
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
With the rapid development of cloud computing technology, more and more users choose to outsource image data to clouds. To protect users’ privacy and guarantee data’s confidentiality, images need to be encrypted before being outsourced to CSP, but this brings new difficulties to some basic yet important data services, such as content-based image retrieval (CBIR). In this paper, a privacy-preserving image retrieval method based on an improved BoVW model is proposed. An improved BoVW method based on Hamming embedding can provide binary signatures that refine the matching based on visual words; therefore, retrieval precision is improved significantly; orthogonal transformation is utilized to implement privacy-preserving image retrieval, where image features are divided into two different fields with orthogonal decomposition, for which encryption and distance comparison are executed separately, and two kinds of operation results are fused in the final vector with orthogonal composition. As a result, cloud server can extract components from encrypted features directly and compare distance with those of query image, without violating the privacy of images and features. Any algorithm can be used to encrypt features, which enhance the practicability of the proposed method. The security analysis and experimental results prove its security and retrieval performance.
1. INTRODUCTION
Along with the development of cloud computing technology, public cloud service can provide unlimited storage space and computing ability for massive multimedia. At the same time, it brings serious security problems because data owners lose physical control of data while CSP (cloud service provider) is considered “honest but curious”, which means that it may lead to unauthorized access to data and cause leakage of personal privacy [Citation1–3]. Given such circumstance, data must be encrypted before being outsourced to the CSP to protect its confidentiality. Although data security can be guaranteed by encryption, it also brings many new challenges to data management and data sharing service, such as image retrieval. Content-based image retrieval (CBIR) is a very promising method in image retrieval field which is characterized by extracting image features and comparing the distance between features automatically, and it has grown rapidly and made progresses in both the derivation of new features and the construction of signatures based on these features [Citation4–6]. However, conventional CBIR methods cannot be applied under cloud environment directly because encrypted data fail to preserve the distance between feature vectors. If users want to retrieve images from CSP, encrypted image need to be decrypted first, then retrieval can be operated on plaintext, which makes the sensitive information being exposed to attackers, breaks privacy, and hence is not desired. Therefore, it is important to develop technologies of CBIR over encrypted domain, which is also called private/privacy-preserving CBIR (PCBIR) [Citation7–9].
Many advances have been achieved in image retrieval over cryptographic domain. Early technology mainly originated from retrieval on text document for example, Song et al. [Citation10] proposed a ciphertext scanning method based on streaming cipher to make sure whether the search term exists in the ciphertext; Boneh et al. [Citation11] proposed a keyword search method based on public-key encryption; Swaminathan et al. [Citation12] ranked the order the documents securely and extracted the most relevant documents from an encrypted collection; Cao et al. [Citation13] proposed privacy-preserving multi-keyword ranked search over encrypted data. Although these methods can be extended to image retrieval based on user-assigned tags, extension to CBIR is not straightforward. CBIR typically relies on comparing the distance of image features, but comparing similarity among high-dimensional vectors using cryptographic primitives is challenging.
Recently, several methods have been proposed to solve the problem of PCBIR. Lu et al. [Citation14] proposed three distance-preserving methods: bit plane randomization, random projection, and random unary encoding, which are applied on low-level features such as color histogram. Karthik et al. [Citation15] proposed a transparent privacy-preserving hash method, which keeps the statistical rules of encrypted AC coefficients but ignores the spatial information distribution of the image. Xu et al. [Citation16] proposed a secure retrieval method for JPEG images, which preserves the distribution of the AC coefficients and the statistical rule of color after the decoding of encrypted images. Ferreira et al. proposed a method in [Citation17], where color information is encrypted by deterministic encryption techniques to support color-feature-based CBIR, and texture information is encrypted by probabilistic encryption algorithms for better security. Zhang et al. [Citation18] use Pallier encryption algorithm to protect some lower level features such as color, texture, and shape, and achieve secure retrieval effects. Some local-feature-based PCBIR methods are also proposed. Hsu et al. [Citation19] put forward a homomorphic encryption-based secure SIFT method which has good security at the cost of serious ciphertext extensions. Xia et al. [Citation20] proposed to use SIFT features and transform earth mover’s distance (EMD) in a way that the cloud server can evaluate the similarity between images without learning sensitive information. Huang et al. [Citation21] convert the high-dimensional VLAD descriptors to compact binary codes, and then adapt the asymmetric scalar-product-preserving encryption to design PCBIR to achieve the privacy requirements in the cloud environment. In contrast with global feature approaches, local-feature-based PCBIR methods achieve higher retrieval accuracy, but it requires quite complex methods to implement distance preserving, which is not suitable for large-scale image retrieval under cloud environment.
