
Abstract
Palantir is among the most secretive and understudied surveillance firms globally. The company supplies information technology solutions for data integration and tracking to police and government agencies, humanitarian organizations, and corporations. To illuminate and learn more about Palantir’s opaque surveillance practices, we begin by sketching Palantir’s company history and contract network, followed by an explanation of key terms associated with Palantir’s technology area and a description of the firm’s platform ecosystem. We then summarize current scholarship on Palantir’s continuing role in policing, intelligence, and security operations. Our primary contribution and analysis are a computational topic modeling of Palantir’s surveillance patents (n = 155), including their topics and themes. We end by discussing the concept of infrastructuring to understand Palantir as a surveillance platform, where we theorize information standards like administrative metadata as phenomena for structuring social worlds in and through access to digital information.
Palantir is among the most secretive and understudied surveillance firms globally (Harris Citation2017). The company supplies information technology (IT) solutions for data integration and tracking to police and government agencies, humanitarian organizations, and corporations. A handful of qualitative studies have examined the use of Palantir’s platform in police field operations through ethnographies (Brayne Citation2017, Citation2020), legal case studies (Ferguson Citation2017), and critical and rhetorical analyses of Palantir-related marketing, reports, and public-facing literature describing Palantir’s software products and services (Knight and Gekker Citation2020; Munn Citation2017, Citation2019). While these qualitative studies are valuable for offering unique interpretive insights into Palantir, as are speculative descriptions of Palantir’s surveillance capabilities in press reporting, significantly less attention has focused on potential opportunities afforded by quantitative, large-scale analyses of Palantir’s publications and the ways that Palantir plans, imagines, and speaks about its surveillance capabilities within primary documents it publishes.
To illuminate and learn more about Palantir’s opaque surveillance practices, we begin by sketching Palantir’s company history and contract network, followed by an explanation of key terms associated with Palantir’s technology area and a description of the firm’s platform ecosystem. We then summarize current scholarship on Palantir’s continuing role in policing, intelligence, and security operations. Our primary contribution and analysis are a computational topic modeling (Abood and Feltenberger Citation2018; Choi and Song Citation2018; Hu, Fang, and Liang Citation2014; Venugopalan and Rai Citation2015; Yun and Geum Citation2020) of Palantir’s surveillance patents, including their topics and themes. This approach follows recent literature that uses patents as primary data for researching the documented technology capabilities of media companies and opaque IT firms (Bucher Citation2020; Cochoy and Soutjis Citation2020; Delfanti and Frey Citation2020; Jethani Citation2020; Owen Citation2018; Parisi Citation2019; Shapiro Citation2020; Vats Citation2020). We end by discussing the concept of infrastructuring (Bowker et al. Citation2010; Bowker and Star Citation2000; Karasti and Blomberg Citation2018; Dantec and DiSalvo Citation2013) to understand Palantir as a surveillance platform, where we theorize information standards like administrative metadata as phenomena for structuring social worlds in and through access to digital information.
Palantir is a controversial organization, according to several reports. In recent years press reporting has documented Palantir’s links to the US National Security Agency’s (NSA) surveillance operations through the Edward Snowden whistleblowing revelations (Biddle Citation2017). According to Amnesty International, Palantir has been accused of human rights violations by “targeting parents and caregivers of unaccompanied migrant children” (Bell and Kleinman Citation2020). Others have reproached Palantir’s unethical approaches and attendant shortcomings in responsible corporate conduct (Posner Citation2019). Yet, Palantir recently received a $20 billion valuation (Sen et al. Citation2020), and there are only a few academic studies about the company’s organizational aspirations and surveillance capabilities (Brayne 2017, 2020; Ferguson Citation2017; Knight and Gekker Citation2020; Munn Citation2017, Citation2019). In this article, we contribute to this scholarship by providing firsthand, primary source documentation of Palantir’s contracts and surveillance platform, supported by computational analysis of its published patents, thus offering insight into how Palantir documents its broad surveillance capabilities. We build on classic studies in the political economy of personal information and data surveillance activities of commercial firms (Agre Citation1997; Andrejevic Citation2007; Clarke Citation1994; Gandy Citation1993) with contemporary work in surveillance, infrastructure, and platform studies (Monahan and Murakami Wood Citation2018; Plantin et al. Citation2018), thus conceptualizing Palantir as a surveillance platform that different agencies hire to document, track, and control data about individuals.
Background on Palantir
Palantir (the name comes from the crystal ball-like seeing stones from The Lord of the Rings, which could be used for communication and to know the past and the future) was founded in 2003 by Peter Thiel, Nathan Gettings, Joe Lonsdale, Stephen Cohen, and Alex Karp. Initially based in Palo Alto, California, the company’s headquarters has since been relocated to Denver, Colorado. In its early years, Palantir received startup funding from the US Central Intelligence Agency’s (CIA) venture capital arm, In-Q-Tel. In 2020, the company debuted on the New York Stock Exchange (NYSE) with the ticker PLTR via a direct listing, ending a 16-year run of private holdings and financial secrecy (Gregg and MacMillan Citation2020). Palantir’s most well-known clients include US police departments accused of using Palantir’s predictive policing and facial recognition technologies for racial profiling (Hvistendahl Citation2021) and US security agencies like the Federal Bureau of Investigation (FBI) and Immigration and Customs Enforcement (ICE), which reports say Palantir assists with digitally tracking undocumented immigrants, including children, for deportation. For example, a raid on the workplace of 680 migrant workers in Mississippi on August 7, 2019, was “carried out by the unit of ICE that uses Palantir software to investigate potential targets and compile evidence against them” (MacMillan and Dwoskin Citation2019). Further, Palantir is reported to have had, as early as 2012, a “role in a far-reaching customs system,” following US Customs and Border Protection training documents obtained by the Electronic Privacy Information Center (Woodman Citation2016).
In addition to US policing and security agencies, Palantir’s clients include financial companies like JPMorgan Chase (Waldman, Chapman, and Robertson Citation2018) and humanitarian organizations like the World Food Programme (WFP)—the food-assistance branch of the UN—which Palantir assisted with distributing food supplies during the COVID-19 pandemic (Parker Citation2019). WFP received criticism for partnering with Palantir; in fact, several Palantir partners have also faced public pressure campaigns to dissociate with the company due to the firm’s controversial surveillance activities related to policing and immigration (Sherman Citation2020). WFP eventually clarified that its partnership would not include provision of data to Palantir and that neither would Palantir provide data to WFP (Porcari Citation2019). Palantir has likewise faced resistance from its employees, ranging from petitions to resignations over its work with ICE (Chafkin Citation2021). Like the New York Police Department (NYPD), other organizations have faced problems when attempting to secure their analytics data after ending contracts with Palantir (Alden Citation2017; Irani and Whitney Citation2020). Palantir is also litigious and adversarial with its customers; in 2016, the firm won a lawsuit against its client, the Pentagon, for a lucrative army contract worth $206 million (Davenport Citation2016).
Palantir wants its software to be the primary surveillance tool of US law enforcement and government security agencies. In Palantir’s registration statement with the US Securities and Exchange Commission (SEC), the company stated its aim was to “become the default operating system for data across the U.S. government” (Palantir Citation2020a, 7), adding that its technologies are hired “across 36 industries and in more than 150 countries” (2). These goals are criticized by some in the US government, including Representative for New York’s 14th congressional district Alexandria Ocasio-Cortez, who requested that the SEC investigate Palantir before its NYSE debut over secrecy and human rights abuses (Hatmaker Citation2020). Regardless of the hesitancy of some US lawmakers, in the US government alone, our search of the Federal Procurement Data System revealed 940 Palantir contracts with various intelligence and security entities totaling 470 pages and over $1.5 billion from 2007 to 2021, including 123 contracts with the FBI ($76 million), 90 with Special Operations Command ($305 million), and 81 with ICE ($172 million), among others across the US government. The contracts are for surveillance products and services relating to digital networking, hardware/software, telecommunications, IT strategy and architecture, transmissions, and systems development for intelligence and security. A list of these Palantir contracts with US government entities is available in our appendices, and copies are available in our data deposit. The Latinx political activist group Mijente (Citation2019) (mijente.net) first examined these contracts and provided a political-economic overview of Palantir’s technological support of ICE in a report titled The War Against Immigrants: Trump’s Tech Tools Powered by Palantir.
As mentioned above, Palantir’s data integration tools for federal governments are not limited to border control. Health services, procurement systems, and food and drug safety organizations use the firm’s surveillance platform—though most of Palantir’s contracts and partnerships, especially in its early history, have been with organizations involved in security, intelligence, and defense. Palantir recently won or renewed several US federal contracts with the Centers for Disease Control and Prevention (CDC) and the Food and Drug Administration (FDA) for tracking COVID-19 data, evaluating drugs, and tracking supply chains for materials like sanitizer and vaccines—these activities are said to have increased its share price (e.g., O’Donnell Citation2020). Palantir’s list of clients recently grew to include the UK’s National Health Service (NHS), and the firm continues to expand globally (Balakrishnan et al. Citation2020), among others, through renewed contracts with the UK’s Royal Navy (Gordon Citation2021a). This growth comes despite public campaigns such as “No Palantir in Our NHS,” which seek to end Palantir’s partnerships with the UK government (Shead Citation2021). Like the public pressure directed at WFP, such campaigns are based in part on reports about Palantir’s work in policing and immigration, rare interviews with company leadership (Steinberger Citation2020), and leaked documents about how Palantir’s software “helped expand and accelerate the NSA’s global spy network” by contributing to “one of the most expansive and potentially intrusive tools in the NSA’s arsenal” (Biddle Citation2017).
Palantir’s clientele also includes utilities and multinational corporations. In the first half of 2021, Palantir regularly issued press releases via Business Wire to announce contracts with California’s Pacific Gas and Electric Company for electronic surveillance and asset management; Latin America’s largest media company, Grupo Globo, for integrating data across its digital operations; one of Japan’s most prominent IT firms, Fujitsu Limited, for data set integration in sensitive data environments; the British oil and gas company, BP, for finding and extracting oil deposits; and one of the world’s largest mining corporations, Rio Tinto, for integrating raw data from multiple sources. The company recently began supporting startups from “healthcare to robotics, to software and fintech” (Gordon Citation2021b). Palantir’s SEC filing describes expansion of its business from 2008 to 2019 across numerous government and commercial entities, including capital markets, airlines, and industrial conglomerates (Palantir Citation2020a, 161). These contracts and press releases show a macro-level picture of a company involved in producing data integration and visualization software for customers to model and surveil their data, as if Palantir aspires to be a Google for organizations that value secrecy (Harris Citation2017)—the two companies have indeed been described as “two sides of the same coin” (Oremus Citation2020), though some question Palantir’s ultimate value and ability to scale to the likes of Google (Weinberger Citation2020).
Metadata, ontologies, and semantic technologies
Clients use Palantir’s surveillance platform for triangulating data to produce “knowledge” of and “predict” events, and such processes exploit the metadata, ontologies, and semantic technologies of information science. “Metadata” are “data about data” (Zeng and Qin Citation2016) and allow people and machines to add context to primary data, including timestamps, geolocation, and authorship. The digital data trails produced by machines often contain metadata, and scholars have long described metadata’s wide variety of uses (Baca Citation2016; Iliadis et al. Citation2021), which include labeling unique objects (e.g., people, places, things), properties (e.g., colors, height, weight), and their relationships (e.g., familial, organizational, physical), all for different purposes (e.g., descriptive, structural, administrative). Metadata can also link different types of data (e.g., formats, locations, domains), thus producing a bridge between two other data points or more.
Metadata are thus helpful for identifying digital traces and connecting widely divergent data that may otherwise have remained non-interoperable (Fidler and Acker Citation2017; Mayernik and Acker Citation2018). Standardizing this metadata for such linking purposes in larger projects requires what information science knows as an “ontology,” which is a highly regulated set of formal metadata rules, terms, values, and relationships with which different groups of people or machines may serialize, tag, and model their data (Pomerantz Citation2015). The purpose of an ontology is to maintain metadata consistency over time and between users (or organizations), thus ensuring that divergent data may cohere for browsing and consumption. The ontologies made from metadata are instantiated (serialized and visualized) in pieces of code and software (e.g., in standardized syntaxes, dashboards, analytics pages), and these pieces of code/software typically are known as “semantic technologies” which allow for users to curate, browse, share, and further refine their data organizing activities (Fürber Citation2016).
