Résumé
Cette étude compare, pour la région sud du Québec (Canada), différents estimateurs des courbes intensité–durée–fréquence (IDF) basés sur les séries de durées partielles (SDP) et sur celles des maximums annuels (SMA). Deux modèles ont été considérés pour les SMA, le premier utilisant un paramètre local (SMA-1), et le second utilisant deux paramètres locaux (SMA-2). Pour les SDP, les séries ont été construites en fixant, d'une part, un seuil régional (SDP-1) et, d'autre part, le nombre moyen régional de dépassements du seuil (SDP-2). Les quantiles et les intervalles de confiance à 90% des différents modèles ont été estimés et comparés. Le modèle SDP-1 a été finalement retenu puisque, d'après la littérature, il conviendrait à une région comme celle sous étude dont l'hétérogénéité est raisonnable. Par ailleurs, le modèle SDP-1 reproduit relativement bien les quantiles et probabilités empiriques. Les quantiles générés, à chaque site, par ce modèle régional sont comparés à ceux obtenus à partir d'un modèle SDP local.
Citation Kingumbi, A. & Mailhot, A. (2010) Courbes Intensité–Durée–Fréquence (IDF): comparaison des estimateurs des durées partielles et des maximums annuels. Hydrol. Sci. J. 55(2), 162–176.
This study compares, for the southern region of Quebec (Canada), different estimators of intensity–duration–frequency (IDF) curves based on the partial duration series (SDP) or series of annual maxima (SMA). Two models were considered for the SMA, the first one with one local parameter (SMA-1), and the second with two local parameters (SMA-2). For the SDP, the series were built defining, in one case, a regional threshold (SDP-1), and in the other case, the regional average number of threshold exceedences (SDP-2). The quantiles of these models and their 90% error bounds were estimated and compared. The SDP-1 model was finally selected because, according to the literature, it would suit a region like that under study which displays reasonable heterogeneity. Furthermore, the SDP-1 model fits the empirical quantiles and probabilities relatively well. At each site, quantiles estimated by this regional model are compared to those obtained using the local SDP model.
INTRODUCTION
La conception de tout ouvrage hydraulique nécessite que soit précisé le niveau de performance souhaité. Ce niveau de performance est souvent déterminé en fonction des dommages potentiels et de la sévérité des aléas météorologiques susceptibles d'entraîner un bris, un dysfonctionnement ou un dépassement de capacité de l'ouvrage en question. Ainsi, dans le cas des infrastructures de gestion des eaux pluviales, la dimension des différentes composantes du système (par ex. conduites, bassins de rétention, etc.) est établie en fonction de la période de retour des événements de pluies intenses (Bourrier, Citation1981; Mailhot et al., Citation2006; Mohymont & Demarée, Citation2006; Segond et al., Citation2007). Cette information est souvent exprimée sous la forme de courbes Intensité–Durée–Fréquence (IDF) obtenues à partir d'une étude statistique des événements extrêmes enregistrés sur un territoire donné (voir par exemple Hogg & Carr, Citation1985).
Considérant que les séries de mesures sont souvent courtes et que les précipitations intenses sont, de par leur nature même, peu fréquentes, il est important d'utiliser au mieux l'information disponible afin d'obtenir les estimateurs les plus fiables. À cet égard, il peut être intéressant de regrouper les données de différentes stations afin d'augmenter la durée totale des séries disponibles. Un tel regroupement est possible si ces séries possèdent certaines caractéristiques statistiques communes. L'analyse fréquentielle régionale (AFR) permet un tel regroupement et définit une procédure permettant de vérifier si les conditions d'homogénéité des séries étudiées sont respectées, d'identifier la distribution “régionale” et d'en estimer les paramètres (voir Hosking & Wallis, Citation1997; St-Hilaire et al., Citation2003).
Dans le cadre de cette étude, les précipitations pour quatre durées (1, 2, 6 et 12 h) enregistrées pendant la période estivale (Mai–Octobre) sur une cinquantaine de stations du sud de la province de Québec ont été considérées. Les séries annuelles des précipitations maximales, que nous désignerons dans la suite de cet exposé par séries des maximums annuels (SMA), et les séries des valeurs supérieures à un seuil, appelées aussi séries des durées partielles (SDP), ont été utilisées. Les performances de ces deux familles d'estimateurs (basées sur les SMA et les SDP) ont été comparées en vue de déterminer le niveau relatif de performance de chacune et de sélectionner celle qui sera utilisée pour produire les courbes IDF des pluies estivales pour le sud du Québec. Une approche de régionalisation a été préconisée afin de tirer le meilleur parti des historiques disponibles aux diverses stations.
ANALYSE FREQUENTIELLE REGIONALE (AFR)
L'analyse fréquentielle régionale (AFR) comporte trois étapes principales (Alila, Citation1999; St-Hilaire et al., Citation2003): (a) l'identification des régions homogènes; (b) le choix, pour chaque région, de la distribution de probabilité régionale parente; et (c) l'estimation des paramètres de chaque distribution et des quantiles correspondant à différentes périodes de retour.
Plusieurs approches de régionalisation ont été proposées dans la littérature. Cunnane (Citation1988) et GREHYS (Citation1996) proposent une description assez détaillée des différentes approches disponibles. La procédure d'indice de crues est cependant la plus largement utilisée (Boes et al., Citation1989; Stedinger & Lu, Citation1995; Adamowski et al., Citation1996; Madsen & Rosbjerg, Citation1997; Heo et al., Citation2001; Cunderlik & Ouarda, Citation2006). Elle a été proposée par Dalrymple (Citation1960) pour l'AFR des séries des débits, d'où son appellation. Elle est cependant aussi utilisée pour d'autres types de variables, notamment les précipitations. L'indice de crues s'appuie sur l'hypothèse que les distributions aux différents sites d'une région sont similaires à un facteur de normalisation près très souvent pris comme la moyenne des données en chaque site.
MeTHODES D'ESTIMATION DES QUANTILES DES eVENEMENTS INTENSES
La caractérisation des événements intenses s'effectue généralement selon deux approches: l'approche des séries maximales annuelles (SMA) et celle des séries des durées partielles (SDP). La première utilise les séries des valeurs maximales enregistrées pendant une durée donnée (par exemple 1 h, 2 h, etc.) sur une période donnée (généralement l'année mais possiblement aussi une partie de l'année). Des procédures robustes ont été mises au point et ont été largement utilisées pour produire des courbes IDF à partir des séries hydrométéorologiques (Hosking et al., Citation1985a; Hosking & Wallis, Citation1988; Shaefer, Citation1990; Pilon & Adamowski, Citation1992; Adamowski et al.,
Citation1996; Onibon et al.,
Citation2004; Khaliq et al., Citation2006; Mailhot et al., Citation2007; Neppel et al., Citation2007). La distribution généralisée des valeurs extrêmes (“generalized extreme value”; GEV) est utilisée pour modéliser les SMA (la notation utilisée pour les paramètres des différentes distributions est similaire à celle de Hosking & Wallis, Citation1997). La fonction cumulative de la distribution GEV s'écrit:Equation(1)
avec ξ le paramètre de position (–∞ < ξ < +∞), α le paramètre d'échelle (α > 0) et k le paramètre de forme (–∞ < k < +∞). Le domaine de définition de la GEV est donné par (ξ + α/k) ≤ x< ∞ pour k < 0, –∞ < x < +∞ pour k = 0 et –∞ < x ≤ (ξ + α/k) pour k > 0.
