
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Domestic robots are often required to understand spoken commands in noisy environments, including service appliances' operating sounds. Most conventional domestic robots use electret condenser microphones (ECMs) to record the sound. However, the ECMs are known to be sensitive to the noise in the direction of sound arrival. The laser Doppler vibrometer (LDV), which has been widely used in the research field of measurement, has the potential to work as a new speech-input device to solve this problem. The aim of this paper is to investigate the effectiveness of using the LDV as an optical laser microphone for human-robot interaction in extremely noisy service environments. Our robot irradiates an object near a speaker with a laser and measures the vibration of the object to record the sound. We conducted three experiments to assess the performance of speech recognition using the optical laser microphone in various settings and showed stable performance in extremely noisy conditions compared with a conventional ECM.
GRAPHICAL ABSTRACT
1. Introduction
Human-robot interaction applications, which have been in high demand for future services in domestic environments, require the capabilities to accurately receive and understand the user's linguistic instructions. Speech is a natural and effortless way for humans to communicate. The use of spoken commands to operate domestic robots involves the implementation of an automatic speech recognition system. For example, when the user says to the robot ‘Tell me the name of the person in the dining room,’ the robot should search the dining room and identify the person there. In a practical setting, both the user and the robot are not fixed but often move, so the speech recognition performance should be robust to their relative positions. We should also consider the presence of noise around the robot, e.g. sounds of service appliances and conversation voices of people in the same room, as well as the robot operation noise due to electric fans and actuators. Thus, developing techniques for recording clean speech is crucial to achieve high-quality speech recognition of domestic robots.
Most conventional robots [Citation1] use beamforming with microphone arrays to filter interfering noise and reverberation, which estimates the direction of arrival of the speech signal. Electret condenser microphones (ECMs), such as gunshot microphones, provide the same solution at a hardware level. However, in an environment in which a speaker and some noise sources exist in the same direction, as shown in Figure (a), these conventional microphones might enhance not only the speech signal but also the noise.
Figure 1. Different relative positions between a microphone and a robot in noisy domestic environments. (a) Conventional microphones might fail to collect speech if noise sources exist between the speaker and the robot or behind the speaker; (b) The robot directly measures the vibration of an object near the speaker. (a) Conventional microphone and (b) Proposed optical laser microphone.
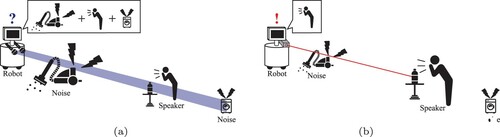
The sound recording quality of the conventional microphones would also be affected when an object emitting the noise exists behind the speaker. The sound wave is attenuated if a microphone is distant from a speech source, which makes the energy of speech low and decreases the signal-to-noise ratio (SNR). Thus, we should develop a microphone robust to these possible conditions in service environments. In the research field of measurement, the laser Doppler vibrometer (LDV) [Citation2] has been developed to directly record the vibration around a target object. The use of the LDV for the purpose of sound recording is called an optical laser microphone, which has recently attracted much attention [Citation3,Citation4]. Using a laser to measure the vibration of objects near a speaker, we can obtain the clean speech uttered by the speaker avoiding the noise around the microphone.
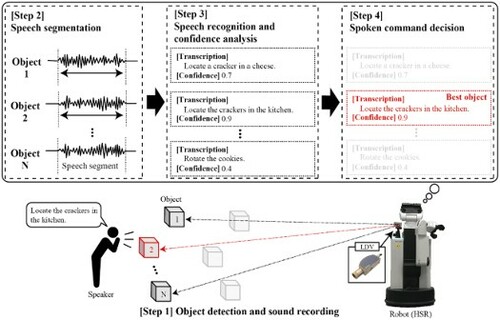
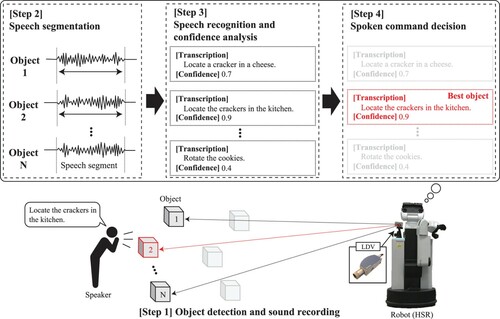
The main objective of this paper is to investigate the effectiveness of an optical laser microphone for human-robot interaction in a noisy service environment. After detecting a speaker using the camera sensor of the robot, the robot uses a LDV to measure the vibration of an object, which is located near the speaker, as a speech signal. Then, the robot sends speech segments extracted from the speech signal to an automatic speech recognition module. Finally, the robot selects the single sentence with the highest confidence of the recognition as a command provided by the speaker. The proposed method enables to understand the speaker's command even in the extremely noisy environment shown in Figure (b). Our experiments were conducted following the task defined by RoboCup@Home,Footnote1 which is one of the most famous competitions of domestic robot applications in Japan. The results demonstrated that our optical laser microphone has an advantage that can lead to stable speech recognition performances compared to a conventional ECM.
In summary, the main contributions of this paper are as follows.
To the best of our knowledge, this is the first study to construct a robot that recognizes the user's spoken commands using an optical laser microphone.
