
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We investigate the convergence properties of incremental mirror descent type subgradient algorithms for minimizing the sum of convex functions. In each step, we only evaluate the subgradient of a single component function and mirror it back to the feasible domain, which makes iterations very cheap to compute. The analysis is made for a randomized selection of the component functions, which yields the deterministic algorithm as a special case. Under supplementary differentiability assumptions on the function which induces the mirror map, we are also able to deal with the presence of another term in the objective function, which is evaluated via a proximal type step. In both cases, we derive convergence rates of in expectation for the kth best objective function value and illustrate our theoretical findings by numerical experiments in positron emission tomography and machine learning.
1. Introduction
We consider the problem of minimizing the sum of nonsmooth convex functions
(1)
(1) where
is a nonempty, convex and closed set and, for every
, the so-called component functions
are assumed to be proper and convex and will be evaluated via their respective subgradients. Implicitly we will assume that m is large and it is therefore very costly to evaluate all component functions in each iteration. Consequently, we will examine algorithms which only use the subgradient of a single component function in each iteration. These so-called incremental algorithms, see [Citation1,Citation2], have been applied for large-scale problems arising in tomography [Citation3], generalized assignment problems [Citation2] or machine learning [Citation4]. We refer also to [Citation5] for a slightly different approach, where in the spirit of incremental algorithms only the gradient of one of the component functions is evaluated in each step, but gradients at old iterates are used for the other components. Both subgradient algorithms and incremental methods usually require decreasing stepsizes in order to converge, which makes them slow near an optimal solution. However, they provide a very small number of iterations a low accuracy optimal value and possess a rate of convergence which is almost independent of the dimension of the problem. We refer the reader to [Citation6] for a subgradient algorithm designed for the minimization of a nonsmooth nonconvex function under the making use of proximal subgradients.
When solving optimization problems of type (Equation1(1)
(1) ), one might want to capture in the formulation of the iterative scheme the geometry of the feasible set C. This can be done by a so-called mirror map, that mirrors each iterate onto the feasible set. The Bregman distance associated with the function that induces the mirror map plays an essential role in the convergence analysis and in the formulation of convergence rates results (see [Citation7,Citation8]). So-called mirror descent algorithms were first discussed in [Citation9] and more recently in [Citation8,Citation10,Citation11] in a very general framework, in [Citation4,Citation12] from a statistical learning point of view and in [Citation13] for the case of dynamical systems. The mirror map can be viewed as a generalization of the ordinary orthogonal projection on C in Hilbert spaces (see Example 2.4), but allows also for a more careful consideration of the structure of the problems, as it is the case when the objective function is subdifferentiable only on the relative interior of the feasible set. In such a setting, one can design a mirror map which maps not onto the entire feasible set but only on a subset of it where the objective function is subdifferentiable (see Example 2.5).
There exists already a rich literature on incremental algorithms dealing with similar problems. In [Citation1,Citation2] incremental subgradient methods with a random selection of the component functions and even projections onto a feasible set are considered, but no mirror descent. Incremental subgradient algorithms utilizing mirror descent techniques are investigated in [Citation3]; however, an additional projection onto the feasible set is required which thus excludes the case where (this is taken care of in our case by the weak assumption that
). Furthermore, the results appearing in Section 4 discussing Bregman proximal steps appear to completely novel for this kind of problems and are only known from a forward–backward setting [Citation7].
The basic concepts in the formulation of mirror descent algorithms are recalled in Section 2. We also provide some illustrating examples, which present some special cases, as the general setting might not be immediately intuitive. In Section 3 we formulate an incremental mirror descent subgradient algorithm with random sweeping of the component functions which we show to have a convergence rate of in expectation for the kth best objective function value. In Section 4 we ask additionally for differentiability of the function which induces the mirror map and are then able to add another nonsmooth convex function to the objective function which is evaluated in the iterative scheme by a proximal type step. For the resulting algorithm, we show a similar convergence result. In the last section, we illustrate the theoretical findings by numerical experiments in positron emission tomography (PET) and machine learning.
