Abstract
There is a continuing effort to advance the skill of long-range hydrological forecasts to support water resources decision making. The present study investigates the potential of an extended Kalman filter approach to perform supervised training of a recurrent multilayer perceptron (RMLP) to forecast up to 12-month-ahead lake water levels and streamflows in Canada. The performance of the RMLP was compared with the conventional multilayer perceptron (MLP) using suites of diagnostic measures. The results of the forecasting experiment showed that the RMLP model was able to provide a robust modelling framework capable of describing complex dynamics of the hydrological processes, thereby yielding more accurate and realistic forecasts than the MLP model. The performance of the method in the present study is very promising; however, further investigation is required to ascertain the versatility of the approach in characterizing different water resources and environmental problems.
Citation Muluye, G. Y. (2011) Improving long-range hydrological forecasts with extended Kalman filters. Hydrol. Sci. J. 56(7), 1118–1128.
Résumé
Il y a un effort constant pour faire progresser la qualité des prévisions hydrologiques à longue échéance en vue d'aider la prise de décision en matière de ressources en eau. La présente étude examine le potentiel d'une approche par filtre de Kalman étendu pour effectuer un apprentissage supervisé d'un perceptron multicouches récurrent (RMLP) pour prévoir jusqu'à 12 mois à l'avance des niveaux de lacs et des débits au Canada. La performance du RMLP a été comparée à celle du perceptron multicouches conventionnel (MLP) en utilisant un ensemble de mesures de diagnostic. Les résultats de l'expérience ont montré que le modèle RMLP a pu fournir un cadre de modélisation robuste, capable de décrire la dynamique complexe des processus hydrologiques, donnant ainsi des prévisions plus précises et réalistes que le modèle MLP. Les performances de la méthode dans la présente étude sont très prometteuses, mais des investigations complémentaires sont nécessaires pour s'assurer de la versatilité de l'approche dans la caractérisation de divers problèmes environnementaux et de ressources en eau.
INTRODUCTION
Artificial neural networks, in particular, a multilayer perceptron (MLP) has demonstrated its potential as a universal function approximation to describe diverse water resources problems (ASCE Citation2000a, Citation2000b, Giustolisi and Laucelli Citation2005, Abrahart et al. Citation2007, Koutsoyiannis et al. Citation2008, Kisi et al. Citation2008, Londhe and Charhate Citation2010). Multilayer perceptrons, together with time-lag feedforward network architectures have been applied to describe both spatial and temporal dynamics of hydrological processes (e.g. Muluye and Coulibaly Citation2007). However, it has been shown that a neural network containing a state feedback is more effective, possesses more computational advantages, and is less vulnerable to external noises than input–output models (Palma et al. Citation2001). Furthermore, the state–space models employ fewer parameters, and are capable of describing a large-class of dynamical systems than common input–output models (Palma et al. Citation2001, Haykin Citation2008). One method of effective characterization of state feedback is through the use of recurrent neural networks. Several algorithms are available to perform supervised training of recurrent neural networks. The most widely-used algorithms are back-propagation through time (BPTT), real-time recurrent learning (RTRL) and extended Kalman filters (EKF). While BPTT is the most commonly used method, RTRL is mathematically straightforward, and EKF is arguably the technique that performs the best (Jaeger Citation2002). Among others, Jonsson and Palsson (Citation1994) and Puskorius and Feldkamp (Citation1994) are the pioneer investigators of the EKF application, who showed that a state filter based on recurrent neural networks can converge to the minimum variance filter. Since then, the EKF algorithm has found applications in several nonlinear dynamical systems to perform supervised training of recurrent neural networks (Haykin Citation2008).
