
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.SYNOPTIC ABSTRACT
In this article, we propose a new class of distributions; namely, the double Lindley distribution (DLD) and investigate some of its important properties. We discuss the estimation of parameters of the location-scale extended class of DLD and illustrate the procedures with the help of certain real life data sets. A simulation study is carried out to examine the performance of estimators of the parameters of the distribution.
1. Introduction
Lindley (Citation1958) introduced a new class of continuous probability distributions through the probability density function (p.d.f),
(1)
(1)
for any
and
. The distribution with p.d.f Equation(1)
(1)
(1) is known in literature as Lindley distribution which has found useful applications in several areas of research, especially in lifetime data analysis. There are several continuous distributions available in the literature for modeling lifetime data. Among them, the exponential distribution is of prime importance, mainly due to the possession of closed form expression for its survival function. Even then, the Lindley distribution has an advantage over exponential distribution, because of the fact that while the exponential distribution has constant hazard rate and mean residual life function (MRLF), the Lindley distribution possess increasing hazard rate and decreasing mean residual life function. This may be the reason why the Lindley distribution has received much attention in the literature. Certain properties and applications of this distribution has been studied recently by Al-Mutairi et al. (Citation2013) and Ghitany et al. (Citation2008). Several generalized versions of Lindley distribution have been developed in the recent literature. For example, Bakouch et al. (Citation2012) obtained an extended form of Lindley distribution, Elbatal and Elgarhy (Citation2013) studied Kumaraswamy quasi Lindley distribution, Gómez-Déniz et al. (Citation2014) considered Log-Lindley distribution, Ashour and Eltehiwy (Citation2015) considered exponentiated power Lindley distribution, and Nedjar and Zeghdoudi (Citation2016) introduced Gamma Lindley distribution. Another extended form of generalized Lindley distribution with applications to lifetime data is considered by Torabi et al. (Citation2014), whereas certain properties and applications of generalized weighted Lindley distribution is discussed by Ramos and Louzada (Citation2016).
The Laplace distribution and its related versions have received much attention in the recent statistical literature. For example, see Dixit and Khandeparkar (Citation2017, Citation2018) and Dixit and Subramanian (Citation2016). The Laplace distribution is a two-tailed version of the exponential distribution and, hence, it is known in the literature as the double exponential distribution. Analogous to this, throughout here we consider a two-tailed version of Lindley distribution for getting a more flexible class of distributions, which we call the double Lindley distribution. We investigate several interesting properties of this distribution and highlight the relevance of such a class of distributions, compared to the Laplace distribution, by considering certain real life data sets.
In section 2, we present the definition of the DLD and obtain the cumulative distribution function of the same. Section 3 deals with the moments and generating functions of the DLD. Certain reliability measures of the DLD are given in section 4, and in section 5 we discuss some order statistics related properties of the distribution. Section 6 contains the derivation of the Rényi entropy measure of the DLD, and in section 7 we discuss the definition and some important properties of the location-scale extension of the DLD which we termed as the extended double Lindley distribution (EDLD). Section 8 deals with the maximum likelihood estimation of the EDLD, and in section 9 we illustrate the estimation procedures with the help of certain real life data sets. A simulation study has been carried out in section 10 for examining the performance of likelihood estimators for the parameters of the EDLD. In order to make the justification of the relevance of the proposed model more explicit, we have included some concluding remarks in section 11.
2. Definition and Properties
In this section, we present the definition of the DLD along with a brief discussion on its important properties.
Definition 1.
A continuous random variable Y is said to follow double Lindley distribution (DLD) with parameter θ, if its p.d.f is given by,
(2)
(2)
for
and
.
