
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Recently, several studies have been working on multi-view object-centric models, which predict unobserved views of a scene and infer object-centric representations from several observation views. In general, multi-object scenes can be uniquely determined if both the properties of individual objects and the spatial arrangement of objects are specified; however, existing multi-view object-centric models only infer object-level representations and lack spatial information. This insufficient modeling can degrade novel-view synthesis quality and make it difficult to generate novel scenes. We can model both spatial information and object representations by introducing a hierarchical probabilistic model, which contains a global latent variable on top of object-level latent variables. However, how to execute inference and training with that hierarchical multi-view object-centric model is unclear. Therefore, we introduce several crucial components which help inference and training with the proposed model. We show that the proposed method achieves good inference quality and can also generate novel scenes properly.
GRAPHICAL ABSTRACT
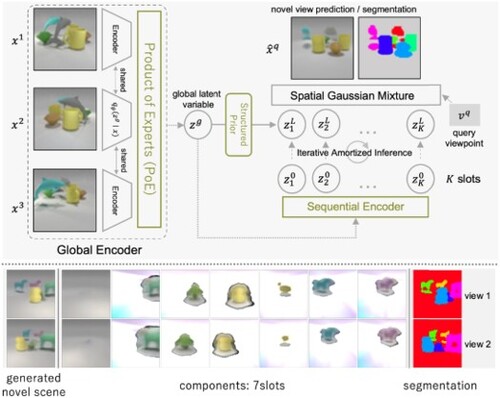
1. Introduction
Extracting representations of individual objects from direct perception (e.g. visual input) is called object-centric representation learning. It is considered to be effective in many aspects such as robotics [Citation1–3], reasoning [Citation4], and sample efficiency [Citation5]. Among them, the deep generative model (DGM)-based method is one of the promising directions, as it can infer rich information about objects in a fully unsupervised manner, and some of its models can also generate novel scenes [Citation6–13].
Since this kind DGM-based models capture and reconstruct the environment from limited observation, this can be used as a simulator of the environment. Thus, they are regarded as so-called world model [Citation14] or internal model [Citation15]. World model is a basis of model-based reinforcement learning(RL), and it has been used for RL agents and robots [Citation16,Citation17].
Recently, several studies have been working on multi-view object-centric models, which predict unobserved views of a scene: novel view synthesis and infer object-centric representations from several observation views [Citation18,Citation19]. In addition, this setting can also be regarded as an object-centric expansion of the Generative Query Network (GQN) [Citation20].
To represent multi-object scenes properly, the properties of individual objects and the spatial arrangement of objects should be specified. However, existing multi-view object-centric methods only explicitly model representations of individual objects, and each of them includes its own spatial information separately. Namely, the relationship between objects is not represented in this case. This modeling can degrade novel view synthesis and segmentation because the model needs to solve occlusions and spatial ambiguity virtually without prior knowledge about objects' spatial relationships. This can be serious especially when the number of available observation views is limited. In addition, this modeling can also lead to the inability to generate physically plausible novel scenes, because they need to place objects independently, which often brings about collisions and misplacement of objects.
Spatial information of the whole scene can be represented by introducing another latent variable besides object-level latent variables. This variable can be independent of object-level latent variables or can be modeled as a global latent on top of object-level latent variables. In the former formulation, those latent variables need to be disentangled during training, which can often be challenging. From another point of view, it is a common assumption in cognitive science that humans recognize the whole and parts, or objects, separately [Citation21]. In feature integration theory [Citation22], visual feature maps become ‘master map of locations’ combined with positions of objects in visual space. Then, attention binds those features to recognize individual objects. Modeling the spatial arrangement of objects as a global latent variable closely adheres to this point of view due to its hierarchical property. For the above reasons, we believe that introducing a global latent variable is a more natural step for improving object-centric generative models.
In this paper, we build a new multi-view object-centric model which has a latent variable for global spatial information to improve inference: novel view synthesis and segmentation. In addition, our model can also generate physically plausible novel scenes. The problem is that how to execute inference and training with the proposed model is unclear. In regards to this point, we propose several crucial components: Global Encoder, Sequential Encoder, and Structured Prior. Firstly, the model needs to infer global representation from variable number of input views, thus we introduced an encoder using Product of Experts (PoE) [Citation23], which we refer to as Global Encoder. Also, we applied Normalizing Flow (NF) [Citation24] to enhance the representational capacity of the latent variable. Secondly, we introduced an encoder using an auto-regressive model called Sequential Encoder. This module supports the Global Encoder and stabilizes inference and training with the hierarchical probabilistic model of the proposed method. Lastly, the structured, complex posterior of object-level latent variables need to be sampled, including spatial relationships between objects in order to generate physically plausible novel scenes. Therefore, we introduced a learnable prior called Structured Prior, which is implemented by Transformer [Citation25].
