
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we revisit the classical problem of solving over-determined systems of nonsmooth equations numerically. We suggest a nonsmooth Levenberg–Marquardt method for its solution which, in contrast to the existing literature, does not require local Lipschitzness of the data functions. This is possible when using Newton-differentiability instead of semismoothness as the underlying tool of generalized differentiation. Conditions for local fast convergence of the method are given. Afterwards, in the context of over-determined mixed nonlinear complementarity systems, our findings are applied, and globalized solution methods, based on a residual induced by the maximum and the Fischer–Burmeister function, respectively, are constructed. The assumptions for local fast convergence are worked out and compared. Finally, these methods are applied for the numerical solution of bilevel optimization problems. We recall the derivation of a stationarity condition taking the shape of an over-determined mixed nonlinear complementarity system involving a penalty parameter, formulate assumptions for local fast convergence of our solution methods explicitly, and present results of numerical experiments. Particularly, we investigate whether the treatment of the appearing penalty parameter as an additional variable is beneficial or not.
1. Introduction
Nowadays, the numerical solution of nonsmooth equations is a classical topic in computational mathematics. Journeying 30 years back to the past, Qi and colleagues developed the celebrated nonsmooth Newton method, see [Citation1, Citation2], based on the notion of semismoothness for locally Lipschitzian functions which is due to Mifflin, see [Citation3]. Keeping the convincing local convergence properties of Newton-type methods in mind, this allowed for a fast numerical solution of Karush–Kuhn–Tucker systems, associated with constrained nonlinear optimization problems with inequality constraints, without the need of smoothing or relaxing the involved complementarity slackness condition. Indeed, the latter can be reformulated as a nonsmooth equation with the aid of so called NCP-functions, see [Citation4–6] for an overview, where NCP abbreviates nonlinear complementarity problem. Recall that a continuous function is referred to as an NCP-function whenever
is valid. A rather prominent example of an NCP-function is the famous Fischer–Burmeister (FB) function
given by
(1)
(1) see [Citation7] for its origin. Another popular NCP-function is the maximum function
. We refer the reader to [Citation7–10] for further early references dealing with semismooth Newton-type methods to solve nonlinear complementarity systems. Let us note that even prior to the development of semismooth Newton methods 30 years ago, the numerical solution of nonsmooth equations via Newton-type algorithms has been addressed in the literature, see e.g. [Citation11–15]. We refer the interested reader to the monographs [Citation16–18] for a convincing overview.
Let us mention some popular directions of research which have been enriched or motivated by the theory of semismooth Newton methods. Exemplary, this theory has been extended to Levenberg–Marquardt (LM) methods in order to allow for the treatment of over-determined or irregular systems of equations, see e.g. [Citation10, Citation19–22]. It also has been applied in order to solve so-called mixed nonlinear complementarity problems which are a natural extension of nonlinear complementarity problems and may also involve pure (smooth) equations, see e.g. [Citation23–28]. Recently, the variational notion of semismoothness* for set-valued mappings has been introduced in [Citation29] in order to discuss the convergence properties of Newton's method for the numerical solution of so-called generalized equations given via set-valued operators. There also exist infinite-dimensional extensions of nonsmooth Newton methods, see e.g. [Citation30–36]. In contrast to the finite-dimensional case, in infinite dimensions, the underlying concept of semismoothness is often replaced by so-called Newton-differentiability. In principle, this notion of generalized differentiation encapsulates all necessities to address the convergence analysis of associated Newton-type methods properly. Noteworthy, it does not rely on the Lipschitzness of the underlying mapping. In the recent paper [Citation37], this favourable advantage of Newton-derivatives has been used to construct a Newton-type method for the numerical solution of a certain stationarity system associated with so-called mathematical programs with complementarity constraints, as these stationarity conditions can be reformulated as a system of discontinuous equations.
Let us point the reader's attention to the fact that some stationarity conditions for bilevel optimization problems, see [Citation38, Citation39] for an introduction, can be reformulated as (over-determined) systems of nonsmooth equations involving an (unknown) penalization parameter λ. This observation has been used in the recent papers [Citation40–42] in order to solve bilevel optimization problems numerically. In [Citation40], the authors used additional dummy variables in order to transform the naturally over-determined system into a square system, and applied a globalized semismooth Newton method for its computational solution. The papers [Citation41, Citation42] directly tackle the over-determined nonsmooth system with Gauss–Newton or LM methods. However, in order to deal with the nonsmoothness, they either assume that strict complementarity holds or they smooth the complementarity condition. In all three papers [Citation40–42], it has been pointed out that the choice of the penalty parameter λ in the stationarity system is, on the one hand, crucial for the success of the approach but, on the other hand, difficult to realize in practice.
The contributions in this paper touch several different aspects. Motivated by the results from [Citation37], we study the numerical solution of over-determined systems of nonsmooth equations with the aid of LM methods based on the notion of Newton-differentiability. We show local superlinear convergence of this method under reasonable assumptions, see Theorem 3.2. Furthermore, we point out that even for local quadratic convergence, local Lipschitzness of the underlying mapping is not necessary. To be more precise, a one-sided Lipschitz estimate, which is referred to as calmness in the literature, is enough for that purpose. Thus, our theory applies to situations where the underlying mapping can be even discontinuous. Our next step is the application of this method for the numerical solution of over-determined mixed nonlinear complementarity systems. Here, we strike a classical path and reformulate the appearing complementarity conditions with the FB function and the maximum function in order to obtain a system of nonlinear equations. To globalize the associated Newton methods, we exploit the well-known fact that the squared norm of the residual associated with the FB function is continuously differentiable, and make use of gradient steps with respect to this squared norm in combination with an Armijo step size selection if LM directions do not yield sufficient improvements. We work out our abstract conditions guaranteeing local fast convergence for both approaches and state global convergence results in Theorems 4.6 and 4.12. Furthermore, we compare these findings with the ones in the classical paper [Citation9] where a related comparison has been done in the context of semismooth Newton-type methods for square systems of nonsmooth equations. Finally, we apply both methods in order to solve bilevel optimization problems via their over-determined stationarity system of nonsmooth equations mentioned earlier. In contrast to [Citation41, Citation42], we neither assume strict complementarity to hold nor do we smooth or relax the complementarity condition. Some assumptions for local fast convergence are worked out, see Theorems 5.3 and 5.4. As extensive numerical testing of related approaches has been carried out in [Citation40–42], our experiments in Section 5.2 focus on specific features of the developed algorithms. Particularly, we comment on the possibility to treat the aforementioned penalty parameter λ as a variable, investigate this approach numerically, and compare the outcome with the situation where λ is handled as a parameter.
The remainder of the paper is organized as follows. Section 2 provides an overview of the notation and preliminaries used in the manuscript. Furthermore, we recall the notion of Newton-differentiability and present some associated calculus rules in Section 2.2. A local nonsmooth LM method for Newton-differentiable mappings is discussed in Section 3. Section 4 is dedicated to the derivation of globalized nonsmooth LM methods for the numerical solution of over-determined mixed nonlinear complementarity systems. First, we provide the analysis for the situation where the complementarity condition is reformulated with the maximum function in Section 4.1. Afterwards, in Section 4.2, we comment on the differences which pop up when the FB function is used instead. The obtained theory is used in Section 5 in order to solve bilevel optimization problems. In Section 5.1, we first recall the associated stationarity system of interest and characterize some scenarios where it provides necessary optimality conditions. Second, we present different ways on how to model these stationarity conditions as an over-determined mixed nonlinear complementarity system. The numerical solution of these systems with the aid of nonsmooth LM methods is then investigated in Section 5.2 where results of computational experiments are evaluated. The paper closes with some concluding remarks in Section 6.
2. Notation and preliminaries
2.1. Notation
By , we denote the positive integers. The set of all real matrices with
rows and
columns will be represented by
, and
denotes the all-zero matrix of appropriate dimensions while we use
for the identity matrix in
. If
is a matrix and
is arbitrary, then
shall be the matrix which results from M by deleting those rows whose associated index does not belong to I. Whenever the quadratic matrix
is symmetric,
denotes the smallest eigenvalue of N. For any
,
is the diagonal matrix whose main diagonal is given by x and whose other entries vanish.
For arbitrary , the space
will be equipped by the standard Euclidean inner product as well as the Euclidean norm
. Further, we equip
with the matrix norm induced by the Euclidean norm, i.e. with the spectral norm, and denote it by
as well as this cannot cause any confusion. For arbitrary
and
,
represents the closed ε-ball around x. Recall that a sequence
is said to converge superlinearly to some
whenever
. The convergence
is said to be quadratic if
.
Frequently, for brevity of notation, we interpret tuples of vectors as a single block column vector, i.e. we exploit the identity
for any
with
and
.
A function is called calm at
whenever there are constants
and
such that
We note that calmness can be seen as a one-sided local Lipschitz property which is, in general, weaker than local Lipschitzness. Indeed, one can easily check that there exist functions which are calm at some fixed reference point but discontinuous in each neighbourhood of this point.
Next, let be differentiable at
. Then
denotes the Jacobian of H at
. Similarly, for a differentiable scalar-valued function
,
is the gradient of h at
. Clearly,
by construction. In the case where h is twice differentiable,
denotes the Hessian of h at
. Partial derivatives with respect to particular variables are represented in analogous fashion.
We use is order to express that Γ is a so-called set-valued mapping which assigns to each
a (potentially empty) subset of
. For any such set-valued mapping, the sets defined by
and
are the domain and the graph of Γ, respectively. We say that Γ is inner semicontinuous at
whenever for each sequence
such that
, there exists a sequence
such that
which satisfies
for all large enough
. We emphasize that whenever Γ is inner semicontinuous at
, then
is an interior point of
. At a fixed point
, Γ is said to be calm whenever there are constants
such that
We note that whenever
is a single-valued function which is calm at
, then the set-valued mapping
is calm at
. The converse is not necessarily true.
