
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The performance of stochastic gradient descent (SGD), which is the simplest first-order optimizer for training deep neural networks, depends on not only the learning rate but also the batch size. They both affect the number of iterations and the stochastic first-order oracle (SFO) complexity needed for training. In particular, the previous numerical results indicated that, for SGD using a constant learning rate, the number of iterations needed for training decreases when the batch size increases, and the SFO complexity needed for training is minimized at a critical batch size and that it increases once the batch size exceeds that size. Here, we study the relationship between batch size and the iteration and SFO complexities needed for nonconvex optimization in deep learning with SGD using constant or decaying learning rates and show that SGD using the critical batch size minimizes the SFO complexity. We also provide numerical comparisons of SGD with the existing first-order optimizers and show the usefulness of SGD using a critical batch size. Moreover, we show that measured critical batch sizes are close to the sizes estimated from our theoretical results.
1. Introduction
1.1. Background
First-order optimizers can train deep neural networks by minimizing loss functions called the expected and empirical risks. They use stochastic first-order derivatives (stochastic gradients), which are estimated from the full gradient of the loss function. The simplest first-order optimizer is stochastic gradient descent (SGD) [Citation1–5], which has a number of variants, including momentum variants [Citation6, Citation7] and numerous adaptive variants, such as adaptive gradient (AdaGrad) [Citation8], root mean square propagation (RMSProp) [Citation9], adaptive moment estimation (Adam) [Citation10], adaptive mean square gradient (AMSGrad) [Citation11], and Adam with decoupled weight decay (AdamW) [Citation12].
SGD can be applied to nonconvex optimization [Citation13–22], where its performance strongly depends on the learning rate . For example, under the bounded variance assumption, SGD using a constant learning rate
satisfies
[Citation18, Theorem 12] and SGD using a decaying learning rate (i.e.
) satisfies that
[Citation18, Theorem 11], where
is the sequence generated by SGD to find a local minimizer of f, K is the number of iterations, and
is the upper bound of the variance.
The performance of SGD also depends on the batch size b. The convergence analyses reported in [Citation14, Citation17, Citation21, Citation23, Citation24] indicated that SGD with a decaying learning rate and large batch size converges to a local minimizer of the loss function. In [Citation25], it was numerically shown that using an enormous batch reduces both the number of parameter updates and model training time. Moreover, setting appropriate batch sizes for optimizers used in training generative adversarial networks were investigated in [Citation26].
1.2. Motivation
The previous numerical results in [Citation27] indicated that, for SGD using constant or linearly decaying learning rates, the number of iterations K needed to train a deep neural network decreases as the batch size b increases. Motivated by the numerical results in [Citation27], we decided to clarify the theoretical iteration complexity of SGD with a constant or decaying learning rate in training a deep neural network. We used the performance measure of previous theoretical analyses of SGD, i.e. , where ϵ
is the precision and
. We found that, if SGD is an ϵ–approximation, i.e.
, then it can train a deep neural network in K iterations.
In addition, the numerical results in [Citation27] indicated an interesting fact wherein diminishing returns exist beyond a critical batch size; i.e. the number of iterations needed to train a deep neural network does not strictly decrease beyond the critical batch size. Here, we define the stochastic first-order oracle (SFO) complexity as N := Kb, where K is the number of iterations needed to train a deep neural network and b is the batch size, as stated above. The deep neural network model uses b gradients of the loss functions per iteration. The model has a stochastic gradient computation cost of N = Kb. From the numerical results in [Citation27, Figures 4 and 5], we can conclude that the critical batch size (if it exists) is useful for SGD, since the SFO complexity
is minimized at
and the SFO complexity increases once the batch size exceeds
. Hence, on the basis of the first motivation stated above, we decided to clarify the SFO complexities needed for SGD using a constant or decaying learning rate to be an ϵ–approximation.
1.3. Contribution
1.3.1. Upper bound of theoretical performance measure
To clarify the iteration and SFO complexities needed for SGD to be an ϵ–approximation, we first give upper bounds of for SGD to generate a sequence
with constant or decaying learning rates (see Theorem 3.1 for the definitions of
and
). As our aim is to show that SGD is an ϵ–approximation
, it is desirable that the upper bounds of
be small. Table indicates that the upper bounds become small when the number of iterations and batch size are large. The table also indicates that the convergence of SGD strongly depends on the batch size, since the variance terms (including
and b; see Theorem 3.1 for the definitions of
and
) in the upper bounds of
decrease as the batch size becomes larger.
