
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This study presents a control framework leveraging vision language models (VLMs) for multiple tasks and robots. Notably, existing control methods using VLMs have achieved high performance in various tasks and robots in the training environment. However, these methods incur high costs for learning control policies for tasks and robots other than those in the training environment. Considering the application of industrial and household robots, learning in novel environments where robots are introduced is challenging. To address this issue, we propose a control framework that does not require learning control policies. Our framework combines the vision-language CLIP model with a randomized control. CLIP computes the similarity between images and texts by embedding them in the feature space. This study employs CLIP to compute the similarity between camera images and text representing the target state. In our method, the robot is controlled by a randomized controller that simultaneously explores and increases the similarity gradients. Moreover, we fine-tune the CLIP to improve the performance of the proposed method. Consequently, we confirm the effectiveness of our approach through a multitask simulation and a real robot experiment using a two-wheeled robot and robot arm.
GRAPHICAL ABSTRACT
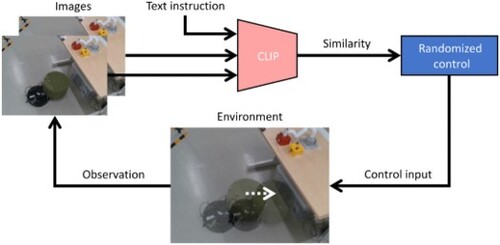
1. Introduction
In recent years, control methods using vision-language models (VLMs) have attracted attention in robotics and have been applied to navigation [Citation1–9] and manipulation [Citation10–15] tasks. Because VLMs are trained using numerous images and texts on the web, they are expected to improve the generalization of control policies for various tasks using arbitrary texts as inputs that specify a task.
Existing control methods using VLMs have achieved high performance for various tasks and robots [Citation16–19] in training environments. However, these methods incur high costs in learning control policies for tasks and robots that differ from the training environment. Consider a scenario in which a user utilizes a shipped robot at home or in a factory. In this scenario, the user cannot easily train the control policies in these environments after the robot is introduced. Therefore, it is crucial to construct a control framework that can reduce the cost of learning control policies.
In this study, we proposed a control framework without learning control policies. Our framework combined the vision language model CLIP [Citation20] with randomized control [Citation21], as shown in Figure . CLIP is a model trained using numerous images and text on the web. It computes the similarity between images and texts by embedding them into the feature space. In our method, the similarity between camera images and text representing the target state was computed using CLIP. The robot was controlled using a randomized control system that alternately repeated stochastic and deterministic movements. The former was used to compute the gradient of similarity, and the latter increased the similarity using the gradient. Moreover, we fine-tuned the CLIP to improve the performance of the proposed method. Although the proposed method commonly employs VLMs to be applicable for multiple tasks and robots, it differs from those in the literature [Citation16–19] in that it does not require learning control policies.
Figure 1. Chair rearrangement task using CLIP feature-based randomized control. The text instruction is ‘place a green chair under the table.’
To confirm the effectiveness of the proposed method, we conducted a multitask simulation using a robot arm and real experiment utilizing a two-wheeled robot and robot arm. We confirmed that the proposed method could be applied to multiple tasks in which a robot arm closes and opens a drawer, door, or window. Furthermore, we confirmed that the proposed method can be applied to different robots through a task wherein a two-wheeled robot places a chair under a table, and that in which a robot arm places a box next to another box.
The contributions of this study can be summarized as follows:
We proposed a CLIP feature-based randomized control that can apply to multiple tasks and robots without learning control policies.
We confirmed the generalization of the proposed method for multiple tasks via a multitask simulation using a robot arm.
We verified the generalization of the proposed method for different robots via a real experiment using a two-wheeled robot and robot arm.
The remainder of this paper is organized as follows: Section 2 introduces related work. Section 3 outlines robot control strategies using images and text for multiple tasks. Section 4 presents multitask simulation results utilizing a robot arm. Section 5 describes a real experiment using a two-wheeled robot and robot arm. Section 6 discusses the limitations of this study and the scope of future work. Finally, Section 7 summarizes the study.
2. Related work
In recent years, VLMs have attracted attention in the field of robotics and have been applied to various tasks, including object-goal navigation [Citation1–6], room-to-room navigation [Citation7–9], pick and place [Citation10–12], and rearrangement tasks [Citation13–15]. Leveraging the numerous images and texts on the web, VLMs are expected to enhance the generalization of control policies for extensive tasks.