We provide a comprehensive evaluation of the speech recognition performance, especially in terms of different irradiated targets as well as different relative positions of a robot, speaker, and the irradiated targets. We also tested the performance not only in a clean environment but also in an extremely noisy, real home-like environment.
The remainder of this paper is organized as follows. Section 2 describes conventional studies on robot microphones and related to signal processing technologies. Section 3 presents the robot that uses an optical laser microphone as an input device of spoken commands. Section 4 presents three experiments to assess the performance of the optical laser microphone and validate its effectiveness. Finally, Section 5 summarizes the paper and suggests some future research topics.
2. Related work
A variety of microphones have been used in the field of audio and speech recognition. Air conduction microphones, such as parabolic microphones and shotgun microphones, measure the vibrations of the microphone diaphragm to record speech from a speaker. Some autonomous robots employ a directional microphone [Citation5] or a microphone array [Citation6,Citation7] as an input device for spoken dialog system. In particular, a shotgun microphone which is one of directional microphones was used as a popular input device in the RobotCup@Home league [Citation8]. However, air conduction microphones have the following two limitations: (i) the farther the distance between a robot and a speaker is, the greater the energy of sound wave decay, which produces a distorted speech in an extremely noisy environment; and (ii) the measurement is affected by not only noise around the robot but also noise around the speaker. To tackle these problems, several researchers developed noise reduction techniques, such as microphone-array signal processing [Citation9], filtering-based methods [Citation10], spectral subtraction [Citation11,Citation12], and signal subspace methods [Citation13]. For example, robot audition developed by Nakadai et al. used adaptive filtering based on the human auditory characteristics [Citation14,Citation15] and semi-blind independent component analysis with a microphone array [Citation16]. Model-based signal processing techniques are also popular, e.g. noise reduction based on a maximum a posteriori estimation [Citation17] and speech enhancement based on phase restoration [Citation18]. Recent studies estimated the amplitude spectrum of speech signal based on deep learning [Citation19,Citation20]. However, these post-processing methods often suffer from performance degradation of speech recognition in diverse combinations of noise types, noise stationary, and SNR. Therefore, we need to improve the quality of the speech recording itself as much as possible. As mentioned above, the optical laser microphone has the potential to enhance the noise suppression performance of previous studies because it is less sensitive to the noise around the microphone and can record distant-talking speech that is otherwise difficult to measure with air-conduction microphones.
Optical laser microphones use the LDV to measure the vibrations of the objects near the speakers, thus avoiding the noise around the microphones. The LDV has been widely developed and applied in several fields: for example, lung sound measurement and breast cancer screening in medical research [Citation21,Citation22], or damage detection of bridges and plates in architectural research [Citation23,Citation24]. In acoustics, Oikawa et al. [Citation25] used the LDV to measure the sound field to analyze the physical phenomena of sound, such as propagation, attenuation, reflection, and diffraction. In robotics, Morita et al. [Citation26] used the LDV as a slip sensor to control robot hands. Margerit et al. [Citation27] mounted LDVs on industrial robot arms as sensors for full-field velocity measurements. To the best of our knowledge, there is no previous research that introduces the LDV into robots' speech recognition systems. Recent attempts to downsize the LDVs and reduce their manufacturing cost have a great potential to spread optical laser microphones into domestic applications.
Our study considers a situation in which a user speaks to a robot. However, another approach to give robot speech commands can be to use the microphone of a wireless device, such as a smart speaker or smartphone [Citation28], which requires additional wireless repeaters to transfer the recorded sound from the device to the robot. Since this paper does not focus on such internet-of-things systems but on human-robot interaction, we will discuss the possibility of combination between these techniques in future works.
3. Proposed robot
This section describes our robot that uses an optical laser microphone as an input device of spoken commands. Figure shows an overview of the proposed robot's processing to receive a spoken instruction. Below, we explain the hardware and software aspects of the proposed robot, respectively.
Figure 2. Overview of the proposed method's processing to receive a spoken instruction.
3.1. Hardware description: robot framework
We use a Human Support Robot (HSR) [Citation29] provided by Toyota Motor Corporation with the aim to improve quality of life at home. The HSR is equipped with various sensors, such as a stereo camera, RGB-D camera, and wide-angle camera to visually recognize objects in the environment.
Instead of using the HSR's built-in microphone array of ECMs, our study uses the LDV (Polytec NLV-2500) as an optical laser microphone. The LDV irradiates a vibrating object with a laser and detects frequency change of the laser due to the irradiation position movement according to the vibration. Specifically, when a laser beam is reflected from a vibrating object, the frequency of the laser beam changes according to the object's vibration speed. The LDV converts the measured frequency change into an electrical signal, which corresponds to the sound signal. The laser of our LDV corresponds to Class 2 laser, or lower, as described by Japanese Industrial Standards (JIS) C6802 based on the International Electrotechnical Commission (IEC) standard which requires that the protection of the eyes can be achieved by an antipathetic response that includes blinking.
3.2. Software description: automatic speech recognition
Using the optical laser microphone, the proposed robot receives spoken instruction commands. We present the four steps to achieve it.