When θ = 1, the p.d.f Equation(2)(2)
(2) of the DLD reduces to,
(3)
(3)
A distribution with p.d.f Equation(2)(2)
(2) hereafter we denoted as DLD(θ), and a distribution with p.d.f Equation(3)
(3)
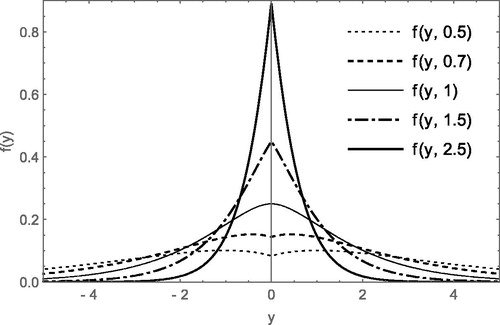
(3) we named as standard double Lindley distribution (SDLD). Probability plots of the DLD(θ) are given in for particular values of θ. From , we can observe that DLD exhibits unimodal and bimodal nature. On differentiating Equation(2)
(2)
(2) with respect to y, we obtain,
(4)
(4)
Figure 1. The probability density function of the DLD for various values of θ.
Now, based on Equation(4)(4)
(4) we have the following cases.
For
implies that
For
Therefore, in the light of Equation(4)(4)
(4) , the mode of the DLD is given by,
(5)
(5)
From Equation(5)(5)
(5) , we can say that when
, the distribution is bimodal and when
, the distribution is unimodal.
Next, we obtain the cumulative distribution function (c.d.f) of the DLD(θ) as follows.
For , the c.d.f of the DLD is,
and for
, the c.d.f of the DLD is,
Thus, the c.d.f of the DLD with p.d.f Equation(2)
(2)
(2) is,
(6)
(6)
When θ = 1 in Equation(6)
(6)
(6) , we get the c.d.f of the SDLD as,
(7)
(7)
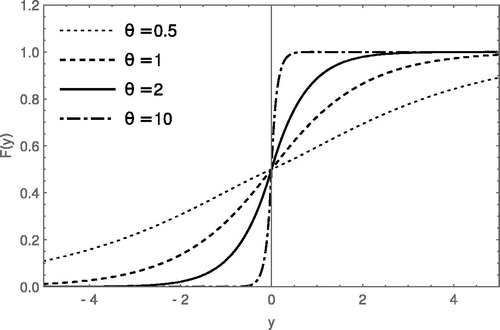
The non-decreasing and continuity nature shown by the c.d.f of the DLD can be observed from for various parameter values.
Figure 2. The cumulative distribution function of the DLD for different values of θ.
Next, we prove the following theorem, which gives how the DLD(θ) and Lindley(θ) are related.
Theorem 1.
If DLD (θ), then
Lindley (θ).
Proof.
For any , the c.d.f of Z is,
which is the c.d.f of the Lindley distribution with parameter θ. □
3. Moments and Generating Functions
In this section, we derive expressions for rth raw moment, moment generating function and cumulant generating function of the DLD and discuss related properties of the distribution. In the case of DLD, we derive the general expression for the rth moment as given below.
By definition, for , the rth raw moment
of the DLD is obtained as,
(8)
(8)
In particular, the
, and
central moments of the DLD take the form,
and
Thus, the coefficient of skewness and the coefficient of kurtosis
of the DLD are, respectively,
and
Clearly, for all
, the value of
is minimum at θ = 0. Thus,
and
for all θ, which indicated that the DLD is always symmetric and leptokurtic.
Consequently, we have the following remark.
Remark 1.
For , the rth raw moment of the standard DLD is,
For , the rth absolute moment of the DLD is obtained as,
(9)
(9)
(10)
(10)
It is to be noted that the mean deviation about mean (first absolute moment) of the DLD(θ) can be obtained when r = 1 in Equation(10)(10)
(10) and is given by,
Now, we derive the moment generating function(m.g.f) of the DLD(θ) as follows. For any
, by definition, the moment generating function (m.g.f) of the DLD with p.d.f Equation(2)
(2)
(2) is given by,
(11)
(11)
Clearly, when θ = 1, from Equation(11)(11)
(11) we have the m.g.f of the SDLD as,
For any and
, we can readily obtain the characteristic function(c.f)
, of the DLD
, by replacing t by it in Equation(11)
(11)
(11) and it is given by,
(12)
(12)
Remark 2.