Table 1. Upper bounds of for SGD using a constant or decaying learning rate and the critical batch size to minimize the SFO complexities and achieve
(
and
are positive constants, K is the number of iterations, b is the batch size,
,
, and L is the Lipschitz constant of
).
1.3.2. Critical batch size to reduce SFO complexity
Section 1.3.1 showed that using large batches is appropriate for SGD in the sense of minimizing the upper bound of the performance measure. Here, we are interested in finding appropriate batch sizes from the viewpoint of the computation cost. This is because the SFO complexity increases with the batch size. As indicated in Section 1.2, the critical batch size minimizes the SFO complexity, N = Kb. Hence, we will investigate the properties of the SFO complexity N = Kb needed to achieve an ϵ–approximation. Here, let us consider SGD using a constant learning rate. From the “Upper Bound” row in Table , we have
We can check that the number of iterations,
, needed to achieve an ϵ–approximation is monotone decreasing and convex with respect to the batch size (Theorem 3.2). Accordingly, we have that
, where SGD using the batch size b generates
. Moreover, we find that the SFO complexity is
. The convexity of
(Theorem 3.3) ensures that a critical batch size
whereby
exists such that
is minimized at
(see the “Critical Batch Size” row in Table ). A similar discussion guarantees the existence of a critical batch size for SGD using a decaying learning rate
, where
,
, and
is the floor function (see the “Critical Batch Size” row in Table ).
Meanwhile, for a decaying learning rate , although
is convex with respect to b, we have that
for all
(Theorem 3.3(iii)). Hence, for this case, a critical batch size
defined by
does not exist. However, since the critical batch size minimizes the SFO complexity N, we can define one as follows:
. Accordingly, we have that
, where SGD using
generates
.
1.3.3. Iteration and SFO complexities
Let be an L–smooth function class with
and
(see (C1)) and let
be a stochastic first-order oracle class (see (C2) and (C3)). The iteration complexity
[Citation21, (7)] and SFO complexity
needed for SGD to be an ϵ–approximation are defined as
(1)
(1)
(2)
(2)
Table summarizes the iteration and SFO complexities (see also Theorem 3.4). Corollaries 6 and 7 in [Citation14] are the same as our results for SGD with a constant learning rate in Theorems 3.1 and 3.3, since the randomized stochastic projected gradient free algorithm in [Citation14] which is a stochastic zeroth-order (SZO) method that coincides with SGD and it can be applied to the situations where only noisy function values are available. In particular, Corollary 6 in [Citation14] gave the convergence rate of the SZO methods using a fixed batch size, and Corollary 7 indicated the SZO complexity of the SZO method is the same as the SFO complexity. Hence, Corollaries 6 and 7 in [Citation14] lead to the finding that the iteration complexity of SGD using a constant learning rate is
and the SFO complexity of SGD using a constant learning rate is
.
Table 2. Iteration and SFO complexities needed for SGD using a constant or decaying learning rate to be an ϵ–approximation (The critical batch sizes are used to compute and
)
Since the positive constants and
depend on the learning rate, we need to compare numerically the performance of SGD with a constant learning rate with that of SGD with a decaying learning rate. Moreover, we also need to compare SGD with the existing first-order optimizers in order to verify its usefulness. Section 4 presents numerical comparisons showing that SGD using the critical batch size outperforms the existing first-order optimizers. We also show that the measured critical batch sizes are close to the theoretical sizes.
2. Nonconvex optimization and SGD
2.1. Nonconvex optimization in deep learning
Let be a d-dimensional Euclidean space with inner product
inducing the norm
and
be the set of nonnegative integers. Define
for
. Let
and
be positive real sequences and let
, where
. O denotes Landau's symbol; i.e.
if there exist c>0 and
such that
for all
, and
if there exists c>0 such that
. Given a parameter
and a data point z in a data domain Z, a machine-learning model provides a prediction whose quality can be measured in terms of a differentiable nonconvex loss function
. We aim to minimize the empirical loss defined for all
by
, where
denotes the training set (We assume that the number of training data n is large) and
denotes the loss function corresponding to the i-th training data
.