The use of recurrent neural networks in the context of hydrological applications is rather limited and has received modest attention when compared with multilayer perceptron models (e.g. Chang et al. Citation2004, Pan and Wang Citation2005, Muluye and Coulibaly Citation2007, Carcano et al. Citation2008, Coulibaly Citation2010). Furthermore, none of these studies has investigated the EKF algorithm to perform training of recurrent neural networks for use in hydrology-related problems. The present study, therefore, attempts to address this gap in the framework of improving long-range hydrological forecasts. The specific goals of this study are to: (a) investigate the potential of the EKF approach to perform supervised training of the recurrent multilayer perceptron (RMLP) to forecast long-range horizon lake water levels and streamflows; and (b) evaluate the forecasting skill of the proposed model over the conventional neural network, namely, the MLP using suites of diagnostic measures. The MLP model is selected in the present study based on preliminary analysis and literature review. Other neural network architectures and regression-based models have also been investigated; however, their forecasting results did not show significant improvement over the MLP for the study basin. Furthermore, given that the MLP model is the most widely-used and a well-tested architecture, its use as a basis for comparison is considered appropriate (ASCE Citation2000a, Citation2000b, Giustolisi and Laucelli Citation2005, Koutsoyiannis et al. Citation2008, Adamowski Citation2008, Pramanik and Panda Citation2009, Londhe and Charhate Citation2010). Therefore, only the MLP model is included in the comparison.
MODEL DESCRIPTION
This section describes the recurrent multilayer perceptron and its training techniques. The multilayer perceptron, which is selected as a benchmark for model comparison, is also briefly described.
Multilayer perceptron
Artificial neural networks have witnessed increased application due to the development of more sophisticated algorithms and the emergence of powerful computational tools (ASCE Citation2000a). The multilayer perceptron, which is also referred to as feedforward multilayer perceptron, is the most widely-used neural network (ASCE Citation2000a, Citation2000b, Haykin Citation2008). In the present study, a simple MLP with a single hidden layer was used. Let x I(n) represent the output of the hidden layer, x o(n) represent the output of the output layer, and u (n) represent the input vector, then the operational principles of the MLP can be mathematically expressed by the following equations (Haykin Citation2008):
where ϕ I(.,.) and ϕo(.,.) are the activation functions of the hidden layer and output layer, respectively; and w I and w o represent the weight matrices of the hidden layer and output layer, respectively. The network biases were integrated with the network weights in order to simplify the computation of network parameters. The activation function of the network could be a linear, sigmoid or hyperbolic tangent function, depending on the complexity of the problem. The network parameters were estimated by presenting a training example ( u (n), x o(n)), with the input vector, u (n), applied to the input layer, and the desired response, x o(n), presented to the output layer of the computational neuron. The training of the network was then conducted using a gradient-based optimization technique, which utilizes derivatives of the error with respect to the network parameters calculated by the back-propagation algorithm (Muluye and Coulibaly Citation2007). The detailed theory and derivation of the back-propagation algorithm can be found in Haykin (Citation2008).
Recurrent multilayer perceptron
The application of artificial neural networks in the modelling of nonlinear and dynamical processes is primarily dominated by static architectures (e.g. MLP) trained by a gradient descent algorithm. An effective way of representing temporal and sequential information is through the use of recurrent network architectures, where feedback connections exist between nodes of the same layer or to nodes of preceding layers (Puskorius and Feldkamp Citation1994). The present study used a recurrent neural network with a single hidden layer. The operational principles of the network can be expressed mathematically by (Haykin Citation2008):
Although representation and processing of temporal information are intrinsic capabilities of recurrent neural networks, their applications are primarily restricted by two inter-related difficulties (Puskorius and Feldkamp Citation1994): (i) the computation of dynamic derivatives of the RMLP outputs with respect to its weights by the RTRL algorithm is computationally intensive; and (ii) the training of the RMLP with pure gradient descent methods is typically slow and ineffective. In the present study, the first issue has been addressed using approximate methods, such as a truncated BPTT algorithm, whereas the latter issue has been partially addressed using second-order training algorithms, such as an extended Kalman filter.
Extended Kalman filter
An extended Kalman filter is a modified and nonlinear version of the Kalman filter. This algorithm has found applications in a number of problems including learning the weights of neural networks (Puskorius and Feldkamp Citation1994, Choi et al. Citation2005). The complete coverage of the subject can be found in one of many sources (e.g. Haykin Citation2008). The basic framework for the EKF involves estimation of the parameters by re-writing a new state–space representation of Equationequations (3)(3) and Equation(4)
(4) (Haykin Citation2008):
where the parameter
w
(n) corresponds to stationary connection weights for the entire network (i.e.
w
(n) is the aggregation of weight vectors
w
I and
w
o), driven by an artificial process noise ω(n), the variance of which is a small value during the training process and zero after the training process is complete and determines convergence;
v
(n) is the vector containing all recurrent inputs; (n) is the measurement noise vector;
u
(n) is the network input vector as defined earlier, and the nonlinear map or transfer function
c
(·) is parameterized by the vector
w
.