Step 1: Object detection and sound recording
The LDV mounted on the robot first irradiates an object near to a speaker with a laser beam and measure the object's vibration. The target objects should be chosen from a predefined category list including plastic bottles, glasses, and snack packs, which tend to easily vibrate. Specifically, using an image recognition-based object detector, such as YOLO [Citation30], the robot detects the position of a speaker. Then, the robot searches for objects near the speaker and whose categories belong to the predefined list. In our experiments, a reflective tape was attached to a target object when measuring speech with the LDV. The number of objects detected is denoted by N. The robot obtains the sound by receiving the results of the LDV measurement.
Step 2: Speech segmentation
While constantly recording the sound, it is necessary to detect segments in the uttered speech. The use of deep neural networks has become mainstream in recent speech segment detection methods [Citation31–34], and their toolkits are publicly available. We conducted a preliminary experiment using a subset of our corpus and confirmed that both the LDV and the ECM successfully detected the speech segments that are necessary for recognizing spoken commands. Specifically, using the voice activity detection (VAD) toolkit [Citation35], a Python interface of Google WebRTC,Footnote2 there was almost no difference in VAD performance between the ECM and the LDV. Our future work will further detail results of more domestic robot-related modules, including VAD.
Step 3: Speech recognition and confidence analysis
The robot needs to perform synchronous recognition of speech segments. Our robot uses the Google Cloud Speech-to-Text API,Footnote3 which have been popular in recent RoboCup competitions. As parameters of the API, we set Encoding to ‘LINEAR16’ (Linear PCM which means 16-bit linear pulse-code modulation encoding), Language to ‘en-US’ (American English), and Model to ‘video’ (the model used for transcribing audio in video clips that includes multiple speakers). Finally, for a given speech segment, we obtain a recognized transcription and its estimation confidence score, which corresponds to the likelihood of the recognition model.
Step 4: Spoken command decision
The robot is required to accurately perform users' instructions. Therefore, as shown in Figure , our robot repeats Steps 1 to 3 for N objects near to the speaker and recognizes the speech at each object. The robot finds a ‘best object,’ i.e. with the highest confidence score, and selects the transcription at the best object as a user's spoken command.
4. Experiments
This section presents the results of experimentsFootnote4 that followed an early test of our proposed system at RoboCup@Home General Purpose Service Robot (GPSR). Specifically, in a single trial, the participant of the experiments gives a speech command to the robot, and the robot should recognize it to perform an appropriate service task. The commands and scenarios of each trial were prepared using the GPSR Sentence Generator,Footnote5 producing 15 imperative English sentences (5 sentences × 3 categories), as shown in Table . Although some commands have grammatical errors, they were generated identically during RoboCup@Home. For comparison purpose with the robotics community, we left the generated sentences untouched.
Table 1. 15 speech commands used in the experiments.
To investigate the effectiveness of the optical laser microphone for this task, we conducted the following three experiments:
Experiment 1: We first provide a performance comparison of different objects as laser irradiation targets in a recording studio.
Experiment 2: We compared the performance of the optical laser microphone and a conventional gunshot microphone for different positions of speakers, microphones, and irradiated objects in a recording studio.
Experiment 3: We compared the performance of the optical laser microphone and a conventional gunshot microphone in a domestic environment.
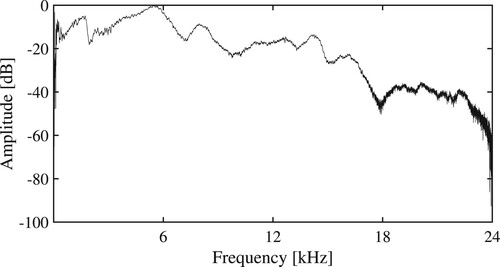
In all experiments, each participant should speak the same sentence at the same volume for a fair comparison of the microphones. Thus, we decided to first record the participants' voices in Experiment 1 and reproduce the recorded speech from a loudspeaker in Experiments 2 and 3. Figure represents the amplitude spectrum of the directional loudspeaker used in our experiments. The noise was emitted according to this amplitude characteristic. We can find from this figure that the frequency band corresponding to human speech (i.e. frequencies up to 16 kHz) is almost stable, resulting in successful speech reproduction. The sound pressure level was normalized for each experiment across all participants. Note that this study focuses on revealing the difference in the automatic speech recognition performance between the ECM and the LDV. Thus, our experiments started by recognizing the same speech segments to avoid contamination with performance degradation in the voice activity detection module.
Figure 3. Amplitude spectrum of the loudspeaker.
4.1. Experiment 1: comparison of different objects irradiated by the laser
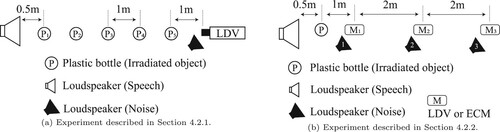
The quality of the sound recorded using LDV depends on the material of the irradiated objects. In Experiment 1, we compared the performance of the following nine objects as irradiation targets: a speaker's throat, an aluminum bottle, a tissue box, a bag of potato chips, an instant noodle cup, a mug, a paper cup, and a plastic bottle, which can be found in domestic environments. All the bottles, cups, and mugs were empty to remove the effect of the contents in this experiment. Table shows details of these irradiated objects. The speech recordings were performed as follows. We asked 10 subjects, whose native languages were not English but Japanese or Chinese, to read out each of the 15 speech commands listed in Table . Figure shows the spatial relationships between the participant and the devices used in the recording. The distance between the LDV and the irradiated object was set to 1 m. As shown in Figure (a), the speech uttered by the subject was simultaneously measured using the ECM (Sennheiser MKH 416-P48U3) and the LDV (as described in Section 3.1). The LDV targeted the laser to the speaker's throat.Footnote6 Here, the ECM successfully recorded voices due to the noiseless studio, and we denote the resulting speech data by clean speech. We reproduced the clean speech from the loudspeaker when irradiating a target object, as shown in Figure (b), which allows a fair comparison of different objects.
