Employing robots will expand the horizon of linguistics. Cognitive linguistics introduced the notion of embodiment, leading to significant progress [Citation23–25]. However, so far, actual embodied systems have not been employed as ‘materials and methods’ in the study of language, despite embodiment and real-world uncertainty being crucial for intelligence. We believe that including robots in the study of language will broaden the horizon of cognitive linguistics as well.
The field of linguistics has mainly been focused on the language spoken or written by adults, i.e. learned and used language. NLP has mainly dealt with correct written sentences. However, humans can not only use but also learn a language. In the developmental process, input data received during the learning process is not written text data, but rather speech signals with multimodal sensor–motor information including haptic, visual, auditory, and motor information. Language learning needs to be performed in a real-world environment that is full of uncertainty. It is unrealistic to assume that an infant can acquire complete linguistic knowledge from speech signals alone. To model language acquisition, we need to deal with real-world information, including at least sensor–motor information. This means that at the minimum, a robot would be required for further study of the language.
In understanding a language, real-world multimodal information is essential as well. When one says, ‘please take it', to another person while pointing at an object, visual information is used to reduce uncertainty in the interpretation of ‘it’ (exophora). This indicates that many sentences require additional information, i.e. context, for interpretation. In practice, most context cannot be captured by considering written sentences alone. In various situations, the existence of real-world, i.e. embodied, information is essential to language understanding.
NLP has mainly been handling written text. NLP has led to many achievements, of course, as many linguistic phenomena and problems could be addressed using written text alone. However, many open questions, which cannot be solved solely with written text, remain in NLP. The NLP research community is also expanding in the direction of studies involving multimodal sensor information, e.g. multimodal machine translation, image and video captioning, and visual question answering [Citation26–29]. A new academic challenge regarding NLP using sensor–motor information in real-world environments, namely, language and robotics, is now being introduced.
Having an embodied system is crucial to the modeling of many linguistic phenomena. For example, the meaning of metaphors is based on cross-modal inference. Metaphors cannot be understood without the notion of embodiment. Robotics will be able to provide an appropriate model for metaphors by leveraging its multimodal servomotor information.
Affordance learning is also crucial for language understanding. The concept of a tool is linked to actions. For example, ‘chair’ cannot be defined without referring to the ‘sit down’ or ‘be seated’ action. Affordance learning has been studied in cognitive robotics in the past decade [Citation30]. This demonstrates that there is scope for robotics to contribute to language understanding.
2.3. Scope of survey on frontiers of language and robotics
We have pointed out several challenges and important topics in this section. Many challenges still abound at the frontier of language and robotics. To create a robot that can learn and understand language through natural interactions with human participants, as does a human infant, we must tackle the following problems.
Logic probabilistic programming and learning distributed semantics (Section 3)
Unsupervised syntactic parsing with grounding phrases and predicates (Section 4)
Category and concept formation (Section 5)
Metaphor and embodiment (Section 6)
Affordance and action learning (Section 7)
Pragmatics and social language (Section 8)
Dataset, simulator, and competition (Section 9)
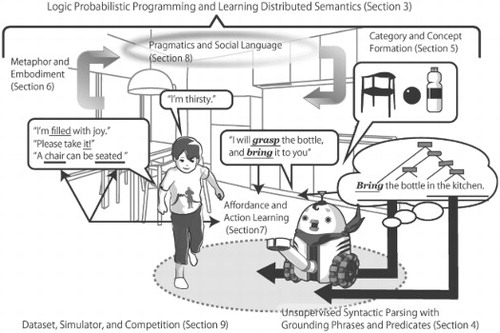
Although these are the topics that must be studied, they do not cover all the problems in language and robotics. We have intentionally chosen the topics that are related to language understanding and acquisition and have been relatively lacking in the context of studies of robotics and NLP to highlight its frontiers. We have excluded the topics that have been intensively studied. For example, we have excluded robot audition and vision studies. In addition, we have excluded nonverbal communication in social robotics as well, because we focus on natural language in this survey. Figure summarizes the issues in an illustration. We describe their current status and more detailed challenges in the following sections.
Figure 1. Overview of challenges and relationships between topics described in this survey.
3. Probabilistic logic programming and distributed representations
As exemplified by Sherlock Holmes, humans can predict what happens next, or what happened before, by combining observed facts with their knowledge of the world. The ability to draw a conclusion with reasoning, henceforth, inference, is one of the crucial components of future intelligent robots [Citation31].
For example, in Figure , the robot brings a bottle, responding to the user utterance ‘I'm thirsty ’. In order to achieve this, the robot needs to infer that it should bring the bottle, based on the user utterance and problem-solving knowledge, e.g. ‘a bottle of water can solve thirstiness', and ‘there is a bottle of water in the kitchen'. Even if the robot can recognize the sentence spoken and has knowledge, it may not be capable of doing this if it does not have the ability to derive a conclusion by combining these types of information.
Conventional studies of logic programming (LP) have been focused on this issue. However, developing methods that enable a robot to learn logic programs and distributed representations on a large-scale knowledge base via sensor–motor experiences in a real-world environment is still a challenge.
This section discusses the latest advances in reasoning in two areas, LP and distributed representations in NLP, and points to future challenges.
3.1. Probabilistic logic programming
3.1.1. Logic programming
LP is essentially a declarative programming paradigm based on formal logic. LP has its roots in automated theorem proving, where the purpose is to test whether or not a logic program Γ can prove a logical formula, or query, ψ, i.e. or
. For computational efficiency, the language used in logic programs is typically restricted to a subset of first-order logic (e.g. Horn clauses [Citation32]). From a reasoning perspective, LP serves as an inference engine. Hobbs et al. [Citation33] propose an Interpretation as Abduction framework, where natural language understanding is formulated as abductive theorem proving. In this context, a logic program Γ is a commonsense knowledge base (e.g.
) and a query ψ will be a question that is of interest (e.g.
).
Typically, reasoning involves a wide variety of inferences (e.g. coreference resolution, word sense disambiguation, etc.), where the inferences are dependent on each other. Thus, it is difficult to define the types of inferences that should precede in advance algorithmically. Although there is a wide variety of approaches to implementing reasoning, ranging from conventional, feature-based machine learning classifiers such as logistic regression to modern deep learning techniques, LP provides an elegant solution to this issue, by virtue of its declarative nature. In declarative programming, all that is required to solve a problem is to provide general knowledge around problem-solving; procedures on how to actually solve this specific problem are not needed. For example, for Sudoku, we would write rules such as ‘for all ', where
represents a cell value at the ith row and jth column, and then simply run the inference engine. In the literature, a number of LP formalisms have been proposed such as Prolog, Answer Set Programming [Citation34], where the expressivity of logic programs and their logical semantics, etc., are different from each other.
3.1.2. Reasoning with uncertainty
Conventional LP cannot represent uncertainty in knowledge. For example, a rule such as ‘If it rains, John will be absent from school with the probability of 60%’ is not representable in LP. To solve this problem, probabilistic logic programming (PLP), a probabilistic extension of LP, has been developed. A wide variety of formalisms has been proposed, such as PRISM [Citation35], stochastic logic programming [Citation36], and ProbLog [Citation37]. In the field of statistical relational learning, certain logic-based formalisms have also been proposed such as Markov logic [Citation38] and probabilistic soft logic [Citation39]. Most of the popular PLP formalisms to date are based on distribution semantics (DS), proposed by Sato [Citation35].
We briefly provide an overview of DS. DS introduces a probabilistic semantics for logic programs. The idea is as follows. We assume that a logic program Π consists of facts F and rules R (i.e. ). Consider a probabilistically sampled subset of facts
, according to some probability distribution, and a logic program
. We then derive a logical consequence, e.g. in terms of a minimal model. After we repeat the sampling many times, we obtain a set of logical consequences (or interchangeably, interpretation or truth assignment) from the sampled program in terms of some LP semantics, e.g. minimal model semantics. In DS, the probability mass is distributed over these logical consequences. Let
be a set of all such logical consequences, namely
. In DS,
is set to be 1. The probability function of I can be designed arbitrarily.
One instantiation of DS is ProbLog [Citation37]. The basic syntax of ProbLog resembles that of Prolog. As an LP semantics, ProbLog employs a well-founded model [Citation40] and assumes that the program given is a locally stratified normal logic programs; under a locally stratified LP, a well-founded model coincides with the minimal model and the stable model. One important extension is probabilistic fact denoted by p::f, which means that fact f is selected with probability p and not selected with probability 1−p. A ProbLog program consists of three components: (i) facts F, (ii) probabilistic facts , and (iii) rules R. Assuming probabilistic independence over the probabilistic facts, the probability of interpretation I is defined as follows:
(1)
(1) where
is a family of sets of probabilistic facts that has I as a logical consequence, that is,
. ProbLog also has several strong, built-in mechanisms to perform efficient inference, e.g. computing a marginal probability and a maximum a posteriori (MAP) inference, and learn its probabilistic parameters [Citation41].
3.2. Reasoning with distributed representations
Representing the meaning of words, phrases, or even sentences using low-dimensional dense vectors is shown to be effective in a wide range of NLP tasks, such as machine translation, textual entailment, and question answering [Citation42–45, etc.]. Such representations are called distributed representations. The benefit of distributed representations is that they allow us to estimate the proximity of meaning based on vector similarity. In the field of reasoning, researchers started to leverage distributed representations in the reasoning process. This section discusses two recent advances in reasoning leveraging distributed representations: automated theorem proving and knowledge base embedding.
3.2.1. PLP with distributed representations
One weakness of PLP is that a symbol used in logic programs is assumed to represent a unique concept. Consider the logic program {grandfather
happy}. Under the above assumption, PLP does allow us to deduce happy given that grandfather holds; however, given that grandpa holds, it does not allow us to deduce happy, regardless of the conceptual similarity between these two symbols. If we could exhaustively enumerate ontological axioms in the world, i.e. grandpa
grandfather in this case, then this would not be a problem. However, this assumption is impractical from a knowledge engineering perspective.
To overcome this weakness, researchers embed PLP, or other logic-based formalisms, into a continuous space using advances in distributed representations [Citation46–52, etc.], which is an active topic in both the NLP and machine learning research communities. For instance, Rocktaschel and Riedel [Citation52] propose a Prolog-style theorem prover, i.e. selective linear definite clause (SLD) derivation, in a continuous space. Given a goal (or query), SLD derivation subsequently attempts to prove the goal (or subgoal) by unifying it with the head of a rule in the knowledge base. However, as mentioned previously, the unification of a goal grandfatherOf(John, Bob) and head grandpaOf(John, Bob) fails even when these are semantically similar.
To solve this problem, Rocktaschel and Riedel [Citation52] employ soft unification based on the similarity of predicates and constants instead of hard pattern matching. The proposed theorem prover returns a score representing how successful the proof is, instead of whether the proof is successful or not. Specifically, predicates and constants occurring in a knowledge base are embedded into a continuous space by assigning a low-dimensional dense vector to them. When proving a goal, the similarity between a goal and a rule head in the knowledge base is calculated. Because unification is always successful, the proof process is performed up to depth d. The vectors representing predicates and constants are tuned such that a query that can be proven by the knowledge base receives a higher score.
3.2.2. Embedding knowledge into continuous space
Embedding a knowledge base into a continuous space has received much attention in recent years [Citation53–56]. The most basic and simple form of knowledge embedding methods is TransE [Citation57].
We assume that a knowledge base contains a set of triplets (h,r,t), where h,t represent an entity and r represents a relation between the entities (e.g. (Tokyo, is_capital_of, Japan)). TransE represents each entity and relation as a point in a n-dimensional continuous space. The core idea of TransE is that for each triplet in a knowledge base, the corresponding vector representations
can be learned by minimizing the following loss function:
(2)
(2) where γ is a margin,
represent a set of triplets contained, or not contained, in a knowledge base K, respectively, and
.
(or L1 norm), represents the quality of triplet
based on the corresponding vectors. During training, for a triplet
contained in a knowledge base,
becomes closer to
.
These learned distributed representations can be used for automated question answering, for instance. For example, consider a question ‘Where was Obama born?'. Let the distributed representation of Obama and is_born_in be . Let the distributed representation of an arbitrary entity t be
. To answer the question, we need to find an entity t that maximizes
. Compared to simple pattern matching, the advantage here is flexibility—the system can answer the question in a situation where (Obama, is_born_in, ·) does not exist in the knowledge base, but similarly related instances such as (Obama, is_given_birth_in, ·) do.
3.3. Challenges in PLP and distributed representations
Despite recent advances in the community, many obstacles remain to integrate logical inference within robots in the real world.
First, in the work we have seen so far, the model of the world is not grounded in the real world. Second, the vocabulary set, i.e. predicates and terms, used for representing observations and a knowledge base is predefined by the user. Third, the knowledge acquisition bottleneck is still present. The use of distributed representations partially solves this issue, i.e. through ontological knowledge; however, a separate mechanism is required for other types of knowledge, e.g. relations between events such as causal relations. Therefore, the following challenges remain as open questions:
Developing a method for logical inference where the model of the world is grounded on continuous and constantly changing real-world sensory inputs.
Developing a mechanism to associate new concepts emerging from inputs with existing predicates, i.e. ‘packing’ similar concepts from robots' perceptions and ‘labeling’ them.
Enhancing purely symbolic logical inference with causal inference in the physical world, e.g. using a physics simulator.
4. Unsupervised syntactic parsing with grounding phrases and predicates
To conduct the logical inferences described earlier, syntactic parsing should be perfected in advance to be suitable for real-world communication. For example, the robot in Figure is inferring the latent syntactic structure of the sentence given, and understands it needs to bring ‘the bottle’, not ‘the kitchen'. Syntactic parsing is indispensable for semantic parsing, semantic role identification, and other semantics-driven tasks in NLP. Syntactic parsing can essentially be categorized as follows, in the current practice of NLP [Citation58]: (a) dependency parsing, (b) constituent parsing, such as context-free grammars (CFG), tree adjoining grammars (TAG), and (c) combinatory categorial grammars (CCG).
Dependency parsing has become widespread by virtue of its simplicity and universality, and downstream tasks are often designed assuming dependencies. However, as it can be converted into a specific form of CFG [Citation59], constituent parsing such as CFG is still a key issue. Furthermore, because CCG can also handle information that cannot be dealt with using other formalisms (such as λ-calculus expressions), CCG has attracted much attention of late and much research has emerged around CCG, following [Citation60].
4.1. Unsupervised and supervised parsing
Learning a grammar is straightforward if equipped with a corpus of annotated ground truth trees, i.e. data labels for training a syntactic parser. However, in the realm of robotics, we need the unsupervised learning of grammars to be flexible and to fit the utterances of users. Indeed, aside from developmental considerations, users often speak in a way that cannot be handled by a predefined grammar, which is usually based on written text prepared in a different environment. Such colloquial expressions are especially characteristic of robotics. Unsupervised models are also necessary for semi-supervised learning as a prerequisite of using existing grammars [Citation61,Citation62]. Below, we describe the current status of the aforementioned three approaches to parsing.