The nonlinearity in the transfer function prevents the direct application of a classical Kalman filter approach for learning network parameters. This serious limitation is resolved by applying the extended Kalman filter as a sub-optimal filter. In the implementation of the EKF, the nonlinear measurement terms are linearized using a Taylor series. By simplifying and considering only the first-order linear terms we obtain (Haykin Citation2008):
where is the first order approximation of
x
o(n), and
C
(n) is the p-by-W measurement matrix of the linearized model. The Jacobian matrix
C
(n) is computed as (Haykin Citation2008):
where
c
p
(·) = [c1, c
2, …, cp
] are the p outputs of the network, and
w
= [w
1, w
2, …, wW
] are ordered wW
weights of the network. The current estimate of the state is used in the computation of the derivatives. Obviously, the computation of the Jacobian makes the main distinction in the application of the EKF training to the MLP and the RMLP architectures. Finally, the network weights are updated by the following EKF recursion (Haykin Citation2008):
where i = 1, 2, …, g, and g is the number of groups; (n) = p-by-p matrix, representing the global conversion factor for the entire network;
G
i
(n) = Wi
-by-p matrix, representing the Kalman gain group i of neurons; α(n) = p-by-1 vector, representing the innovations defined as the difference between the desired response
d
(n) for the linearized system and its estimate
based on input data available at time n − 1; the estimate
is represented by the actual output vector
y
(n) of the network residing in state {
w
i
(n/(n – 1))}, which is produced in response to the input
u
(n);
= W-by-1 matrix, representing the estimate of the weight vector
w
i
(n) for group i at time n, given the observed data up to time n – 1;
K
i
(n, n – 1) = Wi
-by-Wi
matrix, representing the error covariance matrix for group i of neurons;
R
(n) is the diagonal covariance matrix for the measurement noise vector ξ(n); and
Q
(n) is a diagonal covariance matrix for the artificial process noise that provides a mechanism by which the effect of the artificial process noise vector ω (n), is included in the Kalman recursion. This algorithm is known as the decoupled extended Kalman filter (DEKF). In the limit of a single weight group (g = 1), the DEKF algorithm reduces exactly to the global extended Kalman filter (GEKF). The computational complexity and the storage requirements for the DEKF can be considerably less than the GEKF, but at the expense of a slightly reduced accuracy (Puskorius and Feldkamp Citation1994).
Back-propagation through time
In order to compute the Jacobian matrix C (n), an efficient gradient algorithm, such as the BPTT or the RTRL, is typically used. The present study employed the BPTT algorithm. The solution of the BPTT approach is to unfold the RMLP in time into a multilayer feedforward network by stacking identical copies of the RMLP, and then redirecting connections within the network to obtain connections between subsequent copies, which are amenable to the back-propagation algorithm (Jaeger Citation2002). This method of unfolding the RMLP leads to the generation of a network with an infinite number of layers. For practical application, the truncated version of the original BPTT algorithm is used. In the truncated BPTT algorithm, the past network states are saved up to some truncation depth h, and information beyond this depth is not considered. The detailed description of the BPTT algorithm can be found in Haykin (Citation2008).
CASE STUDY: HYDROLOGICAL FORECASTING
Catchment description and data sets used
Two different hydrological variables are used for the evaluation and investigation of the EKF approach to perform supervised training of the recurrent multilayer perceptron. The two hydrological variables are from different basins located at different geographical locations.
Athabasca River basin
The first basin considered is the Athabasca River basin in western Canada. The Athabasca River is part of the Mackenzie hydrological system (). It originates from the Colombia Glacier at an altitude of about 1600 m and flows along various landscapes including ice fields and gorges, which in turn create favourable conditions for flora and fauna to flourish. These habitats are protected by several national and provincial parks, including the Jasper National Park, part of a spectacular World Heritage Site. Several communities are on the banks of the river, and Hinton is one of them (Schindler et al. Citation2007). Because of the wide-ranging topographic variations, the climate of the basin is significantly different from one sub-basin to the other. To provide a sense of the basin's climate, data reported at Jasper station located at an altitude of 1062.2 m are presented. Based on Canadian Climate Normals (1971–2000), the daily average annual temperature is 3.3°C and the extreme minimum and maximum temperatures are −46.7°C and 36.7°C, respectively. On average, the station receives 398.8 mm of precipitation annually, of which 35% is in the form of snowfall. The basin has a sub-Arctic climate with four distinct seasons: winter, spring, summer and autumn. The region experiences long, very cold and snowy winters, and mild and very short summers because of the higher latitude and the greater influence of Arctic air masses.