2.2. Newton-differentiability
In order to construct numerical methods for the computational solution of nonsmooth equations, one has to choose a suitable concept of generalized differentiation. Typically, the idea of semismoothness is used for that purpose, see [Citation2, Citation3]. Here, however, we strike a different path and exploit the notion of Newton-differentiability, see [Citation32, Citation35], whose origins can be found in infinite-dimensional optimization. The latter has the inherent advantage that, in contrast to semismoothness, it is defined for non-Lipschitz functions and enjoys a natural calculus which follows the lines known from standard differentiability. These beneficial features have been used recently in order to solve stationarity conditions of complementarity-constrained optimization problems which can be reformulated as systems of discontinuous equations, see [Citation37].
Let us start with the formal definition of Newton-differentiability before presenting some essential calculus rules. Most of this material is taken from the recent contribution [Citation37, Section 2.3].
Definition 2.1
Let and
be given mappings and let
be nonempty. We say that
is Newton-differentiable on M with Newton-derivative
We note that the Newton-derivative of a mapping is not necessarily uniquely determined if
is Newton-differentiable on some set
. It can be easily checked that any continuously differentiable function
is Newton-differentiable on
when
is chosen. If, additionally,
is locally Lipschitz continuous, then the order of Newton-differentiability is 1.
In the recent paper [Citation37], the authors present several important calculus rules for Newton-derivatives including a chain rule which we recall below, see [Citation37, Lemma 2.11].
Lemma 2.2
Suppose that is Newton-differentiable on
with Newton-derivative
, and that
is Newton-differentiable on
with Newton-derivative
. Further, assume that
is bounded on a neighbourhood of M, and that
is bounded on a neighbourhood of
. Then
is Newton-differentiable on M with Newton-derivative given by
. If both
and
are Newton-differentiable of order
, then
is Newton-differentiable of order α with the Newton-derivative given above.
Let us note that Lemma 2.2 directly gives a sum rule which applies to the concept of Newton-differentiability. However, a direct proof via Definition 2.1 shows that a sum rule for Newton-differentiability holds without additional boundedness assumptions on the Newton-derivatives of the involved functions.
Let us inspect some examples which will be of major interest in this paper.
Example 2.3
The function
For arbitrary
Let us investigate Newton-differentiability of the aforementioned FB function
3. A local nonsmooth Levenberg–Marquardt method
The paper [Citation8] introduces a semismooth Newton-type method for square complementarity systems whose globalization is based on the FB function. An extension to LM-type methods (which even can handle inexact solutions of the subproblems) can be found in [Citation10, Citation19]. A theoretical and numerical comparison of these methods is provided in [Citation9]. An application of the semismooth LM method in the context of mixed complementarity systems can be found in [Citation20], and these ideas were applied in the context of semiinfinite optimization e.g. in [Citation21, Citation22].
In this subsection, we aim to analyse the local convergence properties of nonsmooth LM methods in a much broader context which covers not only the applications within the aforementioned papers, but also some new ones in bilevel optimization, see e.g. Section 5 and our comments in Section 6. Our approach via Newton-derivatives is slightly different from the one in the literature which exploits semismoothness of the underlying map of interest and, thus, particularly, local Lipschitz continuity.
Throughout the subsection, we assume that is a given mapping with
and inherent nonsmooth structure. We aim to solve the (over-determined) nonlinear system of equations
(3)
(3) Classically, this can be done by minimizing the squared residual of a first-order linearization associated with
. The basic idea behind LM methods is now to add a classical square-norm regularization term to this optimization problem. Let us consider a current iterate
where
is Newton-differentiable, and consider the minimization of
which is a strictly convex function. Above, we exploited the Newton-derivative in order to find a linearization of
at
, and
is a regularization parameter. By means of the chain rule, a necessary optimality condition for this surrogate problem is given by
(4)
(4) Observing that the matrix
is at least positive semidefinite, (Equation4
(4)
(4) ) indeed possesses a uniquely determined solution
.
This motivates the formulation of Algorithm 3.1 for the numerical treatment of (Equation3(3)
(3) ). We assume that
is a given function which serves as a Newton-derivative on a suitable subset of
which will be specified later.

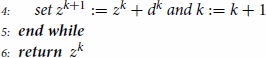
In the subsequent theorem, we present a local convergence result regarding Algorithm 3.1.
Theorem 3.2
Let be a set such that a solution
of (Equation3
(3)
(3) ) satisfies
. Assume that
is Newton-differentiable on M with Newton-derivative
. We assume that there are
and
such that, for all
,
possesses full column rank p such that
(5)
(5) Then there exists
such that, for each starting point
and each null sequence
, Algorithm 3.1 terminates after finitely many steps or produces a sequence
which converges to
superlinearly. Furthermore, if
is even Newton-differentiable on M of order 1, and if
while
is calm at
, then the convergence is quadratic.
Proof.
Due to the assumptions of the theorem, and by Newton-differentiability of , we can choose
so small such that the following estimates hold true for all
and
:
(6a)
(6a)
(6b)
(6b)
(6c)
(6c) Using
, for each
and
, we find
(7)
(7) Thus, we have
, i.e.
. Thus, if
and
, we have
in the case where Algorithm 3.1 generates an infinite sequence. Furthermore, the definition of Newton-differentiability, (Equation7
(7)
(7) ), and
give
, i.e. the convergence
is superlinear.
Finally, assume that is Newton-differentiable of order 1 and calm at
, and that
. Then there is a constant
such that the estimate (Equation7
(7)
(7) ) can be refined as
where we used
and the calmness of
at
in the last step.
Let us briefly compare the assumptions of Theorem 3.2, which are used to guarantee the superlinear or quadratic convergence of a sequence generated by Algorithm 3.1, with the ones exploited in the literature where nonsmooth LM methods are considered from the viewpoint of semismoothness, see e.g. [Citation10, Section 2]. Therefore, we fix a solution of (Equation3
(3)
(3) ). The full column rank assumption on the Newton-derivative, locally around
, corresponds to so-called BD-regularity of the point
which demands that all matrices within Bouligand's generalized Jacobian at
(if available), see e.g. [Citation1, Section 2], possess full column rank. We note that, by upper semicontinuity of Bouligand's generalized Jacobian, this full rank assumption extends to a neighbourhood of
. Hence, these full rank assumptions are, essentially, of the same type although the one from Theorem 3.2 is more general since it addresses situations where the underlying map is allowed to be non-Lipschitz. Second, Theorem 3.2 assumes boundedness of the Newton-derivative, locally around
. In the context of semismooth LM methods, local boundedness of the generalized derivative holds inherently by construction of Bouligand's generalized Jacobian and local Lipschitzness of the underlying mapping. Third, for quadratic convergence, the regularization parameters need to satisfy
in Theorem 3.2, and this assumption is also used in [Citation10]. Similarly, since Newton-differentiability of order 1 is a natural counterpart of so-called strict semismoothness, the assumptions for quadratic convergence are also the same. Summarizing these impressions, Algorithm 3.1 and Theorem 3.2 generalize the already existing theory on nonsmooth LM methods to a broader setting under reasonable assumptions. We also note that our analysis made no use of deeper underlying properties of the generalized derivative, we mainly used its definition for our purposes. However, it should be observed that a sophisticated choice of the Newton-derivative, which is not uniquely determined for a given map as mentioned in Section 2.2, may lead to weaker assumptions in Theorem 3.2 than a bad choice of it. Indeed, it even may happen that the assumptions of Theorem 3.2 are valid for a particular choice of the Newton-derivative while they are violated for another one. Thus, when Algorithm 3.1 (or a suitable globalization) is implemented, one has to keep in mind to choose the Newton-derivative in such a way that the assumptions of Theorem 3.2 are valid (if this is actually possible), as the requirements of Theorem 3.2 need to be satisfied for one particular choice of the Newton-derivative (and not for all possible choices). Clearly, this choice depends on structural properties of the nonsmooth mapping
under consideration and is, potentially, a laborious task as we will see in Section 4, see [Citation37] as well.
The following corollary of Theorem 3.2 shows that can be expected under reasonable assumptions, and this will be of essential importance later on.
Corollary 3.3
Under the assumptions of Theorem 3.2 which guarantee the superlinear convergence of generated by Algorithm 3.1, we additionally have
provided
is calm at
.
Proof.
We choose as in the proof of Theorem 3.2 and observe
. Exploiting the Newton-differentiability of
and
, we have
and some transformations give, for sufficiently large
and by boundedness of the sequence
,
i.e.
due to (Equation5
(5)
(5) ). Thus, we find
as
, where
is a local calmness constant of
at
.
In [Citation37, Section 3.2], a function is constructed which possesses the following properties:
it is Newton-differentiable on its set of roots with globally bounded and nonvanishing Newton-derivative,
it is discontinuous in each open neighbourhood of its set of roots, and
it is calm at each point from its set of roots.
This function is then used to construct a nonsmooth Newton-type method for the computational solution of stationarity systems associated with complementarity-constrained optimization problems. We note that it crucially violates the standard requirement of local Lipschitzness which is typically exploited in the context of nonsmooth Newton-type methods. Similarly as in [Citation37], the analysis in Theorem 3.2 and Corollary 3.3 only requires calmness of the mapping (as well as some other natural assumptions) in order to get local fast convergence of a nonsmooth LM method. Thus, the ideas from [Citation37] can be carried over to the situation where over-determined stationarity systems of complementarity-constrained optimization problems need to be solved (such systems would, exemplary, arise when applying the theory from Section 5.1 to bilevel optimization problems with additional complementarity constraints at the upper-level stage or to the so-called combined reformulation of bilevel optimization problems which makes use of the so-called value function and Karush–Kuhn–Tucker reformulation at the same time, see [Citation43]).
For the globalization of Algorithm 3.1, one typically needs to impose additional assumptions like the smoothness of . In the next section, we address the prototypical setting of mixed nonlinear complementarity systems and carve out two classical globalization strategies.