L'approche des SDP consiste, pour sa part, à sélectionner les données supérieures à un seuil déterminé. Cette approche est nettement moins répandue que l'approche des SMA. Plusieurs études ont été cependant consacrées aux SDP (Rosbjerg, Citation1985; Buishand, Citation1989; Wang, Citation1991; Rosbjerg et al., Citation1992; Madsen & Rosbjerg, Citation1997; Madsen et al., Citation1998; Lang et al., Citation1999; Ashkar & Tatsambon, Citation2007; Ribatet et al., Citation2007) et des comparaisons ont été faites avec les estimateurs obtenus des SMA (Cunnane, Citation1973; Wang, Citation1991; Madsen et al., Citation1997a, Citation1997b). Deux principales raisons expliquent la moins grande popularité de l'approche des SDP: (a) la difficulté de sélectionner un seuil; et (b) la nécessité de s'assurer que les données extraites sont statistiquement indépendantes (voir Madsen et al., 1997a pour une discussion de ces deux points). L'avantage de cette approche par rapport à celle des SMA est que, en incluant un nombre plus important de données, elle permet, en principe, d'intégrer certains événements extrêmes qui n'auraient pas été considérés autrement dans le cadre d'une approche de type SMA. La distribution de Pareto généralisée (GPA) est généralement utilisée pour modéliser les SDP (Hosking & Wallis, Citation1987; Coles, Citation2001). La fonction cumulative de la distribution GPA est de la forme:
Le domaine des valeurs possibles de la distribution GPA est donné par ξ ≤ x ≤ ∞ pour k ≤ 0 et ξ ≤ x ≤ (ξ + α/k) pour k > 0. Le paramètre de position correspond, dans ce cas particulier, au seuil utilisé pour la construction des séries SDP. À noter qu'il est possible de dériver la distribution GEV à partir de la distribution GPA et d'ainsi établir une relation entre les paramètres de ces deux distributions (voir Madsen et al., 1997a).
Dans le cas d'une estimation régionale des quantiles, Madsen et al. (Citation1997b) ont montré que, si la région comporte un niveau réaliste d'hétérogénéité, le modèle SDP/GPA doit être favorisé comparativement au modèle SMA/GEV (une comparaison de divers estimateurs locaux des quantiles a aussi été réalisée; voir Madsen et al., 1997a). Le nombre moyen annuel de dépassements du seuil (λ) à considérer afin d'assurer la supériorité de l'estimateur SDP/GPA dépend toutefois de la valeur du facteur de forme, de la durée des historiques disponibles et de la période de retour considérée. A titre d'exemple, mentionnons que λ doit être de l'ordre de 3.6 pour assurer la supériorité des estimateurs SDP/GPA pour des périodes de retour inférieures à 100 ans dans le cas d'une région parfaitement homogène comportant une vingtaine de stations dont les historiques couvrent 30 ans et pour laquelle k ≈ –0.1 (Madsen et al., Citation1997b). Une plus grande hétérogénéité de la région favoriserait des valeurs critiques de λ plus faibles.
METHODE D'ESTIMATION DES PARAMETRES
La méthode des L-moments proposée par Hosking & Wallis (Citation1993, 1997) a été considérée dans le cadre de cette étude. Elle dérive de la méthode des moments de probabilité pondérés (Landwehr et al., Citation1979; Greis & Wood, Citation1981; Hosking, Citation1990) et présente l'avantage de fournir des estimateurs moins biaisés des valeurs des paramètres à la fois pour les échantillons de petites et de grandes tailles. Elle a été retenue tant pour l'analyse des séries maximales annuelles que pour les séries de valeurs supérieures à un seuil (pour une description de la méthode des L-moments voir par exemple, Hosking & Wallis, Citation1993, Citation1997; Trefry et al., Citation2005; Mailhot et al., Citation2007; Norbiato et al., Citation2007).
DONNEES DISPONIBLES
La présente la carte de la région sous étude et localise l'ensemble des stations météorologiques considérées. Les données pluviométriques de 61 stations ont été préalablement retenues, sélectionnées sur la base de la durée des historiques disponibles. Les séries des pluies maximales journalières pour quatre durées ont été ainsi colligées et analysées (1, 2, 6 et 12 h). Ces données, provenant du ministère du Développement durable, Environnement et Parcs du Québec, couvrent la période de Mai à Octobre, les pluviomètres à augets n'étant pas opérationnels durant la période hivernale (Mailhot et al., Citation2006). La validation des séries aux différentes stations a été effectuée essentiellement en comparant leurs cumuls journaliers avec ceux des pluviomètres standards. Le processus de validation des données postérieures à 1999 n'ayant pas été complété, elles n'ont pu être intégrées à la présente analyse. Les données utilisées couvrent donc, dans le meilleur des cas, la période 1957–1999.
Fig. 1 Localisation des stations météorologiques.
Le seuil et le nombre correspondant d'événements annuels dépassant le seuil (λ) ont d'abord été déterminés pour chaque durée et chaque station en utilisant l'approximation asymptotique selon laquelle le nombre annuel moyen de dépassements croît linéairement en fonction du seuil (Coles, Citation2001). Il appert que les valeurs moyennes de λ ainsi obtenues sont sensiblement les mêmes pour toutes les durées et varient entre 2.2 et 2.6.
Afin de tenir compte des données manquantes, la probabilité P(X = 0) de ne pas observer d'événements supérieurs au seuil à chaque station pendant la période totale où les données sont manquantes à chaque année d'observation a été estimée. Le nombre moyen annuel d'événements supérieurs aux seuils étant assez faible (environ deux événements par an), les années pour lesquelles la probabilité P(X = 0) est inférieure à 50% n'ont pas été retenues. Cette probabilité correspond à un nombre N de jours manquants qui varie, selon les stations, entre 25 (pour λ = 5.2) et 105 (pour λ = 1.2) et dont la moyenne est d'environ 53 jours (P(X = 0) = exp{–λ[N/(365/2)]}). Suivant cette méthode, 54 stations dont le nombre d'années de données dépasse 15 ans ont été sélectionnées (). Le nombre moyen d'années disponibles par station est de 27 ans et 18 stations disposent d'un historique supérieur ou égal à 30 ans.