Several studies employing VLMs have succeeded in generalizing multiple tasks and robots using large datasets collected by real-world robots. Brohan et al. [Citation16] proposed Robotics Transformer 1 (RT-1), which is a vision-language-action model based on transformer architecture. RT-1 inputs camera images and task instruction text, encodes them as tokens using a pre-trained FiLM EfficientNet model [Citation22], and compresses them using TokenLearner [Citation23]. The compressed tokens are input to the transformer, which outputs the action tokens. The model was trained with extensive real manipulation dataset that consists of over 130k episodes, which contain over 700 tasks. Moreover, based on RT-1, they introduced Robotics Transformer 2 (RT-2) [Citation17], which employs VLMs such as PaLI-X [Citation24] and PaLM-E [Citation25]. Training on both real manipulation and web data improves generalization performance for unknown tasks better than RT-1. Vuong et al. [Citation18] proposed the Robotic Transformer X (RT-X), which can be applied to different types of robots. They presented two model architectures, RT-1-X and RT-2-X, which employed RT-1 and RT-2, respectively, and trained these models using 1M+ trajectories collected from 22 types of robot arms. Although these methods exhibit high performance for extensive tasks and robots in training environments, they incur high costs for learning control policies for tasks and robots other than the training environments because the control policy is trained end-to-end.
Other studies have enhanced generalization of control policies through sample-efficient adaptation. Shridhar et al. presented CLIPort [Citation26], a VLM-based imitation-learning for 2D manipulation. CLIPort combines semantic understanding of CLIP with spatial precision of Transporter [Citation27], which can predict pick-and-place locations on 2D pixels. The model was trained with only 179 demonstrations across 9 different real-manipulation tasks. However, it is limited to 2D observation and action spaces. To address this issue, they proposed Perceiver-Actor (PerAct) [Citation28], a VLM-based behavior-cloning for 3D manipulation. PerAct inputs a language instruction and RGB-D voxel observations using the Perceiver Transformer [Citation29], and outputs the next best voxel action. The model was trained with only 53 demonstrations across 7 different real-manipulation tasks. Mees et al. proposed Hierarchical Universal Language Conditioned Policies 2.0 (HULC++) [Citation30], a VLM-based imitation learning for 3D manipulation. HULC++ inputs a language instruction and an image from a static camera to predict an affordance, a pixel corresponding to an object. The low-level policy computes actions, including end-effector velocity, end-effector rotation, and gripper action, using RGB observations from both the gripper and static camera. Real robot experiments demonstrate that HULC++ can perform over 25 manipulation tasks while requiring an order of magnitude less data than previous approaches. Furthermore, Huang et al. proposed VoxPoser [Citation31], a VLM-based zero-shot motion planner for 3D manipulation. VoxPoser adopts the large language model (LLM) and VLM to generate an affordance map and constraint map from programming codes, and then combines these maps into a value map. The value map serves as a motion planner to compute end-effector velocity, end-effector rotation, and gripper action using model predictive control. Real robot experiments demonstrate that VoxPoser can perform a variety of manipulation tasks without requiring additional training.
The proposed framework combines a vision-language model, CLIP, with randomized control [Citation21] for multiple tasks and robots without learning control policies. Although we may adopt other non-learning control methods, such as PID control, optimal control, and adaptive control methods, these approaches cannot be applied without the target position of the object. While we may adopt model predictive control by predicting the object state, it cannot be applied without a dynamics model. On the other hand, the randomized control can be applied without the target position of the object and the dynamics model by alternately repeating the stochastic and deterministic movements. Therefore, we adopted randomized control among non-learning control methods. To the best of our knowledge, no similar work using randomized controls with VLMs has been reported so far. Although the present study has commonly used VLMs that can be applied to multiple robots and tasks, it differs from [Citation16–18] in that our method does not require learning control policies because our method adopts the randomized control without training control policy end-to-end. Moreover, other VLM studies [Citation26, Citation28, Citation30, Citation31] have achieved few-shot and zero-shot adaptation to similar tasks using a robot arm. However, these methods design low-level controllers or motion planners specifically for the robot arm and cannot be applied if the action space differs from that of the robot arm. On the other hand, our method can be applied even if the robot's action space changes, and we have confirmed the generalization of our method for different types of robots, including a two-wheeled robot and robot arm, whereas other studies were limited to robot arms.
3. Robot control using images and text for multiple tasks and robots
3.1. Problem setting
This section describes the problem setting for robot control using images and text. The environment was observed using a camera at a fixed position and orientation. Note that the target position of the object is unknown. Instead, text instructions were used to enable the robot to perform tasks. For example, in a door-open task, the text instruction is given as ‘open a door.’ The robot cannot know the target position of the door handle because it is not possible to know the structure of the door in advance using a camera. In this scenario, the VLM model is suitable because we can control the robot by making the camera image closer to the text instruction without the target position of the object. In this study, we assumed that the position and orientation of the robot and position of the object can be observed, and these values were assigned to the robot as inputs.
