
SYNOPTIC ABSTRACT
Let Π1, Π2, …, Πk be k (≥2) exponential populations with unknown scale parameters σ1, σ2, …, σk, respectively, and an unknown but common location parameter μ. First, we consider the estimation of scale parameters when an isotonic ordering among the scale parameters is present. We show the superiority of a class of mixed estimators over the maximum likelihood estimators of scale parameters under a scale-invariant loss function. Bayes and generalized Bayes estimates of scale parameters are obtained assuming proper and improper prior distributions, respectively. As an application of these new estimators, we have considered the problem of classifying an observation into one of k populations under order restrictions on scale parameters. Classification rules are proposed based on mixed estimators. We also derive plug-in Bayes classification rules and likelihood ratio-based classification rules. Extensive simulations are performed to compare these rules with respect to the expected probability of correct classification. An application of the classification rules is done on a real data set.
1. Introduction
Suppose an observation x has come from one of k (≥2) populations Π1, Π2, …, Πk but the exact population is unknown. The random variable Xi corresponding to Πi is exponentially distributed with an unknown location parameter μ and unknown scale parameter σi, (i = 1, 2, …, k). The probability density function (pdf) of the random variable Xi is
(1) where
Suppose an observation x has to be classified into one of these k populations. As an example, suppose a rocket is launched from a surface (ground or sea). At a certain stage of launching, process failure has occurred due to damage to an individual component out of two major components. It is known that the failure rate of one component is greater than that of another component. From the observed failure time, we need to identify which particular component may have failed.
The problem of estimation of the parameters of several shifted exponential distributions having a common location parameter μ but different scale parameters has received considerable attention from many researchers. For this model, Pal and Sinha (Citation1990) compared the risk of maximum likelihood estimate (MLE), modified MLE, and uniformly minimum variance unbiased estimator (UMVUE) of μ in terms of Pitman measure of closeness. They proposed a class of estimators of μ dominating over the MLE under a particular condition. For this model, the testing on the parameter μ has been studied by Chang, Lin, and Pal (Citation2013). Recently, when the scale parameters are ordered, Tripathi, Kumar, and Misra (Citation2014) derived estimators of μ improving over the modified MLE and the UMVUE derived by Ghosh and Razmpour (Citation1984). As far as we know, there are no studies on the estimation of the ordered scale parameters for this model.
The problem of classification of an observation into one-parameter exponential populations was first studied by Basu and Gupta (Citation1974). For this model, Adegboye (Citation1993) showed that the probability of misclassification of an observation depends on the ratio of the scale parameters only. They established that the plug-in Bayes classification rule is superior to the Fisher's discriminant rule. Basu and Gupta (Citation1977) extended the results of Basu and Gupta (Citation1974) to k (≥2) two-parameter exponential distributions and proposed the likelihood-ratio criterion–based rules. They also derived rules based on a Bayes predictive approach. Wakaki (Citation1998) considered the problem of classification of an observation into one of the two multivariate elliptical populations with different mean vectors and different covariance matrices. He used the asymptotic distribution of the classification statistic to express the conditional probabilities of misclassification of an observation. In recent years, classification rules of an observation into k (≥2) populations have been improved using additional information on the parameters. Long and Gupta (Citation1998) first improved the linear classification rules for classifying an observation into one of the two multivariate normal populations with identity matrices as covariance matrices. They also assumed an ordering between the components of the mean vectors. They showed that the proposed rule is better than the linear discriminant rule of Anderson (Citation1951). When the mean vectors are assumed to be restricted to a cone, Fernández, Rueda, and Salvador (Citation2006) developed improved classification rules. For two univariate normal populations having a common mean but different variances, Jana and Kumar (Citation2015) showed that the classification rule based on the Graybill Deal estimator of the common mean performs better than other rules in terms of expected probability of misclassification (EPM). They also proposed rules when variances are ordered. Conde, Fernández, and Salvador (Citation2005) improved classification rules proposed by Basu and Gupta (Citation1974) for two exponential populations, assuming that the mean of the first population is greater than that of the second population. Jana, Kumar, and Misra (Citation2014) proposed a class of classification rules that includes the rule proposed by Conde et al. (Citation2005). To the best of our knowledge, the classification rule for the exponential distribution having an unknown common mean and ordered scale parameters has not been studied in literature. We shall consider an example where such ordering among the scale parameters arises. Consider an electronic water purifier machine. Due to stepwise removal of impurities at k different steps, the average longevity of components is expected to be in an increasing order, though the minimum guarantee time will be the same for each of the components due to the terms and conditions of the manufacturer.