2. Elements of convex analysis and the mirror descent algorithm
Throughout the paper, we assume that is endowed with the Euclidean inner product
and corresponding norm
. For a nonempty convex set
we denote by
its relative interior, which is the interior of C relative to its affine hull. For a convex function
we denote by
its effective domain and say that f is proper, if
and
. The subdifferential of f at
is defined as
, for
, and as
, otherwise. We will write
for an arbitrary subgradient, i.e. an element of the subdifferential
.
Problem 2.1
Consider the optimization problem
(2)
(2) where
is a nonempty, convex and closed set,
is a proper and convex function, and
is a proper, lower semicontinuous and σ-strongly convex function such that
and
.
We say that is σ-strongly convex for
, if for every
and every
it holds
. It is well known that, when H is proper, lower semicontinuous and σ-strongly convex, then its conjugate function
, is Fréchet differentiable (thus it has full domain) and its gradient
is
-Lipschitz continuous or, equivalently,
is Fréchet differentiable and its gradient
is σ-cocoercive, which means that for every
it holds
. Recall that
.
The following mirror descent algorithm has been introduced in [Citation10] under the name dual averaging.
Algorithm 2.2
Consider for some initial values and sequence of positive stepsizes
the following iterative scheme:
We notice that, since the sequence is contained in the interior of the effective domain of f, the algorithm is well defined. The assumptions concerning the function H, which induces the mirror map
, are not consistent in the literature. Sometimes H is assumed to be a Legendre function as in [Citation7], or strongly convex and differentiable as in [Citation8,Citation11]. In the following section, we will only assume that H is proper, lower semicontinuous and strongly convex.
Example 2.3
For we have that
and thus
is the identity operator on
. Consequently, Algorithm 2.2 reduces to the classical subgradient method:
Example 2.4
For a nonempty, convex and closed set, take
, for
, and
, otherwise. Then
, where
denotes the orthogonal projection onto C. In this setting, Algorithm 2.2 becomes:
This iterative scheme is similar to, but different from the well-known subgradient projection algorithm, which reads:
Example 2.5
When considering numerical experiments in PET, one often minimizes over the unit simplex . An appropriate choice for the function H is
for
, where
, and
, if
. In this case
is given for every
by
and maps into the relative interior of Δ.
The following result will play an important role in the convergence analysis that we will carry out in the next sections.
Lemma 2.6
Let be a proper, lower semicontinuous and σ-strongly convex function, for
,
and
. Then it holds
Proof.
The function is convex and
. Thus
or, equivalently,
Rearranging the terms, leads to the desired conclusion.
3. A stochastic incremental mirror descent algorithm
In this section, we will address the following optimization problem.
Problem 3.1
Consider the optimization problem
(3)
(3) where
is a nonempty, convex and closed set, for every
, the functions
are proper and convex, and
is a proper, lower semicontinuous and σ-strongly convex function such that
and
.
In this section, we apply the dual averaging approach described in Algorithm 2.2 to the optimization problem (Equation3(3)
(3) ) by only using the subgradient of a component function at a time. This incremental approach (see, also, [Citation1,Citation2]) is similar to but slightly different from the extension suggested in [Citation8]. Furthermore, we introduce a stochastic sweeping of the component functions. For a similar strategy, but in the random selection of coordinates we refer to [Citation14].
Algorithm 3.2
Consider for some initial values and sequence of positive stepsizes
the following iterative scheme:
where
valued random variable for every
and
, such that
is independent of
and
for every
and
.
One can notice that in the above iterative scheme for every
and
.
In the convergence analysis of Algorithm 3.2 we will make use of the following Bregman-distance-like function associated to the proper and convex function and defined as
(4)
(4) We notice that
for every
and every
, due to subgradient inequality.
