
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
With the rapid development of Internet of Things and multimedia technologies, people are paying more attention to the security of images and videos. To further improve the security of video content, a video watermarking algorithm based on the high efficiency video coding (HEVC) compression domain is proposed in this paper. The scheme embeds watermark information in the quantized coefficients, which can solve the cumulative error caused by watermark embedding. Moreover, the all phase biorthogonal transform (APBT), an improved transform, is used to compress the watermark data at the digital watermark preprocessing stage, optimize the watermark embedding scheme, and improve the embedding capacity of video watermarking. Due to the characteristics of HEVC video coding, most HEVC video watermarking schemes based on compression domain cannot resist recompression attack. To solve this problem, on the basis of APBT and singular value decomposition, an anti-HEVC recompression video watermarking algorithm is proposed and can effectively resist the HEVC recompression. Experimental results show that even when the quantization parameter is larger than 40, the extracted watermark still has good image quality. In addition, the algorithm also has a good performance in noise resistance.
1. INTRODUCTION
Video watermarking is a digital watermarking technology applied to video and is an active subject in current research with a number of problems to be addressed. With the development of the Internet, the demands for multimedia services, live webcast, and video on-demand are growing. Meanwhile, the duration of online video has experienced explosive growth. Additionally, piracy, duplication, and infringement of digital video are becoming more common. Therefore, the technology used for copyright protection, piracy tracking, and copy control of video content is urgently needed. Video watermarking technology emerges at a historic moment.
Video watermarking algorithms are based on the time and spatial redundancies of the video content for watermark information embedding. At the same time, as separate branches of information hiding, both video and image watermarking have some common characteristics, such as invisibility, security, robustness, and reliability. Although video content has more data storage than still images, due to the complexity of video compression, video watermarking technology is still facing the challenges of concealment, security, and robustness.
With the new generation of high efficiency video coding (HEVC), the video coding standards [Citation1] have been gradually developed for application in many fields, and HEVC video copyright protection has become an urgent problem for multimedia development. There are two common digital copyright protection methods: data encryption and digital watermarking [Citation2]. According to the visibility of the watermark, digital watermarking can be divided into visible watermarking and invisible watermarking [Citation3]. According to different functions, digital watermarking can be divided into robust watermarking and fragile watermarking. Robust watermarking is used for copyright protection, while fragile watermarking is generally used for content authentication and recovery. According to the embedded location, digital watermarking can be further divided into spatial domain watermarking [Citation4] and transform domain watermarking [Citation5].
At present, compared with H.264-based video watermarking technology, there are a few studies on watermarking technology for HEVC videos. To achieve video copyright protection and content authentication [Citation6], the watermark information can be embedded in spatial domain or compression domain. Qiu et al. [Citation7] proposed a mixed H.264 video watermarking algorithm with low distortion, embedding the robust watermark into the discrete cosine transform (DCT) domain and the fragile watermark into the motion vector (MV). Gong and Lu [Citation8] extracted the robust geometric features of the 4 × 4 image block luminance component in H.264 video sequence by singular value decomposition (SVD) and embedded the watermark. The algorithm can effectively resist H.264 video compression. Kuo et al. [Citation9] proposed an H.264 fragile video watermarking method for content authentication, and statistically analysed the MV by using the H.264 rate distortion cost function to obtain the optimal position of the MV suitable for watermark embedding. Fallahpour et al. [Citation10] took the macroblock index and frame index as watermark data and embedded them into nonzero quantized DCT blocks, thus realizing spatial and time tamper detection, and improved the security of the system with content-based encryption system. Qian et al. [Citation11] proposed a video text detection and location algorithm based on intra-frame integer DCT coefficients. The algorithm realizes the rough detection of the text block based on the size of macroblock and the adaptive threshold of the quantization parameter, and achieves the location of the video text line according to the intra-frame video text characteristics of H.264. Zhang et al. [Citation12] achieved content authentication by embedding an 8-bit grayscale image watermark in the compression domain. The algorithm selects an intermediate frequency coefficient in the DCT coefficient matrix as the embedding position and embeds the 1-bit watermark information into the sign bit of the coefficient. Chang et al. [Citation13] proposed a data hiding algorithm based on DCT, discrete sine transform, and HEVC intra-coding error-free transmission. Dutta and Gupta [Citation14] proposed a robust watermarking for blind watermark extraction in HEVC encoded video. The watermark embedding is achieved by analysing the characteristics of the HEVC compression. Wang et al. [Citation15] proposed an algorithm based on HEVC by establishing a mapping relationship between intra-prediction mode and secret information. Van et al. [Citation16] proposed an HEVC-based information hiding algorithm with low complexity. This algorithm can effectively reduce the effect of information hiding on video quality. Li et al. [Citation17] put forward an HEVC information hiding algorithm based on the MV space, and achieved the information hiding by modifying the mapping values of MV set. Xu et al. [Citation18] proposed an HEVC information hiding algorithm based on Hamming+1 in which the information was hidden in the 4 × 4 luminance blocks of complex texture regions. Xu et al. [Citation19] proposed a video information hiding algorithm based on the difference of intra-prediction modes. According to the prediction mode modulated by a Lagrange distortion-rate model, the information is embedded by establishing the mapping relationship between the information to be hidden and the prediction mode difference value. Cai et al. [Citation20] proposed to divide the 33 angle prediction modes into four mode sets, and established a mapping relationship between current block and next block for watermark embedding. Finally, the watermark is embedded according to the mode set to which the block belongs. Dutta and Gupta [Citation21] presented a robust HEVC-based video watermarking by adopting the informed detector, where the watermark information was embedded in P frames. Besides, video features and random keys are utilized to improve the security and robustness of the watermarking. Mohamed et al. [Citation22] integrated two robust watermarking algorithms in HEVC codec, which includes XY method and LSB method for watermark embedding. These two watermarking methods are implemented by altering the value of quantized and transformed coefficients in HEVC coding. Gaj et al. [Citation23] embedded the watermark information by modifying the number of the nonzero transform coefficients in 4 × 4 transform blocks, which can achieve the robustness to the recompression attack in HEVC framework. Additionally, Gaj et al. [Citation24] introduced a drift compensated watermarking scheme with high embedding capacity and video quality, where watermark embedding was achieved by choosing MV and transformed residual in constant I frames. To give the overview and introduction of the watermarking algorithms on HEVC standard, Elrowayati and Abdullah [Citation25] reviewed and investigated the applicability of watermarking algorithms, and gave the motivation for modifying and applying the existing watermarking in the HEVC standard.