This study aims to control the object position to reach the target position for multiple tasks and robots.
3.2. Overview of our control framework
An overview of the control framework is presented in Figure . The original CLIP computes the similarity between an image feature and a text feature using the CLIP encoder. In our framework, we compute the similarity between the difference of two image features and a text feature for two opposite text instructions. We used the difference between two image features because object motions such as open and close cannot easily be determined using a single image. Moreover, we compute the similarity for two opposite text instructions because it is difficult to determine whether the object state is closed to the text instruction using a single text instruction. The robot's actions are computed to increase the similarity.
Figure 2. Overview of our control framework.
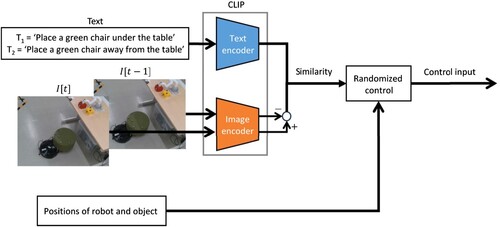
The robot inputs the positions of the robot and object, image at the current control step t, image
at the control step t−1, the instruction texts
and
, where
represents an opposite action to
. The robot computes the image features
and
using the CLIP image encoder. Moreover, the robot computes the text features
and
of
and
using the CLIP text encoder. The robot computes the similarity
(i = 1, 2) between
and
. The control input is computed such that the similarity difference
is positive.
3.3. CLIP feature-based randomized control
This subsection describes the details of our CLIP feature-based randomized control. To generate motion from two images, we compute the cosine similarity of and
(i = 1, 2) using
(1)
(1) Furthermore, the similarity gradient is computed using
(2)
(2) where
represents the position of the robot along the axis i at control step t.
Next, we introduce our CLIP feature-based randomized control method, which increases the similarity between images and text. Randomized control [Citation21] is a control law that maximizes an unknown evaluation function by alternately repeating stochastic and deterministic movements. The former computes the gradient of the evaluation function, and the latter increases the evaluation function using the gradient. Using this control law, the control input is computed as follows:
(3)
(3) where i is the x, y, or z axis;
is a random variable that randomly becomes
or
with a probability of 0.5, c>0; and f is a function that determines the updated amount using the gradient. If t is an odd number, the robot selects a stochastic movement in each axis direction to compute the similarity gradient. If t is an even number, the robot selects a deterministic movement by using a gradient to increase the similarity. In [Citation21], the control input is calculated using
(k>0). However, if
changes significantly, the position of the robot may vibrate.
In this study, the function f is computed using RMSprop [Citation32] as follows: (4)
(4)
(5)
(5) where
,
, and
. The moving average in (Equation5
(5)
(5) ) was employed to prevent the vibration of the robot, even if
changed significantly. We adopted RMSprop because RMSprop achieved a better performance than Adam [Citation33] when applying randomized control.
As our method calculates control inputs using the similarity of CLIP features by alternately repeating stochastic and deterministic movements, it can be applied to different robots without learning control policy.
3.4. Fine-tuning of the CLIP model for multiple tasks
This section introduces the fine-tuning of the CLIP model, which can be applied to multiple tasks. Although the original CLIP model is suitable for classifying the names of objects, it is not appropriate for classifying object motions such as open and close. Therefore, we aim to fine-tune the CLIP model to classify the object motions for multiple tasks. The fine-tuning algorithm is presented in Algorithm 1.

The first step is the collection of data for multiple tasks. For task i (), data
at control step k, where
is a negative value of the distance between the object position and its target position, as follows:
(6)
(6) where
represents the target position of the object, and
indicates its current position. In addition, to collect images when the object motion changes, data are collected if
is satisfied, where
is the threshold for data collection. Data collection was repeated until the number of data reached a certain value M for each task.
From the collected data ,
, and
are randomly sampled. The ground truth of the text is given by
(7)
(7) Using the CLIP features
and
of images
and
, the difference in CLIP features
is computed. For text
, the CLIP feature
is computed.
Finally, the cosine similarity is calculated for each element of and
, and the CLIP model is updated to minimize the cross-entropy loss. See [Citation20] for details of the optimization.
4. Simulation
In this section, we confirm the generalization of the proposed method for multiple tasks through a multitask simulation using a robot arm. This simulation is aimed to confirm that the presented method can perform multiple tasks even if the target position of the object is unknown.
