
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.SYNOPTIC ABSTRACT
This article deals with problems of estimation and prediction under classical and Bayesian approaches when lifetime data following a lognormal distribution are observed under type-I progressive hybrid censoring. We first obtain maximum likelihood estimates, Bayes estimates, and corresponding interval estimates of unknown lognormal parameters. We then develop predictors to predict censored observations and construct prediction intervals. Further, we analyze two real data sets and conduct a simulation study to compare the performance of proposed methods of estimation and prediction. Finally, optimal censoring schemes are constructed under cost constraints and a conclusion is presented.
KEY WORDS AND PHRASES:
1. Introduction
Hybrid censoring is a mixture of the traditional type-I and type-II censoring schemes. In this censoring, a test is terminated either when a prefixed time T reaches or a prefixed m number of units has failed, whichever happens earlier/later (type-I/type-II hybrid). The main disadvantage with this censoring is that live units can be removed from a test only at the terminal point of the experiment. The concept of progressive censoring introduced by Cohen (Citation1965) allow the units to remove at intermediate stages of a test, and this censoring has received much attention in the area of life testing and reliability data analysis (see Balakrishnan & Cramer, Citation2014). Later development in this direction is type-I progressive hybrid censoring (type-I phcs) introduced by Kundu and Joarder (Citation2006). In this censoring, n test units are put on an experiment and the test is conducted in a manner similar to the type-I hybrid censoring. However, in addition, this censoring allows removal of R1 number of live units randomly from the test at the time of first failure, say x1 likewise progressive censoring. Similarly, at the time of second failure x2, R2 number of units are removed from the remaining test units. Finally, all the remaining
number of units can be removed from the experiment if mth unit fails at a time xm such that
, say case (i), and
number of units are removed if T reaches before the mth failure such that
, say case (ii). Consequently, the observed data
under this censoring turn out to have r number of failures where r = m if case (i) occurs and let r = d number units fails before time T which is case (ii). Notice, that
are prefixed prior to the start of the test with
. Problems of estimation and prediction have been discussed for various distributions under this censoring, and one may refer to Cramer and Balakrishnan (Citation2013) for exponential distribution, Golparvar and Parsian (Citation2016), Asl et al. (Citation2017) for Burr type XII distribution, and Tomer and Panwar (Citation2015) for Maxwell distribution. The objective here is to study lognormal distribution under this censoring, and derive inference from classical and Bayesian viewpoints.
The probability density function (PDF) and the cumulative distribution function (CDF) of a lognormal distribution are, respectively, given by,
(1)
(1)
(2)
(2)
where μ and τ denote unknown parameters of the distribution. This distribution has been studied using a series of censoring methodologies, including applications related to the normal distribution. Balakrishnan et al. (Citation2003) obtained maximum likelihood and approximate maximum likelihood estimates of unknown mean and variance of a normal distribution under progressive type-II censoring. Authors also constructed confidence intervals based on the Fisher information matrix. In a subsequent paper, Balakrishnan and Mi (Citation2003) discussed uniqueness and existence of maximum likelihood estimators (MLEs), and further, Ng et al. (Citation2002) employed EM algorithm to derive MLEs. Recently, Singh et al. (Citation2015) investigated the problem of estimating unknown lognormal parameters under progressive type-II censoring. Authors obtained both classical and Bayes estimates of unknown parameters, and compared the performance of proposed estimates using simulations. Dube et al. (Citation2011) derived MLEs and approximate MLEs under hybrid censoring, and further Singh and Tripathi (Citation2016) obtained different Bayes estimates of unknown parameters against informative and non-informative prior distributions. Authors also derived the prediction of future observations along with the corresponding prediction intervals from a Bayesian perspective. Hemmati and Khorram (Citation2013) also studied the lognormal distribution under type-II progressive hybrid censoring. Authors obtained maximum likelihood and approximate maximum likelihood estimators of unknown model parameters. They also constructed the associated asymptotic interval estimates using the Fisher information matrix. However, the problems of estimation and prediction for lognormal distribution have not been discussed under type-I progressive hybrid censoring. In this article, we provide statistical inference for lognormal parameters and censored observations under classical and Bayesian approaches. We also discuss optimal plans under the given sampling conditions.
The rest of this article is organized as follows. In Section 2, we obtain maximum likelihood estimators of unknown parameters by making use of an EM algorithm. The asymptotic variance-covariance matrix is also computed using the missing information method. We further obtain approximate MLEs of unknown parameters and then we use these estimates as initial values in the EM algorithm. Section 3 deals with Bayesian estimation under informative and non-informative priors using symmetric and asymmetric loss functions. Sections 4 and 5, respectively, deal with classical prediction and Bayesian prediction of future observations. Simulation study and analysis of real data sets are presented in Section 6. Finally, optimal censoring is discussed in Section 7, and a conclusion is presented in Section 8.