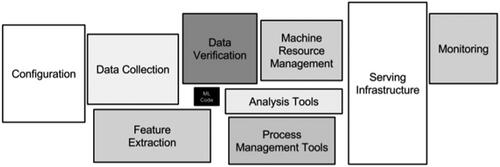
According to in-house researchers at internet firms, such organizational technologies are employed in the backend by companies like Google, Microsoft, Amazon, and Facebook to assist with labeling and modeling their vast and diverse troves of data stores (e.g., data about their users and products) and this supposedly allows them to derive “knowledge” from their triangulated data (see Noy et al. Citation2019 for a paper on “knowledge graphs” which is coauthored by employees from Google, Microsoft, and Facebook, among others). Semantic technologies also play key behind-the-scenes roles in algorithmic media and act as organizational support systems for algorithms that deliver content. According to researchers at Google, algorithms are only a tiny part of a complex digital media system’s operations and are supported by digital infrastructures that must be refactored (updated and maintained), including techniques for modeling, querying, and managing the large quantities of data that are produced by machine learning. An overreliance on “efficient” machine learning systems can thus send a “burden” of financial and technical costs “downstream” when they are not considered next to the potentially necessary modifications of attendant data organizing software such as metadata, ontologies, and semantic technologies. This downstream burden in software systems is traditionally referred to as technical debt (Cunningham Citation1992; Brown et al. Citation2010; Seaman and Guo Citation2011; Kruchten, Nord, and Ozkaya Citation2012; Tom, Aurum and Vidgen Citation2013), i.e., the extra financial and technical costs that are incurred when one technology (e.g., machine learning) is hastily employed due to a perceived efficiency without considering its effects on connecting technologies and infrastructures (e.g., semantic technologies). Thus, there can be a vast amount of hidden technical debt in the machine learning systems of large companies and organizations (Bender et al. Citation2021; Sculley et al. Citation2015). represents a relatively small amount of algorithmic code (the black box in the center) and the necessary surrounding digital infrastructure for such large-scale systems, among which sit several areas where metadata, ontologies, and semantic technologies for modeling and tracking play key roles, including data analysis and management. All of this is to say that Palantir specializes in domains where background data modeling and integration between different datasets and organizations are key areas of focus.
Figure 1. Hidden technical debt in machine learning systems (Sculley et al. Citation2015).
Such technologies for labeling, organizing, and tracking data are an extension of early ontology engineering and knowledge representation systems (Abbas Citation2010; Glushko Citation2013; Kejriwal, Knoblock, and Szekely Citation2021; Kendall and McGuiness Citation2019; McComb Citation2004) and also have a long and complex history related to web metadata standards, infrastructure, and governance systems (DeNardis Citation2014; Domingue, Dieter, and Hendler Citation2011) beginning with web inventor Sir Tim Berners-Lee’s semantic web initiative and the World Wide Web Consortium (W3C), one of the web’s leading international standards organizations (Berners-Lee Citation1999; Berners-Lee, Hendler and Lassila Citation2001) developing semantic web resources. Where Berners-Lee originally envisioned the semantic web and W3C as offering transparency and interoperability for data across an open, democratic, and decentralized web, today, such tools are used or imitated for proprietary purposes by large internet companies (Hitzler Citation2021) and in enterprise data management more broadly, thus inverting the semantic web’s original proposition. Instead of an open web, what has arguably resulted is a closed and fractured web that increasingly consists of propriety (instead of open and public) modeling tools, closed platforms, and walled gardens (Zittrain Citation2008).
Palantir is said to use these and related data modeling technologies for surveillance and preemptive decision making; to put it in Agre’s (Citation1994) words, who was critiquing the proclivity of AI researchers, it is “explicitly searching for ontological systems that would allow a computer to represent cleanly and accurately a wide range of human knowledge—including … human activities and social organizations” (108). Following Gandy’s (Citation1989) classic analysis, we view such surveillance as “directed toward preventing or avoiding loss or injury, rather than detecting crime that has already occurred” (64). Palantir wants its systems to extract “knowledge” and “predict” events concerning people (Robertson et al. Citation2017); there is thus a need to know more about how Palantir describes these capabilities for preemption, or what Massumi (Citation2015) refers to as an operative logic of power “that combines an ontology with an epistemology in such a way as to trace itself out as a self-propelling tendency” (5). Amoore (Citation2009) provides an early analysis of such predictive and ultimately speculative technologies in the context of the US “war on terror” post-9/11, which are variously described as “preemptive lines of sight … visualizing unknown futures” (17), the “preemptive visualization of an unknown person,” and “preemptive decision making” (22). Following Amoore (Citation2009), our article analyses Palantir’s technologies which target unknown people as “a matter of both positioning in the sights (targeting and identifying) and visualizing through a projected line of sight (pre-empting, making actionable)” (24). The present study also turns the preemptive gaze back onto Palantir and seeks to visualize its technological affordances through patent analysis and extraction of topics. We thus simultaneously follow recent calls for critical data and internet studies (Acker and Donovan Citation2019; Iliadis and Russo Citation2016) and empirical investigative research of IT companies (Carter, Acker, and Sholler Citation2021) to understand surveillance platforms like Palantir, which we view as complementary to but distinct from the platform surveillance of social media companies (Murakami Wood and Monahan Citation2019; Turow and Couldry Citation2018). Our article views Palantir as a surveillance platform where the primary focus is surveillance services and preemptive decision analytics for facilitating the tracking of people and things both in and outside the US. As Mattern (Citation2018) identifies in a discussion of the US border, “failures to see and be seen are central to the American political crisis.” Palantir thus plays an increasingly central role in these politics of visualization.
Palantir’s surveillance platform
The previously cited press often describes Palantir as providing data-gathering and integration services supporting preemptive decision analytics. Still, such reports rarely provide any first-hand or primary source details about how the technology is supposed to operate. Commonly, they describe Palantir as providing a way to link digital objects in different databases. The company offers this data-object linking as a type of “Software as a Service” (SaaS), renting itself out to purchasers who require assistance with integrating data from heterogeneous sources (e.g., data silos might include one database of arrest reports, another database of credit card receipts), thus positioning itself as a platform service provider.
Yet, it appears that Palantir is not SaaS in a strict sense. The company often sends what it refers to as “forward deployed software engineers” (Rocha Citation2019) to its customers and on-premises appliances. These forward-deployed engineers develop custom “on-prem” software and assist with data integration, practices that somewhat elide the SaaS label due to embedded engineering expertise on location. Nevertheless, Palantir also promotes itself as “Data as a Service” (Gordon Citation2021c), maintaining its strictly “digital service” image despite the physically present personnel who may briefly manage products and data orchestration for clients after the sale. Following West (Citation2019) on new surveillance services offered by Amazon, we think a more accurate term would be “Surveillance as a Service” owing to Palantir’s contracts, press releases, and (as we shall see) patents. These forward-deployed engineers provide an opportunity for media and communication researchers to study the organizational, interpersonal, and small group dimensions of surveillance employees, including via lines of the research Gates and Magnet (Citation2007) describe in their introduction to the “Surveillance and Communication” special issue of The Communication Review, critical approaches to communication technology described in Bakardjieva and Gehl (Citation2017) and Gehl (Citation2015) on data engineers.
According to material written by its in-house engineers, Palantir publicly promotes three platforms—Gotham, Foundry, and Apollo—that make up its surveillance platform ecosystem (). Gotham is the primary, public-facing platform interface that Palantir customers use to navigate through their data objects; a previous description of Gotham, which has been removed from Palantir’s website but remains retrievable via the Internet Archive’s Wayback Machine, describes Gotham as “a suite of integrated applications for semantic, temporal, geospatial, and full-text analysis for users to derive meaning from their organization’s data asset” (Palantir Citation2021a). Foundry sits “above” Gotham and is the “cloud-native SaaS with a microservice architecture” (Krishnaswamy, Minor, and Fink Citation2020). Palantir customers can experiment and test preemptive decisions based on their data in a safe cloud environment to partition separate programs. Apollo is the continuous delivery system that serves Foundry and Gotham, providing updates and powering the software that Palantir’s customers use; it is the “automation and delivery infrastructure” for public and private clouds and on-site hardware (Krishnaswamy, Minor, and Fink Citation2020). These three platforms are the primary products and services that the firm provides and represent a meso-level view of the company (in most of what follows, we use “Palantir” when referring to the company and this suite of technologies that make up its surveillance platform). shows images of Palantir’s platforms which we have extracted from Palantir’s SEC filing (Palantir Citation2020a, 134–152).
Figure 2. Palantir’s surveillance platform ecosystem (Krishnaswamy, Minor, and Fink Citation2020).
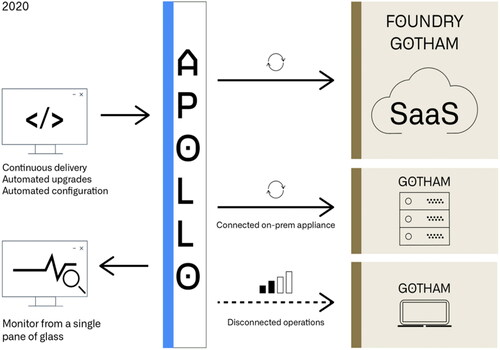
Figure 3. Images of Palantir’s platforms from Palantir’s SEC filing (Palantir Citation2020a, 134–152).
Palantir uses the language of “ontology” (commonly found in information science, as discussed above) to describe its highly modeled data flows, data networking, and data interoperability across each platform; for example, its website currently states that Palantir technology offers “an enterprise-wide semantic layer that effectively translates raw data into a recognizable language for end users” and “provides this semantic layer through its unique data model, or ‘ontology’” (Palantir Citation2021b). While Gotham, Foundry, and Apollo are the suite of platforms that operate in the Palantir ecosystem, the data that becomes semantically labeled with metadata and visualized in that ecosystem is described by Palantir as a “dynamic ontology” (Sudo Null Citation2019 reproduces content relating to the dynamic ontology from a now unavailable and private video in Palantir Citation2012) of graphed data with objects, properties, and relationships customized for each client (and at least in some instances, initialized by Palantir’s forward-deployed software engineers). This kind of ontology layer (basically, building descriptions via metadata “on top” of or “wrapping” primary data) adds a cohesive semantics that helps create context and meaning for Palantir’s users, allowing them to browse previously separate data sets after they have become ontologically triangulated.
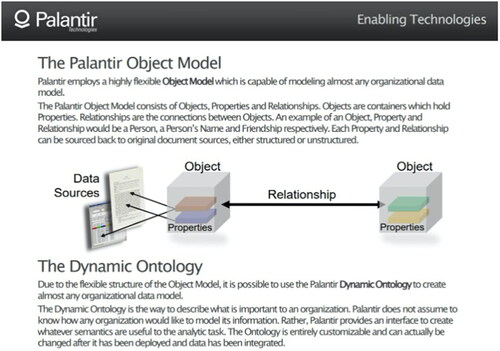
Leaks of company documents describe the Palantir ontology, including those from the IT security company HBGary. Palantir’s internal emails released by Wikileaks (2016) under the title “The HBGary Emails” reference this Palantir ontology, and the company continues to describe the ontology on its website vaguely. Slides contained in the Wikileaks emails release show Palantir’s internal presentations outlining its dynamic ontology and the description of data objects, data-object linking, relationships, properties, and data sources in the metadata modeling (). Such examples are the closest available primary source documentation of Palantir’s micro-level information infrastructure, next to rare, published accounts and images of its meso-level Gotham platform interface. While helpful, the latter is limited in scope to specific domains or does not provide a comprehensive understanding of how Palantir itself technically describes and imagines how its software will be used for data integration by customers across industries. What, for example, does Palantir claim or imagine will fill the role of these data objects, relationships, and properties in the metadata modeling? If the value of Palantir’s surveillance software is in digitally modeling entities through an ontology, how has the company itself described this technical process, and to what end? Palantir has distanced itself from the image of a surveillance firm that assists in tracking people like workers and immigrants.
Figure 4. Palantir slide describing the dynamic ontology model (Wikileaks Citation2016).
We attempt to move beyond the obfuscation that Palantir has fostered concerning its objectives and to learn more about the firm by providing evidence of internal documentation concerning its technical capabilities and practices aimed at data modeling and facilitating preemptive decision making for its customers. Through a computational topic modeling (Abood and Feltenberger Citation2018; Choi and Song Citation2018; Hu, Fang, and Liang Citation2014; Venugopalan and Rai Citation2015; Yun and Geum Citation2020) and natural language processing of Palantir’s patents, we aim to answer the following two research questions:
RQ1: Since the beginning of Palantir’s patent filings, what types of topics do the patents contain, and how are those topics thematically related and defined?