Suppose independent random samples are taken from k exponential populations having a common unknown location parameter μ and unknown scale parameters σ1, σ2, …, σk, respectively, where the scale parameters are assumed to follow an ordering; 0 < σ1 ≤ σ2 ≤ … ≤ σk < ∞. In Section 2 of this article, we have considered the problem of estimating scale parameters. For the case k = 2, mixed estimators are proposed and shown to dominate over the unrestricted MLEs for specific range of the mixing parameter. Further, we derive Bayes and generalized Bayes estimates of scale parameters with respect to a gamma prior and a noninformative prior distribution, respectively. The loss function is the squared error. The problem of estimating ratio of scale parameters is also considered and a class of affine equivariant estimators is derived. Risk functions of all proposed estimators are compared numerically.
In Section 3, the problem of classification of an observation into one of two exponential populations is considered under isotonic ordering among scale parameters. Several rules are proposed using estimators proposed in Section 2. Likelihood-based classification rules are also derived under order restrictions. These rules are further extended to the case k ≥ 3. Finally, the performance of these rules is then compared numerically with respect to the expected probability of correct classification.
2. Estimation Under Restrictions on Scale Parameters
Define as a random sample from the population Πi, (i = 1, 2, …, k) and these random samples are mutually independent. Suppose
and
. The statistic
is complete and sufficient for
, where
. Note that Z and
are independently distributed with the probability density functions
and
(2) respectively, where p = ∑ki = 1niσi− 1. Under the ordering, the isotonic regression of
s with appropriate weights nis are given by the following min–max formula (see Barlow, Bartholomew, Bremner, & Brunk, Citation1972).
where
For k = 3, using the pool-adjacent-violators algorithm (Barlow et al., Citation1972), the MLE of
, when σ1 ≤ σ2 ≤ σ3, is obtained as follows:
When no such ordering between the parameters is present, Ghosh and Razmpour (Citation1984) derived the UMVUE and the modified MLE of μ given by
and
respectively. Assuming the ordering σ1 ≤ σ2 ≤ … ≤ σk, Tripathi et al. (Citation2014) proposed the following isotonic version of the unrestricted modified MLE:
(3) For two populations, in the presence of the restriction σ1 ≤ σ2, they derived the estimators
and
improving over the estimators
and
of μ, respectively, where
and
We utilize these estimators to propose new classification rules in Section 3.
2.1. Mixed Estimators
We shall use the existing basic estimators to propose a class of mixed estimators for the scale parameters of the exponential distributions when an additional information among the parameters is known. Katz (Citation1963) first proposed a mixed estimator of the ordered probabilities of successes (say, θ1 and θ2), where 0 < θ1 ≤ θ2 ≤ 1. They showed that any estimator of the parameter
satisfying Pθ(δ1 > δ2) > 0, for all θ ∈ Θ, is dominated by the mixed estimator
based on
where δ1α = min (δ1, αδ1 + (1 − α)δ2) and δ2α = max (δ2, (1 − α)δ2 + αδ1). Kumar and Sharma (Citation1988) proposed the mixed estimators of the ordered scale parameters of two normal distributions. For two exponential distributions having known location parameters, Vijayasree and Singh (Citation1993) considered mixed estimators and obtained minimal complete class among the class of estimators. Following these, we propose the mixed estimators based on the MLE of the scale parameters. The usual MLEs of σ1, σ2 are
(4) respectively. We define the following mixed estimators when the ordering σ1 ≤ σ2 is known:
(5)
(6) Note that when α = n1/(n1 + n2), the estimator
is the restricted MLE of σ1 and when α = n2/(n1 + n2), the estimator
is the restricted MLE of σ2. We denote the restricted MLE of σi by σrmi for i = 1, 2. Now, we compare the risk of estimator δi of the parameter σi with respect to the loss function
(7) We have the following results.
