
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Benson's outer approximation algorithm and its variants are the most frequently used methods for solving linear multiobjective optimization problems. These algorithms have two intertwined parts: single-objective linear optimization on one hand, and a combinatorial part closely related to vertex enumeration on the other. Their separation provides a deeper insight into Benson's algorithm, and points toward a dual approach. Two skeletal algorithms are defined which focus on the combinatorial part. Using different single-objective optimization problems yields different algorithms, such as a sequential convex hull algorithm, another version of Benson's algorithm with the theoretically best possible iteration count, and the dual algorithm of Ehrgott et al. [A dual variant of Benson's ‘outer approximation algorithm’ for multiple objective linear programming. J Glob Optim. 2012;52:757–778]. The implemented version is well suited to handle highly degenerate problems where there are many linear dependencies among the constraints. On problems with 10 or more objectives, it shows a significant increase in efficiency compared to Bensolve – due to the reduced number of iterations and the improved combinatorial handling.
1. Introduction
Our notation is standard and mainly follows that of [Citation1,Citation2]. The transpose of the matrix M is denoted by . Vectors are usually denoted by small letters and are considered as single column matrices. For two vectors, x and y of the same dimension, xy denotes their inner product, which is the same as the matrix product
. The ith coordinate of x is denoted by
, and
means that for every coordinate i,
. The non-negative orthant
is the collection of vectors
with
, that is, vectors whose coordinates are non-negative numbers.
For an introduction to higher-dimensional polytopes, see [Citation3], and for a description of the double description method and its variants, consult [Citation4]. Linear multiobjective optimization problems, methods, and algorithms are discussed in [Citation1,Citation5,Citation6] and the references therein.
1.1. The MOLP problem
Given positive integers n, m, and p, the matrix A maps the problem space
to
, and the
matrix P maps the problem space
to the objective space
. For better clarity, we use x to denote points of the problem space
, while y denotes points in the objective space
. In the problem space, a convex closed polyhedral set
is specified by a collection of linear constraints. For simplicity, we assume that the constraints are given in the following special format. This format will only be used in Section 5.
(1)
(1) where
is a fixed vector. The p-dimensional linear projection of
given by the
matrix P is
(2)
(2) Using this notation, the multiobjective linear optimization problem can be cast as follows:
MOLP
MOLP where minimization is understood with respect to the coordinate-wise ordering of
. The point
is non-dominated or Pareto optimal, if no
different from
is in
; and it is weakly non-dominated if no
is in
. Solving the multiobjective optimization problem is to find (a description of) all non-dominated vectors
together with corresponding pre-images
such that
.
Let , the Minkowski sum of
and the non-negative orthant of
, see [Citation3]. It follows easily from the definitions, but see also [Citation1,Citation7,Citation8], that non-dominated points of
and of
are the same. The weakly non-dominated points of
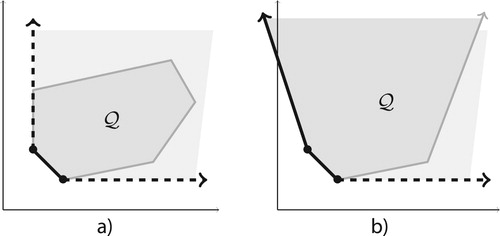
form its Pareto front. Figure illustrates non-dominated (solid line), and weakly non-dominated points (solid and dashed line) of
when (a) all objectives are bounded from below, and when (b) the first objective is not bounded.
is the unbounded light grey area extending
.
Figure 1. Pareto front with (a) bounded, (b) unbounded objectives.
1.2. Facial structure of polytopes
Let us recall some facts concerning the facial structure of n-dimensional convex closed polytopes. A face of such a polytope is the intersection of
and some closed halfspace (including the empty set and the whole
). Faces of dimension zero, one, n−2, and n−1 are called vertex, edge, ridge, and facet, respectively.
An n-dimensional halfspace is specified as , where
is a non-null vector (normal), and M is a scalar (intercept). The positive side of H is the open halfspace
; the negative side is defined similarly. Each facet of
is identified with the halfspace which contains
and whose boundary intersects
in that facet.
is just the intersection of all halfspaces corresponding to its facets.
The halfspace H is supporting if it contains , and there is a boundary point of
on the boundary of H. The boundary hyperplane of a supporting halfspace intersects
in one of its faces. All boundary points of
are in the relative interior of exactly one face.
A recession direction, or ray of is a vector
such that for some
,
for all real
. d is extreme if whenever
for two recession directions
and
, then both
and
are non-negative multiples of d.
1.3. Working with unbounded polytopes
When is unbounded but does not contain a complete line – which will always be the case in this paper – Burton and Ozlen's ‘oriented projective geometry’ can be used [Citation9]. Intuitively this means that rays are represented by ideal points, extreme rays are the ideal vertices which lie on a single ideal facet determining the ideal hyperplane. Notions of ordering and convexity can be extended to these objects seamlessly even from a computational point of view. In particular, all non-ideal points are on the positive side of the ideal hyperplane. Thus in theoretical considerations, without loss of generality,
can be assumed to be bounded.
1.4. Assumptions on the MOLP problem
In order that we could focus on the main points, we make some simplifying assumptions on the (MOLP) to be solved. The main restriction is that all objectives are bounded from below. From this, it follows immediately that neither nor
contains a complete line; and that the Pareto optimal solutions are the bounded faces of dimension p−1 and less of
as indicated on Figure (a). One can relax this restriction at the expense of computing the extreme rays of
first (also checking that
does not contain a complete line), as is done by the software package Bensolve [Citation10]. Further discussions are postponed to Section 6, where we also extend our results to the case where the ordering is given by some cone different from
.