2. Maximum Likelihood Estimation
The objective of this section is to obtain maximum likelihood estimators of unknown lognormal parameters under type-I progressive hybrid censoring. Suppose that n independent and identically distributed test units whose lifetimes follow a lognormal distribution with PDF and CDF, respectively, given by EquationEquations (1)(1)
(1) and Equation(2)
(2)
(2) are put on an experiment. Let
denote the observed data under type-I progressive hybrid censoring with assumption that T, m, and
are prescribed before the start of the test. Then, the associated likelihood function of
given the observed data
can be written as,
(3)
(3)
where for case (i) we have
, and for case (ii), we have
. Notice, that case (i) provides data which are similar to progressive type-II censoring. Furthermore, in the above likelihood function hybrid censoring correspond to the case when all Ri values are considered equal to zero with
. We mention that d = 0 implies that no failure times are recorded during the experimentation; thus, it is difficult to make any inference on unknown quantities of interest. So, for further consideration it is assumed that d > 0 and in consequence we have r > 0. Now taking partial derivatives with respect to μ and τ of the log-likelihood function and then equating them to zero, we get,
(4)
(4)
(5)
(5)
where
and
which corresponds to case (ii). Also,
and
denote the standard normal density and distribution functions respectively. Now, the maximum likelihood estimates of μ and τ can be obtained by simultaneously solving the non-linear EquationEquations (4)
(4)
(4) and Equation(5)
(5)
(5) . It is seen that solutions cannot be obtained analytically, and so one needs to employ some numerical methods in order to derive the desired estimates. The traditional Newton-Raphson method can be used for this purpose. Instead, we propose to use Expectation-Maximization (EM) algorithm which is a very useful tool compared to the Newton-Raphson method, particularly when data are censored in nature. Before we proceed further, for details on uniqueness and existence of maximum likelihood estimators one may refer to the work of Balakrishnan and Mi (Citation2003). We next discuss the EM algorithm.
2.1. EM Algorithm
Suppose that represent lifetimes of n test units put on a life test. Also assume that
denote lifetimes of units censored at ith failure xi,
. Further let
represent lifetimes of the censored units when experiment is terminated at time T, that is when case (ii) occurs. Then, the complete sample W can be seen as a combination of observed data and censored data, that is
where
. Then utilizing the complete sample, the expectation step in the EM algorithm can be implemented as,
Now, we first take partial derivatives of the above function with respect to μ and τ and then equate them to zero. Subsequently, in the maximization step (M-step), if we denote as the kth estimates of
, then the next updated estimators of
are given by,
where
and
. Now, MLEs of μ and τ, respectively, denoted as
and
can be obtained using an iterative procedure where the process can be repeated until the desired convergence is achieved; that is, for some
we should have
. One of the main advantages of the EM algorithm is that the Fisher information matrix can be obtained using the idea of Louis (Citation1982). This method suggests that the observed information can be written as the difference between the complete information and the missing information; that is,
, where
. The complete information is given by,
and the missing information is given by
. Notice, that here
represents the missing information in a single observation truncated from left at xi, and is given by (see also, Singh et al., Citation2015),
In a similar way, can be obtained by replacing i by T in the above matrix. Now the asymptotic variance-covariance matrix of the MLEs can be obtained as
and, subsequently, it can be further used to construct asymptotic confidence intervals of unknown lognormal parameters. It is to be noticed that the EM algorithm requires an initial guess
of unknown parameters
. We next compute the approximate maximum likelihood estimates of
which can be used as an initial guess for implementing the EM algorithm.
2.2. Approximate Maximum Likelihood Estimation
This section deals with deriving approximate maximum likelihood estimators (AMLEs) of μ and τ. The MLEs of μ and τ do not admit closed forms because EquationEquations (4)(4)
(4) and Equation(5)
(5)
(5) contain terms like
and
which are non-linear in nature. In this connection, we observe that
corresponds to Ui in distribution where Ui denote the ith progressive type-II censored observation from the uniform U(0, 1) distribution. We then expand the function
in the Taylor series about the point
and keep terms only up to first order derivatives. Noticing that
with
given by,
we find that we have
where
and
. Proceeding in a similar manner we expand the function
around
where
. Subsequently, we get
with
, and
. One may further refer to Balakrishnan et al. (Citation2003) and Dube et al. (Citation2011) for more details. Next, inserting the approximated expressions of
and
in the EquationEquations (4)
(4)
(4) and Equation(5)
(5)
(5) and solving them simultaneously we get AMLEs of μ and τ as,
where
and
. Now, the approximate confidence intervals of μ and τ can be constructed using the asymptotic variance-covariance matrix of the AMLEs which can be obtained by inverting the observed information at AMLEs. Notice that
, the quantities of observed information can be obtained by using the expression
and
in the likelihood function given by EquationEquation (3)
(3)
(3) . Details of calculations not presented for the sake of conciseness.