4.1. Simulation environment
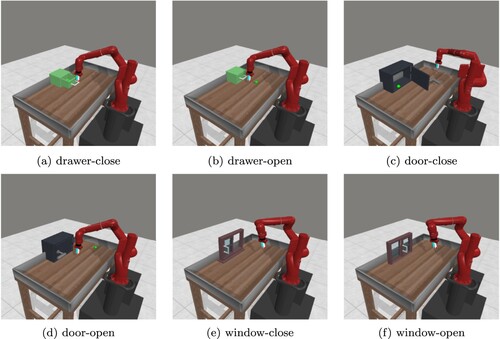
The simulation was performed using a simulator Metaworld [Citation34], which can verify various tasks using a robot arm. The simulation environment is shown in Figure . The success of each task is determined as follows:
drawer-close/open: the distance between the position of the drawer handle and its target position is within 0.03 m.
door-close/open: the distance between the position of the door handle and its target position is within 0.05 m.
window-close/open: the distance between the position of the window handle and its target position is within 0.05 m.
Figure 3. Simulation environment (the green dot indicates the target position of the handle). (a) drawer-close. (b) drawer-open. (c) door-close. (d) door-open. (e) window-close and (f) window-open.
4.2. Control implementation
The control time step was set to 0.1 s, and the total number of steps was set to 5.0 for window-close and window-open tasks and 1.0
for other tasks. Moreover, we set c = 0.2,
,
, and
. These parameters were set such that the robot arm could reach the target position of the end effector while avoiding overshooting.
In the simulation, the positions of the robot and object were considered as those of the end effector and handle, respectively. To make the end effector approach the handle, we add the distance between the end effector and handle to (Equation2(2)
(2) ) as follows:
(8)
(8) where
represents the handle position along the i-axis.
Furthermore, to prevent the gradient from changing significantly, we adopted the upper and lower limits in (Equation2(2)
(2) ) as follows:
(9)
(9) where we set
in the simulations.
Moreover, the robot sometimes encountered a stuck where the handle did not move, even if it moved the end effector when it was sufficiently close to the handle. To address this issue, we replace the position of the object with
(10)
(10) where the first condition determines that the end effector is stuck if the travel distance of the end effector
in the last 1.0 s is less than a certain threshold
. The second condition determines whether the end effector is stuck if the distance between the initial and current positions of the handle is less than a certain threshold
. If the two conditions are satisfied, the robot arm avoids being stuck by setting the target position to be a point, which is located 0.05 m above the handle position. In the simulation, we set
m and
m.
To confirm the effectiveness of the proposed method, we compared it with our method with a reinforcement-learning algorithm PPO [Citation35], which is a deep actor-critic algorithm. The inputs of the policy are set as , where i (
) is a task ID, and the target position of the handle is unknown. The reward function is used as described in [Citation34]. We trained the same policy for six tasks by using the code in [Citation36]. The critic and actor networks contained two hidden layers of 128 units, respectively. The activation function of the output layer in the critic network is linear, whereas that in the actor network is tanh. The hyperparameters used in the PPO algorithm are presented in Table .
Table 1. Hyperparameters used in the PPO algorithm.
Moreover, we evaluated several control methods using the proposed method. To evaluate performance under ideal conditions, where the robot knows the target position of the handle, we evaluated a control method by setting the first term in (Equation8(8)
(8) ) to
(11)
(11) where
represents the target position of the handle. This control method is denoted by the Goal. Moreover, we evaluated several control methods using the CLIP models ViT-B/32 and ViT-L/14, which employ a Vision Transformer [Citation37] with a higher performance than ResNet [Citation38]. In addition, we evaluated a control method using fine-tuned ViT-B/32, which was trained on the same model for multiple tasks, using the method described in Subsection 3.3. These methods are denoted as ViT-B/32, ViT-L/14, and ViT-B/32 (finetune). We collected the training data for fine-tuning by controlling the robot using the Goal method.
The texts used in the simulation are presented in Table . These texts were determined through prompt engineering to improve the performances of ViT-B/32 and ViT-L/14.
Table 2. Texts used in a multitask simulation.
4.3. Result
Table compares the success rates of applying each method to six tasks for 100 trials. Notably, the target positions of the handles are unknown except for Goal. The results showed that the PPO method could not perform the drawer-open and door-open tasks. In these tasks, the PPO method could make the end effector approach the handle but could not move the handle toward the goal. Meanwhile, ViT-B/32 and ViT-L/14 achieved higher success rates than the PPO method. Furthermore, ViT-B/32 (finetune) achieved higher success rates than ViT-B/32 and ViT-L/14 for various tasks, indicating that the performance of our method could be improved by fine-tuning the CLIP model. Furthermore, the number of collected images for fine-tuning the CLIP is 1.0 while those for training the policy using PPO is 1.5
. This result indicates that the proposed method requires fewer images than PPO.