Assumption
The optimization problem (MOLP) satisfies the following conditions:
the n-dimensional polytope
defined in (Equation1
each objective in
An immediate consequence of the first assumption is that the projection is non-empty either, and then
is full-dimensional. According to Assumption 2,
and
is contained in
for some (real) vector
. Thus
has exactly p ideal vertices, namely the positive endpoints of the coordinate axes, and these ideal vertices lie on the single ideal facet of
.
1.5. Benson's algorithm revisited
The solution of the (MOLP) can be recovered from a description of the Pareto front of , which, in turn, is specified by the list of its vertices and (non-ideal) facets. Indeed, the set of Pareto optimal points is the union of those faces of
which do not contain ideal points. Thus solving (MOLP) means find all vertices and facets of the polyhedron
.
Benson's ‘outer approximation algorithm’ and its variants [Citation1,Citation2,Citation5–8,Citation10] do exactly this, working in the (low-dimensional) objective space. These algorithms have two intertwined parts: scalar optimization on one hand, and a combinatorial part on the other. Their separation provides a deeper insight into how these algorithms work.
Benson's algorithm works in stages by maintaining a ‘double description’ of an approximation of the final polytope . A convex polytope is uniquely determined as the convex hull of a finite set of points (for example, the set of vertices) and directions (in our case: ideal points) as well as the intersection of finitely many closed halfspaces (for example, halfspaces corresponding to the facets plus the ideal facet). The ‘double description’ refers to the technique keeping and maintaining both lists simultaneously. The iterative algorithm stops when the last approximation equals
. At this stage, both the vertices and facets of
are computed, thus the (MOLP) has been solved.
During the algorithm, a new facet is added to the approximating polytope in each iteration. The new facet is determined by solving a smartly chosen scalar LP problem (specified from the description of the actual approximation). Then, the combinatorial step is executed: the new facet is merged to the approximation by updating the facet and vertex lists. This step is very similar to that of incremental vertex enumeration [Citation4,Citation11–13], and can be parallelized.
Section 2 defines two types of black box algorithms which, on each call, provide data for the combinatorial part. The point separating oracle separates a point from the (implicitly defined) polytope by a halfspace. The plane separating oracle is its dual: the input is a halfspace, and the oracle provides a point of
on the negative side of that halfspace.
Two general enumeration algorithms are specified in Section 3 which call these black box algorithms repeatedly. It is proved that they terminate with a description of their corresponding target polytopes. Choosing the initial polytope and the oracle in some specific way, one gets a convex hull algorithm, a (variant of) Benson's algorithm, and the Ehrgott–Löhne–Shao dual algorithm.
Aspects of the combinatorial part are discussed in Section 4. Section 5 explains how the oracles in these algorithms can be realized. Finally, Section 6 discusses other implementation details, limitations and possible generalizations.
1.6. Our contribution
The first skeletal algorithm in Section 3.1 is the abstract versions of Benson's outer approximation algorithm and its variants, where the combinatorial part (vertex enumeration) and the scalar LP part has been separated. The latter one is modelled as an inquiry to a separating oracle which, on each call, provides the data the combinatorial part can work on. Using one of the point separation oracles in Section 5.1, one can recover, e.g. Algorithm 1 of [Citation1]. The running time estimate in Theorem 3.4 is the same (with the same proof) as the estimate in [Citation1, Theorem 4.6].
The other skeletal algorithm is the dual of the outer approximation one. The ‘inner’ algorithm of this paper uses the plane separation oracle defined in Section 5.3. Another instance is Algorithm 2 of Ehrgott et al. [Citation1], called ‘dual variant of Benson's outer approximation algorithm’.
Studying these skeletal algorithms made it possible to clarify the role of the initial approximation, and prove general terminating conditions. While not every separating oracle guarantees termination, it is not clear what are the (interesting and realizable) sufficient conditions. Benson's outer approximation algorithm is recovered by the first separation oracle defined in Section 5.1. Other two separation oracles have stronger termination guarantees, yielding the first version which is guaranteed to take only the theoretically minimal number of iterations. Oracles in Section 5.3 are particularly efficient and contribute significantly to the excellent performance of the implemented inner approximation algorithm.
It is almost trivial to turn any of the skeletal algorithms to an incremental vertex (or facet) enumeration algorithm. Such algorithms have been studied extensively. Typically there is a blow-up in the size of the intermediate approximation; there are examples where even the last but one approximation has size where m is the final number of facets (or vertices) and p is the space dimension [Citation14]. This blow-up can be significant when p is 6 or more.
An interesting extension to the usual single objective LP have been identified, where not one but several goals are specified, and called ‘multi-goal LP’. Optimization is done for the first goal, then within the solution space the second goal is optimized, that is, in the second optimization there is an additional constraint specifying that the first goal has an optimal value. Then within this solution space, the third goal is optimized, etc. Section 5.2 sketches how existing LP solvers can be patched to become an efficient multi-goal solver. We expect more interesting applications for this type of solvers.
2. Separating oracles
In this and in the following section, is some bounded, closed, convex polytope with non-empty interior. As discussed in Section 1.3, the condition that
is bounded can be replaced by the weaker assumption that
does not contain a complete line.
Definition 2.1
A point separating oracle for the polytope
is a black box algorithm with the following input/output behaviour:
a point
‘inside’ if
Definition 2.2
A plane separating oracle for the polytope
is a black box algorithm with the following input/output behaviour:
a p-dimensional closed halfspace H;
‘inside’ if
The main point is that only the oracle uses the polytope in the enumeration algorithms of Section 3, and
might not be defined by a collection of linear constraints. In particular, this happens when the algorithm is used to solve the multiobjective problem, where the polytope passed to the oracle is
or
.