4.1.1. Dependency parsing
The most basic model of unsupervised dependency parsing was first introduced by Klein and Manning [Citation63] and was referred to as the dependency model with valenceFootnote1 (DMV). DMV is a statistical generative model that yields a sentence by iteratively generating a dependent word in a random direction from the source word in a probabilistic fashion. DMV has been improved markedly through many studies since [Citation64–66]. For example, Headden et al. [Citation64] introduced enhanced smoothing and lexicalization based on the Bayesian treatment of equivalent probabilistic CFG. Spitkovsky et al. [Citation65] controlled the data fed to the inference algorithm from straightforward to complex, mimicking a baby learning a language, and yielded better accuracy than a simple batch inference. Jiang et al. [Citation66] recently leveraged neural networks to deal with possible correlations in grammar rules, defining the state of the art as an extension of a basic DMV.
However, dependency parsing has limitations: the most prominent issue is that large syntactic structures such as relative clauses or compositional sentences cannot be recognized. For example, ‘that…’ in ‘it is true that…’ contains a sentence, but dependency parsing just attaches ‘that’ to the head of the sentence and cannot recognize the fact that the term ‘that’ is not a pronoun here but introduces a relative clause. For this purpose, constituent parsing is a better alternative, as described below.
4.1.2. Constituent parsing
Constituent parsing is a general term referring to a model that assigns hierarchical phrase structures to a sentence. The most basic of these is CFG and its probabilistic extension, probabilistic CFG (PCFG) [Citation67]. For example, PCFG decomposes a sentence (S) into a noun (N) and a verb phrase (VP), VP in turn decomposes into a verb (V) and N, and finally N and V are substituted with actual words such as ‘she plays music'. This approach has a long history in the field of NLP, and many extensions and inference methods have been proposed [Citation58,Citation67].
However, unsupervised learning of PCFG is a notoriously difficult problem, because we usually only need to find few valid parses of a sentence within possibilities, where N is the length of the sentence and K is the number of nonterminal symbols, i.e. syntactic categories. Therefore, inference in unsupervised PCFG induction is quite prone to being trapped by local maxima, and thus has been avoided for a long time. Johnson et al. [Citation68] recently proposed a novel MCMC sampling scheme for this problem that avoids local maxima by using a Bayesian inference on PCFG induction. For simplicity, these studies on PCFG parsing assumed part-of-speech (POS) tags, i.e. preterminals, as input. Pate and Johnson [Citation69] showed that using a word itself instead of a POS improves parsing accuracy; Levy et al. [Citation70] employed a sequential Monte Carlo method for the online inference of grammars, which resembles actual situations found in robotics research.
4.1.3. CCGs
Although CFG recognizes phrase structures, it is still limited, because these structures only have a symbolic meaning. For example, a rule S NP VP merely states that the symbol ‘NP’ can be decomposed into a pair of symbols ‘NP’ and ‘VP', which has nothing to do with the fact that the actual words it governs are nouns or verbs. Therefore, the CFG analysis of sentence inevitably becomes a type of hierarchical POS tagging, i.e. a combinatorial process to yield preterminals such as N or V.
CCG [Citation60] is a formalism that does not suffer from this issue: all phrase structures in CCG are functions and derived from the bottom. For example, because VPs require a noun phrase (NP) to be an S, a VP is actually denoted by Footnote2 instead of a distinct, and meaningless, symbol VP. An NP is also an artifact that possibly takes a determiner (DT) to function as an N, thus denoted by
; therefore a VP is finally denoted as
. CCG was introduced to NLP around 2002 [Citation71], and supervised learning was readily available. By contrast, the unsupervised learning of CCG was only introduced in 2013 [Citation72] using a framework of hierarchical Dirichlet processes (HDP) [Citation73]. From a statistical perspective, it has a clear advantage over an unsupervised PCFG also using HDP [Citation74], in that it simply utilizes an infinite-dimensional vector of probabilities as opposed to a matrix of infinite × infinite dimensions. Martínez-Gómez et al. [Citation75] recently introduced ccg2lambda, which combines CCG parsing with a λ-calculus to enable an inference on textual entailment. It also has the advantage of handling ambiguities by virtue of a statistical formulation using logistic regression.
4.2. Semantic parsing and grounding
Once these syntactic analyses of the sentence are available, we can associate them with external information. This process is sometimes called ‘grounding’ and is also studied in the field of NLP [Citation76]. The term ‘grounding’ is related to the symbol grounding problem [Citation20]. However, the symbol grounding problem does not concern the interpretation of symbols, i.e. semiosis, or language understanding [Citation18]. The ‘grounding’ here could be rephrased as ‘language understanding using sensory–motor information'. Semantic parsing and ‘grounding’ by robots, i.e. sensory–motor systems, that can associate syntactic structure with dynamic information, is important for language acquisition and understanding in a real-world environment.
In a discrete case, Poon [Citation77] leverages a travel planning database called ATIS and associates nodes and edges in a syntactic tree with the database. This is essentially a nested hidden Markov model (HMM), based on unsupervised semantic parsing [Citation78] that automatically clusters each predicate in a tree by maximizing the likelihood of a sentence computed by a Markov logic network. It has the clear advantage of abstracting away various possible linguistic expressions with respect to the database; however, the database must be given in advance and usually has a narrow scope. Because of its discrete nature, this approach cannot discern subtle differences in linguistic expression and adjust the actual behavior of the robots accordingly.
In a continuous case, there is an abundance of research connecting linguistic expressions with images [Citation79–82]. As an example more closely inspired by robotics, [Citation83] and its extension [Citation84] aim to discriminate which predicates are applicable to a given object, such as ‘lift’ and ‘move', but not ‘sing', for a box. To solve this problem, the former employs consensus decoding and the latter uses a mixed observability Markov decision process (MDP) leveraging sensory information. Although these works connect linguistic expression with sensory information, this content, such as imagery, is usually static and the objective is discriminative. Moreover, the candidate predicates are known in advance, and thus the approach does not cover broad linguistic expressions in general.
Note that we are not insisting on ‘grounding’ any word or phrase on the sensory–motor information provided by robots, i.e. external information. Sensory–motor information provides the cognitive system of a robot with observations, e.g. visual, auditory, and haptic information. However, many words representing abstract concepts cannot be directly ‘grounded’ on such sensory–motor information. For example, we cannot determine a proper probabilistic distribution of sensory–motor information for ‘in', ‘freedom’, or ‘the'. Even a verb can be considered as an abstract concept. ‘Through’ can represent different trajectories or a controller depending on target objects. Even though ‘in’ is abstract, ‘in front of the door’ seems concrete and more conducive to an association with sensory–motor information. Semantic parsing with real-world information and finding a way to handle abstract concepts is an important challenge.
4.3. Challenges in unsupervised syntactic parsing with grounding phrases and predicates
Studies involving the unsupervised learning of syntactic parsing in robotics are still in the preliminary stage. Attamimi et al. developed an integrative robotics system that can learn word meaning and grammar in an unsupervised manner [Citation85]. However, this approach relies on HMM, which does not have a hierarchical structure, for modeling grammar. Aly et al. introduced an unsupervised CCG to enable a robot to find the syntactic role of each word in a situated human–robot interaction [Citation86].
In connection with the topics described in this section, we identified the following challenges:
Enabling robust unsupervised parsing of colloquial or nonstandard sentences with the help of multimodal information obtained from robots.
Associating syntactic structures and substructures (such as those in CCG) with sensor–motor information for grounded language interpretation and generation.
Developing a machine learning algorithm to associate the predicates in semantic parsing with a distributed meaning representation in robots, organized based on sensor–motor information.
5. Category and concept formation
The ability to categorize and to conceptualize is essential to living creatures. A creature may not to survive if it is not capable of distinguishing beneficial items from harmful ones including, with regard to food, whether it is edible or not. Humans have categorized objects, actions, events, emotions, intentions, and phenomena. In addition, we label these using language. Thus, it is reasonable to say that language reflects the way we think and perceive the world around us, and considering linguistic categories is an effective way to comprehend the human ability to categorize and the way robots should operate in this respect. To understand human language, a robot needs to be able to categorize objects and events, and to handle concepts. In Figure , the robot grasps the concepts of ‘chair', ‘bottle’, and ‘ball', and can understand utterances from the user. Of course, the robot needs to understand ‘grasp', ‘bring’, ‘thirsty’, and ‘joy’ as well. During this decade, unsupervised categorization and concept formation have been studied in robotics [Citation17]. This section describes the foundation of category and concept formation, the current state of robotics, and future challenges.
5.1. Linguistic categories
5.1.1. Similarities and differences
A linguistic category represents ‘the conceptualization of a collection of similar experiences thatare meaningful and relevant to us [Citation87]'. The existence of such categories proves that humans have the ability to find similarities between objects. For instance, whether a car is manufactured by Toyota, Honda, or Renault, we can categorize it as a ‘car’ as long as it fits the conceptualized form of a ‘car'. However, if a vehicle accommodates a group of people, then we would think of it as a ‘bus'. This leads to the following questions: Can a robot categorize ‘similar’ items into a group? Can a robot draw a line between linguistic categories such as a ‘car’ and a ‘bus?’
It should be noted here that the lines between categories are by no means definitive. While traditional semantics presupposes binary features (see [Citation88] for an overview), current trends in cognitive semantics consider a prototype with both central and peripheral members in each category (cf. [Citation89]).
We should also point out that categories are related to language [Citation90]. English speaking people distinguish a ‘bush', i.e. short tree, from a ‘tree’ in a daily context, but Japanese people usually do not. Conversely, there is only one word for ‘flatfish’ in English, whereas Japanese people delineate between two types of flatfish, namely ‘karei’ and ‘hirame'. Separate cultures and communities may consider distinct categories and concepts. This implies that there may even be separate categories for robots, as they have a completely different sensory system from human beings.
5.1.2. Taxonomy and partonomy
Linguistic categories often exhibit hierarchical relations [Citation87]. This type of lexical relation is called taxonomy. For example, ‘cucumbers', ‘cabbages’, and ‘onions’ are considered members of the ‘vegetable’ category. Similarly, ‘dogs', ‘cats’, and ‘horses’ are grouped in the category of ‘animals', These superordinate terms are usually abstract notions; no specific entity is labeled as a ‘vegetable’ or an ‘animal'. This leads to another question: Can a robot form abstract categories on top of concrete groups?
Another type of lexical relation is called partonomy, where one word denotes a part of another. Winston et al. [Citation91] proposes six types of partonomic relations, including a component and integral object, e.g. a ‘cup’ and a ‘handle'; a member and a collection, e.g. a ‘tree’ and a ‘forest'; and a material and an object, e.g. ‘steel’ and a ‘bike'. This naturally leads to the following question: Can a robot identify components, or ingredients, of an object?
5.1.3. Semantic network via frame
Words have semantic relations in relation to a frame or scene [Citation92,Citation93]. For example, a ‘menu', ‘dish’, ‘knife’, and ‘fork’ are linked through a designated ‘restaurant’ frame, and a ‘plane', ‘train’, ‘hotel’, and ‘camera’ are linked through a ‘travel’ frame. The important distinction from other types of linguistic categories is that words can be categorized based on human activity and social customs. The link between ‘hotel’ and ‘camera’ is by no means linguistic but rather it is situational and even subjective. A question then arises as to whether a robot can understand these semantic networks.
Note that a word can belong to several frames; ‘knife’ can be viewed as a member of the restaurant frame when used for eating, whereas it can also be a weapon and linked to words such as ‘sword’ and ‘arrow’ when used in the context of fighting.
5.1.4. Abstract concepts and ad-hoc categories
In many studies discussing concepts and categories, we tend to exhibit a nominal bias, i.e. we tend to think of nouns. Many concepts and categories corresponding to nouns, e.g. objects, places, and movements, are observable and a statistical categorization method can be a constructive model with a categorization and conceptualization capability. However, forming abstract concepts, e.g. ‘in', a preposition, ‘use', a verb, and ‘democracy', a conceptual word, requires other mechanisms and is important in many senses [Citation94]. In daily language, we tend to use an abundance of abstract words. Therefore, enabling a robot to grasp abstract concepts is also important [Citation95,Citation96].
Moreover, many categories are not static but dynamic. People can form so-called ad-hoc categories instantly based on the situations they face [Citation97]. From this viewpoint, categorization may even be considered as a type of inference. How to model the learning capability for ad-hoc categories in the cognitive system of a robot is another question.
5.2. Multimodal categorization
5.2.1. Concept formation by robots
To enable robots to implement concept formation, several studies assume that concepts are internal representations related to words or phrases that enable robots to infer categories into which they may classify sensory information. Regarding categorization, image classification using deep neural networks has been widely studied [Citation98–102]. These studies use a large amount of labeled data and achieve very accurate object recognition. However, humans do not use such labeled data and it is important that the concepts are formed in an unsupervised manner. Studies on unsupervised image classification have also been conducted [Citation103–108]. However, the importance of multimodality in concept formation has been recognized [Citation109] and the difficulty in forming human-like concepts using single modality has been acknowledged. In studies using multimodal information, methods to learn relationships among modalities by using nonnegative matrix factorization and neural networks have been proposed [Citation110–117]. In these studies, the learned latent space can be interpreted as representing concepts.
Several methods have been proposed to classify multimodal information into categories in an unsupervised manner using stochastic models. Methods based on latent Dirichlet allocation (LDA) [Citation118], initially proposed for unsupervised document classification and LDA, were extended to a multimodal LDA (MLDA) [Citation119] for the classification of multimodal information. Here, category z is learned by classifying multimodal information acquired through the sensors of a robot. The concepts are represented in a continuous space linked to a probability distribution
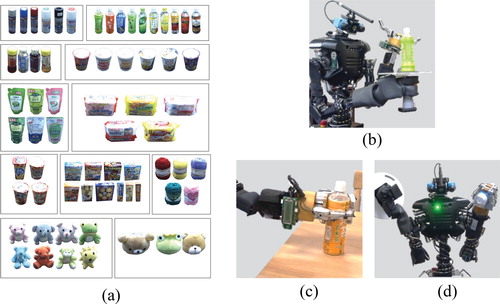
, and concept formation is equivalent to learning the parameters of this distribution. Using MLDA, the robot classified visual, haptic, and auditory information obtained by observing (Figure (b)), grasping (Figure (c)), and shaking (Figure (c)) the objects shown in Figure (a), and was able to form the basic-level categories shown in Figure (a). The probability distribution
can be computed using learned parameters and the multimodal information that maximizes this probability is considered to represent the prototype of the category:
Because this probability distribution is continuous, this concept model can represent not only a central member but also a peripheral member.
Figure 2. Object concept formation in a robot: (a) objects used in the experiment, and obtaining visual, haptic, and auditory information by (b) observing, (c) grasping, and (d) shaking objects.
Other nominal concept formation methods have also been developed. For example, locational, or spatial, concept formation methods have been proposed Taniguchi et al. [Citation120,Citation121].
5.2.2. Word meaning acquisition
The benefit of using multimodal information is that it makes it possible to infer abstract information from observations. For example, in neural network studies, relationships between modalities are learned, and they can therefore be inferred, to an extent, from other information. In MLDA, this inference is also possible by computing , which is the probability that modal information
is derived from other information.
