
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We introduce a subspace inertial line search algorithm (SILSA), for finding solutions of nonlinear monotone equations (NME). At each iteration, a new point is generated in a subspace generated by the previous points. Of all finite points forming the subspace, a point with the largest residual norm is replaced by the new point to update the subspace. In this way, SILSA leaves regions far from the solution of NME and approaches regions near it, leading to a fast convergence to the solution. This study analyzes global convergence and complexity upper bounds on the number of iterations and the number of function evaluations required for SILSA. Numerical results show that SILSA is promising compared to the basic line search algorithm with several known derivative-free directions.
1. Introduction
This paper introduces an efficient derivative-free algorithm for solving monotone equations
(1)
(1) where x is a vector in
and
is a monotone function, possibly with large n. In finite precision arithmetic, for a given threshold
and an initial point
, the algorithm finds an ε-approximate solution
of the problem (Equation1
(1)
(1) ), where the residual norm of
is below
. Here
is the Euclidean norm.
The problem (Equation1(1)
(1) ) appears in various practical applications, including constrained neural networks [Citation1], nonlinear compressed sensing [Citation2], phase retrieval [Citation3], and economic and chemical equilibrium problems [Citation4].
Different algorithms [Citation5–17] have been proposed and analyzed for finding an ε-approximate solution of the problem (Equation1(1)
(1) ). However, these approaches either require the computation of the (real) Jacobian matrix, which can be computationally expensive and memory-intensive, making them unsuitable for high-dimensional problems, or use its approximation, which may require a large number of function evaluations in high dimensions. As a result, these methods are not ideal for tackling large scale nonlinear systems of equations.
To address these limitations, Solodov and Svaiter [Citation18] proposed a basic line search algorithm (BLSA) augmented with a projected scheme for finding an ε-approximate solution of (Equation1(1)
(1) ). Compared to methods that require the (real) Jacobian matrix or its approximation, derivative-free methods [Citation19–38] have a simpler structure and lower memory requirements, making them suitable for solving large-scale problems. Nevertheless, it should be noted that BLSA does not provide a guarantee for reducing the residual norm at every accepted point. Instead, the residual norm can non-monotonically jump down or up until an ε-approximate solution of (Equation1
(1)
(1) ) is obtained. Hence, the convergence rate of BLSA is relatively slow.
To accelerate the convergence rate of BLSA and obtain an ε-approximate solution of (Equation1(1)
(1) ), one potential approach is to integrate BLSA with inertial methods, such as those proposed in [Citation39–45], which construct steps based on the two previous accepted points, as described in [Citation29–31]. Despite using two previous points to generate new points, these methods still do not guarantee that the resulting points have the lowest residual norms in comparison to the prior accepted points. Another potential approach proposed in [Citation46] is to augment the algorithm with an extrapolation step in the line search condition to enforce residual norm reduction at each accepted point. However, in ill-conditioned problems, this technique may face challenges in finding such points since it does not accept points whose residual norms have not been reduced.
The global convergence of BLSA with various derivative-free directions to find an ε-approximate solution of (Equation1(1)
(1) ), has been established in [Citation24,Citation29–32,Citation35]. However, based on our knowledge, no attempt has been made to find out the maximum number of iterations and the maximum number of function evaluations required to find an ε-approximate solution of (Equation1
(1)
(1) ) for BLSA. Thus, if complexity upper bounds on the number of function evaluations and the number of iterations are found, it would be interesting to know the cost of the algorithm before the algorithm is implemented and to know what parameters are appeared in such complexity bounds.
1.1. Contribution
This study proposes a new derivative-free line search algorithm, named subspace inertial line search algorithm (SILSA), which aims to find an ε-approximate solution of the problem (Equation1(1)
(1) ) in Euclidean space. The underlying mapping of (Equation1
(1)
(1) ) is monotone and Lipschitz continuous. The proposed subspace inertial point uses the information of the previous evaluated points. It uses a procedure to replace a point with the largest residual norm in the subspace with a new evaluated point. Due to this replacement, SILSA moves from regions containing points with large residual norms to regions containing points with low residual norms, leading to a fast convergence to an ε-approximate solution of the problem (Equation1
(1)
(1) ). Additionally, the algorithm employs a spectral derivative-free direction based on the efficient direction of Liu and Storey [Citation32], along with an improved version of BLSA by Solodov and Svaiter [Citation18]. Moreover, we establish the global convergence property of SILSA under mild conditions and derive complexity upper bounds on the number of iterations and the number of function evaluations required by SILSA to find an ε-approximate solution of (Equation1
(1)
(1) ).
1.2. Organization of the paper
The paper is structured as follows. Section 2 provides preliminaries. Section 3 introduces SILSA, which comprises a new subspace inertial technique in Subsection 3.1 and a new derivative-free direction in Subsection 3.2. Section 4 investigates theoretical results for SILSA, which include auxiliary results in Subsection 4.1, global convergence in Subsection 4.2, and complexity results in Subsection 4.3. In Section 5, we compare SILSA with BLSA using several known derivative-free directions. Conclusion is given in Section 6.
2. Preliminaries
A mapping is said to be monotone if the condition
(2)
(2) holds in a Euclidean space
.