Fig. 1 Location map of the study areas.
The present study considers part of the Athabasca River basin covering approximately 9765 km2 at the mouth of Hinton gauging station. The grounds for selecting this particular river basin are three-fold:
| a. | Reliable and accurate flow forecasts in this river basin could have great consequences for the tourism industry, in particular, and the local community, in general. | ||||
| b. | The hydrology of the basin is largely driven by glacier and snow melt, which, together with the wide-ranging landscape and land-use patterns, pose great challenges to the reliability of hydrological forecast models. Investigating the forecasting skill of the RMLP model under such a hydrological system is imperative. | ||||
| c. | The basin contains reliable hydrometric data for a long period, which is a fundamental requirement for the design and successful implementation of artificial neural networks. | ||||
Lake Ontario
The second basin considered in this study is Lake Ontario, one of the five Great Lakes of North America (). It covers a total area of 82 990 km2, of which 18 960 km2 is water area and 64 030 km2 is land drainage area. The lake stands at about 74 m above mean sea level and has an average depth of 86 m. The drainage area features four distinct seasons, winter, spring, summer and autumn, with significant variations in day-to-day temperature, particularly during autumn and winter. According to the Detroit District of the US Army Corps of Engineers, the lake's long-term (1900–2008) mean precipitation is 907 mm. The respective minimum and maximum long-term average (1992–2010) surface water temperatures are 2°C and 22°C (Great Lakes CoastWatch Node: http://coastwatch.glerl.noaa.gov/). The largest tributary of Lake Ontario is the Niagara River (from Lake Erie). The water from the lake is mostly discharged into the Atlantic Ocean through the St Lawrence River. Lake Ontario is a hub of commercial activities, including transport for bulk goods, water supply, recreational boating and tourism.
Table 1 Basic descriptive statistics of the data sets used in modelling: all data (January 1960–December 2006), training data (January 1960–December 1993), and test data (January 1994–December 2006) for both streamflow and lake water-level data series, respectively, for the Athabasca River, at Hinton (07AD002), Alberta (Canada) and for Lake Ontario, at Toronto (02HC048), Ontario (Canada)
The grounds for selecting Lake Ontario for the present study, among others, include:
| a. | Accurate prediction of the lake level: this is vital to sustain Ontario's economy, particularly the western shore of the lake, which includes the Toronto-Hamilton area. | ||||
| b. | An extensive study by Coulibaly (Citation2010) indicated that prediction of the Lake Ontario water level is relatively difficult compared to the other Great Lakes (lakes Superior, Michigan, Huron and Erie). | ||||
Therefore, predicting Lake Ontario water levels offers further opportunity to investigate the forecasting skill of the proposed model on a nonlinear hydrological system. Furthermore, the results of the proposed model can be readily compared with those of Coulibaly (Citation2010). It is noteworthy to mention that the data sets used for training and testing the forecasting models in the Coulibaly (Citation2010) study and the proposed model are different. Though the comparison provides a good indication in terms of the relative performance of the proposed model, it would be difficult to establish whether the improved performance shown in the present study can be attributed to the difference in the models or to the length of data set used. Therefore, caution should be exercised when comparing the two sets of results.
The experimental data sets used in the present study were collected and maintained by Environment Canada (Hydat). The respective average monthly streamflow and lake water-level data for a period of 47 years (January 1960–December 2006) were compiled for the Athabasca River, at Hinton (07AD002), Alberta (Canada) and Lake Ontario, at Toronto (02HC048), Ontario (Canada). The geographical locations of the hydrometric stations are approximately at 53.41°N and 117.58°W for Athabasca River, and 43.64°N and 79.38°W for Lake Ontario. Out of 47 years of monthly time series data, a sub-set of data, from January 1960 to December 1993, was used for model calibration/training, and the remaining data, January 1994–December 2006, were used for model validation/testing. The basic descriptive statistics for the data sets used in modelling are presented in .