2.2. SGD
2.2.1. Conditions and algorithm
We assume that a stochastic first-order oracle (SFO) exists such that, for a given , it returns a stochastic gradient
of the function f, where a random variable ξ is independent of
. Let
be the expectation taken with respect to ξ. The following are standard conditions.
(C1)
is L–smooth, i.e.
(C2) Let
(C3) For each iteration k, SGD samples a batch
Algorithm 1 is the SGD optimizer under (C1)–(C3).

2.2.2. Learning rates
We use the following learning rates:
(Constant rate) does not depend on
, i.e.
, where the upper bound
of α is needed to analyse SGD (see Appendix A.2). (Decaying rate)
is monotone decreasing for k (i.e.
) and converges to 0. In particular, we will use
, where
and
. It is guaranteed that there exists
such that, for all
,
. Furthermore, we assume that
, since we can replace
with
, where
is defined as in (Constant).
3. Our results
3.1. Upper bound of the squared norm of the full gradient
Here, we give an upper bound of , where
stands for the total expectation, for the sequence generated by SGD using each of the learning rates defined in Section 2.2.2.
Theorem 3.1
Upper bound of the squared norm of the full gradient
The sequence generated by Algorithm 1 under (C1)–(C3) satisfies that, for all
,
where
Theorem 3.1 indicates that the upper bound of consists of a bias term including
and a variance term including
and that these terms become small when the number of iterations and the batch size are large. In particular, the bias term using (Constant) is
, which is a better rate than using (Decay 1)–(Decay 3).
3.2. Number of iterations needed for SGD to be an ϵ–approximation
Let us suppose that SGD is an ϵ–approximation defined as follows:
(3)
(3)
where
is the precision and
. Condition (Equation3
(3)
(3) ) implies that
. Theorem 3.1 below gives the number of iterations needed to be an ϵ–approximation (Equation3
(3)
(3) ).
Theorem 3.2
Numbers of iterations needed for nonconvex optimization using SGD
Let be the sequence generated by Algorithm 1 under (C1)–(C3) and let
be
where
,
,
, and
are defined as in Theorem 3.1, the domain of K in (Constant) is
, and the domain of K in (Decay 2) is
. Then, we have the following:
The above K achieves an ϵ–approximation (Equation3
The above K is a monotone decreasing and convex function with respect to the batch size b.
Theorem 3.2 indicates that the number of iterations needed for SGD using constant or decay learning rates to be an ϵ–approximation is small when the batch size is large. Hence, it is appropriate to set a large batch size in order to minimize the iterations needed for an ϵ–approximation (Equation3(3)
(3) ). However, the SFO complexity, which is the cost of the stochastic gradient computation, grows larger with b. Hence, the appropriate batch size should also minimize the SFO complexity.
3.3. SFO complexity needed for SGD to be an ϵ–approximation
Theorem 3.2 leads to the following theorem on the properties of the SFO complexity N needed for SGD to be an ϵ–approximation (Equation3(3)
(3) ).
Theorem 3.3
SFO complexity needed for nonconvex optimization of SGD
Let be the sequence generated by Algorithm 1 under (C1)–(C3) and define
by
where
,
,
and
are as in Theorem 3.1, the domain of N in (Constant) is
, and the domain of N in (Decay 2) is
. Then, we have the following:
The above N is convex with respect to the batch size b.
There exists a critical batch size
For (Decay 2),
Theorem 3.3(ii) indicates that, if we can set a critical batch size (Equation4(4)
(4) ) for each of (Constant), (Decay 1), and (Decay 3), then the SFO complexity will be minimized. However, it would be difficult to set
in (Equation4
(4)
(4) ) before implementing SGD, since
in (Equation4
(4)
(4) ) involves unknown parameters, such as L and
(computing L is NP-hard [Citation28]). Hence, we would like to estimate the critical batch sizes by using Theorem 3.3(ii) (see Section 4.3). Theorem 3.3(ii) indicates that the smaller ϵ is, the larger the critical batch size
in (Constant) becomes. Theorem 3.3(iii) indicates that the critical batch size is close to
when using (Decay 2) to minimize the SFO complexity N.