If θ = 1 in Equation(12)(12)
(12) we get the c.f of SDLD as,
(13)
(13)
which shows that
, where Z1, Z2 are independent standard Laplace random variables, so that the SDLD random variate can be viewed as the sum of two independent standard Laplace random variables.
The cumulant generating function of DLD is,
(14)
(14)
(15)
(15)
Now, by expanding the logarithmic terms in Equation(15)(15)
(15) , we obtain the following.
(16)
(16)
On equating coefficients of in the right hand side expression of Equation(14)
(14)
(14) and Equation(16)
(16)
(16) , we get the nth cumulant, Kn of the DLD as follows.
(17)
(17)
From Equation(17)(17)
(17) , it can be noted that all the odd cumulants of DLD are zero. In particular, the first few even order cumulants of the DLD are,
4. Reliability Measures
It is essential to derive expressions for the reliability measures, like survival function, hazard function, and mean residual life function for DLD since it can be used to study the reliability of a system involving one unit.
The survival function S(y) of the DLD(θ) is given by,
(18)
(18)
and the failure rate function (hazard rate function) of the DLD(θ) is given by,
(19)
(19)
The proof follows directly from the definition of hazard rate function and is, hence, omitted.
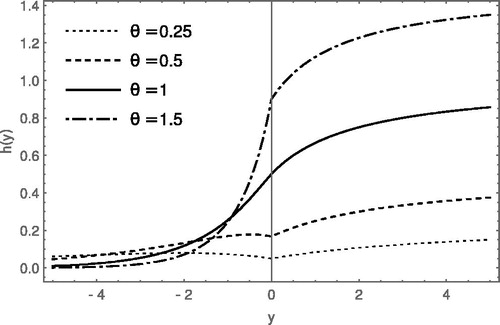
It is important to analyze whether the failure rate function is increasing or decreasing, because this phenomenon describes where the probability of an event in a fixed time interval in the future increases or decreases over time. The failure rate function of the DLD is graphically represented in . From , we can observe that the failure rate function of the DLD shows both increasing and decreasing failure rates. The following theorem establishes the nature of the failure rate function of the DLD in a more precise manner.
Figure 3. The hazard rate function of the DLD for various parameter values.
Theorem 2.
If Y follows DLD with failure rate function as given in Equation(19)(19)
(19) , then Y has decreasing failure rate (DFR) for any
such that
and non-decreasing failure rate (IFR) elsewhere.
Proof.
On differentiating Equation(19)(19)
(19) with respect to y, we have,
(20)
(20)
From Equation(20)(20)
(20) , it follows that when
for
and
, for all other values of y and θ. Therefore, for
such that
, the hazard rate function of DLD is DFR and when
and
it is IFR. The hazard rate function is IFR for all values of θ when
.□
Lariviere and Porteus (Citation2001) has defined the generalized failure rate of a continuous random variable X with hazard rate function h(x) as . Thus, X has an increasing generalized failure rate (IGFR) if g(x) is non-decreasing and decreasing generalized failure rate (DGFR) if g(x) is non-increasing. Generalized failure rate distributions have various applications in the areas of inventory management, pricing and supply chain problems etc. The GFR nature of DLD is stated in the following theorem.
Theorem 3.
If Y follows DLD with failure rate function as given in Equation(19)(19)
(19) , then Y has decreasing generalized failure rate (DGFR) for
and increasing generalized failure rate (IGFR) elsewhere.
Proof.
In the case of DLD,
and
(21)
(21)
From Equation(21)(21)
(21) , it follows that when
and for
. Therefore, for
, the hazard rate function h(y) of the DLD is DGFR and for all other values of y, it is IGFR. □
In reliability studies, life expectancy or mean residual life is an important characteristic of the model. In life tesing situations, it is exciting to know about the expected additional lifetime of a component given that it has survived until a particular time. Based on the survival function given in Equation(18)(18)
(18) , one can compute the mean residual life function of the DLD as follows.