3. Bayesian Estimation
This section deals with deriving Bayes estimators with respect to informative and non-informative prior distributions. The non-informative prior for is considered as
. The corresponding posterior distribution is then obtained as,
(6)
(6)
Next, we consider informative prior for which is a bivariate conditional prior distribution. Accordingly, we take an inverse gamma prior for τ such as
and then a conditional normal prior distribution for μ as
. Here, hyper-parameters
and q2 reflect the prior knowledge about unknown parameters of interest. The joint prior distribution of
can now be written as
. Then, the corresponding posterior distribution turns out to be,
(7)
(7)
We derive Bayes estimators under different loss functions; namely, a symmetric loss function like squared error and asymmetric loss function such as LINEX. Squared error loss (SEL) is widely used in Bayesian analysis, and it puts an equal weight to over estimation and under estimation which may not be an appropriate assumption in many practical situations. For example, in reliability and related area of inference overestimation may be more serious than under estimation or vice versa may happen. In such situations asymmetric loss function can be considered. In this connection, we propose to use LINEX loss function which is defined as . Here, under estimation is heavily penalized when h is negative and vice versa for positive h. The Bayes estimator of a parametric function
under the LINEX loss function is obtained as,
(8)
(8)
Further, under SEL function defined as , the Bayes estimator is given by,
(9)
(9)
It is seen that estimators given by EquationEquations (8)(8)
(8) and Equation(9)
(9)
(9) cannot be expressed into some closed form expressions as it is quite difficult to simplify associated integrals. So one needs to apply some approximation methods in order to simplify them. Accordingly, we may use the method of Lindley (Citation1980) and can obtain explicit expressions for desired estimates. Several researchers have applied this method in different inference problems and one may refer to Singh et al. (Citation2015), Singh and Tripathi (Citation2016), and references cited therein. In this article, we first make use of this method and obtain various Bayes estimates of unknown parameters. Both likelihood and approximate likelihood function are taken into account for computing these estimates. The details of calculations involved are not presented here for the sake of conciseness. It should be noted that the Lindley method is not so useful in interval estimation. Alternatively, the Metropolis-Hastings (MH) algorithm can be used for this purpose. Samples generated from this method can also be used in estimating unknown parameters. We next illustrate this procedure.
3.1. Metropolis-Hastings Algorithm
In this section, Metropolis-Hastings (MH) algorithm is discussed which is widely used in Bayesian inference in case where posterior distribution is not analytically tractable. In general, a symmetric proposal distribution of type can be considered to approximate a given posterior distribution. Next, we propose a bivariate normal density
where
is the inverse of the observed Fisher information matrix as obtained in Section (2.1), also see Dey et al. (Citation2016). Since, we take observations from a bivariate normal distribution therefore negative observations may appear for τ which is not acceptable. Keeping this in check, we propose following steps to draw samples from the corresponding posterior distribution.
Step 1. Take an initial guess of as
.
Step 2. For repeat the following steps.
(a) Set
.
(b) Generate a new candidate parameter value δ from
(c) Set
(d) Calculate
(e) Update
Finally, from the total N observations of , some of the initial samples (burn-in) can be discarded, and the remaining samples can be further utilized to compute Bayes estimates. In the present work, we consider a sample of size s for computation purpose where
with N0 being the burn-in samples. Subsequently, the Bayes estimators of μ as given in EquationEquations (8)
(8)
(8) and Equation(9)
(9)
(9) can be obtained as,
Similarly, Bayes estimators of τ can be obtained. Further, we make use of the Chen and Shao (Citation1999) method to obtain the highest posterior density (HPD) intervals of unknown lognormal parameters.
4. Classical Prediction
In previous sections, we derived classical and Bayes estimates of unknown parameters based on type-I progressive hybrid censored samples. Now, we investigate the problem of predicting future observations, and this section deals with the classical prediction. Suppose that are observed data from distribution as defined in EquationEquation (1)
(1)
(1) under type-I progressive hybrid censoring. Now, let us assume that zij,
and
denote ordered lifetimes of the censored observations. Then, the conditional density of zij given the observed data
can be written as,
(10)
(10)
where
and
. Also, note that
with zij > xi when the interest is to predict the Ri observations censored at
, and
, likewise
with
when the interest is to predict the RT observations censored at a prefixed time T, in this case i = T and
. Next, we provide different predictive inference for the zij observations.
4.1. Maximum Likelihood Predictor
In this section, we obtain predictors of censored observations based on maximum likelihood method. Note, that given the observed data , the predictive likelihood function (PLF) of zij and
can be written as,
(11)
(11)
Here, is the conditional density function given by EquationEquation (10)
(10)
(10) , and
is the likelihood function given by EquationEquation (3)
(3)
(3) . Now, if
and
are some functions of observations for which,
holds then we will have
as the maximum likelihood predictor (MLP) of
, also
and
will provide the predictive maximum likelihood estimates (PMLEs) of μ and τ, respectively. Now, using the predictive log-likelihood function
, and on simultaneously solving the respective partial derivatives with respect to zij, μ and τ to zero, we can obtain the MLP and PMLEs. In the present work, we use nleqslv package in R-language for solving these equations and in the process
can be considered as an initial guess for
.
4.2. Best Unbiased Predictor
In this section, we provide the best unbiased predictor (BUP) of the censored observations zij. Notice, that a statistic that is used to predict zij is called (BUP) of it if the prediction error
has mean zero and the corresponding prediction error variance
of
is less than or equal to any other unbiased predictor of zij. Following this the BUP of zij is obtained as,
If we take in EquationEquation (10)
(10)
(10) then distribution of u follows a Beta
distribution. Subsequently, the above integral expression reduces to
Note, that parameters μ and τ in the above expression are unknown and they need to be estimated. Here, we have used maximum likelihood estimates of μ and τ for this purpose.
