
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The paper studies a financial portfolio selection problem under 1st-order stochastic dominance constraints. These constraints constitute lower bounds on the return profile of the portfolio. In particular, they allow searching for a better portfolio than some reference portfolio by comparing their cumulative distribution functions. Candidate objective functions are the average return, a value at risk, or the average value at risk. The optimization problems obtained are computationally hard because of possibly non-convex constraints and possibly discontinuous objective functions. In the case of a discrete distribution of the return, we develop numerical procedures to solve the problem. The proposed approach uses new exact penalty functions to tackle with the 1st-order stochastic dominance constraints. The resulting penalized objective function is further optimized be the stochastic successive smoothing method as a local optimizer within some branch and bound global optimization scheme. The approach is numerically and graphically illustrated on small portfolio selection problems up to dimension 10.
1. Introduction
We consider the general, constrained optimization problem
(1)
(1) where the set
constitutes the set of feasible solutions. The projective exact penalty method (cf. [Citation1]) involves a map
such that
(2)
(2) The map
in (Equation2
(2)
(2) ) is not specified. For
convex, the projection
(3)
(3) is well-defined and thus is a candidate for the global optimization problem (Equation4
(4)
(4) ). However, the projection (Equation3
(3)
(3) ) might not be available at cheap computational costs.
For a star domain , there exists a point
so that every line segment
is fully contained in
, provided that
. The function
where
as well satisfies the conditions (Equation2
(2)
(2) ).
For a single-valued and continuous projection mapping , the global and local solutions of the constrained problem (Equation1
(1)
(1) ) and the unconstrained, global optimization problem
(4)
(4) coincide. Hence, the global, unconstrained optimization problem (Equation4
(4)
(4) ) can be considered instead of the constrained optimization problem (Equation1
(1)
(1) ).
The problem (Equation4(4)
(4) ) is not necessarily smooth nor convex. So solving (Equation4
(4)
(4) ) requires applying non-smooth local and global optimization methods (cf. [Citation1]).
The present paper outlines the described methodology for a financial portfolio optimization problem under specific constraints, namely 1st-order stochastic dominance constraints (FSD), where each feasible portfolio stochastically dominates a given reference portfolio. This means that a decision maker with non-decreasing utility function will prefer any feasible portfolio to the reference one. Such portfolio optimization settings were considered in [Citation2,Citation3] (with the 2nd-order stochastic dominance constraints, SSD) and in [Citation4] (for linear problems with 1st-order stochastic dominance constraints). Problems with FSD constraints are much harder than the ones with SSD constraints, because the former are non-convex. Noyan and Ruszczyński [Citation5] reduce such problems to linear mixed-integer problems. The present paper develops a different approach to such problems, which is applicable to the nonlinear case as well. Our approach consists in an application of the exact penalty method to remove the FSD constraints and solution of the obtained penalty problem by non-smooth global optimization methods.
Outline of the paper.
First, Section 2 reviews the literature on decision-making and portfolio optimization under stochastic dominance constraints.
In Section 3, we set the problem of a portfolio optimization under 1st-order stochastic dominance constraints and provide some examples of such problems. Next (cf. Section 4), we reduce the portfolio optimization problem under 1st-order stochastic dominance constraints to the unconstrained problems by means of new exact projective non-smooth and discontinuous penalty functions.
Forth, we review the successive smoothing method for local optimization of non-smooth and discontinuous functions. This method is used as a local optimizer within the branch and bound framework for the global optimization of the penalty functions. We finally give numerical illustrations (Section 5) of the proposed approach to financial portfolio optimization under 1st-order stochastic dominance constraints on portfolios containing up to 10 components with one risk-free asset.
2. Literature review
The problem of financial portfolio optimization belongs to the class of decision-making problems under uncertainty. The choice of a particular portfolio is accompanied by an uncertain result in the form of a distribution of future returns. This and more general decision problems under stochastic uncertainty are studied in the theory of stochastic programming (cf. [Citation6]). In the general case, the formalization of such problems is carried out using preferences defined on the set of possible uncertain results of decisions made. Preferences establish partial order relationships on the set of decision outcomes, i.e. they satisfy the axioms of reflexivity, transitivity, and antisymmetry. Partial order relations make it possible to narrow the choice of preferable solutions to a subset of non-dominated alternatives. Under additional assumptions about the properties of preferences, the latter can be represented in a numerical form, and then the problem of choosing preferred outcomes turns into a problem of multi-objective optimization. A discussion of stochastic programming problems from this perspective can be found in [Citation7]. Conversely, any numerical function on the set of outcomes specifies a preference relation.
In optimization and financial portfolio management problems, investments are often allocated according subject to utility and risk criteria. The original settings of this type were proposed by Markowitz [Citation8] and Roy [Citation9], who used the mean return as a measure of utility and the variance of returns as a measure of risk. An attractive feature of these formulations is the relative simplicity of the resulting optimization problems.
Subsequently, other utility and risk measures were proposed and used, such as quantiles, averaged quantiles, semi-deviations of returns from the average value, probabilities of returns falling into a profit or loss area, general coherent risk measures, and others (the references include [Citation10–25], cf. also the references therein). The corresponding decision selection problems are computationally more complex and require adapting known methods, or even developing new solution methods. For example in [Citation26], the problems of optimizing a financial portfolio in terms of averaged quantiles are reduced to a linear programming problem and can be effectively solved by existing software tools. However, problems that involve quantiles or probabilities are much more difficult because they are non-convex and non-smooth with a possibly non-convex and disconnected admissible region. The problem may be even harder, if the return depends nonlinearly on the portfolio structure (see, e.g. the discussion of the properties of these problems in [Citation12,Citation13]). For example, in the works by Noyan et al. [Citation4], Benati and Rizzi [Citation11], Luedtke et al. [Citation18], Norkin and Boyko [Citation19], Kibzun et al. [Citation16] and Norkin et al. [Citation20], such problems are reduced to problems of mixed-integer programming in the case of a discrete distribution of random data. Gaivoronski and Pflug [Citation13] developed a special method for smoothing a variational series to optimize a portfolio by a quantile criterion. Wozabal et al. [Citation25] give a review of the quantile constrained portfolio selection problem, present a difference-of-convex representation of involved quantiles, and develop a branch and bound algorithm to solve the reformulated problem.
On the other hand, natural relations of stochastic dominance of the first, second and higher orders are known on the set of probability distributions. For example, the first order stochastic dominance relation is defined as the excess of one distribution function over another distribution function. The relation of stochastic dominance of the second order is determined by the relation of the integrals of the distribution functions of random variables. With the second-order stochastic dominance relation, the decision maker's negative attitude towards risk can be expressed (see a discussion of these issues in [Citation27,Citation28]).
A natural question arises about the connection between decision-making problems in a multi-criteria formulation and in terms of certain preference relations, in particular, stochastic dominance relations. The connection between mean-risk models and second-order stochastic dominance relations was studied in the works by Ogryczak and Ruszczyński [Citation29–31]. In the works by Dentcheva and Ruszczyński [Citation27,Citation32] it is shown under what conditions the problem of decision-making in terms of preference relations is reduced to the problem of optimizing a numerical indicator.