Table 3. Comparison of success rates for the multitask simulation (the target position of the handle is unknown except for †).
To investigate the factors that ViT-B/32 (finetune) achieved a high success rate, we evaluated the accuracy rate of the text for the two images. This is because the higher the accuracy rate of the text, the more accurate the sign of the gradient in (Equation2(2)
(2) ), which can increase the similarity. The accuracy rate of the text is defined as
(12)
(12)
(13)
(13) where
in (Equation12
(12)
(12) ) is the total number of trials, and
(i = 1, 2) in (Equation13
(13)
(13) ) is computed using (Equation1
(1)
(1) ) for the two randomly sampled images.
Table compares the text accuracy rates for trials when each CLIP model is applied to the 2.0
images. The results show that ViT-B/32 (finetune) achieved higher text accuracy rates than ViT-B/32 and ViT-L/14 for all tasks. Furthermore, the text accuracy and success rate of ViT-L/14 were higher than those of ViT-B/32 for all the tasks, as presented in Tables and . These results indicated that the higher the text accuracy rate, the higher the success rate.
Table 4. Comparison of text accuracy rates for the simulator images.
Overall, we confirmed that the proposed method can control an object for multiple tasks without learning the control policy. Moreover, we improved the performance of our method by fine-tuning the CLIP model through a multitask simulation.
4.4. Other complex tasks
To better highlight the limitations of our current method, we performed more complex tasks described as follows:
push-button-press-wall: the robot arm pushes the button in the presence of the wall.
assembly: the robot arm places a tool with a hole through a bar placed vertically on the ground.
box-close: the robot arm closes the box by placing the lid onto the box.
shelf-place: the robot arm places the object onto the top shelf.
The evaluation was conducted using ViT-L/14 without fine-tuning. Because our current method is not capable of handling grasping, a built-in controller was used to grasp the object. The texts used in the simulation are shown in Table .
Table 5. Texts used in more complex simulation tasks.
One of the demonstrations is shown in Figure . The results show that our method succeeded in the push-button-press-wall task, while it failed in the assembly, box-close, and shelf-place tasks. In these tasks, the robot arm could place the object near the goal but could not perform the tasks, as shown in Figure (b–d).
Figure 4. Control results for more complex tasks when applying our method. (a) button-press-wall. (b) assembly. (c) box-close and (d) shelf-place.

Furthermore, Table shows the success rate when applying our ViT-L/14 to each task for 100 trials. Our method achieved success rates of 0.81 for the push-button-press-wall task. These results indicate that our method can be applied to the task involving 1D motion with an obstacle. However, it showed a low success rate of 0.16 for the box-close task and completely failed in the assembly and shelf-place tasks. In these tasks, our method failed because the object got stuck on the bar, the lid got stuck on the side of the box, or the object got stuck on the second shelf or on the side of the shelf. This can be attributed to the fact that our current method does not consider 3D motion planning, which would determine the direction in which objects are placed.
Table 6. Success rate for more complex tasks when applying our ViT-L/14.
5. Real robot experiment
In this section, we confirm the generalization of the proposed method for different robots through real robot experiments using a two-wheeled robot and robot arm. This experiment aims to confirm that our method can control objects for different robots, even if the target position of the object is unknown.
5.1. Experimental configuration
The experimental configuration is shown in Figure . The position of the object was observed using motion capture Optitrack V120: Duo at 100 fps. We set the position of the robot to be the same as that of the object because the robot was rigidly attached to the object. Images were captured using an Intel RealSense D435 camera at 30 fps with a fixed position and angle.
Figure 5. Experimental configuration.

To confirm the effectiveness of our method, we performed two rearrangement tasks using a two-wheeled robot vizbot [Citation39] and a robotic arm, myCobot 280 M5 (Elephant Robotics Co., Ltd.). The tasks are described as follows:
chair-rearrangement: the vizbot places a green chair under a table. Success is determined when the position of the chair is inside the edge of the table.
box-rearrangement: the myCobot, which is fixed on the table, places a red box next to a yellow box. Success is determined when the position of the red box is within 0.05 m from the position exactly adjacent to the yellow box.