4. A global nonsmooth Levenberg–Marquardt method for mixed nonlinear complementarity systems
For functions and
being continuously differentiable, we aim to solve the mixed nonlinear complementarity system
(MNLCS)
(MNLCS) where, in the application we have in mind,
holds true, see Section 5. A comprehensive overview of available theoretical and numerical aspects as well as applications of mixed nonlinear complementarity problems can be found in the monograph [Citation16]. Typical solution approaches are based on nonsmooth Newton-type methods, see [Citation26], smoothing methods, see [Citation23, Citation27], active-set and interior-point methods, see [Citation24, Citation28], as well as penalty methods, see [Citation25]. Let us note that the classical formulation of mixed nonlinear complementarity systems as considered in [Citation23, Citation24, Citation26–28] is essentially equivalent to the one we are suggesting in (EquationMNLCS
(MNLCS)
(MNLCS) ), see [Citation23, Section 4] and [Citation24, Section 1] for arguments which reveal this equivalence. However, in Section 5, it will be beneficial to work with the model (EquationMNLCS
(MNLCS)
(MNLCS) ) to preserve structural properties.
For later use, we introduce some index sets depending on a pair of vectors :
Above,
are the component functions of
.
Based on NCP-functions, see Section 1, the complementarity condition
(8)
(8) can be restated in form of a (nonsmooth) equality constraint. In this paper, we will focus on two popular choices, namely the maximum function and the famous FB function. Clearly, (Equation8
(8)
(8) ) is equivalent to
where
is exploited to express the componentwise maximum. Using
, given by
where
is the FB function defined in (Equation1
(1)
(1) ), (Equation8
(8)
(8) ) is also equivalent to
These nonsmooth equations motivate the consideration of the special residual mappings
given by
(9)
(9) since precisely their roots are the solutions of (EquationMNLCS
(MNLCS)
(MNLCS) ). Let us note that, in a certain sense, these residuals are equivalent. This can be distilled from [Citation44, Lemma 3.1].
Lemma 4.1
There exist constants such that
Due to the inherent nonsmoothness of and
from (Equation9
(9)
(9) ), we may now apply Algorithm 3.1 in order to solve
or
. Note that we have
and
in the context of Section 3. In the literature, the approach via
is quite popular due to the well-known observation that the mapping
given by
is continuously differentiable, allowing for a globalization of suitable local solution methods. This is due to the fact that the squared FB function is continuously differentiable, see e.g. [Citation45, Lemma 3.4]. However, it has been reported in [Citation9] in the context of square nonlinear complementarity systems that a mixed approach combining both residuals from (Equation9
(9)
(9) ) might be beneficial since the assumptions for local fast convergence could be weaker while the local convergence is faster.
4.1. The mixed approach via both residual functions
First, let us focus on this mixed approach where the central LM search direction will be computed via given in (Equation9
(9)
(9) ) in order to end up with less complicated Newton-derivatives in the LM system. Still, we exploit the smooth function
for globalization purposes. Later, in Section 4.2, we briefly comment on the method which exclusively uses
.
Below, we provide formulas for a Newton-derivative of and the gradient of
for later use.
Lemma 4.2
On each bounded subset of , the mapping
is Newton-differentiable with Newton-derivative given by
and this mapping, again, is bounded on bounded sets. Whenever the derivatives of
and
are locally Lipschitzian, the order of Newton-differentiability is 1. Above, the index sets
and
are given by
and, for each
,
is the diagonal matrix given by
Proof.
This follows easily from Lemma 2.2, Example 2.3(a), and our comments right after Definition 2.1.
Throughout the section, we will denote the Newton-derivative of which has been characterized in Lemma 4.2 by
.
The next result follows simply by computing the derivative of the squared FB function and using the standard chain rule.
Lemma 4.3
At each point ,
is continuously differentiable, and its gradient is given by
where
Above,
are the vectors given by
(10)
(10)
For local superlinear convergence of our method of interest, we need the following result.
Lemma 4.4
Fix a solution of (EquationMNLCS
(MNLCS)
(MNLCS) ) and assume that for each index set
, the matrix
where we used
, possesses linear independent columns. Then the matrices
, where
are uniformly positive definite in a neighbourhood of
.
Proof.
Suppose that the assertion is false. Then there exist sequences ,
,
, and
such that
,
,
, and, for each
,
as well as
For brevity of notation, we make use of the abbreviations
(11)
(11) for all
. Due to
, the above gives
(12)
(12) By continuity of
, each index
lies in
for sufficiently large
. Furthermore, any
lies in
for sufficiently large
. For
, two scenarios are possible. Either there is an infinite subset
such that
for all
, or
holds for all large enough
. Anyhow, since there are only finitely many indices in
, we may choose an infinite subset
as well as an index set
such that
and
is valid for each
, where
. Hence, for each
, (Equation12
(12)
(12) ) is equivalent to
(13)
(13) Clearly, along a subsubsequence (without relabelling),
converges to some
such that
. Thus, taking the limit
in (Equation13
(13)
(13) ) gives
This implies that the matrix
, where
which is naturally positive semidefinite by construction, is not positive definite. Thus, cannot possess full column rank, contradicting the lemma's assumptions.
The qualification condition postulated in Lemma 4.4 actually corresponds to the linear independence of the columns of all elements of Bouligand's generalized Jacobian of at
, i.e. these assumptions recover the BD-regularity condition from the literature, and the latter is well established in the context of solution algorithms for nonsmooth systems. Let us also mention that it can be easily checked by means of simple examples that full column rank of the Newton-derivative of
at
, as constructed in Lemma 4.2, does, in general, not guarantee the uniform positive definiteness which has been shown under the assumptions of Lemma 4.4.
We note that each solution of (EquationMNLCS(MNLCS)
(MNLCS) ) is a global minimizer of
and, thus, a stationary point of this function. The converse statement is not likely to hold. Even for quadratic systems, one needs strong additional assumptions in order to obtain such a result.
Next, we present the method of our interest in Algorithm 4.5. For brevity of notation, we introduce
and similarly, we define
and
. Recall that
denotes the Newton-derivative of
at z characterized in Lemma 4.2.
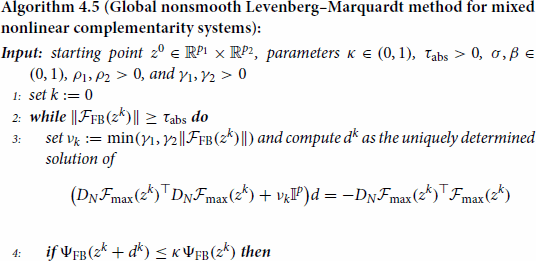
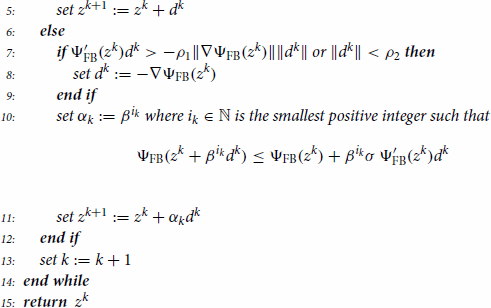
We now present the central convergence result associated with Algorithm 4.5. Its proof is similar to the one of [Citation37, Theorem 5.2] but included for the purpose of completeness.
Theorem 4.6
Let be a sequence generated by Algorithm 4.5.
| (a) | If | ||||
| (b) | Each accumulation point of | ||||
| (c) | If an accumulation point | ||||
Proof.
We note that Algorithm 4.5 is a descent method with respect to
If the assumptions of the first statement hold, the assertion is clear. Thus, we may assume that, along the tail of the sequence,
If
Next, consider the case
Finally, we assume that
Let
Remark 4.7
Clearly, Algorithm 4.5 is a descent method with respect to
Besides the standard angle test, there is another condition in Step 7 which avoids that the LM direction is chosen if it tends to zero while the angle test is passed. This is due to the following observation. Suppose that (along a suitable subsequence without relabelling), the LM directions
as well as the index set
Following the literature, see e.g. [Citation9, Citation10], it is also possible to incorporate inexact solutions of the LM equation in Algorithm 4.5 in a canonical way. Combined with a suitable solver for this equation, this approach may lead to an immense speed-up of the method. For brevity of presentation, we omit this discussion here but just point out the possibility of investigating it.
4.2. On using the Fischer–Burmeister function exclusively
In this subsection, we briefly comment on an algorithm, related to Algorithm 4.5, which fully relies on the residual introduced in (Equation9
(9)
(9) ). For completeness, we first present a result regarding the Newton-differentiability of this function which basically follows from the chain rule stated in Lemma 2.2 and Example 2.3(c).
Lemma 4.8
On each bounded subset of , the mapping
is Newton-differentiable with Newton-derivative given by
and this mapping, again, is bounded on bounded sets. Whenever the derivatives of
and
are locally Lipschitzian, the order of Newton-differentiability is 1. Above, the matrices
are those ones defined in Lemma 4.3.
Subsequently, we will denote the Newton-derivative of characterized above by
. Observe that, due to Lemma 4.3, we have
for each
.
We also need to figure out, in which situations the Newton-derivative from Lemma 4.8 satisfies the assumptions for local fast convergence.
Lemma 4.9
Fix a solution of (EquationMNLCS
(MNLCS)
(MNLCS) ) and assume that for each pair
of vectors satisfying
(15)
(15) the matrix
(16)
(16) where we used
possesses linearly independent columns. Then the matrices
, where
are uniformly positive definite in a neighbourhood of
.
Proof.
