Abstract
This article presents a decision-making approach based on a hybrid genetic algorithm (GA) and a technique for order performance by similarity to ideal solution (TOPSIS) simulation (HGTS) for determining the most efficient number of operators and the efficient measurement of operator assignment in cellular manufacturing systems (CMS). The objective is to determine the labor assignment in a CMS environment with the optimum performance. We use HGTS for getting near optimum ranking of the alternative with best fit to the fitness function. Also, this approach is performed by employing the number of operators, average lead time of demand, average waiting time of demand, number of completed parts, operator utilization, and average machine utilization as attributes. Also, the entropy method is used to determine the weight of attributes. Furthermore, values of attributes are procured by means of computer simulation. The unique feature of this model is demonstration of efficient ranks of alternatives by reducing the distance between neighborhood alternatives. The superiority and advantages of the proposed HGTS are shown through qualitative and qualitative comparisons with TOPSIS, data envelopment analysis (DEA), and principal component analysis (PCA).
1. Introduction
Cellular manufacturing systems (CMS) are typically designed as dual resource constraint (DRC) systems, where the number of operators is fewer than the total number of machines in the system. The productive capacity of DRC systems is determined by the combination of machine and labor resources. Jobs waiting to be processed may be delayed because of the non-availability of a machine or an operator or both. This fact makes the assignment of operators to machines an important factor for determining the performance of CMS and therefore, the development of a multifunctional workforce a critical element in the design and operation of CMS.
The efficiency of a many-inputs, many-outputs decision-making unit (DMU) may be defined as a weighted sum of its outputs divided by a weighted sum of its inputs. This so-called “engineering ratio” is the most popular of a number of alternative measures of efficiency e.g., Doyle and Green (Citation1994). Hsu-Shih (Citation2008) exploits incremental analysis or marginal analysis to overcome the drawbacks of ratio scales utilized in various multi-criteria or multi-attribute decision-making (MCDM/MADM) techniques. Yang et al. (Citation2007) presented two MADM methods in solving the proposed case study. Both methods use the analytic hierarchy process (AHP) to determine attribute weights a priori. The first method is a TOPSIS and the second method is fuzzy-based. Sarkis and Talluri (Citation1998) proposed an innovative framework for evaluating flexible manufacturing systems (FMS) in the presence of both cardinal and ordinal factors. Ertay (Citation2002) proposed a framework based on multi-criteria decision-making for analyzing a firm's investment justification problem in a normal and high mold production technology to cope with the competition in the global market. Ertay and Ruan (Citation2005) proposed a decision model for an operator assignment problem in CMS using a two-phase procedure. In the first phase, an empirical investigation is conducted using an exploratory case study with the purpose of finding the factors that affect the development and deployment of labor flexibility. In the second phase, based on the findings from the empirical investigation, a set of propositions is translated into a methodology framework for examining labor assignments. Zhang et al. (Citation2006), via analyzing the character of an iRS/OS problem, used the concept of multistage decision making to formulate an efficient multi-objective model for minimizing the makespan, balancing the workload, and minimizing the total transition times simultaneously by decomposing the problem into two main phases. Chauvet et al. (Citation2000) developed two operator assignment problems in which the task times are dependent on both the assigned task and the assigned operator. The number of operators is greater than the number of tasks and one operator can be only assigned to one task. They aimed to minimize the maximum completion time of all tasks. This problem is also known as a bottleneck assignment problem.
Data envelopment analysis (DEA) is a non-parametric linear programming-based technique for measuring the relative efficiency of a set of similar units, usually referred to as DMUs. Because of its successful implementation and case studies, DEA has achieved much attention and widespread use by business and academic researchers. Evaluation of data warehouse operations (Mannino et al. Citation2008), selection of FMS (Liu Citation2008), assessment of bank branch performance (Camanho and Dyson Citation2005), and analysis of the firm's financial statements (Edirisinghe and Zhang Citation2007) are examples of using DEA in various areas.
Wittrock (Citation1992) developed a parametric preflow algorithm to solve the problem of assigning human operators to operations in a manufacturing system. Also, Süer and Tummaluri (Citation2008) present a three-phase approach to assigning operators to various operations in a labor-intensive cellular environment. First, finding alternative cell configurations; second, loading cells and finding crew sizes; and third, assigning operators to operations. Bidanda et al. (Citation2005) discussed human-related issues in a cellular environment and presented the results of a survey they have performed. Askin and Huang (Citation2001) and Fitzpatrick and Askin (Citation2005) discussed forming effective teams in cellular systems. Cesani and Steudal (Citation2005) studied labor flexibility in CMS, particularly in cell implementations allowing intra-cell operator mobility. Slomp and Molleman (Citation2000), Slomp et al. (Citation2005) and Molleman and Slomp (Citation1999) discussed training and cross-training policies and their impact on shop floor performance. Nembhard (Citation2001a, b), Nembhard and Mustafa (Citation2000) and Scott et al. (Citation2001) proposed a heuristic approach to assign workers to tasks based on individual learning rates and discussed the correlation between learning and forgetting rates. Jeff et al. (Citation2001) presented a discrete event simulation model to understand the dynamics of learning and forgetting to predict variable manufacturing costs and capacity accurately.
Ayag and Özdemir (Citation2006) present an AHP that is used for machine tool selection problems due to the fact that it has been widely used in evaluating various kinds of MCDM problems in both academic research and in practice. Also, Önüt et al. (Citation2008) describe a fuzzy TOPSIS-based methodology for evaluation and selection of vertical CNC machining centers for a manufacturing company in Istanbul, Turkey. The criteria weights are calculated using the fuzzy AHP. In fact, they introduced two phased methodology based on fuzzy AHP and fuzzy TOPSIS for selecting the most suitable machine tools. Recently, Rao (Citation2006) presented a material selection model using graph theory and a matrix approach. However, the method does not have a provision for checking consistency in the judgments of relative importance of the attributes. Further, the method may be difficult to deal with if the number of attributes is more than 20.