In this paper, we assume the following assumptions:
| (A1) | The function | ||||
| (A2) | F is monotone, i.e. the condition (Equation2 | ||||
| (A3) | The solution set | ||||
In the following subsections, we review the important concepts (basic line search, least and most promising points, inertial point, and complexity bound) that we are using during our study.
2.1. Basic line search algorithm (BLSA)
In this subsection, we introduce the concept of BLSA, which generates a sequence of iterates, denoted as , to find an ε-approximate solution of (Equation1
(1)
(1) ). It enforces the condition that
must satisfy the line search condition
(3)
(3) After the direction
satisfies the descent condition
(4)
(4) and the step size
is found by satisfying the line search condition (Equation3
(3)
(3) ), BLSA accepts the new point
(5)
(5)
2.2. Least and most promising points
In this subsection, we define two important concepts, which are needed to clarify our algorithm: the least promising point (LP point), defined as the point with the highest residual norm among the evaluated points, and the most promising point (MP point), defined as the point with the lowest residual norm among the evaluated points. These definitions are motivated by the fact that there is no guarantee of a residual norm reduction in each step of BLSA.
2.3. Inertial step
In this subsection, the traditional inertial point
(6)
(6) is defined, where
are the two distinct points generated by BLSA and
is called extrapolation step size, which can be updated in various ways [Citation29–31,Citation39–43,Citation45], one of which is
(7)
(7) where
is a tuning parameter. This choice guarantees the global convergence for BLSA in combination with the initial step (Equation7
(7)
(7) ), e.g. see [Citation29, Lemma 4.5].
Due to existing of no guarantee of producing and
as MP points by applying BLSA, it may decrease the effectiveness of inertial point. However, employing a subspace inertial point based on the previous MP points, gives us this chance to generate a new MP point or a point close to two previous MP points. In this way, the new generated point would be far from the previous LP points.
2.4. Complexity bound
In this subsection, we define the complexity bound, i.e. the maximum number of iterations and the maximum number of function evaluations required to find an ε-approximate solution of the problem (Equation1
(1)
(1) ) that satisfies the theoretical criterion
(8)
(8) Let us define
and its true gradient by
of F at x, where
denotes the true Jacobian of F at x. Using the linear approximation of
, we have
where the function
is a convex function. Assumptions (A1)–(A2) implies that for every
, we have
(9)
(9) where γ depends on x and d and also satisfies
(10)
(10) The following result is a variant of [Citation47, Proposition 2], which is a crucial component to obtain the complexity bound for our algorithm. This result is independent of a particular derivative-free line search. Here we use the basic line search algorithm, which is different from the line search algorithm of [Citation47].
Proposition 2.1
Consider and
, where
is a threshold on f. Then, we show that at least one of the following conditions is satisfied:
| (i) |
| ||||
| (ii) |
| ||||
| (iii) |
| ||||
Proof.
We assume that (iii) does not satisfy. Hence, we have
Although the condition (Equation4
(4)
(4) ) holds, we cannot guarantee
because the true matrix
at x is not available in
. Hence, we consider the proof in the following two cases:
Case 1. If , from (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ), we have
(11)
(11) hence (i) holds.
Case 2. If , from (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ), we have
(12)
(12) hence the second inequality of (ii) holds. The first inequality of (ii)
is obtained.
In exact precision arithmetic, the aim is to obtain an exact solution of the problem (Equation1(1)
(1) ). However, in the presence of finite precision arithmetic, the algorithm may get stuck before finding an approximate solution of (Equation1
(1)
(1) ), especially in nearly flat areas of the search space. For a finite termination, the theoretical criterion (Equation8
(8)
(8) ) is used to find an ε-approximate solution of (Equation1
(1)
(1) ).
2.5. Existing derivative-free directions
We here discuss several conjugate gradient (CG) type directions and their derivative-free variants.
Let us begin with a well-known CG method that aims to minimize an unconstrained smooth function , using the iterative formula:
(13)
(13) where
is a step size determined by a line search procedure. The search direction
(14)
(14) is computed, where
is the true gradient of
at
and
is the CG parameter.
Some classical famous formulas of the CG parameter are
of Polak–Ribere–Polyak (PRP) [Citation36,Citation37], where
For the other CG type directions; see the survey [Citation28].
To identify an ε-approximate solution of (Equation1(1)
(1) ), BLSA generates the sequence
given by
(15)
(15) with the trial point
. As a cheap and useful choice for
, based on CG directions this paper focuses on the following three derivative-free search directions:
Motivated by the PRP method, the derivative-free direction
Inspired by the FR method, the derivative-free direction
Motivated by the LS method, the derivative-free direction
These methods are particularly well-suited for tackling large-scale non-smooth problems, since they utilize only function values and require minimal memory. Furthermore, the stability of the search directions is independent of the type of line search employed. It has been demonstrated that the sequence generated by these methods globally converges to the solution of (Equation1
(1)
(1) ), provided that the underlying mapping F is monotone and L-Lipschitz continuous [Citation18]. In Section 5, we present and evaluate several derivative-free directions that are based on the well-known CG directions and compare them with our proposed method.