Moreover, considering as words that represent object features and are taught by humans, the robot can acquire word meanings [Citation122]. The robot can recall the multimodal information
that can be represented by the word. The robot is considered to have understood word meanings through its own body. It has also been suggested that humans understand word meanings through their bodies [Citation123,Citation124] and MLDA partially implements this capability in robots.
Furthermore, a stochastic model [Citation125] enabling the robot to learn the parameters of a language model in the speech recognizer was proposed by introducing a nested Pitman–Yor language model [Citation126] into MLDA. Using this model, the robot can form an object concept and learn speech recognition similarly to infants by using multimodal information obtained from objects and teaching utterances given by humans. Moreover, by connecting the recognized words and concepts, the robot can also acquire word meanings. The robot on which this model is installed (Figure (b)) obtained multimodal information from the objects shown in Figure (a); meanwhile, a human user taught object features to the robot. Finally, the robot was able to recognize unseen objects with an 86% accuracy and teaching utterances with a 72% accuracy.
Figure 3. Learning concepts and language model in a robot: (a) objects and (b) robot used in the experiment.

5.2.3. Hierarchical concept formation
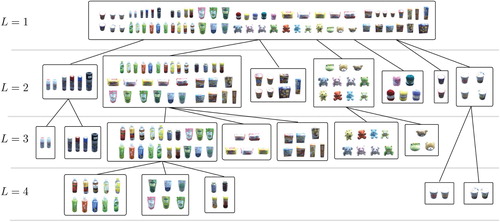
Concepts have a hierarchical structure and hence studies on the hierarchical classification of images using labeled data have been conducted [Citation127,Citation128]. However, as we mentioned earlier, learning concepts using multimodal information in an unsupervised manner is important. To implement such a hierarchical concept, a nested Chinese restaurant process [Citation129] was introduced into MLDA [Citation130]. Using multimodal information obtained by observing, grasping, and shaking objects as well as the studies discussed in the previous section, concepts were classified into categories and hierarchical relationships were estimated. As a result, the hierarchical structure shown in Figure was estimated by the robot, and one can see that hierarchical relationships based on feature similarities are captured. Applying this model to localization in the concept formation problem, Hagiwara et al. proposed a hierarchical spatial formation method [Citation131].
Figure 4. Hierarchical concepts formed by robot.
Moreover, studies to detect parts of objects [Citation132,Citation133] and faces [Citation134–136] are conducted regarding partonomy. However, in these studies, supervised learning based on visual information is utilized, and, currently, unsupervised learning based on multimodal information has not yet been implemented. A future challenge for robots is to learn partonomy using multimodal information in an unsupervised manner.
5.2.4. Integrated concept
Machine learning methods for forming various concepts and, furthermore, for learning relationships between them has been proposed. Moreover, as the transition in these concepts can be viewed as grammar, the proposed method enables robots to learn grammar using a bottom-up approach [Citation85]. The multimodal information obtained from scenes where individuals manipulate objects is classified by MLDAs and the individual, object, motion, and localization concepts are formed. Furthermore, another MLDA is placed on top of these MLDAs to learn the relationships between concepts. Using this model, for example, the meaning of motion can change based on simultaneous observations of objects. We consider that a type of semantic network has been implemented. However, this is a very limited, and inflexible network with a structure that changes depending on the context, as explained in Section 5.1.3. Concepts change depending on the context, situation, and purpose, as seen in the ad-hoc category [Citation97]. We need to change our perspective on concepts and no longer consider them as static objects, but rather as dynamic processes.
5.3. Challenges in category and concept formation
So far, we have shown that significant progress in category and concept formation is being made in current robotics. However, previous studies have mainly focused on nominal categories and concepts, e.g. objects, location, and movement, which are concrete and observable. Therefore, some of the remaining challenges are as follows:
Inventing a mechanism for representing abstract concepts including emotions, e.g. anger, happiness, and sadness, and social concepts, e.g. democracy, freedom, and society.
Inventing unsupervised machine learning methods to represent verbs, e.g. grasp, throw, and kick, and functional words, e.g. in, on, and over, from sensor–motor information.
Identifying and implementing the process of categorical extension, especially for polysemous words, e.g. gift as a present and gift as a talent.
Enabling a robot to spontaneously form ad-hoc categories to achieve a given goal within a certain context [Citation97].
Inventing a model for the distributed representation of concepts that can be used for logical inference, as discussed in Section 3.
6. Metaphorical expressions
Daily conversations, which a future service robot is expected to face, are full of metaphorical expressions. In Figure , ‘I'm filled with joy’ embeds a metaphor in which emotion is compared to a liquid. Even though metaphors play a crucial role in semantics, very few related studies have been performed in robotics.
6.1. Metaphor as a cognitive process
Before the advent of cognitive linguistics, metaphors were only viewed as linguistic ornaments, outside of the main scope of linguistic studies. However, since Lakoff and Johnson [Citation137], metaphors have been regarded as one of the important linguistic phenomena that reflect our way of thinking. They claim that, by analyzing language, we can find conceptual metaphors that reside at the core of the human conceptual system.
Conceptual metaphors are pervasive in language. As such, we are rarely conscious of their existence, but metaphors are the instruments that enable us to form abstract notions. Using metaphors, we understand and experience abstract concepts in the context of others. For example, when people are happy, they might say ‘I'm filled with joy.’ This sentence seems natural enough and may not sound metaphorical, but the subject for the verb ‘fill’ in the literal sense is usually liquid, whereas ‘joy’ is not. Here, we clearly understand ‘joy', as the target domain, which is invisible and intangible, in terms of a ‘liquid', as the source domain, and this expression is underpinned by a conceptual metaphor ‘emotions are liquids.’ The existence and pervasiveness of this metaphor is proven by its effectiveness in expressions such as ‘she is overflowing with love’ and ‘my anger is welling up.’ Thus, human beings are capable of metaphorical understanding, among other basic cognitive abilities. It should also be noted that the conventionality of this metaphor has led to the categorical extension of the verb ‘fill’ and dictionaries have an entry for the meaning of ‘be filled with emotions.’ If robots are to simulate the human cognitive process, then metaphors may play a vital role not only in terms of the cognitive ability to understand abstract notions, but also as a device for extending linguistic categories (see Section 5.1). It seems, however, that almost no attempts have been made in this respect in the field of robotics, and hence the mechanism supporting metaphorical understanding and extension requires further research.
6.2. Metaphor and embodied experiences
The process of metaphorical understanding involves two domains. One is the target domain, which is usually an abstract notion. The other is the source domain, which is concrete and a concept that we can observe or experience. The properties of the source domain are mapped onto the target domain and linguistic expressions accordingly. Fauconnier and Turner [Citation138] provides an actual model of conceptual blending. Some researchers in the field of cognitive linguistics and cognitive science argue that bodily experiences are embedded in the source domain [Citation23–25] claims that ‘abstract thoughts grow out of concrete embodied experiences, typically sensory–motor experiences.’ For example, in the ‘purposes (target domain) are destinations (source domain)’ metaphor that can be found in a sentence such as ‘he'll ultimately be successful, but he isn't there yet', the underlying sensory–motor experience, according to Feldman [Citation25], is ‘reaching a destination', and thus we can easily understand the metaphorical expression based on our own physical experiences. In addition, Grady [Citation139] claims that seemingly abstract metaphors can be decomposed into more basic elements identified there as primary metaphors, such as ‘more is up’ and ‘affection is warmth', with an experiential basis or experiential co-occurrences.
These findings have significant implications in robotics. If metaphors are grounded in embodied experiences, the body of a robot itself is an important interface for understanding the world. In other words, having a body is a considerable advantage for forming concepts as a robot. It also opens a way to connect concrete and abstract notions. Because metaphors may be used as devices for understanding abstract notions, robots may be able to understand abstract meaning based on embodied experiences, just as humans do. However, again, little research has been conducted on the topic, and hence whether a human-like body is advantageous to understanding abstract notions remains an open question.
6.3. Metaphor resources and universality
Several linguistic endeavors have aimed at identifying the various types of metaphors used in the human language. This effort ended up as an attempt to understand how we perceive and conceptualize the world, and identify the types of bodily experiences embedded using the inventory of basic primary metaphors. This included constructing dictionaries of metaphors [Citation140–142]. Among them, Seto et al. [Citation143] is particularly noteworthy in that it tries to uncover the polysemy of English words in terms of metaphors and metonymies. This has the potential to reveal how meaning emerges from very basic building blocks and thus provide a useful model for categorical extension. MetaNet [Citation144] is an online resource for metaphors based on frame semantics [Citation145]. The aim of the MetaNet project is to systematically analyze metaphors in a computational way; it now provides more than 600 conceptual metaphors, e.g. anger as a fire, happy as being up, and machines as people, with links to FrameNet frames [Citation144]. There have also been some attempts to identify metaphors using linguistic resources [Citation146], but the task was challenging, as metaphors are deeply interweaved into the language.
Comparing resources across several languages (cf. [Citation147]), it appears that many metaphors are surprisingly universal. Meanwhile, naturally, differences should be considered [Citation148,Citation149]. The universality of metaphors can be attributed to the universality of human bodily experiences, but robots may form completely different metaphors because of their physical differences. This may imply that having the body type of a human is one of the necessary conditions for robots to have a cognitive system similar to that of a human.
6.4. Challenges in metaphorical expressions
As pointed out above, there have been few endeavors in the field of robotics centered on metaphors and embodiment, despite their importance and the potential benefits. This could be due to the difficulty in implementing metaphorical thinking and the fact that robotics has not advanced enough to cope with metaphors. Nevertheless, we believe it is worth listing some of the challenges here, and we summarize them as follows:
Clarifying the computational process of categorical extension through metaphors, e.g. from ‘being physically drained’ to ‘emotionally drained.’
Inventing a computational way to understand abstract concepts based on bodily experience, e.g. using an experience tied to ‘reaching somewhere’ to understand the concept of ‘accomplishing something’ and thus, expanding the meaning of ‘reach.’
Inventing a computational mechanism for understanding creative uses of metaphors, e.g. ‘streaming is killing cable’ to mean ‘streaming is displacing cable.’
Metaphorical expressions are also one of the actively researched topics in cognitive linguistics and developmental psychology. Hence, new insights may come from related fields and interdisciplinary cooperation may be a key to unlocking new possibilities in the field.
7. Affordance and action learning
Language and actions are deeply related to each other. We can talk about ourselves and the actions of others using sentences, understand language instructions, and act accordingly. From a neuroscientific perspective, the motor and auditory areas are connected to each other, enabling, for example, the autonomous activation of the corresponding motor signals when auditory stimuli tied to a specific word are provided [Citation150,Citation151]. This type of phenomenon may be useful to the understanding of the meaning of verbs. Furthermore, to understand the language, constraints imposed by the physical body and the concept of possible actions, which is related to the idea of affordance, play an important role [Citation30]. Moreover, grammar learning is based on temporal information, namely the order of words, and it seems to be deeply related to an action-planning ability [Citation152,Citation153]. This section provides an overview of the research area of affordance and action learning, which are key to the understanding and generation of language based on embodiment.
7.1. Affordance learning
7.1.1. Affordance and functions of objects
The concept of an object is not only determined by multimodal information that can be directly observed via sensor systems, such as perception, but also by the functions of an object. Multimodal categorization, which was introduced in Section 5, is insufficient to explain object concept formation. Therefore, the functions of an object are important attributes of an object concept. The same can be said about robots [Citation154–156]. For example, considering the identification of a chair, what is important to us is the ability to sit down on it, whereas its appearance is not essential. Of course, we do have knowledge of the appearance of chairs and their usual location; however, whether we can sit on them is ultimately the decisive factor. In particular, it is considered that a function of a tool is perceived by an action–effect relationship. Such action-oriented perception learning is often referred to as affordance learning in cognitive robotics [Citation154–156].
Affordance is a concept proposed by Gibson, a psychologist who promoted ecological psychology [Citation157]. According to this concept, the meaning of the environment is not held in the human brain but instead exists as a set of possible actions by the human body. In other words, the meaning is naturally defined by the environment and the body facing the environment.
By contrast, for an object (chair) recognition using a deep neural network, the situation is completely different. For identification using a neural network learning from a large number of chair images, appearance is essential. Of course, functionality could correlate with visual information, but this does not necessarily hold. Affordance is an important concept in the quest for human intelligence, and a perfect example of the fact that intelligence and the body cannot be separated. Hence, affordance is a key concept in intelligent robotics.
7.1.2. Affordance learning
In studies on affordance in robotics, researchers often focus on ways to improve the performance of a robot using the concept of affordance. The other important area of interest regarding affordance in robotics is the issue of how to make robots learn, i.e. acquire, affordance. Here, we introduce several studies from the perspective of learning affordance.
The first work centered on the usage of affordance in navigation and obstacle avoidance for autonomous mobile robots. Sahin et al. proposed a model of affordance that links the motion of the robot to changes in the visual sensor [Citation158]. With this model, the robot can take actions to avoid obstacles naturally.
The second study contributed a learning tool to be used by robots. Stoytchev proposed a method that enables a robot to learn affordance in connection with a tool by gripping and moving a T-shaped tool in order to pick a target item [Citation159,Citation160]. This allowed robots to pick items with a high probability using the T-shaped tool.
The third work provided an example of learning more complex tools. Nakamura et al. defined the change in the object affected by tools such as scissors and staples as a function of the tool [Citation161]. Then, a method to learn the relationship between the local features of the tool and an action was proposed using Bayesian networks. Here, the robot could associate, for instance, the functionality of a tool with certain visual features and potential action. It should be noted that this affordance learning is deeply related to the multimodal categorization described in Section 5.
Many of these studies demonstrate that robots can acquire affordance in practice and that robots make better decisions using affordance.
7.2. Action learning
Action learning in robotics is often referred to as learning from demonstration (LfD) or programming by demonstration (PbD), which focuses on the issue of programming a robot motion [Citation162–164]. Action leaning is important in language and robotics, because it enables robots to understand the meaning of verbs by acting in the real world. In other words, there is no point in using a robot in the first place unless it can learn actions and form concepts in the actual, physical world. A robot capable of learning the mapping between language and actions, leading to the essential understanding of verbs, becomes very useful in practice, as language instructions can then be used to direct work.
7.2.1. Imitation learning
There are various types of action learning. In general, they can be divided roughly into two types according to the existence of supervision. In the presence of supervision, learning is sometimes referred to as imitation learning. In robotics, imitation learning often refers to the regeneration of the trajectories of the instructor, also known as LfD. In this case, the problem reduces to the modeling of the demonstrations, i.e. trajectories, of the instructor.
It should be noted that mimicking the trajectories of an expert is not essential for action learning. An important aspect of an action is its function, and one must be able to reproduce this function inherently. However, considering imitation learning by children, it is initially difficult to notice and to imitate the functional aspects of the actions. Instead, by imitating the trajectory, children eventually uncover its functional underpinnings through their own actions. In other words, it appears that it is also key to simulate trajectories initially in imitation learning. The problem currently revolves around the concept of a unit of action. In other words, we must segment continuous actions into meaningful units. From the perspective of mapping to language, segmented actions lead to discrete symbols, which facilitate the connection between the action and a word. To categorize the segmented unit actions, a Gaussian process hidden semi-Markov model (GP-HSMM) was proposed in [Citation165], with the ability to segment time series using the idea of state transitions in a hidden semi-Markov model (HSMM).