RQ2: What do Palantir’s patent topics and themes tell us about the surveillance platform’s aspirations, imaginings, and technical capabilities?
Scholarship on Palantir
Scholars have analyzed Palantir from perspectives that include ethnographies of the tech firm’s products as used in field operations to critical reviews of associated policy and reporting materials. Among the first studies to research Palantir, Brayne (Citation2017, Citation2020) offers a comprehensive ethnography of the Los Angeles Police Department’s (LAPD) use of Palantir’s Gotham platform interface and notes that “there is virtually no public research available on Palantir, and media portrayals are frustratingly vague” (2020, 37). Through interviews and photos, Brayne provides a detailed account of how Gotham is deployed on the frontend in the field by police agencies to investigate, predict, surveil, and patrol crime. As per Brayne’s interviews with officers, the Palantir platform helped the LAPD combine different siloed data sets, allowing officers to conduct comprehensive queries quickly. Furthermore, Brayne describes a demonstration by one of Palantir’s forward-deployed engineers dispatched to assist the LAPD. The Palantir employee who initiates the sample search scenario for Brayne describes it as an example of “dragnet surveillance” where previously separated databases (containing legacy data items like criminal records, license numbers, etc.) become connected, thus making searches easier. Brayne further notes that Palantir’s system sits “on top” of the LAPD’s systems and that Palantir does not own the data and instead provides an interface for data-object linking.
In another work describing Palantir and policing, Ferguson (Citation2017) discusses the rise of big data and offers legal insights from several case studies in predictive policing. The work comments on Palantir’s software integrating, analyzing, and sharing data from several law enforcement sources. Ferguson describes Palantir’s use by the New Orleans Police Department (NOPD) after receiving approval from New Orleans’ mayor to identify the top causes of violent crime. The NOPD relied on Palantir to identify hidden relationships among legacy data systems and integrate this information across sectors, including police records and city data related to infrastructure, health services, etc. After data integration, Palantir preemptively identified roughly 3000 individuals from New Orleans who were likely to die of homicide (Ferguson Citation2017). Ferguson further notes that, based on the data sets, emergency services sought additional preemptive measures; the New Orleans Fire Department adjusted its presence around schools, the Health Department focused on high-risk schools, etc., decisions that were all informed by the same data that Palantir integrated from several citywide, legacy data systems.
Other media scholars have analyzed Palantir’s IT through critical and rhetorical methods. Knight and Gekker (Citation2020), echoing Brayne (2020), note that “the company’s software products have received limited academic critique from a sociological or humanities perspective” (236)—we would add that this is even true with regard to quantitative studies. Knight and Gekker (Citation2020) textually analyze a government policy document about the relational database system employed by ICE to track federal immigration, while Munn (Citation2017, Citation2019) critically and philosophically examines video documentation of public Palantir presentations about the Gotham interface on the company’s official YouTube account (these videos are currently marked as unavailable and set to private). Our article thus addresses the concerns raised by Brayne (2020) and Knight and Gekker (Citation2020), further emphasized by Munn (2017, 2019), regarding the lack of investigative research studies on Palantir’s products and outputs, using topic modeling of a large set of official Palantir data.
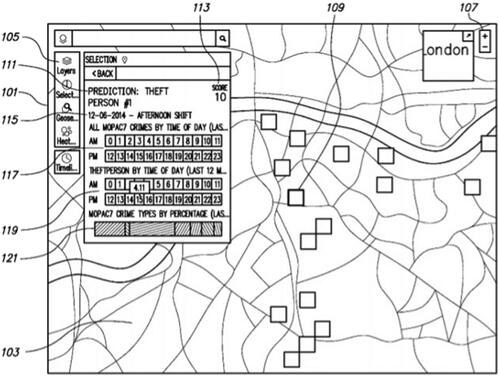
Conceptual works from the perspective of surveillance studies (Lyon Citation2007; Monahan and Murakami Wood Citation2018) have theorized the notion of predictive policing and have occasionally referenced Palantir as an exemplar due to the use of Palantir’s surveillance platform by police and security agencies. The special issue of Surveillance & Society “Platform Surveillance” (Murakami Wood and Monahan Citation2019) contains several papers that address predictive policing; Gates (Citation2019) theorizes policing as a digital platform; Wilson (Citation2019) conceptualizes how platform policing uses data to increase the flexibility of police organizations; Egbert (Citation2019) further theorizes predictive policing and the platformization of police work, and Ritchie (Citation2020) examines passive state surveillance and active infrastructures of racialization. Each of the above studies theorizes policing, surveillance, and security through the lens of Palantir’s types of predictive technologies. Indeed, one of the patents we found in our search of Palantir’s patents is entitled “Crime Risk Forecasting,” which describes how users can “more effectively gauge both the level of increased crime threat and its potential duration … then leverage the information conveyed by the forecasts to take a more proactive approach to law enforcement” (Robertson et al. Citation2017). contains an image from Palantir’s crime risk forecasting (predictive policing) patent showing a sample crime prediction scenario that includes information on an individual (“PERSON #1”), the crime committed (“PREDICTION: THEFT”), a map of the location (“London”), and dates with the time of day (“12-06-2014 AFTERNOON”) and displays further options to sort crimes and persons by the time of day.
Figure 5. Image from Palantir’s predictive policing patent (Robertson et al. Citation2017).
Patents as data source
Patents document the intellectual property of inventions and delimit the rights of owners or inventors to make, use, or sell an invention. Typically, patents describe the context, content, and processes that make inventions unique, how they are to be employed, who is the intended user or use case, the current state of the art, and how the invention is particularly innovative. We acknowledge that patents are occasionally broad and speculative and are sometimes solely employed for hyping projected futures (Liao and Iliadis Citation2021) and legal proceedings as much as they indicate demonstrated technological innovations. However, upon our research, we can attest to Palantir’s patent filings’ depth, breadth, and significance. The average length of the patents we looked at was 33 pages. Each typically contained hundreds of citations, often ten or more images, and explicit, fine-tuned details of the technical specifications. For example, is a sample syntax section of a typical Palantir patent (Ducott et al. Citation2016), including the level of detail which would often provide extended feature descriptions, code examples, application scenarios, etc.
Figure 6. Syntax section of a typical Palantir patent (Ducott et al. Citation2016).

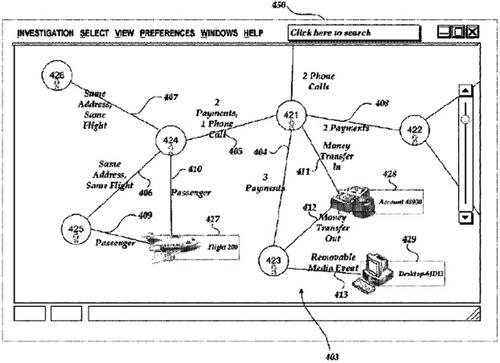
includes a description of metadata and ontology syntax related to categorizing a “Person” such as an “Employee” or “Contractor” for cross-analysis and replication among heterogeneous databases, including information about “parent” and “child” relationships. provides another sample image taken from a Palantir patent (Ryan et al. Citation2017) describing context-sensitive views in an interface visualization of its surveillance platform, including how users can interact with Palantir’s triangulated data in an investigation. The patent presents a hypothetical scenario including information about six associated people, including identifying information about financial “Payments,” “Money Transfer,” and cellular “Phone Calls” between individuals, as well as “Same Address” and “Same Flight” identifying information, further supplemented by a reader, map, and post-board. Our corpus reviewed hundreds of images that displayed Palantir’s serializations and syntaxes, diagrams and visualizations of its surveillance platform on frontend products and backend infrastructure, and abstract representations of Palantir’s data parsing exercises.
Figure 7. Sample image showing data triangulation of people’s activities (Ryan et al. Citation2017).
Patents are often introduced as evidence in courtrooms and intellectual property disputes, yet we acknowledge that they may not be isomorphic with the existing technical capabilities of the organizations that file them. We understand these patents as a product of how Palantir wishes to appear and that they trace processes of imagination. Still, upon reviewing these patents (and consulting with two of our colleagues in the legal field), we also note that the information presented in them constitutes a realistic representation, or at least a close approximation, of Palantir’s technical capabilities. This conclusion is further supported by our review of Palantir’s extensive contract history with organizations such as the CIA, NSA, ICE, FBI, CDC, FDA, LAPD, NYPD, NOPD, etc. domestically in the US, and surveillance organizations internationally, which we take to be at least some evidence of the efficacy of Palantir’s surveillance platform. Such effectiveness is corroborated by several of the reports we cite above concerning arrests and apprehensions.
Researchers widely employ patents as data sources for their studies. Indeed, several media and communication scholars have used patents to study the ideation, development, design, technical capabilities, and projected futures of organizations and companies. Vats (Citation2020) analyzes how patent language shapes conceptions of race and socioeconomic status; Bucher (Citation2020) uses patents to investigate Facebook’s news feed; Shapiro (Citation2020) theorizes smart cities through patents; Cochoy and Soutjis (Citation2020) analyze patents to study digital price displays; Delfanti and Frey (Citation2020) explores the future of work as seen through Amazon patents; Jethani (Citation2020) examines how patents mark the evolution of tracking devices; Parisi (Citation2019) discusses patents related to haptics and video games; Owen (Citation2018) analyzes the history of patent protections in HIV/AIDS medicines.
Patents have further been employed as data to characterize epistemic communities and knowledge production. In earlier research on science and technology studies, Coward and Franklin (Citation1989) use patents to study the connection between scientific research and industrial technology; Weiner (Citation1987) examines patenting in academic research through historical case studies; Packer and Webster (Citation1996) discuss patenting culture in the commercialization of university science; Mackenzie, Keating, and Cambrosio (Citation1990) analyze patenting’s constricting influence on scientific research in biotechnology; Russell (Citation2011) uses patents to analyze web standards policy in the W3C as mentioned above. Patents are thus a rich primary data resource and particularly helpful for an extensive quantitative study of opaque IT and surveillance firms. By tracking patents over time and isolating repeating topics and themes in their content, researchers can understand patents as a mechanism for projecting an IT firm’s aspirations and, in some cases, as evidence of technology sought, approved, developed, adopted, and deployed.
Methods
For this study, we scraped all Palantir’s patents that contained the word “ontology” (as of August 25, 2020) from Google Patents (a complete list of these patents along with their names, authors, and critical dates are available in the online appendices on Taylor & Francis’s website). This process produced a purposive sample (n = 155) of Palantir patents, consisting of 5197 pages, over 2.5 million words, and over 18.5 million characters. We then prepared the data set for processing by stripping all the metadata and unique features, converting formats, compressing, and collating the patents into a single document. We consulted with a colleague in computer science and imported several Python libraries used for data processing (Pandas, Matplotlib, NumPy, and Seaborn). We used Google Collaboratory to assemble the patent data, loaded in a textual paragraph format. Preprocessing was then carried out, including punctuation, null value, stop word removal, lemmatization, lowercase conversion, and tokenization, resulting in a preprocessed data set. Part-of-speech (POS) tagging was performed, and the tokens were targeted by their corresponding POS based on context and definition (this produced the most frequent nouns, verbs, etc.). Named entity recognition was performed to locate and classify entities in the text into predefined categories such as persons, organizations, locations, times, quantities, monetary values, and percentages. Topic modeling was performed using a bag-of-words model and Latent Dirichlet Allocation (an automated process that identifies the cooccurrence of words in clusters under unnamed specialized topics to be determined by the researchers) (Blei, Ng, and Jordan Citation2003). Once the final corpus was produced, we collaboratively and iteratively reviewed the results and interpreted the 20 topics modeled from the automated output, which contained the 20 most frequent words related to each topic. We then manually developed three overarching themes that emerged from these 20 topics. Lastly, we collaboratively and iteratively made a list of keywords we were interested in exploring (divided into social, technical, and proper name keywords). We automatically looked for their most common proximal word frequencies. We then manually reviewed the topics and keywords, looking for interesting examples in sample sentences and visualizations that we could extract for presentation. All raw and processing data are in our data deposit, and additional supplementary materials are in our online appendices.
Analysis
First, all the Palantir patents in our corpus described, in some form, various acts of digital surveillance through data tracking and triangulation across systems. Some of the more interesting patents in our data set include titles describing data integration, context-building processes, entity, property, relationship identification, and threat detection. is a small sample of patent titles extracted from our corpus.