It should be noted that the above research results are all relying on specific encryption methods, such as shuffling and homomorphic encryption, which limit its universality. For example, homomorphic encryptions are too computation- and communication-intensive to be used in low-profile devices and large-scale systems, while shuffling is not suitable for some situations that have high requirements to security. Besides, these methods are all relying on global features or local features to evaluate the similarity of images, whose retrieval accuracy can hardly meet requirements of practical applications because of “semantic gap” between the visual features and the richness of human semantics [Citation22]. Aiming to solve these problems, we propose a privacy-preserving image retrieval method under cloud environment in this paper, where an improved BoVW model is employed to improve retrieval precision, orthogonal transformation is combined together to implement privacy-preserving retrieval under cloud environment. An improved BoVW method based on Hamming embedding can provide binary signatures that refine the matching based on visual words; therefore, retrieval precision is improved significantly; orthogonal transformation are used to divide features into two different domains, for which encryption and distance comparison are executed separately. As a result, cloud server can extract components from encrypted features directly and compare distance with those of query image, without violating the privacy of images and features. Because the encryption operation and distance comparison operation are independent, any algorithm can be used to encrypt features, which enhance the practicability of the proposed method. The experimental results prove its effectiveness and security.
The organization of this paper is as follows: Chapter 2 introduces system architecture and preliminaries; Chapter 3 proposes our scheme. Chapter 4 provides experimental results and performance analysis, and Chapter 5 presents conclusions.
2. SYSTEM ARCHITECTURE AND PRELIMINARIES
2.1 System Architecture
The system model used in this paper is given in Figure .
Figure 1: System model of the proposed method
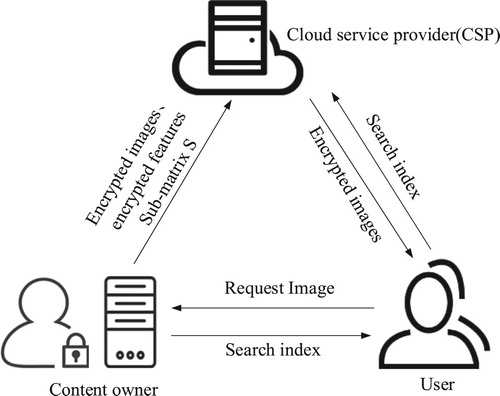
There are three entities involved in this model: content owner, CSP, and user. Content owner trains visual dictionaries, extracts features from images, and constructs search index, which are then encrypted together with images and outsourced to the CSP. CSP stores cipher images and secure index and performs image retrieval when receiving user request. Users send retrieval request to content owner and CSP, decrypt cipher-images returned by CSP, and get requested images.
2.2 Preliminaries
2.2.1 BoVW Algorithm
Bag of visual words (BoVW) model is extended from natural language processing and information retrieval field to computer vision in [Citation23]. Descriptors are quantized into visual words with the k-means algorithm, and then image can be represented by the frequency histogram of visual words obtained by assigning each descriptor of the image to the closest visual word. Fast access to the frequency vectors is achieved by an inverted file system. BoVW has been successfully adopted to enable fast indexing and retrieval of large image collections [Citation24]. The retrieval process consists of four steps: image content is described by means of a set of visual descriptors such as SIFT and SURF.; descriptors are clustered into visual words which form a vocabulary; descriptors are compared and assigned to one or more visual words so as to map the image into a histogram of visual word frequencies; images with the closest histogram distance will be returned as retrieval results.