In conclusion, the current HEVC video coding standard is continuously improved, and the scope of its application becomes more and more extensive. As the new generation of video coding standard, it will gradually replace the commercial status of H.264. Therefore, the copyright protection of HEVC video content becomes one of the urgent problems to be solved. Although there are many video watermarking algorithms based on H.264, the research on video watermarking algorithm based on HEVC is relatively rare, especially studies on video watermarking algorithms that can resist HEVC recompression. Additionally, watermark embedding location in HEVC-based watermarking field is one of the problems to be solved for better performance and lower computational complexity. Moreover, most of the HEVC-based video watermarking algorithms have the robustness to common video attacks but cannot resist the HEVC recompression attack. Thus, the main contributions of this paper can be listed as (1) a novel transform, all phase biorthogonal transform (APBT) [Citation26], is introduced for the application in the video watermarking; (2) an analysis of the HEVC video coding standard is made and APBT is utilized to compress the watermark information; and (3) an APBT-based HEVC compression domain watermarking algorithm is proposed for the robustness to HEVC recompression. In the proposed video watermarking algorithm, the watermark image is first preprocessed to improve the embedding capacity, and the embedding position of HEVC video watermarking is selected on the basis of APBT-based JPEG image coding. To solve the problem that HEVC compression domain watermarking cannot resist HEVC recompression, this paper proposes an anti-HEVC recompression video watermarking algorithm based on APBT and SVD.
The rest of this paper is organized as follows. Section 2 presents the video watermarking model in detail. Section 3 introduces the concrete procedures of HEVC-based video watermarking in compression domain. The anti-HEVC recompression video watermarking as well as the experimental results and analysis for the proposed algorithm are described in Section 4. Conclusions and remarks on possible further work are given in Section 5.
2. RELATED WORK
The overviews of video watermarking model and embedding location in HEVC-based watermarking are demonstrated in this section. Besides, for better comprehension, APBT and its application are introduced.
2.1. Video Watermarking Model
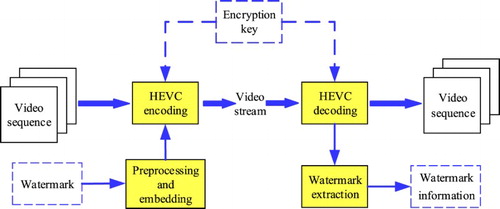
Video watermarking is an extension of digital watermarking. Similar to digital image watermarking, the main process of video watermarking can be divided into embedding and extraction processes, which are shown in . In video watermark embedding process, the watermark information is first preprocessed, such as encryption, scrambling, and compression, and then the preprocessed secret data are embedded into the watermark carrier. In conventional digital watermarking, the carrier can be text, image, audio, and video. Video watermarking specifically refers to the digital watermarking for which the carrier is video. When the watermark is embedded into the host video, the watermarked video is obtained. In the watermark extraction process, there are two main steps: watermark detection to determine whether the video contains a digital watermark, and watermark extraction to extract the watermark from the video. In practice, watermark embedding strategy in the video watermarking algorithm can be flexibly chosen according to the applications.
Figure 1 Video watermarking model
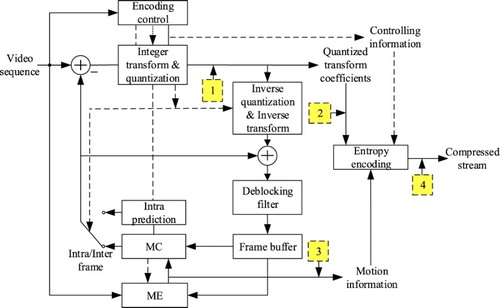
By researching current video watermarking systems, the watermark embedding locations of compression domain video watermarking concentrate on four locations in the video compression process. is a schematic diagram of the video watermark embedding positions. MC means motion compensation and ME is the motion estimation. Cell 1 indicates that watermark information is embedded in DCT transform coefficients. Cell 2 indicates that the watermark information is embedded in the quantized transform coefficients, and the positions indicated by cells 3 and 4 denote that the watermark information is embedded by modifying the MV and variable length coding stream, respectively. Currently, most of the digital watermarking algorithms based on the frequency domain will select position 1 and position 2 as the embedding positions. Additionally, the video watermarking algorithm in the compression domain, if a reversible digital watermark is adopted, can completely remove the watermark information on the decoding side, which does not affect the video quality and can adjust the watermark based on human eyes. However, in the time domain-based watermarking scheme, the watermark information may be lost after compression, which may affect the video quality.
Figure 2 Schematic diagram of video watermark embedding positions
2.2. APBT
Hou et al. [Citation26] presented a novel and improved transform, APBT, to obtain better energy concentration in low frequencies and attenuation characteristics in high frequencies. Owing to these characteristics, APBT can be applied in many fields of image processing, such as image compression, image watermarking, image denoising, and image demosaicking. The two-dimensional APBT transform can be expressed as Equation (1):
(1)
(1)
where
is an
image block, and
represents the APBT matrix with size of
.
is the transpose matrix of
. Transformed image can be reconstructed by Equation (2):
(2)
(2)
where
is the inverse matrix of
.
In APBT theory, there are two commonly used transform matrices, the all phase discrete cosine biorthogonal transform and the all phase inverse discrete cosine biorthogonal transform, which are defined as Equations (3) and(4), respectively:
(3)
(3)
(4)
(4)
In this paper, for watermark image compression, APBT is performed on the image block obtained by 8 × 8 subdividing to get the APBT transformed coefficients for Zig-zag scanning and run-length coding (RLC). As for watermark information embedding, block APBT is performed on the image to get different transformed blocks, and then the DC coefficients of all blocks will be picked out to form a new coefficient matrix. SVD is performed to embed the watermark information.
3. VIDEO WATERMARKING IN HEVC COMPRESSION DOMAIN
Video watermarking in the HEVC compression domain embeds watermark information during the HEVC compression process. By analysing the HEVC video coding framework, it can be seen that the positions where the watermark can be embedded in the video compression domain are the transform coefficients before quantization, the quantized transform coefficients, the MV, and the entropy coding process. Because the transformation and quantization are involved in the prediction process during HEVC video coding, it is not suitable for watermark embedding. When the watermark is embedded into the MV, the watermark should be extracted on the decoding side; otherwise, the video cannot be reconstructed with the watermark. Due to the above factors, the watermark is embedded into the entropy coding process in this paper, and a reversible video watermarking algorithm is proposed to recover the reconstructed video without affecting the video quality. To further increase the watermark embedding capacity, based on the APBT-based JPEG image coding, the watermark is preprocessed.