Theorem 1.
Let and
be the MLE and the mixed estimators of σi as defined in (Equation4
(4) )–(Equation6
(6) ). Suppose
denotes the risk of the estimator σ*i in estimating σi for i = 1, 2. Then for all 0 < σ1 ≤ σ2,
| (i) |
| ||||
| (ii) |
| ||||
| (iii) | For α ∈ [0, 1], and n1 = n2 = n, | ||||
Proof.
(i) Suppose is the joint pdf of T1 and T2. The difference in risk of
and
is
where IS(.) denote the indication function defined over the region S = {(T1, T2): 0 < n1T2 < n2T1 < ∞}. Now on substituting t1 = n1yz/n2, t2 = y and solving the inner integral, we have
(8) where
Let g(z) = (n1 + n2)((1 + α)z + 1 − α) − 2(n1z + n2ρ). Clearly, g is an increasing function of z for α ≥ α1. The function g achieves zero value at
Note that z0 < 1. Since g is an increasing function and it is nonnegative on [z0, ∞) for all α ≥ α1, we conclude g(z) > 0 for z > 1 and α > α1. Therefore, the integrand of (Equation8
(8) ) is negative. Hence Δ1 < 0 and this completes the proof.
The proofs of (ii) and (iii) follow in a similar fashion.
Remark 1.
The right-hand side of (Equation8(8) ) is a function of ρ only. Hence, the risk difference of the estimators
and
of the parameter σi for i = 1, 2 depends on the parameters only through ρ.
2.2. Bayes and Generalized Bayes Estimators
Now we consider the Bayes estimation of the scale parameters assuming a known prior distribution of the scale parameters. Consider the noninformative prior density of the parameters (σ1, σ2) as given by Π(σ1, σ2) = 1/(σ1σ2), 0 < σ1 ≤ σ2 < ∞. The joint PDF of and
is given by
The marginal probability density function of
is given by
and the posterior probability density of
given
is
where
is the normalizing constant. With respect to the scale equivariant squared error loss function (Equation7
(7) ), the generalized Bayes estimator for σ1 is the mean of the posterior distribution.
(9) where R1 = {(σ1, σ2): 0 < σ1 ≤ σ2 < ∞}. Suppose s = t1/t2. Using the transformations t1/σ1 = ss1s2, t2/σ2 = s2, we evaluate the integral and the generalized Bayes estimator of σ1 as
(10) Similarly, the generalized Bayes estimator of σ2 is given by
(11)
Similarly, assuming the inverse gamma prior distribution of σi with probability density function
for i = 1, 2, the Bayes estimators of σ1 and σ2 are
(12) and
(13) respectively. We apply these estimators to propose classification rules in Section 3 of this article.
2.3. Affine Equivariant Estimators
In this section, we consider the estimation of the parameter ρ = σ1/σ2 under the loss function
(14) where δ is an estimator of the parameter ρ. Consider the affine group of transformations
Then under the transformations
the family of distributions remains invariant and we have Xi(1) transforms to aiXi(1) + bi and Ti transforms to aiTi. The complete sufficient statistic of (μ, σ1, σ2) is (Z, T1, T2). Let T = T1/T2,
Then we have the following result.
Theorem 2.
The estimator c*T improves the estimator cT if c < c* and the estimator c*T improves cT if c > c*. The class of estimators {cT: c* ≤ c ≤ c*} forms an admissible class within estimators of the form cT for estimating ρ.
Proof.