The proposed model has representation about the whole, or spatial information of a scene and has representations about a part of a scene (i.e. individual properties of objects); hence, we call this model as Whole-Part Representation Learning Model for Object-Centric 3D Scene Inference and Sampling (WeLIS).
Contributions
We introduce a multi-view object-centric model with a global latent variable that represents the spatial configuration of objects in a scene.
We introduce essential components for introducing a global latent variable as well as stable learning and inference for our multi-view object-centric model.
We show that the proposed model performs well in terms of inference quality, and can generate novel scenes and corresponding segmentation masks properly, unlike existing methods.
2. Related work
Object-Centric Models: The objective of object-centric representation learning is to obtain representations of each object from visual input. It is applicable to many domains such as robotics [Citation1,Citation2,Citation27], reasoning [Citation4] and reinforcement learning [Citation5]. One of the promising directions of object-centric representation learning is variational autoencoder (VAE)-based [Citation28] methods, as they can obtain rich information about objects that can also be disentangled, and some of them can generate novel scenes outside of the empirical distribution [Citation8–13]. VAE-based object-centric models are often referred to as ‘scene interpretation models’ due to their inference ability. Some models are capable of object-centric generation [Citation29–31]; however, these methods focus on generation and not for inference.
Multi-view information: In a robotics field, multi-view information has been used for many area such as 3D reconstruction as stereo imaging [Citation32], SLAM and novel view synthesis [Citation33], and 3D pose estimation of rooms and objects [Citation34]. In terms of neural network-based methods, Generative Query Network (GQN) [Citation20] for novel view synthesis and Neural Radiance Fields (NeRF) [Citation35] for 3D modeling depend on multi-view information.
Multi-View Object-Centric Models: Lately, several studies have been working on multi-view scene interpretation models [Citation18,Citation19]. These methods predict images of a 3D scene from arbitrary viewpoints in an object-centric way, using several observation views as input. This problem setting can be regarded as an object-centric expansion of GQN family [Citation20,Citation26,Citation36]. The above-mentioned single-view setting is referred to as multi-object-single-view (MOSV), and the multi-view setting is defined as multi-object-multi-view (MOMV) in [Citation18].
Table compares methods related to the MOMV setting. Novel view synthesis stands for prediction of unobserved viewpoints, and novel scene generation stands for random generation of novel scenes. Among these models, ROOTS and MulMON [Citation18,Citation19] are the only generative models that work on a MOMV setting. In addition to this, O3V [Citation37] have a similar problem setting, but it takes a fixed number of viewpoints as input. ObSuRF [Citation38] and uORF [Citation39] also work on MOMV setting, but these are not generative models and are based on Slot Attention [Citation7] and NeRF [Citation35]. Therefore, these methods cannot generate novel samples and do not obtain low-dimensional representation space, or latent space.
Table 1. Comparison of the methods related to Multi-Object-Multi-View (MOMV) setting.
In this paper, we introduce a new MOMV model with a global latent variable, which can potentially represent the spatial arrangement of objects in a scene. The proposed model is the only MOMV model that can generate novel scenes. In this paper, we set MulMON as our baseline model due to the following reasons. Firstly, MulMON uses segmentation masks to represent objects' regions in contrast to ROOTS which uses bounding boxes. Bounding box-based methods, which originate from [Citation11] tend to be more sensitive to object size and shape [Citation40]. Secondly, MulMON is more robust in terms of the number of observation views required. Although we built our model based on MulMON, a similar approach can be applied to ROOTS and other methods.
Introducing the global latent variable itself has been done in some studies in various areas [Citation41,Citation42]. In particular, Generative Neurosymbolic Machine [Citation13] introduces a global latent variable to bounding box-based single-view object-centric model for random generation. However, how to execute stable inference and training with the proposed MOMV model is unclear and is thus the point of investigation in this paper.
3. Method
Our objective was to introduce a MOMV model that has both object-level representations and the spatial arrangement of the scene to obtain further inference quality and novel scene generation ability.
We achieved this by introducing a global latent variable for global spatial information on top of object latent variables, which is formulated as a hierarchical probabilistic model. In this paper, we introduce several crucial components to realize stable inference and training with this MOMV model. An overview of the proposed model is shown in Figure .