The function is an extension of the Bregman distance (see [Citation4,Citation7,Citation11]), which is associated to a proper and convex function
fulfilling
and defined as
(5)
(5)
Theorem 3.3
In the setting of Problem 3.1, assume that the functions are
-Lipschitz continuous on
for
. Let
be a sequence generated by Algorithm 3.2. Then for every
and every
it holds
Proof.
Let be fixed. For y outside this set the conclusion follows automatically.
For every and every
it holds
Rearranging the terms, this yields for every
and every
to
From here we get for every
and every
which, by using that H is σ-strongly convex and Lemma 2.6, yields
Using the fact that
is
-Lipschitz continuous, it follows that
, for every i=1,...,m and every
, thus
Since all the involved functions are measurable, we can take the expected value on both sides of the above inequality and get due to the assumed independence of
and
for every
and every
Since
, we get for every
and every
Summing the above inequality for
and using that
it yields for every
or, equivalently,
Thus, for every
,
(6)
(6) On the other hand, by using the Lipschitz continuity of
it yields for every
Therefore, for every
(7)
(7) Combining (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ) gives for every
(8)
(8) Since
and
we get for every
that
By summing up this inequality from k=0 to N−1, where
, we get
Since
, as
, we get
and this finishes the proof.
Remark 3.4
The set from which the variable y is chosen in the previous theorem might seem to be restrictive, however, we would like to recall that in many applications
is the set of feasible solutions of the optimization problem (Equation3
(3)
(3) ). Since
, the inequality in Theorem 3.3 is fulfilled for every
.
Remark 3.5
Note furthermore that so far we have not made any assumptions about the stepsizes in Theorem 3.3. It is, however, clear from the statement that in the case where for an optimal solution
and the stepsizes
fulfil the classical condition that
and
it follows that
.
The optimal stepsize choice, which we provide in the following corollary, is a consequence of [Citation8, Proposition 4.1], which states that the function
where
and
is a symmetric positive definite matrix, attains its minimum on
at
and this provides
as optimal objective value.
Corollary 3.6
In the setting of Problem 3.1, assume that the functions are
-Lipschitz continuous on
for
. Let
be an optimal solution of (Equation3
(3)
(3) ) and
be a sequence generated by Algorithm 3.2 with optimal stepsize
Then for every
it holds
Remark 3.7
In the last step of the proof of Theorem 3.3, one could have chosen to use the following inequality
given by the convexity of
in order to prove convergence of the function values for the ergodic sequence
for all
. This would lead for every
and every
to
and for the optimal stepsize choice from Corollary 3.6 to
and might be beneficial, as it does not require the computation of objective function values, which are by our implicit assumption of m being large expensive to compute.
4. A stochastic incremental mirror descent algorithm with Bregman proximal step
In this section, we add another nonsmooth convex function to the objective function of the optimization problem (Equation3(3)
(3) ) and provide an extension of Algorithm 3.2, which evaluates in particular the new summand by a proximal type step. However, this asks for supplementary differentiability assumption on the function inducing the mirror map.
Problem 4.1
Consider the optimization problem
(9)
(9)
where
is a nonempty, convex and closed set, for every
, the functions
are proper and convex and
is a proper, convex and lower semicontinuous function, and
is a proper, σ-strongly convex and lower semicontinuous function such that
, H is continuously differentiable on
,
and
.
For a proper, convex, lower semicontinuous function we define its Bregman-proximal operator with respect to the proper, σ-strongly convex and lower semicontinuous function
as being
Due to the strong convexity of H, the Bregman-proximal operator is well defined. For
it coincides with the classical proximal operator.
We are now in the position to formulate the iterative scheme we would like to propose for solving (Equation9(9)
(9) ). In case g=0, this algorithm gives exactly the incremental version of the iterative method in [Citation8], actually suggested by the two authors in this paper.
Algorithm 4.2
Consider for some initial value and sequence of positive stepsizes
the following iterative scheme:
where
valued random variable for every
and
, such that
is independent from
and
for every
and
.