5.2. Control implementation
The control time step and total number of steps were set to 0.2 s and steps, respectively, for the vizbot and these values were set to 1.0 s and
steps for the myCobot. When we set the camera to capture the entire range that the myCobot can move, the distance between the camera and the myCobot increased. As a result, the change in the image after each control time step became smaller. Therefore, we set the control time step for the myCobot to be longer. The control inputs are the linear and angular velocity inputs for vizbot and the amount of movement of the end effector in the x- and y-axes for myCobot. We set c = 0.1 and c = 0.02 for vizbot and myCobot while setting the parameters of RMSprop similar to the simulation. These parameters were set so that the robots could allow the object to reach its target position while avoiding overshooting. The texts used in the experiment are shown in Table .
Table 7. Texts used in the experiment.
We evaluated several control methods, Goal, ViT-B/32, ViT-L/14, and ViT-B/32 (finetune), as described in the simulation. In the experiment, we collected 4.0 data for each robot via manual control, and the CLIP model was trained on the same model for the robot arm and two-wheeled robot. Note that the model parameters by fine-tuning in the experiment differs from those in the simulation.
5.3. Result
Table compares the success rates when applying each method to 30 trials, where we set five different initial positions and performed six experiments for each. The target positions of the objects are unknown except for Goal. The results show that ViT-B/32 and ViT-L/14 could perform both tasks in several trials without fine-tuning the CLIP model. Furthermore, ViT-B/32 (finetune) achieved higher success rates than ViT-B/32 and ViT-L/14 for both tasks, indicating that the performance of our method could be improved by fine-tuning the CLIP model.
Table 8. Comparisons of success rate for the real robot experiment (The target position of the object is unknown except for †).
Table compares the text accuracy rates for trials when applying each CLIP model to
images. The results showed that ViT-B/32 (finetune) achieved higher accuracy rates than the other methods for both tasks. Furthermore, ViT-L/14 achieved a higher text accuracy and success rate than ViT-B/32 for the box-arrangement task, whereas ViT-B/32 achieved these values higher than ViT-L/14 for the chair-rearrangement task. These results indicate that the higher the text accuracy rate, the higher the success rate.
Table 9. Comparison of text accuracy rates for the real images.
Figure shows an example of the control results when each method was applied to two tasks for the same initial position. The results show that ViT-B/32 could not accomplish either task, whereas ViT-L/14 could only accomplish the box arrangement. Furthermore, ViT-B/32 (finetune) completed both tasks.
Figure 6. An example of control results when applying each method. (a) ViT-B/32. (b) ViT-L/14 and (c) ViT-B/32 (finetune).

Overall, we confirmed that the proposed method can control an object for different robots without learning control policies. Moreover, we improve the performance of our method by fine-tuning the CLIP model through a real experiment.
6. Discussion
This section discusses the limitations of this study and future work.
Through a multitask simulation, it was confirmed that the proposed method could be applied to six tasks using the same CLIP model. However, the original CLIP could not achieve a high performance, and our method required fine-tuning for each task to improve performance. Therefore, a generalized CLIP model that can extract information about robot movement should be constructed. Moreover, our method requires ad hoc changes specific to the tasks using (Equation8(8)
(8) )–(Equation10
(10)
(10) ). Therefore, we should improve our method so that it can be applied to tasks other than the ones in this paper.
Several assumptions were made in the simulations and experiments. In the simulation, we assumed that the position of the object handle was known because the current system could not make the end effector approach the handle. Therefore, an object handle should be detected using object detection methods such as YOLOv8 [Citation40] or Detic [Citation41] and the position of the object handle should be estimated. Moreover, the effectiveness of the proposed method should be confirmed using the estimated object position. In the experiment, we assumed that the robot was rigidly attached to the object because the current method cannot determine which part of the object the robot should push. To address this issue, we combine our method with AffordanceNet [Citation42] to determine the pushing point of the object.
A possible future direction is to apply our method to robots equipped with onboard cameras. To this end, we should make our method robust to changes in camera position and angle by collecting several combinations of camera positions and angles and confirming the effectiveness of our approach. The current method cannot perform tasks that involve rotation, such as the bottle-open task performed by VoxPoser. Since our method generates actions using the difference in two images, it cannot be applied to tasks where there are no differences between the images. To extend our method to handle such tasks, it is necessary to develop a control law that incorporates torque feedback from a force sensor. Specifically, the control input is computed to minimize the torque exerted on the end-effector while gripping the cap. It would be interesting to apply our method to various types of robots other than two-wheeled robots and robot arms. Furthermore, we may combine our method with VLMs other than the CLIP to examine which VLM model is the best suited for our method.