Although BoVW has shown good performance in image retrieval task, it still suffers from some problems, such as insufficient discriminative power of visual words, quantization error caused by assigning descriptors to visual words, and low efficiency caused by comparing distance between high dimensions of vectors. Many methods are proposed to improve the performance of BoVW, such as [Citation25,Citation26]. Among these methods, [Citation27] is the one that achieves higher accuracy for large-scale image search based on Hamming embedding (HE). The main idea of HE is to select low number of centroids k in k-means clustering to form a rough visual dictionary and refine the quantized index (
) (the index of the centroid closest to the descriptor
) with those of a db-dimensional binary signature, thus the Euclidean distance between two descriptors can be mapped into the Hamming distance, and mismatch points can be removed by setting proper threshold; thus, retrieval performance is improved. This method includes four steps:
Assign descriptors x to their closest centroid, resulting in
; project x by means of a
Compute the signature
Use HE matching function to match the distance of
Given a query image represented by its local descriptor
2.2.2 Distance-Preserving Method Based on Orthogonal Transformation
Orthogonal transformation is a kind of vector representation method that consists of two processes: orthogonal decomposition and orthogonal composition. Any vector can be expressed as a sum of a set of component coefficients by orthogonal decomposition, and component coefficients are fused into one composite vector by orthogonal composition.
Suppose vector , orthogonal matrix
, then
can be expressed as follows:
(5)
(5)
Vector
can be expressed as follows:
(6)
(6)
If we divide
into two sub-matrix
and
, then
is divided into
correspondingly, and we can obtain the following:
(7)
(7)
If encryption is operated on
and feature is extracted from
, respectively, then we can obtain the following:
(8)
(8)
Two different operations will be independent and will not interfere with each other because of the independence of the orthogonal decomposition, while two kinds of operation results are fused in final vector
because of the fusion of the orthogonal composition. We can also obtain the following:
(9)
(9)
(10)
(10)
From these equations, we can see that features can be extracted from encrypted vectors directly, and the distance between the component vectors is similar to the one between the original vectors because of the distance-preserving characteristic of the orthogonal transformation.
3. THE PROPOSED METHOD
Based on algorithms mentioned in Section 2, we proposed a privacy-preserving CBIR method combined with an improved BoVW model and orthogonal transformation.
The specific retrieval process is given as follows:
3.1 Configuration Stage
In configuration stage, visual dictionary, encryption/ decryption key, and Gaussian orthonormal matrix are constructed for later usage.
3.2 Content Owner Side
Data owner uploads cipher-images and corresponding secure image index to CSP.
3.3 User Side
User sends query request to the data owner. After identity authentication, owner sends secure parameters (R, S, P,
3.4 CSP Side
CSP obtains sub-matrix S content data owner securely, operates orthogonal decomposition on encrypted feature
4. EXPERIMENTAL RESULTS
In this chapter, we present an experimental evaluation of the proposed method and compare retrieval results with several classical privacy-preserved image retrieval methods, including random projection, bit-plane randomization, and randomized unary encoding proposed in [Citation14], Pallier algorithm put forward in [Citation19]. We perform experiment on INRIA Holidays dataset [Citation28] containing 1491 images, which are divided into 500 queries and 991 corresponding relevant images. The performance of our scheme is evaluated in terms of security and retrieval performance.
4.1 Security
The orthogonal decomposition is implemented on image features instead of images, and images can be encrypted by any encryption method. We use AES-128 encryption algorithm to encrypt images. Even with the most powerful biclique attacks, the computational complexity is , which means the security of AES will not be broken. For the encrypted features, since S is known by CSP, and as a sub-matrix of B, R, and S are not completely independent, so there is a potential secure problem. The complexity of attack B and R in the case of known the sub-matrix S is as follows:
(14)
(14)
(15)
(15)
where the size of B is n, element of B is k-bit fixed word-length integer, m is the number of columns of the sub-matrix S, and
is a factor that includes the efficiency improvement achieved over an exhaustive search by using a different algorithm. Therefore, the complexity of attacking B and attacking R tend to O(
) and O(
), which means even if orthogonal sub-matrix S is known, the computational complexity of attacking the orthogonal matrix B and the orthogonal sub-matrix R is exponentially increasing; therefore, the security of features can also be guaranteed.
Three different metrics are used to evaluate the security of features: autocorrelation function, information entropy, and histogram distribution.