The two oracles are dual in the sense that if is the geometric dual of the convex polytope
with the usual point versus hyperplane correspondence [Citation3], then
and
are equivalent: when a point is asked from oracle
, ask the dual of this point from
, and return the dual of the answer.
The object returned by a weak separating oracle is not required to be a facet (or vertex), but only a supporting halfspace (or a boundary point) separating the input from the polytope. The returned separating object, however, cannot be arbitrary, it must have some structural property. Algorithms of Section 3 work with the weaker separating oracles defined below, but the performance guarantees are exponentially worse. On the other hand, such weak oracles can be realized easier. Actually, strong separating oracles in Section 5 are implemented as tweaked weak oracles.
Definition 2.3
A weak point separating oracle ) for the polytope
is a black box algorithm which works as follows. It fixes an internal point
.
a point
‘inside’ if
Definition 2.4
A weak plane separating oracle for the polytope
is a black box algorithm which works as follows.
a halfspace H;
‘inside’ if
A strong oracle is not necessarily a weak one (for example, it can return any vertex on the negative side of H, not only the one which is farthest away from it), but can always give a response which is consistent with being a weak oracle. Similarly, there is always a valid response of a weak oracle which qualifies as correct answer for the corresponding strong oracle.
While strong oracles are clearly dual of each other, it is not clear whether the weak oracles are dual, and if yes, in what sense of duality.
3. Approximating algorithms
The skeletal algorithms below are called outer and inner approximations. The outer name reflects the fact that the algorithm approximates the target polytope from outside, while the inner does it from inside. The outer algorithm is an abstract version of Benson's algorithm where the computational and combinatorial parts are separated.
3.1. Skeletal algorithms
On input, both algorithms require two convex polytopes: and
. The polytope
is the initial approximation; it is specified by double description: by the list of its vertices and facets. The polytope
is passed to the oracle, and is specified according to the oracle's requirements. Both
and
are assumed to be closed, convex polytopes with non-empty interior. For this, exposition they are also assumed to be bounded; this condition can (and will) be relaxed to the weaker condition that none of them contains a complete line.

Theorem 3.1
The outer approximation algorithm using the oracle terminates with the polytope
. The algorithm makes at most v + f oracle calls, where v is number of vertices of
and f is the number of facets of
.
Proof.
First, we show that if the algorithm terminates, then the result is . Each approximating polytope is an intersection of halfspaces corresponding to certain facets of
(as
returns halfspaces which correspond to facets of
), and all halfspaces corresponding to facets of
thus
.
If is a proper subset of
, then
has a vertex
not in
. This vertex
cannot be marked ‘final’ as final vertices are always points of
. (All vertices of
are points of the initial
, and when the oracle returns ‘inside’, the queried point is in
.) Thus, the algorithm cannot stop at
.
Second, the algorithm stops after making at most v + f oracle calls. Indeed, there are at most v oracle calls which return ‘inside’ (as a final vertex is never asked from the oracle). Moreover, the oracle cannot return the same facet H of twice. Suppose H is returned at the ith step. Then
. If j>i and
is a vertex of
, then
is on the non-negative side of H, i.e. the oracle cannot return the same H for the query
.
From the discussion above, it follows that vertices marked as ‘final’ are vertices of , thus they are vertices of all subsequent approximations. This justifies the sentence in parentheses in the description of the algorithm.
Theorem 3.2
The outer approximation algorithm using the weak oracle terminates with the polytope
. The algorithm makes at most
oracle calls, where v is the number of vertices of
and f is the number of facets of
.
Proof.
Similarly to the previous proof, for each iteration, we have , as each H contains
. If
is a proper subset of
, then
has a vertex
not in
, thus not marked as ‘final’, and the algorithm cannot stop at this iteration.
To show that the algorithm eventually stops, we bound the number of oracle calls. If for the query the response is ‘inside’, then
is a vertex of
, and
will not be asked again. This happens at most as many times as many vertices
has.
Otherwise, the oracle's response is a supporting halfspace whose boundary touches
at a unique face
of
, which contains the point where the segment
intersects the boundary of
.
If an internal point of the line segment intersects the face
, then
must be on the negative side of
. As
and all subsequent approximations are on the non-negative side of
, if j>i, then
cannot intersect
, and then the face
necessarily differs from the face
. Thus, there can be no more iterations than the number of faces of
. As each face is the intersection of some facets, this number is at most
.
Now, we turn to the dual of outer approximation.

Theorem 3.3
The inner approximation algorithm using the oracle terminates with
the convex hull of
and
. The algorithm makes at most v + f oracle calls, where v is the number of vertices of
and f is the number of facets of
.
Proof.
This algorithm is the dual of Algorithm 3.1. The claims can be proved along with the proof of Theorem 3.1 by replacing notions by their dual: vertices by facets, intersection by convex hull, calls to by calls to
, etc. Details are left to the interested reader.
Theorem 3.4
The inner approximation algorithm using the weak oracle terminates with
. The algorithm makes at most
oracle calls, where v is the number of vertices of
and f is the number of facets of
.
Proof.
As weak oracles are not dual, the proof is not as straightforward as it was for the previous theorem. First, if the algorithm stops, it computes the convex hull. Indeed, , and if they differ, then
has a facet with the corresponding halfspace H and a vertex of
is on the negative side of H. This facet cannot be final, thus the algorithm did not stop.