This research is divided into three phases. In the first phase, the proposed approach is described. In the second phase, we use a simulation model for evaluation of the identified scenarios. Finally, the scenarios are translated into HGTS to find the best scenario.
1.1. Technique for order performance by similarity to ideal solution
The Technique for Order Performance by Similarity to Ideal Solution (TOPSIS) method, which is based on choosing the best alternative having the shortest distance to the ideal solution and the farthest distance from the negative-ideal solution, was first proposed in 1981 by Hwang and Yoon (Citation1981). The ideal solution is the solution that maximizes the benefit and also minimizes the total cost. On the contrary, the negative-ideal solution is the solution that minimizes the benefit and also maximizes the total cost. The following characteristics of the TOPSIS method make it an appropriate approach which has good potential for solving decision-making problems:
-
An unlimited range of cell properties and performance attributes can be included.
-
In the context of operator assignment, the effect of each attribute cannot be considered alone and must always be seen as a trade-off with respect to other attributes. Any change in, for instance, amount of demand, lead time or operator utilization indices can change the decision priorities for other parameters. In light of this, the TOPSIS model seems to be a suitable method for multi-criteria operator assignment problems as it allows explicit trade-offs and interactions among attributes. More precisely, changes in one attribute can be compensated for in a direct or opposite manner by other attributes.
-
The output can be a preferential ranking of the alternatives (scenarios) with a numerical value that provides a better understanding of differences and similarities between alternatives, whereas other MADM techniques (such as the ELECTRE methods e.g., Roy Citation1991, Citation1996) only determine the rank of each scenario.
-
Pair-wise comparisons, required by methods such as the Analytical Hierarchy Process (Saaty Citation1990, Citation2000), are avoided. This is particularly useful when dealing with a large number of alternatives and criteria; the methods are completely suitable for linking with computer databases dealing with scenario selection.
-
It can include a set of weighting coefficients for different attributes.
-
It is relatively simple and fast, with a systematic procedure.
Hwang and Yoon (Citation1981) introduced the TOPSIS method based on the idea that the best alternative should have the shortest distance from an ideal solution. They assumed that if each attribute takes a monotonically increasing or decreasing variation, then it is easy to define an ideal solution. Such a solution is composed of all the best attribute values achievable, while the worst solution is composed of all the worst attribute values achievable. The goal is then to propose a solution which has the shortest distance from the ideal solution in the Euclidean space (from a geometrical point of view). However, it has been argued that such a solution may need to have simultaneously the farthest distance from a negative ideal solution (also called nadir solution). Sometimes, the selected solution (here candidate scenario) which has the minimum Euclidean distance from the ideal solution may also have a short distance from the negative ideal solution as compared to other alternatives. The TOPSIS method, by considering both the above distances, tries to choose solutions that are simultaneously close to the ideal solution and far from the nadir solution. In a modified version of the ordinary TOPSIS method, the ‘city block distance’, rather than the Euclidean distance, is used so that any candidate scenario which has the shortest distance to the ideal solution is guaranteed to have the farthest distance from the negative ideal solution.
The TOPSIS solution method consists of the following steps:
-
Normalize the decision matrix. The normalization of the decision matrix is done using the following transformation:
-
Multiply the columns of the normalized decision matrix by the associated weights. The weighted and normalized decision matrix is obtained as
-
Determine the ideal and nadir ideal solutions. The ideal and the nadir value sets are determined, respectively, as follows:
-
Measure distances from the ideal and nadir solutions. The two Euclidean distances for each alternative are, respectively, calculated as
-
Calculate the relative closeness to the ideal solution. The relative closeness to the ideal solution can be defined as
The higher the closeness means the better the rank.
The methods for assessing the relative importance of criteria must be well defined.
For solving MADM problems, it is generally necessary to know the relative importance of each criterion. It is usually given as a set of weights, which are normalized, and which add up to one. The importance coefficients in the MADM methods refer to intrinsic ‘weight’. Some papers deserve mention because they include information concerning the methods that have been developed for assessing the weights in an MADM problem, these are Refs. Olson (Citation2004), Simos and Gestion (Citation1990), and Roy (Citation1991). The entropy method is the method used for assessing the weight in a given problem because, with this method, the decision matrix for a set of candidate scenarios contains a certain amount of information. In other words, the entropy method works based on a predefined decision matrix. Since there is, in scenario selection problems, direct access to the values of the decision matrix, the entropy method is the appropriate method. Entropy, in information theory, is a criterion for the amount of uncertainty, represented by a discreet probability distribution, in which there is agreement that a broad distribution represents more uncertainty than does a sharply packed one. The entropy idea is particularly useful for investigating contrasts between sets of data. The entropy method consists of the following procedure:
-
Normalizing the decision matrix
-
Calculating the entropy with data for each criterion, the entropy of the set of normalized outcomes of the jth criterion is given by
Using the entropy method, it is possible to combine the scenario designer's priorities with those of sensitivity analysis. Final weights defined are a combination of two sets of weights. The first is the set of objective weights that are derived directly from the nature of the design problem using the entropy method, and with no regard to the designer's desires. The second is the set of subjective weights that are defined by the scenario designer's preferences to modify the previous weights and find the total weights. When the scenario designer finds no reason to give preference to one criterion over another, the principle of insufficient reason suggests that each one should be equally preferred.