(1) Autocorrelation function
The autocorrelation function of a feature vector measures how correlated the neighboring feature elements are [Citation29]. Suppose n is the size of feature vectors, T is the delay of signals, then the autocorrelation function R(T) is calculated as follows:
(16)
(16)
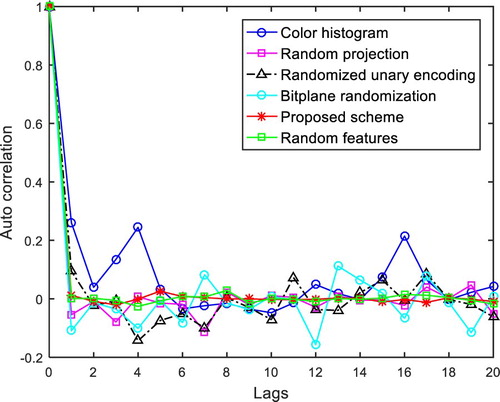
The autocorrelation function for the raw color histogram, randomized features of three different retrieval methods of Lu, random uniform vector, and the encrypted features using algorithm proposed in this paper are shown in Figure . We can see that the raw color feature has non-negligible correlation, which indicates there exists strong association between adjacent vectors, while our method has similar autocorrelation as random features encrypted by Pallier algorithm and is much lower than Lu’s three methods, which shows encrypted features using our method has low autocorrelation thus has good confidentiality.
Figure 2: Autocorrelation function on different algorithms
(2) Information entropy
Information entropy describes the uncertainty of random variables. A higher entropy of encrypted features means that it has a distribution closer to uniform, thus higher randomness and higher security. The entropy is defined as follows:
(17)
(17)
where
is the feature, n is the length of
,
is the probability of
. A higher entropy of encrypted features means it has a distribution closer to uniform, thus higher randomness and higher security. The entropy of encrypted features for different algorithm is given in Table .
Table 1: Entropy for different methods
From this table, we can see that both the color histogram and visual words have low entropy, which means that there is strong inherent correlation among feature values. The features encrypted by the proposed method achieve higher entropy than Lu’s three methods but lower than uniform random features encrypted by Pallier’s algorithm. Although its security is not as good as features encrypted by complex homomorphic algorithm, its time complexity consumed by encryption is much lower than Pallier’s algorithm; therefore, it is a more practical method.
(3) Histogram distribution
Histogram distribution is usually employed to evaluate security of encrypted data. In the proposed method, secure image index of each image is outsourced to CSP, which consists of two parts: ),
means the encrypted cluster centers that feature
belonging to;
means the encrypted binary signature of xj. The CSP can obtain only the frequency histogram distribution of encrypted visual words, but it can hardly acquire image features from its encrypted binary signature. Therefore it is difficult for the CSP to only use frequency histogram distribution to recover the image features and infer the image content without correct decryption key.
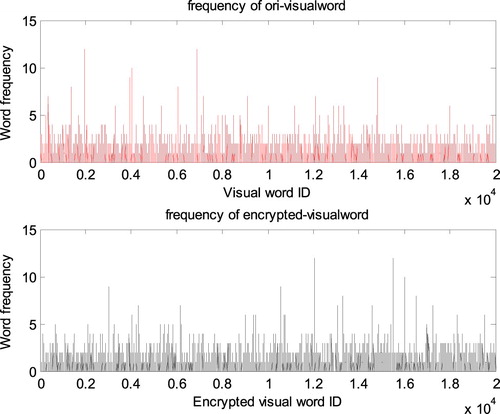
Figure shows the comparative results of frequency histogram distribution between the encrypted visual words and the original visual words of an image. From Figure , we can see that the histogram of encrypted visual words is different from that of original visual words, and it is difficult for attackers to infer the image content information only through frequency histogram distribution of the encrypted visual words.
Figure 3: The comparative results of histogram distribution
4.2 Analysis of Time Complexity
Assume the size of the selected operation data X is n, the dimension of sub-matrix S is k(k < n), g is the number of bit-planes to randomize, m is the dimension of projected features, M is the eigenvector of the feature vector, then the time complexity comparison results with other methods are given in Table .
Table 2: Time complexity comparison of different methods
From Table , we can see that the time complexity of the Pallier homomorphism method is the highest; Randomized unary encoding is higher; the proposed method is lower than these methods and similar to random projection proposed by Lu.
4.3 Retrieval Precision
Retrieval precision is evaluated by mean average precision (mAP) that is widely used to measure image retrieval performance for a group of queries [Citation30]. It is defined as follows:
(18)
(18)
where Q is the number of queries, avePq represents the average value of all the precisions measured each time a new relevant image is retrieved. In this experiment, a group of 500 query images are retrieved in a database containing 991 images, and the MAP of query images for different encryption methods are computed as Table shows.