MODELES REGIONAUX DES SERIES DES MAXIMUMS ANNUELS
Deux modèles régionaux basés sur les SMA ont été évalués: (a) le modèle SMA-1 avec un paramètre local et deux paramètres régionaux; et (b) le modèle SMA-2 avec deux paramètres locaux et un paramètre régional. Dans le cas du modèle SMA-1, les équations permettant d'estimer les paramètres de la distribution GEV par la méthode des L-moments ont été proposées par Hosking et al. (Citation1985b). La fonction quantile xi
(T) à la station i correspondant à une période de retour T est donnée par l'équation:Equation(3)
avec:Equation(4)
Equation
(5)
Equation
(6)
où τ R et τ3 R sont les ratios des L-moments régionaux, Γ la fonction Gamma et l 1 i la moyenne des données à la station i.
Pour le modèle SMA-2, seul le paramètre de forme est régional. Les deux autres paramètres de la distribution GEV sont calculés à partir des données locales (Madsen et al., Citation1997b). La fonction quantile xi
(T) est définie dans ce cas par l'équation:Equation(7)
avec kR
le paramètre de forme régional tel que défini à l'équation (4) et pour les paramètres locaux d'échelle α
i
et de position ξ
i
à la station i, on a:Equation(8)
Equation
(9)
où l 2 i est le L-moment d'ordre 2 calculé à partir des données de la station i.
MODeLES ReGIONAUX DES SeRIES DES DUREES PARTIELLES
Pour l'approche des SDP, deux modèles régionaux pour lesquels l'on fixe respectivement le seuil (SDP-1) et le nombre annuel de dépassements (SDP-2) ont été considérés. Madsen et al. (Citation1994) ont proposé d'utiliser un seuil régional δ
R
défini comme étant la moyenne des seuils locaux, calculé à partir de l'équation suivante:Equation(10)
avec Ei
(x) et Si
(x) respectivement la moyenne et l'écart-type des données maximales journalières au site i, N le nombre total de sites et ρ un facteur fréquentiel dont les valeurs devraient être comprises entre 3 et 3.5 selon Madsen et al. (Citation1994). Toutes les données supérieures ou égales à δ
R
peuvent être ainsi extraites et, en utilisant les séries ainsi générées, le quantile xi
(T) peut être défini par (Madsen & Rosbjerg, Citation1997):Equation(11)
avec λ i le nombre annuel moyen de dépassement du seuil à la station i et kR = 1/τ R – 2 le paramètre régional de forme de la distribution GPA. Cette méthode, caractérisée par deux paramètres locaux et deux paramètres régionaux, a été proposée par Madsen et al. (Citation1998) pour l'estimation des courbes IDF des précipitations extrêmes au Danemark.
Si l'on fixe le nombre moyen de dépassements des seuils à l'échelle régionale (λ
R
), on peut sélectionner les n
i
× λ
R
plus grandes valeurs à considérer à chaque station i (n
i
étant le nombre d'années de données disponibles à la station i). En utilisant ces données, la fonction quantile x
i
(T) peut être calculée à l'aide de l'équation suivante (Trefry et al., Citation2005):Equation(12)
avec:Equation(13)
Equation
(14)
Equation
(15)
Cette méthode suppose, en fixant λ R , que les valeurs des seuils diffèrent d'un site à l'autre (seuils locaux définis par δ i = l 1 i ξ R ). Conformément au domaine de définition de la distribution GPA, il importe de vérifier la cohérence de la méthode en comparant les seuils locaux δ i ainsi fixés par le modèle avec les valeurs minimales des séries de données utilisées. Ce modèle a été utilisé par Trefry et al. (Citation2005) dans le cadre d'une AFR des précipitations de l'état du Michigan aux Etats-Unis.
RESULTATS ET DISCUSSIONS
Les hypothèses d'indépendance, d'homogénéité et de stationnarité ont été respectivement vérifiées à l'aide des tests statistiques de Wald-Wolfowitz, de Wilcoxon et de Mann-Kendall pour toutes les SMA et les SDP en chaque station. Avec un niveau de confiance de 5%, les résultats montrent que ces séries sont indépendantes et identiquement distribuées.
Modèles régionaux des SMA
L'hypothèse selon laquelle les données de toutes les stations de la zone d'étude constituaient une région homogène a d'abord été vérifiée. Le montre que, pour toutes les durées, aucune valeur de la statistique H (voir Hosking & Wallis, Citation1997) n'est supérieure à 2 et qu'à l'exception d'une seule valeur (pour la durée de 1 heure pour laquelle H3 > 1), la région peut être déclarée raisonnablement homogène.
Tableau 1 Valeurs des statistiques H et Z et valeurs des paramètres de la distribution régionale GEV choisie pour le modèle SMA-1
La statistique Z montre que la distribution GEV semble mieux décrire les données disponibles que les distributions logistique généralisée (GLO), log normale (LGN) et Pearson type III (PE3) (voir Hosking & Wallis, Citation1997, pour une description de ces distributions) pour les durées de 1 h, 6 h et 12 h. Pour la durée de 2 h, la distribution GLO serait la plus adéquate malgré une performance acceptable de la distribution GEV (). La distribution GEV a tout de même été choisie pour toutes les durées parce qu'elle semble globalement mieux s'ajuster au nuage de points du diagramme des ratios des L-moments.
Les valeurs des paramètres de la fonction de distribution régionale GEV ont finalement été calculées pour le modèle SMA-1 (). À noter aussi que les valeurs du paramètre de forme du modèle SMA-2 sont identiques à celles du modèle SMA-1. Les quantiles correspondant à ces deux modèles ont été ainsi estimés en utilisant les équations (3) et (7) pour les modèles SMA-1 et SMA-2 respectivement.
Modèle des SDP avec un seuil régional (SDP-1)
Le modèle SDP-1 nécessite de préciser un seuil régional à partir duquel les séries à chaque station sont construites. Un facteur fréquentiel égal à 3.5, constituant la borne supérieure de la fourchette proposée par Madsen et al. (Citation1994), a été utilisé pour l'estimation du seuil régional (équation (10)). Le nombre de données retenues en considérant ρ = 3.5 semble suffisant puisqu'un nombre moyen annuel de dépassements de 3.2 a été obtenu pour chacune des durées considérées. Cette valeur est légèrement supérieure à celle suggérée par Madsen et al. (Citation1997b) pour assurer l'équivalence des estimateurs SDP/GPA et SMA/GEV pour une région légèrement hétérogène (–0.15 < k < –0.05) d'environ 20 stations où les historiques disponibles sont de l'ordre de 30 ans.