3.4. Iteration and SFO complexities of SGD
Theorems 3.2 and 3.3 lead to the following theorem indicating the iteration and SFO complexities needed for SGD to be an ϵ–approximation (see also Table ).
Theorem 3.4
Iteration and SFO complexities of SGD
The iteration and SFO complexities such that Algorithm 1 under (C1)–(C3) is an ϵ–approximation (Equation3(3)
(3) ) are as follows:
where
and
are defined as in (Equation1
(1)
(1) ), the critical batch sizes in Theorem 3.3 are used to compute
and
. In (Decay 2), we assume that
. (see also (Equation4
(4)
(4) )).
Theorem 3.4 indicates that the iteration and SFO complexities for (Constant) are smaller than those for (Decay 1)–(Decay 3).
4. Numerical results
We numerically verified the number of iterations and SFO complexities needed to achieve high test accuracy for different batch sizes in training ResNet [Citation29] and Wide-ResNet [Citation30]. The parameter α used in (Constant) was determined by conducting a grid search of . The parameters α and T used in the decaying learning rates (Decay 1)–(Decay 3) defined by
were determined by a grid search of
and
. The parameter a was set to
in (Decay 1) and
in (Decay 3). We compared SGD with SGD with momentum (momentum), Adam, AdamW, and RMSProp. The learning rates and hyperparameters of these four optimizers were determined on the basis of the previous results [Citation9, Citation10, Citation12] (The weight decay used in the momentum was
). The experimental environment consisted of an NVIDIA DGX A100×8GPU and Dual AMD Rome7742 2.25-GHz, 128 Cores×2CPU. The software environment was Python 3.10.6, PyTorch 1.13.1, and CUDA 11.6. The code is available at https://github.com/imakn0907/SGD_using_decaying.
4.1. Training ResNet-18 on the CIFAR-10 and CIFAR-100 datasets
First, we trained ResNet-18 on the CIFAR-10 dataset. The stopping condition of the optimizers was 200 epochs. Figure indicates that the number of iterations is monotone decreasing and convex with respect to batch size for SGDs using a constant learning rate or a decaying learning rate. Figure indicates that, in each case of SGD with (Constant)–(Decay 3), a critical batch size exists at which the SFO complexity is minimized.
Figure 1. Number of iterations needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.9 versus batch size (ResNet-18 on CIFAR-10).
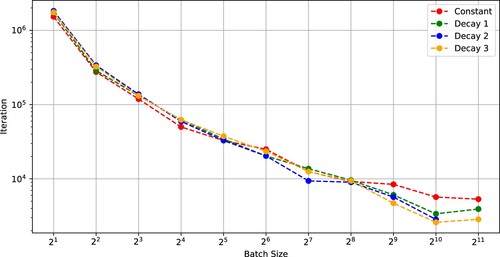
Figure 2. SFO complexity needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.9 versus batch size (ResNet-18 on CIFAR-10).
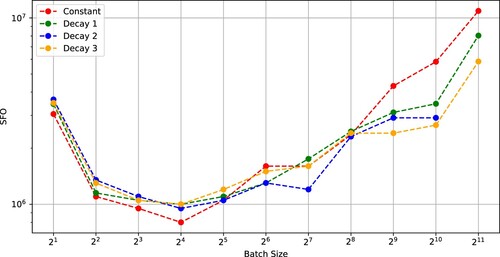
Figures and indicate that the number of iterations and the SFO complexity for four different learning rates in achieving a test accuracy of 0.6 when training ResNet-18 on the CIFAR-100 dataset. The figures indicate that critical batch sizes existed when using (Constant)–(Decay 3).
Figure 3. Number of iterations needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.6 versus batch size (ResNet-18 on CIFAR-100).
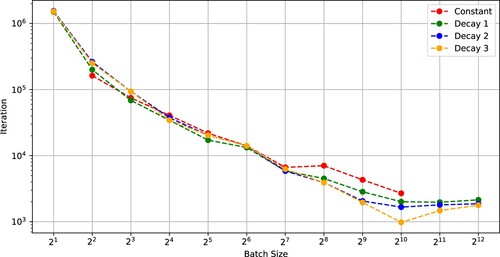
Figure 4. SFO complexity needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.6 versus batch size (ResNet-18 on CIFAR-100).