Dentcheva and Ruszczyński [Citation2,Citation3] proposed a mixed financial portfolio optimization model in which a numerical criterion is optimized, and constraints are specified using second-order stochastic dominance relations. The feasible set in this setting consists of decisions, which dominate some reference one and are preferred by any risk averse decision maker. In the case of a discrete distribution of random data, the problem is reduced to a linear programming problem of (large) dimension. These works have given rise to a large stream of work on stochastic optimization problems under second-order stochastic dominance constraints (see the reviews by Gutjahr and Pichler [Citation7], Dai et al. [Citation33], Dentcheva and Ruszczyński [Citation34] and Fábián et al. [Citation35]).
Noyan et al. [Citation4,Citation5] and Dentcheva and Ruszczyński [Citation36] considered similar mixed problems, but with first-order stochastic dominance relations in the constraints. To solve them, a method of reduction to problems of linear mixed-integer programming with subsequent continuous relaxation of Boolean constraints and the introduction of additional cutting constraints is proposed. The paper [Citation33] develops a quite different approach to solving the problem based on the dual reformulation from [Citation37] by discretization of the space of one-dimensional utilities by step-wise functions, smoothing the latter, and applying the stochastic gradient method for the (local) optimization of the approximate dual function. Dentcheva et al. [Citation38] studied the stability of these problems with respect to perturbation of the involved distributions on the basis of general studies of the stability of stochastic programming problems.
In this article, we consider similar financial portfolio optimization problems under 1st-order stochastic dominance constraints, but from a different point of view and apply a different solution approach that is also applicable to problems with nonlinear random return functions. This problem is viewed as the problem of optimizing the risk profile of the portfolio according to the preferences of the decision maker. Namely, the decision maker sets the desired risk profile (the form of the cumulative distribution function) and tries to find an acceptable portfolio that dominates this risk profile. This is one statement, and the other is that, under the condition of the existence of an admissible portfolio, i.e. portfolio dominating some reference portfolio, it can be any index or risk-free portfolio, choose a portfolio with the desired risk profile by optimizing one or another function (for example risk measures, as average quantiles, etc.).
In this way it is possible to satisfy the needs of both a risk seeking decision maker and a risk averse decision maker. In the first case, the average quantile function for high returns is maximized, and in the second case, the mean quantile function for low returns is maximized, in both cases with a lower bound on the quantile risk profile. In the first case, the risk profile is stretched, and in the second case, it is compressed and becomes more like a profile of a deterministic value. The reshaping of the risk profile can be made both through selection of different objective function and by adding new securities to the portfolio, e.g. as commodities, etc., cf. [Citation39].
In the problems under consideration, the objective function is nonlinear, non-convex, and possibly non-smooth or even discontinuous, and the number of constraints is continual (uncountable). But when the reference profile has a stepped character, one can limit oneself to a finite number of restrictions by the number of steps of the reference profile. In this problem, the admissible area may turn out to be non-convex and disconnected. Thus, the problem under consideration is a global optimization problem with highly complex and nonlinear constraints. To solve it, we first reduce it to an unconstrained global optimization problem by applying new penalty functions, namely, discontinuous penalty functions as in [Citation40,Citation41] and the so-called projective penalty functions as in [Citation1,Citation42]. In the first case, the objective function outside the allowable area is extended by large but finite penalty values, and in the second case, it is extended at infeasible points by summing the value of the objective function in the projection of this point onto the feasible set and the distance to this projection. In this case, the projection is made in the direction of some known internal feasible point. After such a transformation, the problem is still a complex unconstrained global optimization problem. In order to solve it, we further apply the method of successive smoothing of this penalty function, i.e. we minimize successive smoothed approximations of the penalized function, starting from relatively large smoothing parameters with its gradual decreasing to zero. It is known that the smoothed functions can be optimized by the method of stochastic gradients, where the latter have the form of finite difference vectors in random directions, cf. [Citation43–46]. Here, smoothing plays a dual role. Firstly, it allows optimizing non-smooth and discontinuous functions and, secondly, it levels out shallow local extrema. Although smoothing makes it possible to ignore small local extrema, it does not guarantee convergence to the global extrema. Therefore, we put the method of sequential smoothing in a general scheme of the stochastic branch and bound method, where the smoothing method plays the role of a local optimizer on subsets of the optimization area. The scheme of the branch and bound method is designed in such a way that the calculations are concentrated in the most promising areas of the search for the global extrema. Our approach is similar to that of Dai et al. [Citation33], but applied to the primal problem, it applies an exact penalty method instead of the Lagrangian one, and optimizes the penalized function by stochastic finite-difference gradient methods. Besides, we provide global search by a specific stochastic branch and bound algorithm, which is well-suited for parallelization.
This article describes the financial portfolio optimization model with 1st-order stochastic dominance constraints and illustrates the proposed approach to its solution on the problems of reshaping the risk profile of portfolios of small dimension. At the same time, the results of changing the shape of the risk profile are presented in graphical form, which allows visually comparing the resulting profile with the reference one, and, if necessary, continue adaptation of the profile to the preferences of the decision maker.
3. Mathematical problem setting
The financial portfolio is described by a vector of values
and by a random vector of returns
of assets,
, in some fixed time interval;
denotes the transposition of a vector. Denote by
the set of admissible portfolios with a unit maximal total cost of the whole portfolio,
is a lower bound on the value of component i of the portfolio (e.g. a short-selling constraint or a limitation on borrowing assets). In the definition of the set X, the inequality
is used, which means that
– the non-invested funds – have zero yield. The portfolio is characterized by a random return
, by the mean return
for the considered period of time and by the variance of return
, where
denotes the mathematical expectation with respect to the distribution of random variable ω.
The classical financial portfolio models assume a linear dependence of the return on the portfolio structure, for which alternative problem reformulations are available. Nonlinearities appear when random returns are modelled by some parametric distribution. Another example of nonlinear portfolio return appears in the dynamic portfolio optimization problem with fixed mix portfolio control strategy, cf. [Citation47].
Suppose the random vector ω is given by a discrete (an empirical, e.g.) distribution with equiprobable values
,
. Then the average portfolio return
and the cumulative distribution function (CDF) of the portfolio return
are given by
and
The portfolio optimization problem under 1st-order stochastic dominance constraint is
(5)
(5)
(6)
(6) The objective function
in (Equation5
(5)
(5) ) quantifies the profit, which is to be maximized. As objectives
in the master problem (Equation5
(5)
(5) ), we consider
the mean value
,
some Value-at-Risk function (
the average Value-at-Risk function
The constraints (Equation6(6)
(6) ) address risk: the cumulative distribution function
of the feasible portfolio x must not be worse than the reference function
(also called a reference risk profile) for all
. The reference function itself may be given by
, where
is some reference portfolio with cumulative distribution function
.
We formally can associate some random variable with the CDF
. Then, the family of inequalities (Equation6
(6)
(6) ) ensures that the random variable
dominates the random variable
in 1st stochastic order. We further remark that there can be several stochastic dominance constraints with corresponding reference CDF
, which can be replaced by the single CDF
.
The constraints (Equation6(6)
(6) ) are tight– often too tight to ensure a non-empty set of feasible solutions. The function
relaxes these tight constraints by accepting higher losses at given probabilities.
The function is non-decreasing and continuous from the right (upper semicontinuous), the functions
and
are assumed right continuous.
Lemma 3.1
The feasible set in (Equation6(6)
(6) ) is either empty or compact.
Proof.
Indeed, define
with right continuous
,
, and left continuous
. On one hand it holds that
, since
. On the other hand, if
, then it holds for any t that
So
and, hence,
. In such case, the function
appears to be lower semicontinuous in
, hence the sets
are closed and the sets
are closed for each t. If the feasible set
in (Equation6
(6)
(6) ) is non-empty, then it is closed and bounded and, hence, compact. This completes the proof.