The value j is: j = 1, 2, … , m otherwise, if the scenario designer wants to add the subjective weight according to the experience, particular constraint of design and so on, the weight factor is revised as
In this article, the revised Simos method (Shanian and Savadogo Citation2006) has been used to define the subjective weights in a given problem by the following algorithm:
-
The non-normalized subjective weights λ(1) … λ(r) … λ(
) associated with each class of equally placed criteria, arranged in the order of increasing importance. The criterion or group of criteria identified as being least important is assigned the score of 1, i.e., λ(1) = 1.
-
The normalized subjective weight:
It is concluded that the introduced combined weighting scheme is important for decision-making problems. It can take into account both the nature of conflicts among criteria and the practicality of the decisions. This opportunity reflects the advantage of more controllable design selections. The entropy approach can be used as a good tool in criteria evaluation. This possibility makes the entropy method very flexible and efficient for scenario design.
1.2. Genetic algorithm
GA is a part of evolutionary computing, which is rapidly growing in the area of artificial intelligence (AI). Also, it was inspired by Darwin's theory of evolution. Simply said, problems are solved by an evolutionary process resulting in a best (fittest) solution (survivor). In GA, the solution is repeatedly evolved until the best solution is fixed. For using GA, the solution must be represented as a genome (or Chromosome). The GA then creates a population of solutions and applies genetic operators such as mutation and crossover to evolve the solutions in order to find the best one(s).
The general outline of GA is summarized below:
Algorithm 1: Genetic algorithm
Step 1
Generate random population with n chromosomes by using symbolic representation scheme (suitable size of solutions for the problem).
Step 2
Evaluate the fitness function of each chromosome x in the population by using the proposed objective functions.
Step 3
Create a new population by iterating loop highlighted in the following steps until the new population is complete.
-
Select two parent chromosomes from a population according to their fitness from Step 2. Those chromosomes with the better fitness will be chosen.
-
With a preset crossover probability, crossover will operate on the selected parents to form new offspring (children). If no crossover is performed, offspring are observed to be the exact copies of parents. Here, multi-point crossover is used while partially matched crossover is employed for Problem.
-
With a preset mutation probability, mutation will operate on new offspring at each gene. Chosen genes are swapped to perform mutation.
-
Place new offspring in the new population.
Step 4
Deliver the best solution in the current population. If the end condition is satisfied, stop.
Step 5
Go to Step 2.
According to the description of GAs in the above, the proposed method should be specially designed in accordance with the nature of the problem. Therefore, aspects including chromosome representation, fitness evaluation, parent selection, crossover (reproduction), and mutation will be tailor-made for the problem (Haupt and Haupt Citation1998).
The mentioned model has a few limitations. Because the variables are constrained to integer values, the model is difficult to solve for a large number of scenarios and machines due to the computational complexity. Also, this model does not offer cell designers the flexibility to change objective functions and constraints. In this section, we use an approach using GAs developed by Ebrahimipour et al. (Citation2007), to solve the simultaneous multi-criteria decision and operator assignment problem.
1.2.1. Representation and initialization
The initialization operator is used to create the initial population by filling it with randomly generated individuals. Each individual is a representative of the problem solution which is identified by its digit string. The deletion operator deletes all members of the old population who cannot contribute as influential parents for the next generation.
1.2.2. Evaluation
This stage involves checking the individuals to see how well they are able to satisfy the objectives in the problem. The fitness operator quantifies the total characters of each chromosome (individual) in the population. The evaluating fitness operator assesses the value of fitness function of each chromosome in order to satisfy the objectives based on maximum or minimum level.
1.2.3. Crossover and mutation
Crossover is aimed at exchanging bit strings between two parent chromosomes. The crossover used in this model is one cut-point method. For example, the parent chromosomes are randomly selected and the cut point is then randomly selected at position 2 as follows:
In this article, we use multi-point crossover based on a single point.
Mutation is performed as random perturbation. Any gene in the chromosome may be randomly selected to be mutated, at a preset rate. The mutation operator for the cell design problem is designed to perform random exchange. For a selected gene mk, it will be replaced by a random integer with [1, upper bound]. An example is given as follows:
In this chromosome, the fourth gene is selected for mutation. The value of the gene is replaced by five.
After mutation: .
1.2.4. Selection
In this study, Tournament selection is used to select pairs for mating. Tournament selection is a recent approach that closely mimics mating competition in nature. The procedure is to pick a small subset of chromosomes randomly (two or three) from the mating pool, and the chromosome with the lowest cost in this subset becomes a parent. The tournament repeats for every parent needed. Threshold and tournament selection make a nice pair, because the population never needs to be sorted. Tournament selection works best for larger population sizes because sorting becomes time-consuming for large populations.
2. The hybrid GA-TOPSIS simulation
The hybrid GA-TOPSIS-simulation (HGTS) is an extremely efficient approach for selection of the optimum operator allocations in CMS. First, we define the scenarios by considering all available conditions. In this stage, we study the CMS environment. Then, we define significant scenarios based on the number of working shifts and operators. A simulation model is developed and run to identify the efficiency of each scenario. To avoid bias, each scenario is run 30 times. After this stage, we have a data set about all scenarios which shows the value of each criterion. Then, by HGTS, we solve the problem. The steps of HGTS are presented as follows:
-
By the entropy method, we define the weight factor for the each criterion. This step can be ignored if the weight factors are available.
-
In the next step, the procured data from the previous section is used by GA for initialization process.
-
After determining the weight factor, TOPSIS method is used to solve the problem to define the best scenarios.
-
In the fourth step, GA uses the output of TOPSIS as input. In fact, the initial population for GA is the TOPSIS solution.
-
The problem is finally solved by GA and checked by TOPSIS. Moreover, we define the best ranking of scenarios.
The details of how HGTS works in practice are shown in the next section (Section 3). presents the proposed HGTS approach for optimum operator assignment.