3.1. Watermark Preprocessing
To improve the security and reliability of the watermarking system, it is necessary to scramble the watermark information before embedding the watermark, which can ensure the safety of the watermark information. The watermark information cannot be recovered under the condition that the watermark information is extracted illegally. There are two common ways of scrambling, namely, scrambling by logistic map and Arnold transform [Citation27].
In this paper, the Arnold transform is applied for image scrambling, and this method was proposed by V. J. Arnold. This method is widely used in the field of digital watermarking. Watermark information with stronger correlations between pixels can be scrambled into irrelevant two-dimensional matrices by the Arnold transform. Generally, the width and length of the image are considered to be equal for simplification. The Arnold transform can be defined as:
(5)
(5)
where
and
are the parameters, and they are integers,
,
is the width of the image, and
and
are positions of the pixels before and after the scrambling, respectively. For convenience, we usually take
and
. Now, the Arnold transform can be expressed as:
(6)
(6)
The advantages of using the Arnold transform are that it has good periodicity and can recover the original image easily. By re-scrambling the scrambled watermark, we can get the original image. For an image with size
, the period of transformation is noted as
, and when
,
satisfies
. shows the part of Arnold transform periods.
Table 1 Periods of Arnold transform
As is shown in , a scrambled image ((b)) is obtained by performing the Arnold transform 24 times on the watermark image with size 80 × 80 ((a)). As is shown in , if the scrambled image continues to be transformed 36 times, the reconstructed image ((c)) will be obtained, which is the same as the original image.
Figure 3 Arnold image scrambling: (a) original watermark image, (b) scrambled image, and (c) reconstructed image

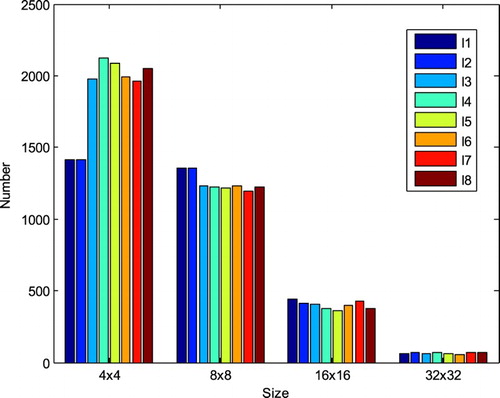
In HEVC video coding standard, there are I, P, and B frames, and four sizes of transform blocks are referred in the framework, which are 4 × 4, 8 × 8, 16 × 16, and 32 × 32. Because less information is carried in the P and B frames, the subjective quality of the video will be seriously affected when the watermark is embedded. Hence, current HEVC compression domain video watermarking algorithms mostly embed the watermarks into the I frame luminance component of 4 × 4 transform blocks. Because 4 × 4 coding blocks are concentrated on complex texture areas, the human eyes are not sensitive to their changes which affect the subjective quality and bit rate of the video slightly. However, due to the limited amount of 4 × 4 coding blocks in intra-frame luminance components, this embedding scheme can affect the watermark embedding capacity. In , the distribution of different nonzero transform units (TUs) in the first eight I frames of luminance components is shown when the video sequence BasketballDrill (resolution: 832 × 480, format: YUV) is performed by HEVC compression. If the watermark image with size of 80 × 80 is embedded, at least four I frames are required for watermark embedding.
Figure 4 The nonzero TU distribution of the first eight I frames in HEVC compressed luminance components of the BasketballDrill
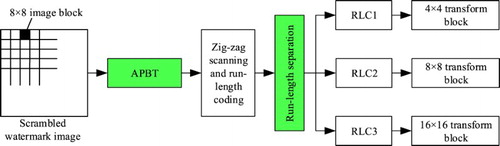
To increase the watermark embedding capacity, the APBT-based JPEG image compression algorithm [Citation28] is used to conduct lossless compression of watermark information in this paper. Here, the quantization step is omitted. shows the diagram of watermark compression, which can be concluded as five steps: (1) the watermark information is firstly scrambled by Arnold scrambling to obtain the scrambled watermark; (2) the scrambled watermark image is divided into several non-overlapping image blocks with size of 8 × 8; (3) APBT is performed on 8 × 8 sub-image blocks to obtain the APBT transform coefficients; (4) a run-length sequence is obtained by performing Zig-zag scanning and RLC on transform coefficients; and (5) the run-length sequence will be separated by run-length separation to get three run-length sequences, which will be embedded in different transform blocks in the HEVC framework.
Figure 5 The diagram of the lossless watermark compression
The main purpose of run-length separation is to separate the larger values in the run length and embed them after the conversion of the number systems. The main reason for this approach is that there are some large numbers such as DC coefficients, AC coefficients with larger values, run-length, and length of run-length ending in the run-length sequence. After transformation and quantization, the value of the quantization coefficient of TUs in HEVC will be smaller. At this time, the data that are processed by run-length separation will be closer to the quantized coefficients of HEVC, which can reduce the effect of watermark embedding on video quality.
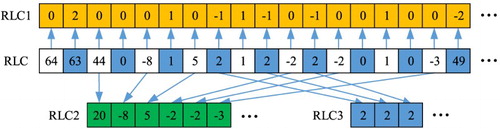
The flow chart of run-length separation algorithm is shown in . For a binary image, the maximum DC coefficient after APBT is 64. Therefore, we subtract 64 from the DC coefficient at the initial stage of algorithm, and then we get the processed RLC sequence, with DC/AC coefficients at the odd position of the sequence and length of run-length at the even position. Every time the algorithm processes a pair of data [Coef, Pos], where Coef represents the DC/AC coefficients and Pos means the length of run-length. If the run-length in RLC is 63, which means DC coefficient is 64, then [0, 2] is written into the sequence RLC1. If the run-length position in RLC is the end of the run-length, −2 is written into the sequence RLC2. When the absolute values of both Coef and Pos are greater than 1, [0, −1] is written in RLC1, Coef is written in RLC2, and Pos is written in RLC3. When the absolute value of Coef is greater than 1 and the absolute value of Pos is not greater than 1, [0, Pos] is written in RLC1 and Coef will be written in RLC2. When the absolute value of Coef is not greater than 1 and the value of Pos is greater than 1, [Coef, −1] is written in RLC1 and Coef is written in RLC2. If the absolute values of both Coef and Pos are smaller than 1, [Coef, Pos] will be written in RLC1.