Figure 4. Recording situation: (a) the speech was simultaneously measured using ECM and LDV, in which the ECM recording was regarded as clean speech, and the laser was targeted to the speaker's throat; and (b) the clean speech was played back from the loudspeaker, and the laser of the LDV irradiated a target object (e.g. plastic bottle). (a) Clean speech recording and throat-based measurement of the LDV and (b) Clean speech playback and plastic bottle-based measurement of the LDV.

Table 2. Details of the irradiated objects.
The quality of a microphone's sound recording can be quantified by evaluating the speech recognition results. We calculated the following three types of performance measures: the word error rate (WER), the perceptual evaluation of speech quality (PESQ) [Citation36], and the short time objective intelligibility (STOI) [Citation37]. The WER was calculated using the following equation:
(1)
(1) where I, S, D, and C are the numbers of inserted words, substituted words, deleted words, and correct words, respectively. The PESQ evaluates how the speech was distorted from its clean speech, especially in the telephone band (0.3–3.4 kHz). The STOI measures the intelligibility of a given speech on the basis of the correlations between the power spectra of the clean and testing speech at each octave band. Table shows the results of WER, PESQ, and STOI for each irradiated object in Experiment 1. Note that the PESQ and STOI of the clean speech cannot be calculated since their calculation requires both clean and reference speeches. The WER of the clean speech recorded using the ECM was 21.5%. The tissue box achieved the best WER and PESQ in Table . When a plastic bottle was irradiated by the LDV, the WER was 35.9% (i.e. a quality decrease of about 15% from clean speech). On the other hand, when the speaker's throat was irradiated by the LDV, the WER significantly degraded to 99%. Figure shows the spectrograms of a single clean speech, a speech measured using the nine target objects. We can observe that the result in Figure (c), which was obtained from the LDV that irradiates the throat, drastically changed from the clean speech result shown in Figure (a). Based on these results, we decided to use a plastic bottle, which achieved a moderate result in Table , as the target object in subsequent experiments.
Figure 5. Spectrograms of speech measured using the ECM and LDV with different irradiation targets. (a) clean speech recorded using the ECM. (b) speech measured using the LDV with an aluminum bottle. (c) speech measured using the LDV with a tissue box. (d) speech measured using the LDV with a bag of potato chips. (e) speech measured using the LDV with a glass cup. (f) speech measured using the LDV with an instant noodle cup. (g) speech measured using the LDV with a mug. (h) speech measured using the LDV with a paper cup. (i) speech measured using the LDV with a plastic bottle and (j) speech measured using the LDV with a speaker's throat.
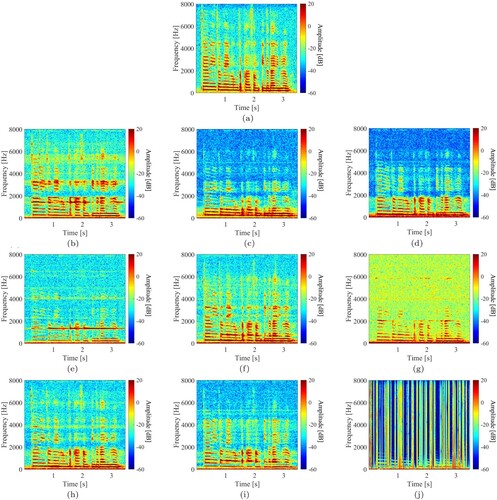
Table 3. Results of WER, PESQ, and STOI for each irradiated object in Experiment 1.
4.2. Experiment 2: comparison of different positions of speakers, microphones, and irradiated objects
In Experiment 2, we changed the relative position between a speaker, the robot, and an irradiated object and analyzed its effect on the speech recognition performance and the sound recording quality. We conducted two experiments whose layouts are shown in Figure . The first experiment analyzed the relationship between the speaker and an object (see Section 4.2.1), while the second experiment focused on the relationship between the speaker and the microphone (see Section 4.2.2).
Figure 6. Equipment layout in Experiment 2. (a) Experiment described in Section 4.2.1 and (b) Experiment described in Section 4.2.2.
4.2.1. Performance evaluation of different distances between the speaker and the vibrating object
The purpose of the first evaluation was to determine the distance between a vibrating object and a loudspeaker, in which the speech can be accurately recognized using an optical laser microphone. As shown in Figure (a), the distance between the loudspeaker and the LDV was fixed to 5.5 m. The plastic bottles corresponding to vibrating objects were placed at intervals of 1 m between the loudspeaker and the LDV. The loudspeaker emitted a speech signal at about 80 dBA. We also placed another loudspeaker, which emitted white noise and fan noise at three different sound pressure levels of 65, 75, and 85 dBA near the LDV. The white noise has the same power in all frequency bands, while the fan noise has a strong power in lower frequency bands. This procedure made the given speech noisy.