Figure 1. The overview of the integrated HGTS approach.
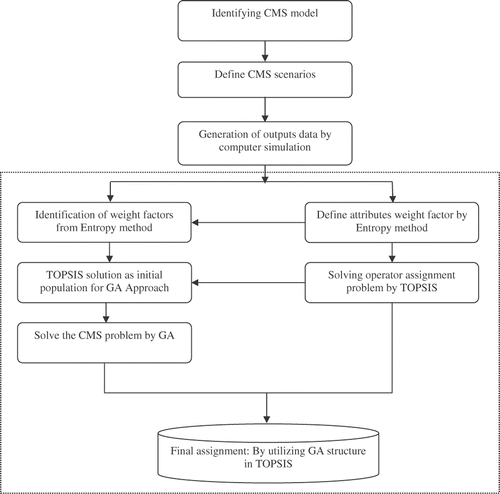
3. Empirical illustration
Manned cells are a very flexible system that can adapt to changes in the customer's demand or other changes quite easily and rapidly in the product design. The cells described in this study are designed for flexibility, not line balancing. The walking multi-functional operators permit rapid rebalancing in a U-shaped manner. The considered cell has eight stations and can be operated by one or more operators, depending on the required output for the cell. The times for the operations at the stations do not have to be balanced. The balance is achieved by having the operators walk from station-to-station. The sum of operation times for each operator is approximately equal. In other words, any division of stations that achieves balance between the operators is acceptable. Operators perform scenario movements in cells. Once a production batch size arrives at a cell, it is divided to transfer batch sizes. Transfer batch size is the transfer quantity for intra-cell movements of parts. The ability to rebalance the cell quickly to obtain changes in the output of the cell can be demonstrated by the developed simulation model. The existing manned cell example for a case model is presented in (Azadeh and Anvari Citation2006).
Figure 2. The existing manned cell example for the case model.
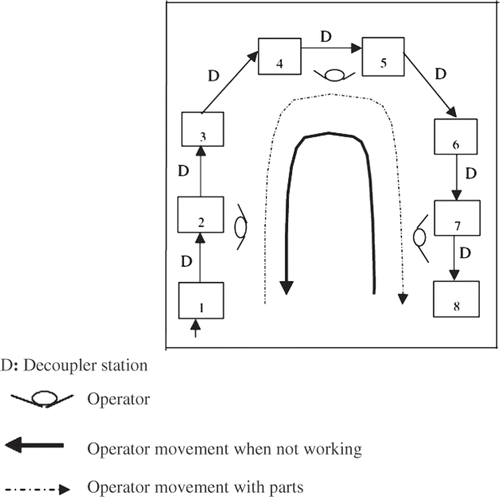
Alternatives for reducing the number of operators in the cell are as follows:
-
Eight operators (one operator for each machine).
-
Seven operators (two operators handling two machines and one operator for each of the rest).
-
Six operators (two operators handling two machines and one operator for each of the rest).
-
Five operators (three operators handling two machines and one operator for each of the rest).
-
Four operators (each operator handling two machines).
-
Six operators (one operator for three machines, others with one machine each).
-
Four operators (one operator handling five machines, three operators with one machine each).
-
Three operators (two operators handling three machines each and one operator handling two machines).
-
Five operators (one operator to four machines and one operator for each of others).
-
Three operators (one operator to four machines and two operators handling two machines each).
-
Three operators (one operator to four machines and one operator to three machines and one operator to one machine).
-
Two operators (one operator for four machines).
In simulation experiments, when the machines are assigned to the operators, the cycle time of the bottleneck resource is chosen as close as possible to the cycle time of the operator. The developed model includes the some assumptions and constraints as follows:
-
The self-balancing nature of the labor assignment accounts for differences in operator efficiency.
-
The machines have no downtime during the simulated time.
-
The time for the operators to move between machines is assumed to be zero. The machines are all close to each other.
-
The sum of the multi-function operation times for each operator is approximately equal.
-
There is no buffer for the station work.
As mentioned, outputs collected from simulation model are the average lead time of demand, the average of waiting time of demand, average operator and machine utilization, and the number of completed parts per annum. The results of the simulation experiment are used to compare the efficiency of the alternatives. Each labor assignment scenario considers three shifts with 1, 2, or 3 shifts per day. Moreover, a flexible simulation model () is built by Visual SLAM (Pritsker Citation1995), which incorporates all 36 scenarios for quick response and results. Furthermore, ability to rebalance the cell quickly to obtain changes in output of cell can be demonstrated by the simulation model. So, in the developed model, different demand levels and part types have been taken into consideration.
Figure 3. Simulation model of operators’ allocation in CMS.
System performance was monitored for different workforce levels and shifts by means of simulation. In simulation experiments, each of the demanded parts had a special type and level. The types of parts that the cell can produce and levels of demand within the cell were determined as two and three by experiment. The time processing of jobs for each of the stations works is related to the part type. The objective of scenarios consists of reducing the number of operators in the cell, and observing how the operation is distributed among the operators. After deletion of transient state, the 36 scenarios were executed for 2000 h (250 working days, each day composed of three shifts, each shift consisting of 8 h of operation). Each scenario was also replicated 30 times to insure that reasonable estimates of means of all outputs could be obtained.
The shows the output of the simulation model.
Table 1. Simulation results for the case model (decision matrix).
3.1. Application of HGTS approach
A total of 36 scenarios were selected as the core of our study. The values of the six indices for the operator assignment are presented in . The main structure of HGTS in this study is based on the assumption that the best scenario is identified with the indices in which each is the maximum value of its possible values. Therefore, for the scenario 36, a scenario with the best possible attribute, called our goal in the problem, illustrates the maximum present abilities in operator assignment. To achieve the appropriate rank (array), every possible array, comprising 36 scenarios, is considered as a 64-bit chromosome. Then, in accordance with the sequence in the chromosome, the total distance among the first scenario which can be scenario from 1 to 36 and our goal (scenario 36), the second scenario with the first and the next with upper-ranked scenario are calculated.