For , the MRLF of the DLD is given by,
and for
, the mean residual life function (MRLF) of the DLD is given by,
Thus, the MRLF of the DLD is,
(22)
(22)
5. Order Statistics
In this section, we derive the distribution of order statistics and the qth moment of the kth order statistics of the DLD.
Suppose is a random sample from Equation(2)
(2)
(2) . Let
denote the corresponding order statistics. For
, the p.d.f and c.d.f of the kth order statistic
of the DLD are given by,
(23)
(23)
and
(24)
(24)
respectively. Now, by using Equation(23)
(23)
(23) , we obtain the following result.
Result 1.
The qth moment of the kth order statistic, of the DLD is given by,
(25)
(25)
Proof.
by binomial expansion, then we get Equation(25)
(25)
(25) , by evaluating the integrals. □
The above results on the distribution of order statistics and its qth moment will be much useful for inference problems as well.
6. Entropy
In this section, we derive Rényi entropy measure of the DLD. An entropy of a random variable X is a measure of variation of the uncertainty.
By definition, Rényi entropy of a distribution with p.d.f is given by,
(26)
(26)
where
and
. Thus, the Rényi entropy of DLD with p.d.f Equation(2)
(2)
(2) is given by,
in which,
Now, using the series expansions,
(27)
(27)
and
(28)
(28)
for any
and
for
with
(Pochhammer symbol). Then, we get,
Here, using the expression,
, we can write,
Then, the entropy of DLD is obtained as,
(29)
(29)
where
(30)
(30)
is the Gauss Hypergeometric Function.
7. Location Scale Extension
Here, we consider an extended form of the DLD by introducing the location parameter μ and scale parameter σ in the p.d.f of DLD and call it as” the extended double Lindley distribution (EDLD)”. We define the EDLD as follows.
Definition 2.
Let with p.d.f. Equation(2)
(2)
(2) . Then
is said to have an extended double Lindley distribution (EDLD) with parameters
and σ and its p.d.f is of the form,
(31)
(31)
for
and
.
We denote the distribution with p.d.f Equation(31)(31)
(31) as EDLD
. Analogous to the findings in the case of DLD, here, we are given expressions for certain characteristics of EDLD, which we present through the following results. Their proofs are omitted, as they are the direct consequence of the corresponding expressions given in sections 2–6.
Result 2.
The cumulative distribution function of the EDLD is given by,
(32)
(32)
When we put μ = 0 and σ = 1 in Equation(32)(32)
(32) , it reduces to the c.d.f of the DLD as given in Equation(6)
(6)
(6) .
Result 3.
For , the rth moment,
about origin of EDLD is,
(33)
(33)
Result 4.
For , the central moments of the EDLD are given by,
(34)
(34)
From Equation(34)(34)
(34) , we can find that all the odd central moments of EDLD are zero. In particular, for the EDLD, we have,
and
Remark 3.
The coefficient of variation , coefficient of skewness
and the coefficient of kurtosis
of the EDLD are given below.
and
Result 5.
For , the rth absolute moment of the EDLD is given by,
(35)
(35)
From Equation(35)(35)
(35) , when r = 1, we can obtain the mean deviation about mean of the EDLD as,
Result 6.
The characteristic function of EDLD is given by,
(36)
(36)
Result 7.
All the odd cumulants of EDLD, except the first cumulant are zero. The general expression for cumulants of EDLD is given by,
(37)
(37)
In particular, the cumulants of the EDLD are,
Result 8.
The hazard rate function of the EDLD is obtained as,
(38)
(38)
Result 9.
The mean residual life function of the EDLD is given by,
Here, we discuss the distribution of order statistics and the qth moment of the kth order statistics of the EDLD.
Result 10.