The loss function (Equation14(14) ) will be invariant if δ transforms to
We have
where a1, a2 > 0 and
. The form of the scale equivariant estimator is δc(T) = cT, where c > 0. The risk
is minimum when
where ρ = σ1/σ2 ∈ (0, 1]. Since φ(ρ) is a decreasing function of ρ for n2 > 3,
and
. An application of the Brewster and Zidek (Citation1974) technique shows that the estimator
improves the estimator cT if c* < c, the estimator
improves cT if c* > c and the estimator δc is admissible among all δc if c* ≤ c ≤ c*.
We apply these estimators to evaluate the EPC given in Eq. (Equation16(16) ) of the forthcoming section when the parameters are unknown.
2.4. Numerical Comparisons
We shall now provide the risk comparison of the estimators of σ1 with respect to the loss function (Equation7(7) ) using simulation. The risk calculations are based on 50,000 generations of random samples from each of two exponential populations. We denote the risk of the estimator δ by R(δ). The risk of the estimators of the parameters σi (i = 1,2) are functions of ρ = σ1/σ2 only. In , for a fixed value of σ2 = 1, the risks of the estimators of σ1 are reported considering different values of ρ and for different sample sizes such as (n1, n2) = (3, 3), (6, 6), (9, 9), (12, 12), (9, 12), (12, 9). We observe the following conclusions.
Table 1. Risk performance of proposed estimators of σ1.
| 1. | The restricted MLE σrm1 of the scale parameter σ1 performs better than estimators | ||||
| 2. | The estimators | ||||
| 3. | If σ1 is close to σ2, the relative percentage improvement of the estimator σrm1 over the estimator | ||||
shows the risks of the estimators of the parameter σ2 for various values of n1, n2, σ2, where σ1 is fixed as one. We have evaluated the risks of the estimators considering size of the samples as (n1, n2) = (3, 3), (6, 6), (9, 9), (12, 12), (9, 12), (12, 9). We mention the following observations.
Table 2. Risk performance of proposed estimators of σ2.
| 1. | The estimators | ||||
| 2. | For small size samples, when ρ is close to one, the estimator σrm2 has the lowest risk than all proposed estimators; however, for the large sample, both the estimators σrm2 and σgb2 have similar risk performance. | ||||
| 3. | For unequal as well as for equal size samples, when ρ is close to one, the estimator σgb2 performs better than estimator | ||||
3. Classification Rules
In this section, we present the classification rules to classify an observation using the estimators derived in the previous section. Suppose x is an observation that is to be classified into one of the populations Π1, Π2, …, Πk. Assume that the priori probability that an observation comes from the ith population is qi, i = 1, 2, …, k, where ∑ki = 1qi = 1. If an observation actually comes from one population and we assign it to another population, then it is considered as misclassified. Suppose C(i|j) denotes the cost of misclassification where i, j = 1, 2, …, k and i ≠ j. The performance of the classification rules is measured with respect to the expected probability of correct classification (EPC). Let P(i|j) denote the probability of classifying an observation into the ith population when it actually belongs to the jth population. Then the EPC is ∑ki = 1qiP(i|i) and the expected cost of misclassification (ECM) is ∑i ≠ jqjP(i|j)C(i|j). When all parameters are known, minimizing the ECM, Anderson (Citation1951) derived the Bayes classification rule: Classify x into Πi if
First, we consider the classification rules for two exponential populations with a common location but ordered scale parameters and then for k (≥2) such populations.
3.1. Rules for Two Populations
In this subsection, we study the rule for classifying an observation x into two populations Π1 and Π2 assuming C(1|2) = C(2|1) and q1 = q2. When the parameters are known, the usual classification rule is as follows: Classify the observation x into Π1 if and only if U(x) ≤ 0, where
(15) The probabilities of correct classification P(1|1) and P(2|2) can be expressed as
and
respectively, where l = log ρ/(ρ − 1), and FY is the distribution function of an exponentially distributed random variable with mean equal to one. Therefore, the expected probability of correct classification is
(16) When the parameters are unknown, we plug in the estimators and propose the classification rule, R1.
R1: Classify the observation x into Π1 if and only if U1(x) ≤ 0, where
The rule based on the mixed estimators of the parameters σ1 and σ2 is given by R(α)2.