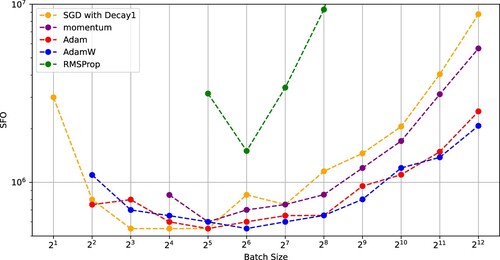
Figures and compare SGD with (Decay 1) with the other optimizers in training ResNet-18 on the CIFAR-100 dataset. These figures indicates that SGD with (Decay 1) and a critical batch size () outperformed the other optimizers in the sense of minimizing the number of iterations and the SFO complexity. Figure also indicates that the existing optimizers using constant learning rates had critical batch sizes minimizing the SFO complexities. In particular, AdamW using the critical batch size
performed well.
Figure 5. Number of iterations needed for SGD with (Decay 1), momentum, Adam, AdamW, and RMSProp to achieve a test accuracy of 0.6 versus batch size (ResNet-18 on CIFAR-100).
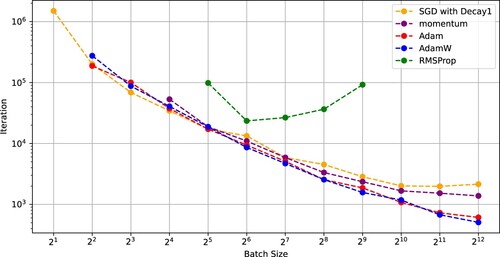
Figure 6. SFO complexity needed for SGD with (Decay 1), momentum, Adam, AdamW, and RMSProp to achieve a test accuracy of 0.6 versus batch size (ResNet-18 on CIFAR-100).
4.2. Training Wide-ResNet on the CIFAR-10 and CIFAR-100 datasets
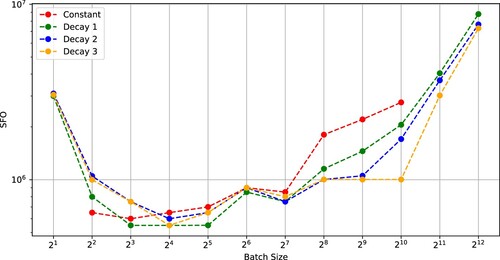
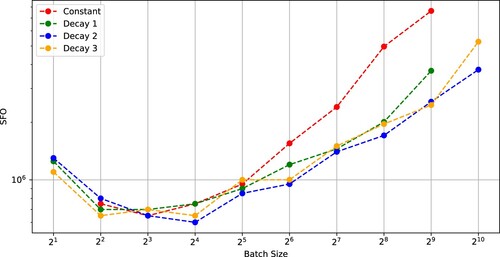
Next, we trained Wide-ResNet-28 [Citation30] on the CIFAR-10 and CIFAR-100 datasets. The stopping condition of the optimizers was 200 epochs. Figures and show that the number of iterations and the SFO complexity of SGD to achieve a test accuracy of 0.9 (CIFAR-10) versus batch size. Figures and indicate that the critical batch size was in each case of SGD using (Constant)–(Decay 3).
Figure 7. Number of iterations needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.9 versus batch size (Wide-ResNet-28-10 on CIFAR-10).
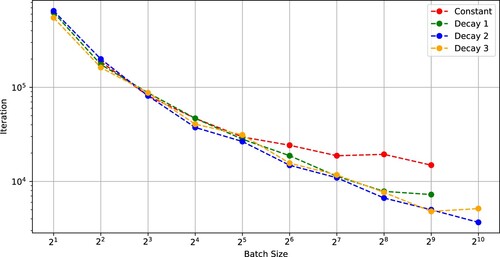
Figure 8. SFO complexity needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.9 versus batch size (Wide-ResNet-28-10 on CIFAR-10).
Figures and indicate that the number of iterations and the SFO complexity of SGD to achieve a test accuracy of 0.6 (CIFAR-100) versus batch size and show that a critical batch size existed for (Constant)–(Decay 3).