Lemma 3.2
If the function has only finitely many jumps, e.g. at
then
Proof.
Let ,
for
,
, and
for
. Then
for all
,
. Besides,
for all
.
An alternative problem formulation. A reformulation of the problem (Equation5(5)
(5) )–(Equation6
(6)
(6) ) involves the inverse cumulative distribution functions instead of the CDFs. To this end let
be the return quantile (generalized inverse) function associated with the decision x, and
be some reference quantile function, continuous from below (lower semicontinuous).
Consider the problem (7)
(7)
(8)
(8) The following lemmas demonstrate that problem (Equation7
(7)
(7) )–(Equation8
(8)
(8) ) is well-defined and equivalent to the initial problem statement (Equation5
(5)
(5) )–(Equation6
(6)
(6) ).
Lemma 3.3
Define and
, then
both functions
and
are upper semicontinuous in
, and hence the feasible set in (Equation8
(8)
(8) ) is compact.
Proof.
First, it holds for any that
Let us prove the opposite inequality,
For a given α there exists
such that
and thus
for all
. For any
, it holds that
Hence, we obtain the required opposite inequality,
and thus
Next, the
is the maximum function, by Aubin and Ekeland [Citation48, Ch. 1, Sec. 1, Prop. 21] it is upper semicontinuous in
. Hence, the feasible set in (Equation8
(8)
(8) ) is either empty or compact as intersection of compact sets
,
. The proof is complete.
The next lemma states that problems (Equation5(5)
(5) )–(Equation6
(6)
(6) ) and (Equation7
(7)
(7) )–(Equation8
(8)
(8) ) are equivalent.
Lemma 3.4
Let
cf. (Equation8
(8)
(8) )
, where
is the same (right continuous) reference distribution function as in (Equation6
(6)
(6) ). Then the problems (Equation5
(5)
(5) )–(Equation6
(6)
(6) ) and (Equation7
(7)
(7) )–(Equation8
(8)
(8) ) are equivalent, i.e. they have the same objective function and their feasible sets coincide.
Proof.
We have to prove that (Equation6(6)
(6) ) and (Equation8
(8)
(8) ) define the same feasible set. Assume (Equation6
(6)
(6) ) is fulfilled but (Equation8
(8)
(8) ) is not. Then there exists
such that
. This implies that
From here, by assumption (Equation6
(6)
(6) ),
. The supremum in
is achieved at
then
a contradiction.
Assume (Equation8(8)
(8) ) is fulfilled but (Equation6
(6)
(6) ) is not. Then there exists
such that
. By assumption,
and by definition of a quantile,
thus
. On the other hand, due to the right continuity of a distribution function, there is
such that
so
, a contradiction. This completes the proof.
Lemma 3.5
If the reference function has a step like character with steps at
, i.e.
for
,
, then
Proof.
Assume for all
. Then
for all
,
and
.
Employing different objective functions in (Equation7
(7)
(7) ) allows reshaping the risk profile
and
in a desirable manner. For example, the problem
can be used for searching more risky but potentially more profitable portfolios than some reference one
with risk profile
and step back function
. The problem
can be used to obtain less risky and less profitable portfolio than a reference portfolio
. Note, however, that the objective functions in these problems can be discontinuous.
Examples
The following two examples address particular cases of the problem setting (Equation7(7)
(7) ) and (Equation8
(8)
(8) ) involving the generalized inverse. Example 3.7 extends the problem setting from portfolio optimization to decision-making under dangerous threats.
Example 3.6
Portfolio selection under a single Value-at-Risk () constraint, cf. [Citation25] and corresponding references therein
Let be the α-quantile of the random return
for a given α,
be the reference value for
, and
a.s. Consider the problem
(9)
(9) where
is a fixed risk level.
With the reference quantile function
the constraints in this example are equivalent to
,
,
, of form the form (Equation8
(8)
(8) ).
Example 3.7
Decision making under catastrophic risks, [Citation49]
Catastrophic risks, as catastrophic floods, earthquakes, tsunami, etc., designate some ‘low probability – high consequences’ events. Usually, they are described by a list of possible extreme events (indexed by ) that can happen once in 10, 50, or 100, etc., years. Decision-making under catastrophic risks means designing a certain mitigation measures to prevent unacceptable losses. It is proposed the following framework for decision-making under catastrophic risks.
Let vector of parameters describes a decision (a complex of countermeasures) from some (compact) set X of possible decisions, each associated with costs
. For each kind of event i, experts can define reasonable (‘acceptable’) levels of losses
due to this event,
. Suppose we can model each event i, its consequences and losses
under the decision
. Then the corresponding decision-making problem is
(10)
(10) Although the framework does not include explicit probabilities of the events i, we can formally introduce probabilities
, e.g.
,
,
, etc., that event i happens in any given year. By defining two quantile functions
we can formally express the constraints (Equation10
(10)
(10) ) as
for all
, i.e. in terms of 1st-order stochastic dominance.
4. The solution approach: exact penalty functions
In case of a discrete random variable ω, the function in (Equation6
(6)
(6) ) is discontinuous in t and x. For the solution of the problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ), we apply the exact discontinuous and the exact projective penalty functions from [Citation1,Citation40–42,Citation50].
4.1. Finding a feasible solution
If the distribution function has a stepwise character with jumps at step points
, we may set
With that, due to Lemma 3.2, the stochastic dominance constraints in (Equation6
(6)
(6) ) are equivalent to the inequality
.
To find a feasible solution for the problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ), we solve the problem
(11)
(11) If for some
it holds that
, then
is a feasible solution of the problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ).
Similarly, due to Lemma 3.5, to find a feasible solution of problem (Equation7(7)
(7) )–(Equation8
(8)
(8) ), we solve the problem
(12)
(12) where
is the set of jump points of
.
4.2. Structure of the feasible set
The structure of the feasible set of the problems (Equation5(5)
(5) )–(Equation6
(6)
(6) ) and (Equation7
(7)
(7) )–(Equation8
(8)
(8) ) heavily depends on the choice of the reference profiles
and
. Figure illustrates disconnected and non-convex feasible sets for a portfolio consisting of 3 components only.
Figure 1. Possible (disconnected and non-convex) shapes of feasible sets under 1st-order SDC (,
).

Suppose the portfolio includes the first two assets of Table 9 from the appendix, with random return ω given by the first two columns of this table. Let
be the risk profile of this portfolio and
(with constant
) be the reference risk profile. The left figure in Figure displays the shape of the non-convex disjoint feasible set of problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ) for this example. The figure in the middle gives an example of the feasible set of problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ), when a risk-free asset is infeasible. The right figure of Figure corresponds to the case of a feasible risk-free portfolio.
When the distribution of returns ω is discrete (i.e. represented by scenarios), the distribution function of the portfolio return is discontinuous in x as a weighted sum of step-wise indicator functions, so the stochastic dominance constraints are represented by discontinuous functions. So generally, we deal with discontinuous optimization problems, which are a challenge for optimization theory. In particular, the constraints in these problems can be non-convex and disjoint. Our first step towards a solution of such problems is to eliminate constraints by a penalty method. However, the standard exact penalty methods that add a penalty term to the objective function is invalid in this case. In the next section we consider two new exact penalty methods, discontinuous and projective ones.
