
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Synoptic Abstract
The problems of classical and Bayesian estimation of the parameters of the power-exponential hazard rate distribution (P-EHRD) based on record values and the prediction of future record values are considered. The parameters of P-EHRD are estimated by the maximum likelihood and the least squares methods, and the Bayes estimates are obtained by the Metropolis-Hastings method under the squared error loss and LINEX loss functions. Also, an asymptotic confidence interval, two bootstrap confidence intervals and the highest posterior density (HPD) credible interval for the unknown parameters are constructed. The problem of predicting the future record values from the P-EHRD based on the past record values is considered using the maximum likelihood and Bayesian approaches. To investigate and compare the performance of the different proposed methods, a Monte Carlo simulation study is conducted. Finally, an example is presented to illustrate the estimation and prediction procedures.
1. Introduction
Record values arise naturally in many real life applications, such as climatology, sports, economics, life tests and so on. For example, it might be interesting to a researcher in a manufacturing industry to determine the minimum failure stress of the product sequentially, while the amount of the rainfall that is greater (smaller) than the previous ones is of importance to climatologists and hydrologists. For more examples and details, see Arnold, Balakrishnan, and Nagaraja (Citation1998).
Let be a sequence of independent and identically distributed (iid) random variables with an absolutely continuous cumulative distribution function (cdf), F(x), and probability density function (pdf), f(x). An observation Xj is called an upper record if its value exceeds all previous observations, i.e. Xj is an upper record if
for every i < j. The record time sequence
at which the records appear, is defined as,
and
with probability 1. Then, the sequence of upper record values is defined by
An analogous definition can be given for lower records. It is important to note that there are two sampling schemes for generating record data: the random sampling scheme and the inverse sampling scheme. Under the random sampling scheme, a random sample
is examined sequentially and successive maximum values are recorded, while under the inverse sampling scheme, units are taken sequentially and sampling is terminated when a prespecified number of record values m are observed. These sampling schemes play an important role in statistical inference when one considers record values with inter-record times.
Chandler (Citation1952) first introduced the topic of record values and studied their basic properties. Since then, such ordered data has been studied extensively in the literature. The problem of making inference based on record observations from a particular distribution has received attention of many researchers, and for literature on this topic one may refer to Soliman, Abd Ellah, and Sultan (Citation2006) for the Weibull distribution, Asgharzadeh and Fallah (Citation2011) for the exponentiated family of distributions, Dey, Dey, Salehi, and Ahmadi (Citation2013) for the generalized exponential distribution, Kumar, Kumar, Saran, and Jain (Citation2017) for the Kumaraswamy-Burr III distribution, Asgharzadeh, Fallah, Raqab, and Valiollahi (Citation2018) for the Lindley distribution, Raqab, Bdair, and Al-Aboud (Citation2018) for the two-parameter bathtub-shaped distribution, and Pak and Dey (Citation2019) for the power Lindley distribution.
The hazard rate function is an important characteristic of lifetime distributions, since it describes the instantaneous failure rate at any time and is a useful tool to monitor the lifetime of a unit in life testing and reliability studies. If the lifetime of a unit is described by a random variable X with pdf f(x) and cdf F(x), then the hazard rate function h(x) is defined by
Lifetime distributions are often specified by choosing a particular hazard rate function in reliability theory. In this regard, the linear hazard rate function (
) by Bain (Citation1974), the power hazard rate function (
) by Mugdadi (Citation2005) and the exponential hazard rate function (
) by Gompertz (Citation1825) were considered by some researchers. Unfortunately, these hazard rate functions are monotone and therefore they do not provide a reasonable parametric fit for modeling phenomenon with bathtub-shaped hazard rates which are common in biological and reliability studies. Recently, Tarvirdizade and Nematollahi (Citation2019) introduced a more general hazard rate function by combining the power hazard rate function and the exponential hazard rate function. This is the power-exponential hazard rate function, defined as
(1)
(1)
where a, b, c and k are the parameters such that
The power-exponential hazard rate function can cover bathtub-shaped case when
and k < 0. The cdf and the pdf corresponding to this hazard rate function are given by
(2)
(2)
and
(3)
(3)
respectively. This distribution is called the power-exponential hazard rate distribution (P-EHRD). The exponential, Rayleigh, Weibull, modified Weibull, Gompertz, Gompertz-Makeham, linear hazard rate and power hazard rate distributions are the most important sub-models of the P-EHRD. Some distributional properties and estimation of the parameters based on a complete sample for the P-EHRD were studied by Tarvirdizade and Nematollahi (Citation2019). They have also showed that the P-EHRD provides a better fit than other four-parameter distributions for data with a bathtub-shaped hazard rate while its hazard rate function is very simple in comparison with those of the competitor distributions.