The segmentation of continuous signals is also important in speech signal segmentation. Taniguchi et al. proposed the concept of a double articulation analyzer (DAA) in order to carry out the segmentation and categorization simultaneously based on the double articulation property of speech signals [Citation166]. The DAA was implemented based on a hierarchical Bayesian formulation. The segmentation of actions, i.e. trajectories, and speech signals is highly significant in the relationship between actions and language [Citation167]. Indeed, each segmented word, i.e. verb, may be connected to a corresponding discrete action, leading to a word acquisition process that is extremely easy to understand.
In order to act based on the learned discrete actions, robots need to have a decision-making process. This is usually a matter of policy learning, and RL can be used for this. Learned discrete actions are selected based on the learned policy.
There are other types of imitation learning. In fact, Schaal discussed imitation learning from the perspective of efficient motor learning, the connection between action and perception, and modular motor control in the form of movement primitives [Citation168]. In [Citation169], a recurrent neural network with parametric bias (RNNPB) model was used to enable the identification and imitation of motions by robots. These were pioneering works on sensor–motor learning based on imitation; however, language was not involved.
Recent developments in deep learning technologies have opened a new direction in imitation learning. More specifically, generative adversarial imitation learning (GAIL) [Citation170] has been proposed based on generative adversarial networks (GAN). This approach is made possible by the fact that the output of the discriminator network can be seen as a reward for the action imitated.
Although language is not involved in GAIL, the idea has huge potential for action and language learning.
From a language learning perspective, Hatori et al. [Citation14] succeeded in building an interactive system in which the user can use unconstrained spoken language instructions to pick up a common object using an NLP technology based on deep learning. Actions are not learned but predefined in the study. However, the challenge will be to combine action learning and spoken language instruction understanding for picking tasks.
7.2.2. Reinforcement learning (RL)
RL can handle policy learning [Citation171,Citation172]. Thus, the problem mentioned above regarding the decision-making process can be solved by RL. RL techniques are roughly divided into two categories, the model-free and model-based methods. Q-learning is a well-known model-free RL method, which is suitable for discrete actions. Recent advances in deep learning have contributed to the improved performance of Q-learning using functional approximation. Deep Q-network (DQN) is the most famous method in this line of research [Citation173]. Owing to the end-to-end nature of deep learning, policy learning with continuous actions generalizes action learning, i.e. the modeling and segmentation of trajectories, and RL can be combined naturally through end-to-end learning. Deep deterministic policy gradient (DDPG) [Citation174] is one of the most frequently used algorithms for this purpose. In robotics, Levine developed a method that can be used to learn policies by mapping raw image observations directly to the torque of the motors of the robot [Citation175]. The authors demonstrated that the joint end-to-end training of the perception and control systems achieves better performance than the separate training of each component. From the perspective of connecting actions and language, end-to-end learning does not provide an explicit structure. However, an interesting approach to language acquisition by a computer agent in a simulation environment has been proposed by DeepMind Lab using deep reinforcement learning [Citation176]. The authors present an agent that learns to interpret language in a simulated 3D environment, where it is rewarded for the successful execution of written instructions. A combination of reinforcement and unsupervised learning enables the agent to learn to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. Although the actions contemplated in the study, such as pick-ups, are limited and relatively simple, the approach has potential for creating agents with a genuine understanding of language.
By contrast, model-based RL tries to capture the dynamics of the environment [Citation177]. Therefore, the agent can use the model to learn the policy. Although current performance is limited, model-based RL may potentially have advantages making it more applicable to complex tasks in the real world compared to model-free RL. From a language learning perspective, there have been few attempts to apply model-based RL to the language learning task, which could be a solution.
7.2.3. Syntax and actions
In generative grammar, the basic design of language capability in humans is assumed to comprise the following three modules: (1) the sensor–motor system, which is related to externalization such as utterance and gestures; (2) the conceptual and intentional system linked to the concept of semantics; and (3) the syntactic computational system, i.e. syntax, which connects the sensor–motor system to the conceptual and intentional system.
From the perspective of evolutionary linguistics, it can be argued that the syntactic operation system precedes hierarchical and sequential object manipulation abilities (action grammar [Citation178]), typically observed in the use and creation of tools. One must also insist that the conceptual and intentional interface and lexicon arise from this syntactic operation system [Citation153,Citation179]. In other words, the claim is that the syntactic operation system is derived from the sensor–motor system, i.e. syntactic bootstrapping [Citation180,Citation181]. These evolutionary linguistic viewpoints are very important for language and robotics, because affordance and action learning using robots is indispensable for acquiring language in a true sense.
7.3. Challenges in affordance and action learning
In this section, we described several studies on affordance and action learning in robotics with a close connection to language learning. From the above evolutionary linguistic viewpoint, language, especially syntax, has a strong relationship with affordance and action planning. Unfortunately, there are few existing studies focusing on learning affordance, actions, and language using real robots. Therefore, a future challenge will be to study the links among affordance, actions, and language. However, there have certainly been some pioneering attempts. In [Citation182], the authors proposed a bidirectional mapping between whole-body motion and language using deep recurrent networks. Yamada et al. proposed paired recurrent autoencoders, translating robot actions and language in a bidirectional way [Citation183]. Although the network architectures are different, these recent studies both share the concept of end-to-end learning. These deep-learning-based studies yielded promising results; however, the end-to-end learning approach has a limitation, as it does necessarily clarify the structure and the relationship between language and actions, as we explained earlier. Moreover, affordance is not explicitly taken into consideration in these studies. Therefore, achieving a comprehensive understanding of the language system, taking affordance and action learning into account, is a major challenge.
The challenges in this section can be summarized as follows:
Developing a synchronous method for learning action and affordance for language use and understanding.
Developing a computational model that forms a joint representation of action planning and syntax learning, i.e. a computational model realizing syntactic bootstrapping.
Inventing an action learning method that leads to the emergence of the concept of a verb.
The use of robots with physical bodies is an indispensable step toward this goal.
8. Pragmatics and social language
In daily conversations, spoken sentences do not always mean ‘what they literally mean.’ For example, in Figure , a person says ‘I'm thirsty.’ His utterance is a type of request to the robot rather than a declaration of his appetitive state. In many cases, language use cannot be handled without pragmatics.
There are three representative theories currently supported in pragmatics: (1) speech act theory [Citation184], (2) a theory of implicature by Grices [Citation185], and (3) relevance theory [Citation186]. These theories have provided many reasonable explanations, analyses, suggestions, and implications regarding language use, and have had a great influence on several academic disciplines. However, pragmatics and the social aspect of language have rarely been taken into consideration in robotics.
These theories tend to analyze the phenomena of language use based on reductionism, and have not yet been successful in dealing with holistic properties linked to the interdependency between foreground spoken stimuli and background beliefs. Explaining and analyzing the phenomenon in terms of language alone may lead to a limitation. Another issue may be that these approaches manipulate languages, but do not have any consideration of the body, nor its surroundings.
In addition, in terms of the social aspect of language, meaning is determined by use in a social context; here, context is linked to the culture and situation of a specific social group.
Considering these issues, it is important to equip the robot with knowledge of pragmatics and a sense for the use of language in a social context.
8.1. Pragmatics
8.1.1. Pragmatics in AI
In terms of AI research, several studies have been conducted on pragmatics. SHRDLU was primarily a language parser that allowed user interaction with a robot in a simulated physical world. The user instructed SHRDLU to move various objects around in the ‘blocks world’ containing various basic objects. This program was very innovative and promising, and made many important suggestions not just for the development of artificial conversational systems, but also for the human cognition of language use in the physical world. This scheme still has a great influence on conversational systems. However, Winograd [Citation187] himself pointed to the limits of the SHRDLU scheme in terms of background and subjectivity as follows:
We cannot provide a program with background in the sense of pre-understanding emphasized by Heidegger [Citation188].
The rationalistic approach to meaning that underlies systems such as SHRDLU is founded on the assumption that the meaning of words, and of the sentences and phrases they form, can be characterized independently of the interpretation given by individuals in a situation.
In terms of background, Heidegger [Citation188] mentioned that a hearer interprets the intention of a speaker based on the background beliefs that were formed through past experiences; these prior understandings themselves were based on background beliefs that had been formed through more distant experiences, and this recursive structure continues indefinitely. Based on this, he concluded that such background beliefs could not be described explicitly in any way.
Regarding subjectivity, the theories of pragmatics mentioned above have not contributed sufficient analysis or a reasonable explanation. This may be because, until recently, science has tended to exclude or ignore subjectivity in all research subjects. As mentioned above, the body plays an important role in holistic cognition, and can be a hub for subjectivity. Searle [Citation189] thought the philosophy of language had reached relative stagnation because it took the position of so-called externalism, the idea that the meaning of words does not reside inside our heads but is a matter of causal relations between our heads and the external world.
8.1.2. Holistic property of language use
Cognitive linguistics attempts to explain language phenomena in a holistic way rather than by reductionism [Citation190,Citation191]. However, it suffers from the same shortcomings as the pragmatics theories. That is, it has not been successful in analyzing and explaining holistic phenomena in language, because the description is again inherently elementary, even if it effectively makes use of figures or images as a bridge between linguistic meanings and embodied experiences.
We have been tackling this problem for approximately two decades based on a constructive approach [Citation12,Citation13,Citation19,Citation192–199]. In our approach, language is viewed as a holistic system that merges other cognitive capabilities. We focused on the connection to sensory–motor capabilities in the context of multimodal processes. We developed a language acquisition robot, LCore [Citation192], that could learn a whole language system, including language, multimodal concepts, and actions through interactions with humans from scratch. The sophisticated constructive scheme for information integration, SERKET [Citation200], developed by Nakamura et al. seems to be promising to model the phenomena in pragmatics in a holistic way.
8.1.3. Recursive property of background beliefs
With the rapid progress in machine learning, we gained access to a powerful tool for representing the recursive property of phenomena, i.e. recurrent neural networks. Hauser et al. [Citation201] hypothesized that recursion was a uniquely human component in the faculty of language from the perspective of ethology and linguistics. In contrast, in the AI field, Elman et al. [Citation202] found that simple recurrent neural networks could learn a nested structure of grammar with a small amount of learning data and raised doubts with respect to the innate nature of grammatical structures. Owing to advances in AI, new discoveries are occurring at a rapid pace. Sophisticated recurrent neural networks recently enabled the development of high-accuracy machine translation systems (e.g. [Citation203]. In addition, a dialogue system was also enabled to utilize sequential contextual information as background [Citation204]. Heidegger insisted that background knowledge could not be described. However, recent advances in AI suggest that such background could be described.
8.1.4. Cooperation with humans
The creation of robots capable of cooperating with humans must be the ultimate goal of our language and robotics research. During the cooperation, humans and robots need to understand the physical and mental state of the other and share a common target for their activities. We tend to think that such capability is higher-level than either expressing something accurately using language or independently acting sophisticatedly. However, even twenty-four-month-old infants can cooperate with others in collaborative physical activities [Citation205]. They can understand the intentions of others, share a common target, and infer the roles of the participants attending to the activities. During the process of language acquisition by infants, they must understand the roles of others and themselves, here referred to as speaker–hearer or teacher–learner, and further understand the reversibility of such roles. However, twenty-month-old infants do not yet have a sophisticated grammatical capability. Thus, we can say that cooperation capability is the basis of language capability. In fact, psychological experiments have shown the correlation between language capability and the physical role reversal imitation capability [Citation206].
Dialogue is also a cooperative activity. We clarify the difference between physical cooperation and dialogue. During physical cooperation, information is explicitly exchanged through physical behaviors, whereas during dialogue, information is exchanged in a deictic and implicit way. Therefore, managing the ambiguity that invariably occurs during a dialogue is a major challenge. In order to manage such ambiguity in artificial cooperative systems, the probability that information linked to utterances is transmitted and received correctly should be calculated [Citation195,Citation207]. Whereas physical cooperation achieves common purpose in the here and now, conversational cooperation also enables achieving common purpose, not just here and now, but also in a way that transcends time and space.
8.2. Social language
In order to clarify differences between the cognitive approach that has been discussed so far and the social approach, we describe the perspective of social language. For this purpose, we introduce a systemic functional linguistic theory representative of functional linguistics, with the notion that language is a social semiotic system [Citation208].
8.2.1. Language as a social semiotic system
As a functional approach to understanding the nature of social language, we introduce systemic functional linguistics (SFL) in this section. SFL is a linguistics developed by Halliday [Citation209]. The big difference between other linguistics and SFL is that SFL introduces the ideas of ‘context’ and ‘system’ as part of its theoretical framework and discusses the linguistic system from the functional view of language in society [Citation210], although many linguistics only focus on grammar, owing to the difficulty in dealing comprehensively with the various characteristics of semantics. The idea of ‘context’ comes from the study [Citation211] by Malinowski, a cultural anthropologist. The previous idea of ‘context’ before the study by Malinowski focused on particular sentences before or after the current one; in other words, it indicated the idea of ‘togetherness with a text', i.e. ‘con-text.’ By contrast, the concept of context according to Malinowski points to the necessity of considering the cultural and situational backgrounds against which the text originated. To represent these two types of background as context, he introduced new concepts for the context defined as the ‘context of culture’ and the ‘context of situation.’
As for the relation between a context and a text, Halliday regards a text in a context as functional language. Here, ‘functional’ means the function to have a certain meaning in a specific context; in other words, it corresponds to conveying the appropriate meaning to the participants in a communication in the context of a culture and a situation [Citation212]. The meaning accompanying the functions to be conveyed to the participants is instantiated as a text in the context using the appropriate linguistic resources in terms of lexico-grammar and expressions.
Halliday indicated that linguistics is a semiotics, but tends to be regarded as independent rather than being related to another semiotics. Based on this, he did not study language as a semiotics but defined linguistics as the study of the system of semiosis, and regarded the meaning of language as the system being operated through semiosis. In these circumstances, a text has a systematically representable structure and is instantiated through the process of choosing a meaning from the system of semiosis, also called the ‘system network.’ The process of instantiating a text through picking the meaning from a system is called the ‘meaning making process.’ The text is instantiated by reflecting social functions to exchange meaning, and is regarded as that which encapsulates meaning through the system that binds the social environment and the functional constituency of the language.
Halliday's perspective on language is that meaning comes from being used in a social context and is an instrument to exchange messages and values. This is consistent with the later viewpoint on language in Wittgenstein's philosophy, namely that meaning is defined by the use of language in our everyday lives. In this sense, the use of language and actions by a robot must be based on its environment and instantiated as that which has meaning in this environment. Hence, the information a robot observes and recognizes must be closely related to the context of its actions and the use of language in order for a robot to truly use language.
8.2.2. Linguistic system defined by SFL
In SFL, the situation is instantiated against the cultural background of a social group, i.e. context of culture. Figure shows the hierarchy of a linguistic system in SFL. The situation, i.e. context of situation, consists of three elements, i.e. ‘field', ‘tenor’, and ‘mode', which represent the register in terms of linguistics, social role, and method of communication, respectively.