Les valeurs de la statistique H suggèrent que, pour les séries SDP-1, la région peut être déclarée raisonnablement homogène (). Les diagrammes des ratios des L-moments (non présentés par souci de concision) et les valeurs de la statistique Z () montrent que, pour toutes les durées, la distribution GPA l'emporte sur les distributions LGN et PE3. Les quantiles associés aux différentes périodes de retour ont été ainsi calculés à l'aide de l'éEquationquation (11(11)).
Tableau 2 Valeurs des statistiques H et Z et valeurs régionales du seuil et du paramètre de forme de la distribution régionale GPA choisie pour les données du modèle SDP-1
Modèle des SDP avec un nombre moyen de dépassements (SDP-2)
Tavares & Da Silva (Citation1983) ont montré que, pour qu'un modèle de SDP ait une variance inférieure à celle d'un modèle de SMA, il fallait que λ R soit supérieur ou égal à 2. Par ailleurs, Madsen et al. (Citation1997b) ont montré que ce paramètre devait être supérieur à 2.8 pour que, dans une région homogène où le paramètre de forme est de l'ordre de –0.1, les performances des estimateurs de ces deux approches soient équivalentes. Trefry et al. (Citation2005), quant à eux, ont considéré une valeur λ R = 2 pour dériver les courbes IDF de l'état du Michigan. Afin de comparer ces résultats avec ceux du modèle SDP-1, une valeur de λ R égale à la moyenne des dépassements calculée à partir du modèle SDP-1 a été considérée, soit λ R = 3.
Les données ainsi générées pour le modèle SDP-2 caractérisent une région qui varie de raisonnablement homogène à possiblement hétérogène pour les durées de 1 à 6 h (). Pour la durée de 12 h, elle varie de raisonnablement homogène, pour H2 et H3, à définitivement hétérogène pour H1 (). Par ailleurs, la distribution GPA a été choisie comme étant la mieux à même de représenter l'ensemble des données de ce modèle et les valeurs de ses paramètres ont été estimées (). À chaque station, les quantiles pour différentes périodes de retour ont été ainsi calculés à l'aide de l'équation (12).
Tableau 3 Valeurs des statistiques H et Z et valeurs des paramètres de la distribution régionale GPA choisie pour le modèle SDP-2
Comparaison des quantiles estimés selon les différents modèles
Les quantiles et leurs intervalles de confiance (IC) estimés selon chacun des modèles considérés ont été comparés. Pour chaque paire de modèles, le rapport, le biais relatif (BR):Equation(16)
et la racine carrée de l'erreur quadratique moyenne relative (REQMR) des quantiles ont été calculés pour chaque période de retour:Equation(17)
avec xi A (T) et xi B (T) les quantiles de période de retour T calculés à la station i respectivement par les modèles A et B, et N le nombre total de stations de la région.
Les valeurs de │BR(A/B│ près de zéro indiquent que les écarts absolus entre les quantiles des deux modèles sont en moyenne faibles (aucun biais) tandis que de grandes valeurs de │BR(A/B│ indiquent que les quantiles de l'un des modèles sont en moyenne supérieurs à ceux de l'autre modèle. Le critère REQMR(A/B) calcule la somme des écarts entre les quantiles des modèles A et B. Les faibles valeurs de cet indice indiquent que les écarts sont faibles alors que les fortes valeurs indiquent l'existence d'importants écarts entre les quantiles des deux modèles.
La comparaison des modèles de types différents (SDP et SMA) montre que les quantiles des modèles SDP sont en moyenne plus grands que ceux des modèles SMA pour les faibles périodes de retour et que, généralement, cette tendance diminue au fur et à mesure que la période de retour augmente ((c), (d), (e) et (f)). Cependant, sauf pour la comparaison SMA-1/SDP-2 ((d)) où les écarts restent constants et relativement faibles, les écarts entre les quantiles des autres paires augmentent pour les grandes périodes de retour ((c), (e) et (f)). Les quantiles des modèles de mêmes types (SMA-1 et SAM-2 ou SDP-1 et SDP-2) sont en moyenne plus proches ((a) et (b)), mais leurs écarts augmentent sensiblement avec la période de retour ((a) et (b)).
Fig. 2 Biais relatifs (BR) calculés pour chaque paire de modèles: (a) SDP-1/SDP-2; (b) SMA-1/SMA-2; (c) SDP-1/SMA-1; (d) SDP-2/SMA-1; (e) SDP-2/SMA-2; (f) SDP-1/SMA-2.
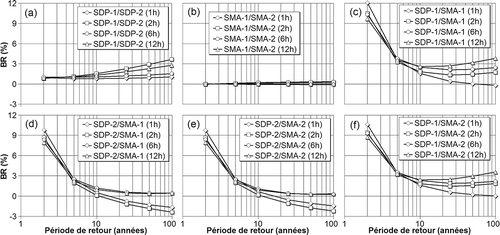
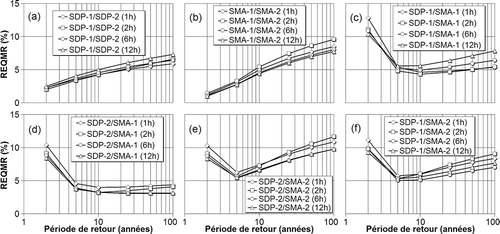
Fig. 3 Valeurs de la racine carrée de l'erreur quadratique moyenne relative (REQMR) calculées pour chaque paire de modèles: (a) SDP-1/SDP-2; (b) SMA-1/SMA-2; (c) SDP-1/SMA-1; (d) SDP-2/SMA-1; (e) SDP-2/SMA-2; (f) SDP-1/SMA-2.
Les intervalles de confiance (IC) ont été calculés pour chaque quantile à un niveau de confiance de 90% à l'aide de l'approche de bootstrap (Efron & Tibshirani, Citation1993). Ce calcul a été réalisé en générant, à partir des valeurs de paramètres régionaux, un grand nombre de séries (10 000 dans le présent cas) en tenant compte de la corrélation spatiale entre les stations (Hosking & Wallis, Citation1997) dont les valeurs demeurent relativement faibles (variant de 0.06 pour la durée 1 h à 0.12 pour la durée 12 h). Ainsi, pour les modèles SDP-1 et SMA-2, un seul paramètre régional a été généré, alors que pour les modèles SDP-2 et SMA-1, trois paramètres ont été générés à chaque simulation.