4.3. Exact discontinuous penalty functions
To find an optimal solution for problem (Equation5(5)
(5) )–(Equation6
(6)
(6) ), we solve the problem
(13)
(13) where
, for example,
with
Obviously, the global maximums of the problems (Equation5(5)
(5) )–(Equation6
(6)
(6) ) and (Equation13
(13)
(13) ) coincide.
We can further remove the constraint from problem (Equation13
(13)
(13) ) by subtracting the exact projective penalty term
, where
is the projection of x on X, from the objective function (Equation13
(13)
(13) ), and solve the global problem
(14)
(14) instead.
4.4. Exact projective penalty functions
Let be some feasible solution of problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ), i.e.
and
. For any
denote
. Define a projection point
(15)
(15) where
Now instead of the constrained problem (Equation5
(5)
(5) )–(Equation6
(6)
(6) ) consider the unconstrained problem
(16)
(16) Similarly, instead of constrained problem (Equation7
(7)
(7) )–(Equation8
(8)
(8) ), we can consider the unconstrained problem
(17)
(17) The exact projective penalty method was studied and tested in Norkin [Citation1,Citation42], Galvan [Citation50]. The main features of the method are: it is exact, it does not require selection of the right penalty parameter, and it does not use the objective function values outside the feasible set. Also, for the considered portfolio reshaping problem, the exact projective penalty function can be found in a closed form.
By Norkin [Citation1, Theorem 4.4], the global maximums of problems (Equation5(5)
(5) )–(Equation6
(6)
(6) ) and (Equation16
(16)
(16) ) coincide, and, if the mapping
is continuous, also the local maximums of both problems coincide, i.e. the optimization problems are equivalent. The mapping
is continuous, if the feasible set is convex and the projection mapping (Equation15
(15)
(15) ) uses an internal point
of the feasible set of the considered problem. For example, a feasible risk-free portfolio can represent such point.
Remark 4.1
Computational aspects
The calculations of the projections and
requires finding roots of the equations
and
. This requires multiple evaluations of the functions
and
, and hence, multiple construction of
or
for different portfolios
. This may take considerable time in case of large number of observations m. However, in case of a specific feasible point, namely a risk-free (feasible) portfolio, these functions can be easily found through
and
as the following statements show.
Proposition 4.2
Let be a risk-free portfolio with fixed return r,
be an arbitrary portfolio, with the random return
, the return cumulative distribution function
,
, and the corresponding inverse (quantile) one
,
,
. Consider a mixed portfolio of the form
,
. Its distribution function and inverse distribution function are expressed through
and
as
and
Proof.
Denote and
. Then
Next, by definition,
is the optimal value of the optimization problem
With the variable
, the latter problem is equivalent to
The optimal value of this problem equals the expression
which completes the proof.
The preceding proposition shows that the quantile function of the mixed portfolio
is the weighted quantile function the return r of the risk-free portfolio
and
, the return quantile function of the portfolio x.
Thus, for a known risk-free feasible portfolio with a fixed return r>0, the calculations can be reduced considerably. Indeed, we need to calculate only one CDF
and can re-use it for the CDFs
for different values of λ. In case of a discrete reference CDF
with jump points
, the projection
can be found in an analytical form as the following proposition states.
Proposition 4.3
Assume that , then there exists a risk-free internal feasible portfolio
with return r. Further, the projection
can be stated in the closed form
, where
Proof.
It holds that , i.e. the risk-free portfolio
is feasible and internal.
For we have, by definition,
. So assume that
. Consider the portfolios
,
, and the function
For
such that
it holds that
and
and the function
is linear strictly monotone. So the projection corresponds to the minimal λ such
, that is to
,
which completes the proof.
The proposition shows that given the conditions, the feasible set has a star shape with respect to the feasible point
that represents a risk-free portfolio.
If ,
, are continuous functions in x, then, given the conditions of the preceding proposition,
is continuous. Hence, the projection mapping
is also continuous. It follows from [Citation1, Theorem 4.4] that the problems (Equation7
(7)
(7) )–(Equation8
(8)
(8) ) and (Equation17
(17)
(17) ) are equivalent.
5. Numerical optimization of discontinuous penalty functions
In this section, we consider a numerical method for the optimization of generally discontinuous functions ,
and
in (Equation11
(11)
(11) )–(Equation17
(17)
(17) ). The idea consists in sequential approximations of the original function by smooth (averaged) ones and optimizing the latter by stochastic optimization methods. For this we develop a stochastic finite-difference estimates of gradients of the smoothed functions. Although the successive smoothing method has certain global optimization abilities (as discussed in [Citation42]), to strengthen this property we embed it as a local optimizer into some branch and bound scheme.
The problem setting satisfies the following conditions, which justify the tools employed to numerically solve the problem.
The original optimization problems are correctly set, i.e. they have feasible and optimal solutions. The Lemmas 3.1, 3.3 and 3.4 ensure this assumption.
The original constrained problems are transformed to unconstrained ones and this transformation are assumed to be exact. The exact discontinuous and exact projective penalty methods discussed in Section 4 and in [Citation1] provide this transformation.
Penalty functions are approximated by a sequence of smoothed functions, and this sequence epi-converges to the target penalty function. The so-called strongly lower semicontinuous functions (see Definition 5.1 and Theorem 5.4 in Subsection 5.1 below) ensure this property.
The level sets of the penalty and the smoothed functions are uniformly bounded. This property is provided by penalty term
For the unconstrained minimization of smoothed functions we apply stochastic finite-difference gradient method in a combination of a branch and bound method, which are assumed to approximately find their global minimums. Both applied methods are heuristic, their structure and convergence properties are discussed in Subsection 5.2 below.
Convergence of the approximate global minimums to global minimums of the penalty function (on a subset, where penalty function values can be approached through its continuity points) is guaranteed by properties of epi-convergence, cf. [Citation51, Theorem 7.33].
5.1. Averaged functions
We limit the consideration to the case of the so-called strongly lower semicontinuous functions.
Definition 5.1
Strongly lower semicontinuous functions, cf. [Citation43]
A function is called lower semicontinuous (lsc) at a point x, if
for all sequences
.
A function is called strongly lower semicontinuous (strongly lsc) at a point x, if it is lower semicontinuous at x and there exists a sequence
such that it is continuous at
(for all
) and
. A function F is called strongly lower semicontinuous (strongly lsc) on
, if this is the case for all
.
The property of strong lower semi-continuity is preserved under continuous transformations. Some further properties of these functions are discussed in [Citation52].
If the function is continuous almost everywhere (i.e. it is discontinuous on some set of measure zero), then its (lower) regularization
(18)
(18) is strongly lower semicontinuous and coincides with F almost everywhere.
The averaged functions obtained from the original non-smooth or discontinuous function by convolution with some kernel have smoother characteristics. For this reason, they are often used in optimization theory (see [Citation43,Citation53] and references therein).
Definition 5.2
The set (family) of bounded and integrable functions satisfying for any
the conditions
is called a family of mollifiers. The kernels
are said to be smooth if the functions
are continuously differentiable.
A function is called bounded at infinity if there are positive numbers C and r such that
for all x with
.
Given a locally integrable, bounded at infinity, function and a family of smoothing kernels
, the associated family of averaged functions
is
(19)
(19) Smoothing kernels can have an unlimited support
. To ensure the existence of the integrals (Equation19
(19)
(19) ), we assume that the function F is bounded at infinity. We can always assume this property if we are interested in the behaviour of F within some bounded area. If
for
, then this assumption is superfluous.