To the best of our knowledge, inference based on record data from the P-EHRD is not available in the literature. Because of the importance of record values in many fields of application and since the P-EHRD can be used quite effectively in analyzing the lifetime data, especially the data with a bathtub-shaped hazard rate, in this paper the record values are used to estimate the parameters of the P-EHRD and predict the future record values for this distribution. First the maximum likelihood estimates of the parameters are obtained, which then are used to construct asymptotic and bootstrap confidence intervals. Next, the least squares method is used for estimating the parameters of the P-EHRD, and the Bayes estimates of the parameters based on symmetric and asymmetric loss functions are obtained. The HPD credible intervals for the parameters are constructed using random samples generated from the MCMC method. The prediction of future record values based on the observed upper record values from the P-EHRD is discussed. An example is used to demonstrate the application of inference techniques and a simulation study is conducted to compare different methods of estimation and prediction.
The rest of the paper is organized as follows. In Section 2, the maximum likelihood (ML) and the least squares (LS) methods are used for estimating the parameters of the P-EHRD based on upper record values. The asymptotic confidence intervals and two bootstrap confidence intervals for the parameters of the P-EHRD are also considered. In Section 3, the Bayes estimates of unknown parameters under the squared error (SE) and linear-exponential (LINEX) loss functions via the Metropolis-Hastings method are obtained, and the HPD credible interval for the parameters are constructed. The problem of predicting the future record values from the P-EHRD is considered using the ML and Bayesian approaches in Sections 4 and 5, respectively. In Section 6, an example is presented to illustrate the estimation and prediction procedures discussed in the previous sections. To investigate and compare the performance of the different methods of estimation and prediction presented in this paper, outcomes of a Monte Carlo simulation study are also presented. Finally, some conclusions are provided in Section 7.
2. Classical Estimation
The ML estimates of the parameters of the P-EHRD based on upper record values are obtained in this section and then used them to construct asymptotic and bootstrap confidence intervals. The LS method for estimating the parameters of the P-EHRD is also presented.
2.1. Maximum Likelihood Estimation
Let be the first n upper record values observed from a population with cdf F(x) and pdf f(x). The joint density function of the first n upper record values is given by (Ahsanullah, Citation2004),
(4)
(4)
From (Equation4(4)
(4) ) with F and f replaced by (Equation2
(2)
(2) ) and (Equation3
(3)
(3) ), respectively, it follows that the likelihood function is given by
(5)
(5)
Now taking partial derivatives the log-likelihood function with respect to
the likelihood equations can be obtained as follows
(6)
(6)
(7)
(7)
(8)
(8)
(9)
(9)
Using (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ), we can obtain a as a function of b, c and k as
(10)
(10)
By replacing (Equation10
(10)
(10) ) into Equation(7)–(9), we get the following system of nonlinear equations
(11)
(11)
(12)
(12)
(13)
(13)
By solving Equation(11)–(13) with respect to b, c and k, the ML estimates of the parameters, say
and
respectively, can be obtained. These equations are very complicated and cannot be solved analytically. Therefore, a numerical iteration method such as Newton-Raphson method is recommended to solve these simultaneous equations to obtain
and
Then substituting
and
in place of b, c and k in (Equation10
(10)
(10) ), the ML estimate of a, say
can be obtained. The subroutines to solve non-linear optimization problem are available in R software. We used nlm() package for this purpose. For maximizing the log-likelihood function, the nlm function was executed for a wide range of initial values. This procedure usually leads to more than one maximum. In such cases, the MLEs corresponding to the largest value of the maxima is used. For a few initial values, no maximum was identified, in such cases, a new initial value was used to obtain a maximum.