To show termination, observe that at most f oracle calls return ‘inside’. In other calls, the query was the halfspace , and the oracle returned
from the boundary of
such that the distance between
and
is maximal. Consider the face
of
which contains
in its relative interior. We claim that the same
cannot occur for any subsequent query. Indeed, all points of
are at exactly the same (negative) distance from
,
,
is a point of
and all subsequent approximations. If j>i and
is a facet of
, then
is on the non-negative side of
. Consequently
is not an element of the face
, and then
and
differ.
Thus the number of such queries cannot be more than the number of faces in , which is at most
.
3.2. A convex hull algorithm
The skeleton algorithms can be used with different oracles and initial polytopes. An easy application is computing the convex hull of a point set . In this case
, the convex hull of V. If the initial approximation
is inside this convex hull, then Algorithm 3.2 just returns the convex hull
. There is, however, a problem. Algorithm 3.2 uses the facet enumeration as discussed in Section 4. This method generates the exact facet list at each iteration, but keeps all vertices from the earlier iterations, thus the vertex list can be redundant. When the algorithm stops, the facet list of the last approximation gives the facets of the convex hull. The last vertex list contains all of its vertices but might contain additional points as well. A solution is to check all elements in the vertex list by solving a scalar LP: is this element a convex linear combination of the others? Another option is to ensure that points returned by the oracle are vertices of the convex hull – namely using a strong oracle – and vertices of the initial polytope are not, thus they can be omitted without any computation. This is what Algorithm 3.3 does.

3.3. Algorithms solving multiobjective linear optimization problems
Let us now turn to the problem of solving the multiobjective linear optimization problem. As discussed in Section 1.5, this means that we have to find a double description of the (unbounded) polytope . To achieve this, both skeletal algorithms from Section 3.1 can be used. Algorithm 3.4 is (a variant of) Benson's original outer approximation algorithm [Citation1], while Algorithm 3.5 uses inner approximation. The second algorithm has several features which makes it better suited for problems with large number (at least six) of objectives, especially when
has relatively few vertices.
As is unbounded, both algorithms below use ideal elements from the extended ordered projective space
as elaborated in [Citation9]. Elements of
can be implemented using homogeneous coordinates. For
, the ideal point at the positive end of the ith coordinate axis
is denoted by
. For a (non-ideal) point
the p-dimensional simplex with vertices v and
is denoted by
. One facet of
is the ideal hyperplane containing all ideal points; the other p facets have equation
, and the corresponding halfspaces are
as
is a subset of them. The description of how the oracles in Algorithms 3.4 and 3.5 are implemented is postponed to Section 5.
The input of Algorithms 3.4 and 3.5 are the n-dimensional polytope as in (Equation1
(1)
(1) ), and the
projection matrix P defining the objectives, as in (Equation2
(2)
(2) ). The output of both algorithms is a double description of
. The first one gives an exact list of its vertices (and a possibly redundant list of its facets), while the second one generates a possibly redundant list of the vertices, and an exact list of the facets.

By Theorems 3.1 and 3.2, this algorithm terminates with , as required. When creating the initial polytope
in step (1), the scalar LP must have a feasible solution (otherwise
is empty), and should not be unbounded (as otherwise the ith objective is unbounded from below). After
has been created successfully we know that its ideal vertices are also vertices of
, thus they can be marked as ‘final’. As these are the only ideal vertices of
, no further ideal point will be asked from the oracle at all. These facts can be used to simplify the oracle implementation.
Recall that is the p-dimensional simplex whose vertices are v and the ideal points at the positive endpoints of the coordinate axes.

Theorems 3.3 and 3.4 claim that this algorithm computes a double description of , as the convex hull of
and
is just
. Observe that in this case, the oracle answers questions about the polytope
, and not about
. The ideal facet of
is also a facet of
, thus it can be marked ‘final’ and then it will not be asked from the oracle. No ideal point should ever be returned by the oracle.
To simplify the generation of the initial approximation , the oracle may accept any normal vector
as a query, and return a (non-ideal) vertex (or boundary point) v of
which minimizes the scalar product hv, and leave it to the caller to decide whether
is on the non-negative side of the halfspace
. This happens when
for the returned point v.
If the initial approximation is
for some vertex v of
(as indicated above) and the algorithm uses the strong oracle
, then vertices of all approximations are among the vertices of
. Consequently, the final vertex list does not contain redundant elements. In case of using a weak plane separating oracle or a different initial approximation, the final vertex list might contain additional points. To get an exact solution, the redundant points must be filtered out.
4. Vertex and facet enumeration
This section discusses the combinatorial part of the skeleton Algorithms 3.1 and 3.2 in some detail. For a more thorough exposition of this topic please consult [Citation4,Citation11,Citation15]. At each step of these algorithms the approximation is updated by adding a new halfspace (outer algorithm) or a new vertex (inner algorithm). To maintain the double description, we need to update both the list of vertices and the list of halfspaces. In the first case, the new halfspace is added to the list (creating a possibly redundant list of halfspaces), but the vertex list might change significantly. In the second case, it is the other way around: the vertex list grows by one (allowing vertices which are inside the convex hull of the others), and the facet (halfspace) list changes substantially. As adding a halfspace and updating the exact vertex list is at the heart of incremental vertex enumeration [Citation12,Citation13], it will be discussed first.