Il est observé que les amplitudes des IC des différents modèles augmentent avec la période de retour et que, généralement, les modèles avec un nombre moindre de paramètres régionaux admettent les plus faibles IC. Comme lors de la comparaison des quantiles, généralement les IC des modèles appartenant à la même catégorie (SMA-1 et SMA-2 ou SDP-1 et SDP-2) se chevauchent plus souvent pour la période de retour de deux ans alors que les IC des modèles de catégories différentes (SMA et SDP) sont presque toujours complètement décalés (). De manière générale, le recoupement croît avec la période de retour pour atteindre un recoupement maximal à la période de retour 100 ans (). Quant au modèle SMA-2, le niveau de recoupement avec les IC des autres modèles est en général moindre pour toutes les périodes de retour (sauf pour la comparaison de 2 et 5 ans avec le modèle SMA-1).
Tableau 4 Nombre moyen (pour toutes les durées) de stations dont les IC (à 90%), calculés pour chaque paire de modèles, se chevauchent en tout ou en partie (54 stations au total)
Analyse des résultats à partir des séries disponibles
Origines des différences entre les modèles
Afin de mieux comprendre l'origine des écarts entre les quantiles estimés par les modèles SMA-1 et SDP-1, deux cas de figure ont été considérés, à savoir les stations qui ont enregistré le plus petit et le plus grand rapport entre les quantiles estimés selon ces deux modèles, à savoir les stations d'Island-Brook (7023312) et de Saint-Michel-des-Saints (7077570) ().
Tableau 5 Rapports (SMA-1/SDP-1) des quantiles estimés par les modèles SMA-1 et SDP-1 pour les stations d'Island Brook (rapports supérieurs à 1 pour les périodes de retour supérieures à 2 ans) et Saint-Michel-des-Saints (rapports inférieurs à 1)
La comparaison montre que, lorsque les événements ajoutés aux SDP par rapport aux SMA sont d'amplitudes moyennes à faibles (cas de Island-Brook; (a)), les quantiles, pour les périodes de retour de 5 à 100 ans, estimés par le modèle SDP-1 ont tendance à être inférieurs à ceux calculés par le modèle SMA-1. L'ajout dans les SDP d'événements de faibles périodes de retour a pour conséquence l'augmentation de la fréquence de ces événements par rapport à la fréquence observée dans les SMA et diminue ainsi les valeurs des quantiles des événements de faibles périodes de retour. Par ailleurs, une augmentation du nombre de ces événements (de faibles et moyennes amplitudes) dans les séries SDP diminue en terme relatif le caractère intense et rare des événements les plus intenses observés dans les séries SDP et SMA, d'où une diminution des quantiles des événements de périodes de retour plus élevées pour les estimateurs SDP par rapport aux estimateurs SMA. En revanche, dans le cas de Saint-Michel-des-Saints, les événements rares récupérés par le modèle SDP-1 et la présence de nombreux événements SMA-1, dont les valeurs sont inférieures au seuil utilisé par le modèle SDP-1, font en sorte que les quantiles estimés par le modèle SDP-1 sont généralement supérieurs à ceux estimés à partir du modèle SMA-1 ((b)). Il ressort donc que la comparaison des quantiles estimés à partir de ces deux approches dépend certes du nombre d'événements intenses récupérés par l'approche SDP mais aussi du nombre d'événements de faibles intensités récupérés par l'une ou l'autre approche.
Fig. 4 Comparaison des données utilisées par les modèles SMA-1 et SDP-1 aux stations de (a) Island-Brook et (b) Saint-Michel-des-Saints, et de celles utilisées par les modèles SDP-1 et SDP-2 à (c) Duchesnay et (d) Saint-Michel-des-Saints. Les symboles en gris représentent les évènements utilisés seulement par le modèle SMA-1 et ceux en noir correspondent aux données supplémentaires utilisées par l'un des modèles par rapport à l'autre.
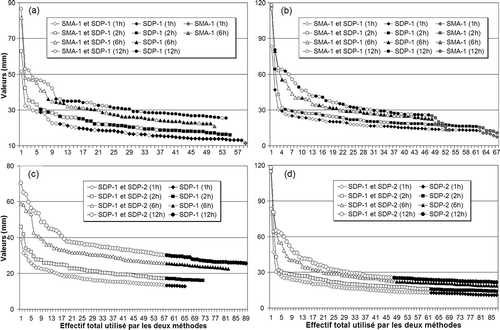
Les stations de Duchesnay et de Saint-Michel-des-Saints sont celles ayant enregistré les plus faibles et les plus grands rapports de quantiles calculés par les modèles SDP-1 et SDP-2 respectivement. Les différences entre les quantiles de ces modèles s'expliquent simplement par les différences des seuils utilisés. Ainsi, dans le cas de Duchesnay, le seuil SDP-2 est supérieur au seuil SDP-1 alors que, dans le cas de Saint-Michel-des-Saints, le seuil SDP-2 est inférieur au seuil SDP-1. Il en résulte, selon le cas, l'ajout de plusieurs événements de faibles intensités qui diminueront les valeurs des quantiles associés au modèle où ces événements sont ajoutés ((c) et (d)). Ainsi, les quantiles SDP-1 sont plus petits que les quantiles SDP-2 dans le cas Duchesnay ((c)) alors que les quantiles SDP-2 sont plus petits que les quantiles SDP-1 dans le cas de Saint-Michel-des-Saints ((d)).
Reconstitution des quantiles et fréquences empiriques
Les quantiles et les fréquences empiriques ont été comparés aux valeurs correspondantes obtenues des différents modèles. Il apparaît que, sur la quasi-totalité des stations où de grands écarts ont été observés, les quantiles et les fréquences des modèles SDP-1 et SMA-2 reproduisent mieux les valeurs empiriques et que, de ces deux modèles, le modèle SMA-2 offre parfois une reconstitution légèrement meilleure des événements rares (voir à titre d'exemple).
Fig. 5 Comparaison des quantiles et probabilités empiriques avec les valeurs estimées par les modèles SMA-1, SDP-1, SDP-2 et SMA-2 pour la durée de 6 h à la station de Saint-Georges-de-Beauce.
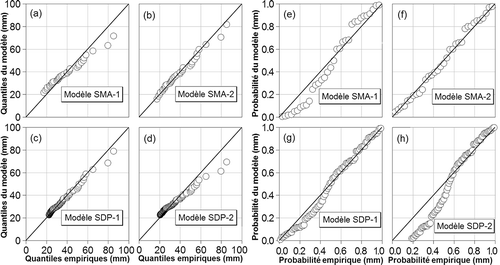
Par ailleurs, le modèle SDP-2 fait l'hypothèse que les seuils locaux δ i = l 1 i ξ R définis par ce modèle (z) sont équivalents aux valeurs minimales des données sélectionnées à chaque station (y). Avec un ajustement linéaire qui frôle la première bissectrice (y = 1.02z – 0.20) et dont le coefficient de corrélation est de 0.99, cette hypothèse semble être globalement vérifiée. Cependant, pour toutes les stations où les écarts importants ont été constatés entre les quantiles SDP-1 et SDP-2, on constate que les seuils locaux δ i définis par le modèle SDP-2 sont toujours supérieurs aux valeurs minimales des séries utilisées à ces stations. Ceci se traduit par une mauvaise reconstitution des probabilités empiriques par le modèle SDP-2 surtout pour les plus faibles valeurs observées (voir (h) à titre d'exemple).