Figure shows the spectrograms of clean and noisy speech for each distance between the vibrating object and the loudspeaker used for reproducing the speech, and Table shows the results of the WER, PESQ, and STOI. We found that as the plastic bottle moved farther from the speech source, the speech recognition rate and sound quality decreased. As shown in Figure (a–c), because the sound pressure level of the speech decreased due to distance attenuation, we can consider that the plastic bottle did not sufficiently vibrate. Furthermore, as shown in Figure (d–f), as the plastic bottle was farther away from the speech source and closer to the noise source near the LDV, the plastic bottle was more sensitive to the vibration due to the noise, which accelerated the decrease in speech recognition rate and sound quality. Focusing on the type and sound pressure level of noise, there was no significant difference in the results of PESQ and STOI. On the other hand, the fan noise tended to decrease the WER compared with the white noise. The reason is because the frequency components of fan noise were concentrated in the band specific to speech. From the above results, it is necessary for the LDV to measure the vibration of an object close to the speech source and far away from the noise source (at the lowest sound pressure level possible) to receive the speech in high quality.
Figure 7. Spectrograms of clean and noisy speech at different distances between the vibrating object and the loudspeaker for reproducing the speech. (a) Clean speech (0.5 m). (b) Clean speech (2.5 m). (c) Clean speech (4.5 m). (d) Noisy speech (0.5 m). (e) Noisy speech (2.5 m) and (f) Noisy speech (4.5 m).
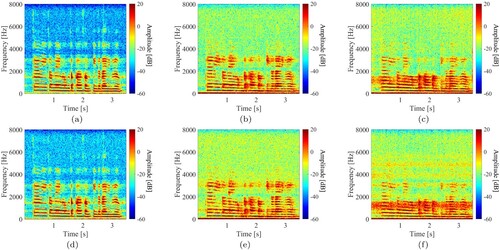
Table 4. Results of WER, PESQ, and STOI for each distance between the irradiated object and the loudspeaker for reproducing the speech.
4.2.2. Performance evaluation for different distances between the speaker and the microphone
Setting the distance between the vibrating object and the loudspeaker for reproducing the speech to the best distance found in the first evaluation, the purpose of the second evaluation was to investigate the distance between the microphone and the loudspeaker, in which the speech can be accurately recognized using an air-conduction microphone or an optical laser microphone. Figure (b) shows the layout of the experimental equipment. The distance between the vibrating object and the loudspeaker for reproducing the speech was fixed at 0.5 m. The microphones ECM and LDV were placed at 2 m intervals from 1.5 to 5.5 m from the loudspeaker. We tested both a clean, noiseless environment and an extremely noisy environment. As shown in Figure (b), we prepared the noise source positions 1 to 3 and the microphone positions 1 to 3, and conducted experiments under 9 combinations of these positions (i.e. ). The reproduced sound pressure levels of the speech and the noise were the same as in Section 4.2.1.
Figure shows the spectrograms of the noisy speech (white noise, 75 dBA) measured using ECM and LDV for each distance between the microphone and the loudspeaker, and Table shows the results of the WER, PESQ, and STOI. The experiments demonstrated that the performance of the ECM became significantly worse when the noise source was close to the microphone. On the other hand, the LDV achieved better performance than the ECM in any conditions. However, its performance was also affected when the noise source was near the irradiated object. In a clean environment, i.e. a noiseless environment, the WER of speech measured using the LDV was lower than that of the ECM at each distance between the microphone and the loudspeaker. On the other hand, in an extremely noisy environment, all the WER, PESQ, and STOI decreased when the reproduced sound pressure of the noise was high for both microphones. In particular, when the ECM was used, all performance measures decreased significantly. The results of Figure implied that the ECM can accurately measure the speech at a high sound pressure level (i.e. high SNR) when it is close to the loudspeaker. Similarly, when the LDV is close to the loudspeaker, the noise around the LDV make the plastic bottle vibrate strongly, which increases the noise mixed in the speech.
Figure 8. Spectrograms of noisy speeches at different distances between the microphone and the loudspeaker for reproducing the speech. The noise source was fixed near the microphone. (a) ECM (1.5 m). (b) ECM (3.5 m). (c) ECM (5.5 m). (d) LDV (1.5 m). (e) LDV (3.5 m) and (f) LDV (5.5 m).
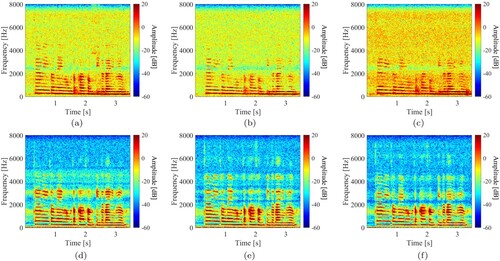
Table 5. WER, PESQ and STOI results for each distance between the microphone and the loudspeaker for reproducing the speech.
We should emphasize that no post-processing was applied to the ECM results, such as noise and reverberation techniques, which are usually used in conventional speech recognition applications. In general, the better the quality of original recordings is, the further these techniques improve the recognition results. Thus, using sophisticated speech post-processing approaches has the potential to improve not only the ECM's recorded speech but also the LDV's recorded speech. Such a comprehensive analysis should be included in our future work.