Suppose is to be intersected by the (new) halfspace H. Vertices of
can be partitioned as
: those which are on the positive side, on the negative side, and those which are on the boundary of H. As the algorithm proceeds, H always cuts
properly, thus neither
nor
is empty; however,
can be empty. Vertices in
and in
remain vertices of
; vertices in
will not be vertices of
any more, and should be discarded. The new vertices of
are the points where the boundary of H intersects the edges of
in some internal point. Such an edge must have one endpoint in
, and the other endpoint in
. To compute the new vertices, for each pair
with
and
we must decide whether
is and edge of
or not. This can be done using the well-known and popular necessary and sufficient combinatorial test stated in Proposition 4.1(b). As executing this test is really time-consuming, the faster necessary condition (a) is checked first which filters out numerous non-edges. A proof for the correctness of the tests can be found, e.g. in [Citation15].
Proposition 4.1
If
Observe that Proposition 4.1 remains valid if the set of facets are replaced by the boundary hyperplanes of any collection of halfspaces whose intersection is . That is, we can have ‘redundant’ elements in the facet list. We need not, and will not, check whether adding a new facet makes other facets ‘redundant’.
Both conditions can be checked using the vertex–facet adjacency matrix, which must also be updated in each iteration. In practice, the adjacency matrix is stored twice: using the bit vector for each vertex v (indexed by the facets), and the bit vector
for each facet H (indexed by the vertices). The vector
at position H contains 1 if and only if v is on the facet H; similarly for the vector
. Condition (a) can be expressed as the intersection
has at least p−1 ones. Condition (b) is the same as the bit vector
contains only zeros except for positions
and
. Bit operations are quite fast and are done on several (typically 32 or 64) bits simultaneously. Checking which vertex pairs in
are edges, and when such a pair is an edge computing the coordinates of the new vertex, can be done in parallel. Almost the complete execution time of vertex enumeration is taken by this edge checking procedure. Using multiple threads, the total work can be evenly distributed among the threads with very little overhead, practically dividing the execution time by the number of the available threads. See Section 6.4 for further remarks.
Along updating the vertex and facet lists, the adjacency vectors must be updated as well. In each step, we have one more facet, thus vectors grow by one bit. The size of facet adjacency vectors change more erratically. In the implementation, we have chosen a lazy update heuristics: there is an upper limit on this size. Until the list size does not exceed this limit, newly added vertices are assigned a new slot, and positions corresponding to deleted vertices are put on a ‘spare indices’ pool. When no more new slots are available, the whole list is compressed, and the upper limit is expanded if necessary.
In Algorithm 3.2, the sequence of intermediate polytopes grows by adding a new vertex rather than cutting it by a new facet. In this case, the facet list is to be updated. As this is the dual of the procedure above, only the main points are highlighted. Here, the vertex list can be redundant, meaning some of them can be inside the convex hull of others, but the facet list must (and will) contain no redundant elements.
Let v be the new vertex to be added to the polytope . Partition the facets of
as
such that v is on the positive side of facets in
, on the negative side of facets in
, and is on hyperplane defined by the facets in
. The new facets of
are facets in
and
, plus facets determined by v and a ridge (a
-dimensional face) which is an intersection of one facet from
and one facet from
. One can use the dual of Proposition 4.1 to check whether the intersection of two facets is a ridge or not. We state this condition explicitly as this dual version seems not to be known.
Proposition 4.2
If the intersection of facets
5. Realizing oracle calls
This section describes how the oracles in Algorithms 3.4 and 3.5 can be realized. In both cases, a weak separating oracle is defined first, and then we show how it can be tweaked to become a strong oracle. The solutions are not completely satisfactory. Either the hyperplane returned by the point separating oracle for Benson's algorithm 3.4 will be a facet with ‘high probability’ only, or the oracle requires a non-standard feature from the underlying scalar LP solver. Fortunately, weak oracles work as well, thus the failure of the oracle is not fatal: it might add further iterations but neither the correctness nor termination is affected. (Numerical stability is another issue.) In Section 5.2, we describe how a special class of scalar LP solvers – including the GLPK solver [Citation16] used in the implementation of Bensolve [Citation10] and Inner – can be patched to find the lexicographically minimal element in the solution space.
The polytopes on which the oracles work are defined by the and
matrices A and P, respectively, and by the vector
as follows:
The next two sections describe how the weak and strong oracles required by Algorithms 3.4 and 3.5 can be realized.
5.1. Point separation oracle
The oracle's input is a point , and the response should be a supporting halfspace (weak oracle) or a facet (strong oracle) of
which separates v and
. As discussed in Section 3.3, several simplifying assumptions can be made, namely
v is not an ideal point;
if v is in
Let us consider first the weak oracle. According to Definition 2.3, the must choose a fixed internal point
. The vertices of the ideal facet of
are the positive endpoints of the coordinate axes. If all coordinates of
are positive, then the ideal point corresponding to this vector is in the relative interior of the ideal facet. Fix this vector
, and let o be the ideal point corresponding to
. While o is not an internal point of
, this choice works as no ideal point is ever asked from the oracle according to the assumptions above. Thus let us fix o this way.
Given the query point v, the ‘segment’ vo is the ray . The vo line intersects the boundary of
at the point
, where
is the solution of the scalar LP problem
(P(v,e*))
(P(v,e*)) Indeed, this problem just searches for the largest λ for which
. By the assumptions above (
) always has an optimal solution.
Now the line vo intersects in the ray
. Thus
if and only if
; in this case, the oracle returns ‘inside’. In the
case the oracle should find a supporting halfspace H to
at the boundary point
. Interestingly, the normal of these supporting hyperplanes can be read off from the solution space of the dual of (
), where the dual variables are
and
:
As the primal (
) has an optimal solution, the strong duality theorem says that the dual (
) has the same optimum
.