Figure 1. Overview of the proposed model. In this example, the model predicted an image and corresponding segmentation masks from unobserved query viewpoint , using three observation views
-
.
is a global latent variable that represents spatial relationships between objects, and
is object-level latent variables that represent each object. Note that the
and segmentation shown in this figure are the actual results from our model.
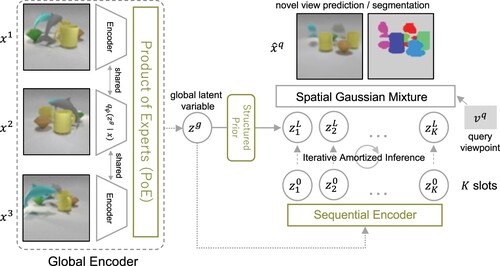
In this section, we first explain the problem setting in this paper, and then the probabilistic model of our proposed model. Lastly, the training method and additional details of the introduced components are explained.
3.1. Problem setting
The target of this research is 3D scenes with multiple objects, and thus a dataset with N data points can be defined as , where
, which corresponds to a scene with M views, and
is a viewpoint vector that represents the camera pose.
The task is to predict queried unobserved views of the scene and infer K representations given several observations
. Here, each
corresponds to an object in the scene. In practice, the M views in
is split into
observations and
queries in the training process.
can be varied in each iteration if necessary.
3.2. Probabilistic model
3.2.1. Generative model
As mentioned above, we introduced the hierarchical probabilistic model with global latent on top of object-level latent variables
. In the following sections, object-level latent variables are abbreviated as
, as required. The marginal likelihood is thus:
(1)
(1) where
. The generative model
is a spatial Gaussian mixture model derived from prior works [Citation8,Citation18] that can be written as:
(2)
(2) where
is the number of image pixels, and K is the number of mixture components which are often referred to as ‘slots’. The factor
is a pixel-wise assignment of slots, or segmentation mask. The decoder has parameters θ and implemented by a broadcast decoder [Citation43].
and
are first concatenated and projected onto a single vector
by an MLP and then fed to the decoder. The decoder generates K components
and corresponding segmentation masks from
.
The second factor in the RHS of Equation (Equation1(1)
(1) ):
is a learnable prior, which we refer to as the Structured Prior, and the third factor is a standard Gaussian distribution. The Structured Prior is explained in Section 3.3.
3.2.2. Inference model
We used amortized variational inference [Citation28] and computed variational approximate posteriors because the marginal likelihood in Equation (Equation1(1)
(1) ) is intractable. We factorized the variational posteriors as:
(3)
(3) where
. The first RHS term and second RHS term are approximate posteriors of
and
respectively. We refer to these encoders as Sequential Encoder and Global Encoder.
The Global Encoder adopts PoE [Citation23] to deal with a variable number of input observation views . In particular, we used PoE with prior expert [Citation44]. In addition to this, we applied normalizing flow (NF) [Citation24] after the PoE. Although this is optional, the posterior should be expressive enough to represent the spatial configuration of complex 3D multi-object scenes. Therefore, the variational approximate posterior is:
(4)
(4) where T is the number of transformations of NF, and
is the number of available observation views. We used planar flow for its simplicity, but any methods can be applied and can improve the results potentially. Thus, the transform
in the above equation is
The Sequential Encoder was implemented in auto-regressive manner using LSTM [Citation45]. We tried several architectures, but non-auto-regressive models were unstable as long as we have tested. Firstly, this auto-regressive part infers K initial latent variables
and then, they are updated using iterative amortized inference (IAI) [Citation46] as MulMON and IODINE [Citation9] do. However, we omitted image-sized inputs as in [Citation47]. Thus, the Sequential Encoder with parameter ψ can be defined as:
(5)
(5)
(6)
(6) where, subscript l is the update steps,
is a gradient of negative log-likelihood in that iteration, and
is a refinement network that is implemented by an MLP followed by an LSTM. Then, the posterior can be updated arbitrary times. The details of
is explained in the next section.
3.2.3. Training
All the parameters in this model can be trained end-to-end by maximizing evidence lower bound (ELBO) on the log-marginal likelihood . The ELBO of the proposed model is
(7)
(7) Here, KL stands for Kullback–Leibler divergence. Then, introducing two coefficient
and
for balancing KL terms, the objective can be written as
(8)
(8) Moreover, due to the iterative process of IAI, negative log-likelihood is computed as
(9)
(9)
(10)
(10) where L is the number of iterations in IAI. We set L = 5 in this paper. As shown in Equation (Equation9
(9)
(9) ), log-likelihoods in the later steps of iterative refinement are emphasized as in MulMON and IODINE.