4.3. Experiment 3: comparison between the LDV and ECM in a domestic environment
In Experiment 3, we compared the performance of our optical laser microphone with the conventional gunshot microphone in a kitchen room assuming a scenario in which a speaker and a robot interact at home. Figure shows the layout of the experimental equipment. We reproduced the situation in which a speaker, who stood at different positions s1 to s5, spoke to a robot at the position R. We measured the speech using both the LDV and ECM. To test the LDV, we placed nine plastic bottles as vibrating objects at 1 m intervals in all directions and detected the best object, i.e. with the highest confidence score, using the proposed approach in Section 3.2. In this experiment, we prepared the following two noise types: (i) the sound of flowing water in a sink with a sound pressure level of about 70 dBA, which corresponds to usual housework [Citation38], such as washing hands and dishes, and (ii) the noise generated by home appliances around the robot. Specifically, the latter includes white noise and fan noise with three sound pressure levels of 65, 75, and 85 dBA. For example, we denote the case of adding white noise at 85 dBA with flowing water by ‘White(85)+F.’ The loudspeaker emitted the noise toward the center of the room as shown in .
Figure 9. Equipment layout.
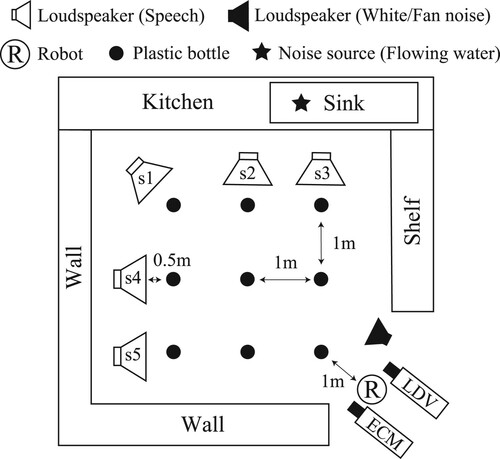
Table shows the WER, PESQ, and STOI for each position of the loudspeaker that emits the speech. An overall trend was that the speech measurement of the LDV yielded better WER, PESQ, and STOI than that of the ECM. For example, in extremely noisy environments such as ‘White(85)+F’ and ‘Fan(85)+F,’ the LDV obtained about 33% of WER, while the ECM produced over about 90% of WER, implying that the ECM was sensitive to noise. The WER, PESQ, and STOI also got worse as the sound pressure level of the noise increased. Table implied that even though the amount of water flowing was normal and equivalent to usual housework, it disturbed the sound recording of the ECM. On the other hand, when using the LDV, the WER ranged from 30.2 to 34.8% in all noisy environments, indicating that the speech measurement of the LDV was robust to noise compared to the ECM. As shown in Figure , the distance between the microphone and the loudspeaker becomes farther in the order of s3 and s5, s2 and s4, and s1. Table demonstrated that the larger the distance between the ECM and the loudspeaker is, the worse the WER, PESQ, and STOI became. This tendency was consistent even when water was flowing. On the other hand, the LDV's results did not depend on a distance change because our method always irradiated an object near the loudspeaker. These results confirmed the effectiveness of using an optical laser microphone for a domestic robot that usually works in a noisy environment.
Figure 10. Recording scene.

Table 6. WER, PESQ and STOI results for each position of the loudspeaker that emits speech.
5. Conclusion
This paper presented a new speech measurement method using an optical laser microphone to realize spoken dialogue for service robots. The proposed method makes the robots' speech recognition systems robust to the noise around the microphone. The results of the experiments conducted in various noisy environments showed that the recognition of speech measured with a optical laser microphone achieved a higher WER, PESQ, and STOI than that obtained using a conventional air-conduction microphone.
There are several research directions to further develop our robot. Although the evaluations in this paper assumed that the proposed system can accurately detect an object irradiated by the laser, it is necessary to investigate advanced object recognition techniques and analyze the relationship between object recognition performance and speech recording quality. Besides, our experiments used the Google Speech-to-Text API whose recognition model was trained on speech recorded with an air-conduction microphone. We should compare it with a model trained using speech recorded using the optical laser microphone. We will also implement several functions on our robot, such as to help a user to recognize the distant-talking speech and sound events in service environments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Takahiro Fukumori
Takahiro Fukumori received his B.E., M.E., and Ph.D. degrees from Ritsumeikan University in 2010, 2012, and 2015, respectively. From 2012 to 2015, he was a JSPS research fellowship for young scientists (DC1). From 2015 to 2020, he was an assistant professor at Ritsumeikan University. He is currently a lecturer at Ritsumeikan University. His current research interests include speech recognition and speech enhancement. He is a member of IEEE, RSJ, ASJ, IPSJ, and IEICE.
Chengkai Cai
Chengkai Cai received the M.E. from the Chiba Institute of Technology, Japan, in 2018. He is currently a Ph.D. student at the Graduate School of Information Science and Engineering, Ritsumeikan University. His current research interests include speech enhancement for optical laser microphone. He is a member of ASJ.