3. Modified derivative-free algorithm
As mentioned in the introduction, several iterative inertial methods have been proposed in [Citation29–31] for obtaining an ε-approximate solution of nonlinear monotone Equation (Equation1(1)
(1) ) in Euclidean space. The authors established that the sequences generated by their methods converge globally to the solution of the problem under mild conditions. Their primary contribution is in achieving an ε-approximate solution to (Equation1
(1)
(1) ) at a faster rate.
As discussed in Section 2, the concepts of MP and LP points were defined. Since BLSA cannot guarantee that the two points used to construct the inertial method are the previous MP points, the traditional inertial point has a low probability of being an MP point. To address this issue, the inertial point must ideally be constructed based on the previous MP points, or at the very least, a point in close proximity to the previous MP points. Hence, SILSA reduces the oscillation intensity of the residual norm by moving from regions containing LP points to regions containing MP points.
3.1. Novel subspace inertial method
In this section, we present a novel subspace inertial method that chooses the ingredients of the subspace from the previous MP points, thereby accelerating convergence to an ε-approximate solution of (Equation1(1)
(1) ).
Let be the sequence generated by our method. At the kth iteration of SILSA, we save the points generated by SILSA as the columns of the matrix
and their residual norms as the components of the vector
Here the jth column of
is denoted by
and m is the subspace dimension. We now introduce our novel subspace inertial point
(16)
(16) where the extrapolation step size
(17)
(17) is computed, so that the condition
(18)
(18) is satisfied. Here
is the maximum value for
and
for
are called subspace step sizes, satisfying
(19)
(19) These subspace step sizes will be chosen in Section 5 such that (Equation19
(19)
(19) ) holds. The condition (Equation18
(18)
(18) ) results in
(see Lemma 4.1, below), where
satisfies the line search condition (Equation3
(3)
(3) ). This result guarantees the global convergence for SILSA (see Theorem 4.3, below).
To update the matrix and the vector
at the kth iteration of SILSA, we replace the LP point with a new MP point (if any). Therefore, we use the new subspace inertial point (Equation16
(16)
(16) ), which involves a weighted average of the m previous MP points. This increases the chance of discovering an MP point by SILSA, i.e.
with
.
It should be noted that when m=2, the traditional inertial point (Equation6(6)
(6) ) differs from our subspace inertial point (Equation16
(16)
(16) ), because (Equation16
(16)
(16) ) replaces the LP point among the previous MP points with a new point. This means that (Equation16
(16)
(16) ) is not restricted to using only the two previous points
and
, while the traditional inertial point (Equation6
(6)
(6) ) is limited to exactly these two points. If these two points are LP points, then BLSA using (Equation6
(6)
(6) ) cannot move quickly from regions with LP points to regions with MP points, while SILSA using (Equation16
(16)
(16) ) has a good chance of having more MP points in the subspace inertial, since the subspace inertial is updated by removing LP points as described above.
3.2. Novel derivative-free direction
Motivated by the CG method given in [Citation32], we introduce the spectral derivative-free direction
(20)
(20) with the scalar parameter
(21)
(21) and the spectral parameter
(22)
(22) where 0<c<1 is given and
comes from (Equation16
(16)
(16) ).
Lemma 3.1
The search direction computed by (Equation20
(20)
(20) ) for
satisfies the descent condition (Equation4
(4)
(4) ).
Proof.
For the tuning parameter 0<c<1, and
hence
satisfies (Equation4
(4)
(4) ) for all
.
3.3. Subspace inertial line search with SILSA
In this subsection, we introduce a detailed description of our subspace inertial derivative-free algorithm, which we call SILSA. This algorithm is designed to find an ε-approximate solution of (Equation1(1)
(1) ) and is an improved version of BLSA that incorporates the subspace inertial method for faster convergence. In practice, the new subspace inertial method generates points that are, at worst, close to the previous MP points. Specifically, the new method replaces one of the previous MP points with the greatest residual norm. This substitution causes SILSA to move from regions with LP points to regions with MP points, and in practice quickly finds an approximate solution of (Equation1
(1)
(1) ).

The SILSA algorithm incorporates several tuning parameters: and
(the line search parameters),
(the minimum threshold for
),
(the initial value for
),
(the parameter for updating
), 0<c<1 (the parameter for computing
),
(the subspace dimension),
(the parameter for reducing
), and
(the maximum value for
).
We now describe how SILSA algorithm works:
| (S0) | (Initialization) First, we choose an initial point | ||||
| (S1) | (Line search algorithm) At the kthe iteration, SILSA performs lineSearch (line 5) along the derivative-free direction | ||||
| (S2) | (Checking reduction of the residual norm) If | ||||
| (S3) | (Projection of | ||||
| (S4) | (Update of the subspace of the old points) If the norm of the residual vector at the next point | ||||
| (S5) | (Computation of a new inertial point) After calculating the new subspace inertial point | ||||
| (S6) | (Computation of the search direction) If the value of The tuning parameters | ||||
4. Convergence analysis and complexity
In this section, we first present several auxiliary results, that are necessary to establish global convergence and the complexity bounds, and then the main theoretical results.
4.1. Some auxiliary results
The following results have a key role in proving global convergence.