Network topology and training
The flow and lake water-level time series were analysed using partial autocorrelation function (PACF) to identify significant time lags. For the case of streamflow time series, lags 1–12 were significant. For the case of lake water-level time series, lags 1, 2, 4, 7, 8 and 9 were significant. Since the PACF provides information based on a linear relationship, further analysis was undertaken using a nonlinear relationship. Sensitivity analysis using a neural network model indicated that the use of all lags yielded better forecast accuracy. Consequently, lags 1–12 were used as inputs to the forecasting model. Once the model inputs were identified, both the MLP and the RMLP models were set up to forecast 1-month to 12-months ahead. Prior to the forecasting experiment, appropriate network architectures were designed and the various network parameters were optimized. For modelling with the MLP, the search for an optimal network began with a simple network having one hidden layer, keeping the number of neurons to vary from 2 to 30. Different learning rules (such as variable learning rate, conjugate gradient, Levenberg-Marquardt and Bayesian regularization with Levenberg-Marquardt) and transfer functions (such as tangent hyperbolic, sigmoid and linear) in both the hidden layer and output layer were investigated in the search for an optimal network (Muluye and Coulibaly Citation2007). For the case of modelling with the MLP, one hidden layer with 10 and 16 neurons generally provided the best performing network for forecasting lake water levels and streamflows, respectively. A hyperbolic tangent and linear activation function in the hidden layer and output layer, respectively, and a learning rule with Bayesian regularization with Levenberg-Marquardt provided the optimal network for both lake water-level and streamflow forecasting. Similarly, for the case of modelling with the recurrent multilayer perceptron, one hidden layer with 8 and 12 neurons provided the best performing network for forecasting lake water levels and streamflows, respectively. While the MLP model was trained with the conventional back-propagation algorithm, the RMLP model was trained with the decoupled version of an extended Kalman filter. In the process of training the RMLP model, the covariance matrix of artificial noise
Q
(n) was linearly annealed from 10-2 to 10-6 in order to avoid numerical divergence and poor local minima. The diagonal entry of the covariance matrix of the measurement noise (n) was also decreased linearly from 100 to 5. For the computation of the transfer function,
C
(n), the truncated BPTT algorithm was used. A truncation depth of two was retained as there was no significant difference in network performance beyond this depth. It is noteworthy to mention that while Matlab's Neural Network Toolbox was used for designing the MLP model, the procedure described in this work and Haykin (Citation2008) was followed for designing the RMLP model.
RESULTS AND DISCUSSION
This section compares and discusses the MLP and the RMLP models for forecasting 1-, to 12-months-ahead lake water levels and streamflows. Suites of diagnostic measures were computed for the test period to aid model evaluation. The diagnostic measures provided key statistics including bias (%), root mean squared error (RMSE), Pearson correlation coefficient (r) and deterministic skill score (SS). Observed and simulated line plots are also presented and discussed. The SS explains the relative improvement of the forecast over some reference forecast. In the present study, forecasts from climatology and MLP were used as reference forecasts. When the mean squared error (MSE) is used as a score in the SS formulation, the resulting statistic is called the reduction of variance (Stanski et al. Citation1989). The SS is given by:
presents the biases associated with 1- to 12-months-ahead forecasts. These biases were expressed as a percentage of the mean climatology. For the case of streamflow forecasting, the RMLP model provided smaller biases (<2%) when compared to the MLP model (up to 15%). The simulated streamflows using the MLP model showed a tendency to over-forecast (positive bias) the observed streamflows. For the case of lake water level forecasting, both models generally yielded smaller biases (<0.1%), indicative of adequate representation of the observed mean lake water levels. The Pearson correlation coefficients between the simulated and the observed lake water levels and streamflows indicate that the RMLP model had an advantage over the MLP model for all forecast horizons considered: r values for the RMLP model were between 0.86 and 0.91, and those for the MLP model were between 0.8 and 0.88, for forecasting streamflows. Similarly, r values between 0.73 and 0.95, and 0.62 and 0.9 were obtained using the RMLP and MLP model, respectively, for lake water level forecasting. The superiority of the RMLP model was supported by the smaller RMSE statistics yielded for both streamflow and lake water levels ().