In addition to this, we used GECO [Citation48] as in some existing methods [Citation10,Citation47]. GECO reinterprets the maximization of ELBO as a constrained optimization problem that takes KL terms as the main objective and log-likelihood as the constraint. This optimization is done by the method of Lagrange multipliers, namely, the coefficient of KL terms β is regarded as a Lagrange multiplier and automatically tweaked during training. GECO is not necessary for our model, but a proper balancing of β further improves random generation quality.
The reinterpreted optimization objective thus becomes
(11)
(11) where
is the maximum allowed negative log-likelihood, which is a hyperparameter in GECO instead of β, and
,
stands for observation views. Note that even when we use GECO, adjusting relative strength between two KL terms in Equation11
(11)
(11) using coefficients still makes sense, but we omitted them for clarity. Although all the parameters can be trained end-to-end, we found that end-to-end training, including the parameters of Structured Prior ϕ is slightly unstable and often degrades novel scene generation. Thus, we introduced a separate training strategy, in which ϕ is updated after the training of the other parameters. The detail of this method is explained in the next section.
3.3. Structured prior
In this section, we explain the detail of the Structured Prior and corresponding separate training strategy.
First of all, the Structured Prior is defined as .
As we mentioned in Equation (Equation6(6)
(6) ), the latent variables of each slot are iteratively updated by IAI in the inference process. However, it makes sampling from the updated posterior
difficult. Though IAI updates latent variables using reconstruction error and auxiliary inputs, the generative model can not use such information and need to blindly capture this refinement process without them.
Therefore, in order to model this process, we implemented Structured Prior as Transformer [Citation25]. Firstly, initial K variables are computed from
using the Sequential Encoder
. Then, Transformer takes the K latent variables as input and approximates updated ones
. Note that the parameter of Sequential Encoder is shared with inference.
3.3.1. Separate training
As we mentioned above, we introduced a separate training method for the Structured Prior. In the first stage, WeLIS is trained without the parameters of Structured Prior ϕ. Namely, ϕ is frozen and in Equation (Equation8
(8)
(8) ) is set to zero or the second term of Equation (Equation11
(11)
(11) ) is excluded if we use GECO. Then, as a second stage, ϕ is updated while other parameters are frozen.
4. Experiments
We evaluated our model with three different datasets derived from the MulMON paper [Citation18]. CLEVR Multi-View (CLEVR MV) is a multi-view version of the CLEVR dataset [Citation49], and CLEVR Augmented (CLEVR AUG) extends CLEVR MV with more complex and various objects for additional difficulty. GQN Jaco is a simulation-based robot arm dataset introduced originally in [Citation20]. The dimension of viewpoint vector in both CLEVR datasets is three since it always faces toward the center of the scenes, and is seven for GQN Jaco as defined in the original dataset. Ultimately, the viewpoints are supposed to be actively inferred by the agents to capture the scene accurately, they are fixed in this experiment. Figure shows examples of these datasets. All the datasets are used in resolution Footnote1. Up to six views are given as observation during training, and we trained all the models with Adam optimizer for
iterations. Besides, we adapted the official implementation of MulMON for reproduction.
Figure 2. Ground truth samples of the three datasets: CLEVR MV, CLEVR AUG and GQN Jaco.

In the following sections, firstly, we evaluated inference quality, i.e. novel view synthesis and segmentation quantitatively and qualitatively. Then, we show WeLIS can also generate physically plausible novel scenes, in contrast to the previous works. Lastly, we conducted a few experiments to look into the global latent space .
4.1. Novel view synthesis and segmentation
In this section, we evaluate novel view synthesis and segmentation quality. Figure shows quantitative evaluation of three models: WeLIS, WeLIS without NF (ablation) and MulMON. We used two metrics for the evaluation of novel view synthesis. Image quality is evaluated by Root Mean Squared Error (RMSE), and segmentation quality is evaluated by mean Intersection over Union(mIoU). Note that lower is better for RMSE, and higher is better for mIoU. Random four seeds are used to calculate these scores. As GQN Jaco does not provide ground truth segmentation, we instead show qualitative results in Figure . In addition, Figure shows an evaluation about observation viewpoints, namely, this figure shows simple reconstruction and segmentation quality without novel view synthesis.
Figure 3. Quantitative evaluation of novel view synthesis. Lower is better for root mean squared error(RMSE), and higher is better for mean intersection over union (mIoU). mIoU is not available for GQN Jaco dataset since ground truth segmentation masks are not provided.