Figure 9. Number of iterations needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.6 versus batch size (WideResNet-28-12 on CIFAR-100).
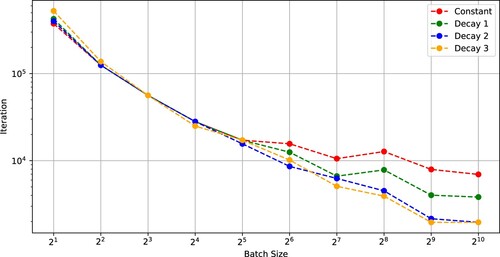
Figure 10. SFO complexity needed for SGD with (Constant), (Decay 1), (Decay 2), and (Decay 3) to achieve a test accuracy of 0.6 versus batch size (WideResNet-28-12 on CIFAR-100).
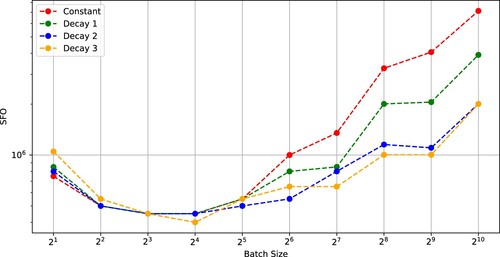
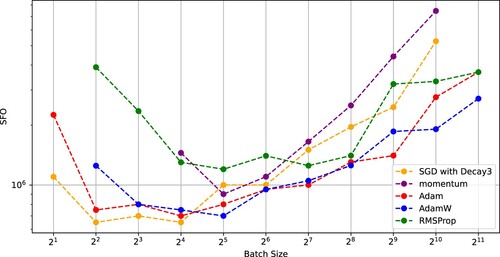
Figures and indicate that SGD using (Decay 1) and the existing optimizers using constant learning rates had critical batch sizes minimizing the SFO complexities. Also, Figures and show similar results for SGD using (Decay 3).
Figure 11. Number of iterations needed for SGD with (Decay 3), momentum, Adam, AdamW, and RMSProp to achieve a test accuracy of 0.9 versus batch size (WideResNet-28-10 on CIFAR-10).
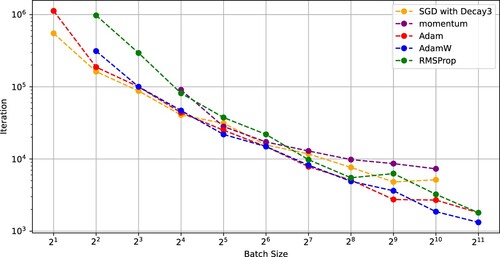
Figure 12. SFO complexity needed for SGD with (Decay 3), momentum, Adam, AdamW, and RMSProp to achieve a test accuracy of 0.9 versus batch size (WideResNet-28-10 on CIFAR-10).
4.3. Estimation of critical batch sizes
We estimated the critical batch sizes of (Decay 3) using Theorem 3.3 and measured the critical batch sizes of (Decay 1). From (Equation4(4)
(4) ) and
((Decay 1)), we have that, for training ResNet-18 on the CIFAR-10 dataset,
, i.e.
. Then, the estimated critical batch size of SGD using (Decay 3) (
) for training ResNet-18 on the CIFAR-10 dataset is
which implies that the estimated critical batch size
is close to the measured size
. We also found that the estimated critical batch sizes are close to the measured critical batch sizes (see Table ).
Table 3. Measured (left) and estimated (right; bold) critical batch sizes (D1 and D3 stand for (Decay 1) and (Decay 3)).
5. Conclusion and future work
This paper investigated the required number of iterations and SFO complexities for SGD using constant or decay learning rates to achieve an ϵ–approximation. Our theoretical analyses indicated that the number of iterations needed for an ϵ–approximation is monotone decreasing and convex with respect to the batch size and the SFO complexity needed for an ϵ–approximation is convex with respect to the batch size. Moreover, we showed that SGD using a critical batch size reduces the SFO complexity. The numerical results indicated that SGD using the critical batch size performs better than the existing optimizers in the sense of minimizing the SFO complexity. We also estimated critical batch sizes of SGD using our theoretical results and showed that they are close to the measured critical batch sizes.