Figure 6 The flowchart of run-length separation algorithm
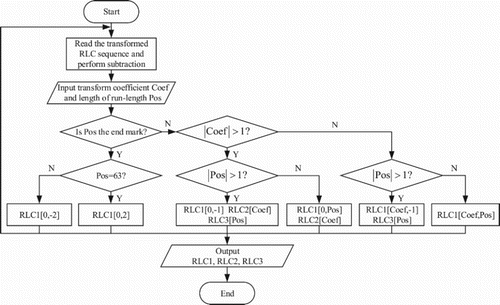
shows the illustration of the run-length separation algorithm. Three RLC sequences will be obtained after separating the run-length sequence. Each value in RLC1 is that whose absolute value is less than or equal to 2; each value in RLC2 is the transform coefficient whose absolute value is greater than 1; and each value in RLC3 is that whose run-length is greater than 1. After conducting experimental statistics, the number of RLC1 is equal to the number of RLC; the number of RLC2 is greater than the number of RLC3 and less than the number of RLC1, while the number of RLC3 is the least. Then, the obtained RLC2 and RLC3 sequences will be converted by the ternary conversion, which can ensure that the median values in RLC2 and RLC3 do not exceed 2. This process can further reduce the effect of watermark on video quality.
Figure 7 Run-length separation algorithm
3.2. Watermark Embedding and Extraction
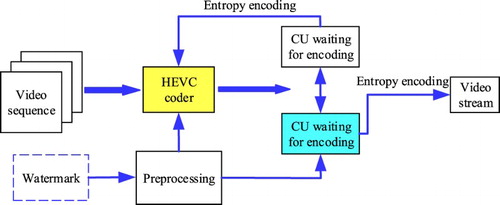
As mentioned above, the embedding position of a video watermark can be divided into four categories: transform coefficients before quantization, transform coefficients after quantization, MV, and the entropy coding process. In HEVC video coding, both transformation and quantization are involved in the prediction process, which makes it difficult to determine the ultimate optimal transform blocks. In addition, embedding the watermark in the transformed or quantized coefficients can result in intra-frame error propagation. The information carried by the MV is limited. If watermark information is embedded into the MV, the video cannot be reconstructed correctly without extracting the watermark first on the decoding side. Therefore, in this paper, the watermark information is embedded in the encoding process of the I frames. To eliminate the intra-frame error propagation, coefficients to be encoded will be copied for watermark embedding and the watermarked coefficients will be encoded to output the bit stream. The original coefficients to be encoded will take part in the HEVC coding processing. shows the HEVC-based watermark embedding process, where CU means the coding unit.
Figure 8 HEVC video watermark embedding diagram
Eliminating intra-frame error propagation is one of the problems that need to be solved in video watermarking to reduce the effect of watermark on video quality. In [Citation13], according to the characteristics of transform and prediction mode, the watermark information is embedded in the specific position of quantization coefficient to eliminate intra-frame error propagation. However, the embedding process is complex and the location of the embedding is limited. By using the embedding scheme proposed in this paper, watermark embedding and extraction become more flexible and simpler.
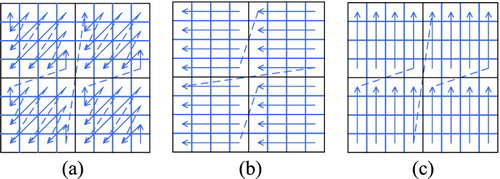
In the HEVC standard, before performing the entropy coding on quantized transform coefficients, the transform coefficients should be scanned and rearranged into a one-dimensional vector. The type of scanning depends on the distribution of the amplitude of the reference coefficients. The scanning methods in HEVC include diagonal scanning, horizontal scanning, and vertical scanning, which are shown in . For the transform blocks whose sizes are larger than 4 × 4 in HEVC, they are first divided into several 4 × 4 transform blocks, and sub-blocks are scanned according to the order of scanning sequence in large transform blocks.
Figure 9 HEVC transform coefficient scanning methods: (a) diagonal scanning, (b) horizontal scanning, and (c) vertical scanning
In HEVC standard, the symbol data hiding technique [Citation29] is used in inter-frame luminance coding blocks with the size of 4 × 4 to improve the coding efficiency. Symbol data hiding technology uses the parity of coefficient sum to determine the symbol of DC coefficient. Therefore, when the watermark is embedded into the 4 × 4 coefficient block of the inter-frame luminance component, it is necessary to ensure that the parity of coefficient sum is not changed before and after watermark embedding. Otherwise, it will result in the change of the brightness in the reconstructed frame and affect its subjective quality.
In this paper, the watermark is mainly embedded into the nonzero coefficient blocks of intra-frame luminance components with the size of 4 × 4, 8 × 8, and 16 × 16. To reduce the effect on video quality and bit rate, the watermark is embedded into the scanned coefficients. The location of the first coefficient after the last non-zero coefficient is selected as the embedding position. For the special 4 × 4 transform blocks, it will depend on the parity of the last nonzero coefficient and the parity of coefficient sum of the block. If the parity of the watermark to be embedded is same as the parity of coefficient sum, then the watermark will be embedded directly. If the parity of the watermark to be embedded is different from the parity of coefficient sum, the last nonzero coefficient will be added to 1.
The watermark extraction process is much simpler. The last nonzero coefficient is extracted from the entropy decoded coefficient. Then, the watermark extracted from 4 × 4 coefficient block is written in RLC1, the watermark extracted from 8 × 8 coefficient block is written in RLC2, and the watermark extracted from the 16 × 16 coefficient block is written in RLC3. Finally, these three sequences will be composed as RLC by run-length separation algorithm, and then the watermark information can be recovered by the reverse process of watermark preprocessing.
3.3. Experimental Results and Analysis
The experimental environment is Intel Core i3 3.1 GHz CPU, 6 GB RAM, 512 GB ROM, and GTX 480 GPU; the software environment is Visual Studio 2013 and MATLAB 2014; the operating system is Windows 10 64-bit professional version; and HEVC codec test model (HM) with version 16.0 is used. By modifying the HM codec for watermark embedding and extraction, the experiment uses Elecard YUV Viewer to compare the subjective quality of the reconstructed image. Different video sequences with different resolutions are performed by the HEVC-based video watermarking, which are Basketball (resolution: 832 × 480, format: YUV), ChinaSpeed (resolution: 1024 × 768, format: YUV), BQTerrace (resolution: 1920 × 1080, format: YUV), and Traffic (resolution: 2560 × 1600, format: YUV). Experimental results show that video files with larger sizes will cause more execution time. Besides, a binary watermark image marked “sdusry” with size of 80 × 80 is used as the watermark, as shown in . HEVC encoder parameter uses the default configuration file: encoder_intra_main.cfg, and only I frame coding is chosen as the coding method.