Lemma 4.3
In the setting of Problem 4.1, Algorithm 4.2 is well defined.
Proof.
As , it follows for every
and every
immediately that
, thus a subgradient of
at
exists.
In what follows we prove that this is the case also for , for every
. To this aim, it is enough to show that
for every
. For k=0 this statement is true by the choice of the initial value. For every
we have that
which, according to
, is equivalent to
Thus,
for every
and this concludes the proof.
Example 4.4
Consider the case when m=1, for every
and
for
, while
for
, where
is a nonempty, convex and closed set. In this setting,
is equal to the orthogonal projection
onto the set C. Algorithm 4.2 yields the following iterative scheme, which basically minimizes the sum
over the set C:
(10)
(10) The difficulty in Example 4.4, assuming that it is reasonably possible to project onto the set C, lies in evaluating
, for every
, as this itself is a constraint optimization problem
When
, the iterative scheme (Equation10
(10)
(10) ) becomes the proximal subgradient algorithm investigated in [Citation15].
Theorem 4.5
In the setting of Problem 4.1, assume that the functions are
-Lipschitz continuous on
for
. Let
be a sequence generated by Algorithm 4.2. Then for every
and every
it holds
Proof.
Let be fixed. For y outside this set the conclusion follows automatically.
As in the first part of the proof of Theorem 3.3, we obtain instead of (Equation8(8)
(8) ) the following inequality which holds for every
and every
(11)
(11) As pointed out in the proof of Lemma 4.3, for every
we have
thus
The three point identity leads to
or, equivalently,
for every
. Since the involved functions are measurable, we can take the expected value on both sides and obtain for every
(12)
(12) Combining (Equation11
(11)
(11) ) and (Equation12
(12)
(12) ) gives for every
By adding and subtracting
and by using afterwards the Lipschitz continuity of
, we get for every
By the triangle inequality, we obtain for every
which, due to Young's inequality and the strong convexity of H, leads to
Since
we get for every
that
Young's inequality and the strong convexity of H imply that for every
and every
and thus
Summing up this inequality from k=0 to N−1, for
, we get
This shows that
and therefore finishes the proof.
The following result is again a consequence of [Citation8, Proposition 4.1].
Corollary 4.6
In the setting Problem 4.1, assume that the functions are
-Lipschitz continuous on
for
. Let
be an optimal solution of (Equation9
(9)
(9) ) and
be a sequence generated by Algorithm 4.2 with optimal stepsize
Then for every
it holds
Remark 4.7
The same considerations as in Remark 3.7 about ergodic convergence are applicable also for the rates provided in Theorem 4.5 and Corollary 4.6.
Remark 4.8
Note the straightforward dependence of the optimal stepsizes as well as the right-hand side of the convergence statement on the data, i.e. the distance of the initial point to optimality, the Lipschitz constants and the probabilities
. This backs up the intuition that the decreased gradient evaluation, i.e. smaller
, does not come for free but at the cost of a worse constant in the convergence rate.
5. Applications
In the numerical experiments carried out in this section, we will compare three versions of the provided algorithms. First of all, the non-incremental version, which takes full subgradient steps with respect to the sum of all component functions instead of every single one individually. This can be viewed as a special case of the algorithms given, when m=1 and for all
. Secondly, we discuss the non-stochastic incremental version, which uses the subgradient of every single component function in every iteration and thus corresponds to the case when
for every i=1,...,m and every
. Lastly, we apply the algorithms as intended by evaluating the subgradients of the respective component functions incrementally with a probability different from 1.
5.1. Tomography
This application can be found in [Citation3] and arises in the reconstruction of images in PET. We consider the following problem
(13)
(13) where
and
denotes for
and
the entry of the matrix
in the i-th row and j-th column and all of these are assumed to be strictly positive. Furthermore,
denotes for
the positive number of photons measured in the i-th bin. As discussed in Example 2.5 this can be incorporated into our framework with the mirror map
for
and
, otherwise. As initial value, we use the all ones vector divided by the dimension n.