Courbes IDF pour la région étudiée
La section précédente a montré que les fréquences et les quantiles calculés par les modèles SMA-2 et SDP-1 reproduisaient mieux les quantiles et les probabilités empiriques aux différents sites. Madsen et al. (Citation1997b) ont par ailleurs montré que le modèle SDP-1 donnait de meilleures performances par rapport à SMA-1 et SMA-2 dans le cas de régions présentant un niveau d'hétérogénéité régionale faible à moyen lorsque le facteur de forme médian est négatif (à noter que selon ces auteurs le nombre de données en chaque site n'aurait que peu d'influence sur ce résultat). Cependant une augmentation du niveau d'hétérogénéité favoriserait le modèle SMA-2.
Les moments d'ordre 2 (coefficients de variation (C v ) ou ratios de L-moments τ2) sont souvent utilisés pour décrire l'hétérogénéité d'une région (Stedinger & Lu, Citation1995; Hosking & Wallis, Citation1997). Afin d'avoir une idée du niveau d'hétérogénéité de la région sous étude nous avons utilisé la grandeur C a qui représente le coefficient de variation des C v locaux (Stedinger & Lu, Citation1995). La moyenne de C a = 0.2 a été calculée pour la région d'étude avec les valeurs, pour les différentes durées, qui varient entre 0.13 et 0.24. Stedinger & Lu (Citation1995) ont indiqué que C a = 0.2 correspond à une valeur normale pour une région avec un niveau d'hétérogénéité réaliste alors que C a ≥ 0.4 désigne une région très hétérogène. Madsen et al. (Citation1997b) ont considéré les mêmes niveaux d'hétérogénéité dans leur comparaison des méthodes régionales SMA et SDP. La région sous étude serait donc caractérisée par un niveau réaliste d'hétérogénéité. Ce constat rejoint celui obtenu en utilisant la statistique H de Hosking et Wallis (Citation1997) (voir Tableaux 1, 2 et 3). Ce niveau moyen d'hétérogénéité désigne, selon Madsen et al. (Citation1997b), le modèle SDP-1 comme plus adapté pour dériver les quantiles de la région d'étude au détriment des modèles SMA-1 et SMA-2.
L'estimation des courbes IDF pour la région étudiée s'est effectuée en reprenant l'équation (11) décrivant les estimateurs SDP-1 et les valeurs régionales du seuil et du paramètre de forme (). Il est possible de réécrire l'équation (11) en prenant comme variable dépendante QR = [x i (T) –δ R ]/l 1 i . La présente les courbes IDF “régionales” ainsi obtenues avec les IC à 90% correspondants. Les quantiles en un site donné sont obtenus en considérant les valeurs locales de l 1 i et λ i et les seuils régionaux δ R (). Le présente ces valeurs locales pour quelques villes de la région d'étude.
Fig. 6 Courbes IDF régionales calculées par le modèle SDP-1 pour les différentes durées: (a) 1 h, (b) 2 h, (c) 6 h et (d) 12 h.
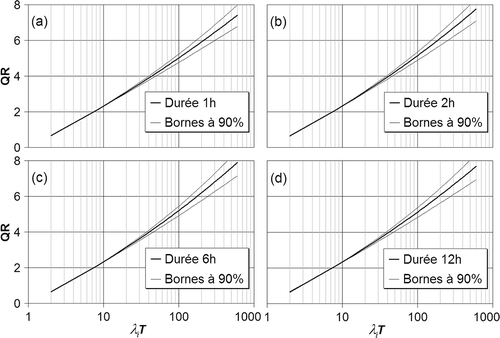
Tableau 6 Valeurs des paramètres locaux l 1 i (mm) et λ i (nombre/an) calculées pour quelques villes majeures reparties sur la zone d'étude par le modèle régional SDP-1 (voir )
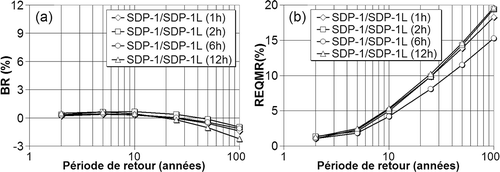
Les estimateurs régionaux SDP-1 ont ensuite été comparés aux estimateurs SDP-1 locaux (modèle local SDP-1L). Les estimateurs SDP-1L ont été obtenus en considérant la distribution GPA dont les paramètres locaux ont été déterminés par la méthode des L-moments. Un examen de la montre que, même si le biais est faible et négatif ((a)) pour les grandes périodes de retour (indicatif d'une légère surestimation relative des estimateurs SDP-1L), les REQMR tendent à croître avec la période retour pour toutes les durées ((b)), indiquant donc que des écarts relatifs importants peuvent survenir en certains sites. Considérant que la région est suffisamment homogène, les différences appréciables entre estimateurs locaux et régionaux pour les grandes périodes de retour justifient le recours à l'AFR.
Fig. 7 Critères (a) BR et (b) REQMR pour la comparaison des modèles SDP-1 et SDP-1L.
CONCLUSIONS
Les courbes IDF des pluies maximales estivales pour la région sud du Québec ont été estimées. Les séries de précipitations disponibles proviennent de 54 stations disposant d'historiques de plus de 15 ans. Les approches régionalisées basées sur les séries des maximums annuels (SMA) et sur les séries des durées partielles (SDP) ont été considérées. Pour chaque type de séries, deux modèles d'estimation des quantiles ont été présentés: SMA-1 (deux paramètres régionaux) et SMA-2 (un paramètre régional) pour le premier type, et SDP-1 (seuil régional) et SDP-2 (seuils locaux) pour le second. La comparaison des résultats issus de ces différents modèles montre que, de façon globale, pour les petites périodes de retour (cinq ans et moins), les quantiles obtenus par les modèles SMA sont systématiquement plus petits que ceux des modèles SDP. Par contre, pour les grandes périodes de retour (dix ans et plus), les estimateurs SMA et SDP sont comparables (aucun biais significatif) alors que les écarts moyens croissent dans plusieurs cas avec la période de retour.
Le modèle SDP-1 a été préféré pour l'estimation régionale des courbes IDF. Deux raisons principales motivent ce choix. D'abord, une comparaison avec les quantiles et fréquences empiriques suggère que ce modèle, avec le modèle SMA-2, reproduisent mieux les comportements empiriques. Ensuite, une analyse visant à déterminer le niveau d'hétérogénéité de la région sous étude suggère une région d‘une hétérogénéité réaliste (selon les critères Hosking & Wallis (Citation1997) et les considérations de Stedinger & Lu (Citation1995)) qui favoriserait les estimateurs SDP-1 au détriment des estimateurs SMA-2 dont la performance serait meilleure dans le cas d'une région plus hétérogène.