4.3. Conditional Median Predictor
In this section, we use the conditional median predictor (CMP) to predict the censored observations zij. The statistics denotes the conditional median predictor of zij if it is the median of conditional density of zij, that is (see Raqab and Nagaraja, Citation1995),
Observe that follows Beta
distribution. Also recall that
distribution. Subsequently, by making use of the distribution of U, we obtain the CMP of zij as,
where M stands for the median of
distribution. Further, the corresponding
prediction interval is given by,
Here, Bp stands for the th percentile of Beta
distribution. Notice that the corresponding PDF of U is given by,
which is a unimodal function of u. Subsequently, the highest conditional density (HCD) prediction interval is obtained as,
where w1 and w2 denote solutions of the following equations,
or equivalently of equations,
where
represents CDF of a
distribution.
5. Bayesian Prediction
In this section, we obtain predictive estimates of the censored observations zij using the Bayesian approach. Observe that under the prior the corresponding posterior predictive density of zij can be obtained as,
Then, jth future observation from Ri censored units under the LINEX loss function can be predicted as . However, this posterior expectation cannot be derived in a closed form expression. So far, upon further consideration we rewrite this expectation as,
(12)
(12)
where,
In order to approximate , we make use of the MH algorithm and generate samples
from the corresponding posterior density. Then, Bayes predictors of zij under LINEX loss and squared error loss functions turn out to be,
where,
Next, we obtain the corresponding Bayesian credible interval for zij observations. Observe that the posterior predictive survival function is given by,
where
denotes the prior predictive survival function defined as,
Now, the equal tail Bayesian credible interval (L, U) of zij can be obtained by solving the following two equations.
The above equations can be solved using the uniroot function in R language, or one may refer to the algorithm given by Singh and Tripathi (Citation2016). Further, we compute the highest posterior density (HPD) prediction interval of zij observations. In HPD prediction interval, the posterior predictive density at every point inside the interval is greater than the posterior predictive density at every point outside the interval. We suggest using the algorithm proposed by Turkkan and Pham-Gia (Citation1993) to compute the corresponding HPD interval. However, alternatively, the predictive HPD prediction interval (L, U) can also be obtained by simultaneously solving the following two nonlinear equations.
One can use the nleqslv package in R language for this purpose and in the process, the corresponding Bayesian credible interval (L, U) can be considered as an initial guess.
6. Simulation Study and Data Analysis
6.1. Simulation Study
In this section, we conduct a simulation study to compare the performance of all proposed estimators and predictors. We generate data from the LN(0, 1) distribution using type-I progressive hybrid censoring for different choices of (n, m) and T in R-statistical language. We further consider following two censoring schemes.
S-I:First removal censoring scheme: .
S-II:Middle removal censoring scheme: for odd value of m and
for even value of m.
In , we report average estimates and mean square error (MSE) values of MLEs and AMLEs of . Further, reports associated 95% asymptotic confidence intervals, average interval lengths (AILs), and coverage percentages (CPs). Tabulated values suggest that behavior of AMLEs and MLEs follow a similar pattern. However, MLEs obtained using the EM algorithm are relatively closer to the true parameter values, and have smaller MSE values compared to the approximate MLEs. It is further seen that AILs of asymptotic intervals obtained using MLEs are smaller than those obtained using AMLEs. The corresponding CPs of intervals using MLEs are marginally higher than the CPs of AMLEs. Thus, performance of MLEs computed using the EM algorithm is quite good compared to AMLEs as far as bias and MSE values are concerned. Furthermore, CPs of both the interval estimates show satisfactory behavior as they deviate marginally from the nominal level. It is also observed that higher values of m and T lead to better estimation procedures. Also, in such situations, AILs of asymptotic intervals tend to become smaller and CPs tend to increase. This holds for all the tabulated values. In general, censoring scheme S-II provides better estimates of unknown parameters compared to the censoring scheme S-I.
Table 1. Average estimates and MSE values (in parenthesis) of MLEs and AMLEs.
Table 2. Asymptotic confidence intervals and associated CPs and AILs.
reports Bayes estimates obtained using the MH algorithm and Lindley method under both squared error and LINEX loss functions. Further, we consider two choices for h, such as h = 0.5 and h = 1.5 under LINEX loss, respectively, denoted as LL1 and LL2 in the tables. Note, that Bayes estimates from the Lindley method can also be obtained using AMLEs. However, we have observed that the performance of Lindley estimates obtained using MLEs is better than those obtained using AMLEs. So we have only reported Lindley estimates obtained using MLEs. Further, under informative prior setup hyper-parameters are assigned values as , and
. These choices are considered in such a manner that prior means and variances remain close to true parameter values. For convenience, we denote the non-informative prior as the prior I and the informative prior as the prior II. Tabulated values suggest that estimates obtained using the prior II have smaller MSE values than those obtained using the prior I. In general, LINEX loss provides better estimates than the SEL function. Higher values of n, m, and T lead to smaller MSE values for all estimators. Further, reports HPD intervals of μ and τ. It is seen that the AILs of the intervals obtained under the prior II are smaller compared to corresponding AILs obtained under the prior I. We also observed that for fixed n and m when T increases the AILs in general tend to decrease. The behavior of CPs of these intervals are highly satisfactory and remain close to the nominal level for almost all tabulated results.