Lemma 4.1
Let and
be the two sequences generated by SILSA, assume that the assumptions (A1)–(A3) hold, and define
. Then:
| (i) | The inequality
| ||||
| (ii) | The sequence | ||||
| (iii) |
| ||||
| (iv) | There exists a positive constant | ||||
| (v) | If the direction | ||||
| (vi) | If | ||||
Proof.
Let be the solution of Equation (Equation1
(1)
(1) ) and
be the set of feasible solutions.
| (i-ii) | The proof can be done like the proof of [Citation29, Lemma 4.5], but with the difference that the extrapolation step size (Equation17 | ||||
| (iii) | There exist two positive integers | ||||
| (iv) | From (ii), since | ||||
| (v) | From (Equation23 | ||||
| (vi) | From (Equation4 | ||||
In the following result, under the assumption that the residual norms are bounded below, upper and lower bounds for search directions and step sizes are restricted.
Proposition 4.2
Let and
be the two sequences generated by SILSA and assume that the assumptions (A1)–(A3) hold. If there is a positive constant
such that
for all k, then the following two statements are valid:
| (i) | The search directions | ||||
| (ii) | If the line search condition (Equation25 | ||||
Proof.
By the Cauchy-Schwartz inequality and (Equation25(25)
(25) ), we have
Thus, we obtain
(38)
(38) It follows from Lemma 4.1(iv), (Equation4
(4)
(4) ), (Equation20
(20)
(20) ), (Equation34
(34)
(34) ), and (Equation38
(38)
(38) ) that,
and
, resulting in
(ii) From Lemma 4.1(vi),
. We show that lineSearch always terminates in a finite number of steps. From (Equation23
(23)
(23) ), we have
. Then according to the role of updating
in (Equation24
(24)
(24) ) we have
. If the condition (Equation25
(25)
(25) ) with
does not hold, i.e.
(39)
(39) as j goes to infinity, we have
, which contradicts (Equation4
(4)
(4) ), since
,
(from (i)), and
. Hence lineSearch terminates finitely; there is a positive integer
such that
satisfying (Equation25
(25)
(25) ). As long as (Equation39
(39)
(39) ) holds, applying (Equation22
(22)
(22) ) into (Equation4
(4)
(4) ) and using (A2), we have
leading to
from Lemma 1(iv).
4.2. Convergence analysis
The following result is the main global convergence of SILSA. The variants of this result can be found in [Citation29–31], but with the different inertial point.
Theorem 4.3
Suppose that (A1)–(A3) hold and ,
,
are the three sequences generated by SILSA. Let
. Then, at least one of
(40)
(40) holds. Moreover, the sequences
and
converge to a solution of (Equation1
(1)
(1) ).
Proof.
If , then SILSA terminates and accepts
as a solution of (Equation1
(1)
(1) ) (see line 13 of SILSA). Otherwise, SILSA performs and therefore there is a positive constant
such that
, for all k, holds. Hence Proposition 4.2(i) results in that there is a positive constant
such that
for all k (
from Lemma 4.1(vi)). Moreover, if
, then SILSA terminates and accepts
as a solution of (Equation1
(1)
(1) ) (here
is a positive integer value such that
satisfying (Equation25
(25)
(25) )). Otherwise, from Lemma 4.1(iv), there is a positive constant
such that
As such, the assumptions of Proposition 4.2(ii) are verified and this proposition results in that there is a positive constant
such that
for all k. Hence, from Lemma 4.1(vi), we obtain
for all k, which contradicts (Equation32
(32)
(32) ). Therefore,
is obtained. From (Equation32
(32)
(32) ),
and the continuity of F results in
which consequently implies
(41)
(41) From the continuity of F, the boundedness of
and (Equation41
(41)
(41) ), it implies that the sequence
, generated by SILSA, has an accumulation point
such that
. On the other hand, the sequence
is convergent by Lemma 4.1, which means that the sequence
globally converges to the solution
of (Equation1
(1)
(1) ).
4.3. Complexity results
This section concerns an investigation of the complexity of SILSA. Firstly, we establish an upper limit on the number of function evaluations required by lineSearch. Following that, we determine an upper bound on the number of iterations needed for SILSA to converge, with or without a reduction in residual norms. Consequently, we derive an upper threshold for the total number of function evaluations necessary to successfully find an approximate solution of (Equation1(1)
(1) ) by SILSA.
Proposition 4.4
Let be the sequence generated by SILSA and assumes that (A1)–(A3) hold. Assuming that the initial step size is bounded by
and that the parameter 0<r<1 is utilized to decrease the step size in lineSearch, the number nf of function evaluations used by lineSearch (line 5 of SILSA) can be constrained by
where
is a positive constant derived from Proposition 4.2(ii).
Proof.
From Proposition 4.2(ii), we have for all k. By (Equation23
(23)
(23) ) and (Equation24
(24)
(24) ), we have
leading to
since
.
By means of (Equation27(27)
(27) ), we define the index set
as the set of all iterations k such that
. This set encompasses iterations exhibiting at most
reductions in the residual norms, while the index set
is the complement of
.