Figure 10 The binary watermark for embedding
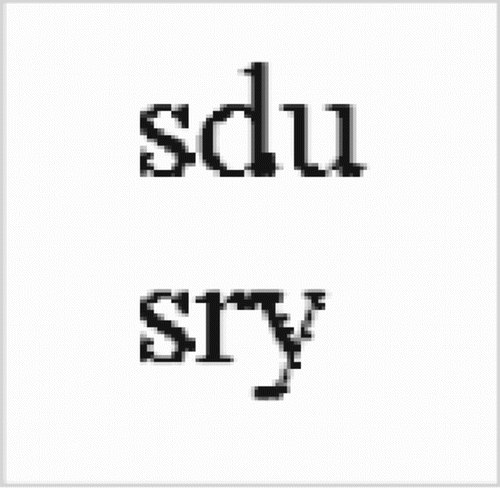
shows the reconstructed frames before and after watermark embedding. (a) is the reconstructed frame after compression without embedding the watermark, and (b) is the watermarked frame. (c) is the difference image between (a) and (b), which is obtained by using Elecard YUV Viewer, and (d) is a reconstructed frame after watermark extraction. (e) is the difference image between (a) and (d), and (f) is the original video frame. shows peak signal-to-noise rate (PSNR) of each frame in the BasketballDrill sequence before and after the watermark embedding. From , it can be seen that the watermarking algorithm has little effect on the image objective quality. Combined with , the proposed method can effectively reduce the effect of watermark on the subjective quality of watermark carrier.
Figure 11 The subjective quality of reconstructed frames: (a) original frame, (b) watermarked frame, (c) difference image between (a) and (b), (d) frame after extracting the watermark, (e) the difference image between (a) and (d), and (f) video frame

Figure 12 PSNR of each watermarked frame in BasketballDrill
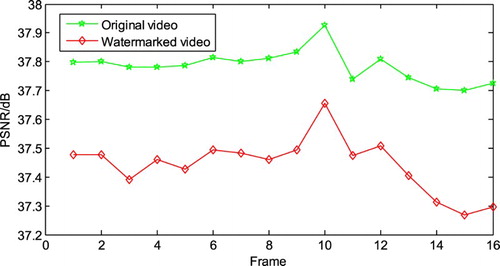
To further analyse the performance of the algorithm, shows the PSNR comparisons of the watermarked frames obtained by Chang et al. [Citation13] and the proposed method. It can be seen from that the proposed algorithm has a smaller impact on video quality. At the same time, because of the APBT-based watermark preprocessing, the capacity of watermark embedding is greatly improved. At least three binary images shown in can be embedded into each video frame, while the embedding scheme in [Citation13] requires at least three video frames for one watermark image embedding. Therefore, the APBT-based HEVC video watermarking method proposed in this paper greatly improves the watermark embedding capacity while reducing the impact of watermark on the video carrier.
Table 2 Experimental results at different resolutions
4. ANTI-HEVC RECOMPRESSION VIDEO WATERMARKING
In the video watermarking method based on the HEVC compression domain, the watermark is embedded into the coding block. When the HEVC stream with the watermark information is decoded and recompressed, the coding blocks will be redivided, resulting in the failure of watermark extraction. Thus, the video watermarking based on HEVC compression domain cannot resist the HEVC recompression attack. shows the comparison of the CU blocks before and after HEVC recompression. As seen from , the division of CU has been changed after HEVC recompression.
Figure 13 Comparison of CU division before and after HEVC recompression: (a) the reconstructed image of the watermarked stream and (b) the reconstructed image after HEVC recompression

To solve the problem in the HEVC-based video watermarking, an anti-HEVC compression video watermarking algorithm based on APBT and SVD is proposed in this paper to embed video watermarks into the transform domain of a video sequence using APBT and SVD, which can effectively solve the problem that HEVC video watermarking methods cannot resist HEVC recompression.
4.1. Watermarking Algorithm Based on SVD
SVD is a matrix transform and can divide a matrix into a multiplication form of one diagonal matrix and the other two matrices. Because of its unique characteristics, the energy of the matrix can be focused on the diagonal coefficients and it has strong anti-interference ability. Therefore, it is often used in digital watermarking algorithm. SVD can be expressed as:
(7)
(7)
where
is the original matrix with size of
, and we assume that
.
is the
order matrix,
is the
order matrix,
and
are orthogonal matrices, and
is a diagonal matrix with size of
:
(8)
(8)
where the element
on the diagonal is the singular value of the matrix
obtained by SVD. Thus, the matrix
is also called the singular value matrix of
.
Based on SVD, the watermarking algorithm can be mainly divided into two categories: one is the watermarking algorithm based on singular value vector, and the other is the watermarking algorithm based on the eigenvectors of the orthogonal matrix. The watermark information is usually embedded into the diagonal matrix, and then the watermarked matrix
is recovered through the matrix multiplication. This process can be expressed as:
(9)
(9)
where
is the transpose matrix of
.
In the watermark extraction, the watermarked matrix is first decomposed by SVD, and then the watermarked diagonal matrix can be obtained:
(10)
(10)
The watermark information
can be recovered by extracting the value of diagonal matrix
.
The SVD has the following properties: (1) after SVD, the information carried by the diagonal matrix reflects the energy information of the image and has better stability; (2) the singular value obtained by SVD does not contain the visual characteristics of the image, but it characterizes the brightness characteristics; (3) SVD does not require that the transform matrix is a square matrix; and (4) the singular value obtained by SVD has rotation and proportional invariance.
SVD is widely used in image processing, and it was introduced into digital watermarking because of the singular value’s high stability. At present, digital watermarking based on SVD is usually combined with discrete wavelet transform (DWT) or DCT to embed digital watermark into singular values of DWT domain or DCT domain. The digital watermarking methods can effectively resist JPEG compression.
4.2. Anti-HEVC Recompression Video Watermarking Based on APBT and SVD
Video watermarking based on the original video sequence can be divided into transform domain watermarking and spatial domain watermarking. The spatial domain watermarking has greater influence on the original video sequence, and the video watermarking based on the transform domain can effectively guarantee the robustness and invisibility of watermark without affecting the video quality. In this paper, to solve the problem that HEVC video watermarking methods cannot resist HEVC recompression, a video watermarking algorithm based on APBT and SVD with anti-HEVC recompression ability is proposed.