Suppose is a random sample from EDLD. Let
denote the corresponding order statistics. It follows from Equation(31)
(31)
(31) that the p.d.f of the kth order statistics of EDLD is given by,
(39)
(39)
From Equation(32)(32)
(32) , we can obtain the c.d.f of the kth order statistic of EDLD as
(40)
(40)
The qth moment of the kth order statistics, of the EDLD can be expressed as,
(41)
(41)
Result 11.
The Rényi entropy of the DLD is obtained as,
(42)
(42)
where
and
is the Gauss Hypergeometric Function given in Equation(30)
(30)
(30) .
8. Maximum Likelihood Estimation
Let be a random sample of size n taken from EDLD with p.d.f given in Equation(31)
(31)
(31) . Let
be the ordered sample. Assume
, for a particular
. Then,the loglikelihood function
of the sample is the following, in which
, denotes the summation over the set Ij such that
and
.
(43)
(43)
On differentiating Equation(43)(43)
(43) with respect to the parameters θ, μ and σ and then equating to zero, we obtain the following normal equations.
(44)
(44)
(45)
(45)
and
(46)
(46)
On solving the Equationequations (44)–(46) we get maximum likelihood estimators of the parameters of EDLD.
9. Applications
For numerical illustration, in this section we consider the following three data sets, among them the first is a rocket propellant data, and the second is a hardwood data. Both these data sets are taken from Montgomery et al. (Citation2015). Data set 1 contains 20 observations on the age of the propellant, while data set 2 concerning the tensile strength of kraft paper. Data set 3 consists of data regarding lung cancer rates for 44 US states. The data is available at www.calvin.edu/∼stob/data/cigs.csv.
Data set 1: 15.5 23.75 8.0 17.0 5.5 19.0 24.0 2.5 7.5 11.0 13.0 3.75 25.0 9.75 22.0 18.0 6.0 12.5 2.0 21.5
Data set 2: 6.3 11.1 20.0 24.0 26.1 30.0 33.8 34.0 38.1 39.9 42.0 46.1 53.1 52.0 52.5 48.0 42.8 27.8 21.9
Data set 3: 17.05 19.8 15.98 22.07 22.83 24.55 27.27 23.57 13.58 22.8 20.3 16.59 16.84 17.71 25.45 20.94 26.48 22.04 22.72 14.2 15.6 20.98 19.5 16.7 23.03 25.95 14.59 25.02 12.12 21.89 19.45 12.11 23.68 17.45 14.11 17.6 20.74 12.01 21.22 20.34 20.55 15.53 15.92 25.88
We have fitted the EDLD() and Laplace(
) to all these data sets and computed Kolmogorov-Smirnov statistic (KSS) in all three cases. Moreover, the numerical results obtained are presented in . From these tables, it can be obtained that the EDLD fits the data sets better than the existing Laplace distribution of Kotz et al. (Citation2012). For model comparison, we have computed some well-known information criterion, such as Akaike’s Information Criterion (AIC), the Bayesian Information Criterion (BIC), and the corrected Akaike’s Information Criterion (AICc), which are also given in .
Table 1. Estimated values of the parameters for the EDLD and Laplace distribution with respective KSS, AIC, BIC, and AICc values for the rocket propellant data.
Table 2. Estimated values of the parameters for the EDLD and Laplace distribution with respective KSS, AIC, BIC, and AICc values for the hardwood data.
Table 3. Estimated values of the parameters for the EDLD and Laplace distribution with respective KSS, AIC, BIC, and AICc values for the cigarette sales and cancer rate data.
10. Simulation
In this subsection, we investigate the behavior of the maximum likelihood estimators for a finite sample size (n) by conducting a brief simulation study as follows. We have simulated data sets of size 100, 200, and 500 from the EDLD for the parameter values θ = 2, μ = 5, and σ = 3. We have generated 60 independent samples of size n = 100, 200, and 500 from EDLD and computed the maximum likelihood estimates of these parameters for each of the 60 samples. Then, we compute the mean of the obtained estimates over all 60 samples. The results obtained are presented in . From , it can be observed that both the bias and MSE decreases as the sample size increases.
Table 4. Estimates of the parameters and the corresponding bias and mean square error.