For the proof, we partially mimic our arguments from the proof of Lemma 4.4. Thus, let us suppose that the assertion is false. Then there exist sequences ,
,
, and
such that
,
,
, and, for each
,
as well as
Again, we make use of the abbreviations from (Equation11
(11)
(11) ) and obtain, by definition of the matrix
,
(17)
(17) where we exploited the vectors
and
defined in (Equation10
(10)
(10) ). For each
,
holds for large enough
by continuity of
, and we find the convergences
and
as
. Similarly, for each
, we find
for all large enough
, and we also have
and
in this case. It remains to consider the indices
. By construction, we know that the sequence
belongs to the sphere of radius 1 around
for each
and, thus, possesses an accumulation point in this sphere. Thus, taking into account that
is a finite set, we find an infinite set
and vectors
satisfying
,
, and (Equation15
(15)
(15) ). We may also assume for simplicity that the convergences
and
hold for a pair
which is nonvanishing. Taking the limit
in (Equation17
(17)
(17) ) then gives
which, similar as in the proof of Lemma 4.4, implies that
belongs to the kernel of the matrix from (Equation16
(16)
(16) ). This, however, contradicts the lemma's assumptions.
We note that the assumption of Lemma 4.9, which corresponds to the full row rank of all matrices in Bouligand's generalized Jacobian of at the reference point, i.e. BD-regularity, is more restrictive than the one from Lemma 4.4. Indeed, if the assumption of Lemma 4.9 holds, then one can choose the vectors
such that
for arbitrary
and
in order to validate the assumption of Lemma 4.4. Clearly, the assumptions of Lemmas 4.4 and 4.9 coincide whenever the biactive set
is empty. This situation is called strict complementarity in the literature.
The subsequent example shows that the assumptions of Lemma 4.9 can be strictly stronger than those ones of Lemma 4.4.
Example 4.10
Let us consider the mixed linear complementarity system
which possesses the uniquely determined solution
. In the context of this example, the functions
are given by
Clearly, the assumption of Lemma 4.4 holds since the matrices
possess full column rank 2. However, the matrix
possesses column rank 1 for
, i.e. the assumptions of Lemma 4.9 are violated.
From the viewpoint of semismooth solution methods, it also has been observed in [Citation9, Propositions 2.8 and 2.10, Example 2.1] that the mixed approach via needs less restrictive assumptions than the one via
in order to yield local fast convergence.
Next, we state the globalized nonsmooth LM method for the numerical solution of (EquationMNLCS(MNLCS)
(MNLCS) ) via exclusive use of
from (Equation9
(9)
(9) ) in Algorithm 4.11.

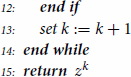
Below, we formulate a convergence result which addresses Algorithm 4.11.
Theorem 4.12
Let be a sequence generated by Algorithm 4.11.
| (a) | If | ||||
| (b) | Each accumulation point of | ||||
| (c) | If an accumulation point | ||||
Proof.
The only major difference to the proof of Theorem 4.6 addresses the second statement. More precisely, we need to show that, if the ratio test in Step 4 is violated along the tail of the sequence, and if along a subsequence (without relabelling) while
for some
, then
is stationary for
. As in the proof of Theorem 4.6, this is clear if
holds infinitely many times. Thus, without loss of generality, let us assume that
is the LM direction for all
, i.e. the uniquely determined solution of (18). Boundedness of
together with Lemma 4.8 gives boundedness of the matrices
. Thus,
gives
by continuity of
and definition of
in (18).
5. Applications in optimistic bilevel optimization
5.1. Model problem and optimality conditions
We consider the so-called standard optimistic bilevel optimization problem
(OBPP)
(OBPP) where
is given by
(19)
(19) The terminus ‘standard’ has been coined in [Citation46]. Above,
are referred to as the upper- and lower-level objective function, respectively, and assumed to be twice continuously differentiable. Furthermore the mapping,
is the twice continuously differentiable upper-level constraint function, and the set-valued mapping
is given by
where the describing lower-level constraint function
is also assumed to be twice continuously differentiable. The component functions of g will be denoted by
.
We consider the so-called lower-level value function reformulation
(VFR)
(VFR) where
is the lower-level value function given by
(20)
(20) It is well known that (EquationOBPP
(OBPP)
(OBPP) ) and (EquationVFR
(VFR)
(VFR) ) possess the same local and global minimizers.
Let us fix a feasible point of (EquationOBPP
(OBPP)
(OBPP) ). Under mild assumptions, one can show that the lower-level value function φ is locally Lipschitz continuous in a neighbourhood of
, and its Clarke subdifferential, see [Citation47], obeys the upper estimate
(21)
(21) where
is the lower-level Lagrange multiplier set which comprises all vectors
such that
Let us now assume that
is already a local minimizer of (EquationOBPP
(OBPP)
(OBPP) ) and, thus, of (EquationVFR
(VFR)
(VFR) ) as well. Again, under some additional assumptions,
is a (non-smooth) stationary point of (EquationVFR
(VFR)
(VFR) ) (in Clarke's sense). Keeping the estimate (Equation21
(21)
(21) ) in mind while noting that, by definition of the lower-level value function,
is valid, this amounts to the existence of
,
, and
such that
(22a)
(22a)
(22b)
(22b)
(22c)
(22c)
(22d)
(22d)
(22e)
(22e)
(22f)
(22f) In the subsequently stated lemma, we postulate some conditions which ensure that local minimizers of (EquationOBPP
(OBPP)
(OBPP) ) indeed are stationary in the sense that there exist multipliers which solve the system (Equation22
(22a)
(22a) ). Related results can be found e.g. in [Citation48–50]. As we work with slightly different constraint qualifications, we provide a proof for the convenience of the reader.
Lemma 5.1
Fix a local minimizer of (EquationOBPP
(OBPP)
(OBPP) ) such that
is an interior point of
. The fulfillment of the following conditions implies that there are multipliers
,
, and
which solve the system (Equation22
(22a)
(22a) ).
| (a) | The functions f and | ||||
| (b) | Either the functions f and g are affine in | ||||
| (c) | The set-valued mapping | ||||
Proof.
The imposed convexity assumptions on the lower-level data functions guarantee that φ is convex, see e.g. [Citation51, Lemma 2.1]. Given that is an interior point of
, we have
for all x in some neighbourhood of
, and therefore φ is Lipschitz continuous around
. Thus, (EquationVFR
(VFR)
(VFR) ) is a Lipschitz optimization problem around the point
. Hence, it follows from [Citation52, Theorem 4.1] and [Citation53, Theorem 6.12] that the calmness of Φ at
yields the existence of
,
,
, and
such that condition (Equation22c
(22c)
(22c) ) holds together with
(23a)
(23a)
(23b)
(23b) Above,
denotes for the normal cone, in the sense of convex analysis, to the graph of Y (which is a convex set under the assumptions made) at the point
. Due to the validity of LMFCQ or the fact that
are affine, there exists some
satisfying (Equation22d
(22d)
(22d) ) such that
, see e.g. [Citation53, Theorem 6.14] for the nonlinear case (in the linear case, this is a consequence of the well-known Farkas lemma). Furthermore, combining the fulfillment of LMFCQ with the full convexity of the lower-level data functions implies that inclusion (Equation21
(21)
(21) ) holds, see e.g. [Citation51, Theorem 2.1]. On the other hand, if f and g are affine, then (Equation21
(21)
(21) ) holds due to [Citation54, Proposition 4.1]. In both situations, we can find some
such that (Equation22b
(22b)
(22b) ), (Equation22e
(22e)
(22e) ), and
are satisfied. Plugging this information into (Equation23a
(23a)
(23a) ) gives
Now, making use of (Equation22b
(22b)
(22b) ) yields (Equation22
(22a)
(22a) ). Finally, it remains to show that (Equation23b
(23b)
(23b) ) reduces to (Equation22f
(22f)
(22f) ). This, however, is obvious as
holds due to
.
Remark 5.2
Note that assumption (a) in Lemma 5.1 can be replaced by so-called inner semicontinuity of the lower-level optimal solution mapping S from (Equation19
We note that assumption (c) is potentially weaker than the standard conditions used in the literature which combine a so-called partial calmness condition, see [Citation55], with MFCQ-type conditions with respect to the upper- and lower-level inequality constraints. On the one hand, we admit that a calmness-type assumption on the constraint including the lower-level value function is comparatively restrictive, see e.g. [Citation56–58] for discussions, so that (Equation22
In the case where the functions f and g are affine in
A second standard approach to optimality conditions for bilevel optimization problems is based on its so-called Karush–Kuhn–Tucker reformulation, but as shown in [Citation59], both approaches are, in general, completely different when comparing the resulting optimality conditions and associated constraint qualifications. Optimality conditions which are based on the reformulation (EquationVFR
Let us now transfer the necessary optimality conditions from (Equation22(22a)
(22a) ) into a mixed nonlinear complementarity system. In order to do it in a reasonable way, we need to comment on the role of the appearing real number λ. Therefore, let us mention again that system (Equation22
(22a)
(22a) ) is nothing else but the (nonsmooth) Karush–Kuhn–Tucker system of (EquationVFR
(VFR)
(VFR) ) where the (Clarke) subdifferential of the implicitly known function φ has been approximated from above by initial problem data in terms of (Equation21
(21)
(21) ). Having this in mind, there are at least two possible interpretations of the meaning behind λ. On the one hand, it may represent the Lagrange multiplier associated with the constraint
in (EquationVFR
(VFR)
(VFR) ). Clearly, in order to incorporate optimality for the lower-level problem into the system (Equation22
(22a)
(22a) ), the multiplier
characterized in (Equation22b
(22b)
(22b) ), (Equation22e
(22e)
(22e) ), has to be meaningful, i.e. λ has to be positive. Similarly, we can interpret λ as a partial penalty parameter which provides local optimality of
for
whose (nonsmooth) Karush–Kuhn–Tucker system reduces to (Equation22
(22a)
(22a) ) under mild assumptions, and this is the fundamental idea behind the aforementioned concept of partial calmness from [Citation55]. We note that, whenever a feasible point
of (EquationOBPP
(OBPP)
(OBPP) ) is a local minimizer of the above partially penalized problem for some λ, then this also holds for each larger value of this parameter. Similarly, the case
would not be reasonable here as this means that lower-level optimality is not a restriction at all. Summing up these considerations, we may work with
.
Subsequently, we will introduce some potential approaches for the reformulation of (Equation22(22a)
(22a) ) as a mixed nonlinear complementarity system.