Table 3. Bayes estimates and MSE values (in parenthesis) of μ and τ.
Table 4. HPD interval estimates and associated CPs and AILs.
Finally, we report various predictive estimates and prediction intervals for censored observations in and , respectively. For the sake of conciseness, predictive estimates of only first two censored observations are reported. It is seen from that prediction estimates obtained under the Bayesian approach are in general bigger than estimates obtained using BUP, CMP, and MLP methods. Among classical predictors MLP provides smaller estimates than the CMP method. In fact, BUP estimates are also moderately larger than CMP estimates. We also observe that prediction estimates obtained under the LINEX loss are relatively smaller compared to estimates obtained under the SEL function. Further, it is noticed that predictive estimates obtained under the prior II are smaller than those obtained under the prior I. suggests that AILs of the pivotal method are relatively wider compared to AILs of the HCD method. Also, Bayesian prediction intervals (PIs) are wider than PIs obtain under pivotal and HCD methods. We also observe that HPD prediction intervals have a smaller length than equal tail (ET) intervals. It is further observed that AILs of the prediction intervals obtained under the informative prior are smaller compared to AILs obtained against the non-informative prior. In general, prediction intervals for higher order future observations are wider than the lower order future observations.
Table 5. Point predictive estimates.
Table 6. Interval predictive estimates.
6.2. Data Analysis
In this section, we consider two real data sets. In data set 1, we analyze progressive type-II censored case for the small sample size, and in data set 2, we analyze type-II and type-I censored cases for moderate and large sample sizes in support of suggested methods of estimation and prediction.
Data set 1. This data set represents failure times of 30 air conditioning systems of airplanes, see Linhardt and Zucchin (Citation1986). The corresponding failure times are listed below as,
1, 3, 5, 7, 11, 11, 11, 12, 14, 14, 14, 16, 16, 20, 21, 23, 42,
47, 52, 62, 71, 71, 87, 90, 95, 120, 120, 225, 246, 261.
We first estimate the shape of the hazard function, and for this purpose, we plot empirical scaled total time on test (TTT) (see, Aarset (Citation1987)). Notice, that if F(x) and denote a distribution function and a survival function, respectively, then the scaled TTT transform is defined as
and the corresponding empirical scaled TTT transform for
, is given by,
where xi denote the ith ordered lifetime of the given sample. reports the scaled TTT plot, and it suggests that the empirical hazard function is not bathtub shaped in the range. Therefore, lognormal distribution can be considered to analyze this data set. However, for checking the adequacy of proposed model we made comparison with some other popular models, like Weibull, gamma, and generalized exponential distributions using various information criterion such as negative log-likelihood criterion (NLC), Akaike information criterion (AIC), Bayesian information criterion (BIC), and Kolmogorov-Smirnov (K-S) test statistic value. Notice, that smaller the values of these criteria the better a model fits the corresponding data set. reports all the goodness-of-fit test statistic values, and tabulated values indicate that the lognormal distribution fits this data set very good compared to the other competing distributions.
Figure 1. Empirical scaled TTT transform for data set 1.
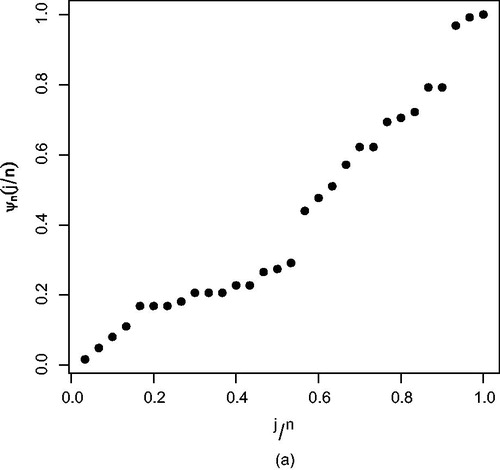
Table 7. Goodness of fit tests for different distributions.
We mention that this data set resembles the complete sample case with failure times of all n = 30 air conditioning systems of airplanes. Now, instead of considering the complete sample, we next generate a sample correspond to with the censoring scheme
, and get progressive type-II censored sample with the observations up to failure lifetime 71 and the rest are censored observations. Our purpose is to demonstrate that whether the censored observations are close to the predictive estimates obtained using various predictors. Also, our interest is to see that whether the predictive intervals contain censored observations or not. Now, based on the generated data set, we first report maximum likelihood, approximate maximum likelihood, and Bayes estimates in , and the associated 95% asymptotic confidence and HPD interval estimates in . We mention that Bayes estimates are obtained based on non-informative prior. From tabulated values it is observed that the estimated values of MLEs and AMLEs and Bayes estimates using Lindley and MH algorithm, are very close to each other. Further, the Bayes estimates obtained using LINEX loss with h = 1.5 have smaller estimated values which is followed by h = 0.5 and squared error Bayes estimates. We next report the predictive estimates for the first three censored observations in , and the associated predictive interval estimates in . The true observations are also reported in the tables. It is seen that the predictive estimates obtained using different predictors are quite close to the true observations. However, predictive estimates using MLP are smaller followed by the estimates of CMP and BUP. Further, predictive Bayes estimates under SEL have larger values as compared to Linex loss with h = 0.5 and h = 1.5. From , we observe that all prediction intervals contain the true values. It is also noticed that the interval estimates obtained using the HCD method have smaller intervals than those obtained using the pivotal method under classical approach, and further HPD prediction intervals are usually smaller compared to equal tail (ET) prediction intervals under Bayesian approach. It is further observed that all the intervals tend to become wider for higher order predicted values.