Figure 5. Linguistic system.
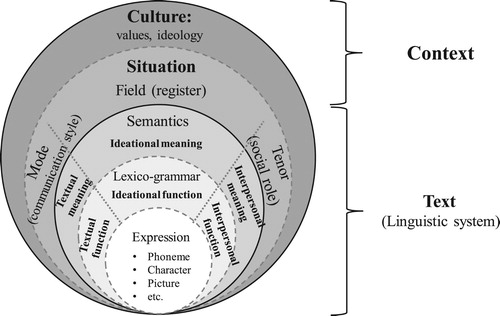
The field refers to the content of the conversations. For example, when one talks about a professional topic, one speaks differently from when they discuss daily affairs. Tenor refers to the context related to a social role. One uses different words or expressions when acting as a teacher or as a husband. Mode refers to the context related to the communication style. When one calls a friend over the phone, the talk is different from a conversation face to face. These clearly reflect our ability to use language adequately for communicating with each other in a social environment. Future service robots should definitely use language naturally in social contexts.
Furthermore, the linguistic system constitutes a stratification with separate semiotic systems, i.e. semantics, lexico-grammar, and expression, linking each other. The linguistic system exists in the context and a linguistic text is instantiated to realize three metafunctions, called the ‘ideational function', ‘interpersonal function', and ‘textual function', reflecting the three contextual elements, respectively.
Meaning is not static but dynamic, and its essential characteristics reside in instantiating a text by dynamically choosing linguistic resources based on the social context. The linguistic resources chosen from the linguistic system are used to instantiate a text followed by a rule, i.e. grammar. The process of instantiating appropriate texts in their context is called ‘wording’ and, therefore, SFL says ‘wording makes meaning.’
In the same vein, when considering the meaning of language, it is quite important to consider the role of grammar. Meaning without grammar is the meaning according to semiotics, which is different from the meaning of language.
8.3. Challenges in pragmatics and social language
We have so far demonstrated that pragmatics plays a big role in achieving communication, as well as the necessity of considering social factors to use language properly for exchanging meaning among dialogue participants. Based on these considerations, to achieve more advanced robotics, future challenges in pragmatics and social language include the following:
Creating holistic language processing systems that involve physical, psychological, social, conceptual, and experiential constraints.
Inventing machine learning methods to represent the recursive property of background beliefs for holistic language processing.
Developing computational models for collaborative tasks in the physical world, leading to the emergence of dialogue (see e.g. [Citation207,Citation213]).
Inventing methods to enable a robot to make use of contexts, e.g. situation and culture, and to grow the ability to use language to exchange meaning by referring to social factors: field, tenor, and mode.
9. Dataset, simulator, and competition
In research on pattern recognition such as image processing and speech recognition, datasets play an important role for the evaluation of learning and recognition performance. The same is true for the acquisition of languages by robots; however, the differences from conventional pattern recognition and annotation research are roughly divided into two groups. These are:
handling of multimodal information including time-series data
relationship between actions and information from the sensory systems of the robot.
Additionally, the ability to handle not just a static dataset but also a mechanism to allow the database to grow dynamically is important for the machine learning technique. To implement the dynamic growth of the dataset, competition and crowdsourcing would be useful strategies and may lead to a huge data collection. In this section, we discuss the dataset repository, simulation platforms, and robot competition to accelerate the research on language acquisition.
9.1. Dataset
9.1.1. Scenes dataset
One of the most fundamental datasets related to language acquisition is the image and scene datasets contributed by the computer vision community. ImageNet [Citation214], TinyImage [Citation215], LabelMe [Citation216], Flickr 8K/30K, MS COCO [Citation217] are brief examples of image and scene datasets. These datasets comprise a set of images and category labels. The PASCAL dataset extends the category information to sentences to describe the context of the image. The DAQUAR dataset includes question-answering sentences with the image data.
9.1.2. Locations dataset
In addition to objects, locations and scenes are also important factors to convert into symbolic representations. In terms of indoor environments, there are several image scene datasets [Citation218,Citation219]. Zhou et al. [Citation220] proposed a huge location dataset that contains more than seven million images with 476 location categories to overcome the data shortage in conventional location datasets.
9.1.3. Multimodal dataset including motion and action
Another important multimodal dataset for robots to understand activity in daily life consists of the motion and action of human users. Conventional motion datasets consist of motion patterns and category information, such as the CMU Mocap database, the CMU motion of body database, the HumanEva database, the HDM05 database, and the Human Motion database [Citation221]. In addition to category information, the KIT Motion-Language dataset [Citation221] contains sentence descriptions corresponding to the motion patterns. The sentences are collected using crowdsourcing as well as Takano's work [Citation222].
The datasets above include motion capture data, but movie datasets with language descriptions have also been provided. For example, cooking behaviors [Citation223,Citation224] and Hollywood movies [Citation225] are often selected as target movies. Because most of these datasets depend on the crowdsourcing process, a more general dataset based on YouTube [Citation226] has also been proposed.
9.1.4. Dialogue and action
A dataset with dialogues, namely questions and answers, in a social and embodied environment, is also strongly linked to NLP in robotics. VQA [Citation227] is one of the famous datasets for questions and answers linked to images. MovieQA [Citation228] contains movie data instead of still images. Embodied question answering (EQA) [Citation229] provides questions and answers for a navigation task in a 3D simulation environment. Because the 3D simulation world can be readily connected to machine learning techniques for robotics [Citation230], research activity on the use of natural language for navigation in simulation [Citation231,Citation232] should accelerate.
Talk the walk [Citation233] has over 10k dialogues for a tourist navigation task. Both a tourist and a guide communicate via natural language to achieve a goal, consisting of having the tourist navigate to a target location. Because the set of activities for the tourist, walking in New York City, the explanation by the guide, and sequence of realistic landscape pictures from the tourist's view, are collected via crowdsourcing, the database could be applied to the evaluation of grounding a conversation in a navigation task. A similar attempt was also proposed using crowdsourcing through virtual reality [Citation234].
9.2. Simulation platform
To date, an abundance of simulation platforms has originated from various sources including research projects, the robotics community, and software production companies. A conventional robotics simulator tends to focus on physics simulation to provide a reliable evaluation of the control and physical behavior of robots. As the main target is accuracy, it takes a long time to obtain a simulation result. Recently, several simulation environments focusing on approximative physics simulation, but with connectivity to a variety of useful tools in the AI community, were introduced. For example, DeepMind Lab [Citation235] by DeepMind, Open AI gym/universe [Citation236] by Open AI, and the Malmo project by Microsoft recently launched. In this environment, we can easily put an AI agent into an environment resembling a video game such as an ATARI game or Minecraft, to accelerate machine learning processes such as RL, as the video game environment provides a variety of actions for an AI agent; however, a more realistic and social environment is required for human–robot interaction in daily life. HoME [Citation237], AI2-THOR [Citation238], and MINOS [Citation239] are recent platforms providing multimodal sensor information to AI agents in an indoor house environment. The basic strategy to learn symbols or a lexicon in such an environment is to access the ground truth provided by the simulation platform. The AI agent should use a specific API to access the ground truth. Behind the inquiring action is the use of natural communication between two AI agents, or a human–robot interaction. Therefore, aiming at a more natural fundamental acquisition of language requires an additional communication function. For example, the restaurant game [Citation240] and Mars escape [Citation241] are famous research projects using communication between an agent and a human. A key technique for both projects is to use crowdsourcing. The general public can access the project software to establish communication with the AI agent through the Internet. The researcher therefore easily collects a large communication log in the simulated world. The aim of a more natural and complicated environment as the next target, is a more natural and wide variety of actions for humans and agents in the simulation. Controlling the humanoid agent in the systems above is difficult. However, the language acquisition process has a strong relationship between not just simple actions such as ‘go forward’ or ‘turn right', but also more complex actions using a realistic body and limbs. To close the gap between a conventional robotics simulation by a humanoid agent and recent simulation systems for AI, Inamura et al. proposed a unique simulation named SIGVerse [Citation242]. The latest version of the SIGVerse [Citation243] integrates ROS [Citation244] and Unity to provide a flexible simulation environment for both robots and human users. A user can log in to a virtual avatar through a head-mounted display and a motion capture device, and have a social and embodied interaction with a virtual robot controlled with the same software as the real robot. The location concept and lexicon acquisition by Taniguchi uses the SIGVerse simulator to confirm the basic performance. Because this simulator works on a cloud computing resource, it is easy to apply the human–robot interaction experiment through crowdsourcing. This software is adopted in the robot competition, as described in the next subsection.
9.3. Competition
Competition is another social factor to improve the research on robotics and language acquisition, as well as the multimodal dataset. One of the popular competitions in the robotics field is RoboCup. In the early days, when the RoboCup was first established, the main competition was a soccer game; however, a more social and complex environment was added as the evaluation target, named RoboCup@Home [Citation245].
The RoboCup@Home project aims to promote the development of general service robots that act in a daily life environment. The typical task in the competition is to perform a physical service with an understanding of the user's request by means of a natural language expression. For example, in a task named general purpose service robot (GPSR), a user issues instructions to a robot such as ‘Take the milk from the fridge and bring it to me.’ The robot must understand the meaning of the instructions and carry out the request. Understanding the instructions requires multiple capabilities including object recognition, manipulation of a target object, human and face recognition, speech recognition, and motion planning. This means that the robot must establish a representation linking language expression and physical action in the real world. The evaluation criteria focus on the physical behavior of the robot, including whether the robot grasps the objectives, arrives at the target place, and succeeds in avoiding the obstacles. The score thus indicates the quality of the NLP performance in the robot. The competition framework is one of the best ways to evaluate performance based on the linguistics skills of the robots; however, the evaluation target is biased toward physical functions because (1) the aim is the development of physical robot systems, and (2) objective physical characteristics can readily be evaluated. Another expected evaluation target should be the ability to deal with uncertain or contradictory instructions, because the usual conversation in the daily life is invariably filled with vague expressions and humans sometimes mistakenly issue a contradictory request after misunderstanding a situation. In an ideal competition, service robots should cover this type of situation; however, RoboCup@Home has recently not focused on the problem. Competitions in conversational language processing systems such as conversational intelligence challenge (ConvAI) [Citation246], and dialogue system technology challenges (DSTC) [Citation247] tend to evaluate the ability to deal with vague expressions and contradictions. The difficulty in recent research is to implement both (1) the generation of physical actions from natural language expression and (2) dealing with uncertainty and contradiction in the real world, and also expected from robot competition systems.
9.4. Challenges in dataset, simulator, and competition
The remaining perspective in the dataset for language processing in robot systems is the social and embodied experience data with annotations. It requires subjective sensor information for the robot system, not just the overhead view such as the movie database, to learn the correspondence between sensor information and language expression. The simulation environment is one of the important components to predict and associate with sensor information in robot systems. To summarize this section, the remaining challenges are:
Building a social and embodied experience dataset for robots.
Developing a method to predict and associate the social behavior of agents in simulation systems, not just the physical simulation.
Designing sophisticated robot competition systems that support building social and embodied experience datasets.
10. Conclusion
In this paper, we surveyed the existing challenges at the intersection of NLP and robotics. First, we discussed the importance of the intersection of NLP and robotics from both perspectives: language and robotics. Language understanding and acquisition in real-world environments is an important task for future service robotics, because our social environment is full of rich and dynamic linguistic interactions. Service robots must perform tasks based on understanding people's utterances and contexts, e.g. situation and culture. Based on this, we visited seven frontiers that we will need to explore further in future studies of language and robotics.
It is now clear that many challenges remain, ranging from semantics to pragmatics. In particular, the social aspect of language has not been explored in robotics, although the future language used in human–robot interactions will be based on pragmatics and social language in the same way as human-to-human communication.
We would like to address the notion of symbol emergence systems [Citation17,Citation18]. Figure shows a schematic view of a symbol emergence system, with a comprehensive view of a multi-agent system using language and a dynamic symbol system emerging through semiotic interactions between agents. The emergent symbol system is organized through inter-agent semiotic communication and internal representations formed by the agents. The internal representations are formed based on both semiotic communications and physical interactions, e.g. multimodal categorization and affordance learning. The problems in language and robotics can be interpreted as a part of the phenomena in a symbol emergence system.
Figure 6. Symbol emergence system [Citation17] is an integral view of dynamic language phenomena involving cognitive and social processes.
![Figure 6. Symbol emergence system [Citation17] is an integral view of dynamic language phenomena involving cognitive and social processes.](/cms/asset/514f1d79-02bf-46cc-8bd3-817762a2d84f/tadr_a_1632223_f0006_ob.jpg)
Language itself is a dynamic, systemic, cognitive, and social phenomenon. Therefore, to understand language in a scientific manner and to engineer it, we need a model with a sensor–motor system that can be involved in human linguistic communication: this is definitely a robot. We now repeat our claim that language and robotics are becoming an inevitably important academic field. To push this important research field forward, our future work will be to tackle the challenges identified systematically.
Disclosure statement
No potential conflict of interest was reported by the authors.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
Notes on contributors
T. Taniguchi
Tadahiro Taniguchi received the ME and PhD degrees from Kyoto University, in 2003 and 2006, respectively. From April 2005 to March 2006, he was a Japan Society for the Promotion of Science (JSPS) Research Fellow (DC2) at the Department of Mechanical Engineering and Science, Graduate School of Engineering, Kyoto University. From April 2006 to March 2007, he was a JSPS Research Fellow (PD) at the same department. From April 2007 to March 2008, he was a JSPS Research Fellow at the Department of Systems Science, Graduate School of Informatics, Kyoto University. From April 2008 to March 2010, he was an Assistant Professor at the Department of Human and Computer Intelligence, Ritsumeikan University. From April 2010 to March 2017, he was an Associate Professor at the same department. From September 2015 to September 2016, he is a Visiting Associate Professor at Department of Electrical and Electronic Engineering, Imperial College London. From April 2017, he has been a Professor at the Department of Information and Engineering, Ritsumeikan University. From April 2017, he has been a visiting general chief scientist, AI solution center, Panasonic, as well. He has been engaged in research on machine learning, emergent systems, intelligent vehicle and symbol emergence in robotics.
D. Mochihashi
Daichi Mochihashi received BS from the University of Tokyo and and MS, PhD from Nara Institute of Science and Technology in 1998, 2000 and 2005, respectively. He was a researcher at ATR Spoken Language Research Laboratories from 2003 and NTT Communication Science Research Laboratories from 2007. Since 2011, he has been an associate professor at the Institute of Statistical Mathematics, Japan. His research interests are statistical natural language processing and machine learning, including robotics. Currently he has been serving as an action Editor of the Transactions of the Association of Computational Linguistics (TACL) since 2016.