The results in this paper can be only applied to SGD. This is a limitation of our work. Hence, in the future, we should investigate whether our results can be applied to variants of SGD, such as the momentum methods and adaptive methods.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Robbins H, Monro H. A stochastic approximation method. Ann Math Stat. 1951;22:400–407. doi: 10.1214/aoms/1177729586
- Zinkevich M. Online convex programming and generalized infinitesimal gradient ascent. In: Proceedings of the 20th International Conference on Machine Learning; Washington, DC, USA; 2003. p. 928–936.
- Nemirovski A, Juditsky A, Lan G, et al. Robust stochastic approximation approach to stochastic programming. SIAM J Optim. 2009;19:1574–1609. doi: 10.1137/070704277
- Ghadimi S, Lan G. Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization I: A generic algorithmic framework. SIAM J Optim. 2012;22:1469–1492. doi: 10.1137/110848864
- Ghadimi S, Lan G. Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization II: shrinking procedures and optimal algorithms. SIAM J Optim. 2013;23:2061–2089. doi: 10.1137/110848876
- Polyak BT. Some methods of speeding up the convergence of iteration methods. USSR Comput Math Math Phys. 1964;4:1–17. doi: 10.1016/0041-5553(64)90137-5
- Nesterov Y. A method for unconstrained convex minimization problem with the rate of convergence O(1/k2). Doklady AN USSR. 1983;269:543–547.
- Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. J Mach Learn Res. 2011;12:2121–2159.
- Tieleman T, Hinton G. RMSProp: divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw Mach Learn. 2012;4:26–31.
- Kingma DP, Ba J. Adam: a method for stochastic optimization. In: Proceedings of The International Conference on Learning Representations; San Diego, CA, USA; 2015.
- Reddi SJ, Kale S, Kumar S. On the convergence of Adam and beyond. In: Proceedings of The International Conference on Learning Representations; Vancouver, British Columbia, Canada; 2018.
- Loshchilov I, Hutter F. Decoupled weight decay regularization. In: Proceedings of The International Conference on Learning Representations; New Orleans, Louisiana, USA; 2019.
- Ghadimi S, Lan G. Stochastic first- and zeroth-order methods for nonconvex stochastic programming. SIAM J Optim. 2013;23(4):2341–2368. doi: 10.1137/120880811
- Ghadimi S, Lan G, Zhang H. Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization. Math Program. 2016;155(1):267–305. doi: 10.1007/s10107-014-0846-1
- Vaswani S, Mishkin A, Laradji I, et al. Painless stochastic gradient: interpolation, line-search, and convergence rates. In: Advances in Neural Information Processing Systems; Vancouver, British Columbia, Canada; Vol. 32; 2019.
- Fehrman B, Gess B, Jentzen A. Convergence rates for the stochastic gradient descent method for non-convex objective functions. J Mach Learn Res. 2020;21:1–48.
- Chen H, Zheng L, AL Kontar R, et al. Stochastic gradient descent in correlated settings: a study on Gaussian processes. In: Advances in Neural Information Processing Systems; Virtual conference, Vol. 33; 2020.
- Scaman K, Malherbe C. Robustness analysis of non-convex stochastic gradient descent using biased expectations. In: Advances in Neural Information Processing Systems; Virtual conference, Vol. 33; 2020.
- Loizou N, Vaswani S, Laradji I, et al. Stochastic polyak step-size for SGD: an adaptive learning rate for fast convergence. In: Proceedings of the 24th International Conference on Artificial Intelligence and Statistics; Virtual conference, Vol. 130; 2021.
- Wang X, Magnússon S, Johansson M. On the convergence of step decay step-size for stochastic optimization. In: Beygelzimer A, Dauphin Y, Liang P, et al., editors. Advances in Neural Information Processing Systems; Virtual conference, 2021. Available from: https://openreview.net/forum?id=M-W0asp3fD.
- Arjevani Y, Carmon Y, Duchi JC, et al. Lower bounds for non-convex stochastic optimization. Math Program. 2023;199(1):165–214. doi: 10.1007/s10107-022-01822-7
- Khaled A, Richtárik P. Better theory for SGD in the nonconvex world. Trans Mach Learn Res. 2023.