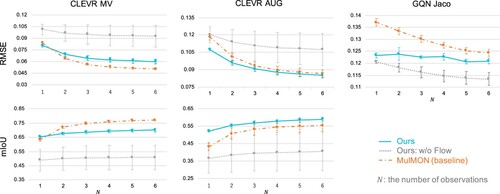
Figure 4. Novel view synthesis results on GQN Jaco with four difference scenes. These images are prediction of unobserved query views. The number of observation views is three (N = 3).
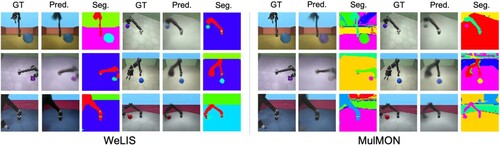
Figure 5. Quantitative evaluation of reconstruction and segmentation. This figure is about observed views, i.e. input images in contrast to which is about unobserved views.
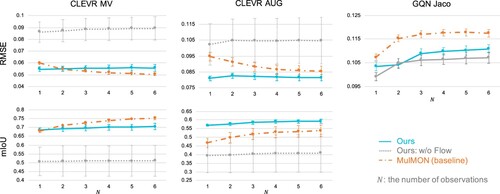
We can see that WeLIS outperforms MulMON in CLEVR AUG, GQN Jaco and CLEVR MV with a small number of observation views N. WeLIS is relatively stable in terms of N, which means that WeLIS is good at inferring the whole scene from limited, partial observation. Introducing global latent in addition to object-level latent variables leads to more precise modeling of the world, thus we consider that it helps inference with a small number of observations. As for GQN Jaco (Figure ), WeLIS has cleaner segmentation and captures the balls more consistently.
In addition, we show some samples from WeLIS and MulMON in Figure with their RMSE and mIoU to show how quantitative difference affects perceptual quality. There is a distinctive difference between mIoU and segmentation quality. Though the difference about RMSE is relatively unnoticeable to human eyes, we can see that WeLIS has slightly sharper images, especially for objects with a complex shape such as dolphins and ducks.
Figure 6. Quantitative scores of novel view synthesis and qualitative comparisons. The left most column in each group show ground truth (GT) images from an unobserved viewpoint. The second columns in each group show images predicted by the model (Pred.). The third columns show segmentation masks (Seg.). The number of observation views N is three in this figure.

4.1.1. Ablation studies (Novel view synthesis)
We validate each component introduced in WeLIS by ablation studies. Figure shows ablation results of the components and training methods.
Figure 7. Ablation studies of each component: Global Encoder (PoE), GECO, separate training of Structured Prior. ‘observation’ is about observed view points and ‘query’ is about unobserved ones.
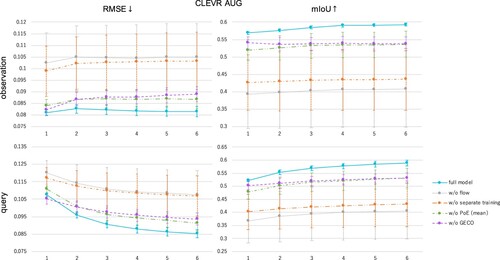
As for NF (gray lines), it is important for stable inference and training. Without NF, the model often falls into local minima that does not properly represent one object per slot. This can be confirmed by relatively large standard errors. However, when the training succeeded, the model achieved the almost same performance as the full model.
Also, we can see that other components and training methods also contribute to the result: separate training of Structured Prior, PoE encoder, and GECO.
4.2. Novel scene generation
In this section, we evaluate novel scene generation (random generation) results. Figure shows component-by-component generation results. We can see that WeLIS successfully generates objects and segmentation masks, and as a result, generates physically plausible novel scenes from multiple viewpoints. On the other hand, MulMON generates blurred and spatially ambiguous images. Top row of Figure shows more samples. As shown in Table , WeLIS is the first multi-view model that can do both object-centric inference and novel scene generation.
Figure 8. Component-by-component random generation results of WeLIS and the baseline. Each row corresponds to a different query viewpoint. The first column shows generated images, and the next seven columns show each slot (), while last column shows generated segmentation masks.

Figure 9. Random generation results from WeLIS, MulMON(baseline) and ablated models. The top row shows results from WeLIS and MulMON, and the bottom row shows WeLIS without Structured Prior and without normalizing flow for ablation study. We generated these images by randomly sampling eight for WeLIS, and by sampling each slot independently for MulMON. Note that the same set of
is used in the full model(top left) and in the ablation of the Structured Prior(bottom left).