Proposition 5.1
The problem () takes its optimal value
at
(together with some
if and only if s is a normal of a supporting halfspace to
at
.
Proof.
By definition s is a normal of a supporting halfspace to at
if and only if
for all
. From here, it follows that
(as otherwise sy is not bounded from below for some large enough
), and as
has all positive coordinates, s can be normalized by assuming
.
Knowing that , if
holds for some
, then it also holds for every
. Thus, it is enough to require
for all
only, that is,
(3)
(3) The polytope
is non-empty. According to the strong duality theorem, all
satisfies a linear inequality if and only if it is a linear combination of the defining (in)equalities of
. Thus (Equation3
(3)
(3) ) holds if and only if there is a vector
such that
Plugging in
and using
we get that s is a normal of a supporting halfspace of
at
if and only if
namely
is in the solution space of (
).
Proposition 5.1 indicates immediately how to define a weak separating oracle.
Oracle 5.2
weak
Fix the vector with all positive coordinates. On input
, solve (
). Let the minimum be
, and the place where the minimum is attained be
. If
, then return ‘inside’. Otherwise let
, and the supporting halfspace to
at
is
.
The oracle works with any positive . Choosing
to be all one vector is a possibility which has been made by Bensolve and other variants. Choosing other vectors,
can be advantageous. Randomly chosen direction works quite well in practice.
Oracle 5.3
probabilistic
Choose randomly according to the uniform distribution from the p-dimensional cube
. Then execute Oracle 5.2 using this random vector
.
As there is no guarantee that Oracle 5.3 always returns a facet, this is only a weak separating oracle.
Proposition 5.1 suggests another way to extract a facet among the supporting hyperplanes. The solution space of () in the first p variables spans the (convex polyhedral) space of the normals of the supporting hyperplanes. Facet normals are the extremes among them. Pinpointing a single extreme among them is easy. As in the case of the convex hull algorithm in Section 3.2, choose its lexicographically minimal element: this will be the normal of a facet.
Oracle 5.4
strong
Fix the vector with all positive coordinates, e.g. take the all one vector. On input
solve (
). The LP solver must return the minimum, and the lexicographically minimal
from the solution space. Proceed as in Oracle 5.2.
The question how to find the lexicographically minimal element in the solution space is addressed in the next section.
5.2. A ‘multi-goal’ scalar LP solver
Scalar LP solvers typically stop when the optimum value is reached, and report the optimum, the value of the structural variables, and optionally the value of the dual variables. The lexicographically minimal vector from the solution space can be computed by solving additional (scalar) LP problems by adding more and more constraints which restrict the solution space. For Oracle 5.4, this sequence could be
The first LP solves (
). The second one fixes this solution and searches for the minimal
within the solution space, etc. Fortunately, certain simplex LP solvers – including GLPK [Citation16] – can be patched to do this task more efficiently. Let us first define what do we mean by a ‘multi-goal’ LP solver, show how it can be used to realize the strong Oracle 5.4, and then indicate an efficient implementation.
Definition 5.5
A multi-goal LP solver accepts as input a set of linear constraints and several goal vectors, and returns a feasible solution after minimizing for all goals in sequence:
Constraints: a collection of linear constraints.
Goals: real vectors
Let satisfies the given constraints
; and for
let
is minimal among
.
Result: Return any vector x from the last set
Oracle 5.4 can be realized by such a multi-goal LP solver. Fix . We need the lexicographically minimal
from the solution space of (
). Let
be the coordinate vector with 1 in position i. Call the multi-goal LP solver as follows:
Constraints:
Goals: the p + m dimensional vectors
Parse the p + m-dimensional output as , and compute
,
. Return ‘inside’ if
, and return the halfspace equation
otherwise.
In the rest of the section, we indicate how GLPK [Citation16] can be patched to become an efficient multi-goal LP solver. After parsing the constraints, GLPK internally transforms them to the form
Here,
is the vector of all variables, A is some
matrix,
,
is a constant vector, and
are the lower and upper bounds, respectively. The lower bound
can be
and the upper bound
can be
meaning that the variable
is not bounded in that direction. The two bounds can be equal, but
must always hold (otherwise the problem has no feasible solution). The function to be minimized is gx for some fixed goal vector
. (During this preparation only slack and auxiliary variables are added, thus g can be got from the original goal vector by padding it with zeroes.)
GLPK implements the simplex method by maintaining a set of m base variables, an invertible matrix M so that the product MA contains (the permutation of) a unit matrix at column positions corresponding to the base variables. Furthermore, for each non-base variable
there is a flag indicating whether it takes its lower bound
or upper bound
. Fixing the value of non-base variables according to these flags, the value of base variables can be computed from the equation MAx = Mc. If the values of the computed base variables fall between the corresponding lower and upper bounds, then the arrangement (base, M, flags) is primal feasible.Footnote1
The simplex method works by changing one feasible arrangement to another one while improving the goal gx. Suppose we are at a feasible arrangement where gx cannot decrease. Let be a vector such that
contains zeros at indices corresponding to base variables. As MA contains a unit matrix at these positions, computing this φ is trivial. Now
, thus
is minimal as well. By simple inspection
cannot be decreased if and only if for each non-base variable
one of the following three possibilities hold:
When this condition is met, the optimum is reached. At this point, instead of terminating the solver, let us change the bounds to
as follows. For base variables
and when
keep the old bounds:
,
. If
then set
(shrink it to the upper limit) and if
then set
(shrink it to the lower limit).
Proposition 5.6
The solution space of the scalar LP
is the collection of all
which satisfy
Proof.