R(α)2: Classify the observation x into Π1 if and only if U(α)2(x) ⩽ 0, where
Since the distribution of (Z − x) is independent of μ, the distributions of the classification statistic U1(x) and U(α)2(x) are independent of μ.
Remark 2.
The EPC does not depend on the location parameter. The classification rule proposed by Basu and Gupta (Citation1977) is different from the above rule, since the MLE Z of the common location parameter μ has been used in the proposed rule.
We have the following result on the individual probability of correct classification.
Theorem 3.
The probability P(1|1) of the rule R1, is greater than P(1|1) corresponding to the rule R(0)2.
Proof.
We have to show that P(U1(x) ⩽ 0|X ∈ Π1) ⩾ P(U(0)2(x) ⩽ 0|X ∈ Π1). Note that under the condition n2T1 < n1T2, and
and therefore the classification functions U1(x) and U(0)2(x) are equal. Also, if n2T1 > n1T2, then the classification statistic U(0)2(x) = −U1(x). The difference between the probabilities of correct classification into population Π1 corresponding to the rule R1 and R(0)2 is
(17) where D = {(T1, T2): n2T1 > n1T2},
(18) and
is the cumulative distribution function of the random variable (T1, T2). When the observation belongs to Π1, the distribution of U = (x − Z) is given by the probability density function
where p = n1/σ1 + n2/σ2. Therefore, the integrand in (Equation17
(17) ) is reduced to 1 − 2(1 + pσ1)−1 exp {g(t1, t2)}, which is negative since g(t1, t2) > 0. The proof follows immediately.
The comparison of the rules, when the observation is correctly classified into second population, is established here.
Theorem 4.
The probability P(2|2) of rule R1, is less than the probability P(2|2) corresponding to the rule R(0)2.
Proof.
We have to show that P(U1(x) > 0|X ∈ Π2) ⩽ P(U(0)2(x) > 0|X ∈ Π2). The difference between the probabilities of correct classification into Π2 corresponding to the rule R1 and R(α)2 is
(19) where D and g(t1, t2) are defined in (Equation18
(18) ). When the observation belongs to Π2, the distribution of V = (x − Z) is given by the probability density function
Therefore, the integrand in (Equation19
(19) ) is reduced to 2(1 + pσ2)−1 exp {g(t1, t2)} − 1, which is negative since g(t1, t2) < 0. The proof follows immediately.
Theorem 5.
The ordered classification rule R(0)2 is better than the usual classification rule R1 with respect to the EPC.
Proof.
It is sufficient to show
From Eqs. (Equation17
(17) ) and (Equation19
(19) ), we have
Since σ1 ≤ σ2, we have Δ1 + Δ2 ≤ 0. Thus the proof follows.
Theorems 3, 4, and 5 also hold when we have to classify a sample y1, y2, …, ym of size m > 1 coming from the same population. In this case, we use the sufficient statistic ∑mi = 1yi, instead of x for classification. The proof follows in a similar way since ∑mi = 1yi/m follows Exp(μ, σ1/m) if the sample belongs to Π1 and ∑mi = 1yi/m follows Exp(μ, σ2/m) if the sample belongs to Π2.
We also propose classification rules based on these Bayes estimators of the scale parameters. Plugging in estimators δgb1, δ2gb and in (Equation15
(15) ), we have the classification rule R3. Similarly, the rule R4 is obtained substituting the estimators δb1, δ2b, and
for the parameters in (Equation15
(15) ). The comparison of the rules R1, R(0)2, R3, and R4 is carried out in the numerical comparison section.