Table 8. Maximum likelihood and Bayes estimates of μ and τ for real data sets.
Table 9. Asymptotic confidence and HPD interval estimates.
Table 10. Point prediction.
Table 11. Interval prediction.
Data set 2. The second data set (see, Meeker and Escobar (Citation2014), page-131) represents the number of cycles (in thousands) of fatigue life for 67 of 72 alloy T7987 specimens that failed before 300 thousand cycles. The observed data are,
94, 96, 99, 99, 104, 108, 112, 114, 117, 117, 118, 121, 121, 123, 129, 131,
133, 135, 136, 139, 139, 140, 141, 141, 143, 144, 149, 149, 152, 153, 159,
159, 159, 159, 162, 168, 168, 169, 170, 170, 171, 172, 173, 176, 177, 180,
180, 184, 187, 188, 189, 190, 196, 197, 203, 205, 211, 213, 224, 226, 227,
256, 257, 269, 271, 274, 291.
reports the TTT plot, and tabulated values from suggest that lognormal distribution fits this data set well as compared to other considered distributions. We next generate a moderate sample of size 40 from the given data set correspond to thousand cycles with the censoring scheme
. report the estimates under classical and Bayesian approaches, associated interval estimates, predictive and associate predictive interval estimates. We observed the same behavior as mentioned in the previous section. However, in this case, we noticed that the 95% upper predictive bounds for the first three censored observations are also less than T = 200 thousand cycles. Therefore, if the experiment budget associated to a fixed time is available then this information may also help the experimenter to select the value of m accordingly.
Figure 2. Empirical scaled TTT transform for data set 2.
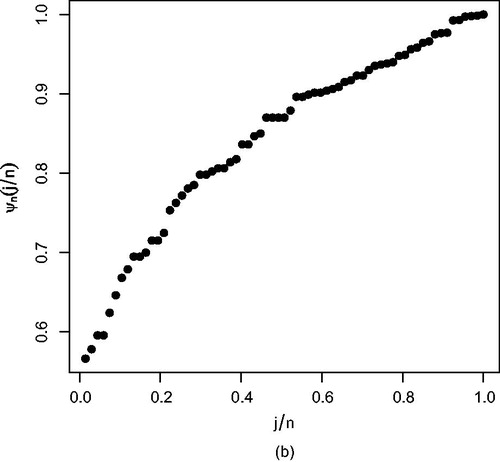
Observe that the data set 2 resembles the case of type-I censoring having and termination time T = 300 thousand cycles with five censored observations. Now we do not know the true values of the censored observations, and the predictive information from and can be useful for the experimenter. From , we observed that with a higher sample size values of all estimates increase under classical and Bayesian approach, and further the lengths of associated interval estimates decrease(see ). Also, the length of predictive intervals are smaller in the case of a large sample size, followed by moderate and small sample sizes.
7. Optimal Censoring
In previous sections, we considered problems of estimation and prediction for prescribed censoring schemes and taking into account prefixed time points, and we observed that the selection of different censoring schemes and times may lead to efficient estimates for unknown quantities of interest. Thus, selection of optimal plans and time points can be of important concerns to reliability practitioners. In the recent past, this problem has received much attention under different censoring methodologies, particularly progressive type-II censoring has been analyzed by several researchers. For instance, Ng et al. (Citation2004) discussed D-optimality and A-optimality criteria for constructing optimal plans for a Weibull distribution, Pradhan and Kundu (Citation2009) obtained optimal censoring schemes for a generalized exponential distribution based on optimizing the corresponding quantile function. However, the criterion based on pth quantile depends upon the value of . Later, Kundu (Citation2008) proposed a more generalized criterion of the type optimizing
where
represents the logarithm of pth quantile and W(p) denotes a non-negative weight function, such that
. Singh et al. (Citation2015) also used this criterion for lognormal distribution and obtained sub-optimal censoring plans from the total possible schemes which belong to the convex hull generated by the points
. Observe that for a given value of n and m, a total of
choices are available to select a scheme
such that
. Thus, searching an optimal scheme among all possible schemes may be computationally inconvenient for higher values of n and m. Recently, Bhattacharya et al. (Citation2016) proposed a meta heuristic based variable neighborhood search (VNS) algorithm which is quite useful in constructing optimal plans for moderate to large values of n and m. The main advantage of using VNS algorithm is that it provides near optimal solution with relatively less computation time. Construction of optimal plans under hybrid censoring is equivalent to selecting the values of m and T based on a given optimal criterion, and one may refer to Dube et al. (Citation2011) for optimal hybrid censoring plans for a lognormal distribution. The objective of this section is to obtain optimal type-I progressive hybrid censoring plans for lognormal distribution. The construction of such plans under type-I progressive hybrid censoring is to select a scheme
and a time T for a given (n, m) based on a optimal criterion. We observed that selection of a time T is scale invariant and large time duration ca n be taken into account corresponding to a particular censoring scheme (see Bhattacharya et al.,Citation2014). In this view, we next impose cost constraints like Cf, cost of each failed unit and Ct, operation cost for each time unit. So, the total cost associated with the experiment becomes
. Here, E(r) and
, respectively, denote expected number of failures and expected duration of the experiment, and are given, respectively, by
and
The above expectations are computed with respect to the density as given in EquationEquation (14)(14)
(14) . One may further refer to Kundu and Joarder (Citation2006) for more details on how to compute E(r). Also, the logarithmic of pth quantile is given by
where
and
denote maximum likelihood estimates of μ and τ, respectively. Therefore, construction of optimal plans under this criterion becomes equivalent to the optimization problem with cost constraints, and is given by,
(13)
(13)
Here,
where,
and
The elements, and
of the Fisher information matrix are obtained from (see Park et al., Citation2011),
where
represents the hazard function of X , and
represent the PDF of the ith order statistics given by,
(14)
(14)
with
and
.