4.2.1. Ablation studies (Novel scene generation)
The bottom row of Figure shows ablation studies of Structured Prior and NF. Firstly, we look into Structured Prior. In this experiment, the results from the full model (top left) and ablation study of Structured Prior (bottom left) are generated from the same . Generated images without Structured Prior are severely blurred, however, we can see that the spatial arrangement of objects itself is similar to the full model. This indicates that Structured Prior only contributes to object-level generation quality, and spatial consistency is secured by the global latent variable.
Secondly, the bottom right images in Figure show ablation results of NF. As you can see, the quality is almost the same with the full model even without NF, which indicates that NF is not essential for generation itself. However, as we mentioned in Section 4.1, NF is important for stable inference and training, thus it is also useful for novel scene generation in practice.
4.2.2. Quantitative evaluations
We also quantitatively evaluated novel scene generation by Fréchet Inception Distance(FID) score in Table . WeLIS outperforms MulMON in every dataset, and as shown in the above section, WeLIS without NF achieved similar quality to the full model, as long as the training succeeded. Scores without NF in CLEVR AUG and GQN Jaco are degraded because the training fails more frequently as datasets become difficult.
Table 2. Evaluation of FID score on three models: WeLIS(Ours), WeLIS without Normalizing Flow and MulMON.
Poor generation quality of MulMON comes from mainly two reasons: insufficient modeling of spatial arrangement and difficulty in sampling actual posterior. In WeLIS, the former one is dealt with by introducing global latent which represents spatial information of a whole scene, and the latter one is dealt with by a Structured Prior which estimates complex posterior inferred and updated by IAI. Effectiveness of introducing
is evaluated in Section 4.3 and that of Structured Prior is already investigated in Figure .
4.3. Applying perturbation to the global latent variable
To look into the representation obtained by the global latent variable , we show images generated from four different
(A-D) and their four neighborhoods
in Figure . Here,
is a small perturbation randomly sampled from a standard normal distribution. The leftmost images in the each group is the one from each
, and the other four images are the ones generated with different perturbations. Thus, each group (A-D) represents a ‘cluster’ around
.
Figure 10. Random generation results from four different (A–D) and four neighborhoods
, where
is Gaussian noise as a perturbation. Each row corresponds to a different
. The left most columns of each group show the original
, and other columns are added small perturbations
. Therefore, each row represents a ‘cluster’ of each
. We can see that images in the same row share a similar spatial structure. The schematic of the latent space on the right side is just for illustration purposes.

We can see that generated scenes from the same have similar spatial structure, while their objects vary. This indicates that the latent space of
obtains the spatial configuration of a scene as we expected.
Moreover, we show latent traversal results in Figure . Each row shows different interpolation results from randomly sampled two : sample A and sample B. We can see that spatial arrangement changes continuously, but the property of individual components changes quickly. This result also indicates that the global latent variable holds information about the spatial arrangement but individual objects.
Figure 11. Traversal of global latent space.

4.4. Downstream tasks
In the above sections, we evaluated our method mainly by reconstruction and segmentation. Though they are inevitably important metrics, they can not evaluate how good the representation obtained by latent variables are. One of the important things for deep generative models is whether the obtained representation is useful for various unknown tasks, i.e. downstream tasks. Here, we evaluate the representation by counting the number of objects in an observed scene. The number of objects is predicted from inferred latent variables using a linear probe. It is a fully connected layer which takes K (objects) latent variables as input, and output one-hot vector which represents the number of objects in the scene. With this task, we can evaluate how much information the representations hold.
Table shows the accuracy from each model. Since WeLIS has two types of latent variables, we tried three combinations: ,
, and concatenation of
and
. In CLEVR MV dataset,
contributes to the accuracy the most, and In CLEVR AUG dataset,
performs well especially in combination with
. This result also shows that
effectively captures global information of the scene comparing to the combination of single object representations
.
Table 3. Accuracy of a downstream task.
5. Conclusion
We introduced a new multi-view object-centric model: WeLIS, which can perform multi-view object-centric inference and sampling in 3D scenes. We introduced several components to WeLIS, in order to adapt a global latent variable and to enable inference and training with that model. The global latent variable improved inference quality especially when the observation is limited (Section 4.1) and also enabled the model to generate physically plausible novel scenes (Section 4.2). We also conducted ablation studies (Section 4.1.1 and 4.2.1) and looked into the representation obtained by global latent space (Section 4.3).
One of the future directions of this research is to sophisticate inference methods such as normalizing flow and IAI. There is room for improvement with an optimal choice of normalizing flow. In addition, we used simplified IAI without image-sized input which can reduce computational cost, however, there is a possibility that this sacrificed the ability to distinguish similar, ambiguous objects such as rounded cubes and spheres in CLEVR MV dataset.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Yuya Kobayashi
Yuya Kobayashi is a researcher in SONY Computer Laboratory. He received Ph.D in Engineering from The University of Tokyo. He has been engaged in Deep Generative Models, Compuitational Neuroscience, Non-invasive Brain Recordings.