Table 2 Comparative model performance statistics between the MLP and the RMLP models for forecasting streamflows and lake water levels, respectively, for Athabasca River, at Hinton (07AD002), Alberta (Canada) and for Lake Ontario, at Toronto (02HC048), Ontario (Canada). The testing is based on the test period January 1994–December 2006
The performance of the RMLP was further evaluated using the SS statistics. The positive SS in suggests that the forecasts made by both models were superior to climatology. For the case of streamflow forecasting, SS values for the RMLP model were between 74 and 82% and those for the MLP model were between 62 and 77%. The corresponding SS values for forecasting lake water levels were 47–90% for RMLP and 34–81% for MLP. When the MSE of the MLP model was used as a reference forecast, the improvements in MSE due to RMLP (SSfor) were 20–35% for streamflow forecasting and 10–47% for lake water-level forecasting. This clearly underscores the superiority of the RMLP model over the MLP model.
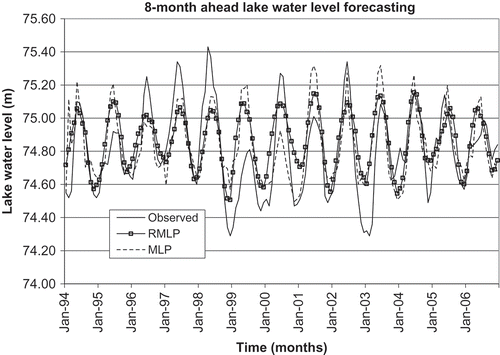
and depict plots of observed and simulated streamflows and lake water levels, respectively, for the 8-month-ahead forecast. Both models appeared to adequately represent the general time series patterns of the variables considered. Nevertheless, the extreme (low and high) lake water levels are poorly represented by both models (). Similar difficulties have also been observed for forecasting streamflows, particularly in representing the highest portion of the time series (). In general, the RMLP model has shown better representation for the lowest portion of the streamflow series, whereas the MLP model demonstrated some difficulties and appeared to under- and over-represent the lowest portion of the streamflow series. The RMLP model generally yielded better representation than the MLP model.
Fig. 2 Observed and simulated 8-month ahead streamflow forecasting using the MLP and the RMLP models for the test period (January 1994–December 2006) for Athabasca River, at Hinton (07AD002), Alberta (Canada).
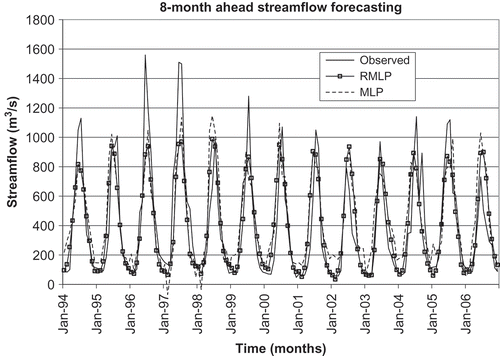
Fig. 3 Observed and simulated 8-month ahead lake water level forecasting using the MLP and the RMLP models for the test period (January 1994–December 2006) for Lake Ontario, at Toronto (02HC048), Ontario (Canada).
The performance of the RMLP model was compared with the Coulibaly (Citation2010) study in terms of forecasting Lake Ontario water levels. The Coulibaly (Citation2010) study compared echo state networks (ESN), recurrent neural networks (RNN) and Bayesian neural networks (BNN), and identified the ESN model as the best performing model. It is noteworthy to mention that the RNN model presented by Coulibaly (Citation2010) typically used a gradient decent approach for training network weights and biases. The major difference between the conventional MLP model trained with the gradient decent approach and the RNN model used in Coulibaly (Citation2010) is that the RNN model contains feedback connections, in this case, up to a truncation depth h, using the BPTT algorithm. Training of the RNN model with pure gradient descent method is typically slow and ineffective. In order to address this limitation, second-order training algorithms, such as an extended Kalman filter, are typically used (Haykin Citation2008). The RMLP model used in the present study employed an extended Kalman filtering approach, thus obviating the limitations of the RNN model used by Coulibaly (Citation2010). It should also be noted that a conventional fully-connected RNN has the potential to approximate any dynamical system, provided that (Haykin Citation2008): (i) a large enough number of computational units is used; and (ii) an appropriate and effective learning technique is applied.