5.1.1. Parametric approach
Following the ideas in [Citation42], we suppose that is not a variable in the system (Equation22
(22a)
(22a) ), but a given parameter which has to be chosen before the system is solved. Although this approach is challenging due to the obvious difficulty of choosing an appropriate value for λ, it comes along with some theoretical advantages as we will see below.
For a compact notation, let us introduce the block variables
as well as, for some fixed
, functions
of Lagrangian type given by
Setting
(24)
(24) the solutions of the associated nonlinear complementarity system (EquationMNLCS
(MNLCS)
(MNLCS) ) are precisely the solutions of (Equation22
(22a)
(22a) ) with a priori given λ. We note that
does not depend on the multipliers in this setting.
Let us now state some assumptions which guarantee local fast convergence of Algorithms 4.5 and 4.11 when applied to the above setting. Therefore, we first need to fix a point which satisfies the stationarity conditions (Equation22
(22a)
(22a) ) with given
. For such a point, we introduce the following index sets:
Furthermore, we make use of the so-called critical subspace defined by
We say that the lower-level linear independence constraint qualification (LLICQ) holds at
whenever the gradients
are linearly independent (note that, at the lower-level stage, only y is a variable). Analogously, the bilevel linear independence constraint qualification (BLICQ) is said to hold at
whenever the gradients
are linearly independent.
The following two theorems are inspired by [Citation41, Theorem 3.3]. Our first result provides conditions which guarantee validity of the assumptions of Lemma 4.4 in the setting (Equation24(24)
(24) ). These assumptions, thus, give local fast convergence of Algorithm 4.5 in the present setting.
Theorem 5.3
Let be a solution of the stationarity system (Equation22
(22a)
(22a) ) with given
. Let LLICQ and BLICQ be satisfied at
. Finally, assume that the second-order condition
(25)
(25) holds. Then, in the specific setting modelled in (Equation24
(24)
(24) ), the assumptions of Lemma 4.4 are valid.
Proof.
For each sets ,
, and
, we need to show that the system comprising
(26a)
(26a)
(26b)
(26b) as well as the sign conditions
(27a)
(27a)
(27b)
(27b)
(27c)
(27c)
(27d)
(27d)
(27e)
(27e) only possesses the trivial solution. Above, we used
,
, and
.
Multiplying (Equation26a(26a)
(26a) ) from the left with
and respecting (Equation27a
(27a)
(27a) ) gives
. On the other hand, (Equation27a
(27a)
(27a) ) and (Equation27b
(27b)
(27b) ) yield
. Hence, the assumptions of the theorem can be used to find
. Now, we can exploit LLICQ in order to obtain
from (Equation26b
(26b)
(26b) ) and (Equation27e
(27e)
(27e) ). Finally, with the aid of BLICQ, (Equation26a
(26a)
(26a) ), (Equation27c
(27c)
(27c) ), and (Equation27d
(27d)
(27d) ), we find
and
. This shows the claim.
Let us note from the proof that Theorem 5.3 remains correct whenever (Equation25(25)
(25) ) is replaced by the slightly weaker condition
(28)
(28) However, (Equation25
(25)
(25) ) is related to second-order sufficient optimality conditions for the characterization of strict local minimizers of (EquationOBPP
(OBPP)
(OBPP) ), see e.g. [Citation62], and as we aim to find local minimizers of (EquationOBPP
(OBPP)
(OBPP) ), this seems to be a more natural assumption than (Equation28
(28)
(28) ) which seemingly concerns saddle points of
.
Under slightly stronger conditions, we can prove that even the assumptions of Lemma 4.9 hold in the precise setting from (Equation24(24)
(24) ) which, in turn, guarantee local fast convergence of Algorithm 4.11 in the present setting.
Theorem 5.4
Let be a solution of the stationarity system (Equation22
(22a)
(22a) ) with given
. Let LLICQ and BLICQ be satisfied at
, and let
hold. Finally, assume that the second-order condition (Equation25
(25)
(25) ) holds. Then, in the specific setting modelled in (Equation24
(24)
(24) ), the assumptions of Lemma 4.9 are valid.
Proof.
For each , let
satisfy
Similarly, for each
(
), let
(
) satisfy
We need to show that the system comprising the conditions from (Equation26
(26a)
(26a) ) as well as the sign conditions
(29a)
(29a)
(29b)
(29b)
(29c)
(29c)
(29d)
(29d)
(29e)
(29e)
(29f)
(29f)
(29g)
(29g) only possesses the trivial solution.
For later use, we introduce index sets by means of
Let us note that
holds for each
, which gives
by (Equation29c
(29c)
(29c) ). Furthermore, for each
, we have
, while
is valid for each
. Let the index sets
and
be defined in analogous fashion. Note that for each
, (Equation29b
(29b)
(29b) ) and (Equation29e
(29e)
(29e) ) give
.
Clearly, (Equation29a(29a)
(29a) ) and (Equation29b
(29b)
(29b) ) give
. Multiplying (Equation26a
(26a)
(26a) ) from the left with
while respecting (Equation25
(25)
(25) ), (Equation29a
(29a)
(29a) ), and the above discussion gives
Thus, we have
, so (Equation25
(25)
(25) ) yields
. Now, we can argue as in the proof of Theorem 5.3 in order to obtain
,
, and
from (Equation26b
(26b)
(26b) ), (Equation29f
(29f)
(29f) ), and (Equation29g
(29g)
(29g) ) with the aid of LLICQ and BLICQ. This completes the proof.
Let us note that both Theorems 5.3 and 5.4 drastically enhance [Citation41, Theorem 3.3] where strict complementarity is assumed.
5.1.2. Variable approach
The discussions in [Citation40, Citation42] underline that, from a numerical point of view, treating λ as a parameter in (Equation22(22a)
(22a) ) is nontrivial since the particular choice of it is quite involved. We therefore aim to interpret λ as a variable which is determined by the solution algorithm. In this section, we suggest two associated approaches.
First, we may consider the block variables
as well as Lagrangian-type functions
given by
Setting
(30)
(30) we can reformulate (Equation22
(22a)
(22a) ) as a mixed complementarity system of type (EquationMNLCS
(MNLCS)
(MNLCS) ). Here, λ is treated as part of the Lagrange multiplier vector associated with (Equation22
(22a)
(22a) ), and this seems to be rather natural.
A second idea is based on a squaring trick. Observe that the system (Equation22(22a)
(22a) ) can be equivalently reformulated by combining
with (Equation22b
(22b)
(22b) )–(Equation22e
(22e)
(22e) ) for multipliers
,
, and
. This eliminates the sign condition (Equation22f
(22f)
(22f) ). Thus, using the block variables
as well as Lagrangian-type functions
given by
we can recast the resulting system in the form (EquationMNLCS
(MNLCS)
(MNLCS) ) when using
(31)
(31) Note that in both settings (Equation30
(30)
(30) ) and (Equation31
(31)
(31) ), the mapping
does not depend on the multiplier.
Let us point the reader's attention to the fact that both approaches discussed above come along with the heavy disadvantage that a result similar to Theorem 5.3 does not seem to hold. In order to see this, one can try to mimic the proof of Theorem 5.3 in the setting (Equation30(30)
(30) ) and (Equation31
(31)
(31) ), respectively. After all possible eliminations, one ends up with
and
, respectively, and both of these linear equations possess a nonvanishing kernel. Clearly, these arguments extend to Theorem 5.4 as well.
5.2. Computational experiments
We would like to point the reader's attention to the fact that the numerical application of Gauss–Newton or LM methods for the numerical solution of a smoothed version of system (Equation22(22a)
(22a) ) has been investigated in [Citation41, Citation42]. Therein, the authors challenged their methods by running experiments on the 124 nonlinear bilevel optimization problems which are contained in the BOLIB library from [Citation63]. Let us note that only some of these examples satisfy the assumptions of Lemma 5.1, leading to the fact that (Equation22
(22a)
(22a) ) does not provide a reliable necessary optimality condition, i.e. system (Equation22
(22a)
(22a) ) does not possess a solution in many situations. In this regard, it is not surprising that, in [Citation41, Section 5.4], the authors admit that the methods under consideration most often terminate since the maximum number of iterations is reached or since the norm of the difference of two consecutive iterates becomes small, which is clearly not satisfying. In [Citation42, Section 4.1.4], the authors introduce additional termination criteria, based on the difference of the norm of the FB residual and certain thresholds of the iteration number, to enforce termination even in situations where the algorithm did not fully converge. It is not clarified in [Citation42] why the authors do not check for approximate stationarity of the squared FB residual. Summarizing this, the experiments in [Citation41, Citation42] visualize some global properties of the promoted solution approaches but do not respect the assumptions needed to ensure (local fast) convergence. The results are, thus, of limited expressiveness.
Here, we restrict ourselves to the illustration of certain features of our nonsmooth LM methods from Algorithms 4.5 and 4.11 on problems where the assumptions of Lemma 5.1 or even Theorems 5.3 and 5.4 hold. Furthermore, we take care of distinguishing between the parametric approach from Section 5.1.1, where the multiplier λ is treated as a parameter which has to be chosen a priori, see [Citation40, Citation41] for further comments on how precisely this parameter can be chosen in numerical practice, and the variable approach from Section 5.1.2, where λ is an additional variable.
5.2.1. Implementation and setting
We implemented Algorithm 4.5 (method mixLM) and Algorithm 4.11 (method FBLM) for the three different settings described in (Equation24(24)
(24) ) (setting Para), (Equation30
(30)
(30) ) (setting Var1), and (Equation31
(31)
(31) ) (setting Var2) (making a total number of six algorithms) in MATLAB2022b based on user-supplied gradients and Hessians. Numerical experiments were ran for two bilevel optimization problems whose minimizers satisfy the stationarity conditions from (Equation22
(22a)
(22a) ):
| Experiment 1 | the problem from [Citation62, Example 8] where (Equation22 | ||||
| Experiment 2 | the inverse transportation problem from [Citation64, Section 5.3.2, Experiment 3] whose lower-level problem and upper-level constraints are fully affine. | ||||
For each experiment, a certain number of (random) starting points has been generated, and each of the algorithms has been run based on these starting points. If the termination criterion (Term=1) is violated in Algorithms 4.5 and 4.11, we additionally check validity of
(Term=2) for some constant
in order to capture situations where a stationary point of the squared FB residual
has been found. Furthermore, we equip each algorithm with a maximum number of possible iterations, and terminate if it is hit (Term=0).