Masahiro Suzuki
Masahiro Suzuki is a assistant professor in The University of Tokyo. He received Ph.D in Engineering from the University of Tokyo in 2018. His research topic is Artificial Intelligence and Deep Learning.
Yutaka Matsuo
Yutaka Matsuo is a Professor in the University of Tokyo. He was a director of The Japanese Society for Artificial Intelligence in 2020–2022. He received Ph.D in Engineering from The University of Tokyo in 2002. His specialization is Artificial Intelligence, Deep Learning, Web Engineering.
Notes
1 According to the supplemental material, MulMON uses CLEVR AUG in resolution, but we used all the datasets in
for consistent comparison.
References
- Devin C, Abbeel P, Darrell T, et al. Deep object-centric representations for generalizable robot learning. In: 2018 IEEE International Conference on Robotics and Automation (ICRA); 2018. p. 7111–7118. IEEE.
- Veerapaneni R, Co-Reyes JD, Chang M, et al. Entity abstraction in visual model-based reinforcement learning. In: Conference on Robot Learning; 2019. Osaka, Japan
- Kulkarni T, Gupta A, Ionescu C, et al. Unsupervised learning of object keypoints for perception and control. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems; 2019. Vancouver, Canada. Curran Associates, Inc.
- Ding D, Hill F, Santoro A, et al. Attention over learned object embeddings enables complex visual reasoning. CoRR. 2020. arXiv:2012.08508.
- Watters N, Matthey L, Bosnjak M, et al. COBRA: data-efficient model-based RL through unsupervised object discovery and curiosity-driven exploration. CoRR. 2019. arXiv:1905.09275.
- Greff K, van Steenkiste S, Schmidhuber J. Neural expectation maximization. In: Guyon I, Luxburg UV, Bengio S, et al., editors. Advances in Neural Information Processing Systems; Vol. 30. Curran Associates, Inc.; 2017. Long Beach, CA, USA.
- Locatello F, Weissenborn D, Unterthiner T, et al. Object-centric learning with slot attention. CoRR. 2020. arXiv:2006.15055.
- Burgess CP, Matthey L, Watters N, et al. Monet: unsupervised scene decomposition and representation. CoRR. 2019. arXiv:1901.11390.
- Greff K, Kaufmann RL, Kabra R, et al. Multi-object representation learning with iterative variational inference. CoRR. 2019. arXiv:1903.00450.
- Engelcke M, Kosiorek AR, Jones OP, et al. Genesis: generative scene inference and sampling with object-centric latent representations. In: International Conference on Learning Representations; 2020.
- Eslami SA, Heess N, Weber T, et al. Attend, infer, repeat: fast scene understanding with generative models. In: Advances in Neural Information Processing Systems; 2016. p. 3225–3233. Barcelona Spain.
- Crawford E, Pineau J. Spatially invariant unsupervised object detection with convolutional neural networks. In: Proceedings of the AAAI Conference on Artificial Intelligence; Vol. 33; 2019. p. 3412–3420. Honolulu, Hawaii, USA.
- Jiang J, Ahn S. Generative neurosymbolic machines. Advances in Neural Information Processing Systems. 2020;33.
- Ha D, Schmidhuber J. World models. arXiv preprint arXiv:180310122. 2018.
- Kawato M. Internal models for motor control and trajectory planning. Curr Opin Neurobiol. 1999;9(6):718–727.
- Hafner D, Lillicrap T, Ba J, et al. Dream to control: learning behaviors by latent imagination. In: International Conference on Learning Representations; 2019. New Orleans, LA, USA.
- Wu P, Escontrela A, Hafner D, et al. Daydreamer: world models for physical robot learning. In: Conference on Robot Learning. 2022. Auckland, New Zealand.
- Nanbo L, Eastwood C, Fisher RB. Learning object-centric representations of multi-object scenes from multiple views. In: 34th Conference on Neural Information Processing Systems; 2020. Curran Associates, Inc.
- Chen C, Deng F, Ahn S. Roots: object-centric representation and rendering of 3D scenes. CoRR. 2021. arXiv:2006.06130.
- Eslami SA, Rezende DJ, Besse F, et al. Neural scene representation and rendering. Science. 2018;360(6394):1204–1210.
- Schmidt T. Perception: the binding problem and the coherence of perception. In: Banks WP, editor. Encyclopedia of consciousness. Oxford: Academic Press; 2009. p. 147–158.