3.2. Likelihood Ratio-Based Rule
We derive the likelihood ratio-based classification rule (LR rule) following Anderson (Citation2003) through the testing procedure of a composite hypothesis versus its alternative composite hypothesis. To classify an observation x, we test the hypothesis H1: belong to Π1 and
belong to the population Π2 versus the alternative hypothesis H2:
belong to Π1 and
belong to population Π2. The likelihood ratio is given by
(20) where
,
and
Suppose r = (n1 + 1)−1 and s = (n2 + 1)−1. Under the hypothesis H1, the MLEs of μ, σ1, and σ2 are
,
and
respectively and under the hypothesis H2, the MLEs of μ, σ1, and σ2 are
and
, respectively. Therefore, the LR rule, say, R5, is as follows:
R5: Classify x into Π1 if λ* ≥ c else classify x into Π2, where
3.3. Rules for k Populations
We consider k(≥2) exponential populations Πis with unknown scale parameters σ1, σ2, …, σk and a common unknown location parameter μ. Suppose the prior probabilities that an observation may come from exactly one of these k populations are equal. An observation x has to be classified into one of these k populations. When the parameters are known, the classification function related to the ith and jth population is
(22) Plugging in the MLEs
, and
of the parameters μ, σi, and σj, respectively, the estimated classification function is
If the prior probabilities are known, then the classification rule, say, Rm, is as follows:
Rm: Classify the observation x into Πi if uij(x) > 0 for j = 1, …, k, i ≠ j.
Now we consider that random variables associated with the k exponential populations Πis have unknown scale parameters but they follow a simple order restriction 0 < σ1 ≤ σ2 ≤ … ≤ σk < ∞. Under this ordering, the isotonized version estimators of the parameters are mentioned in Section 2. Corresponding to the estimators and
, we get the classification rule RIR.
RIR: Classify the observation x into Πi if uij(x) > 0 for j = 1, …, k, i ≠ j, where
3.4. Numerical Comparisons
In this section, we describe the results of comprehensive simulation study considering 50,000 replications. We compare the classification rules with respect to EPC. The probability of correct classification corresponding to each classification rule is estimated using the frequency definition of probability. Firstly, we perform the classification into two exponential populations and predict the results. The plot of the EPC of the rules R(α)2 for several values of α is shown in . Among these rules based on the mixed estimators, the rule corresponding to α = 0 is the best rule. We have chosen the cutoff point c = 1.6 for the classification rule R5 in . The following conclusions are drawn from the plot of the EPC of rules R1, R(0)2, R3, R4, and R5 as shown in .
Figure 1. EPC of rule R(α)2 for different values of α.
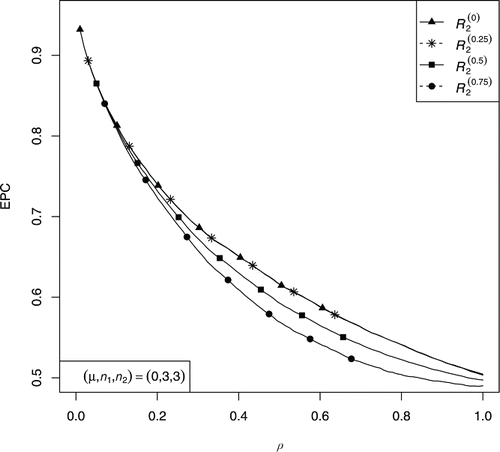
Figure 2. Plot of the EPC corresponding to classification rules vs. ρ.