Coulibaly (Citation2010, Table 3) provided model and performance statistics, which indicated that the ESN model had yielded the best performance statistics in terms of r values ranging from 0.61 to 0.96. In contrast, the RMLP model yielded r values ranging from 0.73 to 0.95. Although the ESN and the RMLP models showed competitive performances up to 5-months-ahead forecasts, the RMLP model demonstrated some advantage beyond 5-months-ahead forecasts, indicating the effectiveness of the RMLP model for long lead-time forecasts. The MLP model used in the present study also demonstrated a good performance when compared with the ESN, the RNN and the BNN models. The MLP model generally yielded r values ranging from 0.62 to 0.90, which is competitive to the ESN model, and even superior to the RNN and the BNN models, particularly for longer lead-time forecasts. The better performance of the MLP model was mainly attributed to the training mechanism employed, i.e. Bayesian regularization with Levenberg-Marquardt. Moreover, although the MLP model is a static nonlinear model, the model inputs (lags 1–12) provided the network a short-term memory and helped improve the forecast performance.
The RMLP model used in the present study has the following advantages over the MLP model:
| a. | A static MLP model is made into a dynamic neural network via a long-term memory structure. This enables time to be built into the network through the use of global feedback. It should be noted that the RMLP model described herein subsumes the MLP model. | ||||
| b. | The RMLP model can be effectively described by the state–space model of Equationequations (5) | ||||
| c. | The supervised training of the RMLP model using the EKF algorithm is efficient and optimal. EquationEquations (10) | ||||
SUMMARY, CONCLUSIONS AND RECOMMENDATIONS
This study presented the findings of the extended Kalman filter approach to perform supervised training of the recurrent multilayer perceptron. The general framework was implemented on two basins in Canada in order to characterize long-range horizon streamflow and lake water-level forecasts. Out of 47 years (January 1960–December 2006) of monthly data, a sub-set of data, from January 1960 to December 1993, was used for model training, and the remaining data, from January 1994 to December 2006, were used for model testing. Suites of diagnostic measures were employed to evaluate the performance of the RMLP-based forecasts over climatology and the MLP-based forecasts.
The results from the forecasting experiment showed that the RMLP model yielded better performance statistics in each forecast horizon, and outperformed the MLP model by a wide margin. Furthermore, the extended Kalman filter algorithm demonstrated stronger learning capability, better convergence properties, and faster training speed than the standard gradient descent algorithm. Some of the major features that demonstrated improved performance include: the ability of the RMLP model to capture spatio-temporal information from the flow and the lake water-level series, and the optimal filtering capability of the extended Kalman filter while training the network. While the present study concludes that the RMLP model outperformed the MLP model in all performance measures, further investigation is recommended on different variables and study areas to ascertain the overall skill and versatility of the approach.
The cubature Kalman filter (CKF) approach is a recent state-of-the-art technique that can be applied to perform supervised training of the RMLP model. The CKF method is built on the Kalman filter theory and is the closest known direct approximation to the Bayesian filter. The method has been shown to outperform the EKF approach (Haykin Citation2008). Investigating the potential of the CKF approach on hydrology-related problems is something to consider.
Acknowledgements
This research was supported by the School of Graduate Studies at McMaster University. Drs Brian Baetz and Sarah Dickson are gratefully acknowledged for their review comments and suggestions. Environment Canada is gratefully acknowledged for providing the experimental data. Matlab's Neural Network Toolbox was used for designing the MLP model. Dr Sitotaw Yirdaw-Zeleke and Mr Kibreab Amare are gratefully acknowledged for drawing location maps of the study area. The co-editor and the two anonymous reviewers are also gratefully acknowledged for their constructive comments and suggestions that have improved the quality of the original manuscript.
Related Research Data
REFERENCES
- Abrahart , R.J. , Heppenstall , A.J. and See , L.M. 2007 . Timing error correction procedure applied to neural network rainfall–runoff modelling . Hydrological Sciences Journal , 52 ( 3 ) : 414 – 431 .
- Adamowski , J.F. 2008 . Development of a short-term river flood forecasting method for snowmelt driven floods based on wavelet and cross-wavelet analysis . Journal of Hydrology , 353 : 247 – 266 .
- ASCE Task Committee on Application of Artificial Neural Network in Hydrology . 2000a . Artificial neural network in hydrology. I: Preliminary concepts . Journal of Hydrological Engineering , 5 : 115 – 123 .