Theorem 4.5
Let ,
,
be the sequences generated by SILSA, let
be an ε-approximate solution of (Equation1
(1)
(1) ) found by SILSA, and assume that (A1)–(A3) hold. Moreover, the tuning parameters
(parameter for line search),
(initial and minimal threshold for the step size
), 0<r<1 (parameter for reducing step size by lineSearch),
(parameter for updating the step size
) are given. Then the following statements are valid:
| (i) | The number of iterations of SILSA with reductions in the residual norms is bounded by
| ||||
| (ii) | The number of iterations of SILSA without reductions in the residual norms is bounded by
| ||||
| (iii) | The number of iterations of SILSA is bounded by
| ||||
| (iv) | The number of function evaluations of SILSA is bounded by
| ||||
| (v) | If there is a positive constant | ||||
Proof.
The index set
The set
Combining the results from (i) and (ii) yields the desired outcome.
The result is obtained from (iii) and Proposition 4.4.
Consider any
Case 1: If
Case 2 Assuming that
As stated in the introduction, our complexity bound is of the same order as the bounds obtained by Cartis et al. [Citation50], Curtis et al. [Citation51], Dodangeh and Vicente [Citation52], Dodangeh et al. [Citation53], Kimiaei and Neumaier [Citation47], and Vicente [Citation54] for other optimization methods.
5. Numerical experiments
In this section, we present a comparative analysis of our algorithm, SILSA, with 10 well-known algorithms (discussed below) on a set of 18 test problems with the dimensions
This results in a total of 108 test functions. The Matlab codes of these 18 problems are available in the Section 7. To ensure that all test problems used are monotone in finite precision arithmetic, we randomly generated
distinct points x and y and verified that the condition
was fulfilled.
We compare SILSA with the following algorithms:
BLSA-DY, BLSA with the derivative-free direction using the CG direction of Dai and Yuan [Citation25].
BLSA-HZ, BLSA with the derivative-free direction using the CG direction of Hager and Zhang [Citation27].
BLSA-PR, BLSA with the derivative-free direction using the CG direction of Polak-Ribere-Polyak (PRP) [Citation36,Citation37].
BLSA-FR, BLSA with the derivative-free direction using the CG direction of Fletcher and Reeves (FR) [Citation26].
BLSA-3PR, BLSA with the derivative-free direction using the CG direction of Zhang et al. [Citation38].
BLSA-3A, BLSA with the derivative-free direction using the CG direction of Andrei [Citation22].
BLSA-IM, BLSA with the derivative-free direction of Ivanov et al. [Citation55].
BLSA-AK, BLSA with the derivative-free direction of Abubakar and Kumam [Citation56].
BLSA-HD, BLSA with the derivative-free direction of Huang et al. [Citation57].
BLSA-SS, BLSA with the derivative-free direction of Sabi'u et al. [Citation58].
In our comparison, the line search parameters for all algorithms were set to and r=0.5. We performed a tuning process to choose these two values for the selected test problems. The values of the other tuning parameters of the proposed algorithms are default values. For SILSA, the default values of the tuning parameters are as follows:
(the initial step size
),
(the minimum threshold for the step size
),
(the parameter for updating the step size
), c=0.5 (the direction parameter),
(maximum value for
),
(the line search parameter),
(the initial values for weights), and m=10 (the subspace inertial dimension). Here
was chosen and the normalized version
of
for
was computed.
Following the data profile of Mor'e and Wild [Citation59] and the performance profile of Dolan and Mor'e [Citation60],
the data profile
the performance profile
In particular, the fraction of problems that the solver s wins compared to the other solvers is and the fraction of problems for sufficiently large τ (or κ) that the solver s can solve is
(or
)). The measure for efficiency considered in this paper is the number nf of function evaluations. The efficiency with respect to nf is called nf efficiency. All algorithms terminated when exactly one of the conditions
,
, and
sec was satisfied. Here sec denotes time in seconds.
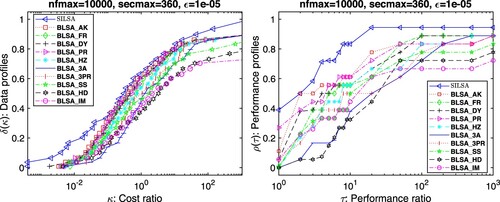
To evaluate their robustness and efficiency, we plot the data and performance profiles of all algorithms. From Figure , we conclude that SILSA is competitive with the other algorithms. Of the 112 test functions, SILSA is able to solve 95% of them, while also having the lowest number of function evaluations on 45% of these problems.
Figure 1. Results for problems with , the maximum number of function reevaluations (
), the maximum time in seconds (
sec), and
: Data profiles
(left) in dependence of a bound κ on the cost ratio, performance profiles
(right) in dependence of a bound τ on the performance ratio, in terms of nf. Problems solved by no solver are ignored.
6. Conclusion
The paper discusses an improved derivative-free line search method for nonlinear monotone equations. Our line search is a combination of the basic line search algorithm proposed by Solodov and Svaiter [Citation18] and a novel subspace inertial point whose goal is to speed up reaching an approximate solution of nonlinear monotone equations. The subspace is generated based on a finite number of the previous MP points such that a point with largest residual norm among the previous MP points is replaced by a new evaluated point. The global convergence and worst case complexity results are proved. Numerical results show that our improved line search method is competitive with the state-of-the-art derivative-free methods.