Yutao Zhang
Yutao Zhang received his M.E. degree from the Ritsumeikan University, Japan, in 2019. He is currently a Ph.D. student at the Graduate School of Information Science and Engineering, Ritsumeikan University. His current research interests include acoustic event detection and speech recognition. He is a member of ASJ.
Lotfi El Hafi
Lotfi El Hafi received his M.S.E. from the Université catholique de Louvain, Belgium, and his Ph.D. from the Nara Institute of Science and Technology, Japan, in 2013 and 2017, respectively. His thesis focused on STARE, a novel eye-tracking approach that leveraged deep learning to extract behavioral information from scenes reflected in the eyes. Today, he works as a Research Assistant Professor at the Ritsumeikan Global Innovation Research Organization, as a Specially Appointed Researcher for the Toyota HSR Community, and as a Research Advisor for Robotics Competitions for the Robotics Hub of Panasonic Corporation. His research interests include service robotics and artificial intelligence. He is also the recipient of multiple research awards and competition prizes, an active member of RSJ, JSME, and IEEE, and the President & Founder of Coarobo GK.
Yoshinobu Hagiwara
Yoshinobu Hagiwara received his Ph.D. degree from Soka University, Japan, in 2010. He was an Assistant Professor at the Department of Information Systems Science, Soka University, from 2010, a Specially Appointed Researcher at the Principles of Informatics Research Division, National Institute of Informatics, from 2013, and an Assistant Professor at the Department of Human & Computer Intelligence, Ritsumeikan University, from 2015. He is currently a Lecturer at the Department of Information Science and Engineering, Ritsumeikan University. His research interests include human-robot interaction, machine learning, intelligent robotics, and symbol emergence in robotics. He is also a member of IEEE, RSJ, IEEJ, JSAI, SICE, and IEICE.
Takanobu Nishiura
Takanobu Nishiura received his M.E. and Ph.D. degrees from Nara Institute of Science and Technology, in 1999 and 2001, respectively. From 2001 to 2004, he was an Assistant Professor at Wakayama University. From 2004 to 2014, he was an Associate Professor at Ritsumeikan University. Since 2014, he is a Professor at Ritsumeikan University. He has been engaged in research on acoustic signal processing, acoustic field reproduction, noise control, parametric loudspeaker, visual microphone, and optical laser microphone. He is also a member of IEEE, IEEJ, IEICE, IPSJ, VRSJ and ASJ.
Tadahiro Taniguchi
Tadahiro Taniguchi received his M.E. and Ph.D. degrees from Kyoto University, in 2003 and 2006, respectively. From 2005 to 2008, he was a Japan Society for the Promotion of Science Research Fellow in the same university. From 2008 to 2010, he was an Assistant Professor at the Department of Human and Computer Intelligence, Ritsumeikan University. From 2010 to 2017, he was an Associate Professor in the same department. From 2015 to 2016, he was a Visiting Associate Professor at the Department of Electrical and Electronic Engineering, Imperial College London. Since 2017, he is a Professor at the Department of Information and Engineering, Ritsumeikan University, and a Visiting General Chief Scientist at the Technology Division of Panasonic Corporation. He has been engaged in research on machine learning, emergent systems, intelligent vehicle, and symbol emergence in robotics.
Notes
4 This study was carried out following Ritsumeikan University Research Ethics Guidelines. The laser corresponds to Class 2, which is safe for humans. An ethical review process was not required for this study because none of the conditions for such a review based on the checklist provided by the Research Ethics Committee of Ritsumeikan University were satisfied. All participants gave written informed consent.
6 Although we confirmed the safety of the laser beam, the speakers wore light-shielding glasses to protect their eyes during the experiments.
References
- Nakadai K, Okuno HG, Mizumoto T. Development, deployment and applications of robot audition open source software HARK. J Robot Mechatron. 2017;29(1):16–25.
- Rothberg S, Allen M, Castellini P, et al. An international review of laser Doppler vibrometry: making light work of vibration measurement. Opt Lasers Eng. 2017;99:11–22.
- Bicen B, Jolly S, Jeelani K, et al. Integrated optical displacement detection and electrostatic actuation for directional optical microphones with micromachined biomimetic diaphragms. IEEE Sens J. 2009;9(12):1933–1941.
- Leclère Q, Laulagnet B. Nearfield acoustic holography using a laser vibrometer and a light membrane. J Acoust Soc Am. 2009;126(3):1245–1249.
- Chen Y, Wu F, Shuai W, et al. Kejia robot–an attractive shopping mall guider. In: International Conference on Social Robotics. Springer; 2015. p. 145–154.
- Novoa J, Wuth J, Escudero JP, et al. DNN-HMM based automatic speech recognition for HRI scenarios. In: Proceedings of the 2018 ACM/IEEE International Conference on Human-Robot Interaction. Association for Computing Machinery; 2018. p. 150–159.
- Lee SC, Wang JF, Chen MH. Threshold-based noise detection and reduction for automatic speech recognition system in human-robot interactions. Sensors. 2018;18(7). DOI:https://doi.org/10.3390/s18072068.
- Suzuki M, Honjo T. Spot-forming method by using two shotgun microphones. In: Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Hong Kong; 2015. p. 188–191.
- Valin J, Yamamoto S, Rouat J, et al. Robust recognition of simultaneous speech by a mobile robot. IEEE Trans Robot. 2007;23(4):742–752.