- ASCE Task Committee on Application of Artificial Neural Network in Hydrology . 2000b . Artificial neural network in hydrology. II: Hydrologic applications . Journal of Hydrological Engineering , 5 : 124 – 137 .
- Carcano , E.C. , Bartolini , P. , Muselli , M. and Piroddi , L. 2008 . Jordan recurrent neural network versus IHACRES in modeling daily streamflows . Journal of Hydrology , 362 ( 3-4 ) : 291 – 307 .
- Chang , L.C. , Chang , F.J. and Chiang , Y.M. 2004 . A two-step-ahead recurrent neural network for stream-flow forecasting . Hydrological Processes , 18 : 81 – 92 .
- Choi , J. , Yeap , T. H. and Bouchard , M. 2005 . Online state–space modeling using recurrent multilayer perceptrons with unscented Kalman filter . Neural Processing Letters , 22 : 69 – 84 . doi: doi:10.1007/s11063-005-2157-2
- Coulibaly , P. 2010 . Reservoir computing approach to Great Lakes water level forecasting . Journal of Hydrology , 381 : 76 – 88 .
- Giustolisi , O. and Laucelli , D. 2005 . Improving generalization of artificial neural networks in rainfall–runoff modelling . Hydrological Sciences Journal , 50 ( 3 ) : 439 – 457 .
- Haykin , S. 2008 . Neural Networks and Learning Machines , 3rd , Upper Saddle River, NJ : Prentice-Hall .
- Jaeger , H. 2002 . A tutorial on training recurrent neural networks, covering BPPT, RTRL, EKF and the “echo state network” approach . Fraunhofer Institute for Autonomous Intelligent Systems (AIS). ,
- Jonsson , G. and Palsson , O.P. 1994 . An application of extended Kalman filtering to heat exchanger models . ASME Journal of Dynamic Systems., Measurement and Control , 116 : 257 – 264 .
- Kisi , O. , Yuksel , I. and Dogan , E. 2008 . Modelling daily suspended sediment of rivers in Turkey using several data-driven techniques . Hydrological Sciences Journal , 53 ( 6 ) : 1270 – 1285 .
- Koutsoyiannis , D. , Yao , H. and Georgakakos , A. 2008 . Medium-range flow prediction for the Nile: a comparison of stochastic and deterministic methods . Hydrological Sciences Journal , 53 ( 1 ) : 142 – 164 .
- Londhe , S. and Charhate , S. 2010 . Comparison of data-driven modelling techniques for river flow forecasting . Hydrological Sciences Journal , 55 ( 7 ) : 1163 – 1174 .
- Muluye , G.Y. and Coulibaly , P. 2007 . Seasonal reservoir inflow forecasting with low frequency climatic indices: a comparison of data-driven methods . Hydrological Sciences Journal , 52 ( 3 ) : 508 – 522 .
- Palma , L. Application of an extended Kalman Filter for on-line identification with recurrent neural networks . Proceedings of the Seventh Jornadas Hispano-Lusas de Ingenieria Electrica . Madrid, Spain.
- Pan , T.Y. and Wang , R.Y. 2005 . Using recurrent neural networks to construct rainfall-runoff processes . Hydrological Processes , 19 ( 18 ) : 3603 – 3619 .
- Pramanik , N. and Panda , R.K. 2009 . Application of neural network and adaptive neuro-fuzzy inference systems for river flow prediction . Hydrological Sciences Journal , 54 ( 2 ) : 247 – 260 .
- Puskorius , G.V. and Feldkamp , L.A. 1994 . Neurocontrol of nonlinear dynamical systems with Kalman filter trained recurrent networks . IEEE Transactions on Neural Networks , 5 ( 2 ) : 279 – 297 .
- Schindler , D.W. , Donahue , W.F. and Thompson , J.P. 2007 . “ Running out of steam? Oil sands development and water use in the Athabasca River-Watershed: science and market based solutions. Section 1: Future water flows and human withdrawals in the Athabasca River ” . In Environmental Research and Studies Centre , Canada : University of Alberta .
- Stanski , H.R. , Wilson , L.J. and Burrows , W.R. 1989 . Survey of common verification methods in meteorology , Geneva : World Meteorological Organization, World Weather Watch Tech. Rept. no. 8, WMO/TD no.358 .