For example, a family of kernels can be as follows. Let ψ be some probability density function with bounded support , a positive numerical sequence
tending to 0 as
. Then the smoothing kernels on
can be taken as
where
is a bandwidth.
If the function F is not continuous, then we cannot expect the averaged functions to converge to F uniformly. But we don't need that. We need such a convergence of the averaged functions
to F that guarantees the convergence of the minima of
to the minima of F. This property is guaranteed by the so-called epi-convergence of functions.
Definition 5.3
Epi-convergence, cf. Rockafellar and Wets [Citation54]
A sequence of functions epi-converges to a function
at a point x, iff
The sequence epi-converges to F, if this is the case at every point
.
Theorem 5.4
Epi-convergence of averaged functions, cf. [Citation43], Theorem 3.7 and [Citation51], Example 7.19
For a strongly lower semicontinuous locally integrable function , any associated sequence of averaged functions
epi-converges to F as
.
Note that in the optimization problem without constraints it follows that
cf. [Citation51, Theorem 7.33].
We remark that for almost everywhere continuous function F, the corresponding averaged functions epi-converge to its regularization
defined in (Equation18
(18)
(18) ).
To optimize discontinuous functions, we approximate them with averaged functions. The convolution of a discontinuous function with the corresponding kernel (probability density) improves analytical properties of the resulting function, but increases the computational complexity of the problem, since it transforms the deterministic function into an expectation, which is a multidimensional integral. This transformation of the problem, which involves probability measures, naturally links to well-studied and well-established methods in stochastic optimization.
We can consider smoothed functions obtained by employing differentiable kernel with unbounded support, for example the Gaussian kernel given by the probability density
Consider the family
of averaged functions. Suppose that F is globally bounded (one may even assume that
with some non-negative constants
,
and
). Then for the strongly lsc function F, the average functions
epi-converge to F as
and each function
is analytical with gradient (cf. Stein's lemma)
or
(20)
(20) where the random vector η follows the standard normal distribution and
is the mathematical expectation over η.
It follows that the random vector
(21)
(21) with Gaussian random variable η is an unbiased random estimate of the gradient
.
5.2. Stochastic methods for minimization of discontinuous penalty functions
Consider a problem of constrained minimization of a generally discontinuous function subject to a box or other convex constraints. The target problems are (Equation11(11)
(11) )–(Equation17
(17)
(17) ).
Such problems can be solved, e.g. by collective random search algorithms. In this section, we develop stochastic quasi-gradient algorithms to solve these problems.
A problem of constrained optimization can be reduced to the problem of unconstrained optimization of a coercive function by using non-smooth or discontinuous penalty functions as described in [Citation1,Citation42,Citation50] (for the case of the present paper see Section 4).
Suppose the function is strongly lower semicontinuous. In view of Theorem 5.4, it is always possible to construct a sequence of smoothed averaged functions
that epi-converges to F. Due to this property, the global minima of
converge to the global minima of F as
. Convergence of local minima was studied in [Citation43].
Let us consider some procedures for optimizing the function F using approximating averaged functions .
Suppose one can find the global minima of the functions
,
. Then any limit point of the sequence
is a global minimum of the function F. However, finding global minima of
can be a quite difficult task, so consider the following method.
The successive stochastic smoothing method, cf. [Citation42]
The method sequentially minimizes a sequence of smoothed functions with decreasing smoothing parameter
. The sequence of approximations
is constructed by implementing the following steps (cf. [Citation42]).
The successive smoothing method as a local optimizer.
Initialization. Fix a box
Smoothing iterations. For a fixed smoothing parameter
Initialization of the Nemirovski-Yudin method (NYM). Fix
Batch estimation of the gradient
Itarations of NYM:
Stopping of NYM. Increase k by 1. If k<K, then go to (ii)b, else continue with 5.2.
Gelfand–Zetlin–Nesterov step. Set
Transition to the next less smoothing step (or stop). Increase the smoothing iteration number ν by 1, decrease the smoothing parameter
The successive smoothing method described above starts with a more smooth function that disregards the fine structure of the objective to find the most promising regions in the search space before gradually making the approximation more exact. The successive smoothing with gradual vanishing degree of smoothing distinguishes our method from other smoothing methods, which use fixed smoothing for minimization of non-smooth functions. In our method we allocate a fixed number K of iterations to minimize a smoothed function . For a particular case K=1 (and
), the convergence rate of the successive smoothing method on the class of Lipschitz non-smooth convex functions was studied in [Citation55]. Roughly speaking, the rate of convergence (in function) of the method is proportional to the range of the function on the feasible set multiplied by factor
, where n is the dimension of the space, m is the number of finite differences for estimation of gradients. This method stops after N smoothing iterations. The other practical stopping rule is to stop computations, if there is no progress of the algorithm after several iterations.
For the minimization of the smoothed function under fixed
, one can apply any (not necessary NY mirror descent [Citation56] but, e.g. a stochastic version of the Nesterov's method [Citation57]) stochastic finite-difference optimization method based on the finite difference representations (Equation20
(20)
(20) ), (Equation21
(21)
(21) ) of the gradients of the smoothed function. In the described NY algorithm, the local optimization of
stops after K iterations.
One more possible stopping rule is based on estimating gradients during the iterative optimization process. In general, this is a rather complicated and time-consuming procedure that requires calculation of multidimensional integrals. However, such asymptotically consistent estimates can be constructed in parallel with the construction of the main minimization sequence by using the following so-called averaging procedure [Citation45,Citation58,Citation59].
Consider the stochastic optimization procedure
for an iterative optimization of a function
and parallel evaluation of its gradients
, where the vectors
are given by (Equation21
(21)
(21) ). For the conditional expectations it holds that
. Let the numbers
,
satisfy the conditions
Then, with probability one, it holds (cf. Ermoliev [Citation58, Theorem V.8]) that
If
, then, by results of [Citation43,Citation45,Citation60], the constructed sequence
asymptotically converges to the set, which satisfies necessary optimality conditions for F. Some other stopping rules for stochastic gradient methods are discussed, e.g. in [Citation61].
Figure provides a graphical illustration of the performance of the successive smoothing method on problem (Equation14(14)
(14) ).
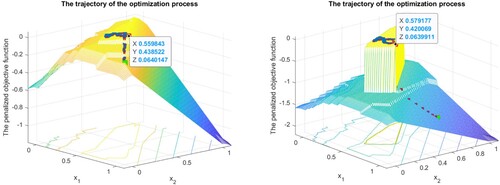
Figure 2. Illustration of the smoothing method performance on two asset (1,2) portfolio selection. Examples of the trajectories of the method for different discontinuous penalties. ,
.
Global optimization issues.
The optimization problems under consideration (Equation5(5)
(5) )–(Equation6
(6)
(6) ) and (Equation7
(7)
(7) )–(Equation8
(8)
(8) ) are challenging, they are non-convex and multi-extremal, discontinuous, disconnected and constrained. So we apply a number of different techniques to tackle and solve them.
To remove discontinuous constraints, we use exact discontinuous penalty functions, and to remove structural portfolio constraints and bound constraints, we apply exact projective penalty functions, cf. [Citation1,Citation42,Citation50].
In the case of multi-extremal problems (as in Figure ) we employ a version of the branch and bound method [Citation1] with the successive smoothing method as a local minimizer (in [Citation1], the successive quadratic approximation method was used as a local optimizer).