Respectively, the total distance mentioned above is a variable, dependent on the scenarios’ positions in the array. Consequently, in each chromosome, we can find a new value for total distance. Undoubtedly, the best sequence of the scenarios is an array which has the minimum total distance with high internal cohesion among its scenarios. In fact, our fitness function is a multivariate combination in which its most prominent components are total distance and variance. The above genetic concepts are achieved through a set of well-defined steps as follows:
Step 1
Normalize the index vectors. The six attributes must be normalized and have same order to be used in HGTS. Indices X 1, X 2, and X 3 have opposite order than the rest of the indices.
Step 2
Standardize the indices X 1 − X 6. The indices are standardized and shown in . They are standardized through predefined mean and standard deviation for each index.
Table 2. Standardized matrix for the six indices.
Step 3
Define the production module. This module is defined to create and manipulate the 50-individual population by filling it with randomly generated individuals. Each individual is defined by a 64-bit string.
Step 4
Define recombination module which comprises four sections:
-
Tournament selection operator chooses individuals with probability 80% from the population for reproduction.
This is considered a popular type of selection method in HGTS. The basic concept in a tournament is that the best string in the population will win both its tournaments, while the worst will never win, and thus will never be selected. However, in this study, the other kinds of selection methods named sigma scaling and rank selection are considered in order to determine the best method.
-
Uniform crossover operator which combines bits from the selected parents with the probability of 85%.
-
Mutation operator consists of making (usually small) alterations to the values of one or more genes in a chromosome.
-
Regeneration operator which is used to create 100-individual generations.
Step 5
Define evaluation module:
The fitness function to determine the goodness of each individual based on the objectives is defined by the total distance and variance that can be shown by
In the above-mentioned formula, d Total indicates the total distance between adjacent scenarios.
The evaluation of operator assignment is the ability of each chromosome to satisfy the objective function. Therefore, our motivation to obtain the best array in this problem is to minimize the fitness function mentioned above. After producing 1000 generations, we reach the best fitness function value, 295.362, related to the chromosome which can be shown by the sequence at .
Table 3. Simulation results for the case model (decision matrix).
3.2. Implementation of TOPSIS
For the first step of this methodology, the decision matrix (), representing the performance values of each alternative with respect to each criterion, is computed by a simulation model. Next, these performance values are normalized by Equation Equation2. In Step 3, the normalized matrix is multiplied with the criteria weights calculated by the entropy method (). The step of defining the ideal solution consists of taking the best values of alternatives and using similar principles, obtaining the negative-ideal solution by taking the worst values of alternatives. Subsequently, the alternatives are ranked with respect to their relative closeness to the ideal solution ().
Table 4. Entropy-weighted coefficients.
Table 5. The rankings of HGTS versus TOPSIS.
4. Results and discussion
According to the above results, scenario 12-2 (one operator for four machines, two shifts per day) is the most efficient one. The second best scenario is the scenario 12-1, which is similar to scenario 12-2 only with one shift per day. The third best scenario is 9-1 with five operators (one operator for four machines and one operator per machine for the rest with one shift per day). presents the rankings of the proposed HGTS versus TOPSIS for the best 18 rankings.
4.1. Verification and validation
DEA and principal component analysis (PCA) are used to verify and validate the results of the proposed HGTS. DEA and PCA are among the most powerful tools in multivariate analysis. However, we show that the proposed algorithm has several advantages over these methods. These are discussed in the following sections. First, mathematical models of DEA and PCA are discussed and their efficiency scores and ranking are evaluated. Then, their ranking scores together with TOPSIS are compared with the proposed HGTS.
4.1.1. Data envelopment analysis
The two basic DEA models are CCR based on Charnes, Cooper and Rhodes (Charnes et al. Citation1978) and BCC based on Banker, Charnes and Cooper (Banker et al. Citation1984) with constant returns to scale and variable returns to scale, respectively. DMUo is assigned the highest possible efficiency score θo ≤ 1 that constraints allow from the available data by choosing the optimal weights for the output and inputs. If DMUo receives the maximal value θo = 1, then it is efficient, but if θo < 1, it is inefficient, since with its optimal weights, another DMU receives the maximal efficiency. Basically, the model divides the DMUs into two groups, efficient (θo = 1) and inefficient (θo < 1), by identifying the efficient in the data. The original DEA model is not capable of ranking efficient units and therefore it is modified to rank efficient units (Andersen and Petersen 1993).
The original fractional CCR model (14) evaluates the relative efficiencies of 36 scenarios (j = 1, … , 36), each with 3 inputs (average lead-time of demands, average waiting time of demands and the number of the operators (in a working day) and 3 outputs (average operator/machine utilization and numbers of completed parts per year) denoted by x 1 j , x 2 j , x 3 j , y 1 j , and y 2 j and y 3 j , respectively. This is done by maximizing the ratio of weighted sum of output to the weighted sum of inputs:
In model (14), the efficiency of DMUo is θ o and ur and vi are the factor weights. However, for computational convenience, the fractional programming model (14) is re-expressed in linear program (LP) form as follows:
The output-oriented CCR model is given as follows:
If ∑λj = 1 (j = 1, … , 36) is added to model (16), the BCC model is obtained which is input oriented and its return to scale is variable:
The output-oriented BCC model is shown in Equation (Equation18).