Table 1. Sample list of Palantir patent titles.
Along with titles, the corpus included data for patent ID codes, assignee names, inventor’s names, priority dates, filing and creation dates, publication dates, result links, and representative figure links, among other standard structured information found in technology patents. Among the 155 patents, only 51 have granted information, indicating that roughly a third of Palantir’s surveillance patents are granted by their respective countries’ patent and trademark offices. This information does not mean that a large majority of these patents will fail to become granted, as the longest observable time between priority date (first date) and grant date (final date) was 12 years, from 11/20/06 to 08/28/18. There are patents within the corpus that have priority dates within the last two or three years. Among the filing countries and regions, the breakdown was 31 from the European Patent Office, four from Germany, one from Australia, one from the UK, one from the Netherlands, and 117 from the US, clearly showing that Palantir files most of its surveillance patents domestically.
Among proper names, we distilled platform companies’ names from the corpus in that we were interested in seeing if Palantir imagined integrating data from social media and platform sources. These included Amazon, Apple, Facebook, Google, Instagram, LinkedIn, Microsoft, and Twitter. The patents mention Google and Microsoft much more overall than the other companies, usually in Palantir’s integration with and surveilling their various services (business and personal). The data here shows that Palantir envisions its platform surveilling data from the products and services of, among others, social media platforms. below shows the proper name keywords and most common proximal word frequencies.
Table 2. Internet media companies described in Palantir patents with proximal word frequencies.
Below is an example in the form of a short excerpt from the Palantir corpus describing Palantir’s ability to integrate disparate data sets from external sources such as platforms, financial companies, social media, and government organizations, and includes a sample of some of the proper names for the social media companies listed in our results above (Michel et al. Citation2018):
Consuming entity data systems can include public computing systems such as computing systems affiliated with the U.S. Bureau of the Census, the U.S. Bureau of Labor Statistics, or FedStats, or it can include private computing systems such as computing systems affiliated with financial institutions, credit bureaus, social media sites, marketing services, advertising agencies, or some other organization that collects and provides demographic data or data about individual consumers. In some embodiments consumer entity data systems can include advertising information related to individual consumers such as, ad views, clicks, ad impressions, ad details, or other advertisement related information. In some embodiments, consumer entity data systems may include web browsing history (e.g., browsing data provided by Apple Safari, Microsoft Internet Explorer, Google Chrome, Mozilla Firefox, or other web browser), social network interactions (e.g., from social networking providers like, among others, Facebook, LinkedIn, and Instagram), or other available online behavior related to a consumer or group of consumers.
While there are other examples of extended passages that we could choose from in the corpus, the above excerpt we thought was appropriate to show the breadth of how Palantir describes its surveillance platform integrating various data about individuals across systems, including from their web browsing and search history, social network connections, and how these data can be connected and integrated with government and banking data about the same individuals, via uniform resource identifiers, application programming interfaces, etc. This passage gives a sense of what Palantir imagines as filling some of the content of its data integration efforts, hinting at only what the company is publicly willing to say, which we think already presents worrying privacy concerns. According to the firm, Palantir does not collect information directly but offers software for data integration; this is the argument presented in documents like Privacy Impact Assessments for federal and health organizations (Edge and Neuman Citation2016). Thus, lines of critique concerning hypothetical data sourcing can be defended. Yet, Palantir remains open to the critique of potentially being an accessory to acts of deportation, imprisonment, and racism through its contracts.
Of particular interest concerning the media companies described in the patents, several companies were mentioned concerning obtaining data from private emails and correspondences, social media relationships and connections, and credit ratings. These items could have significant adverse effects for individuals if triangulated and employed by administrators for adjudicating activities such as seeking a loan, employment, immigration and visas, or criminal background checks, in addition to creating potentially ‘abstract’ concerns such as guilt by association. In these patents, Palantir is explicitly admitting the aim of its platform, which is the collection and tracking of personal information for surveillance purposes across domains (see Ribes et al. Citation2019 on the “logic of domains” in computing).
Our primary analysis object was the topic modeling, which included the topics, associated keywords for each topic, and our own manually chosen examples taken from the data in excerpts ( and ). Examination of these topics and passages provides researchers with firsthand evidence and primary source documentation relating to the approaches, services, data types, and integration actions featured in Palantir’s surveillance platform. The topics further reveal information about the infrastructuring (Bowker and Star Citation2000; Bowker et al. Citation2010; Karasti and Blomberg Citation2018; Dantec and DiSalvo Citation2013) that can be accomplished with the surveillance platform and the pervasive managerial and administrative tools that data managers use in their work to document and track data relating to domains such as healthcare, immigration, and alleged criminal activities.
Table 3. Topic modeling of Palantir patents (1–10)
Table 4. Topic modeling of Palantir patents (11–20)
Among the twenty topics, we see three themes that reveal Palantir’s positionality as a data integration firm and how Palantir’s surveillance platform provisions can be differentiated across patent applications for its software technologies. The one topic that does not follow these strands is Topic 17, which internally refers to the documents as patents, their structure, and parts (e.g., data concerning dates and references). When taken together and stacked, these three thematic strands represent a data funnel (discussed below) of how traces of human behavior are prepared for sorting actions as digital data objects that are then rendered into representational software systems (metadata, ontologies, and semantic technologies), which are then themselves finally processed and interpreted through the surveillance platform analytics that Palantir provides. Thus, the topic modeling (in answer to RQ1) allows us to understand the surveillance aspirations, imaginings, and technical capabilities of Palantir (in answer to RQ2).
Finding 1: Labeling of human traces and sorting actions
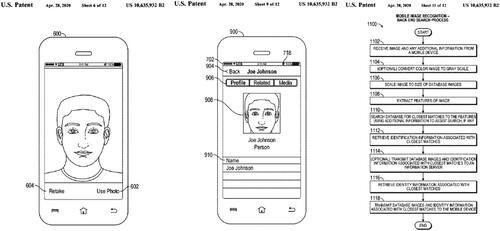
The first theme that emerged from the topic modeling was about how Palantir’s software labels human traces and begins sorting actions; this contains topic 1 (identifying data matches, associations, and their relationships), topic 5 (segmentation and partitioning objects using sets, claims, time series, and values), topic 10 (medical and healthcare fraud claims), topic 16 (financial fraud detection), and topic 19 (security, attack, fraud, kill chain, hacking). These represent topics related to identifying normative objects and relations in IT systems to flag fraud, alleged criminality, hacking, or unusual events. Labeling human traces and sorting actions at this stage (i.e., beginning of the data funnel) can facilitate data organizing for detection, prediction, and analysis. For example, one patent (Goenka et al. Citation2019) describes taking an image of a person with a smartphone and then extracting the data from the image to send to a server for detecting matches (facial recognition) and links to the person’s various profiles and related (social) media content, allowing for cross-media search and retrieval for labeling ().
Figure 8. Facial recognition for matching with media sources (Goenka et al. Citation2019).
These topics (1, 5, 10, 16, 19) relate to identifying entities, sorting them using domain information to produce matches, and creating labels at the level of objects and their relationships (e.g., a patient to a health care provider, facial data to social media accounts, criminals to risk scores). Palantir had attempted to distance itself from the idea that the company facilitates the integration of certain types of controversial data (Palantir Citation2020b), such as when the company downplayed its involvement in the Cambridge Analytica (CA) scandal, despite CA whistleblower Christopher Wylie’s testimony to British lawmakers that there were “senior Palantir employees that were also working on the Facebook data” (Confessore and Rosenberg Citation2018), or in Palantir’s continuing denial that it provides any direct assistance to ICE through data integration concerning undocumented immigrants for deportation (Pressman Citation2019). Earlier in the company’s history, Palantir was embroiled in another Facebook data scraping controversy involving a law firm working for the US Chamber of Commerce. The law firm wanted to spy on the Chamber’s political opponents and social media profiles (Johnson Citation2011). We present the below quote from a Palantir patent (Beard et al. Citation2016) which describes how unstructured social media content may be integrated via Palantir.
Data structuring system may also include one or more structuring components that may parse the unstructured social media content … Entity types may define a person, place, thing, or idea. Examples, of entity types include social media platform profile (e.g., Facebook, or Twitter user profile), IP address, email address, photo album, friend’s list, and location. Event types may define a type of social media platform event associated with the subject of a criminal investigation. Event types may include, for example, the subject logging into their social media platform profile, posting a photo to the subject’s social media platform profile, sending friend requests, and accepting friend requests. Document types may define a type of social media platform document created by the subject or the subject’s contacts. Examples of document types include private messages, status updates, microblog posts (e.g., Facebook wall posts Twitter Tweets), comments on other users’ microblog posts, pictures, and videos.
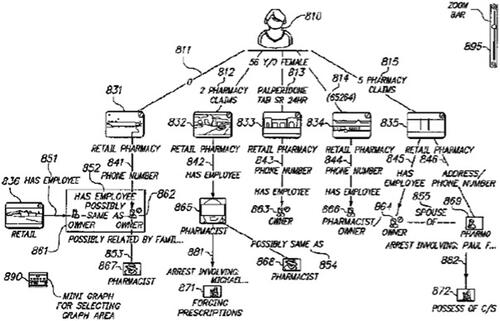
Furthermore, some secondhand accounts from Palantir’s customers have corroborated and reported on Palantir’s access to domain data (relating to healthcare, finance, social media, etc.) such as those listed above (beyond the customers who are the users of its software), as evidenced by the NHS’ “Data Protection Impact Assessment: NHS COVID-19 Data Store” (NHS Citation2020) which clearly states that Palantir is in contact with sensitive medical and health data of UK citizens and that Palantir must follow local rules and regulations such as the General Data Protection Regulation (GDPR). Regarding health data, contains an image from a Palantir patent (Wang et al. Citation2014) describing a person’s prescription information and pharmacist network, framed to detect medical and healthcare fraud claims.
Figure 9. Image showing person’s prescription and pharmacist network (Wang et al. Citation2014).
The findings from this first themed group of patents related to the labeling of human traces and sorting actions thus provide evidence that Palantir has conceptualized, designed, and implemented technologies that are targeted and domain-specific concerning identifying data objects and relations, and that, in some instances, there is a likelihood Palantir has access to those data which are often in sensitive areas requiring privacy accommodations and regulations. The patent evidence in this group, supplemented with secondary case reports such as those of the NHS and NYPD, where Palantir is described as either in direct contact with domain data or with the secondary analysis and results produced from domain data, potentially shows that the company is not entirely domain agnostic or “hands-off” in its approaches to data integration and that it must comply with regulations such as the GDPR.
Finding 2: Leveraging of metadata, ontologies, and semantic technologies
The second theme that emerged from our topic modeling pertains to how Palantir conducts its data integration by leveraging the power of metadata, ontologies, and semantic technologies. This theme contains topic 3 (selecting customizable data objects in graphs with nodes and edges), topic 4 (modeling and linking ontologies, entities, objects, relationships, and properties related to people, events, and things), topic 12 (levels of abstraction using layers, maps, graphs), topic 14 (schemas with sets, types, and properties), and topic 20 (representation and meaning, internal standardization and structure, metadata). This second thread shows themes relating to the development of technologies for orchestrating data integration to produce network ties and relationships across multiple domains, such as those in the first theme.
The topics in this second theme represent a higher level of abstraction than the topics in the first theme. Instead, the focus here is on producing second-order meaning and context from triangulating the extensive data collected and labeled in the first theme. These topics rely on significant data integration and meaningful assembly via large volumes of data from different domains. At this scale, there is compelling evidence of linkages between these disparate domain entities beyond labeling objects and events from initial data integration procedures. For example, one Palantir patent (Cervelli, GoGwilt, and Prochnow Citation2013) shows how an ontology is used to connect the information that has been labeled and retrieved from parsers, such as those represented in our first theme, with links, data objects and properties, which are then modeled and stored in a database (, top). Notice the central role of the “Ontology” in Palantir’s diagram of this information ecosystem. An example below (Carter and Cohen Citation2018) shows how an “Employee” is identified, along with data about who they have “Visited” or where they were “Seen at,” who they are “Married to,” and things that the person “Owns” (, bottom).
Figure 10. Palantir’s ontology infrastructure (Cervelli, GoGwilt, and Prochnow Citation2013) and an example (Carter and Cohen Citation2018).