7. Test problems in Matlab
The Matlab codes of all 18 test problems are as follows:
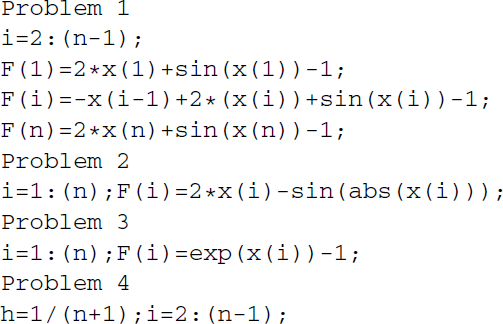


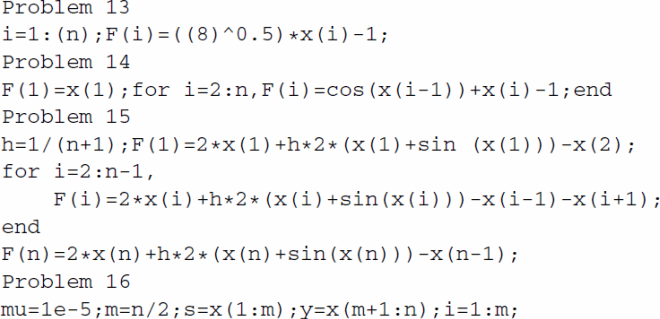
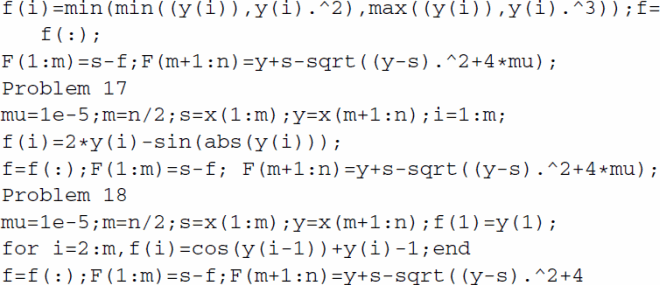
The problems 1–4, 6–8, 10, 13 are from [Citation46], the problem 5 is from [Citation14], the problems 9, 14, 15 are from [Citation61], the problems 12 is from [Citation62], and the problems 16-18 are from the present paper. To obtain the problems 16-18, the nonlinear complementarity problem is converted to the nonsmooth equations
(45)
(45) where F is a monotone operator. Following [Citation63], by defining
the problem (Equation45
(45)
(45) ) is transformed into
For all test problems, the initial points were chosen to be
for
.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chorowski J, Zurada JM. Learning understandable neural networks with nonnegative weight constraints. IEEE Trans Neural Netw Learn Syst. 2015;26(1):62–69. doi: 10.1109/TNNLS.2014.2310059
- Blumensath T. Compressed sensing with nonlinear observations and related nonlinear optimization problems. IEEE Trans Inf Theory. 2013;59:3466–3474. doi: 10.1109/TIT.2013.2245716
- Candes EJ, Li X, Soltanolkotabi M. Phase retrieval via wirtinger flow: theory and algorithms. IEEE Trans Inf Theory. 2015 Apr;61(4):1985–2007. doi: 10.1109/TIT.2015.2399924
- Dirkse SP, Ferris MC. Mcplib: a collection of nonlinear mixed complementarity problems. Optim Methods Softw. 1995 Jan;5(4):319–345. doi: 10.1080/10556789508805619
- Ahookhosh M, Amini K, Bahrami S. Two derivative-free projection approaches for systems of large-scale nonlinear monotone equations. Numer Algorithms. 2012 Oct;64(1):21–42. doi: 10.1007/s11075-012-9653-z
- Ahookhosh M, Artacho FJA, Fleming RMT, et al. Local convergence of the Levenberg–Marquardt method under Hölder metric subregularity. Adv Comput Math. 2019 Jun;45(5-6):2771–2806. doi: 10.1007/s10444-019-09708-7
- Ahookhosh M, Fleming RMT, Vuong PT. Finding zeros of hölder metrically subregular mappings via globally convergent Levenberg–Marquardt methods. Optim Methods Softw. 2020 Jan;37(1):113–149. doi: 10.1080/10556788.2020.1712602
- Amini K, Shiker MA, Kimiaei M. A line search trust-region algorithm with nonmonotone adaptive radius for a system of nonlinear equations. 4OR. 2016;14(2):133–152. doi: 10.1007/s10288-016-0305-3
- Brown PN, Saad Y. Convergence theory of nonlinear Newton–Krylov algorithms. SIAM J Optim. 1994;4(2):297–330. doi: 10.1137/0804017
- Dennis JE, Moré JJ. A characterization of superlinear convergence and its application to quasi-Newton methods. Math Comput. 1974;28(126):549–560. doi: 10.1090/mcom/1974-28-126
- Esmaeili H, Kimiaei M. A trust-region method with improved adaptive radius for systems of nonlinear equations. Math Methods Oper Res. 2016;83(1):109–125. doi: 10.1007/s00186-015-0522-0
- Kimiaei M. Nonmonotone self-adaptive Levenberg–Marquardt approach for solving systems of nonlinear equations. Numer Funct Anal Optim. 2018;39(1):47–66. doi: 10.1080/01630563.2017.1351988
- Kimiaei M, Esmaeili H. A trust-region approach with novel filter adaptive radius for system of nonlinear equations. Numer Algorithms. 2016;73(4):999–1016. doi: 10.1007/s11075-016-0126-7
- Li D, Fukushima M. A globally and superlinearly convergent Gauss–Newton-based bfgs method for symmetric nonlinear equations. SIAM J Numer Anal. 1999;37(1):152–172. doi: 10.1137/S0036142998335704
- Yamashita N, Fukushima M. On the Rate of Convergence of the Levenberg-Marquardt Method. In: Alefeld G, Chen X, editors. Topics in Numerical Analysis. Springer Vienna.2001. p. 239–249.