11. Concluding Remarks
In this article, we introduced a two-tailed version of the Lindley distribution through the name double Lindley distribution (DLD) and showed that it can be used for modeling a wide range of data sets, especially in the field of engineering statistics, as illustrated in section 9. Here, DLD is compared with the well-known Laplace distribution and found that for certain data sets, the DLD is better suited than the Laplace distribution. Several important characteristics of the DLD have been derived, and it is observed from those characteristics that the mathematical properties of DLD are more flexible compared to that of the Laplace distribution. Thus, it may be possible for one to conclude that the proposed version of the Lindley distribution is appropriate for modeling data sets in certain practical situations compared to the Laplace distribution and, hence, it can also be viewed as an alternative to the existing Laplace distribution in several practical applications.
Acknowledgements
The authors wish to express their sincere gratitude to the Editor in Chief, Associate Editor, and anonymous referees for their valuable comments on an earlier version that greatly improved the quality.
References
- Al-Mutairi, D., Ghitany, M., & Kundu, D. (2013). Inferences on stress-strength reliability from Lindley distributions. Communications in Statistics-Theory and Methods, 42, 1443–1463.
- Ashour, S. K., & Eltehiwy, M. A. (2015). Exponentiated power Lindley distribution. Journal of Advanced Research, 6, 895–905.
- Bakouch, H. S., Al-Zahrani, B. M., Al-Shomrani, A. A., Marchi, V. A. A., & Louzada, F. (2012). An extended Lindley distribution. Journal of the Korean Statistical Society, 41, 75–85.
- Dixit, V. U., & Khandeparkar, P. P. (2017). Estimation of parameters of skew log Laplace distribution. American Journal of Mathematical and Management Sciences, 36, 277–291.
- Dixit, V. U., & Khandeparkar, P. P. (2018). Tests for scale parameter of skew log Laplace distribution. American Journal of Mathematical and Management Sciences, 37, 93–106.
- Dixit, V. U., & Subramanian, L. (2016). Characterization properties of two-piece double exponential distribution. American Journal of Mathematical and Management Sciences, 35, 227–232.
- Elbatal, I., & Elgarhy, M. (2013). Statistical properties of Kumaraswamy quasi Lindley distribution. International Journal of Mathematics Trends and Technology, 4, 237–246.
- Ghitany, M., Atieh, B., & Nadarajah, S. (2008). Lindley distribution and its application. Mathematics and Computers in Simulation, 78, 493–506.
- Gómez-Déniz, E., Sordo, M. A., & Calderín-Ojeda, E. (2014). The log-Lindley distribution as an alternative to the beta regression model with applications in insurance. Insurance: Mathematics and Economics, 54, 49–57.
- Kotz, S., Kozubowski, T., & Podgorski, K. (2012). The Laplace Distribution and Generalizations: a Revisit with Applications to Communications, Economics, Engineering, and Finance. Springer Science & Business Media.
- Lariviere, M. A., & Porteus, E. L. (2001). Selling to the newsvendor: An analysis of price-only contracts. Manufacturing & Service Operations Management, 3, 293–305.
- Lindley, D. V. (1958). Fiducial distributions and Bayes’ theorem. Journal of the Royal Statistical Society. Series B, 20, 102–107.
- Montgomery, D. C., Peck, E. A., & Vining, G. G. (2015). Introduction to Linear Regression Analysis. John Wiley & Sons.
- Nedjar, S., & Zeghdoudi, H. (2016). On gamma Lindley distribution: Properties and simulations. Journal of Computational and Applied Mathematics, 298, 167–174.
- Ramos, P. L., & Louzada, F. (2016). The generalized weighted Lindley distribution: Properties, estimation, and applications. Cogent Mathematics, 3, 1256022.
- Torabi, H., Falahati-Naeini, M., & Montazeri, N. (2014). An extended generalized Lindley distribution and its applications to lifetime data. Journal of Statistical Research of Iran, 11, 203–222.