T. Nagai
Takayuki Nagai received his BE, ME, and PhD degrees from the Department of Electrical Engineering, Keio University, in 1993, 1995, and 1997, respectively. Since 1998, he had been with the University of Electro-Communications, and from 2018 he has been a professor of the graduate school of Engineering Science, Osaka University. From 2002 to 2003, he was a visiting scholar at the Department of Electrical Computer Engineering, University of California, San Diego. He also serves as a specially-appointed professor at UEC AIX, a visiting researcher at Tamagawa University Brain Science Institute, a visiting researcher at AIST AIRC. He has received IROS Best Paper Award Finalist, Advanced Robotics Best Paper Award, JSAI Best Paper Award, etc. His research interests include intelligent robotics, cognitive developmental robotics, and robot learning. He aims at realizing flexible and general intelligence like human by combining AI and robot technologies.
S. Uchida
Satoru Uchida received his BA from Tokyo University of Foreign Studies in 2005 and obtained his MA and PhD from the University of Tokyo in 2007 and 2013, respectively. He was a lecturer at Tokyo University of Foreign Studies from 2010 to 2014 and is currently an associate professor at Kyushu University, Japan. He belongs to the School of Interdisciplinary Science and Innovation established in 2018, where he teaches linguistics from interdisciplinary perspectives. His research interests include cognitive semantics, pragmatics, corpus linguistics, lexicography, and applied linguistics.
N. Inoue
Naoya Inoue received his MS degree of engineering from Nara Institute of Science and Technology in 2010 and his PhD degree in Information Science from Tohoku University in 2013. He joined DENSO Corporation as a researcher in 2013. He has been an assistant professor at Tohoku University since 2015. He has also been a visiting researcher at RIKEN Center for Advanced Intelligence Project since 2018. His research interests are in inference-based discourse processing and language grounding problems.
I. Kobayashi
Ichiro Kobayashi received the ME and PhD degrees from Tokyo Institute of Technology, in 1991 and 1995, respectively. From October 1995 to March 1996, he was an Assistant Professor at the Faculty of Economics, Hosei University. From April 1996 to March2003, he was an Associate Professor at the Faculty of Economics, Hosei University. From April 2000 to March 2005, he was a Visiting Researcher at Brain Science Institute of RIKEN. From April 2003 to December 2010, he was an Associate Professor at Department of Information Science of Ochanomizu University. Sine January 2011, he is a Professor at Advanced Sciences, Graduate School of Humanities and Sciences, Ochanomizu University. Since August 2017, he is a Visiting Research Scholar at National Institute of Advanced Industrial Science and Technology (AIST). He has been engaging in research on natural language processing, machine learning, artificial intelligence, systemic functional linguistics.
T. Nakamura
Tomoaki Nakamura received his BE, ME, and Dr. of Eng. degrees from the University of Electro-Communications in 2007, 2009, and 2011. From April 2011 to March 2012, He was a research fellow of the Japan Society for the Promotion of Science. In 2013, he worked for Honda Research Institute Japan Co., Ltd. From April 2014 to March 2018, he was an Assistant Professor at the Department of Mechanical Engineering and Intelligent Systems, the University of Electro-Communications. Since April 2019, he has been an Associate Professor at the same department. His research interests are intelligent robotics and machine learning.
Y. Hagiwara
Yoshinobu Hagiwara received his PhD degree from Soka University, Japan, in 2010. He was an Assistant Professor at the Department of Information Systems Science, Soka University from 2010, a Specially Appointed Researcher at the Principles of Informatics Research Division, National Institute of Informatics from 2013, and an Assistant Professor at the Department of Human & Computer Intelligence, Ritsumeikan University from 2015. He is currently a Lecture at the Department of Information Science and Engineering, Ritsumeikan University. His research interests include human–robot interaction, machine learning, intelligent robotics and symbol emergence in robotics. He is a member of IEEE, RSJ, IEEJ, JSAI, SICE, and IEICE.
N. Iwahashi
Naoto Iwahashi received the BE degree in Engineering from Keio University, Yokohama, Japan, in 1985. He received the PhD degree in Engineering from Tokyo Institute of Technology, in 2001. In April 1985, he joined Sony Corp., Tokyo, Japan. From October 1990 to September 1993, he was at Advanced Telecommunications Research Institute International (ATR), Kyoto, Japan. From October 1998 to June 2004, he was with Sony Computer Science Laboratories Inc., Tokyo, Japan. From July 2004 to March 2010, he was with ATR. From November 2005 to March 2011, he was a visiting professor at Kobe University. In April 2008, he joined the National Institute of Information and Communications Technology, Kyoto, Japan. Since April 2014, he has been a professor at Okayama Prefectural University. Since April 2011, he has also been a visiting researcher at Tamagawa University Brain Science Institute. Since April 2018, he has also been a visiting researcher at Ritsumeikan University. His research areas include machine learning, artificial intelligence, and brain science.
T. Inamura
Tetsunari Inamura received the BE, MS, and PhD degrees from the University of Tokyo, Japan, in 1995, 1997, and 2000, respectively. He was a Researcher of the CREST Program, Japanese Science and Technology Cooperation, from 2000 to 2003, and then joined the Department of Mechano-Informatics, School of Information Science and Technology, University of Tokyo, as a Lecturer, from 2003 to 2006. He is currently an Associate Professor with the Principles of Informatics Research Division, National Institute of Informatics, and an Associate Professor with the Department of Informatics, School of Multidisciplinary Sciences, SOKENDAI (The Graduate University for Advanced Studies), Tokyo, Japan. His current research interests include imitation learning, symbol emergence on social robots, and development of interactive robots through virtual reality-world.
Notes
1. Valence in linguistics means the number of arguments controlled by a verbal predicate.
2. Depending on the position of the argument taken by the NP, it can be written as or
, but here we collectively denote them as
.
References
- Mavridis N. A review of verbal and non-verbal human–robot interactive communication. Rob Auton Syst. 2015;63:22–35.
- Kanda T, Ishiguro H, Imai M, et al. Body movement analysis of human–robot interaction. International Joint Conferences on Artificial Intelligence (IJCAI); Acapulco, Mexico; Vol. 3; 2003. p. 177–182.
- Okuno Y, Kanda T, Imai M, et al. Providing route directions: design of robot's utterance, gesture, and timing. ACM/IEEE International Conference on Human Robot Interaction; San Diego, California, USA; 2009. p. 53–60.
- Admoni H, Scassellati B. Social eye gaze in human-robot interaction: a review. J Hum Rob Interact. 2017;6(1):25–63.
- Mutlu B, Yamaoka F, Kanda T, et al. Nonverbal leakage in robots: communication of intentions through seemingly unintentional behavior. ACM/IEEE International Conference on Human Robot Interaction; San Diego, California, USA; 2009. p. 69–76.
- Nakadai K, Takahashi T, Okuno HG, et al. Design and implementation of robot audition system'hark'-open source software for listening to three simultaneous speakers. Adv Robot. 2010;24(5–6):739–761.
- Kostavelis I, Gasteratos A. Semantic mapping for mobile robotics tasks: a survey. Rob Auton Syst. 2015;66:86–103.
- Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. Int J Comput Vis. 2015;115(3):211–252.
- Noda K, Yamaguchi Y, Nakadai K, et al. Audio-visual speech recognition using deep learning. Appl Intell. 2015;42(4):722–737.
- Siagian C, Itti L. Rapid biologically-inspired scene classification using features shared with visual attention. IEEE Trans Pattern Anal Mach Intell. 2007;29(2):300–312.
- Wu J, Rehg JM. Centrist: a visual descriptor for scene categorization. IEEE Trans Pattern Anal Mach Intell. 2010;33(8):1489–1501.
- Iwahashi N. Language acquisition through a human–robot interface by combining speech, visual, and behavioral information. Inf Sci. 2003;156:109–121.
- Iwahashi N. Interactive learning of spoken words and their meanings through an audio-visual interface. IEICE Trans Inf Syst. 2008;2:312–321.
- Hatori J, Kikuchi Y, Kobayashi S, et al. Interactively picking real-world objects with unconstrained spoken language instructions. IEEE International Conference on Robotics and Automation (ICRA); Brisbane, Australia; 2018. p. 3774–3781.
- Anderson P, Wu Q, Teney D, et al. Vision-and-language navigation: interpreting visually-grounded navigation instructions in real environments. IEEE/CVF Conference on Computer Vision and Pattern Recognition; Piscataway, NJ; 2018. p. 3674–3683.
- Hermann KM, Hill F, Green S, et al. Grounded language learning in a simulated 3D world. CoRR. 2017. abs/1706.06551.
- Taniguchi T, Nagai T, Nakamura T, et al. Symbol emergence in robotics: a survey. Adv Robot. 2016;30(11–12):706–728.
- Taniguchi T, Ugur E, Hoffmann M, et al. Symbol emergence in cognitive developmental systems: a survey. IEEE Trans Cogn Dev Syst. 2018. doi: 10.1109/TCDS.2018.2867772
- Iwahashi N. A method for forming mutual beliefs for communication through human–robot multi-modal interaction. Proceedings of the Fourth SIGdial Workshop on Discourse and Dialogue; Sapporo, Japan; 2003. p. 79–86.
- Harnad S. The symbol grounding problem. Phys D. 1990;42(1):335–346.
- Plunkett K, Sinha C, Moller MF, et al. Symbol grounding or the emergence of symbols? vocabulary growth in children and a connectionist net. Conn Sci. 1992;4(3–4):293–312.
- Steels L. The symbol grounding problem has been solved, so what's next? Symbols and embodiment: debates on meaning and cognition. Oxford, UK: Oxford University Press; 2008. p. 223–244.
- Lakoff G, Johnson M. Philosophy in the flesh. Vol. 4. New York, USA: Basic books; 1999.
- Gibbs RW Jr, Lima PLC, Francozo E. Metaphor is grounded in embodied experience. J Pragmat. 2004;36(7):1189–1210.
- Feldman J. From molecule to metaphor: a neural theory of language. Cambridge, MA: MIT press; 2008.
- Huang PY, Liu F, Shiang SR, et al. Attention-based multimodal neural machine translation. Proceedings of the First Conference on Machine Translation (WMT16); Berlin, Germany; Vol. 2; 2016. p. 639–645.
- Kiros R, Salakhutdinov R, Zemel RS. Unifying visual-semantic embeddings with multimodal neural language models. Preprint; 2014. arXiv:14112539.
- Vinyals O, Toshev A, Bengio S, et al. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans Pattern Anal Mach Intell. 2016;39(4):652–663.
- Antol S, Agrawal A, Lu J, et al. VQA: visual question answering. Proceedings of the IEEE International Conference on Computer Vision; Santiago, Chile; 2015. p. 2425–2433.
- Jamone L, Ugur E, Cangelosi A, et al. Affordances in psychology, neuroscience and robotics: a survey. IEEE Trans Cogn Dev Syst. 2016;10(1):4–25.
- Savage J, Rosenblueth DA, Matamoros M, et al. Semantic reasoning in service robots using expert systems. Rob Auton Syst. 2019;114:77–92.
- Horn A. On sentences which are true of direct unions of algebras. J Symbolic Logic. 1951;16(1):14–21.
- Hobbs JR, Stickel ME, Appelt DE, et al. Interpretation as abduction. Artif Intell. 1993;63(1–2):69–142.
- Gelfond M, Lifschitz V. The stable model semantics for logic programming. In: Kowalski R, Bowen, Kenneth, editors. Proceedings of International Logic Programming Conference and Symposium. MIT Press; 1988. p. 1070–1080.
- Sato T. A statistical learning method for logic programs with distributional semantics. The 12th International Conference on Logic Programming; Tokyo; 1995. p. 715–729.
- Muggleton S. Stochastic logic programs. Adv Induct Logic Program. 1996;32:254–264.
- De Raedt L, Kimmig A, Toivonen H. ProbLog: a probabilistic prolog and its application in link discovery. International Joint Conference on Artificial Intelligence; 2007. p. 2468–2473.
- Richardson M, Domingos P. Markov Logic Networks. Mach Learn. 2006;62(1–2):107–136.
- Bach SH, Broecheler M, Huang B, et al. Hinge-loss markov random fields and probabilistic soft logic. J Mach Learn Res (JMLR). 2017;18:1–67.
- Van Gelder A, Ross KA, Schlipf JS. The well-founded semantics for general logic programs. J ACM. 1991;38(3):619–649.
- Fierens D, Van den Broeck G, Renkens J, et al. Inference and learning in probabilistic logic programs using weighted boolean formulas. Theory and Pract Log Program. 2015;15:358–401.
- Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems; Stateline, Nevada, USA; 2013. p. 3111–3119.
- Pennington J, Socher R, Manning CD. GloVe: global vectors for word representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing; Doha, Qatar; 2014. p. 1532–1543.
- Kiros R, Zhu Y, Salakhutdinov RR, et al. Skip-thought vectors. Advances in Neural Information Processing Systems; Montreal, Canada; 2015. p. 3294–3302.
- Conneau A, Kiela D, Schwenk H, et al. Supervised learning of universal sentence representations from natural language inference data. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Copenhagen, Denmark; 2017. p. 670–680.
- Cohen WW. Tensorlog: a differentiable deductive database. CoRR; 2016. abs/1605.06523.
- Lewis M, Steedman M. Combined distributional and logical semantics. Trans Assoc Comput Linguist Action Editor. 2013;1:179–192.
- Wang WY, Cohen WW. Learning first-order logic embeddings via matrix factorization. Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence; New York, USA; 2016. p. 2132–2138.
- Bowman SR, Potts C, Manning CD. Learning distributed word representations for natural logic reasoning; 2014. p. 10–13.
- Tian R, Okazaki N, Inui K. Learning semantically and additively compositional distributional representations. Annual Meeting of the Association for Computational Linguistics; 2016. p. 1277–1287.
- Yanaka H, Mineshima K, Martínez-Gómez P, et al. Determining semantic textual similarity using natural deduction proofs. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Copenhagen, Denmark; 2017 Sep. Association for Computational Linguistics. p. 681–691.
- Rocktäschel T, Riedel S. End-to-end differentiable proving. 2017. p. 3788–3800.
- Modi A. Event embeddings for semantic script modeling. Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning; Berlin, Germany; 2016. p. 75–83.
- Cai H, Zheng VW, Chang KCC. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Trans Knowl Data Eng. 2018;30:1616–1637.
- Wang Q, Mao Z, Wang B, et al. Knowledge graph embedding: a survey of approaches and applications. IEEE Trans Knowl Data Eng. 2017;29(12):2724–2743.
- Weber N, Balasubramanian N, Chambers N. Event representations with tensor-based compositions. CoRR; 2017. abs/1711.07611.
- Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data. Advances in Neural Information Processing Systems 26 (NIPS); Stateline, Nevada, USA; 2013. p. 2787–2795.
- Jurafsky D, Martin JH. Speech and language processing. 2nd ed. Upper Saddle River, NJ: Prentice Hall; 2008. (Prentice hall series in artificial intelligence).
- Kong L, Rush AM, Smith NA. Transforming dependencies into phrase structures. Denver, CO: North American Chapter of the Association for Computational Linguistics; 2015. p. 788–798.
- Steedman M. The syntactic process. Cambridge, MA: MIT Press; 2000.
- Shindo H, Miyao Y, Fujino A, et al. Bayesian symbol-refined tree substitution grammars for syntactic parsing. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics; Jeju Island, Korea; 2012. p. 440–448.