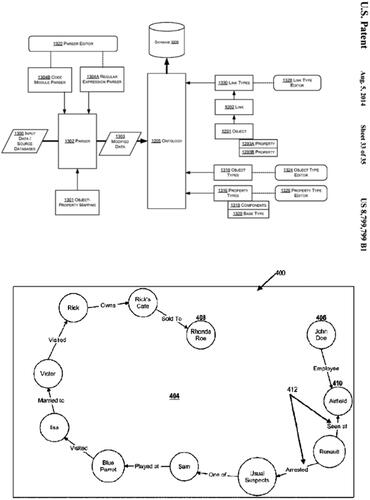
The topics in this second theme (3, 4, 12, 14, 20) triangulate domain data via metadata to produce a networked abstraction (i.e., the middle stage of the data funnel). This stage involves taking the data points from the first bin concerning the labeling of human traces and sorting actions and building them out into a more comprehensive ontology. Palantir’s software is employed here to provide a semantic middle layer between these data points and their eventual preemptive decision making. Palantir’s software builds and models these entities and their relationships in the metadata, producing new “knowledge” for Palantir’s customers. In this stage, infrastructuring happens and is afforded by Palantir’s ability to connect and relate different domains of siloed data, producing new levels of association, triangulation, coordination, etc., a practice that has historically occurred in information institutions that create large-scale knowledge graphs such as those by Google, Microsoft, Amazon, etc. discussed above. It is important to note that these descriptions of “knowledge” are about leveraging technology to create schemas and derive patterns from data repositories. These practices are based on a pre-established ontology that understands the world in a certain way.
There is evidence in this theme that Palantir has infrastructural aspirations to become a general classification system for data integration (what in information science is referred to as an “upper-level ontology,” which are domain-agnostic ontologies consisting of abstract categories and terms for integrating domain data) that can be tailored into a universal knowledge graph. In the same way that Google’s propriety knowledge graph introduces ethical problems relating to how it represents knowledge and monopolizes facts and meanings when presenting general information to users who engage with Google Search (Vang Citation2013), the topics described in this theme potentially show that Palantir similarly imagines a world where its platform might serve as a “shadow” universal knowledge graph for governments, industries, and organizations. For example, the word “knowledge” occurs 110 times in the corpus. It often refers to absorbing, leveraging, or abstracting domain “knowledge” into a generalized ontology that other users and non-specialists outside of a domain may be able to query for search results.
Finding 3: Interpretive processing for preemptive decision making
The last theme was about interpretive processing for preemptive decision making and contains topic 2 (memory, processing, and storage devices), topic 6 (provenance, receipts, and verification of claims, descriptions, disclosures), topic 7 (logical rule-based scoring and analysis with alerts), topic 8 (communication and notification with messages), topic 9 (visualizations with process flowcharts, figures, and diagrams), topic 11 (client-side code, datasets, templates), topic 13 (server-side software operation, implementation, and performance), topic 15 (sandboxing, cloud, experimenting, running tests, decision making, analytics), and topic 18 (geo-location, filtering/panes). These topics represented in this theme (2, 6, 7, 8, 9, 11, 13, 15, 18) reveal the legible data work and SaaS items that Palantir provides to its customers, that is, the ability to interact with meaningful representations out of the information that users receive in the form of dashboards, visualizations, interfaces, documentation, communication, etc. (i.e., the end-stage of the data funnel). Analytics data are presented here to provide a global survey of the data.
These final topics focus on how Palantir allows its users to manage data at scale using informative client or user-side systems to support prediction and decision analytics. Actionable items are included at this end stage, provided by data that have been semantically rendered through the data work of interpretive processing for management, analytics, and the prediction that occurs in Palantir’s surveillance platform, and this supports knowledge workers and data professionals. The images presented below () show types of visualizations that Palantir’s surveillance platform users can employ to assist with investigations and cases, allowing users to interact with and manage their data. Though these images are sketches, journalists have reported on sources who claim that Palantir’s surveillance platform interface “is slicker and more user friendly than the alternatives created by defense contractors” (Weinberger Citation2020).
Figure 11. From top: interactive classified cable reader (Lee et al. Citation2014), route detection for security threats (Simaitis Citation2019), and database entity matching (McGrew and Cohen Citation2013).

Most of the topics in the corpus fit into this final category showing that Palantir is highly concerned with the human-centered administrative and bureaucratic analytics processes involved in data work. Palantir’s patents show that the company designs products focused on communication among people within and between surveillance-focused organizations. The topics in this theme speak to the multiple stakeholders that Palantir imagines using its products, from programmers and managers to lawyers and financial services employees. represents some of the search scenarios Palantir imagines its users will engage. The image at the top shows a mockup of classified information relating to security and intelligence news and events (mainly in the Middle East) and how this will be orchestrated with analytics data. The second image represents a terror incident in London using a map and analytics data, including the ability to “discriminate” between data points to gain “knowledge” and potentially circumvent future incidents. The final image contains a series of Arabic names in a tool for detecting relationships and familial ties across databases.
The material presented here (Middle East, Arabic, etc.) is evidence of Palantir’s biases and how the company imagines its products will be employed (mainly by western policing, security, and intelligence agencies). However, the company has not shied from articulating its approval of western hegemony and US exceptionalism. In Karp’s letter accompanying the SEC filing, the Palantir CEO states that “Our software is used to target terrorists and to keep soldiers safe … We have chosen sides” (Palantir Citation2020a, ii) and other sections of the filing remark on Palantir’s support of “Western liberal democracy” (34). More infamously, Karp has further elaborated on Palantir’s ideological stance by stating that “our product is used on occasion to kill people” (Allen Citation2020), and Thiel himself is on record calling diversity and multiculturalism a “myth” (Sacks and Thiel Citation1999) while supporting monopolistic capitalism (Thiel and Masters Citation2014), once writing “I no longer believe that freedom and democracy are compatible” (Thiel 2009). Weigel (Citation2020) discusses early ideological and academic influences on Palantir’s leadership, including Thiel and Karp.
The themes in our corpus present evidence that Palantir envisions its surveillance platform serving as a preemptive and predictive technology that will thwart what Palantir imagines as criminal events before they happen (Andrejevic, Dencik, and Treré Citation2020). Here, following Massumi (Citation2015), we view Palantir as assuming that “what it must deal with has an objectively given existence prior to its own intervention” (5) and as combining “a proprietary epistemology with a unique ontology in such a way as to make present a future cause that sets a self-perpetuating movement into operation” (14). This operative logic uses Palantir’s surveillance platform to combine ontology with epistemology “in such a way as to endow itself with powers of self-causation” (200). Palantir thus tracks human traces and sorts them, leverages metadata, ontologies, and semantic technologies, and presents them using analytics for administrators, producing a data funnel that leads to preemptive decision making. We imagine the three themes presented above as part of a data funnel representation ().
Figure 12. Representation of Palantir’s data funnel containing three themes.
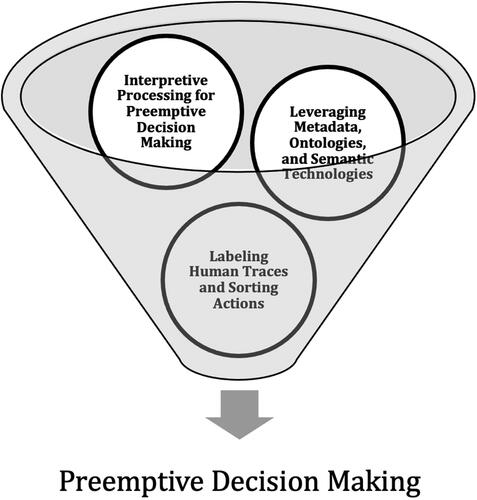
Palantir’s technologies that support preemptive decision making, based on probabilistic data sorting and ontological labeling of subjects as “criminals” etc. within broader networked connections, are involved in what De Goede (Citation2008) refers to as a “politics of preemption” and force of law where interpretive violence may occur. These connections between governance, risk, surveillance, and the ontological labeling of marginal groups are documented in studies of the “war on terror” (Amoore and De Goede Citation2005). As Amoore (Citation2013, 59) shows, there is an “ontology of association” that technologies such as Palantir make visible, rendering subjects based on probabilistic correlation of data traces and where the “possibility of action” remains open to security and administrative forces (64). Palantir’s expansion in providing these types of technology services from government security agencies to businesses and nonprofits in the public sector shows “the ease with which antiterrorist technologies and antiterrorist funding can be leveraged for civilian surveillance” (Hong, Citation2020, 26). In our final section, we conceptualize Palantir’s surveillance platform through the theoretical notion of infrastructuring.
Discussion: Infrastructuring
We conceptualize Palantir’s surveillance platform and the preemptive decision making that it enables as benefitting from acts of infrastructuring. While scholars in Science and Technology Studies, Media Studies, Communication, and Information Studies have focused on defining infrastructure, increasingly, scholars have attended to how researchers observing and those who build and maintain information infrastructure participate in active practices of infrastructuring. For Karasti and Blomberg (Citation2018), infrastructuring is “the ongoing and continual processes of creating and enacting information infrastructures” (234). Shifting the focus to practices of infrastructuring drives our critical attention to the processual nature of infrastructural phenomena, or what others have called “scalar devices” (Ribes Citation2014) and how they can be engaged, taken up, and shape dynamic futures. Others have described how the articulation work in infrastructuring “extends problems of use into the heterogeneous relations involved in large-scale, long-term, and interdisciplinary infrastructure projects” (Mikalsen, Farshchian, and Dahl Citation2018).
Information infrastructures that implement systems typically use metadata, ontologies, and semantic technologies to enact and enroll subjects, and they are often invisible in their provision and impact. How such categories have impacted infrastructuring has been studied as the politics of knowledge representation and classification, debated by standards engineers and infrastructure designers. Yet, we know from infrastructure scholars who have examined the power of semantic technologies (Allhutter Citation2019; Waller Citation2016) that metadata standards, database designs, and document-driven capture techniques all enroll subjects in several ways that have long-term, lasting effects beyond initial or inaugural acts of being rendered, captured, or made legible in systems. Poirier (Citation2019) has argued that such semiotic infrastructures and how individuals become eligible are forms of data power. But even as people and things are rendered by formal data modeling, such standards are always contested and evolving, even as they claim to institute unchanging, objective concepts. Poirier has described this as the double bind of catachresis in classificatory semiotic infrastructures like data models. Such ontological formalisms schematize meaning in ways that render people into or out of categories, while there are phenomena that resist types or variants that do not fit such categories. Infrastructure standards such as data labels used for Palantir’s surveillance platform are examples of the firm’s infrastructuring when labeling is used to represent and commensurate different streams of evidence into predictive analytics (for surveillance, policing purposes, or other applications).
Palantir’s software products and surveillance platform are underwritten by standards and can be said to affect the infrastructuring of surveillance software in the lives of those subjected to these technologies. In their work on the formation of publics, Dantec and DiSalvo (Citation2013) argue that such infrastructuring work can often reveal the power and structure of hegemony in these systems but may further offer a response to the entrenched authority that they represent. For Le Dantec and DiSalvo, an essential feature of infrastructuring is the distinction between fixed systems and systems that change beyond intended use cases, or “the work of creating socio-technical resources that intentionally enable adoption and appropriation beyond the initial scope of the design” (247). Others have pointed out the benefits of studying infrastructuring in that it allows researchers to examine ongoing and continuous processes (Bowker and Star Citation2000; Pipek and Wulf Citation2009). This mutable quality can be a two-edged sword; while models found in infrastructure can be edited, updated, modified, or changed in their creation and development, as enactments of infrastructure, they can further slowly seep beyond their intended use-cases and be applied (or misapplied) too broadly as they become entrenched over long periods (Ribes and Finholt Citation2009). Here, an essential feature of investigating infrastructuring through metadata, ontologies, and semantic technologies is their processual qualities; this open-endedness can eventually calcify, become brittle, and even drift from intended meanings. Anticipating this processual quality of infrastructuring allows us to examine and even mitigate “ontology troubles” that arise from the visibility and impact of data models upon the individuals they identify and represent in systems (Iliadis Citation2018, Citation2019).