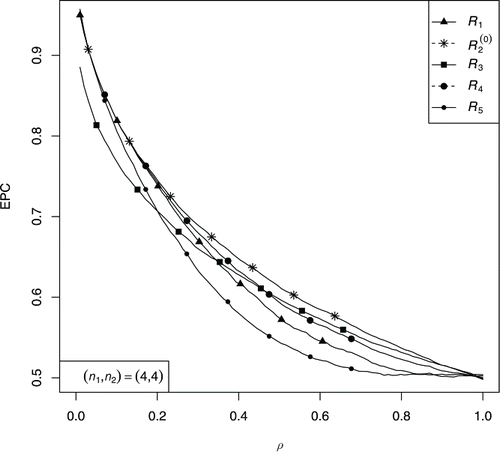
| 1. | The rule R4 based on the restricted MLEs of σis is better than the usual rule R1. | ||||
| 2. | The classification rule R(0)2 has the highest EPC among all classification rules and therefore for application, it is the best rule among all proposed rules. | ||||
| 3. | For high and moderate values of ρ, the rule R3 is better than the usual rules R1 and R5, however, the rule R3 has lower EPC than both rules R1 and R(0)2 for small values of ρ. | ||||
| 4. | If ρ is close to zero or one, the performance of rules R1, R(0)2, and R3 is equally good. | ||||
| 5. | For large sample sizes, all classification rules exhibit more or less the similar performance. | ||||
We define the relative percentage improvement of EPC for the rule Ri over the rule R1 by
In , the relative percentage improvements of the EPC of the rules over the usual rule R1 are mentioned for the equal size samples as well as for the unequal size samples. The rules R(0)2 and R4 always show improvement over the usual rule R1 and among the classification rules R(0)2 and R4, rule R(0)2 is better. For small sample size and for moderate values of ρ, the amount of improvement is 7–10%. Therefore, for classifying an observation, we recommend the rule R(0)2 based on the mixed estimators of the scale parameters corresponding to α = 0 for all values of ρ.
Table 3. Relative improvement of EPC of the ordered rules over the usual rule.
Now we consider the case for classifying an observation into one of the three populations, assuming that the costs of misclassifications are equal and qi = 1/3 for i = 1, 2, 3. In , the EPC of an observation is listed for fixed values of ρ1( = σ1/σ2) and ρ2( = σ2/σ3) and for different configuration of the samples. For each value of ρ1, the first and the second rows of represent the EPC of the rules Rm and RIR, respectively. We observed the following conclusions.
Table 4. EPC of rules R1 and RIR for three populations.
| 1. | For low values of ρ1 and ρ2, the EPC is more than 60% for small as well for large size samples. | ||||
| 2. | For fixed values of ρ2, as ρ1 increases the EPC decreases. Similarly, when ρ1 is fixed, EPC decreases with respect to ρ2. | ||||
| 3. | The performance of the classification rule significantly increases as the sample size increases. | ||||
| 4. | The rule Rm dominates the classification rule RIR in terms of EPC. | ||||
Hence, we recommend the rule Rm based on the MLE for classifying an observation into one of the three exponential populations.
For two exponential populations, we show an application of the proposed rule using a real data set given in Barlow et al. (Citation1972, p. 271).
Example:
Consider the following data representing the operational times (in hours) between successive failures of air conditioning equipments in two aircrafts (plane 7915 and plane 8044).
Plane 7915 (sample size n1 = 9): 359, 9, 12, 270, 603, 3, 104, 2, 438
Plane 8044 (sample size n2 = 10): 487, 18, 100, 7, 98, 5, 85, 91, 43, 230
Barlow et al. (Citation1972) showed that the sample values fit exponential distribution. The equality of the common location parameter is justified at a 10% significance level. Suppose the expected lifetime of the air-conditioner used in plane 8044 is greater than that of the air-conditioner used in plane 7915. The samples corresponding to planes 7915 and 8044 can then be assumed as samples from two exponential populations with a common location μ and different scale parameters σ1 and σ2, respectively. We want to classify the observation x = 130. Suppose the exact population is unknown due to faulty record-keeping. For the given data, using the symbols as defined in Section 2, we have X = 2, T1 = 1782, and T2 = 1144. Since T1/n1 > T2/n2, the ordered classification rule R(0)2 as defined in Subsection 3.1 must show better performance than rule R1. The classification statistic U(0)2(x) has value −0.0761. Therefore, we classify the observation 130 into the plane 7915 using the rule R(0)2.
4. Conclusion
In this article, we have introduced mixed estimators of scale parameters of two exponential distributions with an unknown but common location parameter. We have also derived Bayes and generalized Bayes estimators of scale parameters with respect to a gamma prior and a noninformative prior, respectively, when the loss function is the squared error. For the invariant loss function, the risk improvements of the ordered estimators over the usual estimators are also noticed. Using the Bayes estimators, the restricted MLE, modified MLE, and mixed estimators, we suggested rules for classification of an observation into two populations. For two populations, we have shown that the rule based on the mixed estimator is better than the usual classification rule and other ordered rules in terms of EPC. In addition, we have numerically obtained the EPC of the rules for classifying an observation into more than two populations. Although the restricted MLEs of the scale parameters have lower risk than that of the other estimators, use of the mixed estimators of the scale parameters with mixing constant zero in the classification rule provides higher EPC than the rule based on restricted MLEs for the purpose of classification.