- Matsuzaki T, Miyao Y, Tsujii J. Probabilistic CFG with latent annotations. Association for Computational Linguistics; Michigan, USA; 2005. p. 75–82.
- Klein D, Manning C. Corpus-based induction of syntactic structure: Models of dependency and constituency. Annual Conference of Association for Computational Linguistics; Barcelona, Spain; 2004. p. 478–485.
- Headden WP III, Johnson M, McClosky D. Improving unsupervised dependency parsing with richer contexts and smoothing. Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Boulder, CO, USA; 2009. p. 101–109.
- Spitkovsky VI, Alshawi H, Jurafsky D. From baby steps to leapfrog: how “less is more” in unsupervised pependency parsing. Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Los Angeles, USA; 2010. p. 751–759.
- Jiang Y, Han W, Tu K. Unsupervised neural dependency parsing. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Texas, USA; 2016. p. 763–771.
- Manning CD, Schütze H. Foundations of statistical natural language processing. Cambridge, MA: MIT Press; 1999.
- Johnson M, Griffiths T, Goldwater S. Bayesian inference for PCFGs via Markov chain Monte Carlo. Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Proceedings of the Main Conference; Rochester, NY, USA; 2007. p. 139–146.
- Pate JK, Johnson M. Grammar induction from (lots of) words alone. International Conference on Computational Linguistics; Osaka, Japan; 2016. p. 23–32.
- Levy RP, Reali F, Griffiths TL. Modeling the effects of memory on human online sentence processing with particle filters. Advances in Neural Information Processing Systems 21; Vancouver, BC, Canada; 2009. p. 937–944.
- Hockenmaier J, Steedman M. Generative models for statistical parsing with combinatory categorial grammar. Annual Meeting of the Association for Computational Linguistics; Philadelphia, Pennsylvania, USA; 2002. p. 335–342.
- Bisk Y, Hockenmaier J. An HDP model for inducing combinatory categorial grammars. Trans Assoc Comput Linguist. 2013;1:75–88.
- Teh YW, Jordan MI, Beal MJ, et al. Hierarchical Dirichlet processes. J Amer Statist Assoc. 2006;101(476):1566–1581.
- Liang P, Petrov S, Jordan M, et al. The infinite PCFG using hierarchical Dirichlet processes. Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL); Prague, Czech Republic; 2007. p. 688–697.
- Martínez-Gómez P, Mineshima K, Miyao Y, et al. ccg2lambda: a compositional semantics system. ACL-2016 System Demonstrations; 2016. p. 85–90.
- Bansal M, Matuszek C, Andreas J, et al. Proceedings of the first workshop on language grounding for robotics; 2017. Available from: https://robonlp2017.github.io.
- Poon H. Grounded unsupervised semantic parsing. ACL 2013; 2013. p. 933–943.
- Poon H, Domingos P. Unsupervised semantic parsing. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing; Singapore; 2009. p. 1–10.
- Socher R, Karpathy A, Le QV, et al. Grounded compositional semantics for finding and describing images with sentences. Trans Assoc Comput Linguist. 2014;2(1):207–218.
- Vinyals O, Toshev A, Bengio S, et al. Show and tell: a neural image caption generator. IEEE/CVF Conference on Computer Vision and Pattern Recognition; Boston, MA, USA; 2015. p. 3156–3164.
- Xu K, Ba J, Kiros R, et al. Show, attend and tell: neural image caption generation with visual attention. International Conference on Machine Learning (ICML); Lille, France; 2015. p. 2048–2057.
- Karpathy A, Fei-Fei L. Deep visual-semantic alignments for generating image descriptions. IEEE/CVF Conference on Computer Vision and Pattern Recognition; Boston, MA, USA; 2015. p. 3128–3137.
- Thomason J, Sinapov J, Mooney RJ, et al. Guiding exploratory behaviors for multi-modal grounding of linguistic descriptions. AAAI; 2018.
- Amiri S, Wei S, Zhang S, et al. Multi-modal predicate identification using dynamically learned robot controllers. Proceedings of the 25th International Joint Conference on Artificial Intelligence; Stockholm, Sweden; 2018. p. 4638–4645.
- Attamimi M, Ando Y, Nakamura T, et al. Learning word meanings and grammar for verbalization of daily life activities using multilayered multimodal latent Dirichlet allocation and bayesian hidden markov models. Adv Robot. 2016;30(11–12):806–824.
- Aly A, Taniguchi T, Mochihashi D. A probabilistic approach to unsupervised induction of combinatory categorial grammar in situated human-robot interaction. IEEE-RAS 18th International Conference on Humanoid Robots; Beijing, China; 2018. p. 1–9.
- Radden G, Dirven R. Cognitive English grammar. Vol. 2. Amsterdam, The Netherlands: John Benjamins Publishing; 2007.
- Taylor JR. Linguistic categorization. Oxford, UK: Oxford University Press; 2003.
- Croft W, Cruse DA. Cognitive linguistics. Cambridge, UK: Cambridge University Press; 2004.
- Gumperz JJ, Levinson SC. Rethinking linguistic relativity. Curr Anthropol. 1991;32(5):613–623.
- Winston ME, Chaffin R, Herrmann D. A taxonomy of part–whole relations. Cogn Sci. 1987;11(4):417–444.
- Fillmore CJ. An alternative to checklist theories of meaning. Annual Meeting of the Berkeley Linguistics Society; Vol. 1; 1975. p. 123–131.
- Fillmore CJ. Frame semantics. Seoul: Hanshin Publishing Co.; 1982. p. 111–137.
- Dove G. Thinking in words: language as an embodied medium of thought. Top Cogn Sci. 2014;6(3):371–389.
- Cangelosi A, Stramandinoli F. A review of abstract concept learning in embodied agents and robots. Philos Trans R Soc B. 2018;373(1752):20170131.
- Akira U. A distributional semantic model of visually indirect grounding for abstract words. Proceedings of NIPS 2018, Workshop on Visually Grounded Interaction and Language (ViGIL); Montreal, Canada; 2018.
- Barsalou LW. Ad hoc categories. Mem Cognit. 1983;11(3):211–227.
- Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems; Stateline, Nevada, USA; 2012. p. 1097–1105.
- Zeiler MD, Fergus R. Visualizing and understanding convolutional networks. European Conference on Computer Vision; Springer; 2014. p. 818–833.
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. International Conference on Learning Representations; San Diego, CA; 2015.
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Las Vegas, Nevada; 2016. p. 770–778.
- Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning. AAAI; Vol. 4; 2017. p. 12.
- Fergus R, Perona P, Zisserman A. Object class recognition by unsupervised scale-invariant learning. IEEE Conference on Computer Vision and Pattern Recognition; Madison, Wisconsin, USA; Vol. 2; 2003. p. 264–271.
- Sivic J, Russell BC, Efros AA, et al. Discovering object categories in image collections. IEEE International Conference on Computer Vision; Beijing, China; 2005. p. 17–20.
- Fei-Fei L. A Bayesian Hierarchical model for learning natural scene categories. IEEE Conference on Computer Vision and Pattern Recognition; San Diego, CA, USA; 2005. p. 524–531.
- Wang C, Blei D, Fei-Fei L. Simultaneous image classification and annotation. IEEE Conference on Computer Vision and Pattern Recognition; Miami Beach, FL, USA; 2009. p. 1903–1910.
- Krause A, Perona P, Gomes RG. Discriminative clustering by regularized information maximization. Advances in Neural Information Processing Systems; Vancouver, Canada; 2010. p. 775–783.
- Zhu JY, Wu J, Xu Y, et al. Unsupervised object class discovery via saliency-guided multiple class learning. IEEE Trans Pattern Anal Mach Intell. 2015;37(4):862–875.
- Smith L, Gasser M. The development of embodied cognition: six lessons from babies. Artif Life. 2005;11(1–2):13–29.
- Wermter S, Weber C, Elshaw M, et al. Towards multimodal neural robot learning. Rob Auton Syst. 2004;47(2):171–175.
- Ridge B, Skocaj D, Leonardis A. Self-supervised cross-modal online learning of basic object affordances for developmental robotic systems. IEEE International Conference on Robotics and Automation; Anchorage, Alaska, USA; 2010. p. 5047–5054.
- Ogata T, Nishide S, Kozima H, et al. Inter-modality mapping in robot with recurrent neural network. Pattern Recognit Lett. 2010;31(12):1560–1569.
- Lallee S, Dominey PF. Multi-modal convergence maps: from body schema and self-representation to mental imagery. Adapt Behav. 2013;21(4):274–285.
- Mangin O, Oudeyer PY. Learning semantic components from subsymbolic multimodal perception. IEEE Third Joint International Conference on Development and Learning and Epigenetic Robotics; Osaka, Japan; 2013. p. 1–7.
- Mangin O, Filliat D, Bosch LT, et al. Mca-nmf: multimodal concept acquisition with non-negative matrix factorization. PLoS ONE. 2015;10, e0140732(10).
- Chen Y, Filliat D. Cross-situational noun and adjective learning in an interactive scenario. Joint IEEE International Conference on Development and Learning and Epigenetic Robotics; Providence, Rhode Island, USA; 2015. p. 129–134.
- Yürüten O, Şahin E, Kalkan S. The learning of adjectives and nouns from affordance and appearance features. Adapt Behav. 2013;21(6):437–451.
- Blei DM, Ng AY, Jordan MI. Latent Dirichlet allocation. J Mach Learn Res. 2003;3:993–1022.
- Nakamura T, Nagai T, Iwahashi N. Multimodal object categorization by a robot. IEEE/RSJ International Conference on Intelligent Robots and Systems; San Diego, CA; 2007. p. 2415–2420.
- Taniguchi A, Taniguchi T, Inamura T. Spatial concept acquisition for a mobile robot that integrates self-localization and unsupervised word discovery from spoken sentences. IEEE Trans Cogn Dev Sys. 2016;8(4):285–297.
- Taniguchi A, Hagiwara Y, Taniguchi T, et al. Online spatial concept and lexical acquisition with simultaneous localization and mapping. IEEE/RSJ International Conference on Intelligent Robots and Systems; Vancouver, BC, Canada; 2017. p. 811–818.
- Nakamura T, Araki T, Nagai T, et al. Grounding of word meanings in lda-based multimodal concepts. Adv Robot. 2012;25:2189–2206.
- Barsalou LW. Perceptual symbol system. Behav Brain Sci. 1999;22:277–660.
- Bergen BK. Louder than words: the new science of how the mind makes meaning. New York, NY: Basic Books; 2012.
- Nishihara J, Nakamura T, Nagai T. Online algorithm for robots to learn object concepts and language model. IEEE Trans Cogn Dev Sys. 2017;9(3):255–268.
- Mochihashi D, Yamada T, Ueda N. Bayesian unsupervised word segmentation with nested Pitman-Yor language modeling. Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing; Singapore; Vol. 1; 2009. p. 100–108.
- Yan Z, Zhang H, Piramuthu R, et al. Hd-cnn: hierarchical deep convolutional neural networks for large scale visual recognition. Proceedings of the IEEE International Conference on Computer Vision; Beijing, China; 2015. p. 2740–2748.
- Guo Y, Liu Y, Bakker EM, et al. Cnn-rnn: a large-scale hierarchical image classification framework. Multimed Tools Appl. 2018;77(8):10251–10271.
- Blei D, Griffiths T, Jordan M. The nested Chinese restaurant process and Bayesian nonparametric inference of topic hierarchies. J ACM. 2010;57(2):7.
- Ando Y, Nakamura T, Araki T, et al. Formation of hierarchical object concept using hierarchical latent Dirichlet allocation. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); Tokyo, Japan; 2013. p. 2272–2279.
- Hagiwara Y, Inoue M, Kobayashi H, et al. Hierarchical spatial concept formation based on multimodal information for human support robots. Front Neurorobot. 2018 Mar;12(11):1–16. doi: 10.3389/fnbot.2018.00011
- Felzenszwalb PF, Girshick RB, McAllester D, et al. Object detection with discriminatively trained part-based models. IEEE Trans Pattern Anal Mach Intell. 2010;32(9):1627–1645.
- Chen X, Shrivastava A, Gupta A. Neil: extracting visual knowledge from web data. IEEE International Conference on Computer Vision; Sydney, Australia; 2013. p. 1409–1416.
- Taigman Y, Yang M, Ranzato M, et al. Deepface: closing the gap to human-level performance in face verification. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Columbus, Ohio, USA; 2014. p. 1701–1708.
- Cao Z, Simon T, Wei SE, et al. Realtime multi-person 2D pose estimation using part affinity fields. IEEE Conference on Computer Vision and Pattern Recognition; Honolulu, HI, USA; Vol. 1; 2017. p. 7.
- Yang S, Luo P, Loy CC, et al. Faceness-net: face detection through deep facial part responses. IEEE Trans Pattern Anal Mach Intell. 2018;40(8):1845–1859. doi: 10.1109/TPAMI.2017.2738644.
- Lakoff G, Johnson M. Metaphors we live by. Chicago, IL: University of Chicago press; 1980.
- Fauconnier G, Turner M. The way we think: conceptual blending and the mind's hidden complexities. New York, NY: Basic Books; 2008.
- Grady J. Foundations of meaning: primary metaphors and primary stress. 1997. Retrieved from https://escholarship.org/uc/item/3g9427m2
- Deignan A. Cobuild guides to English 7: metaphor. New York, NY: Harper Collins; 1995.
- Sommer E, Weiss D. Metaphors dictionary. Cambridge, UK: Cambridge University Press; 2001.
- Wilkinson D. Concise thesaurus of traditional English metaphors. London, UK: Routledge; 2013.
- Seto KI, Takeda K, Yamaguchi H, et al. Shogakukan dictionary of English lexical polysemy. Tokyo, Japan: Shogakukan; 2007.
- Petruck MR. Introduction to metanet. Constr Frames. 2017;8(2):133–140.
- Fillmore CJ, Johnson CR, Petruck MR. Background to framenet. Int J Lexicogr. 2003;16(3):235–250.
- Steen GJ, Dorst AG, Herrmann JB, et al. A method for linguistic metaphor identification: from MIP to MIPVU. Vol. 14. Amsterdam, The Netherlands: John Benjamins Publishing; 2010.
- Makino S, Oka M. A bilingual dictionary of English and Japanese metaphors. Tokyo, Japan: Kuroshio Shuppan; 2017.
- Kövecses Z. Metaphor and emotion: language, culture, and body in human feeling. Cambridge, UK: Cambridge University Press; 2003.
- Kövecses Z. Metaphor in culture: universality and variation. Cambridge, UK: Cambridge University Press; 2005.
- Rizzolatti G. The mirror neuron system and its function in humans. Anat Embryol (Berl). 2005;210(5–6):419–421.
- Rizzolatti G, Fadiga L, Gallese V, et al. Premotor cortex and the recognition of motor actions. Cogn Brain Res. 1996;3(2):131–141.
- Lee K, Ognibene D, Chang HJ, et al. STARE: spatiooral attention relocation for multiple structured activities detection. IEEE Trans Image Process. 2015;24(12):5916–5927.