2.2. Asymptotic Confidence Intervals
Since the exact sampling distribution of the ML estimates cannot be obtained in closed form, the approximate confidence intervals are obtained for the parameters a, b, c, and k by using the approximate distributions of their ML estimates which is need to calculate the Fisher information matrix. The observed information matrix is computed since the expected information matrix is too complicated and requires numerical integration. The elements of the 4 × 4 observed information matrix I are given in the Appendix. The asymptotic distribution of the ML estimators of the parameters a, b, c, and k are given by (see Miller, Citation1981)
(14)
(14)
where V is the variance-covariance matrix and can be approximated by the reciprocal of the observed information matrix I, i.e.,
which involves the unknown parameters a, b, c, and k. Since the ML estimators are consistent estimators, the parameters are replaced by the corresponding ML estimates in order to obtain an estimate of V, which is given by
(15)
(15)
where
is the (i, j)th element of the observed information matrix I with a, b, c and k replaced by
and
respectively. Now, using (Equation14
(14)
(14) ), the
approximate confidence intervals for the parameters a, b, c, and k are given, respectively, by
(16)
(16)
where
is the
th quantile of the standard normal distribution.
According to Arnold et al. (Citation1998), records are rare in practice and so anyone developing inferential techniques involving record values will usually be faced with small samples. Therefore, confidence intervals based on the asymptotic results are expected not to perform very well. In such situations, one can use some resampling techniques to provide more accurate approximate confidence intervals. Here, two bootstrap confidence intervals are proposed and the performance of the various approximate intervals for different sample sizes are compared in Section 6 using their coverage probability and expected length.
2.3. Bootstrap Confidence Intervals
In this subsection, two bootstrap resampling method to find approximate confidence intervals for the parameters a, b, c and k of P-EHRD are proposed. The first is the percentile bootstrap (Boot-p) confidence interval based on the idea of Efron (Citation1982), and the second is the student’s t bootstrap (Boot-t) confidence interval based on the idea of Hall (Citation1988). First, generate the upper record samples from P-EHRD using the algorithm suggested in Arnold et al. (Citation1998) to generate n independent samples from the standard exponential distribution, Exp(Equation1
(1)
(1) ) and solving the following equation for given values of the parameters a, b, c and k:
Then
are the required upper record samples from the P-EHRD. As suggested by Efron and Tibshirani (Citation1993), the following algorithm is used to generate parametric bootstrap samples.
Algorithm 1
Step 1. Compute and
the ML estimates of the parameters a, b, c, and k based on the upper record samples
Step 2. Generate the bootstrap upper record samples from the P-EHRD with the parameters
and
by using the method described before Algorithm 1. From these data, compute the bootstrap estimates say,
and
Step 3. Repeat step 2, B times to obtain a set of bootstrap samples of a, b, c, and k, say and
To construct the bootstrap confidence intervals of the parameter θ (which is a, b, c or k), the bootstrap samples generated by Algorithm 1 are used, and two different bootstrap confidence intervals are obtained as follows:
(I) Boot-p method
Let be the cdf of
Define
for a given x. Then the
bootstrap percentile interval for θ is defined by
(17)
(17)
which are the
th and
th quantiles of the bootstrap sample
(II) Boot-t method
Let
where
is an estimate of the standard error of
and can be replaced by its asymptotic standard error. Then the
bootstrap student’s t interval is given by
(18)
(18)
where
is the αth quantile of
and
is the bootstrap estimate of the standard error based on
2.4. Least Squares Estimation
For estimation of the parameters of Beta distribution under the complete sample, Swain, Venkatraman, and Wilson (Citation1988) introduced the least squares (LS) estimation. Then, several authors used this method to estimate the parameters of some distributions under censored and record data, for example, Lin, Wu, and Balakrishnan (Citation2003) and Krishna and Kumar (Citation2013). In this subsection, this method is used to estimate the parameters of P-EHRD based on upper record values. Let be the first n upper record values observed from a population with cdf F(x) and pdf f(x). Then, the LS estimates of the parameters can be obtained by minimizing
with respect to the parameters. The marginal pdf of
for
is given by (Ahsanullah, Citation2004)
Thus, it can be easily shown that
Now, for the P-EHRD, the LS estimates of the parameters can be obtained by minimizing
(19)
(19)
with respect to the parameters a, b, c, and k. Thus, the LS estimates of the parameters a, b, c, and k are the solutions of the simultaneous equations obtained from the partial derivatives (Equation19
(19)
(19) ) with respect to the parameters a, b, c, and k. Since these equations are complicated function of the parameters a, b, c, and k, they are difficult to solve analytically. Instead, iterative techniques such as a Newton-Raphson can be used to obtain the LS estimates of the parameters a, b, c and k, say
and
respectively.