In order to compare the output of the six methods, we make use of so-called performance profiles, see [Citation65], based on the following indicators: total number of iterations, execution time (in seconds), upper-level objective value, and percentage of full LM steps (i.e. the quotient # full LM steps/# total iterations). We denote by the metric of comparison (associated with the current performance index) of solver
for solving the instance
of the problem, where
is the set of solvers and
represents the different starting points. We define the performance ratio by
This quantity is the ratio of the performance of solver
to solve instance
compared to the best performance of any other algorithm in
to solve instance i. The cumulative distribution function
of the current performance index associated with the solver
is defined by
The performance profile for a fixed performance index shows (the illustrative parts of) the graphs of all the functions
,
. The value
represents the fraction of problem instances for which solver
shows the best performance. For arbitrary
,
shows the fraction of problem instances for which solver
shows at most the τ-fold of the best performance.
Finally, let us comment on the precise construction of the performance metric. For the comparison of the total number of iterations and execution time (in seconds), we simply rely on the index under consideration. Computed upper-level objective values are shifted by the minimum function value known in the literature to ensure that the associated performance metric does not produce negative outputs (additionally, we also add a small positive offset to ensure positivity). In order to benchmark the percentage of full LM steps, we subtract the aforementioned quotient of full LM steps over total number of steps from 1 (again, a positive offset is added to ensure positivity). This guarantees that small values of the metric indicate a desirable behaviour.
5.2.2. Numerical examples
Experiment 1 We investigate the bilevel optimization problem from [Citation62, Example 8] which is given by
Its global minimizer is
, and the corresponding stationarity conditions from (Equation22
(22a)
(22a) ) hold for each
when choosing
,
, and
. One can easily check that the assumptions of Theorem 5.3 are valid. If
is chosen, strict complementarity holds. However, even for
, we have
so that the assumptions of Theorem 5.4 hold as well for each feasible choice of the multipliers.
For this experiment, we took the maximum number of iteration to be and chose the following parameters for the algorithms: q: = 0.8,
,
,
,
,
,
,
, and
. We challenged our algorithms with 121 starting points constructed in the following way. The pair
is chosen from
. For the multipliers, we always chose
and
. In the case of setting Var2, we made use of
. The results of the experiments are illustrated in Figure and Table .
Figure 1. Performance profiles for Experiment 1. From top left to bottom right: number of total iterations, execution time, upper-level objective value, and percentage of full LM steps.
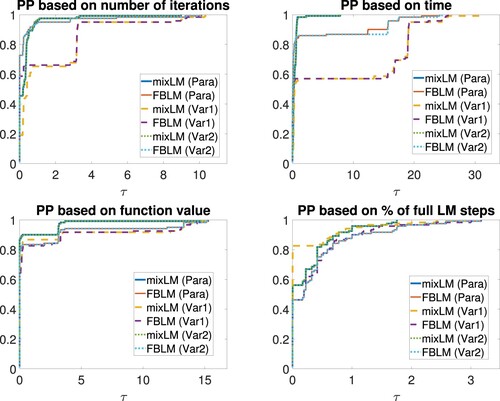
Table 1. Averaged performance indices for Experiment 1.
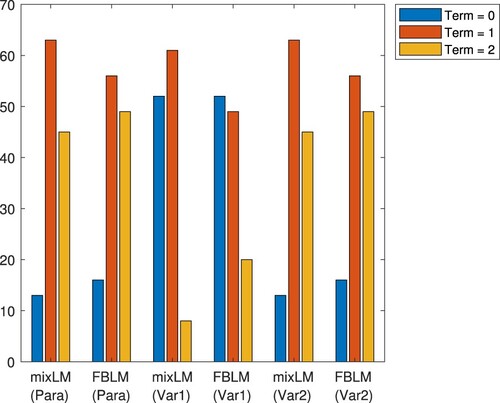
We immediately see that the approaches Para and Var2 perform almost equally good. These methods terminate due to a small residual or stationarity of the squared FB residual in 90% of all runs, and the actual optimal solution is found in approximately 60% of all runs with slight advantages for mixLM. Let us now report on Var1. The optimal solution is found in about 57% of all runs. However, in this setting, both algorithms much more often do not terminate due to stationarity of the squared FB residual but are aborted since the maximum number of iterations is reached – the latter happens in 43% of the runs. Often, both algorithms seem to be close (but not too close) to a stationary point of the squared FB residual in this case, but this is not detected by our termination criterion. For a better overview, Figure illustrates the termination behaviour of all six methods. Coming back to an overall comparison, mixLM in setting Para converges to the global minimizer of the problem for starting points chosen from
In most of the associated runs, a total number of 6 to 10 iterations is performed out of which almost all are full LM steps, i.e. we observe local fast convergence in our experiments. Related phenomena can be observed for the remaining five approaches. Particularly, despite the absence of any theoretical guarantees, local fast convergence is present in the variable settings described in Section 5.1.2. More precisely, we observed that whenever our algorithms approach the global minimizer, then this happens in a few number of full LM steps, and the convergence is, indeed, quadratic. The large average number of iterations documented in Table results from the fact that whenever the algorithms do not approach the global minimizer, they tend to get stuck in stationary points of the squared residual which are approached by slow gradient steps. Typically, the algorithms are aborted in this situation since the maximum number of iterations is reached. The performance profiles in Figure indicate that settings Para and Var2 are superior to Var1 when the total number of iterations and execution time are investigated. Recalling that Var1 does not stop until the maximum number of iterations is reached in comparatively many runs, its (averaged) running time is twice as large as for Para and Var2. We note that mixLM (even in setting Var1) performs more full LM steps than FBLM, see Table as well. For more than 80% of all starting points, mixLM in setting Var1 carries out the highest number of full LM steps among the six methods which we are comparing here. However, there are some critical instances where, in the setting Var1, comparatively many gradient steps are done, which explains the numbers in Table . All this is in line with the above comments, and also extends to the computed upper-level objective value, although one has to be careful as all six methods compute the global minimizer almost equally often. However, Var1 ends up in points with comparatively high objective value in much more runs than the other two settings. Taking a look at the averaged numbers in Table , we observe that mixLM performs slightly quicker than FBLM for all three settings. Furthermore, mixLM finds the global minimizer more often than FBLM. The highest number of total iterations can be observed for FBLM in setting Var1.
Figure 2. Reason for termination for Experiment 1.
Experiment 2 We consider the bilevel optimization problem
where
is the solution mapping of the parametric transportation problem
(TR$(x)$)
(TR$(x)$) Here,
is a positive integer,
is an integer vector modelling the minimum demand of the ℓ consumers, and
is a cost matrix. In (TR(x)), the parameter
represents the offer provided at n warehouses which is unknown and shall be reconstructed from a given (noisy) transportation plan
. For our experiments, we chose n: = 5,
, and relied on the data matrices given in [Citation64, Appendix]. As mentioned in [Citation64], the best known solution of this bilevel optimization problem comes along with an upper-level objective value of
.
All six methods were tested based on a collection of 500 random starting points which were created in the following way. For the construction of the pair , the components of x are chosen randomly from the interval
while the components of y are chosen randomly from
, based on a uniform distribution, respectively. The associated multiplier vectors as well as ζ in setting Var2 are defined as in our first experiment. For our algorithms, we chose a maximum number of
iterations, and we made use of the following values for all appearing parameters: q: = 0.9,
,
,
,
,
,
, and
. The resulting performance profiles and averaged performance indices are documented in Figure and Table .
Figure 3. Performance profiles for Experiment 2. From top left to bottom right: number of total iterations, execution time, upper-level objective value, and percentage of full LM steps.
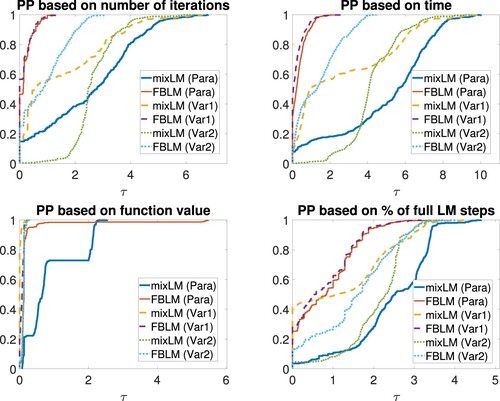
Table 2. Averaged performance indices for Experiment 2.
From Figure , it is easy to see that FBLM performs better than mixLM considering the total number of iterations, execution time, and the percentage of full LM steps although FBLM in setting Var2 cannot challenge the same algorithm in settings Para and Var1 for these three criteria, see Table as well. Our choice of and
caused that all six methods terminated either due to a small residual or stationarity of the squared FB residual in most of the runs. Let us point out that mixLM terminated due to stationarity of the squared FB residual in most of the runs, and the same holds true for FBLM in setting Var1, see Figure as well.
Figure 4. Reason for termination for Experiment 2.