However, the LP model (16) does not allow for ranking of efficient units as it assigns a common index of one to all the efficient scenarios in the data set. Therefore, the dual model (16) was modified by Andersen and Petersen for DEA-based ranking purposes, as follows (Andersen and Petersen 1993):
4.1.2. Principle component analysis
The objective of PCA is to identify a new set of variables such that each new variable, called a principal component, is a linear combination of original variables. Second, the first new variable y 1 accounts for the maximum variance in the sample data and so on. Third, the new variables (principal components) are uncorrelated. PCA is performed by identifying the eigenstructure of the covariance or the singular value decomposition of the original data.
Here, the former approach will be discussed. It is assumed that there are 9 variables (indexes) and 36 DMUs, and djir = yrj /xij (i = 1, … ,3; r = l, … ,3) represents the ratios of individual output (average operator/machine utilization and numbers of completed parts per year) to individual input (average lead-time of demands, average waiting time of demands, and the number of the operators (in a working day)) for each DMU j (j = l, … , 36). Obviously, the bigger the djir , the better the performance of DMU j in terms of the rth output and the ith input. Now let djk = djir , where k = 1, … , 9 and 9 = 3 × 3. We need to find some weights that combine those nine individual ratios of di for DMU j . Consider the following 36 × 9 data matrix composed by djk : D = (d l, … , d 5)36×9 with each row representing nine individual ratios of di for each DMU and each column representing a specific output/input ratio. That is, dk = (dk 1, … , dk 36)T. The PCA is employed here to find new independent measures (principal components) which are, respectively, different linear combinations of d l, … , d 9 so that the principal components can be combined by their eigenvalues to obtain a weighted measure of djk . The PCA process of D is carried out as follows:
Step 1
Calculate the sample mean vector đ and covariance matrix S .
Step 2
Calculate the sample correlation matrix R.
Step 3
Solve the following equation.
We obtain the ordered p characteristic roots (eigenvalues) λ 1 ≥ λ 2 ≥ ··· ≥ λ 9 with ∑λj = 9 (j = 1, … , 9) and the related p characteristic vectors (eigenvectors) (lm 1, lm 2 … , lm 9) (m = 1, … , 9). Those characteristic vectors compose the principal components Yi . The components in eigenvectors are, respectively, the coefficients in each corresponding Yi :
Step 4
Calculate the weights (wi ) of the principal components and PCA scores (zi ) of each DMU (i = 1, … , 36). Furthermore, the z vector (z 1, … , z 9) where zj shows the score of jth DMUs is given by
The DEA and PCA methods are applied to the data set of 36 DMUs. The DEA results show that 12 out of the 36 DMUs are relatively efficient. However, exact ranking cannot be obtained for these DMUs. In order to improve the discriminating power of DEA, the Andersen and Petersen (1993) model was utilized. Also, PCA rankings of 36 DMUs with respect to 9 indicators (output/input) were obtained. DEA efficiency scores and PCA scores together with rankings of DMUs are shown in .
Table 6. Results of DEA and PCA for 36 labor-assignment scenarios.
4.1.3. Correlation analysis
shows a correlation between HGTS and other methods, namely, DEA and principal component analysis (PCA). also reports the results of nonparametric statistical tests of the relationship between the stated techniques which result in the rejection of H 0 at 0.01 levels.There is a high correlation between HGTS and TOPSIS. Also, correlation between HGTS and PCA is very high (0.809), which shows that HGTS results are reasonable. Spearman's rho correlations comparing these methods imply that results of all methods except DEA are not statistically different. Thus, there is a direct relationship between HGTS, DEA, PCA, and TOPSIS in terms of data sets generated by computer simulation with respect to the 36 scenarios. Particularly, the Spearman test statistic rs > 0.75 indicates a strong direct relationship. Also, we apply analysis of variance (ANOVA) to show if the proposed approach produces greater efficiency scores than DEA, PCA, and TOPSIS.
Table 7. Non-parametric Spearman (rs ) correlations analysis.
Table 8. ANOVA results of HGTS versus other methods.
4.1.4. Analysis of variance
ANOVA was used to evaluate the effects of the optimum operator assignment in CMS model. DMU's efficiencies were considered for HGTS model in comparison with DEA, PCA, and TOPSIS methods. First, it was tested whether efficiencies have the same behavior in HGTS (τ
1), DEA (τ
2), PCA (τ
3), and TOPSIS (τ
4) models. Furthermore, it is tested whether the null hypothesis H
0: μ
1 = μ
2 = μ
3 = μ
4 was to be accepted. It was concluded that the four treatments differ at α = 0.05. Furthermore, the least significant difference (LSD) method is used to compare the pairs of treatment means μ
1, μ
2, μ
3 and μ
4. That is H
0: μi
= μj
for all . The results of LSD revealed that at α = 0.05, μ
1 > μ
2, μ
3, μ
4 and μ
2 > μ
3, μ
4 also μ
3 = μ
4 and hence treatment 1 (HGTS) produces a significantly greater efficiency than other treatments. The advantages of the HGTS model with respect to efficiencies are shown in and .
Table 9. Multiple comparisons between HGTS and other methods.
4.1.5. Qualitative comparison
We have proved that the proposed approach of this study provides good correlation with other robust multivariate methods. We have also shown that HGTS provides higher efficiency scores than previous methods through ANOVA and LSD. A comparative study between HGTS and other methods is presented in . All methods can solve problems with multiple inputs and outputs, but HGTS can locate the best DMU with both specified and unspecified priori weights. Clearly, the hybrid model is capable of solving decision-making models with great flexibility and it consequently demonstrates efficient ranking of alternatives.
Table 10. Distinct features of HGTS versus other methods.