From the discussion above, it is clear that if gx is optimal, then x must satisfy , otherwise gx can decrease. On the other direction for all x satisfying these constraints
(and then g) takes the same value, one of which is optimal.
This indicates how GLPK can be patched. When the optimum is reached, change the bounds to
. After this change, all feasible solutions are optimal solutions for the first goal. Change the goal function to the next one and resume execution. The last arrangement remains feasible, thus there is no overhead, no additional work is required, just continue the usual simplex iteration. Experience shows that each additional goal adds only a few or no iterations at all. The performance loss over returning after the first minimization is really small.
5.3. Plane separation oracle
The plane separation oracles used in Algorithm 3.5 can be implemented as indicated at the end of Section 3.3. The oracle's input is a vector and an intercept
. The oracle should return a point
on the boundary of
(weak oracle), or a vertex of
(strong oracle) for which the scalar product hv is the smallest possible. Both the oracle (and the procedure calling the oracle) should be prepared for cases when
is empty, or when
is not bounded from below.
Oracle 5.7
weak
On input and intercept
find any
where the scalar LP problem
(P(h))
(P(h)) takes its minimum. If the LP fails, return failure. Otherwise compute
. Return ‘inside’ if M is specified and
, otherwise return v. □
The scalar LP problem () searches for a point of
which is farthest away in the direction of h. As all oracle calls specify a normal
, the LP can fail only when some of the assumptions on the MOLP in Section 1.4 does not hold. In such a case, the MOLP solver can report the problem and abort.
The very first oracle call can be used to find a boundary point of Algorithm 3.5 starts with. In this case, the oracle is called without the intercept. This first oracle call will complain when the polytope
is empty, but might not detect if
is not bounded from below in some objective direction. The input to subsequent oracle calls is the facet equation of the approximating polytope, thus have both normal and intercept.
To guarantee that the oracle returns a vertex of , and not an arbitrary point on its boundary at a maximal distance, the multi-goal scalar LP solver from Section 5.2 can be invoked.
Oracle 5.8
strong
On input and intercept
call the multi-goal LP solver as follows:
Constraints: Ax = c,
Goals:
where is the ith row of the objective matrix P. The solver returns
. Compute
. Return ‘inside’ if M is specified and
, otherwise return
.
The point is lexicographically minimal among the boundary points of
which are farthest away from the specified hyperplane, thus – assuming the oracle did not fail – it is a vertex.
Observe that the plane separating oracles in this section work directly on the polytope without modifying or adding any further constraints. Thus, the constraints and all but the first goal in the invocations of the multi-goal LP solver are the same.
6. Remarks
6.1. Using different ordering cone
In a more general setting the minimization in the MOLP
MOLP
MOLP is understood with respect to the partial ordering on
defined by the (convex, closed, pointed, and polyhedral) ordering cone
. In this case, the solution of the MOLP is the list of facets and vertices of the Minkowski sum
. The MOLP is
-bounded just in case the ideal points of
are the extremal rays of
. In this case, the inner algorithm works with the same plane separating oracles
and
as defined in Section 5.3 whenever the vertices of the initial approximation
are just these extremal ideal points and some point
. Indeed, in this case, we have
, and the algorithm terminates with a double description of this polytope.
When using the outer approximation algorithm, the point separating oracle is invoked with the polytope . The vector
should be chosen to be an internal ray in
, and the scalar LP searching for the intersection of
and the boundary of
is
see Section 5.1. The analogue of Proposition 5.1 can be used to realize the oracles
and
. The base of the initial bounding
is formed by the ideal vertices at the end of the extremal rays of
, as above. The top vertex can be generated by computing a H-minimal point of
for each facet H of
.
6.2. Relaxing the condition on boundedness
When the boundedness assumption in Section 1.4 does not hold, then the ideal points of (or the polytope
above) are not known in advance. As the initial approximation of the Outer algorithm 3.4 must contain
, these ideal points should be computed first. For Algorithm 3.5, there are two possibilities. One can start from the same initial polytope
, but then the oracle can return ideal points. Or, as above, the initial approximation could contain all ideal points, and then all points returned by the oracle (which could just be
or
) are non-ideal points.
The ideal points of (or
) are the convex hull of the ideal points of
and that of the positive orthant
(or the ordering cone
). To find all the ideal vertices, Algorithm 3.5 can be called recursively for this
-dimensional subproblem.
6.3. The order of oracle inputs
The skeletal Algorithms 3.1 and 3.2 do not specify which non-final vertex (facet) should be passed to the oracle; as far as the algorithm is concerned, any choice is good. But the actual choice can have a significant effect on the overall performance: it can affect the size (number of vertices and facets) of the subsequent approximating polytopes, and, which is equally important, numerical stability. There are no theoretical results which would recommend any particular choice. Bremner in [Citation14] gave an example where any choice leads to a blow-up in the approximating polytope.
The implementation of Algorithm 3.2 reported in Section 6.5 offers three possibilities for choosing which vertex is to be added to the approximation polytope.
Ask the oracle the facets in the order they were created (first facets from the initial approximation
Pick a non-final facet from the current approximation randomly with (roughly) equal probability, ask this facet from the oracle, and use the returned vertex to create the next approximation.
Keep a fixed number of candidate vertices in a ‘pool’. (The pool size can be set between 10 and 100.) Fill the pool by asking the oracle non-final facets randomly. Give a score for each vertex in the pool and choose the vertex with the best score to create the next approximation.
In the last case, the following heuristics gave the best result consistently: choose the vertex from the pool which discards the largest number of facets (that is, the vertex for which the set is the biggest). It would be interesting to see some theoretical support for this heuristics.