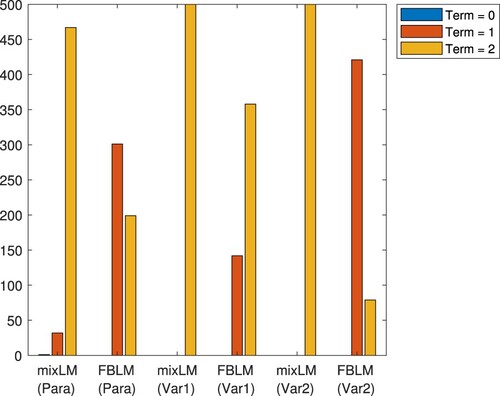
This, however, does not tell the full story. In the last row of Table , we document the number of runs where the final iterate produces an upper level objective value between and
, i.e. we count the number of runs where a point is produced whose associated upper-level function value is close to the best known one (below, we will refer to such points as reasonable). As it turns out, mixLM in setting Var1 is not competitive at all in this regard. Indeed, this method most often terminates in points possessing upper-level objective value around
and norm of the FB residual around
. We suspect that this method tends to get stuck in stationary points of the squared FB residual which are not feasible for the inverse transportation problem. Hence, the performance profile which monitors the upper-level objective value in Figure is of limited meaningfulness. The situation is far better for FBLM where reasonable points are computed much more frequently, although it has to be mentioned that the settings Para (79% reasonable) and Var2 (76% reasonable) again outrun Var1 (32% reasonable) in this regard. Interestingly, mixLM in setting Var2 always terminated due to a small value of the squared FB residual, but produced reasonable points in more than 82% of all runs. An individual fine tuning of the parameters for the settings Para, Var1, and Var2 may lead to more convincing termination reasons, but we abstained from it for a better comparison of all methods under consideration. The performance profiles in Figure show that FBLM in the settings Para and Var1 are superior to Var2, and when only computed function values are taken into account, then, for the price of higher computation time, mixLM in setting Var2 is acceptable as well.
Let us note that (Equation22(22a)
(22a) ) turns out to be an over-determined mixed linear complementarity system in the particular setting considered here and, thus, a certain error bound condition is present. In the light of available literature on smooth LM methods, see e.g. [Citation66], this could be a reason for the observed local fast convergence for a large number of starting points, although we did not prove such a result in this paper. Furthermore, it has to be observed that a reformulation via Var2 abrogates linearity of the system, but we obtained the best results in this setting when convergence to reasonable points is the underlying criterion.
Summary Let us briefly summarize that our experiments visualized competitiveness of the settings Para and Var2, while setting Var1 has turned out to come along with numerical disadvantages in both experiments. While, in our first experiment, there was no significant difference between Para and Var2, our second (and, by far, more challenging) experiment revealed that Var2 also could have some benefits over Para. Our experiments do not indicate whether it is generally better to apply mixLM or FBLM, but at least we can suggest that whenever the parameter λ is unknown, then it might be reasonable to apply mixLM in setting Var2 to obtain good solutions.
6. Concluding remarks
In this paper, we exploited the concept of Newton-differentiability in order to design a nonsmooth Levenberg–Marquardt method for the numerical solution of over-determined nonsmooth equations. Our method possesses desirable local convergence properties under reasonable assumptions and may be applied in situations where the underlying nonsmooth mapping is even discontinuous. We applied this idea to over-determined mixed nonlinear complementarity systems where a suitable globalization is possible via gradient steps with respect to the squared norm of the residual induced by the Fischer–Burmeister function. However, we investigated the method in two different flavors regarding the computation of the Levenberg–Marquardt direction namely via a residual given in terms of the maximum function on the one hand and in terms of the Fischer–Burmeister function on the other hand. For both methods, global convergence results have been derived, and assumptions for local fast convergence have been specified. Our analysis recovers the impressions from [Citation9], obtained in a slightly different framework, that the approach via the maximum residual works under less restrictive assumptions. Finally, we applied these globalized nonsmooth Levenberg–Marquardt methods in order to solve bilevel optimization problems numerically. Theoretically, we were in position to verify local fast convergence of both algorithms under less restrictive assumptions than those ones stated in the literature which among others assume strict complementarity, see [Citation41, Section 3]. Some numerical experiments were discussed in order to visualize interesting computational features of this approach.
Our theoretical and numerical investigation of bilevel optimization problems solely focused on the optimistic approach, but it might be also possible to address (similarly over-determined) stationarity systems related to pessimistic bilevel optimization via a similar approach. Next, we would like to point the reader's attention to the fact that the (inherent) inner semicontinuity assumption on the solution mapping in Lemma 5.1, see Remark 5.2 as well, is comparatively strong and may fail in many practically relevant scenarios. However, it is well known from the literature that in the presence of so-called inner semicompactness, which is inherent whenever the solution mapping is locally bounded, slightly more general necessary optimality conditions can be derived which comprise additional geometric constraints of polyhedral type addressing the multipliers, see e.g. [Citation49, Theorem 4.9]. For the numerical solution of this stationarity system, a numerical method would be necessary which is capable of solving an over-determined system of equations subject to polyhedral constraints where either the polyhedral constraint set is not convex or the equations are non-smooth. Exemplary, we refer the interested reader to [Citation67–69] for examples of such methods. In the future, it needs to be checked how these methods apply to the described setting of bilevel optimization, and how the assumptions for local fast convergence can be verified in this situation. Yet another way to extend our approach to more general bilevel optimization problems could be to consider the combined reformulation of bilevel optimization problems which merges the value function and Karush–Kuhn–Tucker reformulation, see [Citation43]. A potential associated stationarity system can be reformulated as an overdetermined system of discontinuous nonsmooth equations which, similar as in [Citation37], still can be solved with the aid of the nonsmooth Levenberg–Marquardt method developed in Section 3 as the latter one is reasonable for functions which are merely calm at their roots, and this property is likely to hold, see [Citation37, Lemma 3.3(d)]. Let us also mention that it would be interesting to study whether an error bound condition is enough to yield local fast convergence of Algorithms 4.5 and 4.11 even in the nonsmooth setting, see [Citation66] for the analysis in the smooth case. Furthermore, it remains to be seen whether some reasonable conditions can be found which guarantee local fast convergence of our algorithms when applied to stationarity systems of bilevel optimization problems where the multiplier associated with the value function constraint is treated as a variable, see Section 5.1.2.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Qi L. Convergence analysis of some algorithms for solving nonsmooth equations. Math Oper Res. 1993;18(1):227–244. https://doi.org/10.1287/moor.18.1.227
- Qi L, Sun J. A nonsmooth version of Newton's method. Math Program. 1993;58:353–367. https://doi.org/10.1007/BF01581275
- Mifflin R. Semismooth and semiconvex functions in constrained optimization. SIAM J Control Optim. 1977;15(6):959–972. https://doi.org/10.1137/0315061
- Galántai A. Properties and construction of NCP functions. Comput Optim Appl. 2012;52(3):805–824. https://doi.org/10.1007/s10589-011-9428-9
- Kanzow C, Yamashita N, Fukushima M. New NCP-functions and their properties. J Optim Theory Appl. 1997;94(1):115–135. https://doi.org/10.1023/A:1022659603268
- Sun D, Qi L. On NCP-functions. Comput Optim Appl. 1999;13(1):201–220. https://doi.org/10.1023/A:1008669226453
- Fischer A. A special Newton-type optimization method. Optimization. 1992;24(3-4):269–284. https://doi.org/10.1080/02331939208843795
- De Luca T, Facchinei F, Kanzow C. A semismooth equation approach to the solution of nonlinear complementarity systems. Math Program. 1996;75:407–439. https://doi.org/10.1007/BF02592192
- De Luca T, Facchinei F, Kanzow C. A theoretical and numerical comparison of some semismooth algorithms for complementarity problems. Comput Optim Appl. 2000;16:173–205. https://doi.org/10.1023/A:1008705425484
- Facchinei F, Kanzow C. A nonsmooth inexact Newton method for the solution of large-scale nonlinear complementarity problems. Math Program. 1997;76:493–512. https://doi.org/10.1007/BF02614395
- Kojima M, Shindo S. Extensions of Newton and Quasi-Newton methods to systems of PC1 equations. J Oper Res Soc Japan. 1986;29(4):352–374. https://doi.org/10.15807/JORSJ.29.352
- Kummer B. Newton's method for non-differentiable functions. In: Guddat J, Bank B, Hollatz H, Kall P, Klatte D, Kummer B, Lommatzsch K, Tammer K, Vlach M, Zimmermann K, editors. Advances in mathematical optimization. Berlin: Akademie-Verlag; 1988. p. 114–125. https://doi.org/10.1515/9783112479926-011
- Kummer B. Newton's method based on generalized derivatives for nonsmooth functions: convergence analysis. In: Oettli W, Pallaschke D, editors. Advances in optimization. Springer: Berlin; 1992. p. 171–194. https://doi.org/10.1007/978-3-642-51682-5_12
- Pang J-S. Newton's method for B-differentiable equations. Math Oper Res. 1990;15(2):311–341. https://doi.org/10.1287/moor.15.2.311