3. Bayes Estimation
One of the attractive methods of estimation of the parameters of a distribution is the Bayes estimation. In this method, for estimation the parameter θ by the estimator the researcher needs a prior distribution,
for θ, as well as a loss function,
for estimation process. The Bayes estimate of θ is obtained by minimizing the posterior risk
with respect to θ.
In literature, for simplicity, the squared error (SE) loss function is used for estimation problems. Under the SE loss function, the Bayes estimator of θ is given by
This loss function is convex and symmetric, and assigns equal losses to the overestimation and underestimation. However, in some practical situations overestimation may by more serious than underestimation or vice versa. For example, overestimation is usually more serious than underestimation in the estimation of reliability and hazard rate functions. In these cases, the use of symmetric loss functions may be inappropriate. Instead, the use of an asymmetric loss function which assigns greater importance to overestimation or underestimation may be more appropriate. Varian (Citation1975) proposed an asymmetric linear-exponential loss function known as LINEX loss function which is given by
(20)
(20)
where the shape parameter d is known and gives the degree of asymmetry. If d > 0, the overestimation is more serious than underestimation and if d < 0, underestimation is more serious than overestimation. If d close to zero, the LINEX loss function is approximately same as the SE loss function and therefore almost symmetric. Under the LINEX loss function of (Equation20
(20)
(20) ), the Bayes estimator of θ that minimizes the posterior risk
is given by
(21)
(21)
provided that the expectation exists and is finite.
Now, to find the Bayes estimates of the unknown parameters, assume that a, b, c, and have independent gamma priors as
and
respectively, with the pdf’s given by
(22)
(22)
where θ is one of the parameters a, b, c, and
and the hyperparameters
are assumed to be known. From the likelihood function (Equation5
(5)
(5) ) and the prior distributions of (Equation22
(22)
(22) ), the joint posterior density function of a, b, c, and k can be obtained as
(23)
(23)
Since the joint posterior density
in (Equation23
(23)
(23) ) does not have a closed form, simulation technique is used to compute the Bayes estimates and credible intervals of the parameters. The Gibbs sampling technique is used to generate samples from the posterior distribution (see Gelfand & Smith, Citation1990). To do this, at first, the joint posterior distribution is decomposed into full conditional distributions for each parameters a, b, c, and k, respectively as follows:
(24)
(24)
(25)
(25)
(26)
(26)
and
(27)
(27)
Since the full conditional distributions for a, b, c, and k do not have explicit expressions, it is not possible to sample directly by standard methods. Therefore, to generate values of a, b, c, and k from (Equation24
(24)
(24) ) to (Equation27
(27)
(27) ), the algorithm by Tierney (Citation1994) is used, which is the Metropolis-Hastings method used in the Gibbs sampling. The following algorithm is used for the Gibbs sampling.
Algorithm 2
Step 1. Start with an initial guess and set t = 1.
Step 2. Using Metropolis-Hastings method, generate from
with the proposed distribution
where
is a scaling factor,
is given in (Equation15
(15)
(15) ) and
denotes the normal distribution
truncated on
Step 3. Using Metropolis-Hastings method, generate from
with the proposed distribution
where
is a scaling factor and
is given in (Equation15
(15)
(15) ).
Step 4. Using Metropolis-Hastings method, generate from
with the proposed distribution
where
is a scaling factor and
is given in (Equation15
(15)
(15) ).
Step 5. Using Metropolis-Hastings method, generate from
with the proposed distribution
where
is a scaling factor and
is given in (Equation15
(15)
(15) ).