- Treisman AM, Gelade G. A feature-integration theory of attention. Cogn Psychol. 1980;12(1):97–136.
- Hinton GE. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002;14(8):1771–1800.
- Rezende D, Mohamed S. Variational inference with normalizing flows. In: Bach F, Blei D, editors. Proceedings of the 32th International Conference on Machine Learning; Vol. 37; 07–09 Jul; Lille; 2015. p. 1530–1538.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. CoRR. 2017. arXiv:1706.03762.
- Kosiorek AR, Strathmann H, Zoran D, et al. Nerf-vae: a geometry aware 3D scene generative model. In: Meila M, Zhang T, editors. Proceedings of the 38th International Conference on Machine Learning; Vol. 139; 2021. p. 5742–5752. PMLR.
- Florence P, Manuelli L, Tedrake R. Self-supervised correspondence in visuomotor policy learning. IEEE Robot Autom Lett. 2019;5(2):492–499.
- Kingma DP, Welling M. Auto-encoding variational Bayes. CoRR. 2013. arXiv:1312.6114.
- Dai S, Li X, Wang L, et al. Learning segmentation masks with the independence prior. In: Proceedings of the AAAI Conference on Artificial Intelligence; Vol. 33; Jul.; 2019. p. 3429–3436. Honolulu, Hawaii, USA.
- Nguyen-Phuoc T, Richardt C, Mai L, et al. Blockgan: learning 3D object-aware scene representations from unlabelled images. Advances in Neural Information Processing Systems. Nov 2020;33:6767–6778.
- Niemeyer M, Geiger AG. Representing scenes as compositional generative neural feature fields. In: Proceeding IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2021. IEEE.
- Yao Y, Luo Z, Li S, et al. BlendedMVS: a large-scale dataset for generalized multi-view stereo networks, Computer Vision and Pattern Recognition (CVPR), 2020.
- Kuo J, Muglikar M, Zhang Z, et al. Redesigning slam for arbitrary multi-camera systems. In: 2020 IEEE International Conference on Robotics and Automation (ICRA); 2020. p. 2116–2122. IEEE.
- Lin Y, Tremblay J, Tyree S, et al. Multi-view fusion for multi-level robotic scene understanding. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); 2021. p. 6817–6824. IEEE.
- Mildenhall B, Srinivasan PP, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis. In: ECCV; 2020.
- Tobin J, Zaremba W, Abbeel P. Geometry-aware neural rendering. Adv Neural Inf Process Syst. 2019;32:11559–11569.
- Henderson P, Lampert CH. Unsupervised object-centric video generation and decomposition in 3D. CoRR. 2020. arXiv:2007.06705.
- Stelzner K, Kersting K, Kosiorek AR. Decomposing 3D scenes into objects via unsupervised volume segmentation. CoRR. 2021. arXiv:2104.01148.
- Yu HX, Guibas LJ, Wu J. Unsupervised discovery of object radiance fields. CoRR. 2021. arXiv:2107.07905.
- Engelcke M, Jones OP, Posner I. Genesis-v2: inferring unordered object representations without iterative refinement. CoRR. 2021. arXiv:2104.09958.
- Vasco M, Melo FS, Paiva A. MHVAE: a human-inspired deep hierarchical generative model for multimodal representation learning. CoRR. 2020. arXiv:2006.02991.
- Akuzawa K, Iwasawa Y, Matsuo Y. Information-theoretic regularization for learning global features by sequential vae. Mach Learn. 2021;110, 2239–2266:1–28.
- Watters N, Matthey L, Burgess CP, et al. Spatial broadcast decoder: a simple architecture for learning disentangled representations in VAEs. CoRR. 2019. arXiv:abs/1901.07017.
- Wu M, Goodman N. Multimodal generative models for scalable weakly-supervised learning. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems; 2018. p. 5580–5590. Montréal, Canada.
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997 Nov;9(8):1735–1780.
- Marino J, Yue Y, Mandt S. Iterative amortized inference. CoRR. 2018. arXiv:1807.09356.
- Emami P, He P, Ranka S, et al. Efficient iterative amortized inference for learning symmetric and disentangled multi-object representations. In: Meila M, Zhang T, editors. Proceedings of the 38th International Conference on Machine Learning; Vol. 139; 18–24 Jul. 2021. p. 2970–2981. PMLR.
- Rezende DJ, Viola F. Taming vaes. 2018. arXiv:1810.00597.
- Johnson J, Hariharan B, Van Der Maaten L, et al. Clevr: a diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2017. p. 2901–2910. IEEE.