- Robinson SM. Newton's method for a class of nonsmooth functions. Set-Valued Anal. 1994;2:291–305. https://doi.org/10.1007/BF01027107
- Facchinei F, Pang J-S. Finite-dimensional variational inequalities and complementarity problems. New York: Springer; 2003. https://doi.org/10.1007/b97543
- Izmailov AF, Solodov MV. Newton-type methods for optimization and variational problems. New York: Springer; 2014. https://doi.org/10.1007/978-3-319-04247-3
- Klatte D, Kummer B. Nonsmooth equations in optimization. regularity, calculus, methods and applications. Boston: Kluwer Academic; 2002. https://doi.org/10.1007/b130810
- Jiang H. Global convergence analysis of the generalized Newton and Gauss–Newton methods of the Fischer–Burmeister equation for the complementarity problem. Math Oper Res. 1999;24(3):529–543. https://doi.org/10.1287/moor.24.3.529
- Kanzow C, Petra S. On a semismooth least squares formulation of complementarity problems with gap reduction. Optim Methods Softw. 2004;19(5):507–525. https://doi.org/10.1080/10556780410001683096
- Ma C, Wang C. A nonsmooth Levenberg–Marquardt method for solving semi-infinite programming problems. J Comput Appl Math. 2009;230(2):633–642. https://doi.org/10.1016/j.cam.2009.01.004
- Qi L, Wu S-Y, Zhou G. Semismooth Newton methods for solving semi-infinite programming problems. J Glob Optim. 2003;27:215–232. https://doi.org/10.1023/A:1024814401713
- Chen C, Mangasarian OL. A class of smoothing functions for nonlinear and mixed complementarity problems. Comput Optim Appl. 1996;5:97–138. https://doi.org/10.1007/BF00249052
- Daryina AN, Izmailov AF, Solodov MV. A class of active-set Newton methods for mixed complementarity problems. SIAM J Optim. 2005;15(2):409–429. https://doi.org/10.1137/S105262340343590X
- Huang C, Wang S. A penalty method for a mixed nonlinear complementarity problem. Nonlinear Anal Theory Methods Appl. 2012;75(2):588–597. https://doi.org/10.1016/j.na.2011.08.061
- Kanzow C. Global optimization techniques for mixed complementarity problems. J Glob Optim. 2000;16:1–21. https://doi.org/10.1023/A:1008331803982
- Li D, Fukushima M. Smoothing Newton and quasi-Newton methods for mixed complementarity problems. Comput Optim Appl. 2000;17:203–230. https://doi.org/10.1023/A:1026502415830
- Monteiro RDC, Pang J-S. Properties of an interior-point mapping for mixed complementarity problems. Math Oper Res. 1996;21(3):629–654. https://doi.org/10.1287/moor.21.3.629
- Gfrerer H, Outrata JV. On a semismooth* Newton method for solving generalized equations. SIAM J Optim. 2021;31(1):489–517. https://doi.org/10.1137/19M1257408
- Brokate M, Ulbrich M. Newton differentiability of convex functions in normed spaces and of a class of operators. SIAM J Optim. 2022;32(2):1265–1287. https://doi.org/10.1137/21M1449531
- Chen X, Nashed Z, Qi L. Smoothing methods and semismooth methods for nondifferentiable operator equations. SIAM J Numer Anal. 2000;38(4):1200–1216. https://doi.org/10.1137/S0036142999356719
- Hintermüller M, Ito K, Kunisch K. The primal-dual active set strategy as a semismooth Newton method. SIAM J Optim. 2002;13(3):865–888. https://doi.org/10.1137/s1052623401383558
- Ito K, Kunisch K. Lagrange multiplier approach to variational problems and applications. Philadelphia: SIAM; 2008. https://doi.org/10.1137/1.9780898718614
- Schiela A. A simplified approach to semismooth Newton methods in function space. SIAM J Optim. 2008;19(3):1417–1432. https://doi.org/10.1137/060674375
- Ulbrich M. Semismooth Newton methods for operator equations in function spaces. SIAM J Optim. 2002;13(3):805–841. https://doi.org/10.1137/s1052623400371569
- Ulbrich M. Semismooth newton methods for variational inequalities and constrained optimization problems in function spaces. Philadelphia: SIAM; 2011. https://doi.org/10.1137/1.9781611970692
- Harder F, Mehlitz P, Wachsmuth G. Reformulation of the M-stationarity conditions as a system of discontinuous equations and its solution by a semismooth Newton method. SIAM J Optim. 2021;31(2):1459–1488. https://doi.org/10.1137/20M1321413
- Dempe S. Foundations of bilevel programming. Dordrecht: Kluwer; 2002. https://doi.org/10.1007/b101970
- Dempe S, Kalashnikov V, Pérez-Valdéz G, et al. Bilevel programming problems – theory, algorithms and applications to energy networks. Berlin: Springer; 2015. https://doi.org/10.1007/978-3-662-45827-3
- Fischer A, Zemkoho AB, Zhou S. Semismooth Newton-type method for bilevel optimization: global convergence and extensive numerical experiments. Optim Methods Softw. 2022;37(5):1770–1804. https://doi.org/10.1080/10556788.2021.1977810
- Fliege J, Tin A, Zemkoho AB. Gauss–Newton-type methods for bilevel optimization. Comput Optim Appl. 2021;78:793–824. https://doi.org/10.1007/s10589-020-00254-3
- Tin A, Zemkoho AB. Levenberg–Marquardt method and partial exact penalty parameter selection in bilevel optimization. Optim Eng. 2023;24:1343–1385. https://doi.org/10.1007/s11081-022-09736-1
- Ye JJ, Zhu DL. New necessary optimality conditions for bilevel programs by combining the MPEC and value function approaches. SIAM J Optim. 2010;20(4):1885–1905. https://doi.org/10.1137/080725088
- Tseng P. Growth behavior of a class of merit functions for the nonlinear complementarity problem. J Optim Theory Appl. 1996;89(1):17–37. https://doi.org/10.1007/bf02192639
- Facchinei F, Soares J. A new merit function for nonlinear complementarity problems and a related algorithm. SIAM J Optim. 1997;7(1):225–247. https://doi.org/10.1137/S1052623494279110
- Zemkoho AB. Solving ill-posed bilevel programs. Set-Valued Var Anal. 2016;24:423–448. https://doi.org/10.1007/s11228-016-0371-x
- Clarke FH. Optimization and nonsmooth analysis. Philadelphia: SIAM; 1990. https://doi.org/10.1137/1.9781611971309
- Dempe S, Dutta J, Mordukhovich BS. New necessary optimality conditions in optimistic bilevel programming. Optimization. 2007;56(5-6):577–604. https://doi.org/10.1080/02331930701617551
- Dempe S, Zemkoho AB. The generalized Mangasarian–Fromovitz constraint qualification and optimality conditions for bilevel programs. J Optim Theory Appl. 2011;148(1):46–68. https://doi.org/10.1007/s10957-010-9744-8
- Mordukhovich BS, Nam NM, Phan HM. Variational analysis of marginal functions with applications to bilevel programming. J Optim Theory Appl. 2012;152(3):557–586. https://doi.org/10.1007/s10957-011-9940-1
- Tanino T, Ogawa T. An algorithm for solving two-level convex optimization problems. Int J Syst Sci. 1984;15(2):163–174. https://doi.org/10.1080/00207728408926552
- Henrion R, Jourani A, Outrata J. On the calmness of a class of multifunctions. SIAM J Optim. 2002;13(2):603–618. https://doi.org/10.1137/S1052623401395553
- Rockafellar RT, Wets RJ-B. Variational analysis. Berlin: Springer; 1998. https://doi.org/10.1007/978-3-642-02431-3
- Ye JJ, Wu S-Y. First order optimality conditions for generalized semi-infinite programming problems. J Optim Theory Appl. 2008;137(2):419–434. https://doi.org/10.1007/s10957-008-9352-z
- Ye JJ, Zhu DL. Optimality conditions for bilevel programming problems. Optimization. 1995;33(1):9–27. https://doi.org/10.1080/02331939508844060
- Henrion R, Surowiec TM. On calmness conditions in convex bilevel programming. Appl Anal. 2011;90(6):951–970. https://doi.org/10.1080/00036811.2010.495339
- Ke R, Yao W, Ye JJ, et al. Generic property of the partial calmness condition for bilevel programming problems. SIAM J Optim. 2022;32(2):604–634. https://doi.org/10.1137/20M1371403
- Mehlitz P, Minchenko LI, Zemkoho AB. A note on partial calmness for bilevel optimization problems with linearly structured lower level. Optim Lett. 2021;15:1277–1291. https://doi.org/10.1007/s11590-020-01636-6
- Zemkoho AB, Zhou S. Theoretical and numerical comparison of the Karush–Kuhn–Tucker and value function reformulation in bilevel optimization. Comput Optim Appl. 2021;78:625–674. https://doi.org/10.1007/s10589-020-00250-7
- Robinson SM. Some continuity properties of polyhedral multifunctions. In: König H, Korte B, Ritter K, editors. Mathematical programming at oberwolfach. Berlin: Springer; 1981. p. 206–214. https://doi.org/10.1007/BFb0120929
- Dempe S, Mordukhovich BS, Zemkoho AB. Necessary optimality conditions in pessimistic bilevel programming. Optimization. 2014;63(4):505–533. https://doi.org/10.1080/02331934.2012.696641
- Mehlitz P, Zemkoho AB. Sufficient optimality conditions in bilevel programming. Math Oper Res. 2021;46(4):1573–1598. https://doi.org/10.1287/moor.2021.1122
- Zhou S, Zemkoho AB, Tin A. BOLIB: bilevel optimization LIBrary of test problems. In: Dempe S, Zemkoho AB, editors. Bilevel optimization: advances and next challenges. Cham: Springer International; 2020. p. 563–580. https://doi.org/10.1007/978-3-030-52119-6_19
- Mehlitz P. Asymptotic regularity for Lipschitzian nonlinear optimization problems with applications to complementarity constrained and bilevel programming. Optimization. 2023;72(1):277–320. https://doi.org/10.1080/02331934.2022.2031190
- Dolan ED, Moré JJ. Benchmarking optimization software with performance profiles. Math Program. 2002;91(2):201–213. https://doi.org/10.1007/s101070100263
- Yamashita N, Fukushima M. On the rate of convergence of the Levenberg–Marquardt method. In: Alefeld G, Chen X, editors. Topics in numerical analysis. Vienna: Springer; 2001. p. 239–249. https://doi.org/10.1007/978-3-7091-6217-0_18
- Behling R, Fischer A, Haeser G, et al. On the constrained error bound condition and the projected Levenberg–Marquardt method. Optimization. 2017;66(8):1397–1411. https://doi.org/10.1080/02331934.2016.1200578
- Facchinei F, Fischer A, Herrich M. A family of Newton methods for nonsmooth constrained systems with nonisolated solutions. Math Oper Res. 2013;77:433–443. https://doi.org/10.1007/s00186-012-0419-0
- Facchinei F, Fischer A, Herrich M. An LP-Newton method: nonsmooth equations, KKT systems, and nonisolated solutions. Math Program. 2014;146:1–36. https://doi.org/10.1007/s10107-013-0676-6