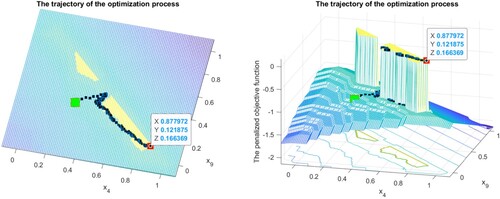
Figure 3. Illustration of the smoothing method performance on two asset (4,9) portfolio selection. Example of the trajectory of the method for non-connected feasible set. ,
. The green is the starting point, the red is the final one.
To solve problem (Equation11(11)
(11) )–(Equation17
(17)
(17) ), we apply the following branch and bound (cut) algorithm acting in a box
.
The Branch & Bound algorithm.
| Initialization. | Set the initial partition | ||||
| B&B iteration. | Suppose at iteration k we have partition For each such set If the values When all elements | ||||
| Check for the stop. | If there is no progress of the B&B method during p B&B iterations, i.e. | ||||
Remark 5.5
The described B&B aims at subdividing a non-convex multiextremal problem into sub-problems, each containing only one local minimum. To prevent the method from early stop, two mechanisms are used. First, the stopping parameter is introduced: the method stops after p unproductive B&B iterations. In all numerical experiments, p=5 was sufficient to find the global minimum. Second, for each new run of the local minimizer, a random starting point is used, that increases the probability of finding a new local minimum of the sub-problem.
Let us emphasize that as local optimization algorithm within the B&B scheme one can apply any reasonable (even heuristic) algorithm, which allows improving the current solution. In particular, in numerical experiments we also used well implemented optimization algorithms from the shelf, e.g. a sequential quadratic approximation algorithm, which formally is not applicable to the considered problem, but which quickly finds local optimums and thus considerably speeds up the overall optimization procedure.
The function values of the objective provide upper bounds for the optimal values
. If there were known lower bounds
, then the subsets
such that
can be safely ignored, i.e. excluded from the current partition
. Heuristically, if some set
remains unchanged during several (say p) B&B iterations, it can be ignored or rare examined in the future iterations. Further results of the B&B algorithm described above are available in [Citation1].
6. Numerical illustration
For the numerical illustration of the algorithm proposed we return to portfolio optimization under 1st-order stochastic dominance constraints. We use a small data set of annual returns of nine US companies from [Citation62, Table 1, page 13] provided in the appendix.
6.1. Testing the successive smoothing method on the discontinuous portfolio optimization problems
First, let us illustrate the proposed approach on a two-dimensional portfolio (the first two columns of the table from the appendix) by solving the problem (Equation5(5)
(5) )–(Equation6
(6)
(6) ). For this we first fix some initial reference portfolio,
with average return
and corresponding CDF
. Then, we relax the constraint (Equation6
(6)
(6) ) by replacing
with the shifted function
, where
, independent of t. With this new reference function we solve the problem (Equation13
(13)
(13) ) with different values of the parameter
by the stochastic smoothing method from Subsection 5.2.
Figure presents the results. The pictures illustrate how the method climbs up to the global maximum of the discontinuous objective function. In the two presented examples, the method finds better portfolios with average return . The right picture also highlights the set of feasible portfolios, because by setting a larger c, we decrease the values of the penalized function at the infeasible points. It can be seen that the proposed version of the smoothing method is not very sensible to discontinuities of the minimized function.
One more example is presented on Figure . The reference 2-security portfolio is ,
. In this example, the feasible set is not connected. The optimal portfolio consists of the two assets
with the expected return
. If we extend the portfolio to nine assets, we can obtain by the proposed method the better return
with the optimal portfolio
, within the same bounds on risk,
.
6.2. Lower bounding the risk-return profile and maximizing the tail return
This subsection presents results of optimization of 3- and 10-component portfolios under 1st-order stochastic dominance constraints. The constraint is given by its (reference) CDF, and as objective functions we employ the average value of the portfolio return (AV), the Value-at-Risk (quantile, ) and Average Value-at-Risk indicators (
) with levels
and
. Results are provided in tabular and graphical form, each set of experiments is specified by the number of portfolio components (3 or 10), the parameter α (
or
), and the exact penalty method applied (discontinuous or projective from Subsections 4.3 and 4.4).
Each table contains three numerical rows corresponding to three kinds of the objective functions:
the mean,
the
the
The rows ‘Mean’, ‘’ and ‘
’ show the objective values of the corresponding indicators for the three optimal portfolios. The other columns show the structure of the obtained portfolios. Each table is supplemented by a reference figure containing three graphs displaying the optimal risk profile. The blue broken line in a graph depicts the reference CDF, a (left) bound on the portfolio return, CDF([0.05; 0.05; 0.1; 0.11; 0.125])=[0; 0.2; 0.4; 0.6; 1]. The red (right) broken line shows the CDF of the actual optimal portfolio return. So the lines display the reference and the actual risk profiles of the optimal portfolios.
Tables and (and the corresponding Figures and ) compare results of solving portfolio optimization problems by means of discontinuous and projective penalty methods, respectively, . As can be seen, both figures, Figure and , are very similar, that can be a proof that both penalty methods are applicable and give close results.
Figure 4. Profiles of optimal 3 component portfolios: maximizing the tail returns under the risk-return lower bound. Discontinuous penalties. 1) Optimal average return. 2) Optimal . 3) Optimal
; cf. Table .
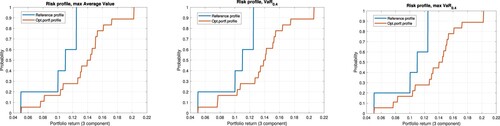
Figure 5. Profiles of optimal 3 component portfolios: maximizing the tail returns under the risk-return lower bound. Analytical projective penalties. (1) Optimal average return. (2) Optimal . (3) Optimal
. See Table .

Table 1. Optimal 3 component portfolios, discontinuous penalties: (1) Max mean; (2) Max ; (3) Max
.
Table 2. Optimal 3 component portfolios, analytical projection: (1) Max mean. (2) Max . (3) Max
.
The next two Tables and (and the corresponding Figures and ) show the effect of extension of a portfolio for account of new securities, from 3 to 10, for . The objective functions values in Table are greater than the corresponding values in Table . The corresponding Figures and indicate changes in the risk profiles of optimal portfolios due to this enlargement. The increase of the objective functions happens also for account of huddling the risk profiles to the reference ones. The pictures also show the influence of the different objective functions on the risk profiles of the optimal portfolios. Finally, Table shows the structures of the optimal 10-component portfolios.
Figure 6. Profiles of optimal 3 component portfolios: maximizing the tail returns under the risk-return lower bound. Analytical projective penalties. (1) Optimal average return. (2) Optimal . (3) Optimal
. See Table .

Figure 7. Profiles of optimal 10 component portfolios: maximizing the tail returns under the risk-return lower bound. Analytical projective penalties. (1) optimal average return; (2) optimal ; (3) optimal
; cf. Tables and .

Table 3. Optimal 3 component portfolios, analytical projection: (1) Max mean. (2) Max . (3) Max
.
Table 4. Optimal 10 component portfolios, analytical projection: (1) Max mean. (2) Max . (3) Max
.
Table 5. The optimal 10 component portfolio.