Next, we conduct a simulation study for different choices of (n, m) and total budget Cb along with the cost of failed units considered as Cf = 20 and the duration cost as Ct = 50. We employed the VNS algorithm and constructed optimal censoring schemes, and the results are reported in . We observed that when Cb increases the optimum values of T increase but the variance decreases. We mention that if one considers the Cp as the unit cost due to variance of the estimates of the unknown model parameters, available to the experimenter. Then, an alternative model which minimizes the total cost (TC) to obtain the optimum scheme can also be taken into account,
which is a unconstrained optimization problem, and one can use the VNS algorithm along with nlminb package in R-statistical language to obtain the desire optimum scheme
. In , we report optimal censoring schemes based on this criterion with consideration of
. Notice that Lin et al. (Citation2012) computed the optimum plan under Bayesian setup with fixed constraints using MCMC technique. Computation of such plans and, furthermore, consideration of plans with constraints also under a Bayesian setup, can be seen as future direction.
Table 12. Optimal censoring schemes and associated values of the criterion .
Table 13. Optimal censoring schemes based on minimization of TC criterion.
8. Conclusion
In this article, we considered problems of estimation and prediction under classical and Bayesian approaches when lifetime data following a lognormal distribution are observed under type-I progressive hybrid censoring. We observed that maximum likelihood estimators (MLEs) of unknown parameters do not admit closed forms expressions. To compute these estimates, we employed an EM algorithm which has an advantage over the Newton-Raphson method but still requires an initial guess to implement. Therefore, we next obtained the approximate maximum likelihood estimators (AMLEs), and used these estimates as an initial guess for implementing the EM algorithm. In the simulation study, we also compared the performance of AMLEs with MLEs, and we observed that MLEs provide more efficient estimates than AMLEs. Similar behavior is noted in the comparison of corresponding asymptotic confidence intervals. Further, we obtained informative and non-informative Bayes estimates against squared error and LINEX loss functions. We first employed the Lindley method to compute these estimates. However, this method is not useful for interval estimation, and therefore, we next generated samples from the posterior densities using MH algorithm and constructed HPD intervals. In the simulation study, we found the performance of MH estimates quite satisfactory compared to the other proposed estimates. We mention that under the considered priors given by EquationEquations (6)(6)
(6) and Equation(7)
(7)
(7) , the corresponding posterior densities can also be written in the following form.
where
. Now, in both cases, the associated posterior densities are of type
and so one can also apply importance sampling procedure to obtain Bayes estimates. But, if we take independent prior distributions like
and
for μ and τ in the present work, then for such consideration, the posterior density does not appear in a tractable form and so it becomes relatively difficult to use the importance sampling procedure. On the other hand, the proposed MH algorithm can still be applied. Next, we obtained prediction estimates of censored observations using maximum likelihood predictor, best unbiased predictor, conditional median predictor, and Bayesian predictors. Using the conditional density given by EquationEquation (10)
(10)
(10) , we were able to construct predictive intervals using the pivotal method and the highest conditional density method. In the simulation study, we observed that HCD intervals provide smaller lengths compared to the pivotal intervals. Likewise, under the Bayesian approach, we observed that predictive highest posterior density intervals provide smaller interval lengths compared to the predictive equal tail intervals. In the data analysis, we found that all predictive estimates remain relatively close to the true observations, and also all the predictive intervals contain the true observations. Finally, we presented a discussion on optimal censoring using various optimality criteria. We established optimal plans with respect to cost constraints based on suggested optimal criterion, and reported results for different sampling situations.
Acknowledgements
The authors are thankful to two anonymous reviewers for their constructive suggestions that led to substantial improvements in the earlier version of this manuscript. Authors also extend their sincere thanks to the Editor and the Associate Editor for some very useful suggestions.
References
- Aarset, M. V. (1987). How to identify a bathtub hazard rate. IEEE Transactions on Reliability, R-36(1), 106–108.