6.4. Parallelizing
While the simplex algorithm solving scalar LP problems is inherently serial, the most time-consuming part of vertex enumeration – the ridge test – can be done in parallel. There are LP intensive problems – especially when the number of variables and constraints are high and there are only a few objectives – where almost the total execution time is spent by the LP solver; and there are combinatorial intensive problems – typically when the number of objectives is 20 or more – where the LP solver takes negligible time. In the latter cases, the average number of ridge tests per iteration can be as high as –
and it takes hours to complete one iteration. Doing it in parallel can reduce the execution time as explained in Section 4.
In a multithread environment, each thread is assigned a set of facet pairs on which it executes the ridge test as defined in Proposition 4.2, and computes the coordinates of the new facet if the pair passes the test. Every thread uses the current facet and vertex bitmaps with total size up to –
byte, while every thread requires a relative small private memory around
byte. Run on a single processor the algorithm scales well with the number of assigned threads. On supercomputers with hundreds of threads (and processors) memory latency can be an issue [Citation17].
6.5. Numerical results
An implementation of Algorithm 3.5 is available at the GitHub site https://github.com/lcsirmaz/inner, together with more than 80 MOLP and their solutions. The problems come from combinatorial optimization, have highly degenerate constraint matrices and large number of objectives. Table contains a sample of this set. Columns vars and eqs refer to the columns and rows of the constraint matrix A in (Equation1(1)
(1) ), and objs is the number of objectives. The next three columns contain the number of vertices and facets of
as well as the running time on a single desktop machine with 8 Gbyte memory and Intel i5-4590 processor running on 3.3 GHz. There is inherent randomness in the running time as the constraint matrix is permuted randomly, and during the iterations the next processed facet is chosen randomly as explained in Section 6.3. The difference in running time can be very high as it depends on the size of the intermediate approximations.
Table 1. Some computational results.
Acknowledgments
The author would like to thank the generous support of the Institute of Information Theory and Automation of the CAS, Prague. The careful and thorough report of the reviewers helped to improve the presentation, clarify vague ideas, and correcting my sloppy terminology. I am very much indebted for their valuable work.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Observe that the constraint matrix A never changes. GLPK stores only non-zero elements of A in doubly linked lists, which is quite space-efficient when A is sparse. All computations involving A are made ‘on the fly’ using this sparse storage.
References
- Ehrgott M, Löhne A, Shao L. A dual variant of Benson's ‘outer approximation algorithm’ for multiple objective linear programming. J Glob Optim. 2012;52:757–778. doi: 10.1007/s10898-011-9709-y
- Löhne A. Projection of polyhedral cones and linear vector optimization. 2014 Jun; ArXiv:1404.1708.
- Ziegler GM. Lectures on polytopes. New York Heidelberg Dordrecht London: Springer; 1994. (Graduate texts in mathematics; 152).
- Avis D, Fukuda K. A pivoting algorithm for convex hulls and vertex enumeration of arrangements and polyhedra. Discrete Comput Geom. 1992;8:295–313. doi: 10.1007/BF02293050
- Hamel AH, Löhne A, Rudloff B. Benson type algorithms for linear vector optimization and applications. J Glob Optim. 2014;59(4):811–836. doi: 10.1007/s10898-013-0098-2
- Löhne A, Rudloff B, Ulus F. Primal and dual approximation algorithms for convex vector optimization problems. J Glob Optim. 2014;60(4):713–736. doi: 10.1007/s10898-013-0136-0
- Dörfler D, Löhne A. Geometric duality and parametric duality for multiple objective linear programs are equivalent. 2018 Mar; ArXiv:1803.05546.
- Löhne A, Weißing B. Equivalence between polyhedral projection, multiple objective linear programming and vector linear programming. ArXiv:1507.00228.
- Burton BA, Ozlen M. Projective geometry and the outer approximation algorithm for multiobjective linear programming. 2010 Jun; ArXiv:1006.3085.
- Löhne A, Weißing B. The vector linear program solver Bensolve – notes on theoretical background. Eur J Oper Res. 2016;206:807–813. arXiv:1510.04823.
- Avis D, Bremner D, Seidel R. How good are convex hull algorithms?. Comput Geom. 1997;7:265–301. doi: 10.1016/S0925-7721(96)00023-5
- Genov B. Data structures for incremental extreme ray enumeration algorithms. Proceedings of the 25th Canadian Conference on Computational Geometry; CCCG 2013; Waterloo, Ontario, 2013 Aug.
- Zolotykh NYu. New modification of the double description method for constructing the skeleton of a polyhedral cone. Comput Math Math Phys. 2012;52:146–156. doi: 10.1134/S0965542512010162
- Bremner D. Incremental convex hull algorithms are not output sensitive. In: Asano T, Igarashi Y, Nagamochi H, Miyano S, Suri S, editors. Algorithms and Computation; ISAAC 1996. Berlin, Heidelberg: Springer. (Lecture notes in computer science; vol. 1178).
- Fukuda K, Prodon A. Double description method revisited. In: Deza M, Euler R, Manoussakis I. editors. Combinatorics and Computer Science; CCS 1995. Berlin, Heidelberg: Springer. (Lecture notes in computer science; vol. 1120).
- Makhorin A. GLPK (GNU linear programming kit), version 4.63. 2017. Available from: http://www.gnu.org/software/glpk/glpk.html.
- Bücker HM, Löhne A, Weißing B, et al. On parallelizing Benson's algorithm. In: Gervasi O, et al., editors. Computation Science and its Applications; ICCSA 2018. Cham: Springer. (Lecture notes in computer science; vol. 10961).