Table 3: mAP for different methods
From the table, we can see that the retrieval result of our scheme is much better than those of other methods. Meanwhile, we also compute the mAP of the unencrypted HE method, and its MAP is 80.59 which is roughly equal to the result of our encrypted scheme, namely, our method can hardly reduce retrieval accuracy of original HE.
Through the above analysis of retrieval performance, it is proved that the proposed method has a good trade-off between security and retrieval performance, it not only guarantees the security of retrieval in cloud environment but also ensures the high precision of retrieval for practical applications.
5. CONCLUSION
A privacy-preserving image retrieval method based on improved BoVW model in cloud computing is proposed in the paper. An improved BOVW method based on Hamming embedding which provides binary signatures refining visual words are combined with orthogonal transformation to achieve privacy-preserving image retrieval under cloud environment. Experiments show that our scheme has obvious advantages in security and retrieval precision compared with other methods. Future research will focus on exploring retrieval efficiency further.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors

Jiaying Gong
Jiaying Gong received her master’s degree in communication and information system from the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, China. Her research interest is multimedia information security. E-mail: [email protected]

Yanyan Xu
Yanyan Xu is a professor of the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, China. Her main research interests include cloud computing security and big data privacy protection, multimedia network communications.

Xiao Zhao
Xiao Zhao is a master’s degree candidate of communication and information system in the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, China. His research interests include multimedia information security and multimedia network communication. E-mail: [email protected]
References
- S. Subashini, and V. Kavitha, “A survey on security issues in service delivery models of cloud computing,” J. Netw. Comp. Appl., Vol. 34, no. 1, pp. 1–11, 2011. doi: 10.1016/j.jnca.2010.07.006
- L. Ferretti, F. Pierazzi, M. Colajanni, and M. Marchetti, “Security and confidentiality solutions for public cloud database services,” in Proceedings of the Seventh International Conference on Emerging Security Information, Systems and Technologies, 2013.
- R. Huang, X. Gui, S. Yu, and Z. Wei, “Study of privacy-preserving framework for cloud storage,” Comp. Sci. Inf. Syst. Vol. 8, no. 3, pp. 801–19, 2011. doi: 10.2298/CSIS100327029R
- R. Datta, D. Joshi, J. Li, and J. Z. Wang, “Image retrieval: ideas, influences, and trends of the new age,” ACM Comput. Surv. Vol. 40, no. 2, pp. 5–60, 2008. doi: 10.1145/1348246.1348248
- Y. Liu, D. Zhang, L. Lu, and W. Ma, “A survey of content-based image retrieval with high-level semantics,” Pattern Recogn. Vol.40, pp. 262–282, 2007. doi: 10.1016/j.patcog.2006.04.045
- J. Wang, T. Li, Y-Q. Shi, S. Lian, and J. Ye, Forensics feature analysis in quaternion wavelet domain for distinguishing photographic images and computer graphics. Multimed Tools Appl., 76, no. 22, pp. 23721–37, 2017. doi: 10.1007/s11042-016-4153-0
- J. Shashank, P. Kowshik, K. Srinathan, and C. V. Jawahar, “Private content based image retrieval,” in Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, 2008, pp. 1–8.
- W. Lu, A. L. Varna, and M. Wu, “Confidentiality-preserving image search: a comparative study between homomorphic encryption and distance-preserving randomization,” IEEE Access, Vol. 2, pp. 125–41, 2014. doi: 10.1109/ACCESS.2014.2371994
- L. Weng, L. Amsaleg, A. Morton, and S. Marchand-Maillet, “A privacy-preserving framework for large-scale content-based information retrieval,” IEEE Trans. Inf. Forensics Secur., Vol. 10, no.1, pp. 152–67, 2015. doi: 10.1109/TIFS.2014.2365998
- D. X. Song, D. Wagner, and A. Perrig. “Practical techniques for searches on encrypted data,” in Proceedings of the 2000 IEEE Symposium on Security and Privacy, 2000, pp. 44–55.
- D. Boneh, G. Di Crescenzo, R. Ostrovsky, and G. Persiano, “Public key encryption with keyword search,” in Proceedings of the International Conference On the Theory and Applications of Cryptographic Techniques, Springer, Berlin, 2004, pp. 506–22.
- A. Swaminathan, et al., “Confidentiality-preserving rank-ordered search,” in Proceedings of the 2007 ACM Workshop on Storage security and Survivability, 2007, pp. 7–12.