- Asl, M. N., Belaghi, R. A., & Bevrani, H. (2017). On Burr XII distribution analysis under progressive type-ii hybrid censored data. Methodology and Computing in Applied Probability, 19(2), 665–683.
- Balakrishnan, N., & Cramer, E. (2014). Art of Progressive Censoring. Berlin, Germany: Springer.
- Balakrishnan, N., Kannan, N., Lin, C.-T., & Ng, H. T. (2003). Point and interval estimation for gaussian distribution based on progressively type-ii censored samples. IEEE Transactions on Reliability, 52(1), 90–95.
- Balakrishnan, N., & Mi, J. (2003). Existence and uniqueness of the MLES for normal distribution based on general progressively Type-II censored samples. Statistics & Probability Letters, 64(4), 407–414.
- Bhattacharya, R., Pradhan, B., & Dewanji, A. (2014). Optimum life testing plans in presence of hybrid censoring: A cost function approach. Applied Stochastic Models in Business and Industry, 30(5), 519–528.
- Bhattacharya, R., Pradhan, B., & Dewanji, A. (2016). On optimum life-testing plans under Type-II progressive censoring scheme using variable neighborhood search algorithm. TEST, 25(2), 309–330.
- Chen, M.-H., & Shao, Q.-M. (1999). Monte Carlo estimation of Bayesian credible and HPD intervals. Journal of Computational and Graphical Statistics, 8(1), 69–92.
- Cohen, A. C. (1965). Maximum likelihood estimation in the Weibull distribution based on complete and on censored samples. Technometrics, 7(4), 579–588.
- Cramer, E., & Balakrishnan, N. (2013). On some exact distributional results based on Type-I progressively hybrid censored data from exponential distributions. Statistical Methodology, 10(1), 128–150.
- Dey, S., Singh, S., Tripathi, Y. M., & Asgharzadeh, A. (2016). Estimation and prediction for a progressively censored generalized inverted exponential distribution. Statistical Methodology, 32, 185–202.
- Dube, S., Pradhan, B., & Kundu, D. (2011). Parameter estimation of the hybrid censored log-normal distribution. Journal of Statistical Computation and Simulation, 81(3), 275–287.
- Golparvar, L., & Parsian, A. (2016). Inference on proportional hazard rate model parameter under type-i progressively hybrid censoring scheme. Communications in Statistics-Theory and Methods, 45(24), 7258–7274.
- Hemmati, F., & Khorram, E. (2013). Statistical analysis of the log-normal distribution under Type-II progressive hybrid censoring schemes. Communications in Statistics-Simulation and Computation, 42(1), 52–75.
- Kundu, D. (2008). Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics, 50(2), 144–154.
- Kundu, D., & Joarder, A. (2006). Analysis of type-ii progressively hybrid censored data. Computational Statistics and Data Analysis, 50(10), 2509–2528.
- Lin, C. T., Chou, C. C., & Huang, Y. L. (2012). Inference for the Weibull distribution with progressive hybrid censoring. Computational Statistics and Data Analysis, 56(3), 451–467.
- Lindley, D. V. (1980). Approximate Bayesian methods. Trabajos De Estadística y De Investigación Operativa, 31(1), 223–245.
- Linhardt, H., & Zucchin, W. (1986). Model Selection. New York, NY: Wiley.
- Louis, T. A. (1982). Finding the observed information matrix when using the EM algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 226–233.
- Meeker, W. Q., & Escobar, L. A. (2014). Statistical methods for reliability data. Hoboken, NJ: John Wiley & Sons.
- Ng, H., Chan, P., & Balakrishnan, N. (2002). Estimation of parameters from progressively censored data using EM algorithm. Computational Statistics & Data Analysis, 39(4), 371–386.
- Ng, H., Chan, P., & Balakrishnan, N. (2004). Optimal progressive censoring plans for the Weibull distribution. Technometrics, 46(4), 470–481.
- Park, S., Balakrishnan, N., & Kim, S. W. (2011). Fisher information in progressive hybrid censoring schemes. Statistics, 45(6), 623–631.
- Pradhan, B., & Kundu, D. (2009). On progressively censored generalized exponential distribution. Test, 18(3), 497–515.
- Raqab, M. Z., & Nagaraja, H. (1995). On some predictors of future order statistics. Metron, 53(12), 185–204.
- Singh, S., & Tripathi, Y. M. (2016). Bayesian estimation and prediction for a hybrid censored lognormal distribution. IEEE Transactions on Reliability, 65(2), 782–795.
- Singh, S., Tripathi, Y. M., & Wu, S.-J. (2015). On estimating parameters of a progressively censored lognormal distribution. Journal of Statistical Computation and Simulation, 85(6), 1071–1089.
- Tomer, S. K., & Panwar, M. (2015). Estimation procedures for Maxwell distribution under Type-I progressive hybrid censoring scheme. Journal of Statistical Computation and Simulation, 85(2), 339–356.
- Turkkan, N., & Pham-Gia, T. (1993). Computation of the highest posterior density interval in bayesian analysis. Journal of Statistical Computation and Simulation, 44(3-4), 243–250.