- Fujita K. A prospect for evolutionary adequacy: merge and the evolution and development of human language. Biolinguistics. 2009;3(2–3):128–153.
- Jamone L, Ugur E, Cangelosi A, et al. Affordances in psychology, neuroscience, and robotics: a survey. IEEE Trans Cogn Dev Syst. 2018;10(1):4–25.
- Min H, Yi C, Luo R, et al. Affordance research in developmental robotics: a survey. IEEE Trans Cogn Dev Syst. 2016;8(4):237–255.
- Horton TE, Chakraborty A, Amant RS. Affordances for robots: a brief survey. AVANT. 2012 Dec;3:70–84.
- Gibson JJ. The ecological approach to visual perception. Boston, MA: Houghton Mifflin; 1979.
- Şahin E, Çakmak M, Doğar MR, et al. To afford or not to afford: A new formalization of affordances toward affordance-based robot control. Adapt Behav. 2007;15(4):447–472.
- Stoytchev A. Behavior-grounded representation of tool affordances. Proceedings of IEEE International Conference on Robotics and Automation; Barcelona, Spain; 2005. p. 3071–3076.
- Stoytchev A. Learning the affordances of tools using a behavior-grounded approach. In: Rome E, Hertzberg J, Dorffner G, editors. Towards affordance-based robot control. Berlin, Heidelberg: Springer; 2008. p. 140–158.
- Nakamura T, Nagai T. Forming object concept using bayesian network. 2010 Aug.
- Argall BD, Chernova S, Veloso M, et al. A survey of robot learning from demonstration. Rob Auton Syst. 2009;57(5):469–483.
- Billard A, Calinon S, Dillmann R, et al. Robot programming by demonstration. Berlin, Heidelberg: Springer; 2008. p. 1371–1394.
- Chernova S, Thomaz AL. Robot learning from human teachers. Synth Lect Artif Intell Mach Learn. 2014;8(3):1–121.
- Nakamura T, Nagai T, Mochihashi D, et al. Segmenting continuous motions with hidden semi-Markov models and gaussian processes. Front Neurorobot. 2017 Dec;11. doi: 10.3389/fnbot.2017.00067
- Taniguchi T, Nagasaka S, Nakashima R. Nonparametric Bayesian double articulation analyzer for direct language acquisition from continuous speech signals. IEEE Trans Cogn Dev Syst. 2016;8(3):171–185.
- Taniguchi T, Nagasaka S. Double articulation analyzer for unsegmented human motion using Pitman-Yor language model and infinite hidden Markov model. IEEE/SICE International Symposium on System Integration; Kyoto, Japan; 2011. p. 250–255.
- Schaal S. Is imitation learning the route to humanoid robots? Trends Cogn Sci. 1999;3:233–242.
- Yokoya R, Ogata T, Tani J, et al. Experience based imitation using rnnpb. 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems; Beijing, China; 2006. p. 3669–3674.
- Ho J, Ermon S. Generative adversarial imitation learning. In: Lee DD, Sugiyama M, Luxburg UV, et al., editors. Advances in neural information processing systems 29. Curran Associates, Inc.; 2016. p. 4565–4573.
- Kaelbling LP, Littman ML, Moore AP. Reinforcement learning: a survey. J Artif Intell Res. 1996;4:237–285.
- Arulkumaran K, Deisenroth MP, Brundage M, et al. Deep reinforcement learning: a brief survey. IEEE Signal Process Mag. 2017;34(6):26–38.
- Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature. 2015;518(7540):529–533.
- Lillicrap TP, Hunt JJ, Pritzel A, et al. Continuous control with deep reinforcement learning. CoRR; 2016. abs/1509.02971.
- Levine S, Finn C, Darrell T, et al. End-to-end training of deep visuomotor policies. J Mach Learn Res(JMLR). 2016 Jan;17(1):1334–1373.
- Hermann KM, Hill F, Green S, et al. Grounded language learning in a simulated 3D world. CoRR; 2017. abs/1706.06551.
- Polydoros AS, Nalpantidis L. Survey of model-based reinforcement learning: applications on robotics. J Intell Rob Syst. 2017;86(2):153–173.
- Greenfield PM. Language, tools and brain: the ontogeny and phylogeny of hierarchically organized sequential behavior. Behav Brain Sci. 1991;14(04):531–551.
- Fujita K. Facing the logical problem of language evolution (l. Jenkins, variation and universals in biolinguistics). English Linguist. 2007;24:78–108.
- Pulvermüller F. The syntax of action. Trends Cogn Sci. 2014;18(5):219–220.
- Garagnani M, Shastri L, Wendelken C. A connectionist model of planning via back-chaining search. Proceedings of the Annual Meeting of the Cognitive Science Society; California, USA; Vol. 24; 2002.
- Plappert M, Mandery C, Asfour T. Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks. Rob Auton Syst. 2018 Nov;109:13–26.
- Yamada T, Matsunaga H, Ogata T. Paired recurrent autoencoders for bidirectional translation between robot actions and linguistic descriptions. IEEE Rob Autom Lett. 2018;3(4):3441–3448.
- Austin J. How to do things with words. Cambridge, MA: Harvard University Press; 1962.
- Grice P. Studies in the way of words. Cambridge, MA: Harvard University Press; 1989.
- Sperber D, Wilson D. Relevance: communication and cognition. Cambridge, MA: Harvard University Press; 1986.
- Winograd T, Flores F. Understanding computers and cognition. New York: Ablex Publishing Corporation; 1986.
- Heidegger M. Being and time. Oxford, UK: BLACI WELL; 1927.
- Searle JR. Mind: a brief introduction. Oxford, UK: Oxford University Press; 2004.
- Lakoff G. Woman, fire, and dangerous things. What Categories Reveal about the Mind. Chicago and London: The University of Chicago Press; 1987.
- Langacker R. Concept, image, and symbol: the cognitive basis of grammar. Berlin: Mouton de Gruyter; 1991.
- Iwahashi N. Robots that learn language: Developmental approach to human-machine conversations. Symbol grounding and beyond. Rome, Italy: Springer; 2006. p. 143–167.
- Iwahashi N. Robots that learn language: a developmental approach to situated human-robot conversations. Human–robot interaction. I-Tech; 2007. Chapter 5. doi: 10.5772/5188
- Iwahashi N, Sugiura K, Taguchi R, et al. Robots that learn to communicate: a developmental approach to personally and physically situated human-robot conversations. AAAI Fall Symposium: Dialog with Robots; 2010.
- Sugiura K, Iwahashi N, Kashioka H, et al. Object manipulation dialogue by estimating utterance understanding probability in a robot language acquisition framework (in japanese). J Rob Soc Japan. 2010;28(8):978–988.
- Sugiura K, Iwahashi N, Kawai H, et al. Situated spoken dialogue with robots using active learning. Adv Robot. 2011;25(17):2207–2232.
- Nakamura T, Attamimi M, Sugiura K, et al. An extended mobile manipulation robot learning novel objects. J Intell Rob Syst. 2012;66(1):187–204.
- Araki T, Nakamura T, Nagai T, et al. Online learning of concepts and words using multimodal LDA and hierarchical Pitman-Yor Language Model. IEEE/RSJ International Conference on Intelligent Robots and Systems; Vilamoura, Algarve, Portugal; 2012. p. 1623–1630.
- Nakamura T, Nagai T, Funakoshi K, et al. Mutual Learning of an Object Concept and Language Model Based on MLDA and NPYLM. IEEE/RSJ International Conference on Intelligent Robots and Systems; Chicago, IL USA; 2014. p. 600–607.
- Nakamura T, Nagai T, Taniguchi T. Serket: an architecture for connecting stochastic models to realize a large-scale cognitive model. Front Neurorobot. 2018;12. doi: 10.3389/fnbot.2018.00025
- Hauser MD, Chomsky N, Fitch WT. The faculty of language: what is it, who has it, and how did it evolve? Science. 2002;298(5598):1569–1579.
- Elman JL, Bates EA, Johnson MH. Rethinking innateness: a connectionist perspective on development. Vol. 10. MIT press; 1998. ISBN:026255030X, 9780262550307
- Wu Y, Schuster M, Chen Z, et al. Google's neural machine translation system: bridging the gap between human and machine translation. Preprint; 2016. arXiv:160908144.
- Lowe R, Pow N, Serban I, et al. Incorporating unstructured textual knowledge sources into neural dialogue systems. Neural information processing systems workshop on machine learning for spoken language understanding; Montreal, Quebec, Canada; 2015.
- Tomasello M. Cooperation and communication in the 2nd year of life. Child Dev Perspect. 2007;1(1):8–12.
- Carpenter M, Tomasello M, Striano T. Role reversal imitation and language in typically developing infants and children with autism. Infancy. 2005;8(3):253–278.
- Iwahashi N. Robots that learn language: a developmental approach to situated human-robot conversations. INTECH Open Access Publisher; 2007. ISBN:9783902613134
- Halliday MAK. Collected works of M. A. K. Halliday. Napa Valley, CA: Continuum; 2009.
- Halliday MAK. Halliday: system and function in language: selected papers. Oxford: Oxford University Press; 1977.
- Halliday MAK. Language as social semiotic: the social interpretation of language and meaning. London: Edward Arnold; 1978.
- Malinowski B. The meaning of meaning. London: Kegan Paul; 1923.
- Halliday MAK, Hasan R. Language, context, and text: aspects of language in a social-semiotic perspective. Oxford: Oxford University Press; 1991.
- Maturana H, Varela F. Autopoiesis and cognition: the realization of the living. Dordrecht: Reidel; 1980. p. 2–62.
- Deng J, Dong W, Socher R, et al. ImageNet: a large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition; Miami, Florida; 2009. p. 248–255.
- Torralba A, Fergus R, Freeman W. 80 Million tiny images: a large data set for nonparametric object and scene recognition. IEEE Trans Pattern Anal Mach Intell. 2008;30(11):1958–1970.
- Russell BC, Torralba A, Murphy KP, et al. LabelMe: a database and web-based tool for image annotation. Int J Comput Vis. 2008 May;77(13):157–173.
- Lin Ty, Zitnick CL, Doll P. Microsoft COCO: common objects in context. p. 1–15.
- Quattoni A, Torralba A. Recognizing indoor scenes. 2009 IEEE Conference on Computer Vision and Pattern Recognition; Miami, Florida; 2009. p. 413–420.
- Xiao J, Hays J, Ehinger KA, et al. SUN database: large-scale scene recognition from abbey to zoo. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition; San Francisco, CA; 2010. p. 3485–3492.
- Zhou B, Lapedriza A, Xiao J, et al. Learning deep features for scene recognition using places database. Advances in Neural Information Processing Systems (NIPS); Montréal, Canada; 2014. p. 487–495.
- Plappert M, Mandery C, Asfour T. The KIT motion-language dataset. Big Data. 2016;4(4):236–252.
- Takano W. Learning motion primitives and annotative texts from crowd-sourcing. ROBOMECH J. 2015;2(1):1–9.
- Regneri M, Rohrbach M, Wetzel D, et al. Grounding action descriptions in videos. Trans Assoc Comput Linguist. 2013;1:25–36.
- Rohrbach A, Rohrbach M, Qiu W, et al. Coherent multi-sentence video description with variable level of detail. 2014. p. 184–195. (Lecture notes in computer science; 8753. (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)).
- Sigurdsson GA, Varol G, Wang X, et al. Hollywood in homes: crowdsourcing data collection for activity understanding. 2016. p. 510–526. (Lecture notes in computer science; 9905 LNCS. (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)).
- Abu-El-Haija S, Kothari N, Lee J, et al. Youtube-8m: a large-scale video classification benchmark. CoRR; 2016. abs/1609.08675.
- Agrawal A, Lu J, Antol S, et al. VQA: visual question answering. p. 1–25.
- Tapaswi M, Zhu Y, Stiefelhagen R, et al. MovieQA: understanding stories in movies through question-answering. IEEE Conference on Computer Vision and Pattern Recognition; Las Vegas, NV; 2016. p. 4631–4640.
- Das A, Datta S, Gkioxari G, et al. Embodied question answering. IEEE/CVF Conference on Computer Vision and Pattern Recognition; Salt Lake City, Utah; 2018. p. 1–10.
- Hermann KM, Hill F, Green S, et al. Grounded language learning in a simulated 3D world. CoRR; 2017. abs/1706.06551.
- MacMahon M, Stankiewicz B, Kuipers B. Walk the talk: connecting language, knowledge, and action in route instructions. AAAI Conference on Artificial Intelligence (AAAI); Boston, MA; 2006. p. 1475–1482.
- Mei H, Bansal M, Walter MR. Listen, attend, and walk: neural mapping of navigational instructions to action sequences. AAAI Conference on Artificial Intelligence (AAAI); Phoenix, AZ; 2016.
- de Vries H, Shuster K, Batra D, et al. Talk the walk: navigating New York city through grounded dialogue. CoRR; 2018. abs/1807.03367.
- Inamura T, Mizuchi Y. Robot competition to evaluate guidance skill for general users in VR environment. International Conference on Human-Robot Interaction; Daegu, Korea; 2019.
- Beattie C, Leibo JZ, Teplyashin D, et al. Deepmind lab. CoRR; 2016. abs/1612.03801.
- Brockman G, Cheung V, Pettersson L, et al. OpenAI gym; 2016.
- Brodeur S, Perez E, Anand A, et al. Home: a household multimodal environment. CoRR; 2017. abs/1711.11017.
- Kolve E, Mottaghi R, Gordon D, et al. AI2-THOR: an interactive 3D environment for visual AI. CoRR; 2017. abs/1712.05474.
- Savva M, Chang AX, Dosovitskiy A, et al. MINOS: multimodal indoor simulator for navigation in complex environments. CoRR; 2017. abs/1712.03931.
- Orkin J, Roy D. The restaurant game: learning social behavior and language from thousands of players online. J Game Dev (JOGD). 2007;3(1):39–60.
- Breazeal C, Depalma N, Orkin J, et al. Crowdsourcing human-robot interaction: new methods and system evaluation in a public environment. J Hum Rob Interact. 2013;2(1):82–111.
- Inamura T, Shibata T, Sena H, et al. Simulator platform that enables social interaction simulation – SIGVerse: SocioIntelliGenesis simulator. IEEE/SICE International Symposium on System Integration; Sendai, Japan; 2010. p. 212–217.
- Mizuchi Y, Inamura T. Cloud-based multimodal human-robot interaction simulator utilizing ROS and unity frameworks. IEEE/SICE International Symposium on System Integration; Taipei, Taiwan; 2017. p. 948–955.
- Quigley M, Conley K, Gerkey BP, et al. ROS: an open-source Robot Operating System; 2009.
- Van Der Zant T, Iocchi L. RoboCup@Home: adaptive benchmarking of robot bodies and minds. 2011. p. 214–225. (Lecture notes in computer science; Vol. 7072 LNAI (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)).
- Dinan E, Logacheva V, Malykh V, et al. The second conversational intelligence challenge (convai2). CoRR; 2019. abs/1902.00098.
- Hori C, Perez J, Higashinaka R, et al. Overview of the sixth dialog system technology challenge: DSTC6. Comput Speech Lang. 2019;55:1–25.