Les éventuels gains apportés par l'analyse régionale reposent évidemment sur l'hypothèse de l'existence d'un modèle statistique régional permettant ainsi le regroupement des séries en diverses stations (meilleure inférence des paramètres). La vérification d'une telle hypothèse pour une région donnée, et surtout l'établissement du niveau d'hétérogénéité de cette région, restent cependant une opération délicate (comme la présente étude l'a montré). Dans le cas présent, il appert que, selon les critères avancés par Hosking & Wallis (Citation1997), la région pourrait être déclarée raisonnablement homogène (pour les modèles SMA-1, SMA-2 et SDP-1) et donc faire l'objet d'une AFR. Une comparaison entre les quantiles estimés par le modèle régional SDP-1 et ceux estimés par un modèle local (SDP-1L) montre par ailleurs que les estimations locales et régionales diffèrent pour des périodes de retour de 25 ans et plus (voir (b)).
Les modèles SDP présentent, par ailleurs, un avantage par rapport aux modèles SMA dans le cas où les séries comptent plusieurs données manquantes. En effet, la construction des séries SMA impose de définir un critère visant à établir le seuil de données manquantes à considérer, seuil au-delà duquel le maximum annuel d'une année donnée ne serait pas retenu. Une telle contrainte n'existe pas pour les séries SDP dans l'hypothèse où la période d'occurrence de données manquantes ne favorise pas systématiquement des valeurs en deçà ou au-delà du seuil. Dans cette optique, les séries annuelles couvrant la période étudiée (comme la période Mai–Octobre dans le cas présent) peuvent être regroupées pour ne former qu'une seule longue série même si, par exemple, une année donnée comporte plusieurs données manquantes. Le traitement des données manquantes est donc plus simple dans un tel contexte, ce qui peut conférer un avantage important à l'approche SDP.
Il reste cependant difficile de définir, de façon rigoureuse, le seuil à utiliser pour les modèles SDP. Cette difficulté demeure un frein opérationnel majeur à la mise en place de ce type d'approche. Même si conceptuellement il semble avantageux de considérer une approche SDP (ajouts éventuels d'événements majeurs autrement non pris en compte dans les séries des maximums annuels), les avantages réels de cette approche dans un cadre régional en matière de qualité et de performance des estimateurs restent difficiles à établir. Plus spécifiquement, la méthode SDP-2 pose un problème de cohérence puisque les seuils locaux obtenus en construisant les séries sur la base de l'hypothèse d'un nombre fixe de dépassements en chaque site sont parfois supérieurs aux valeurs effectivement retenues, ce qui, d'une part, est insatisfaisant d'un point de vue formel, et, d'autre part, conduit à une mauvaise reconstitution des probabilités et fréquences empiriques associées aux événements de faibles périodes de retour. L'approche de SDP étant toujours limitée par le choix du seuil, il serait intéressant d'estimer l'incidence du choix du seuil sur les performances du modèle SDP-1. Incidemment, une analyse préliminaire du modèle SDP-2 avec λ R = 2 (au lieu de λ R = 3) n'a pas permis de noter de changement significatif dans les performances de ce modèle par rapport aux autres modèles considérés dans cette étude.
REFERENCES
- Adamowski , K. , Alila , Y. and Pilon , J. P. 1996 . Regional rainfall distribution for Canada . Atmos. Res. , 42 : 75 – 88 .
- Alila , Y. 1999 . A hierarchical approach for the regionalization of precipitation annual maxima in Canada . J. Geophys. Res. , 104 ( D24 ) : 31645 – 31655 .
- Ashkar , F. and Tatsambon , N. 2007 . Revisiting some estimation methods for the generalized Pareto distribution . J. Hydrol. , 346 : 136 – 143 .
- Boes , D. C. , Heo , J. H. and Salas , J. D. 1989 . Regional flood quantile estimation for a Weibull model . Water Resour. Res. , 25 ( 5 ) : 979 – 990 .
- Bourrier , R. 1981 . Les réseaux d'assainissement: calculs, applications et perspectives , Paris, , France : Technique et Documentation .
- Buishand , T. A. 1989 . The partial duration series method with a fixed number of peaks . J. Hydrol. , 109 : 1 – 9 .
- Coles , S. 2001 . An Introduction to Statistical Modelling of Extreme Values , Berlin, , Germany : Springer Series in Statistics, Springer-Verlag .
- Cunderlik , J. M. and Ouarda , T. B. M. J. 2006 . Regional flood-duration-frequency modeling in the changing environment . J. Hydrol. , 318 : 276 – 291 .
- Cunnane , C. 1973 . A particular comparison of annual maxima and partial duration series methods of flood frequency prediction . J. Hydrol. , 18 : 257 – 271 .
- Cunnane , C. 1988 . Methods and merits of regional flood frequency analysis . J. Hydrol. , 100 : 269 – 290 .
- Dalrymple , T. 1960 . Flood frequency methods . US Geol. Survey Water Supply Paper 1543–A , : 11 – 51 .
- Efron , B. and Tibshirani , J. R. 1993 . An Introduction to the Bootstrap , New York, , USA : Chapman & Hall/CRC .
- GREHYS (Groupe de Recherche en Hydrologie Statistique) . 1996 . Presentation and review of some methods for regional flood frequency analysis . J. Hydrol. , 186 : 63 – 84 .
- Greis , N. P. and Wood , E. F. 1981 . Regional flood frequency estimation and network design . Water Resour. Res. , 17 ( 4 ) : 1167 – 1177 .
- Heo , J. H. , Salas , J. D. and Boes , D. C. 2001 . Regional flood frequency analysis based on Weibull model: Part 2. Simulations and applications . J. Hydrol. , 242 : 171 – 182 .
- Hogg , W. D. and Carr , D. A. 1985 . Rainfall Frequency Atlas for Canada , Environment Canada, Atmospheric Environment Service .
- Hosking , J. R. M. 1990 . L-moments: analysis and estimation of distributions using linear combinations of order statistics . J. R. Stat. Soc. Ser. B , 52 ( 1 ) : 105 – 124 .
- Hosking , J. R. M. and Wallis , J. R. 1987 . Parameter and quantile estimation for the generalized Pareto distribution . Technometrics , 29 ( 3 ) : 339 – 349 .
- Hosking , J. R. M. and Wallis , J. R. 1988 . The effect of intersite dependence on regional flood frequency analysis . Water Resour. Res. , 24 : 588 – 600 .