5. Conclusion
This article presented a decision-making approach based on a HGTS for determining the most efficient number of operators and the efficient measurement of operator assignment in CMS. The objective was to determine the labor assignment in a CMS environment with the optimum performance. We used HGTS for obtaining near optimum ranking of the alternative in accordance with fitness function. Also, this approach was performed by employing the number of operators, average lead time of demand, average waiting time of demand, number of completed parts, operator utilization, and average machine utilization as attributes. Entropy method was used to determine the weight of attributes. Furthermore, values of the attributes were procured by means of computer simulation. The unique feature of this model is demonstration of efficient ranks of alternatives by reducing the distance between neighborhood alternatives. The superiority and advantages of the proposed HGTS were shown through a comparative study composed by TOPSIS, DEA, and PCA.
HGTS used was introduced as a powerful method for ranking the scenarios in the operator assignment problem based on the attributes discussed in this article. Also, the TOPSIS approaches verified our findings. But TOPSIS is not able to present efficient ranking of scenarios for complicated problems. Furthermore, the HGTS approach is capable of ranking the alternatives by near optimum fitness function and it determines the best solution with minimum distance.
The decision matrix is introduced for selecting the appropriate scenario for the operator assignment in CMS. The weighted coefficients are obtained for every attribute by making use of the entropy method. The decision matrix and weighted coefficients are taken as the inputs for ordinary TOPSIS. These models list candidate scenarios from the best to the worst, taking into account all scenario selection criteria including attributes. Methods that determine both the score and the rank of each candidate scenario may be preferred over methods that provide only the ranks of scenarios. The score option can provide better insight for designers and it takes into account both the differences and similarities of the candidate scenarios. HGTS can be considered an efficient tool to enhance the accuracy of the final decision in designing a CMS system, as we have shown in this article.
Nomenclature
| Ci | = |
the relative closeness of ith candidate material to the ideal solutions |
| Ej | = |
the entropy value for jth attribute |
| J | = |
the set of decision attributes |
| k | = |
constant of the entropy equation |
| K | = |
set of benefit criteria |
| K′ | = |
set of cost criteria |
| m | = |
the number of scenarios |
| n | = |
the number of criteria |
| nij | = |
an element of the normalized decision matrix |
| pij | = |
an element of the decision matrix in the normalized mode for entropy method |
| rij | = |
an element of the decision matrix |
|
| = |
the best value of jth attribute |
|
| = |
the worst value of jth attribute |
|
| = |
distance of design to the ideal solution for the ith candidate material |
|
| = |
distance of design from the negative ideal solution for the ith candidate |
| s | = |
the number of outputs |
| V | = |
weighted normalized decision matrix |
| Vij | = |
an element of the weighted normalized decision matrix |
|
| = |
ideal solution for jth attribute |
|
| = |
negative ideal solution for jth attribute |
| vi | = |
the weight given to input i |
|
| = |
the weight coefficient of jth attribute |
| wj | = |
balanced weight coefficient of jth attribute |
| X | = |
the vector of optimization variables |
| Xj | = |
jth attribute in the decision matrix |
| Xij | = |
the amount of input i produced by unit j |
| Yrj | = |
the amount of output r produced by unit j |
| μr | = |
The weight given to output r |
| λ j | = |
the priority of jth attribute comparing with others |
| θ jo | = |
the efficiency score of DMU0 |
| ε | = |
a non-Archimedean infinitesimal |
Related Research Data
References
- Anderson , P. and Peterson , N.C. 1993 . A procedure for ranking efficient units in data envelopment analysis . Management Science , 39 ( 10 ) : 1261 – 1264 .
- Askin , R and Huang , Y . 2001 . Forming effective worker teams for cellular manufacturing . International journal of production research , 39 ( 11 ) : 2431 – 2451 .
- Ayag , Z and Ozdemir , RG . 2006 . A fuzzy AHP approach to evaluating machine tool alternatives . Journal of intelligent manufacturing , 17 ( 2 ) : 179 – 190 .
- Azadeh , A and Anvari , M . 2006 . Implementation of multivariate methods as decision making models for optimization of operator allocation by computer simulation in CMS . In: Proceedings of the 2006 summer computer simulation conference . 2006 , Calgary, Canada. pp. 34 – 41 .
- Banker , RD , Charnes , A and Cooper , WW . 1984 . Some models for estimating technical and scale inefficiencies in data envelopment analysis . Management science , 30 ( 9 ) : 1078 – 1092 .
- Bidanda , B . 2005 . Human related issues in manufacturing cell design, implementation, and operation: a review and survey . Computers and industrial engineering , 48 ( 3 ) : 507 – 523 .
- Camanho , AS and Dyson , RG . 2005 . Cost efficiency measurement with price uncertainty: a DEA application to bank branch assessments . European journal of operational research , 161 ( 2 ) : 432 – 446 .
- Cesani , VI and Steudel , HJ . 2005 . A study of labour assignment flexibility in cellular manufacturing systems . Computers and industrial engineering , 48 ( 3 ) : 571 – 591 .
- Charnes , A , Cooper , WW and Rhodes , E . 1978 . Measuring the efficiency of decision making units . European journal of operational research , 2 ( 6 ) : 429 – 444 .
- Chauvet , F , Proth , JM and Soumare , A . 2000 . The simple and multiple job assignment problems . International journal of production research , 38 ( 14 ) : 3165 – 3179 .
- Doyle , J and Green , R . 1994 . Efficiency and cross-efficiency in DEA: derivations, meanings and uses . Journal of the operational research society , 45 ( 5 ) : 567 – 578 .
- Ebrahimipour , V . 2007 . A GA–PCA approach for power sector performance ranking based on machine productivity . Applied mathematics and computation , 186 ( 2 ) : 1205 – 1215 .
- Edirisinghe , NCP and Zhang , X . 2007 . Generalized DEA model of fundamental analysis and its application to portfolio optimization . Journal of banking & finance , 31 ( 11 ) : 3311 – 3335 .