- Lim JS, Oppenheim AV. Enhancement and bandwidth compression of noisy speech. Proc IEEE. 1979;67(12):1586–1604.
- Boll S. A spectral subtraction algorithm for suppression of acoustic noise in speech. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, Washington, DC, USA; Vol. 4; 1979. p. 200–203.
- Berouti M, Schwartz R, Makhoul J. Enhancement of speech corrupted by acoustic noise. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, Washington, DC, USA; Vol. 4; 1979. p. 208–211.
- Hansen P, Jensen S. Subspace-based noise reduction for speech signals via diagonal and triangular matrix decompositions: survey and analysis. EURASIP J Adv Signal Process. 2007;2007:092953. DOI:https://doi.org/10.1155/2007/92953.
- Nakadai K, Okuno HG. Robot audition and computational auditory scene analysis. Adv Intell Syst. 2020;2(9):Article ID 2000050.
- Nakadai K, Lourens T, Okuno H, et al. Active audition for humanoid. In: Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, Austin, USA; 2000. p. 832–839.
- Takeda R, Nakadai K, Takahashi T, et al. Efficient blind dereverberation and echo cancellation based on independent component analysis for actual acoustic signals. Neural Comput. 2012;24:234–272.
- Lotter T, Vary P. Noise reduction by joint maximum a posteriori spectral amplitude and phase estimation with super-Gaussian speech modelling. In: European Signal Processing Conference, Vienna, Austria; 2004. p. 1457–1460.
- Krawczyk M, Gerkmann T. STFT phase reconstruction in voiced speech for an improved single-channel speech enhancement. IEEE/ACM Trans Audio Speech Lang Process. 2014;22(12):1931–1940.
- Li K, Lee C. A deep neural network approach to speech bandwidth expansion. In: IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia; 2015. p. 4395–4399.
- Rethage D, Pons J, Serra X. A Wavenet for Speech Denoising. In: IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, Canada; 2018. p. 5069–5073.
- Aygün H, Apolskis A. The quality and reliability of the mechanical stethoscopes and laser Doppler vibrometer (LDV) to record tracheal sounds. Appl Acoust. 2020;161:Article ID 107159.
- Ismail HM, Pretty CG, Signal MK, et al. Laser doppler vibrometer validation of an optical flow motion tracking algorithm. Biomed Signal Process Control. 2019;49:322–327.
- Malekjafarian A, Martinez D, OBrien EJ. The feasibility of using laser doppler vibrometer measurements from a passing vehicle for bridge damage detection. Shock Vib. 2018;2018; DOI:https://doi.org/10.1155/2018/9385171.
- Chen DM, Xu Y, Zhu W. Identification of damage in plates using full-field measurement with a continuously scanning laser doppler vibrometer system. J Sound Vib. 2018;422:542–567.
- Oikawa Y, Goto M, Ikeda Y, et al. Sound field measurements based on reconstruction from laser projections. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, USA; Vol. 4; 2005. p. 661–664.
- Morita N, Nogami H, Hayashida Y, et al. Development of a miniaturized laser Doppler velocimeter for use as a slip sensor for robot hand control. In: IEEE International Conference on Micro Electro Mechanical Systems, Estoril, Portugal; 2015. p. 748–751.
- Margerit P, Gobin T, Lebée A, et al. The robotized laser doppler vibrometer: on the use of an industrial robot arm to perform 3D full-field velocity measurements. Opt Lasers Eng. 2021;137:Article ID 106363.
- Jungbluth J, Siedentopp K, Krieger R, et al. Combining virtual and robot assistants – a case study about integrating amazon's Alexa as a voice interface in robotics. In: Robotix-Academy Conference for Industrial Robotics, Luxembourg; 2018. p. 1–5.
- Yamamoto T, Takagi Y, Ochiai A, et al. Human support robot as research platform of domestic mobile manipulator. In: RoboCup 2019: Robot World Cup XXIII. Springer International Publishing; 2019. p. 457–465.
- Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection. In: IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA; 2016. p. 779–788.
- Zhang X, Wang D. Boosting contextual information for deep neural network based voice activity detection. IEEE/ACM Trans Audio Speech Lang Process. 2016;24(2):252–264.
- Eyben F, Weninger F, Squartini S, et al. Real-life voice activity detection with LSTM Recurrent Neural Networks and an application to Hollywood movies. In: IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, Canada; 2013. p. 483–487.
- Zazo R, Sainath TN, Simko G, et al. Feature learning with raw-waveform CLDNNs for voice activity detection. In: Interspeech, San Francisco, USA; 2016. p. 3668–3672.
- Kim J, Hahn M. Voice activity detection using an adaptive context attention model. IEEE Signal Process Lett. 2018;25(8):1181–1185.
- Wiseman J. py-webrtcvad. 2016. [last accessed: 2021 Sep 23]. Available from: https://github.com/wiseman/py-webrtcvad/.
- Rix A, Beerends J, Hollier M, et al. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, USA; Vol. 2; 2001. p. 749–752.
- Taal C, Hendriks R, Heusdens R, et al. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In: IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, USA; 2010. p. 4214–4217.
- Jackson GM, Leventhall G. Household appliance noise. Appl Acoust. 1975;8:101–118.