Step 6. Set
Step 7. Repeat Steps 2–6, N times, and obtain the posterior sample
Let be the sample generated from the Algorithm 2. From this sample, compute the Bayes estimate of θ under the SE and LINEX loss functions as follows
(28)
(28)
and
(29)
(29)
respectively, where M is the burn-in period and θ can be each of the parameters a, b, c, and k. Also, this sample is used to construct the 100
HPD credible intervals for the parameters of the P-EHRD, by the method of Chen and Shao (Citation1999), as follows
(30)
(30)
where
and
are the
th smallest integer and the
th smallest integer of
respectively.
4. Maximum Likelihood Prediction
One of the most interesting problems in record data is the problem of prediction of the future record value based on the past record values. For example, having observed record values of the rainfall or snowfall until the present time, one will be naturally interested in predicting the amount of rainfall or snowfall when the present record will be broken for the first time in future.
In this section, the problem of predicting the sth upper record value based on previously observed records, s > n, using the maximum likelihood approach is considered. Suppose that the first n upper record values
have been observed from a population with pdf
To find a predicted value of
s > n, the joint predictive likelihood function of
and θ is needed, which is given by (Basak & Balakrishnan, Citation2003)
(31)
(31)
where
Thus, by using Equation(1)–(3), the log predictive likelihood function for the P-EHRD is given by
(32)
(32)
where
Hence, the log-likelihood equations are given by
(33)
(33)
(34)
(34)
(35)
(35)
(36)
(36)
(37)
(37)
Solving Equation(33)–(37) numerically, one will be able to predict the value of the sth upper record for the P-EHRD.
5. Bayesian Prediction
In this section, Bayesian approach to predict future record values under SE and LINEX loss functions is used. Suppose that are the values of the first n upper records from a population with pdf
Based on this data one wants to predict sth upper record
s > n. The Bayes predictive density function of Y given
is given by (Ahsanullah, Citation2004)
(38)
(38)
where the conditional pdf of Y given
is
(39)
(39)
Now, for the P-EHRD with pdf given by (Equation3
(3)
(3) ), the conditional density function in Equation(Equation39
(39)
(39) )
(39)
(39) is given by
(40)
(40)
It is clear that
cannot be expressed in a closed form and hence cannot be computed analytically, even for the simplest form of
The consistent estimator of
can be constructed by using the hybrid of Metropolis-Hastings and Gibbs sampling procedure described in Section 3. Suppose that
are samples obtained from
using the hybrid of Metropolis-Hastings and Gibbs sampling technique in Algorithm 2. The consistent estimator of
based on these samples can be obtained as
Then, the Bayes predictor of the sth upper record under the SE loss function is given by
(41)
(41)
and that under the LINEX loss function, is given by
(42)
(42)
6. Numerical Study
In this section, a simulation study is conducted to examine the performances of point estimators and confidence intervals of the parameters and predictors of the future records and an example is presented to illustrate methods described so far.
6.1. A Simulation Study
The performance of the ML, LS and Bayes estimators is compared in terms of their estimated risk (ER). The ER of the estimator for the parameter θ by different methods are obtained as,
and
where T is the number of replications and
is the estimate of θ in ith replication. The mean squared prediction errors (MSPEs) are used to compare point predictors. Also, the performances of the asymptotic confidence intervals (AMLE), the bootstrap confidence intervals, and the HPD credible intervals are compared in terms of their coverage probability and expected length. To this end, upper record samples are generated under the inverse sampling scheme from P-EHRD with three different values for the parameters
From , as expected all the ERs are decreasing as the sample size increases. Comparison of the ML and LS estimates shows that the ERs of the LS estimates are smaller than those of the ML estimates for parameters a and b while the ML estimates provide smaller ERs for estimation of parameters c and k in most of the cases, especially when the sample size is large. Based on our simulation results, the Bayes estimators under various loss functions show different performances. In most of the cases, except for estimation of b, the Bayes estimates under SE loss function have better performances than the ML and LS estimates. Also, the performances of Bayes estimates under the LINEX loss function are different for the values of the shape parameter d = 2 and d = −1. Note that the Bayes estimates under the LINEX loss function with shape parameter d = 2 perform better than the other estimators in the Case I, while the Bayes estimates under the LINEX loss function with shape parameter d = −1 provide smaller ERs for the Cases II and III in most of the cases. As expected, for small values of d, the ERs of the of Bayes estimates under the LINEX loss function are closer to the ERs of Bayes estimates under the SE loss function.