- Yuan Y. Recent advances in numerical methods for nonlinear equations and nonlinear least squares. NACO. 2011;1(1):15–34. doi: 10.3934/naco.2011.1.15
- Zhou G, Toh KC. Superlinear convergence of a Newton-type algorithm for monotone equations. J Optim Theory Appl. 2005;125(1):205–221. doi: 10.1007/s10957-004-1721-7
- Solodov MV, Svaiter BF. A globally convergent inexact Newton method for systems of monotone equations. In: Reformulation: Nonsmooth, piecewise smooth, semismooth and smoothing methods. Springer; 1998. p. 355–369.
- Al-Baali M, Narushima Y, Yabe H. A family of three-term conjugate gradient methods with sufficient descent property for unconstrained optimization. Comput Optim Appl. 2014 May;60(1):89–110. doi: 10.1007/s10589-014-9662-z
- Aminifard Z, Babaie-Kafaki S. A modified descent Polak–Ribiére–Polyak conjugate gradient method with global convergence property for nonconvex functions. Calcolo. 2019;56(2):1–11. doi: 10.1007/s10092-019-0312-9
- Aminifard Z, Hosseini A, Babaie-Kafaki S. Modified conjugate gradient method for solving sparse recovery problem with nonconvex penalty. Signal Process. 2022;193:108424. doi: 10.1016/j.sigpro.2021.108424
- Andrei N. A simple three-term conjugate gradient algorithm for unconstrained optimization. Comput Appl Math. 2013;241:19–29. doi: 10.1016/j.cam.2012.10.002
- Andrei N. Nonlinear conjugate gradient methods for unconstrained optimization. 1. Cham, Switzerland: Springer Cham; 2020.
- Cheng W. A PRP type method for systems of monotone equations. MCM. 2009;50(1-2):15–20.
- Dai YH, Yuan Y. A nonlinear conjugate gradient method with a strong global convergence property. SIAM J Optim. 1999;10(1):177–182. doi: 10.1137/S1052623497318992
- Fletcher R, Reeves CM. Function minimization by conjugate gradients. Comput J. 1964;7(2):149–154. doi: 10.1093/comjnl/7.2.149
- Hager WW, Zhang H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J Optim. 2005;16(1):170–192. doi: 10.1137/030601880
- Hager WW, Zhang H. A survey of nonlinear conjugate gradient methods. Pacific J Optim. 2006;2(1):35–58.
- Ibrahim A, Kumam P, Abubakar AB, et al. A method with inertial extrapolation step for convex constrained monotone equations. J Inequal Appl. 2021;2021(1):1–25. doi: 10.1186/s13660-021-02719-3
- Ibrahim AH, Kumam P, Abubakar AB, et al. Accelerated derivative-free method for nonlinear monotone equations with an application. Numer Linear Algebra Appl. 2021 Nov;29(3):e2424. doi: 10.1002/nla.v29.3
- Ibrahim AH, Kumam P, Sun M, et al. Projection method with inertial step for nonlinear equations: application to signal recovery. J Ind Manag. 2021;19:30–55.
- Liu Y, Storey C. Efficient generalized conjugate gradient algorithms, part 1: theory. J Optim Theory Appl. 1991;69(1):129–137. doi: 10.1007/BF00940464
- Liu Y, Zhu Z, Zhang B. Two sufficient descent three-term conjugate gradient methods for unconstrained optimization problems with applications in compressive sensing. J Appl Math Comput. 2021;68:1787–1816. doi: 10.1007/s12190-021-01589-8
- Lotfi M, Mohammad Hosseini S. An efficient hybrid conjugate gradient method with sufficient descent property for unconstrained optimization. Optim Methods Softw. 2021;37:1725–1739. doi: 10.1080/10556788.2021.1977808
- Papp Z, Rapajić S. FR type methods for systems of large-scale nonlinear monotone equations. Appl Math Comput. 2015;269:816–823.
- Polak E, Ribiere G. Note sur la convergence de méthodes de directions conjuguées. ESAIM: Mathematical Modelling and Numerical Analysis-Modélisation Mathématique et Analyse Numérique. 1969;3(R1):35–43.