- Ertay , T . 2002 . An analytical approach to technology selection problem: a case study in plastic mold production . International journal of operations and quantitative management , 8 ( 3 ) : 165 – 179 .
- Ertay , T and Ruan , D . 2005 . Data envelopment analysis based decision model for optimal operator allocation in CMS . European journal of operational research , 164 ( 3 ) : 800 – 810 .
- Fitzpatrick , E and Askin , R . 2005 . Forming effective worker teams with multi-functional skill requirements . Computers and industrial engineering , 48 ( 3 ) : 593 – 608 .
- Haupt , SE and Haupt , RL . 1998 . Practical genetic algorithm, , 2nd , New York, NY : John Wiley .
- Hsu-Shih , S . 2008 . Incremental analysis for MCDM with an application to group TOPSIS . European journal of operational research , 186 ( 2 ) : 720 – 734 .
- Hwang , CL and Yoon , K . 1981 . Multiple attributes decision making methods and applications , Berlin, Germany : Springer .
- Jeff , KS , Aleda , VR and Wendell , GG . 2001 . The deployment of temporary production workers in assembly operations: a case study of the hidden costs of learning and forgetting . Journal of operation management , 21 ( 6 ) : 689 – 707 .
- Liu , ST . 2008 . A fuzzy DEA/AR approach to the selection of flexible manufacturing systems . Computers and industrial engineering , 54 ( 1 ) : 66 – 76 .
- Mannino , M , Hong , SN and Choi , IJ . 2008 . Efficiency evaluation of data warehouse operations . Decision support systems , 44 ( 4 ) : 883 – 898 .
- Molleman , E and Slomp , J . 1999 . Functional flexibility and team performance . International journal of production research , 37 ( 8 ) : 1837 – 1858 .
- Nembhard , DA . 2001a . An empirical comparison of forgetting model . IEEE transactions on engineering management , 48 ( 3 ) : 283 – 291 .
- Nembhard , DA . 2001b . Heuristic approach for assigning workers to tasks based on individual learning rates . International journal of production research , 39 ( 9 ) : 1955 – 1968 .
- Nembhard , DA and Mustafa , VU . 2000 . Experiential learning and forgetting for manual and cognitive tasks . International journal of industrial ergonomics , 25 ( 4 ) : 315 – 326 .
- Olson , DL . 2004 . Comparison of weights in TOPSIS models . Mathematical and computer modeling , 40 ( 7–8 ) : 721 – 727 .
- Önüt , S , Soner Kara , S and Efendigil , T . 2008 . A hybrid fuzzy MCDM approach to machine tool selection . Journal of intelligent manufacturing , 19 ( 4 ) : 443 – 453 .
- Pritsker , AAB . 1995 . Introduction to simulation and SLAM II, , 4th , New York, NY : John Wiley and System Publishing Corporation .
- Rao , RV . 2006 . A material selection model using graph theory and matrix approach . Material science engineering , 43 ( 1–2 ) : 248 – 255 .
- Roy , B . 1991 . The outranking approach and the foundations of ELECTRE methods . Theory and decision , 31 ( 1 ) : 49 – 73 .
- Roy , B . 1996. Multicriteria methodology for decision aiding. Vol. 12 of non-convex optimization and its applications. Dordrecht, Netherlands: Kluwer Academic Publishers
- Saaty , TL . 1990 . Decision making for leaders, the analytical hierarchy process for decision in a complex world , Pittsburgh, PA : RWS Publications .
- Saaty , TL . 2000 . Fundamentals of decision making and priority theory with the analytic hierarchy process , Pittsburgh, PA : RWS Publications, University of Pittsburgh .
- Sarkis , J and Talluri , S . 1998 . A decision model for evaluation of flexible manufacturing systems in the presence of both cardinal and ordinal factors . International journal of production research , 37 ( 13 ) : 2927 – 2938 .
- Scott , MS , Nembhard , DA and Mustafa , VU . 2001 . The effects of worker learning, forgetting, and heterogeneity on assembly line productivity . Management science , 47 ( 12 ) : 1639 – 1653 .
- Shanian , A and Savadogo , O . 2006 . TOPSIS multiple-criteria decision support analysis for material selection of metallic bipolar plates for polymer electrolyte fuel cell . Journal of power sources , 159 ( 2 ) : 1095 – 1104 .
- Simos , J and Gestion , J . 1990. D′echets solides urbains Genevois: les faits, le traitement, l’analyse. Presses Polytechniques et Universitaires Romandes, Lausanne, Switzerland
- Slomp , J , Bokhorst , J and Molleman , E . 2005 . Cross training in a cellular manufacturing environment . Computer and industrial engineering , 48 ( 3 ) : 609 – 624 .
- Slomp , J and Molleman , E . 2000 . Cross training policies and performance of teams . Proceedings of the group technology/cellular manufacturing world symposium 2000. San Juan . 2000 , Puerto Rico. pp. 107 – 112 .
- Süer , GA and Tummaluri , RR . 2008 . Multi-period operator assignment considering skills, learning and forgetting in labour-intensive cells . International journal of production research , 46 ( 2 ) : 469 – 493 .
- Wittrock , RJ . 1992 . Operator assignment and the parametric preflow algorithm . Management science , 38 ( 9 ) : 1354 – 1359 .
- Yang , T , Chen , M-C and Hung , C-C . 2007 . Multiple attribute decision-making methods for the dynamic operator allocation problem . Mathematics and computers in simulation , 73 ( 5 ) : 285 – 299 .
- Zhang , H , Gen , M and Seo , Y . 2006 . An effective coding approach for multiobjective integrated resource selection and operation sequences problem . Journal of intelligent manufacturing , 17 ( 4 ) : 385 – 397 .