Acknowledgements
The authors are thankful to the referee and the editor for the valuable comments, which have substantially improved the article.
References
- Adegboye, O. S. (1993). The optimal classification rule for exponential populations. Australian Journal of Statististics., 35(2), 185–194.
- Anderson, T. W. (1951). Classification by multivariate analysis. Psychometrika, 16(1), 31–50.
- Anderson, T. W. (2003). An introduction to multivariate statistical analysis (3rd ed.). Hoboken, NJ: Wiley-Interscience.
- Barlow, R. E., Bartholomew, D. J., Bremner, J. M., & Brunk, H. D. (1972). Statistical inference under order restrictions: The theory and application of isotonic regression. New York, NJ: John Wiley.
- Basu, A. P., & Gupta, A. K. (1974). Classification rules for exponential populations. In F. Proschan & R. J. Serfling (Eds.), Proceedings of the Conference on Reliability and Biometry, (pp. 637–650). Philadelphia, PA: SIAM.
- Basu, A. P., & Gupta, A. K. (1977). Classification rules for exponential populations: Two parameter case. The Theory and Applications of Reliability with Emphasis on Bayesian and Nonparametric Methods, 1, 507–525.
- Brewster, J. F., & Zidek, J. V. (1974). Improving on equivariant estimators. Annals of Statistics, 2(1), 21–38.
- Chang, C.-H., Lin, J.-J., & Pal, N. (2013). Hypothesis testing on the common location parameter of several shifted exponential distributions: A note. Journal of the Korean Statistical Society, 42(1), 51–59.
- Conde, D., Fernández, M. A., & Salvador, B. (2005). Classification rule for ordered exponential populations. journal of Statistical Planning Inference, 135(2), 339–356.
- Fernández, M. A., Rueda, C., & Salvador, B. (2006). Incorporating additional information to normal linear discriminant rules. Journal American Statistical Association, 101(474), 569–577.
- Ghosh, M., & Razmpour, A. (1984). Estimation of the common location parameter of several exponentials. Sankhyā, Series A, 46(3), 383–394.
- Jana, N., & Kumar, S. (2015). Classification into two normal populations with a common mean and unequal variances. Communications Statistics in Simulation and Computation. doi: 10.1080/03610918.2014.970697
- Jana, N., Kumar, S., & Misra, N. (2014). Classification rules for exponential populations under order restrictions on parameters. Springer Proceedings in Mathematics & Statistics, 91, 243–250.
- Katz, M. W. (1963). Estimaing ordered probabilities. Annals of Mathematical Statistics, 34, 967–972.
- Kumar, S., & Sharma, D. (1988). Simultaneous etimation of ordered parameters. Communications in Statistics Theory and Methods, 17, 4315–4336.
- Long, T., & Gupta, R. D. (1998). Alternative linear classification rules under order restrictions. Communications in Statistics Theory and Methods, 27(3), 559–575.
- Pal, N., & Sinha, B. (1990). Estimation of a common location of several exponentials. Statistics Decisions, 8, 27–36.
- Tripathi, M. R., Kumar, S., & Misra, N. (2014). Estimating the common guarantee time of two exponential populations under order restricted failure rates (or mean lifetimes). American Journal of Mathematical and Management Sciences, 33(2), 125–146.
- Vijayasree, G., & Singh, H. (1993). Mixed estimators of two ordered exponential means. Journal of Statistical Planning and Inference, 35(1), 47–53.
- Wakaki, H. (1998). Asymptotic expansions for the studentized best linear discriminant function under two elliptical populations. American Journal of Mathematical and Management Sciences, 18(1–2), 89–108.