- Polyak BT. The conjugate gradient method in extremal problems. USSR Comput Math Math Phys. 1969;9(4):94–112. doi: 10.1016/0041-5553(69)90035-4
- Zhang L, Zhou W, Li DH. A descent modified Polak–Ribière–Polyak conjugate gradient method and its global convergence. IMA J Numer. 2006;26(4):629–640. doi: 10.1093/imanum/drl016
- Alvarez F. Weak convergence of a relaxed and inertial hybrid projection-proximal point algorithm for maximal monotone operators in hilbert space. SIAM J Optim. 2004 Jan;14(3):773–782. doi: 10.1137/S1052623403427859
- Alvarez F, Attouch H. An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Var Anal. 2001;9(1):3–11. doi: 10.1023/A:1011253113155
- Attouch H, Peypouquet J, Redont P. A dynamical approach to an inertial forward-backward algorithm for convex minimization. SIAM J Optim. 2014;24(1):232–256. doi: 10.1137/130910294
- Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J Imaging Sci. 2009;2(1):183–202. doi: 10.1137/080716542
- Boţ RI, Grad SM. Inertial forward–backward methods for solving vector optimization problems. Optimization. 2018 Feb;67(7):959–974. doi: 10.1080/02331934.2018.1440553
- Boţ RI, Nguyen DK. A forward-backward penalty scheme with inertial effects for monotone inclusions, applications to convex bilevel programming. Optimization. 2018 Dec;68(10):1855–1880.
- Boţ R, Sedlmayer M, Vuong PT. A relaxed inertial forward-backward-forward algorithm for solving monotone inclusions with application to GANs. arXiv e-prints, arXiv:2003.07886, 2020 Mar.
- Ibrahim AH, Kimiaei M, Kumam P. A new black box method for monotone nonlinear equations. Optimization. 2021 Nov;72:1119–1137. doi: 10.1080/02331934.2021.2002326
- Kimiaei M, Neumaier A. Efficient global unconstrained black box optimization. Math Program Comput. 2022 Feb;14:365–414. doi: 10.1007/s12532-021-00215-9
- Dai YH, Liao LZ. New conjugacy conditions and related nonlinear conjugate gradient methods. Appl Math Optim. 2001 Jan;43(1):87–101. doi: 10.1007/s002450010019
- Li M. An Liu-Storey-type method for solving large-scale nonlinear monotone equations. Numer Funct Anal Optim. 2014;35(3):310–322. doi: 10.1080/01630563.2013.812656
- Cartis C, Sampaio P, Toint P. Worst-case evaluation complexity of non-monotone gradient-related algorithms for unconstrained optimization. Optimization. 2014 Jan;64(5):1349–1361. doi: 10.1080/02331934.2013.869809
- Curtis FE, Lubberts Z, Robinson DP. Concise complexity analyses for trust region methods. Optim Lett. 2018 Jun;12(8):1713–1724. doi: 10.1007/s11590-018-1286-2
- Dodangeh M, Vicente LN. Worst case complexity of direct search under convexity. Math Program. 2014 Nov;155(1-2):307–332. doi: 10.1007/s10107-014-0847-0
- Dodangeh M, Vicente LN, Zhang Z. On the optimal order of worst case complexity of direct search. Optim Lett. 2015 Jun;10(4):699–708. doi: 10.1007/s11590-015-0908-1
- Vicente L. Worst case complexity of direct search. EURO J Comput Optim. 2013 May;1(1-2):143–153. doi: 10.1007/s13675-012-0003-7
- Ivanov B, Milovanović GV, Stanimirović PS. Accelerated dai-liao projection method for solving systems of monotone nonlinear equations with application to image deblurring. J Glob Optim. 2022 Jul;85(2):377–420. doi: 10.1007/s10898-022-01213-4
- Abubakar AB, Kumam P. A descent Dai-Liao conjugate gradient method for nonlinear equations. Numer Algorithms. 2018 May;81(1):197–210. doi: 10.1007/s11075-018-0541-z
- Huang F, Deng S, Tang J. A derivative-free memoryless BFGS hyperplane projection method for solving large-scale nonlinear monotone equations. Soft Comput. 2022 Oct;27(7):3805–3815. doi: 10.1007/s00500-022-07536-4
- Sabi'u J, Shah A, Stanimirović PS, et al. Modified optimal Perry conjugate gradient method for solving system of monotone equations with applications. Appl Numer Math. 2023 Feb;184:431–445. doi: 10.1016/j.apnum.2022.10.016
- Moré JJ, Wild SM. Benchmarking derivative-free optimization algorithms. SIAM J Optim. 2009 Jan;20(1):172–191. doi: 10.1137/080724083
- Dolan ED, Moré JJ. Benchmarking optimization software with performance profiles. Math Program. 2002 Jan;91(2):201–213. doi: 10.1007/s101070100263
- La Cruz W, Martínez J, Raydan M. Spectral residual method without gradient information for solving large-scale nonlinear systems of equations. Math Comput. 2006;75(255):1429–1448. doi: 10.1090/S0025-5718-06-01840-0
- Gao P, He C. An efficient three-term conjugate gradient method for nonlinear monotone equations with convex constraints. Calcolo. 2018 Nov;55(4):53. doi: 10.1007/s10092-018-0291-2
- Geiger C, Kanzow C. On the resolution of monotone complementarity problems. Comput Optim Appl. 1996 Mar;5(2):155–173. doi: 10.1007/BF00249054