Table 1. Average estimates and estimated risk (in parentheses) of the parameters for values of a = 0.25, b = 1, c = 0.75, and
Table 2. Average estimates and estimated risk (in parentheses) of the parameters for values of a = 1, b = 0.75, c = 0.5, and
Table 3. Average estimates and estimated risk (in parentheses) of the parameters for values of a = 0.5, b = 0.25, c = 1, and k = 0.75.
As expected, it can be observed from that the expected lengths of all intervals decrease with an increase in the size of the record values. The results show that the asymptotic confidence intervals provide the least coverage probabilities in comparison with the other confidence intervals and therefore their performances are not satisfactory in general. The coverage probabilities of the asymptotic confidence intervals are considerably lower than their corresponding nominal levels in most of the cases, even for very large sample sizes. Comparing the bootstrap confidence intervals, observe that the Boot-p confidence intervals provide the shorter expected lengths than the Boot-t confidence intervals in most of the cases, while their performances in terms of coverage probabilities are almost similar. Also, in most of the cases, except for estimation of b, the performances of the HPD credible intervals are better than the asymptotic confidence intervals but their performances are not preferable to the Boot-p confidence intervals in general.
Table 4. Expected lengths and coverage probabilities (in parentheses) of the parameters a, b, c, and k.
From , observe that the MSPEs of the point predictors decrease as the sample size increases in all cases. The performances of the Bayes predictors are better than the ML predictors in terms of MSPEs. It is observed that the the Bayes predictors under the LINEX loss function with shape parameter d = 2 perform better than the other predictors.
Table 5. Average predictors and MSPEs (in parentheses) for
6.2. Example
Consider a data set consisting 72 exceedances of flood peaks (in ) of the Wheaton River near Carcross in Yukon Territory, Canada, for the years 1958–1984 (Choulakian & Stephens, Citation2001). The data are presented in .
Table 6. Data set (exceedances of flood peaks).
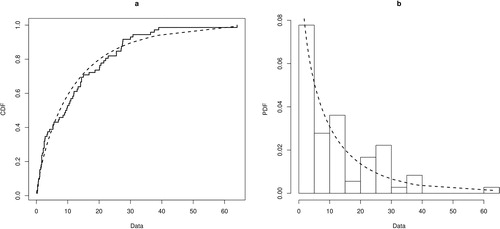
First, fit the P-EHRD to the data and compare its goodness-of-fit, using Kolmogorov-Smirnov (K-S) statistic, with its sub-models such as the linear hazard rate distribution (LHRD), the power hazard rate distribution (PHRD), and the exponential hazard rate distribution (EHRD). The ML estimates of the unknown parameters are obtained and then the values of K-S statistics and their corresponding p-values are calculated. The results are presented in . It is clear from that the P-EHRD has the highest p-value of K-S test statistic and thus yields a better fit than LHRD, PHRD and EHRD. The empirical cdf versus fitted cdf and the histogram of the data versus fitted pdf for the P-EHRD are presented in which indicate the P-EHRD provides a good fit to the data.
Table 7. ML estimates of the parameters, K-S statistic, and corresponding p-value.
Figure 1. (a) The empirical cdf (stair) versus fitted cdf (dotted curve). (b) Histogram of the data versus fitted pdf.
During this period, the following eight upper record values were observed under the random sampling scheme:
Based on these record data, the ML estimates of the parameters a, b, c and k, respectively from (Equation10(10)
(10) ) to (Equation13
(13)
(13) ) are obtained as
with the corresponding standard errors (Se), respectively as
Substituting the ML estimates of the unknown parameters in (Equation15
(15)
(15) ), the estimate of the variance-covariance matrix
is obtained as
The LS and Bayes estimates of the parameters a, b, c and k under SE and LINEX loss functions are obtained and the 95% asymptotic, Boot-p and Boot-t confidence intervals and the 95% HPD credible intervals of the parameters a, b, c, and k are computed. The predict value of the next record,
using the ML and Bayesian approaches is also computed. The Boot-p and Boot-t confidence intervals are obtained based on 1,000 bootstrap samples. To compute the Bayes estimates of the parameters a, b, c, and k, and the associated 95% HPD credible intervals, the hyperparameters as
and
to reflect little prior information are used. A total of N = 10,000 MCMC samples were generated and the first M = 2,000 values were discarded as burn-in period. shows the simulated values and Histogram of the parameters a, b, c, and k generated by Algorithm 2. All the point and interval estimates of the parameters are tabulated in .