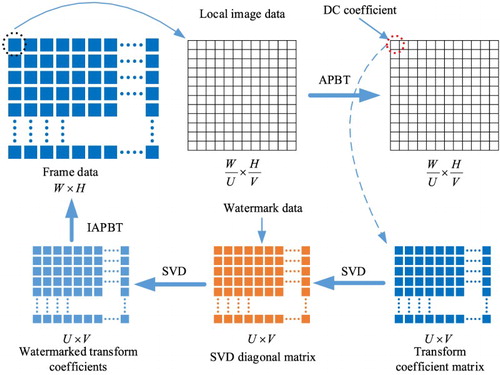
The main idea of the anti-HEVC recompression video watermarking algorithm is to perform block APBT on the Y components of the original video sequence and then extract the DC coefficient in each transform block to form a new matrix. Then, the matrix is transformed by SVD, and the watermark is embedded in the singular value matrix of the image. Meanwhile, to reduce the effect of watermark on the video sequence as much as possible, the algorithm uses SVD twice to the transform coefficients.
presents the schematic diagram of the anti-HEVC recompression video watermarking algorithm. In , the first step is to pick out one video frame from video sequence, and the Y component is utilized as a video watermark carrier. The size of Y component is set as , and the size of watermark information is set as
. In order to simplify the calculation, the condition that
is set. To embed watermark information into the Y component, it can be inferred that sizes of matrix formed by the DC coefficients and the diagonal matrix
obtained by SVD should be
. To obtain DC coefficients with size of
, the number of image blocks performed by block APBT should be at least
. Meanwhile, the APBT requires that the transform matrix should be a square matrix, and in order to ensure the quality of reconstructed image, the minimum value of
and
is 8. Hence, the size of transform block should be:
(11)
(11)
After determining the size of the transform block, the Y component is performed by block APBT, and the DC coefficient of each transform block is extracted to form a matrix with size of
. Because DC coefficients have good anti-interference capabilities, they are suitable for watermark embedding. Then, SVD is performed on the matrix composed of the DC coefficients, and the binary watermark is embedded into the singular value matrices. To reduce the effect of watermark embedding on video, we perform the SVD on the matrix carrying the watermark information for the second time. The obtained singular value matrix is used to recover the DC coefficients. The watermarked DC coefficients can be put back into the APBT coefficients of each block, and each APBT coefficient block is then transformed by the inverse APBT (IAPBT) to recover the watermarked video sequence.
Figure 14 Anti-HEVC recompression video watermarking algorithm
In the anti-HEVC recompression video watermarking algorithm, the proposed double SVD watermark embedding algorithm is one of the core technologies and can effectively reduce the effect of watermark embedding on video subjective quality. The algorithm process can be expressed as follows. Assuming that the matrix of the DC coefficients obtained by the block APBT is , SVD is performed on it. As seen in Section 4.1, after the first SVD on the matrix of the DC coefficients, we can get:
(12)
(12)
where
is the
matrix composed of DC coefficients,
is the matrix with
order,
is the matrix with
order, and
is the matrix with size of
. The diagonal matrix can be expressed as:
(13)
(13)
At this time, the binary watermark image data matrix
is embedded into
to obtain the
by
, where
is the scaling factor, and
, an element in
, is the value at the position of
in the watermark image.
(14)
(14)
SVD is performed on
again, and then Equation (15) can be obtained.
(15)
(15)
Then, the matrix
composed of DC coefficients can be obtained by Equation (16) after embedding watermark:
(16)
(16)
The extraction process of the double SVD watermark embedding algorithm is the inverse of the embedding process. First, the Y component of the reconstructed video sequence is transformed by block APBT. Then, the matrix
composed by the DC coefficients is obtained, and SVD is performed:
(17)
(17)
Then, we get the watermarked matrix
by
. Finally, the binary watermark information can be recovered by Equation (18):
(18)
(18)
The anti-HEVC recompression video watermarking algorithm based on APBT and SVD has good anti-HEVC recompression performance and can change the size of the block to adjust the watermark capacity. shows the comparison of the extracted watermarks before and after the optimization. When the watermark information is embedded into the diagonal position of the diagonal matrix obtained by SVD, the diagonal position will produce noise during the restoration of the watermark image, which is shown in (a). Therefore, the extracted watermark has been optimized, and the optimized result is shown in (b). In the watermark embedding process, the watermark information will not be embedded into the diagonal position of the diagonal matrix obtained by SVD. Therefore, the transform block with size of
should be adjusted to:
(19)
(19)
In this case, we need to reconstruct the
matrix into a matrix with size of
. Then, we use Equation (20) for watermark embedding.
(20)
(20)
Figure 15 Subjective quality comparison of the extracted watermarks before and after optimization for HEVC compressed video watermarking algorithm: (a) before optimization and (b) after optimization
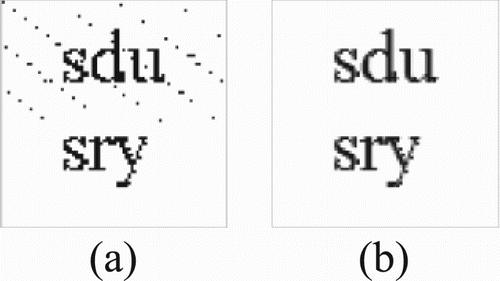
4.3. Experimental Results and Analysis
In this paper, we propose a video watermarking algorithm that can resist HEVC recompression. To test the performance of the proposed scheme in this paper, the BasketballDrill video sequence (resolution: 832 × 480, format: YUV) is selected as the carrier of the binary watermark. HEVC coding of the watermarked video sequence is carried out under different quantization parameters (QPs) (22, 28, 32, 36, 40, 44, and 48), and the extracted watermarks are evaluated by the normalized correlation (NC) coefficient:
(21)
(21)
where
is the extracted watermark after recompression,
is the original watermark,
, and
is the size of the watermark image. The value of NC is between 0 and 1, and the larger the value is, the more similar the two watermarks will be.
shows the effect of the size of the watermarked block on the reconstructed image quality in this algorithm. To reduce the effect of watermark embedding on video image quality as much as possible, this paper adopts the block with size 8 × 8. shows the watermarked image and the difference image between original and watermarked images. It can be seen from that before and after watermark embedding, the naked eye cannot distinguish the difference, and there is almost no difference by observing the difference image. Therefore, the algorithm achieves a good subjective effect.