- Jain P, Kakade SM, Kidambi R, et al. Parallelizing stochastic gradient descent for least squares regression: mini-batching, averaging, and model misspecification. J Mach Learn Res. 2018;18(223):1–42.
- Cotter A, Shamir O, Srebro N, et al. Better mini-batch algorithms via accelerated gradient methods. In: Advances in Neural Information Processing Systems; Granada, Spain; Vol. 24; 2011.
- Smith SL, Kindermans PJ, Le QV. Don't decay the learning rate, increase the batch size. In: International Conference on Learning Representations; Vancouver, British Columbia, Canada; 2018.
- Sato N, Iiduka H. Existence and estimation of critical batch size for training generative adversarial networks with two time-scale update rule. In: Proceedings of the 40th International Conference on Machine Learning; (Proceedings of Machine Learning Research; Vol. 202). PMLR; 2023. p. 30080–30104.
- Shallue CJ, Lee J, Antognini J, et al. Measuring the effects of data parallelism on neural network training. J Mach Learn Res. 2019;20:1–49.
- Virmaux A, Scaman K. Lipschitz regularity of deep neural networks: analysis and efficient estimation. In: Advances in Neural Information Processing Systems; Vol. 31; 2018.
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016. p. 770–778.
- Zagoruyko S, Komodakis N. Wide residual networks. arXiv preprint arXiv:160507146. 2016.
Appendix
A.1. Lemma
First, we will prove the following lemma.
Lemma A.1
The sequence generated by Algorithm 1 under (C1)–(C3) satisfies that, for all
,
where
stands for the total expectation.
Proof.
Condition (C1) (L-smoothness of f) implies that the descent lemma holds, i.e. for all ,
which, together with
, implies that
(A1)
(A1)
Condition (C2) guarantees that
(A2)
(A2)
Hence, we have
(A3)
(A3)
Taking the expectation conditioned on
on both sides of (EquationA1
(A1)
(A1) ), together with (EquationA2
(A2)
(A2) ) and (EquationA3
(A3)
(A3) ), guarantees that, for all
,
Hence, taking the total expectation on both sides of the above inequality ensures that, for all
,
Let
. Summing the above inequality from k = 0 to k = K−1 ensures that
which, together with (C1) (the lower bound
of f), implies that the assertion in Lemma A.1 holds.
A.2. Proof of Theorem 3.1
(Constant): Lemma A.1 with implies that
Since
, we have that
(Decay): Since
converges to 0, there exists
such that, for all
,
. We assume that
(see Section 2.2.2). Lemma A.1 ensures that, for all
,
which, together with
, implies that
Hence, we have that
which implies that
Meanwhile, we have that
and
Here, we define
Accordingly, we have that
which, together with
and the condition on a, implies that
A.3. Proof of Theorem 3.2
Let us consider the case of (Constant). We consider that the upper bound
It is sufficient to prove that
(Constant): Let . Then, we have that
(Decay 1): Let
. Then, we have that
(Decay 2): Let
. Then, we have that
which, together with
and
, implies that
Moreover,
which implies that
(Decay 3): Let
. Then, we have that
A.4. Proof of Theorem 3.3
(Constant): Let . Then, we have that
If
, we have that
, i.e.
. Moreover,
which implies that N is convex. Hence, there is a critical batch size
at which N is minimized.
(Decay 1): Let N = Kb. Then, we have that
If
, we have that
Moreover,
which implies that N is convex. Hence, there is a critical batch size
.
(Decay 2): Let N = bK. Then, we have that
If
, we have that
, i.e.
. Moreover,
which implies that N is convex. We can check that
for all
.
(Decay 3): Let N = bK. Then, we have that
If
, we have that
Moreover,
which implies that N is convex. Hence, there is a critical batch size
.
A.5. Proof of Theorem 3.4
Using K defined in Theorem 3.2 leads to the iteration complexity. For example, SGD using (Constant) satisfies (Theorem 3.3). Using the critical batch size
in (Equation4
(4)
(4) ) leads to
A similar discussion, together with using N defined in Theorem 3.3 and the critical batch size
in (Equation4
(4)
(4) ), leads to the SFO complexities of (Decay 1) and (Decay 3). Using N defined in Theorem 3.3 and a batch size
leads to the SFO complexity of (Decay 2).