6.3. Summary of numerical experience
The concrete computational results of the numerical experiments depend on the following settings. We used
three different objective functions, the mean value, quantile and average quantile functions at different risk levels;
two kind of penalty functions, discontinuous and projective penalty ones (the latter is applied when there is an internal risk three portfolio);
a specific heuristic stochastic branch and bound algorithm with adjustable parameters;
several local optimization algorithms, Nemirovski-Yudin and Nesterov finite-difference stochastic optimization algorithms, and also a deterministic sequential quadratic programming one;
random starting points and adjustable parameters for local optimization algorithms.
The concrete computational results depend on all these options.
The problems under consideration can have many local optimums close to the global optimum, so the combined B&B algorithms may stick at different deep local optimums and may have different random running times (from several seconds to several minutes). To validate the global optimum, it is necessary to change the parameters of the algorithm and re-run it.
It was observed that the algorithm, combined algorithm with Nesterov's local optimization method, works better than combined with Nemirovski-Yudin's one. Besides, the combined heuristic B&B algorithm, which uses a well implemented deterministic sequential quadratic approximation algorithm (sqp from Matlab's optimization toolbox) as a local optimizer, works much faster (10 times or more) than stochastic optimization algorithms (seconds against minutes).
7. Conclusions
The paper considers a specific method for optimization, which transforms a constraint optimization problem to an unconstrained global optimization problem. The paper illustrates the procedure for an optimization problem with uncountable many constraints. More specifically, the paper considers financial portfolio optimization under 1-st order stochastic dominance constraints.
The designed optimization techniques are aimed at interactive solving the portfolio reshaping problem, i.e. interactive adaptation of the portfolio risk profile to the portfolio manager's preferences by changing risk bounds and optimization of different risk criteria.
In the literature, similar portfolio optimization problems are mostly considered under 2nd-order stochastic dominance constraints, which constitute convex problems. Few exceptions include [Citation4,Citation5,Citation27,Citation33,Citation37,Citation63]. The 1st-order constraints put lower bounds on the risk profile (CDF) of the optimized portfolio. As objective functions, different aggregated indicators can serve, e.g. the expected value, the Value-at-Risk, or the average Value-at-Risk, etc. In this setting, we put lower bounds on low returns and try to maximize higher returns.
Such constraints make the problem non-convex and hard for numerical treatment. We propose the new exact penalty functions to handle the constraints and a new stochastic B&B algorithm and new stochastic optimization (smoothing) techniques for solving penalty problems. The approach is numerically and graphically illustrated on small test examples. The advantage of the proposed approach to financial portfolio optimization consists in an additional visual control of the risk profile of the optimal portfolio.
The proposed B&B algorithm is well-suited for effective parallelization (parallel implementation of the B&B iteration) and thus has much room for acceleration and scaling and this may be a topic for future research.
Disclosure statement
This study builds upon publicly available data collected in Table 9. The corresponding data, codes, and tests are available at the first author's ResearchGate web-page. The authors have no conflicts of interest to disclose.
Additional information
Funding
References
- Norkin VI. The projective exact penalty method for general constrained optimization. Preprint. V. M. Glushkov Institute of Cybernetics, Kyiv, 2022..
- Dentcheva D, Ruszczyński A. Optimization with stochastic dominance constraints. SIAM J Optim. 2003;14:548–566. doi: 10.1137/s1052623402420528
- Dentcheva D, Ruszczyński A. Portfolio optimization with stochastic dominance constraints. J Bank Financ. 2006;30:433–451. doi: 10.1016/j.jbankfin.2005.04.024
- Noyan N, Rudolf G, Ruszczyński A. Relaxations of linear programming problems with first order stochastic dominance constraints. Oper Res Lett. 2006;34:653–659. doi: 10.1016/j.orl.2005.10.004
- Noyan N, Ruszczyński A. Valid inequalities and restrictions for stochastic programming problems with first order stochastic dominance constraints. Math Program. 2008;114:249–275. doi: 10.1007/s10107-007-0100-1
- Shapiro A, Dentcheva D, Ruszczyński A. Lectures on stochastic programming. 3rd ed. SIAM; 2021. (MOS-SIAM Series on Optimization). doi: 10.1137/1.9781611976595
- Gutjahr WJ, Pichler A. Stochastic multi-objective optimization: a survey on non-scalarizing methods. Ann Oper Res. 2013;236(2):1–25. doi: 10.1007/s10479-013-1369-5
- Markowitz HM. Portfolio selection. J Finance. 1952;7(1):77–91. doi: 10.2307/2975974
- Roy AD. Safety first and the holding of assets. Econometrica. 1952;20:431–449. doi: 10.2307/1907413
- Artzner P, Delbaen F, Eber J-M, et al. Coherent measures of risk. Math Financ. 1999;9:203–228. doi: 10.1111/mafi.1999.9.issue-3
- Benati S, Rizzi R. A mixed integer linear programming formulation of the optimal mean/value-at-risk portfolio problem. Eur J Oper Res. 2007;176:423–434. doi: 10.1016/j.ejor.2005.07.020
- Gaivoronski AA, Pflug GC. Finding optimal portfolios with constraints on value-at-rrisk. In: Green B, editor, Proceedings of the Third International Stockholm Seminar on Risk Behaviour and Risk Management. Stockholm University; 1999.
- Gaivoronski AA, Pflug GC. Value at risk in portfolio optimization: properties and computational approach. J Risk. 2005;7:1–31. doi: 10.21314/JOR.2005.106
- Kataoka S. A stochastic programming model. Econometrica. 1963;31:181–196. doi: 10.2307/1910956
- Kibzun AI, Kan YS. Stochastic programming problems with probability and quantile functions. Chichester: John Wiley & Sons; 1996.
- Kibzun AI, Naumov AV, Norkin VI. On reducing a quantile optimization problem with discrete distribution to a mixed integer programming problem. Autom Remote Control. 2013;74:951–967. doi: 10.1134/S0005117913060064
- Kirilyuk V. Risk measures in stochastic programming and robust optimization problems. Cybern Syst Anal. 2015;51:874–885. doi: 10.1007/s10559-015-9780-3
- Luedtke J, Ahmed S, Nemhauser G. An integer programming approach for linear programs with probabilistic constraints. Math Program. 2010;122:247–272. doi: 10.1007/s10107-008-0247-4
- Norkin VI, Boyko SV. Safety-first portfolio selection. Cybern Syst Anal. 2012;48:180–191. doi: 10.1007/s10559-012-9396-9
- Norkin VI, Kibzun AI, Naumov AV. Reducing two-stage probabilistic optimization problems with discrete distribution of random data to mixed-integer programming problems. Cybern Syst Anal. 2014;50:679–692. doi: 10.1007/s10559-014-9658-9
- Pflug GC, Römisch W. Modeling, measuring and managing risk. River Edge (NJ): World Scientific; 2007. doi: 10.1142/9789812708724
- Prekopa A. Stochastic programming. Dordreht: Kluwer Academic Publisher; 1995.
- Sen S. Relaxation for probabilistically constrained programs with discrete random variables. Oper Res Lett. 1992;11:81–86. doi: 10.1016/0167-6377(92)90037-4
- Telser LG. Safety first and hedging. Rev Econ Stud. 1955/56;23:1–16. doi: 10.2307/2296146
- Wozabal D, Hochreiter R, Pflug GC. A D. C. formulation of value-at-risk constrained optimization. Optimization. 2010;59:377–400. doi: 10.1080/02331931003700731
- Rockafellar RT, Uryasev S. Optimization of conditional value-at-risk. J Risk. 2000;2(3):21–41. doi: 10.21314/JOR.2000.038
- Dentcheva D, Ruszczyński A. Risk preferences on the space of quantile functions. Math Program Ser B. 2013;148:181–200. doi: 10.1007/s10107-013-0724-2
- Müller A, Stoyan D. Comparison methods for stochastic models and risks. Chichester: John Wiley & Sons; 2002.