Figure 2. Simulated values and histogram of the parameters a, b, c, and k.
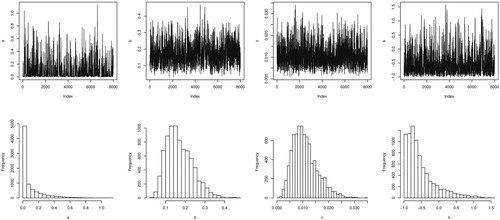
Table 8. The point and interval estimates of the parameters based on record flood values.
7. Conclusions
In this paper, upper record samples from the P-EHRD are considered for estimating the unknown parameters and predicting the future record values. A Monte Carlo simulation study is conducted to examine and compare the performance of the proposed methods for parameters estimation and prediction of the future record values. The performances of the ML, LS and Bayes estimates under SE and LINEX loss functions are compared in terms of their ERs. The performances of the asymptotic, Boot-p and Boot-t confidence intervals and the HPD credible intervals are compared in terms of their coverage probability and expected length. The MSPEs are also used to compare the performances of the ML and Bayes point predictors. Based on simulation results, it was observed that the LS estimates perform better than the ML estimates in the estimation of parameters a and b, while the ML estimates perform better for the estimation of parameters c and k in most of the cases, especially when the sample size is large. The Bayes estimates under various loss functions show different performances in terms of their ERs. The performances of the Bayes estimates under SE loss function are better than the ML and LS estimates in most of the cases, except for estimation of b. The performances of the Bayes estimates under the LINEX loss function are dependent on the values of the shape parameter d and incomparable in general. Also, the Boot-p confidence intervals have better performances in comparison with the approximate confidence intervals and the Boot-t confidence intervals. The HPD credible intervals perform better than the approximate confidence intervals in most of the cases, except for estimation of b, but their performances are not preferable to the Boot-p confidence intervals in general. The point Bayes predictors were observed to perform better than the ML predictors in terms of MSPEs. Finally, an example of record flood values is used to illustrate the proposed methods of parameters estimation and prediction of the future record value.
Acknowledgments
The authors are grateful to the Editor, Associate Editor, and anonymous referees for making helpful comments and suggestions on an earlier version of this article which resulted in this improved version.
References
- Ahsanullah, M. (2004). Record values: Theory and applications. Lanham, MD: University Press of America Inc.
- Arnold, B. C., Balakrishnan, N., & Nagaraja, H. N. (1998). Records. New York: John Wiley and Sons.
- Asgharzadeh, A., & Fallah, A. (2011). Estimation and prediction for exponentiated family of distributions based on records. Communications in Statistics - Theory and Methods, 40(1), 68–83. doi:10.1080/03610920903350564
- Asgharzadeh, A., Fallah, A., Raqab, M. Z., & Valiollahi, R. (2018). Statistical inference based on Lindley record data. Statistical Papers, 59(2), 759–779. doi:10.1007/s00362-016-0788-1
- Bain, L. (1974). Analysis for the linear failure-rate life testing distribution. Technometrics, 15, 551–559. doi:10.1080/00401706.1974.10489237
- Basak, P., & Balakrishnan, N. (2003). Maximum likelihood prediction of future record statistic. Mathematical and statistical methods in reliability. In Series on quality, reliability and engineering statistics (pp. 159–175), Eds. Lindquist, B. H. and Doksum, K. A., vol 7. Singapore: World Scientific Publishing.