Scholars who study standards engineering and infrastructure designers locate metadata, ontologies, and semantic technology communities and their institutions in their archives and well-documented debates over standards development (Russell Citation2014). There is a rich history of discussions documented in organizational listservs and meeting minutes in standards archives. Accounts of early web technologies are sourced from such records and web archives. But increasingly, data modeling standards decisions of design infrastructure are being enclosed into platforms that restrict our ability to follow these choices, intervene in such representations, or audit how data subjects are made legible or eligible in systems (Acker Citation2018). In their study on the promises and pitfalls of digital passages, Latonero and Kift (Citation2018) argue that the logic of different surveillance technologies can reinforce different categories of classification of groups of people, particularly with the rise in digital border control systems. For example, in the EU, while drones and satellites for border surveillance used through the European Border Surveillance System (Eurosur) enforce externalized borders through the sorting of groups, the European Asylum Dactyloscopy Database (Eurodac), which uses biometric information to classify asylum seekers and undocumented immigrants, enforces “internal boundaries through the identification of individuals” (Latonero and Kift Citation2018, 2). By pulling two types of digital classification together, surveillance technologies such as Eurosur and Eurodac enact a secure infrastructure for micro identification and macro sorting across borders throughout the EU.
As an ontologizing force that has the potential to combine different data stores, and in its extensive reach of configuring and integrating data sources for the state, Palantir’s surveillance platform becomes an indelible process for the infrastructuring of contemporary digital surveillance and governance. Yet, there are tensions between technological enterprise and propriety platforms that intermediate infrastructures and social systems such as standards for interoperability; the infrastructuring activity of data modeling remains an open challenge for information infrastructures in terms of domain incommensurability, yet the work of platformization allows Palantir to circumvent or restrict these issues of indeterminacy through its technology products (and restricting access), thus also highlighting the critical role of streamlined platform design and esthetics in facilitating the uptake of these restrictive systems.
Conclusion
Quantitative analysis of patents with topic modeling can provide a multi-level understanding of opaque technology firms and, more importantly, we argue, provide evidence relating to the technologies and business practices of IT firms. Patents are documents that can shed light on organizational logic, and future studies can look to patents as primary sources for investigative analyses of IT firms. Logics concerning resources, capabilities, capacities, goals, aspirations, partnerships, and planning can be made visible through patents and provide opportunities for researchers. We recommend several paths to patent analyses of these tech firms. First, researchers can scrape publicly available patents from repositories. Second, the patents contain several research opportunities, from images to metadata labeling. Third, the contents of patents can be diagrammatically laid out to provide multi-level insight. As our literature review shows, media and communication scholars (among others) are already using patents as a beneficial form of primary data use among several types of methods.
Palantir characterizes its work in nonspecific ways in interviews and engineering blog posts that tend to downplay the global aspirations of the company and its handling of some of the world’s most sensitive data. The patents described in this article show a different story, providing primary evidence of the types of all-encompassing data integration work toward which the company imagines it is working. Palantir envisions its technologies synchronizing with other organizations and platforms—including Amazon, Google, Microsoft, and the US and UK governments—to integrate the data of customers, citizens, refugees, patients, and alleged criminals, among others. While Palantir attempts to distance itself publicly from the image of a global tech firm that facilitates the modeling of data where civil liberties and human rights might be at stake, the patents show that such processes were imagined, designed, and implemented as far back as 2006; healthcare, security, immigration, social media, and financial data collection, sorting, and modeling for preemptive decision making are all described. More recently, Palantir’s SEC filing appears to confirm this mission, including rationalization of the nature of such work (Palantir Citation2020a, i–ii):
Our partners require something more. They need generalizable platforms for modeling the world and making decisions. And that is what we have built. […] The construction of software platforms that enable more effective surveillance by the state of its adversaries or that assist soldiers in executing attacks raises countless issues, involving the points of tension and tradeoffs between our collective security and individual privacy, the power of machines, and the types of lives we both want to and should lead. The ethical challenges that arise are constant and unrelenting. … We embrace the complexity that comes from working in areas where the stakes are often very high and the choices may be imperfect. … The engineering elite of Silicon Valley may know more than most about building software. But they do not know more about how society should be organized or what justice requires.
Palantir’s characterization of “adversaries” and its critique of Silicon Valley’s understanding of “justice” and “how society should be organized” are curious when read alongside the patents presented in this article, where technologies for data gathering, labeling, and modeling are described in contexts that include facial recognition, predictive policing, workplace surveillance, and social media mining.
Lastly, Palantir’s patents also reveal an image of a tech firm that uses its surveillance platform to work toward something like infrastructuring or to assist clients in amassing a shadow data infrastructure for purposes of governing and control. The patents are rich resources for encountering and interpreting a surveillance platform’s descriptions and mechanics, which increasingly shape critical digital infrastructures of the state, corporations, and institutions. They further reveal that creating these technologies involves lengthy processes, and in certain instances, for Palantir, these have lasted over ten years. These documents move through time in stages and an organized manner in ways that company blog posts and other media (news articles, reports, etc.) do not, providing a more detailed and informative view of Palantir’s aspirations for its technology. Palantir wants its surveillance platform to become the de facto operating system for governments and the world’s most sensitive data across private industries and domains while also ingesting open data from public institutions. While Palantir may claim otherwise, we believe there is enough evidence in these patents to suggest that Palantir has an internal knowledge base or knowledge graph for labeling entities in the world, along with their attributes and relationships, and that these occluded resources are not fully released to users, but that users are subject to them in using the products. Thus, the relevance of Palantir to emerging media and communication is found in the company’s technology which acts as a mediator between the social worlds of data and information.
Data Deposit
Supplemental Material
Download PDF (1.2 MB)References
- Abbas, J. 2010. Structures for organizing knowledge: Exploring taxonomies, ontologies, and other schema. New York: Neal-Schuman.
- Abood, A, and D. Feltenberger. 2018. Automated patent landscaping. Artificial Intelligence and Law 26 (2):103–25. doi: 10.1007/s10506-018-9222-4.
- Acker, A. 2018. A death in the timeline: Memory and metadata in social platforms. Journal of Critical Library and Information Studies 2 (2):1–27. doi: 10.24242/jclis.v2i2.66.
- Acker, A, and J. Donovan. 2019. Data craft: A theory/methods package for critical internet studies. Information, Communication & Society 22 (11):1590–609. doi: 10.1080/1369118X.2019.1645194.
- Agre, P. E. 1994. Surveillance and capture: Two models of privacy. The Information Society 10 (2):101–27. doi: 10.1080/01972243.1994.9960162.
- Agre, P. E. 1997. Computation and human experience. Cambridge, MA: MIT Press.
- Alden, W. 2017. There’s a fight brewing between the NYPD and Silicon Valley’s Palantir. BuzzFeed News, 28 June. Accessed March 20, 2021. https://www.buzzfeednews.com/article/williamalden/theres-a-fight-brewing-between-the-nypd-and-silicon-valley.
- Allen, M. 2020. AXIOS on HBO: Alex Karp, CEO of Palantir (promo). Accessed August 5, 2021. https://www.youtube.com/watch?v=AzY7H_rr0w4.
- Allhutter, D. 2019. Of “working ontologists” and “high-quality human components”: The politics of semantic infrastructures. In digitalSTS: A field guide for science & technology studies, eds. D. Ribes and J. Vertesi, 326–48. Princeton, NJ: Princeton University Press.
- Amoore, L. 2009. Lines of sight: On the visualization of unknown futures. Citizenship Studies 13 (1):17–30. doi: 10.1080/13621020802586628.
- Amoore, L. 2013. The politics of possibility: Risk and security beyond probability. Durham, NC: Duke University Press.
- Amoore, L, and M. De Goede. 2005. Governance, risk and dataveillance in the war on terror. Crime, Law and Social Change 43 (2-3):149–73. doi: 10.1007/s10611-005-1717-8.
- Andrejevic, M. 2007. iSpy: Surveillance and power in the interactive era. Lawrence, KS: University Press of Kansas.
- Andrejevic, M., L. Dencik, and E. Treré. 2020. From pre-emption to slowness: Assessing the contrasting temporalities of data-driven predictive policing. New Media & Society 22 (9):1528–44. doi: 10.1177/1461444820913565.
- Baca, M. ed. 2016. Introduction to metadata, 3rd ed. Los Angeles, CA: Getty Research Institute.
- Bakardjieva, M, and R. W. Gehl. 2017. Critical approaches to communication technology: The past five years. Annals of the International Communication Association 41 (3-4):213–9. doi: 10.1080/23808985.2017.1374201.
- Balakrishnan, M., N. Bastani, M. Mahmoudi, Q. Tsui, and J. Zionts. 2020. All roads lead to Palantir: A review of how the data analytics company has embedded itself throughout the UK. London: Privacy International. Accessed March 30, 2021. https://privacyinternational.org/sites/default/files/2020-11/All%20roads%20lead%20to%20Palantir%20with%20Palantir%20response%20v3.pdf.
- Beard, M., C. Brahms, T. Huber, K. Kapitanova, O. Kwon, C. Richbourg, M. Stoeckel, S. Robinson, and J. M. Doyle. 2016. Systems and methods for structuring data from unstructured electronic data files. EU Patent. EP3139328A1, filed September 2, 2016.
- Bell, D, and M. Kleinman. 2020. As Palantir goes public, consider its troubling human rights record. Fortune, September 30. Accessed July 25, 2021. https://fortune.com/2020/09/30/palantir-direct-listing-human-rights/.
- Bender, E. M., T. Gebru, A. McMillan-Major, and S. Shmitchell. 2021. On the dangers of stochastic parrots. Can language models be too big? In FAccT ’21: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623. New York: ACM. doi: 10.1145/3442188.3445922.
- Berners-Lee, T., J. Hendler, and O. Lassila. 2001. The semantic web. Scientific American, May 17. Accessed July 26, 2021. https://www.scientificamerican.com/article/the-semantic-web/.
- Berners-Lee, T. 1999. Weaving the web: The original design and ultimate destiny of the World Wide Web. New York: Harper.
- Biddle, S. 2017. How Peter Thiel’s Palantir helped the NSA spy on the whole world. The Intercept, February 22. Accessed March 30, 2021. https://theintercept.com/2017/02/22/how-peter-thiels-palantir-helped-the-nsa-spy-on-the-whole-world/.
- Blei, D. M., A. Y. Ng, and M. I. Jordan. 2003. Latent Dirichlet allocation. Journal of Machine Learning Research 3:993–1022.
- Bowker, G, and S. L. Star. 2000. Sorting things out: Classification and its consequences. Cambridge, MA: MIT Press.
- Bowker, G., K. Baker, F. Millerand, and D. Ribes. 2010. Toward information infrastructure studies: Ways of knowing in a networked environment. In International handbook of internet research, eds. J. Hunsinger, L. Klastrup, and M. Allen, 97–117. Dordrecht, The Netherlands: Springer.
- Brayne, S. 2017. Big data surveillance: The case of policing. American Sociological Review 82 (5):977–1008. doi: 10.1177/0003122417725865.
- Brayne, S. 2020. Predict and surveil: Data, discretion, and the future of policing. Oxford, UK: Oxford University Press.
- Brown, N., Y. Cai, Y. Guo, R. Kazman, M. Kim, P. Kruchten, E. Lim, A. MacCormack, R. Nord, I. Ozkaya, et al. 2010. Managing technical debt in software-reliant systems. In FoSER ’10 Proceedings of the FSE/SDP Workshop on Future of Software Engineering Research, 47-52. New York: ACM. doi: 10.1145/1882362.1882373.
- Bucher, T. 2020. The right-time web: Theorizing the kairologic of algorithmic media. New Media & Society 22 (9):1699–714. doi: 10.1177/1461444820913560.
- Carter, D., A. Acker, and D. Sholler. 2021. Investigative approaches to researching information technology companies. Journal of the Association for Information Science and Technology 72 (6):655–66. doi: 10.1002/asi.24446.
- Carter, L, and D. Cohen. 2018. Concurrent automatic adaptive storage of datasets in graph databases. EU Patent. EP3511842A1, filed December 17, 2018.
- Cervelli, D., C. GoGwilt, and B. Prochnow. 2013. Interactive geospatial map. US Patent. US8799799B1, filed June 13, 2013, and granted August 5, 2014.
- Chafkin, M. 2021. The contrarian: Peter Thiel and Silicon Valley’s pursuit of power. New York: Penguin.
- Choi, D., and B. Song. 2018. Exploring technological trends in logistics: Topic modeling-based patent analysis. Sustainability 10 (8, 2810):1–26. doi: 10.3390/su10082810.
- Clarke, R. 1994. The digital persona and its application to data surveillance. The Information Society 10 (2):77–92. 1993 doi: 10.1080/01972243.1994.9960160.
- Cochoy, F, and B. Soutjis. 2020. Back to the future of digital price display: Analyzing patents and other archives to understand contemporary market innovations. Social Studies of Science 50 (1):3–29. doi: 10.1177/0306312719884643.