- Ogryczak W, Ruszczyński A. From stochastic dominance to mean-risk models: semideviations as risk measures. Eur J Oper Res. 1999;116:33–50. doi: 10.1016/S0377-2217(98)00167-2
- Ogryczak W, Ruszczyński A. On consistency of stochastic dominance and mean–semideviation models. Math Program Ser B. 2001;89:217–232. doi: 10.1007/s101070000203
- Ogryczak W, Ruszczyński A. Dual stochastic dominance and related mean-risk models. SIAM J Optim. 2002;13(1):60–78. doi: 10.1137/S1052623400375075
- Dentcheva D, Ruszczyński A. Common mathematical foundations of expected utility and dual utility theories. SIAM J Optim. 2013;23(1):381–405. doi: 10.1137/120868311
- Dai H, Xue Y, He N, et al. Learning to optimize with stochastic dominance constraints. In: International Conference on Artificial Intelligence and Statistics, PMLR; 2023; p. 8991–9009.
- Dentcheva D, Ruszczyński A. Portfolio optimization with risk control by stochastic dominance constraints. In: Infanger G., editor, Stochastic Programming. The State of the Art. In Honor of George B. Dantzig, chapter 9, pages 189–212. New York: Springer; 2011.
- Fábián CI, Mitra G, Roman D, et al. Portfolio choice models based on second-order stochastic dominance measures: An overview and a computational study. In M. Bertocchi, G. Consigli, and M. A. H. Dempster, editors, Stochastic optimization methods in finance and energy, International Series in Operations Research & Management Science, chapter 18, Springer: New York; 2011; p. 441–470. ISBN 978-1-4419-9586-5. doi: 10.1007/978-1-4419-9586-5_18
- Dentcheva D, Ruszczyński A. Risk preferences on the space of quantile functions. Math Program. 2014;148(1-2):181–200. doi: 10.1007/s10107-013-0724-2
- Dentcheva D, Ruszczyński A. Semi-infinite probabilistic optimization: first order stochastic dominance constraints. Optimization. 2004;53:583–601. doi: 10.1080/02331930412331327148
- Dentcheva D, Henrion R, Ruszczyński A. Stability and sensitivity of optimization problems with first order stochastic dominance constraints. SIAM J Optim. 2007;18:322–337. doi: 10.1137/060650118
- Frydenberg S, Sønsteng Henriksen TE, Pichler A, et al. Can commodities dominate stock and bond portfolios? Ann Oper Res. 2019;282(1-2):155–177. doi: 10.1007/s10479-018-2996-7
- Batukhtin V. On solving discontinuous extremal problems. J Optim Theory Appl. 1993;77:575–589. doi: 10.1007/BF00940451
- Knopov P, Norkin V. Stochastic optimization methods for the stochastic storage process control. M. J. Blondin et al. (eds.), Intelligent Control and Smart Energy Management, Springer Optimization and Its Applications 181, 2022; p. 79–111. doi: 10.1007/978-3-030-84474-5_3
- Norkin VI. A stochastic smoothing method for nonsmooth global optimization. Cybernetics and Computer technologies: 2020; p. 5–14. doi: 10.34229/2707-451X.20.1.1
- Ermoliev YM, Norkin VI, Wets RJ-B. The minimization of semicontinuous functions: mollifier subgradients. SIAM J Control Optim. 1995;33:149–167. doi: 10.1137/S0363012992238369
- Mayne D, Polak E. On solving discontinuous extremal problems. J Optim Theory Appl. 1984;43:601–613. doi: 10.1007/BF00935008
- Mikhalevich VS, Gupal AM, Norkin VI. Methods of nonconvex optimization. Moscow: Nauka; 1987. (In Russian).
- Nesterov Y, Spokoiny V. Random gradient-free minimization of convex functions. Found Comput Math. 2017;17:527–566. doi: 10.1007/s10208-015-9296-2
- Norkin V, Pflug GC, Ruszczyński A. A branch and bound method for stochastic global optimization. Math Program. 1998;83:425–450. doi: 10.1007/bf02680569
- Aubin J-P, Ekeland I. Applied nonlinear analysis. New York: John Wiley and Sons; 1984.
- Norkin VI. On measuring and profiling catastrophic risks. Cybern Syst Anal. 2006;42(6):839–850. doi: 10.1007/s10559-006-0124-1
- Galvan G, Sciandrone M, Eucidi S. A parameter-free unconstrained reformulation for nonsmooth problems with convex constraints. Comput Optim Appl. 2021;80:33–53. doi: 10.1007/s10589-021-00296-1
- Rockafellar RT, Wets RJ-B. Variational analysis. Grundlehren der mathematischen Wissenschaften. Springer, 1st ed. 1998, 3rd printing, springer edition, 2009. ISBN 3540627723; 9783540627722. doi: 10.1007/978-3-642-02431-3
- Ermoliev Y, Norkin V. On constrained discontinuous optimization. In: Stochastic Programming Methods and Technical Applications: Proceedings of the 3rd GAMM/IFIP-Workshop on ‘Stochastic Optimization: Numerical Methods and Technical Applications’ held at the Federal Armed Forces University Munich, Neubiberg/München, Germany, June 17–20, 1996, Springer: Berlin, Heidelberg; 1998; p. 128–144.
- Gupal AM, Norkin VI. Algorithm for the minimization of discontinuous functions. Cybernetics. 1977;13(2):220–223. doi: 10.1007/BF01073313
- Rockafellar RT, Wets RJ-B. Variational analysis. Switzerland AG: Springer Nature; 1997. Available at https://books.google.com/books?id=w-NdOE5fD8AC.doi: 10.1007/978-3-642-02431-3
- Norkin V, Pichler A, Kozyriev A. Constrained global optimization by smoothing. arXiv; 2023. doi: 10.48550/arXiv.2308.08422
- Nemirovsky A, Yudin D. Informational complexity and efficient methods for solution of convex extremal problems. New York: J. Wiley & Sons; 1983.
- Nesterov Y. A method of solving a convex programming problem with convergence rate. Soviet Math Dokl. 1983;27(2):372–376.
- Ermoliev YM. Methods of stochastic programming. Moscow: Nauka; 1976. (In Russian).
- Gupal AM. Stochastic methods for minimzation of nondifferentiable functions. Autom Remote Control. 1979;4(40):529–534.
- Polyak BT. Introduction to optimization. New York: Optimization Software, Inc. Publications Division; 1987.
- Pflug GC. Stepsize rules, stopping times, and their implementation in stochastic quasigradient algorithms. In: Ermoliev Y. and Wets RJ-B, editors, Numerical Techniques for Stochastic Optimization. Berlin: Springer-Verlag; 1988; chapter 17, p. 353–372.
- Markowitz HM. Portfolio selection. efficient diversification of investments. New York: John Wiley & Sons, Chapman & Hall; 1959.
- Luedtke J. New formulations for optimization under stochastic dominance constraints. SIAM J Optim. 2008;19(3):1433–1450. doi: 10.1137/070707956
Appendix
Table A1. Return data set from [Citation62, Table 1, page 13], with artificial bond column.