Figure 16 The relationship between the sizes of the watermarked blocks and the reconstructed image quality
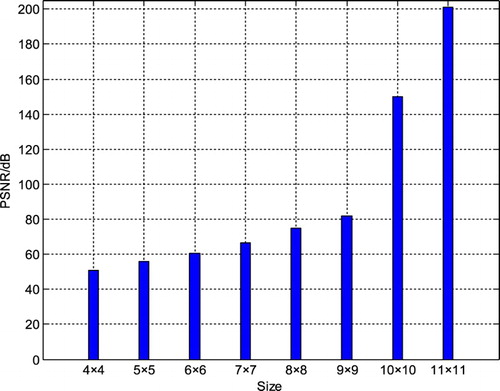
Figure 17 The performance of anti-HEVC recompression video watermarking: (a) original video frame, (b) watermarked frame, and (c) difference image

To test the performance of the algorithm mentioned in this paper, we adopt different QPs (22, 28, 32, 36, 40, 44, and 48) to perform HEVC video compression on watermarked video sequences. Then, the compressed stream is decoded, and the watermark is extracted. At the same time, NC coefficients are used to evaluate the performance of watermark against HEVC recompression. The experimental results are shown in .
Table 3 Experimental results of the anti-HEVC compression watermarking algorithm under different compression parameters
shows the watermarked reconstructed image and the extracted watermark under different HEVC compression parameters. It can be seen from and that with the increase of QP, the PSNR of the reconstructed image after compression is getting smaller, which means the subjective quality is getting worse. However, the extracted watermark is not affected. That is, the anti-HEVC video watermarking algorithm proposed in this paper shows excellent performance in resisting HEVC recompression.
Figure 18 Anti-HEVC recompression test: (a) watermarked reconstructed frame (QP = 28), (b) the watermark extracted from (a), (c) watermarked reconstructed frame (QP = 44), and (d) the watermark extracted from (c)

To further test the performance of the anti-HEVC recompression video watermarking algorithm proposed in this paper, this paper also carries out noise test experiment, such as salt and pepper noise with different intensities of 0.1, 0.01, 0.001, and 0.0001, and Gaussian noise with mean value of 0 and variances of 0.1, 0.01, 0.001, and 0.0001, respectively. Then, the watermark is extracted, and the NC coefficient of the extracted watermark is calculated. The experimental results are shown in . It can be seen from the data in that the proposed algorithm can resist some common noise attacks with good robustness.
Table 4 Experimental results under different noise types and intensities
5. CONCLUSION
In this paper, a video watermarking algorithm in the HEVC compression domain and an anti-HEVC recompression video watermarking algorithm are proposed. In the video watermarking algorithm based on the HEVC compression domain, the watermark data are preprocessed by APBT to increase the watermark embedding capacity by more than threefold. The watermark embedding algorithm has little effect on video quality and can restore reconstructed video losslessly in the extraction. Based on APBT and SVD, an anti-HEVC recompression video watermarking algorithm is proposed and can effectively resist HEVC compression. Even when QP is larger than 40, the effect on the quality of reconstructed watermark is also small. In addition, the algorithm also has a good performance in resisting noise.
In the future work, some improvements can be achieved: (1) Speed-up algorithm should be utilized to improve the efficiency of the proposed algorithm. Based on GPU parallel computing technology, the APBT-based HEVC video watermarking algorithm proposed in this paper can be improved to realize HEVC video watermarking based on parallel APBT. (2) To make the application of HEVC video watermarking more extensive and practical, on the basis of the video watermarking algorithm mentioned in this paper, we can select some feature points in the video for the watermark embedding, which can further reduce the effect of watermark on video quality. (3) More experiments on content-based attacks should be executed for comprehensive robustness assessments.
Acknowledgement
The authors thank Yunpeng Zhang and Heng Zhang for their kind help and valuable suggestions in revising this paper.
ORCID
Chengyou Wang http://orcid.org/0000-0002-0901-2492
Rongyang Shan http://orcid.org/0000-0003-2780-6947
Xiao Zhou http://orcid.org/0000-0002-1331-7379
Additional information
Funding
Notes on contributors

Chengyou Wang
Chengyou Wang received his BE degree in electronic information science and technology from Yantai University, China, in 2004, and his ME and PhD degrees in signal and information processing from Tianjin University, China, in 2007 and 2010, respectively. He is currently an associate professor and supervisor of postgraduate students with Shandong University, Weihai, China. His current research interests include digital image/video processing and analysis, computer vision, machine learning, and wireless communication technology. E-mail: [email protected]

Rongyang Shan
Rongyang Shan received his BE degree in communication engineering from Shandong University, Weihai, China, in 2014, and his ME degree in signal and information processing from Shandong University, China, in 2017. He currently works in the Beijing Jingdong Century Trading Co., Ltd., Beijing, China. His research interests include image/video transform coding, parallel computing, and video watermarking. E-mail: [email protected]

Xiao Zhou
Xiao Zhou received her BE degree in automation from Nanjing University of Posts and Telecommunications, China, in 2003; her ME degree in information and communication engineering from Inha University, Korea, in 2005; and her PhD degree in information and communication engineering from Tsinghua University, China, in 2013. She is currently a lecturer and supervisor of postgraduate students with Shandong University, Weihai, China. Her current research interests include wireless communication technology, digital image processing, and computer vision.
Reference
- ISO/IEC, “Information technology – High efficiency coding and media delivery in heterogeneous environments – part 2: High efficiency video coding,” ISO/IEC 23008-2: 2015, Aug. 2015 .
- K. Ogawa and G. Ohtake, “Watermarking for HEVC/H.265 stream,” in Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, Jan. 9–12, 2015, pp. 102–3.
- S. Gaj, A. Kanetkar, A. Sur, and P. K. Bora, “Drift-compensated robust watermarking algorithm for H.265/HEVC video stream,” ACM Trans. Multimedia Comput. Commun. Appl., Vol. 13, no. 1, 24 pages, Jan. 2017, article no. 11. doi: 10.1145/3009910
- S. Rawat and B. Raman, “A chaotic system based fragile watermarking scheme for image tamper detection,” AEU Int. J. Electron. Commun., Vol. 65, no. 10, pp. 840–7, Oct. 2011. doi: 10.1016/j.aeue.2011.01.016
- W. Wang, J. Dong, and T. N. Tan, “Exploring DCT coefficient quantization effects for local tampering detection,” IEEE Trans. Inf. Forensic. Secur., Vol. 9, no. 10, pp. 1653–66, Oct. 2014. doi: 10.1109/TIFS.2014.2345479
- Q. B. Sun, D. J. He, Z. S. Zhang, and Q. Tian, “A secure and robust approach to scalable video authentication,” in Proceedings of the IEEE International Conference on Multimedia and Expo, Baltimore, MD, USA, Jul. 6–9, 2003, Vol. 2, pp. 209–12.
- G. Qiu, P. Marziliano, A. T. S. Ho, D. J. He, and Q. B. Sun, “A hybrid watermarking scheme for H.264/AVC video,” in Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, Aug. 23–26, 2004, Vol. 4, pp. 865–8.