7. Conclusion
In this study, we proposed a CLIP-feature-based randomized control system without learning control policies. Our framework combines the vision-language CLIP model with a randomized control. In our method, the similarity between the camera images and text instructions was computed using CLIP. Moreover, the robot was controlled by a randomized control system that alternately repeated stochastic and deterministic movements. This renders our method applicable to multiple tasks and robots without learning the control policy. Through a multitask simulation and real robot experiment, we confirmed that our method using the original CLIP could achieve a success rate to some extent without learning the control policy for multiple tasks, and its performance was improved by fine-tuning the CLIP model. In future work, we plan to improve the CLIP model to extract knowledge regarding robot movements and confirm the effectiveness of the proposed method for numerous robots and tasks.
Supplemental Material
Download MP4 Video (9 MB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Kazuki Shibata
Kazuki Shibata received the B.E. degree in engineering science from Kyoto University, Kyoto, Japan, in 2012, the M.E. degree from the Department of Aeronautics and Astronautics, The University of Tokyo, Tokyo, Japan, in 2014, and the Ph.D. degree from the Graduate School of Science and Technology, Nara Institute of Science and Technology, Nara, Japan, in 2023. From 2014 to 2024, he was a Researcher with Toyota Central R&D Labs., Inc., Aichi, Japan. Since 2024, he has been an Associate Professor at Nara Institute of Science and Technology. His research interests include machine learning and control theory for robotics.
Hideki Deguchi
Hideki Deguchi received the B.E. and M.E. degrees from Nagoya University, Japan, in 2015 and 2017, respectively. In 2017, he joined Toyota Central R&D Labs., Inc., Japan. He had researched about simultaneous localization and mapping, topological mapping systems, and robotics. His current research interests include visual-language navigation and human-robot interaction control.
Shun Taguchi
Shun Taguchi received the B.E. and M.E. degrees from Nagoya University, Japan, in 2007 and 2009, respectively. In 2009, he joined Toyota Central R&D Labs., Inc., Japan. He had researched about Bayesian filtering, data assimilation, and their applications to intelligent transportation systems and robotics. His current research interests include vision-based navigation, and localization using machine learning methods for robotics application.
References
- Majumdar A, Aggarwal G, Devnani B, et al. Zson: zero-shot object-goal navigation using multimodal goal embeddings. Adv Neural Inf Process Syst. 2022;35:32340–32352.
- Dorbala VS, Sigurdsson G, Piramuthu R, et al. Clip-nav: using clip for zero-shot vision-and-language navigation. arXiv preprint arXiv:221116649; 2022.
- Shah D, Osinski B, Ichter B, et al. LM-Nav: robotic navigation with large pre-trained models of language, vision, and action; 2022.
- Gadre SY, Wortsman M, Ilharco G, et al. CoWs on pasture: baselines and benchmarks for language-driven zero-shot object navigation; 2022.
- Zhou K, Zheng K, Pryor C, et al. Esc: exploration with soft commonsense constraints for zero-shot object navigation. arXiv preprint arXiv:230113166; 2023.
- Huang C, Mees O, Zeng A, et al. Visual language maps for robot navigation. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE; 2023. p. 10608–10615.
- Li J, Tan H, Bansal M. Envedit: environment editing for vision-and-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA. 2022. p. 15407–15417.
- Huo J, Sun Q, Jiang B, et al. GeoVLN: learning geometry-enhanced visual representation with slot attention for vision-and-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada. 2023. p. 23212–23221.
- Li J, Bansal M. Panogen: text-conditioned panoramic environment generation for vision-and-language navigation. arXiv preprint arXiv:230519195; 2023.
- Mees O, Hermann L, Rosete-Beas E, et al. Calvin: a benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robot Autom Lett. 2022;7(3):7327–7334. doi: 10.1109/LRA.2022.3180108
- Xiao T, Chan H, Sermanet P, et al. Robotic skill acquisition via instruction augmentation with vision-language models; 2023.
- Chen B, Xia F, Ichter B, et al. Open-vocabulary queryable scene representations for real world planning. In: 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK. 2023. p. 11509–11522.
- Khandelwal A, Weihs L, Mottaghi R, et al. Simple but effective: clip embeddings for embodied AI. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA. 2022. p. 14829–14838.
- Goodwin W, Vaze S, Havoutis I, et al. Semantically grounded object matching for robust robotic scene rearrangement. In: 2022 International Conference on Robotics and Automation (ICRA). Philadelphia, PA, USA: IEEE; 2022. p. 11138–11144.