- Confessore, N, and M. Rosenberg. 2018. Spy contractor’s idea helped Cambridge Analytica harvest Facebook data. The New York Times, March 27. Accessed July 28, 2021. https://www.nytimes.com/2018/03/27/us/cambridge-analytica-palantir.html.
- Coward, H. R, and J. J. Franklin. 1989. Identifying the science-technology interface: Matching patent data to a bibliometric model. Science, Technology, and Human Values 14 (1):50–77. doi: 10.1177/016224398901400106.
- Cunningham, W. 1992. The WyCash Portfolio Management System. ACM SIGPLAN OOPS Messenger 4 (2):29–30. doi: 10.1145/157709.157715.
- Dantec, C. A. L, and C. DiSalvo. 2013. Infrastructuring and the formation of publics in participatory design. Social Studies of Science 43 (2):241–64. doi: 10.1177/0306312712471581.
- Davenport, C. 2016. Peter Thiel’s Palantir scores a win in fight for lucrative Army contract. The Washington Post, October 31. Accessed May 30, 2022. https://www.washingtonpost.com/business/economy/peter-thiels-palantir-scores-a-win-in-fight-for-lucrative-army-contract/2016/10/31/7e0682fa-9f8a-11e6-a44d-cc2898cfab06_story.html
- De Goede, M. 2008. The politics of preemption and the war on terror in Europe. European Journal of International Relations 14 (1):161–85. doi: 10.1177/1354066107087764.
- Delfanti, A, and B. Frey. 2020. Humanly extended automation or the future of work seen through Amazon patents. Science, Technology, and Human Values 46 (3):1–28. doi: 10.1177/0162243920943665.
- DeNardis, L. 2014. The global war for internet governance. Cambridge, MA: MIT Press.
- Domingue, J., F. Dieter, and J. A. Hendler, eds. 2011. Handbook of semantic web technologies. Berlin: Springer.
- Ducott, R. A., J. K. Garrod, J. A, and K. Brainard. 2016. Carrino Cross-ontology multi-master replication. US Patent. US10061828B2, filed May 2, 2016, and granted August 28, 2018.
- Edge, P. T, and K. L. Neuman. 2016. Privacy impact assessment for ICE investigative case management DHS/ICE/PIA-045. Washington, DC: U. S. Department of Homeland Security. Accessed March 30, 2021. https://www.dhs.gov/sites/default/files/publications/privacy-pia-ice-icm-june2016.pdf.
- Egbert, S. 2019. Predictive policing and the platformization of police work. Surveillance & Society 17 (1/2):83–8. doi: 10.24908/ss.v17i1/2.12920.
- Ferguson, A. G. 2017. The rise of big data policing: Surveillance, race, and the future of law enforcement. New York: New York University Press.
- Fidler, B, and A. Acker. 2017. Metadata, infrastructure, and computer mediated communication in historical perspective. Journal of the Association for Information Science and Technology 68 (2):412–22. doi: 10.1002/asi.23660.
- Fürber, C. 2016. Data quality management with semantic technologies. Berlin: Springer.
- Gandy Jr., O. H. 1989. The surveillance society: Information technology and bureaucratic social control. Journal of Communication 39 (3):61–76. doi: 10.1111/j.1460-2466.1989.tb01040.x.
- Gandy Jr., O. H. 1993. The panoptic sort: A political economy of personal information. Boulder, CO: Westview Press.
- Gates, K, and S. Magnet. 2007. Communication research and the study of surveillance. The Communication Review 10 (4):277–93. doi: 10.1080/10714420701715357.
- Gates, K. 2019. Policing as digital platform. Surveillance & Society 17 (1/2):63–8. doi: 10.24908/ss.v17i1/2.12940.
- Gehl, R. W. 2015. Sharing, knowledge management and big data: A partial genealogy of the data scientist. European Journal of Cultural Studies 18 (4–5):413–28. doi: 10.1177/1367549415577385.
- Glushko, R. J., ed. 2013. The discipline of organizing. Cambridge, MA: MIT Press.
- Goenka, A., A. Jain, A. Taheri, D. Isaza, J. Zhu, W. Manson, V. D. Turan, and S. Jastrzebski. 2019. Database systems and user interfaces for dynamic and interactive mobile image analysis and identification. US Patent. US10635932B2, filed May 16, 2019, and granted April, 28, 2020.
- Gordon, L. 2021a. Palantir Technologies and the Royal Navy extend contracts. Business Wire, May 7. Accessed July 26, 2021. https://www.businesswire.com/news/home/20210506006341/en/Palantir-Technologies-and-the-Royal-Navy-Extend-Contracts.
- Gordon, L. 2021b. Palantir introduces Foundry for Builders world-class software platform now available to early-stage companies. Business Wire, July 20. Accessed July 26, 2021. https://www.businesswire.com/news/home/20210720005346/en/Palantir-Introduces-Foundry-for-Builders.
- Gordon, L. 2021c. Palantir and space force expand partnership. Business Wire, May 24. Accessed July 24, 2021. https://www.businesswire.com/news/home/20210524005231/en/Palantir-and-Space-Force-Expand-Partnership.
- Gregg, A, and D. MacMillan. 2020. Palantir goes public at $10 per share, ending 16 years of privately held secrecy. The New York Times, September 30. Accessed March 30, 2021. https://www.washingtonpost.com/business/2020/09/29/palantir-public-offering/.
- Harris, M. 2017. How Peter Thiel’s secretive data company pushed into policing. Wired, August 9. Accessed October 7, 2021. https://www.wired.com/story/how-peter-thiels-secretive-data-company-pushed-into-policing/
- Hatmaker, T. 2020. AOC flagged “material risks” to Palantir investors in letter to SEC. TechCrunch.com, September 30. Accessed July 24, 2021. https://techcrunch.com/2020/09/30/aoc-palantir-letter/.
- Hitzler, P. 2021. A review of the semantic web field. Communications of the ACM 64 (2):76–83. doi: 10.1145/3397512.
- Hong, S-h 2020. Technologies of speculation: The limits of knowledge in a data-driven society. New York: New York University Press.
- Hu, Z., S. Fang, and T. Liang. 2014. Empirical study of constructing a knowledge organization system of patent documents using topic modeling. Scientometrics 100 (3):787–99. doi: 10.1007/s11192-014-1328-1.
- Hvistendahl, M. 2021. How the LAPD and Palantir use data to justify racist policing. The Intercept, January 30. Accessed August 5, 2021. https://theintercept.com/2021/01/30/lapd-palantir-data-driven-policing/.
- Iliadis, A, and F. Russo. 2016. Critical data studies: An introduction. Big Data & Society 3 (2):205395171667423. doi: 10.1177/2053951716674238.
- Iliadis, A. 2018. Algorithms, ontology, and social progress. Global Media and Communication 14 (2):219–30. doi: 10.1177/1742766518776688.
- Iliadis, A. 2019. The tower of babel problem: Making data make sense with Basic Formal Ontology. Online Information Review 43 (6):1021–45. doi: 10.1108/OIR-07-2018-0210.
- Iliadis, A., T. Liao, I. Pedersen, and J. Han. 2021. Learning about metadata and machines: Teaching students using a novel structured database activity. Journal of Communication Pedagogy 4:152–65. doi: 10.31446/JCP.2021.1.14.
- Irani, L, and C. Whitney. 2020. Broken promises of civic innovation: Technological, organizational, fiscal, and equity challenges of GE Current CityIQ. San Diego, CA: Institute for Practical Ethics, University of California. Accessed March 30, 2021. http://quote.ucsd.edu/lirani/files/2020/05/Smart-streetlighs-memo.pdf.
- Jethani, S. 2020. Doing time in the home-space: Ankle monitors, script analysis, and anticipatory methodology. In Embodied computing: Wearables, implantables, embeddables, ingestibles, eds. I. Pedersen and A. Iliadis, 161–81. Cambridge, MA: MIT Press.
- Johnson, B. 2011. ChamberLeaks: Pro-Chamber conspiracy illicitly scraped Facebook. ThinkProgress.org, February 14. Accessed July 28, 2021. https://thinkprogress.org/chamberleaks-pro-chamber-conspiracy-illicitly-scraped-facebook-eb3ff047a577/.
- Karasti, H, and J. Blomberg. 2018. Studying infrastructuring ethnographically. Computer Supported Cooperative Work 27 (2):233–65. doi: 10.1007/s10606-017-9296-7.
- Kejriwal, M., C. Knoblock, and P. Szekely. 2021. Knowledge graphs: Fundamentals, techniques, and applications. Cambridge, MA: MIT Press.
- Kendall, E. F, and D. McGuiness. 2019. Ontology engineering. Williston, VT: Morgan & Claypool.
- Knight, E, and A. Gekker. 2020. Mapping interfacial regimes of control: Palantir’s ICM in America’s post-9/11 security technology infrastructures. Surveillance & Society 18 (2):231–43. doi: 10.24908/ss.v18i2.13268.
- Krishnaswamy, A., C. Minor, and R. Fink. 2020. Palantir Apollo: Powering SaaS where no SaaS has gone before. Palantir Blog, September 29. Accessed March 30, 2021. https://medium.com/palantir/palantir-apollo-powering-saas-where-no-saas-has-gone-before-7be3e565c379.
- Kruchten, P., R. L. Nord, and I. Ozkaya. 2012. Technical debt: From metaphor to theory and practice. IEEE Software 29 (6):18–21. doi: 10.1109/MS.2012.167.
- Latonero, M, and P. Kift. 2018. On digital passages and borders: Refugees and the new infrastructure for movement and control. Social Media + Society 4 (1):205630511876443–11. doi: 10.1177/2056305118764432.
- Lee, B., J. Goldenberg, D. Wolpert, D. Cervelli, B. Yonge, C. Freeland, T. Zhong, and G. Martin. 2014. Cable reader labeling. EU Patent. EP2835770A2, filed August 8, 2014.
- Liao, T, and A. Iliadis. 2021. A future so close: Mapping 10 years of promises and futures across the augmented reality development cycle. New Media & Society 23 (2):258–83. doi: 10.1177/1461444820924623.
- Lyon, D. 2007. Surveillance studies: An overview. Cambridge, UK: Polity.
- Mackenzie, M., P. Keating, and A. Cambrosio. 1990. Patents and free scientific information in biotechnology: Making monoclonal antibodies proprietary. Science, Technology, & Human Values 15 (1):65–83. doi: 10.1177/016224399001500108.
- MacMillan, D, and E. Dwoskin. 2019. The war inside Palantir: Data-mining firm’s ties to ICE under attack by employees. Washington Post, August 22. Accessed March 30, 2021. https://www.washingtonpost.com/business/2019/08/22/war-inside-palantir-data-mining-firms-ties-ice-under-attack-by-employees/.
- Massumi, B. 2015. Ontopower: War, powers, and the state of perception. Durham, NC: Duke University Press.
- Mattern, S. 2018. All eyes on the border. Places Journal (2018) doi: 10.22269/180925.
- Mayernik, M. S, and A. Acker. 2018. Tracing the traces: The critical role of metadata within networked communications. Journal of the Association for Information Science and Technology 69 (1):177–80. doi: 10.1002/asi.23927.
- McComb, D. 2004. Semantics in business systems: The savvy manager’s guide. New York: Morgan Kaufmann.
- McGrew, R, and S. Cohen. 2013. Resolving database entity information. US Patent. US9501552B2, filed August 29, 2013, and granted November 22, 2016.
- Michel, J.-B., A. Hampton, A. Shukla, and I. K. A. Sivakumar. 2018. Entity data attribution using disparate data sets. US Patent. US20190108173A1, filed December 4, 2018, and granted March 9, 2021.
- Mijente. 2019. The war against immigrants: Trump’s tech tools powered by Palantir. Accessed June 19, 2022. https://mijente.net/wp-content/uploads/2019/08/Mijente-The-War-Against-Immigrants_-Trumps-Tech-Tools-Powered-by-Palantir_.pdf
- Mikalsen, M., B. A. Farshchian, and Y. Dahl. 2018. Infrastructuring as ambiguous repair: A case study of a surveillance infrastructure project. Computer Supported Cooperative Work 27 (2):177–207. doi: 10.1007/s10606-017-9302-0.
- Monahan, T., and D. Murakami Wood. eds. 2018. Surveillance studies: A reader. Oxford, UK: Oxford University Press.
- Munn, L. 2017. Seeing with software: Palantir and the regulation of life. Studies in Control Societies 2 (1):1–16.