We also want to point out that a similar example given in [Citation8] in which the minimization of a convex function over the unit simplex Δ somehow does not match the assumption made throughout the paper as the interior of Δ is empty and the function H can therefore not be continuously differentiable in a classical sense. However, with the setting of Section 3 we are able to tackle this problem.
The bad performance, see Figure , of the deterministic incremental version of Algorithm 3.2 can be explained by the fact that many more evaluations of the mirror map are needed, which increases the overall computation time dramatically. The stochastic version, however, performs rather well, after only evaluating merely roughly a fifth of the total number of component functions, see Table .
Figure 1. Results for the optimization problem (Equation13(13)
(13) ). A plot of
, where
, as a function of time, i.e.
is the last iterate computed before a given point in time.
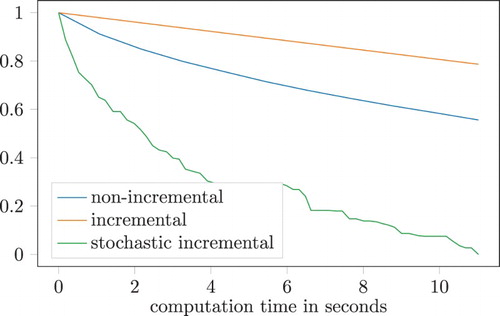
Table 1. Results for the optimization problem (Equation13 (13) (13) ), where NI denotes the non-incremental, DI the deterministic incremental and SI the stochastic incremental version of Algorithm 3.2.
(13) (13) ), where NI denotes the non-incremental, DI the deterministic incremental and SI the stochastic incremental version of Algorithm 3.2.
5.2. Support vector machines
We deal with the classic machine learning problem of binary classification based on the well-known MNIST dataset, which contains 28 by 28 images of handwritten numbers on a grey-scale pixel map. For each of the digits, the dataset comprises around 6000 training images and roughly 1000 test images. In line with [Citation4], we train a classifier to distinguish the numbers 6 and 7, by solving the following optimization problem
(14)
(14) where for
,
denotes the i-th training image and
denotes the label of the i-th training image. The 1-norm serves as a regularization term and
balances the two objectives of minimizing the classification error and reducing the 1-norm of the classifier w. To incorporate this problem into our framework, we set
which leaves us with the identity as mirror map as this problem is unconstrained. The results comparing the three versions of Algorithm 4.2 discussed at the beginning of this section are illustrated in Figure . As initial value we simply use the all ones vector. All three versions show classical first-order behaviour, giving a fast decrease in objective function value first but then slowing down dramatically. More information about the performance can be seen in . All three algorithms result in a significant decrease in objective function after being run for only 4 s each. However, from a machine learning point of view, only the misclassification rate is of actual importance. In both regards, the stochastic incremental version clearly trumps the other two implementations. It is also interesting to note that it needs only a small fraction of the number of subgradient evaluations in comparison to the full non-incremental algorithm.
Figure 2. Numerical results for the optimization problem (Equation14(14)
(14) ) with
. The plot shows
as a function of time, i.e.
is the last iterate computed before a given point in time.
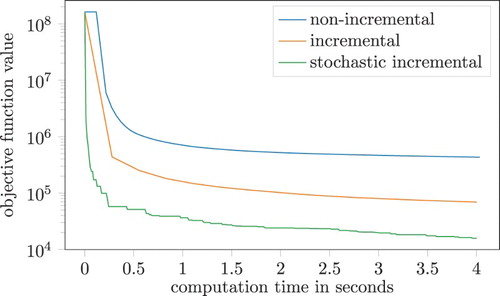
Table 2. Numerical results for the optimization problem (Equation14(14) (14) ), where NI denotes the non-incremental, DI the deterministic incremental and SI the stochastic incremental version of Algorithm 4.2.