- Hosking , J. R. M. and Wallis , J. R. 1993 . Some statistics useful in regional frequency analysis . Water Resour. Res. , 29 ( 2 ) : 271 – 281 .
- Hosking , J. R. M. and Wallis , J. R. 1997 . Regional Frequency Analysis: An Approach Based on L-moments , Cambridge, , UK : Cambridge University Press .
- Hosking , J. R. M. , Wallis , J. R. and Wood , E. R. 1985a . An appraisal of the regional flood frequency procedure in the UK Flood Studies Report . Hydrol. Sci. J. , 30 ( 1 ) : 85 – 109 .
- Hosking , J. R. M. , Wallis , J. R. and Wood , E. R. 1985b . Estimation of the generalized-extreme value distribution by the method of the probability-weighted moments . Technometrics , 27 ( 3 ) : 251 – 261 .
- Khaliq , M. N. , Ouarda , T. B. M. J. , Ondo , J. C. , Gachon , P. and Bobée , B. 2006 . Frequency analysis of a sequence of dependent and/or non-stationary hydro-meteorological observations: a review . J. Hydrol. , 329 : 534 – 552 .
- Landwehr , J. M. , Matalas , N. C. and Wallis , J. R. 1979 . Probability weighted moments compared with some traditional techniques in estimating Gumbel parameters and quantiles . Water Resour. Res. , 15 ( 5 ) : 1055 – 1064 .
- Lang , M. , Ouarda , T. B. M. J. and Bobée , B. 1999 . Towards operational guidelines for over-threshold modelling . J. Hydrol. , 225 : 103 – 117 .
- Madsen , H. , Mikkelsen , C. P. , Rosbjerg , D. and Harremoes , P. 1998 . Estimation of regional intensity-duration-frequency curves for extreme precipitation . Water Resour. Res. , 37 ( 11 ) : 29 – 36 .
- Madsen , H. , Pearson , C. P. and Rosbjerg , D. 1997b . Comparison of annual maximum series and partial duration series method for modelling extreme hydrologic events: 2. regional modelling . Water Resour. Res. , 33 ( 4 ) : 759 – 769 .
- Madsen , H. , Rasmussen , P. F. and Rosbjerg , D. 1997a . Comparison of annual maximum series and partial duration series method for modelling extreme hydrologic events: 1. at site modelling . Water Resour. Res. , 33 ( 4 ) : 747 – 757 .
- Madsen , H. and Rosbjerg , D. 1997 . The partial duration series method in regional index-flood modelling . Water Resour. Res. , 33 ( 4 ) : 737 – 746 .
- Madsen , H. , Rosbjerg , D. and Harremoës , P. 1994 . PDS-modelling and regional Bayesian estimation of extreme rainfalls . Nordic Hydrol. , 25 ( 4 ) : 279 – 300 .
- Mailhot , A. , Duchesne , S. , Caya , D. and Talbot , G. 2007 . Assessment of future change in Intensity-Duration-Frequency (IDF) curves for Southern Quebec using the Canadian Regional Climate Model (CRCM) . J. Hydrol. , 347 ( 1-2 ) : 197 – 210 . doi:10.1016/j.jhydrol.2007.09.019.
- Mailhot , A. , Rivard , G. , Duchesne , S. and Villeneuve , J. P. 2006 . Impacts et adaptations liés aux changements climatiques en matière de drainage urbain au Québec . Rapport no. R-874, INRS-ETE, Québec, Canada. ,
- Mohymont , B. and Demarée , G. R. 2006 . Courbes intensité–durée–fréquence des précipitations à Yangambi, Congo, au moyen de différents modèles de type Montana . Hydrol. Sci. J. , 51 ( 2 ) : 239 – 253 .
- Neppel , L. , Arnaud , P. and Lavabre , J. 2007 . Connaissance régionale des pluies extrêmes. Comparaison de deux approches appliquées en milieu méditerranéen . C. R. Geoscience , 339 : 820 – 830 .
- Norbiato , D. , Borga , M. , Sangati , M. and Zanon , F. 2007 . Regional frequency analysis of extreme precipitation in the eastern Italian Alps and the August 29, 2003 flash flood . J. Hydrol. , 345 : 149 – 166 .
- Onibon , H. , Ouarda , T. B. M. J. , Barbet , M. , St-Hilaire , A. , Bobée , B. and Bruneau , P. 2004 . Analyse fréquentielle régionale des précipitations journalières maximales annuelles au Québec, Canada . Hydrol. Sci. J. , 49 ( 4 ) : 717 – 735 .
- Pilon , P. J. and Adamowski , K. 1992 . The value of regional information to flood frequency analysis using the method of L‐moments . Can. J. Civil Engng , 19 : 137 – 147 .
- Ribatet , M. , Sauquet , E. , Grésillon , J. M. and Ouarda , T. B. M. J. 2007 . A regional Bayesian POT model for flood frequency analysis . Stochast. Environ. Res. Risk Assess. , 21 : 327 – 339 .
- Rosbjerg , D. 1985 . Estimation in partial duration series with independent and dependent peak values . J. Hydrol. , 76 : 183 – 195 .
- Rosbjerg , D. , Madsen , H. and Rasmussen , P. F. 1992 . Prediction in partial duration series with generalized Pareto distributed exceedances . Water Resour. Res. , 28 ( 11 ) : 3001 – 3010 .
- Segond , M. L. , Neokleous , N. , Makropoulos , C. , Onof , C. and Maksimovic , C. 2007 . Simulation and spatio-temporal disaggregation of multi-site rainfall data for urban drainage applications . Hydrol. Sci. J. , 52 ( 5 ) : 917 – 935 .
- Shaefer , M. G. 1990 . Regional analysis of precipitation annual maxima in Washington State . Water Resour. Res. , 26 ( 1 ) : 119 – 131 .
- Stedinger , J. R. and Lu , L. H. 1995 . Appraisal of regional and index flood quantile estimators . Stochastic Hydrol. Hydraul. , 9 ( 1 ) : 49 – 75 .
- St-Hilaire , A. , Ouarda , T. B. M. J. , Lachance , M. , Bobée , B. , Barbet , M. and Bruneau , P. 2003 . La régionalisation des précipitations: une revue bibliographique des développements récents . Rev. Sci. Eau , 16 ( 1 ) : 27 – 54 .
- Tavares , L. V. and Da Silva , J. E . 1983 . Partial duration series revisited . J. Hydrol. , 64 : 1 – 14 .
- Trefry , C. M. , Watkins , D. W. and Johnson , D. 2005 . Regional rainfall frequency analysis for the State of Michigan . J. Hydrol. Engng , 10 ( 6 ) : 437 – 449 .
- Wang , Q. J. 1991 . The POT model described by the generalized Pareto distribution with Poisson arrival rate . J. Hydrol. , 129 : 263 – 280 .