- Kapelyukh I, Vosylius V, Johns E. Dall-e-bot: introducing web-scale diffusion models to robotics. IEEE Robot Autom Lett. 2023;8(7):3956–3963.
- Brohan A, Brown N, Carbajal J, et al. RT-1: robotics transformer for real-world control at scale; 2023.
- Brohan A, Brown N, Carbajal J, et al. RT-2: vision-language-action models transfer web knowledge to robotic control; 2023.
- Vuong Q, Levine S, Walke HR, et al. Open x-embodiment: robotic learning datasets and RT-x models; 2023. Available from: https://openreview.net/forum?id=zraBtFgxT0.
- Li X, Liu M, Zhang H, et al. Vision-language foundation models as effective robot imitators; 2023.
- Radford A, Kim JW, Hallacy C, et al. Learning transferable visual models from natural language supervision. In: Meila M, Zhang T, editors. Proceedings of the 38th International Conference on Machine Learning; (Proceedings of Machine Learning Research; Vol. 139). Jul 18–24; PMLR; 2021. p. 8748–8763. Available from: https://proceedings.mlr.press/v139/radford21a.html.
- Azuma S, Yoshimura R, Sugie T. Broadcast control of multi-agent systems. Automatica. 2013;49(8):2307–2316. doi: 10.1016/j.automatica.2013.04.022
- Tan M, Le Q. Efficientnet: rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning. Long Beach, CA, USA: PMLR; 2019. p. 6105–6114.
- Ryoo M, Piergiovanni A, Arnab A, et al. Tokenlearner: adaptive space-time tokenization for videos. Adv Neural Inf Process Syst. 2021;34:12786–12797.
- Chen X, Djolonga J, Padlewski P, et al. PaLI-X: on scaling up a multilingual vision and language model. arXiv preprint arXiv:230518565; 2023.
- Driess D, Xia F, Sajjadi MSM, et al. PaLM-E: an embodied multimodal language model; 2023.
- Shridhar M, Manuelli L, Fox D. Cliport: what and where pathways for robotic manipulation. In: Conference on Robot Learning. London, UK: PMLR; 2022. p. 894–906.
- Zeng A, Florence P, Tompson J, et al. Transporter networks: rearranging the visual world for robotic manipulation. In: Conference on Robot Learning. Cambridge, MA, USA: PMLR; 2021. p. 726–747.
- Shridhar M, Manuelli L, Fox D. Perceiver-actor: a multi-task transformer for robotic manipulation. In: Conference on Robot Learning. Auckland, New Zealand: PMLR; 2023. p. 785–799.
- Jaegle A, Borgeaud S, Alayrac JB, et al. Perceiver io: a general architecture for structured inputs & outputs. arXiv preprint arXiv:210714795; 2021.
- Mees O, Borja-Diaz J, Burgard W. Grounding language with visual affordances over unstructured data. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE; 2023. p. 11576–11582.
- Huang W, Wang C, Zhang R, et al. Voxposer: composable 3D value maps for robotic manipulation with language models. arXiv preprint arXiv:230705973; 2023.
- Hinton G, Srivastava N, Swersky K. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited On. 2012;14(8):2.
- Kingma DP, Ba JA. Adam: a method for stochastic optimization. arXiv preprint arXiv:14126980; 2014.
- Yu T, Quillen D, He Z, et al. Meta-world: a benchmark and evaluation for multi-task and meta reinforcement learning. In: Kaelbling LP, Kragic D, Sugiura K, editors. Proceedings of the Conference on Robot Learning; (Proceedings of Machine Learning Research; Vol. 100); 30 Oct–1 Nov. Osaka, Japan: PMLR; 2020. p. 1094–1100. Available from: https://proceedings.mlr.press/v100/yu20a.html.
- Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms; 2017.
- Barhate N. Minimal pytorch implementation of proximal policy optimization [accessed 2024 Jan 4]; 2021. Available from: https://github.com/nikhilbarhate99/PPO-PyTorch.
- Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: Transformers for image recognition at scale; 2021.
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition; 2015.
- Niwa T, Taguchi S, Hirose N. Spatio-temporal graph localization networks for image-based navigation. In: 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan. 2022. p. 3279–3286.
- Reis D, Kupec J, Hong J, et al. Real-time flying object detection with yolov8; 2023.
- Zhou X, Girdhar R, Joulin A, et al. Detecting twenty-thousand classes using image-level supervision. In: European Conference on Computer Vision. Tel Aviv, Israel: Springer; 2022. p. 350–368.
- Deng S, Xu X, Wu C, et al. 3D affordancenet: A benchmark for visual object affordance understanding. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA. 2021. p. 1778–1787.