- X. Gong, and H. M. Lu, “Robust perceptual image hashing based temporal synchronization for watermarked H.264 frames,” in Proceedings of the 5th International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kyoto, Japan, Sept. 12–14, 2009, pp. 153–6.
- T. Y. Kuo, Y. C. Lo, and C. I. Lin, “Fragile video watermarking technique by motion field embedding with rate-distortion minimization,” in Proceedings of the 4th International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Harbin, China, Aug. 15–17, 2008, pp. 853–6.
- M. Fallahpour, S. Shirmohammadi, M. Semsarzadeh, and J. Y. Zhao, “Tampering detection in compressed digital video using watermarking,” IEEE Trans. Instrum. Meas., Vol. 63, no. 5, pp. 1057–72, May 2014. doi: 10.1109/TIM.2014.2299371
- X. M. Qian, H. Wang, and X. S. Hou, “Video text detection and localization in intra-frames of H.264/AVC compressed video,” Multimedia Tools Appl., Vol. 70, no. 3, pp. 1487–1502, Jun. 2014. doi: 10.1007/s11042-012-1168-z
- J. Zhang, A. T. S. Ho, G. Qiu, and P. Marziliano, “Robust video watermarking of H.264/AVC,” IEEE Trans. Circuits Syst. II Express Briefs, Vol. 54, no. 2, pp. 205–9, Feb. 2007. doi: 10.1109/TCSII.2006.886247
- P. C. Chang, K. L. Chung, J. J. Chen, C. H. Lin, and T. J. Lin, “A DCT/DST-based error propagation-free data hiding algorithm for HEVC intra-coded frames,” J. Vis. Commun. Image Represent., Vol. 25, no. 2, pp. 239–53, Feb. 2014. doi: 10.1016/j.jvcir.2013.10.007
- T. Dutta and H. P. Gupta, “A robust watermarking framework for high efficiency video coding (HEVC) – Encoded video with blind extraction process,” J. Vis. Commun. Image Represent., Vol. 38, pp. 29–44, Jul. 2016. doi: 10.1016/j.jvcir.2015.12.007
- J. J. Wang, R. D. Wang, D. W. Xu, and W. Li, “An information hiding algorithm for HEVC based on angle differences of intra prediction mode,” J. Softw., Vol. 10, no. 2, pp. 213–21, Feb. 2015. doi: 10.17706/jsw.10.2.213-221
- L. P. Van, J. D. Praeter, G. V. Wallendael, J. D. Cock, and R. V. D. Walle, “Out-of-the-loop information hiding for HEVC video,” in Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, Sept. 27–30, 2015, pp. 3610–4.
- S. B. Li, L. R. Wang, P. Liu, and Y. F. Huang, “A HEVC information hiding approach based on motion vector space encoding,” Chin. J. Comp., Vol. 39, no. 7, pp. 1450–63, Jul. 2016.
- J. Xu, R. D. Wang, M. L. Huang, J. J. Wang, and D. W. Xu, “An information hiding algorithm for HEVC based on intra-prediction modes and Hamming + 1,” J. Comput. Inf. Syst., Vol. 11, no. 15, pp. 5587–98, Aug. 2015.
- J. Xu, R. D. Wang, M. L. Huang, Q. Li, and D. W. Xu, “A data hiding algorithm for HEVC based on the differences of intra prediction modes,” J. Optoelectron. Laser, Vol. 26, no. 9, pp. 1753–60, Sept. 2015.
- C. T. Cai, G. Feng, C. Wang, and X. Han, “Robust video watermarking algorithm for HEVC based on intra-frame prediction modes of muli-partitioning,” J. Comp. Appl., Vol. 37, no. 6, pp. 1772–6, Jun. 2017.
- T. Dutta and H. P. Gupta, “An efficient framework for compressed domain watermarking in P frames of high-efficiency video coding (HEVC) – Encoded video,” ACM Trans. Multimedia Comput. Commun. Appl., Vol. 13, no. 1, pp. 1–24, Jan. 2017, article no. 12. doi: 10.1145/3002178
- M. Mohamed, F. B. Abdallah, L. Abdi, and A. Meddeb, “Integration of a robust watermark scheme in a high efficiency codec H.265/HEVC with capacity-quality-bitrate trade-off,” in Proceedings of the 13th International Conference on Advances in Mobile Computing and Multimedia, Brussels, Belgium, Dec. 11–13, 2015, pp. 375–9.
- S. Gaj, A. Sur, and P. K. Bora, “A robust watermarking scheme against re-compression attack for H.265/HEVC,” in Proceedings of the 5th National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics, Patna, Bihar, India, Dec. 16–19, 2015, pp. 1–4, article no. 7490065.
- S. Gaj, S. Rana, A. Sur, and P. K. Bora, “A drift compensated reversible watermarking scheme for H.265/HEVC,” in Proceedings of the IEEE 18th International Workshop on Multimedia Signal Processing, Montreal, QC, Canada, Sept. 21–23, 2016, pp. 1–6, article no. 7813358.
- A. A. Elrowayati and M. F. L. Abdullah, “Survey and analysis of digital watermarking algorithms on HEVC video coding standard,” in Proceedings of the International Conference on Network Security and Communication Engineering, Hong Kong, China, Dec. 25–26, 2014, pp. 193–6.
- Z. X. Hou, C. Y. Wang, and A. P. Yang, “All phase biorthogonal transform and its application in JPEG-like image compression,” Signal Process. Image Commun., Vol. 24, no. 10, pp. 791–802, Nov. 2009. doi: 10.1016/j.image.2009.08.002
- L. Q. Chen, X. Y. Sun, M. Lu, and C. Shao, “Contourlet watermarking algorithm based on Arnold scrambling and singular value decomposition,” J. Southeast Univ. (Engl. Ed.), Vol. 28, no. 4, pp. 386–91, Dec. 2012.
- R. Y. Shan, X. Zhou, C. Y. Wang, and B. C. Jiang, “All phase discrete sine biorthogonal transform and its application in JPEG-like image coding using GPU,” KSII Trans. Internet Inf. Syst., Vol. 10, no. 9, pp. 4467–86, Sept. 2016.
- J. Sole, R. Joshi, N. Nguyen, T. Y. Ji, M. Karczewicz, G. Clare, F. Henry, and A. Duenas, “Transform coefficient coding in HEVC,” IEEE Trans. Circuits Syst. Video Technol., Vol. 22, no. 12, pp. 1765–77, Dec. 2012. doi: 10.1109/TCSVT.2012.2223055