6. Conclusion
In this paper, we present two algorithms to solve nonsmooth convex optimization problems where the objective function is a sum of many functions which are evaluated by their respective subgradients under the implicit presence of a constraint set which is dealt with by a so-called mirror map. By allowing for a random selection of each component function to evaluate in each iteration, the proposed methods become suitable even for very large-scale problems. We prove a convergence order of in expectation for the kth best objective function value, which is standard for subgradient methods. However, even for the case where all the objective functions are differentiable, it is not clear if better theoretical estimates can be achieved, due to the need of using diminishing stepsizes in order to obtain convergence in incremental algorithms. Future work could comprise the investigation of different stepsizes, such as constant or dynamic stepsizes as in [Citation2]. Another possible extension of this would be to use different selection procedures such as random subsets of fixed size. Our framework, however, does not provide the right setting for such a batch approach as it would leave
and
dependent.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Radu Ioan Boţ http://orcid.org/0000-0002-4469-314X
Additional information
Funding
References
- Bertsekas DP. Incremental gradient, subgradient, and proximal methods for convex optimization: a survey. In: Sra S, Nowozin S, Wright SJ, editors. Optimization for machine learning, Neural Information Processing Series. Cambridge (MA): MIT Press; 2012. p. 85–120.
- Nedic A, Bertsekas DP. Incremental subgradient methods for nondifferentiable optimization. SIAM J Optim. 2001;12(1):109–138. doi: 10.1137/S1052623499362111
- Ben-Tal A, Margalit T, Nemirovski A. The ordered subsets mirror descent optimization method with applications to tomography. SIAM J Optim. 2001;12(1):79–108. doi: 10.1137/S1052623499354564
- Xiao L. Dual averaging methods for regularized stochastic learning and online optimization. J Mach Learn Res. 2010;11:2543–2596.
- Gurbuzbalaban M, Ozdaglar A, Parrilo PA. On the convergence rate of incremental aggregated gradient algorithms. SIAM J Optim. 2017;27(2):1035–1048. doi: 10.1137/15M1049695
- Wei Z, He QH. Nonsmooth steepest descent method by proximal subdifferentials in Hilbert spaces. J Optim Theory Appl. 2014;161(2):465–477. doi: 10.1007/s10957-013-0444-z
- Bauschke HH, Bolte J, Teboulle M. A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications. Math Oper Res. 2017;42(2):330–348. doi: 10.1287/moor.2016.0817
- Beck A, Teboulle M. Mirror descent and nonlinear projected subgradient methods for convex optimization. Oper Res Lett. 2003;31(3):167–175. doi: 10.1016/S0167-6377(02)00231-6
- Nemirovskii AS, Yudin DB. Problem complexity and method efficiency in optimization. Hoboken (NJ): Wiley; 1983.
- Nesterov Y. Primal-dual subgradient methods for convex problems. Math Program. 2009;120(1):221–259. doi: 10.1007/s10107-007-0149-x
- Zhou Z, Mertikopoulos P, Bambos N, et al. Mirror descent in non-convex stochastic programming. arXiv:1706.05681, 2017.
- Shalev-Shwartz S. Online learning and online convex optimization. Found Trends Mach Learn. 2012;4(2):107–194. doi: 10.1561/2200000018
- Bolte J, Teboulle M. Barrier operators and associated gradient-like dynamical systems for constrained minimization problems. SIAM J Control Optim. 2003;42(4):1266–1292. doi: 10.1137/S0363012902410861
- Combettes PL, Pesquet J-C. Stochastic quasi-Fejér block-coordinate fixed point iterations with random sweeping. SIAM J Optim. 2015;25(2):1221–1248. doi: 10.1137/140971233
- Cruz JYB. On proximal subgradient splitting method for minimizing the sum of two nonsmooth convex functions. Set-Valued Var Anal. 2017;25(2):245–263. doi: 10.1007/s11228-016-0376-5