- Munn, L. 2019. Approaching algorithmic power. Doctoral dissertation, Western Sydney University.
- Murakami Wood, D, and T. Monahan. 2019. Platform surveillance. Surveillance & Society 17 (1/2):1–6. doi: 10.24908/ss.v17i1/2.13237.
- NHS. 2020. Data protection impact assessment: NHS COVID-19 data store. London: National Health Service. Accessed March 30, 2021. https://www.england.nhs.uk/wp-content/uploads/2020/06/202004-DPIA-NHS-COVID19-data-store-v1.4.pdf.
- Noy, N., Y. Gao, A. Jain, A. Narayanan, A. Patterson, and J. Taylor. 2019. Industry-scale knowledge graphs: Lessons and challenges. Communications of the ACM 62 (8):36–43. doi: 10.1145/3331166.
- Null, S. 2019. Dynamic ontology: As Palantir engineers explain this to the CIA, the NSA, and the military. Accessed July 3, 2022. https://sudonull.com/post/89367-Dynamic-ontology-As-Palantir-engineers-explain-this-to-the-CIA-the-NSA-and-the-military.
- O’Donnell, C. 2020. Palantir wins $44 million FDA contract, boosting shares 21%. Reuters, December 7. Accessed March 30, 2021. https://www.reuters.com/article/us-palantir-tech-fda-idUSKBN28H2TH.
- Oremus, W. 2020. Google and Palantir are two sides of the same coin: Both companies leverage vast amounts of data for unprecedented surveillance. Medium, October 3. Accessed July 24, 2021. https://onezero.medium.com/what-you-need-to-know-about-the-google-for-spies-a1a472f5d3c5.
- Owen, T. 2018. Twenty one years of HIV/AIDS medicines in the newspaper: Patents, protest, and philanthropy. Media, Culture & Society 40 (1):75–93. doi: https://doi.org/10.1177/0163443717703795.
- Packer, K, and A. Webster. 1996. Patenting culture in science: Reinventing the scientific wheel of credibility. Science, Technology, & Human Values 21 (4):427–53. doi: 10.1177/016224399602100403.
- Palantir. 2012. Dynamic ontology (video). Accessed March 30, 2021. https://www.youtube.com/watch?v=ts0JV4B36Xw.
- Palantir. 2020a. Form S-1 registration statement. Accessed March. 30, 2021. https://www.sec.gov/Archives/edgar/data/1321655/000119312520230013/d904406ds1.htm.
- Palantir. 2020b. Palantir is not a data company (Palantir explained, #1). Palantir Blog, November 11. Accessed October 7, 2021. https://blog.palantir.com/palantir-is-not-a-data-company-palantir-explained-1-a6fcf8b3e4cb.
- Palantir. 2021a. Palantir Gotham platform features. Accessed March 30, 2021. https://www.palantir.com/palantir-gotham/platform-features/.
- Palantir. 2021b. Palantir Foundry. Accessed October 1, 2021. https://www.palantir.com/palantir-foundry/.
- Parisi, D. 2019. Rumble/control: Toward a critical history of touch feedback in video games. ROMchip 1 (2)Accessed March:30–2021. doi: Https://romchip.org/index.php/romchip-journal/article/view/86.
- Parker, B. 2019. New UN deal with data mining firm Palantir raises protection concerns. The New Humanitarian, February 5. Accessed March 30, 2021. https://www.thenewhumanitarian.org/news/2019/02/05/un-palantir-deal-data-mining-protection-concerns-wfp.
- Pipek, V, and V. Wulf. 2009. Infrastructuring: Toward an integrated perspective on the design and use of information technology. Journal of the Association for Information Systems 10 (5):447–73. doi: 10.17705/1jais.00195.
- Plantin, J.-C., C. Lagoze, P. N. Edwards, and C. Sandvig. 2018. Infrastructure studies meet platform studies in the age of Google and Facebook. New Media & Society 20 (1):293–310. doi: 10.1177/1461444816661553.
- Poirier, L. 2019. Classification as catachresis: Double binds of representing difference with semiotic infrastructure. Canadian Journal of Communication 44 (3):361–71. doi: 10.22230/cjc.2019v44n3a3455.
- Pomerantz, J. 2015. Metadata. Cambridge, MA: MIT Press.
- Porcari, E. 2019. A statement on the WFP-Palantir partnership. Accessed March 30, 2021. https://medium.com/world-food-programme-insight/a-statement-on-the-wfp-palantir-partnership-2bfab806340c.
- Posner, M. 2019. How Palantir falls short of responsible corporate conduct. Forbes, September 12. Accessed July 25, 2021. https://www.forbes.com/sites/michaelposner/2019/09/12/what-companies-can-learn-from-palantir/?sh=506f519616e0.
- Pressman, A. 2019. Controversial startup Palantir denies assisting ICE with family separations. Fortune, December 11. Accessed July 28, 2021. https://fortune.com/2019/12/11/palantir-denies-assisting-ice/.
- Ribes, D, and T. A. Finholt. 2009. The long now of technology infrastructure: Articulating tensions in development. Journal of the Association for Information Systems 10 (5):375–98. doi: 10.17705/1jais.00199.
- Ribes, D. 2014. Ethnography of scaling, or, how to a fit a national research infrastructure in the room. In CSCW ’14: Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work and Social Computing, 158–170. New York: ACM. doi: 10.1145/2531602.2531624.
- Ribes, D., A. S. Hoffman, S. C. Slota, and G. C. Bowker. 2019. The logic of domains. Social Studies of Science 49 (3):281–309. doi: 10.1177/0306312719849709.
- Ritchie, M. 2020. Fusing race: The phobogenics of racializing surveillance. Surveillance & Society 18 (1):12–29. doi: 10.24908/ss.v18i1.13131.
- Robertson, D., A. Sparrow, M. Lewin, M. Von Brentano, M. Elkherj, and R. Cosman. 2017. Crime risk forecasting. US Patent. US20170293847A1, filed June 21, 2017.
- Rocha, B. P. S. 2019. Dev versus delta: Demystifying engineering roles at Palantir. Palantir Blog, April 8. Accessed March 30, 2021. https://blog.palantir.com/dev-versus-delta-demystifying-engineering-roles-at-palantir-ad44c2a6e87.
- Russell, A. L. 2011. Constructing legitimacy: The W3C’s patent policy. In Opening standards: The global politics of interoperability, ed. L. DeNardis, 159–76. Cambridge, MA: MIT Press.
- Russell, A. L. 2014. Open standards and the digital age: History, ideology, and networks. Oxford, UK: Oxford University Press.
- Ryan, P., S. Hao, B. Engel, X. Wang, J. Grossman, G. Martin, A. Elder, R. Xie, B. Hamilton, J. Zavilla, C. Richbourg, R. Beiermeister, and M. Frankel. 2017. Systems and interactive user interfaces for automatic generation of temporal representation of data objects. US Patent. US10540061B2, filed November 17, 2017, and granted January 21, 2020.
- Sacks, D. O, and P. A. Thiel. 1999. The diversity myth: Multiculturalism and political intolerance on campus. Oakland, CA: Independent Institute.
- Sculley, D., G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J.-F. Crespo, and D. Dennison. 2015. Hidden technical debt in machine learning systems. In NIPS’15: Proceedings of the 28th International Conference on Neural Information Processing Systems, Vol. 2, 2503–11. Cambridge, MA: MIT Press.
- Seaman, C, and Y. Guo. 2011. Measuring and monitoring technical debt. Advances in Computers 82:25–46. doi: 10.1016/B978-0-12-385512-1.00002-5.
- Sen, A., N. Nishant, J. Franklin, and C. Oguh. 2020. Palantir valued at $20 billion in choppy stock exchange debut. Reuters.com, September 30. Accessed July 28, 2021. https://www.reuters.com/article/us-palantir-ipo-idUSKBN26L3DR.
- Shapiro, A. 2020. Embodiments of the invention”: Patents and urban diagrammatics in the smart city. Convergence: The International Journal of Research into New Media Technologies 26 (4):751–74. doi: 10.1177/1354856520941801.
- Shead, S. 2021. Campaign launches to try to force Palantir out of Britain’s NHS. CNBC, June 4. Accessed September 27, 2021. https://www.cnbc.com/2021/06/04/campaign-launched-to-get-palantir-out-of-nhs.html.
- Sherman, N. 2020. Palantir: The controversial data firm now worth £17bn. BBC News, October 1. Accessed March 30, 2021. https://www.bbc.com/news/business-54348456.
- Simaitis, A. 2019. System and method to analyze routes. EU Patent. EP3528135A1, filed February 15, 2019.
- Steinberger, M. 2020. Does Palantir see too much? The New York Times, October 21. Accessed March 30, 2021. https://www.nytimes.com/interactive/2020/10/21/magazine/palantir-alex-karp.html.
- Thiel, P, and B. Masters. 2014. Zero to one: Notes on startups, or how to build the future. New York: Crown Business.
- Thiel, P. 2009. The education of a libertarian. Cato Unbound, April 13. Accessed March 30, 2021.
- Tom, E., A. Aurum, and R. Vidgen. 2013. An exploration of technical debt. Journal of Systems and Software 86 (6):1498–516. doi: 10.1016/j.jss.2012.12.052.
- Turow, J, and N. Couldry. 2018. Media as data extraction: Towards a new map of a transformed communications field. Journal of Communication 68 (2):415–23. doi: 10.1093/joc/jqx011.
- Vang, K. J. 2013. Ethics of Google’s knowledge graph: Some considerations. Journal of Information, Communication and Ethics in Society 11 (4):245–60. doi: 10.1108/JICES-08-2013-0028.
- Vats, A. 2020. The color of creatorship: Intellectual property, race, and the making of Americans. Palo Alto, CA: Stanford University Press.
- Venugopalan, S, and V. Rai. 2015. Topic based classification and pattern identification in patents. Technological Forecasting and Social Change 94:236–50. doi: 10.1016/j.techfore.2014.10.006.
- Waldman, P., L. Chapman, and J. Robertson. 2018. Palantir knows everything about you. Bloomberg, April 19. Accessed March 30, 2021. https://www.bloomberg.com/features/2018-palantir-peter-thiel/.
- Waller, V. 2016. Making knowledge machine-processable: Some implications of general semantic search. Behaviour & Information Technology 35 (10):784–95. doi: 10.1080/0144929X.2016.1183710.
- Wang, L., C. Ketterling, M. Winlo, and C. R. Luck. 2014. Data processing techniques. NL Patent NL2012435C2 filed March 14, 2014 and granted November 4, 2014.
- Weigel, M. 2020. Palantir goes to the Frankfurt School. boundary 2, 10 July. Accessed July 24, 2021. https://www.boundary2.org/2020/07/moira-weigel-palantir-goes-to-the-frankfurt-school/
- Weinberger, S. 2020. Techie software soldier spy: Palantir, big data’s scariest, most secretive unicorn, is going public. But is its crystal ball just smoke and mirrors? New York Magazine, September 28. Accessed July 24, 2021. https://nymag.com/intelligencer/2020/09/inside-palantir-technologies-peter-thiel-alex-karp.html.
- Weiner, C. 1987. Patenting and academic research: Historical case studies. Science, Technology, & Human Values 12 (1):50–62. doi: 10.1177/016224398701200105.
- West, E. 2019. Amazon: Surveillance as a service. Surveillance & Society 17 (1/2):27–33. doi: 10.24908/ss.v17i1/2.13008.
- Wikileaks. 2016. The HBGary Emails. Accessed March 30, 2021. https://wikileaks.org/hbgary-emails/?file=Palantir+Technology+Summary&count=50#searchresult.
- Wilson, D. 2019. Platform policing and the real-time cop. Surveillance & Society 17 (1/2):69–75. doi: 10.24908/ss.v17i1/2.12958.
- Woodman, S. 2016. Documents suggest Palantir could help power Trump’s ‘extreme vetting’ of immigrants. The Verge, 21 December. Accessed September 27, 2021. https://www.theverge.com/2016/12/21/14012534/palantir-peter-thiel-trump-immigrant-extreme-vetting.
- Yun, J, and Y. Geum. 2020. Automated classification of patents: A topic modeling approach. Computers & Industrial Engineering 147:106636–13. doi: 10.1016/j.cie.2020.106636.
- Zeng, M. L, and J. Qin. 2016. Metadata . 2nd ed. Chicago: Neal-Schuman.
- Zittrain, J. 2008. The future of the internet and how to stop it. New Haven, CT: Yale University Press.