- N. Cao, C. Wang, M. Li, K. Ren, and W. Lou, “Privacy-preserving multi-keyword ranked search over encrypted cloud data, “ IEEE Trans. Parallel and Distributed Syst., Vol. 25, no.1, pp. 222–33, 2014. doi: 10.1109/TPDS.2013.45
- W. Lu, A. L. Varna, A. Swaminathan, and M. Wu, “Secure image retrieval through feature protection,” in Proceedings of the IEEE Conference on Acoustics, Speech Signal Processing, 2009, pp. 1533–6.
- K. Karthik, and S. Kashyap, “Transparent hashing in the encrypted domain for privacy preserving image retrieval,” Signal Image Video Process, Vol. 7, no.4, pp. 647–64, 2013. doi: 10.1007/s11760-013-0471-0
- Y. Xu, J. Gong, L. Xiong, Z. Xu, J. Wang, and Y-Q. Shi, “A privacy-preserving content-based image retrieval method in cloud environment,” J Vis Commun Image Represent, Vol. 43, pp. 164–72, 2017. doi: 10.1016/j.jvcir.2017.01.006
- B. Ferreira, J. Rodrigues, J. Leitao, and H. Domingos, “Privacy-preserving content-based image retrieval in the cloud,” in Proceedings of the IEEE 34th Symposium on Reliable Distributed Systems (SRDS), 2015, pp. 11–20.
- L. Zhang, T. Jung, C. Liu X. Ding, X-Y. Li, and Y. Liu, “Pop: privacy-preserving outsourced photo sharing and searching for mobile devices,” in Proceedings of the IEEE 35th International Conference on Distributed Computing Systems (ICDCS), 2015, pp. 308–17.
- Z. Xia, Y. Zhu, X. Sun, Z. Qin, and K. Ren, “Towards privacy-preserving content-based image retrieval in cloud computing,” IEEE Trans. Cloud Comput., Vol. 6, pp. 276–86, 2018. doi: 10.1109/TCC.2015.2491933
- K. Huang, M. Xu, S. Fu, and D. Wang, “Efficient privacy-preserving content-based image retrieval in the cloud,” in Proceedings of the International Conference on Web-Age Information Management. Springer International Publishing, 2016, pp. 28–39.
- J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman, “Object retrieval with large vocabularies and fast spatial matching,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2007, pp. 1–8.
- C. Wang, L. Zhang, and H. J. Zhang, “Learning to reduce the semantic gap in web image retrieval and annotation,” in Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 2008, pp. 355–62.
- C. Y. Hsu, C. S. Lu, and S. C. Pei, “Image feature extraction in encrypted domain with privacy-preserving SIFT,” IEEE Trans Image Process, Vol. 21, no.11, pp. 4593–607, 2012. doi: 10.1109/TIP.2012.2204272
- S. Avila, N. Thome, M. Cord, E. Valle, and A. de A. Araújo, “Bossa: extended bow formalism for image classification,” in Proceedings of the 18th IEEE International Conference on Image Processing (ICIP), 2011, pp. 2909–12.
- C. Wengert, M. Douze, and H. Jégou. “Bag-of-colors for improved image search,” in Proceedings of the 19th ACM International Conference on Multimedia, 2011, pp. 1437–40.
- J. Yang, J. Liu, and Q. Dai. “An improved bag-of-words framework for remote sensing image retrieval in large-scale image databases,” International Journal of Digital Earth, Vol. 8, no. 4, pp. 273–92, 2015, doi: 10.1080/17538947.2014.882420
- H. Jegou, M. Douze, and C. Schmid. “Hamming embedding and weak geometric consistency for large scale image search,” Computer Vision–ECCV 2008, Vol. 5302, pp. 304–17, 2008. doi: 10.1007/978-3-540-88682-2_24
- http://lear.inrialpes.fr/people/jegou/data.php
- S. Haykin. “Nonlinear methods of spectral analysis,” Optica Acta International Journal of Optics, Vol. 27, no. 2, 142, 1979.
- H. Müller, and W. Müller, D M G. Squire, S. Marchand-Maillet, and T. Pun, “Performance evaluation in content-based image retrieval: overview and proposals,” Pattern Recognition Letters, Vol. 22, no. 5, pp. 593–601, 2001. doi: 10.1016/S0167-8655(00)00118-5