- Chandler, K. N. (1952). The distribution and frequency of record values. Journal of the Royal Statistical Society: Series B (Methodological), 14, 220–228. doi:10.1111/j.2517-6161.1952.tb00115.x
- Chen, M. H., & Shao, Q. M. (1999). Monte Carlo estimation of Bayesian credible and HPD intervals. Journal of Computational and Graphical Statistics, 8, 69–92. doi:10.1080/10618600.1999.10474802
- Choulakian, V., & Stephens, M. A. (2001). Goodness-of-fit for the generalized Pareto distribution. Technometrics, 43(4), 478–484. doi:10.1198/00401700152672573
- Dey, S., Dey, T., Salehi, M., & Ahmadi, J. (2013). Bayesian inference of generalized exponential distribution based on lower record values. American Journal of Mathematical and Management Sciences, 32, 1–18.
- Efron, B. (1982). The jackknife, the bootstrap and other re-sampling plans. CBMS-NSF regional conference series in applied mathematics (No. 38). Philadelphia, PA: SIAM.
- Efron, B., & Tibshirani, R. J. (1993). An introduction to the bootstrap. New York: Chapman and Hall.
- Gelfand, A. E., & Smith, A. F. M. (1990). Sampling-based approaches to calculating marginal densities. Journal of the American Statistical Association, 85(410), 398–409. doi:10.1080/01621459.1990.10476213
- Gompertz, B. (1825). On the nature of the function expressive of the law of human mortality, and on a new mode of determining the value of life contingencies. Philosophical Transaction of the Royal Society of London, 115, 513–583.
- Hall, P. (1988). Theoretical comparison of bootstrap confidence intervals. The Annals of Statistics, 16(3), 927–953. doi:10.1214/aos/1176350933
- Krishna, H., & Kumar, K. (2013). Reliability estimation in generalized inverted exponential distribution with progressively type II censored sample. Journal of Statistical Computation and Simulation, 83(6), 1007–1024. doi:10.1080/00949655.2011.647027
- Kumar, D., Kumar, M., Saran, J., & Jain, N. (2017). The Kumaraswamy-Burr III distribution based on upper record values. American Journal of Mathematical and Management Sciences, 36(3), 205–228. doi:10.1080/01966324.2017.1318099
- Lin, C. T., Wu, S. J. S., & Balakrishnan, N. (2003). Parameter estimation for the linear hazard rate distribution based on records and inter-record times. Communications in Statistics - Theory and Methods, 32(4), 729–748. doi:10.1081/STA-120018826
- Miller, R. G. (1981). Survival analysis. New York: John Wiley.
- Mugdadi, A. R. (2005). The least squares type estimation of the parameters in the power hazard function. Applied Mathematics and Computation, 169(2), 737–748. doi:10.1016/j.amc.2004.09.064
- Pak, A., & Dey, S. (2019). Statistical inference for the power Lindley model based on record values and inter-record times. Journal of Computational and Applied Mathematics, 347, 156–172. doi:10.1016/j.cam.2018.08.012
- Raqab, M. Z., Bdair, O. M., & Al-Aboud, F. M. (2018). Inference for the two-parameter bathtub-shaped distribution based on record data. Metrika, 81(3), 229–253. doi:10.1007/s00184-017-0641-0
- Soliman, A. A., Abd Ellah, A. H., & Sultan, K. S. (2006). Comparison of estimates using record statistics from Weibull model: Bayesian and non-Bayesian approaches. Computational Statistics & Data Analysis, 51(3), 2065–2077. doi:10.1016/j.csda.2005.12.020
- Swain, J., Venkatraman, S., & Wilson, J. (1988). Least squares estimation of distribution function in Johnson’s translation system. Journal of Statistical Computation and Simulation, 29(4), 271–297. doi:10.1080/00949658808811068
- Tarvirdizade, B., & Nematollahi, N. (2019). A new flexible hazard rate distribution: Application and estimation of its parameters. Communications in Statistics - Simulation and Computation, 48(3), 882–899. doi:10.1080/03610918.2017.1402039
- Tierney, L. (1994). Markov chains for exploring posterior distributions. The Annals of Statistics, 22(4), 1701–1728. doi:10.1214/aos/1176325750
- Varian, H. (1975). A Bayesian approach to real estate assessment. In Studies in Bayesian econometrics and statistics in honor of Leonard J. Savege (pp. 195–208). Amsterdam, The Netherlands: North Holland.
Appendix
The elements of the observed information matrix I are as follows: